Measuring Cross-Jurisdictional Transfer of Medical Device Risk Concepts with Explainable AI
Medical device regulators in the United States(FDA), China (NMPA), and Europe (EU MDR) all use the language of risk, but classify devices through structurally different mechanisms. Whether these apparently shared concepts carry transferable classific…
Authors: Yu Han, Aaron Ceross
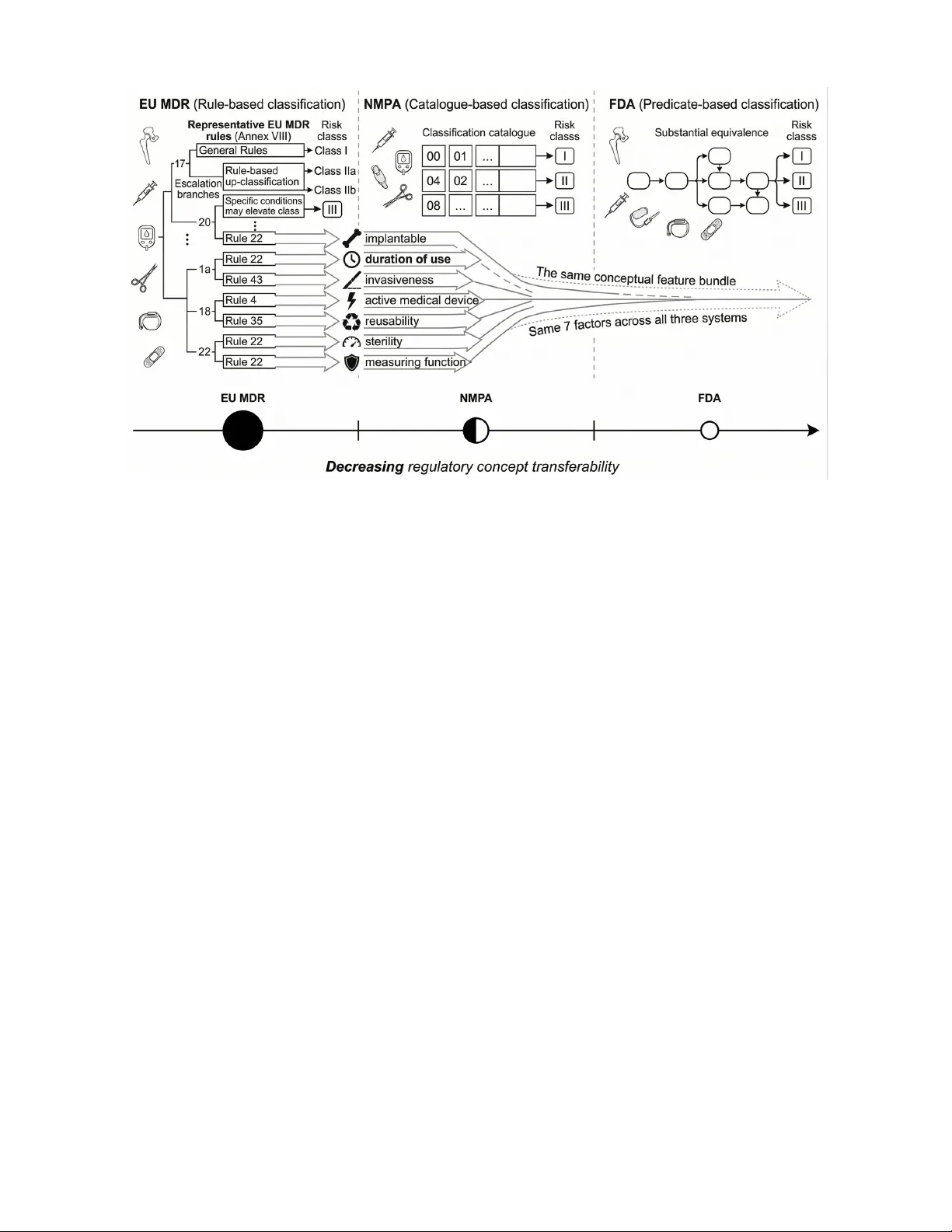
1 Measuring Cross-Jurisdictional T ransfer of Medical De vice Risk Concepts with Explainable AI Y u Han and Aaron Ceross Abstract —Medical device r egulators in the United States (FD A), China (NMP A), and Europe (EU MDR) all use the lan- guage of risk, but classify devices through structurally different mechanisms. Whether these apparently shar ed concepts carry transferable classificatory signal across jurisdictions r emains unclear . W e test this by reframing explainable AI as an empirical probe of cross-jurisdictional regulatory overlap. Using 141,942 device records, we derive seven EU MDR risk factors, including implantability , in vasiv eness, and duration of use, and evaluate their contribution acr oss a three-by-thr ee transfer matrix. Under a symmetric extraction pipeline designed to r emov e jurisdiction-specific advantages, factor contribution is negligible in all jurisdictions (all ∆ F1 < 0.01), indicating that clean cr oss- jurisdictional signal is at most marginal. Under jurisdiction- specific pipelines, a modest gain appears only in the EU MDR- to-NMP A direction ( ∆ F1 = +0.024), but sensitivity analyses show that this effect is weak, context-dependent, and partly confounded by extraction and representation choices. Re verse- direction pr obes show strong asymmetry: FD A-derived factors do not transfer meaningfully in any direction, and NMP A-deri ved factors do not carry signal back to EU MDR. Zero-shot transfer further fails on EU MDR Class I (F1 = 0.001), consistent with a mismatch between residual and positional class definitions. Overall, cross-jurisdictional transfer is sparse, asymmetric, and weak. Shar ed r egulatory vocab ulary does not, under this operationalisation, translate into strong portable classification logic. The findings challenge a common assumption in cross- jurisdictional regulatory AI and show how explainable AI can be used to measure, rather than assume, regulatory overlap. Index T erms —Medical device classification, cr oss-jurisdictional regulation, regulatory concept transfer , explainable AI, regula- tory structure I . I N T RO D U C T I O N Medical device classification determines the regulatory pathway and post-market requirements that apply to a giv en product. All major jurisdictions assign devices to risk-based categories, but they do so through structurally different mech- anisms [1]–[5]. The European Union Medical Device Regula- tion (EU MDR) implements a rule-based system comprising 22 classification rules in Annex VIII, which assign de vices to one of four risk classes (I, IIa, IIb, and III) based on character- istics such as in v asiv eness, duration of contact, and intended purpose. The United States F ood and Drug Administration (FD A) employs a predicate-based system in which a de vice’ s classification depends substantially on whether a substantially equiv alent device already exists on the market, with over 1,700 product codes encoding this regulatory history . China’ s Y u Han is with the Institute of Biomedical Engineering, Department of Engineering Science, Uni versity of Oxford, Oxford O X1 3PJ, United Kingdom (e-mail: yu.han@eng.ox.ac.uk). Aaron Ceross is with Birmingham Law School, Univ ersity of Birmingham, Birmingham, United Kingdom. National Medical Products Administration (NMP A) operates a catalogue-based system in which de vices are matched to entries in a classification catalogue according to their product description and intended use. These structural differences (Figure 1) raise a fundamental question: how much regulatory structure do these systems ac- tually share? Prior work has compared re gulatory framew orks qualitativ ely [6]–[9], but no study has measured the degree of structural ov erlap empirically . Without such measurement, the gro wing number of AI systems proposed for regulatory decision support [10]–[12] must rely on untested assumptions about whether concepts like “in vasi veness” or “implantability” carry the same classificatory weight across jurisdictions. W e test this question by treating classification as an empir- ical probe of regulatory structure. By deriving structured risk factors from one jurisdiction’ s classification logic and measur- ing whether those factors improve classification performance in other jurisdictions, we quantify the degree and directionality of cross-jurisdictional concept o verlap. The resulting cross- transfer matrix, which tests three factor sources against three target jurisdictions, provides an empirical measure of re gu- latory structural distance across major de vice classification systems. A. Infer ential Ladder The ar gument proceeds at three lev els, from predictiv e gain to factor transferability to structural compatibility . 1) Predictiv e gain ( ∆ F1) is the directly observed quantity . It measures the change in classification performance when regulatory factors are added to text features. 2) Factor transferability is the immediate interpretation. It asks whether a specific set of EU MDR-deriv ed factors carries classification signal in other jurisdictions. 3) Structural compatibility of regulatory systems is a higher-le vel inference. Establishing it would require considerably more e vidence than this study provides, and we do not claim to do so. Accordingly , we treat predictive gain as evidence of trans- ferability under this operationalisation, not as proof of struc- tural compatibility . Observed ∆ F1 values support conclusions about factor transferability under the specific operationalisa- tion tested; they do not directly prove or disprove structural compatibility between re gulatory systems. B. Resear ch Questions RQ1. Under one specific factorisation of EU MDR An- nex VIII risk concepts, do these factors carry classification 2 Fig. 1: Study ov erview . The EU MDR classifies medical de vices through 22 explicit rules in Annex VIII, from which we extract se ven regulatory risk factors (implantable, duration of use, in vasi veness, activ e device, sterile, measuring function, and reusable). These factors serve as an empirical probe, testing whether risk concepts that carry classification signal in one regulatory system transfer meaningfully to structurally different ones such as NMP A ’ s catalogue-based approach and FDA ’ s predicate-based approach. The probe beam (centre) illustrates the observed gradient, with factor contrib ution highest within the originating rule-based system (a ceiling case reflecting circularity), dropping to modest lev els in the catalogue-based system and falling to negligible in the predicate-based system. signal in other jurisdictions, and which risk classes benefit most? RQ2. Under what structural conditions do cross- jurisdictional regulatory AI models fail, and what competing explanations remain liv e? C. Scope and Limitations Ground truth classification labels are deri ved from official database fields, specifically the NMP A UDI “classification basis” entries and FDA product code regulatory panel as- signments, rather than from the reasoning chains of human revie wers. For FD A 510(k) de vices, classification depends on predicate chains reflecting substantial equi valence, a mecha- nism that our factor-based approach does not capture. The seven regulatory factors (implantable, duration of use exceeding 30 days, surgically in vasi ve, active de vice, sterile, measuring function, and reusable) are derived from the classi- fication rules in EU MDR Annex VIII. EU MDR is used as the source jurisdiction because, among the three systems examined here, it alone sets out its classification logic as explicit rules tied to device characteristics. By contrast, the FDA relies primarily on substantial equiv alence to e xisting products, and NMP A assigns devices through catalogue matching based on product descriptions. Neither system provides an explicit rule structure from which comparable characteristic-based factors can be e xtracted directly . For that reason, Annex VIII is the only av ailable basis for constructing a systematically defined set of regulatory factors that can then be tested across jurisdictions. The analysis therefore examines transfer in one direction only , from the jurisdiction with codified characteristic-based rules to the two jurisdictions whose classificatory logic is less explicit. For EU MDR devices, the factors are deri ved from the classifi- cation rule recorded in the database through a rule-to-factor mapping, supplemented by multilingual keyword e xtraction from product names. Because this procedure partially encodes the rules themselves, the EU MDR factors contain a degree of circularity , which we address in Section IV -A3. The EU MDR uses a four -class system (I, IIa, IIb, and III), while the FD A and NMP A each use three-class systems (I, II, and III). For the unified cross-regime model, we compress EU MDR to three classes by merging IIa and IIb into a single Class II category . T o disentangle this compression artefact from other sources of cross-jurisdictional failure, we additionally ev aluate EU MDR under its native four-class scheme (Supplementary T able S4). D. Related W ork This study sits at the intersection of explainable AI, reg- ulatory AI, and comparati ve medical device regulation, b ut its contribution is not simply to combine these literatures. W e address a specific gap left by all three, as to whether apparently shared regulatory risk concepts tra vel across jurisdictions as 3 operativ e classificatory signals rather than as surface-le vel vocab ulary . W ithin explainable AI, feature-attribution methods such as SHAP [13], LIME [14], and Integrated Gradients [15] identify influential inputs, but they do not by themselves test whether a model has captured semantically meaningful regulatory abstractions. This limitation matters in legal and regulatory settings, where the relev ant structure is often organ- ised around mid-le vel concepts (e.g., in vasi veness, implantabil- ity , or duration of use) rather than around individual lexi- cal features. Concept-based methods, including TCA V [16], concept bottleneck models [17], and completeness-oriented concept explanations [18], are therefore closer to the object of analysis in this paper . W e draw on this line of work not to explain a model to end users in the usual sense, but to test whether concept bundles deriv ed from one regulatory regime retain classificatory value in another . W e also borrow the perturbational logic used in counterfactual explanation research [19], [20], but use it more modestly as a diagnostic tool to in vestigate reclassification barriers rather than as a claim about causal counterfactuals. In medical AI, explainability research has focused primarily on clinical decision support [21]–[23], with a growing critique that many XAI techniques do not deliv er the transparency or accountability they promise in practice [24]. Related work has begun to document transparency deficits in regulatory- authorised AI devices themselves [25]–[27].Our paper ad- dresses a different question: whether formalised risk concepts extracted from one jurisdiction retain classificatory value in another . W e use the model as an empirical probe of regulatory structure to test the alignment between those concepts and cross-jurisdictional classification outcomes. A separate body of work applies machine learning and language models to legal and regulatory tasks, including medical de vice classification and regulatory text processing [10], [11], [28]. That literature has sho wn that specialized models can achie ve useful within-domain performance, b ut it has generally treated regulatory labels as prediction tar gets rather than as e vidence about the structure of the regimes that generate them. In particular , prior classification studies ask whether models can reproduce decisions within a jurisdiction; they do not test whether the concepts encoded in one re gime remain informati ve when transferred to another . That distinc- tion is central here. Instead of focusing on whether AI can classify devices accurately , our study examines whether cross- jurisdictional regulatory AI rests on a defensible assumption of conceptual portability . Comparativ e work on medical device regulation has anal- ysed differences and conv ergence points in the FD A, EU MDR, and NMP A systems [6]–[8], [12], while harmonisation efforts such as IMDRF [29] and recent revie ws [9] have articulated frameworks for cross-border alignment. The EU AI Act adds another layer of complexity for high-risk AI-enabled devices [30]. Ho wever , this literature remains lar gely doctrinal, descriptiv e, or policy-oriented. It identifies similarities and differences in regulatory architecture, but it does not test whether shared risk vocab ulary corresponds to shared classifi- catory logic. That is the gap this paper addresses. By treating explainable AI as an empirical probe rather than as an end- user transparency tool, we test whether regulatory concepts deriv ed from EU MDR carry measurable classification signal in NMP A and FD A data, and thereby assess the extent and asymmetry of cross-jurisdictional concept transfer . I I . M E T H O D O L O G Y A. Overview The study employs two methodological components, each corresponding to one research question. For RQ1, we conduct a controlled factor ablation study . For each jurisdiction inde- pendently , Random Forest classifiers are trained under three conditions: using both text features and regulatory factors, using text features alone, and using regulatory factors alone. Classification performance is e valuated with per-class F1 scores from fiv e-fold stratified cross-validation. T o assess the reliability of the factor contribution ( ∆ F1), we repeat the fi ve- fold cross-validation across 10 random seeds. For each seed, the mean ∆ F1 is calculated in five folds, yielding 10 summary statistics of the seed-lev el. W e report the mean and 95% confidence interval computed from these 10 seed-lev el means, treating each full cross-validation run as the independent unit of replication. W e foreground effect size and uncertainty rather than null-hypothesis significance testing, as the five-fold design provides limited inferential granularity for p -v alues. All Random Forest classifiers use inv erse class frequency weighting to address class imbalance (e.g., EU MDR Class III constitutes only 1.9% of devices). This design isolates how much of each jurisdiction’ s classification logic is captured by EU MDR-derived regulatory factors compared to text features. For RQ2, we use two diagnostic approaches. W e first conduct zero-shot transfer experiments, ev aluating a model trained on FD A and NMP A data on EU MDR data without any EU MDR training examples. W e then apply a greedy perturbation-based reclassification search to identify the conditions under which valid reclassification paths cannot be found. B. P erturbation-Based Reclassification Searc h For each sampled device, we probe the trained model’ s decision boundaries by searching for factor perturbations that change its predicted class. This analysis characterises the clas- sifier’ s learned behaviour rather than the regulatory systems themselves; a perturbation that fails to reclassify a device in the model does not imply that the regulatory system lacks a valid reclassification path. Gi ven a de vice with feature vector x classified as class c by the trained Random Forest, we seek a minimal modification x ′ such that the model predicts a different target class c ′ = c . The search proceeds as follows: (1) for each of the seven regulatory factors, we enumerate all valid alternative v alues (e.g., in vasi veness ∈ { 0 , 1 , 2 } ); (2) for each candidate perturbation, we query the trained model for its predicted class; (3) among all single-factor perturbations that achie ve the target class c ′ , we select the one requiring the smallest change in factor value (i.e., a change from 0 to 1 is preferred over 0 to 2); (4) if no single-factor perturbation succeeds, we attempt all two-factor combinations, then three- factor combinations, up to a maximum of four simultaneous 4 changes. A reclassification attempt is deemed successful if a perturbation achie ving the target class is found within this search budget, and unsuccessful otherwise. W e sample 500 devices per jurisdiction (stratified by class) and attempt reclassification to each alternative class, yielding up to 1,000 attempts per jurisdiction. C. Re gulatory F actor Extraction Sev en regulatory factors are extracted from device records using jurisdiction-specific methods. For NMP A devices, fac- tors are inferred from the two-digit classification code prefix in the UDI record. For example, prefixes 03, 06, and 13 indicate implantable devices, while prefixes 08, 16, and 22 indicate devices with a measuring or diagnostic function. These code- based assignments are supplemented by keyword matching against the Chinese-language product description field. For FDA devices, factors are extracted through keyword matching against the de vice name and summary fields. T erms such as “implant, ” “prosthesis, ” and “stent” indicate im- plantable devices, while terms such as “catheter , ” “surgical, ” and “needle” indicate surgically in vasi ve devices. For EU MDR devices, a different approach is necessary because EUD AMED records contain limited textual informa- tion, averaging only 36 characters per product description. Factors are therefore deri ved primarily from the MDR Annex VIII classification rule recorded in the database. Each rule corresponds to a characteristic factor profile. For instance, Rule 8, which covers long-term surgically in vasi ve or im- plantable de vices, is coded as implantable = 1 and in vasi veness = 2. Rule 1, which covers non-inv asiv e devices, is coded with all risk factors set to 0 and reusable set to 1. W e supplement this rule-based deriv ation with keyword matching on product names in English, German, and French. The EU MDR approach derives factors from the classifica- tion rule itself, which introduces circularity because the factors partially encode the classification outcome. This circularity is addressed in Section IV -A3. D. F eatur e Representation Each device is represented by a 49-dimensional feature vector consisting of seven regulatory factors and 42 text- deriv ed features. The text features are computed by applying term frequency-in verse document frequency (TF-IDF) weight- ing with character n-grams (1–2 characters, word-boundary aware) to device descriptions, limited to the 500 most frequent features, followed by dimensionality reduction to 42 compo- nents through truncated singular value decomposition (SVD). W e chose a character n-gram analyser because it is language- agnostic and can operate across scripts without language- specific tok enisation. This is necessary because NMP A de- scriptions are in Chinese, FD A descriptions are in English, and EU MDR descriptions span sev eral European languages. An important limitation of this representation is that TF-IDF with character n-grams produces disjoint feature spaces across different writing systems. In the per-jurisdiction experiments (Section IV -C1), this is benign because each model operates T ABLE I: Dataset composition by jurisdiction and risk class Jurisdiction n Class I Class II Class III FD A (US) 53,745 1,373 28,302 24,070 NMP A (China) 65,703 1,309 37,564 26,830 EU MDR (EU) 22,494 9,819 12,255 420 T otal 141,942 within a single language domain. In the unified and zero- shot experiments, howe ver , the SVD components ef fectiv ely encode language identity rather than shared semantic content, rendering the text channel non-functional across jurisdictions. T o address this limitation, we conduct sensitivity analyses with multilingual sentence embeddings that operate in a shared cross-lingual semantic space (Section IV -C5). I I I . E X P E R I M E N TA L S E T U P A. Dataset The dataset comprises 141,942 medical device records drawn from three sources (T able I). FD A data includes 29,681 510(k) premarket notification clearances and 24,064 premarket approv al records, obtained through the openFDA API. NMP A data consists of 65,703 records from the UDI database main- tained by China’ s National Medical Products Administration. EU MDR data includes 22,494 records from the EUD AMED database, spanning four nativ e risk classes: Class I (9,819 devices), Class IIa (9,903), Class IIb (2,352), and Class III (420). For the unified cross-regime model, Class IIa and Class IIb are merged into a single Class II category . B. Experiments For RQ1, we conduct per-jurisdiction Random Forest abla- tion experiments comparing three feature conditions with per- class F1 scores and 95% confidence intervals. W e additionally audit the quality of factor extraction across jurisdictions, ev aluate EU MDR under its nativ e four-class scheme, and analyse concept-to-class correlations per jurisdiction. For RQ2, we report the unified model’ s per-jurisdiction performance breakdown, conduct zero-shot transfer from FD A and NMP A to EU MDR, and perform perturbation-based reclassification failure analysis disaggregated by jurisdiction, class transition direction, and factor complexity . I V . R E S U LT S A. RQ1: Re gulatory Concept T ransfer 1) F actor Extraction Audit: The three extraction pipelines differ in epistemic status. The EU MDR factors are derived from the recorded classification rules, the NMP A factors from the prefixes of the classification code, and the FDA factors from the matching of text ke ywords. T able II summarises cov erage, validation against manual annotation (150 devices per jurisdiction, 450 total), and inter-rater reliability (IRR). EU MDR sho ws a substantially higher undeterminable rate than the other jurisdictions. In total, 51.7% of EU MDR f actor– device pairs could not be annotated from the a vailable text, compared with 15.3% for NMP A and 19.8% for FD A. This 5 T ABLE II: Factor extraction audit. (A) Pipeline validation against manual annotation; undeterminable rate = proportion of factor–de vice pairs where text was insufficient for an- notation. (B) Inter-rater reliability (post-adjudication, n =90 devices). Per-factor IRR detail in Supplementary T able S1. (A) Per-jurisdiction extraction quality Metric EU MDR NMP A FD A Undeterminable rate † 51.7% 15.3% 19.8% Pipeline precision 0.31 0.51 0.66 Pipeline recall 0.65 0.85 0.70 Pipeline F1 0.42 0.64 0.68 (B) Inter-rater reliability (pooled, n =90 devices) Mean Cohen’ s κ (7 factors) 0.781 (range: 0.577–0.966) Mean % agreement 91.9% (range: 88.2–98.3%) † EU MDR EUDAMED records average 36 characters. Coverage is adequate for sterile, duration of use, and reusable across all jurisdictions; limited for implantable, activ e device, and measuring function in EU MDR only . difference is likely due to the extreme brevity of EUD AMED records. Pipeline F1 sho ws the opposite pattern from factor contribution. EU MDR, which shows the largest factor-related classification gain, has the lo west extraction quality . This likely reflects the fact that EU MDR factors are deriv ed directly from classification rules rather than from keyword matching. Inter - rater reliability was substantial ov erall (mean κ = 0.781 [31]). Agreement w as lo west for active device ( κ = 0.577), likely because κ is attenuated under ske wed marginals (10–18 2) Primary Estimand: Symmetric Extraction Pipeline: T o obtain the cleanest estimate of cross-jurisdictional factor contribution, we first report results under a symmetric pipeline that remov es all jurisdiction-specific extraction advantages. This pipeline re-extracts all seven factors using a uniform text- only keyw ord matching method across all three jurisdictions, deliberately discarding the EU MDR rule-to-factor mapping and the NMP A code prefix heuristics. The resulting f actors are noisier but epistemically comparable across jurisdictions, making this the appropriate primary estimand for cross- jurisdictional comparison. T able III presents both estimands side by side. Under the symmetric pipeline, factor contribution is near zero across all three jurisdictions ( ∆ F1 < 0.01), establishing that the clean cross-jurisdictional signal, freed from pipeline-specific ad- vantages, is at most marginal . A nominal ordering across jurisdictions (EU MDR, NMP A, and FDA) is observ ed, b ut the corresponding ef fect sizes are weak and statistically in- distinguishable from noise. Ho wev er, the effect sizes are small and statistically indistinguishable from noise. Under the jurisdiction-specific pipeline, the NMP A gain rises to +0.024, approximately four times the FD A gain, but the six-fold ratio between the two estimands indicates that most of this gain is attributable to the e xtraction method rather than to genuine concept overlap. The FD A result is near-identical under both pipelines, consistent with predicate-based classification whose signal is already encoded in text features. Figure 2 visualises both estimands side by side; EU MDR is visually segre gated as a ceiling case in both panels. a) P er-jurisdiction findings.: The NMP A gain (+0.024, 95% CI [+0.023, +0.024]) is the only non-trivial cross- jurisdictional result and is concentrated in higher-risk classes (Class III benefits most). The FD A g ain (+0.006) is statis- tically non-zero but negligible in magnitude, consistent with predicate-based classification whose signal is already encoded in text. The EU MDR ceiling result (factors-only F1 = 0.900, indicating substantial rule reconstruction) is expected giv en circular deriv ation and is not comparable to NMP A and FD A. Across all jurisdictions, factors-only fails for Class I devices (F1 = 0.014–0.146), confirming that Class I is defined by the absence of risk factors. 3) Cir cularity in EU MDR F actor Derivation: For EU MDR, the factors are deriv ed from the classification rule recorded for each device in the database. They therefore partially encode the classification outcome itself. The high factors-only performance for EU MDR (macro-F1 = 0.900) shows that these factors recov er a substantial part of the rule structure. This does not undermine the cross-jurisdictional analysis, but it does change how the EU MDR result should be read. In the NMP A and FDA analyses, the same seven factors are extracted without this circularity: for NMP A from product descriptions and classification-code prefixes, and for FDA from device names and summary keywords. The EU MDR result is therefore best treated as a source-jurisdiction ceiling, that is, the upper bound on factor utility when the f actors encode the underlying classification logic. It should not be interpreted on the same footing as the NMP A and FD A transfer results (see also Section IV -C3). Class compression has a minimal effect on EU MDR per- formance (macro-F1: 0.804 three-class vs. 0.804 nati ve four- class; Supplementary T able S4). Concept-to-class associations (Cram ´ er’ s V ) sho w that implantable is the strongest predictor across all three jurisdictions, but V magnitudes are not directly comparable because EU MDR has only 1.9% Class III de vices; per-f actor details are in Supplementary Figure S8. B. RQ2: F ailur e Structur e 1) Zer o-Shot T ransfer and Class I Collapse: The unified model achie ves F1-macro of 0.984 for EU MDR (high due to circular factor deriv ation), 0.805 for NMP A, and 0.864 for FD A; per-class details are in Supplementary T able S5. T raining on FD A and NMP A data and ev aluating on EU MDR without any EU MDR training examples yields a macro-F1 of 0.384, with Class I F1 falling to 0.001 (Figure 3). Class I constitutes the largest EU MDR category with 9,819 devices (43.6%), yet the model is effecti vely unable to identify them. The failure likely arises because EU MDR Class I is resid- ual, while FD A and NMP A Class I is positional, as de vices that do not trigger any higher-class classification rule, whereas the FD A and NMP A define Class I positionally through specific product codes or catalogue entries. Howe ver , the study design does not isolate this as the sole or dominant mechanism. There are competing e xplanations, which remain possible: • Class-prior mismatch : EU MDR has 43.6% Class I devices versus ∼ 2.5% in FD A and NMP A, creating a sev ere distributional shift. 6 T ABLE III: Master transfer results. Symmetric ∆ F1 is the primary estimand (uniform ke yword extraction, no pipeline advantages). Jurisdiction-specific ∆ F1 is the upper bound (includes pipeline asymmetry). 95% CI on jurisdiction-specific ∆ F1 from 10 seed-lev el means (each seed = one fiv e-fold CV run). EU MDR is segreg ated as a source-jurisdiction ceiling (see Section IV -A3); its ∆ F1 reflects circular rule deriv ation and is not commensurable with the cross-jurisdictional NMP A and FD A results. Jurisdiction F1 (text+factors) F1 (text-only) ∆ F1 (symmetric) ∆ F1 (jur .-specific) [95% CI] Interpretation EU MDR † ( n =22,494) 0.992 ± 0.004 0.847 ± 0.017 +0.006 +0.192 [+0.187, +0.197] Source-jurisdiction ceiling NMP A ( n =65,703) 0.843 ± 0.007 0.822 ± 0.008 +0.004 +0.024 [+0.023, +0.024] Modest cross-jurisdictional gain FD A ( n =53,745) 0.898 ± 0.007 0.894 ± 0.007 +0.003 +0.006 [+0.005, +0.007] Negligible † EU MDR: factors deriv ed from classification rules; jurisdiction-specific/symmetric ratio = 32-fold (NMP A: 6-fold; FDA: 2-fold). Fig. 2: Factor contrib ution ( ∆ F1) under two estimands (EU MDR hatched grey = source-jurisdiction ceiling, not commensurable with cross-jurisdictional results). (A) Symmetric pipeline (primary estimand): all jurisdictions ∆ F1 < 0.01, confirming the clean cross-jurisdictional signal is at most marginal. (B) Jurisdiction-specific pipeline (upper bound): NMP A + 0.024 [95% CI + 0.023, + 0.024]; FDA + 0.006 [95% CI + 0.005, + 0.007]; EU MDR ceiling + 0.192 (circular , e xcluded from cross-jurisdictional inference). Error bars = 95% CI from 10 seed-le vel means. • Extraction asymmetry : EU MDR factors are deri ved differently from FD A and NMP A factors. • T ext domain shift : EUD AMED’ s 36-character average descriptions dif fer substantially from FDA and NMP A text. • Cross-lingual text barrier : TF-IDF features computed on mixed Chinese (NMP A), English (FD A), and mul- tilingual European (EU MDR) text create language- partitioned feature spaces with near-zero cross-lingual information transfer , meaning the model relies almost entirely on the sev en regulatory factors for cross- jurisdictional signal (Section IV -C5). • Product mix shift : The types of devices registered dif fer by jurisdiction. W e perform three tar geted tests to assess these e xplanations (Section IV -C2). The results strengthen the residual-v ersus- positional interpretation but do not fully exclude the alterna- tiv es. Perturbation-based reclassification analysis (Supplementary Figure S8) characterises the classifier’ s decision boundaries: reclassification succeeds in 100.0% of NMP A cases, 93.0% of FD A cases, and 84.2% of EU MDR cases, with Class I to Class III transitions the hardest (68.3% success). C. Rob ustness and Sensitivity Analyses 1) Rob ustness Checks: Grouped cross-validation does not change the NMP A or FD A cross-jurisdictional transfer results. Exact text duplicates account for 11.9% of NMP A records, 6.9% of FD A records, and 4.9% of EU MDR records, yet ∆ F1 remains at +0.023 for NMP A and +0.006 for FD A (Supplementary T able S6). The same pattern also appears across all three model families (Random Forest, Logistic Regression, and Gradient Boosting) with a modest contribution for NMP A and a negligible one for FDA (Supplementary T able S7). This suggests that the NMP A result is not specific to Random F orest. 2) Class I Zero-Shot F ailur e: Mec hanism T ests: T o adju- dicate among the competing explanations for the EU MDR Class I zero-shot collapse, we conduct three targeted tests. 7 Fig. 3: EU MDR zero-shot transfer failure. (A) Classwise F1 under the unified model (EU MDR in-domain) vs. zero-shot transfer (train FD A+NMP A, test EU MDR) under the multi- lingual sensiti vity protocol (Section IV -C5): Class I collapses to near zero under both encoders (TF-IDF: 0.029; MiniLM: 0.009); under the main analysis protocol, the collapse is even more sev ere (Class I F1 = 0.001, T able III). (B) Mechanism tests: T est A (matched class priors, undersampling Class I to 2.5%) leaves Class I F1 at 0.000, ruling out prior mismatch; T est B (excluding Class I) yields macro-F1 = 0.745, confirm- ing Class I collapse is the dominant degradation source. a) T est A: Rebalancing class priors.: W e undersample EU MDR Class I from 9,819 to 325 devices to match the ∼ 2.5% Class I prev alence in FDA and NMP A. Under these matched priors, Class I F1 remains effecti vely zero (0.000), ruling out class-prior mismatch as the primary explanation. b) T est B: Excluding Class I.: Evaluating zero-shot trans- fer on EU MDR Class II and III only (e xcluding Class I) yields a macro-F1 of 0.745 (Class II F1 = 0.969, Class III F1 = 0.522). This indicates that cross-jurisdictional transfer for higher -risk de vices is substantially more successful than the overall macro-F1 of 0.384 suggests, and that the Class I failure is the dominant source of degradation. c) T est C: Err or analysis.: Of the 9,819 EU MDR Class I devices, 97.9% (9,615) are predicted as Class II under zero- shot conditions. The factor profile of these devices shows that 98.1% hav e reusable =1 and near-zero v alues on all other factors, confirming that EU MDR Class I is defined by the absence of risk triggers. Models trained on FD A and NMP A, where Class I devices ha ve positionally assigned characteristics, lack a representation for this residual category . These tests strengthen the residual-versus-positional inter- pretation as the most plausible e xplanation but cannot fully exclude contributions from text domain shift or extraction asymmetry . 3) Unified Model: Effect of F actors: Removing regulatory factors from the unified model reduces EU MDR F1-macro from 0.984 to 0.785, confirming that high EU MDR perfor- mance is driv en by circular factor deriv ation and should not be cited as evidence of cross-jurisdictional compatibility . NMP A and FD A ef fects are modest (+0.031 and +0.017 respectiv ely; T ABLE IV: Re verse-direction transfer matrix: ∆ F1 by factor source and target jurisdiction (jurisdiction-specific pipelines). Parenthesised values: circular ceiling cases. Bold: only non- trivial cross-jurisdictional transfer . Factor source T arget: EU MDR T arget: NMP A T arget: FDA EU MDR factors (+0.189) +0.023 +0.007 NMP A factors +0.004 (+0.021) +0.005 FD A factors − 0.001 +0.000 (+0.008) Supplementary T able S8). 4) Rever se-Direction T ransfer Pr obes: The main analysis examines transfer in one direction only , using EU MDR- deriv ed factors to classify NMP A and FD A devices. T o assess whether this pattern depends on factor source, we construct two additional factor sets from the other jurisdictions and apply them to the remaining systems. For NMP A, we deri ve se ven features from the catalogue prefix structure, including prefixes 03 and 13 for implants and 68 for IVDs. For non-NMP A devices, these features are extracted by keyw ord matching. For FD A, we derive sev en features from product-code panel families, including cardiov ascular, orthopaedic, and IVD clusters. For non-FD A devices, these features are likewise extracted by keyw ord matching. T able IV shows that transfer is directional rather than symmetric. EU MDR factors improv e NMP A classification, but this effect does not reverse, as NMP A-deri ved factors add little when applied to EU MDR. FD A-deriv ed factors like wise contribute almost no signal outside the source jurisdiction. The only non-tri vial cross-jurisdictional result in the matrix is therefore the EU MDR-to-NMP A transfer . This pattern suggests that the shared signal between EU MDR and NMP A is limited and one-way . It also suggests that FD A factor structure, which is tied to predicate-based classification, does not travel to the other systems in any meaningful way . The re verse-direction probes therefore narro w the interpretation of the main result. What appears is not broad compatibility across regimes, but a specific directional overlap between EU MDR and NMP A. 5) T ext Encoder Sensitivity: The main ablation uses a TF- IDF text baseline built from character n-grams. Because this representation produces largely disjoint feature spaces across Chinese and Latin scripts, the observed factor gain could in principle be inflated by a weak te xt channel rather than by genuine regulatory signal. W e therefore re-run the analysis un- der two alternati ve specifications, using the same jurisdiction- specific f actor e xtraction and cross-validation protocol as in the main ablation (T able III), which is Random Forest with random_state=42 , fi ve-fold stratified cross-v alidation, and seed = 42. a) SVD component sweep.: The NMP A factor gain v aries substantially with the dimensionality of the TF-IDF repre- sentation, ranging from +0.003 to +0.026. The lar gest gain appears at 10 SVD components, which is also the setting in which the text baseline is weakest. This pattern suggests that the estimated factor contribution under TF-IDF is sensitiv e to 8 Fig. 4: T wo-by-two adjudication of NMP A factor contribu- tion ( ∆ F1), crossing text encoder (TF-IDF vs. multilingual MiniLM) with de vice-type control (39 one-hot NMP A cate- gory codes). NMP A factor gain is positive in all four condi- tions, but smaller once device-type control is added. Under TF-IDF , ∆ F1 falls from +0.024 to +0.004 with control; under MiniLM, it falls from +0.023 to +0.016. FD A values remain negligible in all conditions ( ≤ +0 . 003 ). The figure therefore indicates that the NMP A signal is reduced, b ut not eliminated, by device-type control, and that this residual is larger under the stronger multilingual encoder . text encoding capacity rather than fixed across specifications (Supplementary Figure S8; T able S9). b) Multilingual sentence embeddings and device-type contr ol.: W e next replace TF-IDF with 384-dimensional multi- lingual MiniLM embeddings [32] and cross this with a device- type control using 39 one-hot cate gory indicators. This yields a two-by-two design that separates two possible explanations for the NMP A result: (i) weak text encoding and (ii) device- category confounding. The first comparison is across encoders without de vice- type control. Here the estimated NMP A factor gain is nearly unchanged, moving from +0.024 under TF-IDF to +0.023 under MiniLM. The second comparison adds device-type control. Under this stricter specification, the factor gain falls, but it does not disappear: ∆ F1 ctrl is +0.004 under TF-IDF and +0.016 under MiniLM. In other words, strengthening the text representation does not remo ve the NMP A signal, and controlling for device category reduces the gain but does not eliminate it. Figure 4 visualises this pattern. The k ey point is that the residual is larger under the stronger multilingual encoder than under TF-IDF , which is difficult to reconcile with the view that the original NMP A gain was only an artefact of weak text features. The same multilingual specification also improves zero-shot transfer , raising macro-F1 from 0.431 to 0.494, with the largest improv ement in Class III. Class I, howe ver , still collapses to below 0.03. This matters because it narrows the interpretation of the failure. Better cross-lingual text representations help ov erall transfer, but they do not resolve the Class I break- down. That failure therefore appears to arise from structural mismatch rather than from language alone. Supplementary T able S10 reports the full multilingual sensitivity results. V . D I S C U S S I O N A. F actor T ransfer: A F ra gile Signal The central question is whether EU MDR-deriv ed risk fac- tors carry cross-jurisdictional classification signal. The answer depends critically on how the comparison is constructed. Under the symmetric extraction pipeline (T able III), which provides the epistemically cleanest comparison, factor contri- bution is near zero for all three jurisdictions ( ∆ F1 < 0.01). W ithout pipeline-specific adv antages, the cross-jurisdictional signal is at best marginal and likely indistinguishable from noise. In jurisdiction-specific extraction pipelines, the NMP A gain ( ∆ F1 = +0.024) is modest but reproducible. These are stable under grouped cross-validation (Section IV -C1), directionally consistent across three model families (Section IV -C1), and the only cross-jurisdiction link where the 95% CI (computed from 10 seed-level means) excludes zero. Howe ver , this gain must be interpreted as an upper bound that conflates gen- uine concept transfer with pipeline asymmetry , text encoding limitations, and device-category confounding. The six-fold ratio between the jurisdiction-specific and symmetric estimates ( +0 . 024 vs. +0 . 004 ) indicates that at least 80% of the observed effect is attrib utable to pipeline design rather than cross-jurisdictional concept o verlap. Sensitivity analyses resolve this ambiguity through a com- plete tw o-by-two design crossing text encoder (TF-IDF vs. multilingual MiniLM) with de vice-type control (absent vs. present). Under TF-IDF with device-type controls, the factor contribution surviv es but attenuates substantially ( + 0.004; Figure 4), indicating partial confounding with de vice-category information. Under multilingual embeddings with the same device-type controls, the contribution survives more ro- bustly ( + 0.016), confirming genuine regulatory signal beyond device-cate gory structure. 1) Under both text encoders, the factor signal surviv es device-type control, ruling out pure de vice-category con- founding as the explanation for the NMP A gain. 2) The larger residual under multilingual embeddings ( + 0.016 vs. + 0.004) confirms that stronger text encod- ing reveals additional regulatory structure not accessible to TF-IDF . The practical implication is that the magnitude of the factor contribution depends on the te xt encoding conte xt. TF-IDF- based estimates are conservati ve lo wer bounds; multilingual embeddings provide a more informati ve characterisation of genuine cross-jurisdictional re gulatory signal. The FDA result ( ∆ F1 = +0.006 jurisdiction-specific, +0.003 symmetric) is negligible and consistent across all analy- ses. Reverse-direction probes confirm that FD A-deriv ed fac- tors produce no meaningful transfer in any direction (Sec- tion IV -C4), suggesting that predicate-based classification op- erates through an information structure that is fundamentally opaque to factor -based probes. 9 B. Shar ed Risk Intuitions The concept-to-class association analysis re veals that the implantable and in vasi veness f actors are associated with the highest risk class across all three jurisdictions despite their different classification mechanisms. This qualitati ve pattern, namely that implantable de vices are assigned to the highest risk class regardless of whether the jurisdiction classifies through explicit rules, predicate chains, or catalogue matching, is robust across all three systems. These shared risk intuitions represent a potential foundation for cross-jurisdictional regu- latory harmonisation efforts, even in the absence of procedural alignment. W e note that the Cram ´ er’ s V magnitudes are not directly comparable across jurisdictions due to dif fering class distributions (EU MDR has 1.9% Class III devices versus ap- proximately 40–45% for FD A and NMP A), and the qualitative finding of shared directionality should be emphasised ov er the specific numerical v alues. C. F ailur e Structure and Cr oss-Lingual Limitations The zero-shot transfer result, in which Class I F1 falls to 0.001, indicates a sev ere failure when applying models trained on FD A and NMP A data to EU MDR. Multiple mechanisms contribute to this failure, and the study design cannot fully disentangle them. A previously unacknowledged factor is the cross-lingual text barrier . The TF-IDF text features are computed on mixed Chinese (NMP A), English (FD A), and multilingual European (EU MDR) text using character n-grams. Because Chinese and Latin character vocab ularies are almost entirely disjoint, the resulting 42-dimensional SVD features ef fecti vely partition by language rather than capturing shared semantic content. In the unified model and zero-shot experiments, the text channel is therefore lar gely non-functional across jurisdictions, meaning the model relies almost entirely on the seven re gula- tory factors for cross-jurisdictional signal. This interpretation is supported by the multilingual embedding analysis (Sec- tion IV -C5), which shows that replacing TF-IDF with cross- lingually aligned sentence embeddings substantially changes the zero-shot transfer results. The Class I collapse specifically is most parsimoniously explained by the conjunction of two factors: (i) the text features carry no cross-lingual information, forcing the model to rely on re gulatory factors; and (ii) EU MDR Class I is defined residually (absence of risk triggers), which the sev en binary/ordinal factors cannot represent because “absence of all factors” is also the default for undeterminable devices. The nati ve four -class ev aluation confirms that class com- pression contributes negligibly to this failure, with macro- F1 essentially identical under both the compressed three-class (0.804) and nativ e four -class (0.804) schemes (Supplementary T able S4). D. Pipeline Asymmetry and Epistemic Status A methodological consideration that warrants explicit dis- cussion is the asymmetry among the three factor extraction pipelines. EU MDR factors are derived primarily from the recorded Annex VIII classification rule, supplemented by multilingual ke yword matching. NMP A factors are inferred from the tw o-digit classification code prefix plus keywords. FD A factors are extracted from te xt via ke yword matching alone. These pipelines differ in three respects. These include proximity to the classification label, degree of source structure, and the amount of human-encoded regulatory logic they con- tain. Specifically , the EU MDR pipeline is closest to the label (since rules directly determine the class), the NMP A pipeline occupies an intermediate position (code prefixes encode broad device categories but not classification logic per se), and the FD A pipeline is furthest from the label. This asymmetry is a design-defining limitation, not a re- solved objection. It means that the study supports two distinct estimands: 1) Primary comparati ve estimand : what remains under a symmetric extraction regime. This isolates cross- jurisdictional structure from pipeline artefacts and is the epistemically appropriate basis for claims about regulatory concept overlap. 2) Applied upper bound : what one could achiev e with the best av ailable jurisdiction-specific extraction pipeline. This answers the practical question but conflates concept transfer with pipeline design. The symmetric pipeline (Section IV -A2) yields near-zero factor contribution for all jurisdictions (all ∆ F1 < 0.01), indicating that the clean cross-jurisdictional signal is marginal. Manual annotation (Section IV -A1) quantifies e xtraction fi- delity but does not resolve whether the jurisdiction-specific gains reflect genuine concept overlap or extraction artefacts. E. Limitations The EU MDR factor deriv ation introduces circularity be- cause factors are extracted from the classification rule recorded in the database. This contaminates the EU MDR result, which must be treated as a source-jurisdiction ceiling rather than a commensurable data point alongside NMP A and FD A. Pipeline asymmetry across the three extraction methods is a design-defining limitation. The manual annotation and symmetric pipeline analyses mitigate b ut do not close this concern, and the possibility remains that differential extraction fidelity contributes to the observ ed pattern between NMP A and FD A. Although we now test three factor sources (EU MDR, NMP A, and FD A-derived), each factor set represents one operationalisation of that jurisdiction’ s classification logic. Alternativ e operationalisations may yield different results. The rev erse-direction probes (Section IV -C4) confirm that transfer is source-dependent and asymmetric, which limits the scope of generalisable conclusions about inter-jurisdictional compat- ibility . The text baseline (TF-IDF with character n-grams, reduced to 42 SVD components) is architecturally incapable of cross- lingual transfer . In the per-jurisdiction experiments, this is benign because each jurisdiction operates within a single language domain. In the unified and zero-shot experiments, howe ver , the text features carry near-zero cross-lingual infor - mation, meaning the cross-jurisdictional results are effecti vely 10 testing factor-only transfer with 42 dimensions of language- indicator noise. Multilingual sentence embeddings partially address this limitation (Section IV -C5), but the text baseline should be considered a lower bound on text representational capacity . EUD AMED records contain limited textual information, av eraging only 36 characters per product description. This text pov erty constrains the factor extraction quality for EU MDR devices and means that the EU MDR text-only analysis is structurally weak. Under grouped cross-validation, EU MDR text-only F1 drops substantially , confirming that near-duplicate memorisation inflates text-only performance for this jurisdic- tion. The se ven re gulatory factors are correlated with de vice prod- uct categories (e.g., “implantable” correlates with orthopaedic devices). The tw o-by-two device-type control analysis (Sec- tion IV -C5) shows that the NMP A factor signal survives under both encoders (MiniLM: + 0.016; TF-IDF: + 0.004), providing evidence that the signal is not purely a device-type artefact. Howe ver , the 39 category codes used as controls are deriv ed from NMP A classification prefixes, introducing partial circularity: the surviv al of factors beyond these categories does not exclude confounding with finer-grained device-type information not captured by the 39-category encoding. Addi- tionally , EU MDR de vice categories are uniformly “Unkno wn” in EUDAMED, so the device-type control is uninformativ e for this jurisdiction. Manual validation uses 150 devices per jurisdiction with inter-rater reliability assessed on a 90-device subsample after a structured adjudication round (mean κ = 0.781, substantial agreement). Activ e device exhibited the lowest κ (0.577) despite 89.7% raw agreement, reflecting κ attenuation under ske wed prev alence. The adjudication process, while neces- sary to resolve codebook ambiguities (particularly for in va- siv eness), means that the reported κ values represent post- calibration reliability rather than na ¨ ıve agreement. The 51.7% undeterminable rate for EU MDR reflects the extreme text brevity and limits the weight this validation can bear . Ground truth classification labels are derived from database records that capture regulatory outcomes rather than the rea- soning processes that produced those outcomes. V I . C O N C L U S I O N This paper examined whether risk concepts derived from EU MDR Annex VIII provide portable classification signal across three major regulatory systems. Using AI classification as an empirical probe, we tested whether sev en EU MDR- deriv ed f actors improved de vice classification in EU MDR, NMP A, and FDA data. The primary result is negati ve. Under the symmetric extrac- tion pipeline, which provides the cleanest cross-jurisdictional comparison, factor contrib ution is near zero in all three ju- risdictions ( ∆ F1 < 0.01). A non-tri vial result appears only under jurisdiction-specific pipelines, where EU MDR-deri ved factors yield a modest gain in the NMP A setting. That g ain remains positive under stronger multilingual text encoding and device-type control, b ut it is still limited in magnitude and should be interpreted as an upper-bound estimate rather than as e vidence of general cross-jurisdictional transfer . Rev erse- direction probes further show that the effect is directional: NMP A-deri ved factors do not transfer back to EU MDR, and FD A-derived factors add almost no signal outside the source jurisdiction. These findings have two implications for explainable reg- ulatory AI. First, shared regulatory vocab ulary should not be treated as evidence that classification logic is portable across jurisdictions. Cross-jurisdictional models need explicit empirical validation rather than transfer assumptions. Second, estimates of factor utility depend materially on how concepts are extracted and how text is represented. In this setting, the text encoder is not a neutral implementation detail; it changes the measured contrib ution of regulatory factors. More broadly , the study shows that concept-based XAI can be used not only to interpret model behaviour , b ut also to test the limits of model transfer across regulatory en vi- ronments. For medical device informatics, this provides a practical framew ork for ev aluating when regulatory concepts support cross-jurisdictional modelling and when they do not. The results suggest that transfer is limited, directional, and method-sensitiv e, and that robust deployment claims should therefore be based on measured portability rather than on surface similarity between regulatory systems. C O D E A V A I L A B I L I T Y The implementation used in this study is publicly a vailable at: https://github .com/RegAItool/explain reg AI R E F E R E N C E S [1] European Parliament and Council, “Regulation (eu) 2017/745 of the european parliament and of the council on medical devices, ” Official Journal of the European Union , vol. L 117, pp. 1–175, 2017. [2] FD A, “Medical device classification procedures, ” 21 CFR P art 860, 2020, u.S. Food and Drug Administration. [3] NMP A, “Medical device classification catalog, ” 2021, national Medical Products Administration of China. [4] M. Fink and B. Akra, “Comparison of the international regulations for medical devices – USA versus Europe, ” Injury , vol. 54, no. Suppl 5, p. 110908, 2023, pMID: 37365092. [5] B. Chettri and R. Ravi, “ A comparative study of medical device regulation between countries based on their economies, ” Expert Review of Medical Devices , vol. 21, no. 6, pp. 467–478, 2024, pMID: 38832832. [6] U. J. Muehlematter , P . Daniore, and K. N. V okinger, “ Approval of artificial intelligence and machine learning-based medical devices in the USA and Europe (2015–20): A comparative analysis, ” The Lancet Digital Health , vol. 3, no. 3, pp. e195–e203, 2021. [7] U. J. Muehlematter , C. Bluethgen, and K. N. V okinger, “FD A-cleared artificial intelligence and machine learning-based medical devices and their 510(k) predicate networks, ” The Lancet Digital Health , vol. 5, no. 9, pp. e618–e626, 2023, pMID: 37625896. [8] Y . Liu, W . Y u, and T . Dillon, “Regulatory responses and approv al status of artificial intelligence medical devices in China, ” npj Digital Medicine , vol. 7, p. 255, 2024, pMID: 39294318. [9] S. Reddy , “Global harmonization of artificial intelligence-enabled soft- ware as a medical device regulation: Addressing challenges and unifying standards, ” Mayo Clinic Pr oceedings: Digital Health , vol. 3, no. 1, p. 100191, 2025, pMID: 40207007. [10] Y . Han, A. Ceross, and J. H. M. Bergmann, “AI for regulatory affairs: Balancing accuracy , interpretability , and computational cost in medical device classification, ” Expert Systems with Applications , 2025, under revie w . [11] ——, “T oward automated regulatory decision-making: Trustworthy medical device risk classification with multimodal transformers and self- training, ” Expert Systems with Applications , vol. 275, p. 131669, 2025. 11 [12] ——, “Regulatory frameworks for AI-enabled medical de vice software in China: Comparative analysis and review of implications for global manufacturers, ” JMIR AI , vol. 3, p. e46871, 2024, pMID: 39073860. [13] S. M. Lundberg and S.-I. Lee, “ A unified approach to interpreting model predictions, ” in Advances in neural information pr ocessing systems , vol. 30, 2017. [14] M. T . Ribeiro, S. Singh, and C. Guestrin, ““why should I trust you?”: Explaining the predictions of any classifier , ” in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , 2016, pp. 1135–1144. [15] M. Sundararajan, A. T aly , and Q. Y an, “ Axiomatic attribution for deep networks, ” in International confer ence on machine learning . PMLR, 2017, pp. 3319–3328. [16] B. Kim, M. W attenberg, J. Gilmer, C. Carrie, J. W exler , F . V iegas, and R. Sayres, “Interpretability beyond feature attribution: Quantitative test- ing with concept activ ation vectors (TCA V), ” in International conference on machine learning . PMLR, 2018, pp. 2668–2677. [17] P . W . Koh, T . Nguyen, Y . S. T ang, S. Mussmann, E. Pierson, B. Kim, and P . Liang, “Concept bottleneck models, ” in International Confer ence on Machine Learning . PMLR, 2020, pp. 5338–5348. [18] C.-K. Y eh, B. Kim, S. ¨ O. Arik, C.-L. Li, T . Pfister , and P . Ravikumar , “On completeness-aware concept-based explanations in deep neural networks, ” in Advances in Neural Information Processing Systems , vol. 33, 2020, pp. 20 554–20 565. [19] S. W achter , B. Mittelstadt, and C. Russell, “Counterfactual explanations without opening the black box: Automated decisions and the GDPR, ” Harvar d Journal of Law & T echnology , vol. 31, no. 2, pp. 841–887, 2018. [20] R. K. Mothilal, A. Sharma, and C. T an, “Explaining machine learning classifiers through di verse counterfactual explanations, ” in Pr oceedings of the 2020 Conference on F airness, Accountability , and Tr ansparency (F A T*) , 2020, pp. 607–617. [21] E. Tjoa and C. Guan, “ A survey on explainable artificial intelligence (xai): T oward medical xai, ” IEEE transactions on neural networks and learning systems , vol. 32, no. 11, pp. 4793–4813, 2020. [22] J. Amann, A. Blasimme, E. V ayena, D. Frey , and V . I. Madai, “Ex- plainability for artificial intelligence in healthcare: A multidisciplinary perspectiv e, ” BMC Medical Informatics and Decision Making , vol. 20, no. 1, p. 310, 2020. [23] N. Bienefeld, J. M. Boss, R. Luthy , D. Brodbeck, J. Azzati, M. Blaser, J. W illms, and E. Keller , “Solving the explainable AI conundrum by bridging clinicians’ needs and developers’ goals, ” npj Digital Medicine , vol. 6, p. 94, 2023, pMID: 37217779. [24] M. Ghassemi, L. Oakden-Rayner, and A. L. Beam, “The false hope of current approaches to explainable artificial intelligence in health care, ” The Lancet Digital Health , vol. 3, no. 11, pp. e745–e750, 2021. [25] A. A. Shick, C. M. W ebber, N. Kiarashi, J. P . W einberg, A. Deoras, N. Petrick, A. Saha, and M. C. Diamond, “Transparency of artifi- cial intelligence/machine learning-enabled medical devices, ” npj Digital Medicine , vol. 7, p. 21, 2024, pMID: 38273098. [26] V . Muralidharan, B. A. Adew ale, C. J. Huang et al. , “ A scoping revie w of reporting gaps in FD A-approved AI medical devices, ” npj Digital Medicine , vol. 7, p. 273, 2024, pMID: 39362934. [27] S. Chouffani El Fassi, A. Abdullah, Y . Fang, S. Natarajan, A. Bin Mas- roor , N. Kayali, S. Prakash, and G. E. Henderson, “Not all AI health tools with re gulatory authorization are clinically validated, ” Nature Medicine , vol. 30, pp. 2718–2720, 2024, pMID: 39187696. [28] I. Chalkidis, M. Fergadiotis, P . Malakasiotis, N. Aletras, and I. Androut- sopoulos, “LEGAL-BER T: The muppets straight out of law school, ” in F indings of the Association for Computational Linguistics: EMNLP 2020 , 2020, pp. 2898–2904. [29] International Medical Device Regulators Forum, “Software as a medical device (SaMD): K ey definitions, ” T ech. Rep., 2013, iMDRF/SaMD WG/N10FIN AL:2013, updated 2014. [30] M. Aboy , T . Minssen, and E. V ayena, “Navigating the EU AI Act: Im- plications for regulated digital medical products, ” npj Digital Medicine , vol. 7, p. 237, 2024, pMID: 39242831. [31] J. R. Landis and G. G. Koch, “The measurement of observer agreement for categorical data, ” Biometrics , v ol. 33, no. 1, pp. 159–174, 1977. [32] N. Reimers and I. Gure vych, “Sentence-BER T: Sentence embeddings using Siamese BER T-networks, ” in Pr oceedings of the 2019 Conference on Empirical Methods in Natural Language Pr ocessing (EMNLP) , 2019, pp. 3982–3992.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment