LLM과 SAST 도구의 계층적 CWE 예측 평가 ALPHA 벤치마크
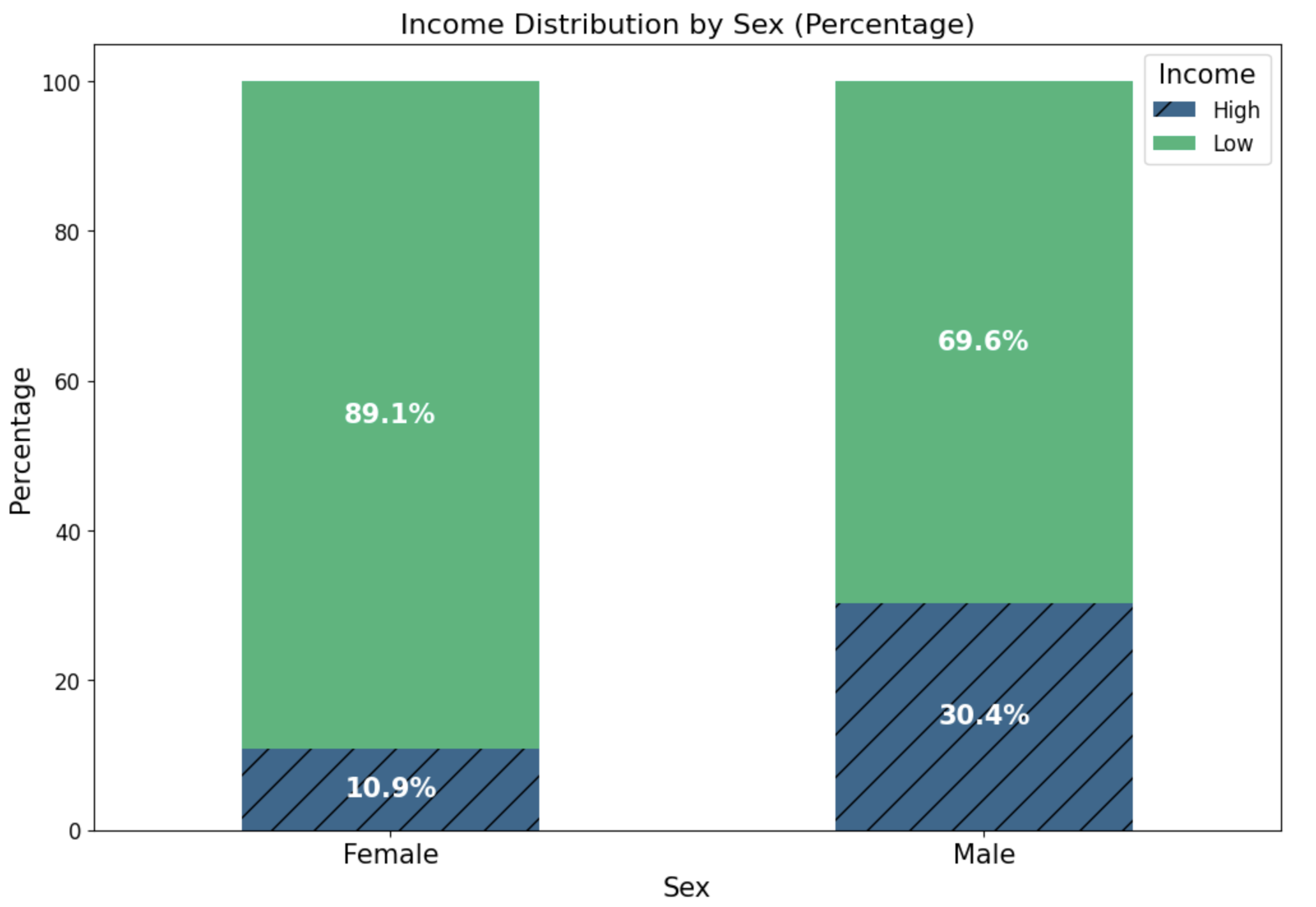
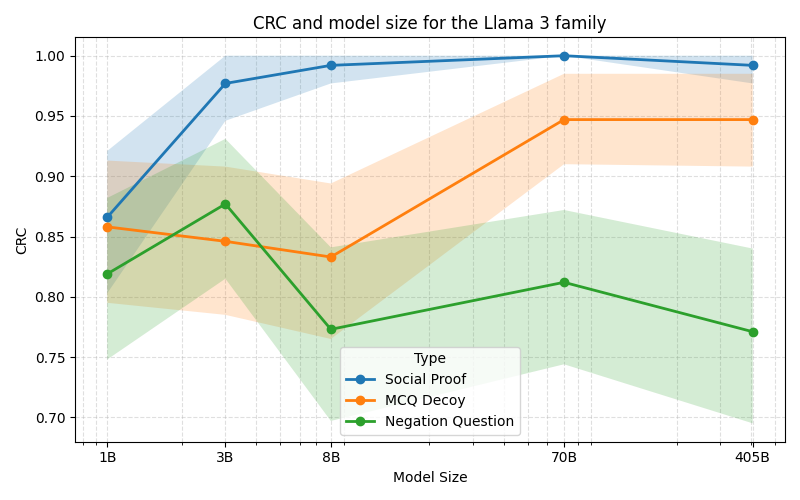
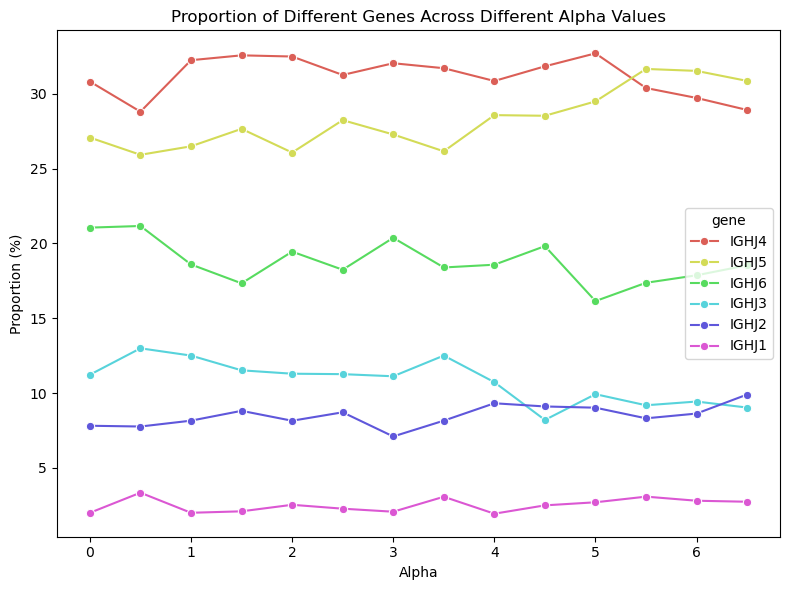
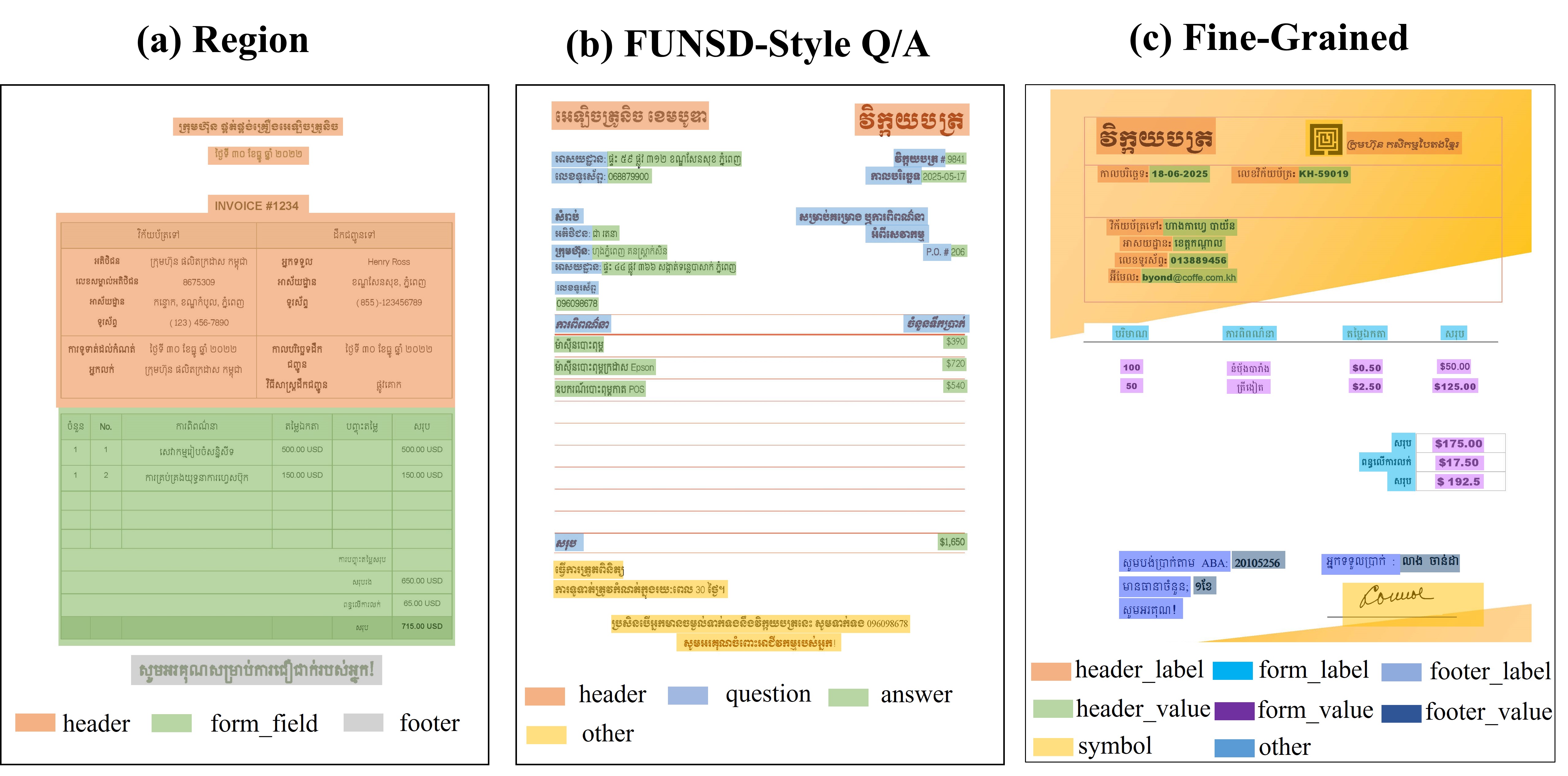
본 논문은 LLM과 전통적인 정적 분석 도구(SAST)의 취약점 탐지 능력을 비교 평가하기 위해 새로운 벤치마크 프레임워크인 ALPHA를 설계한 점에서 학술적·실무적 의의가 크다. 기존의 이진 분류 기반 벤치마크는 “취약점 존재 여부”만을 판단하도록 제한돼, 개발자가 실제 코드 수정에 활용할 수 있는 구체적인 CWE(CWE‑Common Weakness Enumeration) 정보를 제공하지 못한다는 한계가 있었다. ALPHA는 이러한 한계를 극복하기 위해 함수 수준에서 CWE 레이블을 부여하고, 오류 유형을 세 가지 계층적 패널티(
Computer Science
Software Engineering