Shy Guys: A Light-Weight Approach to Detecting Robots on Websites
Automated bots now account for roughly half of all web requests, and an increasing number deliberately spoof their identity to either evade detection or to not respect robots.txt. Existing countermeasures are either resource-intensive (JavaScript cha…
Authors: Rémi Van Boxem, Tom Barbette, Cristel Pelsser
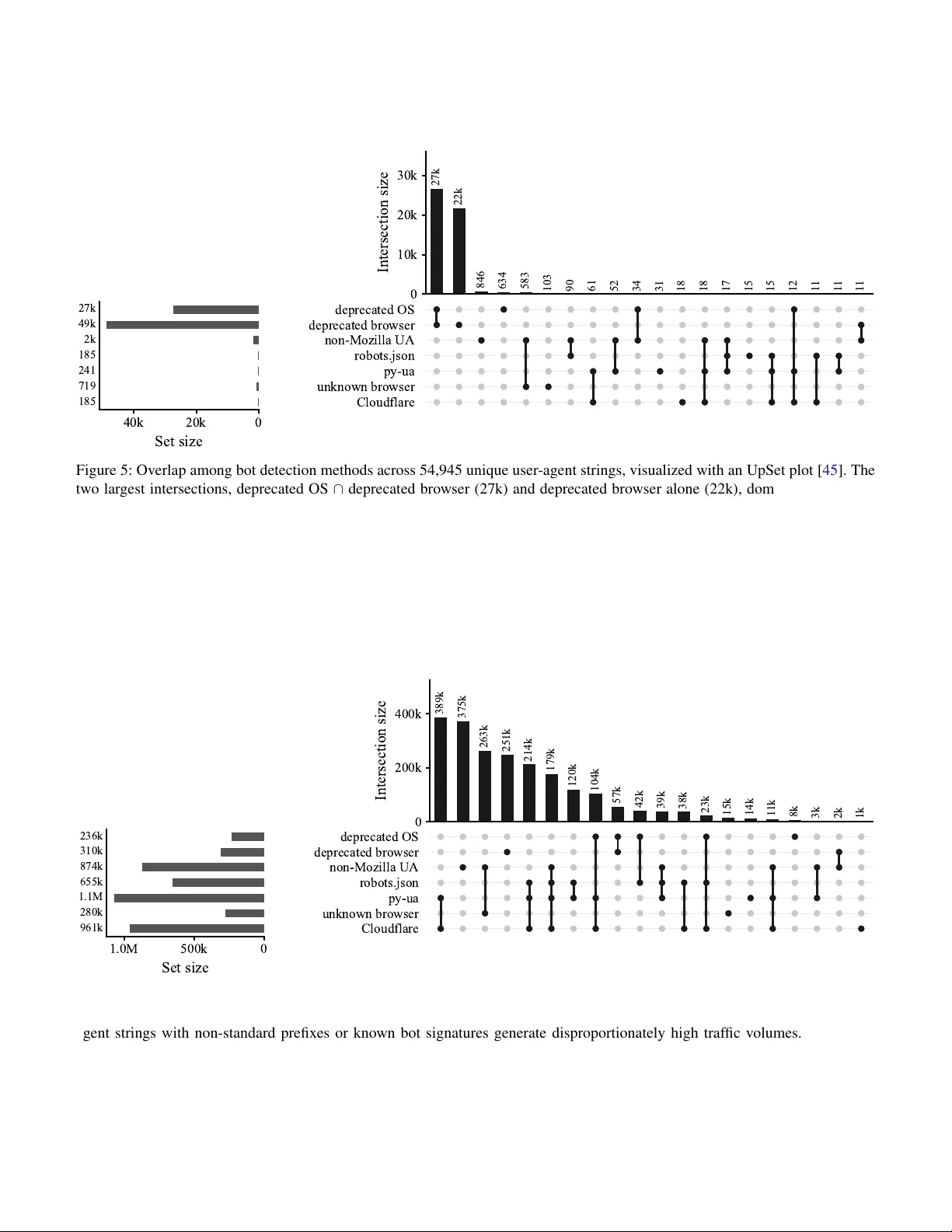
Shy Guys: A Light-W eight Approach to Detecting Robots on W ebsites R ´ emi V an Boxem, T om Barbette, Cristel Pelsser and Ramin Sadre UCLouvain, Institute of Information and Communication T echnologies, Electronics and Applied Mathematics, ICTEAM, P ˆ ole en ing ´ enierie informatique, INGI Place Sainte Barbe 2, Louvain-la-Neuv e, Belgium Email: { firstname.lastname } @uclouvain.be Abstract —A utomated bots now account for r oughly half of all web requests, and an increasing number deliberately spoof their identity to either evade detection or to not r espect robots.txt . Existing countermeasures ar e either resource- intensive (Ja vaScript challenges, CAPTCHAs), cost-prohibitive (commercial solutions), or degrade the user experience. This paper pr oposes a lightweight, passiv e approach to bot detection that combines user -agent string analysis with favicon-based heuristics, operating entirely on standard web server logs with no client-side interaction. W e evaluate the method on o ver 4.6 million requests containing 54,945 unique user-agent strings collected from websites hosted all around the earth. Our approach detects 67.7% of bot traffic while maintaining a false-positive rate of 3%, outperforming state of the art (less than 20%). This method can serve as a first line of defense, routing only genuinely ambiguous requests to activ e challenges and preserving the experience of legitimate users. I . I N T R OD U C T I O N In late 2021, a theory called “Dead Internet Theory” began to gain traction on the internet. This theory suggests that a significant portion of internet traf fic is generated by bots rather than humans [ 1 ]. While often dismissed as a conspirac y theory , the latest annual report from Cloudflare indicates that bots (whether AI or non-AI) are responsible for half of requests to HTML pages, sev en percentage points above human-generated traffic [ 2 ]. The same report also shows that traffic generated by AI crawlers increased to 15 times more than before. In April 2025, W ikimedia, the organization behind W ikipedia, published a blog post explaining its struggle to keep up with bots [ 3 ]. While traffic spikes are not uncommon when major e vents occur and while Wikimedia previously han- dled such surges without difficulty , it explained that baseline traffic had increased by 50% since January 2024 and that the organization has had greater difficulty serving content when major ev ents (traffic spikes) occur . Further analysis showed that 65% of its most expensiv e traf fic comes from bots. Due to Wikimedia’ s infrastructure, expensi ve traffic is associated with less popular pages (less popular pages are not always cached and are requested from the main server). Scrapers tend to read lar ger numbers of pages in bulk than humans, not only the most popular ones, thereby defeating caching strate gies. One year later, the org anization reported that it blocks or throttles approximately 25% of all automated requests and yet continues to face challenges as a ne w generation of crawlers spoofs the identities of real web browsers and routes traf fic through residential proxies to blend in with legitimate users [ 4 ]. This sudden increase in bot traffic can pose a serious threat to performance. It is not uncommon to observe content creators struggling to protect their websites [ 5 ], [ 6 ], forcing them to adopt CAPTCHA; migrate to hosting services that can detect bots and absorb the load of undetected bots; or employ aggressiv e measures that may block legitimate users (e.g., geo- blocking, mandatory JavaScript challenges) [ 7 ]. One of the most common methods to identify bots is to examine their self-reported user-agent string. Ho wev er , this method is not very reliable, as bots can easily spoof their user-agent string to mimic that of a legitimate browser . This paper proposes a lightweight, passive approach to bot detection that combines user-agent string analysis with fa vicon-based heuristics, operating entirely on standard web server logs with no client-side interaction. W e ev aluate our approach on various web server logs and show that it can serve as a first line of defense with a low false positiv e rate. Section II presents methods for detecting web crawlers and the background needed to understand the heuristics introduced in section III and ev aluated in section IV . Finally , the results are discussed in section V , and ethical considerations related to log collection are addressed in section VI . I I . B AC K G RO U N D A N D R E L A T E D W O R K This section provides an introduction to the the user-agent header and a discussion of related work. A. Backgr ound A user agent (U A) is defined as ”the client which initiates a request” in RFC 2616 [ 8 ]. Usually , the user agent is a web browser , but it can also be a bot, a crawler , a mobile application, etc. A user-agent string is usually sent to the server via the ”User-Agent” HTTP header [ 9 ], [ 10 ] and often contains information about the software and hardware of the client, such as the browser name and version, the operating system, the device type, etc. Listing 1: User-Agent string sent by Safari on a MacBook Pro M5. Mozilla/5.0 (Macintosh; Intel Mac OS X 10 _15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/26.3.1 Safari/605.1.15 Listing 1 sho ws a typical user-agent string that contains the following information: • The first part Mozilla/5.0 is a general token that says that the browser is Mozilla-compatible. For historical reasons, almost ev ery browser today sends it. [ 10 ] • The second part (Macintosh; Intel Mac OS X 10_15_7) contains information about the operating system and the device type. Here, it indicates that the client is running macOS 10.15.7 on an Intel-based Mac. • The third part AppleWebKit/605.1.15 (KHTML, like Gecko) contains information about the rendering engine used by the bro wser . In this case, it indicates that the browser is using the W ebKit rendering engine. • The fourth part Version/26.3.1 Safari/605.1.15 contains information about the browser name and version. In this case, it indicates that the browser is Safari version 26.3.1. It is worth to note that the above example user-agent string was actually sent by a bro wser running on a MacBook Pro M5 and not on an Intel-based Mac. Such a discrepancy can be due to one of two reasons: either the user-agent string is forged to av oid robots.txt restricti ve rules [ 11 ], or the user-agent reduction technique is used [ 12 ]. User-Agent reduction is a technique used by some browsers to reduce the amount of information sent in the User-Agent header in order to protect users’ priv acy [ 12 ]. Usually , the user-agent is reduced to a generic string that does not contain sufficient information to fingerprint clients. A common con- vention is to use fixed values for the platform version and the device model. The follo wing values hav e been observed [ 12 ]: • Android 10; K on Android. • Macintosh; Intel Mac OS X 10_15_7 on ma- cOS. • Windows NT 10.0; Win64; x64 on W indows. • X11; CrOS x86_64 14541.0.0 on ChromeOS. • X11; Linux x86_64 on Linux. This initiativ e, led by Chromium, is part of an effort to reduce the amount of information sent by the user agent in order to protect the pri vac y of the users [ 13 ], [ 14 ], [ 15 ]. T oday , any modern bro wser should send this generic information, and any user agent that does not follow this con vention is likely to be a bot as demonstrated in section IV -B . B. Detection of crawlers A robots.txt file is a text file placed on a web site that instructs web crawlers which resources they can or cannot request. Between 2022 and 2024, Liu et al. conducted a large-scale study of crawlers, analyzing robots.txt files on 40,000 websites and detecting that 14% of them imposed restrictions on crawlers, particularly after OpenAI released its crawler in 2023 [ 16 ]. Ho wev er , as the authors point out, many crawlers do not respect robots.txt rules and therefore still access content ev en if they are undesired. Kim et al. show that many crawlers tend to ignore strict rules in robots.txt and do not read it frequently , which means that e ven if a website owner adds a crawler in the file, the bot may continue to access the website content [ 11 ] for some time. Lastly , some crawlers can even go as far as to fake their user-agent string to mimic other crawlers, making it ev en harder to detect them [ 11 ]. For now , the most common method to detect bots is by comparing their self-reported user-agent string to a list of known bots. Other methods include Jav aScript challenges, CAPTCHAs, TLS fingerprinting (J A3/J A4), behavioural anal- ysis, and commercial solutions: 1) Active techniques: T o block bots, some websites use activ e techniques that require client-side JavaScript ex ecution. For example, they can use Jav aScript challenges to check whether the client can ex ecute Ja vaScript code, which most bots cannot do. Anubis, well-known self-hosted option [ 17 ], presents a chal lenge under certain conditions and allows access to the content only if it is successfully completed. This challenge is based on Hashcash, a proof-of-work system that requires the client to perform a certain amount of computa- tional work before being granted access [ 18 ]. Another approach is the use of CAPTCHAs (Completely Automated Public T uring test to tell Computers and Humans Apart). CAPTCHAs are automated challenges designed to dis- tinguish humans from bots [ 19 ], ranging from simple puzzles to behavioural analysis of user interactions [ 20 ]. Both approaches can be effecti ve in prev enting bots from ac- cessing content, but they can also degrade the user experience for legitimate users. Jav aScript challenges can cause delays in page loading and do not work for users with JavaScript disabled. CAPTCHAs can be frustrating for users, particularly when the problems are dif ficult to solve or present accessibility issues. Therefore, although activ e techniques can be ef fectiv e in blocking bots, they should be used with caution to a void negati vely impacting the user experience. 2) P assive header-based techniques: TLS fingerprinting, such as J A3 and J A4, is a passive technique that analyzes the TLS handshake to identify clients based on their TLS fingerprints. The core idea is that when a client initiates an HTTPS connection, the initial handshake (specifically , the ClientHello message) is sent in plaintext and contains a list of supported cipher suites that v aries across client applications [ 21 ]. After the TLS handshake, the client typically sends a user-agent string in the HTTP headers to identify the client application. Because many bots identify themselves as bots, crowdsourced lists exist to detect them. Examples include [ 22 ], [ 23 ], [ 24 ] and [ 25 ], which focus on bots and AI crawlers, with the latter directly providing block rules for NGINX, HAProxy , and Caddy . Howev er , in its basic form, this method is not very reliable, as bots can spoof their user-agent. Another technique is to check IP reputation lists to de- termine whether an IP address is well known for sending bots [ 26 ]. Finally , behavioural techniques such as mouse- mov ement analysis [ 27 ] of fer stronger guarantees by observing client interactions rather than self-declared headers, but require client-side instrumentation. 3) Commercial solutions: All the pre viously discussed techniques require development and installation on the server side and are more or less resource-intensi ve, depending on the technique employed. T o av oid such work, turnkey solutions are av ailable. These solutions, often outsourced and primarily provided by CDNs [ 28 ], [ 29 ], are typically closed source and combine the previous techniques with others, such as intersite tracking based on browsing history patterns. I I I . M E T H O D O L O G Y In this section, we describe our methodology to detect bots from web server logs. W e propose two independent methods that we will then ev aluate in section IV . Both methods take as input information av ailable in most web server log formats, such as the timestamp, client IP , HTTP method, URL, HTTP status code, and user-agent. W e support Caddy , Apache HTTP Server ( httpd ), NGINX, and HAProxy log formats. During our pre-processing phase, we first anonymize IP addresses using Crypto-P An [ 30 ], then extract the fields of interest into CSV files. Figure 1 shows the complete pipeline. A. F avicon A favicon is a small icon displayed in browser tabs and bookmarks to visually identify a website [ 31 ]. Browsers cache it after the initial retriev al and rerequest it only after a defined interval or when the cache is cleared. Our first detection method is based on how favicons are handled by human users and bots. The latter, especially those designed for web scraping, often use headless browsers that do not render the page visually . As a result, they do not request fa vicons at all. W e therefore argue that the presence of a fa vicon request can serve as an indicator that the client is not a bot. Howe ver , false positiv es can occur with this method when clients cache the favicon and then later change their IP address and access the web server again without re-requesting the fa vicon. Such false positi ves can be reduced by forcing clients to regularly refetch the favicon. In the experiments in section IV -A , we achie ve this by daily changing the URL of the fa vicon on the in vestigated web server . B. User-agent Our second method relies on an analysis of the user-agent string provided by the client in the HTTP requests. Because these strings are self-defined data, bot authors can choose whether to indicate that the client is a bot (by providing an explicit user-agent string) or to remain stealthy . 1) Good bots: “Good” bots identify themselves as bots in the user-agent string. For example, the bots of the Google search engine identify themselves as “Googlebot” [ 32 ]. W e can assume that any user agent identifying itself as a bot is indeed a bot, unless it is forged and pretending to be someone else. T o identify good bots, we search for words such as ”bot”, ”crawler”, or ”spider” in the user-agent string using the rege x patterns from the ” user-agents ” Python library [ 33 ], hereafter referred to as ” py-ua ” Furthermore, we look the strings up in a list of kno wn bots. This is necessary as some bots do not put the aforementioned words in their user-agent string. For example, one of OpenAI’ s bots identifies itself as ChatGPT-User [ 34 ]. W e rely on ai-robots.txt , a crowdsourced list that is updated regularly and focuses on AI related bots [ 25 ] (referred as ” robots.json ”). 2) Stealthy bots: When a client does not identify itself as a bot in the user-agent string, it may be either a human user or a stealthy bot (aka: shy guy) designed to mimic a human user . Modern web browsers installed on end user de vices such as PCs or smartphones follow certain rules in their user-agent strings that we exploit to discriminate humans from bots. As cited in section II-A , user-agent strings from major web browsers should start with the ”Mozilla/5.0” prefix for legac y reasons [ 35 ]. User-agent strings deviating from this are unlikely to be sent by any modern web browser . For example, the default user-agent string for curl is curl/VERSION [ 36 ], although since version 4.5.1, curl allo ws setting a custom user- agent [ 37 ]. Similarly , monitoring solutions such as Nagios hav e a default user-agent string starting with check_http [ 38 ], [ 39 ]. W e therefore treat any user -agent string that does not start with ”Mozilla/5.0” as issued by a bot. Another way to detect stealthy bots is to check for dep- recated bro wser or operating system in the user -agent string. W ikimedia Foundation’ s user -agent breakdo wns sho w that the percentage of users using deprecated browser versions is very low for both Google Chrome and Firefox [ 40 ]. Once a new version of a bro wser is released, the previous version is rapidly abandoned by users due to automated updates b uilt in most browsers and operating systems. In 2023, all major browsers showed rapid adoption rates, with more than 80 % of adoption peak in almost a week [ 41 ]. Therefore, we classify clients that report versions that ha ve been deprecated for a long time (in our experiments: two years) as bots that either send fake user- agent strings or rely on old libraries or headless engines. Finally , as stated in section II-A , any modern browser should send a reduced user-agent string that does not contain specific version information, so any user-agent string that contains such information is likely to originate from a bot. Algorithm 1 summarizes our detection method based on user-agent string analysis. It can be used alone or in combi- nation with the fa vicon-based method. I V . E V A L U A T I O N W e ev aluate our proposed bot-detection approach across three dimensions. First, we assess the validity of the fa vicon as a proxy for authenticated traffic, verifying that it captures the same population of legitimate users without exposing any personally identifiable information. Second, we examine the complementary roles of rege x-based rules and curated bot user-agent lists in identifying good bots, and quantify the cov erage lost when either component is omitted. Third, we analyze the user-agent string signatures of bad bots whether F avicon-based Header-based Caddy Apache NGINX HAProxy Raw logs Anonymization (Crypto-P An) Parsing & Normalization (CSV) Fa vicon Analysis User-Agent Analysis Favicon requested? Likely non-bot Unknown yes no Good bot detection (regex + bot lists) Stealth bot detection Mozilla/5.0 prefix Deprecated versions U A reduction check Bot Figure 1: Overview of the bot detection methodology . Raw logs from multiple web server formats are anonymized, normalized, and then analyzed through two complementary approaches: favicon-based analysis and user-agent header-based analysis. Algorithm 1 User-Agent Based Bot Detection 1: function I S B OT ( ua ) ▷ ua : user-agent string 2: if I S B OT B Y R E G E X ( ua ) or I S B OT B Y L I S T ( ua ) then 3: retur n true 4: end if 5: if ¬ ua . S TA RT S W I T H (”Mozilla/5.0”) then 6: retur n true 7: end if 8: if H A S D E P R E C A T E D V E R S I O N ( ua ) then 9: retur n true 10: end if 11: retur n false 12: end function these can reliably distinguish malicious crawlers from legiti- mate bro wsers. Lastly , we compare our resultant method with state-of-the-art methods. T o better study how bots behave across websites, two hon- eypots have been deployed on the internet, both accessible via domain name, IPv4 address, and IPv6 address. Both honeypots are static, one asks to be index ed by Google and the other is not indexed by any search engine. robots.txt files are configured to allow all bots to crawl the website for the first honeypot, while the second honeypot disallows all bots from crawling the website. Other logs are collected from third-party partners, including a Learning Management System (LMS). Our logs are provided from websites hosted in different locations (Japan, USA, Europe,. . . ). These logs are collected directly from the web server and contain only HTTP headers and metadata about the requests; they are not enriched with other information. The dataset used for ev aluation consists of web traffic logs collected from the aforementioned sources ov er a period of sev eral years, starting in July 2024. The logs contain a total of 4,594,072 requests, with 54,945 unique user-agent strings. The dataset is anonymized to protect the pri vac y of indi viduals and organizations inv olved in the study , following the ethical considerations outlined in section VI . A. F avicon The ground truth is composed of an estimation of the number of anonymized authenticated IPs for the LMS logs. T o av oid complex fingerprinting matching IPs to a specific user, which can increase the risk of priv acy breaches and might not respect the ethical considerations outlined in section VI , another , less precise approach is used. By design, most content on the LMS is accessible only to authenticated users. A user can read and view some materials without registering, but must be re gistered and logged in to submit and test their work. Students submit their work to the LMS for grading via the web interface. Under the hood, the browser sends a POST request to a specific endpoint (e.g., /course/ ) to submit the work. An unauthenticated user post ing to this endpoint receiv es a 404 status code, whereas an authenticated user receiv es a 200 status code. Counting the number of unique IP addresses that issue POST requests to the /course/ endpoint provides an estimate of the number of unique authenticated users. This estimate is not perfect, as some users might share the same IP address (e.g., behind a NA T 1 ), some users can access the LMS without submitting any code 2 , and some users might have dynamic IP addresses. This number still provides a baseline to e valuate 1 The university from which the dataset comes does not use any kind of N A T . 2 Due to how this LMS is used, this behaviour is uncommon. Day 1 Day 2 Day 3 Day 4 Day 5 Day 6 Day 7 Day 8 Day 9 Day 10 Day 11 0 1 , 000 2 , 000 3 , 000 Unique IP addresses T otal IPs Fa vicon IPs POST IPs Figure 2: Daily unique IP addresses issuing favicon requests and POST requests to /course/ over the observation period. the performance of our detection method while respecting the ethical considerations outlined in section VI . As stated in section III-A , a CRON task ran daily to up- date the fa vicon URL ( /favicon.ico?v=DATE ), forcing browsers to request it daily . Figure 2 sho ws the number of unique IP addresses that requested the fa vicon, issued POST requests to the /course/ endpoint, and the total number of unique IP addresses that issued any kind of request to the LMS on a daily basis. The numbers of unique IP addresses are similar for both the fa vicon requests and the POST requests, whereas the total number of unique IP addresses is much higher . The difference between the number of unique IP addresses that requested the favicon and the number that issued POST requests to the /course/ endpoint can be explained by the fact that some authenticated users might not hav e submitted any work during the observ ation period or requested the fa vicon from another IP address (e.g., mobile network, home network, etc.). Ho wever , the similarity between the number of unique IP addresses that requested the fa vicon and the number that issued POST requests to the /course/ endpoint suggests that the detection method for bots based on fa vicon requests is effecti ve. A paired t-test found no significant difference between the two daily counts ( t (10) = − 0 . 981 , p = 0 . 350 , Cohen’ s d = − 0 . 3 ), indicating a small and non-significant effect. The negati ve t value indicates that, on average, the first variable (favicon IPs) was slightly lower than the second (POST IPs), which corroborates the fact that the f avicon is retriev ed only once per browser per day , whereas the user may hav e changed IPs multiple times during the day and issued multiple POST requests. Furthermore, a Pearson correlation rev ealed a strong positiv e association between the two series ( r = 0 . 87 , p < 0 . 001 ), suggesting that the number of unique IP addresses requesting the favicon is strongly correlated with the number of unique IP addresses issuing POST requests to the /course/ endpoint. A solution to improv e the accuracy of this detection method, giv en that our uni versity network causes extensiv e IP hopping, would be to use fingerprinting techniques to match the IP T able I: T op 10 most frequent user agents in the logs Browser Operating System Requests Google Chrome 139 W indows 10 1 , 699 , 193 ( 36 . 98 %) Apache-CXF 3.5.8 — 236 , 298 ( 5 . 14 %) Facebook External Agent — 176 , 824 ( 3 . 84 %) Amazonbot 0.1 — 144 , 945 ( 3 . 15 %) Google Chrome 142 W indows 10 142 , 854 ( 3 . 10 %) Bingbot 2.0 — 121 , 909 ( 2 . 65 %) ClaudeBot 1.0 — 108 , 189 ( 2 . 35 %) Internet Explorer 8.0 W indows XP 93 , 610 ( 2 . 03 %) (empty) — 89 , 875 ( 1 . 95 %) Google Chrome 142 macOS 80 , 994 ( 1 . 76 %) Other — 1 , 699 , 381 ( 36 . 99 %) T otal — 4 , 594 , 072 ( 100 %) addresses that requested the fa vicon with the IP addresses that issued POST requests to the /course/ endpoint (session cookies, TLS fingerprints, . . . ). Howe ver , this approach may increase the risk of priv acy breaches and is thus incompatible with our ethical stance. B. User-agent T able I lists the top 10 most frequent user agents in the logs. This top 10 includes well-known bots such as Googlebot, Bingbot, Amazonbot, and ClaudeBot, as well as a large number of requests with an empty user-agent string (”-”). Those user-agents account for a significant portion of the traffic representing approximately 63% of the total requests. W e validate the dif ferent techniques based on the user-agent string separately for good bots and stealthy robots: 1) Good bots: As explained in section III-B1 , good bots identify themselves as bots in the user-agent header . Cloud- flare, one of the largest security and CDN providers, publishes a comprehensiv e directory of ”certified bots” [ 42 ], [ 43 ]. How- ev er , only a fraction of bots are listed in this directory [ 44 ]; the others are kept internal. This directory is used as a baseline to ev aluate the true positi vity of our detection method for good bots. The results of our detection method are compared with the list of bots provided by Cloudflare. Among 54,945 unique user -agents, 373 are identified as robots by using the py-ua and robots.json techniques presented in section III-B1 . T able II shows the distribution and overlap among the different detection methods for good bots. Of these 373 user-agents, 185 were also identified as bots by Cloudflare, while 188 were not listed in the Cloudflare directory . Forty-one Cloudflare-listed bots were not detected by our method, yielding a recall of approximately 81 . 7% with respect to Cloudflare as the ground truth. Although 373 user-agents identified as bots by our method seems low (0.68% of the total unique user-agents), weighting these user-agents by their frequency in the logs shows that they represent a significant portion of the traffic. Specifically , these 373 user-agents account for approximately 25 . 6% of the total requests (with less than 0 . 2% undetected bots) made on all captured traffic. Figure 6 in appendix shows the distribution by reason of flagged user agent weighted by frequency . T able II: Overlap between our bot detection methods ( robots.json and py-ua defined in section III-B1 ) and Cloudflare directory across 373/414 detected bot user -agents, out of 54,945 unique user-agents. robots.json [ 25 ] py-ua [ 33 ] Cloudflare [ 43 ] Count • · · 111 · • • 98 · • 90 · · • 41 • • 28 • • • 25 • · • 21 Set sizes: 185 241 185 414 Looking at the self-declared user-agent strings is not suf fi- cient to detect all bots, as some bots do not identify themselves as such in the user -agent string. Such bots ha ve usually ”badly- forged” user-agents, which can be detected using the user- agent coherence method described in section III-B2 . The next section e valuates the performance of this method for detecting stealthy robots. 2) Stealth robots: Figure 5 shows the distribution and ov erlap among the different detection methods for stealthy robots using an UpSet plot [ 45 ] for a unique set of user-agents. Among 54,945 unique user -agents, 51,268 (93%) are identified as bots by the user-agent coherence method. Of these 51,268 user-agents, 48,646 (94.9%) are identified as bots by the ”deprecated browser” method, 27,496 (53.6%) are identified as bots by the ”deprecated OS” method, 1,688 (3.3%) do not start with ”Mozilla/5.0”, 719 (1.4%) are identified as bots by the ” user-agents ” library , and 241 (0.47%) are found in the ” robots.json ” list. The ”deprecated” heuristic methods (browser and OS) might look like the more ”aggressi ve” ones as they identify a large number of user-agents as bots. One might think they may generate numerous false positives. Howe ver , the majority of flagged user-agents by these methods are using more than 5 years old browsers and operating systems, which are unlikely to be used by legitimate users [ 41 ]. In these cases, it is important to pair our detection method with a more precise activ e one to av oid blocking someone arbitrarily . Figure 3 sho ws the distribution of claimed Android versions in user -agent strings. While a spike should be expected for Android 10 (released in September 2019) because it is the default platform information for Android de vices used in user- agent reduction, the distribution shows that many user-agents claim to use Android versions that are no longer supported by Google (e.g., Android 4.4, released in 2013). According to the Android version distribution, Android 10 and later hav e a 90.8% cumulativ e share [ 46 ], which is not reflected in the user-agent strings, suggesting that many of them use outdated operating systems or forged user-agent strings. Figures 4a and 4b sho w similar distributions for Firefox and Chrome v ersions, respecti vely , with many user-agents claiming to use outdated versions of these browsers. For Firefox, a spike can be observed for version 47, which 0 1 2 3 4 5 6 7 8 9 10 11 12 10 100 1,000 10,000 100,000 Claimed Android version Number of unique user-agents Unique U As Requests Figure 3: Distrib ution of claimed Android versions in user - agent strings. was released in June 2016 and ceased to recei ve updates in September 2017. Inside User-agents claiming to use Firefox 47, the first most common user-agent ” Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0 ” accounts for 11,401 requests and is the one giv en as an example by Mozilla in their documentation for user-agent parsing [ 10 ]. It is also av ailable as an example user-agent used by Colly , a scraping library [ 47 ]. For Chrome versions, a pronounced plateau can be observed for both desktops and mobiles around versions 39 and 60. Chrome 39, the first version of Google Chrome supporting 64- bit architectures, was released in November 2014 and ceased to receiv e updates in January 2015 [ 48 ]. Chrome 61 released in September 2017 was the first version to support Jav aScript Modules nativ ely [ 49 ]. Similarly , our logs contain 558 unique user-agents claim- ing to use Internet Explorer (MSIE), officially discon- tinued by Microsoft in June 2022 and running ver- sions that did not support TLS. The user-agent string Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0) is an Internet Explorer 8.0 user- agent, released in March 2009. This exact user-agent accounts for 93610 requests (2% of the total) and is the eighth most prev alent user-agent in our logs. These requests are highly un- likely to originate from legitimate users. Further inv estigation indicates that web forums identify this user-agent as used by Nessus [ 50 ], [ 51 ], a widely used vulnerability scanner . W e pre viously showed in section IV -A that the fa vicon can be used as a reliable heuristic without compromising user priv acy: the number of IPs requesting the fa vicon per day and the number of authenticated IPs agree in both trend and level across days. W e also showed in section IV -B1 that both regex- based rules and a list of bot user-agent strings are required: the former prev ents missing bots that do not include an obvious keyw ord in their self-declared string, and the latter catches bots that are not present in our list (for example, if the list is not updated). Lastly , we sho wed in section IV -B2 that bad 0 20 40 60 80 100 1 10 100 1 , 000 10 , 000 Claimed Firefox version Number of requests (a) Distribution of claimed Firefox versions in user-agent strings. 0 20 40 60 80 100 120 1 10 100 1 , 000 10 , 000 Claimed Chrome version Number of requests (b) Distribution of claimed Chrome versions in user-agent strings. Chrome and Chrome Mobile are merged for readibility . Figure 4: Distribution of claimed Chrome and Firefox versions in user-agent strings. bots usually use malformed user -agent strings or deprecated browsers that are unlikely to function on modern websites. C. Comparison against state-of-the-art T o validate our results, and because no single fully labelled dataset contains both humans and bots, we constructed one by combining two reliable sources. Human traf fic was drawn from the LMS, where real users were identified using the technique described in section IV -A (augmented with internal traffic and filtered for monitoring requests). Bot traffic was drawn from the honeypot, which real users hav e no reason to access. The honeypot was considered a reliable source of bot traffic: the fiv e most frequent origin providers, Microsoft, Cloudflare, Amazon, DigitalOcean, and Google Cloud Plat- form, accounted for 71% of its requests. This combined dataset serves as ground truth for ev aluating whether our heuristics correctly distinguish humans from bots. The confusion matrix (T able III ) reveals a fav ourable asym- metry: the false positiv e rate is low at 3.0%, meaning that only a small fraction of legitimate human requests are incorrectly flagged. The false negati ve rate is higher at 32.4%, indicating that a nontrivial share of bot requests evades detection. This is an acceptable trade-off in a context where flagging a real user is more disruptive than missing a bot. That’ s why it is important to pair our method with a second line of defense. Importantly , this recall of 67.6% substantially outperforms a naiv e string-matching approach. For reference, the Cloudflare bot pattern list identifies only 8.4% of requests in our log, cov ering 58 of the 873 unique user agents observed (6.6%). By contrast, our method flags 491 unique user agents (56.2%), an eightfold increase in coverage. This suggests that a large proportion of crawlers activ e in the infrastructure deliberately omit or spoof their user -agent strings to avoid rule-based block lists, and that a suspicion-based approach is necessary to sur- face them. It also significantly outperforms CrawlerDetect [ 24 ] (18.1%), Matomo DeviceDetector [ 23 ] (12.0%), and known- bot IP lists [ 26 ] (18.0%), all of which miss over 80% of bot requests in our dataset. T able III: Comparison of Bot Detection Methods Method TP (%) FN (%) FP (%) TN (%) Our method 67.6 32.4 3 . 0 97 . 0 Cloudflare Bot Management [ 43 ] 8 . 4 91 . 6 0 . 1 99 . 9 CrawlerDetect [ 24 ] 18 . 1 81 . 9 0 . 1 99 . 9 Matomo De viceDetector [ 23 ] 12 . 0 88 . 0 0 . 1 99 . 9 Known-bots IP list [ 26 ] 18 . 0 82 . 0 0.0 100.0 Percentages are row-normalised within each class (Bot / Human). TP and FN are computed over the Bot class; FP and TN ov er the Human class. The separator line distinguishes our method from state-of-the-art baselines. W ell-beha ved bots are e xpected to request the robots.txt file to check whether the y are allo wed to crawl a website [ 11 ], [ 52 ]. Howe ver , in the ”Bots” dataset, only 351 of 3,185 unique IPs (11%) requested it, suggesting that the v ast majority deliberately av oid identifying themselves as crawlers. Similarly , only 264 (8%) requested the fa vicon, reinforcing the idea that most bots do not behave like real browsers and that the favicon heuristic may be a reliable discriminator . While our method does not achie ve perfect separation (a 32.4% false negativ e rate indicates that some bots still pass undetected), the primary objectiv e is not to intercept ev ery automated request but to reduce the volume of traffic that must be subjected to acti ve verification challenges. By confidently clearing 97.0% of human requests and flagging 67.6% of bots at the filtering stage, the method substantially narro ws the population that needs further scrutiny . Consequently , the friction imposed by challenge mechanisms is reserved to a much smaller and genuinely ambiguous subset of requests, preserving the e xperience of the v ast majority of le gitimate users. V . C O N C L U S I O N In this paper, we presented a lightweight, passiv e approach to bot detection that combines user-agent coherence analysis with favicon-based heuristics. Unlik e acti ve techniques such as Ja vaScript challenges or CAPTCHAs, our method operates entirely on standard web serv er logs and requires no client- side interaction, preserving the user experience for legitimate visitors. Our ev aluation of over 4.6 million requests demonstrates that the proposed method detects 67.6% of bot traffic while maintaining a false-positi ve rate of only 3.0%. These results indicate that a large proportion of activ e crawlers deliberately spoof or omit identifying information in their user-agent strings and that checks are necessary to surface them. For website operators seeking to detect or block bots, a layered strategy is recommended. As a first line of defense, our user-agent coherence method can be deployed directly in web server configurations or as lightweight middle ware with minimal computational overhead. The f avicon heuristic provides a complementary behavioural signal, particularly effecti ve when combined with periodic cache in validation. Requests that pass both filters can be considered likely human, while flagged requests can be routed to activ e challenges such as CAPTCHAs [ 19 ] or proof-of-work systems [ 17 ], [ 18 ], thereby restricting their friction to a smaller, genuinely ambiguous subset of traffic. Looking ahead, the increasing v olume of bot traf fic- accounting for roughly half of all web requests-necessitates a shift in perspectiv e. Rather than treating all bot access as adversarial, website operators could of fer differentiated service tiers. Lightweight page v ersions, stripped of Jav aScript, stylesheets, and visual assets, could be served to identified crawlers, substantially reducing server load and bandwidth costs while still providing the content they seek. Future work will focus on defining an API and a website representation to facilitate machine readability (for example, for LLM training). V I . E T H I C A L C O N S I D E R A T I O N S This research strictly adheres to ethical guidelines and principles to ensure the responsible conduct of research. Due to the nature of our research, which in volv es analyzing web traffic and user-agent data, several measures were taken to protect the priv acy and confidentiality of individuals and organizations in volv ed in the study , including anonymizing data (using cryptography based priv acy systems [ 30 ]) and removing personally identifiable information before any kind of analysis. R E F E R E N C E S [1] K. T if fany, “Maybe you missed it, but the internet ’ died’ fiv e years ago”, The Atlantic , Aug. 31, 2021. [2] D. Belson. “The 2025 cloudflare radar year in revie w- the rise of AI, post-quantum, and record-breaking DDoS attacks”. [Online]. A vailable: https : / / blog . cloudflare . com/radar- 2025- year - in- revie w/ [3] B. Mueller et al. “How crawlers impact the operations of the wikimedia projects”. [Online]. A v ailable: https : // dif f .wikimedia .org/ 2025/ 04/ 01/ ho w - crawlers- impact - the- operations- of- the- wikimedia- projects/ [4] B. Mueller et al. “Quo vadis, cra wlers? progress and what’ s next on safeguarding our infrastructure”. [On- line]. A v ailable: https : / / dif f . wikimedia . org / 2026 / 03 / 26 / quo - v adis - crawlers - progress - and - whats - next - on - safeguarding- our - infrastructure/ [5] D. Kwon, “W eb-scraping ai bots disrupt databases and journals”, Natur e , vol. 642, p. 281, 2025. [6] M. Arlitt et al., “Characterizing the scalability of a large web-based shopping system”, A CM T rans. Inter- net T ec hnol. , vol. 1, no. 1, pp. 44–69, Aug. 2001. [7] B. Edwards. “Open source devs say AI crawlers dom- inate traffic, forcing blocks on entire countries”. [On- line]. A v ailable: https : / / arstechnica . com / ai / 2025 / 03 / devs- say - ai - crawlers- dominate - traffic - forcing - blocks - on- entire- countries/ [8] H. Nielsen et al., “Hypertext transfer protocol – HTTP/1.1”, Internet Engineering T ask Force, Request for Comments RFC 2616, Jun. 1999. [9] R. T . Fielding et al., “HTTP semantics”, Internet Engi- neering T ask Force, Request for Comments RFC 9110, Jun. 2022. [10] “User-agent header - HTTP — MDN”. [Online]. A vail- able: https : / / de veloper. mozilla . org / en - US / docs / W eb / HTTP/Reference/Headers/User- Agent [11] T . Kim et al., “Scrapers selectiv ely respect robots.txt di- rectiv es: Evidence from a large-scale empirical study”, in Pr oceedings of the 2025 ACM Internet Measurement Confer ence , ser . IMC ’25, New Y ork, NY, USA: A CM, Oct. 28, 2025, pp. 541–557. [12] “User-agent reduction - HTTP — MDN”. [Online]. A v ailable: https : / / de veloper . mozilla . org / en - US / docs / W eb/HTTP/Guides/User - agent reduction [13] “User-agent reduction”. [Online]. A v ailable: https : / / www .chromium.org/updates/ua- reduction/ [14] “User-agent client hints”. [Online]. A vailable: https : / / wicg.github .io/ua- client- hints/ [15] WICG/ua-client-hints , Mar . 1, 2026. [Online]. A vail- able: https://github .com/WICG/ua- client- hints [16] E. Liu et al., “Somesite i used to crawl: A wareness, agency and efficacy in protecting content creators from AI crawlers”, in Pr oceedings of the 2025 ACM Internet Measur ement Confer ence , ser . IMC ’25, Ne w Y ork, NY, USA: Association for Computing Machinery, Oct. 15, 2025, pp. 78–99. [17] T echaro, T echar oHQ/anubis , Feb . 16, 2026. [Online]. A v ailable: https://github .com/T echaroHQ/anubis [18] A. Back, Hashcash - a denial of service counter- measur e , Aug. 1, 2002. [19] L. V on Ahn et al., “CAPTCHA: Using hard AI problems for security”, in Advances in Cryptology — EURO- CRYPT 2003 , E. Biham, Ed., red. by G. Goos et al., vol. 2656, Berlin, Heidelberg: Springer Berlin Heidel- berg, 2003, pp. 294–311. [Online]. A v ailable: http : / / link.springer .com/10.1007/3- 540- 39200- 9 18 [20] V . Shet and reCAPTCHA. “Are you a robot? introduc- ing “no CAPTCHA reCAPTCHA””. [Online]. A vail- able: https :// security . googleblog.com /2014/ 12/are - you- robot- introducing- no- captcha.html [21] M. Hus ´ ak et al., “HTTPS traffic analysis and client identification using passive SSL/TLS fingerprinting”, EURASIP Journal on Information Security , vol. 2016, no. 1, p. 6, Feb . 26, 2016. [22] Ar cjet/well-known-bots , Mar . 18, 2026. [Online]. A v ail- able: https://github .com/arcjet/well- known-bots [23] Matomo, Matomo-or g/device-detector , Mar . 27, 2026. [Online]. A v ailable: https : / / github . com / matomo - org / device-detector [24] M. Beech, J ayBizzle/crawler -detect , Mar . 26, 2026. [Online]. A vailable: https : / / github . com / JayBizzle / Crawler - Detect [25] Ai-r obots-txt/ai.robots.txt , Feb . 26, 2026. [Online]. A v ailable: https://github .com/ai- robots- txt/ai.robots.txt [26] A. R ¨ ohm, AnTheMaker/GoodBots , Mar . 27, 2026. [On- line]. A vailable: https : / / github . com / AnTheMaker / GoodBots [27] A. W ei et al., “A deep learning approach to web bot detection using mouse behavioral biometrics”, in Bio- metric Recognition , Z. Sun et al., Eds., Cham: Springer International Publishing, 2019, pp. 388–395. [28] “Cloudflare bot management solution”. [Online]. A vail- able: https : / / www . cloudflare . com / en - gb / application - services/products/bot- management/ [29] “Bot manager”. [Online]. A vailable: https : / / www . akamai.com/products/bot- manager [30] J. Xu et al., “Prefix-preserving IP address anonymiza- tion: Measurement-based security ev aluation and a new cryptography-based scheme”, in 10th IEEE Interna- tional Confer ence on Network Pr otocols, 2002. Pro- ceedings. , Nov . 2002, pp. 280–289. [31] W . Bamber g. “Favicon”. [Online]. A vailable: https : / / dev eloper .mozilla.org/en- US/docs/Glossary/Fa vicon [32] “What is googlebot”. [Online]. A vailable: https : / / dev elopers .google . com/ search /docs / crawling- indexing / googlebot [33] S. Ong, Selwin/python-user-ag ents , Feb. 23, 2026. [On- line]. A vailable: https:// github .com /sel win/python- user- agents [34] “Overvie w of OpenAI crawlers”. [Online]. A vailable: https://dev elopers.openai.com/api/docs/bots/ [35] A. Andersen. “History of the browser user -agent string”. [Online]. A v ailable: https : / / webaim . or g / blog / user - agent- string- history/ [36] D. Stenberg, Curl/curl , 1996. [Online]. A v ailable: https: //github .com/curl/curl [37] D. Stenberg. “Curl - changes in 4.5.1”. [Online]. A vail- able: https://curl.se/ch/4.5.1.html [38] Nagios-plugins/nagios-plugins , Mar . 11, 2026. [Online]. A v ailable: https : / / github . com / nagios - plugins / nagios - plugins [39] Monitoring-plugins/monitoring-plugins , Feb . 23, 2026. [Online]. A vailable: https : / / github . com / monitoring - plugins/monitoring- plugins [40] W ikimedia Foundation, User agent br eakdowns , 2026. [Online]. A vailable: https : / / analytics . wikimedia . or g / dashboards/browsers/ [41] T . T ijhof. “Browser adoption rates”. [Online]. A vailable: https://timotijhof.net/posts/2023/browser - adoption/ [42] “V erified bots”. [Online]. A vailable: https: //developers. cloudflare.com/bots/concepts/bot/verified- bots/ [43] “Bots directory — cloudflare radar”. [Online]. A vail- able: https://radar .cloudflare.com/bots/directory [44] “Bots”. [Online]. A vailable: https : / / developers . cloudflare.com/bots/concepts/bot/ [45] A. Lex et al., “UpSet: V isualization of intersecting sets”, IEEE T ransactions on V isualization and Com- puter Graphics , v ol. 20, no. 12, pp. 1983–1992, Dec. 31, 2014. [46] E. Belinski. “Android API levels”. [Online]. A vailable: https://apilev els.com/ [47] ascimoo. “The most important HTTP headers for scrap- ing”. [Online]. A vailable: https : / / go - colly. or g / articles / scraping related http headers/ [48] Google. “Stable channel update”. [Online]. A vailable: https: // chromereleases. googleblog.com /2014 /11 /stable- channel- update 18.html [49] P . Lepage. “Ne w in chrome 61”. [Online]. A v ailable: https://dev eloper .chrome.com/blog/new- in- chrome- 61 [50] F5. “W eb server HTTP header internal IP disclosure”. [Online]. A vailable: https : / / community . f5 . com / discussions / technicalforum / web - server - http - header - internal- ip- disclosure/263036 [51] “HTTP TRA CE method on vCenter port 9084”. [On- line]. A vailable: https : / / kno wledge . broadcom . com / external /article / 315560 / http - trace - method - on - vcenter - port- 9084.html [52] M. Koster et al., “Robots exclusion protocol”, Internet Engineering T ask Force, Request for Comments RFC 9309, Sep. 2022. A P P E N D I X Figures 5 and 6 present the distributions of detected user- agent string classifications, reported unweighted and weighted by the number of requests, respecti vely . Comparing the two figures rev eals a notable asymmetry: while deprecated bro wser and OS versions account for the majority of distinct bot user-agent strings, a relatively small set of user-agents with non-Mozilla prefixes or known bot signatures generates dis- proportionately high traffic volumes. This suggests that the most aggressive bots rely on simple, poorly forged user-agents rather than div erse spoofing strategies. 0 10k 20k 30k Intersection size 27k 22k 846 634 583 103 90 61 52 34 31 18 18 17 15 15 12 1 1 1 1 1 1 deprecated OS deprecated browser non-Mozilla UA robots.json py-ua unknown browser Cloudflare 0 20k 40k Set size 27k 49k 2k 185 241 719 185 Figure 5: Overlap among bot detection methods across 54,945 unique user-agent strings, visualized with an UpSet plot [ 45 ]. The two largest intersections, deprecated OS ∩ deprecated browser (27k) and deprecated browser alone (22k), dominate, indicating that the majority of user-agent strings are caught using version-based heuristics. 0 200k 400k Intersection size 389k 375k 263k 251k 214k 179k 120k 104k 57k 42k 39k 38k 23k 15k 14k 1 1k 8k 3k 2k 1k deprecated OS deprecated browser non-Mozilla UA robots.json py-ua unknown browser Cloudflare 0 500k 1.0M Set size 236k 310k 874k 655k 1.1M 280k 961k Figure 6: Overlap among bot detection methods weighted by request frequency . When weighted, the non-Mozilla U A and py-ua [ 33 ] methods gain prominence (874k and 1.1M set sizes, respecti vely), revealing that a smaller number of bot user- agent strings with non-standard prefixes or known bot signatures generate disproportionately high traffic volumes.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment