Toxicity Monitoring Rule for a Two-Cohort Phase II Clinical Trial with Bivariate Beta Prior
Toxicity monitoring is essential in Phase II clinical trials to ensure participant safety. While monitoring rules are well-established for single-arm trials, two-cohort trials present unique challenges because toxicities are expected to be similar be…
Authors: Yu Wang, Aniko Szabo
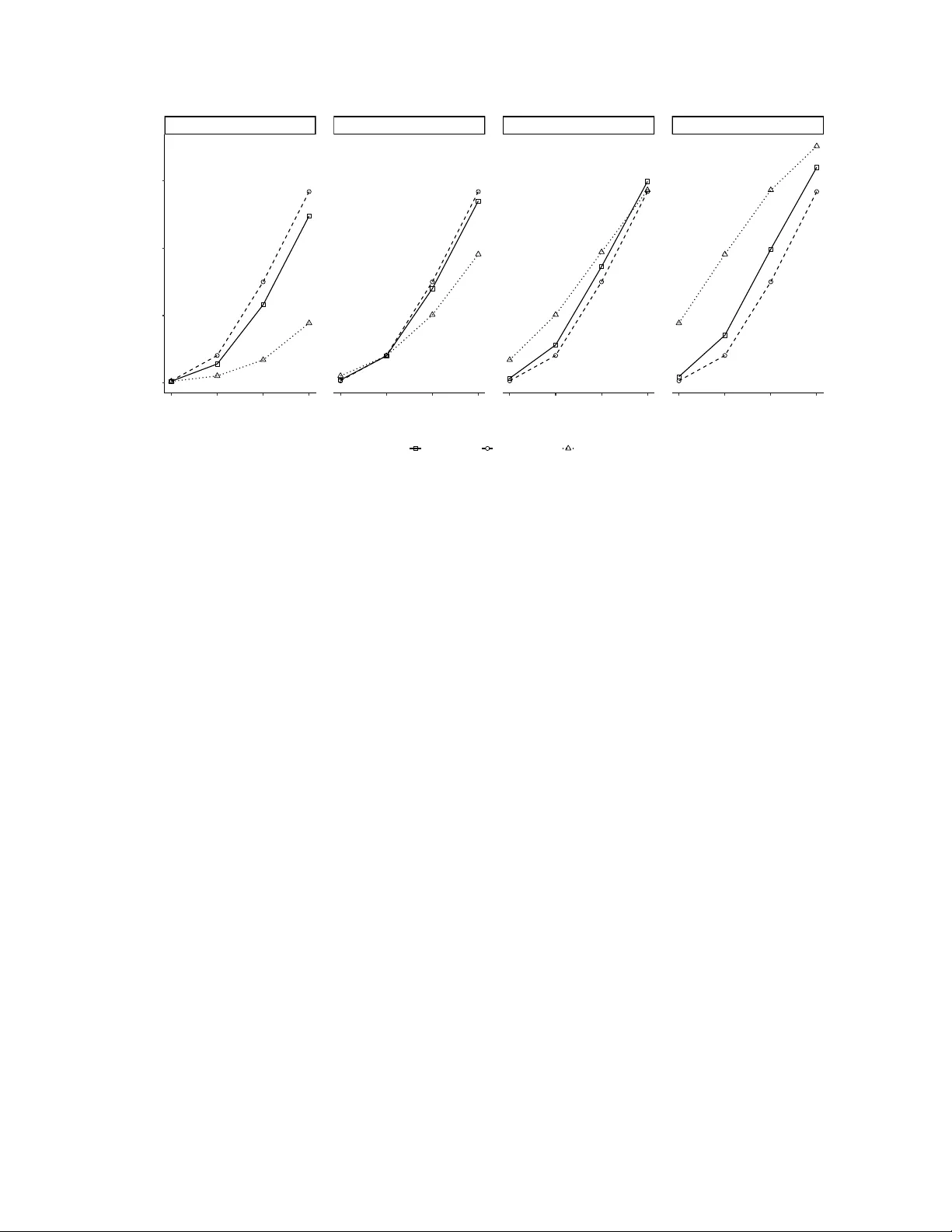
T o xicit y Monitoring Rule for a T w o-Cohort Phase I I Clinical T rial with Biv ariate Beta Prior Y u W ang, Anik o Szab o Medical College of Wisconsin Milw aukee, WI 53222 aszabo@mcw.edu Marc h 31, 2026 Abstract T oxicit y monitoring is essen tial in Phase I I clinical trials to ensure participan t safety . While monitoring rules are w ell-established for single-arm trials, t w o-cohort trials present unique c hallenges because toxicities are expected to b e similar b et ween cohorts but ma y still differ. Curren t approac hes either monitor the tw o cohorts independently , whic h ignores their similarit y , or p ool them together as a single arm, which neglects heterogeneit y b et ween cohorts. W e prop ose a Bay esian metho d based on a biv ariate b eta prior that pro vides a compromise b et ween these tw o approaches. The marginal p osterior distribution is derived as a mixture of beta distributions, enabling exact calculations of the prop osed metho d’s op erating characteristics. Examples demonstrate that join t monitoring offers a balanced approach b etw een the independent and p o oled metho ds. K eyw ords T oxicit y; T wo-cohort; Phase I I clinical trial; Monitoring rules; Biv ariate Beta; Exact Op erating characteristics 1 1 In tro duction Phase I I trials serv e as a critical bridge b et w een Phase I dose-finding studies and Phase I I I confirmatory trials. In these trials, in v estigators seek preliminary evidence of treatment efficacy at the dose level recommended from Phase I trials [ 2 ]. Ho wev er, toxicit y monitoring remains essen tial b ecause the small sample sizes in Phase I trials ma y result in an inaccurate maximum tolerated dose (MTD), p oten tially exp osing patien ts to excessiv e toxicit y in subsequen t trials. Effectiv e toxicit y monitoring inv olves trac king the num b er of adverse ev en ts relative to the n umber of enrolled sub jects as the trial progresses. When to xicit y exceeds a predetermined threshold, the trial m ust b e ev aluated immediately and terminated or mo dified as necessary . P atient heterogeneity often necessitates dividing the Phase I I trial p opulation in to tw o or more cohorts that receiv e the same in terven tion. While these cohorts may exp erience differen t lev els of efficacy , researchers exp ect them to hav e similar toxicit y profiles. F or example, in a breast cancer clinical trial, patients with triple-negativ e breast cancer may exp erience different outcomes compared to those with other subtypes. How ev er, when treated with the same therap eutic agent, they are likely to encoun ter similar side effects. Although the underlying biology of differen t subt yp es v aries, patients may still share comparable adv erse effects due to the systemic nature of treatmen t. A dv erse effects can manifest in v arious organs or tissues, leading to similar toxicit y lev els even when treatment efficacy differs across subtypes. T wo approac hes are commonly employ ed to monitor toxicit y in tw o-cohort studies. The first approac h treats the cohorts as indep endent sub-studies, neglecting the prior exp ectation of similar toxicit y profiles. The second approac h combines the cohorts in to a single group, despite p oten tial differences in to xicity , and monitors them together. Both approac hes hav e limitations: the indep endent approac h fails to leverage the expected similarit y betw een cohorts, while the p o oled approach ignores heterogeneit y b et ween them. In this pap er, w e prop ose a Bay esian compromise metho d that in tegrates both approac hes by explicitly mo deling the correlation b et ween cohort to xicities. 2 2 Bac kground 2.1 Ba y esian Monitoring for One Arm Ba yesian monitoring for single-arm Phase I I trials is w ell-established [ 4 ]. Although originally dev elop ed for treatment efficacy , these guidelines can b e adapted for to xicit y monitoring with minimal mo difications. Let X i , i = 1 , . . . , n denote the binary to xicity outcome for patient i , where X i = 1 indicates an adverse ev ent and X i = 0 indicates no adverse ev ent. Denoting the probability of to xicit y as θ , X i follo ws a Bernoulli distribution B er n ( θ ) , while the sum of X i follo ws a binomial distribution B in ( n, θ ) . The conjugate prior Beta distribution B e ( a, b ) is t ypically c hosen for the binomial parameter b ecause it yields a closed-form p osterior distribution with an intuitiv e in terpretation. Supp ose k to xicity even ts are observed among n enrolled sub jects. The p osterior distribu- tion of θ follo ws a B e ( k + a, n − k + b ) distribution with p osterior mean ( k + a ) / ( n + a + b ) . This result has a meaningful interpretation: the prior contributes a imaginary to xicity even ts and b imaginary no-tox icit y ev ents to the p osterior distribution, represen ting an effective sample size (ESS) of a + b sub jects. Based on these distributional results, toxicit y monitoring pro ceeds b y defining a null h yp othesis that the toxicit y probability θ is acceptably low, for example, θ ≤ 0 . 2 . The stopping b oundary is then defined such that the trial stops for excess to xicity if the p osterior probabilit y P ( θ ≥ 0 . 2 | k out of n ) reac hes or exceeds τ , a pre-sp ecified exceedance probabilit y [ 1 ]. F or instance, if the prior effective sample size is 3 patien ts with θ ∼ B e (0 . 6 , 2 . 4) and τ = 0 . 98 , the stopping b oundary would b e 3 to xicities out of the first 3 patien ts, 4 out of 4, 4 out of 5, and so on. 2.2 Biv ariate Beta Distribution Olkin et al.[ 3 ] introduced a biv ariate b eta distribution constructed from the Diric hlet dis- tribution with correlations ov er the full range [ − 1 , 1] . Let the v ariates U 11 , U 10 , U 01 , U 00 = 3 1 − U 11 − U 10 − U 01 ha ve a Dirichlet distribution with density f ( u 11 , u 10 , u 01 , u 00 ) = 1 B ( α ) u α 11 − 1 11 u α 10 − 1 10 u α 01 − 1 01 (1 − u 11 − u 10 − u 01 ) α 00 − 1 (1) for 0 ≤ u ij ≤ 1 , i, j = 0 , 1 , u 11 + u 10 + u 01 ≤ 1 , α = ( α 11 , α 10 , α 01 , α 00 ) , α ij ≥ 0 , and B ( α ) = Γ( α 11 )Γ( α 10 )Γ( α 01 )Γ( α 00 ) Γ( α 11 + α 10 + α 01 + α 00 ) . The sums X = U 11 + U 10 , Y = U 11 + U 01 (2) follo w a biv ariate b eta distribution, denoted [ X , Y ] ∼ B e 2 ( α ) . By the collapsibility prop ert y of the Dirichlet distribution, the marginal distributions of X and Y are B e ( α 1+ , α 0+ ) and B e ( α +1 , α +0 ) , resp ectiv ely , where α 1+ = α 11 + α 10 , α +1 = α 11 + α 01 , α 0+ = α 01 + α 00 , and α +0 = α 10 + α 00 . The joint density function is f ( x, y ) = 1 B ( α ) Z Ω u α 11 − 1 ( x − u ) α 10 − 1 ( y − u ) α 01 − 1 (1 − x − y + u ) α 00 − 1 du (3) where Ω = { u : max (0 , x + y − 1) < u 11 < min ( x, y ) } . Olkin et al.[ 3 ] also deriv ed an explicit expression for the correlation b et ween X and Y : ρ ( X , Y ) = α 11 α 00 − α 10 α 01 √ α 1+ α +1 α 0+ α +0 . (4) The biv ariate b eta distribution has b een commonly used as a prior distribution for ev en t probabilities in paired binary data. In this work, h o w ever, we apply it to unpaired data from t wo indep enden t cohorts. 4 3 Biv ariate Beta-Binomial Mo del 3.1 Mo del Comp onen ts Consider indep enden t binomial to xicit y counts X ∼ B in ( n 1 , θ 1 ) and Y ∼ B in ( n 2 , θ 2 ) in tw o cohorts. W e prop ose using the prior B e 2 ( α ) for the to xicity probabilities θ 1 and θ 2 . Since the tw o cohorts are indep enden t, the lik eliho od for observing X = k 1 and Y = k 2 is L ( θ 1 , θ 2 ) = n 1 k 1 θ k 1 1 (1 − θ 1 ) n 1 − k 1 n 2 k 2 θ k 2 2 (1 − θ 2 ) n 2 − k 2 . (5) Th us, the p osterior densit y of [ θ 1 , θ 2 ] is p ( θ 1 , θ 2 | n 1 , n 2 , k 1 , k 2 ) ∝ Z Ω u α 11 − 1 ( θ 1 − u ) α 10 − 1 ( θ 2 − u ) α 01 − 1 (1 − θ 1 − θ 2 + u ) α 00 − 1 du × θ k 1 1 (1 − θ 1 ) n 1 − k 1 θ k 2 2 (1 − θ 2 ) n 2 − k 2 . (6) 3.2 Marginal P osterior The p osterior distribution (6) do es not hav e a closed form. Ho w ever, we deriv e prop erties that simplify the calculation of p osterior probabilities needed for toxicit y monitoring and enable a useful interpretation. Theorem 1 The p osterior distribution is a mixtur e of bivariate b eta distributions: [ θ 1 , θ 2 | n 1 , n 2 , k 1 , k 2 ] ∼ k 1 X x 1 =0 n 1 − k 1 X x 2 =0 k 2 X y 1 =0 n 2 − k 2 X y 2 =0 w ( x 1 , x 2 , y 1 , y 2 ) B e 2 α + z ( x 1 , x 2 , y 1 , y 2 ) , (7) wher e z ( x 1 , x 2 , y 1 , y 2 ) = ( x 1 + y 1 , k 1 − x 1 + y 2 , x 2 + k 2 − y 1 , n 1 − k 1 − x 2 + n 2 − k 2 − y 2 ) , w ( x 1 , x 2 , y 1 , y 2 ) = c 0 B ( α + z ) k 1 x 1 n 1 − k 1 x 2 k 2 y 1 n 2 − k 2 y 2 , and c 0 is a sc aling c onstant. The pro of of this theorem is pro vided in the App endix. Analogously to the imaginary even t interpretation of the prior for the univ ariate b eta- binomial distribution describ ed in Section 2.1, we can interpret the parameters of this 5 biv ariate b eta mixture using a p oten tial outcomes framework. F or eac h enrolled sub ject, w e conceptualize t wo p otential outcomes: one if enrolled in cohort 1 and one if enrolled in cohort 2. In practice, only one of these will b e observed. Considering b oth actual and counterfactual outcomes, each sub ject b elongs to one of four groups: those who would exp erience to xicit y in (a) either cohort, (b) only cohort 1, (c) only cohort 2, or (d) neither cohort. T able 1 presen ts the breakdown of observed to xicit y counts into these four sub categories. T able 1: Partitions of observ ed toxicit y outcomes based on p oten tial outcomes in t wo cohorts. The gray background highlights cells corresp onding to observed to xicity . P otential outcome in Cohort 2 Source P otential outcome in Cohort 1 Subtotal T oxicit y Non-T oxicit y T oxicit y Prior α 11 α 01 α +1 Cohort 1 x 1 x 2 x 1 + x 2 Cohort 2 y 1 k 2 − y 1 k 2 Non- T oxicit y Prior α 10 α 00 α +0 Cohort 1 k 1 − x 1 n 1 − k 1 − x 2 n 1 − x 1 − x 2 Cohort 2 y 2 n 2 − k 2 − y 2 n 2 − k 2 Subtotal Prior α 1+ α 0+ E S S Cohort 1 k 1 n 1 − k 1 n 1 Cohort 2 y 1 + y 2 n 2 − y 1 − y 2 n 2 F or sub jects in cohort 1 (rows 2 and 5), we observe only the cohort-1 p oten tial outcome: k 1 to xicities among n 1 sub jects. Ho wev er, among these k 1 patien ts with to xicit y , we p osit that x 1 w ould develop toxicit y in either cohort, while k 1 − x 1 w ould develop toxicit y only in cohort 1. Similarly , among the n 1 − k 1 sub jects without toxicit y , x 2 w ould develop to xicit y only in cohort 2, and n 1 − k 1 − x 2 w ould exp erience no to xicity regardless of cohort. Sub jects in cohort 2 (ro ws 3 and 6) are similarly partitioned, with y 1 coun ting those who w ould develop toxicit y in either cohort among the k 2 who actually do, and y 2 coun ting those who would develop toxicit y only in the other cohort. With α represen ting the n umber of imaginary sub jects enco ded in the prior, each comp o- nen t in the mixture (7) represents a sp ecific set of v alues for x 1 , x 2 , y 1 , y 2 , with con tributions from eac h source to the four p oten tial-outcome groups. The weigh ts w ( x 1 , x 2 , y 1 , y 2 ) quan tify 6 the probability of each com bination. T oxicit y monitoring requires marginal p osterior distributions, which hav e a simpler form: Theorem 2 The mar ginal p osterior distribution of θ i is a mixtur e of b eta distributions: [ θ 1 | n 1 , n 2 , k 1 , k 2 ] ∼ n 2 X y =0 g 1 ( y ) B e ( α 1+ + k 1 + n 2 − y , α 0+ + n 1 − k 1 + y ) , [ θ 2 | n 1 , n 2 , k 1 , k 2 ] ∼ n 1 X x =0 g 2 ( x ) B e ( α +1 + k 2 + n 1 − x, α +0 + n 2 − k 2 + x ) . (8) The exact forms of g 1 and g 2 ar e given in the App endix. A detailed pro of of this theorem based on Theorem 1 is pro vided in the App endix. The marginal subtotals in T able 1 provide an intuitiv e j ustification for this form, where x = x 1 + x 2 and y = y 1 + y 2 coun t the num b er of sub jects in eac h cohort who would ha v e exp erienced to xicity in the other cohort. 4 T w o-Cohort T o xicit y Monitoring The to xicity monitoring framework for t w o cohorts follows the same principles as single-arm monitoring, but with mo difications to account for the correlation b et ween cohorts. W e define the null and alternative h yp otheses, sp ecify the prior dis tribution, and set an exceedance threshold for the p osterior probabilit y . 4.1 Hyp otheses Although w e monitor the tw o cohorts sim ultaneously , we allow different th resholds θ 0 i for acceptable to xicity probability in each cohort. This flexibilit y is useful when patien ts in one cohort ha ve a worse prognosis and a higher to xicit y level might b e acceptable if the treatmen t pro vides ov erall b enefit. Th us, w e define the hypotheses for eac h cohort separately: 7 Cohort i : H 0 : θ i ≤ θ 0 i v ersus H 1 : θ i > θ 0 i i = 1 , 2 . 4.2 Prior Distribution P arameters The biv ariate b eta-binomial prior describ ed in Section 3.1 has four parameters α ij , i = 0 , 1 , j = 0 , 1 . Rather than sp ecifying these parameters directly , we prop ose computing them from more interpretable characteristics: the marginal means, the effective sample size E S S , and the correlation ρ . Based on the exp ectation that cohorts hav e similar toxicit y , we assume prior means p 1 and p 2 for the t w o cohorts, though this is not a necessary restriction. W e then solv e for α based on E S S , ρ , and p using the follo wing system of equations: p 1 = α 11 + α 10 E S S , p 2 = α 11 + α 01 E S S , α 11 α 00 − α 10 α 01 √ α 1+ α +1 α 0+ α +0 = ρ, α 11 + α 10 + α 01 + α 00 = E S S, = ⇒ α 11 = ( ρ p p 1 p 2 (1 − p 1 )(1 − p 2 ) + p 1 p 2 ) × E S S , α 10 = p 1 × E S S − α 11 , α 01 = p 2 × E S S − α 11 , α 00 = E S S − ( α 11 + α 10 + α 01 ) . (9) 4.3 Calculating the Exceedance Probabilit y Within eac h cohort, the stopping decision follows the same principles as single-arm monitoring (Section 2.1). Cohort i stops for excess toxicit y if P ( θ i > θ 0 i | n 1 , n 2 , k 1 , k 2 ) > τ , where τ is a pre-sp ecified cutoff. Based on Theorem 2, the exceedance probability for cohort 1 is P ( θ 1 > θ 01 | n 1 , n 2 , k 1 , k 2 ) = Z 1 θ 01 [ θ 1 | n 1 , n 2 , k 1 , k 2 ] dθ 1 = n 2 X y =0 g 1 ( y ) ¯ F B e ( θ 01 ; α 1+ + k 1 + n 2 − y , α 0+ + n 1 − k 1 + y ) , (10) where ¯ F B e ( x ; α, β ) denotes the surviv al function of the B e ( α, β ) distribution. The exceedance probabilit y for cohort 2 is obtained similarly . 8 When this probabilit y exceeds the threshold τ , w e stop cohort i and record n i and k i . In our framew ork, we contin ue monitoring the other cohort, up dating the calculation with the recorded n i and k i . F or example, if the probability first exceeds τ in cohort 1, we stop cohort 1 and record n 1 and k 1 . W e then con tinue monitoring cohort 2 with up dated n 2 and k 2 and the known n 1 and k 1 un til it stops or the maxim um sample size N is reached. 4.4 P osteriors for Indep enden t and P o oled Monitoring F or indep endent monitoring, w e essen tially apply the single-arm Bay esian monitoring approac h from Section 2.1 to each cohort separately . T reating the t w o cohorts as distinct trials, and to main tain consistency with the correlated prior, we use the priors [ θ 1 ] ∼ B e ( α 11 + α 10 , α 01 + α 00 ) and [ θ 2 ] ∼ B e ( α 11 + α 01 , α 10 + α 00 ) . Th us, [ θ 1 | n 1 , k 1 ] ∼ B e ( α 11 + α 10 + k 1 , α 01 + α 00 + n 1 − k 1 ) , [ θ 2 | n 2 , k 2 ] ∼ B e ( α 11 + α 01 + k 2 , α 10 + α 00 + n 2 − k 2 ) . (11) F or po oled monitoring, we ignore the distinction b et w een cohorts and apply s ingle- arm Ba y esian monitoring with a single toxicit y probability for b oth cohorts. T o maintain consistency with the other monitoring rules, we a v erage the t wo priors, yielding [ θ ] ∼ B e ((2 α 11 + α 10 + α 01 ) / 2 , (2 α 00 + α 01 + α 10 ) / 2) . Th us, [ θ | n 1 + n 2 , k 1 + k 2 ] ∼ B e 2 α 11 + α 10 + α 01 2 + k 1 + k 2 , 2 α 00 + α 01 + α 10 2 + n 1 + n 2 − ( k 1 + k 2 ) . (12) Using these p osterior distributions, we can recalculate the p osterior probabilities and thus the exceedance probabilities for indep enden t and p o oled monitoring using equation (10). 4.5 Stopping T ables The stopping b oundary is determined using the exceedance probabilit y (10). Ho wev er, displa ying the dynamic relationship b et ween k 1 and k 2 in a limited space can b e challenging. 9 W e therefore assume equal n umbers of sub jects in b oth cohorts at each assessmen t p oin t. Stopping tables for the three approac hes are provided in T able 2, with θ 01 = θ 02 = 0 . 2 , E S S = 3 , ρ = 0 . 5 , and τ = 0 . 98 . In T able 2, eac h cell indicates the num b er of toxicit y ev ents in cohort 1 ( k 1 ) required to stop cohort 1, given the n um b er of to xicity ev en ts in cohort 2 ( k 2 ), assuming n 1 = n 2 sub jects are enrolled in each cohort. F or example, when no toxicit y even ts o ccur in cohort 2 and six patien ts are enrolled in each cohort, at least five toxicit y even ts are needed to stop cohort 1 under b oth indep enden t and correlated monitoring rules. Under p o oled monitoring, six to xicity even ts w ould b e required. 4.6 F requen tist Op erating Characteristics of Stopping Rules In vestigators often require frequen tist op erating c haracteristics of the designed trial, including t yp e I error, stopping probabilit y , exp ected total num b er of enrolled patients, and exp ected n umber of even ts. W e prop ose exact calculations using a recursiv e form ula rather than sim ulation. Since n 1 and n 2 are independent, so are k 1 and k 2 , and P ( k 1 , k 2 | n 1 , n 2 ) = P ( k 1 | n 1 ) P ( k 2 | n 2 ) . By the prop ert y of the binomial distribution, P ( k i + 1 | n i + 1) = θ i P ( k i | n i ) + (1 − θ i ) P ( k i + 1 | n i ) , (13) where 0 ≤ k i ≤ n i and P (0 | 0) = 1 . Using the recursive form ula (13), w e calculate P ( k 1 , k 2 | n 1 , n 2 ) . Com bined with the p osterior probability of crossing the b oundary for each ( k 1 , k 2 , n 1 , n 2 ) as in equation (6), we obtain the frequentist op erating c haracteristics for all three approac hes. 10 T able 2: Stopping b oundary table for to xicity ( θ 01 = θ 02 = 0 . 2 , τ = 0 . 98 ) Stopping p 1 = p 2 n 1 = n 2 = Boundary 1 2 3 4 5 6 7 8 9 10 k 2 = 0 0 (Indep endent) . . 3 4 4 5 5 5 6 6 0.5 (Correlated) . . . 4 4 5 5 6 6 6 0.99 (Pooled) . . . . . 6 7 7 8 8 1 0 (Indep endent) . . 3 4 4 5 5 5 6 6 0.5 (Correlated) . . 3 4 4 5 5 6 6 6 0.99 (Pooled) . . . 4 5 5 6 7 7 8 2 0 (Indep endent) . . 3 4 4 5 5 5 6 6 0.5 (Correlated) . 2 3 4 4 4 5 5 6 6 0.99 (Pooled) . 2 3 3 4 5 5 6 6 7 3 0 (Indep endent) . . 3 4 4 5 5 5 6 6 0.5 (Correlated) . . 3 3 4 4 5 5 5 6 0.99 (Pooled) . . 2 2 3 4 4 5 5 6 4 0 (Indep endent) . . . 4 4 5 5 5 6 6 0.5 (Correlated) . . . 3 3 4 4 5 5 5 0.99 (Pooled) . . . 2 2 3 3 4 4 5 5 0 (Indep endent) . . . . 4 4 5 5 6 6 0.5 (Correlated) . . . . 3 4 4 4 5 5 0.99 (Pooled) . . . . 2 2 2 3 3 4 6 0 (Indep endent) . . . . . 4 5 5 6 6 0.5 (Correlated) . . . . . 4 4 4 5 5 0.99 (Pooled) . . . . . 2 2 2 3 3 7 0 (Indep endent) . . . . . . 5 5 6 6 0.5 (Correlated) . . . . . . 4 4 5 5 0.99 (Pooled) . . . . . . 2 2 3 3 8 0 (Indep endent) . . . . . . . 5 6 6 0.5 (Correlated) . . . . . . . 4 5 5 0.99 (Pooled) . . . . . . . 3 3 3 9 0 (Indep endent) . . . . . . . . 5 6 0.5 (Correlated) . . . . . . . . 5 5 0.99 (Pooled) . . . . . . . . 3 3 10 0 (Indep endent) . . . . . . . . . 6 0.5 (Correlated) . . . . . . . . . 5 0.99 (Pooled) . . . . . . . . . 4 Note: θ 01 = 0 . 2 , θ 02 = 0 . 2 , τ = 0 . 98 . 11 5 Comparison Among Three Monitoring Rules W e compare the frequen tist op erating c haracteristics among the correlated, indep enden t, and p o oled stopping rules. W e use a symmetric setting with n 1 = n 2 = 20 , θ 1 = θ 2 = 0 . 2 in the prior, E S S = 3 , ρ = 0 . 5 , and τ = 0 . 98 . This symmetric setup allows us to fo cus on the prop erties of one cohort, with the conclusions applying equally to the other. Without loss of generalit y , w e present op erating characteristics for cohort 1 when not sp ecified. W e demonstrate how to compute these quan tities using the recursive algorithm in Section 4.6. 5.1 T yp e I Error Not surprisingly , the t yp e I errors ( α ) of the three approac hes differ substantially when fixing τ = 0 . 98 and N = 20 . The type I error for cohort 1 is defined as α = P ( θ 1 ≥ 0 . 2 | θ 1 = 0 . 2 , θ 2 ) . (14) θ 2 = 0.1 θ 2 = 0.2 θ 2 =0.3 θ 2 =0.4 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 0.0 0.1 0.2 0.3 0.4 Effectiv e Sample Size(ESS) T ype I Error( α ) T ype Correlated Independent Pooled Figure 1: Type I error in cohort 1 ( ρ = 0 . 5 , N = 20 , τ = 0 . 98 ) Figure 1 shows the t yp e I error panels separated b y the actual toxicit y in cohort 2 ( θ 2 ), 12 with the effectiv e sample size in the prior on the x-axis. Fixing E S S and examining the relationship b et ween α and θ 2 across the three monitoring rules, we observe the follo wing when θ 2 = 0 . 1 (less than the toxicit y threshold of 0.2): p ooled monitoring yields the smallest (most conserv ative) type I error, indep enden t monitoring p erforms worst but remains acceptable ( ≤ 0 . 1 ), and correlated monitoring falls b et ween them. Our intuitiv e explanation is as follows. When p o oled monitoring is applied, the av erage to xicity b et ween the tw o cohorts affects the stopping decision. As θ 2 increases, the p o oled a verage mov es farther from the upp er b ound θ 1 = 0 . 2 , making rejection of the null hypothesis more likely . Th us, α increases substantially as θ 2 increases. In con trast, the p osterior toxicit y for cohort 1 under correlated monitoring is a w eigh ted a verage of b oth cohorts, so the increasing trend is less pronounced. Indep enden t monitoring is unaffected b y th e toxicit y in cohort 2, so α remains constant across panels. T urning to the effect of E S S , all lines in Figure 1 decrease as E S S increases. This is exp ected b ecause we set the prior means θ 1 = θ 2 = 0 . 2 , consistent with the n ull hypothesis. Consequen tly , more evidence is required to reject the null when the prior has greater weigh t. 5.2 Stopping Probabilit y T o make all three rules comparable, w e select τ to ac hieve a common type I error ( α = 0 . 1 ). Con trolling α = 0 . 1 yields the corresp onding op erating characteristics for all three approaches, whic h we present in the following sections. In Figure 2, the o v erall pattern of early stopping probability for cohort 1 increases with the to xicity probability across all three panels. Intuitiv ely , more toxicit y ev en ts are observ ed when true toxicit y is high, making early stopping more likely . First, comparing the three approac hes across panels: the indep endent monitoring app ears iden tical across panels, as exp ected, b ecause the actual toxicit y in cohort 2 ( θ 2 ) do es not affect stopping in cohort 1 when monitored indep endently . The p o oled curve shifts up w ard as θ 2 increases. This o ccurs b ecause higher to xicit y in cohort 2 leads to more total even ts, 13 θ 2 = 0.1 θ 2 = 0.2 θ 2 =0.3 θ 2 =0.4 0.1 0.2 0.3 0.4 0.1 0.2 0.3 0.4 0.1 0.2 0.3 0.4 0.1 0.2 0.3 0.4 0.00 0.25 0.50 0.75 Actual T oxicity in cohort 1 ( θ 1 ) Stopping Probability T ype Correlated Independent Pooled Figure 2: Probability of early stopping in cohort 1 ( ρ = 0 . 5 , N = 20 , τ = 0 . 98 , E S S = 3 ) ev en when cohort 1 to xicit y remains constant. Since p o oled monitoring treats b oth cohorts iden tically , cohort 1 stops more frequently . The correlated approac h shifts upw ard, but less than the p o oled metho d. Whether this upw ard shift is b eneficial dep ends on the sp ecific con text. Next, comparing within eac h panel: w e exp ect the stopping probability for cohort 1 to b e lo w when the actual toxicit y ( θ 1 ) is 0.2 or less, and high when θ 1 exceeds 0.2. Thus, indep enden t monitoring p erforms b est when θ 2 = 0 . 1 or 0 . 2 . Ho wev er, the b est approach is less clear when θ 2 = 0 . 3 or 0 . 4 . In the third panel ( θ 2 = 0 . 2 ), indep enden t monitoring pro duces few er stops than the other t w o approaches when θ 1 = 0 . 2 , but correlated monitoring stops more frequently than the others when θ 1 = 0 . 3 , with indep enden t monitoring in termediate. A similar pattern app ears in the fourth panel. W e exp ect indep enden t monitoring to b e preferable when toxicities differ substantially b et ween cohorts, while p o oled monitoring is more appropriate when toxicities are similar or iden tical. This exp ectation aligns with Figure 2, with one notable exception. In the second panel where θ 1 = 0 . 4 , correlated monitoring stops more frequently than indep enden t monitoring even though θ 1 and θ 2 differ. This observ ation suggests that correlated monitoring 14 ma y b e adv antageous in certain scenarios. 5.3 Exp ected T otal Num b er of Enrolled P atients Considering patient safety and trial costs, few er total enrolled patients is preferable. The o verall pattern in Figure 3 is clear: the total n umber of sub jects required decreases as to xicity increases, b ecause higher to xicity makes detection easier and early termination more likely . Indep enden t monitoring enrolls the few est patien ts when θ 2 = 0 . 1 , but this adv an tage rev erses when θ 1 , θ 2 ≥ 0 . 2 . P o oled monitoring p erforms b etter when θ 1 , θ 2 ≥ 0 . 2 and closely resembles correlated monitoring when θ 2 = 0 . 2 . A cross most scenarios, correlated monitoring provides a balanced effect on sample size. θ 2 = 0.1 θ 2 = 0.2 θ 2 =0.3 θ 2 =0.4 0.1 0.2 0.3 0.4 0.1 0.2 0.3 0.4 0.1 0.2 0.3 0.4 0.1 0.2 0.3 0.4 20 25 30 35 40 Actual T oxicity in cohort 1( θ 1 ) # of patients T ype Correlated Independent Pooled Figure 3: Exp ected num b er of patien ts enrolled at stopping ( ρ = 0 . 5 , N = 20 , τ = 0 . 98 , E S S = 3 ) 5.4 Exp ected Num b er of Ev en ts F rom a safety p ersp ectiv e, we prefer fewer to xicity even ts regardless of true to xicity . W e examine tw o related quantities: the total n umber of even ts when the trial ends (whether 15 due to early stopping or reaching maximum sample size), and the n umber of even ts at early stopping in cohort 1. θ 2 = 0.1 θ 2 = 0.2 θ 2 =0.3 θ 2 =0.4 0.1 0.2 0.3 0.4 0.1 0.2 0.3 0.4 0.1 0.2 0.3 0.4 0.1 0.2 0.3 0.4 4 6 8 10 Actual T oxicity in cohort 1( θ 1 ) Expect number of to xicity events at stopping T ype Correlated Independent Pooled Figure 4: Exp ected n umber of even ts at stopping ( ρ = 0 . 5 , N = 20 , τ = 0 . 98 , E S S = 3 ) In Figure 4, regardless of stopping rules, b oth cohorts should reach the maximum sample size N 1 = N 2 = 20 when true toxicities are acceptable ( θ 1 = θ 2 = 0 . 1 ). Th us, the exp ected total num b er of ev ents is N 1 θ 1 + N 2 θ 2 = 4 . Extending this reasoning to different v alues of θ 1 , θ 2 ≤ 0 . 2 , when θ 1 = 0 . 2 and θ 2 = 0 . 1 , the exp ected quantit y is approximately 20 × 0 . 2 + 20 × 0 . 1 = 6 . The difference from 6 ma y arise b ecause type I error allo ws some c hance of early stopping ev en when true to xicit y is acceptable. Consequen tly , the exp ected n umber of to xicity ev en ts is sligh tly less than 6. The general trend shows increasing exp ected ev ents as toxicit y probabilities increase, with some exceptions for correlated and p o oled monitoring when θ 1 = θ 2 = 0 . 4 . When true tox icities are extremely high, the trial may end v ery early , and the reduced enrollment mitigates the effect of high toxicit y on ev ent coun ts. Notably , all three rules p erform similarly in the second panel ( θ 2 = 0 . 2 ). Correlated monitoring consistently provides intermediate effects across all panels. W e also present the exp ected num b er of toxicit y ev ents at early stopping in cohort 1 for the three approac hes. These v alues are collected only when cohort 1 stops early and exclude 16 θ 2 = 0.1 θ 2 = 0.2 θ 2 =0.3 θ 2 =0.4 0.1 0.2 0.3 0.4 0.1 0.2 0.3 0.4 0.1 0.2 0.3 0.4 0.1 0.2 0.3 0.4 2 3 4 5 Actual T oxicity in cohort 1 ( θ 1 ) Expect number of to xicity events at early stopping in ar m 1 T ype Correlated Independent Pooled Figure 5: Expected num b er of even ts at early stopping in cohort 1 ( ρ = 0 . 5 , N = 20 , τ = 0 . 98 , E S S = 3 ) cases where the trial reac hes the sample size limit. The dashed reference lines in Figure 5 are iden tical across panels b ecause this quan tity dep ends only on cohort 1, indep enden t of cohort 2. These v alues reflect the difficulty of stopping cohort 1. 6 Discussion As discussed earlier, t wo-cohort to xicity monitoring presen ts c hallenges with current metho ds. Indep enden t monitoring ignores the similarity b et w een cohorts, while p o oled monitoring neglects heterogeneit y b etw een them. Both metho ds ha ve scenarios where they outp erform our join t monitoring rule, as demonstrated in the previous section. Ho w ever, the true relationship b et ween to xicities in tw o cohorts is often uncertain in practice, making it difficult to c ho ose the most appropriate monitoring rule a priori for optimal op erating characteristics. Our metho d provides an alternative approach for toxicit y monitoring in tw o-cohort trials. By introducing the biv ariate b eta prior into the Ba yesian framework, we ac hiev e a compromise b et ween the tw o existing rules: neither treating the cohorts as indep enden t nor iden tical. The 17 degree of correlation can b e adjusted through the effectiv e sample size ( E S S ) and correlation co efficien t ( ρ ). Higher prior correlation leads to greater p osterior correlation b et ween cohorts, with the same applying to ESS. A dditionally , compared to traditional sim ulation metho ds, we obtain exact op erating c haracteristics rather than simulated estimates in a relativ ely efficien t manner. This approach yields more stable prop erties across different settings. Although it is not optimal in all scenarios, it consistently p erforms near the b est option. Sev eral limitations should b e noted. Unlike the deterministic b oundaries provided by other approac hes, our metho d pro duces a more dynamic stopping b oundary that requires collab oration with a statistician to monitor to xicity throughout the trial. This may p ose c hallenges for safety monitoring b oards. T o address this limitation, we hav e dev elop ed an R pac k age to facilitate implemen tation. Sev eral extensions are p ossible, including allowing more than t wo cohorts, using a dis- tribution on the prior correlation instead of a single pre-sp ecified v alue ρ , and ev aluating differen t toxicit y thresholds. References [1] Geller, N. (2004). A dvanc es in clinic al trial biostatistics . Marcel Dekk er, New Y ork. [2] Iv anov a, A., Qaqish, B. F., and Schell, M. J. (2005). Con tinuous T o xicity Monitoring in Phase I I T rials in Oncology. Biometrics 61, 540–545. [3] Olkin, I. and T rik alinos, T. A. (2015). Constructions for a biv ariate b eta distribution. Statistics & Pr ob ability L etters 96, 54–60. [4] Thall, P . F. and Simon, R. (1994). Practical Bay esian Guidelines for Phase I IB Clinical T rials. Biometrics 50, 337–349. Publisher: [Wiley , International Biometric So ciet y]. 18 App endices Pro of of Theorem 1 Starting from equation (6), we ha v e K ( θ 1 , θ 2 ) = Z Ω u α 11 − 1 ( θ 1 − u ) α 10 − 1 ( θ 2 − u ) α 01 − 1 (1 − θ 1 − θ 2 + u ) α 00 − 1 θ k 1 1 (1 − θ 1 ) n 1 − k 1 θ k 2 2 (1 − θ 2 ) n 2 − k 2 du = Z Ω u α 11 − 1 ( θ 1 − u ) α 10 − 1 ( θ 2 − u ) α 01 − 1 (1 − θ 1 − θ 2 + u ) α 00 − 1 ( u + θ 1 − u ) k 1 ( θ 2 − u + 1 − θ 1 − θ 2 + u ) n 1 − k 1 · ( u + θ 2 − u ) k 2 ( θ 1 − u + 1 − θ 2 − θ 1 + u ) n 2 − k 2 du = Z Ω u α 11 − 1 ( θ 1 − u ) α 10 − 1 ( θ 2 − u ) α 01 − 1 (1 − θ 1 − θ 2 + u ) α 00 − 1 ( k 1 X x 1 =0 k 1 x 1 u x 1 ( θ 1 − u ) k 1 − x 1 ) · ( n 1 − k 1 X x 2 =0 n 1 − k 1 x 2 ( θ 2 − u ) x 2 (1 − θ 1 − θ 2 + u ) n 1 − k 1 − x 2 ) ( k 2 X y 1 =0 k 2 y 1 u y 1 ( θ 2 − u ) k 2 − y 1 ) · ( n 2 − k 2 X y 2 =0 n 2 − k 2 y 2 ( θ 1 − u ) y 2 (1 − θ 1 − θ 2 + u ) n 2 − k 2 − y 2 ) du = k 1 X x 1 =0 n 1 − k 1 X x 2 =0 k 2 X y 1 =0 n 2 − k 2 X y 2 =0 k 1 x 1 n 1 − k 1 x 2 k 2 y 1 n 2 − k 2 y 2 · Z Ω u α 11 − 1+ x 1 + y 1 ( θ 1 − u ) α 10 − 1+ k 1 − x 1 + y 2 ( θ 2 − u ) α 01 − 1+ x 2 + k 2 − y 1 (1 − θ 1 − θ 2 + u ) α 00 − 1+ n 1 − k 1 − x 2 + n 2 − k 2 − y 2 du = k 1 X x 1 =0 n 1 − k 1 X x 2 =0 k 2 X y 1 =0 n 2 − k 2 X y 2 =0 k 1 x 1 n 1 − k 1 x 2 k 2 y 1 n 2 − k 2 y 2 B ( α ′ ) · f B e 2 ( α 11 + x 1 + y 1 , α 10 + k 1 − x 1 + y 2 , α 01 + x 2 + k 2 − y 1 , α 00 + n 1 − k 1 − x 2 + n 2 − k 2 − y 2 ) . Pro of of Theorem 2 g 1 ( y ) = c 1 Γ( α 1+ + k 1 + n 2 − y )Γ( α 0+ + n 1 − k 1 + y ) min( n 2 − k 2 ,y ) X y 2 =max(0 ,y − k 2 ) k 2 y − y 2 n 2 − k 2 y 2 × B ( α 00 + y 2 , α 01 + y − y 2 ) B ( α 10 + n 2 − k 2 − y 2 , α 11 + k 2 − y + y 2 ) . (15) g 2 ( x ) = c 2 Γ( α +1 + k 2 + n 1 − x )Γ( α +0 + n 2 − k 2 + x ) min( n 1 − k 1 ,x ) X x 2 =max(0 ,x − k 1 ) k 1 x − x 2 n 1 − k 1 x 2 × B ( α 00 + x 2 , α 10 + x − x 2 ) B ( α 01 + n 1 − k 1 − x 2 , α 11 + k 1 − x + x 2 ) . (16) Here, c 1 and c 2 are scaling constants. 19 Since x 1 , x 2 , y 1 , y 2 , and θ 1 are constant with resp ect to θ 2 , and the sum of integrals equals the in tegral of the sum, we can mov e the in tegral inside the summation when integrating the join t p osterior (7) o ver θ 2 . The marginal distribution of θ 1 is B e ( α 1+ , α 0+ ) by the prop ert y of B e 2 ( α 11 , α 10 , α 01 , α 00 ) . Applying the same argumen t with α replaced by α ′ completes the pro of. This completes the pro of. A similar deriv ation holds for θ 2 . Moreo ver, B ( α ′ ) = Q 4 i =1 Γ( α ′ i ) Γ( P 4 i =1 α ′ i ) = Γ( α 11 + k 1 − x 1 + k 2 − y 1 )Γ( α 10 + x 1 + n 2 − k 2 − y 2 )Γ( α 01 + n 1 − k 1 − x 2 + y 1 )Γ( α 00 + x 2 + y 2 ) Γ( α 11 + α 10 + α 01 + α 00 + n 1 + n 2 ) ∝ Γ( α 11 + k 1 − x 1 + k 2 − y 1 )Γ( α 10 + x 1 + n 2 − k 2 − y 2 )Γ( α 01 + n 1 − k 1 − x 2 + y 1 )Γ( α 00 + x 2 + y 2 ) . (17) The term Γ( α 11 + k 1 − x 1 + k 2 − y 1 )Γ( α 10 + x 1 + n 2 − k 2 − y 2 ) is the kernel of a b eta-binomial distribution with n = k 1 , k = x 1 , α = n 2 − k 2 − y 2 + α 10 , and β = k 2 − y 1 + α 11 . Similarly , Γ( α 01 + n 1 − k 1 − x 2 + y 1 )Γ( α 00 + x 2 + y 2 ) is the k ernel with n = n 1 − k 1 , k = x 2 , α = α 00 + y 2 , and β = α 01 + y 1 . Note that if k ∼ Beta-Binomial ( n, α, β ) , then d betabinom ( k ) = n k B ( k + α, n − k + β ) B ( α, β ) = n k Γ( k + α )Γ( n − k + β ) Γ( n + α + β ) Γ( α )Γ( β ) Γ( α + β ) = Γ( α + β ) Γ( n + α + β )Γ( α )Γ( β ) n k Γ( k + α )Γ( n − k + β ) . Th us, n k Γ( k + α )Γ( n − k + β ) = d betabinom ( k ) Γ( n + α + β )Γ( α )Γ( β ) Γ( α + β ) = d betabinom ( k )Γ( n + α + β ) B ( α, β ) . 20 The full deriv ation pro ceeds as follows: p ( θ 1 | n 1 , n 2 , k 1 , k 2 ) ∝ k 1 X x 1 =0 n 1 − k 1 X x 2 =0 k 2 X y 1 =0 n 2 − k 2 X y 2 =0 n k 1 x 1 n 1 − k 1 x 2 k 2 y 1 n 2 − k 2 y 2 · Γ( α 11 + k 1 − x 1 + k 2 − y 1 )Γ( α 10 + x 1 + n 2 − k 2 − y 2 ) · Γ( α 01 + n 1 − k 1 − x 2 + y 1 )Γ( α 00 + x 2 + y 2 ) · d beta ( θ 1 , α 11 + k 1 − y 1 + α 10 + n 2 − y 2 , α 01 + n 1 − k 1 + y 1 + α 00 + y 2 ) o ∝ k 2 X y 1 =0 n 2 − k 2 X y 2 =0 n Γ( k 1 + n 2 − y 2 + α 10 − y 1 + α 11 ) B ( n 2 − k 2 − y 2 + α 10 , k 2 − y 1 + α 11 ) · Γ( n 1 − k 1 + α 00 + y 2 + α 01 + y 1 ) B ( α 00 + y 2 , α 01 + y 1 ) k 2 y 1 n 2 − k 2 y 2 · d beta ( θ 1 , α 11 + k 1 − y 1 + α 10 + n 2 − y 2 , α 01 + n 1 − k 1 + y 1 + α 00 + y 2 ) · k 1 X x 1 =0 d betabinom ( x 1 | n = k 1 , k = x 1 , α = n 2 − k 2 − y 2 + α 10 , β = k 2 − y 1 + α 11 ) · n 1 − k 1 X x 2 =0 d betabinom ( x 2 | n = n 1 − k 1 , k = x 2 , α = α 00 + y 2 , β = α 01 + y 1 ) o ∝ n 2 X y =0 n Γ( k 1 + n 2 − y + α 10 + α 11 )Γ( n 1 − k 1 + α 00 + y + α 01 ) · d beta ( θ 1 , α 11 + k 1 − y + α 10 + n 2 , α 01 + n 1 − k 1 + y + α 00 ) · min( n 2 − k 2 ,y ) X y 2 =max(0 ,y − k 2 ) B ( n 2 − k 2 − y 2 + α 10 , k 2 − y + y 2 + α 11 ) · B ( α 00 + y 2 , α 01 + y − y 2 ) k 2 y − y 2 n 2 − k 2 y 2 o . This completes the pro of. A similar deriv ation holds for θ 2 . 21
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment