Navigating the Mirage: A Dual-Path Agentic Framework for Robust Misleading Chart Question Answering
Despite the success of Vision-Language Models (VLMs), misleading charts remain a significant challenge due to their deceptive visual structures and distorted data representations. We present ChartCynics, an agentic dual-path framework designed to unm…
Authors: Yanjie Zhang, Yafei Li, Rui Sheng
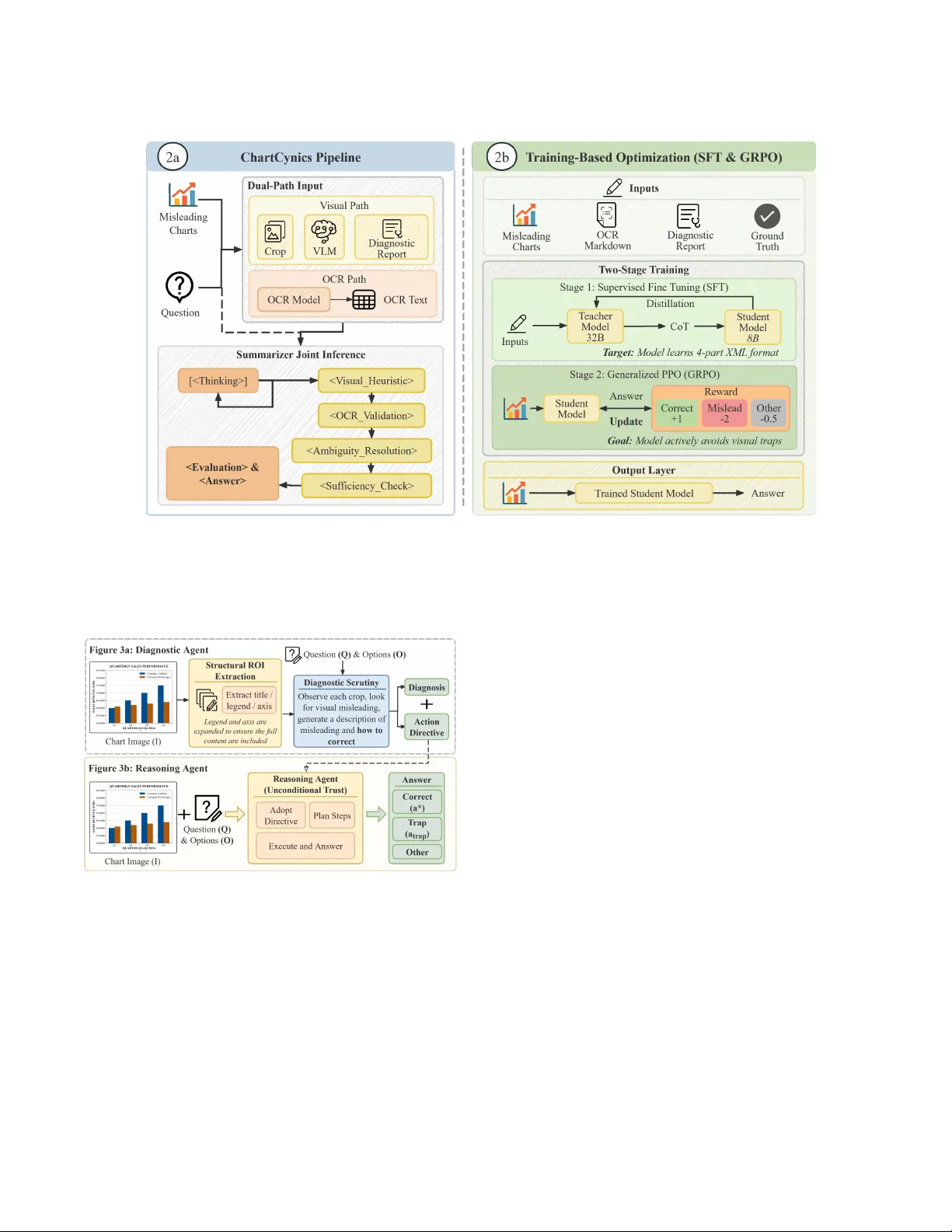
Navigating the Mirage: A Dual-Path Agentic Frame work for Robust Misleading Chart estion Answering Y anjie Zhang 1 , ∗ , Y afei Li 1 , ∗ , Rui Sheng 1 , Zixin Chen 1 , Y anna Lin 1 , Huamin Qu 1 , Lei Chen 1 , 2 , Y ushi Sun 1 , † 1 HKUST , China 2 HKUST(GZ), Guangzhou, China ∗ Equal contribution † Corresponding author: ysunbp@connect.ust.hk Abstract Despite the success of Vision-Language Models (VLMs), mislead- ing charts remain a signicant challenge due to their deceptive visual structur es and distorte d data representations. W e pr esent ChartCynics , an agentic dual-path framework designed to un- mask visual deception via a “skeptical” reasoning paradigm. Unlike holistic models, ChartCynics decouples perception from verica- tion: a Diagnostic Vision Path captures structural anomalies (e.g., inverted axes) through strategic ROI cropping, while an OCR-Driven Data Path ensures numerical grounding. T o resolve cross-modal conicts, we intr oduce an Agentic Summarizer optimized via a two- stage protocol: Oracle-Informed SFT for reasoning distillation and Deception- A ware GRPO for adversarial alignment. This pipeline eectively penalizes visual traps and enforces logical consistency . Evaluations on two benchmarks show that ChartCynics achieves 74.43% and 64.55% accuracy , providing an absolute performance boost of ∼ 29% over the Qwen3- VL-8B backbone, outperforming state-of-the-art proprietary models. Our results demonstrate that specialized agentic workows can grant smaller open-source mod- els superior robustness, establishing a new foundation for trustw or- thy chart interpretation. 1 Introduction Visualizations are ubiquitous in the data-driven w orld, serving as powerful to ols for communicating complex numerical informa- tion. Howev er , this persuasive power is frequently compr omised by misleading charts : visualizations designed to distort data per- ception through tactics such as axis manipulation, cherry-picking, or disproportionate encoding [ 9 , 16 , 25 , 28 , 32 ]. The visualization and human-computer interaction communities have extensively studied how these deceptive designs manipulate human audiences, yielding well-established taxonomies and empirical evaluations [13, 35, 37, 40, 51], as well as literacy assessments [12, 19]. Recently , as Visual Language Models (VLMs) [ 53 , 54 ] become increasingly central to automated chart understanding, a critical new challenge has emerged: ensuring their robustness against these misleading visualizations. Traditional chart comprehension tasks primarily evaluate the extraction of e xplicit visual facts under be- nign assumptions [ 27 , 46 , 48 ]. In contrast, the emerging task of Misleading Chart Question A nswering (MQ A) shifts the paradigm toward visual critical r easoning, requiring models to activ ely detect manipulations and resolve cross-modal contradictions. Howe ver , recent studies r eveal a signicant gap: on targeted benchmarks like the Misleading ChartQA dataset, state-of-the-art VLMs consis- tently score below 50% accuracy[ 7 ]. As corroborate d by diverse evaluations[ 4 , 39 ], these models perform no better than untraine d Figure 1: Overview of ChartCynics resolving an “In- verted Axis” deception. (Left) A counter-intuitive real-world case [ 11 ]: The inverted Y-axis creates a visual illusion of de- clining deaths, hijacking standard VLM attention despite the underlying numerical increase. (Middle) Our dual-path archi- tecture decouples p erception from extraction. Crucially , pure OCR lacks spatial context, causing entity misalignment (e.g., confusing axis ticks with data p oints). The Diagnostic Vision Path detects the scale anomaly via ROI cropping and gener- ates an Action Directive to guide the OCR Path in accurate entity mapping. (Right) The Agentic Summarizer resolves cross-modal conict by combining the complementary infor- mation: vision-derived structural baseline and precise OCR numerals to correctly infer a numerical increase. human observers because they fail to maintain logical consistency against deceptive cues. The current methods for automatically interpreting charts mainly follow two patterns. The rst paradigm, the end-to-end VLM path, leverages multimodal models for direct visual reasoning [ 3 , 33 , 41 , 53 ]. Although these models perform well on standard benchmarks such as ChartQA [ 27 ], they process charts holistically , favoring macro-level visual heuristics (e.g., the o verall slope of a line or r el- ative bar heights) ov er ne-grained structural cues like exact tick values. As highlighted in Figure 1, this architectural limitation makes them highly vulnerable to malicious encodings. For instance, when a Y -axis is inverted (zero at the top), the visual encoder’s atten- tion is hijacked by the steep downward physical slope. This forces the mo del into “cognitive sycophancy , ” erroneously predicting a numerical decline and completely ignoring the actual increasing data values. The second paradigm, the OCR-enhanced pipeline, attempts to circumvent perceptual pitfalls by linearizing charts into structured , , Zhang and Li, et al. text [ 21 – 23 , 52 ]. While this approach successfully retrieves numer- ical literals, it introduces a se vere structural dilemma: standalone OCR models eliminate vital spatial and layout semantics. A s shown in the OCR path of Figure 1, without visual context, the model extracts an unstructured sequence of characters (e.g., 873, 2005, 721). Consequently , it suers from catastrophic entity misalign- ment, lacking the capability to distinguish whether a number is a background axis tick or a for eground data label. Without a visual anchor to establish the mapping baseline, these extracted “cold facts” are practically unusable for reasoning. An ideal solution lies in the synergistic fusion of these two paths, moving b eyond passive description toward active verication: much like a human auditor who cross-veries a visually deceptive trend against literal numerical data. Howev er , integrating diagnostic vi- sion with data-driven reasoning presents three non-trivial chal- lenges that correspond to the perception, reasoning, and optimiza- tion levels: • Diagnostic Lo cality (Perception Level) : Standard VLMs pro- cess charts holistically , making it dicult to force ne-grained inspections on easily overlooked areas, such as non-zero axis baselines or manipulated legends, where visual deceptions are often anchored. • Conict Arbitration (Reasoning Level) : Even if both visual trends and precise OCR numerals are extracted, a robust mecha- nism is required to rationally resolv e the inherent cross-modal contradictions when these two signals provide opposing evi- dence. • Reasoning Calibration (Optimization Level) : How to shift the model from a passive observer to a “skeptical auditor . ” It requires specialized training interventions to suppress the model’s pre- trained visual biases and prioritize evidence over misleading heuristics. T o address these challenges, we propose ChartCynics , an agen- tic dual-path framework designed to unmask visual deception. ChartCynics employs a “skeptical” philosophy that decouples struc- tural perception from literal extraction. A s illustrate d in Figure 1, our Diagnostic Vision Path acts as a structure sensor: it utilizes strategic element cropping to detect anomalies (e.g., an inverted scale) and provides the essential spatial semantics. Guided by this structural baseline, the OCR-Driven Data Path can perform precise entity mapping without misalignment. Finally , to resolve cross- modal conicts, we introduce an Agentic Summarizer that executes a detective Chain-of- Thought (D-CoT). Rather than simply discard- ing visual cues, it synthesizes these complementar y modalities, using the visual structural context to ground the numerical facts, thereby synthesizing a robust and rational answer . A core contribution is our two-stage optimization strategy for the Summarizer . First, w e perform Supervised Fine- T uning (SFT) to inject a detective Chain-of- Thought (Co T). This step establishes the structural framework for skepticism, enabling the model to follow a rigorous 5-step verication process. Second, we apply Group Rel- ative Policy Optimization (GRPO ) with a deception-aware rewar d function. By specically penalizing the sele ction of misleading “trap ” answers, GRPO aligns the model to maintain logical consistency even when faced with high-condence visual illusions. Experimental results demonstrate that while a standard Qwen3- VL-8B baseline achieves only 45 . 57% accuracy on deceptive bench- marks, ChartCynics reaches a state-of-the-art 74 . 43% . Notably , the integration of SFT provides a foundational 22 . 95 percentage point boost over the baseline, while GRPO further optimizes the reasoning trajectory to resolve complex cross-modal contradictions. Further- more, evaluations on a mixed standard-and-misleading benchmark reveal a critical advantage: unlike typical defensive mechanisms that suer from “ over-skepticism” (falsely penalizing benign data), ChartCynics actually enhances fundamental chart comprehension. Our systematic structural investigation yields superior accuracy even on standard, non-misleading visualizations compar ed to spe- cialized chart-parsing SOT A models. Our contributions are summarized as follows: • W e present ChartCynics , an agentic dual-path framework that integrates diagnostic cropping and OCR reasoning for robust defense against misleading visualizations. • W e introduce a two-stage training protocol combining SFT and GRPO , which equips MLLMs with both a structured investigative Co T and an alignment-based defense against visual traps. • W e demonstrate that the fusion of agentic workows and re- inforcement learning signicantly enhances critical thinking, achieving 74 . 43% accuracy across challenging benchmarks. • W e validate the generalized robustness of our framework, proving that equipping models with a “skeptical lens” does not induce over-skepticism. ChartCynics not only unmasks deception but also improv es basic data extraction capabilities on standard, non- misleading charts. 2 Related W ork 2.1 Visual De ception and Chart Literacy Traditional chart comprehension resear ch primarily focused on fac- tual extraction from natural visualizations, as seen in early datasets like FigureQ A [15], D V QA [14], PlotQ A [29] and Chart-HQ A [6]. Misleading charts, which utilize deceptive encodings (such as axis truncation and inverted axes) to exploit human cognitive biases, have long been a subject of concern in visual communication [ 32 , 40 ]. Recent benchmarks like Misleading ChartQ A [ 7 ], LEAF-Q A [ 5 ] and CHARTOM [ 4 ] have further shown that even advanced VLMs are highly susceptible to these visual “traps, ” often performing no better than general audiences in identifying “Theor y-of-Mind” deceptive patterns [26]. 2.2 Multimodal Reasoning for Structured Data The integration of VLMs has signicantly advanced ChartQ A ca- pabilities, particularly through large-scale pre-training on chart- specic tasks [ 5 , 27 ]. Models like MA TCHA [ 22 ] and DEPLOT [ 21 ] leverage math reasoning and plot-to-table translation to link pixels and structured data. Despite this, holistic image pr ocessing based on backbones like ViT [ 10 ] or Pix2Struct [ 18 ] often overlooks ne- grained anomalies, such as non-uniform axis scales. Recent works like ChartX [ 48 ] and AskChart [ 52 ] have explored augmenting VLMs with OCR and textual enhancement to provide numerical constraints. Similar ne-grained feature isolation and modal align- ment strategies have also been veried eective in multimodal misinformation detection [43]. Navigating the Mirage: A Dual-Path Agentic Framework for Robust Misleading Chart estion Answering , , Howev er , VLMs still exhibit “weak gr ounding” in chart elements [ 49 ], and eectively resolving contradictions between visual rep- resentation and raw data remains an op en challenge in complex real-world scenarios [46]. 2.3 Supervise d Fine- T uning and RL-based Alignment Recent advancements in VLM optimization have shifted from gen- eral instruction following to specialized r easoning alignment [ 8 , 31 ]. Supervise d Fine- Tuning (SFT) r emains a cornerstone for injecting domain-specic knowledge, such as the “skeptical” investigative Chain-of- Thought (Co T) [ 45 ] and reective interaction mechanisms like PointCo T [49]. T o further rene this reasoning, resear chers have turned to Re- inforcement Learning (RL), specically Group Relative Policy Op- timization (GRPO) [ 36 ], to align model outputs with complex ob- jectives without excessive computational ov erhead. By employing MCTS-guided sample selection to identify appropriately challeng- ing instances [ 44 ] and designing a reward function that e xplicitly penalizes misleading distractors, W ang et al. achieved high accuracy in challenging samples dataset. This demonstrates the p ower of targeted RL alignment for robust chart interpretation and its ability to bridge the gap in visual The ory-of-Mind, spe cically addressing human-centric “Mind” questions [4]. 3 Methodology 3.1 Concept and Problem Denition W e rst dene the general task of Chart Question A nswering (ChartQA ) and then formalize the visual deception me chanism to establish the denition of Misleading ChartQ A . General ChartQA T ask Formalization. Given a chart image I and a natural language question Q with a set of candidate options O = { 𝑎 1 , 𝑎 2 , . . ., 𝑎 𝑛 } , the goal of a ChartQA system is to predict the correct answer 𝑎 ∗ ∈ O . Traditional VLM appr oaches typically model this as a direct mapping 𝑃 ( 𝑎 | I , Q ) , dening the objective as: 𝑎 ∗ = arg max 𝑎 ∈ O 𝑃 ( 𝑎 | I , Q ) (1) Visual De ception and Trap Answers. A misleading chart I incorporates a manipulation function 𝑓 𝑑 𝑒𝑐 𝑒 𝑝𝑡 𝑖 𝑣𝑒 ( D ) → I , where D is the raw data. This function ensures that the perceived visual trend V 𝑡 𝑟 𝑒𝑛𝑑 contradicts the actual numerical relationship D 𝑟 𝑒𝑙 . A Trap A nswer 𝑎 𝑡 𝑟 𝑎𝑝 ∈ O is thus dene d as: 𝑎 𝑡 𝑟 𝑎𝑝 = Inference ( V 𝑡 𝑟 𝑒𝑛𝑑 ) ≠ 𝑎 ∗ = Inference ( D 𝑟 𝑒𝑙 ) (2) Formalizing Misleading ChartQ A. Building upon the above, we dene Misleading ChartQ A as a specialized task where O explic- itly contains at least one 𝑎 𝑡 𝑟 𝑎𝑝 . Unlike standard ChartQA, where visual cues and data usually align, Misleading ChartQA pr esents a scenario where O contains a Trap Answer 𝑎 𝑡 𝑟 𝑎𝑝 derived from 𝑓 𝑑 𝑒𝑐 𝑒 𝑝𝑡 𝑖 𝑣𝑒 . The challenge lies in complementary reasoning: the sys- tem must leverage V 𝑡 𝑟 𝑒𝑛𝑑 to understand the user’s perceptual con- text while simultaneously using D 𝑟 𝑒𝑙 to ground the nal answer in numerical truth, eectively resolving the inherent conict between the two. The Propose d Agentic Objective. T o achieve this, our Chart- Cynics framework introduces a Misleading T axonomy T as ex- pert prior knowledge to guide the dual-path arbitration. Instead of simply prioritizing one path over the other , the agent performs Inconsistency- A ware Fusion, modeling the objective as: 𝑎 ∗ = arg max 𝑎 ∈ O 𝑃 ( 𝑎 | P 𝑣 ( I ) , P 𝑑 ( I ) , Q , T ) (3) where P 𝑣 and P 𝑑 represent information extracted from the Visual Path (capturing semantic context) and the Data Path (ensuring numerical precision), respectively . The “skeptical” dual-path philosophy of ChartCynics does not aim to ignore visual intuition, but rather to de couple it from the nal decision-making process to prevent “blind” trust. This allows the agent to: (1) identify cross-modal deviations, (2) synthesize responses that calibrate visual perceptions via data verication, and (3) utilize RL-based optimization to learn optimal balancing weights between P 𝑣 and P 𝑑 across diverse deception types. T o operationalize this objective and philosophy , we design a comprehensive architecture as illustrated in Figure 2: the framework implements a dual-path pipeline that decouples visual heuristics from OCR-based numerical facts, feeding them into a Summarizer Joint Inference module. T o internalize this investigative logic, Figure 2b details our tw o-stage optimization strategy: Oracle-Informed SFT for reasoning distillation and Deception- A ware GRPO for adv ersarial alignment. This unied architecture ensures that 𝑎 ∗ is the result of rigorous conict resolution rather than visual sycophancy . 3.2 Vision Path: Diagnostic- A ugmente d Investigation As illustrated in Figure 3, the Vision Path operationalizes the pri- mary visual comp onent 𝑃 𝑣 ( 𝐼 ) of the agentic objective (Eq 3). Rather than a holistic glance, we decouple perception from reasoning through a two-agent architecture: the Diagnostic Agent ( 𝑓 𝑑 𝑖𝑎𝑔 ) and the Reasoning Agent ( 𝑓 𝑟 𝑒𝑎𝑠𝑜 𝑛 ). The goal of this path is to generate a visual-perspective report that identies p otential traps before they reach the nal fusion stage. 3.2.1 Structural ROI Extraction and Semantic Padding. T o capture ne-grained deceptive cues (e.g., tick labels or small legend mark- ers), we implement an automated Region of Interest (ROI) extraction module. Unlike heuristic-base d cropping, we utilize a graphic el- ement detection module to precisely localize the bounding boxes of critical chart components, dening the set C 𝑟 𝑜 𝑖 = { title, legend, x-axis, y-axis }. T o ensure semantic completeness, we apply a padding mecha- nism. For each 𝑐 ∈ C 𝑟 𝑜 𝑖 , the module calculates the spatial spread ( 𝑥 _ 𝑠 𝑝 𝑟 𝑒 𝑎𝑑 , 𝑦 _ 𝑠 𝑝𝑟 𝑒 𝑎 𝑑 ) of detected elements. For instance, legend ROIs are expanded to ensure color-code d markers are included, while axis ROIs are padded vertically to encompass the full extent of tick labels. This ensures that the Diagnostic Agent p erforms literal “reading” rather than visual “ estimation” of the scale. 3.2.2 Decoupled Agentic W orkf low . A core innovation of Chart- Cynics is the functional isolation designed to eliminate conrma- tion bias [42]. As shown in Figure 3a, the Diagnostic Agent executes a Blind T est . It is provided only with I and the high-resolution ROI crops, , , Zhang and Li, et al. Figure 2: Over view of the ChartCynics architecture. (a) Inference Pipeline: A training-free dual-path workow that synthesizes visual diagnostics and OCR-extracted data through a structured reasoning chain. ( b) Training-Based Optimization: A two-stage pipeline comprising Oracle-Informed SFT for logic distillation and Deception-A ware GRPO for adversarial alignment, utilizing asymmetric reward shaping to penalize visual traps. Figure 3: Vision Path: Diagnostic-A ugmented Investigation. The framework decouples p erception from reasoning to miti- gate conrmation bias. The Diagnostic Agent identies struc- tural anomalies via high-resolution ROI extraction and gen- erates an Action Directive . Subsequently , the Reasoning Agent anchors its inference to these directives, ensuring that the nal conclusion is grounded in structural evidence rather than global visual heuristics. while Q and O are strictly withheld. This forces the agent to act as a neutral auditor: R 𝑑 𝑖𝑎𝑔 = 𝑓 𝑑 𝑖𝑎𝑔 ( Crops ( I , C 𝑟 𝑜 𝑖 ) , T ) (4) where R 𝑑 𝑖𝑎𝑔 is the resulting diagnostic Report. This prevents “Self- Prompt Pollution” where the model might other wise hallucinate visual evidence to supp ort a pre-conceived answer derived from the question [20, 55]. The agent sequentially examines each crop for visual anomalies dened in T . By amplifying these localized regions, the process uncovers deceptive structural cues that are otherwise masked by the intuitive global visual trend V 𝑡 𝑟 𝑒𝑛𝑑 . 3.2.3 Cognitive A nchoring and Inference. The Vision Path produces in a structured report R 𝑑 𝑖𝑎𝑔 = { Diagnosis , Action Directive } . The Diagnosis provides factual identication (e.g., “The y-axis starts at 15,000”), while the Action Directive provides prescriptive logic (e.g., “Ignore visual heights; read literal tick values”). T o ensure objective inference, the Reasoning Agent (Figure 3b) follows an unconditional trust policy . It is required to explicitly anchor its Chain-of- Thought (Co T) to R 𝑑 𝑖𝑎𝑔 in its rst reasoning step: 𝑎 ∗ = 𝑓 𝑟 𝑒𝑎𝑠𝑜 𝑛 ( Q , O , R 𝑑 𝑖𝑎𝑔 ) (5) By forcing the model to reiterate the Action Dir ective, we shift the reasoning trajector y from an uncalibrated visual prior 𝑃 ( 𝑎 𝑡 𝑟 𝑎𝑝 | V 𝑡 𝑟 𝑒𝑛𝑑 ) to a comprehensive posterior 𝑃 ( 𝑎 ∗ | V 𝑡 𝑟 𝑒𝑛𝑑 , D 𝑟 𝑒𝑙 , T ) that fuses both modalities. This mechanism eectively transforms the Navigating the Mirage: A Dual-Path Agentic Framework for Robust Misleading Chart estion Answering , , “Trap Answer” into a dete ctable anomaly , leading to the nal correct inference 𝑎 ∗ . 3.3 Data Path: OCR-Driven Serialization T o provide an orthogonal verication layer against visual illusions V 𝑡 𝑟 𝑒𝑛𝑑 , the Data Path ( P 𝑑 ) is engineered to reconstruct the under- lying numerical relationship. This path bypasses deceptive visual encodings (e.g., manipulated areas, lengths, or angles) by establish- ing a “literal backbone” thr ough structured text and numeric data extraction. 3.3.1 Structural Data Serialization. Rather than relying on visual rendering, the rst stage directly reveals the graphical attributes of the chart image I . W e utilize an advanced multimodal OCR parsing module to extract all explicit te xtual and numerical entities, such as axis scales, data lab els, and legends, and serialize them into a unied, structured Markdown format M 𝑜𝑐 𝑟 : M 𝑜𝑐 𝑟 = 𝑓 𝑒 𝑥 𝑡 𝑟 𝑎𝑐 𝑡 ( I ) (6) As this Markdown representation relies strictly on the parsed literal characters rather than their spatial p ositioning, it eectively recovers the numerical data D without being tainted by the decep- tive visual manipulation 𝑓 𝑑 𝑒𝑐 𝑒 𝑝𝑡 𝑖 𝑣𝑒 applied to the chart. 3.3.2 Calibration Directives for Downstream Reasoning. While M 𝑜𝑐 𝑟 provides objectiv e numerical evidence , optical extraction can some- times capture numbers from arbitrary text or hallucinate when la- bels are absent. Therefore , rather than har d-coding a pre-processing lter , the Data Path establishes a set of Calibration Directives that are passed to the downstream Reasoning Agent to evaluate M 𝑜𝑐 𝑟 dynamically during its Chain-of- Thought (Co T). • Dynamic Trust Evaluation: Not all extracted values in M 𝑜𝑐 𝑟 hold equal epistemic weight. The framework denes a dual-tier trust principle: (1) High Trust applies to values originating from explicit data labels plotted directly on elements, treating them as immutable ground truth. (2) Low Trust (Skepticism) applies when the chart relies solely on axis ticks without direct labels, or when visual elements exceed the canvas boundary . In such cases, the agent is instructed to treat the OCR data as potentially imprecise and rely more heavily on visual diagnostic deductions. • T emporal and Structural Integrity Check: T o counter tempo- ral deceptions like Inappropriate Aggregation or Inappropriate Or- dering , the Data Path mandates an integrity audit rule. The agent is explicitly instructed to scrutinize the sequence of categories in M 𝑜𝑐 𝑟 . For instance, it must check whether the time-series is delib erately reversed, or if the nal data p oint represents a deceptive “incomplete period” masquerading as a full cycle. 3.4 Agentic Fusion with Detective Chain-of- Thought The Agentic Fusion module acts as the Summarizer ( S ), tasked with integrating the Diagnostic Report R 𝑑 𝑖𝑎𝑔 from the Vision Path ( P 𝑣 ) and the Calibrated Data M 𝑜𝑐 𝑟 from the Data Path ( P 𝑑 ). As dened in the task formalization, its objective is to maximize the posterior 𝑃 ( 𝑎 | P 𝑣 , P 𝑑 , Q , T ) by explicitly identifying and neutral- izing the manipulation function 𝑓 𝑑 𝑒𝑐 𝑒 𝑝𝑡 𝑖 𝑣𝑒 . Before detailing the train- ing process, we rst mathematically formalize the ideal reasoning policy that the Summarizer must follow via structured prompting to achieve this objective. 3.4.1 Conflict A rbitration via Evidence W eighting. T o resolve dis- crepancies between visual heuristics and numerical literals, the Summarizer S implements a hierarchical weight system gov erned by two Golden Rules of Evidence : • Rule I: Heuristic Calibration. Rather than a naive zero-sum arbitration that bluntly discards information fr om one conicting path, the Summarizer recontextualizes it using the structural anomaly 𝜏 ∈ R 𝑑 𝑖𝑎𝑔 . Formally , the reasoning prompt acts as a structural constraint, for cing the agent’s generation trajectory to align the visually-derived inference with the data-derived truth. The agent recognizes that the calibrate d visual posterior leads to the same optimal decision as the numerical data: arg max 𝑎 ∈ O 𝑃 ( 𝑎 | V 𝑡 𝑟 𝑒𝑛𝑑 , 𝜏 ) = arg max 𝑎 ∈ O 𝑃 ( 𝑎 | D 𝑟 𝑒𝑙 ) = 𝑎 ∗ (7) This ensures the model logically translates the visual shape (e.g., recognizing that a physical downward slope V 𝑡 𝑟 𝑒𝑛𝑑 on an in- verted axis 𝜏 perfectly corroborates a numerical increase derived from D 𝑟 𝑒𝑙 in Figure 1). • Rule II: Dynamic Trust Calibration. The epistemic weight of M 𝑜𝑐 𝑟 is conditioned on the Trust Level ags. If M 𝑜𝑐 𝑟 contains High Trust lab els, it serves as the immutable ground truth for 𝐷 𝑟 𝑒𝑙 . Conversely , if labels are absent and R 𝑑 𝑖𝑎𝑔 indicates a scale violation (e.g., “Exceeding the Canvas”), the agent treats M 𝑜𝑐 𝑟 as a qualitative indicator and prioritizes the Action Directives for relative reasoning. 3.4.2 The Five-Step Detective Framework (D-Co T). The reasoning process is operationalize d via a structured Detective Chain-of- Thought (D-Co T), designed to transform the model from a passive describer into a skeptical auditor . This sequence ensures that the - nal selection 𝑎 ∗ is a logical consequence of debunking the 𝑓 𝑑 𝑒𝑐 𝑒 𝑝𝑡 𝑖 𝑣𝑒 mechanism: (1) Perception A udit (Prior Calibration): The agent rst re- iterates the Action Directives from R 𝑑 𝑖𝑎𝑔 . This step acts as a cognitive anchor to re-e valuate (rather than strictly suppress) the high-condence prior 𝑃 ( 𝑎 𝑡 𝑟 𝑎𝑝 | V 𝑡 𝑟 𝑒𝑛𝑑 ) before performing any calculations. (2) Numerical Anchoring ( 𝐷 𝑟 𝑒𝑙 Reconstruction): The agent maps categories and values from M 𝑜𝑐 𝑟 to the entities in Q . It identies whether the data represents the “actual relationship ” D 𝑟 𝑒𝑙 or just a partial subset of the visual representation. (3) Deception Mapping: Using the T axonomy T as a logic gate, the agent classies the chart’s specic manipulation subtype. For example, if mapped to Inappropriate Ordering , the agent is triggered to re-sort the M 𝑜𝑐 𝑟 sequence before comparison. (4) Suciency & Integrity Check: The agent evaluates if the combined evidence ( R 𝑑 𝑖𝑎𝑔 + M 𝑜𝑐 𝑟 ) is sucient to resolve the contradiction. If the trust lev els are conicting or inadequate, it is permitted to output a “Cannot be Inferred” conclusion to avoid hallucination. (5) Adversarial Trap Reje ction: In the nal step, the agent must explicitly prove why the “Trap Answer” 𝑎 𝑡 𝑟 𝑎𝑝 (derived from V 𝑡 𝑟 𝑒𝑛𝑑 ) is a mathematical fallacy . By articulating the discrep- ancy between the visual illusion and the grounded data, the , , Zhang and Li, et al. model ensures 𝑎 ∗ is selected through critical elimination rather than pattern matching. Figure 4: The Agentic Fusion with Detective Chain-of- Thought (D-CoT) process. The Reasoning Agent integrates the Diagnostic Report and OCR Markdown through a ve- step detective framework, utilizing Golden Rules and Mis- leader T axonomy to ensure adversarial robustness and evidence-based deduction. 3.5 Optimization: SFT and GRPO T o internalize the reasoning heuristics and resolve multimodal conicts, we implement a two-stage optimization pipeline: Oracle- Informed Distillation followed by Deception- A ware Group Relative Policy Optimization (GRPO). 3.5.1 SFT via Oracle-Informed Reasoning Distillation. W e p erform Supervise d Fine- Tuning (SFT) using a dataset generated by a larger model (Qwen3- VL-32B). T o address the information disparity be- tween the source model (which has access to raw CSV data) and the target model (which only processes visual pixels), w e employ a specic prompting strategy . During data generation, the larger model utilizes ground-truth CSV data and trap labels to ensure factual accuracy . Howev er , it is strictly constrained to generate reasoning chains based only on visible chart elements. This process converts inaccessible structured data into visually-grounded log- ical traces, including ⟨ 𝑉 𝑖 𝑠𝑢 𝑎𝑙 _ 𝐻 𝑒𝑢𝑟 𝑖 𝑠 𝑡 𝑖𝑐 ⟩ , ⟨ 𝑂 𝐶 𝑅 _ 𝑉 𝑎𝑙 𝑖 𝑑 𝑎𝑡 𝑖𝑜 𝑛 ⟩ , and ⟨ 𝐴 𝑚𝑏 𝑖𝑔𝑢𝑖 𝑡 𝑦 _ 𝑅𝑒 𝑠 𝑜 𝑙 𝑢 𝑡 𝑖 𝑜 𝑛 ⟩ . Consequently , the target model learns to derive conclusions from evidence present within the image rather than relying on external metadata. 3.5.2 Deception-A ware GRPO. T o evolve the model beyond simple imitation, we apply Group Relative Policy Optimization (GRPO) [ 36 ] to align its reasoning pr ocess with adversarial skepticism. Unlike DPO [ 34 ], which relies on binary preferences, GRPO allows us to utilize a multi-dimensional continuous reward function 𝑅 𝑡 𝑜 𝑡 𝑎𝑙 to evaluate the quality of the generate d reasoning trace within a sampled group 𝐺 : 𝑅 𝑡 𝑜 𝑡 𝑎𝑙 = 𝑤 1 𝑅 𝑓 𝑎𝑐 𝑡 + 𝑤 2 𝑅 𝑐𝑜 𝑛𝑡 𝑟 𝑎 + 𝑤 3 𝑅 𝑙 𝑜𝑔𝑖 𝑐 + 𝑤 4 𝑅 𝑓 𝑚𝑡 + 𝑅 𝑠ℎ𝑎 𝑝𝑖 𝑛𝑔 (8) where the components are dened as follows: • Numerical Grounding ( 𝑅 𝑓 𝑎𝑐 𝑡 ): T o ensure robustness against OCR noise, 𝑅 𝑓 𝑎𝑐 𝑡 calculates the Spearman rank correlation be- tween numeric tokens extracted from the ⟨ 𝑂 𝐶 𝑅 _ 𝑉 𝑎𝑙 𝑖 𝑑 𝑎𝑡 𝑖𝑜 𝑛 ⟩ tag and the Oracle CSV . By rewarding the corr elation of trends (rank) rather than absolute pixel-to-value accuracy , we encourage the model to prioritize relative data relationships. • Semantic Contradiction ( 𝑅 𝑐𝑜 𝑛𝑡 𝑟 𝑎 ): T o prevent “reward hack- ing” via keyword stung, 𝑅 𝑐𝑜 𝑛𝑡 𝑟 𝑎 combines key word hit rates (e .g., “non-zero baseline”) with a semantic overlap constraint . The model is rewarded only if its identie d contradiction aligns with the expert-annotated explanation, ensuring logical consistency across the 5-step D-Co T trajector y . • Structural Enforcement ( 𝑅 𝑓 𝑚𝑡 ): A binary gatekeeper rewar d is applied to penalize “shortcut” generations. If the output fails to strictly follow the four-step XML-tagged structur e, it incurs a sig- nicant baseline deduction, leveraging the LLM’s auto-regressiv e nature to anchor the nal answer in the preceding reasoning steps. • Asymmetric Shaping ( 𝑅 𝑠ℎ𝑎 𝑝𝑖 𝑛𝑔 ): W e implement an adversarial penalty to combat visual sycophancy . While a correct answer yields + 1 . 0 , selecting the specic misleading distractor (the trap) triggers a heavy penalty of − 2 . 0 . This asymmetry forces the policy to prioritize “trap avoidance ” as a primary objective, eectively training the model to b e inherently skeptical of deceptive visual cues. By optimizing for the group-relative advantage of these ne-grained rewards, the model learns to navigate the tension between visual intuition and factual evidence without the computational overhead of a dedicated Critic network. 4 Experiments This section evaluates the ecacy of ChartCynics in mitigating visual misleading. W e detail the experimental conguration, fol- lowed by a mechanistic analysis of performance gains, ablation experiments, and the impact of our specialized RL alignment. 4.1 Datasets and Evaluation Benchmarks T o assess our framework’s robustness and generalization, we e val- uate ChartCynics across three distinct benchmarks. Detailed con- struction protocols, sampling strategies, and statistics for all datasets are presented in the supplementary material. • Misleading ChartQA (MC) [ 7 ]: Our primar y b enchmark for structural visual deception. W e utilize the training set (2,619 samples) for our SFT and GRPO optimization, and evaluate on the ocial test set (305 samples). • Curated De ceptive Chart Collection (CDCC) [ 39 ]: T o test resilience against real-world epistemic conicts, we compile a secondary b enchmark of 110 expert-validated deceptive visual- izations aggregated from established studies in the HCI commu- nity [12, 17, 25]. • Mixed Standard and Misleading Benchmark (MSMB) [ 7 , 47 ]: T o ensure our “skeptical auditor” does not suer from over- skepticism on benign data, we construct a balanced evaluation set of 244 charts (122 standard [ 47 ], 122 misleading [ 7 ]) to verify fundamental chart comprehension remains intact. Navigating the Mirage: A Dual-Path Agentic Framework for Robust Misleading Chart estion Answering , , T able 1: Comparison b etween state-of-the-art baselines and the ChartCynics framework. W e report Accuracy (Acc), Wr ong due to Misleader (WM), and Wrong due to Others (W O). V alues in b old indicate the best performance. MC ( 𝑁 = 305 ) CDCC ( 𝑁 = 110 ) Model & Conguration Acc ↑ WM ↓ WO ↓ Acc ↑ WM ↓ WO ↓ Standard Multimodal Baselines ChartMoE [50] 33.11 43.28 23.61 28.18 46.36 25.45 Gemini-3.1-Pro [38] 70.49 19.34 10.16 68.18 14.54 17.27 Structural Mitigation Heuristics Qwen3- VL-8B + T able-based QA [39] 49.18 29.51 21.31 36.39 20.91 42.73 Qwen3- VL-8B + Redrawn [39] 44.26 35.41 20.33 38.18 20.91 40.91 Ours: ChartCynics Framework over Base Mo dels Qwen3- VL-8B (Base Model) [2] 45.57 40.00 14.43 35.45 31.82 32.73 + ChartCynics (Train-fr ee) 60.66 24.26 15.08 47.47 16.16 36.36 + SFT + GRPO (Full) 74.43 11.15 14.42 64.55 8.18 27.27 GPT -o4-mini (Base Model) [1] 55.08 34.43 10.49 69.09 17.27 13.64 + ChartCynics (Train-fr ee) 71.80 18.69 9.51 79.09 9.09 11.82 Gemini-2.5-Flash (Base Model) [38] 67.21 20.98 11.80 62.73 17.27 20.00 + ChartCynics (Train-fr ee) 71.67 13.67 14.67 75.45 7.27 17.27 4.2 Metrics T o evaluate both authentic reasoning capabilities and specic vul- nerabilities to visual traps, we adopt three core metrics introduced in [ 7 ]. Formal denitions and detailed error attribution criteria are available in the supplementary material. • Accuracy (A cc): The standard grounded accuracy indicating the percentage of correctly answered queries. • WM (Wr ong due to Misleader): A targeted metric tracking errors strictly caused by cognitive sycophancy , where the model’s prediction falls for the visual trap. • W O (Wrong due to Other factors): A general error metric tracking failures unrelated to visual deception (e .g., basic OCR failures or instruction-following errors). 4.3 Baselines T o evaluate ChartCynics , we benchmark against three categories of state-of-the-art methods representing the paradigms discussed in our Introduction. First, to represent the visual-rst paradigm, we evaluate proprietary VLMs (GPT -o4-mini [ 1 ], Gemini-2.5-Flash, and Gemini-3.1-Pro [ 38 ]) and our foundational backbone, Qwen3- VL- 8B [ 2 ], to directly quantify the net gains of our dual-path architec- ture. Second, we include ChartMoE [ 50 ] as a domain-specic base- line to test if standard chart prociency yields adv ersarial robust- ness. Finally , representing the data-rst ( OCR-enhanced) paradigm, we compar e against two inference-time structural mitigations fr om [ 39 ]: T able-based QA and Visualization Redrawing . This contrast eectively highlights the superiority of our synergistic arbitration over rigid, single-path de-rendering techniques. 4.4 Implementation Details The training and evaluation of ChartCynics are conducted on a cluster of 4 × NVIDIA A800 (80GB) GP Us. For dual-path input processing, we utilize nemotron-graphic-elements-v1 [ 30 ] for precise Region-of-Interest (ROI) bounding box extraction in the Vision Path. For the Data Path, w e employ LlamaParse [ 24 ] (cong- ured with GPT -4o) as the underlying multimodal parsing engine—to robustly convert complex chart images into structured Markdown. W e initialize our framework using the open-weight Qwen3-VL-8B as the foundational reasoning backbone and pr oceed with a two-stage optimization pipeline. Stage 1: Oracle-Informed SFT . T o bridge the epistemic gap between pixels and underlying data, we perform Supervise d Fine- T uning (SFT) on 5,238 high-quality reasoning chains. These chains are distilled from the 2,619 samples of the Misleading ChartQA training set [7] using a Qwen3- VL-32B teacher . Stage 2: Deception-A ware GRPO. Following SFT , we utilize GRPO for model alignment, employing a group size of 𝐺 = 8 . The multi-objective r eward function 𝑅 𝑡 𝑜 𝑡 𝑎𝑙 is dened with the following coecients: 𝑤 𝑓 𝑎𝑐 𝑡 = 0 . 20 , 𝑤 𝑐𝑜 𝑛𝑡 𝑟 𝑎 = 0 . 25 , 𝑤 𝑙 𝑜𝑔𝑖 𝑐 = 0 . 20 , and 𝑤 𝑓 𝑚𝑡 = 0 . 10 . Furthermore, we implement an asymmetric reward shaping strategy , applying a − 2 . 0 penalty for selecting “misleading trap” distractors and a + 1 . 0 reward for gr ound-truth alignment. 4.5 Main Results T o comprehensively evaluate our approach, T able 1 presents a detailed performance comparison across the MC and the CDCC. By analyzing the overall Accuracy (A cc) and the error breakdowns, we distill three primary observations: Superiority of Dual-Path Skepticism (Zero-Shot & Aligned). T o demonstrate broad applicability , we evaluate ChartCynics across backbones ranging from open-source to proprietary sys- tems. The training-free framework shows immediate universality , boosting Q wen3- VL-8B by +15.09% (to 60.66%) and GPT -o4-mini by +16.72% (to 71.80%) on MC. Crucially , our two-stage optimiza- tion (SFT +GRPO) propels the 8B model to a state-of-the-art 74.43% , , Zhang and Li, et al. accuracy . This +28.86% absolute gain enables the smaller model to outperform much larger proprietary systems, notably surpassing Gemini-3.1-Pro (70.49%). This robust alignment further translates to the CDCC, where the optimized 8B model nearly doubles its baseline accuracy (35.45% to 64.55%). Mechanistic Suppression of De ception. The error breakdowns validate our Complementary Fusion hypothesis. Across all back- bones, ChartCynics drastically reduces the WM rate without trig- gering a comp ensatory spike in the WO rate. For instance, the training-free GPT -o4-mini drops its WM rate nearly two-fold (fr om 34.43% to 18.69%) on MC. Most notably , the fully optimized Qwen3- VL-8B crushes its WM rate from 40.00% down to 11.15%. This con- rms that the framework successfully anchors its reasoning in structurally-grounded OCR evidence rather than simply guessing blindly to avoid traps. Outperforming Structural Mitigation Heuristics. W e investi- gate whether visual deception can be mitigated simply by r emoving the visual modality . As shown in the middle section of T able 1, converting deceptive charts into raw tables ( T able-based QA ) or standardizing them ( Redrawn ) yields marginal gains or even degra- dation for Qwen3- VL-8B (+3.61% and -1.31%, respectively). This conrms that simply de-rendering an image into text is insucient; models require the active , complementary reasoning provided by ChartCynics (74.43%) to navigate complex structural deceptions. Beyond deceptive scenarios, a critical concern is whether such defensive mechanisms degrade p erformance on b enign data. W e evaluate our training-fr ee framework against ChartMoE [ 50 ] on the Mixed Benchmark (T able 2). While ChartMoE degrades severely on visual deceptions (31.97%), ChartCynics not only doubles this accuracy (68.03%) but also surprisingly outp erforms ChartMoE on standard charts (94.26% vs. 88.52%). The dual-agent structural investigation enhances fundamental data e xtraction acr oss all chart types, proving our framework is a generalized solution rather than a narrow patch. T able 2: Performance on the Mixed Standard and Misleading Benchmark (MSMB) Data Subset ChartMoE ChartCynics (SOT A) (Train-fr ee) Standard ( 𝑁 = 122 ) 88.52% (108) 94.26% (115) Misleading ( 𝑁 = 122 ) 31.97% (39) 68.03% (83) Overall ( 𝑁 = 244 ) 60.25% (147) 81.15% (198) 4.6 Ablation Study T o isolate the contributions of our proposed framework, we conduct a comprehensive ablation study using MC (T able 3). Architectural Ne cessity of Complementar y Fusion. W e rst evaluate the necessity of merging visual structure with OCR liter- als. As shown in the upper section of T able 3, removing the visual diagnostic path ( OCR Only ) yields the highest misle d rate ( WM: 30.16% ), conrming that unstructured OCR data lacks the spatial semantics required for accurate mapping. Conversely , enhancing the model with local crops ( VLM + Crop ) eectively reduces ob- servational errors (WO drops to 15.41%) but fails to resolve the underlying deception. Only the full ChartCynics architecture suc- cessfully leverages multimodal complementarity to minimize both WM and W O simultaneously . Impact of Optimization Stages. W e further validate our two- stage optimization strategy (lower section of Table 3). Applying SFT alone provides a substantial performance leap (A cc: 68.52%), distilling the investigative D-Co T logic into the model. Crucially , the subsequent GRPO alignment propels accuracy further to 74.43% and compresses the WM rate to a mere 11.15% . Notably , while GRPO drastically diminishes susceptibility to visual traps, it main- tains a low rate of errors (WO: 14.42%), proving that our reward shaping successfully aligns the model’s cognitiv e circuits toward skeptical evidence-based reasoning rather than blind guessing. T able 3: Ablation Study (Qwen3- VL-8B) on MC. Setting Acc ↑ WM ↓ WO ↓ A rchitectural Components (Train-free) VLM (Standard) 52.13 27.21 20.66 VLM + Crop 57.38 27.21 15.41 OCR Only (Vision-free) 46.89 30.16 22.95 Full ChartCynics (Train-free) 60.66 24.26 15.08 Optimization Stages (Full Ar chitecture) Full ChartCynics (Train-fr ee) 60.66 24.26 15.08 + SFT Only 68.52 15.08 16.39 + SFT + GRPO (Full) 74.43 11.15 14.42 5 Conclusion This paper presents ChartCynics , an agentic dual-path framework that forties VLMs against misleading visualizations by decoupling intuitive perception from rigorous verication. By synergizing a Diagnostic Vision Path with an OCR-Driven Data Path , our approach systematically unmasks deceptive structures through a skeptical reasoning paradigm. Experimental results show that ChartCynics achieves a state-of-the-art 74.43% accuracy on the Qwen3- VL-8B backbone, outperforming advanced proprietary models. W e demon- strate that while SFT via Oracle-Informe d Reasoning Distil- lation is crucial for distilling structured investigative logic, the subsequent Deception-A ware GRPO is essential for penalizing visual sycophancy and enforcing logical consistency . Ultimately , ChartCynics provides a robust foundation for trustworthy mul- timedia AI, ensuring that automated data interpretation remains grounded in factual reality rather than deceptive visual heuristics. References [1] Josh A chiam, Ste ven A dler , Sandhini A garwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al . 2023. Gpt-4 technical report. arXiv preprint (2023). [2] Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, W ei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Q wen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025). [3] Alexander Bendeck and John Stasko. 2024. An empirical evaluation of the GPT -4 multimodal language model on visualization literacy tasks. IEEE Transactions on Visualization and Computer Graphics 31, 1 (2024), 1105–1115. Navigating the Mirage: A Dual-Path Agentic Framework for Robust Misleading Chart estion Answering , , [4] Shubham Bharti, Shiyun Cheng, Jihyun Rho, Jianrui Zhang, Mu Cai, Y ong Jae Lee, Martina Rau, and Xiaojin Zhu. 2024. CHARTOM: A Visual The ory-of-Mind Benchmark for LLMs on Misleading Charts. arXiv preprint (2024). [5] Ritwick Chaudhry , Sumit Shekhar , Utkarsh Gupta, Pranav Maneriker, Prann Bansal, and Ajay Joshi. 2020. Leaf-qa: Locate, encode & attend for gure question answering. In Procee dings of the IEEE/CVF winter conference on applications of computer vision . 3512–3521. [6] Xiangnan Chen, Yuancheng Fang, Juncheng Li, Qian Xiao, Jun Lin, Siliang T ang, and Y ueting Zhuang. 2025. Chart-HQA: A Benchmark for Hypothetical Question Answering in Charts. In Proceedings of the 33rd ACM International Conference on Multimedia (Dublin, Ireland) (MM ’25) . Association for Computing Machinery , New Y ork, NY, USA, 13297–13303. doi:10.1145/3746027.3758288 [7] Zixin Chen, Sicheng Song, Kashun Shum, Y anna Lin, Rui Sheng, W eiqi W ang, and Huamin Qu. 2025. Unmasking deceptive visuals: Benchmarking multimodal large language models on misleading chart question answering. In Proceedings of the 2025 Conference on Empirical Metho ds in Natural Language Processing . 13767–13800. [8] Aakanksha Chowdhery , Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung W on Chung, Charles Sutton, Se- bastian Gehrmann, et al . 2023. Palm: Scaling language modeling with pathways. Journal of machine learning research 24, 240 (2023), 1–113. [9] Michael Correll and Jerey Heer . 2017. Black hat visualization. In W orkshop on Dealing with Cognitive Biases in Visualisations (DECISIV e), IEEE VIS , V ol. 1. 10. [10] Alexey Dosovitskiy , Lucas Beyer , Alexander Kolesnikov , Dirk W eissenborn, Xi- aohua Zhai, Thomas Unterthiner , Mostafa Dehghani, Matthias Minderer , Ge org Heigold, Sylvain Gelly , et al . 2020. An image is worth 16x16 words: T ransformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020). [11] Pamela Engel. [n. d.]. This chart shows an alarming rise in Florida gun deaths after “Stand your ground” was enacted. https://ww w .businessinsider.com/gun- deaths- in- orida- increased- with- stand- your- ground- 2014- 2 [12] Lily W Ge, Y uan Cui, and Matthew K ay . 2023. Calvi: Critical thinking assessment for literacy in visualizations. In Proceedings of the 2023 CHI conference on human factors in computing systems . 1–18. [13] Darrell Hu. 2023. How to lie with statistics . Penguin UK. [14] Kushal Kae, Scott Cohen, Brian Price, and Christopher Kanan. 2018. D VQ A: Understanding Data Visualizations via Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . [15] Samira Ebrahimi Kahou, Vincent Atkinson, Vincent heranz, Mohammad Akbari, , et al . 2017. FigureQA: An Annotated Figure Dataset for Visual Reasoning. arXiv preprint arXiv:1710.07300 . [16] Xingyu Lan and Yu Liu. 2024. “I Came Across a Junk”: Understanding Design Flaws of Data Visualization from the Public’s Perspective. IEEE transactions on visualization and computer graphics 31, 1 (2024), 393–403. [17] Claire Lauer and Shaun O’Brien. 2020. The deceptive potential of common design tactics used in data visualizations. In Proceedings of the 38th A CM International Conference on Design of Communication . 1–9. [18] Kenton Lee, Mandar Joshi, Iulia Raluca Turc, Hexiang Hu, Fangyu Liu, Julian Mar- tin Eisenschlos, Urvashi Khandelwal, Peter Shaw , Ming- W ei Chang, and Kristina T outanova. 2023. Pix2struct: Screenshot parsing as pretraining for visual lan- guage understanding. In International Conference on Machine Learning . PMLR, 18893–18912. [19] Sukwon Lee, Sung-Hee Kim, and Bum Chul K won. 2016. Vlat: Development of a visualization literacy assessment test. IEEE transactions on visualization and computer graphics 23, 1 (2016), 551–560. [20] Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. 2024. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. In Procee dings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 13872–13882. [21] Fangyu Liu, Julian Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, W enhu Chen, Nigel Collier, and Y asemin Altun. 2023. DeP lot: One-shot visual language reasoning by plot-to-table translation. In Findings of the Association for Computational Linguistics: ACL 2023 . 10381–10399. [22] Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Y asemin Altun, Nigel Collier , and Julian Eisenschlos. 2023. Matcha: Enhancing visual language pretraining with math reasoning and chart derender- ing. In Proceedings of the 61st A nnual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers) . 12756–12770. [23] Yi-Cheng Liu and W ei-T a Chu. 2024. Chart Question Answering based on Modality Conversion and Large Language Mo dels. In Proceedings of the 1st ACM W orkshop on AI-Powered Q&A Systems for Multime dia (Phuket, Thailand) (AIQAM ’24) . Association for Computing Machinery , New Y ork, N Y , USA, 19–24. doi:10.1145/3643479.3662057 [24] LlamaIndex. 2026. LlamaCloud Documentation. https://developers.llamaindex. ai/python/cloud/. Accessed: 2026-03-30. [25] Leo Yu-Ho Lo, A yush Gupta, Kento Shigyo, Aoyu Wu, Enrico Bertini, and Huamin Qu. 2022. Misinformed by visualization: What do we learn from misinformative visualizations? . In Computer Graphics Forum , V ol. 41. Wiley Online Library, 515– 525. [26] Leo Yu-Ho Lo and Huamin Qu. 2024. How good (or bad) are LLMs at detecting misleading visualizations? IEEE Transactions on Visualization and Computer Graphics 31, 1 (2024), 1116–1125. [27] Ahmed Masry, Xuan Long Do, Jia Qing T an, Shaq Joty, and Enamul Hoque. 2022. Chartqa: A b enchmark for question answering about charts with visual and logical reasoning. In Findings of the association for computational linguistics: ACL 2022 . 2263–2279. [28] Andrew McNutt, Gordon Kindlmann, and Michael Correll. 2020. Surfacing visualization mirages. In Proceedings of the 2020 CHI Conference on human factors in computing systems . 1–16. [29] Nitesh Methani, Pranay Ganguly , Mitesh M Khapra, and Pratyush Kumar . 2020. PlotQA: Reasoning ov er Scientic Plots. In Proceedings of the IEEE/CVF Winter Conference on A pplications of Computer Vision (W ACV) . [30] NVIDIA. 2025. Nemotron Graphic Elements v1. https://huggingface.co/nvidia/ nemotron- graphic- elements- v1. Accessed: 2026-03-24. [31] Long Ouyang, Jerey Wu, Xu Jiang, Diogo Almeida, Carroll W ainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray , et al . 2022. Training language models to follow instructions with human fee dback. Advances in neural information processing systems 35 (2022), 27730–27744. [32] Anshul Vikram Pandey , Katharina Rall, Margaret L Satterthwaite, Oded Nov , and Enrico Bertini. 2015. How deceptive are deceptive visualizations? An empirical analysis of common distortion techniques. In Procee dings of the 33rd annual acm conference on human factors in computing systems . 1469–1478. [33] Saugat Pandey and Alvitta Ottley . 2025. Benchmarking visual language models on standardized visualization literacy tests. In Computer Graphics Forum , V ol. 44. Wiley Online Library , e70137. [34] Rafael Rafailov , Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Y our language model is secretly a reward mo del. Advances in neural information processing systems 36 (2023), 53728–53741. [35] Jihyun Rho, Martina A Rau, Shubham Kumar Bharti, Rosanne Luu, Jeremy McMa- han, Andrew W ang, and Jerry Zhu. 2024. V arious misleading visual features in misleading graphs: Do they truly deceive us? . In Proce edings of the A nnual Meeting of the Cognitive Science Society , V ol. 46. [36] Zhihong Shao, Peiyi W ang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y ang Wu, et al . 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024). [37] Danielle Albers Szar . 2018. The good, the bad, and the biased: Five ways visualizations can mislead (and how to x them). interactions 25, 4 (2018), 26–33. [38] Gemini T eam, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Y u, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al . 2023. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023). [39] Jonathan T onglet, Tinne Tuytelaars, Marie-Francine Moens, and Iryna Gurevych. 2025. Protecting multimodal large language models against misleading visualiza- tions. arXiv preprint arXiv:2502.20503 (2025). [40] Edward R Tufte and Peter R Graves-Morris. 1983. The visual display of quantitative information . V ol. 2. Graphics press Cheshire, CT . [41] Matheus V alentim, Vaishali Dhanoa, Gabriela Molina León, and Niklas Elmqvist. 2025. The Plot Thickens: Quantitative Part-by-Part Exploration of MLLM Visual- ization Literacy . arXiv preprint arXiv:2504.02217 (2025). [42] Y ue W an, Xiaowei Jia, and Xiang Lorraine Li. 2025. Unveiling conrmation bias in chain-of-thought reasoning. In Findings of the Association for Computational Linguistics: ACL 2025 . 3788–3804. [43] Bing Wang, Ximing Li, Mengzhe Y e, Changchun Li, Bo Fu, Jianfeng Qu, and Lin Y uanbo Wu. 2025. Remember Past, Anticipate Future: Learning Continual Multimodal Misinformation Detectors. In Proceedings of the 33rd ACM Interna- tional Conference on Multimedia (Dublin, Ireland) (MM ’25) . Association for Com- puting Machinery , New Y ork, N Y, USA, 5490–5498. doi:10.1145/3746027.3754759 [44] Xiyao W ang, Zhengyuan Yang, Chao Feng, Hongjin Lu, Linjie Li, Chung-Ching Lin, Kevin Lin, Furong Huang, and Lijuan W ang. 2025. SOTA with Less: MCTS- Guided Sample Selection for Data-Ecient Visual Reasoning Self-Improvement. arXiv preprint arXiv:2504.07934 (2025). [45] Jason W ei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al . 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems 35 (2022), 24824–24837. [46] Jingxuan W ei, Nan Xu, Junnan Zhu, Yanni Hao , Gaowei Wu, Qi Chen, Bihui Y u, and Lei W ang. 2024. ChartMind: A Comprehensive Benchmark for Complex Real-world Multimodal Chart Question Answering. In Procee dings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) . [47] Yifan W u, Lutao Yan, Leixian Shen, Y unhai W ang, Nan T ang, and Y uyu Luo. 2024. Chartinsights: Evaluating multimodal large language models for low-level chart question answering. In Findings of the Association for Computational Linguistics: EMNLP 2024 . 12174–12200. , , Zhang and Li, et al. [48] Renqiu Xia, Hancheng Y e, Xiangchao Y an, Qi Liu, Hongbin Zhou, Zijun Chen, Botian Shi, Junchi Yan, and Bo Zhang. 2025. Chartx & chartvlm: A v ersatile bench- mark and foundation model for complicated chart reasoning. IEEE Transactions on Image Processing (2025). [49] Zhengzhuo Xu, SiNan Du, Yiyan Qi, Siwen Lu, Chengjin Xu, Chun Y uan, and Jian Guo. 2025. Chartpoint: Guiding mllms with grounding reection for chart reasoning. In Proceedings of the IEEE/CVF International Conference on Computer Vision . 426–436. [50] Zhengzhuo Xu, Bowen Qu, Yiyan Qi, SiNan Du, Chengjin Xu, Chun Yuan, and Jian Guo. 2025. ChartMoE: Mixture of Diversely Aligned Expert Connector for Chart Understanding. In The Thirteenth International Conference on Learning Representations . [51] Brenda W Y ang, Camila V argas Restrepo, Matthew L Stanley, and Elizab eth J Marsh. 2021. Truncating bar graphs persistently misleads viewers. Journal of A pplie d Research in Memor y and Cognition 10, 2 (2021), 298–311. [52] Xudong Y ang, Yifan Wu, Yizhang Zhu, Nan Tang, and Y uyu Luo. 2024. Askchart: Universal chart understanding through textual enhancement. arXiv preprint arXiv:2412.19146 (2024). [53] Pan Zhang, Xiaoyi Dong, Bin Wang, Yuhang Cao, Chao Xu, Linke Ouyang, Zhiyuan Zhao, Haodong Duan, Songyang Zhang, Shuangrui Ding, et al . 2023. Internlm-xcomposer: A vision-language large model for advanced text-image comprehension and composition. arXiv preprint arXiv:2309.15112 (2023). [54] Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. 2023. Multimodal chain-of-thought reasoning in language models. arXiv preprint arXiv:2302.00923 (2023). [55] Yiyang Zhou, Chenhang Cui, Jaehong Y o on, Linjun Zhang, Zhun Deng, Chelsea Finn, Mohit Bansal, and Huaxiu Y ao. 2023. Analyzing and mitigating object hallucination in large vision-language models. arXiv preprint (2023).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment