Dynamic Dual-Granularity Skill Bank for Agentic RL
Agentic reinforcement learning (RL) can benefit substantially from reusable experience, yet existing skill-based methods mainly extract trajectory-level guidance and often lack principled mechanisms for maintaining an evolving skill memory. We propos…
Authors: Songjun Tu, Chengdong Xu, Qichao Zhang
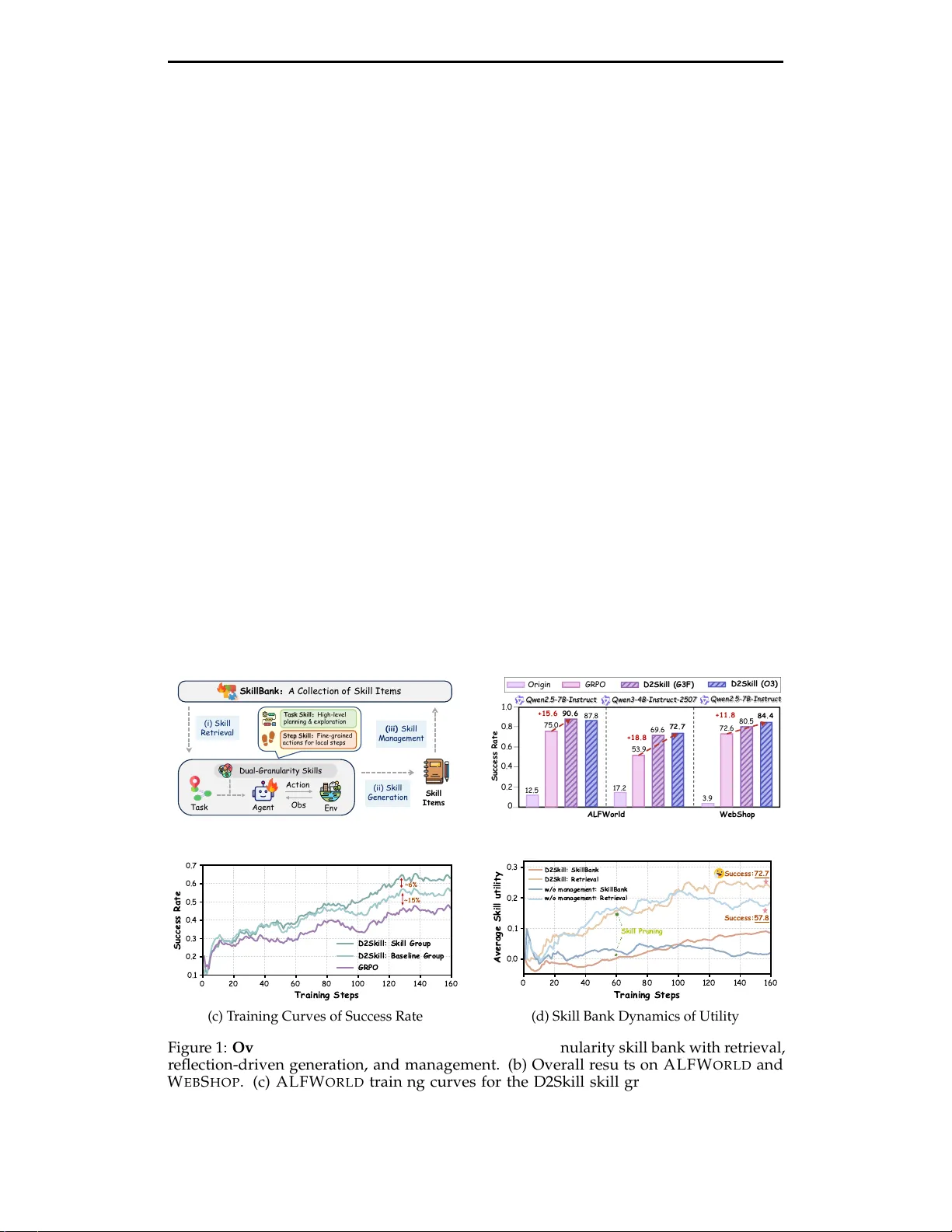
Preprint, In Pr ogress. Dynamic Dual-Granularity Skill Bank for Agentic RL Songjun T u 1,2 , Chengdong Xu 3,2 , Qichao Zhang 1 , Y aocheng Zhang 1 , Xiangyuan Lan 2 , Linjing Li 1 , Dongbin Zhao 1,2 Institute of Automation, Chinese Academy of Sciences 1 Pengcheng Laboratory 2 Sun Y at-Sen University 3 Abstract Agentic r einforcement learning (RL) can benefit substantially fr om r eusable experience, yet existing skill-based methods mainly extract trajectory-level guidance and often lack principled mechanisms for maintaining an evolv- ing skill memory . W e pr opose D2Skill , a dynamic dual-granularity skill bank for agentic RL that organizes r eusable experience into task skills for high-level guidance and step skills for fine-grained decision support and error correction. D2Skill jointly trains the policy and skill bank through paired baseline and skill-injected r ollouts under the same policy , using their performance gap to derive hindsight utility signals for both skill updating and policy optimization. Built entirely from training-time experience, the skill bank is continuously expanded thr ough reflection and maintained with utility-aware retrieval and pruning. Experiments on A L F W O R L D and W E B S H O P with Q W E N 2 . 5 - 7 B - I N S T R U C T and Q W E N 3 - 4 B - I N S T R U C T - 2 5 0 7 show that D2Skill consistently improves success rates over skill-fr ee baselines by 10–20 points. Further ablations and analyses show that both dual-granularity skill modeling and dynamic skill maintenance are critical to these gains, while the learned skills exhibit higher utility , transfer acr oss evaluation settings, and introduce only modest training over head. Project Page: https://github.com/TU2021/D2Skill-AgenticRL . ( ii) Skil l Ge n e ra t io n S k illB a n k : A C olle ct ion of S k ill I te m s Ta sk A g e n t En v ( iii) Skil l M a n a g e me n t ( i) Skil l R e t rie v a l Skil l I t e m s O bs A c t io n Du a l - Gra n ul a rit y Skil l s T a sk S ki l l : H i gh - l ev el p l a nni ng & e x p l o r a t i o n Step S ki l l : F i ne - g r a i ne d a cti o n s f o r lo ca l s tep s (a) D2Skill Framework O rig in GR P O D 2 Skil l ( G3 F) D 2 Skil l ( O 3 ) Suc c e ss Ra t e 0 .2 0 .4 0 .6 0 .8 1 .0 0 1 2.5 90. 6 87.8 3.9 72.6 80.5 84. 4 75.0 +15. 6 +11. 8 A L FWo rl d W eb S h op 1 7.2 53.9 69.6 72. 7 +18. 8 Q w e n 2.5 - 7B - Ins tr u c t Q w e n3 - 4B - Ins tr u c t - 2 507 Q w e n 2.5 - 7B - Ins tr u c t (b) Main Results ~6% ~15% (c) T raining Curves of Success Rate B Skill Pruning Success:72 . 7 Success:57 . 8 (d) Skill Bank Dynamics of Utility Figure 1: Overview of D2Skill. (a) The dynamic dual-granularity skill bank with retrieval, reflection-driven generation, and management. (b) Overall results on A L F W O R L D and W E B S H O P . (c) A L F W O R L D training curves for the D2Skill skill group, paired baseline group, and G R P O . (d) Skill bank dynamics with and without management, shown by average skill utility and retrieval statistics. 1 Preprint, In Pr ogress. 1 Introduction Agentic reinfor cement learning (RL) has recently emerged as a promising paradigm for training language-based agents to solve long-horizon decision-making tasks, including interactive environments ( Jiang et al. , 2026 ), web search ( Zhang et al. , 2025c ), and r esearch scenarios ( T u et al. , 2026 ). In these settings, the policy interacts with the environment through a textual interface and selects actions based on the task description together with a limited history of past observations and actions. However , such history-based context is generally not a sufficient statistic of the underlying state, resulting in severe partial observability and making credit assignment increasingly dif ficult as the decision horizon grows ( Zhang et al. , 2025b ). Under sparse rewar ds and lar ge action spaces, learning each task in isolation is highly inef ficient ( Feng et al. , 2025 ). Effective policies therefor e requir e mechanisms for accumulating reusable knowledge that can be transferr ed across tasks. Recent studies alleviate these challenges by introducing additional supervision signals for agentic RL. Some methods employ outcome-based credit assignment to provide process rewar ds ( Feng et al. , 2025 ), while others derive hindsight supervision from completed trajectories ( Y u et al. , 2025 ). More recent work focuses on enabling agents to accumulate experience across tasks and iteratively r efine it during training ( Zhai et al. , 2025 ; Cai et al. , 2025b ; a ). W ithin this line, reusable skills have emerged as an effective form of past expe- rience and shown strong empirical gains in agentic RL ( W ang et al. , 2026 ). For instance, SkillRL ( Xia et al. , 2026 ) builds a skill bank fr om past trajectories and retrieves relevant skills to guide policy interaction, improving exploration ef ficiency in long-horizon tasks. However , existing skill-based and reflection-driven frameworks remain limited in two respects. Most methods derive skills from complete trajectories and emphasize task-level reflection, which captur es high-level guidance but is less effective for correcting fine-grained errors at individual interaction steps ( Xia et al. , 2026 ; Zhang et al. , 2026a ). In addition, as training progr esses, the skill bank expands continuously , making retrieval and manage- ment increasingly challenging. W ithout principled mechanisms for skill evaluation and pruning, r edundant or ineffective skills can degrade r etrieved guidance and hinder policy optimization ( Zhou et al. , 2025 ; 2026 ). T o addr ess these limitations, we pr opose D ynamic D ual-Granularity Skill Bank ( D2Skill ) for agentic RL, which maintains reusable skills at both the task and step granularities throughout training. As illustrated in Figur e 1a , D2Skill distinguishes between task skills for high-level task guidance and step skills for fine-grained decision support and local error correction during interaction. During training, it contrasts skill-injected and non-injected trajectories under the same policy to estimate hindsight skill utility , which in turn guides skill maintenance, retrieval, and policy optimization; the overall training behavior is further reflected in the success-rate curves in Figure 1c . Meanwhile, D2Skill continuously expands and refines the skill bank through r eflection while pruning r edundant or ineffective skills, keeping the memory compact, informative, and beneficial throughout training, as further illustrated by the skill-bank dynamics in Figure 1d . Experiments on repr esentative agentic tasks show that D2Skill consistently outperforms both non-skill baselines and existing skill-augmented methods (Figure 1b ), while effectively maintaining a dynamically updated skill bank with high utility throughout training. The main contributions of this work are as follows: 1. W e pr esent D2Skill , a dynamic dual-granularity skill bank framework for agentic RL, which organizes r eusable experience into task skills for high-level guidance and step skills for fine-grained interaction support. 2. W e develop a joint training paradigm where the skill bank and policy co-evolve, with skills expanded through reflection and maintained via utility-guided retrieval and pruning , ensuring an efficient memory thr oughout training. 3. W e evaluate D2Skill on A L F W O R L D and W E B S H O P using Q W E N 2 . 5 - 7 B - I N S T R U C T and Q W E N 3 - 4 B - I N S T R U C T - 2 5 0 7 . D2Skill achieves 10–20 point gains in success rate over skill-free baselines (GRPO), and ablations validate its cor e components. 2 Preprint, In Pr ogress. 2 Preliminaries 2.1 Agentic RL as a History-Augmented Decision Process W e consider agentic RL in long-horizon environments modeled as a Markov decision pr ocess (MDP) M = ( S , A , P , r , γ ) , where s t ∈ S , a t ∈ A , and ( s t + 1 , r t , d t ) ∼ P ( · | s t , a t ) . Unlike classical RL, the policy does not dir ectly observe the environment state. Instead, the agent interacts through a textual interface that provides a partial description of the task and the interaction history . For a task instance g , let τ g denote the task specification, o t the textual observation at step t , and H L t = { ( o t − L , a t − L ) , . . . , ( o t − 1 , a t − 1 ) } the most recent L observation–action pairs retained in the prompt. Let A adm t ⊆ A be the admissible action set. The policy acts on the effective context x t = ( τ g , H L t , o t , A adm t ) , and selects actions according to π θ ( a t | x t ) . Although the underlying dynamics are Markovian in ( s t , a t ) , the context x t is a fixed-window summary of past interactions and is generally not a sufficient statistic of the latent state, so the resulting MDP can be viewed as a history-augmented partially observable MDP . 2.2 Skill Bank as an External Knowledge Store In addition to the sliding window H L t , we maintain a persistent skill bank M , where each skill m ∈ M stores language guidance for decision making. At step t , a retrieval operator selects a small set of relevant skills m t ⊆ M conditioned on the current context x t = ( τ g , H L t , o t , A adm t ) , and the policy acts on the augmented context ˜ x t = ( x t , m t ) . T aking GRPO ( Shao et al. , 2024 ) as the RL algorithm for example. For each task g , a group of N trajectories is sampled and advantages ar e computed by normalizing r eturns within the group. Under the skill-augmented context, the GRPO objective is L GRPO ( θ ) = E i min r i ( θ ) ˆ A i , clip ( r i ( θ ) , 1 − ϵ , 1 + ϵ ) ˆ A i − β D KL π θ ( · | ˜ x i ) ∥ π ref ( · | ˜ x i ) . Here ˜ x i t denotes the context augmented with retrieved skills, ˆ A i , t denote the normalized advantage and r i , t ( θ ) = π θ ( a i , t | ˜ x i , t ) π θ old ( a i , t | ˜ x i , t ) be the likelihood ratio. The policy is optimized under skill-augmented observations, while the objective remains the same as in standar d RL. 3 Method 3.1 Overall Framework The framework of D2Skill combines RL with a dynamic skill bank that is continuously updated through r eflection and reused to guide policy interaction. As illustrated in Fig. 2 , the framework consists of three main components. RL training with skill injection. (Section 3.2 ) During training, trajectories are sampled in groups that include both baseline rollouts and skill-injected rollouts under the same policy . Retrieved skills ar e injected into the policy context to guide decision making, and the performance gap between the two gr oups is used to construct hindsight signals for policy optimization and skill utility updates under the GRPO objective. Reflection-driven skill generation. (Section 3.3 ) When performance on a task group falls below a threshold, a r eflection module analyzes representative trajectories to pr oduce new reusable skills. Generated skills are associated with retrieval keys and inserted into the skill bank after normalization and deduplication, allowing the agent to accumulate experience across tasks during training. Skill retrieval and bank management. (Section 3.3 ) During interaction, relevant skills are retrieved fr om the skill bank based on the current task and observation and injected into 3 Preprint, In Pr ogress. S ki l l B a nk T as k - S k i l l - 001 : Un in t er r u p t ed C o m m a n d S eq u en c e " pr i n c i pl e " : " W h e n t a s k e d w i t h movi ng mu l t i p l e … " " w h e n _ t o_a p p ly " : " F or t ask s i nvol vi ng t h e . . . " " r e tr i e val _ o b s ": “ Put t w o s oa p bot t l e i n t oi l e t . " S te p - S k i l l - 0 0 1 : S e ar ch U n vi s i te d R e ce p tacl e s "p r i n ci p l e " : " W h e n s e a r c h i ng f or a r e qu i r e d … " " w h e n _t o_ a p p ly " : ""W he n t he t a r g e t o b j e c t ha s . . . " " r e tr i e val _ o b s " : “ P u t s ome k e yc h a i n on s of a . C ur r en t obs er va t i on : Yo u ar r i v e at l o c 23. … " ... ... A 0 S 1 A 1 S 2 S 0 ... M 0 M 1 M 2 A 0 S 1 A 1 S 2 S 0 ... Ba s e l in e Gro up ... × N /2 S kil l Gro up ... × N /2 R R H in d si gh t Re wa r d S a mp le F a i l ed Tr a j ec t o r i es Re f le c tion T as k S k ills + T as k D e s cr ip t ion S t ep S k i l l s + Fi r st Er r o r S t ep A dd U tility E v a lua tion D elet e S 0 : P ut some k e y c h a in on … Ro llout 0 0 0 0 0 N / 2 N / 2 N / 2 N / 2 N / 2 Figure 2: Overall framework of D2Skill. D2Skill couples RL with a dynamic dual- granularity skill bank. For each task, training rollouts ar e divided into a baseline group and a skill group, whose performance gap yields hindsight signals for policy optimization and skill utility estimation. When performance is poor , r eflection on repr esentative failed trajectories produces task skills for high-level guidance and step skills for local error correction. Skills are stor ed with retrieval keys, r eused during subsequent interaction, and periodically pruned by utility-based bank management. the policy context. Skill utilities ar e updated online according to rollout outcomes, and the skill bank is periodically pruned using utility-based criteria to maintain a bounded memory while preserving ef fective skills. 3.2 RL T raining with Skill Injection and Hindsight Optimization Rollout with skill injection. For each task g , we sample a group of N parallel trajectories, denoted by G g . The group is evenly divided into a skill group G skill g and a baseline group G base g , each containing N / 2 trajectories. Let b i ∈ { 0, 1 } denote the group indicator for trajectory i ∈ G g , where b i = 1 indicates i ∈ G skill g and b i = 0 indicates i ∈ G base g . T rajectories in the skill group retrieve skills fr om the skill bank during interaction, while those in the baseline group follow the same policy without skill injection. Let Y i ∈ { 0, 1 } denote the terminal success indicator of trajectory i . For each task g , the baseline success rate and the skill-group success rate ar e defined as ¯ Y base g = 1 |G base g | ∑ i ∈ G base g Y i , ¯ Y skill g = 1 |G skill g | ∑ i ∈ G skill g Y i . (1) Hindsight signals and utility updates. W e use the performance gap between the skill group and the baseline gr oup to construct hindsight signals for updating skill utilities. For each task g , the task-level hindsight signal ∆ task g and the trajectory-level credit c i for step skills retrieved along skill-injected trajectory i are defined as ∆ task g = ¯ Y skill g − ¯ Y base g , c i = Y i − ¯ Y base g . (2) Each skill m maintains a utility u m updated using an exponential moving average. For a given task g , all retrieved task skills share the same signal ∆ task g , since the task context is identical for the whole group. In contrast, multiple step skills may be retrieved at differ ent steps and fr om differ ent trajectories, and each retrieved step skill is updated using the cr edit of the trajectory in which it appears. The updates are defined as u m ← ( 1 − β task ) u m + β task ∆ task g , u m ← ( 1 − β step ) u m + β step c i , (3) 4 Preprint, In Pr ogress. where the first rule is applied to task skills r etrieved in task g , and the second r ule is applied to each step skill retrieved along skill-injected trajectory i . Hindsight intrinsic reward shaping. T o encourage effective use of retrieved skills, we introduce a hindsight intrinsic reward for trajectories in the skill group. For each skill- injected trajectory i ∈ G skill g , the hindsight intrinsic rewar d is defined as R int i = λ Y i − ¯ Y base g , (4) where λ controls the str ength of the shaping signal. This term measures performance gain over the baseline and encourages effective skill usage. The hindsight intrinsic reward is applied at the end of each skill-injected trajectory and included in the policy optimization. Policy optimization with skill-augmented returns. The policy is optimized on the full samples. For each task g , trajectories in the skill group G skill g are generated under skill- augmented context and receive an additional rewar d R int . Let R i denote the origin return of trajectory i . For skill-injected trajectories, the r eturn is augmented with R int i , and advantages are computed by gr oup normalization over the whole trajectory group: ˜ R i = ( R i + R int i , i ∈ G skill g , R i , i ∈ G base g , A i = ˜ R i − mean { ˜ R j } j ∈ G g std { ˜ R j } j ∈ G g . (5) T aking GRPO as an example, the final policy loss is L = E i ∈ G g [ min ( r i A i , clip ( r i , 1 − ϵ , 1 + ϵ ) A i ) − β D KL ] . (6) 3.3 Skill Generation, Retrieval, and Bank Management Reflection and skill generation. Reflection is triggered only for task groups with low performance, i.e., when ¯ Y skill g < τ ref , where τ ref is a reflection threshold. For each such task g , we sample one failed trajectory τ − g from the skill group and, when available, one successful trajectory τ + g from either the skill or the baseline group, and use them for skill generation . The reflector produces at most one task skill and one step skill for each task group, formalized as m task g = f task reflect ( g , τ − g , τ + g ) , ( m step g , o j ) = f step reflect ( g , τ − g , τ + g ) , (7) where f reflect denotes an external reflector LLM used for skill generation, and o j denotes the observation at the earliest failure step j identified from the sampled failed trajectory . For each skill m , we define a r etrieval key k m that determines when the skill is applicable. For m ∈ M task , the key is defined as k m = g . For m ∈ M step , the key is defined as k m = ( g , o j ) . New skills are inserted into the skill bank after deduplication and participate in subsequent retrieval and utility updates. T wo-stage skill retrieval. When interacting with environment, skills are r etrieved fr om the skill bank by matching the current query key with the retrieval key k m of each skill. For task-level retrieval, the query key is q = g , while for step-level retrieval the query key is q t = ( g , o t ) , where g denotes the task identifier and o t is the observation at step t . In the first stage, we retrieve the top-m candidate skills from the pool M ∈ {M task , M step } according to cosine similarity between the embedding of q and k m . A minimum similarity threshold τ sim is applied, and only skills satisfying sim ( q , k m ) ≥ τ sim are r etained. In the second stage, the candidates ar e ranked using a combination of semantic similarity and utility-based exploration. For each skill m ∈ M , we define the selection scor e score ( m ) = α d sim ( m , q ) + ( 1 − α ) u m + η s log ( 1 + N r ) 1 + n m , (8) 5 Preprint, In Pr ogress. where d sim ( m , q ) ∈ [ 0, 1 ] is the normalized cosine similarity , u m is the utility of skill m , n m is the number of times the skill has been r etrieved, and N r = ∑ m ′ ∈M n m ′ is the total retrieval count in the active pool. The second term corr esponds to a UCB-style bonus that encourages exploration of skills with low retrieval counts. The top-k ( < top-m) skills ranked by this score ar e injected into the policy context. Skill pruning by utility . T o prevent unbounded growth of the skill bank, we periodically prune each skill pool M after validation intervals. Each pool is associated with a capacity limit N max . If |M | > N max , each skill m ∈ M is assigned an eviction score evict ( m ) = u m + η s log ( 1 + N r ) 1 + n m . (9) Then, skills are sorted by evict ( m ) in ascending order , and the lowest-scoring skills are removed until |M | ≤ N max . Skills created within the last T prot training steps, i.e., t − t create m < T prot , are excluded fr om eviction to ensure suf ficient evaluation. 4 Experiments W e evaluate D2Skill on two r epresentative LLM agentic benchmarks, A L F W O R L D ( Shridhar et al. , 2020 ) and W E B S H O P ( Y ao et al. , 2022 ), and compare it against both skill-free RL baselines and prior memory- or skill-augmented methods. Our experiments are designed to answer three questions: 1. Main Performance: Does D2Skill outperform standard RL and existing baselines on agentic tasks? (Section 4.1 ) 2. Ablation: What is the contribution of each major component to the overall gains? (Section 4.2 ) 3. Analysis: How does the dynamic skill bank affect skill utility , training dynamics, and computational overhead, and does the learned policy retain generalization ability without the skill bank at evaluation time? (Section 4.3 ) 4.1 Main Performance T able 1 shows that D2Skill consistently outperforms strong skill-free baselines across both Qwen2.5-7B-Instruct and Qwen3-4B-Instruct-2507 ( Y ang et al. , 2025a ), while also surpassing prior memory- and skill-based methods where available. During validation stage, the skill bank M is fixed, and the agent only performs retrieval from M task and M step to guide policy , without reflection or skill updates. Under Qwen2.5-7B-Instruct , D2Skill achieves 90.6 overall success on A L F W O R L D , exceeding GRPO by 15.6 points and SkillRL by 1.5 points. On W E B S H O P , the best D2Skill variants reach 91.1 in scor e and 84.4 in success rate, compared with 86.0 / 72.6 for GRPO and 85.2 / 72.7 for SkillRL. It also substantially outperforms memory-augmented GRPO variants such as Mem0+GRPO ( Chhikara et al. , 2025 ) and SimpleMem+GRPO ( Liu et al. , 2026a ). Notably , SkillRL constructs skills from validation trajectories and therefor e benefits from str onger privileged information. By contrast, D2Skill acquires and maintains its skill bank using only training-time experience, while still achieving better overall performance under this mor e restrictive setting. Under the smaller Qwen3-4B-Instruct-2507 base model, D2Skill improves A L F W O R L D overall success from 53.9 with GRPO to 69.6 and 72.7, yielding gains of 15.7 and 18.8 points using skills generated by Gemini-3-Flash (G3F) and O3 , r espectively . W e further evaluate D2Skill on a teacher-initialized policy obtained by collecting 300 success- ful trajectories per environment with O3 (for A L F W O R L D ) / Gemini-3-Pro (for W E B S H O P ) and performing SFT on Qwen3-4B-Instruct-2507 before RL. Even in this strong setting, D2Skill continues to improve both training efficiency and final performance. After 40 training steps, D2Skill reaches 92.2 on A L F W O R L D , nearly matching GRPO trained for 6 Preprint, In Pr ogress. T able 1: Performance on A L F W O R L D and W E B S H O P . For A L F W O R L D , we report the average success rate (%) for each subtask and the overall success rate. For W E B S H O P , we report the average score and average success rate (%). Unless otherwise stated, all methods are trained for 160 training steps in each environment, evaluated every 5 training steps on 128 validation tasks by default, and r eported by their best performance over the entire training run. Following SkillRL, we use an SFT -initialized model for Qwen2.5-7B-Instruct to ensure reliable instruction-following for skill usage, while for Qwen3-4B-Instruct-2507 we directly use the original instruct model. For Qwen3-4B-Instruct-2507 , performance on W E B S H O P remains close to zero both before and after training, and is therefore omitted from the table. ∗ denotes results r eplicated from ( Feng et al. , 2025 ) and ( Xia et al. , 2026 ). The best and second-best results ar e highlighted in red and blue , r espectively . Method ALFW orld W ebShop Pick Clean Cool Look Heat Pick2 All Score Success Closed-source LLMs Gemini-3-Flash 96.4 57.1 96.2 85.7 72.2 95.3 85.2 14.1 16.5 O3 64.3 19.1 23.1 64.3 33.3 61.9 43.8 5.8 4.7 Base Model: Qwen2.5-7B-Instruct Origin 17.9 4.8 3.8 64.3 0.0 5.3 12.5 16.6 3.9 GRPO 88.3 73.3 76.0 83.3 81.3 40.0 75.0 86.0 72.6 Mem0+GRPO* 78.1 56.1 65.0 54.8 31.0 26.9 54.7 58.1 37.5 SimpleMem+GRPO* 89.5 60.0 64.9 36.3 50.0 26.3 62.5 67.8 46.9 SkillRL( O3 )* 94.3 90.6 92.0 83.3 93.7 80.0 89.1 85.2 72.7 D2Skill ( Gemini-3-Flash ) 97.1 100.0 75.0 87.5 100.0 78.6 90.6 91.1 80.5 D2Skill ( O3 ) 93.8 94.7 95.5 77.8 95.0 72.0 87.8 90.1 84.4 Base Model: Qwen3-4B-Instruct-2507 Origin 50.0 9.5 0.0 2.1 11.1 4.8 17.2 - - GRPO 73.5 46.6 48.0 61.1 62.5 20.0 53.9 - - SkillRL( O3 ) 90.0 92.3 52.0 63.6 42.9 40.9 67.2 - - D2Skill ( Gemini-3-Flash ) 88.6 75.0 54.2 66.7 60.0 52.6 69.6 - - D2Skill ( O3 ) 89.4 72.4 66.7 54.5 60.0 50.0 72.7 - - Base Model: Qwen3-4B-Instruct-2507 + SFT Origin 53.6 28.6 46.2 71.4 55.5 38.1 47.7 65.6 53.1 GRPO( 40-Steps ) 89.7 77.8 85.7 91.6 86.7 69.6 83.6 77.4 67.2 GRPO( 120-Steps ) 100.0 95.2 80.8 88.9 78.6 88.3 92.9 88.2 79.9 D2Skill ( 40-Steps ) 92.9 100.0 95.2 80.0 90.9 86.7 92.2 84.1 71.9 D2Skill ( 120-Steps ) 97.6 95.8 100.0 88.9 90.0 91.7 95.3 89.2 81.3 120 steps (92.9), and improves W E B S H O P to 84.1 / 71.9 in score / success rate. After 120 steps, it further reaches 95.3 on A L F W O R L D and 89.2 / 81.3 on W E B S H O P , consistently outperforming GRPO under the same budget . An additional finding is that the closed-source teacher models used in our framework are not necessarily strong standalone agents in these environments. Their direct rollout performance is often substantially below that of the final RL-trained policies. However , when deployed as r eflectors to critique trajectories and extract r eusable skills, they still yield clear gains in both training efficiency and final performance. This indicates that the utility of these models in D2Skill comes less from direct action generation and more from their ability to perform trajectory-level diagnosis and skill abstraction , which in turn provides effective supervision for policy improvement . 4.2 Ablation Study W e conduct ablations on A L F W O R L D with Q W E N 3 - 4 B - I N S T R U C T - 2 5 0 7 to assess the contri- bution of each component in D2Skill. During training, we report the peak success rates of the skill and baseline groups, measured by the maximum 10-step moving average, and during validation we report the best held-out success rate. W e consider six ablated variants: (i) w/o task skills , removing task-level skills; (ii) w/o step skills , removing step-level skills; (iii) w/o skill management , disabling skill pruning and retaining all accumulated skills; (iv) w/o 7 Preprint, In Pr ogress. baseline group , r emoving paired baseline r ollouts and training with absolute rewards only; (v) w/o utility r etrieval , removing utility-aware ranking and using similarity-only r etrieval; (vi) w/o utility module , removing the utility mechanism entirely , including baseline-based utility estimation and updates; and (vii) w/o skills (GRPO) as a skill-free refer ence. T able 2: Ablation Study on A L F W O R L D . Method T rain V al Skill Baseline D2Skill 70.9 65.8 72.7 w/o task skills 59.1 53.7 62.7 w/o step skills 57.8 55.8 60.2 w/o skill management 60.0 57.4 57.8 w/o baseline group 63.9 - 68.8 w/o utility retrieval 61.4 51.8 64.8 w/o utility module 60.3 - 62.5 w/o skills (GRPO) - 50.6 53.9 The ablation results in T able 2 reveal three main findings. First, removing either task skills or step skills con- sistently reduces performance , indi- cating that both high-level task guid- ance and fine-grained step support are important to D2Skill. Second, the larger degradation caused by remov- ing skill management highlights the importance of dynamic bank mainte- nance in discarding ineffective skills and retaining compact, high-utility knowledge for reuse. Third, r emoving the baseline gr oup or utility estimation r esults in smaller but still clear dr ops, suggesting that these components primarily enhance credit assignment and skill valuation , thereby improving optimization and r etrieval quality , rather than driving the main gains directly . 4.3 Additional Analysis S u c c e s s R a t e 0.4 0.6 0.8 1 .0 0 61 .7 72.6 84. 4 ALF Wo r l d : Q w e n3 - 4B 53.9 72. 7 W e bs ho p : Q w e n2 . 5 - 7B 68.0 D 2S k i l l ( O3) GRP O 77.3 73.4 Figure 3: Eval with Differ ent Skills. Utility and transferability of the skill bank. As shown in Figure 1d , enabling skill management yields a skill bank and retrieved skills with con- sistently higher average utility , indicating that utility-aware maintenance impr oves memory and retrieval quality by filtering inef fective skills. Fig- ure 3 further shows that the learned skills are transferable . Even without a skill bank at evalua- tion time, the policy trained with D2Skill remains competitive with, or outperforms, GRPO, suggest- ing that part of the gain fr om skill augmentation has been internalized into the policy during training. Moreover , using the Gemini-3-Flash - generated skill bank from the corr esponding training setting at evaluation time still yields clear gains over the no-skill variant in both A L F W O R L D and W E B S H O P , while the self- generated skill bank remains the most effective. This suggests that D2Skill learns r eusable skills that retain utility beyond the specific skill bank used during training. T able 3: T raining Cost. Method T raining Hours GRPO 20.8h (1.0 × ) SkillRL 49.2h (2.4 × ) D2Skill 25.6h (1.2 × ) X1 . 7 Figure 4: V al Success Dynamics. T raining cost. T able 3 reports the wall-clock training time on A L F W O R L D with Qwen3- 4B-Instruct-2507 , measured on 8 × H100 GPUs. D2Skill takes 25.6 hours, remaining close to GRPO (20.8 hours) while being substantially cheaper than SkillRL (49.2 hours). As shown in Figure 4 , D2Skill also reaches strong evalua- tion performance much earlier in wall-clock time, making it about 1.7 × faster than SkillRL in prac- tice. This low over head mainly comes fr om an ef fi- cient retrieval pipeline: retrieval is executed with batched embedding queries and skill embeddings are updated incrementally , so only newly added skills need to be encoded after each bank update. As a result, D2Skill remains close to GRPO in train- ing cost despite introducing skill retrieval and management. Further implementation details are available in our open-source codebase . 8 Preprint, In Pr ogress. 5 Related W orks 5.1 Agent Evolution and Memory Management Recent work has increasingly studied agent evolution to address the limited post-training adaptability of LLMs. A central mechanism in this line is external memory , which supports continual adaptation beyond parameter updates ( Zhang et al. , 2024 ; Gao et al. , 2025 ; Du , 2026 ). Existing studies explore evolving long-term memory from multiple perspectives, including retention and forgetting ( Chhikara et al. , 2025 ), structured updating and orga- nization ( Xu et al. , 2025 ; Y an et al. , 2025 ), retrieval-awar e optimization ( Zhou et al. , 2025 ), and hierarchical or generative memory construction ( Zhang et al. , 2025a ). Beyond storing interaction history , another line of work abstracts experience into reusable knowledge, such as reasoning strategies ( Zhao et al. , 2024 ; Ouyang et al. , 2025 ), r eusable workflows ( W ang et al. , 2024 ), hierarchical experience libraries ( Y ang et al. , 2025b ), and continual experience re- finement ( Cai et al. , 2025b ). Overall, these studies suggest that agent evolution increasingly relies on str uctured, r eusable memory with effective r etrieval and management. 5.2 Memory-augmented Agentic RL Memory serves as a non-parametric complement to RL by storing useful successful or failed experiences in external memory and r etrieving them into the policy context to improve agent performance ( Liu et al. , 2026b ; Zhou et al. , 2026 ). By coupling parametric RL updates with evolving experience repositories, recent methods enable LLM agents to accumulate reusable knowledge beyond model weights, improving both reasoning ( T u et al. , 2025 ; Suzgun et al. , 2026 ) and adaptation on complex tasks ( Bai et al. , 2026 ; Li et al. , 2026 ). This is particularly important in agentic settings, where long-horizon decision making under partial observability often benefits more fr om structured r eusable guidance than from raw trajectory storage. Accordingly , recent work increasingly or ganizes cr oss-task experience into reusable guidance for planning and action selection ( Zhai et al. , 2025 ; Cai et al. , 2025a ), with skills emerging as an especially effective abstraction for improving policy performance on complex agentic tasks ( W ang et al. , 2026 ). 5.3 Comparison with Contemporaneous W ork Contemporaneous works such as RetroAgent ( Zhang et al. , 2026b ) and Complementary RL ( Muhtar et al. , 2026 ) are related in spirit to our approach, showing that self-evolving experience can substantially improve agentic RL performance. However , their results r ely on more elaborate prompting pipelines for retrospection and experience extraction, which may increase system complexity and pr ompt dependence. SkillRL ( Xia et al. , 2026 ) is the most closely related prior work to D2Skill. Although SkillRL also distinguishes between two task types, this mainly r eflects task categorization rather than differ ent skill granularities, and its guidance r emains task-level: each task retrieves skills once and uses them throughout the trajectory . In contrast, D2Skill maintains both task skills and step skills , enabling high- level guidance and fine-grained support with r etrieval at each interaction step. Moreover , D2Skill performs skill generation and management during training , rather than relying on privileged validation information for skill construction. 6 Conclusion W e presented D2Skill , a dynamic dual-granularity skill bank framework for agentic RL. By combining task and step skill reuse with reflection-driven expansion, utility-aware retrieval, and pr uning, D2Skill enables the policy and skill bank to impr ove jointly during training. Experiments show that this design consistently outperforms strong baselines, while ablations and analyses confirm the importance of both dual-granularity skill modeling and dynamic skill management, as well as the utility and transferability of the learned skill bank. Our evaluation is currently limited to two repr esentative benchmarks, and D2Skill still relies on an external r eflector model. Extending it to broader envir onments while r educing this dependency is an important direction for futur e work. 9 Preprint, In Pr ogress. References Fei Bai, Zhipeng Chen, Chuan Hao, Ming Y ang, Ran T ao, Bryan Dai, W ayne Xin Zhao, Jian Y ang, and Hongteng Xu. T owards effective experiential learning: Dual guidance for utilization and internalization. arXiv preprint , 2026. Y uzheng Cai, Siqi Cai, Y uchen Shi, Zihan Xu, Lichao Chen, Y ulei Qin, Xiaoyu T an, Gang Li, Zongyi Li, Haojia Lin, et al. T raining-free group r elative policy optimization. arXiv preprint arXiv:2510.08191 , 2025a. Zhicheng Cai, Xinyuan Guo, Y u Pei, Jiangtao Feng, Jinsong Su, Jiangjie Chen, Y a-Qin Zhang, W ei-Y ing Ma, Mingxuan W ang, and Hao Zhou. Flex: Continuous agent evolution via forward learning fr om experience. arXiv preprint , 2025b. Prateek Chhikara, Dev Khant, Saket Aryan, T aranjeet Singh, and Deshraj Y adav . Mem0: Building production-r eady ai agents with scalable long-term memory . arXiv preprint arXiv:2504.19413 , 2025. Pengfei Du. Memory for autonomous llm agents: Mechanisms, evaluation, and emer ging frontiers. arXiv preprint , 2026. Lang Feng, Zhenghai Xue, T ingcong Liu, and Bo An. Group-in-gr oup policy optimization for llm agent training. arXiv preprint , 2025. Huan-ang Gao, Jiayi Geng, W enyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shilong Liu, Jiahao Qiu, Xuan Qi, Y iran W u, Hongru W ang, Han Xiao, Y uhang Zhou, Shaokun Zhang, Jiayi Zhang, Jinyu Xiang, Y ixiong Fang, Qiwen Zhao, Dongrui Liu, Qihan Ren, Cheng Qian, Zhenhailong W ang, Minda Hu, Huazheng W ang, Qingyun W u, Heng Ji, and Mengdi W ang. A survey of self-evolving agents: What, when, how , and where to evolve on the path to artificial super intelligence. arXiv pr eprint arXiv:2507.21046 , 2025. Zhennan Jiang, Shangqing Zhou, Y utong Jiang, Zefang Huang, Mingjie W ei, Y uhui Chen, T ianxing Zhou, Zhen Guo, Hao Lin, Quanlu Zhang, et al. W ovr: W orld models as reliable simulators for post-training vla policies with rl. arXiv preprint , 2026. Y u Li, Rui Miao, Zhengling Qi, and T ian Lan. Arise: Agent reasoning with intrinsic skill evolution in hierarchical r einforcement learning. arXiv preprint , 2026. Jiaqi Liu, Y aofeng Su, Peng Xia, Siwei Han, Zeyu Zheng, Cihang Xie, Mingyu Ding, and Huaxiu Y ao. Simplemem: Efficient lifelong memory for llm agents. arXiv preprint arXiv:2601.02553 , 2026a. Zeyuan Liu, Jeonghye Kim, Xufang Luo, Dongsheng Li, and Y uqing Y ang. Exploratory memory-augmented llm agent via hybrid on-and off-policy optimization. arXiv preprint arXiv:2602.23008 , 2026b. Dilxat Muhtar , Jiashun Liu, W ei Gao, W eixun W ang, Shaopan Xiong, Ju Huang, Siran Y ang, W enbo Su, Jiamang W ang, Ling Pan, and Bo Zheng. Complementary reinfor cement learning. arXiv preprint , 2026. Siru Ouyang, Jun Y an, I-Hung Hsu, Y anfei Chen, Ke Jiang, Zifeng W ang, Rujun Han, Long T . Le, Samira Daruki, Xiangru T ang, V ishy T irumalashetty , George Lee, Mahsan Rofouei, Hangfei Lin, Jiawei Han, Chen-Y u Lee, and T omas Pfister . Reasoningbank: Scaling agent self-evolving with reasoning memory . arXiv preprint , 2025. Zhihong Shao, Peiyi W ang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y ang W u, et al. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models. arXiv preprint , 2024. Mohit Shridhar , Xingdi Y uan, Marc-Alexandre C ˆ ot ´ e, Y onatan Bisk, Adam T rischler , and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interac- tive learning. arXiv preprint , 2020. 10 Preprint, In Pr ogress. Mirac Suzgun, Mert Y uksekgonul, Federico Bianchi, Dan Jurafsky , and James Zou. Dynamic cheatsheet: T est-time learning with adaptive memory . In Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (V olume 1: Long Papers) , pp. 7080–7106, 2026. Songjun T u, Jiahao Lin, Xiangyu T ian, Qichao Zhang, Linjing Li, Y uqian Fu, Nan Xu, W ei He, Xiangyuan Lan, Dongmei Jiang, et al. Enhancing llm reasoning with iterative dpo: A comprehensive empirical investigation. In Second Conference on Language Modeling , 2025. Songjun T u, Y iwen Ma, Jiahao Lin, Qichao Zhang, Xiangyuan Lan, Junfeng Li, Nan Xu, Linjing Li, and Dongbin Zhao. Paperaudit-bench: Benchmarking error detection in resear ch papers for critical automated peer review . arXiv preprint , 2026. Y injie W ang, Xuyang Chen, Xiaolong Jin, Mengdi W ang, and Ling Y ang. Openclaw-rl: T rain any agent simply by talking. arXiv preprint , 2026. Zora Zhiruo W ang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory . arXiv preprint , 2024. Peng Xia, Jianwen Chen, Hanyang W ang, Jiaqi Liu, Kaide Zeng, Y u W ang, Siwei Han, Y iyang Zhou, Xujiang Zhao, Haifeng Chen, et al. Skillrl: Evolving agents via recursive skill-augmented reinfor cement learning. arXiv preprint , 2026. W ujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao T an, and Y ongfeng Zhang. A-mem: Agentic memory for llm agents. arXiv preprint , 2025. Sikuan Y an, Xiufeng Y ang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Jinhe Bi, Kristian Kersting, Jeff Z. Pan, Hinrich Schuetze, V olker T resp, and Y unpu Ma. Memory-r1: Enhancing large language model agents to manage and utilize memories via reinfor cement learning. arXiv preprint , 2025. An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chengen Huang, Chenxu Lv , et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388 , 2025a. Cheng Y ang, Xuemeng Y ang, Licheng W en, Daocheng Fu, Jianbiao Mei, Rong W u, Pinlong Cai, Y ufan Shen, Nianchen Deng, Botian Shi, Y u Qiao, and Haifeng Li. Learning on the job: An experience-driven self-evolving agent for long-horizon tasks. arXiv preprint arXiv:2510.08002 , 2025b. Shunyu Y ao, Howard Chen, John Y ang, and Karthik Narasimhan. W ebshop: T owards scalable real-world web interaction with grounded language agents. Advances in Neural Information Processing Systems , 35:20744–20757, 2022. Hongli Y u, T inghong Chen, Jiangtao Feng, Jiangjie Chen, W einan Dai, Qiying Y u, Y a-Qin Zhang, W ei-Y ing Ma, Jingjing Liu, Mingxuan W ang, et al. Memagent: Reshaping long- context llm with multi-conv rl-based memory agent. arXiv preprint , 2025. Y unpeng Zhai, Shuchang T ao, Cheng Chen, Anni Zou, Ziqian Chen, Qingxu Fu, Shinji Mai, Li Y u, Jiaji Deng, Zouying Cao, et al. Agentevolver: T owards efficient self-evolving agent system. arXiv preprint , 2025. Guibin Zhang, Muxin Fu, Guancheng W an, Miao Y u, Kun W ang, and Shuicheng Y an. G-memory: T racing hierarchical memory for multi-agent systems. arXiv preprint arXiv:2506.07398 , 2025a. Guibin Zhang, Hejia Geng, Xiaohang Y u, Zhenfei Y in, Zaibin Zhang, Zelin T an, Heng Zhou, Zhongzhi Li, Xiangyuan Xue, Y ijiang Li, et al. The landscape of agentic reinforcement learning for llms: A survey . arXiv preprint , 2025b. Shengtao Zhang, Jiaqian W ang, Ruiwen Zhou, Junwei Liao, Y uchen Feng, Zhuo Li, Y ujie Zheng, W einan Zhang, Y ing W en, Zhiyu Li, et al. Memrl: Self-evolving agents via runtime reinfor cement learning on episodic memory . arXiv preprint , 2026a. 11 Preprint, In Pr ogress. Xiaoying Zhang, Zichen Liu, Y ipeng Zhang, Xia Hu, and W enqi Shao. Retroagent: From solv- ing to evolving via retr ospective dual intrinsic feedback. arXiv preprint , 2026b. Y aocheng Zhang, Haohuan Huang, Zijun Song, Y uanheng Zhu, Qichao Zhang, Zijie Zhao, and Dongbin Zhao. Criticsearch: Fine-grained credit assignment for search agents via a retr ospective critic. arXiv preprint , 2025c. Zeyu Zhang, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Quanyu Dai, Jieming Zhu, Zhenhua Dong, and Ji-Rong W en. A survey on the memory mechanism of lar ge language model based agents. arXiv preprint , 2024. Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Y ong-Jin Liu, and Gao Huang. Expel: Llm agents are experiential learners. arXiv preprint , 2024. Huichi Zhou, Y ihang Chen, Siyuan Guo, Xue Y an, Kin Hei Lee, Zihan W ang, Ka Y iu Lee, Guchun Zhang, Kun Shao, Linyi Y ang, et al. Memento: Fine-tuning llm agents without fine-tuning llms. arXiv preprint , 2025. Huichi Zhou, Siyuan Guo, Anjie Liu, Zhongwei Y u, Ziqin Gong, Bowen Zhao, Zhixun Chen, Menglong Zhang, Y ihang Chen, Jinsong Li, et al. Memento-skills: Let agents design agents. arXiv preprint , 2026. 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment