Enhancing User-Feedback Driven Requirements Prioritization
Context: Requirements prioritization is a challenging problem that is aimed to deliver the most suitable subset from a pool of candidate requirements. The problem is NP-hard when formulated as an optimization problem. Feedback from end users can offe…
Authors: Aurek Chattopadhyay, Nan Niu, Hui Liu
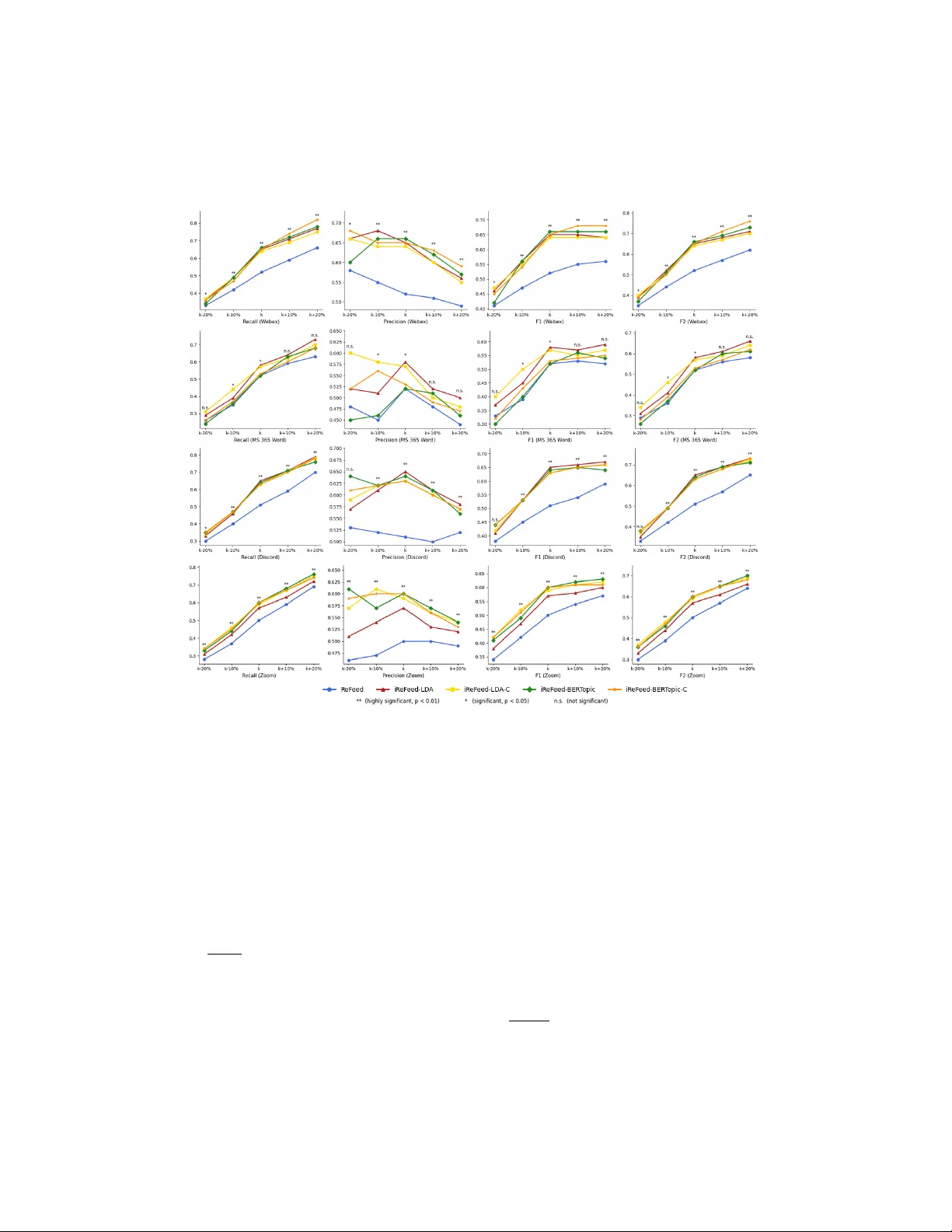
Enhancing User-F eedbac k Driv en Requiremen ts Prioritization Aurek Chattopadh ya y a , Nan Niu b , Hui Liu c , Jianzhang Zhang d a University of Cincinnati, Cincinnati, OH, USA b University of North Florida, Jacksonvil le, FL, USA c Beijing Institute of T e chnolo gy, Beijing, China d Hangzhou Normal University, Hangzhou, Zhejiang, China Abstract Con text: Requiremen ts prioritization is a c hallenging problem that is aimed to deliv er the most suitable subset from a p ool of candidate requiremen ts. The problem is NP-hard when formulated as an optimization problem. F eed- bac k from end users can offer v aluable supp ort for softw are evolution, and ReF eed represen ts a state-of-the-art in automatically inferring a require- men t’s priorit y via quan tifiable properties of the feedbac k messages asso- ciated with a candidate requiremen t. Ob jectiv es: In this paper, we enhance ReF eed b y shifting the focus of prioritization from treating requiremen ts as indep enden t en tities tow ard in- terconnecting them. Additionally , w e explore if in terconnecting requiremen ts pro vides additional v alue for searc h-based solutions. Metho ds: W e lev erage user feedbac k from mobile app store to group re- quiremen ts in to topically coherent clusters. Suc h in terconnectedness, in turn, helps to auto-generate additional “requires” relations in candidate require- men ts. These “requires” pairs are then integrated in to a searc h-based soft ware engineering solution. Results: The exp erimen ts on 94 requirements prioritization instances from four real-w orld soft ware applications show that our enhancement outp er- forms ReF eed. In addition, w e illus t rate ho w incorp orating in terconnected- ness among requiremen ts improv es searc h-based solutions. Conclusion: Our findings show that requirements interconnectedness im- pro ves user feedbac k driv en requiremen ts prioritization, helps unco ver addi- tional “requires” relations in candidate requirements, and also strengthens searc h-based release planning. Keywor ds: strategic release planning, soft ware evolution and maintenance, Cro wdRE, requirements interconnectedness, search-based softw are engineering 1. In tro duction Deciding which requiremen ts really matter is a c hallenging task. Tigh t time-to-mark et constraints and practical budget limitations demand effectiv e and efficient requirements prioritization solutions. Mo dern softw are industry in vests hea vily in strategic release planning [1, 2, 3, 4], where a sp ecial case is known as the next r ele ase pr oblem (NRP). Given a set of candidate re- quiremen ts, the NRP is concerned with prioritizing a subset of requiremen ts o ver the others, so that the prioritized part gets implemen ted and delivered, whereas the remaining requiremen ts would not b e included in the up coming v ersion of the softw are. The literature has offered muc h search-based soft w are engineering (SBSE) supp ort for the NRP [5, 6, 7, 8, 9, 10, 11, 12]. Assuming there are n can- didate requiremen ts, the NRP solutions are b ound in a space of 2 n . Th us, metaheuristic searc h guided by some ob jectiv e function could identify high qualit y but p ossibly sub optimal solutions in a computationally tractable w a y . The ob jective function is defined by commonly referring to some attributes of the requirements. F or example, Bagnall et al. [5] aimed to maximize the v alue of differen t stakeholders’ desired requiremen ts while ensuring that the implemen tation cost would not exceed a certain limit. An imp ortan t attribute relates to the feedback from the end users of the soft ware application. This data source is v aluable for understanding what users request, how they lik e or dislik e the softw are, etc. In a seminal pap er, Kifetew et al. [13] in tro duced ReF eed, a user-feedback driv en requirements prioritization method. ReF eed asso ciates user-feedbac k to requiremen ts, and then computes the requiremen ts priorities based on the extracted prop erties of the asso ciated feedback. Fig. 1-a illustrates ReF eed whic h w e review in more detail later. Inspired b y ReF eed, w e propose a no v el approac h to enhance user-feedbac k driv en requiremen ts prioritization. Fig. 1-b highligh ts the key change. Rather than treating requirements as indep enden t entities, we lev erage user-feedback messages to group the requiremen ts into topically coherent clusters. In this w ay , the messages’ influences on the priorities are no longer done at each 2 candidate requirements r 1 r 2 . . . r n user-feedback messages m m m m m m m F 1 F 2 F n candidate requirements r 1 r 2 . . . r n user-feedback messages m m m m m m m F C1 F Ck m m . . . . . . (a) ReF eed (b) iReF eed Figure 1: Compared with ReF eed [13] that associates user-feedbac k messages to a single requiremen t, our approach of iReF eed asso ciates messages to a cluster of inter c onne cte d requiremen ts. The “i” in iReF eed emphasizes this in terconnectedness. requiremen t’s level, but at a gran ularit y of in terconnected requirements. W e call our approach iReF eed to reflect the interconnectedness of the require- men ts in the same topic cluster. Recognizing the requiremen ts’ interconnectedness is imp ortan t for pri- oritization. Karim and Ruhe [12], for instance, in tro duced “theme” where the requiremen ts within a theme would b e preferably delivered or p ostp oned together. A ydemir et al. [14] further extended it to goal mo deling, e.g., by including all the leaf goals of a theme in the next release or excluding them al- together. While theme mo dels a “requires” relation symmetrically (i.e., “req 1 requires req 2 , and req 2 requires req 1 ”) [15], the asymmetric “requires” is more common and practically influential to prioritization. Suc h one-wa y “requires” manifests itself in differen t w a ys, including functional dep endency [15], tem- p oral relation [16], and refinement structure [14]. T o explore the extent to which iReF eed is conduciv e to “requires” iden- tifications, we exploit large language mo dels (LLMs)—Op enAI’s ChatGPT 4.5 and 4o in particular—to inv estigate whether the topic clusters resulted from our approach would lead to the generation of more “requires” pairs. Surprisingly , compared to feeding ChatGPT with all the requirements once, fo cusing on the requirements within iReF eed’s topic cluster uncov ered addi- tional “requires” pairs. These pairs, in turn, help ed improv e a state-of-the-art SBSE solution to the NRP . This pap er makes three main contributions. • W e improv e ReF eed by incorp orating user-feedback from mobile app 3 T able 1: Snippet of the W ord Pro cessor Data ( adopte d fr om Karim and Ruhe’s work [12] with the data linke d in [17]) Requirement V alue Scores Resource Estimates Stakeholder1 Stakeholder2 . . . Stakeholder4 . . . Design Developmen t QA / T esting r 1 : Create a new file 8 9 . . . 9 . . . 17 22 12 r 2 : Op en an existing file 8 9 . . . 9 . . . 20 25 13 r 3 : Close current file 8 9 . . . 1 . . . 5 1 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . r 49 : Load help file 2 7 . . . 6 . . . 3 3 3 r 50 : Search a text in the 1 7 . . . 6 . . . 2 2 2 help file store in in terconnecting requirements, and the exp erimen ts on four real- w orld applications sho w that our approach consistently achiev es better prioritization results than ReF eed. • T o examine the usefulness of our approac h’s requiremen ts in terconnect- edness, w e prompt ChatGPT on the W ord Pro cessor NR P b enc hmark data [12] and rev eal that additional “requires” pairs could b e generated with the help of our topic-cluster results. • W e demonstrate the added v alue of the “requires” pairs through a well- suited SBSE NRP solution, namely NSGA-I I, on the W ord Pro cessor b enc hmark. W e share our study materials and results publicly at https://doi.org/ 10 .52 81/ zen odo .18 881 986 to facilitate replication. The rest of the pap er is organized as follows. Section 2 describ es the con text of related work in whic h the curren t pap er is located. Section 3 presen ts our iReF eed approach. Section 4 ev aluates iReF eed against ReF eed. Section 5 rep orts our ChatGPT exp erimen ts on iden tifying “requires” pairs. Section 6 illustrates the incorp o- ration of the “requires” pairs into the NSGA-I I algorithm. Section 7 dra ws the conclusion and p oin ts out future w ork directions. 2. Bac kground and Related W ork 2.1. SBSE for A utomating R e quir ements Prioritization Deciding whic h, among a set of requiremen ts, are to b e considered first is a strategic pro cess in softw are developmen t [18, 19]. T raditionally , require- men ts prioritization is done man ually , and hence is effectiv e for only a small n umber of requirements. The man ual approac hes include win-win negoti- ation for deriving a final requiremen ts ranking from an agreement among 4 sub jective ev aluations b y differen t stakeholders [20], the 100-p oin t metho d that lets stak eholders distribute their p oin ts individually b efore aggregating the p oin ts for ranking the requirements [21], and the analytic hierarch y pro- cess (AHP) in whic h the decision mak er compares every pair of requirements in terms of v alue and cost, feeding in to the eigen v alue calculations in order to determine the requirements priorities [22]. Karlsson et al. [23] compared sev eral traditional metho ds, and show ed that AHP was the most promising though limited in scalability . F or n requiremen ts, AHP requires n × ( n − 1) 2 com- parisons in one dimension (e.g., v alue). P erini et al. [24] rep orted that AHP suffers scalabilit y issues with requirements sets larger than ab out 50. In pursuit of scalable solutions, researchers hav e explored computational searc h, esp ecially metaheuristic search. Bagnall et al. [5] were among the first to connect requiremen ts prioritization with SBSE by defining the NRP , i.e., the problem of selecting an optimal set of requirements to b e delivered in the soft ware system’s next stable v ersion. Here, optimalit y means satisfying the stakeholder demands as muc h as p ossible, and mean while ensuring that there are enough resources to undertak e the necessary developmen t. This optimization problem is shown to b e NP-hard [5]. T o illustrate Bagnall et al. ’s NRP form ulation, w e show in T able 1 a snipp et of the W ord Pro cessor data [12]. This b enc hmark contains 50 requiremen ts, some of whic h are listed in the left column of T able 1. The solution to the NRP is given b y the decision v ector: x = { x 1 , x 2 , . . . , x 50 } , x i ∈ { 0 , 1 } for 1 ≤ i ≤ 50. In this v ector, x i =1 if requiremen t r i is selected to b e part of the next release, and x i =0 otherwise. T o determine if a requirement should b e selected or not, one shall consider some critical attributes and their v alues. In T able 1, columns 2–5 illustrate the stak eholder v alue scores, and columns 6–9 displa y the implementation- related resource estimates. Bagnall et al. [5] defined the search ob jectiv e to: Maximize P 50 i =1 x i · v alue( r i ) , sub ject to P 50 i =1 x i · cost( r i ) ≤ B , where v alue( r i ) is the (weigh ted) sum of stakeholders’ v alues placed on r i , cost( r i ) is the total resource estimates of implementing r i , and B is some b ound. Th us, SBSE tec hniques lik e hill climbing and simulated annealing could b e used to find a high qualit y , but p ossibly sub optimal, solution x [5]. Although Bagnall et al. [5] originally presen ted a single ob jective for- m ulation of the NRP , others hav e adopted multi-ob jectiv e optimization ap- proac hes [8, 10, 12, 7]. Karim and Ruhe [12] show ed that maximizing individ- ual requirement’s v alue and theme-based coherence are conflicting ob jectives. Similarly , Finkelstein et al. [8] revealed the trade-offs b et w een maximizing 5 the total v alue and b eing fair (e.g., reducing the v ariance of the num b er of implemen ted requirements for each stakeholder). In a m ulti-ob jective optimization problem, w e are often interested in find- ing Pareto-optimal solutions. Supp ose there are M ob jectiv e functions. A decision v ector x is P areto-optimal if there is no y that is b etter than x in at least one i =1, 2, . . . , M , and no worse than x in the others. Let us consider t wo simple solutions ab out the W ord Pro cessor: α selects only r 1 to release, and β selects only r 2 . With the data given in T able 1, α is b etter than β in resource consumption (i.e., it costs less to implemen t r 1 than r 2 ), and mean- while, α is no worse than β in stak eholder v alues. Therefore, in ligh t of α , β is not a Pareto-optimal solution. Among the man y searc h algorithms in- v estigated in the NRP literature, NSGA-I I is w ell-suited [12, 10, 7], exhibits the b est run time [25, 26], and p erforms the best in finding P areto-optimal solutions [8, 9, 26]. In summary , SBSE offers strategic and automatic w ays to solv e the NRP . Extensiv e empirical studies sho w that one of the b est searc h-based NRP algorithms is NSGA-I I, which w e in tegrate with the kno wledge obtained from our iReF eed approach. 2.2. Interr elate d R e quir ements in Prioritization In addition to stakeholder v alues and effort estimates, the requiremen ts in terrelations are among the most influen tial factors of release planning mo d- els used in industry [27, 28]. Carlshamre et al. [15] observ ed sev eral relation t yp es, suc h as “AND” and “requires”. The distinction is that “AND” suggests a requires-relation in b oth wa ys whereas “requires” indicates the relation in only one wa y . F or example, a printer requires a driver to function, and the driv er also requires the prin ter to function [15]. This is an instance of “AND” relation. In con trast, emailing a scanned do cumen t requires a net work connection, but not the other wa y around [15]. Here, a “requires” relation exists b e- t ween the pair of requirements. Notably , “requires” em b o dies other forms than functional dep endency , e.g., “auto-logout requires a detected inactivit y p eriod, but not the opp osite” is a temp oral relation [16], and “freight man- agemen t improv ement” is refined b y “freight order history logging” [14]. In all these cases, w e use r a → r b to denote “ r a requires r b ”. The implication is that r b shall not b e prioritized low er or later than r a . In case of “AND”, i.e., r a → r b and r b → r a , b oth requirements share the same priority . 6 Referring to the W ord Pro cessor requirements of T able 1, we hav e r 3 → r 2 . No w consider three decisions: β = { r 2 } , γ = { r 3 } , and δ = { r 2 , r 3 } , which w ould resp ectiv ely release r 2 only , r 3 only , and b oth together. Here, γ is not congruen t with r 3 → r 2 , and hence should not b e regarded as a v alid NRP solution. One can impose the “requires” constrain ts in a p ost-processing step of SBSE, or enco de them as part of the SMT/OMT solving [14]. In short, “requires” represents a common and critical relation that influ- ences the quality of prioritization outcomes. Ho wev er, suc h relations were iden tified manually in prior studies [15, 14]. W e exploit ChatGPT for au- tomating the “requires” iden tification, and further in v estigate our approac h’s impact on unco vering the “ r a → r b ” pairs. 2.3. Cr owdRE and R eF e e d Not only are requiremen ts themselves interrelated, but they also relate to other data and sp ecifically to the feedbac k from the end users of the soft- w are. Groen et al. [29] defined crowd-based requirements engineering (RE), or CrowdRE, as a semi-automated approach for obtaining and analyzing an y kind of user feedback from a p o ol of curren t and p oten tial stakeholders. Is- sue rep orts, forum discussion, and app reviews are among the common data sources for Cro wdRE. An earlier to ol, ChangeAdvisor [30], exp erimen ted three topic mo deling algorithms (namely LDA, LDA-GA, and HDP) for clustering user feedback in to groups expressing similar needs. ChangeA dvisor adopted HDP as it pro vided a goo d trade-off b et w een qualit y and execution time. A subsequen t to ol, CLAP [31], trained a random forest classifier to differentiate user re- views into categories like feature and bug. CLAP further in volv ed clustering, e.g., by using DBScan to group the user reviews rep orting the same bug in one cluster. CLAP finally employ ed another random forest to classify whether a cluster w ould b e high priority or low priority . Recently , Radia tion [32] w as in tro duced to recommend the remov al of certain user in terface functionality . Radia tion applied HDP to cluster user reviews, follow ed b y the use of a random forest classifier to determine what to delete based on quantifiable prop erties such as review num b ers, ratings, and sentimen ts. Although other Cro wdRE metho ds exist, the ab o v e to ols illustrate that topic mo deling and clustering are effectiv e in handling the high volume of feedbac k data and that the review aggregates are v aluable for soft ware ev olu- tion [33]. Nev ertheless, ChangeAdvisor traces user feedbac k to source co de, 7 CLAP prioritizes user reviews instead of candidate requiremen ts, and Radi- a tion recommends to remov e existing user in terface features but falls short of p oten tially enric hing the softw are with b etter features. Kifetew et al. [13] pioneered the use of feedback in automatically prior- itizing requirements, which inspires our researc h. As outlined in Fig. 1-a, ReF eed comprises of three ma jor steps: asso ciating feedbac k with each re- quiremen t, extracting feedback prop erties, and inferring the priority of re- quiremen ts. The feedback-requiremen t asso ciations are established on the basis of textual similarit y . ReF eed computes the Jaccard similarity b et ween eac h feedbac k message and ev ery requiremen t, and then forms asso ciations if the similarity is greater than a threshold. Similarity-based asso ciations are common in con temp orary Cro wdRE to ols [30, 32]. ReF eed extracts quantifiable prop erties from user feedback that are rele- v ant for prioritizing the requirements. These prop erties are resulted mainly from sentimen t analysis and sp eec h-acts analysis [13]. Let N b e the total n umber of sentences in a feedbac k message, and N pos (or N neg ) b e the n umber of sentences with positive (or negativ e) sentimen t. Due to neutral sen timen t, N pos + N neg do es not alw ays equal to N . Given a user-feedbac k message, neg = P N n =1 S entimentS core neg ( S entences [ n ]) N neg and pos = P N n =1 S entimentS core pos ( S entences [ n ]) N pos quan tify the message’s negative and positive sen timen ts resp ectiv ely . ReF eed uses StanfordCoreNLP to compute S entimentS cor e at the sentence level [13]. The speech-acts analysis is aimed to calculate the extent a feedback message con veys feature request as opp osed to other in tentions lik e bug fix. T o that end, a message’s inten tion score, int , is calculated as the av erage of the in- ten tions of its sen tences. An int =1 implies the message is a feature request, whereas a low er int score suggests that the feedbac k is less ab out making a feature request. Ha ving asso ciated each requirement r via F with a set of feedbac k mes- sages, Kifetew et al. [13] inferred the requiremen t’s priorit y P in ReF eed as 1 : P r = P | F | i =1 [ sim ( r , F [ i ]) ∗ ( neg F [ i ] + pos F [ i ] + int F [ i ] )] | F | (1) 1 W e ignore the severit y measure from [13] as it is based purely on the negative sentimen t of feedbac k. As can b e seen in equation (1), the negative sentimen t has already b een considered in ReF eed. 8 where F [ i ] denotes the feedbac k message at p osition i in the set mapp ed b y F , and sim ( r, F [ i ]) represen ts the textual similarity v alue b et ween the requiremen t r and the message F [ i ] . If | F | =0, then no feedbac k is asso ciated with r and that requirement’s priorit y is set to b e 0. Intuitiv ely , equation (1) assigns a higher priority to r if its feedbac k is more similar to the requiremen t, em b o dies stronger sentimen t, and has a greater in ten tion to conv ey feature request. In essence, ReF eed offers a fully automatic w ay to prioritize requirements based on user feedback. Impro ving ReF eed with requirements in terconnect- edness is precisely the fo cus of our research. 3. iReF eed W e presen t in Fig. 2 an ov erview of our iReF eed approach. The figure elab orates our newly prop osed steps of p erforming topic mo deling on user feedbac k and then grouping the requirements into topically coheren t clus- ters. Even though iReF eed shares with ReF eed the ov erall steps of asso ciat- ing feedbac k with requirements, extracting feedbac k prop erties, and inferring requiremen ts priorities, imp ortan t differences exist. W e discuss these differ- ences, together with key design rationales and implemen tation details, in this section. Step 1: Our construction of clusters of in terconnected requiremen ts consists of topic mo deling of user feedback and then grouping the candidate require- men ts by using the resulting topics. The primary reason of applying topic mo deling to feedbac k is due to the quantit y of the data. Typically , there topic user feedback candidate requirements topic topic cluster cluster cluster 1a. apply topic modeling 1b. group requirements into topic clusters 2. associate feedback with req.s 3. extract feedback properties 4. infer req.s priorities Figure 2: Overview of iReF eed pro cessing pip eline. 9 are tens to hundreds of candidate requirements, whic h can be inadequate for insigh tful topics to emerge in the laten t space. In contrast, tens or hundreds of thousands of feedbac k messages can b e readily collected for a softw are application, creating a sizeable critical mass for applying topic mo deling. W e implemen t t w o topic mo deling methods in iReF eed: LD A and BER T opic, due to their viable applications in CrowdRE [34, 35]. A salient distinction is that LDA uses the corpus from the tok ens of the user feedback data, while BER T opic exploits a pre-trained transformer mo del with data crawled from external sources like Wikip edia. The literature has not recommended an y common num b er of topics to b e selected [34]. Th us, we exp erimen ted with sev eral n umbers of topics, and selected 20 as an appropriate one to use in our current w ork. Previous studies [36, 37] hav e also found 20 topics to b e appropriate. W e trained LDA on user reviews with 15 passes to ensure con- v ergence, and then con verted eac h candidate requiremen t in to a bag-of-w ords represen tation to cluster them based on the highest topic distributions. F or BER T opic, we applied UMAP (num b er of comp onen ts=5, n umber of neigh- b ors=15, minim um distance=0) for dimensionality reduction and HDBSCAN (minim um num b er of samples=10) for clustering user feedback into topics. W e then conv erted the requiremen ts into sentence-BER T em b eddings and assigned them to the most relev ant topic cluster based on the em b eddings’ cosine similarities. Note that the feedback topics are imp ortan t intermedi- ate results, b ecause they serv e as a means to form clusters of interconnected requiremen ts. Step 2: As in [13, 32], w e exploit textual similarit y to asso ciate feedback with requiremen ts. In [38], for instance, P alomba et al. used the cosine similarity threshold of 0.6 for the purpose of asso ciations; y et, Nay ebi et al [32] adjusted the threshold to 0.65 in order to achiev e a more accurate matching lev el. Similarly , w e slightly increased the Jaccard similarit y threshold of 0 [13] to the cosine similarity of 0.1 to obtain asso ciations in iReF eed and in our ReF eed implementation. Differen t from ReF eed, the asso ciations are established at a requirements cluster level in our w ork. Consider an example of t wo requirements and three feedbac k messages. If their cosine similarities are: sim ( r 1 , m 1 ) =0.15, sim ( r 1 , m 2 ) =0.2, sim ( r 1 , m 3 ) =0.06, sim ( r 2 , m 1 ) =0.07, sim ( r 2 , m 2 ) =0.22, and sim ( r 2 , m 3 ) =0.13, then under a 0.1 threshold, ReF eed would asso ciate { r 1 } with { m 1 , m 2 } and asso ciate { r 2 } with { m 2 , m 3 }. In iReF eed, if r 1 and r 2 are in the same cluster, then we link { r 1 , r 2 } with { m 1 , m 2 , m 3 } b y taking the 10 union of the messages asso ciated with the cluster’s constituen t requirements. In this w ay , for instance, the influence of m 1 on prioritizing r 2 is incorp orated in iReF eed but neglected in ReF eed. The influence, as will be seen later, do es get mo derated by the similarity score. Step 3: T o extract quan tifiable prop erties of the feedbac k messages, w e p erform sen timent analysis via the Stanza library from the Stanford NLP pac k age [ 3 9]. Similar to ReF eed, w e compute negativ e sen timent and p ositiv e sen timent separately . These computations are done first at a sentence level, and then aggregated to a message lev el. Our calculation of an inten tion score adopts a review classification metho d, rather than the user feedbac k on tology used in [13]. While the on tology may need to b e up dated from one domain to another, a classifier trained on di- v erse review data can offer an automatic alternativ e to recognize the type of feedback. T o that end, w e built a random forest classifier on top of the datasets shared b y Scalabrino and colleagues [31]. The datasets con tain 725 reviews from 14 apps, and the reviews are lab eled with six classes: feature, bug, p erformance, usability , security , and energy . Most of the reviews b e- long to the categories of bug or feature. W e developed the random forest with a train-test split ratio of 80-20, and achiev ed an accuracy of 79%. This p erformance is comparable to the random forest classifiers used in the Crow- dRE literature [31, 32]. Note that we applied the same sentimen t analysis and con ten t classification to ReF eed and iReF eed, so there is no difference in extracting feedbac k prop erties. Step 4: The c hief difference in inferring requiremen ts priorit y is illustrated in Fig. 1-b. In iReF eed, the feedback mapping, F C , is no longer from a single requiremen t, but from a cluster. Therefore, a priority of a requiremen t r in iReF eed is defined as: P r = P | F C | i =1 [ sim ( r , F C [ i ]) ∗ ( neg F C [ i ] + pos F C [ i ] + int F C [ i ] )] | F C | (2) where F C represen ts the feedbac k mapping from the cluster that r is in, and the rest of the notations ha ve the same interpretations in equation (1). Orthogonal to LD A and BER T opic, we design a mec hanism to weigh in the coherence of iReF eed’s requirements clusters. W e call it LDA-C or BER T opic- C, and define a requiremen t’s priority in the C v arian ts as: 11 T able 2: Characteristics of RQ 1 Datasets app [source of # of prioriti- # of re- requiremen ts # of user- feedback release notes] zation instances quirements time perio d feedback messages time p eriod Discord [40] 18 373 July 2020–March 2025 368,367 Jan 2020–March 2025 Microsoft 365 W ord [41] 12 295 July 2018–Dec 2024 143,547 Jan 2018–Dec 2024 W eb ex [42] 29 360 F eb 2022–July 2024 17,829 Jan 2022–July 2024 Zoom [43] 35 951 F eb 2022–March 2025 62,074 Jan 2022–March 2025 P r = P | F C | i =1 [ α ( F C ) ∗ sim ( r , F C [ i ]) ∗ ( neg F C [ i ] + pos F C [ i ] + int F C [ i ] )] | F C | (3) where the newly added term α ( F C ) = min (1, a verage pairwise similarity of ∀ r i , r j ∈ F C ). This factor b o osts the priorities of the requirements in an in ternally coherent cluster; how ev er, due to the min ( ) function, α ( F C ) do es not p enalize the p o orly coherent clusters. In fact, when α ( F C ) =1, equation (3) is reduced to equation (2), implying that requiremen ts cluster’s coherence is exp ected to influence the prioritization results in a more general sense. 4. Ev aluating Prioritization Results The research question that we in vestigate in this section is RQ 1 : “Ho w do es iReF eed compare to ReF eed in deliv ering requiremen ts prior- itization results?” W e treat ReF eed as a state-of-the-art metho d of using feedbac k to prioritize candidate requiremen ts, and compare ReF eed with the four v ariants of iReF eed: LD A, BER T opic, LD A-C, and BER T opic-C. 4.1. Datasets and Metrics T o answer RQ 1 , we constructed 94 requiremen ts prioritization instances from four real-world softw are applications: Discord, Microsoft 365 W ord, W e- b ex, and Zo om. T able 2 lists some characteristics of our ev aluation datasets. W e relied on the release notes maintained by the softw are vendors themselves to iden tify requirements. In addition, we collected the release time of each requiremen t. Finally we combined the requirements from tw o consecutive release p eriods to form a prioritization instance. One instance from the Zo om dataset is shown in T able 3. This instance has 71 total requiremen ts: 19 were released in F ebruary 2025 and the other 52 were released in March 2025. The release timestamps give rise to the pri- oritization’s ground truth in an authoritative w a y . When the 71 requirements of T able 3 are prioritized, the ground truth is to select the 19 requirements. Th us, w e note the size of the ground truth here as k =19 and the size of 12 T able 3: Excerpts from One Prioritization Instance of the Zo om Dataset (the top 19 re- quiremen ts w ere released in F ebruary 2025, and the b ottom 52 requirements w ere released in March 2025) # F eature Description In Ground T ruth? 1 Meeting participants can request access to recordings directly from the meeting card or recording Y es link without having to send separate messages through chat, email, or calls. Meeting hosts receive these requests through in-pro duct notifications and emails, which direct them to a viewing page where they can manage access p ermissions. Hosts can view all requesters on the share mo dal, grant or deny access, and manage existing permissions for sp ecific users. The feature resp ects all security settings, including authentication requirements and password protection. 2 After a meeting ends, a dynamic p op-up app ears, based on the assets utilized during the meeting, Y es directing users to the meeting details page. Here, they can access av ailable meeting assets such as meeting recording, summary , continuous chat log, as well as any conten t shared during the session, such as whiteboards, links, and notes. . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 Users can view a complete list of meeting participants directly within the primary meeting card interface. Y es The participant list app ears in the full meeting page, providing clear visibility of all attendees. 1 Hosts and co-hosts can move participants directly from the waiting ro om to designated breakout No rooms without requiring them to enter the main meeting ro om first. A dditionally , they can lock breakout rooms to prevent participants from returning to the main session. This feature works for both signed-in Zo om users and guests. 2 W ebinar hosts can access AI-generated high-level summaries of webinar discussions, serving No as an automated note-taking solution for both live and recorded sessions. Hosts can distribute these summaries through the webinar’s follow-up email workflow or their preferred communication channels. Account owners and admins can control AI summary settings, including usage p ermissions and notification preferences at b oth account and group levels. . . . . . . . . . . . . . . . . . . . . . . . . . . . 52 The Cobrowse feature now supp orts web chat engagements, enabling agents to assist customers No more efficiently while maintaining priv acy . When customers need help with website forms or navigation, agents can request permission to view only the sp ecific webpage where the issue occurs. This enhancement allows for more precise, real-time supp ort while protecting sensitive information through built-in priv acy safeguards. This feature must be enabled by Zoom. the instance as n =71. This instance’s size (71 > 50) illustrates the scalability c hallenge of manually prioritizing requiremen ts [24], echoing the imp ortance of automatic solutions in industrial settings. Our collection of user feedbac k data was done through a Go ogle play store scrap er [44]. Sp ecifically , we extracted the reviews for the four soft ware ap- plications in the same time ranges as the release p erio ds of the requirements. Ho wev er, the reviews were collected one release cycle prior to the require- men ts, as sho wn in T able 2. F or example, w e extracted a total of 62,074 user reviews for Zo om from Jan 2022 to March 2025, but the Zo om requirements w ere collected from F eb 2022 to Marc h 2025. This allo w ed us to ensure time sensitivit y in ev aluating ReF eed and iReF eed. In particular, w e used the reviews up until the b eginning of a prioritization instance. Additionally , to ensure relev an t feedbac k, we used at most the tw o years of reviews preced- ing eac h prioritization instance. When fewer than tw o y ears of reviews w ere a v ailable, we used all a v ailable reviews. F or example, we used the Zo om re- views from Jan 2023 to Jan 2025 for the instance sho wn in T able 3, b ecause the in stance considered releasing the requiremen ts in F eb 2025 and assuming 13 Legends: Figure 3: Answering R Q 1 with av erage p erformances of ReF eed and the four v ariants of iReF eed: LDA, LDA-C, BER T opic, and BER T opic-C. the a v ailabilit y of the user reviews up till Jan 2025 was sensible to us. Giv en the ground truth, w e measure the qualities of ReF eed and iReF eed prioritization results b y computing recall (R), precision (P), F 1 -score (F 1 ), and F 2 -score (F 2 ). These metrics quantify how muc h a prioritization solution o verlaps the ground truth. In tuitively , recall indicates ho w complete the prioritization solution is whereas precision implies ho w noisy it is. Although F 1 = 2 · R · P R + P symmetrically represents b oth recall and precision in one metric, Berry et al. [45] argue that, for automated to ols supp orting RE tasks in the con text of large-scale soft ware developmen t, recall is more imp ortan t than precision. Therefore, we also consider F 2 = 5 · R · P 4 · P + R whic h w eighs recall t wice as 14 imp ortan t as precision. As sho wn in equations (1)–(3), ReF eed and iReF eed rank candidate re- quiremen ts in an ordered list according to requirements’ priority scores. W e th us in vestigate the qualities of the ordered list at fiv e cutoff p oin ts: k , k ± (10% · n ) , and k ± (20% · n ) . Recall that k is the ground truth size (e.g., k =19 in T able 3) and n is the instance size (e.g., n =71 in T able 3). While top- k represents a cutoff in exp erimen tal settings where the exact pri o ritiza- tion n umber is known, the others mimic practical scenarios. T aking T able 3’s instance as an example, the selections of the top-rank ed 5 (i.e., 19 − 20% · 71 ) or 12 (i.e., 19 − 10% · 71 ) requiremen ts reflect aggressiv e prioritization deci- sions, whereas relaxed decisions are represen ted b y choosing the top-ranked 26 (i.e., 19 + 10% · 71 ) or 33 (i.e., 19 + 20% · 71 ) requiremen ts. T o ev aluate statistical significance, w e p erformed the Wilcoxon signed- rank test across all cutoff p oin ts for eac h dataset. F or each metric and iReF eed v ariant, w e compared the scores against ReF eed. The resulting Wilco xon p-v alues of the four iReF eed v arian ts w ere then com bined at eac h cutoff p oin t using Fisher’s metho d. 4.2. R esults and Analysis W e plot the p erformances of ReF eed and iReF eed in Fig. 3. The plots are organized horizontally by the four p erformance ev aluation metrics, and v ertically b y the datasets. Eac h sub-figure sho ws the a verages across the prioritization instances in that dataset. The com bined significance levels are also rep orted in Fig. 3. Overall, a clear trend observed in Fig. 3 is that iReF eed consistently outp erforms ReF eed. This sho ws that clustering re- quiremen ts in to topically coheren t groups p ositiv ely influences prioritization, compared with treating requirements as b eing indep enden t from eac h other in the prioritization pro cess. Using ReF eed as the baseline, we notice from Fig. 3 that the improv e- men ts of recall are more prominen t in Discord, and the precision impro v e- men ts are more salien t in Discord and W eb ex. W e speculate a p ossible reason migh t b e due to the user feedback’s accurate matching and broad cov erage of the candidate requirements in these datasets; how ever, testing the h y- p othesis requires future w ork. Nevertheless, a general trend of Fig. 3 is that LD A-C p erforms b etter than LD A, and BER T opic-C p erforms b etter than BER T opic. Therefore, our results suggest that integrating cluster’s internal coherence into ranking requiremen ts further enhances prioritization qualities. 15 When paying atten tion to differen t cutoff p oin ts, w e identify the pre- cision changes in Fig. 3 as encouraging for iReF eed. As more top-rank ed requiremen ts are analyzed, it is not surprising that recall keeps increasing. F or iReF eed, precision p eaks at top- k in most cases. If the prioritization decision is to con tinue including more requiremen ts, then iReF eed drops pre- cision more than ReF eed’s precision decreases. This shows that the user feedbac k’s influences on prioritization are more accurate to the top- k ranked requiremen ts than to further rank ed requirements. In another w ord, iReF eed ac hieves a go od and balanced p erformance when the n umber of prioritized requiremen ts is near the ground-truth size k . T aking the cutoff at k and the w eighted F 2 as a p erformance indicator, w e note that LDA-C p erforms better than BER T opic-C in Microsoft 365 W ord. LD A-C’s p erformances in Discord, W eb ex, and Zo om are comparable to BER T opic-C’s. Thus, among the four v ariants of iReF eed, we recommend LD A-C, though it is somewhat surprising that the pre-trained BER T mo del with extensive external data do es not definitiv ely outp erform a lo cally op er- ated LD A in user-feedbac k driven requirements prioritization. Through the ab o v e analyses, w e conclude that iReF eed consisten tly outp erforms ReF eed. W e provide an example b elo w to shed ligh t on the differences betw een ReF eed and iReF eed. Consider t wo requirements and three feedbac k messages of a Microsoft 365 W ord instance. • r 1 : “Use @men tions in comments to let co-w orkers know when y ou need their input.” • r 2 : “Tired of b eing lo c k ed out of your do cumen t with macros? Now y our do cm files on OneDrive for Business allow simultaneous editing b y multiple authors.” • m 1 : “This app is sup er easy for reading and sharing w ord files. It has all the imp ortan t features required for writing but steps for using it should b e men tioned or outline of all the editing options should b e mentioned for b eginners. F or me, it sa ved a lot of time. Go od app. Thank y ou” • m 2 : “W orks great with Office 2016 and OneDrive across multiple de- vices/op earting systems. Can’t do without it.” • m 3 : “I absolutely lov e Microsoft’s W ord app. I’m able to do so many imp ortan t things lik e create do cuments that are truly professional, use 16 r 1 r 2 m 1 m 2 m 3 r 1 r 2 m 1 m 2 m 3 iReFeed ReFeed Figure 4: Examples from a Microsoft 365 W ord instance illustrating the differences b et w een ReF eed (left) and iReF eed (righ t). the many templates to make the p erfect letter or resume, upload do c- umen t files in W ord format even from the internet and edit, and if unlo c k ed files I can highlight text and add notes. It allows me to b e the author of my own do cumen t creations and either lo c k it, share it via other applications lik e F aceb o ok or T witter, and giv es me the option to allo w for others to participate in the writing and editing, for instance, a p etition, and so muc h more.” Fig. 4 depicts the asso ciations established in ReF eed and iReF eed for the ab o v e entities. Although lexical clues can be directly sp otted, e.g., “men tion” b et w een r 1 and m 1 , iReF eed is able to recognize deep er seman tic connections. F or example, m 1 touc hes up on editing options and hence is linked to the si- m ultaneous editing of r 2 . Similarly , m 3 adv o cates collab orativ e writing whic h is what r 1 tries to facilitate. In fact, the cluster containing r 1 and r 2 resulted from iReF eed renders collab orativ e editing options as a topic. Consequen tly , iReF eed establishes richer asso ciations that are missed in ReF eed. 4.3. Thr e ats to V alidity The core constructs of our exp erimen ts rep orted in this section are re- quiremen ts prioritization instance and solution quality . Each instance con- tains the requiremen ts that shall b e prioritized to release and those that shall not. The softw are pro jects’ own release histories allow for the ground truth to b e defined authoritatively . Although the instance can b e easily extended to a series of multiple releases, we are interested i n only t wo consecutive release p eriods, as this is also the fo cus of ReF eed. W e measure the prioritization solution’s qualit y with w ell-known metrics at v arious cutoff p oin ts. W e th us b eliev e the threats to construct v alidity are low. 17 The internal v alidit y of exp erimen ts could b e affected b y our choice of extracting review data with a one-release-cycle buffer ahead of requiremen ts data. This av oids solving a prioritization instance without an y review data. A related decision is our use of cum ulative reviews, rather than selecting only recent ones. While our rationale is to maintain a broad time range to capture both short-term and long-term trends of requirements ev olution and in tegration of user feedbac k, determining the optimal amount of review data to exploit in prioritization is b ey ond the scop e of our current work. Keep in mind that, for each prioritization instance, our exp erimen ts of ReF eed and iReF eed ha ve used the same amounts of review and requirements data. As a result, the comparisons rep orted in this section reflect the differences b et w een ReF eed and iReF eed. The results are based on the four real-w orld datasets that we hav e cu- rated. Due to the threats to external v alidity , it w ould b e to o strong to claim iReF eed’s b etter p erformance ov er ReF eed on other prioritization in- stances (e.g., the soft ware applications outside the video conferencing, w ord pro cessing, and so cial netw orking domains). In terms of transparency and reliabilit y , w e share our datasets, along with our implementations and ex- p erimen tal results, in h t t p s : // d o i . o r g/ 1 0 . 5 2 81 / z e n o d o . 1 8 8 8 1 98 6 to facilitate replication and expansion. 5. Unco v ering “Requires” P airs Our R Q 2 examines: “T o what exten t is iReF eed conduciv e to iden tifying the ‘requires’ relations?” As discussed in Section 2.2, “re- quires” relations greatly shap e prioritization decisions. Ho wev er, iden tifying suc h relations remains largely a man ual task [15, 14]. With the adven t of LLMs, researchers hav e exploited them to automate a wide v ariety of RE tasks. Sp ecifically , LLMs lik e Op enAI’s ChatGPT ha ve shown promises in detecting the r elationships among requiremen ts: inconsistency (e.g., “the ma- c hine shall alw ays offer coffee” is in tension with “the machine shall not offer Cappuccino as a b ev erage option”) [46], traceabilit y (e.g., an “error deco d- ing” requirement is traced to a “control and monitoring” feature) [47, 48], satisfaction (e.g., whether a mobile app’s sp ecification satisfies GDPR’s data withdra wal guidance) [49], just to name a few. Motiv ated by this thrust of research, we are interested in LLMs’ capa- bilities of automatically unco vering “requires” relations for the requirements prioritization task. W e c hose the W ord Pro cessor b enc hmark to exp erimen t 18 b ecause the 65 “ r a → r b ” pairs defined on top of the 50 requirements [17] w ould serve as the ground truth. In terms of LLMs, w e tested ChatGPT 4.5 and ChatGPT 4o b ecause these are the latest mo dels from Op enAI, though ChatGPT 4.5 is generally considered an improv emen t o ver ChatGPT 4o with impro ved reasoning and reduced hallucination rates [50]. W e dev elop ed a direct prompt and ran it through the LLMs’ web interfaces in Ma y 2025: A “r e quir es” r elation b etwe en two r e quir ements (r e q_x and r e q_y) is define d as: r e q x r e quir es r e q y for the purp ose of softwar e r ele ase, but not vic e versa. Identify and output al l the “r e quir es” p airs fr om the r e quir ements pr ovide d b elow, using the format: r e q_x – > r e q_y. {r e quir ements} In this prompt the ob jectiv e of “soft w are release” is made explicit, the instruc- tion of “iden tifying all the ‘requires’ pairs” is given, and the output format of “req_x → req_y” is sp ecified. Iden tifying requires relations inv olves understanding the context of dif- feren t requirements. Although LLMs suc h as ChatGPT hav e large context windo ws, analyzing all requiremen ts at once can still confuse the mo del with to o many comp eting semantic cues, esp ecially when the requiremen ts are topically div erse. This motiv ates us to utilize clustering to impro ve fo cus b y grouping requirements that are topically similar based on the user feed- bac k, allowing the LLM to reason more effectively within a fo cused group of interconnected requiremen ts. W e fed all the 50 W ord Pro cessor {require- men ts} once as the baseline . The iReF eed prompt, how ever, w ould feed only the {requiremen ts} of one cluster at a time. T o pro duce the clusters for the W ord Pro cessor requirements, we first applied LD A-C to 146,310 re- views (Jan 2018–Marc h 2025) of Microsoft 365 W ord, as the answers to R Q 1 sho wed that LDA-C was among the b est to implemen t iReF eed. W e then used the user-review topics to group the 50 W ord Pro cessor requiremen ts in to clusters. This resulted in 7 clusters, and hence we ran the iReF eed prompt 7 times, each time with the {requiremen ts} from one and only one cluster. W e made sure to clear ChatGPT’s history while prompting. Therefore, the baseline and iReF eed promptings were indep enden t from each other, and so were the 7 times that the iReF eed prompts w ere executed. Finally , w e treated iReF eed as a supplemen t to the baseline prompting rather than its replacement. The reason w as that iReF eed prompt did not cross cluster b oundaries, so the “requires” of tw o requiremen ts in different clusters w ould not b e detected b y the iReF eed prompts. W e aggregated iReF eed prompts’ results into the baseline results b y eliminating duplicates, and referred to 19 T able 4: Answering RQ 2 with Automatically Identified “Requires” Pairs for the W ord Pro cessor Benc hmark [17] LLM prompting # of dis- R P F 1 F 2 tinct pairs Chat- baseline 18 0.08 0.28 0.12 0.09 GPT iReF eed 26 0.11 0.27 0.15 0.12 4.5 com bined 37 0.17 0.30 0.22 0.19 Chat- baseline 32 0.08 0.16 0.10 0.09 GPT iReF eed 32 0.11 0.22 0.14 0.12 4o com bined 56 0.17 0.20 0.18 0.17 the aggregated “requires” pairs as the com bined results. The results’ accuracies are summarized in T able 4 where the b est p erfor- mances are displa y ed in b oldface. While the complete results are shared in http s ://doi. o rg/10.5 2 81/zeno d o.18881 9 86 , we mak e a couple of obser- v ations. First, ChatGPT 4.5 generally outp erforms ChatGPT 4o, whic h is not surprising giv en the adv anced reasoning capabilities of ChatGPT 4.5 [50]. Second, and more imp ortan tly , regardless of the LLMs, iReF eed do es help unco ver additional “requires” pairs that the baseline prompting fails to iden- tify . This is encouraging in that, b y zo oming in only the requiremen ts inside a single cluster, subtle relationships could b e recognized. In a w ay , iReF eed prompting decomp oses a requirements set into smaller c huc ks, whic h slows do wn ChatGPT’s reasoning and improv es identification accuracies. W e con- clude that iReF eed adds v alue in ChatGPT’s auto-generation of “requires” pairs. A dmittedly , the o verall accuracies of T able 4 are low. On one hand, in ter- relating requiremen ts for prioritization may b e a difficult task that requires LLM fi ne-tuning or adv anced prompting like few-shot and c hain-of-thought. On the other hand, the data leak age concerns app ear to b e alleviated. Data leak age means the LLM merely memorizes the data instead of doing the rea- soning. Giv en that the W ord Pro cessor dataset [17] w as released in 2016 and ChatGPT 4.5 and 4o w ere released in F ebruary 2025 and May 2024 resp ectiv ely , little leak age seemed to hav e o ccurred in our RQ 2 exp erimen ts. 6. In tegrating iReF eed in to SBSE W e explore in R Q 3 : “Ho w could iReF eed b e in tegrated in to SBSE approac hes to solving the NRP?” T o that end, we illustrate in this sec- 20 tion a concrete wa y to fuse the “requires” pairs uncov ered by iReF eed with NSGA-I I, a well-suited SBSE solution to the NRP . Our illustration builds on the W ord Pro cessor dataset [17]. In particular, we tak e the 50 require- men ts and use NSGA-I I to search for solutions for a bi-ob jectiv e optimization problem: Maximize the weigh ted sum of all the stakeholders’ v alue scores (cf. columns 2–5 of T able 1) while at the same time minimizing the developmen t resource estimates (i.e., column 8 of T able 1). Our baseline implementation of NSGA-I I follows the same algorithmic tuning as in tro duced b y Finkelstein et al. [8]: • The initial p opulation is set to 200. • The exp erimen tal execution of NSGA-I I is terminated after 50 genera- tions, i.e., after 10,000 ev aluations. • The genetic approac h uses the tournament selection (with tournamen t size of 5), single-p oin t crosso ver, and bitwise mutation. • The probability of the crosso v er op erator being applied is set to P c =0.8, and the probability of the m utation operator is set to P m = 1 # of requirements = 1 50 =0.02. The result of such a searc h is a Pare to fron t. Each element on this front is a candidate solution to the NRP . All solutions on the Pareto front are non-dominated: no other solution on the front is b etter according to b oth ob jectives. The Pareto front thus represen ts a set of “b est compromises” b et w een the ob jectives that can b e found b y the searc h-based algorithm. As an illustration, we show the search results of the baseline NSGA-I I run in Fig. 5 in which no “requires” pairs are tak en in to accoun t. In this figure, the “ × ” and “ − ” no des denote the Pareto-optimal solutions found by the baseline NSGA-I I algorithm. T o integrate iReF eed into NSGA-I I, w e introduce dep endency v alue (D- v alue). W e utilize the automatically identified requires pairs from ChatGPT 4.5 combined results in RQ2 to compute the D-v alue. Let D b e the set of all the requires pairs identified b y ChatGPT 4.5 in RQ2, where eac h pair “ r a → r b ” indicates that requirement a requires requirement b. Let count i b e defined as the total n umber of requires relations where i app ears on the righ t hand side of a requires pair ( count i = |{ ( r a → r b ) ∈ D , where b=i}|). The D-v alue for a requirement i is defined as follows: 21 D - v alue i = count i D D-V alue for iReF eed is incorp orated as a third ob jective of maximizing D- v alue. W e maximize D-v alue as an ob jectiv e in iReF eed giving imp ortance to the requiremen ts with higher dep endencies for selection. The D v alues ha ve a short range and are sk ewed in nature, so we apply differen t transformations and normalization techniques to explore alternative representations of the dep endency v alues. W e in tro duce fiv e v arian ts: D-v alue, log transformed D v alue, p o wer transformed D-v alue, z-score normalized D-v alue, and in v erse D-v alue. The form ulas for eac h of the v arian ts are rep orted in T able 5. F or the log transformation, we apply log e (1 + D i ) to a v oid undefined v alues when D i = 0 . When applying the z-score normalization, we shift each v alue b y the magnitude of the most negativ e z-score to ensure that all the v alues are non-negativ e, while preserving the relativ e ordering betw een the v alues. The in verse D-v alue serves as a contrasting v ariant that prioritizes requirements with few er dep endencies. This enables us to ev aluate how the searc h is Figure 5: One run of R Q 3 with search results from the baseline NSGA-I I and the iReF eed D-v alue v ariant NSGA-I I. 22 T able 5: Dep endency V alue (D-v alue) V ariants V ariant F ormula D-v alue ( D i ) count i |D | Log-transformed D-v alue log e (1 + D i ) In verse D-v alue 1 − D i P ow er-transformed D-v alue D 0 . 5 i Z-score normalized D-v alue D i − µ σ T able 6: RQ3: av erage across 10 runs of p ercen tage of solutions in reference pareto front V ariants Baseline NSGA-I I iReF eed NSGA-I I D-v alue 80.65 98.18 Log transformed D-v alue 85.17 94.28 In verse D-v alue 95.98 66.28 P ow er transformed D-v alue 83.84 98.1 Z-score normalized D-v alue 82.72 97.45 affected b y the dep endency v alues. In Fig. 5, the “ + ” and “ − ” nodes denote the Pareto-optimal solutions found b y the iReF eed NSGA-I I searc h for one of the runs (run 5) of the D v alue v ariant . The shared solutions are mark ed b y “ − ”. T o ev aluate the solu- tions found by baseline NSGA-I I and iReF eed NSGA-I I, w e construct a r efer- enc e Par eto fr ont informed b y the work of Finkelstein et al. [8]. In a nutshell, the reference Pareto fron t is the result of merging the solutions from differen t searc h algorithms and then excluding the solutions that are dominated by some other merged solutions. Since we are solving for the bi-ob jectiv e opti- mization problem, w e only consider the v alue and cost pairs as solutions when ev aluating the baseline NSGA-I I and iReF eed NSGA-I I solutions. In Fig. 5, for example, although the solution A : (v alue=4097, cost=175) is Pareto- optimal when only the baseline NSGA-I I is considered, A b ecomes dominated b y one of the iReF eed NSGA-I I solutions B : (v alue=4713, cost=167). The reason is that B ’s v alue is higher than A ’s v alue, and at the same time, B ’s cost is lo wer than A ’s cost. In the face of B , A is no longer on the reference P areto fron t. Therefore, the reference P areto front denotes the best a v ailable appro ximation to the r e al Pareto front [8]. 23 (a) D-value (b) Log transformed D-value (c) Inverse D-value (d) Power T ransformed D-value (e) Z-score normalized D-value Figure 6: RQ3: Comparison of each iReF eed v ariant against the Baseline across 10 runs The measure used by Finkelstein et al. [8] to compare different search algorithms is to coun t the num b er of individual algorithm’s solutions on the reference Pareto front, namely the solutions that are not dominated by the reference Pareto fron t. W e rep ort the a v erage results for each iReF eed v arian t against the baseline across 10 runs in T able 6. The results across each run for all the iReF eed v ariants against baseline is shown in Figure 6. W e observ e from T able 6 and Figure 6 that for all iReF eed v arian ts ex- cept the inv erse D-v alue v arian t, iReF eed searc h solutions represen t a higher 24 prop ortion of solutions in the reference pareto front. The greater share, ac- cording to Fink elstein et al. [8], suggests the b etter p erformance of iReF eed NSGA-I I compared to baseline NSGA-I I. Thus, we conclude p ositiv e find- ings of RQ 3 with iReF eed’s sup eriorit y ov er the baseline SBSE solution. W e attribute this to the baseline’s obliviousness to requiremen ts interconnected- ness. The inv erse D-v alue v ariant is particularly interesting. By inv ersing the imp ortance of dep endency v alues, this v ariant priorities requirements with less dep endency on other requiremen ts. As a result, its p erformance drops significan tly compared to baseline. This v ariant further strengthes the im- p ortance of integrating D-v alue in to the iReF eed search. Our study presen ted in this section has several limitations. F rom the con- struct v alidity p erspective, w e use an individual search algorithm’s solutions shared within the reference P areto fron t to ev aluate that algorithm’s p erfor- mance. While Fink elstein et al. [8] hav e used the same ev aluativ e construct, there exist other measures, such as conv ergence and h yp erv olume [26], which could b e considered in future assessmen ts. W e b eliev e the in ternal v alid- it y is high, as the search results rep orted in this section are based on the same parameter setting for b oth the baseline and the iReF eed NSGA-I I al- gorithms. Thus, the different shares of the reference P areto fron t m ust b e caused by the “requires” pairs exploited in iReF eed NSGA-I I. Our results ma y not generalize to other datasets or SBSE algorithms—a threat to the external v alidit y . With the encouraging initial results obtained here, w e are p ositiv e that iReF eed is amenable to b e integrated into other metaheuristic searc h techniques lik e the tw o-archiv e algorithm [8] or even hyper-heuristic searc h metho ds [26]. 7. Conclusion Mo dern soft ware engineering often injects agile’s iterativ e and incremen- tal developmen t. Requiremen ts are con tinuously deliv ered, though challenges exist in terms of lack of long-term planning, p oor resource managemen t, and scop e creep [51]. User feedbac k pro vides an inv aluable source for supp orting agile soft w are pro ject’s strategic releases. In this pap er, w e hav e presented a no vel approach to enhancing user-feedback driven requirements prioritiza- tion. Our main nov elt y lies in the clustering of requirements based on the topics emerged from user reviews. Our ev aluations sho w that iReF eed not only outp erforms ReF eed in making prioritization decisions, but also is con- 25 duciv e to enabling ChatGPT to identify requirements dep endencies. The in tegration of iReF eed and NSGA-I I, to the b est of our knowledge, is the first to syn thesize CrowdRE and SBSE for requirements prioritization. Our future w ork includes carrying out exp erimen tation on more datasets, in vestigating the optimal amount of feedback data to use, testing adv anced prompting metho ds lik e few-shot and chain-of-though t, and guiding meta- heuristic or h yp er-heuristic searc h proactively with the “requires” pairs. References [1] K. Marner, S. W agner, G. Ruhe, Release planning patterns for the au- tomotiv e domain, Computers 11 (6) (2022) 89:1–89:26. URL https://doi.org/10.3390/computers11060089 [2] D. Spinellis, The strategic imp ortance of release engineering, IEEE Soft- w are 32 (2) (2015) 3–5. URL https://doi.org/10.1109/MS.2015.54 [3] M. Nay ebi, G. Ruhe, Analytical pro duct release planning, in: C. Bird, T. Menzies, T. Zimmermann (Eds.), The Art and Science of Analyzing Soft ware Data, Morgan Kaufmann, 2015, pp. 555–589. URL https://doi.org/10.1016/b978- 0- 12- 411519- 4.00019- 7 [4] G. Zorn-Pauli, B. P aech, T. Bec k, H. Karey , G. Ruhe, Analyzing an industrial strategic release planning pro cess - a case study at Ro c he Diagnostics, in: Pro ceedings of the 19th In ternational W orking Con- ference on Requiremen ts Engineering: F oundation for Softw are Qualit y (REFSQ), Essen, German y , 2013, pp. 269–284. URL https://doi.org/10.1007/978- 3- 642- 37422- 7\_19 [5] A. J. Bagnall, V. J. Ra yward-Smith, I. M. Whittley , The next release problem, Information & Soft ware T echnology 43 (14) (2001) 883–890. URL https://doi.org/10.1016/S0950- 5849(01)00194- X [6] M. S. F eather, T. Menzies, Con verging on the optimal attainmen t of re- quiremen ts, in: Pro ceedings of the 10th IEEE Joint International Con- ference on Requirements Engineering (RE), Essen, Germany , 2002, pp. 263–272. URL https://doi.org/10.1109/ICRE.2002.1048537 26 [7] Y. Zhang, M. Harman, S. A. Mansouri, The m ulti-ob jectiv e next release problem, in: Pro ceedings of the 9th Annual Conference on Genetic and Ev olutionary Computation (GECCO), London, UK, 2007, pp. 1129– 1137. URL https://doi.org/10.1145/1276958.1277179 [8] A. Fink elstein, M. Harman, S. A. Mansouri, J. Ren, Y. Zhang, A searc h based approac h to fairness analysis in requiremen t assignments to aid negotiation, mediation and decision making, Requiremen ts Engineering 14 (4) (2009) 231–245. URL https://doi.org/10.1007/s00766- 009- 0075- y [9] J. J. Du rillo, Y. Zhang, E. Alba, M. Harman, A. J. Nebro, A study of the bi-ob jective next release problem, Empirical Soft ware Engineering 16 (1) (2011) 29–60. URL https://doi.org/10.1007/s10664- 010- 9147- 3 [10] X. Cai, O. W ei, Z. Huang, Ev olutionary approac hes for multi-ob jectiv e next release problem, Computing and Informatics 31 (4) (2012) 847–875. [11] J. Xuan, H. Jiang, Z. Ren, Z. Luo, Solving the large scale next release problem with a bac kb one-based multilev el algorithm, IEEE T ransactions on Soft ware Engineering 38 (5) (2012) 261–284. URL https://doi.org/10.1109/TSE.2011.92 [12] M. R. Karim, G. Ruhe, Bi-ob jectiv e genetic searc h for release planning in supp ort of themes, in: Pro ceedings of the 6th In ternational Symp osium on Search-Based Softw are Engineering (SSBSE), F ortaleza, Brazil, 2014, pp. 123–137. URL https://doi.org/10.1007/978- 3- 319- 09940- 8\_9 [13] F. M. Kifetew, A. Perini, A. Susi, A. Siena, D. M. nan te, I. Morales- Ramirez, Automating user-feedbac k driven requirements prioritization, Information & Soft ware T echnology 138 (2021) 106635:1–106635:16. URL https://doi.org/10.1016/j.infsof.2021.106635 [14] F. B. A ydemir, F. Dalpiaz, S. Brinkkemper, P . Giorgini, J. Mylop oulos, The next release problem revisited: A new a ven ue for goal mo dels, in: Pro ceedings of the 26th IEEE International Requirements Engineering 27 Conference (RE), Banff, Canada, 2018, pp. 5–16. URL https://doi.org/10.1109/RE.2018.00- 56 [15] P . Carlshamre, K. Sandahl, M. Lindv all, B. Regnell, J. N. o c h Dag, An industrial surv ey of requiremen ts interdependencies in soft ware product release planning, in: Pro ceedings of the 5th IEEE International Sym- p osium on Requiremen ts Engineering (RE), T oronto, Canada, 2001, pp. 84–91. URL https://doi.org/10.1109/ISRE.2001.948547 [16] W. N. Robinson, S. D. Pa wlo wski, V. V olko v, Requirements interaction managemen t, ACM Computing Surveys 35 (1) (2003) 132–190. URL https://doi.org/10.1145/857076.857079 [17] M. R. Karim, G. Ruhe, Datasets of “bi-ob jective genetic searc h for re- lease planning in supp ort of themes”, https://sites.google.com/sit e/mrkarim/data- sets , Last accessed: March 31, 2026(2016). [18] A. P erini, A. Susi, P . A vesani, A mac hine learning approac h to softw are requiremen ts prioritization, IEEE T ransactions on Soft ware Engineering 39 (4) (2013) 445–461. URL https://doi.org/10.1109/TSE.2012.52 [19] G. Ruhe, Pro duct Release Planning - Metho ds, T o ols and Applications, CR C Press, 2010. [20] G. Ruhe, A. Eb erlein, D. Pfahl, Quantitativ e Win Win: A new metho d for decision supp ort in requiremen ts negotiation, in: Proceedings of the 14th International Conference on Softw are Engineering and Kno wledge Engineering, SEKE’02, Ischia, Italy , 2002, pp. 159–166. doi:h ttps://doi.org/10.1145/568760.568789. [21] D. Leffingw ell, D. Widrig, Managing Soft w are Requiremen ts: A Use Case Approac h, Addison-W esley , 2003. URL https://dl.acm.org/doi/10.5555/829554 [22] J. Karlsson, K. Ry an, A cost-v alue approac h for prioritizing require- men ts, IEEE Softw are 14 (5) (1997) 67–74. URL https://doi.org/10.1109/52.605933 28 [23] J. Karlsson, C. W ohlin, B. Regnell, An ev aluation of metho ds for priori- tizing soft ware requirements, Information & Soft w are T echnology 39 (14- 15) (1998) 939–947. URL https://doi.org/10.1016/S0950- 5849(97)00053- 0 [24] A. Perini, A. Susi, F. Ricca, C. Bazzanella, An empirical study to com- pare the accuracy of ahp and cbranking techniques for requirements pri- oritization, in: Pro ceedings of the 5th International W orkshop on Com- parativ e Ev aluation in Requiremen ts Engineering (CERE), New Delhi, India, 2007, pp. 23–35. URL https://doi.org/10.1109/CERE.2007.1 [25] I. Rahimi, A. H. Gandomi, M. R. Nik o o, F. Chen, A compara- tiv e study on ev olutionary multi-ob jectiv e algorithms for next release problem, Applied Soft Computing 5 2 (3) (2023) 110472:1–110472:13. doi:h ttps://doi.org/10.1016/j.aso c.2023.110472. [26] Y. Zhang, M. Harman, G. Ochoa, G. Ruhe, S. Brinkkemper, An empiri- cal study of meta- and hyper-heuristic search for multi-ob jectiv e release planning, ACM T ransactions on Soft ware Engineering and Metho dology 27 (1) (2012) 3:1–3:32. URL https://doi.org/10.1145/3196831 [27] M. Sv ahnberg, T. Gorschek, R. F eldt, R. T ork ar, S. B. Saleem, M. U. Shafique, A systematic review on strategic release planning mo dels, In- formation & Soft ware T echnology 52 (3) (2010) 237–248. URL https://doi.org/10.1016/j.infsof.2009.11.006 [28] D. Ameller, C. F arré, X. F ranc h, G. Rufián, A survey on softw are release planning mo dels, in: Pro ceedings of the 17th In ternational Conference on Pro duct-F o cused Soft w are Pro cess Improv ement (PR OFES), T rond- heim, Norw ay , 2016, pp. 48–65. URL https://doi.org/10.1007/978- 3- 319- 49094- 6\_4 [29] E. C. Gro en, J. Dörr, S. Adam, T o wards crowd-based requiremen ts en- gineering a research preview, in: Pro ceedings of the 21st International W orking Conference on Requiremen ts Engineering: F oundation for Soft- w are Quality (REFSQ), Essen, Germany , 2015, pp. 247–253. URL https://doi.org/10.1007/978- 3- 319- 16101- 3\_16 29 [30] F. P alomba, P . Salza, A. Ciurumelea, S. Panic hella, H. C. Gall, F. F er- rucci, A. De Lucia, Recommending and lo calizing c hange requests for mobile apps based on user reviews, in: Pro ceedings of the 39th IEEE/A CM International Conference on Softw are Engineering (ICSE), Buenos Aires, Argen tina, 2017, pp. 106–117. URL https://doi.org/10.1109/ICSE.2017.18 [31] S. Scalabrino, G. Bav ota, B. Russo, M. Di P enta, R. Oliveto, Listening to the cro wd for the release planning of mobile apps, IEEE T ransactions on Soft ware Engineering 45 (1) (2019) 68–86. URL https://doi.org/10.1109/TSE.2017.2759112 [32] M. Nay ebi, K. Kuznetsov, A. Zeller, G. Ruhe, User driven functionalit y deletion for mobile apps, in: Pro ceedings of the 31st IEEE In ternational Requiremen ts Engineering Conference (RE), Hannov er, German y , 2023, pp. 6–16. URL https://doi.org/10.1109/RE57278.2023.00011 [33] G. H. Strønstad, I. Gerostathop oulos, E. Guzmán, What’s next in m y bac klog? Time series analysis of user reviews, in: Pro ceedings of the 8th In ternational W orkshop on Empirical Requiremen ts Engineering (Em- piRE), Hanno ver, Germany , 2023, pp. 154–161. URL https://doi.org/10.1109/REW57809.2023.00032 [34] C. M. C. Silv a, M. Galster, F. Gilson, T opic mo deling in soft ware engi- neering research, Empirical Softw are Engineering 26 (6) (2021) 120:1– 120:62. URL https://doi.org/10.1007/s10664- 021- 10026- 0 [35] M. Sihag, Z. S. Li, A. Dash, N. N. Aron y , K. Dev athasan, N. A. Ernst, A. B. Albu, D. E. Damian, A data-driven approac h for finding require- men ts relev an t feedback from TikT ok and Y ouT ub e, in: Pro ceedings of the 31st IEEE International Requirements Engineering Conference (RE), Hanno ver, Germany , 2023, pp. 111–122. URL https://doi.org/10.1109/RE57278.2023.00020 [36] A. Hindle, C. Bird, T. Zimmermann, N. Nagappan, Do topics make sense to managers and developers?, Empirical Softw are Engineering 20 (2) (2015) 479–515. doi:10.1007/s10664-014-9312-1. URL https://doi.org/10.1007/s10664- 014- 9312- 1 30 [37] R. Tiarks, W. Maalej, How do es a typical tutorial for mobile de- v elopment lo ok lik e?, in: Pro ceedings of the 11th W orking Confer- ence on Mining Soft ware Rep ositories (MSR 2014), Asso ciation for Computing Mac hinery , New Y ork, NY, USA, 2014, pp. 272–281. doi:10.1145/2597073.2597106. URL https://doi.org/10.1145/2597073.2597106 [38] F. Palom ba, M. L. Vásquez, G. Ba v ota, M. D. Rocco Oliv eto, D. Posh y- v anyk, A. De Lucia, User reviews matter! T rac king crowdsourced re- views to supp ort evolution of successful apps, in: Pro ceedings of the 31st IEEE International Conference on Softw are Main tenance and Ev o- lution (ICSME), Bremen, German y , 2015, pp. 291–300. URL https://doi.org/10.1109/ICSM.2015.7332475 [39] P . Qi, Y. Zhang, Y. Zhang, J. Bolton, C. D. Manning, Stanza: A Python natural language pro cessing to olkit for many h uman languages, CoRR (Marc h 2020). URL https://doi.org/10.48550/arXiv.2003.07082 [40] Discord, Change Log, htt p s://di scord. com/de velope r s/docs /chan ge- log , Last accessed: March 31, 2026(2026). [41] Microsoft, Microsoft 365 Apps for Windo ws: Arc hived Release Notes, https://learn.microsoft. co m / e n - u s / o f fi c e u p d at e s / m o nt h l y- cha nnel- archived , Last accessed: March 31, 2026(2026). [42] Cisco, W eb ex App: What’s New, https://help.webex.com/en- us/ar ti cl e/ 8d mb cr /W eb ex- A pp - | - W ha t’ s- N ew , Last accessed: March 31, 2026(2026). [43] Zo om, Release Notes for Windows, h t t p s : / / s u p p o r t . z o o m . u s / h c / en- us / a rt i c le s /2 0 1 36 1 9 53 - R e le a s e- no t e s- f o r - W i n do ws , Last accessed: March 31, 2026(2026). [44] Python Softw are F oundation, Google-Play-Scraper, h t t ps : / / p y p i . o r g / p r o j e c t / g o o g l e- p l a y- s c r a p e r / , Last accessed: March 31, 2026(2026). [45] D. M. Berry , J. Cleland-Huang, A. F errari, W. Maalej, J. Mylop oulos, D. Zowghi, P anel: Context-dependent ev aluation of to ols for NL RE 31 tasks: Recall vs. precision, and b ey ond, in: Proceedings of the 25th IEEE In ternational Requirements Engineering Conference (RE), Lisb on, P ortugal, 2017, pp. 570–573. URL https://doi.org/10.1109/RE.2017.64 [46] A. F antec hi, S. Gnesi, L. C. P assaro, L. Semini, Inconsistency detection in natural language requirements using ChatGPT: A preliminary ev al- uation, in: Pro ceedings of the 31st IEEE In ternational Requirements Engineering Conference (RE), Hanno ver, Germany , 2023, pp. 335–340. URL https://doi.org/10.1109/RE57278.2023.00045 [47] A. D. Ro driguez, K. R. Dearstyne, J. Cleland-Huang, Prompts mat- ter: Insigh ts and strategies for prompt engineering in automated soft- w are traceability , in: Pro ceedings of the 11th International W orkshop on Soft ware and Systems T raceabilit y (SST), Hannov er, Germany , 2023, pp. 455–464. URL https://doi.org/10.1109/REW57809.2023.00087 [48] A.-R. Preda, C. Ma yr-Dorn, A. Mashkoor, A. Egy ed, Supp orting high- lev el to low-lev el requirements cov erage reviewing with large language mo dels, in: Pro ceedings of the 14th In ternational Conference on Soft- w are Engineering and Kno wledge Engineering, SEKE’02, Isc hia, Italy , 2024, pp. 159–166. doi:https://doi.org/10.1145/568760.568789. [49] S. San tos, T. D. Breaux, T. B. Norton, S. Haghighi, S. Ghanav ati, In ter- linking user stories and GUI protot yping: A semi-automatic LLM-based approac h, in: Pro ceedings of the 32nd IEEE International Requirements Engineering Conference (RE), Reykja vik, Iceland, 2024, pp. 380–388. URL https://doi.org/10.1109/RE59067.2024.00045 [50] G. Mori, GPT-4.5 vs GPT-4o: Comparing Op enAI’s Latest AI Mo dels, ht tp s: //g ia nc arl om or i. s ub st ac k .c om /p/ gp t- 4 5- vs- g pt - 4 o- c om paring- openais , Last accessed: March 31, 2026(2025). [51] D. Ra ymond, T op 10 Cons or Disadv antages of Agile Metho dology, ht t ps : // p r o j e ct m an a ge r s. n e t/ t op- 1 0- c o ns- or- d i s ad v an t ag e s- o f- agile- methodology/ , Last accessed: March 31, 2026(2023). 32
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment