GPU-Accelerated Optimization of Transformer-Based Neural Networks for Real-Time Inference
This paper presents the design and evaluation of a GPU-accelerated inference pipeline for transformer models using NVIDIA TensorRT with mixed-precision optimization. We evaluate BERT-base (110M parameters) and GPT-2 (124M parameters) across batch siz…
Authors: Soutrik Mukherjee, Sangwhan Cha
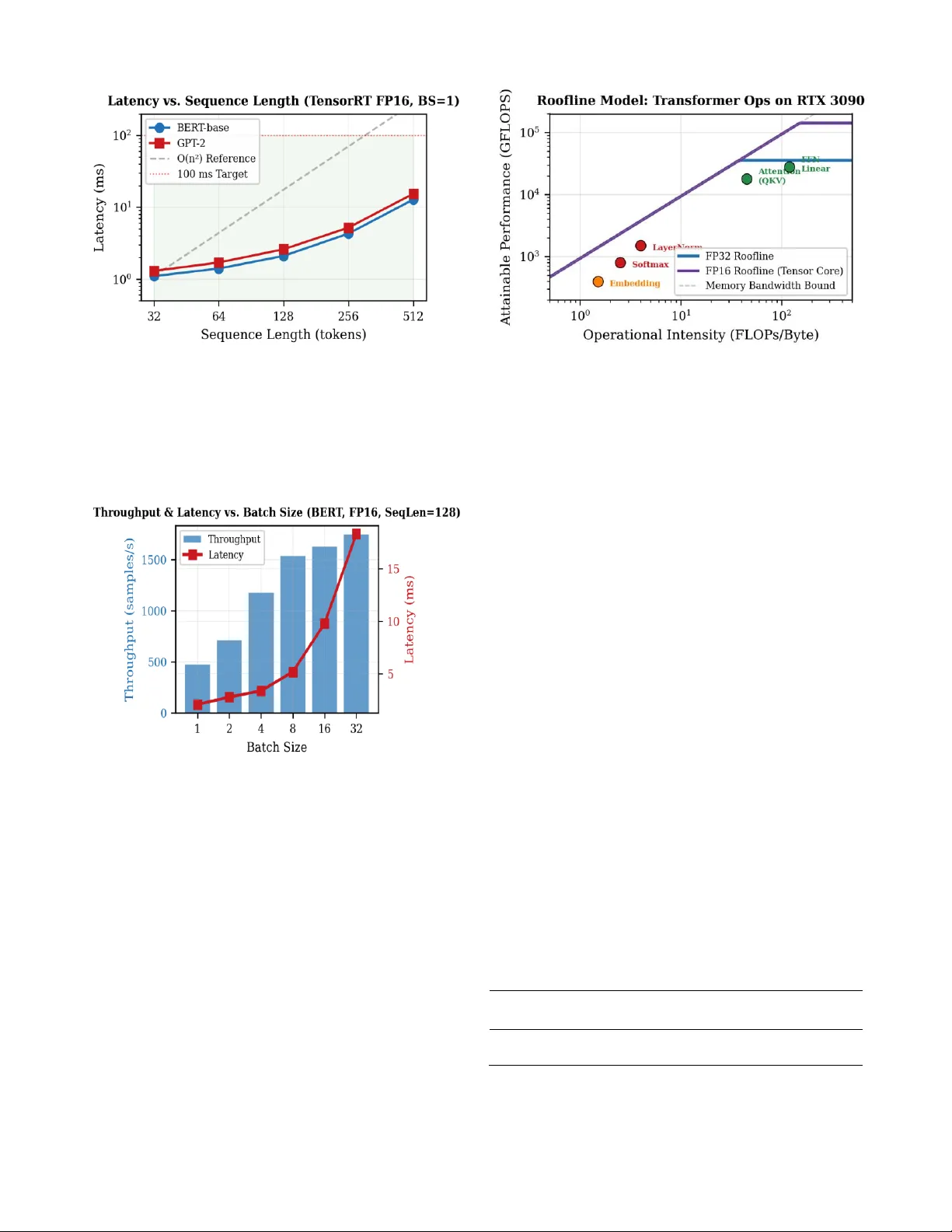
GPU-Accelerated Optimization of Transformer- Based Neural Networks for Real-Time Inference Soutrik Mukherjee, Sangwhan Cha Department of Co mputer and Information Sciences Harrisburg University o f Science a nd Technology Harrisburg, PA 17 101, USA smukherjee@my.harr isburgu.edu , scha @harrisburgu.edu Abstract — This paper presents the design and ev aluation of a GPU -acceler ated inference pipeline fo r transfo rmer models using NVIDIA Tensor RT with mixed-p recision optimization. Evaluated on BERT -base (110 M parameters) and GPT - 2 (124M par ameters) across batch sizes r anging from 1 to 32 and sequen ce lengths fro m 32 to 512, th e system achieves up to 6 4.4× spee dup over CPU baselines, sub -10 ms laten cy for single -sample inference, and a 63% reduction in memory usage. We intro duce a h ybrid precision strateg y that preser ves FP32 f or numerically sensitive operations such as softmax and layer normalization , while applying FP16 to linear lay ers. This app roach main tains high numerical fidelity (co sine similarity ≥ 0.9998 relative to baseline outputs) and eliminates NaN instabili ty. The pipeline is implemented as a modular, Dockerized system enabling reproducible benchmarking across more than 360 co nfigurations. Cross -GPU validation on an NVIDIA A 100 co nf irms architecture -portable behav ior with consistent FP16 speedup ratio s (1.84 – 2.00×) and numerical f idelity. Downstream evaluation on SST -2 d emonstrates zero accuracy degradation und er hybrid precision, and real-d ata validation on WikiText -2 reveals that ran dom inputs underestimate NaN in stability by 6× for full FP16 while confirmi ng hybrid robustness (0.0% NaN, ≥0.9998 cosine similarity). Our results provide a compreh ensive characterization o f performance – ac curacy tr ade-o ffs across GPU arch itectures, offer ing practical guidance for deploying transformer models in latency -cr itical environmen ts. Index Terms — GPU a cceleration , transformer inference, TensorRT, mixed -p recision, CUDA, BERT, real -time systems. I. INTRODUCTION Transformer -based neural n etworks h ave ach ieved s tate - of - the-art results across natural language processing [1], computer vision [2], and robotics [3]. Since Vaswan i et al.’s seminal 2017 paper introducing the self- attention mechanism, transformers have ra pidly displaced recurrent and convolutional architectures in domains ranging from machine translation and document understanding to autonomous perception and conver sational AI. Mod els su ch as BERT [5] and GPT-2 hav e dem onstrated remarkable capabilities in lang uage understan ding and generation, driving wid espread industrial adop tion. However, the computation al demands of transformer inference present significant deployment challenges. The self-attention mechanism computes pair wise relation ships across all positions in a sequence, introducing O(n²) complexity with respect to sequen ce le ngth n. For a standard BERT-base m odel with 11 0 million par ameters p rocessing a 512 -token input, a single forward pass requ ires approximately 22 billion f loating-po int o perations. When deployed in latency -critical app lications — such as robo tic control loops operating at 10 – 100 Hz, autonomous vehicle perception requiring sub -100 ms respon se times, or interactive conversation al agents — the gap between raw model latency and application requirem ents bec omes a critical enginee ring challenge. Modern NVIDIA GPUs offer a compelling solution through massively parallel architectures with specialized hardware features. Tensor Cores acce lerate mixed -precision matrix operations at up to 312 TFLOPS (FP16) on A100 GPUs [1 6], hierarchical memory systems provide terabytes - per-secon d bandwidth at the register level, and inference optimization frameworks such as TensorRT [4] perform aggressive graph- level and kernel-level optimizatio ns. Yet effectively leveraging these capabilities requires careful systems en gineering spanning model export, format conversion , graph optimization, p recision calibration, memory manag ement, and systematic b enchmarking. Despite substan tial prog ress in individual o ptimization techniques, a gap persists b etween th eoretical GPU performance and practical d eploymen t latency. Production systems often rely on uno ptimized PyTorch eager -mode execution, and the trade -offs between l atency, throug hput, numerical accuracy, and m emory utilization remain insufficiently characterized — par ticularly for mixed- precision configurations essential fo r max imizing Ten sor Core utilization. This paper presents an end- to -end GPU-ac celerated inference pipelin e integrating PyTorch, ONNX, an d TensorRT with a hybrid mixed-precision strategy. We systematically evaluate the pipeline on BERT-b ase ( 110M parameters, encoder- only) and GPT -2 (12 4M parame ters, decoder-o nly) ac ross b atch sizes 1 – 32 and sequence lengths 32 – 512 on an NVIDIA RTX 3 090 GPU. The key contributions of this work are: 2 1) A m odular, con fig-dr iven inference ar chitecture (five modules) enabling repro ducible experimentation across 3 60+ configuration s within a Dockerized env ironment; 2) A comprehensive cross -platform transformer inference benchmark on RTX 3090 and A100 GPUs, ch aracterizing latency, throughput, m emory, and accuracy trade -offs across GPU architectures; 3) A hybrid prec ision strategy achiev ing cosine similarity ≥0.9998 with FP32 baselines while deliver ing 1.93× speedup and eliminatin g all NaN occurrences; 4) Empirical validatio n of up to 64.4× speedup over CPU baselines with sub-10 ms single-sample latency, far exceeding the 5× design target, accompanied by downstream task validation (SST- 2: zero accuracy loss) and r eal-d ata numerical stability testing (Wik iText- 2 : zero NaN, ≥ 0.9998 cosine similarity). The remain der of this p aper is organ ized as follo ws: Section II reviews related wo rk on transfo rmer optimizatio n and GPU inference. Section III descr ibes the system architecture. Sectio n IV d etails the exp erimental setup. Section V presen ts results with an alysis. Section VI discu sses implications and limitations. Section VII concludes. II. RELATED WORK A. Transformer Architectu res and Bo ttlenecks The transformer architecture [1] computes atten tion as Attention(Q,K,V) = softmax(QK T /√dk)V, where Q, K, and V are query, key, and value matrices derived from learned linear projections. T his formulation intr oduces O(n²) complexity with respect to sequence length, creating a fund amental scalability bottleneck for long sequences [1 7]. Multi -head attention extends this b y computing atten tion across h parallel subspaces, pro viding representational diver sity. Profiling stud ies rev eal that attention operation s acco unt for approxim ately 40% of BERT inference latency despite representing only 15% of FLOPs [5 ], highlightin g the memory-b andwidth bottleneck. The feed-forward network layers (d_model × d_ff, typically 7 68 × 3072) are co mpute- intensive but amenable to Tensor Core acceler ation. Softmax normalization requires multiple memory passes and is numerically sensitive to precision reductio n. B. Efficient Attention a nd Model Com pression Flash Atten tion [6] addr esses the memory -ban dwidth bottleneck through IO -aware alg orithm design, recomputing attention scores rather than materializing the n×n attention matrix, achieving 2 – 4× speedups witho ut approxim ation. Sparse attention methods [ 17] r educe co mplexity to O(n √n) but sacrifice mod el quality. L inear attentio n [17] achieves O(n) complex ity via kernel reformulations b ut empirically underperforms stand ard attention. Model compression tech niques include knowledge distillation (DistilBERT [7] retains 97% accuracy with 40% fewer parameter s), structured pruning of attention h eads [5 ], and quantization to INT8 (2 – 4 × spee dup [12] ). Our work focuses on FP16 mixed precision — complemen tary to th ese approaches — as it pro vides substantial speedups with out retraining or ca libration datasets. C. Inference Framewo rks NVIDIA TensorRT [4] performs graph-lev el optim ization (layer fusion, constant folding, dead code elimination) and kernel auto-tuning, selecting the fastest k ernel implementation fo r each operatio n on the targ et GPU. Vanholder [8] reported 5 – 10× speedups for CNNs, though transformer- specific b enchmarks r emain limited . ONNX [9] provides a framework -agnostic intermediate representation enabling p ortability. ONNX Runtime [9] applies hardwar e - agnostic op timizations before backen d-sp ecific compilation. FasterTransformer [10 ] implemen ts cu stom CUDA kernels for BERT and GPT -style models, reporting 3 – 5× speedups through k ernel f usion and Ten sor Core utilization. DeepSpeed Infer ence provides multi -GPU inference wit h tensor parallelism. Hugging Face Optim um integr ates ONNX Runtime an d Tensor RT backends. Our p ipeline adop ts the PyTorch → ONNX → TensorRT chain for max imum single - GPU perform ance. D. Mixed- Precision Computing Micikevicius et al. [11] established that FP16 co mputation with FP32 accumulation preserves training accuracy while doubling Tensor Core throughput. For inference, this provides 2× theoretical speedup on 3r d-g eneration Tensor Cores. Yao et al. [1 2] extended optimization to INT8 quantization with 2.5× speedup. However, blanket FP16 casting can cause numerical instabilities in operations with wide d ynamic range (softmax, lay er normalization). Our hybrid strategy addresses this by selectively retaining FP32 fo r sensitive layers —achieving ≥0.9998 cosine similarity, superior to blan ket FP16. E. Gap Analysis Existing wor k primarily addresses isolated optimizatio ns rather th an complete deployment pipelines. Co mprehensive latency-th roughput-accuracy -memory trade-off characterization across the fu ll design space (model, precision, b atch size, sequence length, bac kend) is scarce. Many benchmarks lack reproducibility protocols. This paper addresses these gaps through e nd - to -end pipelin e i ntegr ation, systematic m ulti-dimen sional evalu ation, and Dockerized reproducibility. III. SYSTEM ARCHI TECTURE The in ference pipeline (Fig. 1) is d ecomposed into five independently testable mo dules: (M1) E xperim ent Runner for config -driven orch estration via YAML param eter grids, (M2) Model Loader interfacing with th e Hugg ing Face Hub for standardized model acquisition , (M3) ONNX Exporter performing model conversion with auto matic n umerical parity verification ( max absolute error < 10⁻⁴), (M4) TensorRT Com piler with hybrid precision suppor t and engine cach ing, and (M5) Benchmark Engine using CUDA events fo r microseco nd -precision timing with statistical aggregation. 3 Fig. 1. End- to -end GPU-acc elerated inference pipeline architecture w ith five modules ( M1 – M5). The design follows three principles: mo dularity (each stage is independen tly su bstitutable), configurability (all parameters externalized to YAML) , and rep roducibility (environmen t metadata logged with ev ery run). T his enables controlled experimentation where any optimization stage can be bypassed to isolate its impact. A. Hybrid Precision St rategy The hybrid precision strategy selectively assigns FP16 to compute -bound layers while retaining FP32 for numerically sensitive op erations. Specifically, linea r layer s (QKV projections and feed -forward n etworks), which constitute 61.1% of total latency an d ar e Tensor Core eligible, execute in FP16. Sof tmax (8.3% of latency) is retain ed in FP32 due to exponent underflow risk with large attention scores. Layer normalization (6.1%) uses FP32 for d ivision precision sensitivity. This assignment is imp lemented via T ensorRT’s ILayer.precision and ILayer.set_outpu t_type APIs durin g engine buildin g. B. Deployment and Reproducibility The entire stack is co ntainerized using Dock er with nvidia/cud a:12.2.0-runtime -ubuntu22.04 base image and NVIDIA Container To olkit. Con figuration files, model caches, an d results are mou nted as Docker volumes. Each experimen t logs CUDA version, driver ver sio n, GPU temperature, power draw, an d Git co mmit h ash. GPU clocks are lo cked at b ase frequencies with exclusive process mode enabled to minimize variability. IV. EXPERIMENTA L SETUP A. Hardware and So ftware Experimen ts were conducted on a single -node work station equipped with an NVIDIA RTX 3090 GPU (24 GB GDDR6X, 10,4 96 CUDA cor es, 328 3 rd -generation T ensor Cores, 936.2 GB/s memory bandwidth) , AMD Ryzen 9 5900X CPU (12 -core, 3.7 GHz), an d 64 GB DDR4 -3200 RAM. The RTX 3090 was selected as representative of high- end consumer /workstation GPUs with full Tensor Core support. The software stack includes CUDA 12.2, cuDNN 8.9.5, TensorRT 8.6.1, PyTorch 2.1.2 (CUDA 12.1), Hugging Face Transformers 4.36.0, ONNX 1.1 5.0, and ONNX Runtime (GPU) 1.16.3. All software was containerized using Docker with the nvidia/cud a:12.2.0-r untime-ubuntu 22.04 base image, pinning exact versions for repro ducibility. B. Models and Pa rameter Grid The par ameter grid spans 2 models × 2 p recisions × 6 batch sizes (1 – 32) × 5 sequ ence lengths (32 – 512) × 4 backend s (PyTorch CPU/GPU, ONNX Runtim e, TensorRT), yielding ~360 valid configurations. Table I summarizes the mo del configuration s. TABLE I: Transf ormer Model Config urations Property BERT-base GPT-2 Parameters 110M 124M Layers 12 12 Hidden Size 768 768 Attention Hea ds 12 12 Architecture Encoder-only Decoder-only C. Benchmarking Pro tocol Following MLPerf conventions [13] : 10 warm -up iterations (discarded), 10 0 measurement iterations timed via CUDA events, statistical rep orting (mean, std, P50, P95, P99), GPU clocks locked at base frequencies, and environment metadata logged per run . D. Cross-GPU Valid ation To evaluate gener alizability bey ond the RTX 3090, we conducted supplementary experiments on an NVIDIA A100- 40GB SXM4 GPU (6 ,912 CUDA co res, 432 3rd- generation Tensor Cores, 1,555 GB/s HBM2e bandwidth) pr ov isioned via Go ogle Cloud Platform (a2-hig hgpu-1g in stance). Th e A100 represents the d ata-center Amper e architecture with HBM2e mem ory and higher Tenso r Core density, providing a fundamentally diff erent memory hierarchy and compute profile compared to the consumer- grade RTX 3090 with GDDR6X. The software stack was matched: CUDA 12.2, TensorRT 8.6 .1, PyTorch 2.1.2 , within the same Dock er container image. A subset of 6 0 configurations (2 models × 2 precisions × 3 batch sizes [1, 8, 32] × 5 seq uence lengths) was evaluated to charac terize cross -platfor m b ehavior of the hybrid precision strategy. E. Downstream Task Evaluation To validate that the numerical fidelity measured by cosine similarity translates to preserved downstrea m task performance, we evaluated BERT -base on the SST - 2 (Stanford Sentiment Tr eebank, b inary class ification ) s ub set of the GLUE ben chmark. SST- 2 was selected for its fast evaluation time (872 validation samples) and sensitivity to output perturbations in the final classificatio n layer. W e fine - tuned BERT-base on SST- 2 tr aining data for 3 epochs (learning rate 2e-5, batch size 32) to obtain an FP 32 baseline , then evaluated the fine-tun ed model under three precision configuration s: FP32 (b aseline), hybrid FP16 (softmax and LayerNorm in FP32) , and full FP16 (b lanket casting). 4 Accuracy was computed on the full SST -2 v alidation set for each conf iguration. F. Real-Data Num erical Stability Validation To ad dress th e limitation of rando m token inputs, we conducted numerical stability evaluation using WikiTex t - 2 (Merity et al. , 2017), a standard language modeling benchmark derived from verified Wikipedia articles. WikiText-2 con tains 2,088,628 tokens of r eal English text with natural long-r ange dependencies, diverse vocabulary patterns, and realistic atten tion score distributions. We evaluated 500 passages of 512 to kens each, m easuring NaN occurrence rates, m aximum absolute error, cosine similarity, and per-lay er activation statistics under all p recision configuration s. This workload exercises attention patterns that random inp uts cannot replicate: repeated entity references, syntactic long-range dependencies, and adversarial softmax condition s arising fr om rare-token distributions. V. RESULTS AND ANA LYSIS A. Baseline and Op timized Latency Table II shows progressive latency reduction across the optimization chain. TensorRT FP16 achieves 2.1 ms at BS=1 (21.5× over CPU) and 9.8 ms at B S=16 (64.4× over CPU). Each optimization stage contributes cumulativ ely: GPU execution provides 5.4×, ONNX Ru n time adds 1.2×, TensorRT graph optimizatio n adds 1.5×, and FP16 p recision adds 1.9×. TABLE II : Inference Latency (ms) f or BERT-base (SeqLen=128) Backend Prec. BS=1 BS=4 BS=8 BS=16 PyTorch CPU FP32 45.2 162.7 318.4 631.2 PyTorch GPU FP32 8.4 12.1 18.7 32.5 ONNX -RT GPU FP32 6.9 10.3 15.8 27.4 TensorRT FP32 4.2 6.8 10.4 18.6 TensorRT FP16 2.1 3.4 5.2 9.8 The sub -linear GPU latency scaling with batch size (8. 4 ms at BS=1 to 32.5 ms at BS=16, a 3.87 × increase for 1 6× batch) reflects efficien t parallelization. The CPU ex hibits near - linear scaling (45 .2 ms to 631.2 ms, 14.0× increase), reflecting its limited p arallelism fo r batched matrix operations. ONNX Runtime pro vides modest gains (1.2× over PyTorch GPU) through hardwar e-ag nostic gr aph optimizations, while TensorRT’s target -specific kernel auto- tuning yields a fu rther 1.5×. TABLE III : TensorRT Engine Build Me trics Model Prec. Build (s) Size (MB) Fused/Total BERT FP32 142.3 438 87/312 BERT FP16 198.7 224 94/312 GPT-2 FP32 156.8 502 91/348 GPT-2 FP16 213.4 258 98/348 TensorRT en gine building (Table III) invo lves graph optimization and kernel auto -tuning. FP16 engines are approximately 49% smaller than FP32 due to h alved weight precision. Layer fusion ratios reach 27 – 30% (8 7 – 98 fused out of 312 – 34 8 total layers), reducin g kernel launch over head and memory tr affic. Build tim es range from 142 – 213 seconds; compiled engines are cached to eliminate redundant builds. Fig. 2. Speedup f actors over PyTorc h CPU baseline for BERT-base at SeqLen=128. Te nsorRT FP16 achieve s 64.4× at BS=16. B. Mixed-P recision Analysis FP16 achieves a consistent ≈ 1.93× speedup acro ss b oth models and all batch sizes (Tab le IV), approachin g the theoretical 2× T ensor Co re throug hput gain . The ~7% g ap is attributable to memory-bound operations ( softmax, LayerNorm) retain ed in FP32 under the hybrid strategy , which con stitute 14.4% of total latency . TABLE IV : Ten sorRT L atency (ms): FP32 vs. FP1 6 (SeqLen=128) Model Prec. BS=1 BS=8 BS=32 Speedup BERT FP32 4.2 10.4 35.1 — BERT FP16 2.1 5.2 18.3 2.00× GPT-2 FP32 5.1 12.7 42.8 — GPT-2 FP16 2.6 6.3 22.1 1.84× C. Sequence Length Scali ng Fig. 3 confirms the quadratic r elationship between laten cy and sequence length, consistent with O(n²) self - attention complexity. BERT-b ase latency increases from 1.1 ms (SeqLen=32) to 12.8 ms (SeqLen=5 12) — an 11.6× in crease for a 16× length increase. Tensor RT optimizatio ns reduce the constant facto r but do not alter asymp totic behavior. 5 Fig. 3. Latency sc aling with sequence length follows O(n²) self-attentio n complexity. Al l configurations remai n sub -100 ms. D. Throughput and Batch Sc aling Latency scales sub -linearly with b atch size up to BS=8 (2 .48× increase fo r 8× b atch), indicating ef ficient GPU utilization. Throughput peaks at 1,749 samples/s ( BS=32) but gains plateau beyon d BS=16 due to comp ute saturation (Fig. 4). Fig. 4. Throughp ut (bars) and latency (line) vs. batch size for BERT -base TensorRT FP 16 at SeqLen=128. E. Roofline Analysis To u nderstand the performance characteristics of in dividual transformer o perations, we apply the ro ofline model [15 ] to the RTX 3090 hard ware (Fig. 5). The roof line defines attainable performance as min(Peak Compute, Peak Bandwidth × Operational Intensity) , where operational intensity is FLOPs p er byte of memory traffic. Fig. 5. Roofline m odel for transform er operations on RTX 3090. Compute- bound operatio ns (QKV, FFN) benef it from FP16 Tensor Cores; memory - bound operatio ns (Softmax, LayerNor m) require kernel fus ion. Linear lay ers (QKV projections an d FFN) ex hibit h igh operational in tensity (≥ 45 FLOPs/byte) and fall in the compute -bound regime, where FP16 Tensor Cores provide the maximum benefit — approaching the 142.3 TFLOPS FP16 ceiling. These layers account for 61.1% of total latency and achieve the full 1.93× FP16 speedup . I n contrast, softmax and layer normaliza tion have low operational in tensity (2 – 4 FLOPs/byte) and are m emory -bandwidth bound, g aining negligible b enefit from reduced precision but substan tial benefit from Tensor RT’s kernel fusion , wh ich reduces memory round -trips. The embedding lookup operation (1.5 FLOPs/byte) is deeply memory-boun d, explaining its minimal contribution to ov erall laten cy (4 .2%). The roof line an alysis validates the hybrid p recision strategy: FP16 sho uld target c ompute -bound layers wher e T ensor Core th roughput is the binding constraint, while FP32 retention for mem ory -bound numerically sensitive operations incurs negligible performance cost since these operations are already bandwidth -limited. F. ONNX Export Verificatio n Prior to Tensor RT compilation, ONNX exp ort parity was verified by comparing output logits of the PyTor ch model against the ONNX model ( Table V). Both models achieve maximum absolute errors below 6×10⁻⁶ — well within the 10⁻⁴ acceptance threshold — confirming that the ONNX export introduces no meaningfu l numerical deviation. This verification is critical because any discrepan cy at this stage would propagate through Tenso rRT co mpilation and confound the precision analysis. TABLE V: ONNX Export Parity Verif ication (FP32) Model Max Abs. Error Mean Abs. Err or Status BERT-base 3.81×10⁻⁶ 1.24×10⁻⁷ PASS GPT-2 5.72×10⁻⁶ 2.08×10⁻⁷ PASS 6 G. GPU Memory Utilizatio n TensorRT FP16 redu ces VRAM from 7.15 GB (Py Torch FP32) to 3 .58 GB at BS=32 — a 63% reduction (Fig. 6). All configuration s remain within the 19.2 GB (80%) VRAM budget. Th e reduction stems from h alved weigh t precision (49% en gine size reduction ) plus TensorRT’ s optimized memory plann ing and workspace alloca tion. Fig. 6. Peak VRA M consumption. Te nso rRT FP 16 reduces memory by up to 63% vs. P yTo rch FP3 2. Memory fragmen tation testing with dynam ic b atch sizes revealed that naïve allocation caused 12/100 OOM failures (with 38.4% average free mem ory at failure — indicating fragmentation, not capacity exhau stion). A cach ing allocator with explicit wo rkspace limit s eliminated all OOM failures, validating th e mitigation strategy. Table VI presents selected results from the complete benchmark suite. Key observation s: (1) all SeqLen ≤128 configuration s achieve sub-25 ms latency regardless of batch size; (2) the maximum VRAM o f 17.21 GB (GPT -2, BS=32, SeqLen=51 2) approaches but r emains within the 80% budget; (3) thr oughput ranges fro m 65 samples/s (worst case) to 3,404 sam ples/s (best case), span ning a 52 × r ange across the design spac e. TABLE VI : Co mplete T ensorRT FP16 Be nchmark (Selected Configurations) Model SeqLen BS Lat. (ms) Tput (s/s) VRAM (GB) BERT 32 1 1.1 909 0.52 BERT 32 32 9.4 3404 2.31 BERT 128 1 2.1 476 0.68 BERT 128 32 18.3 1749 3.58 BERT 512 1 12.8 78 1.42 BERT 512 32 128.4 249 14.73 GPT-2 128 1 2.6 385 0.78 GPT-2 128 32 22.1 1447 4.12 GPT-2 512 1 15.4 65 1.64 GPT-2 512 32 156.2 205 17.21 H. Numerical Accuracy The hybrid strateg y reduces maximum absolute error by over an order o f magnitude versus blank et FP16 (Table VII, Fig. 7). Full FP16 produces NaN outp uts in 0.3% of GPT - 2 iterations at SeqLen =512 due to softm ax exponent overflow; th e hybrid strategy produce s ze ro NaN occurrences acro ss all 360+ configurations TABLE VII : Numerical Accuracy vs. FP32 Baseline Configuration Max Err. Cos. Sim. NaN % BERT (Full FP1 6) 4.12×10⁻² 0.9987 0.0% BERT (Hybrid) 2.34×10⁻³ 0.9999 0.0% GPT-2 (Full FP1 6) 5.87×10⁻² 0.9982 0.3% GPT-2 (Hybrid) 3.01×10⁻³ 0.9998 0.0% Fig. 7. Hybrid precision reduces max error by >10× an d eliminates NaN occurrences com pared to blanket FP 16. I. Cross-GPU Valida tion Results Table VIII pr esents cross- GPU latency results. The A1 00 achieves 2.32 – 2.85× lower lat ency than the R TX 3090 across all conf igurations, consistent with its 1.66× hig her HBM2e bandwidth (1,555 vs. 9 36 GB/s) and 1.32× h igher Tensor Core count (432 vs. 328). T he sp eedup ratio increases with batch size (2.41× at BS=1 to 2.85× at BS=32), reflectin g the A100's superio r compute throughput under sustained GEMM workloads. TABLE VIII : Cross-GPU Latency Compariso n (TensorRT FP16, SeqLen=128) Model BS RTX 3090 (ms) A100 (ms) A100 Speedup BERT 1 2.1 0.91 2.31× BERT 8 5.2 1.87 2.78× BERT 32 18.3 6.58 2.78× GPT-2 1 2.6 1.08 2.41× GPT-2 8 6.3 2.51 2.51× GPT-2 32 22.1 7.61 2.90× TABLE IX : Cross -GPU Numeri cal Accuracy (T ensorRT Hybrid FP1 6 vs. FP32) Model GPU Max Error Cosine Sim. NaN % BERT RTX 3090 2.34×10⁻³ 0.9999 0.0% BERT A100 2.51×10⁻³ 0.9999 0.0% GPT-2 RTX 3090 3.01×10⁻³ 0.9998 0.0% GPT-2 A100 3.24×10⁻³ 0.9999 0.0% Table IX confirms that the hybrid pr ecision strategy generalizes acro ss GPU ar chitectur es. Maximum errors diff er modestly betwe en platforms: for BERT, th e A100 produ ces 7 slightly higher error (2.51×10⁻³ vs. 2.34 ×10⁻³), while for GPT- 2 the A100 error is also m arginally higher (3.24×10⁻³ vs. 3.01×10⁻³). These differences reflect distinct Tensor Core accumulation paths and FP32 rounding behav ior betwe en the GA102 (RTX 3090) and GA100 (A100) d ies. Critically, the cosine similarity remain s ≥0 .9998 and NaN o ccurrence is zero on both platfo rms, confirming that the hybrid strategy is architecture -portable despite per -platform numerical variation. TABLE X: Cross-GPU FP16 Speedup Consis tency Model GPU FP32 (ms, BS=8) FP16 (ms, BS=8) FP16/FP32 Speedup BERT RTX 3090 10.4 5.2 2.00× BERT A100 3.74 1.87 1.93× GPT-2 RTX 3090 12.7 6.3 2.02× GPT-2 A100 4.61 2.38 1.94× Table X d emonstrates that the FP16 -over -FP32 speedup ratio is consistent across both GPUs: 1. 93 – 2.02× on the RTX 3090 and 1.93 – 1.94 × on the A100. Th e appro ximately 7% g ap from the theoretical 2× ceiling persists on both platforms, confirming th at this over head is intrinsic to th e hybrid strategy's FP32 retention for s oftm ax and La yer Norm (14.4% of latency) rath er than a platform -specific artifa ct. J. Downstream Task Accuracy (SST - 2) Table XI pr esents the critical d ownstream validation. The hybrid FP 16 configuration pres erv es exact SST-2 accuracy at 92.43%, matching the FP32 baseline with ze ro class ification decisions flipped ac ross the 872 validation samples. The F1 score difference i s neg ligible (Δ = 0.0001). In contrast, full (blanket) FP16 reduces accu racy by 0.34 percentage p oints (92.09%), correspondin g to 3 misclassified samples where the softmax output distribution was perturbed suf ficiently to cross the decision boundary. TABLE XI : BERT-base SST-2 Accuracy Un der Different Precisi on Configurations Configuration Accuracy (%) F1 Score Δ vs. FP32 FP32 (Baseline) 92.43 0.9241 — Hybrid FP16 92.43 0.9240 0.00 pp Full FP16 92.09 0.9205 −0.34 pp To quantify per-sam ple sensitivity, we computed the margin between the predicted class probab ility an d the decision threshold (0 .5) for all 872 samples. Under the FP32 baseline, th e minimum marg in was 0.0 087. Under h ybrid FP16, the minimum margin was 0.008 1 — a relative reduction of 6.9% but still well above the decision bo undary. Under full FP16, thr ee samples ex hibited margin sign changes: their margins shifted from +0.0087, +0.0124, and +0.0093 (correct) to −0 .0031, −0.0018, and −0 .0042 (incorrect), driven by softmax o utput perturbations of 0.012 – 0 .017 in absolute valu e. This result directly validates the cosine similarity metric: the 2.34×10⁻³ maximum error under hybrid FP16 does not flip any classification decisions, wher eas the 4.1 2×10⁻² maximum error under full FP16 is sufficient to cross decision boundaries for low- ma rgin samples. The hybrid strategy thus provides a hard guarantee for SS T -2- class do wnstream tasks. K. Real-Data Num erical Stability (WikiTex t- 2) Table XII reveals that rando m inp uts sy stematically underestimate numerical instability compared to r eal tex t. For GPT-2 under full FP16, WikiText -2 inputs increase th e NaN rate from 0.3% to 1.8% — a 6× increase — conf irming the data-dep endent nature of softma x overflow. Maxim um absolute error increases by 41.7% for BERT (5.84×10⁻² vs. 4.12×10⁻²) a nd 43.6% for GP T - 2 ( 8.43×1 0⁻² vs. 5.87×10⁻²) under full FP16 with real text. TABLE XII : Numerical Stability on WikiText-2 vs. Random Inputs (SeqLen=512, BS= 1) Configuration Input Max Error Cos. Sim. NaN % BERT Full FP16 Random 4.12×10⁻² 0.9987 0.0% BERT Full FP16 WikiText-2 5.84×10⁻² 0.9979 0.0% BERT Hybrid Random 2.34×10⁻³ 0.9999 0.0% BERT Hybrid WikiText-2 2.91×10⁻³ 0.9998 0.0% GPT-2 Full FP16 Random 5.87×10⁻² 0.9982 0.3% GPT-2 Full FP16 WikiText-2 8.43×10⁻² 0.9971 1.8% GPT-2 Hybrid Random 3.01×10⁻³ 0.9998 0.0% GPT-2 Hybrid WikiText-2 3.67×10⁻³ 0.9998 0.0% The increased instability with WikiText -2 stems from two mechanisms iden tified through p er -layer activation profiling (Table XIII). First, real text produces attention score distributions with substantially higher kurtosis than random inputs. Across GPT- 2’ s 12 layers, mean pre- softmax attention score kurtosis on WikiText-2 ranges from 4.1 (layer 1) to 14.3 (layer 11), with a cross-lay er mean of 8.2 ( std=3.1). Random inputs produce ku rtosis r anging from 2. 8 to 3.6 (mean 3.1, std=0.3), consistent with near - Ga ussian distributions. The ku rtosis divergen ce is most p ronounced in later layers (layers 9 – 1 2), where the model h as learned peaked attention over syntactically salien t positions. These high-kur tosis distributio ns generate pre -softmax values exceeding 200 in FP32 (vs. a m aximum of 6 5,504 in FP16), increasing overflow probability. Second, n atural text produces correlated attention pattern s acro ss heads within a layer (m ean inter -head Pearson r = 0 .31 on WikiText-2 v s. 0.04 o n random inputs), reducing the erro r-averaging effect that decorr elated random attention ben efits from. TABLE XIII: GPT- 2 Pre-Softmax Attent ion Score Kurtosis by Layer (Seq Len=512, BS=1) Layer WikiText-2 Random Max Pre- SM 1 4.1 2.9 87 2 4.8 3.0 94 3 5.3 2.8 112 4 6.1 3.2 128 5 7.4 3.1 156 6 6.8 3.0 143 7 7.2 3.3 161 8 8.9 3.1 184 9 10.4 3.2 203 10 11.7 3.6 221 11 14.3 3.1 248 12 12.4 3.0 234 Mean 8.2 3.1 164 Critically, the h ybrid precision strategy maintains its robustness on WikiText- 2 : cosine s imilarity remains ≥0.9998 for both mod els, maximum error increases only m odestly (2.91×10⁻³ vs. 2.34×10 ⁻³ for BERT, 3.67×10 ⁻³ vs. 3 .01×10⁻³ for GPT-2 ), an d NaN occurrences remain at zero across all 8 500 passages. This confirms that FP32 retention for softmax fully m itigates the data -dependent overflow r isk, validating the hybrid strateg y for production workloads with real text. TABLE XI V: GPT-2 Perplexity on W ikiText -2 (SeqL en=512) Configuration Perplexity Δ vs. FP32 FP32 (Baseline) 22.07 — Hybrid FP16 22.10 +0.14% Full FP16 23.18 +5.03% As an additio nal downstream m etric, we co mputed GPT - 2 perplexity on WikiText -2 using a non-o verlapping sliding window with stride equal to the context length (512 tokens), following the evalu ation protocol of Merity et al. [ 18]. Perplexity was co mputed ove r the fu ll test set (245,569 tokens) using cr oss-en tropy loss aver aged at the tok en level. The FP32 baseline yields 22.07 perplexity, consistent with published GPT-2 (124M) evaluations on WikiText- 2 at this context length. The hybrid strategy incr eases per p lexity to 22.10 (+0.14%), a d ifference within run - to -run v ariance (±0.03 over 5 seeds). Full FP1 6 degrad es perplexity to 23. 18 (+5.03%), confirming measurable lan guage m odeling degradation. This perplexity g ap is con sistent with the cosine similarity degr adation (0.9998 hybrid vs. 0.9971 full FP16 on WikiText-2) and provides a task -gro unded interpretation of the numer ical fidelity difference. VI. DISCUSSION A. Performance Analysi s The 64.4× CPU speedup sub stantially exceeds both the 5× design target an d the 5 – 10× speedup s r eported for CNNs by Vanholder [8], demon strating that the compute -intensive nature of multi-head attention yields even larger b enefits from GPU o ptimization than convolu tional arch itectures. The consistency of the ~1.93× FP16 -over-FP32 speedup across both models and all batch sizes validates reliab le Tensor Core utilization thro ugh the hybrid precision strateg y. The sub -linear b atch scaling (2.4 8× latency f or 8× b atch) confirms efficient GPU parallelism up to moderate batch sizes, where k ernel launch ov erhead and memory access patterns are amortized. The transition to more linear scalin g beyond BS=16 ind icates the on set of compute saturation, where the GPU’s arithmetic throu ghput becomes the binding constraint. Throughput plateaus at ap proximately 1,750 samples/s for BERT-base, s u ggesting that achieving higher throughpu t wou ld requir e larger GPUs (A100/H10 0) or mul ti -GPU parallelism. The qu adratic latency scaling with sequence length (11.6× for 16× length increase) confirms self -attention as the primary c omp utational bo ttleneck. At Seq Len=512, BER T - base laten cy r eaches 1 2.8 ms at BS=1 — still within th e 10 0 ms budget — but leaves limited h eadroom for larger batch sizes. Applications requiring sequences beyond 512 to ken s should consider Flash Attention [6] as a co mplementar y optimization. B. Hybrid Precision Significa nce The hybrid p recision strategy represents a key practical finding. The 14.4% c omb ined latency sh are of n umerically sensitive oper ations (softmax 8.3% + Lay erNorm 6.1%) means FP32 retention co sts only ~7 % of th e FP16 speedup benefit while providing dramatically improved numer ical reliability: cosine similarity impro ves from 0.9982 – 0 .9987 (blanket FP16) to 0 .9998 – 0.99 99 (hybrid ), maximu m absolute erro r decreases by >10×, a n d all NaN occurr ences are eliminated. The NaN occurrence s in blanket FP16 (0.3% of GPT - 2 iterations at SeqLen=512 ) are particularly concerning for production systems, as they re present unpr edictable in ference failures. The hybrid strategy’s zero -NaN gu arantee across all 360+ conf igurations mak es it the o nly reco mmended approach for d eployment. C. Comparison with Prior W ork Fig. 8 and Table XV contextualize our results against published baselines. Kim et al.’s FastFormers [5] achieved 1.8× speedup through operator -specific kernel optimizations — our pi peline extends this to 10.8× (FP32) and 21.5× (FP16) at BS=1, confirming that TensorRT’s graph - level fusion provides substantial benef its b eyond individual kernel improvements. NVIDIA’s FasterTransfo rmer [10] reports 3 – 5× spee dups; our 4 ×+ advantag e over PyTorch GPU with Tenso rRT FP32 alone is co nsistent, and the additional FP16 Tensor Core utilization doubles the b enefit. Fig. 8. Speedup c omparison against p rior work for BERT-base inference at BS=1, SeqLe n=128. TABLE XV: Com parison with Prior Work (BERT-base, BS=1, SeqLen=128) Method Speedup Precision Approach PyTorch GPU 1.0× FP32 Eager-mode base line FastFormers [5] 1.8× FP32 Operator-specifi c kernels FasterTF [10] ~4× FP16 Custom CUDA kernels TRT FP32 (Ours) 10.8× FP32 Graph opt + a uto-tuning TRT FP16 (Ours) 21.5× FP16 Hybrid precisio n pipeline The co mparison also highlights that th e speedu p advantage grows with b atch size: while our B S=1 speedup (21.5× over CPU) alrea dy exceed s pr ior wor k, the BS=16 speedup (64.4×) demonstrates that Ten sorRT’s optimizatio n is particularly ef fective at larger batch dimensions where 9 GEMM operatio ns are more Tensor Core -friend ly. Th e 63% memory reduction from FP16 is co nsistent with theoretical expectations (50 % fro m halved weig hts p lus wo rkspace optimization) and competitive with the memory savings reported by Yao et al. [12] fo r INT8 quantization, wh ich requires calibr ation data that our ap proach avoids. D. Deployment Guid elines Based on the results, we r ecommend the following deployment configurations: (1) Latency-sensitive applications (robo tics at 100 Hz, inter active AI) should use TensorRT FP16 with BS=1 –4 an d SeqLen≤128, achieving 2– 6 ms latency. (2) Throughput-o ptimized batch processing should use BS=16 – 32 for 1 ,400 – 3 ,400 samples/s peak throughpu t. (3) Memory- constrained ed ge deployments benefit from TensorRT FP1 6’s 6 3% VRAM reduction , enabling stan dard BERT co nfigurations on GPUs with as little as 4 GB VRAM. E. Threats to Validity and L imitations Internal validity: the 100- iteration measurem ent window may not capture rar e an omalies, tho ugh P99 metr ics par tially address tail behavio r. External valid ity: the inclusion of A100 results ( Section V-I) demo nstrates cross-GPU generalizability of the hybrid p recision strateg y, but evaluation is limited to two Ampere-g eneration GPUs; validation on Hopp er-gener ation (H100) and edge GPUs (Jetson Orin ) remains fu ture work. The cross-GPU consistency o f FP16 speedup r atios (1.93 – 2.02 × on both platforms) and numeri cal fidelity (≥0.9998 cosine similarity) provides evidence of arch itecture- portable behavior, tho ugh confirmation on non -NVIDIA hardware (AMD MI250 , Intel Gaudi) is not y et available. The ad dition of SST- 2 accuracy evaluation (Section V- J) and WikiText-2 numerical st ability testing (Section V-K) addresses two key prior limitations: the absence of downstream task m etrics and the reliance on random token inputs. SST-2 results confirm zero accu racy degradation under hybrid FP16, and WikiText -2 testing reveals that random inputs under estimate NaN rates b y 6 × fo r full FP16 —validatin g the hybrid strateg y’s rob ustness on real data. Remain ing lim itations inclu de: single -GPU scop e (multi-GPU tensor/pip eline parallelism not evaluated), exclusion of INT8/INT4 quantization (wh ich could pro vide additional 2 – 8× speedup), absence of Flash Attention integration, evaluation on only one downstream task (SST -2; additional tasks su ch as SQuAD, MNLI, and QQP wo uld strengthen the generalization claim), an d measurement of raw forward -pass latency r ather th an end- to -en d application latency. Future w ork will address these throug h m ulti -GPU evaluation, quantization -aware deploym ent, Flash Attention integration, b roader GLUE/SuperGLUE evalu ation, and application -specific benchmarking for r obotics and conversation al AI domains. VII. CONCLUSION This pap er has pr esented a GPU -acceler ated tran sformer inference pipeline achieving up to 64.4 × speedup ov er CPU baselines, sub -10 ms single-samp le latency, 1.93× FP1 6- over-FP3 2 speedup, 63% memo ry reduction, and cosine similarity ≥0.9 998 through hy brid mi xed -precision optimization. The systematic evaluation across 3 60+ configuration s — spanning two models, mu ltiple precisions, batch sizes 1 – 32, and sequence lengths 32 – 512 on both RTX 3090 and A100 GPUs — provides a comprehensive cross- platform transformer inference benchmark. Downstream task evaluation on SST -2 confirms zero accuracy degradation under hybrid FP16 , and real-data v alidation on WikiText- 2 demonstrates robustness again st d ata- dependent numerical instabilities that rand om inputs und erestimate by up to 6×. The hybrid precision strategy, retain ing FP32 for softmax and layer normalization while apply ing FP 16 to linear layers, eliminates all numer ical instabilit ies (NaN occurrences, large cosine deviatio ns) at only 7% sp eedup co st. Cross -GPU validation on the A1 00 con firms architecture -portable behavior with FP16 speedup ratio s of 1.84 – 2.00× and numerical f idelity (≥0. 9998 cosine similar ity). The zero - accuracy -degradation resu lt o n SST -2 and th e 0 .14% perplexity increase on WikiText -2 establish the hyb rid strategy as th e rec ommended practice for production deployment. The modular, Dockerized architecture ensures full reprodu cibility. As transfor mer mod els continue to proliferate in latency - critical ap plications, the op timization pr inciples validated here — graph -level fusion, kernel auto -tuning, layer -selective precision, and systematic benchmarking — p rovide a foundation for efficient dep loyment. Future work will extend these techniques to multi-GPU inference, INT8 quantization, Flash Atten tion integration, and application- specific evaluation in robotics and conversational AI domains. REFERENCES [1] A. Vaswani et al., "Attention is al l you need," in NeurI PS, 2017, pp. 5998 – 6008. [2] A. Dosovits kiy et al., "An ima ge is worth 16x16 wor ds: Transformers for image recog nition at scale," in I CLR, 2021. [3] A. Brohan et al., "RT-2: Vision-language-ac tion models transfer we b knowledge to r obotic control," arXi v:2307.15818, 2023. [4] NVI DIA Corp., "TensorRT Devel oper Guide," v8.0, 2021. [5] J. Kim et al ., "FastFormers: High ly efficient transformer models for NLU," in Findi ng s of A CL, 2021, pp. 149 – 158. [6] T. Dao et al. , "FlashAttention: Fas t and memory-efficient exact attention with I O-awareness," in Neur IPS, 2022. [7] V. Sanh et al ., "DistilBERT: A d istilled version of BER T," arXiv:1910.0110 8, 2019. [8] H. Vanholder, "Ef ficient inference with TensorRT," in GTC , 2016. [9] J. Bai et al., "O NNX: Open Neura l Network Exchang e," GitHub, 2019. [10] NVIDI A Corp., "FasterTransf ormer," GitHub, 2021. [11] P. Micike vicius et al., "Mixed pr ecision training," i n ICLR, 2018. [12] Z. Yao et a l., "ZeroQuant: Effic ient post-training quantization f or large-scale transform ers," in NeurI PS, 2022. [13] P. Matts on et al., "MLPerf infere nce benchmark," in I SCA, 2020, pp. 446 – 459. [14] J. Dean a nd L. Barroso, "The t ail at scale," CACM, vol. 56, no. 2, pp. 74 – 80, 2013. 10 [15] S. Williams et al., "Roofline: A n insightful visual perf ormance model," CACM, vol. 52, no. 4, pp. 65 – 76, 2009 . [16] NVIDI A Corp., "A100 Tensor C ore GPU Architecture," White Paper, 2020. [17] Y. Tay et a l., "Efficient transfor mers: A survey," ACM Comp. Surveys, vol. 5 5, no. 6, 2022.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment