C2RustXW: Program-Structure-Aware C-to-Rust Translation via Program Analysis and LLM
The growing adoption of Rust for its memory safety and performance has increased the demand for effective migration of legacy C codebases. However, existing rule-based translators (e.g., \ctorust) often generate verbose, non-idiomatic code that prese…
Authors: Yanyan Yan, Yang Feng, Jiangshan Liu
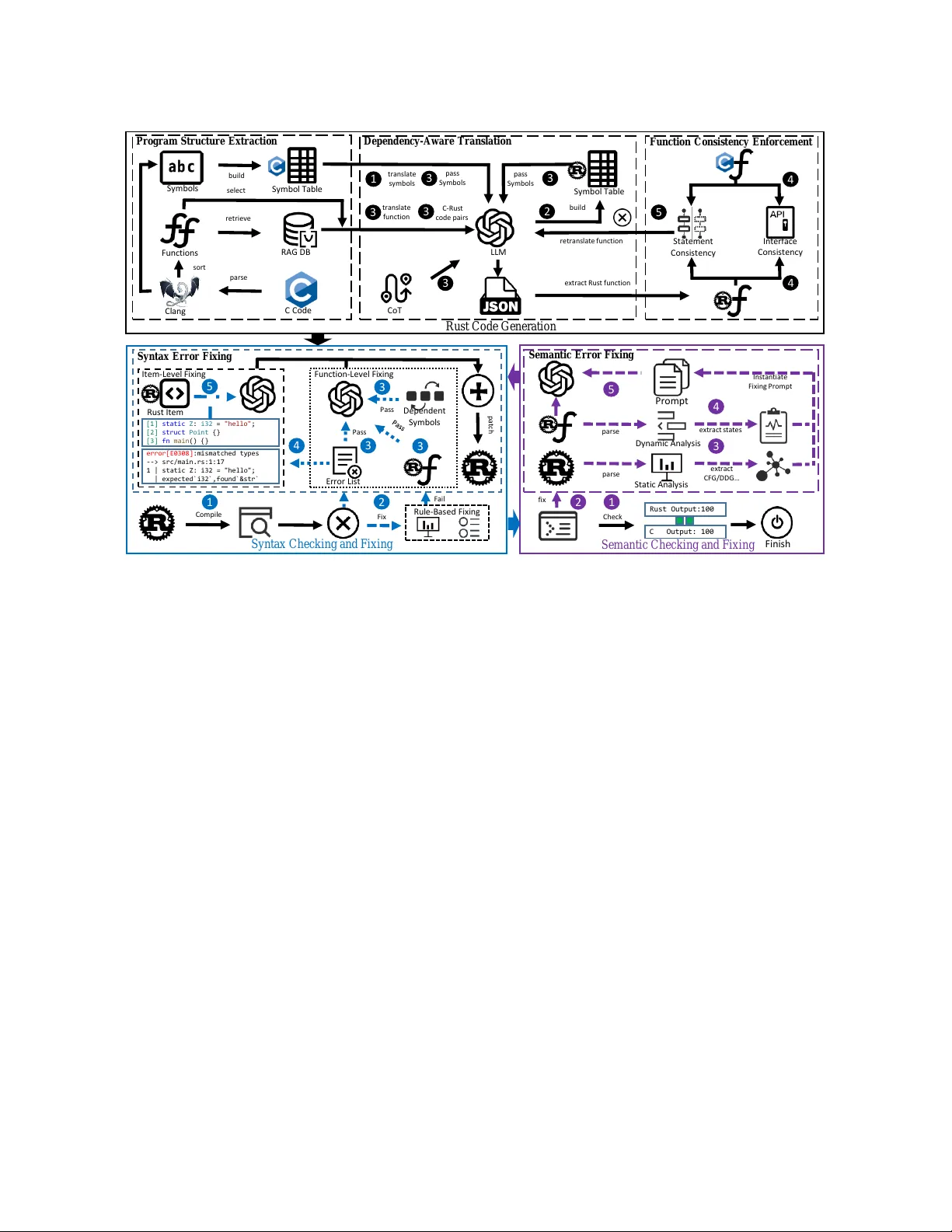
C2RustX W: Program-Structur e- A ware C-to-Rust T ranslation via Program Analysis and LLM Y anyan Y an yanyanyan@smail.nju.edu.cn State Ke y Laborator y for Nov el Software T echnology , Nanjing University Nanjing, JiangSu, China Y ang Feng ∗ State Ke y Laborator y for Nov el Software T echnology , Nanjing University Nanjing, China fengyang@nju.edu.cn Jiangshan Liu State Ke y Laborator y for Nov el Software T echnology , Nanjing University China jiangshanl@smail.nju.edu.cn Di Liu Jiangsu Police Institute China diliujspi@gmail.com Zixi Liu State Ke y Laborator y for Nov el Software T echnology , Nanjing University China zxliu@smail.nju.edu.cn Hao T eng State Ke y Laborator y for Nov el Software T echnology , Nanjing University China 221250008@smail.nju.edu.cn Baowen Xu State Ke y Laborator y for Nov el Software T echnology , Nanjing University China bwxu@nju.edu.cn Abstract The growing adoption of Rust for its memor y safety and perfor- mance has increased the demand for eective migration of legacy C codebases. Ho wever , existing rule-based translators ( e.g., C2Rust) often generate verbose, non-idiomatic code that preserves unsafe C semantics, limiting readability , maintainability , and practical adoption. Moreover , manual post-processing of such outputs is labor-intensive and rarely yields high-quality Rust code, posing a signicant barrier to large-scale migration. T o address these limitations, we present C2RustXW, a program- structure-aware C-to-Rust translation appr oach that integrates pro- gram analysis with Large Language Models (LLMs). C2RustX W ex- tracts the multi-level program structur e, including global symbols, function dependencies, and control- and data-ow information, and enco des these as structured textual representations inje cted into LLM prompts to guide translation and repair . Based on this design, C2RustX W performs dependency-aware translation and adopts a multi-stage repair pipeline that combines rule-based and structure-guided LLM-base d techniques to ensure syntactic cor- rectness. For semantic correctness, C2RustXW further integrates ∗ Y ang Feng is the corresponding author. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for prot or commercial advantage and that copies bear this notice and the full citation on the rst page. Copyrights for components of this work owned by others than the author(s) must be honor ed. Abstracting with credit is permitted. T o copy other wise, or republish, to post on servers or to redistribute to lists, r equires prior specic permission and /or a fee. Request permissions from permissions@acm.org. Conference acronym ’XX, W o o dstock, NY © 2018 Copyright held by the owner/author(s). Publication rights licensed to A CM. ACM ISBN 978-1-4503-XXXX -X/2018/06 https://doi.org/XXXXXXX.XXXXXXX execution-based validation with structure-guided reasoning to lo- calize and repair behavioral inconsistencies. Experimental results show that C2RustXW achieves 100% syntactic correctness on Co- deNet and 97.78% on GitHub , while signicantly reducing code size (up to 43.70%) and unsafe usage (to 5.75%). At the project level, C2RustXW achieves perfect syntactic correctness and an average semantic correctness of 78.87%, demonstrating its eectiveness for practical and scalable C-to-Rust migration. CCS Concepts • Softwar e and its engineering → General programming lan- guages ; Program analysis ; • Computing methodologies → Machine learning . Ke ywords Structure- A ware Information, Program Analysis, Program T ransla- tion, Large Language Model A CM Reference Format: Y anyan Y an, Y ang Feng, Jiangshan Liu, Di Liu, Zixi Liu, Hao T eng, and Baowen Xu. 2018. C2RustXW: Program-Structure- A ware C-to-Rust Translation via Program Analysis and LLM. In Proceedings of Make sure to enter the correct conference title from your rights conrmation email (Conference acronym ’XX). A CM, New Y ork, N Y , USA, 12 pages. https://doi.org/XXXXXXX.XXXXXXX 1 Introduction Rust has gained signicant adoption due to its str ong memory- safety guarantees and competitive performance, making it an ap- pealing target for migrating legacy C codebases prone to memory errors and undened behaviors. Howe ver , the scale of existing C systems and the high cost of manual rewriting pose substantial Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Trovato et al. barriers to practical migration. A utomated translation tools such as C2Rust [ 3 ] provide an initial pathway by converting C co de into Rust while preserving original semantics, but their outputs are often non-idiomatic and heavily rely on unsafe constructs. As a result, these translations typically require extensiv e manual refac- toring to achieve safe, maintainable Rust code, thereby limiting their usability in real-world engineering workows. Existing C-to-Rust translation approaches face fundamental lim- itations. Manual translation is costly and error-prone, requiring experience in both languages, and even idiomatic Rust co de still contains 20–30% unsafe usage. [ 18 , 33 ]. A utomated pipelines such as C2Rust generate largely unsafe Rust code and often increase code size [ 44 ], with over 90% of functions remaining unsafe [ 23 ], thus aecting Rust’s safety goals [ 8 ]. Learning-based approaches [ 21 ] are limited by the scarcity of high-quality parallel C–Rust corpora and high training costs. Recent LLM-base d methods attempt direct translation, but still achieve limited success rates ( e.g., below 40% on real-world pr ojects [ 9 ]). These challenges highlight the need for a translation approach that can simultaneously ensur e structural delity , syntactic correctness, and semantic safety . In this paper , we present C2RustXW, a program-structure-aware C-to-Rust translation approach that integrates static program anal- ysis with LLM-base d generation and repair . Unlike previous ap- proaches that rely on implicit conte xt, C2RustXW e xplicitly models the program structure , including global symbols, function depen- dencies, and control- and data-ow information, and transforms these structures into textual r epresentations that are injected into LLM prompts. This design enables dependency-aware translation with consistent interfaces and structure-guided repair through a multi-stage pip eline combining rule-based and LLM-based tech- niques. T o ensure semantic correctness, C2RustXW further incor- porates dierential testing and structure-guided r easoning using control- and data-ow information and runtime states. For multi- le C projects, C2RustXW extends this design by modeling inter- le dependencies and constructing a unied structural represen- tation, enabling consistent and scalable translation. W e evaluate C2RustXW on benchmark datasets and real-world C pr ojects. At the le level, C2RustXW achieves 100% syntactic correctness on Co- deNet and 97.78% on GitHub, with high semantic accuracy . At the project level, C2RustX W achieves p erfect syntactic corr ectness and an average semantic correctness of 78.87%. In addition, C2RustX W signicantly reduces code size (up to 49.60%) and unsafe usage. These results demonstrate that C2RustX W can produce concise, safe, and semantically consistent Rust code for both le-level and project-level translation. Our contributions are summarized as follows: • A program-structure-aware translation framework. W e pro- pose C2RustX W, a C-to-Rust translation framework that explic- itly models multi-level program structure, including global sym- bols, function dep endencies, and control- and data-ow infor- mation. C2RustXW systematically transforms these structures into textual representations and injects them into LLM prompts, enabling structure-aware translation that preserves dependency consistency and extends from single les to multi-le projects. • A structure-guided translation and repair pipeline. W e de- sign a unied pipeline that integrates structure-aware transla- tion with multi-stage repair . The pipeline combines deterministic rule-based xing with LLM-based r epair at the function and item levels, where program structure is explicitly encoded in prompts to guide consistent, structure-aware xing. For semantic correct- ness, C2RustXW uses dierential testing with structure-guided reasoning, integrating control- and data-ow information and runtime states to repair behavioral inconsistencies. • Comprehensive evaluation on benchmarks and projects. W e evaluate C2RustXW on Co deNet, a GitHub dataset, and mul- tiple real-world C projects. The results show that C2RustXW achieves up to 100% syntactic correctness and strong semantic correctness, while signicantly reducing code size and unsafe usage compared to existing approaches. These results demon- strate the eectiveness of C2RustXW for practical and scalable C-to-Rust migration. 2 Background 2.1 Rust O verview Rust has gained widespread adoption due to its strong memory- safety guarantees and competitive p erformance, making it a promis- ing alternative to C/C++ for systems programming. Its safety model is built on ownership, borrowing, and lifetimes, which enforce mem- ory safety at compile time and eliminate common errors such as null dereferences, data races, and memory leaks without r elying on garbage colle ction. This design enables ecient and concurrent sys- tems while retaining ne-grained control over hardware resources. Howev er , migrating C/C++ codebases to Rust remains challeng- ing due to fundamental dierences in memory management, type systems, and abstraction mechanisms. Although Rust supports in- teroperability with C/C++ through foreign function interfaces (FFI) and provides unsafe constructs for low-level operations, excessive reliance on unsafe undermines Rust’s safety guarantees and re- duces maintainability . Therefore, achieving semantic preservation while minimizing unsafe usage is a central challenge. 2.2 C-to-Rust Challenges Translating legacy C code to Rust remains challenging due to fun- damental dierences in memor y safety mo dels and language ab- stractions. Existing rule-base d tools such as C2Rust [ 39 ] provide an initial solution by preserving C semantics, but rely heavily on unsafe constructs and FFIs, which bypass Rust’s safety guarantees. Prior work shows that such translations can signicantly inate code size and produce co de that is almost entirely wrappe d in unsafe [ 44 ], undermining Rust’s core advantages. Furthermore, the generated code often mixes C-style constructs, low-level types (e .g., libc::c_int ), and external interfaces (e.g., malloc ), resulting in verbose and non-idiomatic implementations that are dicult to maintain. Handling complex C features, such as macr os and low- level system interactions, further complicates translation [ 4 ], and even when successful, the resulting code often requires substantial manual renement. These limitations highlight the need for ap- proaches that not only preserve semantics but also improve safety , code quality , and structural consistency , motivating the integration of program analysis with LLM-based techniques. C2RustXW: Program-Structure-A ware C-to-Rust Translation via Pr ogram Analysis and LLM Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y T able 1: Approaches and their features for C-to-Rust translation Baseline Methodology Syntax xing Semantic xing Granularity Mode OpenSource Rules LLM LLM Rules LLM Rules function le project Transpile Refactor C2RustXW ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✓ C2Rust ✓ ✓ ✓ ✓ ✓ C2SaferRust ✓ ✓ ✓ ✓ ✓ ✓ ✓ GenC2Rust ✓ ✓ ✓ ✓ ✓ PLTranslation ✓ ✓ ✓ ✓ ✓ SACT OR ✓ ✓ ✓ ✓ ✓ ✓ ✓ LAC2R ✓ ✓ ✓ ✓ ✓ ✓ Closed Source VERT ✓ ✓ ✓ ✓ SPECTRA ✓ ✓ ✓ ✓ ✓ Invalid Link 2.3 C-to-Rust Translation Approaches Existing C-to-Rust translation approaches can be broadly catego- rized into rule-base d, refactoring-based, LLM-based, and agent- based methods, as summarized in T able 1. Rule-based approaches, such as C2Rust [ 3 ] and GenC2Rust [ 43 ], rely on predened trans- formations and preserve C semantics, but generate verbose, non- idiomatic Rust code with extensive use of unsafe and limited sup- port for semantic repair . Refactoring-based approaches [ 8 , 11 , 15 , 28 , 48 ] attempt to improve safety through multi-stage rewriting or LLM-assisted transformations, but depend on unsafe intermediate representations and incur additional transformation cost. LLM- based appr oaches [ 5 , 27 , 30 , 45 ] directly generate Rust code and can produce more idiomatic outputs, but often lack structural consis- tency , leading to unstable syntax correctness and incorrect depen- dencies, espe cially for large or multi-le programs. Agent-based approaches [ 37 , 46 ] improve repair via iteration, but introduce sys- tem complexity and scalability challenges. Despite these advances, existing approaches remain fundamen- tally limited by the lack of explicit modeling of program structure. Rule-based methods o ver-preserve low-level semantics, r efactoring- based appr oaches struggle to recover from structurally inconsistent intermediate code, and LLM-based metho ds rely on implicit context that is insucient for maintaining interface and dependency con- sistency . In contrast, C2RustXW adopts a program-structure-aware design that explicitly models global symbols and dependency rela- tionships and incorporates them into both translation and r epair . This enables dependency-aware code generation, structure-guided syntax xing, and semantic repair , allowing C2RustX W to support function-, le-, and pr oject-level translation within a unied frame- work while producing safer , more concise, and more consistent Rust code than existing approaches. 3 Approach C2RustXW is a program-structure-aware framework that trans- lates C programs into safe, compilable Rust. It models program structure as global symbols, function interfaces, and inter-function dependencies, extracted via static analysis (e.g., symbol tables and call graphs). This structure guides both translation and repair pro- cesses. C2RustX W consists of three stages. Rust Code Generation translates symb ols and functions in top ological order , ensuring dependency-aware translation. Syntax Checking and Fixing resolves T able 2: Program structure extraction, representation, and usage in C2RustXW Structure Extraction & con- tents Storage (ex- ample) LLM representation & usage Stage Global symbols ( Σ ) Clang/syn AST; global vars, struct/enum, func- tion signatures dict: {g:int, sum:fn} Retrieved via depen- dency names and in- jected as dependent symbols for type/interface context T , S Functions ( F ) AST nodes; signa- ture + bo dy (or sum- mary) obj: fn sum(a,b) Used as main transla- tion/repair unit with interface constraints preserved T , S Dependencies ( D ) AST traversal; sym- bol usage and calls list: [g, Node] Expanded via Σ lookup into dependency-aware prompt context T , S Call graph Function call analy- sis; DA G graph: main → foo Determines trans- lation order (callee before caller) T Rust item structure syn AST; struct/impl/trait AST node: struct Node Extracted as repair scope for item-level xing S CFG Static analysis; ba- sic blocks + edges blocks: B1 → B2 Serialized into textual control-ow blocks for reasoning M DDG Def-use and vari- able dependencies edges: x → y Converted to depen- dency chains to ex- pose data ow M Runtime state Instrumentation; execution traces map: {x=5,y=10} Injected as variable states to localize se- mantic inconsistencies M File-level dependencies cross-le analysis and symbol usage graph and sym- bol table Guides le translation order and provides unied symbol con- text across les T Note: T = Translation; S = Syntax xing; M = Semantic xing. errors through rule-based and structure-aware LLM repair . Seman- tic Che cking and Fixing ensures behavioral equivalence with dif- ferential testing and structure-guided r epair . Figure 1 shows that program structure is the central abstraction. 3.1 Structure Denition and Representation A key concept in C2RustX W is program structure , which is explicitly modeled and propagated throughout the translation and repair pipeline. Given a C program 𝑃 , we represent its program structur e as a tuple S ( 𝑃 ) = ( Σ , F , D , G ) , where Σ denotes the global symbol table (including types, variables, structs, and function signatures), F represents functions with their interfaces and bodies, D captures Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Trovato et al. Sy mb o l T ab l e 1 tr an s l at e s ym bo l s R u st C o d e G e n e r a t i o n P r o gr am S t r u c t u r e E x t r ac t io n LLM RAG D B Fu n c t i o n s Sy mb o l s Sy m bo l T abl e C l an g C C o d e tr an s l at e f unc ti o n F u n c t ion Co n s is t e n c y E n f o r c e m e n t r etr an s l at e f unc ti o n C - R us t c o de pa i r s r etr i eve C o T bui l d De p e n d e n c y - Aw ar e T r an s lat ion ext r act R us t f unc ti o n St at eme n t C o n s i s t en c y I n t er f ace C o n s i s t en c y bui l d S e man t i c C h e c k i n g a n d F i x i n g C Output: 100 Rust Output:100 C hec k pa r s e pa r s e ext r act C F G / D D G … ext r act s ta tes S e m an t ic E r r o r F ix in g I ns ta nti at e F i x i ng P r o m pt F i n i s h Pr o m p t [1] st at ic Z : i32 = "h el lo " ; [2] st ru ct Po i nt {} [3] fn m ai n () {} error[E0 308] :m is ma tc he d ty pe s -- > src / ma in .r s: 1: 17 1 | stat ic Z: i32 = "hello "; | ex pe ct ed `i 32 `, fo un d` &s tr ` E r r o r Li s t C o m pi l e Syn t a x E r r o r F ix in g S y n t a x C h e c k i n g a n d F i x i n g Ru l e - B as ed Fi x i n g Fu n c t i o n - Lev el Fi x i n g I t em - Lev el Fi x i n g pa tc h D ep en d en t Sy mb o l s F a i l P as s P as s s o r t p a r s e s el ec t Dy n am i c An al y s i s St at i c An al y s i s f i x Ru s t I t em 3 3 2 5 4 4 1 2 3 3 3 4 5 F i x 1 2 3 5 4 3 pa s s S ym bo l s 3 pa s s S ym bo l s 3 Figure 1: The overall architecture design of C2RustX W. dependency relations among program elements (e.g., function calls and symbol usage), and G encodes control- and data-ow structures (e.g., CFG and DDG). This representation is extracted via static analysis and serves as a unied abstraction of program semantics. T o construct S ( 𝑃 ) , C2RustX W p erforms structure extraction and representation for both C and Rust pr ograms. For C code, we use Clang/LLVM to parse the program into an AST , from which global symbols, function denitions, and dependency relations are extracted by traversing AST nodes. Global symbols are stored in a dictionary mapping identiers to their denitions, while function- level dependencies are recorded as symbol lists associated with each function. Control-ow and data-o w structures are obtained via static analysis and represented as node–edge relations (e.g., CFG and DDG). For Rust code, we use the syn parser to construct AST s, from which function bodies, items (e.g., structs, traits, and impls), and symbol information are extracted for subsequent repair and analysis. Across both languages, these structures are stored in lightweight representations such as dictionaries, lists, and graphs that can be eciently queried and incrementally updated. T o enable LLM-based translation and repair , all program struc- tures are further serialized into textual form and structured into prompts. For example, given a function to be translated or repaired, C2RustXW rst retrieves its dependency list from D , then queries Σ to obtain the corresponding symbol denitions, and nally in- serts these denitions into the dependent symbols section of the prompt, with one denition per line. Similarly , control-ow and data-ow structures are conv erted into textual node-edge descrip- tions, and runtime states are represented as key-value mappings. This design bridges structured program analysis and LLM r eason- ing, allowing the model to operate on explicit program structure rather than implicit context. The program structure is not only use d to describ e the input program but also ser ves as a constraint and guidance thr oughout all stages of C2RustXW. During translation, it determines the order of generation and provides dependency-aware context for each func- tion; during syntax xing, it constrains repair within well-dened structural scopes such as statements, functions, and items; and during semantic xing, it enables structure-guided reasoning by incorporating control-o w and data-ow information. By explicitly modeling and preserving S ( 𝑃 ) , C2RustXW ensures that b oth gen- erated and repaired Rust code remain consistent with the original program’s structural and semantic intent. This structure-aware ap- proach minimizes semantic drift, ensuring the nal Rust program accurately reects the original C program’s behavior . 3.2 Rust Co de Generation The Rust code generation stage translates C programs into Rust in a program-structure-aware manner , incorporating extracted struc- tural information into the translation process. Instead of monolithic generation, C2RustX W performs dependency-aware translation by organizing code into structured units and injecting program struc- ture into LLM prompts, ensuring generated code respects symbol dependencies, function interfaces, and program semantics. Dependency- A ware Translation. C2RustX W performs transla- tion in two phases. First, global symbols are translate d into Rust to establish a consistent interface foundation. Then, functions are C2RustXW: Program-Structure-A ware C-to-Rust Translation via Pr ogram Analysis and LLM Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y translated in dependency order , determined by the call graph, en- suring that callees are dened before callers. For each function, C2RustXW retrieves its dependency list from D and queries the global symbol table Σ to obtain the corresponding symbol deni- tions. These denitions, including global variables, typ e declara- tions, and function signatures, are serialized into textual form and inserted into the dependent symbols section of the prompt. As shown in T able 3, the pr ompt for each function consists of the origi- nal C function, its dependent symbol denitions (in both C and Rust forms), and additional constraints, enabling the LLM to generate translations with full structural context. This prompt construction ensures the generated Rust code maintains consistent interfaces and avoids mismatched symbol denitions. Project-Level Dependency Handling. For multi-le C projects, C2RustXW extends this strategy by incorp orating inter-le depen- dencies into the translation process. A le-level dependency graph is constructed based on include relations and cross-le symbol us- age, and a topological order is used to determine the translation sequence. All source les are then unied into a consistent struc- tural representation with deduplicated symbols, forming a project- level extension of S ( 𝑃 ) that enables translation to proceed in a structure-aware manner acr oss les. allowing the translation pro- cess to proceed in the same manner as single-le translation while preserving cross-le consistency . By explicitly inje cting depen- dency information into prompts, C2RustX W ensures that symbols dened in one le are correctly referenced in other les, av oiding inconsistencies that commonly arise during project translation. Function Consistency Enforcement. After initial translation, C2RustXW enforces consistency between C and Rust functions to ensure interface and structural alignment. This includes validat- ing function signatures against the global symbol table, removing invalid or hallucinated constructs, and checking structural cor- respondence between C and Rust function b odies. Rather than requiring exact syntactic equivalence, C2RustX W compares nor- malized statement categories (e .g., control ow , assignments, and declarations) to preser ve the intent of control-ow and data-ow . If inconsistencies are detected, functions are selectively re-translated under rened structural constraints. Finally , translated global sym- bols and functions are integrated into a complete Rust program by removing duplicate denitions and ordering items according to dependency constraints, producing a coherent and compilable output. For project-level translation, outputs from all sour ce les are unied into a single representation to ensure consistency across subsequent stages of syntax and semantic xing. 3.3 Syntax che cking and xing After code generation, C2RustX W ensures that the translated Rust program is syntactically valid through a multi-stage repair pipeline. Syntax checking is performe d by compiling the generated code us- ing cargo , which produces structured diagnostic messages with pre- cise locations and error categories. These diagnostics not only iden- tify syntax violations but also expose deeper inconsistencies such as type mismatches, unresolved symb ols, and ownership-related issues introduced during translation. Given the heterogeneous na- ture of these failures, C2RustX W organizes syntax xing into a hybrid framework applied in order of increasing structural scope, where program structure (T able 2) is progressively incorporated into repair contexts and serialized into prompts (T able 3). Unparsable co de xing. Some generate d Rust code cannot be parsed due to severe syntax errors such as missing delimiters or malformed e xpressions, preventing subse quent analysis. T o address this, C2RustX W rst performs coarse-grained repair by extracting a local code region around the error lo cation and prompting the LLM to rewrite this region. This step r estores syntactic parseability without relying on structured context, enabling subsequent stages to operate on well-formed code. Rule-based Statement-level Fixing. Once the co de be comes parsable, C2RustXW applies deterministic rule-based transforma- tions derived from static analysis. The Rust code is parsed into an AST , and compiler diagnostics are matched to predened error patterns, enabling targeted corrections at the statement level. Rep- resentative rules include: (1) symb ol resolution using the global symbol table Σ , (2) typ e correction to satisfy Rust’s strict typing constraints, (3) import completion and deduplication, (4) variable normalization to resolve naming conicts, and (5) insertion of un- safe contexts when r equired. These transformations directly modify the AST and regenerate code, ensuring high precision and minimal edits. By resolving frequent and well-structured errors without LLM intervention, this stage signicantly reduces the complexity of subsequent structure-aware repair . Dependency- A ware Function-Level Fixing. For errors involv- ing function bo dies and their interactions with global symbols, C2RustXW performs function-level repair guide d by program struc- ture. For each function, we construct a structured repair context consisting of its denition, interface, error messages, and dependent symbols retrieved from Σ (T able 2). These elements are serialized into the function-level xing prompt (T able 3, second column), where dependent symb ol denitions are explicitly listed to pro- vide type and interface context. This dependency-aware prompt enables the LLM to repair multiple errors within the function while preserving structural consistency . Structure- A ware Item-Level Fixing. Remaining errors that span beyond individual functions or involv e higher-le vel constructs (e.g., type denitions or module-level inconsistencies) are handle d at the item level. For each error , C2RustX W identies the minimal enclosing Rust item and extracts its denition along with relevant structural context (e .g., referenced symbols from Σ ). This informa- tion is serialized into the item-le vel xing prompt (T able 3, third col- umn), allowing the LLM to perform repair under explicit structural constraints. T o improve reliability , C2RustX W requires the LLM to return both original and modied co de, ensuring consistency and prev enting unintended changes. These xing techniques are applied iteratively until compilation succeeds or a limit is reached. 3.4 Semantic che cking and xing While syntactic correctness ensures compilability , it does not guar- antee semantic correctness. C2RustX W therefore performs seman- tic checking and xing to ensure that the translate d Rust program faithfully preserves the behavior of the C program. A s illustrated in Fig. 1, this stage follows a closed-loop workow that integrates dierential testing, program structur e (T able 2), and LLM-guided repair via structured prompts (T able 3). Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Trovato et al. T able 3: Unie d prompt templates for function translation, compilation error xing, and semantic error xing Dependancy-aware translation Syntax error xing Semantic error xing Translation instruction Function-level xing Item-level xing T extual CFG/DDG Semantic xing ith C function: Guidelines Guidelines CFG no des C-Rust structure information < Error list> Block i: Dependent symbols Selected Rust function Selected item CFG e dges Block j>
DDG no des RA G co de pairs Dependent symbols Dependent symbols Instrumented runtime states DDG e dges value> Constraints Constraints Constraints Node j> Semantic consistency checking. Semantic checking relies on executable C programs that contain a main function serving as an execution driv er in C2RustX W. This design ensures that each input program can b e compile d and executed indep endently , enabling direct behavioral comparison. Giv en such a driver , we execute both the C program and its translated Rust counterpart under identical test inputs and compare their outputs. All programs are associated with predened test cases, which are reused to drive execution and ensure consistent evaluation conditions. By treating the C pro- gram as the reference implementation, dier ential testing detects semantic inconsistencies whenever the Rust output de viates from the expecte d behavior . This execution-based validation provides a reliable and scalable mechanism for identifying semantic errors that cannot be captured through static checks alone. Semantic Error Lo calization and Analysis. When inconsisten- cies are detected, C2RustX W performs structure-aware analysis to localize and characterize semantic errors. First, output dierences between C and Rust executions are computed to identify b ehavioral mismatches, and output-related statements are used to associate discrepancies with corresponding code regions. T o enable deeper reasoning, C2RustXW retrieves control-ow and data-ow struc- tures (CFG and DDG) from the program structure (T able 2) and serializes them into textual representations. These representations are injected into the xing prompt (T able 3, fourth column), allow- ing the LLM to reason ab out execution paths and data dependencies beyond surface syntax. In addition to static structure, C2RustXW incorporates dynamic program structure by injecting runtime states collected from instrumented Rust execution (T able 2). These states are repr esented as key-value mappings of intermediate variables and provide ne-grained behavioral evidence, enabling the tracing of discrepancies across both control and data-ow dimensions. Structure-Guided Semantic Fixing. Base d on the combined struc- tural context, C2RustXW constructs a semantic repair prompt to guide the LLM in correcting b ehavioral inconsistencies. The prompt (T able 3, fth column) integrates: (1) C and Rust inputs and outputs, (2) output dierences, (3) output-related code statements, (4) textual CFG/DDG representations, and (5) runtime states. This unied rep- resentation explicitly encodes both intended behavior (from C) and observed deviations (from Rust), grounded in program structure. The LLM is then instructed to generate revised Rust code that pre- serves the original semantics while satisfying Rust’s language con- straints. The repaired code is recompile d and re-evaluated through dierential testing, forming an iterativ e renement loop until se- mantic equivalence is achieved or a predened limit is reached. By combining execution-base d validation with structure-guided reasoning, C2RustXW eectively resolves semantic inconsistencies that cannot be addressed through syntax-level r epair alone while maintaining structural consistency across stages. 4 Experiment Setup This section outlines the research questions designed to evaluate the eectiveness of our approach and the experimental setup, including data preparation, baselines, and evaluation metrics. 4.1 Research Questions W e formulate three research questions to evaluate C2RustXW across dierent translation granularities. RQ1. File-level eectiveness. How eectively does C2RustXW translate individual C les into corr ect and high-quality Rust code? This evaluates syntactic correctness, semantic consistency , and code quality at the le level. RQ2. Project-level eectiveness. How ee ctively does C2RustXW translate complete C projects while preser ving correctness and scal- ability? This evaluates p erformance on real-world projects with inter-le dependencies. RQ3. Qualitative analysis. What insights can b e gained about the strengths and limitations of C2RustXW compared to existing approaches? This analyzes representative cases to understand trans- lation behavior and dierences. 4.2 Data Preparation W e evaluate C2RustXW on b oth le-level and project-level datasets to assess its eectiveness under dierent translation granularities. For le-level evaluation, we colle ct 200 C programs from CodeNet [ 1 , 32 ] and 90 programs from GitHub (The-Algorithms [ 2 ]), all of which can be compiled and execute d independently . The programs are categorized by size ( <50, 50–200, >200 LOC) as shown in T able 4. Co- deNet provides standardized benchmarks with well-dened inputs and outputs, while GitHub samples introduce mor e realistic coding styles and structural diversity . For project-level evaluation, w e se- lect six representative multi-le C projects [ 12 , 14 , 22 , 35 , 36 , 40 ] (e .g., genann , libcsv ) following prior work [ 43 , 47 ], which contain non-trivial inter-le dependencies and diverse structures. T o enable semantic evaluation, all programs are associated with predened test cases. Following prior work [ 30 ], we construct stan- dardized input–output pairs for both le-level and project-level programs by reusing and normalizing existing test cases into a unied format. This allows both C and translated Rust programs to C2RustXW: Program-Structure-A ware C-to-Rust Translation via Pr ogram Analysis and LLM Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y T able 4: Statistics of le-level (CodeNet and GitHub) and project-level datasets. File-level datasets Project-level datasets Dataset Categor y Files LOCs Funcs Structs LineCov(%) Project C Files headers CLOC Functions Structs Macros Global V ariables CodeNet <50 149 3260 183 2 94 ht 2 1 246 10 3 4 0 50-200 49 4431 306 41 88 quadtree 6 1 496 31 4 3 0 >200 2 827 58 20 55 rgba 3 1 569 19 2 3 0 GitHub <50 28 1087 56 0 96.38 urlparser 2 1 634 21 1 6 1 50-200 50 4371 186 6 95.18 genann 4 2 877 22 1 10 2 >200 12 3303 106 15 83.51 libcsv 3 1 1115 31 2 35 1 T able 5: File-level eectiveness and code quality comparison on Co deNet and GitHub datasets Approach Category CodeNet GitHub SynCor ↑ SemCor ↑ RLOC ↓ /P UR ↓ #W ↓ /#E ↓ SynCor ↑ SemCor ↑ RLOC ↓ /P UR ↓ #W ↓ /#E ↓ C2Rust <50 147(99.32) 144(97.96) 8485/70.12 761/5 28(100.00) 27 (96.43) 1797/72.62 186/ 0 50-200 49(100.00) 47(95.92) 375147 /30.96 972/8 49(98.00) 49(100.00) 1007082/99.88 787/ 0 >200 2(100.00) 2(100.00) 1543/84.71 161/0 11(91.67) 9 (81.82) 3622/79.60 342/1 T otal 198(99.00) 193(97.47) 385175 /32.04 1894/13 88(97.78) 85 (96.59) 1012501/99.76 1315/ 1 PLTranslation <50 146(98.65) 62(42.47) 4178/1.82 89/4 28(100.00) 24(85.71) 1031/ 0.00 17/ 0 50-200 36(73.47) 9(25.00) 2862 / 8.77 107 /7 38(77.55) 35(92.11) 2576/ 0.00 32/2 >200 0(0.00) 0(0.00) 0/0.00 0/0 8(72.73) 3(37.50) 1385/10.25 17/ 0 T otal 182(91.00) 71(39.01) 7040/4.64 196/11 74(82.22) 62(83.78) 4992/ 2.84 66/2 GenC2Rust <50 147(99.32) 144(97.96) 7317/81.43 772/4 28(100.00) 27 (96.43) 1576/82.99 187/ 0 50-200 49(100.00) 48(97.96) 374759 /30.99 996/8 49(98.00) 49(100.00) 1006578/99.92 789/ 0 >200 2(100.00) 2(100.00) 1513/85.46 188/0 11(91.67) 9 (81.82) 3492/81.36 354/1 T otal 198(99.00) 194(97.98) 383589/32.17 1956/12 88(97.78) 85 (96.59) 1011646/99.83 1330/ 1 SACT OR <50 25(16.78) 2(8.00) 451 / 0.00 2 / 0 4(14.29) 4( 100.00 ) 103 / 0.00 1 / 0 50-200 0(0.00) 0(0.00) 0/0.00 0/0 17(34.69) 17(100.00) 620 /16.29 21 /13 >200 0(0.00) 0(0.00) 0/0.00 0/0 1(9.09) 1( 100.00 ) 109 / 0.00 3 / 0 T otal 25(12.50) 2(8.00) 451 / 0.00 2 / 0 22(24.44) 22( 100.00 ) 832 /12.14 25 /13 C2RustXW <50 149(100.00) 145 (97.32) 3802/9.55 370/4 28(100.00) 27 (96.43) 878/0.80 97/ 0 50-200 49(100.00) 34(69.39) 4962/37.00 721/ 0 50(100.00) 49 (98.00) 2552/4.19 254/2 >200 2(100.00) 1(50.00) 51/0.00 0/0 10(90.91) 8(80.00) 1233/12.49 99/ 0 T otal 200(100.00) 180(90.00) 8815/24.95 1091/4 88(97.78) 84(95.45) 4663/5.75 450/2 be executed under identical inputs, ensuring fair and reproducible dierential testing across all approaches. Finally , we apply a unied preprocessing pipeline to normalize input programs, including pars- ing and basic code normalization, so that all methods are evaluated under consistent and comparable experimental conditions. 4.3 Baselines W e compare C2RustXW with representative C-to-Rust translation approaches at both le and project levels. At the le le vel, we in- clude C2Rust, GenC2Rust, PLTranslation, and SACTOR. C2Rust is a rule-base d transpiler that translates C99 co de into unsafe Rust, ser ving as a strong baseline for syntax-preserving transla- tion. GenC2Rust extends C2Rust by improving the handling of void* pointers. PLTranslation adopts LLM-based direct transla- tion, representing purely generative approaches without structural constraints. SACT OR combines rule-based translation and LLM- guided refactoring in a two-stage pipeline, aiming to impr ove safety and semantic correctness. At the project level, we evaluate C2Rust and GenC2Rust for end-to-end project translation, and C2SaferRust, which further refactors unsafe Rust into safer code using LLM-based techniques and test-driven validation. All LLM- and agent-based approaches, including baselines and C2RustX W, use DeepSeek- V3 for fairness and consistency . W e exclude sev eral approaches due to practical limitations. LAC2R supports both le- and pr oject-level translation, but cannot b e e val- uated due to the lack of publicly available implementation and documentation. VERT relies on the Transcoder-IR dataset [ 38 ], which diers signicantly from real-world C code and is there- fore not suitable for our setting. SPECTRA is also excluded due to unavailable source code. O verall, the sele cted baselines cover rule-based, r efactoring-based, and LLM-based approaches, enabling a comprehensive and fair comparison with C2RustXW. 4.4 Metrics W e evaluate translation correctness using syntactic correctness ( 𝑆𝑦 𝑛 𝐶𝑜 𝑟 ) and semantic correctness ( 𝑆 𝑒𝑚𝐶𝑜 𝑟 ) at both le and project levels. 𝑆𝑦 𝑛 𝐶𝑜 𝑟 measures whether the translated Rust code can be successfully compiled using cargo check , while 𝑆 𝑒𝑚𝐶𝑜 𝑟 measures whether the Rust co de produces outputs consistent with the original C code. Following prior work [ 21 ], we focus on execution-based validation rather than text similarity metrics. Formally , 𝑆𝑦 𝑛 𝐶𝑜 𝑟 = 𝑆 𝑌 𝑁 𝑟 𝑠 𝑁 𝑐 and 𝑆 𝑒𝑚𝐶𝑜 𝑟 = 𝑆 𝐸 𝑀 𝑟 𝑠 𝑆 𝑌 𝑁 𝑟 𝑠 , where 𝑁 𝑐 is the number of C programs, 𝑆 𝑌 𝑁 𝑟 𝑠 is the number of syntactic Rust programs, and 𝑆 𝐸 𝑀 𝑟 𝑠 is the number of semantically correct Rust programs. T o evaluate code quality , we consider code size, safety , and ad- herence to Rust best practices. W e r eport the total lines of Rust co de ( 𝑅 𝐿𝑂𝐶 ) to reect code size . Safety is measured using the proportion of unsafe code ( 𝑃 𝑈 𝑅 = 𝑈 𝐿𝑂 𝐶 𝑅𝐿𝑂 𝐶 ), where 𝑈 𝐿𝑂 𝐶 denotes unsafe Rust lines. In addition, we report the number of Clippy warnings (#W) and errors (#E) as indicators of code quality . Only compilable Rust programs are considered in these metrics. Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Trovato et al. 5 Results 5.1 Answer to RQ1: File-level eectiveness The goal of RQ1 is to evaluate the eectiveness of C2RustXW for le-level C-to-Rust translation, considering both correctness and code quality . W e report code quality metrics only for syntactically correct programs, since semantically correct programs form a sub- set and exhibit similar trends. T able 5 provides a unied comparison across all approaches, including syntactic correctness ( 𝑆𝑦 𝑛 𝐶𝑜 𝑟 ), se- mantic correctness ( 𝑆 𝑒𝑚𝐶𝑜 𝑟 ), code size and safety (RLOC/P UR), and Clippy warnings and errors on the CodeNet and GitHub datasets. Across both datasets, rule-based approaches such as C2Rust and GenC2Rust achieve consistently high 𝑆𝑦 𝑛 𝐶𝑜 𝑟 (around 91-100%) and strong 𝑆 𝑒𝑚𝐶𝑜 𝑟 (average exceeds 96%) by directly preserving C semantics through construct-lev el translation. How ever , this cor- rectness comes at a substantial cost. These methods r etain low-level C abstractions via raw p ointers, unsafe operations, and FFI bindings, leading to a severe code size explosion, particularly in the 50-200 category , and extensive unsafe usage. While FFI enables b ehav- ioral equivalence when external libraries are involved, it introduces complex hybrid builds between Rust and C libraries, increasing developer eort and deployment complexity . Moreover , the gener- ated code is often non-idiomatic, as obser ved in RQ3, wher e C-style memory manipulation is preser ved rather than leveraging Rust ownership abstractions. Hybrid approaches such as SA CTOR and 2 ¸ saferrust attempt to improve these outputs through LLM-based refactoring, but their eectiveness remains limited. Once the initial translation introduces large amounts of unsafe co de and structural complexity , post-hoc rewriting becomes dicult because it must simultaneously preserve semantics, ensure compilability , and sim- plify the code structure. This leads to unstable performance, low syntactic correctness, and high refactoring cost. In contrast, PLTranslation adopts a purely LLM-based strategy and can generate more compact, idiomatic Rust co de with mini- mal unsafe code by leveraging learned knowledge of Rust abstrac- tions and libraries. However , its performance is highly sensitive to program scale. While r esults are acceptable for small programs, translation quality degrades signicantly as code size and depen- dency complexity increase. Without explicit structural guidance, the LLM must infer interfaces and dep endencies from raw code text, often producing incomplete outputs, inconsistent function interactions, or unparsable code. Repair attempts are signicantly limited by the lack of structural information, making it particularly hard to restore consistency once the code becomes structurally invalid. Both rule-based and LLM-base d approaches suer from the absence of structure-aware r easoning, either over-preserving low-level semantics or lacking sucient consistency constraints. In contrast, C2RustXW achieves a more balanced trade-o be- tween correctness, safety , and code quality . It consistently attains high 𝑆𝑦 𝑛 𝐶𝑜 𝑟 (100% on CodeNet and 97.78% on GitHub) and compet- itive 𝑆 𝑒𝑚𝐶𝑜 𝑟 (90.00% and 95.45%, respectively), while signicantly reducing both code size and unsafe usage compared to rule-based baselines. For example, unsafe pr oportions are reduced from ov er 70-99% to 24.95% on CodeNet and 5.75% on GitHub, without the severe code e xpansion observed in rule-based approaches. These improvements stem from the program-structur e-aware design of C2RustXW, which explicitly models global symbols, function de- pendencies, and translation order to ensure interface consistency and avoid redundant or incorrect co de generation. This design prevents over-preserving unsafe C semantics while maintaining structural correctness. Overall, C2RustXW produces substantially more concise and safer Rust code by eliminating redundant sym- bol denitions and replacing low-level pointer manipulations with Rust-native abstractions guided by program structur e. Compared to LLM-based approaches such as PLT ranslation, which generate compact but structurally inconsistent code, C2RustXW maintains dependency correctness and interface consistency , preventing hid- den defe cts even when co de size is slightly larger in some cases. Although C2RustX W generates a moderate number of Clippy warnings, these are primarily stylistic ( e.g., naming conventions) rather than correctness-related, and the consistently low number of Clippy errors further conrms the reliability of the Rust code. 5.2 Answer to RQ2: Project-level eectiveness T able 6 presents a unied comparison of translation eectiveness and co de quality across all approaches, including syntactic cor- rectness ( 𝑆𝑦 𝑛 𝐶𝑜 𝑟 ), semantic correctness ( 𝑆 𝑒𝑚𝐶𝑜 𝑟 ), code size and safety (RLOC/P UR), and Clippy warnings and errors. At the project level, translation becomes signicantly more challenging than le- level scenarios, as it requires consistent handling of cross-le de- pendencies, module organization, and external interfaces. Overall, C2RustXW achieves perfect 𝑆𝑦 𝑛 𝐶𝑜 𝑟 across all projects and strong 𝑆 𝑒𝑚𝐶𝑜 𝑟 (78.87% on average), demonstrating its robustness in con- structing compilable and largely semantically correct Rust projects. Rule-based approaches such as C2Rust and GenC2Rust also achieve perfect 𝑆𝑦 𝑛 𝐶𝑜 𝑟 and, in many cases, p erfect 𝑆 𝑒 𝑚 𝐶𝑜 𝑟 at the project level by preserving C semantics through FFI bindings and low-level C-style abstractions. How ever , this apparent correctness relies on a translation strategy that tightly couples the generated Rust code with the original C e xecution model. As a r esult, these approaches produce signicantly inated code size (e.g., RLOC in- creases excee ding 140%) and extensive use of unsafe constructs (around 78% on average), as shown in T able 6. Moreover , when projects depend on external or system libraries, FFI-based transla- tion requires complex hybrid builds between Rust and C, including manual conguration of modules, symbol resolution, and enabling unstable features, substantially increasing the burden on devel- opers. In addition, the generated co de largely preserves C-style memory management and control ow , yielding non-idiomatic Rust implementations that do not leverage native Rust abstractions. These results indicate that while rule-based methods can preserve behavioral equivalence, their semantic correctness reects C-like execution rather than safe, idiomatic, and maintainable Rust code, limiting their practical applicability . C2SaferRust attempts to address these issues by applying LLM- based refactoring to C2Rust outputs, but its eectiveness remains limited in project-level scenarios. Since the initial translation al- ready introduces substantial unsafe code, expanded low-level logic, and tightly coupled dep endencies, refactoring must operate on structurally complex, potentially inconsistent code. At the project level, this process requires repeatedly rewriting individual frag- ments, followed by compilation and linking, thereby signicantly C2RustXW: Program-Structure-A ware C-to-Rust Translation via Pr ogram Analysis and LLM Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y T able 6: Project-level eectiveness and code quality comparison of six Rust projects Project C2Rust GenC2Rust C2Saferrust C2RustXW SynCor ↑ /SemCor ↑ RLOC ↓ /P UR ↓ #W ↓ /#E ↓ SynCor ↑ /SemCor ↑ RLOC ↓ /P UR ↓ #W ↓ /#E ↓ SynCor ↑ /SemCor ↑ RLOC ↓ /P UR ↓ #W ↓ /#E ↓ SynCor ↑ /SemCor ↑ RLOC ↓ /PUR ↓ #W ↓ /#E ↓ ht 100.00/100.00 265/81.51 41/0 100.00/100.00 251/83.67 41/0 100.00/100.00 304/58.22 10/0 100.00/100.00 200/7.50 20/0 quadtree 100.00/100.00 1207/76.27 8/0 100.00/0.00 1167/79.35 15/0 100.00/19.05 1076/57.81 19/5 100.00/100.00 482/33.61 21/0 rgba 100.00/100.00 1852/38.66 9/0 100.00/100.00 1836/39.00 9/0 100.00/0.00 1617/21.77 117/1 100.00/100.00 924/0.00 35/1 urlparser 100.00/100.00 1449/82.75 70/0 100.00/100.00 1372/84.18 109/0 100.00/61.36 1220/71.64 47/12 100.00/68.18 614/0.00 14/0 genann 100.00/100.00 1863/88.19 114/0 100.00/100.00 1784/89.18 124/0 50.00/0.00 1298/52.47 24/0 100.00/88.35 442/20.36 46/0 libcsv 100.00/100.00 3154/92.33 177/0 0.00/0.00 3201(187.09) 1/2 100.00/0.00 2608/74.42 21/1 100.00/16.67 1009/6.64 106/0 T otal 100.00 / 100.00 9790/77.75 69.83/ 0.00 83.33/66.67 9611/78.80 49.83/0.33 90.00/30.07 8123/57.21 39.67 /3.17 100.00 /78.87 3671 / 8.48 40.33/0.17 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void C o u n t i n g S o r t ( i n t a [] , int b [] , i n t k ){ int c [ I ] , i,j ; for ( i = 0 ;i<= I ; i ++) c [ i ]= 0 ; for (j= 0 ;j< k; j ++) c [ a [ j+ 1 ]]++; for ( i = 1 ;i libc :: c _ i n t { let mut a : * mut l i b c :: c _ i n t = 0 as * m u t libc :: c _ i n t ; let mut b : * mut l i b c :: c _ i n t = 0 as * m u t libc :: c _ i n t ; / / A l l o c a t e m e m o r y u s i n g m a l l o c / / R e l e a s e t h e m e m o r y a f t e r s o r t i n g free ( a as * mut l ib c :: c_ vo i d ); free ( b as * mut l i b c :: c _ v o i d ); r e t u r n 0 as libc :: c_int ; } C C od e C 2Ru s t / Gen C 2Ru s t T r an sla t ed C od e 2 1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 const I : usize = 1 0 0 0 0 ; fn Co un t in gS or t ( a : & [ i 32 ], b : & mut [ i32 ], k : i32 ) { let mut c = vec ! [ 0 ; I ]; for j in 0 .. a . l e n ( ) { c [ a [ j as u s i z e ] as u s i z e ] + = 1 ; } for i in 1 .. I { c [ i as usize ] + = c [( i as i32 - 1 ) as usize ]; } for j in ( 0 .. a . l e n ()). rev ( ) { b [ c [ a [ j as u s i z e ]] as usize ] = a [ j as usize ]; c [ a [ j as us i ze ] as us i ze ] - = 1 ; } } fn main ( ) { let mut i n p u t = S t r i n g :: n e w (); io :: stdin ( ). re ad _l in e (& mut input ). un wr ap (); let n : u s i z e = i n p u t . trim ( ) . p a r s e (). u n w r a p (); let mut a = vec ! [ 0 ; n + 1 ]; let mut b = vec ! [ 0 ; n + 1 ]; / / U s i n g R u s t v e c t o r s i n s t e a d m a l l o c a n d f r e e . // f or a li gn me nt } 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 const I : usize = 1 0 0 0 0 ; fn co un t in g_ so rt ( a : &[ i32 ], b : & mut [ i32 ], k : usize ) { let mut c = [ 0 ; I + 1 ]; for j in 1 ..= k { c [ a [ j ] as u s i z e ] += 1 ; } for i in 1 ..= I { c [ i ] + = c [ i - 1 ]; } for j in ( 1 ..= k ). r e v () { b [ c [ a [ j ] as u s i z e ]] = a [ j ]; c [ a [ j ] as us iz e ] - = 1 ; } } fn main ( ) { let mut i n p u t = S t r i n g :: n e w (); io :: stdin ( ). re ad _l in e (& mut input ). un wr ap (); let n : u s i z e = i n p u t . trim ( ) . p a r s e (). u n w r a p (); let mut a = vec ! [ 0 ; n + 1 ]; let mut b = vec ! [ 0 ; n + 1 ]; / / U s i n g R u s t v e c t o r s i n s t e a d m a l l o c a n d f r e e . // f or a li gn me nt } C 2Ru s t XW T r an sla t ed C od e PL T r an sla t ion T r an sla t ed C od e 2 1 2 1 Figure 2: Counting sort program translate d by C2Rust, GenC2Rust, PLTranslation, and C2RustX W. (CodeNet/s787964396.c). increasing repair costs and latency . More importantly , post-hoc refactoring cannot fundamentally resolve structural inconsistencies, such as mismatched interfaces, implicit dependencies, or r edundant symbol denitions, that ar e introduced during the initial translation. As a result, C2SaferRust exhibits degraded 𝑆 𝑒𝑚𝐶𝑜 𝑟 (30.07%) and only moderate improvements in safety . In contrast, C2RustXW achiev es a fundamentally dierent trade- o between correctness, safety , and code quality . While its 𝑆 𝑒𝑚𝐶𝑜 𝑟 is slightly lower than that of C2Rust, it substantially reduces un- safe usage (from 77.75% to 8.48% on average) and overall code size (achieving a negative co de increment of − 6 . 76% ). This improve- ment stems from its program-structure-aware design, which av oids direct reliance on C FFI and instead lev erages Rust-native abstrac- tions and explicit dependency modeling. By translating programs in a dependency-aware order and enforcing consistency of global symbols and interfaces, C2RustX W eliminates redundant code and prevents structural inconsistencies that commonly arise in project- level translation. Furthermore, although C2RustX W produces a moderate number of Clippy warnings, these are primarily stylis- tic (e.g., naming conventions) rather than functional issues, and the near-zero error rate conrms the reliability of the generate d code. Overall, the results demonstrate that incorporating program structure and dependency information is essential for achieving a better balance between correctness, safety , and maintainability in project-level C-to-Rust translation. 5.3 RQ3: Case study T o better understand the strengths and limitations of dierent ap- proaches, we conduct case studies on representative C pr ograms that expose common challenges in C-to-Rust translation, including array bounds handling and pointer-based data structures. W e focus on two representativ e cases and analyze how dierent approaches behave under these scenarios. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 typedef struct li st { double v a l u e ; struct li st * ne xt , * prev ; } List; List * insert (L is t * list , double value , i n t pos ) { // Finding in se rt io n po in t } // for alignment int search (List * list , double value ) { if (list == N UL L ) return 0 ; if ( list - > va l ue == value) return 1 ; search ( list - > next , value) ; } // for alignment // for alignment 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 struct List { value : f64 , next : Option < Box < List >>, prev : Option < Box < List >>, } fn insert ( list : O pt io n < Box < Li st >>, value : f64 , pos : i32 ) - > Op ti on < Box < Li s t >> { // Finding in se rt io n po in t } fn search ( list : O pt io n < Box < Li st >>, value : f64 ) - > i32 { match list { Some ( list ) => { if list .v al ue == va lu e { 1 } else { search ( list .next , value ) } }}} C C o d e C 2 R u s t XW Tr a n s l a t e d C o d e 1 2 3 Figure 3: Doubly linked list program translated by C2RustXW. (GitHub/doubly_linked_list.c). Case 1: Array handling and b oundary safety . W e rst exam- ine a counting sort implementation from CodeNet, wher e correct array indexing is critical. Rule-based approaches such as C2Rust and GenC2Rust translate the program into unsafe Rust code that preserves the original C-style array manipulation. Although these translations are syntactically corr ect, they lead to runtime err ors due to out-of-bounds access in loop conditions, reecting the lack of proper bounds reasoning. In contrast, PLT ranslation generates more idiomatic Rust code, but may introduce inconsistencies in function interfaces and parameter usage due to the absence of struc- tural constraints. C2RustXW addresses these issues by leveraging program-structure-aware analysis: it enforces function interface consistency and replaces C-style array operations with Rust-native abstractions (e.g., v ector length checks), eectively preventing out- of-bounds errors while maintaining concise code. Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Trovato et al. Case 2: Pointer-based data structures. W e further analyze a doubly linke d list implementation from GitHub, which requires careful handling of pointers and memory ownership. Rule-based approaches again preserve raw pointer semantics, yielding unsafe Rust code that may compile but still causes runtime panics due to incorrect pointer manipulation. GenC2Rust slightly improves type safety through pointer retyping, but does not resolve deeper struc- tural inconsistencies in list op erations. LLM-base d approaches such as PLTranslation and SA CTOR struggle with this case, often produc- ing syntactically incorrect code or failing to preser ve the intended data structur e semantics. In contrast, C2RustX W successfully trans- lates programs by mapping C pointers to Rust o wnership constructs such as Option and Box , ther eby ensuring memor y safety and elim- inating runtime errors. By e xplicitly modeling data dependencies and enforcing consistent interfaces across functions, C2RustX W produces a correct and idiomatic implementation. By explicitly modeling data dependencies and enforcing consistent interfaces across functions, C2RustXW produces a correct and idiomatic im- plementation. This case further demonstrates that incorp orating program structure enables C2RustXW to eectively resolve com- mon translation failures and complements the quantitative ndings. 6 Discussion 6.1 Insights and Implications Our results across RQ1–RQ3 reveal several important insights into the strengths and limitations of existing C-to-Rust transla- tion approaches, and highlight the role of program structure in enabling eective translation. Rule-based methods, such as C2Rust and GenC2Rust, are highly eective in preser ving the original C semantics by directly mapping C constructs to Rust equivalents and relying on unsafe operations or FFI when ne cessary . However , this design has signicant practical drawbacks: the generate d code often exhibits substantial code size ination, a heavy reliance on unsafe constructs, and poor adherence to Rust idioms, as evidenced by both le-lev el and project-level r esults and case studies. Further- more, when e xternal libraries are inv olved, FFI-based translation requires complex hybrid builds, increasing the burden on devel- opers and limiting usability . These ndings suggest that semantic preservation alone is insucient and that code quality , safety , and idiomatic design must be considered as rst-class objectives. Approaches that extend rule-based translation with LLM- or agent-based refactoring, such as SACTOR and C2SaferRust, aim to improve code quality but remain fundamentally limited. Our results show that these methods often exhibit low syntactic and semantic correctness, espe cially at the le level, while incurring substantial computational and engineering costs due to iterative rewriting, compilation, and integration. These challenges are ex- acerbated by large code size, extensive unsafe usage, and comple x dependencies from rule-based outputs, making post-hoc refactor- ing unreliable. This highlights that repairing code without explicit structural guidance is insucient to resolve translation inconsisten- cies. In contrast, purely LLM-based approaches like PLTranslation generate more concise Rust code by leveraging learned knowledge, but their eectiveness diminishes for larger or multi-le codebases, where handling long-range dependencies and cross-le interac- tions consistently is crucial. Without structural constraints, LLMs struggle to maintain interface consistency and pr oduce complete outputs, often resulting in incomplete or inconsistent code. Even with repair mechanisms, their reliance on unstructured code text limits the ability to reason about program semantics ee ctively , hindering reliable recovery from deeper structural errors. These observations highlight that the key limitation of existing approaches is the absence of an e xplicit program structure as a guid- ing signal. In contrast, C2RustX W explicitly models and leverages program structure thr oughout the entire translation pipeline. By extracting and encoding global symb ols, dependency relationships, and control- and data-ow information to all stages, C2RustX W en- ables dependency-aware translation that preser ves interface consis- tency and reduces structural errors. Moreover , by ensuring syntactic correctness and parseability through multi-stage r epair , subsequent function-level, item-level, and semantic repair processes can op- erate on well-structured co de. The integration of both static and dynamic structural information further enables eective semantic error lo calization and correction. As a result, C2RustX W consis- tently achieves high syntactic and semantic correctness at both le and project levels while signicantly improving co de safety and conciseness. Overall, these ndings suggest that incorp orating explicit program structure into both generation and repair is critical for reliable cross-language translation. The structure-to-prompt paradigm adopted in C2RustXW demonstrates that LLMs can be signicantly enhanced when guided by structured program infor- mation, providing a promising direction for future research in code translation and program transformation. 6.2 Threats to V alidity Our evaluation is subject to several threats to validity . For exter- nal validity , although we evaluate C2RustXW on diverse datasets from Co deNet and GitHub as well as multiple real-world C pr ojects, these programs may not fully captur e the complexity of large-scale industrial codebases with deeply neste d dependencies and system- level interactions. For internal validity , while C2RustX W achieves perfect syntactic correctness at the project level, semantic correct- ness varies across projects, indicating that preserving behavior for highly interdependent programs remains challenging. Although dierential testing is employed to validate semantic equivalence, the coverage of available test cases may be insucient to expose all corner cases. For construct validity , although unsafe usage is signicantly reduced, Clippy warnings remain relatively frequent, primarily due to the preservation of C-style naming conventions to maintain traceability . Future work could address these limita- tions by incorporating larger and mor e complex project datasets, improving semantic validation through enhanced static and dy- namic analysis techniques, and introducing automate d refactoring to generate more idiomatic Rust code. 7 Related W ork Program translation has been studied through a wide range of ap- proaches, including rule-based, statistical, neural, and LLM-driven methods. Early work focused on rule-based and abstraction-driven translation [ 34 , 42 ], emphasizing language-independent represen- tations and systematic reimplementation strategies. Subsequent re- search explored statistical machine translation and neural models [ 6 , C2RustXW: Program-Structure-A ware C-to-Rust Translation via Pr ogram Analysis and LLM Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y 7 , 19 ], which improved translation quality by learning mappings between programming languages. More recent approaches leverage intermediate representations and large-scale pretraining [ 17 , 24 , 38 ], achieving strong performance on languages with similar abstrac- tions such as Java, Python, and C++. How ever , these methods are less eective due to fundamental dierences in memor y safety models and the limite d availability of high-quality parallel corpora. Recent advances in LLM-based code generation have further im- proved the exibility and capability of automated translation. Prior work explores techniques such as evaluation-driven generation [ 41 ], compiler testing [ 13 ], hallucination analysis [ 25 ], interactive work- ows [ 10 ], bias mitigation [ 16 ], retrieval augmentation [ 20 ], multi- agent collaboration [ 29 ], and test-driven generation [ 26 , 31 ]. While these approaches improve corr ectness and robustness through test- ing and feedback, they often lack explicit integration of pr ogram structure and static analysis, which is critical for ensuring structural consistency and dependency correctness in code translation tasks. In contrast, C2RustX W incorporates program-structure-aware anal- ysis, dependency-guided translation, and multi-stage syntactic and semantic repair into a unied framew ork. By explicitly modeling global symbols and program dependencies, C2RustX W enables more reliable and scalable C-to-Rust translation across function-, le-, and project-level scenarios, producing code that is both syn- tactically correct and semantically consistent. 8 Conclusion In this paper , we presented C2RustXW, a program-structure-aware framework for C-to-Rust translation that integrates static program analysis with LLM-based generation and repair . C2RustX W explic- itly mo dels multi-level program structure and transforms it into textual representations that are inje cted into LLM prompts, en- abling dependency-aware translation and structure-guided repair within a unie d pip eline. Experimental results demonstrate the eectiveness of C2RustX W across both benchmark datasets and real-world pr ojects: it achieves 100% syntactic corr ectness on Co- deNet and 97.78% on GitHub at the le level, and perfect syntactic correctness with an average semantic correctness of 78.87% at the project level, while signicantly reducing code size and unsafe us- age. These results show that C2RustXW can produce concise, safe, and semantically consistent Rust co de, providing a practical and scalable solution for reliable C-to-Rust migration. References [1] 2021. Codenet: A large-scale ai for code dataset for learning a diversity of coding tasks. arXiv preprint arXiv:2105.12655 (2021). [2] Open Source 2025. The algorithms implemented by C . Open Source. Retrieved September 8, 2025 from https://github.com/The Algorithms/C [3] Galois and Immunant 2025. c2rust source code . Galois and Immunant. Retriev ed September 8, 2025 from https://github.com/immunant/c2rust [4] Galois and Immunant 2025. c2rust documentation . Galois and Immunant. Re- trieved September 8, 2025 from https://c2rust.com/mannual/ [5] Xuemeng Cai, Jiakun Liu, Xiping Huang, Yijun Yu, Haitao Wu, Chunmiao Li, Bo W ang, Imam Nur Bani Yusuf, and Lingxiao Jiang. 2025. RustMap: T owards Project-Scale C-to-Rust Migration via Program Analysis and LLM. arXiv preprint arXiv:2503.17741 (2025). [6] Xinyun Chen, Chang Liu, and Dawn Song. 2018. Tree-to-tree neural networks for program translation. Advances in neural information processing systems 31 (2018). [7] Mehdi Drissi, Olivia W atkins, Aditya Khant, Vivaswat Ojha, Pedro Sandoval, Rakia Segev , Eric W einer , and Robert Keller . 2018. Program language translation using a grammar-driven tree-to-tree model. arXiv preprint (2018). [8] Mehmet Emre, Ryan Schr oeder , K yle Dewey , and Ben Hardekopf. 2021. Trans- lating C to safer Rust. Procee dings of the ACM on Programming Languages 5, OOPSLA (2021), 1–29. [9] Hasan Ferit Eniser , Hanliang Zhang, Cristina David, Meng W ang, Brandon Paulsen, Joey Dodds, and Daniel Kr oening. 2024. T owards Translating Real-W orld Code with LLMs: A Study of Translating to Rust. arXiv preprint (2024). [10] Sarah Fakhoury , Aaditya Naik, Georgios Sakkas, Saikat Chakraborty, and Shu- vendu K Lahiri. 2024. Llm-base d test-driven interactiv e code generation: User study and empirical e valuation. IEEE Transactions on Software Engine ering (2024). [11] Yifei Gao, Chengpeng Wang, Peng xiang Huang, Xuwei Liu, Mingwei Zheng, and Xiangyu Zhang. 2025. PR2: Peephole Raw Pointer Rewriting with LLMs for Translating C to Safer Rust. arXiv preprint arXiv:2505.04852 (2025). [12] Anonymous 2026. A minimal, well-tested library for training and using feedfor ward articial neural networks (ANN) in C . Anonymous. Retrieved March 26, 2026 from https://github.com/immunant/c2rust/tr ee/master/examples/genann [13] Qiuhan Gu. 2023. Llm-based code generation method for golang compiler testing. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering . 2201–2203. [14] Anonymous 2026. Simple hash table implementation using C . Anonymous. Retrieved March 26, 2026 from https://github .com/benhoyt/ht [15] Jaemin Hong and Sukyoung Ryu. 2024. Don’t W rite, but Return: Replacing Output Parameters with Algebraic Data T ypes in C-to-Rust Translation. Proceedings of the ACM on Programming Languages 8, PLDI (2024), 716–740. [16] Dong Huang, Jie M Zhang, Qingwen Bu, Xiaofei Xie, Junjie Chen, and Heming Cui. 2024. Bias testing and mitigation in llm-based code generation. ACM Transactions on Software Engineering and Methodology (2024). [17] Y ufan Huang, Mengnan Qi, Y ongqiang Y ao, Mao quan Wang, Bin Gu, Colin Clement, and Neel Sundaresan. 2023. Program translation via code distillation. arXiv preprint arXiv:2310.11476 (2023). [18] Ralf Jung, Jacques-Henri Jourdan, Robbert Krebbers, and Derek Dreyer . 2021. Safe systems programming in Rust. Commun. ACM 64, 4 (2021), 144–152. [19] Svetoslav Karaivanov , V eselin Raychev , and Martin V echev . 2014. Phrase-base d statistical translation of programming languages. In Proceedings of the 2014 ACM international symposium on new ideas, new paradigms, and reections on program- ming & software . 173–184. [20] Heiko Koziolek, Sten Grüner , Rhaban Hark, Virendra Ashiwal, Soa Linsbauer , and Nase Eskandani. 2024. LLM-based and retrieval-augmented control code generation. In Proceedings of the 1st International W orkshop on Large Language Models for Code . 22–29. [21] Marie- Anne Lachaux, Baptiste Roziere, Lowik Chanussot, and Guillaume Lample. 2020. Unsupervised translation of programming languages. arXiv preprint arXiv:2006.03511 (2020). [22] Anonymous 2026. The libcsv library implemented using C . Anonymous. Retrieved March 26, 2026 from https://github .com/rgamble/libcsv [23] Michael Ling, Yijun Y u, Haitao W u, Y uan W ang, James R Cordy , and Ahmed E Hassan. 2022. In Rust we trust: a transpiler from unsafe C to safer Rust. In Proceedings of the ACM/IEEE 44th international conference on software engineering: companion proceedings . 354–355. [24] Fang Liu, Jia Li, and Li Zhang. 2023. Syntax and domain aware model for unsu- pervised program translation. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) . IEEE, 755–767. [25] Fang Liu, Y ang Liu, Lin Shi, Houkun Huang, Ruifeng W ang, Zhen Y ang, Li Zhang, Zhongqi Li, and Y uchi Ma. 2024. Exploring and evaluating hallucinations in llm-powered code generation. arXiv preprint arXiv:2404.00971 (2024). [26] Noble Saji Mathews and Meiyappan Nagappan. 2024. T est-driven development and llm-based code generation. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering . 1583–1594. [27] Vikram Nitin, Rahul Krishna, and Baishakhi Ray . 2024. Spectra: Enhancing the code translation ability of language models by generating multi-modal specica- tions. arXiv preprint arXiv:2405.18574 (2024). [28] Vikram Nitin, Rahul Krishna, Luiz Lemos do V alle, and Baishakhi Ray . 2025. C2saferrust: Transforming c projects into safer rust with neurosymbolic tech- niques. arXiv preprint arXiv:2501.14257 (2025). [29] Ana Nunez, Nas T anveer Islam, Sumit Kumar Jha, and Peyman Najarad. 2024. Autosafecoder: A multi-agent framework for securing llm code gener- ation through static analysis and fuzz testing. arXiv preprint (2024). [30] Rangeet Pan, Ali Reza Ibrahimzada, Rahul Krishna, Divya Sankar , Lam- bert Pouguem W assi, Michele Merler, Boris Sobolev , Raju Pavuluri, Saurabh Sinha, and Reyhaneh Jabbarvand. 2024. Lost in translation: A study of bugs introduced by large language models while translating code. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering . 1–13. [31] Jinjun Peng, Leyi Cui, Kele Huang, Junfeng Y ang, and Baishakhi Ray . 2025. Cwe- val: Outcome-driven evaluation on functionality and security of llm code gener- ation. In 2025 IEEE/A CM International W orkshop on Large Language Models for Conference acronym ’XX, June 03–05, 2018, W oodstock, N Y Trovato et al. Code (LLM4Code) . IEEE, 33–40. [32] Ruchir Puri, David S Kung, Ge ert Janssen, W ei Zhang, Giacomo Domeniconi, Vladimir Zolotov , Julian Dolby , Jie Chen, Mihir Choudhury , Lindsey Decker, et al . 2021. Codenet: A large-scale ai for code dataset for learning a diversity of coding tasks. arXiv preprint arXiv:2105.12655 (2021). [33] Boqin Qin, Yilun Chen, Zeming Y u, Linhai Song, and Yiying Zhang. 2020. Un- derstanding memory and thread safety practices and issues in real-w orld Rust programs. In Proceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation . 763–779. [34] Lili Qiu. 1999. Programming language translation . Te chnical Report. Cornell University . [35] Anonymous 2026. Simple quadtrees implementation for C . Anonymous. Retrieved March 26, 2026 from https://github .com/thejearson/quadtree [36] Anonymous 2026. RGB/RGBA Parsing and Formatting Librar y in C . Anonymous. Retrieved March 26, 2026 from https://github .com/clibs/rgba [37] HoHyun Sim, Hyeonjoong Cho, Y eonghyeon Go, Zhoulai Fu, Ali Shokri, and Binoy Ravindran. 2025. Large Language Model-Powered Agent for C to Rust Code Translation. arXiv preprint arXiv:2505.15858 (2025). [38] Marc Szafraniec, Baptiste Roziere, Hugh Leather , Francois Charton, Patrick La- batut, and Gabriel Synnaeve . 2022. Co de translation with compiler representa- tions. arXiv preprint arXiv:2207.03578 (2022). [39] Dhiren Tripuramallu, Swapnil Singh, Shrirang Deshmukh, Srinivas Pinisetty , Shinde Arjun Shivaji, Raja Balusamy , and Ajaganna Bandeppa. 2024. T owards a Transpiler for C/C++ to Safer Rust. arXiv preprint arXiv:2401.08264 (2024). [40] Anonymous 2026. URL Parser in C (Node.js–style) . Anonymous. Retrieved March 26, 2026 from https://github .com/immunant/c2rust/tree/master/examples/ urlparser [41] Jianxun W ang and Yixiang Chen. 2023. A review on code generation with llms: Application and evaluation. In 2023 IEEE International Conference on Medical A rticial Intelligence (MedAI) . IEEE, 284–289. [42] Richard C W aters. 2002. Program translation via abstraction and reimplementa- tion. IEEE Transactions on Software Engineering 14, 8 (2002), 1207–1228. [43] Xiafa Wu and Brian Demsky . 2025. GenC2Rust: T owards Generating Generic Rust Code from C. In 2025 IEEE/A CM 47th International Conference on Software Engineering (ICSE) . IEEE Computer Society , 664–664. [44] Lei Xia, Baojian Hua, and Zhiyuan Peng. 2023. An Empirical Study of C to Rust Transpilers. School of Software Engineering, University of Science and T echnology of China, and Suzhou Institute for Advanced Research, University of Science and T echnology of China-04/27 (2023). [45] Aidan ZH Y ang, Y oshiki Takashima, Brandon Paulsen, Josiah Dodds, and Daniel Kroening. 2024. VERT: V eried equivalent rust transpilation with large language models as few-shot learners. arXiv preprint arXiv:2404.18852 (2024). [46] Zhiqiang Y uan, W eitong Chen, Hanlin W ang, Kai Y u, Xin Peng, and Yiling Lou. 2024. Transagent: An llm-based multi-agent system for code translation. arXiv preprint arXiv:2409.19894 (2024). [47] Hanliang Zhang, Cristina David, Yijun Y u, and Meng W ang. 2023. Ownership guided C to Rust translation. In International Conference on Computer Aided V erication . Springer , 459–482. [48] Tianyang Zhou, Haowen Lin, Somesh Jha, Mihai Christodorescu, Kirill Levchenko, and V arun Chandrasekaran. 2025. LLM-Driven Multi-step Translation from C to Rust using Static Analysis. arXiv preprint arXiv:2503.12511 (2025).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment