Safeguarding LLMs Against Misuse and AI-Driven Malware Using Steganographic Canaries
AI-powered malware increasingly exploits cloud-hosted generative-AI services and large language models (LLMs) as analysis engines for reconnaissance and code generation. Simultaneously, enterprise uploads expose sensitive documents to third-party AI …
Authors: Md Raz, Venkata Sai Charan Putrevu, Meet Udeshi
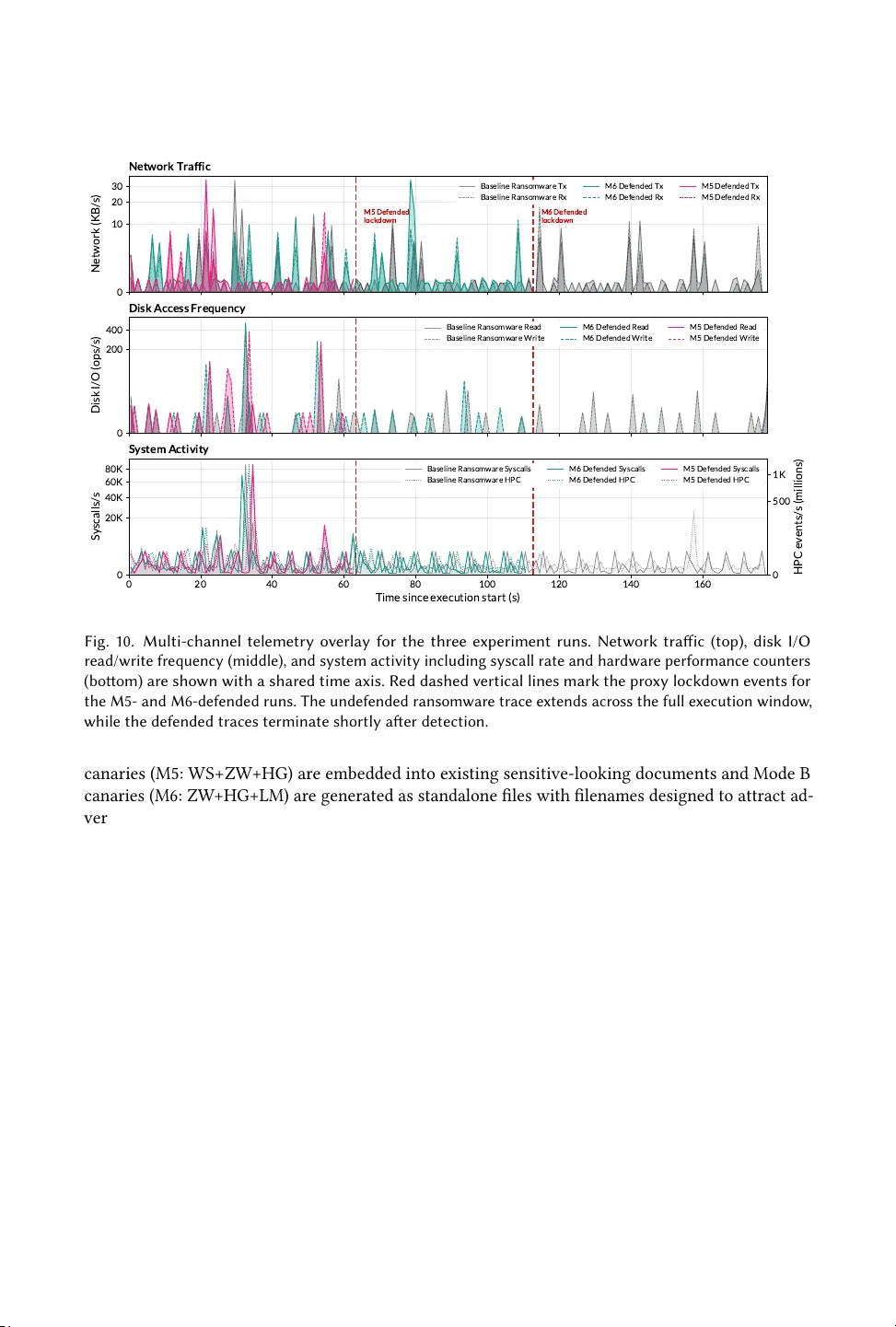
Safeguarding LLMs Against Misuse and AI-Driven Malware Using Steganographic Canaries MD RAZ, VENKA T A SAI CHARAN P U TREV U , MEET UDESHI, PRASAN TH KRISHNA - MURTH Y , F ARSHAD KHORRAMI, and RAMESH KARRI, Department of Electrical and Computer Engineering, T andon School of Engineering, New Y ork University , USA AI-powered malware incr easingly exploits cloud-hosted generative- AI services and large language models (LLMs) as analysis engines for reconnaissance, le triage, and co de generation. Simultaneously , routine enter- prise uploads expose sensitive documents to third-party AI vendors. Both threats converge at the AI service ingestion boundary , yet existing defenses focus on endpoints and network perimeters, leaving organizations with limited visibility once plaintext reaches an LLM service. T o address this, we present a framework based on steganographic canary les: realistic documents carr ying cryptographically derived identiers embedded via complementar y enco ding channels. A pre-ingestion lter extracts and veries these identiers before LLM processing, enabling passive, format-agnostic detection and data provenance without semantic clas- sication. W e support two mo des of operation where Mode A marks existing sensitive do cuments with layered symbolic encodings ( whitespace substitution, zer o-width character insertion, homoglyph substitution), while Mode B generates synthetic canary do cuments using linguistic steganography ( arithmetic coding over GPT -2), augmente d with compatible symbolic layers. W e model increasing document pre-processing and adversarial capability for both modes via a four-tier transport-transform taxonomy: All methods achieve 100% identier recovery under benign and sanitization workows (Tiers 1–2). The hybrid Mode B maintains 97% through targeted adversarial transforms (Tier 3) while symb olic-only Mode A provides full coverage through Tier 2. W e show that improper layer composition can reduce Tier 3 recov ery from 97% to 0% via cross-layer interference, yielding empirical composition principles. V erication via cryptographic identiers (HMAC and EdDSA) pr oduce zero false positives while surfacing deployment trade-os. An end-to-end case study against an LLM-orchestrated ransomware pipeline conrms that both modes dete ct and block canar y-bearing uploads during reconnaissance, before le encryption begins. T o our knowledge, this is the rst frame work to systematically combine symbolic and linguistic text steganography into layered canary documents for detecting unauthorized LLM processing, evaluated against a transport-threat taxonomy tailor ed to AI malwar e. CCS Concepts: • Security and privacy → Malware and its mitigation ; Domain-specic security and privacy architectures ; Information ow control . Additional K ey W ords and Phrases: Large Language Models, T ext Steganography , AI-Powered Malware, Data Provenance , Generative AI, Steganalysis, Data Leakage Prevention. 1 Introduction AI-powered malware depend on cloud-hosted large language models (LLMs) as analysis engines. A utonomous agentic ransomwar e can now execute the full attack lifecycle, including reconnaissance, le targeting, data exltration, encryption, and ransom-note generation, by leveraging an external LLM without human control [ 28 ]. This LLM-analysis dep endency extends to AI-assisted espionage agents that triage exltrated documents for intelligence value [ 17 ], automated cr edential and secret harvesters that use contextual understanding to extract API keys and tokens from conguration les, and social-engineering tools that analyze internal communications to craft targeted spear-phishing This work was supported in part by the DOE NETL grants DE-CR0000051 and DE-CR0000017, the NSF SaTC grant 2039615, and NYSTAR C220160. A uthors’ Contact Information: Md Raz, md.raz@nyu.edu; V enkata Sai Charan Putrevu, v .putrevu@nyu.edu; Meet Udeshi, m.udeshi@nyu.edu; Prasanth Krishnamurthy, prashanth.krishnamurthy@nyu.edu; Farshad Khorrami, khorrami@nyu.edu; Ramesh Karri, rkarri@nyu.edu, Department of Electrical and Computer Engineering, T andon School of Engineering, New Y ork University, Brooklyn, New Y ork, USA. 2 Raz et al. "This document is important ..." "Summarize this text 🥱 ..." "Find and Extract PII 😈 ..." ✦ Process using LLM ✦ + Thinking ⏲ LLM V endor Extracted: canary_token Fig. 1. Overview: steganographic canar y files detect unauthorized document submission to AI services at the ingestion boundary , before LLM processing occurs. campaigns [ 26 ]. In parallel, enterprise adoption of LLM to ols has exposed a new data leakage channel where employ ees submit sensitive documents to third-party AI services, with reports of senior ocials uploading marked government documents to public ChatGPT instances [ 36 ]. Current defenses oer limited protection once plaintext leaves an organization’s boundar y . This gap is acute for AI-powered malware: defenses are signatur e or behavior-based but LLM-assiste d malware maintain a near-imperceptible footprint while conducting reconnaissance , le analysis, and payload generation via external models [ 32 ]. Once an adversary has obtained les, whether through compromise or authorized access, the question becomes whether the les can ee ctively be weaponized via an LLM. This creates a defensive opportunity at the processing boundar y that conventional endpoint and perimeter protections do not cover , namely detecting unauthorized LLM analysis of documents that have already left the organization’s control. Network Data Loss Prevention (DLP) and endpoint controls can block destinations or match patterns, but they are easily bypasse d when data is uploaded through compromised accounts, personal devices, or encrypte d channels. Access contr ols limit who can read a le, but they do not prevent an authorized (or compromised) user fr om leaking data. Semantic classiers for PII and secrets add another layer consistent with emerging AI governance frameworks, but remain brittle in practice as domain-specic language can evade detection, while broad rules create costly false positives. Even when an organization susp ects exposure, it is often impossible to determine whether a specic document was uploaded to a specic AI service as existing controls provide little le-level accountability after data crosses the boundary . A ccordingly , OW ASP’s T op-10 for LLM Applications lists Sensitive Information Disclosure (LLM02:2025) as a top-tier risk [ 29 ]. Our work addresses this core gap wher e there exists a lack of a portable , le-content-lev el tripwir e that remains intact under common transformations and can be detected by the receiving AI ser vice ’s ingestion b oundary before model processing, without relying on semantic inspection of the contents. W e propose a defensive frame work for detecting unauthorized submission of controlled docu- ments to LLM ser vices. The framework uses plaintext canary les se eded across organizational le shares, where each canary carries a visually indistinguishable, cr yptographically derived identier steganographically embedded in the textual content itself. If a user or attacker uploads or pastes the document into a participating AI service, a vendor-side pre-ingestion lter extracts and veries the identier , then blo cks or ags the submission before the LLM processes it. The defense operates as a second line that activates when traditional perimeter defenses have failed, as shown in Figure 1 . W e design framework with three practical properties. First, it provides content-lev el persistence as the embedded identier resides in plaintext and travels with the content, surviving common han- dling such as copy/paste, reow , and format conversion, while also supporting ingestion into LLM input pipelines. Second, it enables passive detection at the processing boundary (the AI vendor’s ingestion boundar y ) rather than relying on callback-based honeytokens that can be blocke d. Third, it implements orthogonal embedding classes that preserve visible content (symbolic encodings) Safeguarding LLMs Against Misuse and AI-Driven Malwar e Using Steganographic Canaries 3 or can survive character-level normalization (linguistic encodings). This layered design improv es robustness to heterogeneous AI pre-processing pipelines using a “defense-in-depth” approach, where deeper layers provide higher chances of encoding survival. T o evaluate the proposed framework, we structure our study ar ound ve research questions to examine feasibility , robustness, and deployment realism end to end: RQ1 Feasibility: Can steganographic identiers b e emb edded into plaintext canar y les such that a per-le cr yptographic identier can be recovered after a representativ e transport and transformation pipeline? RQ2 Robustness: How do symbolic and linguistic embeddings compare in resilience to benign handling, sanitization, and adversarial transformations, and what failure modes are exposed? RQ3 Defense-in-Depth: Does layering multiple methods (e.g., symbolic embeddings on dis- joint character surfaces or hybrid embe ddings) provide measurably broader co verage across transport conditions than any single method or method class alone? RQ4 Practical Deployment: What are the computational costs, textual capacity limits, and operational trade-os of deploying steganographic canary les at organizational scale? RQ5 End-to-End Detection: Can the complete pipeline reliably detect and block unauthorized uploads in a realistic simulated AI-driven ransomware worko w? Through empirical evaluations guided by these questions, we determine whether steganographic canary les with cr yptographically derived embe ddings are technically viable, robust against changes, and deployable in practice. W e make the following key contributions: C1 Defensive framework: W e design a framework that emb eds cryptographically veriable identiers via lay ered symbolic and linguistic steganographic channels, supporting both shar ed- key (HMA C-SHA256) and public-key (EdDSA/Ed25519) verication. Mode A marks existing sensitive documents with symb olic encodings at sub-millise cond cost; Mode B generates synthetic canary documents via arithmetic coding over GPT -2, augmented with compatible symbolic layers. The framework is grounded in a threat model that formalizes the AI-powered malware interception point, where adv ersaries who have obtained les must submit them to an external LLM for analysis, alongside incidental insider uploads. C2 Transport-transform taxonomy and systematic evaluation: W e present a four-tier transport- transform taxonomy for the LLM-upload threat model, with systematic evaluation of individual and stacked method robustness across se ven congurations and six composite transport chains. The evaluation reveals per-le binary recov er y behavior , orthogonal failure surfaces, and layering rules demonstrating reduced survival rates for improper method comp ositions. C3 End-to-end validation: W e demonstrate the full canary le lifecycle in an end-to-end case study against a PromptLock -style LLM-orchestrated ransomware pipeline, dete cting and blocking the attack during its reconnaissance phase before any le encryption o ccurs. The remainder of the paper is organize d as follows. Section 2 presents the background and limitations of e xisting defenses for detecting unauthorized document submission to LLMs. Section 3 formalizes our threat model and assumptions, including the AI-powered malware categories that share the LLM-analysis choke-point. Section 4 presents the steganographic canary le framework and its encode–transport–decode pip eline. Section 5 describ es the evaluation metho dology , datasets, transport transforms, and measurement criteria. Section 6 reports feasibility , robustness, layering, and end-to-end case study results. Section 7 examines deployment considerations, limitations, and broader implications. Finally , Section 8 concludes. 4 Raz et al. 2 Background and Related W ork W e position our work at the intersection of three research threads: the emerging class of AI-powered malware that dep ends on external LLMs for document analysis, data-protection and de ception-based defenses, and text steganography . W e close by comparing our work with prior art. 2.1 AI-Powered Adversaries Cloud-hosted LLM interfaces that enable b enign document analysis have simultaneously created a new operational dependency for adversaries. Greshake et al. showed that LLM-integrated applica- tions blur the boundar y between data and instructions as LLMs can exltrate user data via generate d content through embedded adversarial prompts [ 18 ]. A joint Microsoft–OpenAI disclosure later documented ve nation-state groups and identied their use of ChatGPT for reconnaissance, vul- nerability research, scripting, and so cial-engineering content generation [ 26 ]. Go ogle ’s Threat Intelligence Group (GTIG) subsequently reported an escalation from productivity-oriented LLM misuse to runtime integration, detailing malware families such as PromptFlux and PromptSteal , both of which generate commands and code during execution [ 17 ]. This trend is especially consequential for ransomware. The Ransomw are 3.0 prototype (publicly identied by ESET as PromptLock ) is the rst fully closed-loop, LLM-or chestrated ransomware where a lightweight Go binary emb eds natural-language prompts rather than pre-written attack code, delegates reconnaissance, le-system enumeration, payload generation, data exltration, encryption, and personalize d extortion-note composition to an LLM, and pr oduces polymorphic Lua scripts that adapt to each victim environment at runtime [ 32 ]. The malware cannot execute an intelligent attack without rst ingesting information about the environment and candidate les. Furthermore, the same LLM-analysis dependency extends beyond ransomware to multiple AI- powered malware categories. AI-assisted espionage agents can rapidly triage exltrated document troves for intelligence value, automated credential harvesters leverage contextual LLM under- standing to extract secrets fr om conguration les and source code, and social-engineering tools analyze internal communications to craft targeted spear-phishing campaigns. All share a common operational requirement: submitting stolen documents to an external LLM for analysis. This shared interception point at the AI ser vice ingestion boundary motivates our defensive approach [ 17 , 19 ]. 2.2 The LLM Data Exfiltration Channel Beyond adversarial exploitation, enterprise adoption of LLMs has created a channel for sensitive data leakage. In March 2023, Samsung Electronics employ ees on multiple o ccasions pasted proprietary company materials such as semiconductor source code into ChatGPT , prompting a company-wide ban on all generative-AI services [ 20 ]. Cyb erhaven Labs’ telemetr y across 7 million knowledge workers shows that enterprise AI usage gre w 4.6 × year-over-y ear , with 34.8% of data submitted to AI to ols classied as sensitive, and 83.8% of enterprise AI trac ows to external tools rate d medium, high, or critical risk [ 11 ]. As a result of LLM-assisted workows normalizing the transfer of plaintext to third-party ser vices for summarization, extraction, and co de generation, benign productivity use and deliberate exltration now share the same interface and transport path. 2.3 Existing Defenses and Limitations Existing defenses leave a clear gap at the AI ser vice processing boundar y , especially in the context of agentic malware and benign-looking workows. • Endpoint controls are channel-centric: Network endpoint monitors inspect trac, destina- tions, or host behavior , and work best when exltration paths and signatures are known [ 2 ]. Safeguarding LLMs Against Misuse and AI-Driven Malwar e Using Steganographic Canaries 5 In the LLM setting, how ever , data may leave through personal devices, br owser copy/paste, or encrypted tunnels (i.e. in-content rather than channel), often resembling legitimate use [ 23 ]. • Access control ineective after compromise: File permissions limit who can r ead a document, but once a user (or compromised session) has read access, existing controls generally do not prevent cop ying, reformatting, or uploading the content to an external AI service [ 23 ]. • Semantic inspection is brittle/costly: PII detectors and policy-based classiers can help, but rule-based methods are easy to evade via targeted re-wor ding or jargon-based obfuscation, while semantic models produce higher false p ositives and often require inspection of le contents [ 27 ]. • AI-malware defenses miss the analysis channel: Traditional detection relies on process, lesystem, and behavioral indicators [ 3 , 9 ]. AI-powered malwar e can reduce these signals via polymorphic co de, task decomposition, and low-and-slow disk access patterns [ 19 , 32 ] while outsourcing analysis of les to external LLMs through channels unprotected by endpoint defenses. • LLM safety guardrails are insucient: Modern LLMs employ trained r efusal mechanisms for malicious requests, but these guardrails are routinely bypassed via prompt inje ction [ 18 ], jailbreaks, and multi-prompt de composition where AI malware de composes attacks across discrete prompts such that no single prompt appears overtly malicious [ 32 ]. Guardrails are provider-specic and version-dependent, making them unreliable as security controls. Our defense op erates on do cument content at the ingestion b oundary before content reaches the model, and functions regardless of model refusal behavior . • Post-incident Forensics and attribution: Even when exposure is suspected, organizations often cannot determine provenance of a document uploaded to a specic AI ser vice, or whether it was transformed b efore submission, both of which aid incident response and investigation [ 7 ]. 2.4 Canary Files and Deception-Based Defenses Deception-based defenses dete ct compromise by planting monitored artifacts whose unauthorized access signals attacker activity . Spitzner introduced this paradigm through hone ypots and honeyto- kens [ 35 ], with later work extending it to lesystem honeyles [ 41 ] and beaconed do cuments that trigger hidden H T TP/DNS callbacks when opened outside the enterprise perimeter [ 6 ]. Surveys cover these mechanisms across network, host, and data layers [ 21 , 30 , 42 ]. Modern deployments such as Thinkst Canary / Canarytokens operationalize this mo del using tripwires that alert via network callbacks [ 38 ]. This works well when the e xltration path preserves content, but fails when transport is oine, anonymized, or mediated by services that sanitize macros or active payloads, which is typical for LLM ingestion. 2.5 T ext Steganography T ext steganography provides the technical mechanism underlying our framew ork design, which embeds hidden information into textual content while preserving visible utility . Our framework draws from character-level symbolic steganography and generative linguistic steganography , and then combines them for the defense-in-depth paradigm. 2.5.1 Symbolic steganography . (i) Whitespace substitution (WS) replaces ordinary spaces and line breaks with visually e quivalent Unicode whitespace characters to encode arbitrary bytes. Innamark formalized this as a K otlin multiplatform library that embe ds payloads in inter-w ord gaps [ 22 ], and the earlier AI TSteg employed similar substitutions for covert messaging on social- media platforms [ 37 ]. (ii) Zero-width character insertion (ZW) uses non-printing code points between visible glyphs. StegCloak compresses and HMA C-encrypts a secret b efore enco ding it as a sequence of six zero-width characters, achieving practical invisibility in bro wsers and messaging applications [ 10 ]. (iii) Homoglyph substitution (HG) replaces Latin glyphs with 6 Raz et al. T able 1. Comparison of steganographic canaries (This work) with e xisting defenses: Property Endpoint Protection Active tokens Doc. watermark This W ork Channel-agnostic ✗ ✗ ✓ ✓ Survives copy-paste ✗ ✗ ✗ ✓ Passive (no callback) — ✗ ✓ ✓ Format-agnostic ✗ ✗ ✗ ✓ W orks oine / T or ✗ ✗ ✓ ✓ visually confusable code points from other scripts such as Cyrillic or Greek, using mappings cataloged in the Unico de T e chnical Standard #39 [ 14 ]. Boucher et al. showed that such imperceptible replacements can evade NLP classiers, spam lters, and toxicity detectors [ 5 ]. These sub-types exhibit complementary failure mo des where whitespace and zero-width metho ds oer high capacity but are fragile to normalization, and homoglyph substitution is more robust to whitespace stripping but may be agge d by confusable-character scanners or Unicode se curity-aware steganalysis. This complementarity motivates multilayer symbolic encoding for more robust defense. 2.5.2 Linguistic steganography . The Linguistic Method (LM) , enco des hidden bits by constraining language-model-generated text, so that the output remains coherent while carrying a recoverable payload. Neural linguistic steganography became practical when Ziegler et al. couple d arithmetic coding with GPT -2, achieving several bits encode d per token [ 44 ]. Dai and Cai concurrently propose d patient-Human coding with formal near-imp erceptibility guarantees [ 12 ]. Subsequent work improved both throughput and security , as Self-A djusting Arithmetic Coding ( SAAC ) dynamically tunes the truncation parameter at each decoding step, improving embe dding rate by 15.3% and KL divergence by 38.9% o ver xed baselines [ 34 ], ADG recursively partitions the vocabulary for provably secure encoding [ 43 ], Meteor pro vides a symmetric-key stateful protocol for variable- entropy channels [ 24 ], and Discop samples from “distribution copies” to maximize throughput while maintaining the exact cover distribution [ 15 ]. A practical constraint shar ed by all linguistic methods is decoder synchronization, where the encoder and deco der must use an identical LLM. In our implementation we select GPT -2 (124 M) as the model, accepting lower capacity and vocabulary in exchange for portability and reproducibility . 2.5.3 File-Format-level and Output Marking. Do cument formats such as PDF and OOXML provide embedding channels in container structures such as metadata, internal XML, revision elds, and embedded objects [ 8 ]. Such format-coupled marks are typically lost under plaintext extraction and copy/paste, which dominate many LLM workows. In contrast, LLM output watermarking embeds provenance into model-generated text (e.g., token-bias watermarking [ 25 ] and production- scale SynthID-Text [ 13 ]) to establish whether a given text was AI-generated. W e address the inverse problem of input-side content provenance where we mark pre-existing (or newly-generated) documents to detect unauthorized input ingestion (rather than output) by an AI ser vice. 2.6 Positioning Our W ork Steganographic canaries addr ess a gap not covered by existing defenses, namely a passive , portable, le-content-level tripwire that survives common transformations and can b e detected at the AI processing boundar y without semantic insp ection or classication. W e summarize this distinc- tion against other metho ds in T able 1 . Compared with traditional endpoint defenses and DLP, steganographic canaries are channel-agnostic as the identier travels with the text itself rather than a monitored network path. They also operate as a second line that activates at the processing boundary when network perimeter defenses have already been bypassed. Compared with active canary tokens, they require no callback and remain eective when active content is strippe d or Safeguarding LLMs Against Misuse and AI-Driven Malwar e Using Steganographic Canaries 7 Shared Key Registry / Public Key Agentic Malware Insider Upload C o p y - P a s t e t o A I V e n d o r f o r s u m m a r i z a t i o n S c a n a n d A n a l y z e h i g h - v a l u e t a r g e t f i l e s Untrusted T ransport Pathway Organizational Perimeter V endor-side Perimeter T oken E n c o de HMAC / EdDSA File ⚿ Organizational File Share ⚿ ⚿ Canary File ⚿ T oken ? z LLM Dec o de P r e - Fi lt e r Ve r ifica t i on D o S / F l ag ⚠ Match ✔ No Match Shared Key Registry / Public Key Fig. 2. Threat model scenario showing the tw o motivating threat pathways (AI adv ersaries and insider/inci- dental upload), along with the framew ork encompassing the seeded canar y files within the organizational boundary and steganographic identifier extraction / verification within the vendor-side detection boundary . outbound signaling is blocke d. Compared with document-level watermarking, the y sur vive plain- text extraction and copy/paste into LLM interfaces. Compared with LLM output watermarking, they solve the inverse problem of detecting unauthorized input ingestion of protected content. T o our knowledge, no prior work has combined layered text-steganographic encodings (symbolic and linguistic) into canary do cuments and evaluated their survivability under a tiered transport-threat model tailored to the AI-pow ered malware threats. W e formulate and e valuate this paradigm in this paper . 3 Threat Model W e formalize the scenario (Figure 2 ) in which steganographic canary les operate, the adversary capabilities they must withstand, and the transport transforms for robustness evaluation. Our threat model is motivated by two increasingly common AI security realities: (i) AI-p ow ered malware, including agentic ransomware, AI-assisted espionage agents, automate d credential harvesters, and social-engineering tools, dep end on external LLMs to analyze stolen les, creating a pr ocessing boundary dete ction opportunity that endpoint defenses do not cover; and (ii) routine enterprise LLM adoption normalizes the sensitive plaintext submission to third-parties, blurring the boundary between legitimate use and data exltration [ 11 ]. A key assumption is that the adversary has already obtained the les, whether through compromise or authorized access. The proposed defense does not attempt to prevent exltration at the network perimeter ( already addressed by traditional DLP), but rather focuses on the processing boundary point at which plaintext enters an external AI service for analysis. At this interception point, we ask whether content-level invisible identiers can provide reliable detection, activating when perimeter defenses have failed. 3.1 Scenario An organization (enterprise, government agency , research lab) maintains le shares containing sensitive plaintext artifacts such as source code, internal documentation, and conguration les. The organization se eds these shares with steganographic canary les, which are realistic documents indistinguishable from legitimate content under casual inspection, carrying a cryptographically derived identier embedded via one or more channels. W e detail the embe dding methods, identier construction, and deployment modes in Section 4 , and identify two motivating pathways: • AI-Powered Adversaries: Agentic malwar e or an external attacker with AI-assistance gains user-space access to le shares through compromise , lateral movement, or supply-chain abuse. The adversary submits stolen les to an e xternal LLM for analysis, credential discov ery , sum- marization, or code/payload generation. Multiple AI-p ower ed malware categories share this 8 Raz et al. LLM-analysis dependency: (a) LLM-orchestrated ransomware that analyzes les for extortion leverage [ 32 ], (b) AI-assiste d espionage agents that rapidly analyze exltrated documents for intelligence value [ 17 ], (c) automated credential and secret harvesters that use conte xtual LLM understanding to extract API keys and tokens from conguration les, and ( d) social-engineering tools that analyze internal enterprise communications to craft targeted campaigns [ 26 ]. Because all four categories depend on ingesting stolen documents via an e xternal LLM, the AI service ingestion boundary becomes a shar ed interception point and dete ction opportunity that is absent from traditional endpoint defenses. • Incidental or Insider Upload: An authorize d user , acting negligently or with malicious intent, copies or uploads sensitive content to a thir d-party AI service for summarization, code review , or other analysis. This pathway shares the same transport interface as adversarial exltration, making policy enforcement and forensic attribution challenging via conventional controls. In both cases, an AI ser vice (or an enterprise-controlled monitoring proxy ) runs an ingest-time extraction lter ov er inbound plaintext, checking extracted values against a registry/manifest of known tokens. If a valid identier is recover ed, a congurable response is triggered (e.g., lockdown or breach alert). W e detail the extraction and verication mechanism in Section 4 , while the notication protocol and key-distribution model are considered out of scope. 3.2 Adversary Model W e mo del an adversary whose objective is to access and analyze sensitive plaintext using external AI services. The adversary controls content transport and pre-pr ocessing before submission but does not possess the organization’s secret ke y or embedding conguration. W e assume that the adversary may know the general defense class and embedding method families, but not the specic method selection, parameters, or key material used in a given deployment. W e dene escalating adversary capabilities from basic le access and upload capability up to active countermeasures. At the base level, the adv ersar y can read and copy les from organizational le shares via insider privileges, compromised accounts, malware , or lateral movement, and may select which les to exltrate. The adversary can then submit le contents to external AI services via bro wser upload, copy/paste, or programmatic API calls, targeting complete do cuments or partial excerpts that contain the hidden identier . The upload path may also apply transformations that unintentionally corrupt embedde d channels including Unico de normalization, whitespace collapsing, smart-quote substitution, line reow , or format-character stripping (see T able 2 ). At the upper bound, a sophisticate d adversary suspecting steganographic emb edding can apply targeted sanitization, trading overhead and content delity for reduced detection probability . 3.3 Transport- Transform T axonomy W e organize the transforms an insider/adversary may accidentally or intentionally apply into four tiers where tier subsumes all transforms in lower tiers. T able 2 lists the twelve individual transforms and T able 3 denes the composite chains used e xperimentally . W e nd that one structural property , validated empirically in Se ction 6 , is that no single Tier 1–3 transform destroys all embedding methods simultaneously , causing Tier 4 semantic re writing to be the only tier that defeats all methods. Furthermore, we identify that chained ordering can also produce interaction eects. For example, Unicode Normalization Form K C (NFKC) normalization in Tier-2 may inadvertently preserve signals that a later Tier-3 strip would otherwise destroy . Tier 1 – Benign / Incidental: Standard transforms applied by platforms, editors, and clipboard managers: line-ending normalization, reow , smart-quote replacement, and trailing-whitespace stripping. These represent the minimum adversity any embedding must tolerate. Safeguarding LLMs Against Misuse and AI-Driven Malwar e Using Steganographic Canaries 9 T able 2. T ransport-transform taxonomy . Tiers ref lect increasing adversary sophistication and intent. Each tier subsumes all transforms in lower tiers. ID Transform Tier Typical Source T00 None 0 – Passthrough Baseline T01 Copy-paste normalization 1 – Benign Clipboard, browser T02 Line reow 1 Editor word-wrap T03 Smart-quote replacement 1 W ord processor , CMS T04 Trailing-whitespace strip 1 Editor , version control hooks T05 Unicode NFKC normalization 2 – Sanitization Input validation T06 Whitespace collapse (ASCII) 2 H TML/API ingest T07 Format-character strip (Cf ) 2 Sanitizer , web application rewall T08 Zero-width char stripping 3 – Adversarial T argeted sanitizer T09 Homoglyph normalization 3 Confusable folding T10 Full ASCII strip (Transliteration) 3 Remov e all non-ASCII T11 Punctuation/case strip 4 – Special Content normalization T12 LLM-based paraphrase 4 Intentional rewrite T able 3. Composite transp ort chains used as experimental variables. Each chain applies its constituent transforms in sequence. T11 is teste d individually but excluded from chaining because T11 → T12 is redundant. Chain Composition Models Tier-0 T00 (Passthrough) Baseline / control Tier-1 T01 → T02 → T03 → T04 User copy-paste Tier-2 T05 → T06 → T07 Platform sanitization Tier-3 T08 → T09 → T10 Steganography-aware attacker Tier-1+2 Tier-1 → Tier-2 Combined incidental processing Tier-1+2+3 Tier-1 → Tier-2 → Tier-3 Maximum non-semantic pipeline Tier-4 T12 LLM semantic rewriting Tier 2 – Standard Sanitization: Security-conscious input processing that is not watermark-aware but damages specic encoding surfaces: NFKC normalization (T05), whitespace collapsing (T06), and format-character stripping (T07). Tier 3 – T argeted Adversarial: An adversary suspecting steganographic emb edding applies directed stripping: zero-width character removal (T08), confusable normalization (T09), or full non- ASCII stripping (T10). Tier 4 – Spe cial T ransforms: Punctuation/case stripping (T11) and LLM-based paraphrase (T12) exhibit qualitatively dierent failur e patterns from Tiers 1–3, producing inverse cov erage proles aecting both tokenization and symb ols across embedding classes. 3.4 Security Goals Our security goals align with the intended role of canary les as le-level tripwir es with content- level embeddings detectable at an AI ser vice boundary . Embedded identiers must b e recoverable with high probability under incidental processing (Tier 1) and common sanitization (Tier 2), with layered emb eddings to provide graceful degradation at higher tiers. Detection succe eds if any surviving layer yields a veriable token, while also appearing b enign under casual inspe ction. W e do not claim indistinguishability against targeted statistical tests, as the defense relies instead on volume and the cost asymmetry of per-le analysis. Finally , recovered identiers must be integrity-checked with negligible false positives. 10 Raz et al. NO MATCH MATCH ⚠ NO MATCH MATCH ✔ ⚠ ✔ LLM INPUT FLAG/DoS TRANSPORT INPUT FILE OR CORPUS EMBEDDING EXTRACTION COVER TEXT ZW WS HG ZW WS HG MODE A MODE B COVER TEXT ZW HG LM ZW HG LM Framed Payload TIER 4 SPECIAL/SEMANTIC TIER 3 ADVERSARIAL TIER 2 SANITIZATION TIER 1 BENIGN TIER 0 PASSTHROUGH Token Verification ZW WS HG LM Linguistic Zero-width Whitespace Homoglyph Fig. 3. Framework pipeline overview including encoding stacks, possible transforms, and inverse decoding. Any verified recovery constitutes detection. 3.5 Trust Assumptions & Scope Cooperating detection ser vice: W e assume a cooperating AI vendor or enterprise-controlled monitoring proxy shared across vendors runs extraction and verication on inbound plaintext prior to model processing. The vendor requires only the ability to execute the extraction algorithm and perform key-based verication; it need not have prior access to the organization’s les. K ey distribution and notication protocols are considered important but out of scope. In-scope artifacts and channel: W e restrict attention to te xt-based les and plaintext content submitted to cloud-hosted AI services (pasted into a chat interface or uploaded via API). Our evaluation targets transform suites representativ e of real-world text handling and sanitization. Local and o line LLMs: An adversary running a locally hosted LLM bypasses the vendor-side ingestion boundar y entirely and falls outside this dete ction mo del. This is an acceptable scop e restriction as the curr ent dominant enterprise and adversarial deployment mode is cloud-hosted, agentic malware such as Ransomw are 3.0 delib erately targets external APIs to avoid staging large model weights on victim infrastructure, and lo cal-LLM exltration/execution is more naturally addressed by on-host monitors and defenses. The framework remains composable with such controls in a zero-trust, defense-in-depth deployment and we revisit this paradigm in Section 7.4.1 . Out of scop e: W e explicitly exclude: (i) binar y and multimedia steganography; (ii) le-format watermarks (PDF metadata, OOXML hidden elds) as a primary detection signal; (iii) network-level exltration detection; (iv) automate d generation of realistic canary content at scale; and (v) the privacy and legal framework for v endor cooperation. Furthermore, we treat Tier 4 transforms as an upper-bound adversarial capability evaluated for completeness rather than robustness. 4 Framework Design & Implementation This section presents the steganographic canar y framework end to end. W e organize the presenta- tion by following the data path: secret creation (Section 4.2 ), emb edding (Section 4.3 ), layering and orchestration (Section 4.4 ), and intended vendor-side detection (Section 4.5 ). 4.1 Pipeline Overview Our framework targets the gap identie d in our threat model where AI-powered malware and insider users submit sensitive plaintext to cloud-hosted LLMs through workows that bypass tradi- tional perimeter controls. Rather than attempting to prevent exltration at the netw ork boundar y , our architecture places detection at the AI service’s processing boundary by embe dding crypto- graphically veriable identiers into canary do cuments that survive common text transformations. Figure 3 summarizes this pipeline. The system generates a per-le identier and emb eds it into plaintext canaries, enabling a coop erating AI service to extract and verify the identier before LLM Safeguarding LLMs Against Misuse and AI-Driven Malwar e Using Steganographic Canaries 11 processing. The identier is embe dded across complementary in-text channels, allowing detection if any layer survives transport. W e construct and empirically verify tw o main mo des of deplo yment: Mode A Encode (Symbolic Stack) cover WS . enc − − − − − − → ZW . enc − − − − − − → HG . enc − − − − − → canary Mode B Encode (Hybrid Stack) payload LM . enc − − − − − → cover ZW . enc − − − − − − → HG . enc − − − − − → canary • Mode A – Mark existing do cuments (symbolic stack): Given an existing plainte xt document, the framework applies a sequence of symbolic encoders that each emb ed the full secret indepen- dently on a disjoint character surface, enabling low-friction retrotting of existing sensitive les without altering visible content. • Mode B – Generate canar y documents ( hybrid stack): The linguistic encoder generates synthetic text whose token choices encode the se cret, on top of which compatible symbolic layers are then added as independent detection channels. WS artifacts can b e deleted (rather than normalized) by common sanitization, thereby irre versibly corrupting the byte stream required for LM, and so we omit WS in this mode. The framework is designed such that any stego-technique that conforms to the module interface dened in Section 4.4.1 can b e substituted for , or adde d alongside, the methods evaluated here. The methods, WS, ZW , HG, and LM, were selecte d to span the symbolic and linguistic metho d classes and to demonstrate the composition principles, however they are not the only viable implementations. 4.2 Secret T oken Generation & Framing Each canary embeds a xed-size, per-le identier derived from organization-held ke y material. W e validate the framework via two verication schemes that dier in key management but share the same framing and embedding pipeline, although other schemes may be easily implemente d. 4.2.1 Shared-K ey V erification (HMA C-SHA256): Given a unique le identier le _ id (path, hash, or UUID) and an organization key 𝑘 org , we compute an HMA C-SHA256 tag and truncate it to the rst 16 bytes, yielding a 128-bit token: T oken Construction token = HMAC-SHA256 ( 𝑘 org , le _ id ) [ :16 ] Framed payload (18 bytes) payload = len ( 𝑡 𝑜 𝑘 𝑒 𝑛 ) BE16 | {z } 2 bytes ∥ token | {z } 16 bytes The vendor veries r ecovered payloads against a pre-loaded registry of valid tokens ( 10 3 organi- zations × 10 4 le IDs = 10 7 entries in our evaluation). A random 128-bit candidate matches any registry entry with probability 𝑃 fp ≤ 10 7 × 2 − 128 ≈ 2 . 9 × 10 − 32 . 4.2.2 Public-Key V erification (Ed25519 via EdDSA):. The organization derives an Ed25519 key pair ( sk , pk ) deterministically from 𝑘 org using the EdDSA (Edwards-curve Digital Signature Algorithm). For each le, a 4-byte identier le _ uuid = SHA-256 ( le _ id ) [ :4 ] is signe d: T oken Construction sig = Ed25519_Sign ( sk , le _ uuid ) token = [ le _ uuid ∥ sig ] Framed payload (70 bytes) payload = [ len ( 𝑡 𝑜 𝑘 𝑒 𝑛 ) BE16 | {z } 2 bytes ∥ le _ uuid | {z } 4 bytes ∥ sig | {z } 64 bytes ] The vendor stores only the organization’s 32-byte public ke y pk and veries any recovered payload via Ed25519_Verify ( pk , le _ uuid , sig ) , providing ∼ 128-bit se curity without requiring a p er-le token registry or shared-secret distribution [ 4 ]. A forged signature veries with probability ≈ 2 − 128 per key , where with 10 3 registered organizations, 𝑃 fp ≤ 10 3 × 2 − 128 ≈ 2 . 9 × 10 − 36 . W e refer to this scheme as EdDSA in subsequent sections of the paper . 12 Raz et al. Encode ( text , payload , A , 𝑏 ) 1: 𝐷 ← T oDigits ( len ( payload ) BE16 ∥ payload , 𝑏 ) 2: 𝑃 ← FindEligible ( text , A ) 3: if | 𝑃 | < | 𝐷 | then return None 4: 𝑆 ← SelectPositions ( 𝑃 , | 𝐷 | ) 5: for 𝑖 ← 0 to | 𝐷 | − 1 do text [ 𝑆 [ 𝑖 ] ] ← A [ 𝐷 [ 𝑖 ] ] 6: return text Decode ( text , A , 𝑏 ) 1: 𝐷 ← [ ] 2: for 𝑐 ∈ text do if 𝑐 ∈ A : 𝐷 . append ( A − 1 [ 𝑐 ] ) 3: raw ← FromDigits ( 𝐷 , 𝑏 ) 4: 𝑛 ← int ( raw [ :2 ] ) 5: return raw [ 2:2 + 𝑛 ] (a) Generic symb olic encoding and de coding. WS and ZW instantiate with 𝑏 = 4 ; HG with 𝑏 = 2 ( bit-lev el). Se- lectPositions distributes stride-interleaved for ZW , head-first for WS/HG. Encode ( payload ) 1: prex ← len ( payload ) BE16 2: msg ← T oBits ( P ad ( prex ∥ payload ) ) 3: ctx ← Tokenize ( context _ str ) 4: tokens ← SAAC-Enc ( GPT -2 , msg , ctx ) 5: return Canonicalize ( Detokenize ( tokens ) ) Decode ( text ) 1: text ← Canonicalize ( text ) 2: ctx ← Tokenize ( context _ str ) 3: msg ← SAA C-Dec ( GPT -2 , text , ctx ) 4: raw ← FromBits ( msg ) 5: 𝑛 ← int ( raw [ :2 ] ) 6: return raw [ 2:2 + 𝑛 ] (b) SAAC linguistic encoding/ de coding over GPT -2. Pad extends payload per token to ensure cover-text length for downstream symbolic layers. Canonical- ize strips symbolic encoding before linguistic decode. Fig. 4. Pseudocode for symbolic ( le) and linguistic (right) encoding families. Both produce a self-delimiting framed payload recoverable without external metadata. Both schemes are deterministic and provide ∼ 128-bit security . HMA C produces an 18-byte framed payload and requires the v endor to maintain a shared key or token registry wher eas EdDSA produces a 70-byte framed payload but requires only a one-time public-key registration eliminating registry synchronization. The larger EdDSA payload increases symbolic capacity requirements but remains within the capacity of typical prose (Se ction 5 ). Before embedding, both schemes prepend a 2-byte big-endian length prex to create a self-delimiting framed payload. For Mode B, the linguistic encoder additionally pads the framed payload to ensure the generated cover text provides sucient capacity for subsequent symbolic layers. This padding budget is adjusted per scheme to accommodate the dierence in payload size for cascading embedding layers. 4.3 Embedding Methods W e employ four embedding methods (see T able 4 ) spanning two classes that include three symbolic methods that modify text via disjoint Unicode character surfaces, and one linguistic method that generates synthetic cover text encoding the secret in token-lev el statistical properties. T able 4. Comparison of embedding methods. WS, ZW , and HG ar e symbolic ( character-level); LM is linguistic (token-level). Disjoint encoding surfaces enable stacking. WS ZW HG LM Method class Symbolic Symbolic Symbolic Linguistic Encoding surface Space codepoints Inter-character gaps Confusable glyphs T oken sequence Encoding rule Base-4 substitution Base-4 insertion 1-bit substitution Arithmetic coding T ypical capacity ∼ 0.5 b/space ∼ 2 b/char ∼ 0.35 b/char ∼ 2.5–5 b/token Edits existing text? Y es Y es (additive) Y es No (generates) Length-preserving? Y es No ( +ZW chars) Y es N/A LM required? No No No Y es (GPT -2) Dominant failure mode Normalization / collapse Zero-width stripping Confusable norm. Semantic rewriting Primary vuln. tier Tier 2 Tier 3 Tier 3 Tier 4 Safeguarding LLMs Against Misuse and AI-Driven Malwar e Using Steganographic Canaries 13 4.3.1 Symbolic Methods. The three symbolic methods share a common structur e as they dene an alphabet of visually equivalent Unicode variants, convert the framed payload to a digit stream in the alphab et’s base, and then distribute symbols across the target character surface. T able 4 summarizes the key properties of each method; the paragraphs below focus on encoding mechanics and implementation choices. The algorithm for symbolic enco de and decode is given in Figure 4a ; the three methods instantiate it with the alphabets and capacity expressions derived below . Whitespace Substitution (WS) . WS replaces selecte d ASCII spaces ( U+0020 ) with one of four visually identical Unicode variants, implementing a base-4 alphab et. Each payload byte consumes four space positions (four base-4 digits, LSB-rst), and encoding proceeds left-to-right across the rst 4 ( | prex | + | payload | ) ASCII spaces. In typical English prose ( ∼ 100 spaces per 500 words), this yields ∼ 23 payload bytes. Decoding scans for characters in A ws , reconstructs the base-4 digit stream, and parses the length-prexed payload. WS is fragile to NFKC normalization and whitespace collapsing back to ASCII. W e adapt the implementation of this method from Innamark [ 22 ]. WS alphabet 𝑏 = 4 A ws = { U+2008 , U+2009 , U+202F , U+205F } WS capacity 𝐶 ws = 𝑁 spaces / 4 − 2 bytes Zero- Width Character Insertion (ZW) . This method embeds data in inter-character gaps by inserting invisible Unicode format characters between adjacent visible (non-newline) characters, using a four-symbol alphab et. W e distribute insertions (instead of clustering them) via stride-base d interleaving, where for 𝑛 insertions across 𝑚 candidate gaps, the 𝑖 -th symbol is placed at gap position ⌊ 𝑖 · 𝑚 / 𝑛 ⌋ . Decoding collects all A zw characters in document order and r econstructs the payload. ZW survives normalization that preser ves format characters but is destroyed by targeted zero-width stripping (Tier 3). Since ZW is purely additive, stripping ZW restores the exact original byte stream, satisfying invertibility for cross-class stacking (Section 4.4 ). W e implement this method through extension of zwsp-steg [ 16 ] and unicode_steganography.js [ 1 ]. ZW alphabet 𝑏 = 4 A zw = { U+200B , U+200C , U+200D , U+FEFF } ZW capacity 𝐶 zw = ⌊ ( 𝑁 visible − 1 ) / 4 ⌋ − 2 bytes Homoglyph Substitution (HG) . encodes a bitstream by replacing Latin characters with visually indistinguishable Cyrillic confusables from Unicode U TS #39 [ 14 ]. Each eligible position is a 1-bit channel, where the original Latin form denotes 0, and its Cyrillic counterpart denotes 1. In typical English prose, 35–40% of characters are eligible. W e restrict encoding to 18 high-condence Latin– Cyrillic pairs (T able 5 ) chosen for pixel-level similarity under common fonts. T o avoid ambiguity from pre-existing non-Latin characters, the encoder rst normalizes the cover by mapping any Cyrillic confusables back to their Latin equivalents, then applies substitutions left-to-right according to the payload bitstream. HG is robust to transforms that preserve co depoint identity but fails under confusable normalization or ASCII transliteration (Tier 3). HG stripping maps Cyrillic substitutions T able 5. Homoglyph confusable pairs used for HG enco ding. Latin characters (roman) and their Cyrillic confusables (italic) are visually pixel-identical in common system fonts; Unicode codepoints disambiguate. Lowercase (7 pairs) Latin a c e o p x y Cyrillic a c e o p x y Codepoint 0430 0441 0435 043E 0440 0445 0443 Uppercase (11 pairs) Latin A B C E H K M O P T X Cyrillic A B C E H K M O P T X Codepoint 0410 0412 0421 0415 041D 041A 041C 041E 0420 0422 0425 14 Raz et al. encode ( text, payload ) → text | None Embeds payload into text, or generates text carrying the payload (LM mode). Returns None if capacity is insucient. decode ( text ) → payload | None Scans for embedded symbols and reconstructs a candidate payload. Returns None if no valid payload is found. strip_encoding ( text ) → text Removes method’s artifacts and restores a byte-exact origi- nal, enabling downstream decoders in cross-class stacking. capacity ( text ) → int Returns the maximum number of payload bytes embe ddable in the given text under this method’s surface constraints. Fig. 5. Uniform function interface implemented by all embedding methods, characterized by function name, input arguments, and return objects. back to their Latin originals satisfying byte-exact invertibility for hybrid stacking. W e base the implementation on Rizzo et al. [ 33 ] with confusable pairs from U TS #39 [ 14 ]. 4.3.2 Linguistic Method (LM). This method encodes the secret in output token choices by gener- ating synthetic cov er text via Self- Adjusting Arithmetic Coding (SAA C) [ 34 ] over GPT -2 (124 M parameters) [ 31 ]; the algorithm is given in Figure 4b . The framed payload is interpreted as a fractional value in [ 0 , 1 ) , and at each generation step SAA C partitions the next-token probability distribution and selects the token whose inter val contains the current value, emb edding information while producing uent prose. SAA C dynamically adapts its truncation parameter 𝐾 to per-step entropy and we set the remaining hyperparameters, context strings, and see ds to xed values. Decoding replays the token se quence through the same mo del, reconstructs arithmetic-co ding intervals, and recovers the embedded bitstream. Correctness r equires bit-exact agreement on model weights, tokenizer , context string, and all SAA C parameters. The ee ctive embedding rate is ∼ 2.5–5 bits per token ( ∼ 10 characters per payload byte). The SAAC token budget and minimum output length are adjusted per v erication scheme to accommodate the respective framed payload size (18 bytes for HMAC, 70 bytes for EdDSA), with additional padding to ensure downstr eam symbolic layers have sucient encoding surface. At model load time, the wrapper scans GPT -2’s full 50,257-token vocabulary and suppresses any token whose decoded form would pollute downstream symbolic encoding surfaces. Because LM’s signal resides in the token sequence, any byte-stream modication can cause decoding failure, and only symbolic layers whose stripping is byte-exact-invertible (ZW and HG) can be safely layered on top of the LM output. WS does not satisfy this requirement, as transport transforms can delete substituted Unicode spaces rather than normalizing them back to ASCII, irreversibly corrupting the byte stream. W e validate this interaction empirically in Se ction 6 . W e implement SAA C via StegaText [ 34 ], building on Ziegler et al. [ 44 ], with compatibility wrappers for newer transformers 4.x APIs. 4.4 Layering, Orchestration, and Transport Simulation W e compose the framework’s embe dding methods into congurations that provide layered (stacked) detection cov erage. This subsection denes the module interface , the seven (individual and stacked) congurations used throughout the evaluation, and the enco de/decode ordering that enables hybrid layering for implementation of the pipeline shown in Figure 3 . 4.4.1 Mo dule Interface. Each embe dding method conforms to the uniform interface shown in Figure 5 . Other symbolic methods targeting dierent surfaces (e .g., variation selectors, combining characters) or linguistic methods using dierent models or coding schemes can be integrated without changes to the orchestration, stacking, or detection logic, as long as byte-exact reversal is implemented via strip_encoding() . Safeguarding LLMs Against Misuse and AI-Driven Malwar e Using Steganographic Canaries 15 T able 6. Method configurations. M1–M4 are individual baselines; M5 is the symbolic-only stack (Mode A); M6 is the recommended hybrid stack (Mode B); M7 includes WS and demonstrates cross-layer interference. ID Methods Mode Purpose M1 WS only - Individual method baseline M2 ZW only - Individual method baseline M3 HG only - Individual method baseline M4 LM only - Individual method baseline M5 WS + ZW + HG A Symbolic defense-in-depth M6 ZW + HG + LM B Safe cross-class hybrid stack M7 WS + ZW + HG + LM - Hybrid stack with interference 4.4.2 Method Configurations and Stacking Semantics. W e dene seven embedding congurations (M1–M7 in T able 6 ) spanning single-metho d baselines, symbolic-only stacks, and hybrid layering. M5 stacks the three symb olic methods on disjoint surfaces, providing redundancy against Tier 1–2 normalization. M6 is the recommended cross-class conguration as it applies ZW and HG over linguistically generate d text, excluding WS because of the invertibility constraint discussed in Section 4.3.2 . M7 adds WS to the full stack to empirically expose this cross-layer interference . For Mo de A, the default order is WS → ZW → HG, and since the symb olic channels o ccupy disjoint surfaces, order does not aect correctness. For Mode B, the linguistic enco der runs rst to generate the cover text, after which compatible symbolic layers are applied. Deco ding proceeds in reverse order , with each deco der rst extracting a candidate payload and then calling strip_encoding to remove its artifacts before passing r estored text to the next stage: Mode A Decode (Symbolic Stack) canary HG . dec − − − − − → ZW . dec − − − − − − → WS . dec − − − − − → payload Mode B Decode (Hybrid Stack) canary HG . dec − − − − − → ZW . dec − − − − − − → cover LM . dec − − − − − → payload 4.4.3 Transport Simulation. T o evaluate robustness under realistic handling and adversarial saniti- zation, we implement a transport simulator as a librar y of deterministic text transforms organized into the four tiers of the transport-transform taxonomy dened in the threat model (Section 3.3 , T ables 2 – 3 ). Each transform is a pure function ( 𝑓 ( text ) → text ), and composite transport chains are specied and executed as pre-ordered lists. 4.5 V endor-Side Detection The detection component operates at the AI service’s ingestion boundary where a pre-ingestion lter intercepts inbound plaintext before it reaches the LLM, runs extraction across all congured decoders, and veries any candidate payloads. Under the HMAC scheme, verication is a hash-table lookup against a pre-loaded token registry . Under the EdDSA scheme, verication is a signature check against registered public keys. Detection is declared under the any-layer-recov ers policy and the lter can be deployed in two congurations as outlined in Figure 6 . • Reverse proxy interposed between the client and the LLM API endpoint, extracting plaintext from requests and decoding in realtime pre-LLM invocation. • V endor-native middleware integrated into the AI ser vice ’s request-processing pipeline, oper- ating on parsed input text alongside other input classiers pre-LLM invocation. For our experiments, we implement and validate the reverse-pro xy conguration (shown in Figure 9 ) as an asynchronous H T TP service that sits between an Op enAI-compatible client and a lo cally hosted LLM server ( Ollama ). On each inb ound chat-completion request, the proxy extracts message content and feeds it to a multi-layer scan engine that deploys in two phases: 16 Raz et al. Dec o di n g F r a m e work AI V endor Boundary Decode-Side Deployment Pre- V endorScanning Vendor-Nativ e Scanning Organizational Boundary Local or Third-Party Pro xy ? WS ZW HG M O D E A LLM LLM LLM Vendor 1 Vendor 2 Vendor N Sca n E n gi n e Ve r ifica t i on L o gic Sca n E n gi n e Ve r ifica t i on L o gic Single V endor Boundary L L M text text LM ZW HG M O D E B Chat Completion Chat Completion ① T ok e n S tr ea m A n a lys i s T oken ③ Fi lt e r L o gic ② Pa ylo ad Ve r ifica t i on B lo c k F l ag N ot if y 🚫 🚩 🔔 ✔ ⚠ ✔ ⚠ H M A C E d D S A Registry 7 0 B 1 8 B Fig. 6. Detection via (a) vendor-native middleware or (b) local/third-party reverse proxy . The proxy/middlewar e intercepts outbound LLM API requests and runs the decoding engine, verifying candidate payloads against the canary manifest/registry . A registry match triggers a configurable response logic b efore reaching the LLM. (1) Symbolic extraction. For each registered symbolic decoder (WS, ZW , HG), the engine attempts decode() ; if a payload is returned, it is che cked against the manifest of known hashes. Regardless of match, the engine can call strip_encoding() on the text and recurse to extract deeper layers, up to a congurable depth limit. (2) Sequential decoding. After symbolic extraction, the scan engine runs the linguistic decoder on the cleaned text. Because SAA C requires bit-exact token agreement, symbolic artifacts must rst be removed. In practice , however , full decoding is not always necessar y as the architecture declares detection as soon as the rst recovered payload is veried. Extracted payloads are veried according to the congured scheme. Under HMA C, the proxy checks against a pre-loaded manifest of known tokens keyed by hex digest, maintained as a local hash table for single-organization deployments or queried via a verication API for multi-tenant setups. Under EdDSA, the proxy veries the emb edded signature against the organization’s registered public key , eliminating per-le registry updates and shared-secret distribution. V eried matches trigger a congurable response, demonstrated by a lockdown state in our proxy implementation that rejects all subsequent LLM requests. The deco der requires no access to the organization’s les, no knowledge of which documents are canaries, and no semantic understanding of the content. The lter adds latency only to the extraction and verication steps ( quantied in Section 6 ). 5 Experimental Setup This section denes our evaluation methodology , including experimental structure, test corpus, environment, and evaluation metrics. T echnical details of the framework components, method congurations, and transport transforms are dened in Section 4 and Section 3 , respe ctively . 5.1 Overview W e structure the evaluation as ve controlled experiments and one case study , where T able 7 summarizes the dimensions of each and justication of each experiment follows. Embedding congurations are dened in T able 6 and transp ort transforms and composite chains in T ables 2 – 3 . ( § 6.1 ) Baseline Robustness lo calizes each failure surface across all individual transforms and 100 input les, where symbolic methods use corpus prose and LM uses generated cover texts. ( § 6.2.1 ) Stack Compatibility and Feasibility veries that all methods can coexist in a full stack at Tier-0, validating inverse-order decoding and byte-exact restoration before any transport. ( § 6.2.2 ) Layered Stacking Robustness evaluates the defense-in-depth paradigm, reporting both per-layer and ANY -layer recovery across six composite chains. Safeguarding LLMs Against Misuse and AI-Driven Malwar e Using Steganographic Canaries 17 ( § 6.3.1 ) False-Positive Rejection runs each deco der on 100 unmarked documents from the corpus (Section 5.2 ) and veries output under both verication schemes: HMA C against a 10 7 -token registry ( 10 3 organization keys × 10 4 le IDs), and EdDSA against 10 3 registered public keys. ( § 6.3.2 ) Overhead and Timing measures enco ding/decoding latency across 100 les per mode under both verication schemes. ( § 6.4 ) End-to-End Ransomware Case Study simulates the exltration scenario from the threat model, exercising the canary lifecycle from seeding to vendor-side detection. T able 7. Per-experiment grid dimensions. Section Experiment Methods Transports (§ 6.1 ) Baseline Robustness Per Method 4 (M1–M4) 13 transforms (Table 2 ) (§ 6.2.1 ) Stack Compatibility & Feasibility 1 (M7) Tier-0 (§ 6.2.2 ) Layered Stacking Robustness 7 (M1–M7) 6 chains (T able 3 ) (§ 6.3.1 ) False-Positive Rejection 4 decoders Tier-0 (§ 6.3.2 ) Overhead & Timing 7 (M1–M7) Tier-0 (§ 6.4 ) End-to-End Ransomwar e Case Study 2 (M5, M6) Tier-0 5.2 T est Corpus & T oken Scheme Assignment W e use a test corpus consisting of 100 English prose documents pulled from Wikip edia via the HuggingFace datasets library , ltered to a minimum of 3,000 characters and truncated to that target at word boundaries, yielding ∼ 3 KB documents [ 40 ]. Linguistically generated canaries range from ∼ 1.2 KB (HMAC scheme) to ∼ 2 KB (EdDSA) depending on payload size, while symbolic-only encodings preser ve the original document size. Each le is assigned identiers under both the HMA C and EdDSA schemes p er Se ction 4.2 using a xed evaluation key 𝑘 org . For experiments, symbolic congurations use le _ id = ‘dir_name/file_name’ and linguistic congurations use le _ id = ‘generated_id’ . For congurations including the linguistic encoder , SAAC generates its own cover text per Se ction 4.3.2 . Robustness experiments (Sections 6.1 – 6.2.2 ) are presented using the HMAC scheme since transport-transform recovery depends on encoding-surface survival, not payload size. Deployment e xperiments (Sections 6.3.1 – 6.3.2 ) are run under both schemes to characterize the verication and timing trade-os. 5.3 Environment and Setup All experiments were conducted on a workstation with an Intel Core i9-12900K CP U, 96 GB DDR5 RAM, and an NVIDIA RTX PRO 4000 GP U. All language models and latency measurements w ere executed locally on this hardware . The end-to-end ransomware case study uses an isolated virtual environment, with LLM-driven components ser ved on the local network via the reverse-pro xy described in Section 4.5 , interface d with Ollama . This conguration is depicted in Figure 6 in Section 6.3.2 . The framework is implemented in Python 3.11+ as a set of pluggable method modules conforming to the interface in Figure 5 . All symbolic methods and transport transforms r equire only the Python standard library ( re , unicodedata ); the linguistic metho d additionally requires Py T orch 2.x and HuggingFace transformers 4.x. Random seeds were xed for both Python random and torch.manual_seed() within the experimental runner . For timing measurements, we instrument encode and deco de stages using time.perf_counter() . W e conduct our end-to-end ransomware case study within the SaMOSA sandbox [ 39 ], which provides time-synchronized side-channel telemetry and FakeNet network emulation for safe Linux malware execution. 18 Raz et al. For experimental reproducibility , we x all random seeds, locally cache the GPT -2 Model and BPE tokenizer , and isolate dependency version drift for StegaText via compatibility wrappers introduced in Se ction 4.3.2 . A tokenizer shim is used here to expose the legacy .encoder / .decoder vo- cabulary dictionaries, from which a model wrapper then adjusts the return signature and suppresses tokens whose de coded form is not invariant under canonicalization, and a cache-management patch handles the DynamicCache object introduced in transformers 4.36. T ogether , these ensure that the same canary remains deco dable across toolchain updates. W e implement transform Tiers 1–3 using only standard Python library components ( unicodedata , re ). Tier 4 (LLM paraphrase) is imple- mented via a locally hosted LLM ( Ollama ) using the same model deployment as the end-to-end case study (Section 6.4 ), pro viding genuine semantic re writing via an open-weights LLM. W e execute all experiments via a single CLI entry point and serialize results to CSV . 5.4 Evaluation Metrics • Recovery Rate (RR): Dene d as the fraction of trials that recover the embedde d identier exactly . For stacked congurations (M5–M7), we evaluate detection success using RR per-layer , indicating whether each individual enco ding surface sur vived transport, and using an AN Y (union), where a trial succeeds if at least one layer recovers the corr ect token. • Encoding/Decoding Time ( 𝑇 enc , 𝑇 dec ): This is the wall-clock time for the full encode or decode stage (milliseconds for CP U and seconds for GP U), including all layers for stacked congurations. Experiments show that transport transforms either preserve the encoding surface entirely (RR = 100% ) or destroy it completely (RR = 0% ) for any given le, with no partial-corruption r egime. Thus contin- uous metrics such as bit err or rate (BER) and capacity utilization pro vide no additional information beyond RR and are omitted, along with error corr ection schemes. Population-level survival rates below 100% (e.g., 98% for LM under T10) reect the fraction of les whose encoding surface sur vived, not partial recov ery within any single le. The linguistic method exhibits a minor deviation fr om this per-le binar y pattern where GPT -2’s byte-level BPE vocabular y occasionally produces tokens containing non- ASCII Unicode characters that survive encoding but interfer e arithmetic-coding retokenization during decoding. W e analyze this artifact further in Se ction 7 . 6 Evaluation Results 6.1 Per-Method Robustness Baselines W e evaluate each individual method (M1–M4) under a Tier-0 baseline and all 12 individual trans- forms (T01– T12), across 100 les per method. T able 8 presents the per-transform ablation. Results show that all four methods achieve 100% recovery at Tier 0, conrming baseline feasibility for embedding and recovering a per-le cryptographic identier from realistic plaintext under ideal conditions. 1 They remain intact through Tier 1 (T01– T04), showing that copy-paste , line reow , smart-quote replacement, and trailing-whitespace stripping does not threaten recovery . W e obser ve div ergence at Tier 2, exposing largely orthogonal failure surfaces. WS fails under NFKC normalization (T05) and whitespace collapsing (T06) as expe cted, while ZW fails under format-character stripping (T07) b ecause its alphabet lies in Unico de category Cf, unlike WS characters in category Zs. HG and LM sur vive all Tier 2 transforms. At Tier 3, each targeted transform destroys its intended symb olic method, as T08 breaks ZW , T09 breaks HG, and T10 removes all symbolic channels. LM remains through T10 with 98% recovery , consistent with the GPT -2 vocabulary artifact discussed in Section 5.4 . Tier 4 re veals an inv erse pattern across methods 1 Robustness results are sho wn for the HMAC scheme. EdDSA results were found to be experimentally equivalent as recovery depends on encoding-surface survival, not payload size, providing no new information beyond the RR presented here. Safeguarding LLMs Against Misuse and AI-Driven Malwar e Using Steganographic Canaries 19 T able 8. Per-transform ablation for baseline robustness. Recovery rate (RR) for each individual method under Tier-0 and T01– T12. Each cell aggregates 100 files. Color indicates recov er y rate: 100% , 98% , 8% , 0% . Transform M1 (WS) M2 (ZW) M3 (HG) M4 (LM) T .0 Tier-0 (none) 100% 100% 100% 100% Tier 1 T01 – copy/paste 100% 100% 100% 100% T02 – line reow 100% 100% 100% 100% T03 – smart quotes 100% 100% 100% 100% T04 – trailing WS strip 100% 100% 100% 100% Tier 2 T05 – NFKC normalize 0% 100% 100% 100% T06 – collapse WS 0% 100% 100% 100% T07 – strip format chars 100% 0% 100% 100% Tier 3 T08 – strip ZW 100% 0% 100% 100% T09 – homoglyph norm. 100% 100% 0% 100% T10 – full ASCII strip 0% 0% 0% 98% Tier 4 T11 – punct./case strip 100% 100% 8% 0% T12 – LLM paraphrase 0% 0% 0% 0% as T11 preserves WS and ZW but destroys LM and nearly destroys HG (8%, due to cover text containing no capital letters), while T12 destroys all methods. 6.2 Defense-in-Depth via Layered Comp osition 6.2.1 Stacking Feasibility and Compatibility . W e establish Tier-0 compatibility using 100 generated texts for the full stack (M7: WS+ZW +HG+LM) in Figure 7 , showing all four layers coexist, and inverse-order decoding recovers the embedded payloads correctly . The control column shows that the linguistic encoder achieves 100% recovery before symbolic layering. After full-stack encoding, all four layers r ecover 98 of 100 tokens, and the Restored column shows that symbolic stripping reconstructs the original linguistic output byte-for-byte in those same 98 cases. The remaining 2% loss is due to the GPT -2 vocabulary artifact, where non-ASCII tokens in 2 of the 100 texts disrupt symbolic de coding. This validates M7, and therefore M6 (its subset), under ideal conditions, showing that remaining interference is transport-induced rather than introduced by stacking itself. Control Decode 100/100 Whitespace Subst. 98/100 Zero- Width Insert 98/100 Homoglyph Subst. 98/100 Linguistic Model 98/100 Byte-Exact Restored 98/100 Fig. 7. Stack compatibility (M7, Tier-0, 100 files). Control decode verifies linguistic encoding b efore symbolic layers are applied, and byte-exact Restored confirms byte-for-byte recov ery aer inverse-order extraction. 6.2.2 Layered Stacking Robustness. W e evaluate all seven congurations (M1–M7) under six com- posite transport chains, using 100 les p er conguration. T able 9 reports recovery rates. For multi-layer congurations (M5–M7), we show b oth p er-layer results and the union (any-layer) outcome. From the r esults, we draw the following observations. • Symbolic stacking (M5) adds redundancy without interference: M5 (WS+ZW +HG) achieves the same composite-chain coverage as its strongest component, HG. Detection remains 100% through Tier-2 and Tier-1+2, while WS and ZW are eliminated by those chains. Per-layer results match the standalone baselines M1–M3 exactly , conrming that stacking WS, ZW , and HG on disjoint surfaces does not alter individual metho d behavior . At Tier-3 and b eyond, all layers fail. 20 Raz et al. T able 9. Layered configuration comparison (7 configs × 6 composite chains × 100 files). RR = recovery rate. For M5–M7, ANY = union (at least one layer r ecovers); indented rows show per-layer survival. Conguration Tier-1 Tier-2 Tier-3 Tier-1+2 Tier-1+2+3 Tier-4 M1 (WS) 100% 0% 0% 0% 0% 0% M2 (ZW) 100% 0% 0% 0% 0% 0% M3 (HG) 100% 100% 0% 100% 0% 0% M4 (LM) 100% 100% 98% 100% 98% 0% M5 (WS+ZW+HG) (ANY) 100% 100% 0% 100% 0% 0% WS layer 100% 0% 0% 0% 0% 0% ZW layer 100% 0% 0% 0% 0% 0% HG layer 100% 100% 0% 100% 0% 0% M6 (ZW+HG+LM) (ANY) 99% 99% 97% 99% 97% 0% LM layer 99% 99% 97% 99% 97% 0% ZW layer 99% 0% 0% 0% 0% 0% HG layer 99% 99% 0% 99% 0% 0% M7 (WS+ZW+HG+LM) (ANY) 98% 98% 0% 98% 96% 0% LM layer 98% 98% 0% 98% 96% 0% WS layer 98% 0% 0% 0% 0% 0% ZW layer 98% 0% 0% 0% 0% 0% HG layer 98% 98% 0% 98% 0% 0% • Hybrid Stack (M6) extends coverage through Tier-3: M6 (ZW +HG+LM) is the only con- guration that preserves detection under adversarial non-semantic processing, achieving 97% recovery at Tier-3 and Tier-1+2+3 via the linguistic layer . At Tier-1, all three layers recover independently (99%); at Tier-2 and Tier-1+2, ZW fails but HG and LM r emain intact (99%). For every chain, M6- AN Y matches the LM per-layer result, showing that the any-layer-recovers policy does not change the nal detection outcome while still providing early-tier redundancy . • M7 exposes cross-layer interference: Adding WS to the hybrid stack (M7: WS+ZW +HG+LM) causes the LM layer to collapse to 0% at Tier-3, whereas M6 retains 97%. This is due to T10 since WS replaces existing ASCII spaces with Unicode space variants rather than inserting new characters, and stripping those variants remov es bytes that the linguistic decoder requires for token alignment. By excluding WS, M6 leaves only ZW insertions and HG substitutions above the linguistic text, and both are byte-exact-invertible after stripping (Section 4.4 ). This is a meaningful deviation from standalone behavior as M7’s Tier-3 LM failure reects true cross-layer interference rather than a general stacking artifact. • M7 exhibits fragile chained recovery: Although M7’s LM layer fails completely under isolated Tier-3, it recovers 96% under the cumulative Tier-1+2+3 chain. This occurs because T05 (NFKC normalization) in Tier-2 converts WS Unicode spaces back to ASCII before T10 executes, pre- venting the byte deletions that otherwise break LM de coding. This conrms the transform-order dependency predicted in Se ction 3.3 and shows that M7’s recovery depends on a favorable chain ordering an adversary could avoid. 6.3 Deployment Feasibility 6.3.1 False-Positive Rejection. W e run each of the four decoders on 100 unmarked prose documents under b oth verication schemes: HMA C against a 10 7 -token registry ( 10 3 organization keys × 10 4 le IDs), and EdDSA against 10 3 registered public keys. Figure 8 r eports the results. Zero veried matches were observed across all 800 trials. The linguistic decoder always produces output given Safeguarding LLMs Against Misuse and AI-Driven Malwar e Using Steganographic Canaries 21 HMA C 0 / 400 de co des 𝑃 fp ≤ 2 . 9 × 10 − 32 EdDSA 0 / 400 de co des 𝑃 fp ≤ 2 . 9 × 10 − 36 LM Candidates both schemes 200/200 non-None LM Rejection Rate post-verication 200/200 rejected Fig. 8. False-positive analysis (4 decoders M1–M4 × 100 unmarked texts from prose dataset, both schemes). HMA C tested against a 10 7 -token registry and EdDSA tested against 10 3 public keys yielding zero matches. T able 10. Encoding and de coding latency per verification scheme (100 files per configuration). Symb olic methods run on CP U in sub-millisecond time for both schemes; linguistic configurations are GP U-bound and scale with payload size. The HMA C scheme (18-byte framed payload) requires fewer SAA C tokens; the EdDSA scheme (70-byte payload) requires proportionally more . Conguration Enc. mean ± std Enc. max De c. mean ± std De c. max Enc. OK Dec. OK HMA C-SHA256 (18-byte framed payload) CPU (ms) M1 (WS) 0 . 149 ± 0 . 017 0.311 0 . 172 ± 0 . 020 0.366 100% 100% M2 (ZW) 0 . 298 ± 0 . 008 0.330 0 . 146 ± 0 . 005 0.170 100% 100% M3 (HG) 0 . 213 ± 0 . 009 0.258 0 . 188 ± 0 . 007 0.251 100% 100% M5 (WS+ZW +HG) 0 . 706 ± 0 . 009 0.747 0 . 536 ± 0 . 009 0.582 100% 100% GPU (ms) M4 (LM) 1 , 151 ± 780 5 , 160 172 ± 68 329 100% 99% M6 (ZW +HG+LM) 1 , 403 ± 1 , 321 8 , 860 194 ± 71 317 96% 96% M7 (WS+ZW +HG+LM) 1 , 418 ± 1 , 625 9 , 901 184 ± 70 374 97% 97% EdDSA / Ed25519 (70-byte framed payload) CPU (ms) M1 (WS) 0 . 170 ± 0 . 014 0.294 0 . 208 ± 0 . 005 0.223 100% 100% M2 (ZW) 0 . 350 ± 0 . 011 0.391 0 . 167 ± 0 . 005 0.179 100% 100% M3 (HG) 0 . 238 ± 0 . 011 0.277 0 . 207 ± 0 . 006 0.242 100% 100% M5 (WS+ZW +HG) 0 . 898 ± 0 . 016 0.954 0 . 693 ± 0 . 016 0.820 100% 100% GPU (ms) M4 (LM) 3 , 584 ± 821 7 , 490 512 ± 119 1 , 348 99% 82% M6 (ZW +HG+LM) 3 , 959 ± 1 , 191 9 , 703 508 ± 84 784 95% 95% M7 (WS+ZW +HG+LM) 3 , 783 ± 966 8 , 800 535 ± 121 1 , 353 99% 99% any token sequence, returning a non- None candidate on all 200 documents (100 per scheme), but the extracted bytes are eectively random and fail verication under both schemes. For HMA C, a random 128-bit candidate matches any entr y in a 10 7 -token registry with probability 𝑃 fp ≤ 10 7 × 2 − 128 ≈ 2 . 9 × 10 − 32 per trial. For EdDSA, a random 68-byte payload constitutes a valid signature with pr obability ≈ 2 − 128 per public key; across 10 3 registered keys, 𝑃 fp ≤ 10 3 × 2 − 128 ≈ 2 . 9 × 10 − 36 . The EdDSA bound is four orders of magnitude tighter since the number of registered public keys ( 10 3 ) is far smaller than the HMA C registry ( 10 7 ), and the verication is per-key . 6.3.2 Computational Overhead. W e measure encoding and deco ding wall-clock latency on the test hardware (Section 5.3 ) for all seven congurations across 100 les under b oth verication schemes. T able 10 reports aggregate statistics. Symbolic methods (M1–M3, M5) ar e sub-millisecond on CP U under both schemes, with EdDSA payloads adding 15–30% to encode/decode time (e.g., M5: 0.90 ms vs. 0.71 ms encoding), negligible in absolute terms. The linguistic method dominates timing and scales with payload size: under HMA C, M4 encodes in ∼ 1.2 s and decodes in ∼ 0.17 s; under EdDSA, encoding rises to ∼ 3.6 s and de coding to ∼ 0.51 s, reecting the ∼ 3 . 9 × larger framed payload requiring proportionally more SAA C tokens. The self-delimiting length prex enables the decoder to terminate once the emb edded identier is fully recovered, making decode substantially faster than encode for both schemes. Cross-class congurations (M6, M7) add negligible overhead beyond M4 standalone. EdDSA also exhibits lower success rates for the linguistic method, with M4 22 Raz et al. Runtime Sandbox 🔏 A I - O r c h e s t r a t e d R a n s o m w a r e A M5 B M6 📁 S i m u l a t e d F i l e S h a r e Desktop Documents Downloads Pictures 📝 T e l e m e t r y C a p t u r e H a r n e s s HPC s S ys ca lls Ne twork Di sk Canary Embedding HMAC / EdDSA * * Host Network Bridge Req. Intercept S c a n E n g i n e T oken V erification BLOCK P ASS ✔ ⚠ Filtering Logic A v a i l a b l e D e c o d e r s : M6: LM-ZW-HG M5: WS-ZW-HG Reverse Pro xy LLM Server Data Capture O l l a m a I n t e r f a c e Rec on Le v e r age La un ch N ot if y M o d e l 🔍 Fig. 9. End-to-end ransomware case study experimental infrastructure, where the sample is run within a sandbox collecting relevant telemetry , and the reverse proxy scans inputs before they ar e input to the LLM. decode success at 82% compared to 99% under HMAC. The ∼ 3 . 9 × larger EdDSA payload (70 vs. 18 bytes) requires proportionally more SAAC tokens and thus more GPT -2 generated text. This longer text increases the probability that GPT -2’s byte-level BPE vocabulary emits tokens containing non- ASCII Unicode characters (e .g., multi-byte se quences or rare glyphs); these tokens encode correctly during the SAA C for ward pass, but when downstr eam symb olic layers ar e subsequently stripped before decoding, the byte-stream modications cause the arithmetic-coding interval to desynchronize, producing a cascade failure. Because this is an artifact of GPT -2’s 50,257-token vocabulary rather than a fundamental limitation of arithmetic-coding steganography , a production deployment using a larger model with a cleaner vocabular y would substantially reduce these failures (Section 7 ). For stacke d congurations (M6, M7), encode failures (4–5% under HMAC, 1–5% under EdDSA) arise when the linguistically generated text is too short to provide sucient capacity for the symbolic layers above it. From a deployment perspective, canary se eding is a one-time organizational cost as Mo de A (M5) marks 500 les in under 0.5 s and Mode B (M6) requires approximately 12 minutes (HMA C) to 33 minutes (EdDSA) of GP U time for the same count, acceptable as a batch operation. V endor-side detection is the latency-sensitive path where symbolic-only decoding (M5) adds under 1 ms per inb ound request. Hybrid decoding (M6) adds ∼ 0.19 s (HMAC) to ∼ 0.51 s (EdDSA), dominated by the LM for ward pass. An early-termination policy that stops at the rst veried symbolic match reduces this to sub-millisecond latency when symbolic layers survive transport (Section 7 ). 6.4 End-to-End Detection in an AI-Ransomware Scenario W e validate the framework beyond the transport e xperiments by executing the AI-ransomware exltration scenario from Section 3 using a Ransomw are 3.0 -style attack pip eline in an instru- mented sandbox, with setup and ow of data given in Figure 9 . The experiment exercises the complete canary life cycle fr om simulated organizational se eding through adversarial le targeting and vendor-side dete ction using the reverse proxy deployment describe d in Section 4.5 , using the HMA C verication scheme. This validates end-to-end detection under Tier-0 transport con- ditions where the ransomwar e submits raw extracted text fr om les. The ablations presented in Sections 6.1 – 6.2.2 establish robustness bounds under higher-tier transport transformations. 6.4.1 Scenario and Instrumentation. W e construct a simulated le share containing 288 les within a QEMU/K VM virtual machine running Ubuntu 20.04 (8 GB RAM, 4 vCP Us). Among these, 10 pseudo-sensitive les are seeded, and 2 are selected as canar y candidates ( ∼ 0 . 7% density). Mode A Safeguarding LLMs Against Misuse and AI-Driven Malwar e Using Steganographic Canaries 23 0 10 20 30 Network (KB/s) M5 Defended lockdown M6 Defended lockdown Network Traffic Baseline Ransomware Tx Baseline Ransomware Rx M6 Defended Tx M6 Defended Rx M5 Defended Tx M5 Defended Rx 0 200 400 Disk I/O (ops/s) Disk Access Frequency Baseline Ransomware Read Baseline Ransomware Write M6 Defended Read M6 Defended Write M5 Defended Read M5 Defended Write 0 20 40 60 80 100 120 140 160 Time since execution start (s) 0 20K 40K 60K 80K Syscalls/s System Activity Baseline Ransomware Syscalls Baseline Ransomware HPC M6 Defended Syscalls M6 Defended HPC M5 Defended Syscalls M5 Defended HPC 0 500 1K HPC events/s (millions) Fig. 10. Multi-channel telemetry overlay for the three experiment runs. Network traic (top), disk I/O read/write frequency (middle), and system activity including syscall rate and hardware performance counters (boom) are shown with a shared time axis. Red dashed vertical lines mark the pr oxy lockdown events for the M5- and M6-defended runs. The undefended ransomware trace extends across the full execution window , while the defended traces terminate shortly aer detection. canaries (M5: WS+ZW +HG) are emb edded into existing sensitive-looking documents and Mode B canaries (M6: ZW +HG+LM) are generated as standalone les with lenames designe d to attract ad- versarial interest ( e.g., Crypto_Wallet_Seed_Phrase.txt , Dropbox_API_Token.txt ). The attack agent is a Ransomw are 3.0 -style Go binar y [ 32 ] that queries a locally hoste d LLM (GPT -OSS 20B via Ollama ) to generate Lua scripts for each lifecycle phase. All LLM API trac passes through the reverse proxy (Section 4.5 ), which runs the deco der suite against the canar y registry before forwarding requests to the model. Four telemetr y channels are simultaneously captured includ- ing network trac, disk I/O , syscall activity , and hardwar e performance counters at sub-second temporal resolution. W e execute three run congurations: an undefended baseline ransomware run executes with the proxy in passthr ough mode (no canar y manifest, no scanning) and aims to establish the full attack lifecycle; an M5 defende d run executes the ransomware with the proxy congured for Mo de A detection; and an M6 defended run e xecutes the ransomwar e with the pr oxy congured for Mode B detection. 6.4.2 Aack Life cycle Characterization. The undefended run provides the b ehavioral ground truth for the Ransomw are 3.0 attack lifecycle, which proceeds through seven distinct phases identiable in the program log and corroborated by the telemetry channels (Figure 10 ): (1) Probe: performs recon via Lua script to identify OS, username, hostname, and working director y . (2) Scan: writes co de to enumerate the entirety of the le share , discovering all 288 les. (3) T arget: selects 10 high-value les from the le share based on lename heuristics. (4) Extract: reads target le contents and submits them to the LLM for leverage assessment. 24 Raz et al. T able 11. Per-phase iteration counts and elapsed time for the three ransomware runs. Each iteration involves one or more LLM calls to generate and/or validate a Lua script; elapse d times denote wall-clock duration per phase. ∗ Additional iterations due to non-deterministic LLM code-generation or validation failures. blocked = proxy lockdown pre vented phase execution; blocked = phase partially executed (request sent) but halted. Probe Scan T arget Extract Decide Encrypt Note T otal Iterations Baseline 1 1 1 2 ∗ 1 3 ∗ 1 17 calls / 7 scripts Ransomware + M5 1 1 1 1 − blocked blocked — blocked 6 calls / 3 scripts Ransomware + M6 5 ∗ 2 ∗ 1 1 − blocked blocked — blocked 16 calls / 8 scripts Time (s) Baseline 23 8 10 39 2 78 15 ∼ 177 Ransomware + M5 15 8 32 9 blocked — blocked ∼ 64 Ransomware + M6 60 20 12 21 blocked — blocked ∼ 113 (5) Decide: decides that the les have leverage value and selects encryption as the payload. (6) Encrypt: generates and executes the encryption payload on targeted les. (7) Note: generates the ransom note, completing the full attack lifecycle. The agent employs a phase retry loop (up to 10 iterations) in which the LLM generates a Lua script, executes it, then validates the output, retrying with corrective feedback on failure. Because LLM code generation is non-deterministic, some phases require multiple iterations. Per-phase iteration counts, elapsed times, and total LLM calls for all three runs are compared in T able 11 . T able 12. End-to-end ransomware case study: summary of experiment outcomes. † Proxy entered lockdown aer detection; all subsequent LLM calls and aack phases were rejected. Run Dur . (s) LLM Scripts Trac Lockdown Method Scan Calls Gen. (KB) Time (s) Chain Time Ransomware Baseline 177 17 7 269.0 — — — Ransomware + M5 † 66 6 3 124.7 63.3 WS → ZW → HG 0.2 ms → 0.4 ms → 0.7 ms Ransomware + M6 † 116 16 8 237.0 112.8 ZW → HG → LM 0.2 ms → 0.4 ms → 168.3 ms Δ M5 vs. baseline: − 111 s ( − 63% ), − 11 LLM calls, − 144.3 KB trac Δ M6 vs. baseline: − 61 s ( − 34% ), − 1 LLM call, − 32.0 KB trac 6.4.3 Defense Intervention. In b oth defended runs, the defense is invisible until the Extract phase submits canary-b earing content to the LLM. The variation in pre-detection LLM calls between M5 (6 calls) and M6 (16 calls) is attributed to non-deterministic co de-generation retries in the early phases, and we do not optimize the ransomware to execute in the least tries. In both defended runs, the defense intervened at the rst Extract request that included canar y-bearing content. T ables 11 and 12 summarize the phase-level and quantitative outcomes acr oss all three runs. • Mode A (M5: WS+ZW +HG): The proxy detected the M5 canary at 𝑡 = 63 . 3 s on the rst extraction request containing encoded plaintext in the chat request. The proxy deco ded the full symbolic chain to verify all thr ee layers, where WS recov ered the HMA C token in 0.2 ms, ZW veried in 0.4 ms, and HG veried in 0.7 ms. In a production deployment, early-termination policy would stop at the WS match, but running the full chain here conrms that all three encoding surfaces survived the ransomware’s pr ompt wrapping intact. Once in lockdown, the proxy rejected all subsequent requests (2 blo cked), where the Decide and Note phases each received empty LLM responses and failed, prev enting any encryption or ransom-note generation and ultimately ending the ransomware process. • Mode B (M6: ZW +HG+LM): The proxy dete cted the M6 canary at 𝑡 = 112 . 8 s via the full decoder chain (ZW → HG → LM) operating on the LLM request payload. The Ransomw are 3.0 Safeguarding LLMs Against Misuse and AI-Driven Malwar e Using Steganographic Canaries 25 agent wraps extracted le content in instructional prompts ( e.g., “ A nalyze the following content for potential leverage. . . ”), and the pro xy’s region-aware extraction isolated the document te xt within known delimiters before running the decoder chain. The symbolic de coders resolved quickly (ZW in 0.2 ms, HG in 0.4 ms) and the linguistic decoder conrmed the canary in 168.3 ms via the SAA C decoding pass. This is consistent with the HMA C decode latencies measured in Section 6.3.2 . As with M5, all three encoding layers independently conrm the emb edded token, and lockdown cascade prevented the attack from pr ogressing to encryption. 6.4.4 Case Study Observations. (1) Early ransomware detection: Both Mode A and B were dete cted during the le-analysis stage of the Ransomw are 3.0 lifecycle before progression to encryption or extortion. In the threat model of Section 3 , this corresponds to detection at the LLM ingestion boundary , validating the claim that AI-assisted adversaries create a viable detection interception point by their dependence on external model access. The pro xy lockdown terminated the attack at the earliest possible point in the attack chain, with no les encr ypted in either defended run. (2) Sub-millisecond lockdown via early termination: W e congured the proxy to execute the complete decoder chain in b oth runs rather than stopping at the rst positive match, in order to verify that all encoding layers survived the adversarial pipeline. For M5, all three symbolic decoders conrmed the canar y in under 1 ms total (WS 0.2 ms, ZW 0.4 ms, HG 0.7 ms). For M6, the two symbolic decoders resolved in under 1 ms b efore the linguistic decoder conrmed the payload in 168.3 ms. Since a single symbolic match already provides negligible false-positive risk (Section 6.3.1 ), a production deployment can safely stop at the rst conrmed extraction. This early-termination p olicy would reduce both M5 and M6 dete ction to sub-millisecond latency , conrming the practical optimization noted in Se ction 6.3.2 . (3) Prompt wrapping preserves symbolic encodings: The ransomware agent wraps extracted le content in instructional prompts before submission, which is standard practice often employed to prev ent prompt injection. This wrapping prepends and appends tokens but do es not modify the do cument body , leaving all symbolic encoding surfaces intact. For M6 canaries, the proxy’s region-awar e extraction further isolates the document content from surrounding prompt text via delimiter scanning, ensuring the ZW and HG decoders operate d on clean input. 7 Discussion 7.1 Summary of Findings 7.1.1 Feasibility and Binar y Re covery . All four embedding metho ds achieve 100% recovery at Tier-0 across all tested do cuments, conrming that a per-le cryptographic identier can be reliably embedded and recover ed from realistic plaintext ( RQ1 ). A structural property which emerges from the ablation is that canary token recovery is strictly binary across all methods and transforms. That is, a transform either preserves the encoding surface entirely or destroys it completely , with no correctable partial corruption surface per le. This follows fr om the global natur e of the transforms (operating uniformly on character classes) and the cascading structure of arithmetic coding errors in the linguistic method. Error-correction co ding therefore provides no b enet, as there are no near-miss cases for redundancy to bridge . A naiv e approach of repeating the token within the same encoding surface may aid in increasing chances of recovery in chunked copy-pastes, but does not help with survival as all copies are lost simultaneously per enco ding surface. Due to this, method diversity (i.e., hybrid stacking) rather than r edundancy increases robustness ( RQ2 ). 7.1.2 Orthogonal Failure Surfaces. The per-transform ablation (Se ction 6.1 ) reveals orthogonal failure surfaces since WS fails at Tier 2 (whitespace normalization), ZW at Tier 2–3 (format-character 26 Raz et al. stripping), HG at Tier 3 (confusable normalization), and LM only at Tier 4 (semantic rewriting). Within the symbolic class, T11 (punctuation/case stripping) exposes a ner distinction where WS and ZW survive because their decoders search for specic co depoints regardless of surrounding content and HG fails because case-folding removes uppercase-only confusable pairs from the eligible set. A consequential structural nding is the inverse coverage prole b etween T10 and T11. T10 destroys all symbolic metho ds but LM survives at 98%, while T11 destroys LM and nearly destroys HG (8%) but WS and ZW survive at 100%. This bidirectional complementarity between method classes is the empirical foundation of defense-in-depth through stacking ( RQ2 ). 7.1.3 Principled Composition for Defense-in-Depth. The stacking experiments (Section 6.2.2 ) con- rm that metho d diversity provides broader coverage , but only under principle d composition ( RQ3 ). M5 (WS+ZW +HG) provides triple redundancy at Tier 1 and extends coverage through Tier 2 at 100% via HG. M6 (ZW +HG+LM) further extends detection through Tier 3 at 97% via the linguistic layer , which is the only conguration maintaining detection under adversarial non-semantic pro- cessing. The M7 versus M6 comparison shows that including WS in a cross-class stack reduces Tier 3 coverage fr om 97% to 0% due to T10 deleting WS r eplacement artifacts and corrupting the linguistic decoder’s byte stream. This produces a design principle where insertion-based (ZW) or bijective-substitution (HG) symbolic methods should b e layered on linguistic cov er text. The two deployment modes are complementary since Mode A (M5) covers T11 via WS and ZW and Mode B (M6) covers Tier 3 via the linguistic layer . Only Tier 4 defeats both mo des simultaneously ( RQ3 ). 7.1.4 End-to-End Ransomwar e Detection. This case study (Section 6.4 ) validates the canary lifecycle under a realistic AI-assisted attack workow ( RQ5 ). Both deployment modes were detected during the Extract phase of the Ransomw are 3.0 lifecycle and the proxy lockdown prevented le encr yption. With the self-delimiting payload framing, the linguistic de coder completes in 168.3 ms for the HMA C scheme by terminating once the identier is fully recover ed. Early termination at the rst symbolic match would reduce dete ction to sub-millise cond latency in b oth cases ( RQ4 ). The controlled stacking experiments (Section 6.2.2 ) establish that these capabilities extend to higher adv ersarial tiers since M5 provides cov erage through Tier-2 and M6 through Tier-3. 7.2 Security Implications • Detection at the processing boundar y: AI-powered malware including agentic ransomware , espionage agents, credential harvesters, and social-engineering tools cannot execute intelli- gent attacks without rst submitting stolen les to an external LLM for analysis. Our results demonstrate that this shared dependency creates a viable detection opportunity at the processing boundary where the vendor-side lter identies canar y documents before model processing, with zero false positives under both shared-key verication and public-key verication. From the vendor vie wpoint, the canary identier reveals nothing about le content and thus pr eser ves privacy . The end-to-end case study further validates detection against LLM-orchestrated ran- somware, the mechanism op erates at the interception point common to all four AI-malware categories, as the detection is content-based rather than attack-specic. In the case of agentic ransomware, detection occurs during the reconnaissance phase (before encryption, exltration, or ransom-note generation) and provides early opportunities for mitigation. • Adversarial cost asymmetry: An attacker suspecting canaries must apply aggressive nor- malization to all exltrated les since canaries are visually indistinguishable from legitimate documents. Each sanitization step degrades utility: NFK C normalization alters code semantics, full ASCII stripping destroys non-English te xt and formatting, and LLM paraphrasing changes wording and introduces stylistic artifacts ( see Section 7.4.1 ). The defender forces a choice b etween accepting detection risk and degrading the stolen data. Safeguarding LLMs Against Misuse and AI-Driven Malwar e Using Steganographic Canaries 27 • Insider threat deterrence: For the secondary insider-upload scenario, the canaries change the risk calculus for authorized users, creating a deterrence eect analogous to traditional honeyto- kens but with detection at the AI service b oundary rather than through callback infrastructure. 7.3 Practical Considerations 7.3.1 Encode & Deco de Overhead. Symbolic see ding (Mode A) is eectively free at organizational scale as M5 encodes at under 1 ms per le, completing 10,000 les in under 10 seconds on a consumer- grade CP U. Linguistic generation (Mode B) requires approximately 1.4 s (HMA C) to 4.0 s (EdDSA) per le on GP U, or roughly a one-time batch cost of 4–11 hours for 10,000 generated canaries. At a practical seeding density of 1–5%, an organization with 100,000 les generates 1,000–5,000 canaries, well within these budgets. In terms of decoding, Symb olic-only adds under 1 ms per request while hybrid decoding (M6) adds ∼ 0.19 s (HMA C) to ∼ 0.51 s (EdDSA). Because symbolic layers decode rst and the any-layer-r ecovers policy triggers on the rst veried extraction, an early-termination policy can skip the linguistic deco der when symbolic extraction already yields a conrmed match, reducing average per-request latency to sub-millisecond lev els while pr eserving full-stack cov erage for Mode B canaries under higher-tier transport. 7.3.2 Key Maintenance & V erification Schemes. For HMA C, the vendor maintains a pre-loaded token registry which is updated (via secure transmission, API, or desktop application) as canaries are added or rotated (e.g. e very two weeks). For EdDSA, the vendor stores only the organization’s 32-byte public key with no shared secrets and no p er-le registry updates, allowing any canar y to be veriable on-the-y . This eliminates the key-management and registry-synchronization burden at the cost of a larger emb edded payload (70 vs. 18 bytes frame d), increasing symbolic capacity requirements and linguistic encoding time. 7.4 Limitations 7.4.1 Semantic Rewriting and Lo cal Adversarial LLMs. Tier 4 semantic rewriting defeats all em- bedding methods simultaneously and is identied as the hard limit of the current framework. Robustness against paraphrasing is not achievable with existing steganographic techniques, since rewriting intentionally destroys both character-level and token-level signals. W e argue this is operationally costly for adversaries, but do not claim resilience against it. The T11 vulnerability is related but distinct since punctuation/case stripping defeats LM due to BPE tokenization and HG due to uppercase-only pair r emoval, while WS and ZW survive. A case-invariant linguistic encoder or reduced HG mapping restricted to case-stable pairs could potentially close this gap. An adversary re writing ev ery exltrated le via a local LLM before cloud upload pays three costs: (i) per-le inference latency during time-sensitive operations (ev en a small model at 100ms/le across thousands of les adds meaningful delay to ransomware ’s le-triage phase), (ii) content degradation (small models produce lossy rewrites that can destr oy the exact information the adversary needs, such as credential strings, conguration values, code semantics), and (iii) expanded detection surface (model weights on disk, GP U utilization spikes, and suspicious process tr ees are exactly the behavioral signals endpoint tools are designed to catch). The defense thus for ces the adversary into a costlier , more detectable posture even when canary les are suspected. 7.4.2 Linguistic Method Constraints. SAA C is sequential and each token requires a full GPT -2 forward pass, and so the arithmetic coding interval at step 𝑡 depends on the token sele cted at step 𝑡 − 1 , causing encoding latency to scales with payload size. This latency is irreducible without mo del distillation or architectural changes. GPT -2’s byte-level BPE vocabulary occasionally produces tokens containing non- ASCII Unicode characters; these encode correctly during the SAA C for ward pass but can cause arithmetic-coding desynchr onization during decoding when the intervening 28 Raz et al. symbolic layers are stripped. Because the EdDSA payload requires ∼ 3 . 9 × more generated text than HMA C, the probability of encountering such a token rises, resulting in 82% deco de success for M4 under EdDSA vs. 99% under HMAC. This is a GPT -2 vocabular y artifact, not a fundamental limitation of the arithmetic-coding mechanism. The SAA C scheme is model-agnostic and the framework supports model substitution via its module interface (Section 4.4.1 ), and a pr oduction deployment using a larger model with a BPE vocabular y without multi-byte non- ASCII tokens) would substantially reduce these failures and also impro ve embedding rates. 7.4.3 Scope and Evaluation Boundaries. Sev eral boundaries constrain the generalizability of our results. Our (Tier 1–4) transforms are deterministic approximations and can var y in real-world transport and ingestion workows. The cross-class composition constraint (WS excluded from Mode B) reduces Mode B from four channels to three, though the practical impact is minimal since WS provides no coverage b eyond ZW , and the linguistic layer provides the Tier 3 coverage no symbolic method can. Finally , the framework requires a cooperating vendor or enterprise proxy and the framework pro vides no detection capability in its absence. 8 Conclusion The growing reliance of both enterprise users and adversaries on cloud-hosted LLMs for document analysis has created an exltration channel that traditional data-loss controls do not cover . W e presented a steganographic canar y framework that embeds cryptographically veriable identiers into plaintext documents, enabling detection at the AI service ingestion boundar y before model processing, under both shared-key and public-key (registry-less) verication. Mo de A of the framework marks existing documents with layered symbolic encodings and pro vides reliable detection through Tier 2 sanitization at sub-millisecond cost whereas Mode B adds a linguistic layer to extend robustness through Tier 3 with 97% recovery . Recovery is per-le binary , and so each transport transform either preser ves or destro ys an enco ding surface entirely . Our evaluation further shows that improper layer composition can eliminate robustness through cross-layer interference, motivating the invertibility requirement and safe-combination principles we establish. An end-to-end case study against a PromptLock -style ransomwar e pipeline conrms that both modes detect and blo ck canar y-bearing uploads during reconnaissance, b efore le encr yption occurs. Op en directions include extending the framework to multi-mo dal canaries for non-text documents, integration with enterprise AI governance workows, adversarial robustness analysis under active canary identication, and encoding schemes that intr oduce partial-corruption regimes where error correction coding be comes viable. T o our knowledge, this is the rst framework to systematically combine symbolic and linguistic text steganography into layered canary documents, establish method-agnostic composition principles, and evaluate them against a transport-threat taxonomy tailored to the LLM-upload threat model. References [1] 330k. 2015. Unicode Steganography with Zero- Width Characters. Online tool and JavaScript library . h t t p s : //330k.github.io/misc_tools/unicode_steganography .html [2] Sultan Alneyadi, Elankayer Sithirasenan, and V allipuram Muthukkumarasamy . 2016. A sur vey on data leakage prevention systems. J. Netw . Comput. A ppl. 62, C (Feb. 2016), 137–152. doi:10.1016/j.jnca.2016.01.008 [3] P Mohan Anand, P V Sai Charan, Hrushikesh Chunduri, and Sandeep Kumar Shukla. 2025. LARM: Linux Anti Ransomware Monitor . Computers & Security (2025), 104700. [4] D.J. Bernstein. 2006. Curve25519: new Die-Hellman speed records. In Public Ke y Cr yptography - PKC 2006 (9th International Conference on Practice and Theory in Public-Key Cryptography , New Y ork N Y , USA, April 24-26, 2006, Proceedings) (Le cture Notes in Computer Science) , M. Y ung, Y . Dodis, A. Kiayias, and T . Malkin (Eds.). Springer , Germany , 207–228. doi:10.1007/11745853_14 Safeguarding LLMs Against Misuse and AI-Driven Malwar e Using Steganographic Canaries 29 [5] Nicholas Boucher , Ilia Shumailov , Ross Anderson, and Nicolas Papernot. 2022. Bad Characters: Imperceptible NLP Attacks. In 2022 IEEE Symposium on Security and Privacy (SP) . 1987–2004. doi:10.1109/SP46214.2022.9833641 [6] Brian M. Bowen, Shlomo Hershkop, Angelos D. Keromytis, and Salvatore J. Stolfo. 2009. Baiting Inside Attackers Using Decoy Documents. In Security and Privacy in Communication Networks , Y an Chen, T assos D. Dimitriou, and Jianying Zhou (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 51–70. [7] Fran Casino, Thomas K. Dasaklis, Georgios P . Spathoulas, Marios Anagnostopoulos, Amrita Ghosal, István Bo ¨ ro ¨ cz, Agusti Solanas, Mauro Conti, and Constantinos Patsakis. 2022. Research Trends, Challenges, and Emerging T opics in Digital Forensics: A Review of Revie ws. IEEE Access 10 (2022), 25464–25493. doi:10.1109/ACCESS.2022.3154059 [8] Aniello Castiglione, Bonaventura D’ Alessio, Alfredo De Santis, and Francesco Palmieri. 2011. New Steganographic T e chniques for the OOXML File Format. In A vailability , Reliability and Security for Business, Enterprise and Health Information Systems , A. Min Tjoa, Gerald Quirchmayr , Ilsun Y ou, and Lida Xu (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 344–358. [9] Mingcan Cen, Frank Jiang, Xingsheng Qin, Qinghong Jiang, and Robin Doss. 2024. Ransomware early detection: A survey . Comput. Netw . 239, C (Feb. 2024), 20 pages. doi:10.1016/j.comnet.2023.110138 [10] Jyothishmathi CV , Kandavel A, and Mohanasundar M. 2020. StegCloak: Hide Secrets with Invisible Characters in Plain T ext Securely Using Passwords . https://github.com/KuroLabs/stegcloak [11] Cyberhaven Labs. 2025. 2025 AI Adoption and Risk Report. https://www .cyberhaven.com/resources/report/2025- ai- adoption- risk- report [12] Falcon Dai and Zheng Cai. 2019. T owards Near-imperceptible Steganographic T ext. In Proceedings of the 57th A nnual Meeting of the Association for Computational Linguistics , Anna K orhonen, David Traum, and Lluís Màrquez (Eds.). Association for Computational Linguistics, Florence, Italy , 4303–4308. doi:10.18653/v1/P19- 1422 [13] Sumanth Dathathri, Abigail See, Sumedh Ghaisas, Po-Sen Huang, Rob McAdam, Johannes W elbl, V andana Bachani, Alex K askasoli, Robert Stanforth, T atiana Matejo vicova, Jamie Hayes, Nidhi V yas, Majd Al Merey , Jonah Br own-Cohen, Rudy Bunel, Borja Balle, T aylan Cemgil, Zahra Ahmed, Kitty Stacpoole, Ilia Shumailov , Ciprian Baetu, Sven Gowal, Demis Hassabis, and Pushmeet Kohli. 2024. Scalable W atermarking for Identifying Large Language Model Outputs. Nature 634, 8035 (2024), 818–823. doi:10.1038/s41586- 024- 08025- 4 [14] Mark Davis and Michel Suignard. 2025. Unicode T echnical Standard #39: Unicode Security Mechanisms . Unicode T e chnical Standard 39. Unicode Consortium. https://unicode.org/reports/tr39/ [15] Jinyang Ding, Kejiang Chen, Y aofei W ang, Na Zhao, W eiming Zhang, and Nenghai Yu. 2023. Discop: Provably Secure Steganography in Practice Base d on "Distribution Copies". In 2023 IEEE Symposium on Security and Privacy (SP) . 2238–2255. doi:10.1109/SP46215.2023.10179287 [16] enodari. 2018. zwsp-steg-py: Zero- Width Space Steganography . GitHub repositor y . https://github.com/enodari/zwsp- steg- py [17] Google Threat Intelligence Group. 2025. Advances in Threat Actor Usage of AI T ools. Google Cloud Blog. h ttps: //cloud.google.com/blog/topics/threat- intelligence/threat- actor- usage- of - ai- tools [18] Kai Greshake , Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not What Y ou’ve Signed Up For: Compromising Real- W orld LLM-Integrated Applications with Indirect Prompt Injection. In Pr oc. of the 16th ACM W orkshop on A rticial Int. and Sec. (Copenhagen, Denmark) (AISec ’23) . Association for Computing Machinery , New Y ork, N Y , USA, 79–90. doi:10.1145/3605764.3623985 [19] Maanak Gupta, Charankumar Akiri, Kshitiz Ar yal, Eli Parker , and Lopamudra Praharaj. 2023. From ChatGPT to ThreatGPT: Impact of Generative AI in Cybersecurity and Privacy . IEEE Access 11 (2023), 80218–80245. doi:10.1109/ A CCESS.2023.3300381 [20] Mark Gurman. 2023. Samsung Bans Generative AI Use by Sta After ChatGPT Data Leak. Bloomberg. https://www . bloomberg.com/news/articles/2023- 05- 02/samsung- bans- chatgpt- and- other- generative- ai- use- by- staf f- af ter- leak [21] Xiao Han, Nizar Kheir, and Davide Balzarotti. 2018. Deception T echniques in Computer Security: A Research Perspective. Comput. Surveys 51, 4 (2018), 1–36. doi:10.1145/3214305 [22] Malte Hellmeier , Hendrik Norkowski, Ernst-Christoph Schrewe , Haydar Qarawlus, and Falk Howar . 2025. Innamark: A Whitespace Replacement Information-Hiding Method. IEEE Access 13 (2025), 123120–123135. doi:10.1109/A CCESS.2 025.3583591 [23] Ivan Homoliak, Flavio T oalini, Juan Guarnizo, Y uval Elovici, and Martín Ochoa. 2019. Insight Into Insiders and I T: A Survey of Insider Threat T axonomies, Analysis, Modeling, and Countermeasures. Comput. Sur veys 52, 2, Article 30 (2019), 40 pages. doi:10.1145/3303771 [24] Gabriel Kaptchuk, Tushar M. Jois, Matthew Green, and A viel D. Rubin. 2021. Meteor: Cr yptographically Se cure Steganography for Realistic Distributions. In Proceedings of the 2021 ACM SIGSA C Conference on Computer and Communications Security (Virtual Event, Republic of K orea) (CCS ’21) . Association for Computing Machinery , New Y ork, N Y , USA, 1529–1548. doi:10.1145/3460120.3484550 30 Raz et al. [25] John Kirchenbauer , Jonas Geiping, Yuxin W en, Jonathan Katz, Ian Miers, and T om Goldstein. 2023. A Watermark for Large Language Models. In Proceedings of the 40th International Conference on Machine Learning (Proceedings of Machine Learning Research, V ol. 202) , Andreas Krause, Emma Brunskill, K yunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett (Eds.). PMLR, 17061–17084. https://proce edings.mlr .press/v202/kirchenbauer23a.html [26] Microsoft Threat Intelligence and OpenAI. 2024. Staying Ahead of Threat Actors in the Age of AI. Microsoft Se curity Blog. https://www .microsof t.com/en- us/security/blog/2024/02/14/staying- ahead- of - threat- actors- in- the- age- of - ai/ [27] Kushagra Mishra, Harsh Pagar e, and Kanhaiya Sharma. 2025. A hybrid rule-based NLP and machine learning approach for PII detection and anonymization in nancial documents. Scientic Reports 15 (2025), 22729. doi:10.1038/s41598- 025- 04971- 9 [28] Lily Hay Newman and Matt Burgess. 2025. The Era of AI-Generated Ransomware Has Arrived. WIRED. htt ps: //www .wired.com/story/the- era- of - ai- generated- ransomware- has- arrived/ [29] O W ASP Foundation. 2025. O W ASP T op 10 for Large Language Model Applications 2025. https://genai.owasp.org/re source/owasp- top- 10- for- llm- applications- 2025/ [30] Mohan Anand Putrevu, Hrushikesh Chunduri, V enkata Sai Charan Putrevu, and Sandeep K Shukla. 2024. A compre- hensive analysis of machine learning based le trap selection methods to detect crypto ransomware. arXiv preprint arXiv:2409.11428 (2024). [31] Alec Radford, Jerey W u, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever . 2019. Language Mo dels are Unsupervised Multitask Learners . Te chnical Report. OpenAI. h t t p s : / / c d n . o p e n a i . c o m / b e t t e r - la n g u a ge - models/language_models_are_unsupervised_multitask_learners.pdf [32] Md Raz, Meet Udeshi, V enkata Sai Charan Putrevu, Prashanth Krishnamurthy , Farshad Khorrami, and Ramesh Karri. 2025. Ransomware 3.0: Self-Composing and LLM-Orchestrated. arXiv preprint. arXiv: 2508.20444 [cs.CR] doi:10.48550/arXiv.2508.20444 [33] Stefano Giovanni Rizzo, Flavio Bertini, and Danilo Montesi. 2016. Content-preserving T ext W atermarking through Unicode Homoglyph Substitution. In Proceedings of the 20th International Database Engineering & Applications Sym- posium (Montreal, QC, Canada) (IDEAS ’16) . Association for Computing Machiner y , New Y ork, N Y , USA, 97–104. doi:10.1145/2938503.2938510 [34] Jiaming Shen, Heng Ji, and Jiawei Han. 2020. Near-imperceptible Neural Linguistic Steganography via Self-Adjusting Arithmetic Coding. In Procee dings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , Bonnie W ebb er , Trev or Cohn, Y ulan He, and Y ang Liu (Eds.). Association for Computational Linguistics, Online, 303–313. doi:10.18653/v1/2020.emnlp- main.22 [35] Lance Spitzner . 2003. Honeypots: Tracking Hackers . Addison- W esley Professional. [36] Gyana Swain. 2026. CISA Chief Uploade d Sensitive Gov ernment Files to Public ChatGPT. https://www .csoonline.co m/article/4124320/cisa- chief- uploade d- sensitive- government- les- to- public- chatgpt.html [37] Milad T aleby Ahvanooey , Qianmu Li, Jun Hou, Hassan Dana Mazraeh, and Jing Zhang. 2018. AI TSteg: An Innovative T ext Steganography Technique for Hidden Transmission of T ext Message via Social Media. IEEE Access 6 (2018), 65981–65995. doi:10.1109/ACCESS.2018.2866063 [38] Thinkst Applied Research. 2015. Thinkst Canar y. https://canar y.tools/ [39] Meet Udeshi, V enkata Sai Charan Putrevu, Prashanth Krishnamurthy , Ramesh Karri, and Farshad Khorrami. 2025. SaMOSA: Sandbox for Malware Orchestration and Side-Channel Analysis. arXiv: 2508.14261 [cs.CR] doi:10.48550/arX iv.2508.14261 [40] Wikimedia Foundation. 2023. Wikipe dia Dataset. Hugging Face Datasets. https://huggingf ace.co/datasets/wikimedi a/wikipedia [41] J. Y uill, M. Zappe, D . Denning, and F. Feer . 2004. Honeyles: deceptive les for intrusion detection. In Proceedings from the Fifth A nnual IEEE SMC Information Assurance W orkshop, 2004. 116–122. doi:10.1109/IAW .2004.1437806 [42] Li Zhang and V rizlynn L. L. Thing. 2021. Three Decades of Deception T e chniques in Active Cyber Defense—Retrospect and Outlook. Computers & Security 106 (2021), 102288. doi:10.1016/j.cose.2021.102288 [43] Siyu Zhang, Zhongliang Y ang, Jinshuai Y ang, and Y ongfeng Huang. 2021. Provably Secure Generative Linguistic Steganography . In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , Chengqing Zong, Fei Xia, W enjie Li, and Roberto Navigli (Eds.). Association for Computational Linguistics, Online, 3046–3055. doi:10.18653 /v1/2021.f indings- acl.268 [44] Zachary Ziegler , Y untian Deng, and Alexander Rush. 2019. Neural Linguistic Steganography . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun W an (Eds.). Association for Computational Linguistics, Hong Kong, China, 1210–1215. doi:10.18653/v1/D19- 1115
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment