BACE: LLM-based Code Generation through Bayesian Anchored Co-Evolution of Code and Test Populations
Large Language Models (LLMs) have demonstrated impressive capabilities in code generation. While an interactive feedback loop can improve performance, writing effective tests is a non-trivial task. Early multi-agent frameworks, such as AgentCoder, au…
Authors: Kaushitha Silva, Srinath Perera
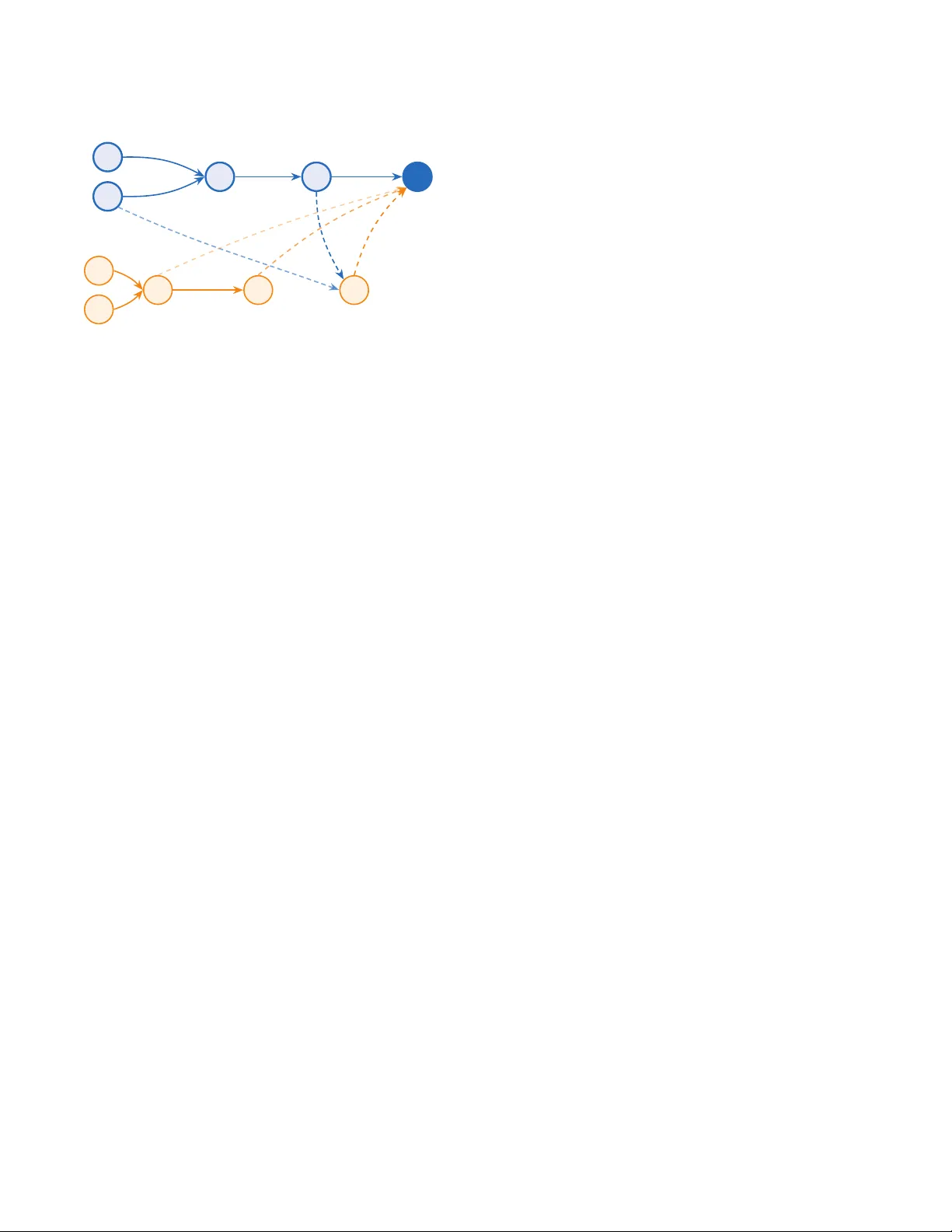
BA CE: LLM-based Code Generation through Bayesian Anchored Co-Evolution of Code and T est Populations Kaushitha Silva WSO2 Santa Clara, CA, USA kaushitha@wso2.com Srinath Perera WSO2 Santa Clara, CA, USA srinath@wso2.com Abstract Large Language Models (LLMs) have demonstrated impressive capa- bilities in code generation. While an interactive fee dback loop can improve performance , writing eective tests is a non-trivial task. Early multi-agent frameworks, such as AgentCoder , automated this process but relied on generated tests as absolute ground truth. This approach is fragile: incorrect code frequently passes faulty or trivial tests, while valid solutions are often degraded to satisfy in- correct assertions. Addressing this limitation, newer methods have largely abandoned test generation in favor of planning and reason- ing based on examples. W e argue, however , that generated tests remain a valuable signal if we model them as noisy sensors guided by bayesian updates. T o this end, we introduce BA CE (Bayesian Anchored Co-Evolution) , a framework that reformulates syn- thesis as a Bayesian co-e volutionary process where code and test populations are evolved, guide d by belief distributions that are reciprocally updated base d on noisy interaction evidence. By an- choring this search on minimal public examples, BACE prev ents the co-evolutionary drift typical of self-validating loops. Extensive eval- uations on LiveCodeBench v6 (post-March 2025) reveal that BA CE achieves superior performance across both proprietary models and open-weight small language models. CCS Concepts • Computing methodologies → Articial intelligence ; Dis- tributed articial intelligence ; Genetic algorithms ; • Software and its engineering → Software verication and validation ; Software development techniques . Ke ywords Large language models, Co-evolution, Software engineering, Soft- ware testing, Program synthesis, Bayesian infer ence A CM Reference Format: Kaushitha Silva and Srinath Per era. 2026. BA CE: LLM-based Code Gener- ation through Bayesian Anchored Co-Evolution of Code and T est Popu- lations. In Genetic and Evolutionar y Computation Conference (GECCO ’26), July 13–17, 2026, San Jose, Costa Rica. A CM, New Y ork, NY, USA, 10 pages. https://doi.org/10.1145/3795095.3805085 This work is licensed under a Cr eative Commons Attribution 4.0 International License . GECCO ’26, San Jose, Costa Rica © 2026 Copyright held by the owner/author(s). ACM ISBN 979-8-4007-2487-9/2026/07 https://doi.org/10.1145/3795095.3805085 Incorrect Code (Candidate 𝑐 𝑖 ) Faulty/Trivial T est (T est 𝑡 𝑗 ) Exec False Positive (A ccepted) (a) False Positive Acceptance V alid Logic (Candidate 𝑐 𝑖 ) Faulty T est (Hallucination) Exec False Negative (Triggers Repair ) W rong Logic Forced Edit (b) False Negative Rejection Figure 1: Systemic failure modes in deterministic test- generation architectures. ( a) False positives occur when in- correct code satises faulty tests. (b) False negatives cause valid logic to b e rejected and subsequently degrade d to sat- isfy incorrect assertions. 1 Introduction The automated synthesis of veried software from natural language is the central pursuit of modern software engineering. While Large Language Models (LLMs) have achieved unprecedented milestones in code generation, a critical bottleneck remains: LLMs frequently synthesize solutions containing subtle logical errors that bypass tra- ditional open-loop generation [ 24 ]. T o resolve this, state-of-the-art frameworks such as AgentCoder [ 11 ] have introduced closed-loop developer–tester paradigms. By iteratively repairing code based on test execution feedback, these systems have demonstrated sub- stantial performance gains over single-shot prompting, setting ne w benchmarks for automated synthesis. Howev er , the ecacy of this paradigm is fundamentally limited by the reliability of the test generation agent. As acknowledged by the authors [ 11 ], incorrect test cases produce problematic feedback, misleading the programmer agent. As illustrated in Figure 1, the reliance on generated tests creates a fragile loop where "false posi- tives" occur because incorrect code satises hallucinate d or trivial GECCO ’26, July 13–17, 2026, San Jose, Costa Rica Kaushitha Silva and Srinath Perera tests, and valid solutions are frequently degrade d by "false nega- tives" resulting from faulty assertions. As we will see in the experi- ment section, AgentCoder underperforme d even Direct prompting baseline in Medium problems with GPT -5-Mini. Due to this unreliability , the most recent state-of-the-art multi- agent frameworks, such as MapCoder [ 12 ] and CodeSIM [ 13 ] have abandoned test generation. These systems instead fo cus on pure reasoning (planning, simulating..etc), eectively conceding that generated tests are too unreliable to ser ve as good signal to improve code generation. W e argue that it is premature to abandon the test generation paradigm. The challenge is not that generate d tests are valueless, but rather that we lack a method to utilize them when they are not ground truth. The central research question eectively becomes: How can a synthesis system converge on a correct solution when the instrument of measurement—the test suite—is itself an unreliable source of truth? T o address this, we introduce BA CE (Bayesian Anchored Co- Evolution) . Our approach b egins by maintaining a population of code and tests rather than single instances. This population- based structure partially mitigates the risk of bad feedback: even if a valid solution is degraded by a faulty test in one instance, the broader population ensures that other valid genetic lineages survive, preventing the immediate loss of correct logic. Howev er , populations alone are insucient. If tness is calcu- lated under the assumption that generated tests are ground truth, the population will simply converge on the errors, leading to co- evolutionary drift. T o solve this, BACE abandons the deterministic view of testing. W e mo del tness as a belief in an individual’s correctness based on a Bayesian formulation. W e treat execution results as noisy signals rather than binar y gates, utilizing these ob- servations to reciprocally update the belief distributions of both the code and test populations. Finally , to prev ent the entir e system from drifting into self-validating loops, we “ Anchor” the code solution on the minimal set of 1–3 input/output samples provided in the problem specication. By conditioning the belief up dates on these high-credibility anchors, w e ensure that the search process remains aligned with ground truth even as the populations co-evolve to explore more comple x boundary conditions. On LiveCodeBench v6 (post-March 2025) [ 14 ], BACE outper- forms leading multi-agent framew orks, including CodeSIM by 3.8% with GPT -5-Mini and 5.0% with Qwen2.5-Coder-7b. The major contributions of this paper are as follows: • Bayesian Co-Evolutionar y Framework : W e reformulate code synthesis as a co-evolutionary process where code and test populations reciprocally evolve based on belief distribu- tions updated via noisy interaction evidence. • Belief Anchoring Mechanism : W e introduce an “ Anchor- ing” mechanism that conditions belief updates on minimal public examples, mitigating co-evolutionary drift. • Behavioral Diversity Retention : W e enforce population diversity through tw o novel strategies: a behavioral-based elitism policy that preserves individuals with unique b ehav- ioral vector , and the strategic use of dierential testing to discover diversity . • State-of-the- Art Performance : W e demonstrate that BA CE achieves superior performance on LiveCodeBench v6 (post-March 2025) compared to leading multi-agent frame- works in both state-of-the-art proprietary models and open- weight small language models (SLMs). 2 Related W ork 2.1 Pre-LLM: Program Synthesis Program synthesis is the automatic construction of an executable program that satises a given high-level specication [ 19 ]. One prominent paradigm, Search-Based Software Engineering (SBSE), reformulates synthesis as a search-based optimization pr oblem. A foundational technique in this domain is Genetic Programming (GP), popularized by Koza [ 16 ], which adapts genetic algorithms to evolve e xecutable structures. Standard GP is prone to premature convergence. Hillis [ 9 ] ad- dressed this via ‘host-parasite’ coevolution, demonstrating that evolving adversarial test cases alongside solutions can force the search out of local optima. Arcuri and Y ao [ 1 ] applied this to pro- gram synthesis, co-evolving programs against unit tests. Unlike standard GP’s static test suites, their method evolves adversarial tests to actively expose faults, creating a competitive arms race that enforces strict adherence to the specication. Howe ver , these co-evolutionary methods typically rely on formal specications to validate correctness. 2.2 Large Language Mo dels for Co de Generation The emergence of Large Language Mo dels (LLMs) has signicantly advanced NL-based program synthesis. While contemporar y mod- els now exceed 90% on HumanEval [ 4 ], these metrics are increas- ingly suspect due to data contamination. T o mitigate this, Jain et al. [ 14 ] introduced Live-CodeBench, which evaluates models on problems released after their training cuto. Experiments reveal that state-of-the-art mo dels exhibit 20-40% pass@1 performance drops on these uncontaminated datasets [ 14 ]. These ndings, con- sistent with observations by W ang et al. [ 24 ], indicate that while LLMs demonstrate robust coding capabilities, zero-shot inference remains insucient to guarantee correctness on novel tasks. 2.3 Enhancing LLM-Driven Code Generation T o enhance zero-shot capabilities, research has focused on opti- mizing inference strategies. Initial “open-loop ” methods, such as Chain-of- Thought (Co T) [ 25 ], Structured SCo T (SCo T) [ 17 ], and Self- Planning [ 15 ], encourage models to decomp ose specications into intermediate reasoning steps. While these strategies were eective, subsequent research established that integrating actual execution feedback improves performance compar ed to purely open-loop rea- soning. Consequently , “closed-loop ” approaches like Ree xion [ 21 ], CodeCo T [ 10 ], IN TERVENOR [ 23 ], and Self-Debugging [ 5 ] incorp o- rated iterative feedback from execution traces, either by generating their own tests or by using publicly available tests. These were then scaled up to multi-agent architectures that simulate software development workows. For instance, AgentCoder [ 11 ] coordinates programmer , test designer , and executor agents to iteratively r ene code through generated unit tests. Similarly , DebateCoder [ 3 ] and CodeCoR [20] also used automated test cases. BACE: LLM-based Code Generation through Bay esian Anchored Co-Evolution of Code and T est Populations GECCO ’26, July 13–17, 2026, San Jose, Costa Rica A critical bottleneck in these fe edback loops is the reliability of the validation mechanism itself. As noted by Huang et al [ 11 ], incor- rect oracles provide misleading signals that degrade performance. T o mitigate this, framew orks like MapCoder [ 12 ] and CodeSIM [ 13 ] employ multi-agent collaboration strategies that bypass test gener- ation entirely , focusing instead on reasoning based on input/output examples. Alternatively , Code T [ 2 ] leverages dual execution agree- ment by generating both solution candidates and test cases. It identi- es consensus sets wher e clusters of solutions pass the same subset of tests, selecting the nal solution from the set maximizing the combined size of code and test populations. This, however , fails if the wrong solution clusters are bigger . The work most closely r elated to ours is CoCoEvo [ 18 ], which applies a co-evolutionary approach to co de and test generation. CoCoEvo denes code tness using a Code T -style dual agreement condence score, while test tness is determined via a Pareto fron- tier of condence and discrimination scores. Due to the lack of reported results on standard benchmarks and the unavailability of the source code, we are unable to benchmark CoCoEvo against the state of the art or include it as a baseline. Our approach distinguishes itself from these predecessors through three key me chanisms. First, unlike the stochastic dis- covery in Arcuri and Y ao [ 1 ], BACE leverages LLMs to initialize plausible candidates, focusing evolution on renement rather than discovery from scratch. Second, in contrast to AgentCoder [ 11 ], which treats generated tests as absolute ground truth, BA CE miti- gates the risk of degrading valid solutions by maintaining a pop- ulation and modeling generated tests as noisy sensors within a Bayesian framework and diversity retention via pass-fail behavioral vectors. Finally , while MapCoder [ 12 ] and CodeSIM [ 13 ] abandon test generation to avoid the inherent unreliability of synthesized or- acles, we demonstrate that anchoring the belief eectively grounds the search, allowing the system to safely exploit the high-value signal from generated tests. 3 Probabilistic Modeling of Code- T est Interactions T o address the limitations of deterministic oracles while incorpo- rating test feedback, we reformulate the co-evolutionary process within a Bayesian framework, interpr eting pass/fail results as evi- dence that accounts for our condence in tests and the code solu- tions. W e build on the Bay esian evolutionary computation frame- work introduced by Zhang et al. [ 26 ] as our theoretical basis, further extending it to accommodate co-evolution . 3.1 Latent V ariables and Belief Notation W e dene a belief distribution repr esenting our condence in the correctness of code and tests relative to a problem specication S . Specically , let C = { 𝑐 1 , . . . , 𝑐 𝑁 } represent a population of candidate solutions and T = { 𝑡 1 , . . . , 𝑡 𝑀 } represent a population of tests. W e associate each individual with a binary latent variable representing its ground-truth correctness: • 𝑋 𝑖 ∈ { 0 , 1 } denotes the correctness of co de candidate 𝑐 𝑖 , where 1 is correct. • 𝑌 𝑗 ∈ { 0 , 1 } denotes the validity of test case 𝑡 𝑗 , where 1 is a valid test of S . W e dene the belief in an individual as its posterior probability of correctness. For brevity , we denote: 𝑏 ( 𝑐 𝑖 ) = 𝑃 ( 𝑋 𝑖 = 1 ) and 𝑏 ( 𝑡 𝑗 ) = 𝑃 ( 𝑌 𝑗 = 1 ) (1) The interaction between 𝑐 𝑖 and 𝑡 𝑗 produces an outcome 𝑑 𝑖 𝑗 ∈ { 0 , 1 } , where 1 indicates a “Pass” and 0 indicates a “Fail” . These outcomes are aggregated into an observation matrix D ∈ { 0 , 1 } 𝑁 × 𝑀 , which serves as the primary data source for belief propagation. 3.2 The Noisy Sensor Model When evaluating generated code against generated tests, we cannot interpret execution r esults as ground truth. In traditional testing, a passing result typically implies the code is correct. How ever , in our setting, a passing execution ( 𝑑 𝑖 𝑗 = 1 ) is an ambiguous signal: it does not necessarily imply that the code 𝑐 𝑖 is correct, nor that the test 𝑡 𝑗 is valid. A "Pass" can o ccur even if the co de is buggy (e.g., if the test is trivial) or if the test is wr ong (e .g., matching a wrong output). T o handle this uncertainty , BACE treats the execution outcome not as a denitive verdict, but as a "noisy sensor" observation condi- tioned on the binary latent variables. While we assume that corr ect code passing a valid test is deterministic ( 𝑃 ( 𝑑 𝑖 𝑗 = 1 | 𝑋 𝑖 = 1 , 𝑌 𝑗 = 1 ) = 1 ), a "Pass" can also be generated in three degenerate scenarios. W e quantify the likelihood of these misleading signals using three noise hyperparameters: (1) False Pass ( 𝛼 ): The probability that valid code passes a bro- ken test ( 𝑃 ( 𝑑 𝑖 𝑗 = 1 | 𝑋 𝑖 = 1 , 𝑌 𝑗 = 0 ) ). (2) Accidental Pass ( 𝛽 ): The probability that incorrect code passes a valid test ( 𝑃 ( 𝑑 𝑖 𝑗 = 1 | 𝑋 𝑖 = 0 , 𝑌 𝑗 = 1 ) ). (3) Coincidental Pass ( 𝛾 ): The probability that incorrect code passes a broken test ( 𝑃 ( 𝑑 𝑖 𝑗 = 1 | 𝑋 𝑖 = 0 , 𝑌 𝑗 = 0 ) ). 3.3 Belief Up dates Based on test execution results. we update the belief of an individual using the Bayesian update rule. The updates are performed in log- odds space ( logit ( 𝑝 ) = ln 𝑝 1 − 𝑝 ) to ensure numerical stability and additive evidence aggregation. T o pre vent prematur e convergence in the early generations, especially when using large populations, we apply a learning rate 𝜂 ∈ ( 0 , 1 ] . For a co de candidate 𝑐 𝑖 , the updated belief is dene d as: logit ( 𝑏 ( 𝑐 𝑖 ) ) = logit ( 𝑏 prior ( 𝑐 𝑖 ) ) + 𝜂 𝑗 Δ code 𝑖 𝑗 (2) where Δ code 𝑖 𝑗 represents the W eight of Evidence (W oE) provided by test 𝑡 𝑗 . A symmetric update is applied to test b eliefs 𝑏 ( 𝑡 𝑗 ) by aggregating evidence Δ test 𝑗 𝑖 from the code population. The summa- tion only includes observations 𝑑 𝑖 𝑗 that have not been previously accounted for in prior generations. If an interaction between 𝑐 𝑖 and 𝑡 𝑗 was already processe d in a previous generation and b oth indi- viduals survive, their beliefs are not up dated again for that specic interaction to avoid double-counting evidence. (Refer the appendix for the more detailed derivation of the belief update equations) GECCO ’26, July 13–17, 2026, San Jose, Costa Rica Kaushitha Silva and Srinath Perera 3.3.1 Code Belief Update. For a code candidate 𝑐 𝑖 , the evidence Δ code 𝑖 𝑗 is conditioned on the current belief of the test 𝑏 ( 𝑡 𝑗 ) : Δ code 𝑖 𝑗 = ln 𝑏 ( 𝑡 𝑗 ) + 𝛼 ( 1 − 𝑏 ( 𝑡 𝑗 ) ) 𝛽𝑏 ( 𝑡 𝑗 ) + 𝛾 ( 1 − 𝑏 ( 𝑡 𝑗 ) ) if 𝑑 𝑖 𝑗 = 1 ln ( 1 − 𝛼 ) ( 1 − 𝑏 ( 𝑡 𝑗 ) ) ( 1 − 𝛽 ) 𝑏 ( 𝑡 𝑗 ) + ( 1 − 𝛾 ) ( 1 − 𝑏 ( 𝑡 𝑗 ) ) if 𝑑 𝑖 𝑗 = 0 (3) 3.3.2 T est Belief Update. Symmetrically , test beliefs are updated by treating the code population as the sensor . The likelihoo d roles invert ( 𝛼 ↔ 𝛽 ), rewarding tests that align with high-belief code candidates: Δ test 𝑗 𝑖 = ln 𝑏 ( 𝑐 𝑖 ) + 𝛽 ( 1 − 𝑏 ( 𝑐 𝑖 ) ) 𝛼𝑏 ( 𝑐 𝑖 ) + 𝛾 ( 1 − 𝑏 ( 𝑐 𝑖 ) ) if 𝑑 𝑖 𝑗 = 1 ln ( 1 − 𝛽 ) ( 1 − 𝑏 ( 𝑐 𝑖 ) ) ( 1 − 𝛼 ) 𝑏 ( 𝑐 𝑖 ) + ( 1 − 𝛾 ) ( 1 − 𝑏 ( 𝑐 𝑖 ) ) if 𝑑 𝑖 𝑗 = 0 (4) 3.3.3 A nalysis of Credibility Thresholds. An analysis of the up date mechanisms in Eq. 3 and Eq. 4 reveals a critical property of BA CE. For a “pass” observation ( 𝑑 𝑖 𝑗 = 1 ) to yield a positive belief update ( Δ > 0 ) for a test 𝑡 𝑗 , and conversely for a “fail” to yield a negative update, the interacting code 𝑐 𝑖 must satisfy the following inequality: 𝑏 ( 𝑐 𝑖 ) ( 1 − 𝛼 − 𝛽 + 𝛾 ) > 𝛾 − 𝛽 (5) Because the term ( 1 − 𝛼 − 𝛽 + 𝛾 ) is generally positive under realistic noise models, this condition establishes a credibility threshold that the interactor must exceed for the update to behave intuitively . If 𝑏 ( 𝑐 𝑖 ) falls below this threshold, the update logic inverts: a “pass” decreases belief in the test, while a “fail” increases it. This counter- intuitive property is essential for system robustness, as it ensur es that tests ar e penalize d for passing low-belief ( likely incorrect) code. A symmetric pr operty applies when updating code beliefs based on the credibility of test cases, where 𝛼 and 𝛽 is interchanged in Eq.5. 3.4 Anchoring T o ground the co-evolutionary process, we utilize an anchor set T 𝑎𝑛𝑐ℎ𝑜 𝑟 consisting of high-delity priors ( 𝑏 ( 𝑡 𝑎𝑛𝑐ℎ𝑜 𝑟 ) ≈ 1 ). These anchors are dene d strictly as the set of public input/output ex- amples provided in the problem specication S . For instance, all problems in the LiveCodeBench dataset include such input/output examples. Anchoring induces an asymmetric evidence signal for the code population C : • Positive Anchoring ( Δ ≈ ln 1 𝛽 ): Code that passes anchors gains immediate credibility , r estricted only by the accidental pass rate 𝛽 . • Negative Anchoring ( Δ → −∞ ): Code that fails anchors is identied as reliably incorrect. Failing an anchor provides an innite penalty , eectively zeroing the belief in the can- didate’s corr ectness. The anchors T 𝑎𝑛𝑐 are always preserved in the test population and their beliefs 𝑏 ( 𝑡 𝑎𝑛𝑐 ) are never updated, serving as immutable refer- ences for the entire evolutionary search. 3.4.1 Order of Belief Up dates. T o stabilize the co-evolutionary dynamics and bootstrap b elief propagation, BA CE follows a strict order of updates within each generation: (1) Code Updates on Anchors: Code beliefs 𝑏 ( 𝑐 𝑖 ) are rst updated using only the anchor set T 𝑎𝑛𝑐ℎ𝑜 𝑟 . This identies a credible core population of candidates. Algorithm 1: BACE: Bayesian Anchoring and Co- Ev olu- tion Input: Problem Specication S , Generations 𝐺 𝑚𝑎𝑥 , Conguration K Output: Best Code ˆ 𝑐 , V alidated T ests T ( 𝑓 𝑖𝑛𝑎𝑙 ) 1 T 𝑎𝑛𝑐 ← ExtractAnchors ( S ) ( C ( 0 ) , T ( 0 ) , b ( C ( 0 ) ) , b ( T ( 0 ) ) ) ← Initialize ( S , K ) 2 for 𝑔 ← 0 to 𝐺 𝑚𝑎𝑥 do 3 D ( 𝑔 ) ← Exe cute ( C ( 𝑔 ) , T 𝑎𝑛𝑐 ∪ T ( 𝑔 ) ) 4 b ( C ) , b ( T ) ← BayesianUpdate ( D ( 𝑔 ) , b ( C ( 𝑔 ) ) , b ( T ( 𝑔 ) ) ) 5 if 𝑔 is even and 𝑔 < 𝐺 𝑚𝑎𝑥 − 1 then 6 T ( 𝑔 + 1 ) , b ( T ( 𝑔 + 1 ) ) ← Evolve ( T ( 𝑔 ) , b ( T ) , K ) 7 C ( 𝑔 + 1 ) , b ( C ( 𝑔 + 1 ) ) ← C ( 𝑔 ) , b ( C ) 8 else if 𝑔 is o dd and 𝑔 < 𝐺 𝑚𝑎𝑥 − 1 then 9 C ( 𝑔 + 1 ) , b ( C ( 𝑔 + 1 ) ) ← Evolve ( C ( 𝑔 ) , b ( C ) , K ) 10 T ( 𝑔 + 1 ) , b ( T ( 𝑔 + 1 ) ) ← T ( 𝑔 ) , b ( T ) 11 end 12 ˆ 𝑐 ← arg max 𝑐 𝑖 ∈ C 𝑏 ( 𝑐 𝑖 ) 13 return ˆ 𝑐 , T ( 𝑓 𝑖𝑛𝑎𝑙 ) (2) T est Updates: T est beliefs 𝑏 ( 𝑡 𝑗 ) are then updated using the evidence from the now-anchored code population. T ests are eectively audited by the most credible code candidates. (3) Code Up dates on T est Priors: Finally , code beliefs are further updated using the evidence from the evolv ed tests. Crucially , this step utilizes the test beliefs from the start of the generation (priors) to pre vent unstable feedback loops and ensure that test-driven e vidence is properly dampened by their initial uncertainty . 4 The BACE Algorithm Algorithm 1 presents the high-level co-evolutionary process of BA CE. The process begins by initializing both the code ( C ) and test ( T ) populations using LLMs to establish initial diversity . Public test cases ( T 𝑎𝑛𝑐ℎ𝑜 𝑟 ), derived from the problem specication 𝑆 , are extracted and assigned high prior credibility ( 𝑏 ( 𝑡 𝑎𝑛𝑐ℎ𝑜 𝑟 ) ≈ 1 ). In each generation, the populations are execute d against one another to form the observation matrix D . These r esults serve as noisy evidence for reciprocal b elief updates. The framework evolves the two populations alternatively . This cycle continues for a xed number of generations 𝐺 𝑚𝑎𝑥 , at which p oint the code candidate with the highest posterior pr obability is selected alongside the nal validated test suite. 4.1 Extracting Anchors The process begins by extracting the Anchor Set ( T 𝑎𝑛𝑐ℎ𝑜 𝑟 ) directly from the problem specication S . As dened in Section 3.4, these are typically the sample input/output pairs provided in the prob- lem statement. Unlike ev olved tests, anchors are assigned a xed maximum prior b elief ( 𝑏 ( 𝑡 ) ≈ 1 ) and remain immutable throughout the evolutionary cycle. 4.2 Initialization of Populations The two populations are initialized via an LLM to establish initial di- versity for b oth co de and test populations. Unlike the anchors, these BACE: LLM-based Code Generation through Bay esian Anchored Co-Evolution of Code and T est Populations GECCO ’26, July 13–17, 2026, San Jose, Costa Rica Algorithm 2: BA CE: Population Evolution Strategy Input: Population P , Belief V ector b , Cong 𝐾 Output: New Population P ′ , New Belief V ector b ′ 1 P 𝑒𝑙 𝑖 𝑡 𝑒 , b 𝑒𝑙 𝑖 𝑡 𝑒 ← Sele ctElites ( P , b , 𝐾 . elitism_rate ) 2 𝑁 𝑡 𝑎𝑟 𝑔𝑒 𝑡 ← ⌈ | P | · 𝐾 . ospring_rate ⌉ 3 P 𝑜 𝑓 𝑓 , b 𝑜 𝑓 𝑓 ← ∅ , ∅ 4 while | P 𝑜 𝑓 𝑓 | < 𝑁 𝑡 𝑎𝑟 𝑔𝑒 𝑡 do 5 𝑜 𝑝 ← SelectOp erator ( 𝐾 . ops_rate ) 6 𝑝 𝑎𝑟 𝑒𝑛𝑡 𝑠 ← SelectParents ( P , b , 𝑘 = arity ( 𝑜 𝑝 ) ) 7 𝑐ℎ𝑖 𝑙 𝑑 ← ApplyOp ( 𝑜 𝑝 , 𝑝 𝑎𝑟 𝑒 𝑛𝑡 𝑠 ) 8 𝑏 𝑐ℎ𝑖 𝑙 𝑑 ← min 𝑝 ∈ 𝑝 𝑎𝑟 𝑒 𝑛𝑡 𝑠 b ( 𝑝 ) 9 P 𝑜 𝑓 𝑓 ← P 𝑜 𝑓 𝑓 ∪ { 𝑐 ℎ𝑖 𝑙 𝑑 } 10 b 𝑜 𝑓 𝑓 ← b 𝑜 𝑓 𝑓 ∪ { 𝑏 𝑐ℎ𝑖 𝑙 𝑑 } 11 end 12 return ( P 𝑒𝑙 𝑖 𝑡 𝑒 ∪ P 𝑜 𝑓 𝑓 ) , ( b 𝑒𝑙 𝑖 𝑡 𝑒 ∪ b 𝑜 𝑓 𝑓 ) generated populations are assigned uninformative constant priors ( 𝑏 ( · ) = 0 . 2 ) to r eect the system’s initial uncertainty regarding their validity . 4.2.1 Code Initialization ( C ( 0 ) ). T o establish a diverse starting man- ifold, we prompt the LLM to generate a batch of 𝑁 𝑎 distinct algo- rithmic approaches for the specication S in a single response. This batch generation process is repeated 𝑁 𝑠 times to populate the initial set of size 𝑁 𝑖𝑛𝑖 𝑡 = 𝑁 𝑎 × 𝑁 𝑠 . 4.2.2 T est Initialization ( T ( ′ ) ). The initial test suite is seeded with 𝑀 𝑖𝑛𝑖 𝑡 unit tests generated to cover basic functionality , edge cases, and large-scale tests as in AgentCoder [11]. 4.3 Execution In every generation, the system executes the current co de p opu- lation C ( 𝑔 ) against the union of the evolved test suite T ( 𝑔 ) and the anchor set T 𝑎𝑛𝑐ℎ𝑜 𝑟 . This produces an observation matrix 𝐷 ( 𝑔 ) , where each entry 𝑑 𝑖 𝑗 represents the binary outcome (Pass/Fail) of code 𝑐 𝑖 executing test 𝑡 𝑗 . 4.4 Bayesian Updates Using the observation matrix D ( 𝑔 ) , the system updates the belief distributions b ( C ) and b ( T ) as described in Se ction 3.4.1. 4.5 Alternating Evolution T o mitigate the instability inherent in co-e volution (e.g., "red queen" dynamics where populations cycle without progress [ 6 ]), BACE employs an alternating evolution strategy . In even generations, the code population is frozen while the test suite T ( 𝑔 + 1 ) , while in odd generations, the test population is frozen while the code population C ( 𝑔 + 1 ) evolves. This stabilizes the learning signal, allowing one population to adapt to the stable pressure provided by the other . 4.5.1 Elite Sele ction. W e preserve high-belief, diverse individuals across generations through a diversity-preserving elitism based on behavioral vectors. W e employ distinct strategies for co de and tests. Code Elitism. T o prevent pr emature convergence , we construct the elite set C 𝑒𝑙 𝑖𝑡 𝑒 via a dual-objective strategy that balances ex- ploitation and diversity . First, we select the top- 𝑘 individuals with 𝑡 1 𝑡 2 𝑡 3 𝑡 4 𝑡 5 𝑐 1 1 1 0 1 1 𝑐 2 1 0 0 0 0 𝑐 3 0 1 1 1 1 𝑐 4 0 1 1 1 1 𝑐 5 1 1 1 0 0 Functional Equivalence (Identical Rows) Functional Redundancy (Identical Cols) Figure 2: Functional Equivalence (Blue): Candidates 𝑐 3 and 𝑐 4 produce identical pass/fail vector across all tests. Func- tional Redundancy (Orange): T ests 𝑡 4 and 𝑡 5 induce identical pass/fail vector across all code candidates. the highest posterior b elief 𝑏 ( · ) (Exploitation). Second, we select the highest-probability representative from ev ery functional equiv- alence group identied in the population (Diversity). Following the methodology of Code T [ 2 ], we dene two candidate solutions 𝑐 𝑎 , 𝑐 𝑏 ∈ C as functionally equivalent with respect to the current test suite if their behavior vector is identical across all tests. Formally , this corresponds to identical rows in the observation matrix D (as visualized in Figure 2) such that D 𝑎, · = D 𝑏, · ⇐ ⇒ ∀ 𝑗 , 𝑑 𝑎 𝑗 = 𝑑 𝑏 𝑗 . This clustering ensures that distinct strategic niches are pre- served ev en if their current probability is marginally lower than the dominant mode. If the combined elite set leaves insucient room for the required ospring quota ( dened by 𝐾 . ospring_rate ), we prune the lowest-probability individuals from this combined set until the limit is met. T est Elitism. For the test population, elitism prioritizes discrim- inative eciency over belief. W e dene two tests 𝑡 𝑎 , 𝑡 𝑏 ∈ T as functionally redundant if they induce identical b ehavioral across the current co de population. Formally , this corr esponds to identical columns in the observation matrix D (as visualized in Figure 2) such that D · , 𝑎 = D · , 𝑏 ⇐ ⇒ ∀ 𝑖 , 𝑑 𝑖𝑎 = 𝑑 𝑖𝑏 . Such redundancy indicates that 𝑡 𝑘 oers no unique information gain over 𝑡 𝑗 regarding the corr ectness of the current candidates. T o maintain a minimal ecient basis for the b elief updates, we cluster these redundant groups and r etain only the single representativ e with the highest posterior belief 𝑏 ( 𝑡 ) . This eectively compresses the test suite into a set of orthogonal sensors. 4.5.2 Parent Selection. W e utilize a tness-proportionate selection (Roulette Wheel Selection) over the belief distributions. The prob- ability of selecting an individual 𝑖 is directly proportional to its normalized belief score 𝑏 ( 𝑖 ) . The selection cardinality is operator- dependent: we sample single parents for unary operations and pairs for binar y op erations, applying this mechanism symmetri- cally across both populations. 4.5.3 A pplying Operations. Once par ents ar e selected, we generate ospring by applying a specic evolutionary operator . The frame- work supports a diverse library of operators for both populations. GECCO ’26, July 13–17, 2026, San Jose, Costa Rica Kaushitha Silva and Srinath Perera 𝑐 0 𝑐 1 𝑐 2 Semantic Crossover 𝑐 3 Re-implement 𝑐 4 𝑡 0 𝑡 1 𝑡 2 Complementary Crossover 𝑡 3 Edge Case Gen 𝑡 4 Divergence Disc. ( 𝑐 1 vs 𝑐 3 ) Debug Failure Feedback Final Solution Figure 3: Ancestral Lineage of a Solution. An illustrative visualization of the BACE co-evolutionary process, tracing the genesis of a candidate solution ( 𝑐 4 ) The specic operator is chosen stochastically at each step based on the operation rate The selected operator dictates b oth the number of parents required (arity) and the specic LLM prompting strat- egy used to synthesize the child. For the specic details of these operators, see Section 5. 4.5.4 Ospring’s Belief Assignment. W e initialize the ospring’s belief as the minimum of its parents’ beliefs: 𝑏 𝑐ℎ𝑖 𝑙 𝑑 = min 𝑝 ∈ 𝜋 𝑏 ( 𝑝 ) . This approach assumes the child r etains the validity of its lineage until proven otherwise. If the ospring intr oduces a regression, it will fail an anchor test, triggering a catastr ophic penalty ( Δ → −∞ ). Conversely , if it pr eserves functionality , it maintains a high enough belief to survive the selection cut. W e avoid resetting the belief to a low uninformativ e prior (e .g., 0 . 2 ) because this w ould force them to re-prov e correctness from scratch, creating an articial bottleneck that unnecessarily stalls evolutionary progress. 4.6 Convergence and Selection After 𝐺 𝑚𝑎𝑥 generations, the algorithm terminates and selects the Maximum A Posteriori estimate from the nal code population: ˆ 𝑐 = arg max 𝑐 𝑖 ∈ C ( 𝑓 𝑖 𝑛𝑎𝑙 ) 𝑏 ( 𝑐 𝑖 ) (6) This ensures the selected solution is the one with the highest accu- mulated b elief, rather than simply the candidate that passes the most tests in T ( 𝑓 𝑖𝑛𝑎𝑙 ) . The system simultaneously returns the evolved test suite T ( 𝑓 𝑖𝑛𝑎𝑙 ) . 5 Populations and Op erations In BA CE, the evolving T est Population is partitioned into two se- mantic categories: Unit T ests ( T 𝑢𝑛𝑖 𝑡 ) and Dierential T ests ( T 𝑑 𝑖 𝑓 𝑓 ), while the Anchor Population ( T 𝑎𝑛𝑐 ) remains immutable. Unlike stan- dard genetic algorithms that rely on stochastic syntactic mutations, BA CE employs Informed V ariation Operators via LLMs. For each operation, the LLM executes the task using a prompt conditioned on the problem specication. 5.1 Code Population Operators ( C ) W e balance exploration of the solution space with exploitation of high-performing logic through three mechanisms: Semantic Crossover ( 𝑐 𝑎 × 𝑐 𝑏 → 𝑐 ′ ) : Given two parent imple- mentations, the LLM integrates the most eective logic from both parents while resolving semantic conicts. The goal is to synthesize an ospring 𝑐 ′ that is functionally superior to either ancestor . Debug ( 𝑐 , T 𝑓 𝑎𝑖𝑙 → 𝑐 ′ ) : This operator targets correctness. The LLM acts on a parent 𝑐 , utilizing a context window contain- ing a subset of failing tests T 𝑓 𝑎𝑖𝑙 ⊂ T and their asso ciated execution traces. T o prioritize valid feedback, T 𝑓 𝑎𝑖𝑙 is sam- pled via rank selection based on test b elief scores 𝑏 ( 𝑡 𝑗 ) . The model is instructed to repair the logic to satisfy the violated constraints. Re-implement ( 𝑐 → 𝑐 ′ ) : T o escape local optima, the LLM is instructed to rewrite 𝑐 using a fundamentally dierent algo- rithmic approach or syntactic structure , while strictly pre- serving its functional intent relative to S . 5.2 Unit T ests ( T 𝑢𝑛𝑖 𝑡 ) The objective of T 𝑢𝑛𝑖 𝑡 is to approximate the ideal manifold of con- straints T ∗ implied by the specication. Operators here focus on expanding the test suite ’s discriminative power and cov erage: Discriminate ( 𝑡 | { 𝑐 𝑎 , 𝑐 𝑏 } → 𝑡 ′ ) : Given a target code pair { 𝑐 𝑎 , 𝑐 𝑏 } and a test 𝑡 : if both pass 𝑡 , the LLM is instructed to write a new test 𝑡 ′ that exposes a latent bug in the weaker candidate. If 𝑡 discriminates ( one pass, one fail), the operator renes 𝑡 to better target the sp ecic failure. If both fail, 𝑡 ′ is rened to distinguish between their failure modes. Complementary Crossover ( 𝑡 𝑎 × 𝑡 𝑏 → 𝑡 ′ ) : Conditioned on two parent tests { 𝑡 𝑎 , 𝑡 𝑏 } , the LLM identies semantic gaps in their combined coverage. It synthesizes an ospring 𝑡 ′ targeting this latent "negative space, " ensuring the evolution explores constraints orthogonal to existing high-tness tests. Edge Case Generation ( 𝑡 → 𝑡 ′ ) : The LLM validates a test 𝑡 . If 𝑡 is incorrect relative to S , it is repaired. If valid, the LLM generates a variant covering a distinct input scenario or boundary condition not covered by the parent. 5.3 Dierential T ests ( T 𝑑 𝑖 𝑓 𝑓 ) The objective of T 𝑑 𝑖 𝑓 𝑓 is to generate a distinguishing input 𝑡 ′ that induces divergent outputs between the candidates, i.e., O ( 𝑐 𝑎 , 𝑡 ′ ) ≠ O ( 𝑐 𝑏 , 𝑡 ′ ) . Unlike the unit test population, there is no initial popula- tion for dierential tests; T ( 0 ) 𝑑 𝑖 𝑓 𝑓 = ∅ , and tests are adde d dynamically only when equivalence clusters are detecte d. W e dene a single operator for this purpose: Divergence Discovery ( { 𝑐 𝑎 , 𝑐 𝑏 , T 𝑝 𝑎𝑠𝑠 } → { 𝑡 ′ 𝑘 } ⊂ T 𝑑 𝑖 𝑓 𝑓 ) : T o split a cluster of candidates { 𝑐 𝑎 , 𝑐 𝑏 } that exhibit identical be- havior vectors, the LLM is prompted to synthesize a Python input generator script. Crucially , we condition this prompt on the subset of tests T 𝑝 𝑎𝑠𝑠 ⊆ T that both candidates cur- rently pass. This context allows the model to infer the shared logic and target edge cases where the implementations likely BACE: LLM-based Code Generation through Bay esian Anchored Co-Evolution of Code and T est Populations GECCO ’26, July 13–17, 2026, San Jose, Costa Rica dier . This methodology is adapted from the Mokav frame- work [ 7 ]. The script produces stochastic inputs 𝑖 𝑘 , on which we execute both candidates. If the outputs diverge ( O 𝑎 ≠ O 𝑏 ), we capture the spe cic input 𝑖 𝑘 and both divergent outputs as two separate test candidates: 𝑡 ′ 𝑎 = ( 𝑖 𝑘 , O 𝑎 ) and 𝑡 ′ 𝑏 = ( 𝑖 𝑘 , O 𝑏 ) . While one of these tests is necessarily incorrect r elative to S , the Bayesian reciprocity me chanism (Se ction 3.2) will naturally lter the erroneous case. Figure 3 provides a visualization of a hypothetical evolutionary trajectory where a nal solution is born through a sequence of operations across generations. 5.4 Experimental Setup 5.4.1 Dataset. W e evaluate BA CE on LiveCodeBench v6, speci- cally focusing on problems released post-March 2025 to mitigate potential data contamination. The evaluation set comprises 80 prob- lems collectively (37 Hard, 25 Medium, 18 Easy). 5.4.2 Baselines. W e compare BA CE with direct prompting to es- tablish a performance lower bound. T o position BA CE within the landscape of feedback-driven generation, we selected three state- of-the-art multi-agent frameworks AgentCoder , MapCoder , and CodeSIM as baselines based on results reported by Islam et al [ 13 ]. 5.4.3 Language Mo dels. W e evaluate the BACE on two distinct classes of Large Language Models: the proprietary GPT -5-Mini and the smaller open-weight Qwen2.5-Coder-7b . 5.5 BA CE Conguration T o ensure reproducibility , we specify the evolutionary parame- ters employed in our experiments. W e run the co-evolution for 𝐺 𝑚𝑎𝑥 = 10 generations. The code population is initialized with 𝑁 𝑖𝑛𝑖 𝑡 = 10 candidates and cappe d at a maximum size of 𝑁 𝑚𝑎𝑥 = 15 , utilizing an elitism rate of 0.3 and an ospring generation rate of 0.3. Code evolutionary operators are selecte d stochastically , priori- tizing Debugging ( 𝑝 = 0 . 6 ) over Rewriting ( 𝑝 = 0 . 2 ) and Semantic Crossover ( 𝑝 = 0 . 2 ). The unit test population is initialized with a xed size of 𝑀 = 20 candidates. T est evolution operators are ap- plied with probabilities of 0.5 for Discrimination, 0.3 for Edge Case Generation, and 0.2 for Complementary Crossover . Additionally , for dierential testing, the system generates 10 tests (derived from 5 diverging inputs) for every identied divergent pair . 5.5.1 Hyperparameters and Calibration. W e adjust these hyperpa- rameters based on the test source and the initial b eliefs, setting the initial belief for both code and tests to 𝑏 𝑖𝑛𝑖 𝑡 = 0 . 2 . For public anchor tests ( T 𝑎𝑛𝑐 ), since these are ground truth, we set 𝛼 = 𝛾 = 0 , while setting 𝛽 = 0 . 2 to account for the limited discriminative power of trivial anchors. Conversely , for evolv ed tests ( T 𝑢𝑛𝑖 𝑡 and T 𝑑 𝑖 𝑓 𝑓 ), we assign parameters of 𝛼 = 0 . 1 , 𝛽 = 0 . 2 , and 𝛾 = 0 . 25 . These values are calibrated against the initial prior ( 𝑏 𝑖𝑛𝑖 𝑡 = 0 . 2 ) to bootstrap the reciprocity belief updates. The anchor parameters ensure that any positive anchoring pushes a code candidate’s belief above the cred- ibility threshold required to validate unit tests, while any negative result dr ops it below . Furthermore , the parameters for evolved tests are set so that their initial prior of 0.2 falls within the code’s credi- bility threshold; this allows even ne wly generated tests to provide a small but positive increase in code belief in the rst generation, jumpstarting the co-evolutionary loop. 5.6 Implementation Details W e run the experiments on a 16-core AMD EPY C 7282 server with 64GB RAM and an RTX A4000 (16GB VRAM). Source code and ex- perimental scripts will b e made publicly available upon publication. 5.7 Results T able 1 summarizes the Pass@1 performance of BACE against state-of-the-art baselines across proprietary GPT -5-Mini and the open-weights Qwen2.5-Coder-7b. 5.7.1 GPT -5-Mini. BACE achieves an ov erall Pass@1 of 71.3%, sur- passing CodeSim (67.5%), and outperforming AgentCoder (52.5%). The performance gap widens on harder problems. Here , BA CE at- tains 51.4% pass@1, pro viding a 5.5% absolute impro vement ov er CodeSIM (45.9%) and a 16.3% improvement ov er MapCoder (35.1%). 5.7.2 Qwen2.5-Coder:7b. BA CE maintains robust performance even with the smaller 7-billion parameter open-source mo del, outperforming all baselines. While it matches the previous best, CodeSIM, on easy problems (72.2%), it outperforms it in the Medium (28.0% vs 16.0%) and Hard (10.8% vs 8.1%) categories . W e exclude MapCoder from the Qwen2.5-Coder-7b results since it frequently failed to adhere to MapCoder’s output schema, resulting in XML parsing errors and code syntax violations that rendered evaluation invalid. 6 Discussion and Lessons Learned Our results on LiveCodeBench v6 (post-March 2025) demonstrate that BA CE surpasses state-of-the-art performance with both pro- prietary models and open source small models across dierent diculty levels of problem specications. This performance sup- ports our central hypothesis: that in the absence of a formal oracle, LLM-generated tests provide a strong learning signal when mo deled as noisy sensors within a probabilistic framework. 6.1 Reclaiming the Signal from Generated T ests AgentCoder occasionally underperforms even the Direct baseline (52.0% vs 60% on Medium problems with GPT -5-Mini), W e attribute this to the ’False Negative Rejection’ failure mode detailed in Fig- ure 1, where faulty tests erroneously degrade valid solutions. In contrast, population-based methods oer a higher likelihoo d that the original valid logic will remain within the broader population, even if a specic candidate undergoes such a destructive update. Howev er , population-based metho ds too are susceptible to drift. Ideally , correct tests serve to preser ve accurate solutions while elim- inating incorrect ones. Y et, the presence of faulty tests diminishes the tness of valid solutions, prompting destructive updates that favor candidates aligning with the err ors. Consequently , these in- correct solutions might gain tness from the faulty tests, creating a fe edback loop that drives the population away from the initial specication. Within BACE, co-evolutionary drift requires an incorrect so- lution to satisfy two simultaneous conditions: it must pass the anchors ( 𝑇 𝑎𝑛𝑐 ) and it must pass high-belief tests. Crucially , these GECCO ’26, July 13–17, 2026, San Jose, Costa Rica Kaushitha Silva and Srinath Perera T able 1: Comparison of Pass@1 (%) performance on LiveCodeBench V6 (Post-March 2025) across problem diculty levels. . GPT -5-Mini Qwen2.5-Coder:7b Method Easy Med Hard Overall Easy Med Hard Overall Direct 83.3 60.0 27.0 50.0 27.8 4.0 0.0 7.5 AgentCoder 88.9 52.0 35.1 52.5 38.9 8.0 2.7 12.5 MapCoder 83.3 80.0 35.1 60.0 – – – – CodeSIM 94.4 80.0 45.9 67.5 72.2 16.0 8.1 25.0 BA CE (Ours) 94.4 84.0 51.4 71.3 72.2 28.0 10.8 30.0 tests achieve high-b elief only after being validated by the positively anchored solutions. Howe ver , the likelihood of an incorrect solu- tion meeting both criteria while still being wrong is much smaller . In other words, as obser ved by Co de T [ 2 ], it is easier for correct solutions and tests to agree than wrong solutions and wrong tests to agree as there are many ways to be wrong than ways to be cor- rect. Furthermore, the moment an incorrect solution fails an anchor , Bayesian updates pr opagate this negativ e signal, r educing the belief in any faulty tests that support the incorrect code. This mechanism eectively breaks the drift fe edback loop, resulting in faster con- vergence. T o quantify this, we conducted a targeted ablation study where we disabled anchoring; on hard problems using GPT -5-Mini, performance plummeted to 37.8% (fr om 51.4%), conrming anchors are essential for prev enting drift. 6.2 Importance of Population Diversity The success of BACE is rooted in an understanding of solution life- cycles. By tracking the lifecycle of individual co de and test identities from generation to extinction, we observed that standard elistim policies (e.g: Global Elitism) can be harmful in this domain. Be- fore BA CE, we initially explored a naive belief-based global elitism strategy , retaining individuals with the highest beliefs across gener- ations. This approach performed poorly , resulting in the dominance of trivial assertions satised by the majority of the co de population. On the code population side, this led to the dominance of function- ally equivalent solutions sharing the same b ehavior across the test suite. T o avoid the system settling on trivial assertions and solutions, we changed the test elitism policy to also favor the tests that dis- criminate using an entropy based discrimination scor e. How ever , we noticed that tests that induced dierent behavior in the code population were killed o, either due to low er discrimination scor es or lower beliefs. This happens because scalar metrics (i.e discrimina- tion, failure rate) could not adequately capture behavioral vectors, discarding unique tests that target dierent behaviors. W e believe diversity is the key workhorse behind BA CE, and it employs several appr oaches to preserve diversity . First, BACE cluster individuals in both populations based on their execution behavior vectors as detailed in Section 4.5.1. In the code population, this preserves distinct strategic niches, ev en retaining the sub-optimal solutions that fail anchors which can be then used by the Bayesian model to provide negative signals for the belief updates. Similarly , this prev ents the test suite fr om lling up with redundant sensors that oer no new information gain. Second, unlike traditional software engineering, where dieren- tial testing is used as a bug-nder . BA CE uses them for Diversity Retention. Although Dierential tests do not generate new co de diversity directly , they serve as discriminators that partition func- tional equivalence groups. The dierential test splits the group, compelling the code elitism mechanism to sele ct and retain better representatives fr om each newly formed cluster . This ensures that there is sucient diversity for ev olution to progress. 6.3 Anchored Dual Agreement W e observed from execution traces that once a candidate solu- tion satised the public anchors, BACE consistently propagated its logic to future generations. This persistence occurred regardless of whether the solution appeared in the initial p opulation or evolved later , ee ctively withstanding the abundance of incorrect candi- dates. W e hypothesize that this persistence is driven by the same "dual agr eement" phenomenon observed in CodeT [2]. Howev er , in BACE, this agreement is strictly regulated by the anchoring process. Unlike unconstraine d consensus, which can drift into spurious agreement, our model restricts unfavorable b elief propagation: if a consensus cluster fails the public anchors, it hurts the beliefs of both the co de and the agreeing tests. It is only when the consensus cluster is positively anchored (i.e., satisfying the ground truth) that the dual agr eement mechanism ee ctively drives the beliefs of both populations, amplifying the signal of the valid minority and propagating their logic to the ospring. 6.4 Future Directions The modular ar chitecture of BA CE establishes a exible foundation for future research and open source development, particularly due to the de coupling of evolutionary logic from LLM-driven opera- tors. For instance, inspired by CodeSIM’s simulation agent, future "Debug" operators could leverage runtime logs to provide richer debugging signals. Among other p ossibilities are incorporating LLM planners into BA CE while creating diverse populations and while debugging existing solutions via evolutionary op erators. Fur- thermore, in addition to dierential testing, we plan to explore how we can incorporate the state of the art testing methodologies such as Property-Based T esting [ 8 ] or Mutation T esting [ 22 ] to rigorously challenge candidates beyond unit and dierential tests. Finally , further investigating the potential for Anchor-Free Evolu- tion remains a priority for extending BA CE to scenarios where no public input/output examples are available. BACE: LLM-based Code Generation through Bay esian Anchored Co-Evolution of Code and T est Populations GECCO ’26, July 13–17, 2026, San Jose, Costa Rica 7 Conclusion The State-of-the-art in LLM-driven code generation has largely abandoned test generation for reasoning-based approaches, cit- ing the unreliability of synthesize d tests as feedback. W e argue, conversely , that generated tests remain a high-value signal when modeled as noisy sensors within a Bayesian framework. BA CE val- idates this hypothesis through a Bayesian co-evolutionary process where code and test populations reciprocally rene one another . By anchoring this search on minimal public examples, we eec- tively mitigate the co-ev olutionary drift typical of self-validating loops. Furthermore, we utilize behavioral based elitism policy and dierential testing to enforce p opulation diversity , a me chanism that prevents the system fr om collapsing into redundant or trivial solutions. Empirical evaluations on LiveCodeBench v6 (Post-March) demonstrate that BACE establishes a new state-of-the-art, yielding performance gains for both proprietary models and open-weight small language models. Looking forward, the mo dular Bayesian backbone of BACE pro- vides a exible foundation for futur e research. Specically , it opens pathways for integrating state-of-the-art code and test generation to co-evolving populations to yield increasingly robust solutions. References [1] Andrea Arcuri and Xin Y ao. 2007. Co evolving programs and unit tests from their specication. In Proceedings of the 22nd IEEE/A CM International Conference on Automated Software Engineering (ASE ’07) . Association for Computing Machinery , New Y ork, NY, USA, 397–400. doi:10.1145/1321631.1321693 [2] Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and W eizhu Chen. 2022. CodeT: Code Generation with Generated T ests. doi:10.48550/arXiv .2207.10397 arXiv:2207.10397 [cs]. [3] Jizheng Chen, Kounianhua Du, Xinyi Dai, W eiming Zhang, Xihuai Wang, Y asheng W ang, Ruiming Tang, W einan Zhang, and Y ong Y u. 2025. DebateCoder: T owards Collective Intelligence of LLMs via T est Case Driven LLM Debate for Code Genera- tion. In Procee dings of the 63rd A nnual Meeting of the Association for Computational Linguistics (V olume 1: Long Pap ers) , W anxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad T aher Pilehvar (Eds.). Association for Computational Linguistics, Vienna, Austria, 12055–12065. doi:10.18653/v1/2025.acl- long.589 [4] Mark Chen, Jerr y T worek, Heewoo Jun, Qiming Y uan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwar ds, Y uri Burda, Nicholas Joseph, Greg Br ockman, Alex Ray , Raul Puri, Gretchen Krueger , Michael Petrov , Heidy Khlaaf, Girish Sastry , Pamela Mishkin, Brooke Chan, Scott Gray , Nick Ryder , Mikhail Pavlov , Alethea Power , Lukasz Kaiser , Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias P lappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-V oss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie T ang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr , Jan Leike, Josh Achiam, V edant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer , Peter W elinder, Bob McGrew , Dario Amodei, Sam McCandlish, Ilya Sutskever , and W ojcie ch Zaremba. 2021. Evaluating Large Lan- guage Models Trained on Code. doi:10.48550/arXiv .2107.03374 [cs]. [5] Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. 2023. T each- ing Large Language Models to Self-Debug. doi:10.48550/arXiv .2304.05128 arXiv:2304.05128 [cs]. [6] Dave Cli and Georey F . Miller. 1995. Tracking the red queen: Measurements of adaptive progress in co-e volutionary simulations. In Advances in Articial Life , Federico Morán, Alvaro Moreno, Juan Julián Mer elo, and Pablo Chacón (Eds.). Springer , Berlin, Heidelberg, 200–218. doi:10.1007/3- 540- 59496- 5_300 [7] Khashayar Etemadi, Bardia Mohammadi, Zhendong Su, and Martin Monp er- rus. 2025. Mokav: Execution-driven Dierential Testing with LLMs. Journal of Systems and Software 230 (Dec. 2025), 112571. doi:10.1016/j.jss.2025.112571 arXiv:2406.10375 [cs]. [8] Lehan He, Zeren Chen, Zhe Zhang, Jing Shao, Xiang Gao, and Lu Sheng. 2025. Use Property-Based T esting to Bridge LLM Code Generation and V alidation. doi:10.48550/arXiv .2506.18315 arXiv:2506.18315 [cs] version: 1. [9] W .Daniel Hillis. 1990. Co-evolving parasites improve simulated ev olution as an optimization procedure. P hysica D: Nonlinear Phenomena 42, 1-3 (June 1990), 228–234. doi:10.1016/0167- 2789(90)90076- 2 [10] Dong Huang, Qingwen Bu, Yuhao Qing, and Heming Cui. 2024. CodeCo T: T ackling Code Syntax Errors in CoT Reasoning for Co de Generation. doi:10. 48550/arXiv .2308.08784 arXiv:2308.08784 [cs]. [11] Dong Huang, Jie M. Zhang, Michael Luck, Qingw en Bu, Y uhao Qing, and Heming Cui. 2024. AgentCoder: Multi-Agent-based Code Generation with Iterative T esting and Optimisation. doi:10.48550/arXiv.2312.13010 arXiv:2312.13010 [cs]. [12] Md Ashraful Islam, Mohammed Eunus Ali, and Md Rizwan Parvez. 2024. MapCoder: Multi-Agent Code Generation for Competitive Problem Solving. doi:10.48550/arXiv .2405.11403 arXiv:2405.11403 [cs]. [13] Md Ashraful Islam, Mohammed Eunus Ali, and Md Rizwan Parvez. 2025. CODESIM: Multi-A gent Code Generation and Problem Solving through Simulation-Driven Planning and Debugging. doi:10.48550/arXiv .2502.05664 arXiv:2502.05664 [cs]. [14] Naman Jain, King Han, Alex Gu, W en-Ding Li, Fanjia Yan, Tianjun Zhang, Sida W ang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2024. Live- CodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code. doi:10.48550/arXiv .2403.07974 arXiv:2403.07974 [cs]. [15] Xue Jiang, Yihong Dong, Lecheng W ang, Zheng Fang, Qiwei Shang, Ge Li, Zhi Jin, and W enpin Jiao. 2024. Self-planning Co de Generation with Large Language Models. doi:10.48550/arXiv .2303.06689 arXiv:2303.06689 [cs]. [16] JohnR. Koza. 1994. Genetic programming as a means for programming computers by natural selection. Statistics and Computing 4, 2 (June 1994). doi:10.1007/ BF00175355 [17] Jia Li, Ge Li, Y ongmin Li, and Zhi Jin. 2023. Structured Chain-of-Thought Prompt- ing for Code Generation. doi:10.48550/arXiv .2305.06599 arXiv:2305.06599 [cs]. [18] Kefan Li, Y uan Yuan, Hongyue Y u, Tingyu Guo, and Shijie Cao. 2025. CoCoEvo: Co-Evolution of Programs and T est Cases to Enhance Code Generation. doi:10. 48550/arXiv .2502.10802 arXiv:2502.10802 [cs]. [19] Zohar Manna and Richard J. W aldinger . 1971. T oward automatic program syn- thesis. Commun. ACM 14, 3 (March 1971), 151–165. doi:10.1145/362566.362568 GECCO ’26, July 13–17, 2026, San Jose, Costa Rica Kaushitha Silva and Srinath Perera [20] Ruwei Pan, Hongyu Zhang, and Chao Liu. 2025. CodeCoR: An LLM-Based Self- Reective Multi-A gent Framew ork for Code Generation. doi:10.48550/arXiv .2501. 07811 arXiv:2501.07811 [cs]. [21] Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao . 2023. Reexion: Language Agents with V erbal Reinforcement Learning. doi:10.48550/arXiv.2303.11366 arXiv:2303.11366 [cs]. [22] Frank Tip , Jonathan Bell, and Max Schaefer . 2025. LLMorpheus: Mutation T esting using Large Language Models. doi:10.48550/arXiv .2404.09952 [cs]. [23] Hanbin W ang, Zhenghao Liu, Shuo W ang, Ganqu Cui, Ning Ding, Zhiyuan Liu, and Ge Y u. 2024. IN TERVENOR: Prompt the Coding Ability of Large Language Models with the Interactive Chain of Repairing. doi:10.48550/arXiv .2311.09868 arXiv:2311.09868 [cs] version: 3. [24] Zhijie W ang, Zijie Zhou, Da Song, Yuheng Huang, Shengmai Chen, Lei Ma, and Tianyi Zhang. 2025. T owards Understanding the Characteristics of Code Generation Errors Made by Large Language Models. doi:10.48550/arXiv .2406. 08731 arXiv:2406.08731 [cs]. [25] Jason W ei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter , Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. doi:10.48550/arXiv .2201.11903 arXiv:2201.11903 [cs]. [26] Byoung- Tak Zhang. 1999. A Bayesian framework for evolutionary computation. In Proceedings of the 1999 Congress on Evolutionary Computation-CEC99 (Cat. No. 99TH8406) , V ol. 1. 722–728 V ol. 1. doi:10.1109/CEC.1999.782004
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment