Learning Partial Action Replacement in Offline MARL
Offline multi-agent reinforcement learning (MARL) faces a critical challenge: the joint action space grows exponentially with the number of agents, making dataset coverage exponentially sparse and out-of-distribution (OOD) joint actions unavoidable. …
Authors: Yue Jin, Giovanni Montana
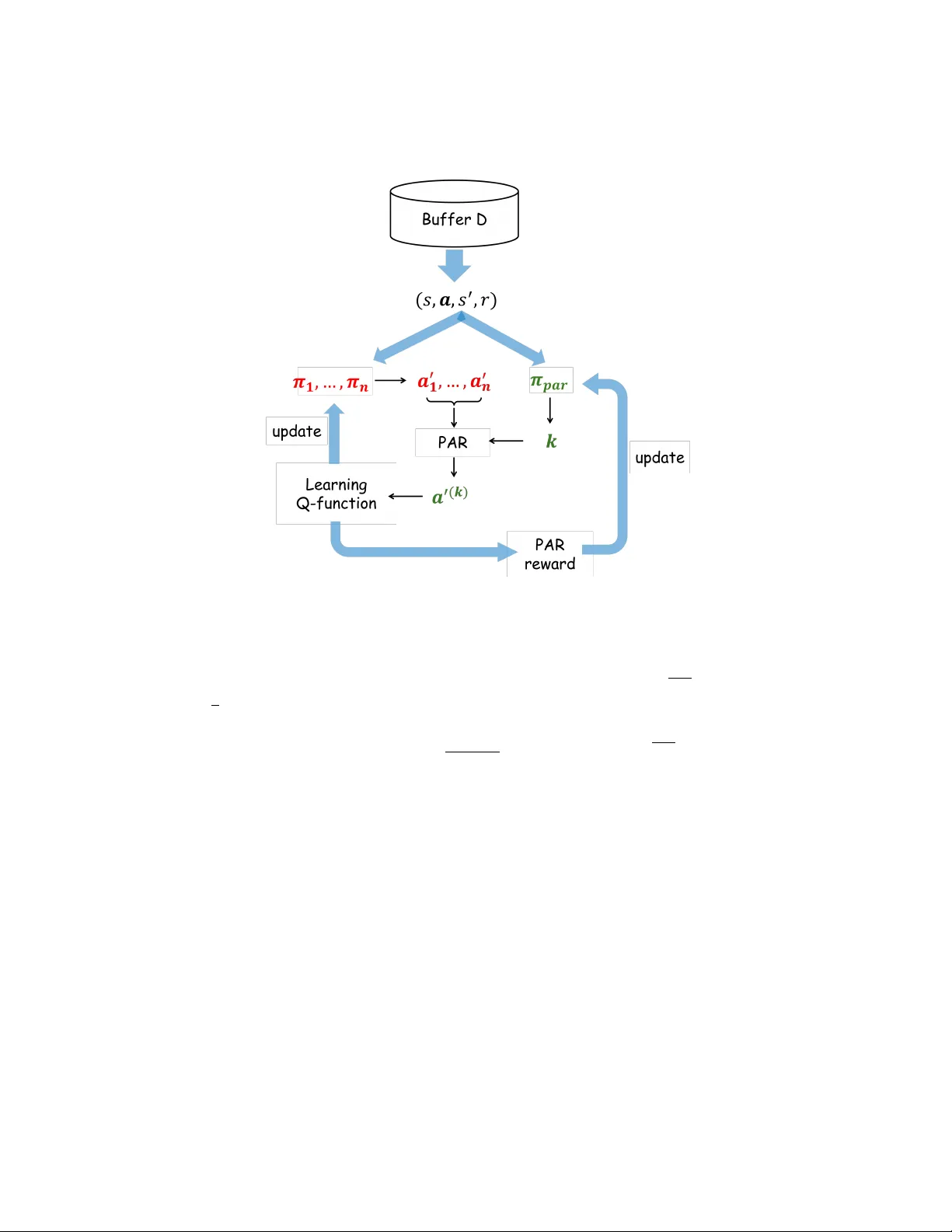
Learning P artial A ction Replacemen t in Offline MARL Y ue Jin 1 and Gio v anni Montana 2 , 3 1 F aculty of Arts, Science & T ec hnology , Univ ersity of Northampton, W aterside Campus, Northampton NN1 5PH, Northamptonshire, UK esther.jin@northampton.ac.uk 2 W arwick Man ufacturing Group, Universit y of W arwick, Cov en try , CV4 7AL, UK 3 Departmen t of Statistics, Univ ersity of W arwic k, Cov entry , CV4 7AL, UK g.montana@warwick.ac.uk Abstract. Offline m ulti-agent reinforcemen t learning (MARL) faces a critical c hallenge: the join t action space gro ws exponentially with the n umber of agen ts, making dataset cov erage exponentially sparse and out- of-distribution (OOD) join t actions unav oidable. P artial Action Replace- men t (P AR) mitigates this by anchoring a subset of agents to dataset actions, but existing approach relies on enumerating multiple subset configurations at high computational cost and cannot adapt to v arying states. W e introduce PLCQL, a framework that form ulates P AR subset selection as a contextual bandit problem and learns a state-dep enden t P AR p olicy using Proximal Policy Optimisation with an uncertain ty- w eighted rew ard. This adaptive policy dynamically determines how man y agen ts to replace at eac h update step, balancing p olicy impro vemen t against conserv ative v alue estimation. W e prov e a v alue-error b ound sho wing that the estimation error scales linearly with the exp ected num- b er of deviating agen ts. Compared with the previous P AR-based metho d SP aCQL, PLCQL reduces the n umber of p er-iteration Q-function ev al- uations from n to 1 , significantly improving computational efficiency . Empirically , PLCQL achiev es the highest normalised scores on 66% of tasks across MPE, MaMuJoCo, and SMA C b enchmarks, outp erforming SP aCQL on 84% of tasks while substantially reducing computational cost. Keyw ords: offline multi-agen t reinforcemen t learning · out-of-distribution · partial action replacement · v alue-error bound. 1 In tro duction Offline m ulti-agent reinforcement learning (MARL) aims to learn co ordinated p olicies from fixed datasets without additional interaction with the environmen t. This setting is particularly attractiv e for real-world applications where online ex- ploration is costly , unsafe, or impractical, such as robotics, autonomous systems, and large-scale resource management [ 19 , 11 , 15 , 23 ]. How ever, offline MARL in- tro duces a fundamental challenge that is significantly more severe than in the 2 Y ue Jin and Giov anni Montana single-agen t setting: the combinatorial explosion of the join t-action space. As the n umber of agents increases, the n umber of p ossible joint actions gro ws exp o- nen tially , while any fixed dataset can cov er only a small fraction of these com- binations. Consequently , learning algorithms must estimate the v alue of many out-of-distribution (OOD) join t actions. When combined with function appro x- imators suc h as neural netw orks, v alue-based metho ds may assign arbitrarily large Q-v alues to these unseen actions, leading to sev ere o verestimation and p olicies that exploit v alue errors rather than effectiv e co ordination [ 25 , 22 , 9 , 8 ]. One promising strategy for mitigating this problem is to constrain p olicy up dates to remain close to the sup p ort of the dataset. Recent work in tro duces partial action replacemen t (P AR), which changes the actions of only a subset of agen ts while keeping the remaining actions fixed to those observed in the dataset [ 5 ]. By anc horing part of the joint action to data-supported actions, P AR reduces distributional shift and stabilizes offline policy learning. How ev er, the effective- ness of P AR critically dep ends on which subset of agents is selected for action replacemen t. Existing metho ds, such as Soft P artial Conserv ative Q-Learning (SP aCQL), attempt to address this issue b y en umerating multiple subset sizes and randomly sampling com binations for eac h size, follo wed b y an uncertaint y- based w eighting scheme ov er the resulting target v alues [ 5 ]. Although this ap- proac h can improv e robustness, it introduces substan tial computational ov erhead b ecause multiple P AR configurations must b e ev aluated at every up date step. Moreo ver, the uncertaint y-based w eigh ting mec hanism do es not explicitly prior- itize subsets that lead to stronger multi-agen t co ordination. As a result, existing P AR-based approac hes rely on computationally expensive enumeration while lac king a principled mechanism for selecting coordination-effective subsets. In this pap er, w e address P AR subset selection by learning an adaptive strat- egy conditioned on the curren t state. W e formulate the problem as a contex- tual bandit, where the P AR p olicy maps states to subset sizes and receives an uncertain ty-w eighted reward derived from the estimated join t-action v alue. This encourages b oth high-v alue co ordination and conserv ative, reliable v alue esti- mation. W e prop ose P AR Learning-based Conserv ativ e Q-Learning (PLCQL), whic h jointly trains the MARL p olicy and the P AR strategy from offline data. By sampling a single P AR subset p er up date step rather than enumerating all configurations, PLCQL substantially reduces computational cost while retaining the benefits of partial action anchoring. T o our kno wledge, this is the first work to form ulate P AR subset selection as a learning problem in offline MARL. The main con tributions are: – W e prop ose PLCQL, a framework that learns a state-dep enden t P AR p ol- icy via con textual bandits, jointly considering agen t co ordination and v alue uncertain ty . PLCQL reduces the num b er of p er-iteration Q-function ev al- uations from n to 1 compared to SP aCQL while retaining the b enefits of partial action anc horing. – W e deriv e a v alue estimation error b ound showing that the estimation error scales linearly with the exp ected num b er of deviating agen ts induced b y the learned P AR p olicy . Learning Partial Action Replacement in Offline MARL 3 – W e provide an empirical ev aluation across MPE, MaMuJoCo, and SMAC b enc hmarks, demonstrating state-of-the-art p erformance on 66% of tasks and outp erforming SP aCQL on 84% of tasks. 2 Related W ork Offline Reinforcemen t Learning. Offline reinforcement learning (RL) aims at learning policies from fixed datasets without additional interaction with the en vironment. A central c hallenge in offline RL is distributional shift, where the learned p olicy may select actions that are not w ell represented in the dataset, leading to unreliable v alue estimates. The main idea of addressing this issue is to constrain p olicy up dates or p enalize out-of-distribution (OOD) actions. Metho ds lik e [ 2 , 3 , 8 , 24 ] rely on b ehaviour regularization to constrain p olicy up dates, en- couraging learned policies to stay close to the b eha viour policy that generated the dataset. Other works lik e [ 10 , 1 , 7 ] fo cus on conserv ative v alue estimation, which reduces ov erestimation of OOD actions b y explicitly penalizing Q-v alues for un- seen actions. While these metho ds hav e b een effective in single-agent settings, extending them to multi-agen t environmen ts introduces additional c hallenges due to the exp onen tial growth of the join t-action space. Offline MARL. Offline MARL extends offline RL to environmen ts in volving m ultiple agents. Compared to the single-agent setting, offline MARL faces sig- nifican tly greater c hallenges due to the com binatorial explosion of joint actions. Ev en when individual agents’ actions are well represented in the dataset, the dataset may contain only sparse cov erage of join t-action combinations. Recen t studies hav e explored adapting offline RL metho ds to the multi-agen t setting b y typically extending conserv ativ e v alue estimation or b ehavior regularization to joint p olicies [ 6 , 5 , 17 , 22 , 25 , 12 ]. How ev er, these metho ds often treat the joint action as a single entit y and do not explicitly address the sparse co verage of joint- action com binations in offline datasets. Consequently , mitigating distributional shift in the join t-action space remains a ma jor c hallenge in offline MARL. P AR for Distribution Shift Mitigation. T o address the joint-action dis- tribution shift problem, recen t w ork proposes P AR strategies [ 5 ]. P AR miti- gates OOD issues by mo difying the actions of only a subset of agen ts while k eeping the remaining actions fixed to those observ ed in the dataset. This de- sign anchors part of the joint action to data-supp orted actions, thereby reduc- ing the likelihoo d of ev aluating completely unseen join t-action combinations. A representativ e approach is Soft Partial Conserv ative Q-Learning (SPaCQL), whic h ev aluates multiple P AR configurations b y considering different subset sizes and randomly sampling agent combinations. SPaCQL further introduces an uncertaint y-based w eighting scheme to combine the resulting target v alues. While this approach mitigates distributional shift, it requires ev aluating m ultiple subset configurations at each up date step, resulting in significan t computational o verhead. Moreo ver, the weigh ting scheme relies on uncertaint y estimates and do es not explicitly prioritize subsets that may lead to b ette r agen t co ordination. 4 Y ue Jin and Giov anni Montana Bandits for algorithmic adaptation. Bandit algorithms hav e b een ap- plied to adaptiv ely select algorithmic comp onents during training, including cur- riculum schedules [ 4 ] and h yp erparameter configurations [ 13 ]. These approaches share the in tuition that the b est algorithmic choice is often con text-dep endent, and that a learned selector can outp erform any fixed configuration. Our use of a con textual bandit for P AR subset selection is in this spirit: rather than fixing subset size k or en umerating all p ossibilities as in SPaCQL, the bandit learns a state-dep enden t selection p olicy that adjusts conserv atism on a p er-state basis. Since the choice of k affects only the curren t Bellman target and do es not alter the environmen t state or the dataset, the bandit formulation captures the full decision structure relev an t to P AR subset selection without the ov erhead of a full MDP o ver k . T o our knowledge, PLCQL is the first metho d to use a contextual bandit to adaptiv ely select P AR subset sizes in offline MARL. In contrast to existing metho ds, our work fo cuses on learning an adaptive strategy for selecting P AR subsets. W e form ulate subset selection as a con textual bandit problem and prop ose PLCQL, whic h learns a P AR p olicy that dynam- ically selects agent subsets based on state context and v alue uncertaint y . This approac h eliminates the need for enumerating multiple subset configurations and in tro duces a principled mechanism for identifying co ordination-effective subsets, thereb y facilitating robust offline m ulti-agent p olicy learning under distributional shift. 3 Preliminaries W e study offline MARL in a Decen tralized Mark ov Decision Pro cess (Dec- MDP) ⟨S , {A i } n i =1 , P, R , n, γ ⟩ , where n agen ts interact in state space S . A t eac h timestep, agent i selects action a t,i ∈ A i , forming joint action a t ∈ A = × n i =1 A i . The environmen t transitions to s t +1 ∼ P ( ·| s t , a t ) and yields reward r t = R ( s t , a t ) . In the offline setting, agents cannot in teract with the en vironment. Learning o ccurs solely from a static dataset D = { ( s, a , r, s ′ ) k } collected by b ehavior p olicy µ ( a | s ) . The goal remains learning a joint p olicy π ( a | s ) that maximises exp ected return J ( π ) = E [ P ∞ t =0 γ t r t ] , with Q-function defined as: Q π ( s, a ) = E π " ∞ X t =0 γ t R ( s t , a t ) s 0 = s, a 0 = a # . Com binatorial co verage gap. The key challenge distinguishing offline MARL from offline single-agen t RL is com binatorial cov erage. In the single-agent case, a dataset of size |D | may co ver a reasonable fraction of the individual ac- tion space A . In the multi-agen t case, the joint action space A = × n i =1 A i gro ws exp onen tially in n . A dataset of the same size therefore co vers an exp onentially smaller fraction, making OOD joint actions unav oidable even when each agen t’s marginal action distribution is w ell represen ted. This is the fundamental mo- tiv ation for P AR: by anchoring n − k agents to dataset actions, it ensures that Learning Partial Action Replacement in Offline MARL 5 at most k dimensions of the joint action are OOD p er update step, directly b ounding the degree of distributional shift. F ormalising how to select this bound adaptiv ely requires a decision-making framework that is resp onsive to state-level uncertain ty — motiv ating the use of contextual bandits, described next. Con textual bandits. The con textual bandit problem models decision mak- ing under context-dependent rewards, in whic h an agen t selects actions based on observ ed context in order to maximise the exp ected reward under the context distribution. At each round t , the agent observes a context x t ∈ X , selects an action a t ∈ A according to a p olicy π ( a | x ) and receives a reward r t = r ( x t , a t ) . Unlik e reinforcemen t learning, contextual bandits do not inv olv e state transi- tions, and the ob jective is to learn a p olicy that maximises the exp ected rew ard under the context distribution. F ormally , the goal is to learn a policy that max- imises E x ∼D ,a ∼ π ( ·| x ) [ r ( x, a )] . Con textual bandits are widely used to mo del decision problems where each action only influences the immediate rew ard. 4 Metho dology In this work, we adopt the con textual bandit framew ork to mo del P AR subset selection. Sp ecifically , the con text corresponds to the b o otstrap state s ′ , i.e., the next state in each sampled transition. The action corresp onds to the subset size k ∈ { 1 , · · · , n } , where n is the num b er of agents. Giv en the selected k , a subset c ⊆ { 1 , · · · , n } with | c | = k is uniformly sampled at each step and used for partial action replacement. The actions of agen ts in c are up dated according to the curren t policy , while the actions of the remaining agen ts are fixed to those observed in the dataset. The resulting joint action is then ev aluated by the v alue function. The reward of the contextual bandit is defined based on the estimated joint-action v alue, weigh ted by the uncertaint y of the v alue function, whic h encourages the selection of subsets that yield high-v alue and reliable policy up dates. Under this formulation, learning the P AR strategy reduces to learning a contextual bandit p olicy that maps states to subset sizes, from whic h agent subsets are uniformly sampled, in order to maximise the exp ected reward. Wh y a contextual bandit rather than a full MDP? One ma y ask whether mo delling k selection as a full MDP would b e more expressive. W e argue the bandit formulation is both sufficient and preferable here. The subset size k affects only the curr ent Bellman target; it does not alter the environmen t state, the dataset, or the tra jectory of the MARL p olicy , so there is no meaningful state transition induced by the k selection itself. Modelling it as an MDP w ould therefore in tro duce unnecessary complexity—requiring a separate repla y buffer and m ulti-step return estimation for the meta-p olicy—without capturing any additional structure. The bandit formulation keeps the framework light weigh t and easy to tune, while fully capturing the decision structure relev ant to P AR subset selection. 6 Y ue Jin and Giov anni Montana 4.1 P AR P olicy Instead of enumerating m ultiple subset configurations, w e introduce P AR Learning- based Conserv ative Q-Learning (PLCQL), which learns an adaptive partial ac- tion replacemen t (P AR) p olicy . The P AR p olicy π par : S → { 1 , · · · , n } , maps states to P AR strategies that determine ho w many agents’ ac tions should b e replaced during target v alue computation. W e denote the P AR action as k ∈ { 1 , · · · , n } , representing the num b er of agen ts whose actions will b e replaced. The P AR p olicy is assumed to b e sto c has- tic, suc h that k ∼ π par ( ·| s ′ ) . Giv en a selected action k , the corresp onding Bellman op erator T k replaces exactly k agen ts’ actions in the next-state join t action. Sp ecifically , k agents are c hosen uniformly at random to deviate from the behaviour p olicy , while the remaining n − k agen ts retain the actions recorded in the dataset. F ormally , for an y k ∈ { 1 , · · · , n } , we define the Bellman operator T k as T ( k ) Q ( s, a ) := E s ′ ∼D , a ′ ( k ) h r + γ Q s ′ , a ′ ( k ) i , (1) where a ′ ( k ) denotes the next-state joint action in whic h exactly k agents’ actions are replaced according to the current p olicy , while the remaining actions are tak en from the logged dataset. Eac h T ( k ) is a γ -contraction under the ℓ ∞ norm. Since the P AR policy induces a sto c hastic mixture o ver these op erators, the resulting op erator T par also preserv es the γ -con traction prop erty . The ob jectiv e of the P AR p olicy is to improv e offline MARL p olicy learn- ing b y selecting effective subset sizes. T o encourage reliable p olicy up dates, we incorp orate the uncertaint y of v alue estimation into the reward signal used to train the P AR p olicy . Sp ecifically , w e define an uncertaint y-weigh ted rew ard r par ( s ′ , k ) = σ ( − u Q · T ) + 0 . 5 Q θ 1 ( s ′ , a ′ ( k ) ) , (2) where the uncertaint y u Q is measured using the v ariance of an ensemble of Q- functions, u Q = q V ar j Q θ j ( s ′ , a ′ ( k ) ) , and T > 0 is a temp erature parameter con trolling the sensitivity of the p enalty to ensemble disagreement. High en- sem ble disagreement indicates p o or cov erage of the corresp onding joint action in the dataset. Therefore, the uncertaint y term reduces the rew ard assigned to P AR actions that rely on unreliable v alue estimates, encouraging the P AR p olicy to select subset sizes that balance v alue improv ement and estimation reliability . 4.2 The PLCQL Algorithm W e learn the P AR p olicy using Proximal Policy Optimisation (PPO) [ 21 ], a p ol- icy gradient algorithm that provides stable and efficient up dates for sto chastic Learning Partial Action Replacement in Offline MARL 7 p olicies. In our framework, the P AR p olicy π par ( k | s ′ ) is parameterised by a neu- ral netw ork that takes the bo otstrap state s ′ as input and outputs a probabilit y distribution o ver subset sizes k ∈ { 1 , · · · , n } . During training, for each transition sampled from the offline dataset, the P AR p olicy selects a subset size k according to π par ( k | s ′ ) . A subset of k agen ts is then uniformly sampled, and the corresponding P AR Bellman op erator T k is used to construct the target v alue for up dating the Q-function. The reward signal for the P AR p olicy is giv en b y the uncertaint y-w eighted reward r par ( s ′ , k ) defined ab ov e. The PPO ob jectiv e is used to up date the P AR p olicy b y maximising the expected rew ard while constraining policy updates to remain close to the previous policy . Sp ecifically , the p olicy parameters are optimised using the clipp ed surrogate ob jectiv e E ( s, a ) ∼D h min ρ par ˆ A par , clip( ρ par , 1 − ϵ, 1+ ϵ ) ˆ A par i , (3) where ρ par = π par ( k | s ′ ) π old par ( k | s ′ ) is the probability ratio b et ween the new and old p olicies, and ˆ A par = r par ( s ′ , k ) − V θ par ( s ′ ) denotes the estimated adv an tage of selecting subset size k . The baseline V θ par ( s ′ ) = E k [ r par ( s ′ , k )] is learned b y minimising L v = E s ′ ∼D , k ∼ π par h V θ par ( s ′ ) − r par ( s ′ , k ) 2 i . (4) The learning ob jectiv e for PLCQL combines the TD error for our adaptiv e Bellman op erator with a conserv ativ e p enalty: L ( θ ) = E D h ( Q θ ( s, a ) − Y par ) 2 i + ξ c , (5) where ξ c = α P n i =1 λ i E ( s, a − i ) ∼D , a i ∼ π i [ Q θ ( s, a i , a − i )] − E ( s, a ) ∼D [ Q θ ( s, a )] is the conserv ative p enalty adopted from CF CQL [ 22 ]. The target Y par is con- structed using the P AR p olicy , with an ensem ble minimum for conserv atism: Y par := r + γ min j Q tar j s ′ , a ′ ( k ) , k ∼ π par ( ·| s ′ ) . (6) A complete description is given in Algorithm 1 and Figure 1 illustrates the o verall w orkflo w. Through joint training, PLCQL simultaneously learns the MARL v alue function and the P AR p olicy , enabling adaptive selection of subset sizes that impro ve offline policy learning while mitigating distributional shift. 4.3 Theoretical V alue-Error Bound of PLCQL PLCQL retains strong theoretical guarantees without in tro ducing additional structural assumptions on the Q-function. The exp ected distribution shift un- der the PLCQL op erator scales linearly with the expected n umber of deviating agen ts, E [ k | s ] = P k π par ( k | s ) · k , which leads directly to our v alue-error b ound. Here ε Subopt denotes the sub optimality of the learned policy relativ e to the op- timal in-supp ort p olicy , and ε FQI is the fitted Q-iteration approximation error arising from function appro ximation and finite data. 8 Y ue Jin and Giov anni Montana Fig. 1. Illustration of the PLCQL algorithm. Theorem 1 (PLCQL V alue-Error Bound). L et ˆ Q b e the function le arne d by PLCQL and define the aver age single-agent p olicy deviation as TV( π , µ ) = 1 n P n i =1 TV( π i , µ i ) . The value estimation err or is b ounde d by: | V π − ˆ V π | ≤ ε Subopt + ε FQI + 4 γ (1 − γ ) 2 E s ′ ∼ d π , k ∼ π par ( ·| s ′ ) [ k ] · TV ( π , µ ) . Pr o of (Pr o of Sketch). The pro of follows the same structure as the P AR v alue- error analysis in [ 5 ]. The k ey difference is that the distribution shift term W 1 ( d π , d µ ) is replaced by the exp ected shift under the PLCQL op erator. This exp ectation is tak en ov er the mixture P k π par ( k | s ′ ) π ( k ) , yielding a dep endency on the state- dep enden t exp ected num b er of deviations, E [ k | s ′ ] . The error scales with the effective n umber of deviations k eff , which PLCQL adapts on a p er-state basis. When π par concen trates on k =1 , only a single agen t’s action is replaced at eac h up date, minimising distributional shift and yielding the tigh test p ossible v alue-error b ound. As probability mass shifts tow ard larger k , more agen ts deviate simultaneously , increasing the exp ected shift and approach- ing the full-join t error b ound. This illustrates how PLCQL adaptively balances conserv atism and coordination across different states. Learning Partial Action Replacement in Offline MARL 9 Algorithm 1 PLCQL 1: Initialize: Q-ensemble { Q θ j } , target ensemble { ¯ Q ¯ θ j } , policies { π ψ i } n i =1 , target p olicies { ¯ π ¯ ψ i } n i =1 , replay buffer D , P AR p olicy π par , v alue baseline V θ par 2: for each iteration do 3: Sample batch B = { ( s, a , r, s ′ , a ′ ) } from D 4: Set L ( θ ) ← 0 , L v ← 0 5: for each transition ( s, a , r, s ′ , a ′ ) in B do 6: Sample k ∼ π par ( ·| s ′ ) 7: Sample k agent indices { σ ρ } k ρ =1 8: Sample { a π σ ρ ∼ π σ ρ ( ·| s ′ ) } k ρ =1 9: Construct a ′ ( k ) ← a ′ : for eac h σ ρ , replace the σ ρ -th comp onent with a π σ ρ 10: Y par = r + γ min j ¯ Q θ j ( s ′ , a ′ ( k ) ) 11: L ( θ ) += P j Q θ j ( s, a ) − Y par 2 12: u Q ← q V ar j Q θ j ( s ′ , a ′ ( k ) ) 13: w ← σ ( − u Q · T ) + 0 . 5 14: r par ← w Q θ 1 ( s ′ , a ′ ( k ) ) // unc ertainty-weighte d r eward at ( s ′ , a ′ ( k ) ) 15: L v += V θ par ( s ′ ) − r par 2 16: end for 17: θ ← θ − η θ ∇ θ L ( θ ) / |B| + ξ c 18: ¯ θ ← (1 − τ ) ¯ θ + τ θ 19: θ par ← θ par − η θ par ∇ θ par L v 20: — A gent p olicy up date — 21: for each agent i do 22: ψ i ← ψ i + η π ∇ ψ i E s, a − i ∼D , a i ∼ π i Q θ 1 ( s, a ) 23: ¯ ψ i ← (1 − τ ) ¯ ψ i + τ ψ i 24: end for 25: — P AR p olicy up date (PPO) — 26: ˆ A par ← r par − V θ par ( s ′ ) 27: Up date π par to maximise: E ( s, a ) ∼D h min ρ par ˆ A par , clip( ρ par , 1 − ϵ, 1+ ϵ ) ˆ A par i 28: end for 5 Exp erimen tal Settings and Results 5.1 Exp erimen tal Setup W e conduct a comprehensive ev aluation of PLCQL on three widely used of- fline MARL b enchmarks: Multi-Agent Particle Environmen ts (MPE) [ 14 ], Multi- Agen t MuJoCo (MaMuJoCo) [ 18 ], and StarCraft Multi-Agent Challenge (SMAC) [ 20 ]. F ollo wing recent w ork [ 5 , 22 , 17 , 6 ], we use the same offline datasets to ensure fair comparisons. F or MPE, there are three distinct tasks: Co operative Na v- igation (CN), Predator-Prey (PP), and W orld. F or MaMuJoCo, there is Half- Cheetah (Half-C). The SMAC benchmark includes four maps with v arying agen t coun ts and difficulties: 2s3z, 3s_vs_5z, 5m_vs_6m, and 6h_vs_8z. T o ev aluate p erformance under differen t levels of dataset qualit y , each MPE and MaMuJoCo task includes four dataset types: Expert (Exp), Medium (Med), 10 Y ue Jin and Giov anni Montana Medium-Repla y (Med-R), and Random (Rand). F or SMAC, w e follow the dataset splits from prior works [ 22 , 5 ], whic h include Medium (Med), Medium-Repla y (Med-R), Exp ert (Exp), and Mixed datasets. These datasets pro vide v arying lev els of p olicy optimality and co verage of the state–action space. Our implemen tation uses an ensemble of ten Q-netw orks to estimate v alue functions and quantify v alue uncertain ty . The P AR p olicy is parameterized b y a neural net w ork with t w o hidden la y ers of 64 units eac h. All other hyperparame- ters follow those sp ecified in the original SPaCQL [ 5 ] implementation to ensure a fair comparison. T o impro v e the reliabilit y of the results, w e run all experiments with fiv e random seeds and rep ort the mean and standard deviation of the nor- malized scores. All exp eriments are implemented in PyT orch and executed on NVIDIA T esla V100 GPUs. 5.2 Baselines W e compare PLCQL against a suite of state-of-the-art offline MARL algorithms, selected to represen t the ma jor metho dological directions in the literature: – P olicy-constrained metho ds: OMAR [ 17 ], IQL [ 6 ], MA-TD3+BC [ 17 ], A W AC [ 16 ], and MAICQ [ 25 ]. – V alue-constrained metho ds: MA CQL [ 22 ], CFCQL [ 22 ], and SP aCQL [ 5 ]. – Diffusion-based metho ds: DoF [ 12 ]. These baselines provide strong comparisons across different paradigms, enabling a thorough ev aluation of the effectiv eness of PLCQL. 5.3 Main Results P erformance is measured using normalised scores ov er fiv e random seeds, with mean and standard deviation rep orted for each task and dataset type. Results are presented in T ables 2 and 3 , where baseline scores are taken from the cor- resp onding pap ers. Ov erall, PLCQL achiev es the highest normalised scores on appro ximately 66% of tasks (21 out of 32). Compared with p olicy-constrained metho ds (OMAR, IQL, MA-TD3+BC), PLCQL demonstrates clear adv antages on nearly all tasks, achieving higher join t- action v alues while maintaining stable learning. Against v alue-constrained meth- o ds (MACQL, CFCQL, and SP aCQL), PLCQL attains comparable or b etter p erformance while incurring significan tly lo w er computational cost, owing to its single-step P AR subset update p er iteration. When compared with the diffusion- based approach DoF, PLCQL shows comp etitive or superior p erformance on most tasks, particularly on non-exp ert datasets where effective exploration of OOD join t actions combined with accurate v alue estimation is most critical. In direct comparison with SP aCQL—which en umerates m ultiple subset con- figurations indep endently of state context—PLCQL ac hieves b etter performance on approximately 84% of tasks (27 out of 32). This highlights the effectiveness of adaptiv e P AR learning: b y dynamically selecting the num b er of agen ts to replace based on state and estimated joint-action v alue, PLCQL better balances p olicy impro vemen t against conserv atism. Learning Partial Action Replacement in Offline MARL 11 5.4 Ablation Study T o isolate the con tribution of eac h component of PLCQL, w e conduct ablations on the CN (Med-R) and 2s3z (Med) tasks, whic h span both contin uous and discrete action spaces. Effe ct of adaptive P AR le arning. W e compare PLCQL against tw o fixed- k v arian ts: PLCQL- k =1 (single-agen t replacemen t only) and PLCQL- k = n (full join t replacement, equiv alent to standard CQL without anchoring). Results in T able 1 sho w that no single fixed k consistently dominates across tasks and dataset types, v alidating the need for state-adaptive selection. The learned P AR p olicy outp erforms fixed- k baselines on all tasks. Effe ct of unc ertainty weighting. W e ablate the uncertaint y-weigh ted rew ard b y setting w =1 (remo ving the σ ( − u Q T ) p enalty). P erformance degrades consis- ten tly , and most sharply on medium-replay datasets where v alue estimates are least reliable. This confirms that the uncertain ty penalty steers the P AR p olicy a wa y from p o orly supp orted joint actions and is not merely a scaling factor. T able 1. Ablation results (normalised score / win rate) on CN Med-R and 2s3z Med. PLCQL (full) uses the learned P AR policy with uncertaint y w eigh ting. V ariant CN Med-R 2s3z Med PLCQL (full) 95.4 ± 6.1 0.51 ± 0.19 Fixed k =1 58.2 ± 8.4 0.43 ± 0.14 Fixed k = n 52.2 ± 9.6 0.40 ± 0.10 No uncertaint y w eighting ( w =1 ) 90.6 ± 8.1 0.48 ± 0.23 5.5 Computational Cost PLCQL ev aluates a single P AR subset per transition up date. SP aCQL, by con- trast, ev aluates n subset configurations p er update step. On the 6-agent SMAC maps ( n =6 ), this corresp onds to 6 configurations for SPaCQL versus 1 for PLCQL. In practice, we observe a wall-clock sp eedup p er training iteration on V100 hardw are, confirming that adaptive P AR learning substantially reduces computational o verhead without sacrificing policy quality . 6 Discussion and Conclusions In this work, we in tro duced PLCQL, a nov el framew ork for offline MARL that lev erages P AR to mitigate distributional shift in the combinatorial joint-action space. By formulating the subset selection problem as a contextual bandit, PLCQL learns a state-dep endent P AR policy that adaptively determines the n umber of agents to replace at eac h up date step, balancing co ordination im- pro vemen t with conserv ativ e v alue estimation. 12 Y ue Jin and Giov anni Montana Our theoretical analysis shows that the exp ected distribution shift under the P AR op erator scales linearly with the exp ected n umber of deviating agen ts, yield- ing a clear and interpretable v alue-error b ound. Empirically , PLCQL ac hieves strong performance across MPE, MaMuJoCo, and SMAC, outp erforming state- of-the-art baselines on approximately 66% of tasks while reducing the computa- tional cost of P AR-based metho ds by eliminating the need to en umerate multiple subset configurations. The uncertaint y-w eighted rew ard mec hanism effectiv ely prioritises subsets that are b oth high-v alue and well-supported b y the dataset, con tributing to more reliable p olicy learning. A central contribution of our w ork is the introduction of adaptive P AR learn- ing. By conditioning subset size selection on the environmen t state, PLCQL pro- vides an efficient and principled mechanism for handling distributional shift in offline MARL. This not only improv es learning p erformance but substan tially re- duces the computational burden compared to metho ds suc h as SPaCQL, making PLCQL a practical solution for large m ulti-agent systems. Despite these adv ances, sev eral limitations remain. The curren t P AR p olicy selects the numb er of deviating agen ts, with the sp ecific agents sampled uni- formly within that subset; future work could explore more expressive selection mec hanisms that explicitly account for inter-agen t dep endencies. A dditionally , while PLCQL reduces per-step computational ov erhead, reliance on Q-function ensem bles may limit scalabilit y to en vironments with v ery large n umbers of agen ts. In conclusion, PLCQL provides an adaptive and theoretically grounded frame- w ork for offline m ulti-agent p olicy learning. By addressing the challenge of joint- action distributional shift through integrated P AR p olicy learning and conserv a- tiv e Q-learning, PLCQL adv ances b oth the metho dology and understanding of offline MARL. W e b elieve that adaptiv e P AR learning represen ts a promising av- en ue for future researc h in scalable, co ordination-intensiv e m ulti-agent systems. Learning Partial Action Replacement in Offline MARL 13 T abl e 2. The av erage normalized score on offline MARL tasks. The best performance is highlighted in b old. Dataset OMAR MA CQL IQL MA-TD3+BC DoF CF CQL SP aCQL PLCQL MPE CN Exp 114.9 ± 2.6 12.2 ± 31 103.7 ± 2.5 108.3 ± 3.3 136.4 ± 3.9 112 ± 4 111.9 ± 4.5 110.9 ± 3.0 Med 47.9 ± 18.9 14.3 ± 20.2 28.2 ± 3.9 29.3 ± 4.8 75.6 ± 8.7 65.0 ± 10.2 78.6 ± 6.4 85.1 ± 5.9 Med-R 37.9 ± 12.3 25.5 ± 5.9 10.8 ± 4.5 15.4 ± 5.6 57.4 ± 6.8 52.2 ± 9.6 71.9 ± 13.2 95.4 ± 6.1 Rand 34.4 ± 5.3 45.6 ± 8.7 5.5 ± 1.1 9.8 ± 4.9 35.9 ± 6.8 62.2 ± 8.1 78.2 ± 14 88.3 ± 4.8 PP Exp 116.2 ± 19.8 108.4 ± 21.5 109.3 ± 10.1 115.2 ± 12.5 125.6 ± 8.6 118.2 ± 13.1 111.2 ± 16.4 107.1 ± 10.8 Med 66.7 ± 23.2 55 ± 43.2 53.6 ± 19.9 65.1 ± 29.5 86.3 ± 10.6 68.5 ± 21.8 61.9 ± 20 84.0 ± 29.0 Med-R 47.1 ± 15.3 11.9 ± 9.2 23.2 ± 12 28.7 ± 20.9 65.4 ± 12.5 71.1 ± 6 75.0 ± 12.7 87.3 ± 10.4 Rand 11.1 ± 2.8 25.2 ± 11.5 1.3 ± 1.6 5.7 ± 3.5 16.5 ± 6.3 78.5 ± 15.6 89.4 ± 13.7 92.8 ± 6.0 W orld Exp 110.4 ± 25.7 99.7 ± 31 107.8 ± 17.7 110.3 ± 21.3 135.2 ± 19.1 119.7 ± 26.4 112.3 ± 7.8 133.0 ± 9.4 Med 74.6 ± 11.5 67.4 ± 48.4 70.5 ± 15.3 73.4 ± 9.3 85.2 ± 11.2 93.8 ± 31.8 98.1 ± 17.7 104.9 ± 22.0 Med-R 42.9 ± 19.5 13.2 ± 16.2 41.5 ± 9.5 17.4 ± 8.1 58.6 ± 10.4 73.4 ± 23.2 105.2 ± 11.1 107.5 ± 11.3 Rand 5.9 ± 5.2 11.7 ± 11 2.9 ± 4.0 2.8 ± 5.5 13.1 ± 2.1 68 ± 20.8 94.3 ± 7.4 84.9 ± 6.9 MaMujo co Half-C Exp 113.5 ± 4.3 50.1 ± 20.1 115.6 ± 4.2 114.4 ± 3.8 - 118.5 ± 4.9 110.5 ± 5.9 111.9 ± 4.4 Med 80.4 ± 10.2 51.5 ± 26.7 81.3 ± 3.7 75.5 ± 3.7 - 80.5 ± 9.6 70.3 ± 7.8 71.9 ± 9.1 Med-R 57.7 ± 5.1 37.0 ± 7.1 58.8 ± 6.8 27.1 ± 5.5 - 59.5 ± 8.2 66.1 ± 3.4 73.1 ± 5.7 Rand 13.5 ± 7.0 5.3 ± 0.5 7.4 ± 0.0 7.4 ± 0.0 - 39.7 ± 4.0 43.8 ± 4.9 40.9 ± 2.8 14 Y ue Jin and Giov anni Montana T abl e 3. A v eraged test winning rate in StarCraft I I micromanagement tasks. The b est performance is highlighted in b old. Map Dataset CF CQL MA CQL MAICQ OMAR MADTKD BC IQL A W AC SPaCQL PLCQL 2s3z Med 0.40 ± 0.10 0.17 ± 0.08 0.18 ± 0.02 0.15 ± 0.04 0.18 ± 0.03 0.16 ± 0.07 0.16 ± 0.04 0.19 ± 0.05 0.46 ± 0.2 0.51 ± 0.19 Med-R 0.55 ± 0.07 0.12 ± 0.08 0.41 ± 0.06 0.24 ± 0.09 0.36 ± 0.07 0.33 ± 0.04 0.33 ± 0.06 0.39 ± 0.05 0.56 ± 0.2 0.76 ± 0.14 Exp 0.99 ± 0.01 0.58 ± 0.34 0.93 ± 0.04 0.95 ± 0.04 0.99 ± 0.02 0.97 ± 0.02 0.98 ± 0.03 0.97 ± 0.03 0.99 ± 0.01 1 ± 0 Mixed 0.84 ± 0.09 0.67 ± 0.17 0.85 ± 0.07 0.60 ± 0.04 0.47 ± 0.08 0.44 ± 0.06 0.19 ± 0.04 0.14 ± 0.04 0.96 ± 0.1 0.97 ± 0.05 3s_vs_5z Med 0.28 ± 0.03 0.09 ± 0.06 0.03 ± 0.01 0.00 ± 0.00 0.01 ± 0.01 0.08 ± 0.02 0.20 ± 0.05 0.19 ± 0.03 0.2 ± 0.4 0.37 ± 0.41 Med-R 0.12 ± 0.04 0.01 ± 0.01 0.01 ± 0.02 0.00 ± 0.00 0.01 ± 0.01 0.01 ± 0.01 0.04 ± 0.04 0.08 ± 0.05 0.12 ± 0.24 0.13 ± 0.18 Exp 0.99 ± 0.01 0.92 ± 0.05 0.91 ± 0.04 0.64 ± 0.08 0.67 ± 0.08 0.98 ± 0.02 0.99 ± 0.01 0.99 ± 0.02 0.98 ± 0.06 0.98 ± 0.05 Mixed 0.60 ± 0.14 0.17 ± 0.10 0.10 ± 0.04 0.00 ± 0.00 0.14 ± 0.08 0.21 ± 0.04 0.20 ± 0.06 0.14 ± 0.03 0.43 ± 0.44 0.47 ± 0.49 5m_vs_6m Med 0.29 ± 0.05 0.01 ± 0.01 0.26 ± 0.03 0.19 ± 0.06 0.21 ± 0.03 0.28 ± 0.37 0.18 ± 0.02 0.22 ± 0.04 0.33 ± 0.03 0.46 ± 0.26 Med-R 0.22 ± 0.06 0.01 ± 0.01 0.18 ± 0.04 0.03 ± 0.03 0.16 ± 0.04 0.13 ± 0.06 0.18 ± 0.04 0.18 ± 0.04 0.23 ± 0.17 0.24 ± 0.13 Exp 0.84 ± 0.03 0.01 ± 0.01 0.72 ± 0.05 0.33 ± 0.06 0.58 ± 0.07 0.82 ± 0.04 0.77 ± 0.03 0.75 ± 0.02 0.82 ± 0.14 0.82 ± 0.23 Mixed 0.76 ± 0.07 0.01 ± 0.01 0.67 ± 0.08 0.10 ± 0.10 0.21 ± 0.05 0.21 ± 0.12 0.76 ± 0.06 0.78 ± 0.02 0.78 ± 0.16 0.82 ± 0.22 6h_vs_8z Med 0.41 ± 0.04 0.06 ± 0.04 0.19 ± 0.04 0.04 ± 0.03 0.22 ± 0.07 0.40 ± 0.04 0.40 ± 0.05 0.43 ± 0.06 0.42 ± 0.28 0.48 ± 0.18 Med-R 0.21 ± 0.05 0.02 ± 0.04 0.07 ± 0.04 0.00 ± 0.00 0.14 ± 0.04 0.11 ± 0.04 0.17 ± 0.03 0.14 ± 0.04 0.22 ± 0.14 0.24 ± 0.2 Exp 0.70 ± 0.06 0.02 ± 0.00 0.24 ± 0.08 0.07 ± 0.03 0.22 ± 0.03 0.60 ± 0.04 0.67 ± 0.03 0.60 ± 0.03 0.73 ± 0.11 0.77 ± 0.10 Mixed 0.49 ± 0.08 0.01 ± 0.01 0.05 ± 0.03 0.00 ± 0.00 0.25 ± 0.07 0.27 ± 0.06 0.36 ± 0.05 0.35 ± 0.06 0.52 ± 0.22 0.56 ± 0.28 Learning Partial Action Replacement in Offline MARL 15 Gener ative AI disclosur e. The authors used large language mo del to ols to assist with proofreading and L A T E X formatting. All scien tific con tent, experimental design, results, and claims are the sole resp onsibilit y of the authors. References 1. An, G., Mo on, S., Kim, J.h., Song, H.O.: Uncertain ty-Based Offline Reinforcemen t Learning with Diversified Q-Ensemble. In: 35th Conference on Neural Information Pro cessing Systems (NeurIPS 2021) (2021) 2. F ujimoto, S., Gu, S.S.: A Minimalist Approac h to Offline Reinforcement Learning. In: 35th Conference on Neural Information Pro cessing Systems (NeurIPS 2021) (2021) 3. F ujimoto, S., Meger, D., Precup, D.: Off-p olicy deep reinforcement learning without exploration _F ull. 36th In ternational Conference on Mac hine Learning, ICML 2019 2019-June , 3599–3609 (2019) 4. Gra ves, A., Bellemare, M.G., Menick, J., Munos, R., Kavuk cuoglu, K.: Automated curriculum learning for neural netw orks. 34th In ternational Conference on Mac hine Learning, ICML 2017 3 , 2120–2129 (2017) 5. Jin, Y., Mon tana, G.: Partial A ction Replacement: T ac kling Distribution Shift in Offline MARL. In Pro ceedings of the AAAI Conference on Artificial Intelligence 40 (27), 22435–22443 (2025), 6. K ostriko v, I., Nair, A., Levine, S.: Offline Reinforcement Learning with Implicit Q- Learning. In International Conference on Learning Representations (2022), http: 7. K ostriko v, I., T ompson, J., F ergus, R., Nach um, O.: Offline Reinforcement Learning with Fisher Div ergence Critic Regularization. Pro ceedings of Mac hine Learning Researc h 139 , 5774–5783 (2021) 8. Kumar, A., F u, J., T uck er, G., Levine, S.: Stabilizing off-policy Q-learning via b o ot- strapping error reduction. In: 33rd Conference on Neural Information Pro cessing Systems (NeurIPS 2019) (2019) 9. Kumar, A., Zhou, A., T uc ker, G., Levine, S.: Conserv ative Q-Learning for Offline Reinforcemen t Learning. In: 34th Conference on Neural Information Pro cessing Systems (NeurIPS 2020) (2020), 10. Kumar, A., Zhou, A., T uc ker, G., Levine, S.: Conserv ative Q-learning for offline reinforcemen t learning. Adv ances in Neural Information Pro cessing Systems 2020- Decem (NeurIPS), 1–13 (2020) 11. Levine, S., Kumar, A., T uck er, G., F u, J.: Offline Reinforcemen t Learning: T utorial, Review, and Perspectives on Op en Problems pp. 1–43 (2020), abs/2005.01643 12. Li, C., Deng, Z., Lin, C., Chen, W., F u, Y., Liu , W., Ab, W., W ang, C., Shen, S.: Dof: A diffusion factorization framew ork for offline multi-agen t reinforcement learning. In: The Thirteenth In ternational Conference on Learning Representations (2025), https://github.com/xmu- rl- 3dv/DoF. 13. Li, L., Jamieson, K., DeSalvo, G., Rostamizadeh, A., T alwalk ar, A.: Hyperband: A no vel bandit-based approac h to hyperparameter optimization. Journal of Mac hine Learning Research 18 , 1–52 (2018) 14. Lo we, R., W u, Y., T amar, A., Harb, J., Abb eel, P ., Mordatc h, I.: Multi-agen t actor-critic for mixed co op erative-competitive environmen ts. Adv ances in Neural Information Pro cessing Systems 2017-Decem , 6380–6391 (2017) 16 Y ue Jin and Giov anni Montana 15. Mandlek ar, A., Xu, D., W ong, J., Nasiriany , S., W ang, C., Kulk arni, R., F ei-F ei, L., Sa v arese, S., Zhu, Y., Martín-Martín, R.: What Matters in Learning from Offline Human Demonstrations for Robot Manipulation. Proceedings of Mac hine Learning Researc h 164 (CoRL), 1678–1690 (2021) 16. Nair, A., Gupta, A., Dalal, M., Levine, S.: A W AC: A ccelerating Online Reinforce- men t Learning with Offline Datasets. arXiv preprint arXiv:2006.09359 (6 2020), 17. P an, L., Huang, L., Ma, T., Xu, H.: Plan Better Amid Conserv atism: Offline Multi- Agen t Reinforcement Learning with Actor Rectification. Pro ceedings of Machine Learning Research 162 , 17221–17237 (2022) 18. P eng, B., Rashid, T., Schroeder de Witt, C.A., Kamienn y , P .A., T orr, P .H., Böh- mer, W., Whiteson, S.: F ACMA C: F actored Multi-Agent Cen tralised Policy Gra- dien ts. Adv ances in Neural Information Processing Systems 15 (NeurIPS), 12208– 12221 (2021) 19. Prudencio, R.F., Maximo, M.R.O.A., Colombini, E.L.: A Survey on Offline Rein- forcemen t Learning: T axonomy , Review, and Open Problems. IEEE T ransactions on Neural Net works and Learning Systems PP , 0–1 (2022). https://doi.org/ 10.1109/TNNLS.2023.3250269 , 20. Sam vely an, M., Rashid, T., De Witt, C.S., F arquhar, G., Nardelli, N., Rudner, T.G., Hung, C.M., T orr, P .H., F o erster, J., Whiteson, S.: The StarCraft m ulti- agen t challenge. Pro ceedings of the International Joint Conference on Autonomous Agen ts and Multiagent Systems, AAMAS 4 (NeurIPS), 2186–2188 (2019) 21. Sc hulman, J., W olski, F., Dhariw al, P ., Radford, A., Klimov, O.: Pro ximal Policy Optimization Algorithms. arXiv preprint arXiv:1707.06347 (2017) 22. Shao, J., Qu, Y., Chen, C., Zhang, H., Ji, X.: Counterfactual Conserv ativ e Q Learn- ing for Offline Multi-agent Reinforcement Learning. 37th Conference on Neural Information Processing Systems (NeurIPS 2023) (2023), 2309.12696 23. T esauro, G., Jong, N.K., Das, R., Bennani, M.N.: A hybrid reinforcement learn- ing approach to autonomic resource allocation. Pro ceedings - 3rd In ternational Conference on Autonomic Computing, ICAC 2006 2006 , 65–73 (2006). https: //doi.org/10.1109/icac.2006.1662383 24. W u, Y., T uck er, G., Nach um, O.: Beha vior Regularized Offline Reinforcemen t Learning pp. 1–25 (2019), 25. Y ang, Y., Ma, X., Li, C., Zheng, Z., Zhang, Q., Huang, G., Y ang, J., Zhao, Q.: Believ e What Y ou See: Implicit Constraint Approach for Offline Multi-Agent Rein- forcemen t Learning. In: 35th Conference on Neural Information Processing Systems (NeurIPS 2021) (2021)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment