FL-PBM: Pre-Training Backdoor Mitigation for Federated Learning
Backdoor attacks pose a significant threat to the integrity and reliability of Artificial Intelligence (AI) models, enabling adversaries to manipulate model behavior by injecting poisoned data with hidden triggers. These attacks can lead to severe co…
Authors: Osama Wehbi, Sarhad Arisdakessian, Omar Abdel Wahab
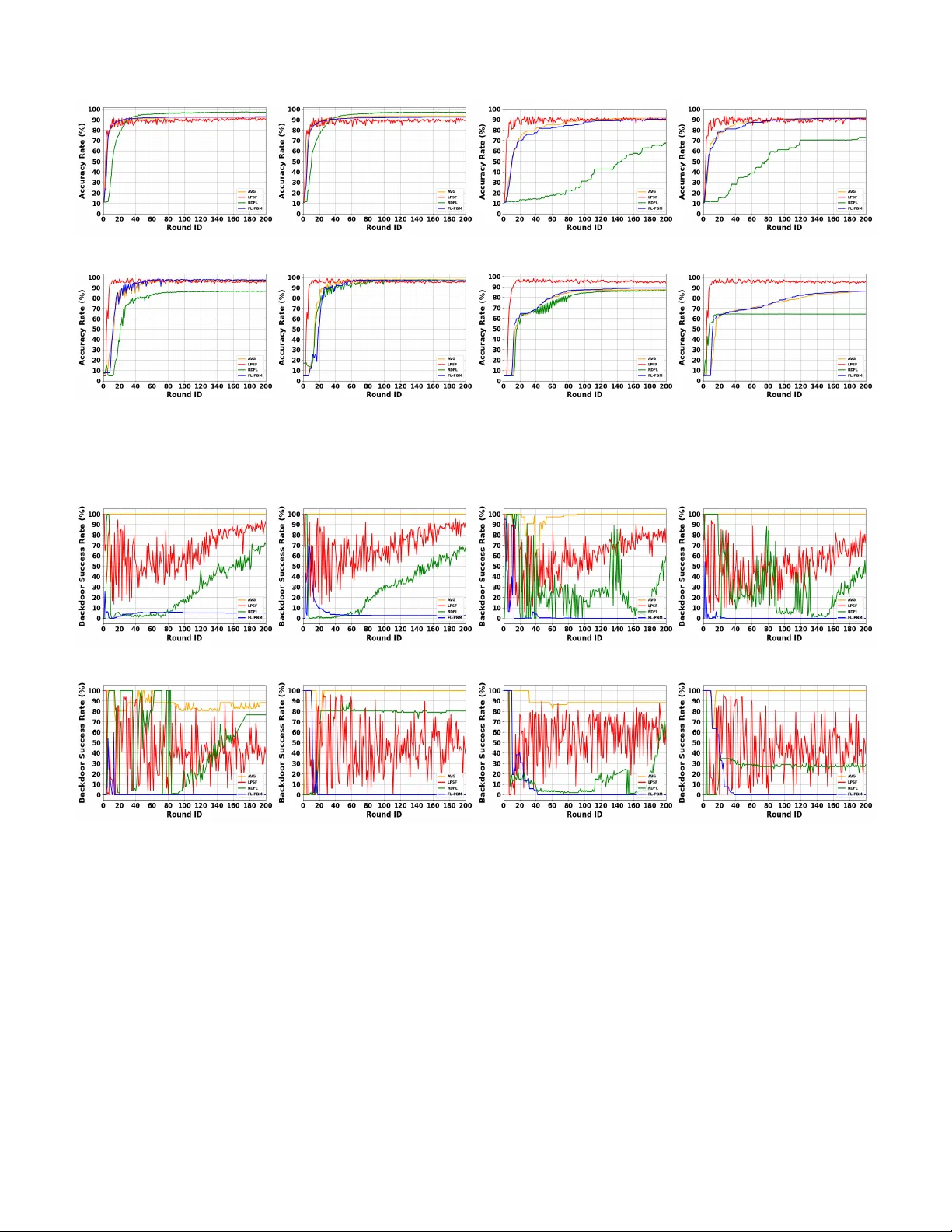
1 FL-PBM: Pre-T raining Backdoor Mitigation for Federated Learning Osama W ehbi, Sarhad Arisdakessian, Omar Abdel W ahab, Azzam Mourad, Hadi Otrok, Jamal Bentahar Abstract —Backdoor attacks pose a significant thr eat to the integrity and reliability of Artificial Intelligence (AI) models, enabling adversaries to manipulate model beha vior by injecting poisoned data with hidden triggers. These attacks can lead to sever e consequences, especially in critical applications such as autonomous driving, healthcare , and finance. Detecting and mit- igating backdoor attacks is crucial across the lifespan of model’s phases, including pre-training, in-training, and post-training . In this paper , we propose Pre-T raining Backdoor Mitigation for Federated Learning (FL-PBM), a nov el defense mechanism that proactively filters poisoned data on the client side before model training in a federated learning (FL) envir onment. The approach consists of three stages: (1) inserting a benign trigger into the data to establish a controlled baseline, (2) applying Principal Component Analysis (PCA) to extract discriminative features and assess the separability of the data, (3) performing Gaussian Mixture Model (GMM) clustering to identify poten- tially malicious data samples based on their distribution in the PCA-transformed space, and (4) applying a targeted blurring technique to disrupt potential backdoor triggers. T ogether , these steps ensure that suspicious data is detected early and sanitized effectively , thereby minimizing the influence of backdoor triggers on the global model. Experimental ev aluations on image-based datasets demonstrate that FL-PBM reduces attack success rates by up to 95% compared to baseline federated learning (FedA vg) and by 30 to 80% relative to state-of-the-art defenses (RDFL and LPSF). At the same time, it maintains over 90% clean model accuracy in most experiments, achieving better mitigation without degrading model perf ormance. Index T erms —Federated Learning (FL), Backdoor Attacks, PCA, GMM, Blurring. I . I N T R O D U C T I O N Artificial Intelligence has seen significant growth and adop- tion across various domains, including healthcare, autonomous driving, finance, and cybersecurity . The increasing reliance on AI-driven systems has highlighted the critical need for Osama W ehbi is with the Department of Computer and Software En- gineering, Polytechnique Montr ´ eal, Montreal, Quebec, Canada (e-mail: osama.wehbi@etud.polymtl.ca). Sarhad Arisdakessian is with the Department of Computer and Software Engineering, Polytechnique Montr ´ eal, Montreal, Quebec, Canada (e-mails: sarhad.arisdakessian@etud.polymtl.ca). Omar Abdel W ahab is with the Department of Computer and Software Engineering, Polytechnique Montr ´ eal, Montreal, Quebec, Canada (e-mails: omar .abdul-wahab@polymtl.ca). Azzam Mourad is with the Department of Computer Science, Khalifa Univ ersity , Abu Dhabi, UAE, as well as the Artificial Intelligence & Cyber Systems Research Center, Department of CSM, Lebanese American Univer - sity (e-mails: azzam.mourad@ku.ac.ae). Hadi Otrok is with the Department of Computer Science, Khalifa Univer - sity , Abu Dhabi, UAE (e-mails: hadi.otrok@ku.ac.ae). Jamal Bentahar is with the KU 6G Research Center, Department of Computer Science, Khalifa University , Abu Dhabi, UAE, and also with the Concordia Institute for Information Systems Engineering, Concordia Univ ersity , Montreal, Quebec, Canada (e-mail: jamal.bentahar@ku.ac.ae). dev eloping reliable and secure AI models that can effec- tiv ely utilize the vast and div erse data generated at the edge while ensuring data priv acy . Lev eraging edge data enables AI systems to learn from diverse and distributed environments, enhancing their adaptability and robustness. Howe ver , this distributed nature also opens up vulnerabilities to adversarial threats like backdoor attacks, which can compromise model integrity and lead to severe consequences, especially in safety- critical applications. Federated Learning (FL) has emerged as a promising solu- tion for collaborativ e model training while preserving client data pri vacy . Unlike centralized learning, FL allows clients to train models locally and share only the model updates with a central server , minimizing the risk of data leakage. This approach not only respects data priv acy but also capitalizes on the diversity of edge devices resources and local data, making AI models more representative and ef fective. Recent research has sho wn that pre-processing data on the client side before training can be effecti ve without compromising priv acy , making it a viable strate gy to mitigate adversarial attacks before data reaches the training phase [1]. Backdoor attacks pose a significant threat to FL, as ad- versaries can inject poisoned data with hidden triggers. In this conte xt, a trigger refers to a small, intentionally crafted pattern (e.g., a patch, pix el pattern, or feature perturbation) that forces the model to output an adv ersary-chosen label during inference. Mitigation strategies for backdoor attacks generally focus on three phases, namely (1) Post-training, (2) In-training, and (3) Pre-training defenses. Post-training methods often employ techniques such as model pruning, neuron clustering, or activ ation pattern analysis to identify and remove backdoors after the global model has been trained. In-training approaches typically in volve anomaly detection, robust aggregation rules, or gradient filtering to limit the influence of malicious updates during the learning process [2]. While a substantial body of research has focused on post-training and in-training strategies, pre-training defenses particularly those applied at the client side through data cleaning, normalization, or trigger sanitiza- tion remain comparatively undere xplored [3]. In this work, we introduce Pr e-T raining Bac kdoor Mitiga- tion for F ederated Learning (FL-PBM) , a proacti ve client- side defense mechanism designed to operate within a T rusted Execution En vironment (TEE), ensuring that the mitigation process is isolated and cannot be altered [4]. FL-PBM identi- fies and neutralizes poisoned data before they can compromise the global model. T o enable efficient separation between clean and poisoned samples in high-dimensional feature spaces, FL- PBM employs Principal Component Analysis (PCA) for fea- ture extraction followed by Gaussian Mixture Model (GMM) 2 clustering. Based on [5], backdoored samples exhibit dis- tinct spectral characteristics in feature space, making PCA and GMM suitable for capturing these statistical deviations compared to alternati ve fixed cluster shapes techniques. Since our ev aluation focuses on image-based datasets, data deemed highly suspicious are e xcluded from training, while moderately suspicious samples undergo targeted image transformations, such as blurring, to diminish the ef fect of potential backdoor triggers. A. Problem Statement Backdoor attacks in FL introduce hidden vulnerabilities into AI models by embedding poisoned data samples containing cov ert triggers that, when activ ated, can manipulate predic- tions toward an attacker’ s goal. These threats are especially critical in domains such as autonomous driving, healthcare, and finance, where malicious outputs can cause severe or e ven life-threatening consequences. The decentralized and pri vacy- preserving design of FL gives adversaries opportunities to inject backdoors during client-side training without easily being detected by the central server . By remaining dormant during normal operation and activ ating only under specific input conditions, these attacks often bypass con ventional per - formance metrics such as accurac y , making them challenging to detect. Existing defense approaches are largely concentrated in two areas: post-training detection, which inspects the model after aggregation, and in-training defenses, which filter or control the model weights of suspicious updates during training. While these techniques have shown effecti veness, they tend to ov erlook early contamination of the training process, lea ving the global model influenced by poisoned data from the very first rounds. In addition, many of these methods are tailored to narrow threat models such as single-trigger or targeted attacks and struggle against more complex scenarios like multi-trigger or collusion-based strategies. The absence of robust pre-training defenses intensifies the vulnerability of FL systems to backdoor attacks, as poisoned data can enter the training process unchecked and compromise the global model. A truly effecti ve solution must act before poisoned data affects the model, adapt to ev olving client behaviors, and remain ef fective across di verse attack strategies. T o meet these needs, in this work we propose Adapti ve Pre- T raining Backdoor Attack Mitigation for Federated Learning (FL-PBM), that proactiv ely mitigates backdoor threats at the source, pre venting poisoned data from compromising the train- ing process and thereby preserving both model integrity and client data priv acy before e ven the training starts. B. Contributions Motiv ated by the need for proacti ve defenses in FL en viron- ments as highlighted in I-A, this work proposes a nov el pre- training backdoor mitigation strategy , called FL-PBM . Unlike traditional defenses that focus on in-training or post-training mitigation, FL-PBM operates in the early stages of training to filter poisoned data before it affects the global model. By lev eraging distributed detection and transformation techniques, our approach significantly reduces the success rate of backdoor attacks while preserving model performance. Accordingly , the main contributions of our work can be summarized as follows: 1) T o the best of our knowledge, we are from the firsts to introduce a client-side pre-training backdoor mitigation technique in FL, proactiv ely identifying and neutraliz- ing poisoned data before local models are trained and aggregated. 2) Combining PCA-based feature extraction with GMM clustering and benign trigger insertion to detect suspi- cious samples in an unsupervised manner , addressing the challenge of distinguishing subtle feature de viations of backdoored data in high-dimensional spaces. 3) Applying selecti ve data-driv en blurring at the client- side prior to training to suppress the effecti veness of hidden triggers, thus weakening the influence of injected backdoors without degrading overall accuracy . 4) Designing our solution in such a way that it remains effecti ve against a wide spectrum of backdoor attack strategies, including one-to-one and multi-trigger sce- narios, thereby ensuring broad applicability across real- world federated learning deployments. These contributions advance the state-of-the-art in proactive backdoor mitigation for FL by addressing threats at the earliest stage of training. FL-PBM’ s priv acy-preserving and attack- agnostic design enables practical deployment in div erse, real- world FL applications, pa ving the way for more secure and trustworthy collaborativ e learning systems. Empirical ev alu- ations demonstrate that FL-PBM substantially mitigates the attack, reducing success rates by more than 95% relativ e to baseline methods. Competing approaches such as RDFL and LPSF show notably lo wer resistance, curbing attacks by roughly 20-70% and 10-60%, respectiv ely . Importantly , FL- PBM sustains clean model accuracy above 90% in both IID and non-IID scenarios across most experiments. C. P aper Outline The rest of the this paper is organized as follo ws: Section II revie ws the related work on backdoor attack detection and mitigation strate gies in FL. Section III discusses the underlying concepts that dri ve this w ork, and highlight the methodology used. Section IV formulates the backdoor attack problem in FL and the corresponding defense mechanisms. W e provide the mathematical formulations of the process including PCA projections, GMM-based anomaly detection, adaptiv e blurring, as well as the adversarial objectiv e, which together establish the basis of our defense framework. Section V describes the implementation of FL-PBM and its operation across multiple training rounds. Section VI reports on the experimental results, ev aluating FL-PBM ef fecti veness using real-world datasets and comparing its performance with state-of-the-art methods in terms of model accuracy and backdoor attack success rates. Section VII concludes the paper , summarizing the key contributions and suggesting potential directions for future research. 3 I I . R E L AT ED W O R K In this section, we re view the state-of-the-art pertaining to backdoor attacks in FL, highlighting their strengths and limitations to motiv ate our proposed approach. The authors of [6] propose Federated Layer Detection (FLD), a pre-aggregation method that analyzes model updates at the layer level to detect backdoor attacks in federated learn- ing (FL). By examining layers individually , FLD captures fine- grained differences between benign and malicious updates, making it effecti ve against complex attacks. Ho wever , the approach can introduce computational o verhead and struggles with varying model architectures and adapti ve attackers who mimic benign patterns. In [7], the authors present ANOD YNE, which uses perturbation techniques like differential priv acy and weight clipping to suppress anomalous updates. While enhancing rob ustness by injecting noise, the method risks degrading model accuracy and increasing computational costs, focusing on sanitization before training. In [8], the authors propose FedDefender , which employs statistical anomaly de- tection during training to filter suspicious client updates, effecti vely reducing backdoor impact. Nevertheless, it incurs high computational cost and may not be ef fective against attackers who closely imitate le gitimate updates. The authors of [9] propose Robust Knowledge Distillation, which mit- igates backdoors by transferring distilled knowledge instead of ra w updates, addressing non-IID data challenges and high dimensionality . Y et, reliance on a teacher model introduces bias and computational overhead, while operating during post-training. The game-theoretic proposed approach called FedGame in [10] anticipates adversarial behaviors to detect backdoors proacti vely during training by analyzing client inter - actions. Despite its proactiv e stance, it depends on predefined attack models, limiting its effecti veness against novel threats. On the other hand, the adaptiv e attack study in [11] exposes vulnerabilities in FL by optimizing trigger patterns based on training dynamics, underscoring challenges existing defenses face against ev olving backdoors. In [12], the authors propose an approach called SCOPE that tar gets constrained backdoor attacks by applying statistical and anomaly detection techniques during aggregation. While effecti ve against sophisticated attacks, its performance may degrade with highly heterogeneous client data and inconsistent benign beha viors, risking false positives or negati ves. In [13], the authors propose Runtime defense via Representational Dis- similarity Analysis (RD A), which iterati vely excludes anoma- lous client updates during aggregation, enhancing robustness with low overhead. Howe ver , The approach might struggle when malicious updates closely resemble benign ones or in en vironments with div erse client data. In [14], the authors propose MDSD, that combines multi-dimensional scaling with norm clipping and weighted aggregation to identify and reduce malicious contributions. Though effecti ve in lo wering attack success, it may be less reliable when attackers mimic benign updates in heterogeneous settings. Meanwhile, the dual-layer defense in fog-based FL by [15] uses gradient metrics and adaptiv e filtering at fog and central servers to detect and mitigate attacks, but may face challenges with unseen attack types and highly non-IID data. The work in [16] proposes FLPurifier , which employs decoupled contrasti ve training to weak en trigger -target as- sociations and adaptiv ely aggregates classifiers, maintaining accuracy while defending backdoors. Howe ver , it is limited to models where feature-classifier decoupling is feasible. The authors in [17] propose SAFELearning, which highlights se- cure aggreg ation with obli vious random grouping and partial parameter disclosure to detect backdoors without compro- mising priv acy . Despite its effecti veness, secure multi-party computations add computational ov erhead. The comprehensi ve framew ork in [18] combines client-side data sanitization and server -side rob ust aggre gation, lo wering attack success but facing difficulties with non-IID data and adaptiv e attackers. The authors of [19] propose robust aggregation that filters outlier updates statistically to defend backdoors in image classification. Howe ver , effecti veness declines when malicious updates resemble benign ones or in highly heterogeneous data scenarios. On the other hand, FedBlock [20] leverages blockchain to secure FL by ensuring transparency and traceability of client updates, improving defense against backdoors. Y et, blockchain ov erhead may limit scalability in large networks. The au- thors of [21] propose LPSF , which introduces Link-Pruning with Scale-Freeness that strengthens essential connections and prunes dormant links in feed-forward neural networks to enhance robustness ag ainst backdoor attacks. While it achie ves 50-94% reduction in attack success on sev eral datasets, its ev aluation is limited to feed-forward networks and may not generalize to deeper architectures. Finally , the work in [22] proposes, a technique called RDFL; an adapti ve FL defense approach that relies on cosine-distance-based parameter se- lection, adapti ve clustering, malicious model remo v al, and clipping with noise. It effecti vely mitigates backdoor attacks in non-IID scenarios.Howe ver , the approach might incur higher computation and communication o verhead in large-scale fed- erated networks. While existing defenses against backdoor attacks in FL have provided v aluable insights, most approaches rely on in-training or post-training mitigation, centralized v erification, and static assumptions about attacker behavior , which limit their adapt- ability in dynamic en vironments. Moreover , many methods ov erlook early-stage client-side defenses that could intercept poisoned data before it propagates into the global model. In contrast, our proposed FL-PBM adopts a proactive, pre- training defense strategy that intervenes at the very beginning of the learning process. By integrating Principal Component Analysis (PCA) for discriminativ e feature extraction, Gaussian Mixture Model (GMM) clustering for anomaly detection, and an adapti ve blurring mechanism to sanitize suspicious samples, FL-PBM mitigates poisoned data before it influences model aggregation; disrupting backdoor threats at their origin while preserving model integrity and client pri vacy . I I I . S Y S T E M P R E L I M I N A R I E S In this section, we introduce the fundamental concepts that underpin our work. W e begin with a high-lev el ov erview of 4 the FL paradigm, then describe backdoor attack strategies, and finally detail the techniques we employ for pre-training backdoor mitigation, including PCA, GMM, and adaptiv e blurring. A high-lev el ov erview of the FL paradigm is provided, followed by a description of backdoor attack strategies, and finally the techniques employed for pre-training backdoor mitigation, including PCA, GMM, and adapti ve blurring, are detailed. A. F ederated Learning Pr ocess Federated Learning is a distributed machine learning frame- work that enables multiple clients (e.g., autonomous vehicles, edge nodes, or or ganizations) to collaboratively train a shared global model under the coordination of a central server , with- out exchanging their raw data. Instead, clients perform local training on their priv ate datasets and periodically communicate model updates to the server . The serv er then aggre gates these updates to improve the global model, which is subsequently redistributed to clients for the ne xt training round. The general workflow of FL can be summarized as follows: 1) Model Initialization: The server initializes a global model and shares it with selected clients. 2) Local T raining: Each client trains the receiv ed model on its priv ate dataset, generating updated local parame- ters. 3) Aggregation: The server collects local model updates and combines them into a new global model. 4) Iteration: Steps 2 and 3 are repeated o ver multiple communication rounds until the model con ver ges to a desired accuracy , or the process stops after a certain amount of rounds. B. Backdoor Attacks in F ederated Learning Backdoor attacks are a type of targeted poisoning attack in which adv ersaries deliberately manipulate local training data or model updates to implant hidden behaviors in the global model. A successful backdoor attack ensures that the model performs normally on clean data but produces attacker- controlled misclassifications when a specific trigger pattern is present in the input. In FL, backdoor attacks are often ex ecuted by mali- cious clients that introduce poisoned samples into their local datasets. These poisoned samples typically contain a visual trigger (such as a small patch or specific pixel pattern) and are mislabeled to a target class. Over multiple training rounds, the global model learns to associate the trigger with the target label, enabling the attacker to control its predictions at inference time. Backdoor attacks can be grouped as follows: • One-to-One (1 → 1): A single trigger causes misclassifi- cation into a single target class. • One-to-N (1 → N): A single trigger with dif ferent varia- tions each mapped to distinct target classes, improving attack robustness. • N-to-One (N → 1): Multiple dif ferent triggers are mapped to the same tar get class, often corresponding to multiple malicious participants. The priv acy-preserving and decentralized nature of FL makes it particularly challenging to detect such attacks, as the server lacks direct access to client training data. C. Pre-T raining Backdoor Mitigation T echniques T o address the threat of backdoor attacks, in this work, we focus on client-side pre-training defenses. These defenses aim to identify and neutralize suspicious samples before they influ- ence local model updates. Our strategy relies on unsupervised methods to analyze data distributions and highlight anomalies, while preserving pri vac y by keeping all computations local to each client. 1) Principal Component Analysis (PCA): Principal Com- ponent Analysis (PCA) is an unsupervised dimensionality reduction technique that transforms the data into a ne w coordinate system, where the axes (principal components) correspond to directions of maximum variance in the data [23]. Unlike supervised methods, PCA does not rely on class label information, making it more suitable in our context, where labels may be unreliable due to backdoor attacks. By projecting data onto the principal components, PCA captures the dominant patterns of variation in the input space. This helps highlight de viations introduced by poisoned samples, as they tend to disturb the natural v ariance structure of clean data. Consequently , PCA provides a robust feature representation that improv es anomaly detection accuracy in the presence of mislabeled or manipulated data. 2) Gaussian Mixtur e Model (GMM) Clustering: The Gaus- sian Mixture Model (GMM) is a probabilistic clustering tech- nique that models data as a combination of multiple Gaussian distributions [24]. After PCA projection, GMM is applied to capture the underlying structure of the transformed data. Samples that fall into low-likelihood clusters or significantly deviate from cluster centers are flagged as suspicious. This unsupervised detection complements PCA by modelling hid- den data patterns relying on distrib utional characteristics rather than label information, making it particularly ef fective in spotting backdoor triggers that subtly distort data distributions. PCA emphasizes the dominant variance structure in the data without relying on labels, while GMM models probabilistic density and captures outliers. D. Adaptive Imag e Blurring Mechanism Image blurring is a common image processing operation that reduces high-frequency details by smoothing pixel intensity variations, often through conv olution with a lo w-pass filter such as a Gaussian kernel [25]. By attenuating fine-grained structures, blurring suppresses subtle patterns while preserving the overall semantic content of an image. In our framew ork, once suspicious samples are identified through the PCA-GMM pipeline, we apply an adapti ve blur - ring strategy as a mitigation step. The approach is two-fold: • High-risk samples: Completely excluded from training to av oid contamination. 5 • Moderate-risk samples: Processed using adapti ve blur - ring, which reduces fine-grained pixel details where trig- gers are likely embedded, while retaining the semantic features necessary for ef fectiv e learning. This selectiv e mechanism balances data utility and security . It degrades malicious triggers without discarding all suspect data. The adapti ve blurring reduces the attacker’ s effecti veness while preserving training di versity and accuracy . I V . P R O B L E M F O R M U L AT I O N In this section, we provide the mathematical formulation of our problem setting. W e first formalize the FL frame work, then describe the backdoor attack model, and finally formulate the pre-training mitigation components, namely PCA, GMM, and adaptiv e blurring. Additionally , T able I summarizes the key notations used throughout this section. Symbol Description N Number of participating clients D i Local dataset of client i G t Global model at communication round t Λ t i Local model of client i at round t L ( · ) Local loss function η Local learning rate x, y Input sample and label pair x ′ Poisoned (triggered) input sample τ T rigger pattern for backdoor attack y a T arget class assigned by attacker ϕ PCA projection matrix z Data representation after PCA projection θ y = { w, µ, Σ } GMM parameters for label y (weights, means, cov ariances) p ( z | θ ) Likelihood of data under GMM P B ( ω ) Mean power spectral densities (PSDs) of benign set d p Distance of image p to malicious cluster center δ p Normalized closeness of suspicious image p σ p Gaussian blur strength for image p G σ p Gaussian kernel with standard deviation σ p I ′ p Defended (blurred) version of image p T ABLE I: List of key symbols used in problem formulation. A. F ederated Learning F ramework W e consider a federated learning system comprising N clients, where each client i possesses a priv ate dataset D i = { ( x j , y j ) } |D i | j =1 , where x j denotes the j -th input sample of client i and y j is its corresponding label. The global model G t is trained collaborativ ely under the coordination of a central server . At each communication round t , the server broadcasts the current global model G t − 1 to a subset of clients. Each selected client performs local loss optimization Λ t i ∈ arg min Λ t i X ( x,y ) ∈D i L (Λ t i , x, y ) (1) and returns the updated local model Λ t i to the server . The server aggreg ates the local updates via a weighted a verage: G t = N X i =1 |D i | P N j =1 |D j | Λ t i (2) B. Backdoor Attack F ormulation Backdoor attacks aim to implant a hidden mapping in the model that is only triggered under specific conditions. These attacks are typically realized by modifying the training data at malicious clients. The attacker introduces a trigger τ and changes the label to a target class y a . W e classify the attacks into three types: 1) One-to-One Attack: A single static trigger τ is applied uniformly , leading to a fixed target label: D ′ i = { ( x j + τ , y a j ) : ( x j , y j ) ∈ D i } (3) This ensures that whene ver the trigger τ is present, the model outputs y a j , regardless of the original class. 2) One-to-N Attack: A trigger family { τ k } is used, with different variants τ k causing misclassification into multiple target labels: D ′ i = { ( x j + τ k , y a j ) : ( x j , y j ) ∈ D i , k = 1 , . . . , K } (4) where k is the total number of trigger variants, each v ariation τ k may correspond to a dif ferent adversarial target, increasing the attack’ s complexity and ev asiv eness. 3) N-to-One Attack: Multiple clients inject distinct triggers τ k designed to collecti vely activ ate the same tar get behavior when combined: D ′ i = { ( x j + N X k =1 τ k , y a j ) : ( x j , y j ) ∈ D i } (5) The attack only activ ates when all components τ k are present together , making it extremely difficult to detect when vie wed in isolation. The adversary’ s objecti ve is to minimize the global loss on benign data while simultaneously maximizing the misclassifi- cation rate of triggered inputs: min G E ( x,y ) ∼D clean [ L ( G , x, y )]+ λ E ( x ′ ,c t ) ∼D poison [ L ( G , x ′ , c t )] ! (6) where E stands for the expectation and λ balances clean accuracy and attack success. C. Principal Component Analysis (PCA) For each client’ s dataset D i , we perform PCA to obtain a projection matrix ϕ that captures the principal components of variance [26]. Specifically , we compute the co variance matrix of the data: Σ = 1 |D i | X x ∈D i ( x − µ )( x − µ ) ⊤ , (7) where µ is the mean of all samples in D i . PCA then solves the eigen value decomposition: Σ ϕ = λϕ, (8) where λ and ϕ are the eigen values and eigen vectors of Σ . The eigen vectors corresponding to the top- k largest eigenv alues form the projection matrix ϕ k . The data is then projected into the reduced space as: z = ϕ ⊤ k x (9) 6 where z represents the lo wer-dimensional feature representa- tion. By retaining the directions of maximum v ariance, PCA emphasizes the dominant structure in the data while filtering out noise. This unsupervised projection is particularly robust in the presence of mislabeled or backdoored samples, since it does not rely on class labels. D. Gaussian Mixtur e Model (GMM) After PCA projection for class y , a two-component GMM is applied to the transformed data [27]: p ( z | θ y ) = 2 X q =1 w q N ( z | µ q , Σ q ) (10) where q ∈ { 1 , 2 } indexes the Gaussian components, with each sample assigned to the Maximum A Posteriori (MAP) component: ˆ q ( z ) = arg max q ∈{ 1 , 2 } w q N ( z | µ q , Σ q ) (11) The cluster containing the largest number of samples is designated as the benign set C B ,y , while the remaining cluster constitutes the suspicious set C S,y : C B ,y = arg max C ∈{ C 1 ,C 2 } | C | , C S,y = { C 1 , C 2 } \ C B ,y (12) E. Cluster V alidation using Silhouette Score T o assess the quality of clustering, we compute the Silhou- ette Coefficient [28] using the PCA-projected features z and the GMM-assigned cluster labels. For each sample i , let a ( i ) denote the mean distance to other samples within the same GMM cluster , and b ( i ) the minimum mean distance to samples in the nearest cluster . The Silhouette v alue is defined as: ψ ( i ) = b ( i ) − a ( i ) max { a ( i ) , b ( i ) } . (13) The overall clustering score is the average over all N samples: ψ = 1 N N X i =1 s ( i ) . (14) W e accept the clustering result only if ψ > 0 . 9 , ensuring that the benign and suspicious sets deriv ed from the GMM are well separated in the PCA space. The threshold of 0.9 is chosen to impose a high-confidence separation criterion, as values above this le vel indicate that clusters are both compact and well distinguished from one another [28]. F . Data-Driven Blurring Let I ∈ R C × H × W be an input image with C channels, height H , and width W . For each image marked as malicious in C S,y , we compute a saliency map S ∈ R H × W that highlights regions likely to contain trigger patterns. Here, h ∈ { 1 , . . . , H } and w ∈ { 1 , . . . , W } denote the pixel coor - dinates. The salienc y map is obtained from the first principal component of a pix el-space PCA trained on malicious samples, as it captures the direction of maximum shared v ariance among these samples corresponding to the consistent trigger pattern embedded across them. This component is reshaped into image space, combined across channels using the Euclidean norm, and then normalized to the range [0 , 1] : S ( h, w ) = q P C c =1 PC 1 ( c, h, w ) 2 − min( S ) max( S ) − min( S ) + ϵ , (15) where PC 1 is the first principal component in image space, and ϵ > 0 is a small constant for stability . Hereafter a binary mask M τ ∈ { 0 , 1 } H × W is then created by thresholding the salienc y map: M τ ( u, v ) = ( 1 , if S ( u, v ) ≥ τ , 0 , otherwise. (16) Next, we identify which images should be blurred. Let z p ∈ R 2 be the PCA embedding of image p in C B ,y , and let µ mal be the mean embedding of malicious samples. The Euclidean distance between z p and the malicious center is: d p = ∥ z p − µ mal ∥ 2 (17) The top K images with the smallest distances are flagged as suspicious. Only this subset, denoted by S ′ , is processed: S ′ = max { 0 , ⌊ K ∗ N ⌋} (18) For each suspicious image, the blur strength depends on its distance to the malicious center . Distances are conv erted into a closeness score: δ p = 1 − d p max j ∈S ′ d j , δ p ∈ [0 , 1] , (19) which is then mapped to a Gaussian blur le vel: σ p = σ min + δ p · ( σ max − σ min ) , (20) with σ min ≥ 0 and σ max > σ min . The final defended image is obtained by replacing suspi- cious pixels of all images in S ′ with their blurred v ersions: I ′ ( u, v , c ) = 1 − M τ ( u, v ) I ( u, v , c ) + M τ ( u, v ) G σ p ⋆ I ( u, v , c ) , (21) for channels c = 1 , . . . , C , where G σ p is a Gaussian kernel with standard deviation σ p . Images not in S ′ remain unchanged. This formulation ensures that malicious samples are ex- cluded, as well as the remov al or weakening of potential triggers. Consequently , retaining essential semantic informa- tion which provides maximal protection against backdoor contamination while preserving model utility on normal tasks. 7 255 110 12 . . . 135 S am p le of c lean an d b ac k d oor e d d ata Class 0 Class 1 Class 2 Bac kd oor e d as Class 0 Class 0 + b e n ign T r igger Class 1 + b e n ign T r igger C lass 2 + be ni gn T r igge r Bac kd oor e d as Class 2 M od ifyin g the data and in se r tin g the beni gn k e y 1 2 P C A P r o j ec t i o n t o 2D App ly PCA to e ac h se t of t h e c lass e s then ap p ly GMM on the pr oje c tion to c lu ste r the data p oin ts Disc ar d the sm all e r c lu ste r an d ap p ly t h e ad ap t ive b lu r r in g to t h e su sp icio u s sampl e s if e xists 3 Use S ali e n c y M ap fr om d iscar d e d to b lu r the s u sp iciou s Fig. 1: Overvie w of the proposed client-side preprocessing pipeline for backdoor mitigation in federated learning. The main components include dataset preprocessing, benign trigger augmentation, dimensionality reduction, clustering, and selectiv e sanitization. V . P O I S O N E D D A T A F I L T E R I N G I N F E D E R A T E D L E A R N I N G In this section, we present the operational flow of our pre- training backdoor mitigation approach in the FL environment, along with the algorithms representing each step of the pro- cess. Fig. 1 shows the proposed architecture, which adds a client- side preprocessing pipeline to reduce backdoor attacks in FL. All preprocessing steps are executed locally on each client un- der server orchestration, ensuring that data pri vac y is preserved while the server coordinates the backdoor mitigation process before training be gins. The process starts with the client’ s local dataset, which can contain both clean and poisoned samples (marked with a black star). T o build a consistent baseline and make classes easier to separate, a benign trigger is added to all class samples, creating augmented references (Step 1). Next, Principal Component Analysis (PCA) is used to project the data into a lower -dimensional space, keeping the main variation while reducing noise. In this space, Gaussian Mixture Models (GMM) are applied to group the data. Smaller or isolated groups are marked as suspicious. Samples from these groups are treated in two ways: clearly abnormal samples are remov ed, while moderately suspicious ones are cleaned further (Step 2). For the remov ed samples, saliency maps are created to locate possible trigger regions. Adaptiv e blurring is then applied to a subset of the kept samples that are very close to the center of the remov ed group. This step helps weaken potential triggers while keeping the main image structure (Step 3). The final cleaned dataset, without highly suspicious samples and with weakened triggers, is then used for local training, reducing the risk of backdoor attacks while maintaining model accuracy on normal data. Algorithm 1 outlines the client-side preprocessing phase, which applies PCA-based dimensionality reduction, GMM clustering, and Silhouette-based validation, followed by the federated training iterations. For ev ery class c in client i Algorithm 1 Client-Side Preprocessing and Local Training Require: Local dataset D i for client i , number of epochs E , Initial model G t i Ensure: Updated local model G t +1 i 1: for each class c ∈ C i do 2: Insert benign trigger into class samples 3: Apply PCA on D ( c ) i using Eq. 9 4: Fit GMM on PCA features using Eq. 10 5: Assign each sample to a cluster using Eq. 11 6: Identify benign ( C B ,y ) and suspicious ( C S,y ) clusters using Eq. 12 7: Approv e clustering using Silhouette score (Eq. 14) 8: Remov e benign triggers from samples 9: Apply Data-Driven Blurring on ( C B ,y , C S,y ) (Alg. 2) 10: end for 11: for each epoch e = 1 to E do 12: T rain local model on preprocessed dataset D ′ i 13: end for 14: Send updated local model G t +1 i to server local dataset D i , a benign trigger is first inserted to help rev eal potential distributional irregularities (Line 2). PCA is then applied to the class-specific data D ( c ) i to obtain low- dimensional representations (Line 3). Using these features, a two-component GMM is fitted to capture the data distribution and detect hidden data clusters (Line 4). Each sample is then assigned to a cluster using the MAP rule (Line 5), after which the benign and suspicious clusters are identified (Line 6). The clustering result is then validated using the Silhouette Coefficient; only clusters achie ving a score S > 0 . 9 are accepted as well-separated (Line 7). After v alidation, benign triggers are removed to restore the data to its clean state (Line 8), and a Data-Driv en Blurring process is applied to the identified clusters ( C B ,y , C S,y ) to mitigate potential backdoor effects (Line 9). Once preprocessing is complete, the model training is performed on the client’ s processed dataset D ′ i ov er E epochs (Lines 11–13). After completing local training, 8 the updated model G t +1 i is sent to the server (Line 14) for aggregation. Algorithm 2 Data-Driven Blurring of Suspicious Samples Require: Benign cluster C B ,y , malicious cluster C S,y , parameters k Ensure: Blurred suspicious samples within C B ,y 1: Compute saliency map S from C S,y using Eq. 15 2: Generate binary mask M τ using Eq. 16 3: S ′ ← Select top k nearest samples from C B ,y using Eq. 18 4: for each suspicious sample I i ∈ S ′ do 5: Compute distance from malicious set C S,y using Eq. 17 6: Assign blur strength using Eq. 19 7: Compute Gaussian kernel G σ i using Eq. 20 8: Apply blur to suspicious regions of I i using Eq. 21 9: end for Algorithm 2 outlines the procedure for applying data-dri ven blurring to suspicious samples. First, a normalized saliency map S is computed from the first PCA component from each sample of the suspicious cluster C S,y to highlight potential trigger regions (Line 1). The salienc y map is then con verted into a binary mask M τ by thresholding at le vel τ (Line 2). Next, the top k nearest suspicious samples S ′ are selected from the benign cluster C B ,y using, based on their proximity to the malicious distribution (Line 3). For each suspicious sample I i ∈ S ′ , the distance d i between the sample’ s embedding z i and the malicious cluster center µ mal is calculated (Line 5). Each sample is then assigned a blur strength according to its normalized distance from the malicious center (Line 6). A Gaussian kernel G σ i with standard de viation σ i is constructed to define the blur le vel (Line 7). Finally , the blur is applied selectiv ely to the suspicious regions of the image, as indicated by the mask M τ , producing a sanitized version I ′ i of I i (Line 8). This process reduces or removes possible triggers while preserving the o verall structure of the data. V I . E X P E R I M E N TA L E V A L U A T I O N Hereafter , we e valuate the proposed FL-PBM to demonstrate its effecti veness against different types of backdoor attacks. W e first describe the experimental setup, including datasets, poisoning configurations, and defense baselines, followed by quantitativ e and visual comparisons across IID and non- IID settings. The analysis highlights how FL-PBM mitigates backdoor effects while preserving model utility across both balanced and highly sk ewed data distributions. A. Datasets and Attack Setup W e ev aluate our approach on two traf fic-sign bench- marks, the German T raffic Sign Recognition Benchmark (GT - SRB) [29] and the Belgian Traf fic Sign Classification dataset (BTSC) [30]. From each benchmark, we derive a 10-class subset ( GTSRB-10 , BTSC-10 ) by selecting the ten classes with the largest number of samples. For the attack setting, a triangular trigger is placed in the image corner with a side length of 5 pixels and an opacity of 0 . 5 . W e ev aluate both one-to-n and n-to-n attack paradigms. For a malicious client, a fraction of the source-class samples is poisoned; this fraction is varied between 0 . 30 and 0 . 70 to explore weak-to-strong poisoning scenarios. At the client-selection lev el, malicious participants constitute 30% of the selected clients at ev ery communication round. Since our approach is applied at the data level, it is essential to consider v arious data distrib utions in the e xperimental setup. W e run experiments under two data-partitioning scenarios to reflect realistic federated and centralized deployments: a) Non-IID: Clients exhibit heterogeneity across classs, where each client holds between 3 and 6 classes, with 100 – 200 images per class. From a population of 100 clients we sample 40 clients per round to participate in training for the GTSRB dataset and each client holds between 3 and 4 classes, with 30 – 60 images per class. From a population of 100 clients we sample 20 clients per round to participate in training for the BTSC dataset; malicious clients among those selected follow the poisoning procedure described abov e. This configuration models practical class imbalance and distrib ution ske w encountered in cross-device FL en vironments. On the other hand, for the centralized approach, a class size imbalance is applied. b) IID: For centralized (non-federated) experiments, we enforce class balance via ov ersampling so that all classes hav e equal size. For federated IID experiments, each client contains all 10 classes with 150 images per class for the GTSRB dataset and 30 samples per class for the BTSC, thereby isolating the impact of statistical heterogeneity from other system-lev el factors. All other experimental settings (trigger positions, poisoning rates, and fraction of malicious clients) are kept identical between IID and non-IID runs to ensure fair comparison. B. Comparison Benc hmarks and Metrics For all e xperiments, we adopt the LeNet-5 architecture, modified to accommodate RGB input and 10 output classes. T raining is performed using stochastic gradient descent (SGD) with a learning rate of 0 . 01 , batch size of 64 , and 5 local epochs per client update. The global training process spans 200 communication rounds. T o assess attack effecti veness, each run includes 400 backdoored test samples for the GTSRB dataset and 200 samples for the BTSC dataset embedded with the triangular trigger . W e benchmark three aggregation strategies representing baseline, centralized, and federated defense paradigms: • FedA vg (baseline): the standard federated averaging algorithm, serving as a reference to assess the impact of backdoor attacks and the effecti veness of defense mechanisms [31]. • LPSF: a centralized defense method that identifies and filters suspicious client updates before aggregation, thereby reducing the influence of poisoned contribu- tions [21]. • RDFL: a federated defense algorithm that dynamically adapts aggregation weights to downscale malicious updates during the model aggreg ation phase [22]. In our experiments, model performance is quantified using two main metrics: 9 (a) GTSRB IID - (1 → 1) Attack (b) GTSRB IID - (N → 1) Attack (c) GTSRB non-IID - (1 → 1) Attack (d) GTSRB non-IID - (N → 1) Attack (e) BTSC IID - (1 → 1) Attack (f) BTSC IID - (N → 1) Attack (g) BTSC non-IID - (1 → 1) Attack (h) BTSC non-IID - (N → 1) Attack Fig. 2: Model accuracy of different approaches over the normal task across datasets and distrib utions over 200 rounds. The color mapping for defense strategies is A V G (orange), LPSF (red), RDFL (green), FL-PBM (blue) (a) GTSRB IID - (1 → 1) Attack (b) GTSRB IID - (N → 1) Attack (c) GTSRB non-IID - (1 → 1) Attack (d) GTSRB non-IID - (N → 1) Attack (e) BTSC IID - (1 → 1) Attack (f) BTSC IID - (N → 1) Attack (g) BTSC non-IID - (1 → 1) Attack (h) BTSC non-IID - (N → 1) Attack Fig. 3: Model accurac y of different approaches o ver the malicious task across datasets and distrib utions for 200 rounds. The color mapping for defense strategies is A V G (orange), LPSF (red), RDFL (green), FL-PBM (blue) • Clean Accuracy Rate (CAR): classification accuracy on clean test samples, measuring the model’ s utility and con- ver gence behavior as well as the impact of the proposed solution on the con ver gence of the global model. • Attack Success Rate (ASR): the proportion of triggered inputs misclassified into the target class, capturing the effecti veness of the proposed approach in mitigating the backdoor attack effect on the global model. These metrics provide a balanced ev aluation of both model utility under normal operation and resilience against adversar- ial manipulation. Results are presented for both non-IID and IID scenarios, where each outcome is depicted as curves of CAR and ASR ov er communication rounds. Figures 2 and 3 show results for the normal and malicious tasks, respecti vely , across datasets, distributions, and attack types. Different defense strategies are distinguished by color , following the mapping A VG (orange), LPSF (red), RDFL (green), and FL-PBM (blue). C. Results on IID Setting W e first examine the IID results, corresponding to subfig- ures (a), (b), (e), and (f) in Figures 2 and 3. Each figure ov erlays clean accuracy rate (CAR) and attack success rate (ASR) across 200 communication rounds, allowing us to track defense ev olution from initialization to conv ergence, as well as the interplay between attack intensity and mitigation strate gies. 10 (a) GTSRB IID, (1 → 1) Attack. In the first 20 rounds, F edA vg is rapidly compromised, with ASR exceeding 90% and CAR below 40%, reflecting the dominance of backdoor updates. LPSF mitigates the attack partially by pruning weakly activ e connections, reducing ASR to approximately 70%, b ut also removes some informati ve features, keeping CAR below 50%. RDFL apply training via adaptive aggregation, achieving CAR near 55% and ASR around 40%, showing a trade-off between robustness and accuracy . FL-PBM demonstrates early resilience, filtering and blurring suspicious samples before local training, which maintains CAR above 55% and lowers ASR below 10%. By 100 rounds, F edA vg remains highly vulnerable CAR ≈ 91%, ASR above 90%, whereas LPSF lowers ASR to around 60% but CAR remains under 90%. RDFL improves both metrics with CAR ≈ 94% and ASR ≈ 20%, while FL-PBM continues to outperform, maintaining CAR above 90% and ASR under 10%. By 200 rounds, FL- PBM consistently achieves CAR above 93% and ASR close to 5%, within normal model misclassification rates, confirming the superiority of proactive client-side mitigation over reactiv e aggregation-based defenses. (b) GTSRB IID, ( N → 1) Attack. During early rounds, F edA vg is overwhelmed with ASR above 90%, CAR ≈ 88%, while LPSF reduces ASR to 70%, while keeping CAR near 87%. RDFL shows early stability with CAR ≈ 77%, ASR ≈ 0%, and FL-PBM prev ents most backdoor effects with CAR abov e 87% and ASR below 15%. At 100 rounds, F edA vg remains highly susceptible at CAR ≈ 93%, ASR abov e 90%, LPSF lowers ASR to ∼ 60%, and RDFL reaches CAR near 96% with ASR ≈ 30%. FL-PBM sustains CAR above 90% and ASR under 4%, confirming its ef fectiveness against multi- source attacks. By 200 rounds, only FL-PBM consistently maintains CAR above 93% and ASR belo w 5%. (e) BTSC IID, (1 → 1) Attack. Initially , F edA vg is highly vulnerable with ASR greater than 80%, CAR lower than 80% due to the quick dominance of poisoned updates in the smaller dataset. LPSF reduces ASR to ∼ 60%, b ut excessi ve pruning keep CAR below 50%. RDFL achieving high CAR ≈ 97%, and moderate ASR ≈ 40%, whereas FL-PBM benefits from early filtering, achieving CAR above 80% and ASR near 0%. By 100 rounds, FL-PBM maintains CAR above 97% with ASR ≈ 0%, clearly outperforming baselines. By 200 rounds, FL-PBM consistently shows strong defense with stable ASR at ≈ 0%, highlighting the advantage of proactiv e client-side mitigation when per-class data is limited. (f) BTSC IID, ( N → 1) Attack. Early on, F edA vg collapses with ASR abov e 80%, CAR ≈ 80%. LPSF reduces ASR to 68% while achieving high CAR abo ve 95%, RDFL achie ves CAR ≈ 70%, with moderate ASR ≈ 45%, and FL-PBM achiev es early robustness with CAR above 60%, while reduc- ing ASR to around 0%. By 100 rounds, FL-PBM maintains CAR above 95% with negligible ASR. By 200 rounds, only FL-PBM consistently sustains CAR above 96% and ASR near 0%, confirming the effecti veness of PCA+GMM clustering combined with blurring transformations for neutralizing one trigger backdoor attack. D. Results on Non-IID Setting The non-IID scenarios, shown in subfigures (c), (d), (g), and (h) of Figures 2 and 3, pose greater challenges due to class imbalance and heterogeneous client distributions. T racking CAR and ASR across rounds reveals the resilience of dif ferent defense mechanisms under these conditions. (c) GTSRB non-IID, (1 → 1) Attack. Early rounds show F edA vg instability with ASR above 85%, CAR nearly 70%, LPSF reduces ASR to 65% while increasing CAR to 89%, whereas RDFL exhibits lo w stability with CAR ≈ 23%, ASR ≈ 40%. FL-PBM achiev es early robustness, maintaining CAR abov e 70% and ASR nearly 0%. At 100 rounds, F edA vg remains fully compromised with CAR ≈ 90%, ASR ≈ 100%, LPSF lo wers ASR to 55%, RDFL records CAR around 32%, while FL-PBM sustains CAR abov e 85% and ASR near 0%. By 200 rounds, FL-PBM achieves CAR ≈ 90% and ASR ≈ 0%, demonstrating ef fectiveness under heterogeneous distributions. (d) GTSRB non-IID, ( N → 1) Attack. In early rounds, F edA vg collapses ASR above 90%, CAR less than 30%, LPSF reduces ASR to around 70% with CAR lo wer than 50%, RDFL stabilizes moderately with CAR ≈ 55%, ASR ≈ 45%, and FL-PBM reaches CAR above 60% with ASR below 25%. At 100 rounds, FL-PBM sustains CAR abov e 78% and ASR under 15%, outperforming baselines. By 200 rounds, FL-PBM achiev es CAR above 86% and ASR near 0%, confirming effecti ve prev ention of poisoned samples propagation to the training process. (g) BTSC non-IID, (1 → 1) Attack. Early rounds show F edA vg vulnerable with ASR above 90%, CAR around 60%, LPSF reduces ASR to 80% while CAR nearly 95%, RDFL stabilizes the model with CAR nearly 55%, ASR less than 20%, and FL-PBM reduces ASR below 40% while CAR remains abov e 60%. By 100 rounds, FL-PBM maintains CAR abov e 85% and ASR near 0%, and by 200 rounds, CAR reaches 89% with ASR consistently at 0%. (h) BTSC non-IID, ( N → 1) Attack. F edA vg get compro- mised rapidly with ASR abov e 90%, CAR around 62%, LPSF reduces ASR to 60%, RDFL stabilizes moderately at CAR ≈ 65%, ASR ≈ 35%, and FL-PBM maintains CAR above 63% with ASR below 10%. By 200 rounds, FL-PBM consistently outperforms all baselines with CAR around 86%, ASR near 0%, demonstrating that FL-PBM effecti vely neutralize multi- trigger backdoor attacks under heterogeneous settings. E. Discussion Across both IID and non-IID scenarios, the comparativ e analysis highlights clear differences in the behavior of the ev aluated approaches. F edA vg , which lacks any defensi ve mechanism, is consistently the most vulnerable, where its clean accuracy rate (CAR) remains modest while its attack success rate (ASR) stays persistently high throughout train- ing. LPSF provides partial robustness by filtering suspicious updates, but its centralized filtering often discards some benign input feature connections, which slows con vergence and limits final accuracy . RDFL performs better by dynamically adjusting 11 aggregation weights, achieving a more balanced trade-off between CAR and ASR, yet it cannot fully suppress backdoor effects, especially under stronger ( N → 1) attacks and in non- IID settings due to its reliance on the model’ s similarity , which can be affected by the data distrib ution as well as the model con vergence. In contrast, FL-PBM consistently demonstrates superior re- silience across all datasets, attack types, and data distributions. Its proactiv e client-side filtering, which combines PCA-based feature reduction with Gaussian Mixture Model clustering and targeted blurring of suspicious samples, prev ents and limits poisoned data from influencing local training. This explains why FL-PBM achiev es high CAR (often above 80%) while reducing ASR to near -zero levels, e ven in the most challenging non-IID and multi-class poisoning scenarios. These results confirm that addressing backdoor threats at the data level before aggregation is more effecti ve than relying solely on weighting aggregation or input feature pruning defences. V I I . C O N C L U S I O N In this work, we proposed FL-PBM , a novel backdoor mitigation for FL. Unlike reactiv e aggregation-based defenses, FL-PBM operates proactively at the client side by identifying and neutralizing poisoned data before it can influence the global model. By combining dimensionality reduction through PCA, unsupervised clustering with Gaussian Mixture Models, and targeted image blurring, our method effecti vely suppresses div erse backdoor attacks while preserving model integrity and performance. Extensi ve e xperiments on both IID and non-IID settings with GTSRB and BTSC datasets show that F edA vg remains highly vulnerable, with attack success rates often remaining near 90–100% even after con vergence. Centralized mitigation LPSF improv es rob ustness b ut at the cost of model learning, with ASR commonly reduced only to 50–70% while CAR drops by 15% to 40% because benign information is lost during filtering. RDFL achieves a more balanced outcome, with ASR reduced to 29–80% and CAR stabilizing between 65% and 95% depending on data distribution. Howe ver , per- formance degrades in non-IID settings where model similarity is harder to exploit. In contrast, FL-PBM deli vers the strongest mitigation across all scenarios, reducing ASR to 0% to 5% in most e xperiments while keeping CAR typically between 87% and 97%, even in the challenging non-IID cases with high data skew and 30% malicious participation. These findings highlight the feasibility and ef fectiv eness of preempti ve data filtering as a powerful defense mechanism in FL based se- curity mechanisms. As future directions, we plan to explore the integration of generati ve adversarial networks (GANs) trained on saliency maps of malicious samples to reproduce potential backdoor patterns and further stress-test the defense. Additionally , collecting metadata from the filtering process and lev eraging advanced feature extraction methods such as autoencoders or pre-trained models may further enhance the robustness and generalization of FL-PBM . A C K N O W L E D G M E N T S This research was supported by the Natural Sciences and Engineering Research Council of Canada (NSERC). The au- thors gratefully acknowledge its financial support. R E F E R E N C E S [1] E. M. Timofte, M. Dimian, A. Graur, A. D. Potorac, D. Balan, I. Croitoru, D.-F . Hrit , can, and M. Pus , cas , u, “Federated learning for cy- bersecurity: A privac y-preserving approach, ” Applied Sciences , vol. 15, no. 12, p. 6878, 2025. [2] T . D. Nguyen, T . Nguyen, P . Le Nguyen, H. H. Pham, K. D. Doan, and K.-S. W ong, “Backdoor attacks and defenses in federated learning: Survey , challenges and future research directions, ” Engineering Appli- cations of Artificial Intelligence , vol. 127, p. 107166, 2024. [3] Y . Li, Z. Guo, N. Y ang, H. Chen, D. Y uan, and W . Ding, “Threats and defenses in the federated learning life c ycle: a comprehensi ve survey and challenges, ” IEEE T ransactions on Neural Networks and Learning Systems , 2025. [4] A. Mondal, Y . More, R. H. Rooparaghunath, and D. Gupta, “Poster: Flatee: Federated learning across trusted execution en vironments, ” in 2021 IEEE European Symposium on Security and Privacy (EuroS&P) , 2021, pp. 707–709. [5] B. Tran, J. Li, and A. Madry , “Spectral signatures in backdoor attacks, ” Advances in neural information pr ocessing systems , vol. 31, 2018. [6] Y . Lin, Y . Liao, Z. Wu, and P . Zhou, “Mitigating backdoors in federated learning with fld, ” in 2024 5th International Seminar on Artificial Intelligence, Networking and Information T echnology (AINIT) . IEEE, 2024, pp. 530–535. [7] Z. Gu, J. Shi, and Y . Y ang, “ Anodyne: Mitigating backdoor attacks in federated learning, ” Expert Systems with Applications , vol. 259, p. 125359, 2025. [8] W . Gill, A. Anwar , and M. A. Gulzar , “Feddefender: Backdoor attack defense in federated learning, ” in Pr oceedings of the 1st International W orkshop on Dependability and T rustworthiness of Safety-Critical Sys- tems with Machine Learned Components , 2023, pp. 6–9. [9] E. Alharbi, L. S. Marcolino, Q. Ni, and A. Gouglidis, “Robust knowl- edge distillation in federated learning: Counteracting backdoor attacks, ” in 2025 IEEE Conference on Secur e and Trustworthy Machine Learning (SaTML) , 2025, pp. 189–202. [10] J. Jia, Z. Y uan, D. Sahabandu, L. Niu, A. Rajabi, B. Ramasubramanian, B. Li, and R. Poovendran, “Fedgame: A game-theoretic defense against backdoor attacks in federated learning, ” Advances in Neural Information Pr ocessing Systems , vol. 36, pp. 53 090–53 111, 2023. [11] H. Zhang, J. Jia, J. Chen, L. Lin, and D. W u, “ A3fl: Adversarially adaptiv e backdoor attacks to federated learning, ” Advances in neural information processing systems , vol. 36, pp. 61 213–61 233, 2023. [12] S. Huang, Y . Li, X. Y an, Y . Gao, C. Chen, L. Shi, B. Chen, and W . W . Ng, “Scope: On detecting constrained backdoor attacks in federated learning, ” IEEE T ransactions on Information F orensics and Security , 2025. [13] X. Zhang, X. Xue, X. Du, X. Xie, Y . Liu, and M. Sun, “Runtime back- door detection for federated learning via representational dissimilarity analysis, ” IEEE T ransactions on Dependable and Secure Computing , 2025. [14] Q. Chen and Y . T ao, “Mdsd: a multi-dimensional scaling-based defensiv e mechanism against backdoor attacks on federated learning, ” Cluster Computing , vol. 28, no. 5, pp. 1–22, 2025. [15] K. Gu, Y . Zuo, J. T an, B. Y in, Z. Y ang, and X. Li, “Dual-layered model protection scheme against backdoor attacks in fog computing- based federated learning, ” IEEE T ransactions on Network and Service Management , 2024. [16] J. Zhang, C. Zhu, X. Sun, C. Ge, B. Chen, W . Susilo, and S. Y u, “Flpu- rifier: backdoor defense in federated learning via decoupled contrastiv e training, ” IEEE T ransactions on Information F orensics and Security , 2024. [17] Z. Zhang, J. Li, S. Y u, and C. Makaya, “Safelearning: Secure aggregation in federated learning with backdoor detectability , ” IEEE Tr ansactions on Information F orensics and Security , vol. 18, pp. 3289–3304, 2023. [18] S. Lu, R. Li, W . Liu, and X. Chen, “Defense against backdoor attack in federated learning, ” Computers & Security , vol. 121, p. 102819, 2022. [19] N. Rodr ´ ıguez-Barroso, E. Mart ´ ınez-C ´ amara, M. V . Luz ´ on, and F . Her- rera, “Backdoor attacks-resilient aggregation based on robust filtering of outliers in federated learning for image classification, ” Knowledge-Based Systems , vol. 245, p. 108588, 2022. [20] D. H. Nguyen, P . L. Nguyen, T . T . Nguyen, H. H. Pham, and D. A. T ran, “Fedblock: A blockchain approach to federated learning against backdoor attacks, ” in 2024 IEEE International Conference on Big Data (BigData) . IEEE, 2024, pp. 7981–7990. 12 [21] S. Kaviani, S. Shamshiri, and I. Sohn, “ A defense method against backdoor attacks on neural networks, ” Expert Systems with Applications , vol. 213, p. 118990, 2023. [22] Y . W ang, D.-H. Zhai, Y . He, and Y . Xia, “ An adaptive robust defend- ing algorithm against backdoor attacks in federated learning, ” Futur e Generation Computer Systems , vol. 143, pp. 118–131, 2023. [23] I. T . Jolliffe and J. Cadima, “Principal component analysis: a revie w and recent developments, ” Philosophical transactions of the royal society A: Mathematical, Physical and Engineering Sciences , vol. 374, no. 2065, p. 20150202, 2016. [24] E. M. Campos, A. Gonzalez-V idal, J. L. Hernandez-Ramos, and A. Skarmeta, “Federated learning for misbehaviour detection with varia- tional autoencoders and gaussian mixture models, ” International Journal of Information Security , vol. 24, no. 2, pp. 1–16, 2025. [25] Y . Shi, M. Du, X. W u, Z. Guan, J. Sun, and N. Liu, “Black-box backdoor defense via zero-shot image purification, ” Advances in Neural Information Processing Systems , vol. 36, pp. 57 336–57 366, 2023. [26] I. Jolliffe, “Principal component analysis, ” in International encyclopedia of statistical science . Springer , 2011, pp. 1094–1096. [27] B. Zong, Q. Song, M. R. Min, W . Cheng, C. Lumezanu, D. Cho, and H. Chen, “Deep autoencoding gaussian mixture model for unsupervised anomaly detection, ” in International conference on learning repr esenta- tions , 2018. [28] K. R. Shahapure and C. Nicholas, “Cluster quality analysis using silhouette score, ” in 2020 IEEE 7th international conference on data science and advanced analytics (DSAA) . IEEE, 2020, pp. 747–748. [29] J. Stallkamp, M. Schlipsing, J. Salmen, and C. Igel, “The german traffic sign recognition benchmark: a multi-class classification competition, ” in The 2011 international joint conference on neural networks . IEEE, 2011, pp. 1453–1460. [30] M. Mathias, R. Timofte, R. Benenson, and L. V an Gool, “Traf fic sign recognition—how far are we from the solution?” in The 2013 international joint confer ence on Neural networks (IJCNN) . IEEE, 2013, pp. 1–8. [31] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data, ” in Artificial intelligence and statistics . PMLR, 2017, pp. 1273– 1282. Osama W ehbi is a Ph.D. candidate in the Department of Computer and Soft- ware Engineering at Polytechnique Montreal, Canada. His primary research areas include cybersecurity , federated learning, and game theory . Sarhad Arisdakessian is a PhD candidate in the Department of Computer and Software Engineering at Polytechnique Montreal, Canada. His primary research interests lie in the fields of Federated Learning and Game Theory . Omar Abdel W ahab holds an assistant professor position with the De- partment of Computer and Software Engineering, Polytechnique Montreal, Canada. His current research activities are in the areas of cybersecurity , Internet of Things and artificial intelligence. Azzam Mourad is a professor of Computer Science with Khalifa University Abu Dhabi, UAE. His research interests include the domains of cloud computing, Artificial intelligence, and Cybersecurity . Hadi Otrok is a professor and chair of the Department of EECS at Khalifa Univ ersity , Abu Dhabi, U AE. His research interests include the domains of computer and network security , crowd sensing and sourcing, ad hoc networks, and cloud security . Jamal Bentahar is a professor of Computer Science with Khalifa University Abu Dhabi, U AE. His research interests include reinforcement and deep learning, multi-agent systems, computational logics, and service computing
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment