CirrusBench: Evaluating LLM-based Agents Beyond Correctness in Real-World Cloud Service Environments
The increasing agentic capabilities of Large Language Models (LLMs) have enabled their deployment in real-world applications, such as cloud services, where customer-assistant interactions exhibit high technical complexity and long-horizon dependencie…
Authors: Yi Yu, Guangquan Hu, Chenghuang Shen
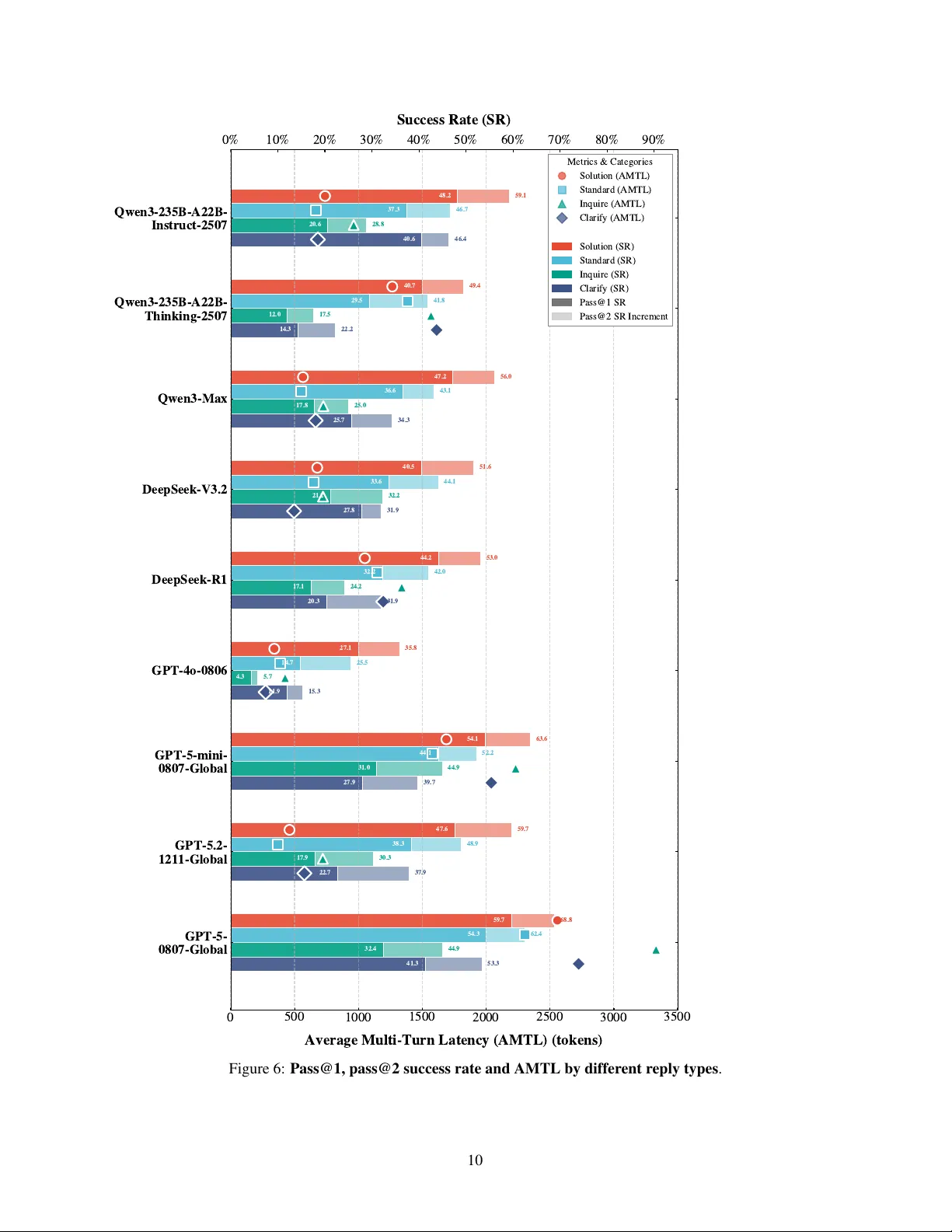
C I R R U S B E N C H : E V A L U A T I N G L L M - B A S E D A G E N T S B E Y O N D C O R R E C T N E S S I N R E A L - W O R L D C L O U D S E R V I C E E N V I RO N M E N T S Y i Y u 1 ∗ , Guangquan Hu 4 ∗ , Chenghuang Shen 2 ∗ , 3 ,Xingyan Liu 3 ∗ , Jing Gu 1 † , Hangyi Sun 1 † , Junzhuo Ma 1 ,W eiting Liu 4 , Jianfeng Liu 3 ‡ , Mingyue Pu 3 , Y u W ang 3 , Zhengdong Xiao 3 , Rui Xie 3 , Longjiu Luo 3 , Qianrong W ang 3 , Gurong Cui 3 , Honglin Qiao 3 , W enlian Lu 1 , 2 , 4 , 5 ‡ 1 School of Mathematics and Sciences, Fudan Univ ersity , Shanghai, China 2 Shanghai Center for Mathematical Sciences, Fudan Univ ersity , Shanghai, China 3 Alibaba Group, Hangzhou, China 4 Institute of Science and T echnology for Brain-Inspired Intelligence, Fudan Uni versity , Shanghai, China 5 Center for Applied Mathematics & Shanghai Ke y Laboratory of Contemporary Applied Mathematics, Fudan Univ ersity , Shanghai, China jiawei.ljf@alibaba-inc.com wenlian@fudan.edu.cn ∗ Contributed equally to this research. † Contributed equally to this research. ‡ Corresponding author . A B S T R AC T The increasing agentic capabilities of Lar ge Language Models (LLMs) ha ve enabled their deployment in real-world applications, such as cloud services, where customer-assistant interactions exhibit high technical complexity and long-horizon dependencies, making robustness and resolution efficiency critical for customer satisfaction. Howe ver , existing benchmarks for LLM-based agents lar gely rely on synthetic en vironments that fail to capture the div ersity and unpredictability of authentic customer inputs, often ignoring the resolution ef ficiency essential for real-world deplo yment. T o bridge this gap, we introduce CirrusBench 1 , a nov el e v aluation frame work distinguished by its foundation in real-world data from authentic cloud service tickets. CirrusBench preserves the intricate multi-turn logical chains and realistic tool dependencies inherent to technical service en vironments. Moving beyond e xecution correctness, we introduce nov el Customer-Centric metrics to define agent success, quantifying service quality through metrics such as the Normalized Efficiency Index and Multi-T urn Latency to explicitly measure resolution ef ficiency . Experiments utilizing our framew ork re veal that while state-of-the-art models demonstrate strong reasoning capabilities, the y frequently struggle in complex, realistic multi-turn tasks and fail to meet the high-ef ficiency standards required for customer service, highlighting critical directions for the future dev elopment of LLM-based agents in practical technical service applications. K eywords Lar ge Language Model, T echnical Service Agent, Multi-turn Ev aluation 1 Introduction The rapid advancement of Large Language Models (LLMs) has enabled their deployment as autonomous agents in complex, real-world applications [ 1 , 2 , 3 ]. For instance, Cloud service represents a typical domain of significant 1 CirrusBench ev aluation framework is released at: https://github.com/CirrusAI difficulty and commercial importance. Interactions in this setting are characterized by high technical complexity , long-horizon dependencies, and a need for sophisticated tool use. Consequently , the agent’ s rob ustness and efficienc y are critical determinants of customer satisfaction [4]. Recent progress in ev aluating LLM agents has been substantial, with benchmarks establishing standards for execution correctness and tool-selection capabilities [ 5 , 6 , 7 ]. Howe ver , current ev aluation methodologies suf fer from two critical limitations that impede progress tow ard real-world viability . First, they largely rely on synthetic en vironments or role-playing simulations [ 8 , 9 , 10 ]. While controllable, these settings fail to capture the div ersity , unpredictability , and "noise" of authentic customer-assistant interactions, leading to an ov erestimation of agent performance in practical scenarios. Second, existing ev aluations prioritize task completion, often ignoring the resolution efficienc y paramount to service quality . In Cloud service, a correct solution deli vered through a prolonged and tedious interaction is a failure from the customer’ s perspectiv e [4]. T o bridge this gap between academic benchmarks and real-world requirements, we introduce CirrusBench , a novel ev aluation framework grounded in the reality of Cloud service technical support. CirrusBench is constructed from a large corpus of authentic cloud service tickets, preserving the intricate multi-turn dialogues, complex tool schemas, and genuine customer inputs inherent to this domain. This foundation allows for a more realistic assessment of agent capabilities. CirrusBench introduces an ev aluation framework that assesses both single-turn subtask e valuation and dynamic multi- turn task ev aluation. Crucially , moving be yond the metrics such as success rate (SR) and T ask Pro gr ession Rate (TPR) quantifying correctness, we introduce novel Customer-Centric Metrics, including Logical J ump (LJ) , Normalized Efficiency Inde x (NEI) , Single-T urn Latency (STL) and Multi-T urn Latency (MTL) , to quantify the customer satisfactory . These metrics explicitly measure the responsi veness and efficienc y that define a successful customer interaction. Our main contributions are: 1. A ne w benchmark, CirrusBench , built from real-world cloud service data, featuring realistic multi-turn interactions and complex tool dependencies. 2. A suite of Customer -Centric Metrics (LJ, NEI, STL, MTL) designed to measure the operational efficienc y and service quality of LLM agents, supplementing traditional correctness-based ev aluations. Experimental analysis re veals a significant gap between SO T A LLMs and real-w orld Cloud service demands, particularly due to bottlenecks in tool integration. "Thinking" models often incur high latency without proportional improvements in problem solving, while long-horizon interactions suffer from error accumulation and logical fragility . And the knowledge embedding shows importance for agent in Cloud service tasks. Additionally , agents exhibit a tendency tow ard premature closure, consistently failing to ask necessary clarifying questions during inquiry tasks. Consequently , future dev elopment must prioritize resolution ef ficiency and multi-turn rob ustness ov er isolated accuracy metrics. 2 Related W ork Our work is situated at the intersection of LLM agent benchmarking, tool-use ev aluation, and customer service automation. Agent Benchmarks and Realism. The ev aluation of LLM agents has ev olved from interactions in static web en vironments like W ebshop [ 11 ] and W ebArena [ 12 ] to more complex domains like software engineering in SWE-bench [ 13 ]. T o assess general capabilities, Agentbench [ 6 ] proposed ev aluating agents across multiple distinct en vironments. A persistent challenge, howe ver , is benchmark realism. Most multi-turn benchmarks rely on synthetic data generation via templates [ 14 , 15 ] or LLM role-playing [ 8 , 9 , 16 , 17 ]. While scalable, these methods often lack the noisy , di verse, and unpredictable nature of genuine human interactions. A notable exception is the ABCD dataset [ 18 ], which uses expert li v e chats. Howe ver , it does not incorporate the comple x tool-use essential for technical support. CirrusBench addresses this gap by providing a benchmark deriv ed from real-world technical tickets that inherently couples authentic multi-turn dialogue with complex tool inte gration. T ool Utilization in Multi-turn Interactions. A significant body of work focuses on ev aluating an agent’ s ability to use tools. Benchmarks like T oolBench [ 7 ], Metatool [ 19 ], and the τ -bench series [ 10 , 20 ] have systematically assessed tool selection and parameterization. Others, such as T oolSandbox [ 21 ], introduce stateful en vironments where tool calls dynamically alter the world state. Recent efforts hav e aimed to embed tool use within con versational contexts [ 8 , 22 , 16 ]. While these works advance the ev aluation of tool-augmented conv ersation, they are typically built on simulated interactions. In contrast, CirrusBench ev aluates an agent’ s ability to na vigate realistic tool dependencies as they or ganically arise in authentic, long-horizon customer support dialogues. 2 Evaluation Metrics and Customer Satisfaction. Early ev aluation methodologies centered on ex ecution accuracy and keyw ord matching [ 23 , 24 ]. Recognizing the limitations of simple accuracy , researchers hav e explored LLM-based judges for more nuanced ev aluation [ 25 , 26 ]. In the specific context of customer service, recent work has begun to formalize metrics for customer satisfaction [27, 28]. Moreover , foundational work in cloud service benchmarking has long emphasized that ef ficiency and latency are critical performance indicators [ 4 ]. CirrusBench builds upon these ideas by operationalizing customer satisfaction through concrete, objectiv e metrics, such as NEI and MTL, thereby creating the first framew ork to directly measure the resolution efficienc y of LLM agents in a realistic technical support setting. 3 CirrusBench T o create a benchmark that not only assesses the correctness of an LLM agent but also its ef ficiency and alignment with real-world customer service w orkflows, we dev elop a nov el Multi-T urn T ask Ev aluation framew ork. Our approach is grounded in the analysis of historical Cloud service tickets and comprises two core components: the metrics measuring correctness and metrics measuring resolution efficienc y , reflecting customer satisfactory . 3.1 Data Definition CirrusBench consists of 1,500 rigorously curated tasks without tool-call requirement and 425 tasks with tool-call requirement, systematically deri ved and refined from authentic dialogue logs obtained from real-world Cloud service operations. These tasks span 20 distinct service categories, including SMS-based support, email correspondence, online technical assistance, and other prototypical service scenarios, thereby ensuring broad coverage of practical inquiry patterns and operational contexts. This div ersity of domains enhances the representati veness and ecological validity , providing a rob ust empirical basis for assessing model performance across heterogeneous service en vironments. 3.2 Data Construction Collection 2 nd - step : De - noise 5 th - step : Tr a n s l a t i o n 1 st - step : De - sensitization 7 th - step : Expert Review Experts Data Processing 6 th - step : Checkpoint Annotation To p F i v e R e l e v a n t Reference Documents CirrusBench Single- Tur n Sub task Evaluation Multi - Tur n T ask Evaluation 3 rd - step : To o l M o c k 4 th - step : Canonicalization Figure 1: The construction of CirrusBench. The process comprises four core phases: Phase 1: Data Collection ; Phase 2: Prepr ocessing (Steps 1–5); Phase 3: Knowledge-Gr ounded Annotation (Step 6); Phase 4: Quality Assurance (Step 7). The final benchmark supports both single-turn subtask ev aluation and multi-turn task e v aluation. W e began by filtering a lar ge volume of real historical tickets, applying multiple layers of screening through the follo wing steps, and finally con verting them into the CirrusBench task-set format. The overall process of construction is shown in Fig. 1. Data Collection The dataset employed in CirrusBench w as systematically constructed from authentic con versational tickets between customers and service assistant, obtained from Cloud service en vironments. In these li ve service contexts, cus- tomer–assistant interactions typically conform to a canonical problem-resolution schema: customer formulate domain- specific inquiries, and assistant respond with targeted, solution-oriented guidance. 3 The tasks were rigorously deri ved from tickets with a successful resolution. Each task instance encapsulates an entire interaction cycle, e xtending from the initial customer query to the final confirmation of the solution, such that e very ticket corresponds to a genuine, closed-loop service case with explicitly identifiable problem-resolution outcomes. This extraction methodology preserves both the structural integrity and conte xtual authenticity of real-world service exchanges while simultaneously yielding well-defined, self-contained e valuation units that are suitable for systematic and reproducible model assessment. 3.2.1 Prepr ocessing De-sensitization : Giv en that CirrusBench is deriv ed from authentic tickets, adhering to strict priv acy standards is paramount. Prior to any functional preprocessing, we implemented a rigorous P ersonally Identifiable Information (PII) Scrubbing pipeline. W e employed a Named Entity Recognition (NER) function to automatically detect and redact sensitiv e entities, including names, phone numbers, email addresses, and account credentials. All identified PII was replaced with standardized placeholders (e.g., Ja***, 157****3190) to maintain the semantic structure of the dialogue while ensuring full anonymity and compliance with data protection re gulations. Denoising and Utterance Pruning : The raw tickets often contain redundant segments that do not contribute to problem-solving. W e performed noise reduction by stripping non-essential conv ersational fillers, such as repetitiv e greetings and generic closing formalities. This ensures the model focuses on the core task logic and information exchange. T ool Mock : A critical challenge in using historical data for tool-use ev aluation is the accessibility of liv e external en vironments. W e address this challenge by adopting a Record-and-Replay methodology to build T ool Mock instances. Specifically , we extracted real-time tool in vocations and their corresponding e xecution results, transforming them into standardized T ool Mock instances. By mapping these to the OpenAI function-calling schema, we enable the benchmark to supply the model with authentic tool outputs without requiring a li ve connection to backend production APIs, thus ensuring task reproducibility . Dialogue Canonicalization : In real-w orld service interfaces, customers frequently transmit their intents across multiple, fragmented messages. T o maintain a rigorous T urn-based Interaction framework, we merged consecutiv e customer queries into single, coherent turns. This process enforces a strict "Query–Reply" (Customer -Assistant) paradigm, ensuring that each assistant response is conditioned on a complete and unambiguous user state. T ranslation : W e translated the original Chinese tickets into English with an expert translation team. Checkpoint Annotation : Given the v olume of the corpus, we employed a high-capability LLM as an auxiliary annotator to scan the filtered dialogues. The model was prompted to identify turns that inv olved functional decision-making or information state updates. Specifically , it flagged segments where the assistant’ s response w as directly tied to the success of the service closed-loop. Beyond kno wledge accuracy , we further identify critical chec kpoints to ev aluate the agent’ s reasoning trajectory . W e define checkpoints as critical junctures where the assistant must perform complex reasoning, such as identifying customer intent, deciding to in v oke a specific tool, or synthesizing tool outputs into a final solution. T o further characterize these interactions, we cate gorized the response types within these checkpoints into four distinct classes: Solution, Standard, Inquire, and Clarify . Knowledge A ugmentation : For each task in the benchmark, we manually curated and associated at most fi ve highly rele vant reference documents. These documents are sourced from official business wikis, standard operating procedures (SOPs), and technical manuals. By providing these documents, we transform the task from a simple text generation problem into a Knowledge-Grounded Generation challenge, requiring the model to synthesize information from e xternal evidence before formulating a response. Quality Control : W e employed sev eral experts in Cloud service to re view the constructed dataset, ensuring the quality of CirrusBench. 3.3 Data Statistics 3.3.1 Real-world Service Category distrib ution T o ensure the practical utility and robustness of our benchmark, the foundational 1,500 tasks are sourced directly from real-world business operations. Rather than using synthetic con versations, we performed a representativ e sampling from the top 20 service cate grories with the highest ticket frequency in the Cloud service en vironment. This ensures that the dataset reflects the genuine complexity and linguistic diversity of professional technical support in real-world Cloud service. The distribution across major service cate gories is detailed in T able 1. 4 T able 1: Distribution of T asks Across Service Categories. The dataset ( N = 1 , 500 ) is sampled from the top 20 service categories with highest ticket frequenc y in real-world service operations. Category T ask Count Frequency (%) Server 280 18.7% Registration 220 14.7% SMS Services 200 13.3% W ebsite 120 8.0% Email 80 5.3% Others (15+ ) 600 40.0% T otal 1,500 100.0% 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2 1 3 1 4 1 5 1 6 1 7 1 8 1 9 Number of Turns 0 5 0 1 0 0 1 5 0 2 0 0 2 5 0 Count 138 271 279 228 173 125 87 52 49 39 17 12 Figure 2: Distribution of the count of con versational turns in preprocessed tickets 1 2 3 4 5 6 7 8 9 1 0 1 1 Number of Checkpoints 0 1 0 0 2 0 0 3 0 0 4 0 0 Count 323 461 311 194 102 61 27 Figure 3: Distribution of the count of checkpoints in processed tickets. 3.3.2 Distribution of interaction complexity T o characterize the interactiv e nature and structural depth of the dataset, we analyze the distrib ution of con versation turns and annotated checkpoints, as illustrated in Figure 2 and Figure 3. Figure 2 presents the distribution of conv ersation turns between customer and assistant. The data rev eals a significant prev alence of multi-turn interactions, which is a hallmark of complex technical support. Figure 3 displays the distrib ution of checkpoints within the con versations. These checkpoints, identified via LLM-based annotation, represent critical reasoning nodes, sub-task transitions, or state verifications necessary to reach a resolution. The variation in the number of checkpoints per instance underscores the logical granularity of the dataset. A higher number of checkpoints indicates a more intricate problem-solving process that demands multi-step reasoning. The complexity and authenticity of real customer-assistant interactions are also illustrated by examples in the Case Study of D. These multi-turn dialogues require the model to maintain long-term coherence, track e v olving customer requirements, and manage state transitions ov er extended conte xts. 3.3.3 Distribution of Input T oken The distrib ution of input tok ens characterizes the dataset’ s complexity , particularly regarding its suitability for long- context processing. The input sequences exhibit a broad range, extending from a minimum of 520 to a maximum of 37,054 tokens, with a mean length of 11,460.6 tokens. The distribution re veals significant challenges for contemporary large language models (LLMs). Specifically , the first, second (median), and third quartiles are 6,328.0, 9,777.0, and 14,856.5 tokens, respectiv ely . Notably , with the third quartile (Q3) reaching approximately 15 K tokens and the peak length exceeding 37 K tokens, a substantial portion of the dataset operates in a long-context re gime that demands high memory efficienc y and robust long-range dependenc y modeling. The significant gap between the median and the maximum value underscores a "long-tail" distribution of exceptionally dense instances.Moreo ver , this heterogeneity reflects the inherent div ersity and authenticity of customer 5 queries in real-world service environments, where inputs vary from concise requests to highly complex problems, thereby ele vating the dif ficulty of the benchmark beyond simple context length. These data points provide a rigorous benchmark for ev aluating a model’ s ability to maintain coherence and retrie ve information across e xtensiv e context windows, ensuring the dataset is well-suited for adv ancing long-context research. 3.3.4 Reply types’ distribution T able 2: Distrib ution of reply types of sub-tasks. Reply T ype Count Proportion (%) Solution 2,095 63.35% Standard 529 16.00% Inquire 483 14.61% Clarify 130 3.93% Appease 70 2.12% T otal 3,307 100.00% T o provide a granular understanding of the functional intent behind the responses, we categorized the sub-task replies annotated by LLM automatedly . The distribution of these reply types is summarized in T able 2. The statistics rev eal that solution is the most prev alent reply type, accounting for 63.35% (2,095 instances) of the dataset. This dominance aligns with the primary objective of technical support, which is to pro vide actionable resolutions to customer queries. Beyond direct solutions, the dataset maintains a balanced variety of auxiliary communicati v e acts: standar d procedures and inquir e (seeking more information) constitute 16.00% and 14.61% of the replies, respectiv ely . More nuanced interactions, such as clarify (3.93%) and appease (2.12%), are also represented. This di verse distrib ution ensures that the dataset co vers the full spectrum of a typical support dialogue, from initial information gathering and emotional management to final problem resolution, thereby challenging the model to master various con versational strategies in a long-conte xt en vironment. 3.3.5 Pre valence and Noise in Image-Deriv ed Content The inclusion of screenshots is a defining characteristic of authentic customer-assistant interactions in Cloud services, reflecting the di versity and unpredictability of real-world inputs. In our dataset, 771 out of 1,500 instances (approximately 51.4%) contain at least one image. T o strictly ev aluate the reasoning capabilities of text-based LLMs, all visual content in the dataset is transformed into textual format via Optical Character Recognition (OCR), thereby processing the interaction as a uni-modal textual sequence rather than a multimodal one. An example shown in Fig. 7 can be found in Appendix. D. Howe ver , this transformation preserv es the high-entropy nature of the original inputs. Unlike curated synthetic data, real-world screenshots contain significant stochastic noise; they frequently capture e xtraneous UI elements—such as system timestamps, battery status, navigation bars, and irrele v ant background logs—that are semantically orthogonal to the reported technical issue. Since the OCR process transcribes these visual artifacts indiscriminately , the resulting input contains substantial unstructured "textual noise." This shifts the challenge from visual perception to robust information extraction: the model must possess the discriminative capacity to sift through dense, noisy OCR outputs and isolate the specific error context from the surrounding irrele v ant information. 3.4 Evaluation Methodology 3.4.1 Single-T urn Subtask Evaluation The foundation of our benchmark is the granular ev aluation of an agent’ s response within a single conv ersational turn. This framew ork allows for a precise diagnosis of the agent’ s capabilities across three critical dimensions: T ool-Use Competency , Problem-Solving Ability , and Customer Service Qualification. T ool-Use Competency . When an agent decides to use a tool, its action is not treated as a monolithic success or failure. Instead, we ev aluate it as a cascading sequence of decisions, each with its own verifiable outcome: (1) T ool In vocation A wareness (TIA) : Describes the correctness of the agent’ s decision regarding the necessity of a tool call. (2) T ool Selection Accuracy (TSA) : Evaluates whether the agent selected the correct tool when a tool was required. (3) T ool Execution V alidity (TEV) : Measures the agent’ s ability to correctly format the inputs for the selected tool, ensuring successful ex ecution. 6 Failed to re ceive verific ation code … Hello. What o perati on were yo u perfo rming… Hello. Please provi de the account and th e operation you performi ng when… ⋮ Yes. Usi ng Shor t Mess age Ser vice… Calling {Age nt_tool_xxxx }… Hello. We see that your SMS signature… ⋮ Hello. Which account are you logging into… Please wait. I am checking your SMS signature… Call {Age nt_tool _xxxx} … … … ⋮ Fluency Che cker Evaluator TPR 0.4 NEI 0.33 ⋮ ⋮ MTL 2112 ⋮ ⋮ Multi - Turn Task Evaluation Single - Turn S ubTask Evaluation RR 1 TI A 1 ⋮ ⋮ STL 2587 Figure 4: The evaluation framework of CirrusBench. The ev aluation of a multi-turn task proceeds as a sequence of single-turn subtask sessions. Problem-Solving Ability . In many Cloud service scenarios, the optimal response is not a tool call but a direct, informativ e answer . For the reply component, we e v aluate: Reply Resolvability (RR) : Determines whether the agent’ s natural language response contains the key information, conclusions, or instructions necessary to resolve the user’ s query at that specific step. This ensures the agent is not just con versational b ut is acti vely dri ving to wards a solution. Customer -Centric Service Qualification Metric . Distinct from functional correctness, we define the Single-T urn Latency (STL) to quantify the quality and ef ficiency of the agent’ s service deli very , which are paramount in the cloud service domain. W e define S T L as the count of output tokens generated for the specific subtask inspired by the studies of LLM latency [29, 30]. The importance of low latency is also illustrated with an e xample in Fig. 8 in Appendix. D. 3.4.2 Dynamic Multi-T urn T ask Evaluation While single-turn subtask evaluation is crucial for diagnostics, real-world problems often require a sequence of interactions. T o e v aluate an agent’ s performance ov er a complete ticket, we introduce a dynamic assessment mechanism that lev erages historical solution paths b ut allows for de viation. The multi-turn process, illustrated in Fig. 4 and Algorithm 1 in the Appendix. B, operates as follo ws: At each beginning checkpoint of a single-turn subtask ev aluation session, the agent recei ves the conv ersation history and the current customer’ s query to generate a response, which includes both a reply component and a tool call component. The single-turn subtask e valuation compares the agent’ s response against the ground truth to compute single-turn metrics, such as Reply Resolvability (RR) and T ool In vocation A wareness (TIA), using an e v aluator and a critic function. This single-turn subtask ev aluation repeats for the ground truth of subsequent checkpoints until the ev aluation returns a "fail to accept" result. Upon the "fail to accept" result, the current single-turn subtask ev aluation terminates, then a Fluency Check er determines whether the subsequent customer query of the failed checkpoint is logically v alid given the agent’ s deviant response. If the Fluency Check er returns T rue, a ne w single-turn subtask session is initiated with the current customer’ s query and updated history messages built upon the historical agent’ s responses and the customer’ s queries; otherwise, the multi-turn task e v aluation terminates. When the multi-turn task ev aluation terminated, global metrics such as T ask Progression Rate (TPR), Normalized Efficienc y Index (NEI), and Multi-T urn Latency (MTL) are computed. Metrics for Multi-T ur n task . Based on the metrics obtained from single-turn subtask ev aluation, we introduce metrics for multi-turn task e v aluation to measure the problem-solving ability , ef ficiency , and latency of the agent. W e define: (1) T ask Pr ogr ession Rate (TPR) : Describes the proportion of successfully resolved single-turn subtasks within a multi-turn task. It is defined as the ratio of the number of successfully resolved single-turn subtasks to the total number of single-turn subtasks within the multi-turn task. (2) Logical J ump (LJ) : Represents the number of skipped single-turn subtasks before the ev aluation of the multi-turn task terminates. It takes a value in { 0 , . . . , k − 1 } , where k is the total number of subtasks successfully processed until termination. (3) Normalized Efficiency Index (NEI) : Evaluates the agent’ s efficienc y in resolving the multi-turn task, defined as the ratio of the Logical Jump (LJ) to the total number of subtasks successfully processed ( k ), that is N E I = LJ k − 1 if k > 1 ; N E I = 1 if k = 1 ; otherwise N E I = 0 . (4) Multi-T urn Latency (MTL) : Defined as the av erage of the Single-T urn Latency (STL) across all successfully processed single-turn subtasks within the multi-turn task. 7 4 Experiments 4.1 Evaluation Settings W e conduct experiments on CirrusBench , which comprises the Qwen series [ 31 ], GPT series [ 32 ] and DeepSeek series [33]. All LLMs are ev aluated via corresponding APIs. 4.2 Evaluation Metrics The e valuation metrics are average of the multi-turn task ev aluation metrics, including: (1) A verage T ask Pr ogr ession Rate (ATPR) , the average of TPR on the dataset. (2) A verage Logical Jump (ALJ) , the av erage of LJ on the dataset. (3) A verage Normalized Efficiency Inde x (ANEI) , the a verage of NEI on the dataset. (4) A verage Multi-T urn Latency (AMTL) , the av erage of MTL on the dataset. And we also include (5) Success Rate (SR) , the rate of successfully resolved multi-turn tasks, which is ev aluated on both pass@1 score and pass@2 score. 4.3 Reliability of Evaluator For the e v aluator used in the single-turn subtask e valuation to judge whether the agent-generated response co vers the key informations of ground truth response, we le verage DeepSeek-V3.2 and a carefully engineered prompt. As shown in T able. 7, the ev aluator achie ves an accurac y of 91.49% on a validation set of 141 annotations provided by human experts, demonstrating the reliability of the proposed judge. For stability of altering judge’ s base model, we altering the base model with GPT -5, DeepSeek-R1, GPT -5.2, Gemini-3-pro, the difference on accurac y of those base models are within 3%. For the benefit of cost, we adopt DeepSeek-V3.2 as our e v aluator’ s base model. 4.4 Main Results 4.4.1 Results on CirrusBench W e compute the ov erall comprehensi ve e valuation results on CirrusBench in the following two dif ferent settings. Firstly , W e ev aluate different LLM models on the dataset with tool-call tasks and the dataset without tool-call tasks separately . As sho wn in T able. 3, in almost all metrics, the performances on the dataset with tool-call tasks are better than on the dataset without tool-call tasks, which demonstrates that the ability for tool-use is a challenge for agent. In GPT series, the models with explicit thinking capability perform better than the models without thinking capability in SR, A TPR, ALJ and ANEI, but cost more in the latenc y metric AMTL. Howe ver , explicit thinking capability is not alw ays benefit for SR, A TPR, ALJ and ANEI, which can be observed from the Qwen series and DeepSeek series. For instance, the thinking model DeepSeek-R1 achiev es a Pass@1 Success Rate (SR) of only 7.9% in tool-use scenarios, which is lower than the 9.6% achiev ed by its non-thinking counterpart, DeepSeek-V3.2. Similarly , Qwen2.5-72B-Thinking achiev es an SR of 11.0% in tool scenarios, sho wing no impro vement o ver the standard Qwen2.5-72B-Instruct (11.0%), while performing significantly worse in non-tool scenarios (13.3% vs. 19.0%). Moreover , the results underscore the trade-offs between model architectures that while standard models like GPT -4o-0806 maintain extremely low latency (188.6/ 250.8 tokens), the y may struggle with the absolute success rates (Pass@1 SR 6.8%/ 7.0 %) compared to larger , more computationally intensiv e models. In Fig. 5, the SR results are obtained by ev aluating these LLM models on the whole dataset of CirrusBench, merging the tool-call tasks and non-tool-call tasks, which is consistent with the ev aluation results in T able. 3. T o analyze the impact of different factors of CirrusBench, we deri ved e xperiments in dataset with different input tokens, different numbers of checkpoints, dif ferent service categories and dif ferent reply types. The results are illustrated in the following. T able 3: Evaluation of various models across dataset with tool-call requirement and dataset without tool-call requirement of CirrusBench. Red color indicates models with explicit thinking capabilities. Bold values indicate the best performance in each column, and underlined values indicate the w orst performance in each column. Models Pass@1 SR (%) ↑ Pass@2 SR (%) ↑ A TPR (%) ↑ ALJ ↑ ANEI (%) ↑ A vg. All T okens A vg. Input T okens AMTL (tokens) ↓ w tool w/o tool w tool w/o tool w tool w/o tool w tool w/o tool w tool w/o tool w tool w/o tool w tool w/o tool w tool w/o tool Qwen3-235B-A22B-Instruct-2507 11.0 19.0 17.4 26.2 25.6 34.2 0.101 0.156 12.3 31.5 11900.1 11714.3 11710.0 11120.6 190.1 593.7 Qwen3-235B-A22B-Thinking-2507 11.0 13.3 18.8 18.5 27.8 24.8 0.106 0.090 12.5 23.7 13659.2 12013.9 12596.1 10973.3 1063.1 1040.5 Qwen3-Max 14.3 17.1 19.4 23.7 28.6 32.2 0.108 0.137 12.5 31.8 12643.3 11666.3 12409.7 11194.5 233.6 471.8 DeepSeek-V3.2 9.6 15.2 15.5 23.5 21.9 31.4 0.104 0.138 12.5 31.5 12006.2 11577.0 11813.4 11060.5 192.8 516.5 DeepSeek-R1 7.9 15.2 10.1 21.1 21.1 29.3 0.082 0.118 11.1 29.0 16039.5 11748.2 14565.3 10881.1 1474.2 867.2 GPT -4o-0806 6.8 7.0 8.7 11.0 15.0 16.0 0.042 0.045 10.9 18.6 12156.2 11318.8 11978.6 11067.9 177.6 250.8 GPT -5-mini-0807-global 15.2 22.1 22.6 31.4 35.4 40.9 0.167 0.193 20.0 37.7 13553.1 13337.6 12323.8 11887.2 1229.3 1450.4 GPT -5.2-1211-Global 10.3 16.8 16.3 25.2 27.3 34.3 0.116 0.125 12.7 32.1 12657.5 11722.1 12388.9 11349.3 268.6 372.8 GPT -5-0807-Global 16.7 23.8 27.8 35.2 39.8 44.0 0.261 0.258 10.7 37.8 25433.0 14282.0 23850.0 12047.6 1583.0 2234.4 8 Qwen3-235B- A22B- Instruct-2507 Qwen3-235B- A22B- Thinking-2507 Qwen3-Max DeepSeek- V3.2 DeepSeek-R1 GPT -4o -0806 GPT -5-mini-0807- global GPT -5.2-1211- Global GPT -5-0807- Global 0 10 20 30 40 Success R ate (%) Non-thinking P ass@1 Non-thinking P ass@2 Thinking P ass@1 Thinking P ass@2 Figure 5: Overall Success Rate results on CirrusBench. T able 4: Model performance across input token ranges. (on GPT -5) T oken Range pass@1 SR (%) ↑ pass@2 SR (%) ↑ TIA ↑ TSA ↑ TEV ↑ 0 – 8,000 40.4 60.7 0.531 0.477 0.261 8,000 – 16,000 43.2 63.4 0.535 0.441 0.244 Over 16,000 44.8 64.8 0.536 0.451 0.267 T able 5: Model performance across dif ferent counts of checkpoints. (on GPT -5) Count of Checkpoints Pass@1 SR(%) ↑ Pass@2 SR(%) ↑ TPR (%) ↑ ALJ ↑ ANEI ↑ AMTL (tokens) ↓ 1 45.8 58.5 58.5 0 0.58 2410 2 28.1 39.6 47.1 0.19 0.33 2270 3 17.4 29.5 42.0 0.28 0.30 2237 4 9.2 19.2 32.9 0.40 0.31 2190 Others (5+ ) 5.3 14.6 15.7 0.59 0.35 2151 T able 6: Model performance across service categories. (on GPT -5) Category Pass@1 SR(%) ↑ Pass@2 SR(%) ↑ TPR (%) ↑ ALJ ↑ ANEI ↑ AMTL (tokens) ↓ Server 21.6 31.4 41.0 0.319 0.364 2304 Registration 19.4 32.0 40.6 0.286 0.322 2099 SMS Services 20.6 34.0 41.8 0.248 0.358 2393 W ebsite 36.8 49.1 54.9 0.281 0.465 2218 Email 18.9 27.5 36.7 0.172 0.347 2190 Others (15+ ) 26.7 37.8 47.2 0.230 0.409 2228 4.4.2 Impact of Input T oken Count W e ev aluate the impact of input token count through single-turn subtask ev alution methodology . T able 4 illustrates the model’ s performance across v arying input context lengths. Contrary to the "lost-in-the-middle" phenomenon often observed in general NLP tasks, our results on CirrusBench rev eal a positiv e correlation between context length and resolution success. The model achieves its peak performance in the Over 16,000 token range, with a Pass@1 of 44.8% and a Pass@2 of 64.8%, significantly outperforming the 0–8,000 token baseline (40.4%). This trend supports the hypothesis that domain-specific professional knowledge and sufficient user information are necessary conditions for LLMs to correctly resolve comple x service tasks. In specialized customer service, issues are inherently intricate, often depending on specific system logs, version compatibility , and detailed error tracebacks. Short inputs may lack these critical constraints, leading to hallucinated or generic advice. Conv ersely , extended contexts provide the comprehensi ve information density required to ground the model’ s reasoning, allowing it to le verage its professional training data effecti vely . Thus, the ability to process long-context inputs is not merely an efficiency metric but a prerequisite for accurac y in this domain. 4.4.3 Impact of Checkpoints Count T o in v estigate the robustness of LLMs ov er extended interactions, we categorize model performance based on the count of checkpoints required to reach a final resolution. The results, summarized in T able 5, re veal a clear in verse correlation between interaction depth and task success. 9 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% Success Rate (SR) 0 5 0 0 1 0 0 0 1 5 0 0 2 0 0 0 2 5 0 0 3 0 0 0 3 5 0 0 Average Multi-Turn Latency (AMTL) (tokens) Qwen3-235B-A22B- Instruct-2507 Qwen3-235B-A22B- Thinking-2507 Qwen3-Max DeepSeek-V3.2 DeepSeek-R1 GPT-4o-0806 GPT-5-mini- 0807-Global GPT-5.2- 1211-Global GPT-5- 0807-Global Metrics & Categories Solution (AMTL) Standard (AMTL) Inquire (AMTL) Clarify (AMTL) Solution (SR) Standard (SR) Inquire (SR) Clarify (SR) Pass@1 SR Pass@2 SR Increment 48.2 59.1 40.7 49.4 47.2 56.0 40.5 51.6 44.2 53.0 27.1 35.8 54.1 63.6 47.6 59.7 59.7 68.8 37.3 46.7 29.5 41.8 36.6 43.1 33.6 44.1 32.2 42.0 14.7 25.5 44.1 52.2 38.3 48.9 54.3 62.4 20.6 28.8 12.0 17.5 17.8 25.0 21.2 32.2 17.1 24.2 4.3 5.7 31.0 44.9 17.9 30.3 32.4 44.9 40.6 46.4 14.3 22.2 25.7 34.3 27.8 31.9 20.3 31.9 11.9 15.3 27.9 39.7 22.7 37.9 41.3 53.3 Figure 6: Pass@1, pass@2 success rate and AMTL by different r eply types . 10 • Complexity of Sustained Reasoning: T asks with more checkpoints show lo wer SR and lower TPR. This sug- gests that while model is capable of "one-shot" problem solving, they struggle to maintain logical consistency and state tracking across extended, multi-turn diagnostic sessions. • Risky Exploration: As the interaction depth grows, the ALJ increases but the ANEI drops. This suggests that while model try to explore paths with deviation b ut obtains much more risk in this exploration, which leads to wrong short path more than reliable resolution path. • Error Accumulation: Minor reasoning errors in early turns propagate and compound, causing the model to deviate irre versibly from the correct solution path ov er time. In summary , multi-turn consistency remains a critical bottleneck. The ability to maintain logical grounding and resist error accumulation across e xtended diagnostic sessions is a prerequisite for deplo ying autonomous agents in professional service en vironments. 4.4.4 Impact of Service categories T able 6 presents the performance of the model across various Cloud service cate gories. The results rev eal a significant performance gap between categories (for instance, pass@1 SR is 36.8% in W ebsite category while 18.9% in Email category), reflecting the inherent technical complexity and heterogeneous nature of real-world cloud troubleshooting scenarios. The performance v ariance across cate gories underscores that a "one-size-fits-all" approach is insuf ficient for service agents,which validates the necessity of CirrusBench’ s multi-category design, as it accurately captures the diverse challenges that autonomous agents must ov ercome in professional service en vironments. 4.4.5 Perf ormance Analysis by Response T ype As sho wn in Figure. 6, a comparati ve analysis of the four response types re veals a substantial performance disparity . The e valuated models exhibit their highest proficienc y in producing Solution-type responses, whereas their performance on the Inquiry response type is consistently the weakest. This pattern indicates that, when operating as service agents, LLMs display a systematic tendenc y to ward premature closure. Instead of engaging in a structured Clarify phase to resolve ambiguities, the models frequently bypass critical information-gathering steps and proceed directly to proposing solutions despite having insuf ficient contextual information. W e attribute this beha vior to two principal capability limitations in current LLMs: 1. Deficiency in Uncertainty Identification: The models exhibit dif ficulty in recognizing “information lacunae” (i.e., missing or incomplete information) and often fail to detect when a user’ s intent is too underspecified to support reliable action. 2. Lack of Proacti ve Strate gy: The models lack robust, goal-directed, and proactiv e questioning strategies that would systematically guide the dialogue tow ard a successful, closed-loop service interaction. Additionally , Figure ?? demonstrates that producing Inquiry and Clarify responses generally incurs a higher a verage token cost. Given their comparativ ely lo w success rates, this increased computational e xpenditure indirectly reflects the models’ difficulty in handling these response types. The elev ated token count suggests that generating precise, diagnostic questions imposes a greater cognitiv e load on the model’ s reasoning processes than does synthesizing a direct solution. This further supports the conclusion that interactiv e information seeking remains a critical bottleneck for the dev elopment of ef fecti ve service-oriented LLM-based agents. 5 Conclusion In this work, we introduced CirrusBench, the first ev aluation framew ork systematically deri ved from authentic, real-world cloud service tickets. Unlike previous benchmarks that rely on synthetic en vironments or role-playing, CirrusBench preserv es the high entropy , long-horizon dependencies, and complex tool usage inherent in actual technical service interactions. By shifting the ev aluation paradigm from simple ex ecution correctness to Customer-Centric Metrics, including metrics such as TPR, NEI, and MTL, we provide a more rigorous standard for assessing an agent’ s practical viability . Our experimental analysis highlight a substantial gap between the current capabilities of state-of-the-art LLMs and the rigorous demands of real-world cloud service support. While models exhibit strong reasoning potential, they face a critical bottleneck in tool integration, where performance suffers a sharp decline compared to pure con versational 11 tasks. The study further rev eals a complex trade-of f regarding "thinking" models; while explicit reasoning capabilities can be beneficial, they frequently introduce prohibitive latency penalties without yielding proportional improv ements in problem solving, effecti vely compromising the ef ficiency required for customer satisfaction. And the knowledge embedding shows importance for agent in Cloud service tasks. Additionally , models demonstrated significant fragility in long-horizon interactions, with problem solving metrics dropping as the number of checkpoints increased due to error accumulation and a f ailure to maintain logical consistency . This is compounded by a tendency to ward premature closure, as agents consistently underperformed in "Inquiry" tasks, failing to proactiv ely ask necessary clarifying questions before attempting a solution. Ultimately , these findings indicate that future development must mo ve be yond isolated accuracy metrics to prioritize resolution efficienc y , multi-turn rob ustness, and responsiv e information-gathering strategies. Ultimately , CirrusBench underscores that for LLM agents to succeed in cloud service support, future research must mov e beyond optimizing for accurac y in isolation. It is imperativ e to dev elop agents that are not only factually correct and proficient in tool use but also responsive and ef ficient enough to maintain customer trust before patience is exhausted. W e hope this benchmark serves as a catalyst for the dev elopment of next-generation agents that truly align with the dynamic needs of human customers. 6 Acknowledgments T o Zhiqiang Liu, Aiyu Chen, Ning Zhang of Alibaba Group, for translating the original Cloud Service tickets into English. Impact Statement This paper introduces a benchmark aimed at advancing research on Large Language Models (LLMs) agent in the application of Cloud Service en vironment. It is important to acknowledge that our experiments and ev aluations rely heavily on LLMs, but this study does not fully explore or mitigate potential biases inherent in their outputs. Addressing these biases and ensuring model alignment with social values remain critical challenges. This underscores the importance of conducting comprehensiv e e valuations that consider di v erse dimensions of human society and their implications, none of which we feel must be specifically highlighted here. References [1] Kimi T eam, Y ifan Bai, Y iping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Y anru Chen, Y uankun Chen, Y utian Chen, et al. Kimi k2: Open agentic intelligence. arXiv pr eprint arXiv:2507.20534 , 2025. [2] Aohan Zeng, Xin Lv , Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang W ang, Da Y in, Hao Zeng, Jiajie Zhang, et al. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models. arXiv preprint arXiv:2508.06471 , 2025. [3] Meituan LongCat T eam, Bei Li, Bingye Lei, Bo W ang, Bolin Rong, Chao W ang, Chao Zhang, Chen Gao, Chen Zhang, Cheng Sun, et al. Longcat-flash technical report. arXiv pr eprint arXiv:2509.01322 , 2025. [4] Da vid Bermbach, Erik W ittern, and Stefan T ai. Cloud service benchmarking . Springer , 2017. [5] Pa weł Budzianowski, Tsung-Hsien W en, Bo-Hsiang Tseng, Iñigo Casanuev a, Stefan Ultes, Osman Ramadan, and Milica Gaši ´ c. Multiwoz–a large-scale multi-domain wizard-of-oz dataset for task-oriented dialogue modelling. The Association for Computational Linguistics , 2018. [6] Xiao Liu, Hao Y u, Hanchen Zhang, Y ifan Xu, Xuanyu Lei, Han yu Lai, Y u Gu, Hangliang Ding, Kaiwen Men, K ejuan Y ang, et al. Agentbench: Evaluating llms as agents. International Confer ence on Learning Representations , 2023. [7] Y ujia Qin, Shihao Liang, Y ining Y e, Kunlun Zhu, Lan Y an, Y axi Lu, Y ankai Lin, Xin Cong, Xiangru T ang, Bill Qian, et al. T oolllm: Facilitating large language models to master 16000+ real-world apis. International Confer ence on Learning Repr esentations , 2023. [8] Nicholas Farn and Richard Shin. T ooltalk: Evaluating tool-usage in a con versational setting. arXiv pr eprint arXiv:2311.10775 , 2023. [9] Cheng Qian, Zuxin Liu, Akshara Prabhakar, Zhiwei Liu, Jianguo Zhang, Haolin Chen, Heng Ji, W eiran Y ao, Shelby Heinecke, Silvio Sav arese, et al. Userbench: An interactive gym en vironment for user-centric agents. Advances in Neural Information Pr ocessing Systems , 2025. 12 [10] Shunyu Y ao, Noah Shinn, Pedram Raza vi, and Karthik Narasimhan. τ -bench: A benchmark for tool-agent-user interaction in real-world domains. International Conference on Learning Repr esentations , 2024. [11] Shunyu Y ao, Ho ward Chen, John Y ang, and Karthik Narasimhan. W ebshop: T ow ards scalable real-world web interaction with grounded language agents. Advances in Neural Information Processing Systems , 35:20744–20757, 2022. [12] Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar , Xianyi Cheng, T ianyue Ou, Y onatan Bisk, Daniel Fried, et al. W ebarena: A realistic web en vironment for b uilding autonomous agents. arXiv pr eprint arXiv:2307.13854 , 2023. [13] Carlos E Jimenez, John Y ang, Alexander W ettig, Shunyu Y ao, Ke xin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? International Confer ence on Learning Repr esentations , 2023. [14] Jason W eston, Antoine Bordes, Sumit Chopra, Alexander M Rush, Bart V an Merriënboer , Armand Joulin, and T omas Mikolov . T o wards ai-complete question answering: A set of prerequisite toy tasks. arXiv pr eprint arXiv:1502.05698 , 2015. [15] Bill Byrne, Karthik Krishnamoorthi, Chinnadhurai Sankar, Arvind Neelakantan, Ben Goodrich, Daniel Duckworth, Semih Y avuz, Amit Dube y , K yuyoung Kim, and Andy Cedilnik. T askmaster-1: T ow ard a realistic and di verse dialog dataset. In Conference on Empirical Methods in Natural Language Pr ocessing and the 9th International Joint Confer ence on Natural Languag e Pr ocessing (EMNLP-IJCNLP) , pages 4516–4525, 2019. [16] W ei He, Y ueqing Sun, Hongyan Hao, Xue yuan Hao, Zhikang Xia, Qi Gu, Chengcheng Han, Dengchang Zhao, Hui Su, K efeng Zhang, et al. V itabench: Benchmarking llm agents with versatile interacti ve tasks in real-world applications. arXiv preprint , 2025. [17] Jie Zhu, Huaixia Dou, Junhui Li, Lifan Guo, Feng Chen, Chi Zhang, and Fang K ong. Evaluating, synthesizing, and enhancing for customer support con versation. arXiv pr eprint arXiv:2508.04423 , 2025. [18] Derek Chen, Howard Chen, Y i Y ang, Alexander Lin, and Zhou Y u. Action-based con versations dataset: A corpus for building more in-depth task-oriented dialogue systems. In Confer ence of the North American Chapter of the Association for Computational Linguistics , pages 3002–3017, 2021. [19] Y ue Huang, Jiawen Shi, Y uan Li, Chenrui Fan, Siyuan W u, Qihui Zhang, Y ixin Liu, Pan Zhou, Y ao W an, Neil Zhenqiang Gong, et al. Metatool benchmark for large language models: Deciding whether to use tools and which to use. International Conference on Learning Repr esentations , 2023. [20] V ictor Barres, Honghua Dong, Soham Ray , Xujie Si, and Karthik Narasimhan. τ 2 -bench: Evaluating conv ersa- tional agents in a dual-control en vironment. arXiv preprint , 2025. [21] Jiarui Lu, Thomas Holleis, Y izhe Zhang, Bernhard Aumayer, Feng Nan, Haoping Bai, Shuang Ma, Shen Ma, Mengyu Li, Guoli Y in, et al. T oolsandbox: A stateful, conv ersational, interacti ve ev aluation benchmark for llm tool use capabilities. In Confer ence of the North American Chapter of the Association for Computational Linguistics , pages 1160–1183, 2025. [22] Pei W ang, Y anan W u, Noah W ang, Jiaheng Liu, Xiaoshuai Song, ZY Peng, Ken Deng, Chenchen Zhang, Junran Peng, Ge Zhang, et al. Mtu-bench: A multi-granularity tool-use benchmark for large language models. In International Confer ence on Learning Repr esentations . [23] Y uchen Zhuang, Y ue Y u, K uan W ang, Haotian Sun, and Chao Zhang. T oolqa: A dataset for llm question answering with external tools. Advances in Neural Information Pr ocessing Systems , 36:50117–50143, 2023. [24] Zishan Guo, Y ufei Huang, and Deyi Xiong. Ctoolev al: A chinese benchmark for llm-powered agent e v aluation in real-world api interactions. In F indings of the Association for Computational Linguistics , pages 15711–15724, 2024. [25] John Mendonça, Patrícia Pereira, Helena Moniz, João Paulo Carv alho, Alon Lavie, and Isabel T rancoso. Simple llm prompting is state-of-the-art for robust and multilingual dialogue e valuation. [26] Michelle Elizabeth, Alicja Kasicka, Natalia Krawczyk, Magalie Ochs, Gwénolé Lecorvé, Justyna Gromada, and Lina M Rojas Barahona. Neural models and language model prompting for the multidimensional e v aluation of open-ended con versations. In The T welfth Dialog System T echnology Challenge , pages 1–16, 2025. [27] Y ing-Chun Lin, Jennifer Neville, Jack Stokes, Longqi Y ang, T ara Safavi, Mengting W an, Scott Counts, Siddharth Suri, Reid Andersen, Xiaofeng Xu, et al. Interpretable user satisfaction estimation for con versational systems with large language models. In Annual Meeting of the Association for Computational Linguistics , pages 11100–11115, 2024. 13 [28] Zhaoyi Joey Hou, T anya Shourya, Y ingfan W ang, Shamik Roy , V inayshekhar Bannihatti Kumar , and Rashmi Gangadharaiah. Multi-faceted ev aluation of tool-augmented dialogue systems. arXiv pr eprint arXiv:2510.19186 , 2025. [29] Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Hongyi Jin, T ianqi Chen, and Zhihao Jia. T owards ef ficient generati ve lar ge language model serving: A surve y from algorithms to systems. A CM Computing Surve ys , 58(1):1–37, 2025. [30] W oosuk Kwon, Zhuohan Li, Siyuan Zhuang, Y ing Sheng, Lianmin Zheng, Cody Hao Y u, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for lar ge language model serving with pagedattention. In Pr oceedings of the 29th symposium on operating systems principles , pages 611–626, 2023. [31] An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chengen Huang, Chenxu Lv , et al. Qwen3 technical report. arXiv preprint , 2025. [32] Josh Achiam, Steven Adler , Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 , 2023. [33] Aixin Liu, Bei Feng, Bing Xue, Bingxuan W ang, Bochao W u, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv pr eprint arXiv:2412.19437 , 2024. 14 A Definition of Metrics A.1 Single-T urn Evaluation Metrics For single-turn e v aluation, we define the follo wing metrics: T ool In vocation A wareness ( T I A ): Describes the correctness of the agent’ s decision regarding the necessity of a tool call. W e define T I A = 1 if the agent correctly in vokes a tool when required, or correctly abstains from calling a tool when none is needed; otherwise, T I A = 0 . T ool Selection Accuracy ( T S A ): Evaluates whether the agent selected the correct tool from the a vailable toolset when a tool was required. This tests the agent’ s ability to dif ferentiate between tool functionalities. If the tool selection is correct, T S A = 1 ; otherwise, T S A = 0 . T ool Execution V alidity ( T E V ): Measures the agent’ s ability to correctly format the inputs for the selected tool, ensuring successful ex ecution. If the tool in vocation is successful, T E V = 1 ; otherwise, T E V = 0 . Reply Resolvability ( RR ): Determines whether the agent’ s natural language response contains the key information, conclusions, or instructions necessary to resolve the user’ s query at that specific step. Single-T urn Latency ( S T L ) ↓ : Quantifies the latency based on the computational cost of the response. W e define S T L as the count of output tokens generated for the specific subtask. A.2 Multi-T urn Evaluation Metrics A multi-turn task consists of a sequence of single-turn subtasks arranged chronologically . For multi-turn e v aluation, we define the following metrics: T ask Progr ession Rate ( T P R ) ↑ : Describes the proportion of successfully resolved single-turn subtasks within a multi-turn task. It is defined as: T P R = number of successfully resolved single-turn subtasks total number of single-turn subtasks in the multi-turn task Logical Jump ( LJ ) ↑ : Represents the number of skipped single-turn subtasks before the ev aluation of the multi-turn task terminates. It takes a value in { 0 , . . . , k − 1 } , where k is the total number of subtasks successfully processed until termination. Normalized Efficiency Index ( N E I ) ↑ : Evaluates the agent’ s efficiency in resolving the multi-turn task, defined as the ratio of the Logical Jump ( LJ ) to the total number of subtasks successfully processed ( k ). Specifically , if the ev aluation terminates after successfully processed k subtasks: N E I = LJ k − 1 if k > 1 1 if k = 1 0 otherwise Multi-T urn Latency ( M T L ) ↓ : Defined as the average of the Single-Turn Latency ( S T L ) across all successfully processed single-turn subtasks within the multi-turn task. A.3 Dataset Evaluation Metrics A dataset consists of multiple multi-turn tasks. For the e v aluation of the dataset, we define the following metrics: A verage T ask Progr ession Rate ( AT P R ) ↑ : The average T P R across all multi-turn tasks in the dataset, taking a value in [0 , 1] . A verage Logical Jump ( ALJ ) ↑ : The av erage LJ across all multi-turn tasks where at least one subtask was success- fully resolved. Formally: ALJ = P tasks with successful subtasks LJ number of tasks with successful subtasks A verage Normalized Efficiency Index ( AN E I ) ↑ : The av erage N E I across all multi-turn tasks where at least one subtask was successfully resolved. Formally: AN E I = P tasks with successful subtasks N E I number of tasks with successful subtasks 15 T able 7: Confusion Matrix Results of e v aluator Actual / Predicted Positiv e Negative (%) Positi ve 60 9 Negative 3 69 My website has been blocked. How can I resolve this? Hello Hello, you are now connected to online human support. A support engineer will assist you as soon as possible. Please wait. Hello \ nAttachment \n\n Image content: \ n This is a screenshot of the Cloud \ “Risk V erification \ ” Page. The overall interface displays a notification that a website has been blocked due to a content violation, along with handling requirements. The top of the page shows the current Time as 10:38. The status bar contains icons for signal, W i - Fi, and battery. The Page Title is \ “Risk V erification \ ”. There is a back arrow on the left, and search, message, User, and menu icons on the top right … \n I just received this message \ nWhen I open our website, it says it is blocked \ nThere isn‘t any prohibited content on it . Hello. May I ask if you still hold the user.zz domain name?~I see here that there is a verification risk … ……. Okay. Thank you. What? I own this. What should I do now? I am very sorry . Accessing http:// www .****.com prompts that the content is forbidden. Y ou need to log on to the account hosting the server and go to … Figure 7: Case Study of Customer’s High-Entr opy Input. A real-world e xample where a customer sup- plements a blocked-website report with a ra w screen- shot. The image contains significant stochastic noise, such as signal strength and timestamps, orthogonal to the issue, requiring the agent to filter visual noise and extract rele v ant error context. Hello. W e recommend entering a real number (landline). Collecting this traffic redirection information now is preparation for future filings. How should I fill this in if I don't have a landline? Could you please reply a bit faster? Hello. Currently, carriers heavily Block text messages containing traffic redirection information such as contact details and links. W e recommend avoiding this type of content to ensure your messages can be sent normally. ……. Please spare me the official script. Y ou just n eed to tell me one thing: how do I fill this out if I don't have a fixed telephone line? I am very sorry . Currently , text message content does not support mobile phone numbers, and there is no other workaround available at the moment. ……. Figure 8: Impact of Latency on User Sentiment. A transcript illustrating the dependency between in- ference latency and customer agitation. The interac- tion demonstrates how delayed responses and rigid scripting cause a functional inquiry to de volv e into an expression of dissatisf action, v alidating the need for latency and sentiment-a ware e v aluation metrics. Success Rate ( S R ) ↑ : Describes the proportion of multi-turn tasks that are completely resolved (i.e., tasks where T P R = 1 ). W e define: S R = count of completely resolved tasks total count of tasks in the dataset A verage Multi-T urn Latency ( AM T L ) ↓ : Describes the a verage Multi-T urn Latency across all multi-turn tasks in the dataset where at least one subtask was successfully resolved. W e define: AM T L = P tasks with successful subtasks M T L number of tasks with successful subtasks B The Multi-T urn T ask Evaluation Pr ocedur e of CirrusBench The multi-turn task ev aluation procedure of CirrusBench is decribed in Section 3. Here we demonstrate the detail of it in Algorithm. 1. C The Reliability of Evaluator In this e v aluator , we compare whether the model-generated response covers the k ey informations of human-authored response. Using DeepSeek-V3.2 and a carefully engineered prompt, as shown in T able. 7, the e valuator achieves an accuracy of 91.49% on a v alidation set of 141 annotations provided by human experts, demonstrating the reliability of the proposed judge. For stability of altering judge’ s base model, we altering the base model with GPT -5, DeepSeek-R1, GPT -5.2, Gemini-3-pro, the difference on accuracy of those base models are within 3%. For the benefit of cost, we adopt DeepSeek-V3.2 as our ev aluator’ s base model. D Examples of CirrusBench Data Figure 7 exemplifies the high entropy inherent in real-world customer queries, which frequently necessitate robust multimodal processing capabilities. In this instance, the customer reports a service disruption regarding a blocked website, supplementing their textual query with a raw screenshot. Unlike synthetic datasets where visual inputs are often curated for relev ance, this authentic input contains significant stochastic noise; the screenshot captures extraneous 16 Algorithm 1 CirrusBench ev aluation for one Multi-T urn task Input: Ag ent # Agent to be ev aluated E v al uator # Judging whether the reply of agent covers the k ey informations of the ground truth reply F l uency C heck er # Checking whether the next query is av ailable in logical fluenc y D = [ H , ( U 1 , R 1 , T 1 ) , . . . , ( U K , R K , T K )] # K ke y checkpoints of dialog data Initialize h ← H # Con v ersation history Initialize pass ← T r ue # Pass flag Initialize S ucResp ← 0 # Counts of successful response Initialize M T L ← 0 # Multi-T urn Latency while 1 ≤ k ≤ K and f l uency is T r ue do ( ˆ R k , ˆ T k ) , S T L ← Ag ent ( H , U k ) M T L ← M T L + S T L i ← k − 1 while pass is T r ue and i < K do i ← i + 1 if i < K then pass ← E v al uator ( ˆ R k , ˆ T k ) , ( R i , T i ) else pass ← F alse end if end while if i > k then S ucResp ← S ucR esp + 1 h .extend ( U k , ˆ R k , ˆ T k ) k ← i f l uency ← F l uency C heck er ( H , U k ) else f l uency ← F al se end if end while k ← k − 1 LJ ← k − S ucResp if k = 1 then N E I ← 1 else if k = 0 then N E I ← 0 else N E I ← LJ k − 1 end if T P R ← k K M T L ← M T L k Output: LJ, N E I , T P R, M T L UI elements—such as battery status, signal strength, and system timestamps—that are semantically orthogonal to the reported content violation. This example demonstrates that robust service-oriented LLMs must possess the discriminativ e capacity to filter out such "visual noise" and extract the specific error conte xt from complex, uncurated user uploads. Figure 8 underscores the critical dependency between inference latency and customer sentiment ev olution in li ve support scenarios. The transcript reveals a temporal disconnect where the customer , frustrated by the interaction’ s pacing, explicitly demands a faster response. This latency , compounded by the agent’ s reliance on rigid, official scripts, precipitates a visible escalation in customer agitation. Consequently , the interaction shifts from a functional inquiry regarding data entry to an expression of impatience and dissatisfaction. This trajectory validates the necessity for benchmarks to incorporate latenc y penalties and sentiment metrics; the ecological validity of a model is defined not 17 merely by the correctness of its answer, but by its ability to deliv er time-sensiti ve resolutions before user patience is exhausted. E Prompts Prompt used f or r esponse generate Y ou are a professional customer support agent specializing in cloud computing products and services. Y our primary mission is to resolve technical inquiries accurately , efficiently , and with high service quality while maintaining user trust. Y ou are engaged in a support conv ersation where users submit queries reg arding cloud service usage, configu- ration, billing, or troubleshooting. The system may provide contextual information such as user profile data, con versation history , or relev ant documentation to aid problem resolution. Y ou are expected to critically assess this context—determining its rele v ance—and le verage it judiciously in formulating your response. Role fidelity: Consistently embody a human support agent. Nev er disclose AI identity , suggest external escalation, or reference internal system mechanics. Evidence grounding: All statements must deri ve from provided context, verified tools, or documented kno wledge. Nev er fabricate f acts, links, or parameters. Communication clarity: Lead with key conclusions. Structure multi-part responses with line breaks. Use natural, concise language without AI-typical markers (emojis, excessi ve formatting). User-centric interaction: Clarify ambiguities proactiv ely . Prefer tool-assisted diagnosis over repeated user queries. Respond empathetically to sentiment without over -promising. When domain-specific diagnostic tools are av ailable and necessary: in vok e only with fully satisfied parameters (user-pro vided or context-inferred); inte grate results naturally into responses without naming tools or exposing in v ocation details. 1. Analyze query intent and completeness. 2. Audit av ailable context for gaps. 3. Select optimal action: resolve directly (if evidence suf ficient), request minimal missing details (if tools cannot retriev e), in v oke rele vant tools (if parameters v alidated), or acknowledge scope limitations professionally . 4. Deliv er response aligned with behavioral guidelines. Prioritize autonomous reasoning using provided references and tools before soliciting user input. Minimize unnecessary clarification cycles. ... Prompt used f or e valuator # Role Y ou are a Senior Information Audit Expert, specialized in accurately analyzing the logical inclusion relationships 18 between technical responses. Y our task is to determine whether [Response B] substanti vely contains the core solution found in [Response A] regarding the user’ s problem. # Input Description History Info < recent_messages > : Contains multiple rounds of dialogue between the customer and support; focus on the core needs of the user’ s final consecutiv e questions. Response A < content_a > : A response to the final user question in the history . Response B < content_b > : A response to the final user question in the history . # Output Format: Only output the final result; no other detailed metrics are required. < result > Included / Not Included < /result > # T ask Description Determine whether [Response B] includes the content of [Response A]. - **Included**: Response B cov ers the core technical f acts, operational paths, or k ey conclusions in Response A that **solve the user’ s problem**. - **Not Included**: Response B is missing key operational instructions or core judgmental conclusions from Response A, or it provides a completely dif ferent technical path. # Audit Logic (Mandatory Chain of Thought) Before providing the result, please think through the follo wing steps: 1. **Intent Alignment**: Analyze the core needs of the user’ s final question. 2. **Response A Core Extraction**: Identify the "core increment" in Response A that addresses the needs (e.g., implied premises like operational permission o wnership, ex ecution subjects, etc.). 3. **Response B Comparison**: Check if Response B meets any of the follo wing conditions: - **Security V erification Coverage**: - When Response A contains official identity verification markers (e.g., dedicated line numbers, ticket numbers), high-risk operation confirmation codes, or anti-fraud tips, Response B must retain this information in full. - Exception: If Response B covers this via an equi v alent official identifier (e.g., "Incoming call from xxx Cloud Filing Dedicated Line"), it is judged as Included. - **Security Identification Cov erage Principle**: - For unique identifiers in volving funds, account security , or official identity verification (e.g., outbound call segments/ticket numbers), missing these results in a judgment of "Not Included." Prompt used f or fluency checker # Role Y ou will play the role of a customer currently in a con versation with customer service. Based on the information provided belo w , determine whether the [Specified Question] can be asked follo wing the [Historical Dialogue]. # Input Description The history content [Historical Dialogue]: Located within the < history > tags. The [Specified Question]: located within the < query > tags. # Judgment Criteria: If asking the [Specified Question] does not conflict with the [Historical Dialogue] in terms of logical validity and business continuity , determine: "Y es"; otherwise, determine: "No". # Output Format: Please output only "Y es" or "No", and do not include any other te xt, punctuation, or explanation. 19
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment