Domain-Invariant Prompt Learning for Vision-Language Models
Large pre-trained vision-language models like CLIP have transformed computer vision by aligning images and text in a shared feature space, enabling robust zero-shot transfer via prompting. Soft-prompting, such as Context Optimization (CoOp), effectiv…
Authors: Arsham Gholamzadeh Khoee, Yinan Yu, Robert Feldt
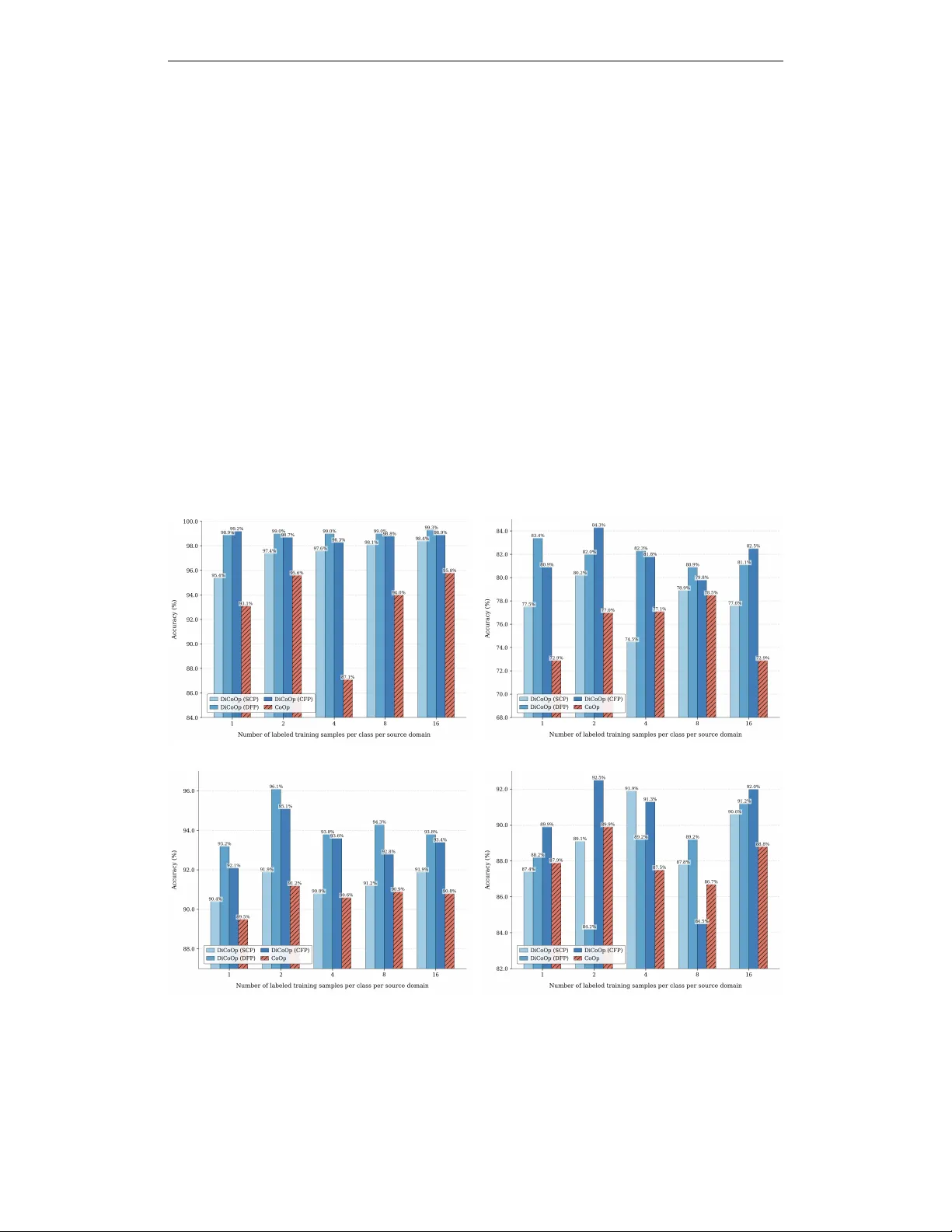
Published as a workshop paper at SCOPE - ICLR 2025 D O M A I N - I N V A R I A N T P R O M P T L E A R N I N G F O R V I S I O N - L A N G UA G E M O D E L S Arsham Gholamzadeh Khoee, Y inan Y u & Robert Feldt Department of Computer Science and Engineering Chalmers Univ ersity of T echnology Gothenbur g, Sweden { khoee,yinan,robert.feldt } @chalmers.se A B S T R AC T Large pre-trained vision-language models like CLIP hav e transformed computer vision by aligning images and text in a shared feature space, enabling robust zero-shot transfer via prompting. Soft-prompting, such as Context Optimiza- tion (CoOp), ef fecti vely adapts these models for do wnstream recognition tasks by learning a set of context vectors. Howe ver , CoOp lacks explicit mechanisms for handling domain shifts across unseen distributions. T o address this, we pro- pose Domain-in variant Context Optimization (DiCoOp), an e xtension of CoOp optimized for domain generalization. By employing an adversarial training ap- proach, DiCoOp forces the model to learn domain-in variant prompts while pre- serving discriminati ve po wer for classification. Experimental results sho w that DiCoOp consistently surpasses CoOp in domain generalization tasks across di- verse visual domains. 1 I N T RO D U C T I O N The emergence of large language models (LLMs) has demonstrated their remarkable capabili- ties, which are now widely recognized. Building upon this success, vision-language models hav e emerged as a po werful alternativ e for visual representation learning. These models aim to align im- ages and their corresponding raw text using two distinct encoders: one for text and the other for vi- sion. For instance, CLIP (Radford et al., 2021), one of the most prominent vision-language models, uses contrastiv e learning to pull together images and their textual descriptions while pushing apart unmatched pairs in the feature space. Unlik e traditional vision models, which are pre-trained on fixed sets of discrete class labels using cross-entropy loss, vision-language models leverage textual semantics for training, allowing them to better understand textual information (Y ang et al., 2024). By pre-training on large-scale datasets, these models can learn div erse visual concepts and transfer them effecti vely to downstream tasks through prompting. For e xample, in image classification tasks, task-relev ant sentences describing categories can be fed to the text encoder, and the resulting text features can be compared with image features produced by the image encoder . Sev eral studies have highlighted the importance and nuances of prompts for achie ving optimal per- formance on downstream datasets. Zhou et al. (2022c) proposed Context Optimization (CoOp), a nov el approach for finding optimized prompts in image classification tasks. In particular , CoOp transforms prompt engineering from a manual process into an optimization problem by using some learnable numerical vectors called context vectors . CoOp has been shown to outperform handcrafted prompts and exhibits stronger robustness than standard zero-shot models with manually designed prompts. Howe ver , while CoOp demonstrates some resilience to domain shifts, it does not explicitly ad- dress the challenge of domain in variance in prompt learning to handle distribution shifts or unseen domains. These challenges are formulated as domain adaptation (DA) and domain generalization (DG) in the literature. D A focuses on adapting models from source to target domains with access to target domain data during training. In contrast, DG aims to generalize to unseen domains with- out such access (Zhou et al., 2022a). DG is particularly rele v ant in real-world scenarios, where 1 Published as a workshop paper at SCOPE - ICLR 2025 models are trained on specific datasets b ut must perform well on new , pre viously unseen data distri- butions (Khoee et al., 2024). T o achiev e both high accuracy for the task and rob ustness to domain shift, we aim to design a prompt that is highly effecti ve for class discrimination but incapable of identifying the domain of the input data. This idea aligns with the definition of a good cross-domain representation proposed by Ben-Da vid et al. (2010), which emphasizes that a model should pre vent domain distinction while maintaining class discrimination. In other words, the model should emphasize task-relev ant infor- mation while promoting domain confusion to achiev e ef fectiv e generalization across domains. In this work, we propose Domain-inv ariant Context Optimization (DiCoOp), an extension of CoOp designed specifically for domain generalization tasks. DiCoOp applies adversarial training princi- ples to prompt learning, explicitly promoting domain inv ariance within the learnable context vectors. W e introduce three implementations of DiCoOp to explore different prompt structures: (1) Domain- First Prompting (DFP), which separates domain and class tokens, placing domain tokens first; (2) Class-First Prompting (CFP), similar to DFP but with class tokens placed before domain tok ens; and (3) Shared Context Prompting (SCP), which does not explicitly separate domain and class tokens, instead using a shared context for joint learning. As a summary , we hav e contributed the follo wing: • W e introduce DiCoOp, an extension of CoOp that le verages domain adversarial prompt learning using the Gradient Re versal Layer (GRL) to enhance the robustness of VLMs against domain shifts ef fectiv ely . • W e propose three distinct prompting strategies—SCP , DFP , and CFP—to explore how prompt design affects domain generalization in vision-language models. Notably , DFP and CFP systematically split and freeze domain- and class-specific tokens, preserving class- discriminativ e kno wledge while addressing domain in variance. • DiCoOp outperforms its baseline, which is CoOp, on P A CS (using ResNet-50) and Mini- DomainNet (using V iT -B/16) datasets, demonstrating the robustness of DiCoOp across domain generalization tasks. 2 P RO P O S E D M E T H O D Let D s = {D s i } n i =1 denote a set of n source domains, each containing input data x i ∈ X i and corresponding labels y i ∈ Y . The probability distribution of each source domain, denoted as P ( D s i ) , differs across domains such that P ( D s i ) = P ( D s j ) for all i, j ∈ 1 , . . . , n where i = j . In DG, our goal is to train a model on these source domains that generalizes well to an unseen target domain D t , where the tar get domain distrib ution P ( D t ) is distinct from all source domain distributions, i.e., P ( D t ) = P ( D s i ) for all i ∈ 1 , . . . , n . This setup is commonly referred to as the multi-source domain generalization problem (Khoee et al., 2024). Due to page constraints, we refer to the related work and preliminaries in Appendices A.1 and A.2, respectiv ely , which provide a detailed description of the V ision-Language model CLIP (Radford et al., 2021) and the learnable soft-prompting method CoOp (Zhou et al., 2022c). 2 . 1 D O M A I N - I N V A R I A N T C O N T E X T O P T I M I Z AT I O N Our objectiv e is to learn domain-inv ariant prompts that reduce domain bias and enable robust per - formance on unseen domains. Drawing inspiration from Domain Adversarial Neural Networks (D ANN) (Ganin et al., 2016), we incorporate a Gradient Rev ersal Layer (GRL) into the prompt tuning process. Our approach exploits both class names and (source) domain names: we perform standard prompt tuning for classification while applying adversarial training (via GRL) to encour- age domain generalization by maximizing domain-specific feature distinguishability . W e aim to optimize the context vectors to maintain strong class discrimination while ensuring in v ariance to domain differences. An ov erview of this architecture is sho wn in Figure 1. W e optimize learnable context vectors v by minimizing the negativ e log-likelihood of the ground- truth label of classes and maximizing the ne gati ve log-likelihood of the ground-truth label of do- mains. W e initially assume a shared set of learnable context vectors v that simultaneously undergo 2 Published as a workshop paper at SCOPE - ICLR 2025 Figure 1: Overvie w of Domain-in v ariant Context Optimization (DiCoOp). Domain First Prompting (DFP) is illustrated, where the first half of the prompt is dedicated to domain information, and the remaining half is dedicated to class information. During domain-related optimization, the class tokens remain frozen, and vice versa. standard gradients (for class prediction) and rev ersed gradients (for domain prediction). Alterna- tiv ely , these learnable vectors can be split into two parts: one dedicated to category classification information and another for domain-in variant information. As a result, the overall training objectiv e combines classification (cls) and domain adversarial (dom) losses: L ( v ) = L cls ( v ) − λ L dom ( v ) = − X i y c i log P ( i | x ) + λ X j y d j log P ( j | x ) , (1) where y c and y d are one-hot encodings of the ground-truth class and domain labels, respectively , and λ ≥ 0 controls the strength of domain adversarial training. P ( i | x ) in the classification loss is the probability that the input image x belongs to the i − th class, while P ( j | x ) in the domain adv ersarial loss is the probability that x comes from the j − th domain. The GRL is essential for domain-in variant context optimization (DiCoOp). During the forward pass, GRL acts as an identity function, allowing standard computation of both class and domain predic- tions. Howe ver , during backpropagation, the GRL multiplies the gradient by − λ for the domain- specific portion of the context. This adversarial approach encourages domain context vectors to become domain-in v ariant while preserving class discrimination. Although we describe the method with a shared context vectors v , referred to as Shared Context Prompting (SCP) , the tokens can be split into domain and class segments: Domain-First Pr ompting (DFP): The first half of the prompt is designated for domain-specific tokens, and the second half for class-specific tokens, i.e., v = [ v d ] 1 · · · [ v d ] M 2 [ v c ] M 2 +1 · · · [ v c ] M . During domain-related optimization, only the domain-specific tokens are updated (class-specific tokens remain frozen), and vice v ersa. This explicit separation helps maintain clear boundaries between domain and class information. Class-First Prompting (CFP): Similar to DFP , but re versed: class-specific tokens come first, fol- lowed by domain-specific tok ens, i.e., v = [ v c ] 1 · · · [ v c ] M 2 [ v d ] M 2 +1 · · · [ v d ] M . Class-specific tokens are frozen during domain-related optimization, and domain-specific tokens are frozen during class-related optimization. Like DFP , CFP preserves a strict separation between domain and class segments. 2 . 2 T R A I N I N G A N D I N F E R E N C E During training , we learn domain-in variant context vectors by performing two forward passes for each input image x : 3 Published as a workshop paper at SCOPE - ICLR 2025 1. Class pass: W e form the prompt for class k by concatenating the learnable context v with the class token [ C LAS S ] k , i.e.: t c k = concat ( v , [ C LAS S ] k ) . (2) This prompt is fed into the model for classification, and standard gradients update v to minimize class prediction loss. 2. Domain pass: W e form the prompt for domain p by concatenating the same context v with the domain token [ DO M AI N ] p , i.e.: t d p = concat ( v , [ DO M AI N ] p ) . (3) This prompt is fed into the model for domain prediction through the GRL, so the gradients are rev ersed to maximize domain prediction loss, encouraging v to become domain-in variant. By alternating between class and domain passes, we learn context vectors v that balance accurate class discrimination with minimal domain bias. At infer ence time, we no longer hav e access to domain labels. W e only perform the class pass, utilizing the learned domain-inv ariant context v to predict class labels for incoming images, ensuring robust classification across unseen domains. 3 E X P E R I M E N TA L R E S U L T S (a) Photo (b) Sketch (c) Cartoon (d) Art Painting Figure 2: Results of few-shot learning on the P A CS dataset using the leave-one-domain-out tech- nique. Each plot is defined by the domain name that is left out during prompt learning, and testing is performed on that same domain. W e ev aluate our model on two publicly av ailable datasets. i) P ACS (Li et al., 2017): This dataset spans four contrasting domains (Photo, Art Painting, Cartoon, and Sketch) and includes sev en object 4 Published as a workshop paper at SCOPE - ICLR 2025 categories. ii) Mini-DomainNet (Y ue et al., 2024; T ang et al., 2024): This dataset consists of four different domains (Clipart, P ainting, Sk etch, and Real), each containing images from 126 categories. T o assess domain generalization performance, we use a leav e-one-domain-out strategy: one domain is held out as the tar get (test) domain, while the remaining domains serve as source domains for training. In all experiments, we set the prompt context length ( M ) to 16, following Zhou et al. (2022c). W e compare DiCoOp—with all three variants (SCP , DFP , CFP)—to CoOp as the baseline. For the P ACS dataset, we use ResNet-50 (He et al., 2016) as the backbone image encoder ( f v ) and test 1- shot, 2-shot, 4-shot, 8-shot, and 16-shot settings. In these n -shot experiments, each source domain contributes n labeled e xamples per class. T o ensure a fair comparison, we ev aluate the baseline under the same conditions. Results on P A CS are illustrated in Figure 2, sho wing the classification accuracy for each tar get domain v ersus the number of labeled training examples per class per domain. Ov erall, DiCoOp demonstrates greater rob ustness and better generalization than CoOp. Among DiCoOp v ariants, CFP and DFP outperform SCP , suggesting explicit separation of domain/class segments improv es handling of domain variation. CFP demonstrates the strongest cross-domain consistency , consis- tently achieving high (and often top) accuracy . Meanwhile, SCP shows less reliable performance, often yielding results comparable to or occasionally lower than the baseline CoOp, indicating that shared context v ectors struggle to effecti vely disentangle domain and class information. For Mini-DomainNet, we switch to a V iT -B/16 (Dosovitskiy, 2020) backbone while using the 16- shot setting. T able 1 reports the accuracy on each target domain. DiCoOp outperforms CoOp on all target domains, underscoring the robustness of domain-inv ariant prompt tuning. Notably , DiCoOp (CFP) and DiCoOp (DFP) achiev e the same average accurac y , improving the results by 2 . 23% over CoOp, while DiCoOp (SCP) sho ws a 1 . 23% improvement. These results affirm that the separation of domain and class tokens (DFP or CFP) enhances generalization compared to fully shared prompts (SCP). T able 1: Accuracy (%) on Mini-DomainNet for domain generalization using a lea ve-one-domain- out approach. Each column shows results on the domain that has been left out, comparing domain generalization performance to the baseline. Bold numbers indicate the best accuracy in each column. Methods Backbone Clipart Painting Sketch Real A vg. CoOp V iT -B/16 83.5 80.3 76.6 88.7 82.27 DiCoOp (SCP) V iT -B/16 83.8 81.9 78.6 89.7 83.5 DiCoOp (DFP) V iT -B/16 83.9 83.2 79.8 91.1 84.5 DiCoOp (CFP) V iT -B/16 84.1 82.7 80.0 91.2 84.5 4 C O N C L U S I O N V ision-language models hav e shown significant promise across various tasks. Ho wev er , for specific downstream classification tasks, effecti vely generalizing these pre-trained models to unseen domains remains an open challenge. T o bridge this gap, we introduced DiCoOP , a nov el framework to im- prov e domain generalization in vision–language models. Built upon CLIP , DiCoOP learns domain- in v ariant prompt tokens by incorporating a domain adversarial loss into prompt tuning. Specifically , we employ a Gradient Reversal Layer (GRL) to penalize domain classification, thereby mitigat- ing domain bias using prompts and encouraging domain inv ariance. This study serves as an ini- tial exploration of incorporating adversarial training into prompt learning to learn domain-in variant prompts and enable robust performance on unseen domains. Our experiments on two benchmark datasets demonstrate that DiCoOP outperforms its baseline (CoOp), highlighting the effecti veness of adversarial prompt tuning. In future work, we plan to extend DiCoOP to more challenging do- main generalization applications such as person re-identification and medical imaging to in vestig ate its effecti veness and guide further advancements in domain generalization for emerging foundation models. 5 Published as a workshop paper at SCOPE - ICLR 2025 A C K N O W L E D G M E N T S The research was supported by two funding sources: the W allenber g AI, Autonomous Systems and Software Program (W ASP) funded by the Knut and Alice W allenberg Foundation, and the Chalmers Gender Initiativ e for Excellence (Genie). R E F E R E N C E S Shai Ben-David, John Blitzer , Koby Crammer , Alex Kulesza, Fernando Pereira, and Jennifer W ort- man V aughan. A theory of learning from dif ferent domains. Machine learning , 79:151–175, 2010. Jacob De vlin. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv pr eprint arXiv:1810.04805 , 2018. Alex ey Dosovitskiy . An image is worth 16x16 words: Transformers for image recognition at scale. arXiv pr eprint arXiv:2010.11929 , 2020. Ruoyu Feng, T ao Y u, Xin Jin, Xiaoyuan Y u, Lei Xiao, and Zhibo Chen. Rethinking domain adap- tation and generalization in the era of clip. In 2024 IEEE International Confer ence on Image Pr ocessing (ICIP) , pp. 2585–2591. IEEE, 2024. Y aroslav Ganin, Evgeniya Ustinov a, Hana Ajakan, Pascal Germain, Hugo Larochelle, Franc ¸ ois Laviolette, Mario March, and V ictor Lempitsk y . Domain-adversarial training of neural networks. Journal of mac hine learning r esear ch , 17(59):1–35, 2016. Peng Gao, Shijie Geng, Renrui Zhang, T eli Ma, Rongyao Fang, Y ongfeng Zhang, Hongsheng Li, and Y u Qiao. Clip-adapter: Better vision-language models with feature adapters. International Journal of Computer V ision , 132(2):581–595, 2024. Chunjiang Ge, Rui Huang, Mixue Xie, Zihang Lai, Shiji Song, Shuang Li, and Gao Huang. Domain adaptation via prompt learning. IEEE T ransactions on Neural Networks and Learning Systems , 2023. Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recog- nition. In Proceedings of the IEEE conference on computer vision and pattern reco gnition , pp. 770–778, 2016. Chao Jia, Y infei Y ang, Y e Xia, Y i-T ing Chen, Zarana P arekh, Hieu Pham, Quoc Le, Y un-Hsuan Sung, Zhen Li, and T om Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In International confer ence on mac hine learning , pp. 4904–4916. PMLR, 2021. Arsham Gholamzadeh Khoee, Y inan Y u, and Robert Feldt. Domain generalization through meta- learning: A survey . Artificial Intelligence Re view , 57(10):285, 2024. Brian Lester , Rami Al-Rfou, and Noah Constant. The po wer of scale for parameter -ef ficient prompt tuning. arXiv pr eprint arXiv:2104.08691 , 2021. Da Li, Y ongxin Y ang, Y i-Zhe Song, and Timoth y M Hospedales. Deeper , broader and artier domain generalization. In Pr oceedings of the IEEE international conference on computer vision , pp. 5542–5550, 2017. Liunian Harold Li, Mark Y atskar , Da Y in, Cho-Jui Hsieh, and Kai-W ei Chang. V isualbert: A simple and performant baseline for vision and language. arXiv pr eprint arXiv:1908.03557 , 2019. Alec Radford, Jong W ook Kim, Chris Hallac y , Aditya Ramesh, Gabriel Goh, Sandhini Agarw al, Girish Sastry , Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International confer ence on machine learning , pp. 8748–8763. PMLR, 2021. Mainak Singha, Harsh Pal, Ankit Jha, and Biplab Banerjee. Ad-clip: Adapting domains in prompt space using clip. In Pr oceedings of the IEEE/CVF International Confer ence on Computer V ision , pp. 4355–4364, 2023. 6 Published as a workshop paper at SCOPE - ICLR 2025 Song T ang, W enxin Su, Mao Y e, and Xiatian Zhu. Source-free domain adaptation with frozen multimodal foundation model. In Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition , pp. 23711–23720, 2024. Y ijun Y ang, T ianyi Zhou, Kanxue Li, Dapeng T ao, Lusong Li, Li Shen, Xiaodong He, Jing Jiang, and Y uhui Shi. Embodied multi-modal agent trained by an llm from a parallel textworld. In Pr o- ceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition , pp. 26275– 26285, 2024. Jiaqi Y ue, Jiancheng Zhao, and Chunhui Zhao. Less b ut better: Enabling generalized zero-shot learn- ing tow ards unseen domains by intrinsic learning from redundant llm semantics. arXiv pr eprint arXiv:2403.14362 , 2024. Kaiyang Zhou, Ziwei Liu, Y u Qiao, T ao Xiang, and Chen Change Lo y . Domain generalization: A surve y . IEEE T ransactions on P attern Analysis and Machine Intelligence , 45(4):4396–4415, 2022a. Kaiyang Zhou, Jingkang Y ang, Chen Change Loy , and Ziwei Liu. Conditional prompt learning for vision-language models. In Pr oceedings of the IEEE/CVF confer ence on computer vision and pattern r ecognition , pp. 16816–16825, 2022b. Kaiyang Zhou, Jingkang Y ang, Chen Change Loy , and Ziwei Liu. Learning to prompt for vision- language models. International J ournal of Computer V ision , 130(9):2337–2348, 2022c. Beier Zhu, Y ulei Niu, Y ucheng Han, Y ue W u, and Hanwang Zhang. Prompt-aligned gradient for prompt tuning. In Pr oceedings of the IEEE/CVF International Conference on Computer V ision , pp. 15659–15669, 2023. A A P P E N D I X A . 1 R E L A T E D W O R K S V ision-language models (VLMs), such as CLIP (Radford et al., 2021), ALIGN (Jia et al., 2021), and V isualBER T (Li et al., 2019), integrate visual and textual data to enhance multimodal understand- ing, achieving state-of-the-art performance across div erse computer vision tasks. A key adv ance- ment in le veraging these models is prompt learning, which adapts pre-trained VLMs to downstream tasks by optimizing task-specific text prompts. In this reg ard, CoOp (Zhou et al., 2022c) de veloped prompt tuning for few-shot image classification by learning continuous prompt vectors, establish- ing a foundation for subsequent methods. Building on this, CoCoOp (Zhou et al., 2022b) intro- duced conditional prompts that dynamically adjust to input images, enhancing the generalization for image classification. ProGrad (Zhu et al., 2023) refined this further by selectively updating the prompt whose gradient is aligned (or non-conflicting) to the general knowledge to prevent prompt tuning from forgetting the general kno wledge learned from VLMs. T aking a different approach, CLIP-Adapter (Gao et al., 2024) focused on fine-tuning feature adapters in both visual and language branches to improv e CLIP’ s classification capabilities. For D A challenges, se veral approaches hav e emerged. D APL (Ge et al., 2023) introduced domain- specific prompt tuning, though its requirement for explicit domain information limits practical ap- plications. AD-CLIP (Singha et al., 2023) aimed to create domain-agnostic prompts through prompt learning; ho wever , its reliance on distribution alignment poses challenges with limited tar get domain samples. Recent work has explored DG using CLIP by incorporating domain-specific learnable residuals in te xt embeddings alongside domain-shared residuals (Feng et al., 2024). The latter is then used at inference to capture common kno wledge across domains. Ho wev er , the effecti veness of these simple domain priors depends heavily on how precisely the domain can be described in natural language, giv en that prompts are handcrafted. One notable approach to address domain shifts is the Domain-Adversarial Neural Networks (D ANN) proposed by Ganin et al. (2016), which trains neural netw orks to be both discriminative (for the classification task) and domain-in variant. DANN minimizes the loss of the main label classifier while maximizing the loss of the domain classifier using Gradient Rev ersal Layers (GRL). GRL adversarially trains the network to confuse the domain classifier , encouraging the emergence of 7 Published as a workshop paper at SCOPE - ICLR 2025 domain-in v ariant features during training. Inspired by D ANN, our work inte grates a GRL into prompt learning to address the challenges of handling domain shifts in prompt learning. A . 2 P R E L I M I N A R I E S W e use CLIP as our backbone architecture, which consists of an image encoder f v ( · ) (either ResNet (He et al., 2016) or V iT (Dosovitskiy, 2020)) and a text encoder f t ( · ) (BER T (Devlin, 2018)). These encoders project their respectiv e inputs from high-dimensional spaces into a shared low-dimensional feature space. CLIP is trained on image-te xt pairs using contrastiv e learning, where associated image-text pairs serve as positiv e samples and non-associated pairs as negativ e samples. The contrastiv e objectiv e maximizes the similarity between positive pairs while minimizing the similarity between negati ve pairs, effecti vely aligning image and text representations in the same feature space. For zero-shot classification, gi ven an input image x and a set of K textual cate gory descriptions, the probability that x belongs to i − th category is computed as: P ( i | x ) = exp( < f t ( t i ) , f v ( x ) > /τ ) P K k =1 exp( < f t ( t k ) , f v ( x ) > /τ ) , (4) where τ is the temperature hyperparameter and < · , · > denotes cosine similarity . The predicted class ˆ y is then determined by: ˆ y = arg max k P ( k | x ) . (5) T raditionally , the input text consists of manually designed prompts composed of discrete tokens. These prompts are transformed into fixed v ectors in the word embedding space. Howe ver , these fixed embeddings may be sub-optimal for cate gory representation (Ge et al., 2023). T o address this, we can optimize continuous embeddings of the prompt tokens, allo wing for more precise semantic feature descriptions (Lester et al., 2021). This is achiev ed through learnable conte xt vectors v , where the prompt for class k is represented as: v = [ v ] 1 [ v ] 2 · · · [ v ] M , t k = concat ( v , [ C LAS S ] k ) , (6) where each [ v ] m ( m ∈ 1 , 2 , . . . , M ) is a vector with the same dimension as the word embedding, and M is the number of context tokens in the prompt. CoOp (Zhou et al., 2022c) optimizes these learnable context v ectors by minimizing the negati ve log-lik elihood of the ground-truth label: L ce ( v ) = − X i y i log P ( i | x ) , (7) where y represents the one-hot encoded ground-truth labels. One key design consideration for this approach is determining the semantic meaning that each con- text v ector [ v ] m should capture, and defining an ef fecti ve training strategy to optimize these conte xt vectors accordingly . 8
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment