Subspace Optimization for Backpropagation-Free Continual Test-Time Adaptation
We introduce PACE, a backpropagation-free continual test-time adaptation system that directly optimizes the affine parameters of normalization layers. Existing derivative-free approaches struggle to balance runtime efficiency with learning capacity, …
Authors: Damian Sójka, Sebastian Cygert, Marc Masana
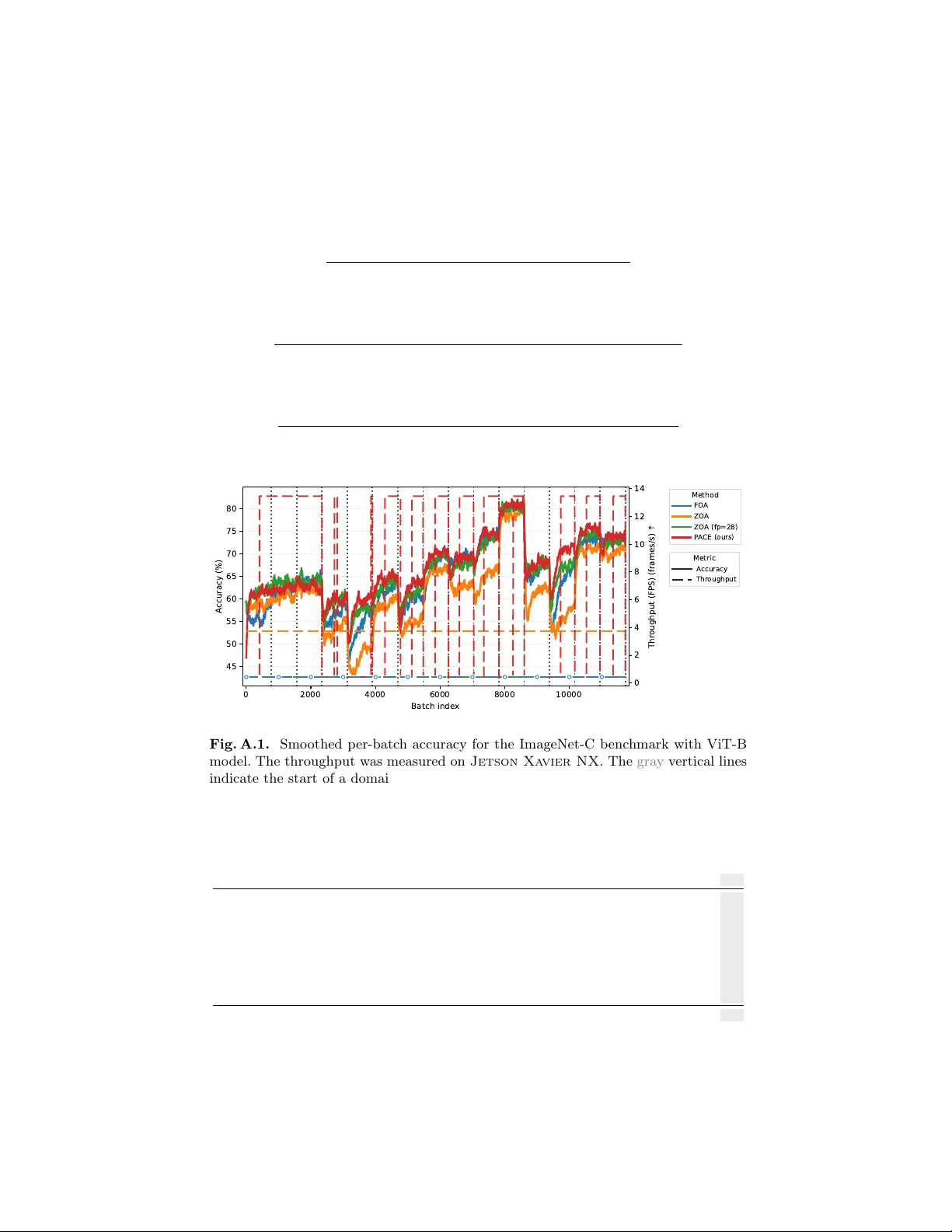
Subspace Optimization for Bac kpropagation-F ree Con tin ual T est-Time A daptation Damian Só jk a 1 , 2 ( ), Sebastian Cygert 3 , 4 , and Marc Masana 5 1 P oznan Univ ersity of T ec hnology 2 IDEAS NCBR 3 NASK - National Research Institute 4 Gdańsk Universit y of T ec hnology 5 Graz Universit y of T ec hnology damian.sojka@doctorate.put.poznan.pl Abstract. W e introduce P A CE, a backpropagation-free contin ual test- time adaptation system that directly optimizes the affine parameters of normalization la yers. Existing deriv ative-free approac hes struggle to balance runtime efficiency with learning capacit y , as they either restrict up dates to input prompts or require contin uous, resource-intensiv e adap- tation regardless of domain stabilit y . T o address these limitations, P A CE lev erages the Cov ariance Matrix Adaptation Ev olution Strategy with the F astfo o d pro jection to optimize high-dimensional affine parameters within a lo w-dimensional subspace, leading to sup erior adaptive per- formance. F urthermore, we enhance the run time efficiency by incorpo- rating an adaptation stopping criterion and a domain-sp ecialized v ec- tor bank to eliminate redundant computation. Our framew ork 1 ac hieves state-of-the-art accuracy across m ultiple b enchmarks under contin ual distribution shifts, reducing run time by o ver 50% compared to existing bac kpropagation-free methods. 1 In tro duction T est-time adaptation (TT A) [31] has emerged as a practical approac h to adapt a deplo yed neural net w orks on-the-fly , increasing its robustness to shifting data distributions. While bac kpropagation (BP)-based metho ds [22, 23, 31, 32] ac hieve strong performance via self-sup ervised learning, their high memory re- quiremen ts and incompatibility with non-differen tiable quan tized mo dels limit their deplo ymen t on resource-constrained edge devices [4, 15, 21]. Con v ersely , although existing BP-free methods reduce memory o verhead and support quan- tization [1, 4, 14, 21], the inherent challenges of deriv ative-free adaptation hinder their abilit y to balance runtime efficiency with learning capacit y (Fig. 1). Existing BP-free metho ds suffer from t w o primary limitations: 1) restricted learning capacity: current state-of-the-art do es not up date the mo del parame- ters [1, 14, 16, 18, 25], limits updates to input prompts [21], or relies on inher- en tly noisy zeroth-order gradient estimation [4, 26], which limits their abilit y to resolv e complex distribution shifts. 2) high computational ov erhead: existing 1 Co de av ailable at https://github.com/dmn- sjk/PACE.git . Pre-print. 2 D. Só jk a et al. 2 4 6 8 10 12 R untime [h] 55.0 57.5 60.0 62.5 65.0 67.5 A ccuracy [%] =0.045 (def .) 0.04 0.06 0.08 0.10 0.12 0.14 NoA dapt FO A ZO A ZO A (fp=28) P A CE (ours) Fig. 1. A ccuracy versus run time trade-off on the ImageNet-C benchmark using a ViT-B mo del, across v arious adaptation stopping thresholds ϵ (star marks the default setting ϵ = 0 . 045 ). The horizon tal dotted line represen ts the NoAdapt baseline accuracy . Existing BP-free metho ds t ypically face a trade-off: they either ac hieve high accuracy at the expense of computational efficiency or reduce runtime b y sacrificing precision. Our approach not only outp erforms curren t baselines but also in tro duces a tunable mec hanism to balance the accuracy-runtime trade-off, preven ting the inefficien t use of resources for diminishing returns. approac hes [4, 21] require numerous forw ard passes to match the p erformance of BP-based metho ds. F urthermore, these metho ds w aste resources by performing adaptation on ev ery batch indefinitely , regardless of domain stability . T o address these c hallenges in TT A, w e in tro duce Pro jected Adaptation via Co v ariance Ev olution (P A CE), an efficien t BP-free adaptation system that ex- pands learning capabilities while minimizing inference o verhead. W e start by adapting the mo del utilizing the Cov ariance Matrix A dapta- tion Evolution Strategy (CMA-ES), since its effectiveness for TT A was already confirmed [21]. The high dimensionality of neural net work weigh ts mak es direct CMA-ES optimization intractable. T o circum ven t this, [21] fo cuses on up dating input prompts rather than in ternal w eights. How ever, our exp eriments demon- strate that input prompt tuning is significantly inferior to up dating the affine pa- rameters of normalization lay ers (Fig. 2), as commonly done in TT A [22, 23, 31]. While this finding motiv ates the application of CMA-ES directly to the nor- malization la y ers to maximize adaptation capabilit y , doing so naiv ely remains computationally intractable due to the high-dimensional nature of these param- eters. Therefore, w e exploit the observ ation of low intrinsic dimensionality for TT A gradients [7], a property we v erify empirically in Fig. 3. P A CE optimizes a lo w-dimensional v ector and pro jects it into the high-dimensional normalization w eight space via the F astfo o d transform [17], enabling highly effectiv e adaptation without bac kpropagation. F urthermore, we observe that the CMA-ES adaptation predominan tly occurs at the onset of a stable domain, yielding negligible accuracy impro vemen ts in later batches (Fig. 4). W e lev erage this b y designing a dynamic stopping criterion based on the mean shift of the CMA-ES distribution. Once adaptation halts, the mo del operates with almost zero computational ov erhead. When a domain shift Subspace Optimization for Backpropagation-F ree TT A 3 is detected, adaptation automatically resumes. Finally , to accumulate knowl- edge across domain shifts, w e maintain a bank of domain-sp ecialized adaptation v ectors, allo wing the system to rapidly reco v er p erformance when encoun tering rep eated domains. These comp onen ts combine to form a fully practical TT A system, esp ecially suitable for long-term deploymen t. In summary , our con tributions are: – W e dev elop P A CE, a BP-free contin ual TT A metho d that efficiently op- timizes normalization la yers using CMA-ES, utilizing F astfoo d transform pro jections to searc h a low-dimensional subspace. – W e in tro duce a dynamic stopping criterion based on the CMA-ES distribu- tion mean that halts adaptation during stable domain phases, eliminating computational o verhead. – W e integrate a domain-specialized v ector bank, enabling the mo del to accu- m ulate knowledge and rapidly adapt to recurring domains. These lead to our prop osed metho d outp erforming the best BP-free approaches in both efficiency and accuracy , ac hieving around 50% reduction in run time. No- ticeably , P A CE significantly surpasses the other CMA-ES-based metho d (F O A). 2 Related W ork T est-Time Adaptation. TT A targets distribution shifts during inference b y adapting pre-trained mo dels without access to source data or labels [31]. Contin- ual TT A further assumes a non-stationary environmen t where domains change without access to domain lab els [32]. Existing metho ds can b e divided into bac kpropagation-based (BP-based) and backpropagation-free (BP-free). BP-based metho ds. These metho ds utilize gradient descen t to up date mo del parameters at test time. T o balance efficiency with learning capacity , most ap- proac hes restrict up dates to affine parameters in normalization la yers [5, 22, 23, 31]. In the absence of labels, these methods employ self-sup ervised ob jec- tiv es suc h as entrop y minimization [22, 28, 31], pseudo-labeling v ariants [5, 32], rotation prediction [27], or feature distribution alignment [19]. Because self- sup ervised signals can b e unreliable, stabilization techniques are often required. F or instance, SAR [23] filters samples by en tropy and seeks flat loss minima, while CoTT A [32] adopts a teacher-studen t framew ork with stochastic weigh t restoration. Despite their effectiv eness, BP-based methods demand high memory and differen tiable w eigh ts, whic h limits their utility on quantized or resource- constrained edge devices. BP-free metho ds. Early BP-free TT A fo cused on adjusting batc h normaliza- tion statistics using test data batc hes [8, 20, 25]. Subsequen t work extended the statistics up date to single-sample adaptation [16] and handling the temp oral class correlation [8, 36]. Ho w ever, these approac hes require the presence of batch normalization lay ers in model arc hitectures. F urther w orks explored prototype- based classifier adjustmen t (T3A) [14] and logits correction (LAME) [1]. None 4 D. Só jk a et al. of those metho ds update core mo del w eights, resulting in significantly limited learning capacit y . Recent w ork introduces weigh t-up dating BP-free methods: F OA [21] adapts input prompts via CMA-ES, and ZOA [4] employs zeroth-order gradien t estimation. While promising, FO A’s prompt-only up dates restrict its flexibilit y . F urthermore, F OA adapts on ev ery batc h, demanding up to 28 forward passes, which is computationally prohibitive for every data sample in real-w orld deplo yment. In contrast, ZOA reliably up dates core mo del weigh ts with only 2 forw ard passes. How ev er, to remain comp etitive with BP-based methods, its computational demands are similar to F OA. Our P ACE impro v es adaptation effectiv eness through subspace adaptation of affine parameters of normalization la yers via CMA-ES and minimizes ov erhead b y in tro ducing an automated stop- ping criterion that halts adaptation once it is no longer beneficial. A dditionally , dra wing on recen t BP-based TT A work [30], we incorporate a domain-specialized v ector bank to aggregate kno wledge across div erse environmen ts. This mec ha- nism enables the mo del to rapidly recov er p erformance when re-encoun tering domains, significan tly enhancing its readiness for practical deploymen t. 3 Problem Statement Con tinual TT A consists of adapting a pre-trained source model f θ (0) to a non- stationary sequence of unlabeled domains. The mo del is initially trained on a lab eled source dataset D s = { ( x i , y i ) } N s i =1 sampled from distribution P s . At in- ference, the mo del encoun ters a sequence of T domains: D (1) t , . . . , D ( T ) t where D ( k ) t = { x ( k ) j } N k j =1 , x ( k ) j ∼ Q ( k ) ( x ) . (1) Eac h domain D ( k ) t consists of unlabeled samples { x ( k ) j } . These domains are out- of-distribution ( Q ( k ) = P s ) and the sequence is non-stationary ( Q ( k ) = Q ( k +1) ). The mo del is adapted on-the-fly using only current samples. 4 Metho dology W e introduce a no v el BP-free con tinual TT A method, named Pro jected Adap- tation via Cov ariance Ev olution (P ACE), designed to be a fully practical TT A system. It comprises three main comp onents: Subspace A daptation 4.1, Adap- tation Stopping 4.2, and Domain-Sp ecialized V ector Bank 4.3. The diagram of our prop osed P ACE method is presented at the end of this section (Fig. 5). 4.1 Subspace A daptation Building on established TT A frameworks [5, 22, 23, 31] and our observ ation that input prompt tuning is less effective than up dating affine parameters of normal- ization lay ers (Fig. 2), w e emplo y CMA-ES to optimize these la yers. T o ensure high-dimensional optimization remains tractable b y CMA-ES, w e lev erage the Subspace Optimization for Backpropagation-F ree TT A 5 1 0 4 1 0 3 1 0 2 1 0 1 L ear ning R ate 60 65 70 A ccuracy [%] Nor m. P r ompt Fig. 2. Observ ed performance gap . A comparison of up dating the affine parame- ters of normalization la yers ( Norm .) versus three input prompts ( Prompt ) for a ViT-B mo del during test-time adaptation on ImageNet-C. W e adapt these using ground-truth lab els with an SGD optimizer with v arying learning rate. Up dating the normalization la yers allo ws the model to more effectiv ely ‘correct’ the cov ariate shift at eac h net work depth for all rep orted learning rate v alues. 0 400 800 1200 1600 P rincipal Component Inde x 0% 10% 20% 30% Expl. V ariance [%] 0% 20% 40% 60% 80% 100% Cum. Expl. V ariance [%] PCs for 90%: 566 Fig. 3. In trinsic dimensionalit y of con tin ual TT A gradients . The affine pa- rameters of normalization la yers from a ViT-B model are optimized via SGD with the loss function from FO A [21]. The concatenated gradien ts from all ImageNet-C do- mains rev eal that only 566 components explain 90 % of the v ariance. This highlights the lo w-dimensional nature of the adaptation space. Note that only the most significant comp onen ts are shown for clarity . The analysis is based on 11 729 gradient batches. observ ation that TT A gradients hav e low intrinsic dimensionality (as noted in [7] and shown in Fig. 3), whic h suggests that effective up dates can b e ac hieved within a lo w-dimensional subspace. This was also noticed b y Duan et al. [7], using a few batc hes from a single domain. W e extend this observ ation to all con- catenated domains, were the ma jor directions are still low despite the domain c hanges. Mo del up date. W e adapt the mo del w eights by adding the constant random pro jection pro j( · ) of a low-dimensional v ector v ∈ R d in to a high-dimensional space pro j( v ) ∈ R D , where D ≫ d . The adapted mo del w eigh ts are the affine parameters of normalization lay ers, therefore w e set D to b e equal to their total dimensionalit y . W e partition pro j( v ) to matc h the dimensionality of each param- 6 D. Só jk a et al. eter tensor and add the resulting components to the initial w eights to get the adapted model f θ (0) +pro j( v ) . Initializing with a zero vector ( v = 0 ) ensures the adaptation starts exactly from the state of the pre-trained model. Our adapta- tion ob jective is to find the optimal low-dimensional v ector v ∗ that minimizes the fitness function L ( · ) giv en test samples x : v ∗ = argmin v L ( f θ (0) +pro j( v ) ( x )) . (2) CMA-ES optimization. W e prop ose to p erform the adaptation using the CMA-ES strategy . Rather than directly optimizing the v ector v , CMA-ES main- tains and optimizes a multiv ariate Gaussian distribution ov er the searc h space. A t eac h iteration t ( t -th test batc h), a p opulation of K candidate solutions is sampled from this distribution: v ( t ) k ∼ m ( t ) + τ ( t ) N ( 0 , Σ ( t ) ) , (3) where k = 1 , · · · , K . Here, m ( t ) ∈ R d represen ts the mean of the search distri- bution at iteration step t , τ ( t ) ∈ R + is the ov erall standard deviation con trolling the global step size, and Σ ( t ) is the co v ariance matrix defining the distribution’s shap e and orien tation. F or eac h candidate v ( t ) k , we ev aluate its fitness by up dating the mo del and computing the loss on the current test sample x ( t ) . This yields a fitness v alue l k for each candidate. CMA-ES then up dates the distribution parameters ( m ( t ) , τ ( t ) , and Σ ( t ) ) for the next generation based on the ranking of the fitness v alues. This pro cess systematically increases the likelihoo d of previously suc- cessful candidates (see [9] for details). F ollowing [21], w e output the prediction asso ciated with the lo west fitness v alue as the final prediction of the mo del. Fitness function. W e utilize the fitness function used in F OA [21] and ZOA [4] due to its pro v en effectiveness, and to enable direct comparison. Prior to adap- tation, w e pass a small set of source data through the mo del to calculate the means and standard deviations of activ ations from L in termediate mo del blocks, denoted as { µ s,i , σ s,i } L i =1 . During test time, we calculate the corresp onding statis- tics on the curren t batc h of test samples x ( t ) , yielding { µ i ( x ( t ) ) , σ i ( x ( t ) ) } L i =1 . The fitness function com bines the prediction en tropy with the difference betw een these activ ation statistics: L ( f θ (0) +pro j( v ( t ) k ) ( x ( t ) )) = 1 B × C X x ∈ x t C X c =1 − y c log y c + λ L X i =1 ∥ µ i ( x ( t ) ) − µ s,i ∥ 2 + ∥ σ i ( x ( t ) ) − σ s,i ∥ 2 (4) where B is the batc h size, C is the total num b er of classes, y c is the c -th elemen t of the prediction probabilit y vector ˆ y = f θ (0) +pro j( v ( t ) k ) ( x ( t ) ) , and λ is a balancing h yp erparameter. Subspace Optimization for Backpropagation-F ree TT A 7 Efficien t dimensionalit y expansion. T o efficien tly pro ject lo w-dimensional v ectors v into the high-dimensional parameter space, w e employ the F astfo od transform [17]. Standard dimensionalit y expansion requires m ultiplying v by a dense pro jection matrix W ∈ R D × d . Storing this dense matrix can incur high memory costs for large netw orks. F astfo o d circum ven ts this bottleneck by ap- pro ximating the dense Gaussian matrix W with a pro duct of structured diagonal matrices and the F ast W alsh-Hadamard T ransform (FWHT). W e redefine the linear pro jection as: W v ≈ SHGPHB v = pro j( v ) , (5) where B ∈ R d × d is a diagonal matrix with entries sampled uniformly from {− 1 , 1 } , P ∈ R D × D is a random p ermutation matrix, and G ∈ R D × D is a di- agonal matrix with en tries drawn from a standard normal distribution N (0 , 1) . The matrix S ∈ R D × D is a diagonal scaling matrix ensuring the rows of the resulting pseudo-random matrix p ossess the correct L 2 norm to approximate the χ -distribution of a true Gaussian random matrix. Finally , H represents the W alsh-Hadamard matrix. W e perform m ultiplication b y H via the FWHT, en- tirely a voiding the instan tiation of the matrix in memory . T o ac hiev e the exact target dimensionality D , w e pad the input to the nearest p o wer of tw o (enabling FWHT), pro cess it through stac ked indep endent F astfo o d blo c ks, and subsequently slice it to the required length. W e initialize the F astfo o d transform comp onents once at the b eginning of the adaptation phase and freeze them for the remainder of the pro cess. By default, we set d = 2304 and the dimensionality of the updated ViT-B mo del parameters is equal to D = 34800 . In that case, the F astfo o d transform significan tly reduces memory ov erhead, requiring only 0 . 13 MB compared to the 306 MB needed for a standard dense pro jection matrix. 100-200 200-300 300-400 400-500 500-600 600-700 700-782 A daptation interval (batch inde x es) 0.0 0.1 0.2 0.3 0.4 A c c . / m i n Fig. 4. Marginal accuracy gain per unit time across adaptation budgets on ImageNet-C with ViT-B model. F or eac h consecutive pair of adaptation step budgets, w e compute the increase in mean accuracy across domains and divide it by the addi- tional estimated wall-clock time required for that interv al using our Subspace A dap- tation with CMA-ES algorithm. The mean of CMA-ES distribution m is used as the ev aluated model up date. Higher bars indicate more efficient use of adaptation time, while decreasing bars indicate diminishing returns from further adaptation. 8 D. Só jk a et al. 4.2 A daptation Stopping W e observe that adaptation at the beginning of a stable domain driv es the ma jorit y of p erformance improv ements (Fig. 4). Ho wev er, the adaptation pro cess incurs significant computational o v erhead. While test data distributions might remain stable for extended p erio ds in real-w orld deploymen t, current BP-free TT A methods adapt indefinitely . This approach w astes computational resources and energy , a critical b ottlenec k for long-term deplo yments on embedded devices. T o address this inefficiency , w e introduce a heuristic to halt adaptation when it yields marginal p erformance gains. Stopping heuristic. CMA-ES contin uously updates its distribution to trac k optimal candidates. Therefore, we monitor the relativ e change in distribution mean m . Sp ecifically , w e stop the adaptation when the normalized difference b et ween the distribution mean at the current time step m ( t ) and the previous time step m ( t − 1) falls b elo w a conv ergence threshold ϵ : ∥ m ( t ) − m ( t − 1) ∥ ∥ m ( t − 1) ∥ < ϵ . (6) W e rely on this sp ecific form ulation because the mean m ( t ) represen ts the algorithm’s current b est estimate for the optimal parameters v . When this rel- ativ e c hange approac hes zero, it indicates that the CMA-ES optimization has con verged to a lo cal optim um for the curren t data distribution. F urthermore, normalizing the difference b y the previous mean ensures that our stopping cri- terion is scale-in v ariant, making it robust across different net work lay ers or pa- rameter magnitudes. Once the stopping criterion in Eq. 6 is satisfied, the model is up dated with the CMA-ES mean m ( t ) and fixed. Resuming the adaptation. Since con tin ual TT A lacks explicit domain lab els, w e require a criterion to re-initialize the adaptation process. T o detect these shifts, w e adopt the domain shift detection sc heme established in [2, 4, 13], which remains in v arian t to up dates to the mo del. W e maintain the exp onential mo ving a verage (EMA) of the activ ation statis- tics from the stem la yer of the model: ϕ ( t − 1) E M A = β ϕ ( t − 1) + (1 − β ) ϕ ( t − 2) E M A , (7) where ϕ ( t − 1) represen ts the activ ation mean and v ariance for the ( t − 1) -th batch, and β = 0 . 8 denotes the moving av erage factor. T o quan tify the shift U , we compute the symmetric Kullbac k-Leibler (KL) div ergence b etw een the curren t batc h statistics ϕ ( t ) and the historical EMA ϕ ( t − 1) E M A : U ( ϕ ( t − 1) E M A , ϕ ( t ) ) = 1 H H X i =1 [ K L ( ϕ ( t − 1) ,i E M A ∥ ϕ ( t ) ,i ) + K L ( ϕ ( t ) ,i ∥ ϕ ( t − 1) ,i E M A )] , (8) where H is the dimensionality of the statistics. A domain shift is detected when this distance exceeds a predefined threshold γ , at whic h point w e re-initialize Subspace Optimization for Backpropagation-F ree TT A 9 the adaptation using the Domain-Sp ecialized V ector Bank. T o ensure robust detection, we cease updating ϕ E M A once the adaptation has stopped, b y the tec hnique describ ed ab ov e. 4.3 Domain-Specialized V ector Bank In real-w orld, long-term deploymen ts, domain recurrence can b e a common phe- nomenon [30]. A fully practical TT A system must account for this b y rapidly reusing kno wledge acquired from previously encountered domains. T o achiev e this, w e main tain a memory bank B of vectors v derived from past domains. Sp ecifically , up on detecting a domain shift, we arc hiv e the curren t mean of the CMA-ES searc h distribution, m , in to the bank. F or the incoming domain, the new CMA-ES optimizer is initialized using the arc hived mean that minimizes the fitness function L on the current data batch x ( t ) : m init = arg min m i ∈B L ( f θ (0) +pro j( m i ) ( x ( t ) )) . (9) A daptation then pro ceeds conv en tionally . This retriev al mechanism facilitates the rapid reuse of learned experiences, effectively preven ting p erformance degra- dation ev en in the presence of sudden domain shifts. T o ensure strict memory b ounds, w e constrain the maximum capacity of the bank to p v ectors. When a newly optimized mean is added to a full bank ( |B| > p ), w e emplo y a redundancy-based remov al policy . W e calculate the av erage pairwise cosine similarity for each mean m i in the bank and discard the v ector that exhibits the highest av erage similarit y to the others: m drop = arg max m i ∈B 1 |B | − 1 X m j ∈B\{ m i } m i · m j ∥ m i ∥∥ m j ∥ (10) Fastfood Transform CMA-ES Optimizer Low-dim. Vector High-dim. Vector + + Updated Fixed CMA-ES (t-1) CMA-ES (t) Updated Fixed Fitness Function Subspace Adaptation + + q q < ϵ Adaptation Stop Adaptation Stopping Transformer Layer 1 Transformer Layer L Fig. 5. Diagram of P A CE . 1) Subspace Adaptation : w e adapt the model b y adding a high-dimensional random pro jection of a small, learnable vector to the mo del’s normalization lay er weigh ts. W e use the CMA-ES strategy to iterativ ely evolv e a p opu- lation of these v ectors, selecting the one that minimizes the loss on curren t test samples. 2) Adaptation Stopping : for efficiency , we stop the adaptation when the mean of the distribution optimized b y CMA-ES is low er than a threshold. Along with the Domain- Sp ecialized V ector Bank , they mak e an effectiv e and efficient TT A system. 10 D. Só jk a et al. This strategy effectiv ely prunes the most redundant information, maximizing the div ersity of the domain represen tations stored in the bank. Subspace adaptation enables memory-efficien t storage of knowledge from pre- vious domains. A single float32 domain v ector with our default dimensionalit y ( d = 2304 ) o ccupies appro ximately 0 . 0088 MB of memory . Consequently , the to- tal memory usage is only ab out 0 . 26 MB when the bank’s maxim um default capacit y p = 30 is utilized. 5 Exp erimen ts Datasets and models. W e conduct exp eriments on three standard TT A b enc h- marks: ImageNet-C [11], ImageNet-R [10], and DomainNet-126 [24]. ImageNet-C consists of 15 corruption functions across five sev erity levels. F ollo wing the pro- to col in [32], w e ev aluate using the classic corruption sequence with the highest sev erity level. ImageNet-R pro vides div erse renditions of 200 ImageNet classes, while DomainNet-126 con tains images from four distinct domains (real, clipart, pain ting, and sketc h). Exp erimen ts are rep orted with b oth full-precision and quan tized v ersions of ViT-B [6] and DeiT-B [29] mo dels. Unless otherwise specified, experiments are rep orted with full-precision mo dels. W e implement quan tization using PTQ4ViT [34], follo wing [21]. F or ImageNet b enc hmarks, w e use chec kpoints trained on the ImageNet-1K [3] training set obtained from the timm reposi- tory [33]. F or DomainNet-126, w e utilize mo dels trained on the r e al domain using the rep ository from [35] and ev aluate on the remaining three domains. Baselines. W e compare against b oth previously defined categories of state-of- the-art TT A metho ds: BP-free, including LAME [1], T3A [14], F O A [21], and ZO A [4], and BP-based, sp ecifically TENT [31], CoTT A [32], and SAR [23]. T o ensure a fair comparison, w e also compare with ZO A (fp = 28 ), a mo dified v ersion of ZO A where we matc h the n umber of forward passes used in FO A and P ACE b y increasing the sampled p erturbations for gradien t estimation to 27 . Finally , NoA dapt represents the fixed source model without adaptation. Implemen tation details. F or all experiments, w e maintain a batch size of 64 to ensure consistency with prior work [4, 21, 32]. W e adopt the h yperparameter settings sp ecified in the original pap ers for all baselines. In the instances where they were not pro vided, the learning rate was sp ecifically tuned for the corre- sp onding exp erimen tal setup and mo del. F or fairness, we configure the CMA-ES p opulation size K of F O A to 28 and set the optimization v ector dimensionalit y d to 2304 . F ollowing both FO A and ZOA, w e use the v alidation set of ImageNet-1K to compute the statistics of ID data and set the λ to 0 . 2 for ImageNet-R and 0 . 4 for all other b enchmarks. W e set the domain shift detection threshold γ to 0 . 03 , the adaptation stopping threshold ϵ is set to 0 . 045 and the maxim um capacit y of domain-sp ecialized vector buffer p to 30 . P ACE specifically up dates the affine parameters of the normalization la yers. F urther details and hyperparameter ablation studies are provided in the Ap- p endix (Sec. A.2 and Sec. A.3.1, resp ectively). Subspace Optimization for Backpropagation-F ree TT A 11 T able 1. A ccuracy on ImageNet-C (IN-C), ImageNet-R (IN-R) and DomainNet-126 (DN-126) with ViT-B and DeiT-B. Bold indicates b est result, underlined second b est. ViT-B DeiT-B Method Bac kprop. IN-C IN-R DN-126 IN-C IN-R DN-126 A vg. NoAdapt ✗ 55.5 59.5 53.1 51.6 52.8 60.2 55.5 TENT ✔ 61.7 63.9 53.8 55.5 56.1 60.4 58.6 CoTT A ✔ 58.4 63.5 62.0 55.4 53.0 60.4 58.8 SAR ✔ 61.5 63.3 53.8 59.4 57.4 60.7 59.4 LAME ✗ 54.1 59.0 51.6 50.9 52.5 58.9 54.5 T3A ✗ 55.4 58.0 56.2 43.5 49.7 61.8 54.1 FO A ✗ 65.0 63.8 56.0 61.3 56.3 63.0 60.9 ZOA ✗ 61.5 60.7 55.8 56.9 53.5 62.4 58.5 ZOA (fp = 28 ) ✗ 66.3 62.6 56.5 61.7 55.8 63.4 61.1 P ACE (ours) ✗ 67.0 64.5 57.0 62.7 59.5 64.3 62.5 5.1 Results on F ull-Precision Mo dels P ACE ac hieves the highest av erage accuracy across all b enchmarks and full- precision models, consisten tly outp erforming other BP-free baselines (T ab. 1). Sp ecifically , it surpasses direct competitors FO A and ZOA by 1 . 7 and 4 . 0 p er- cen tage points, resp ectively . When ZOA is modified to matc h the forw ard-pass budget of P ACE and F OA (ZOA ( f p = 28 )), our metho d main tains a 1 . 4 p ercent- age p oin t lead despite adapting to fewer batc hes. While CoTT A achiev es the highest accuracy on DomainNet-126 by lev eraging bac kpropagation, it is significantly more memory-in tensiv e than P ACE (T ab. 3) and lacks supp ort for quantized mo del updates. It is important to note that BP-based metho ds operate in a distinct category , as BP-free approac hes are inheren tly constrained b y the absence of direct gradien t calculations. The fact that P A CE outperforms BP-based methods on a v erage, despite these inherent limitations, further underscores the effectiv eness of our approach. More detailed results on ImageNet-C are presented in T ab. A.2 and Fig. A.1 in the App endix. 5.2 Results on Quan tized Mo dels W e ev aluate our approach against BP-free baselines for adapting quantized net- w orks on ImageNet-C b enchmark, with results summarized in T ab. 2 for 8-bit and 6-bit ViT-B mo dels. Our method consisten tly outp erforms competing ap- proac hes across b oth bit widths. Notably , our 8-bit mo del ac hiev es 65 . 0 % ac- curacy , matching the 32-bit FO A baseline ( 65 . 0 % ) while significan tly exceeding almost all 32-bit comp etitors. The performance margin ov er ZO A (fp = 28 ) increases as quantization b e- comes more aggressive, rising from 0 . 3 percentage p oints at 8-bit to 0 . 6 per- 12 D. Só jk a et al. T able 2. Corruption Accuracy (%) on ImageNet-C with Quantized ViT-B mo dels. Noise Blur W eather Digital Model Metho d Gauss. Shot Impul. Defoc. Glass Motion Zo om Snow F rost F og Brit. Contr. Elas. Pix. JPEG A vg. 8-bit NoAdapt 55.8 55.8 56.5 46.7 34.7 52.1 42.5 60.8 61.4 66.7 76.9 24.6 44.7 65.8 66.7 54.1 T3A 55.6 55.6 55.9 45.9 34.7 51.8 42.0 59.7 62.0 65.4 76.4 48.5 43.0 65.3 67.7 55.6 FO A 60.7 61.4 61.3 57.2 51.5 59.4 51.3 68.0 67.3 72.4 80.3 63.2 57.0 72.0 69.8 63.5 ZOA 57.9 60.6 61.4 51.2 44.6 56.6 51.8 64.6 61.8 63.6 78.1 54.5 54.4 68.7 68.3 59.7 ZOA (fp = 28 ) 60.4 62.6 63.3 56.8 53.6 62.1 58.5 67.2 67.0 70.4 79.4 60.8 63.7 72.2 72.2 64.7 P ACE (ours) 59.9 61.3 61.6 56.4 55.5 62.1 58.8 68.2 67.0 71.8 80.0 60.6 65.5 73.3 72.3 65.0 6-bit NoAdapt 44.2 42.0 44.8 39.8 28.9 43.4 34.7 53.2 59.8 59.0 75.1 27.4 39.0 59.1 65.3 47.7 T3A 42.9 40.6 42.1 31.4 25.5 40.2 31.9 48.7 58.3 58.1 73.8 27.2 36.7 58.8 65.7 43.3 FO A 53.2 51.8 54.6 49.6 38.8 51.0 44.8 60.3 65.0 68.8 76.7 39.5 46.6 67.3 68.6 55.8 ZOA 48.7 51.0 53.2 43.1 37.4 49.4 43.1 58.4 63.2 62.0 76.1 35.2 47.9 62.6 67.1 54.3 ZOA (fp = 28 ) 52.6 54.6 55.8 49.0 48.5 54.3 51.4 60.5 62.7 64.7 76.4 38.6 57.3 66.6 69.5 57.5 P ACE (ours) 53.2 53.9 55.0 49.2 48.6 55.3 50.8 61.0 64.2 66.4 77.0 42.2 56.8 68.1 69.6 58.1 cen tage p oints at 6-bit. Unlike ZO A, whic h requires bit-width-specific learning rates [4], our approac h main tains constant hyperparameters across all quantiza- tion lev els, demonstrating sup erior robustness. 5.3 Ablation Studies Computational complexit y analysis. T ab. 3 compares the wall-clock time, memory consumption and p ercentage of adaptation batches of P ACE against BP-based and BP-free baselines. While P ACE main tains the lo w memory foot- prin t t ypical of BP-free metho ds, it impro ves efficiency ov er leading alternativ es suc h as F OA and ZO A (fp = 28 ). Sp ecifically , our adaptation stopping technique reduces their wall-clock time by 53 % and 46 % , respectively , cutting runtime from o ver 10 h to 5 . 4 h while sim ultaneously increasing accuracy . When w e increase the threshold ϵ to match the run time of default ZOA (P ACE with ϵ ∈ { 0 . 125 , 0 . 14 } ), accuracy gains diminish to levels similar to ZO A or lo w er. How ev er, P ACE ac hieves this performance b y adapting to only 3 . 5 % – 4 . 8 % of batches, requiring only a single forw ard pass for the remaining samples. F or P ACE ( K = 6 ), w e reduce the p opulation size and main tain the de- fault ϵ , whic h outp erforms ZO A by 0 . 3 p ercentage p oints and reduces run time by an additional 0 . 1 h , despite adapting to 13 . 7 % of batches. These results indicate that the adaptation stopping has its limits and k eeping the ϵ threshold lo w while decreasing p opulation size is a more effective strategy for drastically minimizing total runtime. Notably , ZOA cannot ac hieve similar efficiency gains b ecause it requires at least t wo forw ard passes p er batch for gradient estimation. Effectiv eness of P A CE comp onents. T ab. 4 decomp oses the p erformance gains of P ACE across its three core components. T o isolate the impact of sub- space adaptation, we first compare P A CE v1 against F OA. While both metho ds emplo y CMA-ES, FO A up dates input prompts whereas P ACE v1 exclusiv ely uti- lizes subspace adaptation. P A CE v1 outp erforms FO A by 1 . 1 percentage points, demonstrating that the lo w-dimensional update of normalization la yers is more effectiv e than input prompt tuning. Subspace Optimization for Backpropagation-F ree TT A 13 T able 3. Computation complexity comparison on ImageNet-C with ViT-B. F orward and bac kward passes ( #FP / #BP ) are coun ted for pro cessing a single sample. The w all-clo ck time (hours) and memory usage (MB) are measured for pro cessing the whole ImageNet-C on a single R TX 4090 GPU . Adapted batc hes are indicated b y the p er- cen tage on which adaptation was p erformed. Metho d Bac kprop. #FP #BP A vg. Acc. (%) Run time (hours) Memory (MB) A dapt. Batc hes (%) NoA dapt ✗ 1 0 55.5 0.01 819 0 TENT ✔ 1 1 61.7 0.03 5,165 100 SAR ✔ [1, 2] [0, 2] 61.5 1.1 5,166 100 CoTT A ✔ 3 or 35 1 58.4 1.5 16,836 100 T3A ✗ 1 0 56.9 0.7 957 100 F OA ✗ 28 0 65.0 11.6 832 100 ZO A ✗ 2 0 61.5 0.7 858 100 ZO A (fp = 28 ) ✗ 28 0 66.3 10.0 862 100 P A CE ( ϵ = 0 . 125 ) ✗ 1 or 28 0 61.5 0.8 863 4.8 P A CE ( ϵ = 0 . 14 ) ✗ 1 or 28 0 61.0 0.7 863 3.5 P A CE ( K = 6 ) ✗ 1 or 6 0 61.8 0.6 863 13.7 P A CE ✗ 1 or 28 0 67.0 5.4 863 50.6 T able 4. Ablation study on each comp onent of P ACE on ImageNet-C with ViT-B. Metho d adapt. stopping v ector bank subspace adapt. A vg. A cc. Run time (hours) NoA dapt 55.5 0.01 Baseline (FO A) 65.0 11.6 P A CE v1 ✔ 66.1 10.3 P A CE v2 ✔ ✔ 67.2 10.3 P A CE v3 ✔ ✔ 66.3 5.4 P A CE ✔ ✔ ✔ 67.0 5.4 In tegrating the v ector bank and shift detection (P ACE v2) further impro ves accuracy . This suggests that the mo del effectively reuses fine-tuned v ectors from previously encountered similar domains. This configuration ac hiev es the highest o verall result b y main taining updates for every data p oint. In con trast, P ACE v3 prioritizes efficiency by utilizing adaptation stopping but not the vector bank, whic h reduces run time. Ultimately , the full P A CE pro vides the optimal trade-off, com bining all three comp onents to achiev e high accuracy with low computational o verhead. P erformance On Recurring Domains. T ab. 5 compares P A CE against BP- free approaches in long-term contin ual adaptation scenarios inv olving recur- ring domains, following [12, 21, 30]. W e ev aluate p erformance on the rep eated ImageNet-C. While competing metho ds require multiple passes ov er the b ench- mark to conv erge to w ard our accuracy , P ACE ac hiev es a significantly high accu- racy at the first round, then peaks by the second and main tains stability across 14 D. Só jk a et al. T able 5. Comparisons with state-of-the-art methods on ImageNet-C with ViT-B in long-term contin ual adaptation. W e report av erage accuracy at eac h round of con tinual adaptation. Bold indicates b est result, underlined second. Metho d round 1 round 2 round 3 round 4 round 5 NoA dapt 55.5 55.5 55.5 55.5 55.5 T3A 55.4 55.9 55.2 55.0 54.6 F OA 65.0 65.6 66.1 66.2 66.4 ZO A 61.5 63.0 63.2 63.9 64.0 ZO A (fp = 28 ) 66.3 67.4 67.3 67.8 68.0 P A CE (ours) 67.0 67.9 67.8 68.1 67.8 0 500 1000 1500 2000 2500 3000 3500 Batch inde x 35 40 45 50 55 60 A ccuracy (%) 0.0 2.5 5.0 7.5 10.0 12.5 Thr oughput (FPS) Method FO A ZO A ZO A (fp=28) P A CE (ours) Metric A ccuracy Thr oughput Fig. 6. Smo othed p er-batch accuracy for the repeated Glass Blur domain from ImageNet-C with ViT-B model. The throughput w as measured on a Jetson Xa vier NX . The gra y v ertical lines indicate the start of each repetition. The throughput from ZO A (fp = 28 ) is co vered b y F OA. the subsequent ones. Only ZOA (fp = 28 ) outperforms P ACE after five repe- titions, gaining a marginal 0 . 2 p ercentage points of accuracy after the fourth rep etition, while adapting to all test samples. Fig. 6 illustrates p er-batch accu- racy and throughput for repeated Glass Blur domain from ImageNet-C. P ACE iden tifies when adaptation is no longer necessary and terminates redundan t up- dates, maintaining a throughput of 13 fps on the Jetson Xa vier NX . While F OA and ZOA (fp = 28 ) maintain similar accuracy , they exp end computational resources b y adapting throughout the en tire sequence, resulting in a significan tly lo wer throughput of 0 . 45 fps . 6 Conclusions In this work, we presented P ACE, an efficien t BP-free framework for contin ual test-time adaptation. By exploiting the lo w intrinsic dimensionality of normal- ization la yer up dates in TT A, P ACE ov ercomes the restricted learning capacit y of prior BP-free methods without the prohibitiv e memory requiremen ts of bac k- propagation. F urthermore, the in tro duction of an adaptation stopping criterion Subspace Optimization for Backpropagation-F ree TT A 15 and a domain-specialized v ector bank ensures that P ACE remains efficient and robust during long-term deploymen t across recurring distribution shifts. Our approac h enables high-p erformance adaptation on resource-constrained edge de- vices. Empirical ev aluations shows that P ACE establishes a new state-of-the-art for BP-free metho ds. These results also suggest that high-dimensional weigh t optimization is not a prerequisite for effective TT A. Inste ad, searching lo w- dimensional subspaces via evolution strategies pro vides a viable path tow ard practical, on-the-fly mo del refinemen t. A c kno wledgements This research was funded in whole or in part by National Science Centre, P oland, gran t no 2024/53/N/ST6/03156 and 2023/51/D/ST6/02846. W e grate- fully ac knowledge Polish high-p erformance computing infrastructure PLGrid (HPC Cen ter: A CK Cyfronet AGH) for providing computer facilities and supp ort within computational gran t no. PLG/2025/018634 and PLG/2025/018644. This researc h was funded in whole or in part b y the Austrian Science F und (FWF) 10.55776/COE12. The authors w ould lik e to thank Prof. Piotr Skrzyp czyński for his v aluable feedback on this paper. References 1. Boudiaf, M., Mueller, R., Ben A yed, I., Bertinetto, L.: Parameter-free online test- time adaptation. In: Pro ceedings of the IEEE/CVF Conference on Computer Vi- sion and P attern Recognition. pp. 8344–8353 (2022) 2. Chen, G., Niu, S., Chen, D., Zhang, S., Li, C., Li, Y., T an, M.: Cross-device collab- orativ e test-time adaptation. A dv ances in Neural Information Pro cessing Systems 37 , 122917–122951 (2024) 3. Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., F ei-F ei, L.: Imagenet: A large- scale hierarc hical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009) 4. Deng, Z., Chen, G., Niu, S., Luo, H., Zhang, S., Y ang, Y., Chen, R., Luo, W., T an, M.: T est-time mo del adaptation for quan tized neural net works. In: Proceedings of the 33rd A CM In ternational Conference on Multimedia. pp. 7258–7267 (2025) 5. Döbler, M., Marsden, R.A., Y ang, B.: Robust mean teac her for contin ual and gradual test-time adaptation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7704–7714 (2023) 6. Doso vitskiy , A., Bey er, L., Kolesnik ov, A., W eissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly , S., Uszkoreit, J., Houlsby , N.: An image is w orth 16x16 w ords: T ransformers for image recognition at scale. ICLR (2021) 7. Duan, D., Xu, R., Liu, P ., W en, F.: Lifelong test-time adaptation via online learning in trac ked low-dimensional subspace. In: The Thirty-nin th Ann ual Conference on Neural Information Processing Systems (2025) 16 D. Só jk a et al. 8. Gong, T., Jeong, J., Kim, T., Kim, Y., Shin, J., Lee, S.J.: Note: Robust con tinual test-time adaptation against temp oral correlation. Adv ances in Neural Information Pro cessing Systems 35 , 27253–27266 (2022) 9. Hansen, N.: The cma evolution strategy: A tutorial. arXiv preprint arXiv:1604.00772 (2016) 10. Hendryc ks, D., Basart, S., Mu, N., Kadav ath, S., W ang, F., Dorundo, E., Desai, R., Zhu, T., Para juli, S., Guo, M., et al.: The many faces of robustness: A critical analysis of out-of-distribution generalization. In: Pro ceedings of the IEEE/CVF in ternational conference on computer vision. pp. 8340–8349 (2021) 11. Hendryc ks, D., Dietteric h, T.: Benc hmarking neural net work robustness to common corruptions and p erturbations. Pro ceedings of the International Conference on Learning Representations (2019) 12. Hoang, T.H., V o, M., Do, M.: Persisten t test-time adaptation in recurring testing scenarios. A dv ances in Neural Information Pro cessing Systems 37 , 123402–123442 (2024) 13. Hong, J., Lyu, L., Zhou, J., Spranger, M.: Mecta: Memory-economic con tinual test- time model adaptation. In: The Elev enth International Conference on Learning Represen tations (2023) 14. Iw asaw a, Y., Matsuo, Y.: T est-time classifier adjustment mo dule for mo del-agnostic domain generalization. Adv ances in Neural Information Pro cessing Systems 34 , 2427–2440 (2021) 15. Jia, H., K won, Y., Orsino, A., Dang, T., T alia, D., Mascolo, C.: Tinytta: Efficien t test-time adaptation via early-exit ensembles on edge devices. A dv ances in Neural Information Pro cessing Systems 37 , 43274–43299 (2024) 16. Kh urana, A., P aul, S., Rai, P ., Biswas, S., Aggarwal, G.: Sita: Single image test- time adaptation. arXiv preprint arXiv:2112.02355 (2021) 17. Le, Q., S arlós, T., Smola, A., et al.: F astfo o d-approximating kernel expansions in loglinear time. In: Pro ceedings of the international conference on mac hine learning. v ol. 85 (2013) 18. Lim, H., Kim, B., Choo, J., Choi, S.: Ttn: A domain-shift aw are batch normaliza- tion in test-time adaptation. arXiv preprint arXiv:2302.05155 (2023) 19. Mirza, M.J., Masana, M., Possegger, H., Bischof, H.: An efficien t domain- incremen tal learning approach to drive in all w eather conditions. In: Pro ceedings of the IEEE/CVF Conference on Computer Vision and P attern Recognition. pp. 3001–3011 (2022) 20. Nado, Z., P adhy , S., Sculley , D., D’Amour, A., Lakshminara yanan, B., Snoek, J.: Ev aluating prediction-time batch normalization for robustness under cov ariate shift. arXiv preprin t arXiv:2006.10963 (2020) 21. Niu, S., Miao, C., Chen, G., W u, P ., Zhao, P .: T est-time mo del adaptation with only forward passes. In: The International Conference on Machine Learning (2024) 22. Niu, S., W u, J., Zhang, Y., Chen, Y., Zheng, S., Zhao, P ., T an, M.: Efficient test- time mo del adaptation without forgetting. In: ICML. v ol. 162, pp. 16888–16905 (2022) 23. Niu, S., W u, J., Zhang, Y., W en, Z., Chen, Y., Zhao, P ., T an, M.: T ow ards sta- ble test-time adaptation in dynamic wild w orld. In: In ternetional Conference on Learning Representations (2023) 24. P eng, X., Bai, Q., Xia, X., Huang, Z., Saenko, K., W ang, B.: Momen t matching for m ulti-source domain adaptation. In: Pro ceedings of the IEEE/CVF international conference on computer vision. pp. 1406–1415 (2019) Subspace Optimization for Backpropagation-F ree TT A 17 25. Sc hneider, S., Rusak, E., Eck, L., Bringmann, O., Brendel, W., Bethge, M.: Improv- ing robustness against common corruptions by co v ariate shift adaptation. Adv ances in neural information pro cessing systems 33 , 11539–11551 (2020) 26. Spall, J.C.: Multiv ariate sto chastic approximation using a sim ultaneous pertur- bation gradien t appro ximation. IEEE transactions on automatic con trol 37 (3), 332–341 (2002) 27. Sun, Y., W ang, X., Liu, Z., Miller, J., Efros, A., Hardt, M.: T est-time training with self-supervision for generalization under distribution shifts. In: International conference on mac hine learning. pp. 9229–9248. PMLR (2020) 28. T an, M., Chen, G., W u, J., Zhang, Y., Chen, Y., Zhao, P ., Niu, S.: Uncertaint y- calibrated test-time model adaptation without forgetting. IEEE T ransactions on P attern Analysis and Mac hine Intelligence (2025) 29. T ouvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., Jegou, H.: T rain- ing data-efficien t image transformers & distillation through atten tion. In: Meila, M., Zhang, T. (eds.) Proceedings of the 38th In ternational Conference on Mac hine Learning. Pro ceedings of Mac hine Learning Researc h, v ol. 139, pp. 10347–10357. PMLR (18–24 Jul 2021), https://proceedings.mlr.press/v139/touvron21a. html 30. V ra y , G., T omar, D., Gao, X., Thiran, J.P ., Shelhamer, E., Bozorgtabar, B.: Reser- v oirtta: Prolonged test-time adaptation for ev olving and recurring domains. arXiv preprin t arXiv:2505.14511 (2025) 31. W ang, D., Shelhamer, E., Liu, S., Olshausen, B., Darrell, T.: T en t: F ully test- time adaptation b y en trop y minimization. In: In ternational Conference on Learning Represen tations (2021), https://openreview.net/forum?id=uXl3bZLkr3c 32. W ang, Q., Fink, O., V an Go ol, L., Dai, D.: Contin ual test-time domain adapta- tion. In: Pro ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7201–7211 (2022) 33. Wigh tman, R.: Pytorch image mo dels. https://github.com/rwightman/ pytorch- image- models (2019). https://doi.org/10.5281/zenodo.4414861 34. Y uan, Z., Xue, C., Chen, Y., W u, Q., Sun, G.: Ptq4vit: P ost-training quantization for vision transformers with t win uniform quantization. In: Europ ean conference on computer vision. pp. 191–207. Springer (2022) 35. Zhang, Y., Gong, K., Ding, X., Zhang, K., Lv, F., Keutzer, K., Y ue, X.: T ow ards unified and effectiv e domain generalization (2023) 36. Zhao, B., Chen, C., Xia, S.T.: Delta: degradation-free fully test-time adaptation. arXiv preprint arXiv:2301.13018 (2023) 18 D. Só jk a et al. App endix A.1 Ov erview This Appendix pro vides comprehensiv e implementation details (Sec. A.2) and additional exp erimen ts (Sec. A.3). Exp eriments include the ablation studies (Sec A.3.1) on the optimization dimensionalit y d , capacity of domain-sp ecialized v ector bank p , and domain shift threshold γ . Moreo ver, Sec. A.3.2 includes de- tailed results on the ImageNet-C b enchmark. A.2 Implemen tation Details W e adopt the hyperparameter settings sp ecified in the original pap ers for all baselines, except where they w ere not provided. In those instances, the learning rate was sp ecifically tuned for our model and exp erimental setup. W e utilized metho d implemen tations from the co de rep ository of F OA [21] and ZOA [4]. In the follo wing, we presen t the details regarding eac h metho d. P A CE (ours) . T o ensure a fair comparison with FO A, w e configure the CMA- ES population size K to 28 and set the optimization v ector dimensionality d to 2304. F ollowing FO A and ZO A, w e utilize the v alidation set of ImageNet-1K to compute the statistics of in-distribution data, setting λ to 0.2 for ImageNet-R and 0.4 for all other b enchmarks. W e set the domain shift detection threshold γ to 0.03, the adaptation stopping threshold ϵ to 0.045, and the maximum capacity of the domain-sp ecialized v ector buffer p to 30. Our metho d sp ecifically up dates the affine parameters of the normalization la yers. F ollo wing ZOA, w e k eep the la yer normalization parameters of the first block and the last three blocks of the tested mo dels fixed. F OA [21]. W e set the n umber of input prompt em b eddings to 3 and the popula- tion size K to 28. In-distribution statistics are computed using the ImageNet-1K v alidation set. The loss trade-off parameter λ is set to 0.2 for ImageNet-R and 0.4 for all other b enc hmarks, while the mo ving av erage factor for batc h-to-source shift activ ation is maintained at 0.1. ZO A [4]. The learnable parameters are perturb ed with a step size of 0.02 for gradien t estimation, while the step size for the co efficients of different domain parameters is set to 0.05. The SGD optimizer with a w eigh t deca y of 0.4 is used to up date the mo del parameters, and the Adam W optimizer with a weigh t deca y of 0.1 is used to up date the coefficients. The maximum n um b er of domain kno wledge parameters is set to 32. The learning rate for coefficients is set to 0.01 for all setups. The learning rate for model parameters is set to 0 . 0002 for 6-bit ViT-B and 0 . 0005 for all other models. In terms of ZOA ( f p = 28 ), the optimal learning rate c hosen on ImageNet-C is set to 0 . 005 for all mo dels and datasets. LAME [1]. F ollo wing [21], we use the kNN affinity matrix set to 5, as this v alue w as found to b e optimal for ImageNet-C. T3A [14]. F ollowing [21], the n um b er of supports to restore M is set to 20, as this v alue was found to be optimal for ImageNet-C. Subspace Optimization for Backpropagation-F ree TT A 19 TENT [31]. W e use SGD optimizer, with a momentum of 0.9. The learning rate w as tuned on ImageNet-C and set to 0.0001 for b oth ViT-B and DeiT-B mo dels. SAR [23]. W e use SGD optimizer with a momen tum of 0.9. The learning rate tuned on ImageNet-C is set to 0 . 001 for both ViT-B and DeiT-B. The en tropy threshold E 0 is set to 0 . 4 × lnC , where C is the n umber of task classes. CoTT A [32]. W e use SGD optimizer, with a momentum of 0.9. The learning rate w as tuned on ImageNet-C and set to 0.001 for ViT-B and 0.005 for DeiT-B. The augmentation threshold p th is set to 0.1. The restoration probabilit y is set to 0.01 and the EMA factor for teac her up date is set to 0.999. A.3 A dditional Exp erimen tal Results A.3.1 Ablation Studies Optimization dimensionality ( d ). T ab. A.1 (a) shows performance degra- dation when d is either increased or decreased. The reduction in accuracy at lo wer dimensions indicates insufficien t expressivit y for the optimization updates. Mean while, the drop at higher dimensions is lik ely due to the increased search space complexit y , which would require a larger CMA-ES population than our budget of 28 . Domain-Sp ecialized V ector Bank maxim um capacit y ( p ). T ab. A.1 (b) sho ws the impact of the domain-sp ecialized v ector bank capacity p on the ImageNet-C benchmark. P erformance improv es as p increases, reaching a plateau at p = 15 . This behavior is exp ected since ImageNet-C consists of 15 distinct do- mains. As sho wn in Fig. A.1, our method successfully detects almost ev ery do- main transition and initializes from the bank (see Throughput). Consequently , increasing the capacity b eyond the n umber of a v ailable domains yields no further gains. Domain shift threshold γ . The effect of domain shift threshold γ is ev alu- ated in T ab. A.1 (c). While a lo wer γ increases sensitivit y to distribution shifts, frequen t resets preven t the CMA-ES from reaching an optimal distribution. On the other hand, a higher γ results in insufficient sensitivity , leaving the mo del with sub optimal starting p oints when significan t shifts occur. Our results sug- gest that a balanced threshold is necessary to main tain b oth detection accuracy and optimization stabilit y . A.3.2 Detailed ImageNet-C Results Fig. A.1 illustrates the per-batch accuracy and throughput on the ImageNet-C dataset using a Jetson Xa vier NX . P ACE dynamically leverages throughput b y prioritizing adaptation at the onset of new domains (resulting in temporary throughput drops) and resuming high-sp eed inference once the domain stabilizes. In contrast, comp eting approaches maintain significan tly lo wer throughput while ac hieving inferior accuracy (see T ab. A.2). While certain domain shifts remain undetected due to in ter-domain similarit y , this suggests that re-initiating adap- tation in suc h instances is unnecessary . 20 D. Só jk a et al. T able A.1. Accuracy (%) of P A CE on ImageNet-C with a ViT-B model. (a) low-dimension space ( d ) 300 768 2304 3000 P A CE (ours) 63.8 65.4 67.0 66.5 (b) maximum vector bank capacit y ( p ) 0 5 15 30 40 50 P A CE (ours) 66.3 66.6 67.0 67.0 67.0 67.0 (c) domain shift threshold ( γ ) 0.01 0.02 0.03 0.05 0.1 1.5 P A CE (ours) 65.9 67.0 67.0 66.5 66.6 63.0 0 2000 4000 6000 8000 10000 Batch inde x 45 50 55 60 65 70 75 80 A ccuracy (%) 0 2 4 6 8 10 12 14 Thr oughput (FPS) (frames/s) Method FO A ZO A ZO A (fp=28) P A CE (ours) Metric A ccuracy Thr oughput Fig. A.1. Smo othed p er-batch accuracy for the ImageNet-C b enchmark with ViT-B mo del. The throughput w as measured on Jetson Xa vier NX . The gra y v ertical lines indicate the start of a domain. T able A.2. Comparisons with SOT A methods on ImageNet-C with ViT-B regarding A ccuracy (%) . BP is short for bac kward propagation. Noise Blur W eather Digital Method BP Gauss. Shot Impul. Defoc. Glass Motion Zo om Snow F rost F og Brit. Contr. Elas. Pix. JPEG A vg. NoAdapt ✗ 56.8 56.8 57.5 46.9 35.6 53.1 44.8 62.2 62.5 65.7 77.7 32.6 46.0 67.0 67.6 55.5 TENT ✔ 57.6 59.8 60.9 51.2 49.4 59.6 53.2 64.0 62.7 67.8 78.6 66.5 54.5 70.0 69.7 61.7 CoTT A ✔ 57.4 58.4 59.7 47.5 38.3 54.9 47.3 62.4 63.4 69.9 77.8 54.3 47.8 68.0 68.6 58.4 SAR ✔ 59.1 61.1 61.6 54.2 55.1 58.6 55.7 60.3 61.5 64.3 76.6 58.2 58.1 68.6 68.9 61.5 LAME ✗ 56.5 56.5 57.2 46.4 34.7 52.7 44.2 58.4 61.6 63.1 77.4 24.7 44.6 66.6 67.2 54.1 T3A ✗ 56.4 56.6 56.7 45.5 34.4 51.9 43.4 60.6 62.8 60.9 77.1 45.8 44.5 66.7 68.5 55.4 FO A ✗ 56.3 61.7 63.9 56.1 53.3 61.4 58.9 67.5 69.1 73.0 80.2 65.9 62.1 72.5 73.0 65.0 ZOA ✗ 58.6 60.5 62.3 52.9 46.7 58.8 54.2 66.0 62.7 64.5 78.8 60.6 55.4 70.9 70.3 61.5 ZOA ( f p = 28 ) ✗ 61.3 63.7 64.1 58.8 56.1 62.8 60.5 68.5 67.4 72.1 80.2 66.9 65.4 73.7 72.6 66.3 P ACE (ours) ✗ 61.2 62.3 62.7 59.1 58.2 64.2 61.3 69.6 68.4 73.5 80.7 67.1 68.7 74.9 73.3 67.0
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment