Dynamic Lookahead Distance via Reinforcement Learning-Based Pure Pursuit for Autonomous Racing
Pure Pursuit (PP) is a widely used path-tracking algorithm in autonomous vehicles due to its simplicity and real-time performance. However, its effectiveness is sensitive to the choice of lookahead distance: shorter values improve cornering but can c…
Authors: Mohamed Elgouhary, Amr S. El-Wakeel
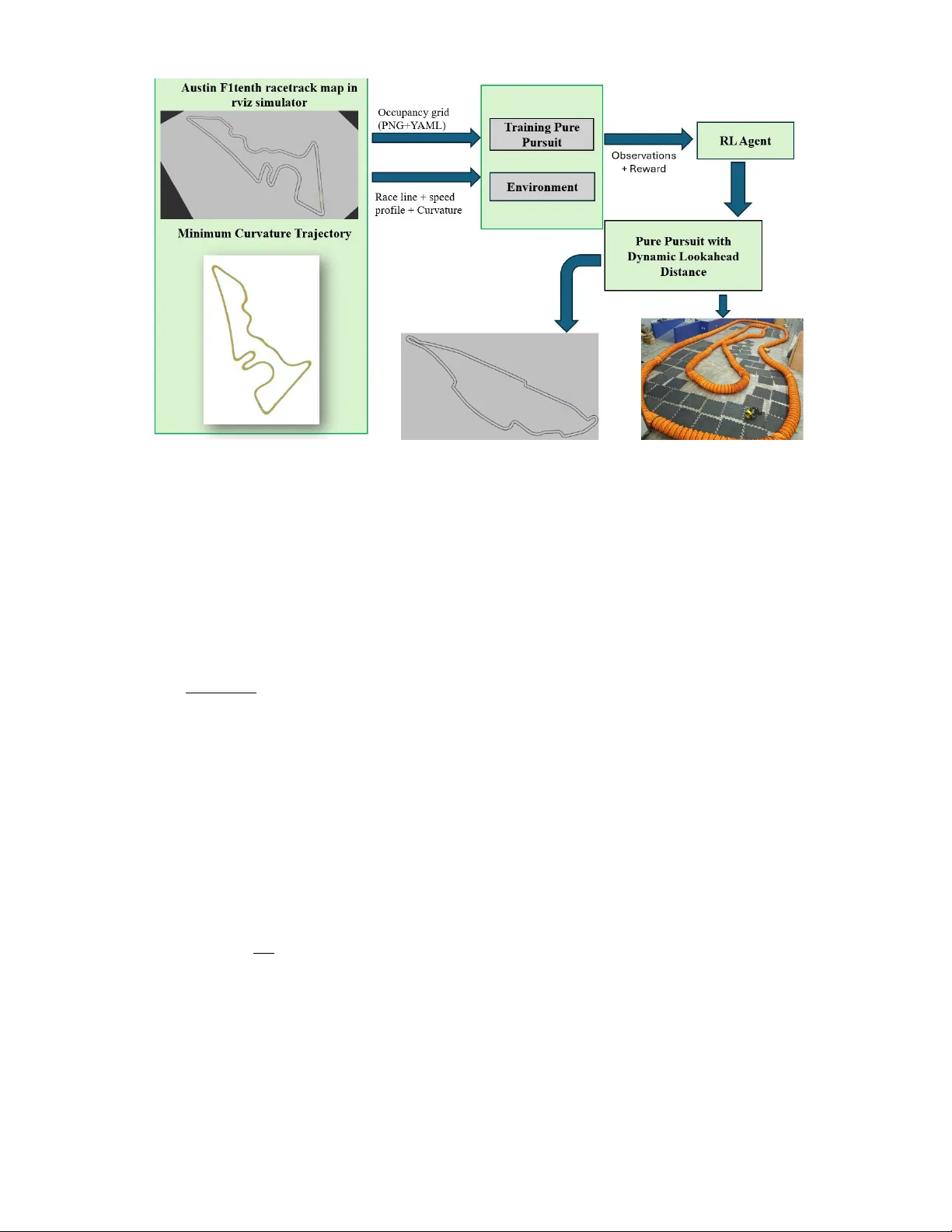
Dynamic Lookahead Distance via Reinforcement Learning-Based Pure Pursuit for Autonomous Racing Mohamed Elgouhary and Amr S. El-W akeel Abstract —Pure Pursuit (PP) is a widely used path-tracking algorithm in autonomous vehicles due to its simplicity and r eal- time performance. However , its effectiveness is sensitive to the choice of lookahead distance: shorter values impro ve cornering but can cause instability on straights, while longer values impr ov e smoothness b ut reduce accuracy in curv es. W e propose a hybrid control framework that integrates Proximal Policy Optimization (PPO) with the classical Pure Pursuit controller to adjust the lookahead distance dynamically during racing. The PPO agent maps vehicle speed and multi-horizon curvature features to an online lookahead command. It is trained using Stable-Baselines3 in the F1TENTH Gym simulator with a KL penalty and learning- rate decay f or stability , then deployed in a ROS2 en vir onment to guide the controller . Experiments in simulation compare the proposed method against both fixed-lookahead Pure Pursuit and an adaptive Pure Pursuit baseline. Additional real-car experi- ments compare the learned controller against a fixed-lookahead Pure Pursuit controller . Results show that the learned policy impro ves lap-time performance and repeated lap completion on unseen tracks, while also transferring zero-shot to hardware. The learned contr oller adapts the lookahead by increasing it on straights and reducing it in curves, demonstrating effectiveness in augmenting a classical controller by online adaptation of a single interpr etable parameter . On unseen tracks, the proposed method achieved 33.16 s on Montreal and 46.05 s on Y as Marina, while tolerating more aggr essiv e speed-profile scaling than the baselines and achieving the best lap times among the tested settings. Initial real-car experiments further support sim-to-real transfer on a 1:10-scale autonomous racing platform. Index T erms —A utonomous Racing, Reinfor cement Learning, Pure Pursuit, PPO, Dynamic Lookahead, Roboracer , Stable- Baselines3 I . I N T RO D U C T I O N Autonomous racing is a rapidly evolving domain that tests the limits of perception, planning, and control algorithms under high-speed and high-precision requirements. Unlike traditional autonomous dri ving, racing inv olv es aggressiv e maneuvers, tight curv es, and the need for real-time adaptation to dynamic vehicle and track conditions. Designing controllers that can operate safely and efficiently in such environments remains a central challenge in robotics and intelligent systems. Among classical trajectory tracking strategies, Pure Pursuit [1] has emerged as a widely adopted geometric controller due The Authors are with the Lane Department of Computer Science and Electrical Engineering, W est V irginia Uni versity , Morganto wn, WV , USA. mae00018@mix.wvu.edu, amr.elwakeel@mail.wvu.edu This work was partially supported by DARP A AI-CRAFT under Grant A WD16069. to its conceptual simplicity , lo w computational overhead, and reasonable performance in many driving scenarios. It works by projecting a lookahead point on a reference trajectory and computing a steering command that aims the vehicle toward that point. Howe v er , despite its popularity , the Pure Pursuit controller exhibits a fundamental limitation: its behavior is highly sensiti ve to the choice of the lookahead distance. The lookahead distance determines the trade-off between stability and responsi veness. A small lookahead v alue can im- prov e curve tracking and allo w faster directional changes, but it often causes steering oscillations and instability on straight segments. A large lookahead v alue usually produces smoother and more stable motion, but it can cut corners and perform poorly in sharp turns. In fixed-lookahead implementations, the controller cannot adapt to changing track conditions, which leads to suboptimal performance, especially in high-speed racing where both accurate cornering and stable straight-line behavior are important. Sev eral heuristic approaches have attempted to address this issue, such as curvature-a ware or speed-dependent lookahead modulation. These methods can improve performance in spe- cific scenarios, but they still rely on manually crafted rules and schedule parameters that often require retuning across tracks, speed profiles, and vehicle platforms. In contrast, a learned adaptation polic y can potentially capture more context- dependent behavior while retaining the structure of the under- lying controller . T o ov ercome these limitations, we propose a hybrid con- trol framew ork that augments classical Pure Pursuit with a learning-based adaptation mechanism [2]. Specifically , we use Proximal Policy Optimization (PPO) [3] to dynamically adjust the lookahead distance in real time based on the vehicle’ s current state. Unlike fixed tuning and hand-crafted adaptive schedules, our approach formulates lookahead selection as a continuous control task, enabling the policy to learn context- dependent behaviors while preserving the structure and inter- pretability of the underlying geometric controller . The PPO agent is trained in simulation using the F1TENTH Gym en vironment [4], where it learns to map vehicle speed and multi-horizon raceline curvature features to an optimal lookahead distance. The integration of PPO with the Pure Pursuit controller ensures that learning remains focused on adaptiv e behavior while retaining the interpretability , robust- ness, and low-latency characteristics of classical control. W e do not replace the underlying geometric controller or learn low-le vel steering and throttle end-to-end. Instead, we focus on a narrower and more interpretable problem: adapting the Pure Pursuit lookahead distance online while preserving the structure, transparency , and lo w computational cost of the clas- sical controller . This framing is especially useful in modular R OS2-based autonomy stacks, where bounded computation and controller interpretability remain important. T o support the learning process, we leveraged a globally optimized race trajectory to extract reference waypoints [5], including x , y positions, target speed, and curv ature at each point. These were used both to guide the baseline controller and to define relev ant state features for the PPO agent. The agent observes vehicle speed and multi-horizon curvature features to learn a dynamic mapping to the lookahead distance. LiD AR is used for collision detection in the en vironment and rew ard to enforce safety during training. For ef ficient and stable training, we utilized Optuna [6] to optimize key hyperparameters, including the initial learn- ing rate and maximum gradient norm. W e further stabilized training by applying KL-div ergence penalties and learning rate decay , enabling smoother con ver gence and improv ed final performance. Because the learned policy adjusts only the Pure Pursuit lookahead parameter while leaving the geometric controller unchanged, the resulting method remains lightweight, inter- pretable, and easy to integrate into modular R OS2 autonomy stacks. Our contributions are as follows: • W e introduce a reinforcement learning-augmented Pure Pursuit controller that dynamically adjusts the lookahead distance online for autonomous racing. • W e design a PPO training setup based on speed and multi- horizon curvature features, together with a reward that promotes progress, smoothness, and safe lap completion. • W e ev aluate the learned policy zero-shot on unseen tracks against both fixed-lookahead and hand-crafted adaptiv e Pure Pursuit baselines, and further v alidate sim-to-real transfer on a real 1:10-scale autonomous racing vehicle against a fixed-lookahead Pure Pursuit baseline. • W e adapt a single interpretable Pure Pursuit parameter ( L d ), yielding behavior consistent with racing intuition while preserving the classical controller structure. This work highlights the potential of combining the adapt- ability of deep reinforcement learning with the reliability and transparency of classical control. The resulting controller is well-suited for high-performance autonomous racing and rep- resents a step toward more intelligent, context-a ware control strategies in robotics. I I . R E L A T E D W O R K Path tracking is a foundational problem in autonomous driving, with numerous classical [7] and learning-based ap- proaches [2] developed over the years. Among classical meth- ods, geometric controllers such as Pure Pursuit [1], Stanle y [8], and the Follo w-the-Carrot algorithm hav e gained widespread popularity due to their simplicity and ease of implementation. In particular, the Pure Pursuit algorithm has seen extensi ve use in autonomous ground vehicles for applications ranging from urban navigation [9], [10] to racing [11], due to its ability to operate in real time with minimal computational resources. Sev eral enhancements to the Pure Pursuit controller have been proposed to improve its adaptability to varying dri ving conditions. One common direction inv olves dynamically ad- justing the lookahead distance based on vehicle speed, track curvature [12], [13], or a combination of both. For example, curvature-a ware lookahead modulation aims to reduce the lookahead in tight curv es to impro ve responsi veness and increase it on straights for stability . Speed-based modulation similarly attempts to increase the lookahead at higher veloci- ties to pre vent ov erreacting to small deviations. While ef fecti ve in specific settings, these heuristics are typically hand-tuned and may not generalize across different vehicle models, tracks, or dri ving scenarios. On the other hand, reinforcement learning (RL) has emerged as a powerful tool for dev eloping adaptive and high- performance control policies [14]. Deep RL algorithms such as Deep Q-Networks (DQN) [15], Deep Deterministic Policy Gradient (DDPG) [16], and Proximal Policy Optimization (PPO) [3] hav e been applied to a wide range of robotic control problems. W ithin the domain of autonomous dri ving, end-to- end learning approaches have demonstrated promising results [17], where policies learn directly from sensory input to output control commands. Howe ver , end-to-end policies that output low-le vel actions can be harder to analyze and validate for deployment, and may degrade under distribution shift (e.g., new tracks or sim-to-real mismatch) [18]–[20]. In the conte xt of autonomous racing, recent work has explored the use of RL for tasks such as trajectory planning, throttle control, and full vehicle control under competitive conditions. En vironments such as Roboracer [4] hav e become common testbeds for these methods. In particular , learning- based approaches hav e demonstrated their ability to outper- form classical controllers in aggressive racing scenarios [21]. Howe ver , most of these methods replace classical control entirely , often at the cost of interpretability and robustness. Our work lies at the intersection of these two paradigms. Rather than replacing the classical controller , we use re- inforcement learning to augment it by tuning a critical hyperparameter—the lookahead distance—based on the cur- rent driving conte xt. This hybrid approach combines the adapt- ability of RL with the prov en stability and interpretability of geometric control [22]. Similar hybrid frameworks hav e been explored in related domains, such as adaptiv e PID tuning [23] and gain scheduling via RL [24]. Ho we ver , few hav e applied this concept to geometric path tracking in autonomous racing [1]. In this study , we compare against both fixed-lookahead Pure Pursuit and a hand-crafted adaptive Pure Pursuit baseline that adjusts lookahead online using rule-based scheduling. This al- lows us to distinguish the benefit of learning-based adaptation from the benefit of dynamic lookahead alone. While related work has explored reinforcement learning for dynamic looka- head generation in truck-dri ving en vironments [25], our formu- lation targets the distinct demands of high-speed autonomous racing. The proposed approach retains the strengths of model- based control while enabling data-dri ven adaptation, making it well-suited for real-time, high-speed, and safety-critical scenarios. In addition to local path-tracking strategies, global trajectory optimization has been employed in autonomous rac- ing to precompute an optimal racing line for the entire track. The minimum-curvature method, as implemented in the TUM global_racetrajectory_optimization framew ork [5], generates a smooth path within track boundaries by min- imizing integrated squared curvature. This approach produces racing lines that balance stability and cornering capability , and is often used as a reference trajectory for downstream controllers such as MPC or Pure Pursuit. I I I . B AC K G RO U N D A N D P RO P O S E D M E T H O D A. Bac kgr ound Components This section summarizes our end-to-end pipeline. W e localize with a LiDAR-based MCL particle filter, generate a minimum- curvature racing line, and overlay a PPO-trained policy that selects a dynamic Pure Pursuit lookahead online. W e then detail the observ ation/action spaces, reward, models, training setup, and how these components integrate in simulation and on the real RoboRacer car . B. Monte Carlo Localization via P article Filter W e estimate global pose with a Monte Carlo Localization (MCL) particle filter [26], [27] that uses LiD AR measurements and a precomputed occupancy grid. The filter maintains a set of weighted pose hypotheses (“particles”) that approximates the posterior over the vehicle’ s ( x, y , ψ ) . At each time step, ev ery particle is propagated forw ard using a bicycle-model kinematics driv en by the commanded speed and steering. Small, zero-mean process noise is injected to capture unmodeled dynamics and odometry uncertainty . For each particle, we ray-cast the occupancy grid to predict LiD AR ranges and compare them with the observ ed scan using a standard beam-based likelihood model. Particles that better explain the scan receiv e higher weights. When weights become overly concentrated (low effecti ve sample size), we apply systematic resampling to refocus par- ticles around high-probability regions while limiting particle impov erishment. The vehicle pose is read out as the weighted a verage of the particle set; the heading is computed via a circular (angle-aware) mean. This implementation follows the classical formulation of Thrun, Burgard, and Fox and the MIT notes. C. Global T rajectory Gener ation via Minimum Curvatur e Optimization T o generate the reference trajectory for our controller , we adopt the minimum curvatur e method implemented in the TUM global_racetrajectory_optimization framew ork [5]. This method computes a racing line that min- imizes integrated squared curvature, producing a smooth and dynamically feasible path within the given track boundaries. 1) T rack Repr esentation: The track is represented by its centerline ( x c ( s ) , y c ( s )) and left/right boundaries ( x l ( s ) , y l ( s )) and ( x r ( s ) , y r ( s )) , parameterized by arc length s ∈ [0 , S ] , where S is the total track length. For optimization, the problem is formulated in the Frenet frame, where each point on the path is defined by: p ( s ) = c ( s ) + d ( s ) · n ( s ) , (1) where c ( s ) is the centerline position, n ( s ) is the unit normal vector to the centerline, and d ( s ) is the lateral offset to be optimized. 2) Curvatur e Cost Function: The path curvature κ ( s ) for a parametric path p ( s ) = ( x ( s ) , y ( s )) is computed as: κ ( s ) = ˙ x ( s ) ¨ y ( s ) − ˙ y ( s ) ¨ x ( s ) [ ˙ x ( s ) 2 + ˙ y ( s ) 2 ] 3 / 2 , (2) where ˙ ( · ) and ¨ ( · ) denote first and second deri vati ves with respect to s . The optimization objective is to minimize the integrated squared curvature: J κ = Z S 0 κ ( s ) 2 ds. (3) This promotes smoothness, reduces lateral acceleration de- mands, and indirectly maximizes the achiev able speed in curves. 3) Optimization Pr oblem: The minimum curvature opti- mization problem is formulated as: min d ( s ) Z S 0 κ ( s ) 2 ds (4) s.t. d min ( s ) ≤ d ( s ) ≤ d max ( s ) , (5) d (0) = d ( S ) , ˙ d (0) = ˙ d ( S ) , (6) where (5) enforces the track boundary constraints and (6) ensures lap closure and continuity . 4) V elocity Pr ofile Generation: Once the optimal path is obtained, a velocity profile is computed using the friction- limited acceleration constraint: a x ( s ) 2 + a y ( s ) 2 ≤ ( µg ) 2 , (7) where: a y ( s ) = v ( s ) 2 κ ( s ) , a x ( s ) = dv ( s ) dt . (8) This yields the maximum feasible speed at each point: v max ( s ) = r µg | κ ( s ) | + ϵ , (9) where ϵ is a small positive constant to avoid di vision by zero on straights. The final reference trajectory T is thus: T = { x ( s ) , y ( s ) , κ ( s ) , v max ( s ) } S s =0 , (10) which is exported as waypoints for the do wnstream Pure Pursuit controller . 5) Inte gration with the Contr ol System: This precomputed minimum-curvature trajectory serves as a global reference, while our RL-augmented Pure Pursuit controller tracks it in real time. This combination le verages the global smoothness of the optimized path and the local adaptability of the RL-tuned lookahead distance. D. System Arc hitecture Our system integrates a reinforcement learning (RL) agent with a geometric path tracking controller to achiev e real-time adaptation in autonomous racing. The control pipeline consists of two core modules: 1) RL-based Lookahead Distance Selection: A PPO agent interacts with a Gym-wrapped Roboracer simu- lation en vironment, observing vehicle states and out- putting an optimal lookahead distance L d . 2) Pure Pursuit Contr ol: The selected L d is used to determine the target waypoint, from which the curvature and steering angle are computed. The vehicle operates in the RoboRacer simulator wrapped in a Gym-compatible API, enabling closed-loop train- ing with synchronous R OS2 message exchange. Fig. 1 shows the system overvie w . Starting from the Austin track map from the roboracer_racetracks repos- itory [28], we visualize the occupancy grid in R V iz and compute a minimum-curvature raceline using the TUM global_racetrajectory_optimization tool- box [5]. The resulting raceline provides curvature features and a speed profile capped at 12 m/s, which, together with the map, feed the training en vironment (simulator with sens- ing/odometry) and a baseline Pure Pursuit controller used during training. Both modules generate trajectories and ob- servations for an RL agent (PPO), which learns a policy that selects a dynamic lookahead distance online. The learned policy is integrated with Pure Pursuit in the Pure Pursuit with Dynamic Lookahead Distance module. W e validate the controller in simulation and then deploy it on the real RoboRacer car . For completeness, the agent observes speed and multi-horizon curvature features deri ved from the raceline and outputs a continuous lookahead distance that is lightly smoothed before use; the detailed observation/action and re ward definitions follow . E. Observation and Action Spaces The PPO agent observes a fiv e-dimensional state vector at each timestep: s t = v t κ 0 ,t κ 1 ,t κ 2 ,t ∆ κ t (11) where: • v t : V ehicle speed in m/s, computed from odometry . • κ 0 ,t , κ 1 ,t , κ 2 ,t : Absolute path curvatures at the closest, medium-horizon, and far-horizon waypoints, respecti vely . • ∆ κ t = κ 1 ,t − κ 0 ,t : Curvature change ahead of the v ehicle. The action space is continuous and one-dimensional: a t = L t +1 ∈ [0 . 35 , 4 . 0] (meters) (12) representing the lookahead distance used by the Pure Pursuit controller . T o reduce jitter , an exponential smoothing filter is applied before publishing L t +1 . These bounds were chosen to cover the practical range of stable lookahead distances observed across low-speed cornering and high-speed straight- line dri ving in our platform and simulator setup. F . Rewar d Function Design The reward at timestep t balances speed, smoothness, cur- vature minimization, collision avoidance, and path progress: R t = w v v t − w e | L t − L ∗ t | − w j | L t − L t − 1 | − w k max( κ 0 ,t , κ 1 ,t , κ 2 ,t ) − w c · I collision + w p · ∆ p t − w s I stall (13) where: • L ∗ t = 0 . 50 + 0 . 28 v t − 3 . 5 · max( κ 0 ,t , κ 1 ,t , κ 2 ,t ) : heuristic ideal lookahead. • ∆ p t : W aypoints advanced since the last step. • I collision : T rue if the minimum LiDAR range < 0 . 2 m. • I stall : T rue if v t < 0 . 05 m/s for a duration. The re ward is clipped to: R t ← clip ( R t , − 20 , 50) , (14) stabilizing training by limiting extreme outcomes. The heuris- tic ideal-lookahead term is used only as a shaping signal to stabilize training; the deployed controller still relies on the learned policy output rather than a hand-crafted online rule. G. Pur e Pursuit Contr ol The Pure Pursuit algorithm selects a target point ( x target , y target ) that lies L d,t meters ahead along the path. T ransforming to the vehicle frame yields coordinates ( x ′ t , y ′ t ) . The instantaneous curvature command is γ t = 2 y ′ t L 2 d,t . (15) T o av oid sudden steering changes, we apply a first-order low- pass filter: ¯ γ t = (1 − β ) ¯ γ t − 1 + β γ t , β = 0 . 4 . (16) The steering angle is then δ t = arctan L w g ( v t ) ¯ γ t , (17) where L w is the wheelbase and g ( v t ) is the speed-dependent steering gain. Fig. 1: Training-and-deplo yment workflo w . A map and minimum-curvature raceline are generated offline and used by the simulator environment and baseline Pure Pursuit controller during training. The PPO agent receiv es observations and re ward from the environment and outputs a dynamic lookahead policy , which is then integrated with Pure Pursuit for simulation validation and real-world deployment on a 1:10-scale autonomous racing platform. H. Curvatur e-A ware Steering Gain The steering gain is dynamically adjusted based on vehicle speed: g ( v ) = max (min( mv + b, g max ) , g min ) (18) with: m = g min − g max v max − v min , b = g max − mv min (19) Here, g min and g max denote the minimum and maximum steering-gain limits used to bound the speed-dependent sched- ule. This prevents oversteering at high speeds and improves corner stability . I. V ehicle Dynamics Model The system assumes a kinematic bicycle model for state ev olution: ˙ x = v cos( θ ) (20) ˙ y = v sin( θ ) (21) ˙ θ = v L w tan( δ ) (22) ˙ v = a (23) where ( x, y ) is position, θ is heading, v is speed, a is acceleration, δ is steering angle, and L w is the wheelbase. This simplified model served as a practical approximation for the training and ev aluation setup used in this work, while real- world validation was used to assess transfer beyond the model assumptions. J. Pr oximal P olicy Optimization (PPO) W e use the Stable-Baselines3 Proximal Policy Optimization (PPO) algorithm to train the policy π θ ( a t | s t ) for adapti ve lookahead tuning. PPO is a polic y-gradient method that seeks to maximize a clipped surrogate objectiv e, thereby improv- ing training stability by prev enting excessi vely large policy updates. T raining uses: • Trajectory length n steps = 10 , 000 , • Batch size 256 , • n epochs = 5 , • Discount factor γ = 0 . 99 , • GAE parameter λ = 0 . 98 , • Clipping parameter ϵ = 0 . 2 , • target KL = 0 . 015 , • Entropy coefficient 0 . 02 for exploration, • V alue function coefficient 0 . 6 , and • Learning-rate schedule: a linear decay implemented as learning_rate(f) = ℓ 0 f with ℓ 0 = 2 . 3927 × 10 − 4 (SB3 passes f ∈ [1 , 0] as remaining training progress). 1 PPO maximizes the clipped surrogate: L clip ( θ ) = E t h min r t ( θ ) ˆ A t , clip( r t ( θ ) , 1 − ϵ, 1 + ϵ ) ˆ A t i (24) with r t ( θ ) = π θ ( a t | s t ) /π θ old ( a t | s t ) . The total loss combines 1 Code: initial_lr = 0.00023927; learning_rate = lambda f: initial_lr * f Eval mean reward Eval episode length Explained variance (critic) Entropy Fig. 2: T raining diagnostics for PPO. Reward and episode length are computed on a fixed ev aluation en vironment; ex- plained v ariance and entropy are logged during training. policy , value, and entropy terms: L ppo ( θ , ϕ ) = −L clip ( θ ) + c v E t ( V ϕ ( s t ) − ˆ R t ) 2 − c s E t H ( π θ ( · | s t )) (25) Here, ˆ A t denotes the generalized-adv antage estimate, ˆ R t the return target for value learning, c v the value-loss weight, and c s the entropy weight. K. Implementation and T raining The training pipeline is implemented using rclpy in R OS2 and utilizes Stable-Baselines3’ s PPO algorithm. Ke y training details include: • 800,000 environment steps • V ecNormalize for online normalization of observ ations and re wards • T ensorBoard logging for rew ard monitoring • Evaluation ev ery 10,000 steps with automatic best-model saving As shown in Fig. 2, ev aluation re ward increases through- out training, accompanied by longer ev aluation episodes and shrinking v ariance—indicating both performance and stability gains. The critic’ s explained variance rises to ∼ 0.9, sug- gesting accurate value estimates that stabilize PPO updates. Meanwhile, entrop y decreases smoothly , reflecting a controlled shift from exploration to exploitation consistent with our linear learning-rate decay . T ogether , these curves evidence a con vergent policy that generalizes to the ev aluation setting and yields robust, longer-horizon driving. T raining is conducted entirely in simulation using the F1TENTH Gym en vironment, with multiple runs to assess consistency and generalization. At each step, the PPO agent outputs L d , which is smoothed and published to ROS. The Pure Pursuit node computes steering and speed commands, and the en vironment returns the next observation and re ward. This closed-loop cycle enables the agent to learn curvature-a ware, speed-adaptiv e lookahead selection for high-performance au- tonomous racing. All runs were executed for approximately 4 hours on a Dell Precision 3660 workstation (Intel Core i9- 13900, 32 GiB RAM), running Ubuntu 22.04.5 L TS (64-bit, X11); graphics were reported as “NVIDIA Corporation / Mesa Intel Graphics (RPL-S)”. I V . E X P E R I M E N TA L R E S U L T S W e ev aluate the proposed method in simulation and present initial real-car validation on a RoboRacer vehicle. F ixed-Lookahead F ailur e Modes: A Pure Pursuit (PP) controller with a fixed lookahead L is highly map- and speed-profile dependent. When L is too small, the vehicle exhibits oscillations on straights and may cut inside on curves; when L is too large, tracking is steadier on straights but it understeers and fails in tighter corners. In practice, each new map demands extensi ve retuning of L (and of any hand-crafted “dynamic” heuristics that couple L to speed), and success is not guaranteed. Setup and zer o-shot evaluation: W e train the Dynamic- L policy with PPO entirely in simulation on the Austin racetrack and ev aluate it without finetuning on two unseen tracks, Mon- treal and Y as Marina, from the roboracer_racetracks repository [28]. W e compare three controllers: fixed-lookahead Pure Pursuit, a hand-crafted adaptive Pure Pursuit baseline, and the proposed RL-based Dynamic- L controller . T o increase ev aluation dif ficulty , we tested the controllers under acceler- ated raceline speed profiles on the unseen tracks whenev er stable repeated lap completion could be achieved. Because each controller tolerated different maximum speed- profile scalings on the unseen tracks, the reported results should be interpreted primarily as evidence of robustness and reduced retuning burden rather than as a strict like-for -like comparison under identical operating conditions. Adaptive Pur e Pursuit baseline: F or the adaptive Pure Pursuit baseline, the lookahead distance is scheduled online as L d = clip( a + bv t , L min , L max ) , where v t is the vehicle speed. W e use the same feasible looka- head bounds as the learned controller , namely L d ∈ [0 . 35 , 4 . 0] m. The same scheduling rule and parameter values are used across all simulator test tracks, without additional per-track retuning. This baseline is included to distinguish the benefit of learned context-dependent adaptation from the benefit of dynamic lookahead scheduling alone. The adaptive baseline is ev aluated in simulation only and is not included in the present hardware comparison. Interpr etability and r obustness evidence: W e use robust- ness to mean the ability to complete laps reliably without per-map retuning when track geometry and speed profiles change, and when transferring from simulation to hardware. Accordingly , we ev aluate (i) zero-shot generalization from the T ABLE I: Montreal track lap times ov er 10 consecutiv e laps (s). Controller Mean Std Min Max RL PP ( +13% speed) 33.16 0.069 33.06 33.28 Adaptiv e PP ( +10% speed) 34.15 0.061 34.02 34.23 Fixed- L PP ( − 10% speed) 41.36 0.067 41.25 41.45 T ABLE II: Y as Marina track lap times over 10 consecutiv e laps (s). Controller Mean Std Min Max RL PP ( +15% speed) 46.05 0.035 46.00 46.10 Adaptiv e PP ( +14% speed) 46.79 0.095 46.67 46.79 Fixed- L PP (orig. speed) 52.81 0.18 52.52 53.10 training map to two unseen maps under accelerated speed profiles, and (ii) deployment on a real RoboRacer vehicle under an independently generated raceline speed profile. The inclusion of an adaptive heuristic Pure Pursuit baseline fur- ther tests whether the gains of the proposed method arise from learned context-dependent adaptation rather than from dynamic lookahead scheduling alone. Montr eal RoboRacer racetr ac k quantitative results (10 consecutive laps): On Montreal, Dynamic- L completes 10/10 laps under a +13% speed profile, achieving a mean lap time of 33.16 s with a standard deviation of 0.069 s , as reported in T able I. The adaptive Pure Pursuit baseline also completes 10/10 laps, but under a slower +10% speed profile, recording 34.15 s with a standard deviation of 0.061 s . The fixed- L PP baseline (with L = 1 . 2 m) completes 10/10 laps only after reducing the speed profile by -10% , where it records 41.36 s with a standard deviation of 0.067 s . Lap-time statistics are reported in T able I. These results indicate that the learned dynamic-lookahead policy reduces sensitivity to per-map tuning and supports reliable operation at a more aggressi ve speed profile than either baseline on this unseen track. Y as Marina RoboRacer racetrac k quantitative results (10 consecutive laps): On Y as Marina, Dynamic- L completes 10/10 laps under a +15% accelerated speed profile, achieving a mean lap time of 46.05 s with a standard deviation of 0.035 s , as reported in T able II. The adaptive Pure Pursuit baseline also completes 10/10 laps, but under a slightly lower +14% speed profile, recording 46.79 s with a standard deviation of 0.095 s . For the fixed- L baseline (with L = 1 . 35 m), stable repeated completion at the accelerated profile was not achiev ed; there- fore, we report its results under the original speed profile, where it records 52.81 s with a standard deviation of 0.18 s . Lap-time statistics are reported in T able II. This comparison further supports that the learned dynamic- lookahead policy reduces retuning burden and tolerates a more aggressiv e speed profile than the fixed-lookahead baseline while also achieving a lower lap time than the adaptive scheduling baseline under a slightly more aggressiv e speed T ABLE III: Real-car lap times over 10 consecutive laps with a raceline speed profile capped at 5 m/s (s). Controller Mean Std Min Max RL PP 11.13 0.26 10.79 11.66 Fixed- L PP DNF / failed to complete repeated laps Fig. 3: Qualitati ve real-car trajectory ov erlay . The learned Dynamic- L controller tracks the reference raceline and com- pletes repeated laps on the mapped track under the tested speed profile. profile on this unseen track. Real-car validation: W e additionally validated the pro- posed Dynamic- L controller on a real 1:10-scale autonomous racing vehicle using a raceline speed profile capped at v max = 5 m/s on a mapped track. On hardware, Dynamic- L completed 10/10 laps with a mean lap time of 11 . 13 ± 0 . 26 s (range 10 . 79 – 11 . 66 s). Under the same profile, a fixed- L Pure Pursuit controller failed to complete repeated laps reliably . Fig. 3 qual- itativ ely shows that Dynamic- L tracks the reference raceline and completes full laps under the tested profile. W e limit the hardware comparison to the fixed-lookahead baseline, while the adaptive Pure Pursuit baseline is ev aluated in simulation only . V . C O N C L U S I O N W e introduced a PPO-based dynamic lookahead policy π θ ( L d | s ) for Pure Pursuit. Trained in simulation on one track and e v aluated zero-shot on unseen tracks, the policy completed repeated laps reliably under aggressiv e speed profiles while preserving the simplicity and interpretability of the underlying geometric controller . Compared with fixed-lookahead Pure Pursuit and a hand-crafted adaptive Pure Pursuit baseline, the proposed method demonstrated stronger robustness to track changes and reduced retuning burden. On Montreal and Y as Marina, Dynamic- L achiev ed 33 . 16 ± 0 . 069 s and 46 . 05 ± 0 . 035 s, respectively , while operating under +13% and +15% speed profiles. In both cases, the learned policy achiev ed the best lap times among the tested settings while also tolerating equal or more aggressiv e speed-profile scaling than the baselines. These results suggest improv ed robustness to track changes and reduced retuning burden, rather than a strict like-for-like comparison under identical operating conditions. Real-car validation. Experiments further support sim-to-real transfer of the learned dynamic-lookahead policy on a 1:10- scale autonomous racing platform. Future work will expand the hardware study to include broader adapti ve scheduling rules and additional learning-based racing controllers and will further analyze which components of the present design—state features, smoothing, steering-gain scheduling, and re ward terms—are most critical to performance. R E F E R E N C E S [1] V . Sukhil and M. Behl, “ Adaptive lookahead pure-pursuit for autonomous racing, ” 2021. [Online]. A vailable: https://arxiv .org/abs/ 2111.08873 [2] D. C. Guastella and G. Muscato, “Learning-based methods of perception and navigation for ground vehicles in unstructured environments: A revie w , ” Sensors , vol. 21, no. 1, p. 73, 2021. [3] J. Schulman, F . W olski, P . Dhariwal, A. Radford, and O. Klimov , “Proximal policy optimization algorithms, ” 2017. [Online]. A vailable: https://arxiv .org/abs/1707.06347 [4] M. O’Kelly , H. Zheng, D. Karthik, and R. Mangharam, “F1tenth: An open-source e valuation en vironment for continuous control and reinforcement learning, ” in Pr oceedings of the NeurIPS 2019 Competition and Demonstration T rack , ser . Proceedings of Machine Learning Research, H. J. Escalante and R. Hadsell, Eds., vol. 123. PMLR, 08–14 Dec 2020, pp. 77–89. [Online]. A vailable: https://proceedings.mlr .press/v123/o- kelly20a.html [5] A. Heilmeier , A. W ischnewski, L. Hermansdorfer , J. Betz, M. Lienkamp, and B. Lohmann, “Minimum curvature trajectory planning and control for an autonomous race car, ” V ehicle System Dynamics , vol. 58, no. 10, pp. 1497–1527, 2020. [Online]. A vailable: https: //doi.org/10.1080/00423114.2019.1631455 [6] T . Akiba, S. Sano, T . Y anase, T . Ohta, and M. K oyama, “Optuna: A next- generation hyperparameter optimization framework, ” in Proceedings of the 25th A CM SIGKDD International Conference on Knowledge Discovery and Data Mining . Anchorage, AK, USA: ACM, 2019, pp. 2623–2631. [7] M. Reda, A. Onsy , A. Y . Haikal, and A. Ghanbari, “Path planning algorithms in the autonomous dri ving system: A comprehensive revie w , ” Robotics and Autonomous Systems , vol. 174, p. 104630, 2024. [Online]. A vailable: https://www .sciencedirect.com/science/article/pii/ S0921889024000137 [8] M. Fazekas, Z. Demeter , J. T ´ oth, ´ A. Bog ´ ar-N ´ emeth, and G. B ´ ari, “Evaluation of local planner-based stanley control in autonomous rc car racing series, ” in 2024 IEEE Intelligent V ehicles Symposium (IV) , 2024, pp. 252–257. [9] S. Mondal, M. Pal, S. Sen, P . Utkarsh, N. Bhattacharjee, and T . Singha, “ Autonomous navigation in dynamic environments using modified pure pursuit, vector field histogram, and lidar -slam, ” in 2025 8th International Confer ence on T r ends in Electronics and Informatics (ICOEI) , 2025, pp. 1660–1664. [10] M. Samuel, M. Hussein, and M. Binti, “ A revie w of some pure-pursuit based path tracking techniques for control of autonomous vehicle, ” International Journal of Computer Applications , vol. 135, pp. 35–38, 02 2016. [11] R. Al Fata and N. Daher, “ Adaptive pure pursuit with de viation model regulation for trajectory tracking in small-scale racecars, ” in 2025 International Conference on Control, Automation, and Instrumentation (IC2AI) , 2025, pp. 1–6. [12] A. L. Garrow , D. L. Peters, and T . A. Panchal, “Curv ature sensitive modification of pure pursuit control1, ” ASME Letters in Dynamic Systems and Control , vol. 4, no. 2, p. 021002, 02 2024. [Online]. A vailable: https://doi.org/10.1115/1.4064515 [13] F . T arhini, R. T alj, and M. Doumiati, “ Adaptiv e look-ahead distance based on an intelligent fuzzy decision for an autonomous vehicle, ” in 2023 IEEE Intelligent V ehicles Symposium (IV) , 2023, pp. 1–8. [14] J. B. Kimball, B. DeBoer , and K. Bubbar , “ Adaptive control and reinforcement learning for v ehicle suspension control: A revie w , ” Annual Reviews in Contr ol , vol. 58, p. 100974, 2024. [Online]. A vailable: https://www .sciencedirect.com/science/article/pii/S1367578824000427 [15] V . Mnih, K. Kavukcuoglu, D. Silver , A. Graves, I. Antonoglou, D. W ierstra, and M. Riedmiller, “Playing atari with deep reinforcement learning, ” 2013. [Online]. A vailable: https://arxiv .org/abs/1312.5602 [16] T . P . Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T . Erez, Y . T assa, D. Silver , and D. Wierstra, “Continuous control with deep reinforcement learning, ” 2019. [Online]. A vailable: https://arxiv .org/abs/1509.02971 [17] M. Ganesan, S. Kandhasamy , B. Chokkalingam, and L. Mihet-Popa, “ A comprehensi ve revie w on deep learning-based motion planning and end-to-end learning for self-driving vehicle, ” IEEE Access , vol. 12, pp. 66 031–66 067, 2024. [18] S. Milani, N. T opin, M. V eloso, and F . Fang, “Explainable reinforcement learning: A surve y and comparativ e review , ” ACM Comput. Surv . , v ol. 56, no. 7, Apr . 2024. [Online]. A vailable: https://doi.org/10.1145/3616864 [19] A. W achi, W . Hashimoto, X. Shen, and K. Hashimoto, “Safe exploration in reinforcement learning: a generalized formulation and algorithms, ” in Pr oceedings of the 37th International Conference on Neural Information Pr ocessing Systems , ser . NIPS ’23. Red Hook, NY , USA: Curran Associates Inc., 2023. [20] J. Qi, H. Gao, H. Su, M. Huo, H. Y u, and Z. Deng, “Reinforcement learning and sim-to-real transfer of reorientation and landing control for quadruped robots on asteroids, ” IEEE T ransactions on Industrial Electr onics , vol. 71, no. 11, pp. 14 392–14 400, 2024. [21] B. D. Evans, H. W . Jordaan, and H. A. Engelbrecht, “Comparing deep reinforcement learning architectures for autonomous racing, ” Machine Learning with Applications , vol. 14, p. 100496, 2023. [Online]. A vailable: https://www .sciencedirect.com/science/article/pii/ S266682702300049X [22] X. Sha and T . Lan, “Massively high-throughput reinforcement learning for classic control on gpus, ” IEEE Access , vol. 12, pp. 117 737–117 744, 2024. [23] R. Muduli, D. Jena, and T . Moger , “ Application of reinforcement learning-based adaptive pid controller for automatic generation control of multi-area power system, ” IEEE T ransactions on Automation Science and Engineering , vol. 22, pp. 1057–1068, 2025. [24] T . K obayashi, “Re ward bonuses with gain scheduling inspired by iterativ e deepening search, ” Results in Contr ol and Optimization , vol. 12, p. 100244, 2023. [Online]. A vailable: https://www .sciencedirect.com/ science/article/pii/S2666720723000462 [25] Z. Han, P . Chen, B. Zhou, and G. Y u, “Hybrid path tracking control for autonomous trucks: Integrating pure pursuit and deep reinforcement learning with adaptiv e look-ahead mechanism, ” IEEE T ransactions on Intelligent T ransportation Systems , vol. 26, no. 5, pp. 7098–7112, 2025. [26] D. Fox, W . Burgard, F . Dellaert, and S. Thrun, “Monte carlo localization: efficient position estimation for mobile robots, ” in Proceedings of the Sixteenth National Confer ence on Artificial Intelligence and the Ele venth Innovative Applications of Artificial Intelligence Conference Innovative Applications of Artificial Intelligence , ser . AAAI ’99/IAAI ’99. USA: American Association for Artificial Intelligence, 1999, p. 343–349. [27] C. W alsh and S. Karaman, “Cddt: Fast approximate 2d ray casting for accelerated localization, ” vol. abs/1705.01167, 2017. [Online]. A vailable: http://arxiv .org/abs/1705.01167 [28] “F1tenth racetracks, ” https://github.com/f1tenth/f1tenth racetracks.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment