Trust-Aware Routing for Distributed Generative AI Inference at the Edge
Emerging deployments of Generative AI increasingly execute inference across decentralized and heterogeneous edge devices rather than on a single trusted server. In such environments, a single device failure or misbehavior can disrupt the entire infer…
Authors: Chanh Nguyen, Erik Elmroth
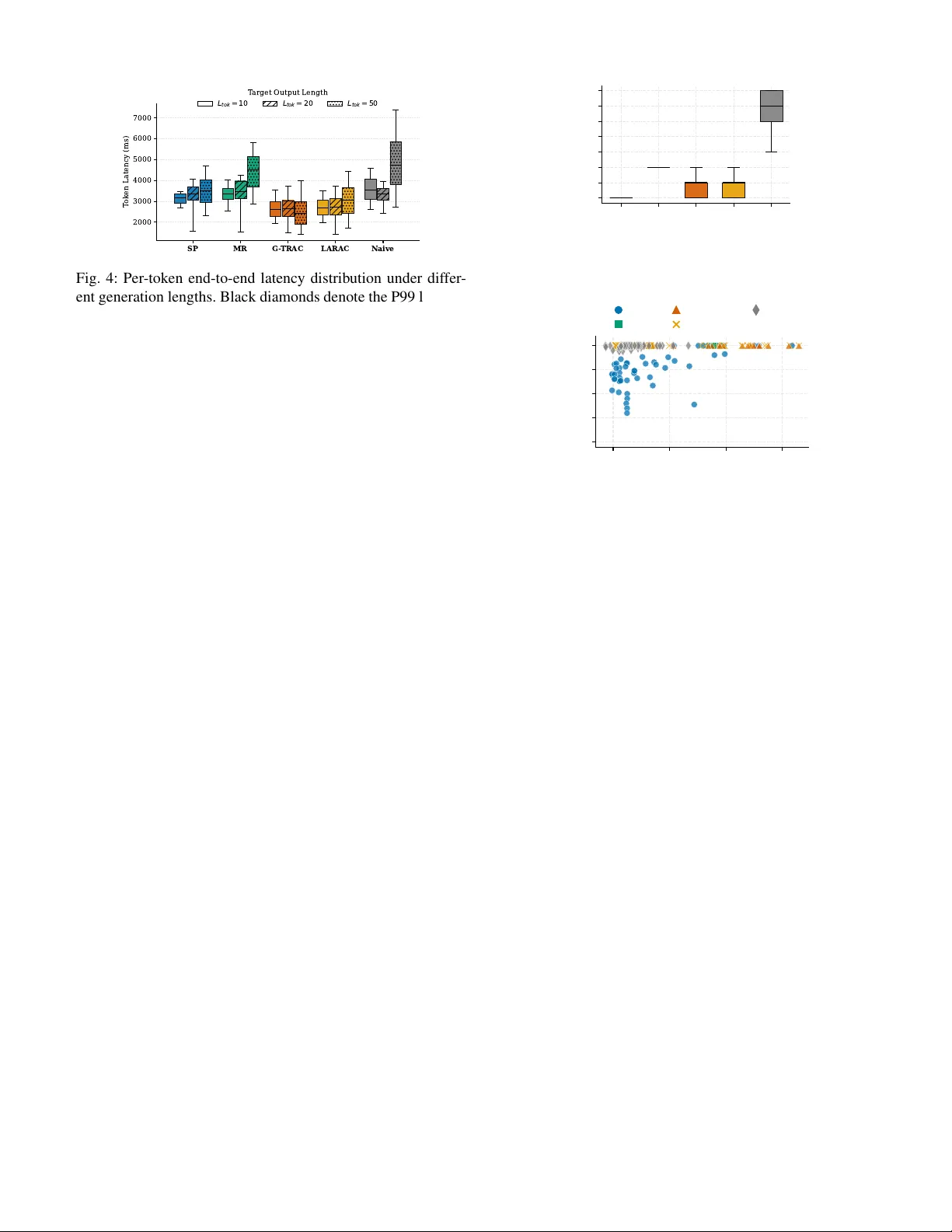
T rust-A ware Routing for Distrib uted Generati ve AI Inference at the Edge Chanh Nguyen, Erik Elmroth Department of Computing Science, Ume ˚ a Univ ersity , SE-90187, Sweden Email: { chanh, elmroth } @cs.umu.se Abstract —Emerging deployments of Generative AI increas- ingly execute inference across decentralized and heterogeneous edge devices rather than on a single trusted server . In such en vironments, a single device failure or misbeha vior can disrupt the entire inference process, making traditional best-eff ort peer - to-peer routing insufficient. Coordinating distributed generative inference theref ore requir es mechanisms that explicitly account for reliability , performance variability , and trust among partici- pating peers. In this paper , we present G-TRAC, a trust-aware coordination framework that integrates algorithmic path selection with system- level protocol design to ensure rob ust distributed inference. First, we formulate the routing pr oblem as a Risk-Bounded Shortest P ath computation and introduce a polynomial-time solution that combines trust-floor pruning with Dijkstra’ s search, achieving sub-millisecond median routing latency at practical edge scales, and remaining below 10 ms at larger scales. Second, to opera- tionally support the routing logic in dynamic envir onments, the framework employs a Hybrid Trust Architecture that maintains global reputation state at stable anchors while disseminating lightweight updates to edge peers via background synchr oniza- tion. Experimental evaluation on a heterogeneous testbed of com- modity devices demonstrates that G-TRA C significantly impro ves inference completion rates, effectively isolates unreliable peers, and sustains rob ust execution even under node failures and network partitions. Index T erms —Edge Computing, Edge Intelligence, Distrib uted LLM Inference, Risk-Bounded Systems, T rust-A ware Routing, Pipeline Parallelism. I . I N T R O D U C T I O N Generativ e artificial intelligence (GenAI) has recently emerged as a transformativ e class of models capable of producing human-like content (e.g., text, image, code, and video) from simple textual prompts [1], [2]. In contrast to traditional AI systems that primarily perform classification or prediction through a single forward pass [3], GenAI synthesizes new content through large-scale, autoregressi ve inference [4], [5]. These systems frequently utilize trillion- scale ar chitectur es and Mixtur e-of-Experts designs [6], [7], introducing significantly higher computational, memory , and latency demands due to the iterativ e and sequential nature of token generation. T o meet these demands, large-scale GenAI models are typically deployed on high-performance server clusters equipped with specialized AI accelerators and ultra- high-speed interconnects [2], [8], [9]. Reliance on such centralized data centers exposes GenAI services to network disruptions, service outages, and increased privacy and data-governance complexity [10], particularly regarding sov ereign data requirements, cross-jurisdictional handling [11], [12], and the risks inherent in large-scale data aggre gation. These limitations hav e motiv ated increasing interest in edge-based GenAI deployment , which promises lower network-induced latency , improved responsiveness, and greater resilience to disconnection. Howe ver , this promise is fundamentally constrained by the nature of edge environments themselves, i.e., edge de vices are highly heterogeneous and sev erely resource-limited, making it infeasible for any single node (e.g., smartphones, IoT gate ways, local edge servers) to host or ex ecute large generativ e models in isolation. T o partially address this mismatch, Small Language Models (typically ranging from hundreds of millions to a fe w bil- lion parameters) [13], [14] hav e been developed for use on resource-constrained de vices [15]. Ne vertheless, a substantial performance gap remains: reducing model scale often degrades complex reasoning ability , factual accuracy [16], and rob ust- ness against hallucinations [17], [18]. Although ex ecuting high-capacity models end-to-end re- mains infeasible on edge de vices, recent advances in model partitioning and pipelined inference [19], [20], [21] enable cooperativ e ex ecution of generati ve workloads across multiple resource-constrained nodes. In such settings, the central chal- lenge extends be yond the technical partitioning of inference computation to ensuring rob ustness and reliability in the presence of stragglers and unreliable peers (e.g., nodes may become ov erloaded, disconnect without warning, or return incorrect or low-quality outputs). Existing peer-to-peer (P2P) framew orks [22], [23], [24] address these challenges only in a best-effort manner , i.e., decentralized inference execution without explicit latency or reliability guarantees, and lack a fundamental notion of computational trust that accounts for the beha vioral history or observed reliability of autonomous edge participants. W e argue that, in decentralized edge environments, r outing becomes a first-class contr ol pr oblem for gener ative infer ence workloads , as execution must be coordinated across heteroge- neous and unreliable peers rather than relegated to passi ve data transport [25]. Unlike con ventional networking, where packets follow stateless forwarding paths, GenAI inference routing must select execution paths under uncertainty , balancing la- tency , reliability , and dynamic av ailability . This requirement formulates the routing task as a Risk-Bounded Shortest Path (RBSP) problem, uniquely complicated by the iterative, token- based nature of the generation process. 1 Smart-city Scenario Leo is a citizen in a high-tech smart city . At a transit hub, he needs to use a GenAI personal assistant to process his citizen digital twin, i.e., sensitive data containing real-time location history , tax status, and biometric verification, to generate a personalized energy subsidy application. The city’ s data sovereignty ordinance mandates that any AI processing involving such sensitive citizen data must remain within the city’ s geographic and administratively controlled network boundaries. However , Leo’s smartphone lacks the compute and energy capacity required to execute the trillion-scale model needed for complex legal reasoning. Leo’ s device activates G-TRAC to select a collaborative pipeline of trusted, city-managed compute assets to execute the request while preserving data locality and compliance. (a) Moti vating smart-city scenario with policy-constrained collaborative edge AI execution T able Peer Trust T ask 0.7 GPT (l0-l5) 0.8 GPT (l6-l10) P1 Trust 70% P3 Trust 40% Service Seeker P2 Trust 80% P4 Trust 70% P3 0.4 GPT (l1 1-l12) P1 P2 P4 0.7 GPT (l1 1-l12) Prompt Result (b) Trust-a ware GenAI execution from the service seeker perspectiv e using GTRA C Fig. 1: Ov erview of a smart-city edge scenario and the role of G-TRA C in coordinating trust-a ware, distributed GenAI execution. T o address these challenges, we present G-TRA C ( G enerativ e T rust-A ware R outing and A daptive C haining), a coordination framew ork for distributed generativ e inference ov er decentralized edge networks. G-TRA C treats inference routing as a multi-objectiv e control problem and dynami- cally selects execution paths across heterogeneous peers using lightweight trust and performance estimates. Our core contributions are as follows: • Hybrid T rust Ar chitecture: A coordination architecture that maintains globally consistent trust and reputation state at stable infrastructure anchors, while disseminat- ing updates to resource-constrained edge participants via periodic backgr ound synchr onization , thereby decoupling control-plane latency from the inference critical path. • Efficient Risk-Bounded Routing: A polynomial-time routing algorithm that solves the Risk-Bounded Shortest Path problem on a trusted subgraph. By combining trust- floor pruning with Dijkstra’ s algorithm, G-TRA C iden- tifies optimal ex ecution paths in sub-millisecond time, av oiding the combinatorial explosion typical of standard multi-constraint routing. • Physical T estbed Evaluation: An end-to-end experi- mental e valuation on a heterogeneous edge testbed com- prising commodity de vices, demonstrating that G-TRA C improv es inference completion rate, isolates underper - forming or unreliable peers, and maintains robust GenAI service execution even under node f ailures and netw ork partitions. It is worth noting that our contributions focus on improving the reliability , robustness, and quality-of-experience of decen- tralized GenAI execution rather than on enhancing the seman- tic accuracy or reasoning capability of the underlying language models. For clarity , Figure 1 illustrates a representativ e edge scenario and the role of G-TRAC in coordinating trust-aw are GenAI ex ecution across heterogeneous peers. I I . R E L AT E D W O R K T o enable large-model inference on hardware with limited memory , systems such as Petals [22] adapt pipeline parallelism to public netw orks. These approaches overcome single-de vice resource constraints through techniques such as quantization and dynamic block loading to maximize peer participation. Recent advances such as Parallax [26] impro ve upon these baselines by introducing a two-phase scheduler that jointly optimizes model placement and runtime chain selection. Simi- larly , DeServe [27] le verages decentralized GPUs to reduce the cost of large-scale inference for offline workloads. Howe ver , these systems primarily optimize throughput and connecti vity , rather than execution trust. They typically rely on greedy latency heuristics or global D A G planning that assumes coop- erativ e peers. In adversarial or highly dynamic edge settings, where peers may be volatile or non-cooperativ e, such best- effort mechanisms leave the inference pipeline vulnerable to failures that are fatal for interactive w orkloads. In contrast to volunteer networks, systems such as He- lix [28], HexGen [29], and HexGen-2 [30] focus on maxi- mizing performance within controlled, heterogeneous clusters. HexGen enables asymmetric tensor and pipeline parallelism across diverse GPU generations, while HexGen-2 further opti- mizes ex ecution through disaggregated prefill–decode schedul- ing. Helix formulates LLM serving as a max-flo w optimization problem to maximize throughput. These systems implicitly assume a managed infrastructure with high node availability and trusted ex ecution. Their reliance on heavyweight central- ized orchestration (e.g., MILP solvers in Helix) makes them unsuitable for decentralized edge en vironments, where global state is difficult to maintain and peers operate autonomously . Recent work has also explored QoS-aware routing of in- ference requests under quality , cost, or energy constraints. Efficient Routing [33] uses genetic algorithms (NSGA-II) to route requests to an optimal cloud or edge instance, while MoE 2 [31] employs a gating network to select suitable expert nodes under latency and energy budgets. Decentralized LLM 2 T ABLE I: Comparison of decentralized and cloud–edge GenAI inference systems W ork Primary Goal Routing / Coordination Logic T rust / Reliability Model T arget En vironment Petals (A CL ’23) [22] Democratize access to large mod- els DHT -based discovery with latency-prioritized chain selection Best-effort (cooperativ e assumption) Consumer GPUs Parallax [26] Maximize throughput under dy- namic availability D AG-based scheduling with pipeline parallelism Best-effort (performance variability only) Decentralized GPU pools DeServe [27] Affordable offline inference (batching) Cost-aware workload distrib u- tion Best-effort (cost-driv en cooperation) Underutilized, preemptible GPUs in shared data centers Helix (ASPLOS’25) [28] Maximize throughput in hetero- geneous clusters Max-flow / min-cost optimiza- tion Managed infrastructure Heterogeneous GPU Clus- ters HexGen (ICML ’24) [29] and HexGen-2 (ICLR’25) [30] Optimize disaggregated prefill/ decoding phases Graph partitioning & Max- Flow scheduling Managed infrastructure Heterogeneous GPU Clus- ters MoE 2 (Mobi- Com’25) [31] Energy-accurac y expert optimization Expert ensemble selection T rust-agnostic optimization Edge Servers Y ang et. al. (TMC 2025) [32] Optimize single-node expert se- lection Deep reinforcement learning T rust-agnostic optimization Mobile-to-Edge Of fload- ing Y u et. al. [33] Balance response time, cost, and quality NSGA-II Multi-objectiv e ge- netic algorithm T rust-agnostic optimization Cloud–Edge Continuum G-TRA C (Ours) Reliable, Risk-bounded Risk-bounded shortest path Explicit trust and risk modeling Heterogeneous IoT & Mobile Edge Deployment [32] reduces inference latenc y in mobile edge computing via parallel communication–computation protocols. While effecti ve for selecting a single execution endpoint or optimizing local parallelism, these approaches do not address multi-hop routing risk. Generative inference in volves a sequen- tially dependent execution chain, so selecting a good node is insufficient if the path to or through it is untrusted. G-TRA C dif fers fundamentally by treating generative infer- ence routing as a risk-bounded shortest path problem, where routing decisions are constrained by empirically measured peer reliability . This enables robust completion of distributed inference pipelines ev en in decentralized, unreliable edge en vironments. W e summarize these state-of-the-art systems, along with our approach, in T able I, highlighting differences in routing strategies, trust assumptions, and deployment environments. I I I . S Y S T E M M O D E L A N D P RO B L E M F O R M U L A T I O N A. Network and Entity Model W e consider a decentralized edge computing en vironment represented by a directed overlay graph G = ( V , E ) . The node set V = { A } ∪ S ∪ P comprises three classes of entities: • Anchor ( A ): A stable, high-av ailability infrastructure node that maintains a global trust and reputation ledger . The Anchor serves solely as a control-plane coordinator and does not ex ecute inference tasks or lie on the data path. • Compute P eers ( P ): A set of heterogeneous edge devices that contribute computational resources. Each peer p i ∈ P is characterized by a dynamic trust score r i ( t ) ∈ [0 , 1] and an estimated execution latency ˆ ℓ i ( t ) . Depending on the deployment model, a peer advertises either (i) a contiguous layer se gment [ L start i , L end i ] of a sharded model, or (ii) a specific pipeline stage s i in a functional inference pipeline. • Service Seekers ( S ): Resource-constrained edge devices (e.g., smartphones) that initiate GenAI inference requests but lack suf ficient memory or compute capacity to exe- cute the full workload locally . The set of edges E represents feasible logical handovers between participating entities. Specifically , a directed edge ( p i , p j ) ∈ E exists between two peers if and only if peer p i hosts model stage k and peer p j hosts the subsequent stage k + 1 , enabling a valid sequential transfer . Peers maintain liv eness via periodic heartbeats to the Anchor , denoted by the indicator a p ( t ) ∈ { 0 , 1 } . B. W orkload Model: Gener ative Service Chains GenAI inference exhibits an inherent sequential dependency due to autoregressi ve decoding [5], where the generation of token t strictly depends on token t − 1 . In datacenter en vironments, systems mitigate this latency by exploiting intra-layer and pipeline parallelism across micro-batches [21], [34]. Howe ver , such dense parallelism is often infeasible in resource-constrained edge en vironments due to bandwidth and memory limitations [35]. Consequently , edge-based inference naturally degrades into a distrib uted sequential process. Accordingly , we model a GenAI inference request as a sequential service chain T = ⟨ τ 1 , τ 2 , . . . , τ K ⟩ , where each stage τ k represents a computation step with a strict ex ecution dependency . The output of τ k serves as the input to τ k +1 . A request is ex ecuted along a physical path π = ⟨ p (1) , . . . , p ( K ) ⟩ , where p ( k ) ∈ P denotes the peer assigned to stage k . At stage 3 k , peer p ( k ) receiv es an intermediate state x k − 1 and computes x k = f p ( k ) ( x k − 1 ) . This abstraction unifies multiple GenAI deployment paradigms: • Layer -Sharded Inference: x k represents a hidden state (e.g., activ ation tensor) propagated between contiguous model layers hosted on different devices. • Agentic and Functional Pipelines: x k represents a semantic artifact (e.g., a retriev al result, generated code fragment, or verification signal) passed between distinct models or tools. The proposed routing and trust mechanisms operate solely on this sequential composition and are agnostic to the internal semantics of x k . W ithout loss of generality , our subsequent analysis and ev aluation focus on the layer-sharded inference model, as it presents the most stringent latency and bandwidth constraints. C. Risk and Reputation Model For each live peer p , the Anchor maintains the trust score r p ( t ) ∈ [0 , 1] , updated based on the peer’ s historical perfor- mance. While peer failures may exhibit correlation due to shared infrastructure or load conditions, we assume that peer failures are conditionally independent giv en their trust scores to obtain a tractable baseline model. Under this assumption, the reliability of a service chain π is giv en by Rel( π ; t ) = Y p ∈ π r p ( t ) (1) Accordingly , the risk of a service chain π is defined as Risk( π ; t ) = 1 − Rel( π ; t ) (2) T o guarantee service quality , an y valid chain π must satisfy Risk( π ; t ) ≤ ϵ , where ϵ denotes the user -defined risk tolerance. D. Risk-Bounded Chain Selection Pr oblem For each peer p , the Anchor observes the per-hop execu- tion time ℓ obs p ( t ) from completed inference requests, which captures the end-to-end delay incurred at peer p (i.e., local computation, serialization, network transmission, and forward- ing overhead). The Anchor maintains a smoothed latency estimate using an Exponentially W eighted Moving A verage (EWMA) [36]: ˆ ℓ p ( t ) = (1 − β ) ˆ ℓ p ( t − 1) + β ℓ obs p ( t ) (3) where β ∈ (0 , 1) is the smoothing factor . In volatile edge en vironments, minimizing raw execution time is insuf ficient if the selected path frequently fails. A fast peer with lo w reliability introduces significant tail latency due to timeouts and repair o verhead. T o capture this trade-of f, we define the ef fective latency cost C p ( t ) as the expected time to complete a hop, explicitly accounting for failure probability: C p ( t ) = ˆ ℓ p ( t ) + 1 − r p ( t ) · T timeout (4) where T timeout is a fixed system penalty reflecting failure detection and re-routing delay . Accordingly , C p ( t ) penalizes DA T A PLANE (Inference Execution) CONTROL PLANE (T rust & Discovery) Global Ledger SEEKER s.t. ANCHOR PEER p1 Layers 1..n PEER p2 Layers n+1..m PEER p2' Repair replica Request Result Repair Feed back Cache 1 2 3 3 3 Fig. 2: G-TRA C architecture and execution flow . unreliable nodes, aligning the routing objective with the sys- tem’ s tail-latency goals. Let Π( t ) denote the set of all li ve, contiguous service chains at time t . Given a user -defined risk tolerance ϵ ∈ (0 , 1) , we formulate the Risk-Bounded Shortest P ath problem as finding the optimal chain π ⋆ that minimizes the total ef fectiv e latency while satisfying the global safety constraint: π ⋆ ( t ) = arg min π ∈ Π( t ) X p ∈ π C p ( t ) s.t. Y p ∈ π r p ( t ) ≥ 1 − ϵ, a p ( t ) = 1 ∀ p ∈ π (5) The optimization in Eq. (5) combines an additive cost function with a multiplicativ e path constraint, a formulation corresponding to the classic Restricted Shortest P ath problem known to be NP-Hard [37]. T o address this computational intractability , Section IV proposes a topological decomposition approach that enforces a strict local trust floor , reducing the problem to a polynomial-time shortest-path search on a trusted subgraph. I V . G - T R AC D E S I G N A N D A L G O R I T H M In this section, we present G-TRA C, an efficient routing algorithm that solves the risk-bounded chain selection problem defined in Eq. (5). T o operate under edge constraints and dynamic peer a vailability , G-TRA C employs a decentralized control loop that separates global state estimation at the Anchor from lightweight, seek er-side routing decisions. Fig- ure 2 illustrates the architecture and ex ecution pipeline. The algorithm proceeds in three phases: 1 State Synchr onization , 2 Constraint Pruning , and 3 F eedback-Driven Execution . A. Phase 1: Asynchr onous State Synchr onization The Anchor acts as the control-plane authority , maintain- ing the global registry Σ t = { ( p, c p , r p , ˆ ℓ p ) } p ∈P . T o a void introducing control-plane latency into the inference critical path, Seekers do not query the Anchor synchronously per request. Instead, they maintain a locally cached view ˜ Σ t ⊆ Σ t , updated through periodic background synchronization. As a result, routing decisions are computed locally without blocking on control-plane communication. 4 Algorithm 1 G-TRAC Seeker-Side Routing and Ex ecution Require: T oken/layer sequence T , trust threshold τ , cached peer state ˜ Σ Ensure: Execution outcome ( S U C C E S S or F A I L U RE ) //T rust-Based Pruning 1: V ′ ← { p ∈ ˜ Σ | a p ( t ) = 1 ∧ r p ( t ) ≥ τ } //Latency-Optimal Path Search 2: G ′ ← B U I L D DAG ( V ′ ) ▷ Construct D A G o ver contiguous layers 3: π ⋆ ← D I J K S T R A ( G ′ , weight = C p ) ▷ Compute minimum-latency chain 4: if π ⋆ = ∅ then 5: return A B O RT ▷ No feasible contiguous chain 6: end if //Execution and Local Repair 7: π exec ← π ⋆ 8: ( res , p fail ) ← C H A I N E X EC ( π exec ) 9: if r es = F A IL U R E and R E PA I R E N A B LE D then 10: p new ← arg min p ∈ V ′ { ˆ L p | p = p fail ∧ L A Y E R S ( p ) = L A Y E R S ( p fail ) } 11: if p new = ∅ then 12: π exec ← S W A P N O D E ( π ⋆ , p fail , p new ) 13: ( r es , ) ← C H A IN E X E C ( π exec ) ▷ Retry with repaired chain 14: end if 15: end if //Feedback 16: U P DAT E T R US T ( r es , p fail ) 17: return r es B. Phase 2: Candidate Pruning via T rust Floors Directly enforcing the end-to-end constraint Q p ∈ π r p ≥ 1 − ϵ typically requires e valuating complete paths, which is computationally expensi ve. T o make the search tractable, G- TRA C relaxes the global constraint into a local sufficiency condition, filtering the peer graph befor e path selection. W e introduce a configurable trust floor τ ∈ (0 , 1) . Lemma 1 (Sufficiency of Local T rust) . F or a service chain π of length K , if every participating peer p ∈ π satisfies r p ( t ) ≥ τ , then the end-to-end failur e risk is bounded by: Risk( π ; t ) ≤ 1 − τ K (6) Pr oof. From Eq. (1), Rel( π ) = Q p ∈ π r p ≥ Q p ∈ π τ = τ | π | = τ K . Thus, Risk( π ) = 1 − Rel( π ) ≤ 1 − τ K . The realized chain length K is not known prior to routing because peers may host different numbers of model layers. Howe ver , K is bounded by system design. Design Guarantee (T rust-floor configuration) . Let K max denote the maximum feasible inference chain length, bounded by the model depth L and the minimum number of layers per peer l min . If the trust floor is configured as τ = (1 − ϵ ) 1 /K max then any ex ecution chain π selected from the pruned graph satisfies Q p ∈ π r p ≥ 1 − ϵ with respect to the current trust estimates. The proof is provided in Appendix A. This pruning step restricts the routing topology to the trusted subgraph G ′ = ( V ′ , E ′ ) , where V ′ = { p ∈ V | a p ( t ) = 1 ∧ r p ( t ) ≥ τ } . Consequently , the complex constrained op- timization problem reduces to a standard shortest-path search ov er G ′ . C. Phase 3: F eedback-Driven Execution Algorithm 1 details the seeker -side procedure ex ecuted during this phase. The Seeker first applies Phase 2 trust-floor pruning by excluding peers with zero liveness ( a p = 0 ) or insuf ficient trust ( r p < τ ) (line 1). From the remaining trusted peers, G-TRA C constructs a directed acyclic graph (DA G) in which edges correspond to feasible handovers between contiguous model layers (line 2). The Seeker then runs Dijkstra’ s algorithm over the resulting subgraph (line 3) to identify the optimal execution chain π ⋆ that minimizes the effecti ve latenc y defined in Eq. (4). During execution, G-TRAC implements a Bounded One- Shot Repair policy to handle the stochastic nature of edge devices (line 9–15). If execution fails at hop p k , the Seeker does not discard the entire progress. Instead, it queries the trusted set for a replacement peer p ′ k (where capabilities match and r p ′ ≥ τ ) and retries the f ailed step exactly once. W e explicitly bound this repair policy to a single attempt, as unbounded retries would obscure failure attribution and trans- form risk-bounded routing into probabilistic retry scheduling. This design choice aligns with established fault-tolerance practices in distributed systems (e.g., circuit breakers) [38], [39], where bounded retries are preferred to pre vent cascading ov erload and to enable accurate failure detection. Conse- quently , the one-shot mechanism does not aim to guarantee ev entual success but serves as a bounded corr ective action that improv es robustness against transient failures while preserving the semantics of risk-bounded routing and the integrity of trust learning. Upon completion, the Seeker reports the execution trace to the Anchor for trust updates. G-TRA C applies targeted failure attribution: on success ( y = 1 ), all peers p ∈ π recei ve a re ward ∆ r + , whereas on failure ( y = 0 ), only the peer responsible for the failed hop is penalized by ∆ r − . D. Complexity Analysis Naiv ely enumerating all feasible service chains induces a search space of size O ( |P | K ) , where |P | is the number of peers and K is the chain length. This exponential growth makes exhausti ve search intractable for large networks. G- TRA C design reduces the selection process to polynomial time through two complementary mechanisms: 1) Pre-sear ch pruning : Peers are filtered based on liv eness a p ( t ) and the trust floor τ . The filtering step runs in O ( |P | ) time and reduces the effecti ve graph size to | V ′ | ≪ |P | by discarding unreliable candidates prior to edge construction. 2) Polynomial time selection : The remaining candidates are organized into a DA G, and chain selection is for- mulated as a shortest-path problem solved using Dijk- stra’ s algorithm. The resulting complexity is bounded by 5 T ABLE II: Experimental testbed with heterogeneous nodes. T ype Processor Mem # P (server) AMD Opteron 6272 47 GB 4 R (legacy server) Intel Xeon E5430 15 GB 4 D (desktop) Intel Core i5-13500 31 GB 1 L (laptop) Intel Core i7-1260P 15 GB 1 S (phone) ARMv8 SoC (2×A76 + 6×A55) 3.6 GB 2 O ( | E ′ | + | V ′ | log | V ′ | ) , where | V ′ | and | E ′ | denote the number of vertices and edges in the pruned graph. As a result, the complexity of G-TRAC depends on the size of the pruned network graph rather than on the number of feasible service chains, with selection overhead remaining efficient ev en in dense networks. The empirical validation of G-TRA C’ s lo w-latency selection is presented in Section VI-E. V . E V A L U A T I O N M E T H O D O L O G Y A. Experimental T estbed and Implementation W e implemented a fully functional G-TRA C prototype using PyTorch 1 , and the transformers 2 library . The testbed executes real-world distributed infer ence where li ve tensors are serialized and transmitted between nodes over HTTP . Hardwar e setup. T o e valuate G-TRA C under realistic hetero- geneity in compute capacity , we deploy a distrib uted testbed comprising a div erse set of edge nodes. T able II summarizes the hardware characteristics of all nodes, including CPU type, core count, memory capacity , and the number of nodes of each type. Android smartphones execute Linux user-space applications via T ermux 3 . Network overlay . The nodes are physically distributed across a campus en vironment and connect via a heterogeneous mix of wired Ethernet and enterprise Wi-Fi (i.e., Eduroam). Due to pervasi ve Network Address Translation (NA T) and inbound connectivity restrictions, direct peer-to-peer communication is not always feasible. W e therefore deploy an encrypted W ireGuard-based mesh overlay using T ailscale 4 , which pro- vides a flat IP addressing scheme and reliable bidirectional connectivity across all nodes. The resulting o verlay latency is included in all reported end-to-end and per-tok en latency measurements, reflecting realistic edge deployment conditions under constrained connectivity . GenAI workload. W e use the pre-trained GPT -2 Larg e model (774M parameters, 36 layers) [40] and partition it across worker nodes using pipeline parallelism. Although larger transformer models exist, GPT -2 Large is suf ficiently complex to be infeasible for stable monolithic execution on commodity edge devices (e.g., smartphones). The workload consists of continuous autoregressiv e infer- ence requests: a smartphone client submits a prompt that trig- 1 https://pytorch.org/ 2 https://huggingface.co/docs/transformers/en/index 3 https://termux.dev/en/ 4 https://tailscale.com/ T ABLE III: System parameters and configuration. Param. V alue Description Model GPT2-L LLM 36 layers τ 0 . 96 T rust floor β 0 . 30 Latency EWMA factor ℓ init 250 ms Initial latency estimate ∆ r + 0 . 03 T rust re ward ∆ r − 0 . 2 T rust penalty T hb 2 s Heartbeat interval T ttl 15 s Node timeout (liveness) T timeout 25 s Request timeout T gossip 2 s Registry sync period gers token-by-token generation. Each generated token must se- quentially pass through the distributed pipeline; consequently , delays or stragglers at any single peer directly impact the end- to-end generation latency . Peer heterogeneity and topology . W e partition the model into contiguous shards 5 (e.g., 3, 6, or 9 layers per shard) and deploy them across the physical machines described in T able II. T o emulate the scale of dense edge en vironments, we instantiate multiple virtual replicas per physical host. These replicas are multiplexed ov er the same physical model shard to ensure realistic inference e xecution times, while their network behavior is software-defined to enforce distinct performance– reliability profiles: • Honey Pot (Risky–F ast): Peers offering ultra-low la- tency (added delay ≈ 1 ms) b ut exhibiting a high failure rate ( p fail ∈ [0 . 20 , 0 . 35] ), intentionally designed to expose the vulnerability of latency-greedy routing algorithms. • T urtle (Safe–Slow): Peers providing near-perfect relia- bility ( p fail ≈ 0 . 1% ) but at the cost of significantly higher network latency ( 150 – 300 ms). • Golden Peers (Guaranteed–Safe): Idealized peers with near-perfect reliability ( p fail = 0 ) and moderate latency ( 20 – 40 ms). In total, the testbed comprises 336 concurrent peers, forming a di verse routing search space that spans all stages of the inference pipeline. T rust and failur e dynamics. T o stress-test the conv ergence of the routing logic under dynamic conditions, we introduce con- trolled stochastic volatility using an additive asymmetric trust model. Specifically , we emulate abstract peer failure behavior by allowing each peer i to fail independently per request ac- cording to a Bernoulli random variable X i ∼ Bernoulli( p fail ,i ) , where the failure probability p fail ,i is determined by the peer’ s profile (e.g., high for Honey Pots, low for T urtles). A failure stalls the request, prev enting activ ation forwarding. The complete set of system and workload parameters is summarized in T able III. 5 Detailed deployment plans and per-peer configurations are provided at https://github .com/anonymous- 123qh/g- trac/tree/main/deployment 6 B. Baselines W e compare G-TRAC against four representati ve routing strategies that span the trade-off space between latency , relia- bility , and computational complexity: • Naive: Enumerates feasible execution chains using Depth-First Search (DFS) before uniformly sampling a valid path. Unlike myopic random walks, which may terminate in local dead-ends, this approach guarantees the selection of a complete, end-to-end pipeline if one exists. In our practical implementation, we cap this search (e.g., at 1000 chains) to bound the latency , though for scalability analysis, we e valuate the unbounded version to demonstrate its inherent complexity . • Shortest Path (SP): Minimizes cumulati ve latency P ˆ ℓ p without enforcing trust constraints ( τ = 0 ). SP represents traditional performance-centric routing protocols that op- timize for speed but do not account for node reliability or failure risks. • Max-Reliability (MR): Maximizes end-to-end reliability ( Q r p ) while disregarding latency cost. MR represents a conservati ve, risk-a verse strategy that prioritizes fault tolerance ov er execution speed. • Lagrangian Relaxation (LARA C): A standard heuristic for the Constrained Shortest Path problem [41] that iterativ ely optimizes a composite objecti ve L ( π ) + λ · R ( π ) . LARAC provides a strong theoretical baseline that attempts to balance latency and reliability , though its iterativ e nature incurs higher computational complexity than single-pass algorithms. C. K ey Metrics W e ev aluate the comparativ e performance of G-TRA C and the baseline strategies using the follo wing metrics: • Service Success Rate (SSR): The fraction of inference r equests that successfully complete and generate the full target token sequence without an unrecoverable failure: SSR = N success N total . SSR captures the ef fective reliability of the routing policy . • Per -T oken Latency: The distribution of per-token end- to-end latency measured ov er tokens from successful requests, capturing typical token emission dynamics and variability during generation. • Selection Overhead: The client-side wall-clock time required to e xecute the pruning and path selection logic. V I . R E S U LT A N D D I S C U S S I O N A. Service Success Rate Analysis W e e valuate the robustness of each routing strategy using SSR metric under prompt generation tasks with varying tar get lengths ( L tok ∈ { 10 , 20 , 50 } tokens). For each configura- tion (algorithm, L tok ), we perform 100 independent prompt- generation requests. T o ensure fair comparison across routing strategies, we reset peer trust states between algorithms. Fig- ure 3 reports the resulting SSR with error bars denote 95% W ilson confidence intervals (CI) [42]. SP MR G- TRAC LARAC Naive 0% 20% 40% 60% 80% 100% Success Rate (SSR) T arget Ouput Length L tok = 10 L tok = 20 L tok = 50 Fig. 3: Service success rate under different generation lengths. W e observe that both SP and Naiv e perform poorly . SP consistently fails to achiev e success rates above 20%, e ven for short sequences. This consistent failure is characteristic of the hone y-pot effect: by aggressi vely minimizing reported latency , SP preferentially selects fast b ut unreliable peers, leading to frequent chain breakages and a substantial degradation in SSR. Similarly , while the Naiv e approach achiev es moderate success ( ≈ 50% ) for short contexts ( L tok = 10 ), it exhibits high variance and fails to scale. For longer sequences, Naiv e’ s performance collapses to < 15% , confirming that simple greedy heuristics lack the foresight required for long-horizon distributed inference. In contrast, the MR baseline consistently achie ves a 100% SSR across all sequence lengths, v alidating that prioritizing peers solely on reliability maximizes service completion. G-TRA C demonstrates comparable robustness, maintaining perfect success for shorter sequences and degrading only marginally at L tok = 50 . The overlap in the W ilson CI for G-TRA C and MR suggests that the two methods offer sta- tistically comparable reliability . These observ ations highlight the effecti veness of the joint optimization of trust and latency , enabling G-TRA C to systematically a void the risky hone y pot peers that cause SP to fail. Finally , LARA C exhibits significant sensiti vity to task length. While it achiev es 100% SSR at L tok = 20 , its perfor- mance significantly degrades to below 40% at L tok = 50 . The non-ov erlapping CIs confirm this degradation is statistically significant, suggesting that although LARAC is ef fectiv e for short sequences, its rigid constraint enforcement struggles with longer , resource-intensiv e request chains. B. P er-T oken Latency Analysis Figure 4 shows the distribution of per-token end-to-end latency for successful inference requests. Across all routing strategies, per-token latency increases as the target generation length gro ws from L tok = 10 to 50 , reflecting inherent GPT -2 scaling effects, where longer conte xts increase self-attention ov erhead due to larger KV caches and more expensiv e matrix multiplications. Despite explicitly optimizing for minimum path latency , the SP baseline exhibits unexpectedly high per-tok en latency in completed runs (average latency of 3.1 s with P99 of 3.6 s at L tok = 10 , increasing to 3.5 s av erage and 5.1 s P99 at L tok = 50 ). This counterintuiti ve behavior is explained by 7 SP MR G - TRAC LARAC Naive 2000 3000 4000 5000 6000 7000 T oken Latency (ms) T arget Output Length L t o k = 1 0 L t o k = 2 0 L t o k = 5 0 Fig. 4: Per -token end-to-end latenc y distribution under differ- ent generation lengths. Black diamonds denote the P99 latency . survivorship bias , i.e., although SP aggressiv ely selects lo w- latency paths, these paths are often unstable and fail before completion. Consequently , the successful SP executions, espe- cially for longer sequences, are dominated by runs that trav erse slower but more stable nodes, inflating the observed per-token latency . The Nai ve baseline performs the worst overall, exhibiting the highest per -token latency across all generation lengths (e.g., an av erage latency of 3.6 s with P99 of 4.8 s at L tok = 10 , increasing to 4.8 s average latency and P99 up to 8.0 s at L tok = 50 ). By selecting peers uniformly at random, Naiv e fails to av oid stragglers and high-latenc y nodes, resulting in consistently poor token-le vel performance. MR achie ves perfect SSR, as discussed earlier , but at the cost of significantly increased per-token latency (from an av erage of 3.3 s with P99 of 4.1 s at L tok = 10 to 4.4 s av erage and P99 of 6.0 s at L tok = 50 ). This confirms that prioritizing highly reliable peers effecti vely reduces chain failures, albeit by routing through slower nodes that degrade latency performance. Finally , both G-TRA C and LARA C demonstrate consis- tently lower per-token latency across all generation lengths. G-TRA C achie ves an average per-token latency of 2.6 s with P99 of 3.8 s at L tok = 10 , remaining stable at 2.4 s av erage with P99 of 4.6 s at L tok = 50 . Similarly , LARAC maintains low latency , increasing from an a verage of 2.7 s with P99 of 3.8 s at L tok = 10 to 3.0 s average and P99 of 5.0 s at L tok = 50 . This advantage stems from their constraint-aware optimization strategies, i.e., both approaches activ ely prune high-latency stragglers from the candidate pool, pre venting slo w nodes from dominating the ex ecution chain. C. Adaptive T opology: Chain Length Distribution Figure 5 sho ws the distrib ution of inference chain lengths across routing strategies. SP e xhibits zero variance, consis- tently selecting a 4-hop chain for all requests. With a model depth of 36 layers and a maximum per-peer capacity of ap- proximately 9 layers, SP minimizes hop count by maximizing shard size per node. While topologically optimal, this rigid strategy concentrates computation on a small number of peers, contributing to the elev ated per-token latency observed in Figure 4. SP MR G- TRAC LARAC Naive 4 5 6 7 8 9 10 11 Chain Length (Hops) Fig. 5: Distribution of inference chain length (hop count). 200 400 600 800 Estimated Latency (ms) 0.00 0.25 0.50 0.75 1.00 Trust Score SP MR G-TRAC LARAC Naive Fig. 6: Distribution of selected peers by T rust and Latency ( L tok = 50 ). In contrast, G-TRA C and LARAC center around a me- dian of 4 hops but exhibit a tail extending to 5–6 hops. Both approaches adaptiv ely select minimal-hop paths when sufficiently trusted peers are available, while dynamically extending the chain to avoid unstable nodes when necessary . Consequently , the y trade a modest increase in hop count for improv ed reliability and lower realized latency . By comparison, MR fa vors longer chains (6 hops), con- sistent with its conservati ve, reliability-first design. Naiv e produces highly variable and often excessi vely long chains, reflecting the absence of informed routing heuristics. D. The P eer Selection Landscape T o explain the di vergent behaviors of the ev aluated strate- gies, we visualize the peer selection landscape , i.e., the trust– latency combinations of the peers chosen by each algorithm. Figure 6 plots the distribution of selected peers for 50-token generation tasks, with estimated latency on the x -axis and trust score on the y -axis. SP concentrates on the low-latency region, including many low-trust peers. Since SP optimizes only for latency , it is frequently attracted to unreliable peers, which is consistent with its reduced success performance. MR selects predominantly high-trust peers across a broader latency range. By prioritizing trust abo ve all else, MR often av oids medium-latency peers when they incur ev en a small trust penalty , explaining its strong reliability b ut higher end- to-end latency . G-TRA C and LARAC more consistently target the interme- diate region that balances trust and latency . In particular , G- 8 50 100 300 500 1000 T otal Network P eers 10 −1 10 0 10 1 10 2 Selection Overhead (ms) SP MR G-TRAC LARAC Naive Fig. 7: Algorithm scalability: Decision time vs Network size. TRA C fav ors peers that retain high trust while a voiding MR’ s latency overhead. LARA C exhibits a more dispersed pattern, reflecting its iterati ve Lagrangian updates when enforcing the delay constraint. E. Routing Decision Overhead at Scale W e ev aluate the computational ov erhead of G-TRA C’ s routing decision logic and compare it against representative baselines. T o isolate control-plane costs, we decouple path selection from inference execution and implement exact ver - sions of all routing algorithms. Experiments are conducted on a smartphone S, with network size varying from N ∈ { 50 , . . . , 1000 } and results averaged over 100 independent trials. Figure 7 sho ws the selection ov erhead trends on a logarith- mic scale for all approaches. G-TRA C consistently maintains negligible latency ( < 10 ms), ev en at N = 1000 nodes. Notably , G-TRAC achie ves lo wer selection overhead than both SP and MR. This is because while SP and MR operate ov er the full network graph G , G-TRA C first constructs a pruned subgraph G ′ ⊂ G by excluding nodes whose trust falls below the admissible threshold, substantially reduces the ef fectiv e search space ( | V ′ | ≪ | V | , | E ′ | ≪ | E | ), allowing Dijkstra’ s algorithm to con verge faster . In contrast, LARA C exhibits poor scaling (approximately 210 ms at N = 1000 ) dri ven by iterati ve relaxation, while Naiv e becomes infeasible in dense networks ( > 2 s timeout) due to DFS combinatorial explosion. Overall, the results empirically validate that G-TRA C intro- duces minimal control-plane o verhead while improving both reliability and scalability , enabling fully decentralized GenAI routing on resource-constrained edge devices. V I I . C O N C L U S I O N In this paper , we presented G-TRAC, a coordination frame- work that elev ates distributed genAI inference routing from a best-effort transport problem to a risk-bounded control prob- lem. By integrating a hybrid trust architecture with a pruned shortest-path algorithm, G-TRA C decouples global state es- timation from the critical routing path, enabling resource- constrained devices to make sub-millisecond routing decisions without centralized bottlenecks. Monolithic 4 Hops 6 Hops 12 Hops 1000 2000 3000 4000 5000 Latency (ms) (a) Per token latency Monolithic 4 Hops 6 Hops 12 Hops 0 5000 10000 15000 20000 25000 CPU Time (ms) (b) Per token CPU time Fig. 8: Per-token time analysis: (a) end-to-end inference la- tency per token and (b) CPU execution time per token. Empirical ev aluation on a heterogeneous edge testbed demonstrates that G-TRA C consistently operates in a f avorable trade-off region between trust and latency . In particular, it mitigates the honey-pot ef fect that degrades latency-dri ven baselines, achieving a near-perfect success rate for standard edge interaction workloads while preserving low end-to-end latency . Future work will extend G-TRA C to dynamic mixture-of- agents workflo ws, in which functional sub-tasks (e.g., retriev al, reasoning, and v erification) are orchestrated across a mesh of untrusted, specialized peers, and will in vestigate the establish- ment of a principled root of trust to safely and ef ficiently harness the largely untapped computational capacity of the network edge. A P P E N D I X A. Pr oof of the Design Guarantee Pr oof. From Lemma 1, any service chain π of length K composed of peers satisfying r p ( t ) ≥ τ has reliability Q p ∈ π r p ( t ) ≥ τ K . Since 0 < τ ≤ 1 , the function τ x is monotonically decreasing in x . By system design, the realized chain length satisfies K ≤ K max , where K max = L l min Therefore, Y p ∈ π r p ( t ) ≥ τ K max Substituting τ = (1 − ϵ ) 1 /K max yields Y p ∈ π r p ( t ) ≥ (1 − ϵ ) K max /K max = 1 − ϵ Hence, any ex ecution chain selected from the pruned graph satisfies the global reliability constraint with respect to the current trust estimates. B. Distributed GenAI F easibility at the Edge W e empirically characterize the feasibility and overheads of distributed GenAI model inference on heterogeneous edge devices. T o this end, we compare monolithic inference of GPT - 2 Large, ex ecuted entirely on a single server -class node 9 Monolithic 4 Hops 6 Hops 12 Hops 0 250 500 750 1000 1250 1500 CPU Utilization (%) (a) CPU utilization Monolithic 4 Hops 6 Hops 12 Hops 1000 1500 2000 2500 3000 3500 4000 4500 Memory Usage (MB) (b) Memory footprint Fig. 9: Resource consumption for monolithic vs. distributed configurations. ( P ), against distrib uted configurations in which the model is partitioned into shards of 3, 6, and 9 layers. These partition sizes correspond to inference chains of 12, 6, and 4 hops, respectiv ely . Because some newer nodes in the testbed may of fer stronger single-node compute performance than P , this comparison is intended to characterize feasibility and deployment ov erheads in a heterogeneous setting rather than to establish an optimal single-node performance baseline. Figure 8a presents the inference time per token for mono- lithic and distributed e xecution across varying hop lengths. Un- der the observed network conditions, the latency overhead is highly dependent on chain length. For shorter chains (4 hops), distributed latency (approximately 2.2 s) remains comparable to the monolithic baseline (approximately 2.3 s). Howe ver , as the chain length increases to 12 hops, cumulativ e ov erheads from serialization and network transmission result in a latency increase of approximately 1 . 7 × (approximately 3.8 s). W e further examine per-tok en CPU time to characterize compute demand. As presented in Figure 8b, monolithic GPT - 2 Large inference requires approximately 22 s of CPU time per generated token on a single de vice, se verely limiting sustained inference and co-location with other workloads. In contrast, distributed ex ecution reduces the per-de vice CPU time to 1.8 - 4.4 s per token, depending on shard size. This massiv e reduction in per-de vice compute demand enables inference to operate within realistic edge compute budgets, allo wing devices to participate in inference without stalling other local background processes. Finally , we analyze the resource consumption for monolithic and distrib uted configurations. Figure 9a illustrates the CPU utilization. Monolithic inference nearly saturates av ailable compute resources, averaging 953% utilization (i.e., spanning multiple cores) with peaks e xceeding 1400%. In contrast, the distributed configuration maintains a minimal CPU footprint on individual peers, with av erage utilization remaining well below 10% across all shard sizes, reflecting the sparse, inter - mittent nature of processing in the distributed chain. Figure 9b depicts the peak Resident Set Size (RSS). Mono- lithic execution consistently demands substantial memory , with a mean footprint of 3.88 GB and P95 peaks reaching 4.38 GB. This renders stable deployment impractical on stan- dard edge hardware (e.g., devices with 4GB unified memory limits). Distributed execution substantially lowers this barrier: peers hosting 9 layers require approximately 1.85 GB, while 3-layer peers consume approximately 900 MB. This reduc- tion enables deployment on resource-constrained nodes and directly mitigates the memory capacity footprint challenges identified for AI agent inference [43]. In summary , distrib uted GenAI mak es large-model inference feasible in a heterogeneous edge environment by alleviating per-node memory and compute bottlenecks, at the cost of a bounded increase in end-to-end latency that grows with hop count. R E F E R E N C E S [1] Y . Cao, S. Li, Y . Liu, Z. Y an, Y . Dai, P . Y u, and L. Sun, “ A surve y of ai-generated content (aigc), ” A CM Computing Surveys , v ol. 57, no. 5, pp. 1–38, 2025. [2] H. Nav eed, A. U. Khan, S. Qiu, M. Saqib, S. Anwar , M. Usman, N. Akhtar , N. Barnes, and A. Mian, “ A comprehensiv e o verview of large language models, ” A CM T ransactions on Intelligent Systems and T echnology , vol. 16, no. 5, pp. 1–72, 2025. [3] Y . LeCun, Y . Bengio, and G. Hinton, “Deep learning, ” Natur e , vol. 521, no. 7553, pp. 436–444, 2015. [4] A. Radford, K. Narasimhan, T . Salimans, I. Sutskev er et al. , “Improving language understanding by generativ e pre-training, ” 2018. [5] A. V aswani, N. Shazeer, N. Parmar , J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “ Attention is all you need, ” Advances in neural information processing systems , vol. 30, 2017. [6] W . Fedus, B. Zoph, and N. Shazeer , “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , ” Journal of Machine Learning Research , vol. 23, no. 120, pp. 1–39, 2022. [7] W . Cai, J. Jiang, F . W ang, J. T ang, S. Kim, and J. Huang, “ A survey on mixture of experts in large language models, ” IEEE T ransactions on Knowledge and Data Engineering , 2025. [8] R. Y . Aminabadi, S. Rajbhandari, A. A. A wan, C. Li, D. Li, E. Zheng, O. Ruwase, S. Smith, M. Zhang, J. Rasley et al. , “Deepspeed-inference: enabling efficient inference of transformer models at unprecedented scale, ” in SC22: International Conference for High P erformance Com- puting, Networking, Storage and Analysis . IEEE, 2022, pp. 1–15. [9] W . Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Y u, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention, ” in Proceedings of the 29th symposium on operating systems principles , 2023, pp. 611–626. [10] P . Hacker , A. Engel, and M. Mauer, “Regulating chatgpt and other large generativ e ai models, ” in Pr oceedings of the 2023 ACM conference on fairness, accountability , and transpar ency , 2023, pp. 1112–1123. [11] F . Leboukh, E. B. Aduku, and O. Ali, “Balancing chatgpt and data protection in germany: challenges and opportunities for policy makers, ” Journal of P olitics and Ethics in New T echnologies and AI , vol. 2, no. 1, pp. e35 166–e35 166, 2023. [12] X. Y e, Y . Y an, J. Li, and B. Jiang, “Pri vacy and personal data risk governance for generative artificial intelligence: A chinese perspective, ” T elecommunications P olicy , vol. 48, no. 10, p. 102851, 2024. [13] F . W ang, Z. Zhang, X. Zhang, Z. W u, T . Mo, Q. Lu, W . W ang, R. Li, J. Xu, X. T ang et al. , “ A comprehensiv e survey of small language models in the era of large language models: T echniques, enhancements, applica- tions, collaboration with llms, and trustworthiness, ” ACM T ransactions on Intelligent Systems and T echnology , vol. 16, no. 6, pp. 1–87, 2025. [14] L. C. Magister , J. Mallinson, J. Adamek, E. Malmi, and A. Severyn, “T eaching small language models to reason, ” in Pr oceedings of the 61st annual meeting of the association for computational linguistics (volume 2: short papers) , 2023, pp. 1773–1781. [15] G. Qu, Q. Chen, W . W ei, Z. Lin, X. Chen, and K. Huang, “Mobile edge intelligence for lar ge language models: A contemporary survey , ” IEEE Communications Surveys & Tutorials , 2025. [16] J. W ei, Y . T ay , R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Y ogatama, M. Bosma, D. Zhou, D. Metzler et al. , “Emergent abilities of large language models, ” T ransactions on Machine Learning Resear ch (TMLR) , 2022. 10 [17] Z. Ji, N. Lee, R. Frieske, T . Y u, D. Su, Y . Xu, E. Ishii, Y . J. Bang, A. Madotto, and P . Fung, “Survey of hallucination in natural language generation, ” ACM computing surveys , vol. 55, no. 12, pp. 1–38, 2023. [18] A. Kulkarni, Y . Zhang, J. R. A. Moniz, X. Ge, B.-H. Tseng, D. Piravipe- rumal, S. Swayamdipta, and H. Y u, “Evaluating evaluation metrics – the mirage of hallucination detection, ” in F indings of the Association for Computational Linguistics: EMNLP 2025 , Suzhou, China, Nov . 2025. [19] I. Ong, “Efficient distributed llm inference with dynamic partition- ing, ” California, Berkeley , T echnical Report UCB/EECS-2024-108, May , 2024. [20] R. Ma, J. W ang, Q. Qi, X. Y ang, H. Sun, Z. Zhuang, and J. Liao, “Poster: Pipellm: Pipeline llm inference on heterogeneous devices with sequence slicing, ” in Proceedings of the ACM SIGCOMM 2023 Conference , 2023, pp. 1126–1128. [21] Y . Huang, Y . Cheng, A. Bapna, O. Firat, D. Chen, M. Chen, H. Lee, J. Ngiam, Q. V . Le, Y . W u et al. , “Gpipe: Efficient training of giant neu- ral networks using pipeline parallelism, ” Advances in neural information pr ocessing systems , vol. 32, 2019. [22] A. Borzuno v , D. Baranchuk, T . Dettmers, M. Riabinin, Y . Belkada, A. Chumachenk o, P . Samygin, and C. Raf fel, “Petals: Collaborati ve inference and fine-tuning of large models, ” in Pr oceedings of the 61st Annual Meeting of the Association for Computational Linguistics (V olume 3: System Demonstrations) , 2023, pp. 558–568. [23] Y . Gao, Z. Song, and J. Y in, “Gradientcoin: A peer-to-peer decentralized large language models, ” arXiv pr eprint arXiv:2308.10502 , 2023. [24] P . P . Ray and M. P . Pradhan, “P2pllmedge: Peer-to-peer framework for localized large language models using cpu only resource-constrained edge, ” EAI Endorsed T ransactions on AI and Robotics , vol. 4, no. 1, 7 2025. [25] R. Morabito and S. Jang, “Smaller, smarter , closer: The edge of collaborativ e generati ve ai, ” IEEE Internet Computing , 2025. [26] C. T ong, Y . Jiang, G. Chen, T . Zhao, S. Lu, W . Qu, E. Y ang, L. Ai, and B. Y uan, “Parallax: Efficient llm inference service over decentralized en vironment, ” arXiv pr eprint arXiv:2509.26182 , 2025. [27] L. W u, X. Liu, T . Shi, Z. Y e, and D. Song, “Deserve: T owards affordable of fline llm inference via decentralization, ” arXiv preprint arXiv:2501.14784 , 2025. [28] Y . Mei, Y . Zhuang, X. Miao, J. Y ang, Z. Jia, and R. Vinayak, “Helix: Serving large language models ov er heterogeneous gpus and network via max-flow , ” in Pr oceedings of the 30th ACM International Confer ence on Ar chitectural Support for Pro gramming Languages and Operating Systems, V olume 1 , 2025, pp. 586–602. [29] Y . Jiang, R. Y an, X. Y ao, Y . Zhou, B. Chen, and B. Y uan, “He xgen: generativ e inference of large language model over heterogeneous en- vironment, ” in Proceedings of the 41st International Confer ence on Machine Learning , ser . ICML ’24. JMLR.org, 2024. [30] Y . JIANG, R. Y an, and B. Y uan, “Hexgen-2: Disaggregated generati ve inference of LLMs in heterogeneous environment, ” in The Thirteenth International Conference on Learning Representations , 2025. [Online]. A vailable: https://openreview .net/forum?id=Cs6MrbFuMq [31] L. Jin, Y . Zhang, Y . Li, S. W ang, H. H. Y ang, J. Wu, and M. Zhang, “Poster: Moe2: Optimizing collaborati ve inference for edge lar ge lan- guage models, ” in Proceedings of the 31st Annual International Con- fer ence on Mobile Computing and Networking , 2025, pp. 1389–1391. [32] J. Y ang, Q. Wu, Z. Feng, Z. Zhou, D. Guo, and X. Chen, “Quality-of- service aw are llm routing for edge computing with multiple experts, ” IEEE T ransactions on Mobile Computing , vol. 24, no. 12, pp. 13 648– 13 662, 2025. [33] S. Y u, M. Goudarzi, and A. N. T oosi, “Ef ficient routing of inference requests across llm instances in cloud-edge computing, ” arXiv pr eprint arXiv:2507.15553 , 2025. [34] C. Jiang, Z. Jia, S. Zheng, Y . W ang, and C. W u, “Dynapipe: Optimizing multi-task training through dynamic pipelines, ” in Pr oceedings of the Nineteenth European Confer ence on Computer Systems , 2024, pp. 542– 559. [35] S. Habibi and O. Ercetin, “Edge-llm inference with cost-aware layer allocation and adapti ve scheduling, ” IEEE Access , 2025. [36] J. S. Hunter, “The exponentially weighted moving average, ” Journal of quality technology , vol. 18, no. 4, pp. 203–210, 1986. [37] M. R. Garey and D. S. Johnson, Computers and Intractability; A Guide to the Theory of NP-Completeness . USA: W . H. Freeman & Co., 1990. [38] J. Dean and L. A. Barroso, “The tail at scale, ” Communications of the ACM , vol. 56, no. 2, pp. 74–80, 2013. [39] B. Beyer , C. Jones, J. Petof f, and N. R. Murphy , Site r eliability engineering: how Google runs production systems . ” O’Reilly Media, Inc. ”, 2016. [40] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutske ver et al. , “Language models are unsupervised multitask learners, ” OpenAI blog , vol. 1, no. 8, p. 9, 2019. [41] A. Juttner , B. Szviatovski, I. M ´ ecs, and Z. Rajk ´ o, “Lagrange relaxation based method for the qos routing problem, ” in Proceedings IEEE INFOCOM 2001. conference on computer communications. twentieth annual joint confer ence of the ieee computer and communications society (Cat. No. 01CH37213) , vol. 2. IEEE, 2001, pp. 859–868. [42] E. B. W ilson, “Probable inference, the law of succession, and statistical inference, ” Journal of the American Statistical Association , vol. 22, no. 158, pp. 209–212, 1927. [43] Y . Zhao and J. Liu, “Heterogeneous computing: The key to powering the future of ai agent inference, ” arXiv pr eprint arXiv:2601.22001 , 2026. 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment