The Unreasonable Effectiveness of Scaling Laws in AI
Classical AI scaling laws, especially for pre-training, describe how training loss decreases with compute in a power-law form. Their effectiveness has a basic and very practical sense: they make progress predictable, albeit at a declining rate. Yet t…
Authors: Chien-Ping Lu
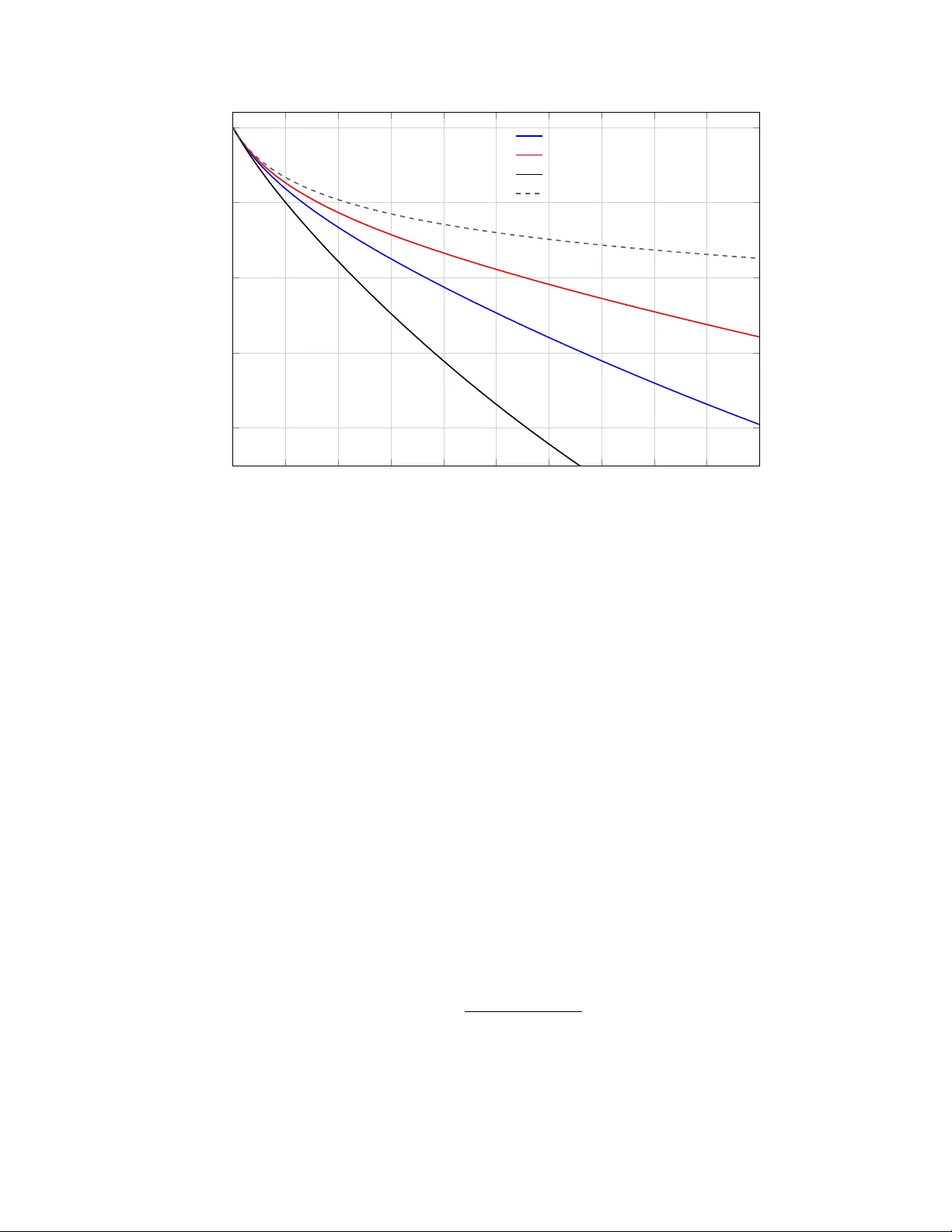
The Unreasonable Effectiv eness of Scaling La ws in AI Logical Compute, Hidden Efficiency , and the Burden of Diminishing Returns Chien-Ping Lu Abstract Classical AI scaling laws are effectiv e in the ordinary sense that they mak e progress predictable despite diminishing returns. Their more surprising effectiv eness is that they remain portable across c hanging regimes while AI progress stays empirically active and economically meaningful despite those same di- minishing returns. This paper argues that b oth facts hav e the same source. The compute v ariable in the classical la w is b est read as lo gic al c ompute , an abstraction o ver mo del-side work that suppresses man y realization details. Practical burden therefore depends not only on the loss exponent, but on the efficiency with whic h physical resources realize that compute. Under that in terpretation, diminishing returns mean rising operational burden, not merely a flatter curve. Once efficiency is made explicit and allo wed to comp ound o ver time, contin ued progress depends on rep eated efficiency doublings in hard- w are, algorithms, and systems. Scaling laws tra vel because they abstract; progress contin ues b ecause the efficiency stack keeps changing what level of logical compute is feasible. 1 In tro duction Classical AI scaling laws, esp ecially for pre-training, are unusually compact. Under compute-optimal condi- tions, training loss is often w ell appro ximated b y a p o wer la w in compute [ 3 , 2 ]: L ∝ C − κ , where L denotes loss, C denotes compute, and κ is the scaling exponent. This is the ordinary effectiveness of scaling la ws: they make progress forecastable. Returns decline, but they do not b ecome arbitrary . But prediction is only the first fact. Scaling la ws are also unreasonably effective in a stronger, Wigner-lik e sense [ 10 ]. They remain surprisingly p ortable across changing arc hitectures, precisions, sparsity patterns, and training-adjacen t regimes, and AI progress has con tinued despite the diminishing returns they encode. The deeper question is therefore not only wh y the la w predicts, but why it keeps trav eling and wh y mo v ement along it k eeps happening in practice. The thesis of this pap er is that b oth facts hav e the same source. Scaling laws are unreasonably effective b ecause they abstract o ver realization details. The compute v ariable is b est read not as a record of a sp ecific implemen tation, but as lo gic al c ompute : an abstract measure of mo del-side w ork. Once that distinction is made, the practical burden of scaling dep ends on a separate efficiency term that gov erns ho w physical resources are conv erted into logical compute. The same abstraction that makes the law p ortable also creates a p ersisten t efficiency game in hardware, algorithms, and systems, b ecause it leav es many wa ys to realize additional logical compute more c heaply . This framing keeps the paper fo cused on one in terpretive claim and one formal extension. The in terpretive claim is that C in the classical la w should b e read as logical compute. The formal extension is that once efficiency comp ounds o ver time, progress depends not only on the static exp onent κ , but on the rate of efficiency doubling. Under that view, diminishing returns are not merely a flatter loss curve. They are rising op erational burden. Recen t work extends classical scaling analyses to inference-a ware training, precision, and sparse routing [ 9 , 5 , 6 , 7 ]. Those refinements matter, but they are not the pap er’s main target. Here they serv e as evidence that the empirical compute–loss relation remains useful across changing realization choices. The goal is not 1 another fitted v arian t of the law. It is to clarify what the classical v ariable means and what the classical form ulation lea ves out when used as a guide to real progress. The pap er therefore pro ceeds in three main mo ves. First, it restates the classical la w and iden tifies what it omits. Second, it separates logical compute from physical burden by making hidden efficiency explicit. Third, it introduces a time-indexed efficiency-doubling extension that connects static diminishing returns to dynamic, contin uing progress. The later sections then dra w out the operational and architectural implications of that extension. 2 Classical Scaling La w and What It Omits The standard starting p oint in the literature is a separable loss model o ver mo del size and dataset size: L ( N , D ) = E + AN − α + B D − β , where N is the num b er of parameters, D is the n umber of training tokens, E is an irreducible loss flo or, and α, β > 0 are empirical exponents. This form captures a familiar idea: increasing either mo del size or data impro ves loss, but with diminishing returns. T o connect this expression to compute, one imposes a training-cost constraint. In dense pre-training, total compute is commonly approximated as C ∝ N D , or, in a standard bac k-of-the-env elope form, C ≈ 6 N D , where the constan t reflects forward pass, bac kward pass, and parameter-up date costs. Under a fixed compute budget, the compute-optimal choice of N and D balances the tw o loss terms, yielding N ∗ ∝ C β α + β , D ∗ ∝ C α α + β . Substituting these relations back in to the loss gives the familiar compute-only law L ( C ) ≈ E + K C − κ , κ = αβ α + β , for some constan t K > 0. This deriv ation helps clarify b oth the p o wer and the limits of the classical law. It captures a robust empirical relationship betw een loss and compute, but it does so at a highly abstract lev el. In particular, κ is a property of ho w loss resp onds to scaling in parameters and data under a compute budget. It is not itself a measure of hardware quality , precision format, or system efficiency . That is wh y the classical law is best understoo d as a ratio la w. It do es not claim that a particular absolute compute budget guarantees a universal level of capability . Rather, it sp ecifies ho w loss changes r elative to changes in compute. This is what giv es the law its immediate predictiv e v alue, and it is also part of what makes scaling laws p ortable across c hanging training stac ks: they preserv e a higher-lev el relation while abstracting aw ay from many of the mec hanisms that realize compute in practice. Recen t extensions that incorporate inference demand, numerical precision, or Mixture-of-Exp erts structure [ 9 , 5 , 6 , 7 ] do not o verturn this basic picture. They sho w that one can refine the law by exp osing v ariables that the baseline formulation lea ves implicit. F or the presen t pap er, how ever, the important point is simpler: the empirical compute–loss relation contin ues to surviv e across c hanging realization c hoices. That is evidence for the robustness of the abstraction, not a reason to replace the present pap er’s central question with a surv ey of every v arian t. Accordingly , the contribution here is not a new fitted la w for a particular arc hitecture or regime. It is in terpretive and unifying. The pap er prop oses a stable reading of the compute v ariable in classical scaling la ws, separates that v ariable from the efficiency with which it is realized, and then uses that separation to in tro duce a simple dynamic extension indexed b y effic iency doublings o ver time. 2 3 Logical Compute and Hidden Efficiency The central omission in the compact law L ( C ) ≈ E + K C − κ is not compute itself, but the r e alization of compute. Classical scaling laws treat compute as an input, y et they do not ask ho w long it takes to supply that compute, how muc h p ow er it requires, or how muc h system engineering is needed to sustain it. In that sense, efficiency is hidden rather than absent. This motiv ates a distinction b etw een tw o quantities: • Logical compute : the abstract mo del-side w ork that enters the scaling la w, defined against a dense, uniform-precision reference realization of the model rather than against any particular sparse, quan tized, or kernel-specific implemen tation. • Physical resource burden : the time, p o wer, hardware, and systems effort required to realize a giv en amoun t of logical compute in practice. W e can express their relationship in reduced form b y writing the physical resource burden as P T = C logical E logical , where P denotes a p ow er budget, T denotes elapsed time, so P T is energy , and E logical summarizes how efficien tly hardware, softw are, precision, and architecture con vert physical resources into logical compute. This makes the core claim explicit: the same logical compute target can imp ose very different real-w orld burdens dep ending on efficiency , and it also makes clear why electricity supply is critical to sustaining con tinued scaling. Equiv alen tly , logical compute efficiency can b e written as E logical = C logical P T , whic h measures how muc h logical compute is pro duced per unit of physical resource expenditure. Dimen- sionally , if C logical is measured in logical FLOP-equiv alen ts, P in w atts, and T in seconds, then E logical has units of logical FLOPs per joule. This distinction is already implicit in engineering practice. Mo del FLOPs Utilization (MFU) is t ypically written as MFU = mo del FLOPs / elapsed time v endor FLOPs/s . If the MFU numerator is iden tified with logical-compute throughput and the vendor p eak is denoted b y F peak , then MFU = C logical /T F peak := E logical P F peak . MFU and logical compute efficiency are therefore related but not iden tical. MFU compares realized model- side throughput against a vendor-defined hardware peak, whereas E logical compares logical compute against ph ysical resources such as time and p ow er. In that sense, the industry has already b een using something close to logical compute efficiency , but in disguised and peak-normalized form. The n umerator is similar in spirit in both cases b ecause it refers to model-implied work. The denominator, how ever, is very different. V endor FLOPs/s figures depend on precision conv en tions, k ernel assumptions, and p eak rep orting conditions, so they are not esp ecially stable as a cross-system baseline. A resource-based denominator is conceptually cleaner for the present argument b ecause it tracks the real burden required to realize a given amount of logical compute. F or that reason, the mo del-side numerator is the natural candidate for the compute v ariable in a scaling la w. Historically , “FLOPs” referred to floating-p oint op erations in a sp ecific numeric format, but in current practice the term often functions more lik e shorthand for mo del-side work. Under the interpretation prop osed 3 here, the quantit y entering the law is b etter though t of as logical compute: the work implied by the mo del’s dense, uniform-precision forward and backw ard passes, independent of the particular implemen tation path used to realize it. One reason this abstraction is useful is practical rather than merely terminological. Engineers typically do not aim to change the target loss curve arbitrarily . They aim to preserve, as closely as p ossible, the loss b eha vior that a dense, uniform-precision reference mo del would hav e ac hieved, while realizing that b ehavior at lo wer pow er, low er cost, or higher throughput through b etter kernels, sparsit y , quan tization, routing, or systems design. When those optimizations succeed, they do not ov erturn the scaling law so m uch as mak e it cheaper to remain on it. Preserving this distinction is imp ortant. If sparsity , quan tization, or system optimization are folded into the definition of compute itself, the baseline of the law b ecomes unstable. The engineering improv emen ts one w ants to explain risk b eing absorb ed into a redefinition of the law rather than standing out as efficiency gains. A cleaner interpretation is to k eep logical compute fixed and let practical inno v ations improv e E logical , the efficiency with which it is deliv ered. 4 A Time-Indexed Efficiency-Doubling Extension Once efficiency is explicit, the next question is temporal: how quickly can logical compute be accumulated o ver calendar time? Let t denote elapsed y ears. In this section, E ( t ) denotes the same logical compute efficiency introduced earlier, now written as a function of time. If efficiency doubles at an annual rate β , measured in doublings p er year, then E ( t ) = E 0 2 β t , where E 0 is initial efficiency . If the physical resource budget contributed per year is approximately constan t at a baseline level P 0 , then cum ulative logical compute added by time t is ∆ C ( t ) = Z t 0 E ( s ) P 0 ds = E 0 P 0 β ln 2 2 β t − 1 . Normalizing the initial condition so that C 0 = E 0 P 0 yields C ( t ) = C 0 + ∆ C ( t ) = C 0 1 + 2 β t − 1 β ln 2 . This expression is the time-indexed coun terpart of the paper’s main claim. Even when the underlying scaling la w is written o ver logical compute, the amount av ailable by year t dep ends on ho w rapidly the surrounding stac k impro ves its efficiency . No w com bine this with the excess-loss form of the classical scaling law, L ( C ) ≈ E + K C − κ . Define relative excess loss ab o ve the irreducible floor b y X ( t ) ≡ L ( t ) − E L (0) − E . Substituting C ( t ) into the classical la w giv es X ( t ) = 1 + 2 β t − 1 β ln 2 − κ . Figure 1 visualizes this relation o v er calendar time. It fixes κ and compares sev eral ann ual efficiency-doubling rates β , with a Mo ore-like rate as the baseline reference. 4 0 2 4 6 8 10 12 14 16 18 20 0 . 6 0 . 7 0 . 8 0 . 9 1 time t (years) relativ e excess loss X ( t ) Mo ore-lik e baseline, β = 0 . 5 slo wer doubling, β = 0 . 25 faster doubling, β = 1 . 0 no doubling, β = 0 Figure 1: Relative excess loss ov er calendar time for several annual efficiency-doubling rates, holding κ = 0 . 063 fixed. The blue curv e uses a Mo ore-like baseline of β = 0 . 5 doublings p er y ear, while the dashed curv e shows the non-doubling case with linear compute growth. F aster annual doubling rates accelerate the accum ulation of logical compute and therefore the decline in excess loss. This equation makes explicit what the static law lea ves hidden. The exp onen t κ still gov erns the severit y of diminishing returns, but progress ov er calendar time also dep ends on the ann ual efficiency-doubling rate β . The class ical law is static: it tells us ho w muc h logical compute is needed. The time-indexed extension is dynamic: it tells us how quic kly that logical compute b ecomes av ailable as efficiency impro ves year b y year. AI scaling therefore dep ends not only on larger raw budgets, but on sufficiently rapid gains in efficiency to k eep the law economically pro ductive. 5 The Op erational Meaning of Diminishing Returns Under the classical reading, diminishing returns mean that further reductions in loss require disprop ortion- ately more compute. That statemen t is mathematically correct, but it b ecomes muc h sharp er once efficiency is made explicit. If L ( C ) ≈ E + K C − κ , then achieving a target loss L target > E requires logical com pute on the order of C logical ( L target ) ∝ ( L target − E ) − 1 /κ . Using P T = C logical /E logical , the corresponding ph ysical resource burden is P T ( L target ) ∝ ( L target − E ) − 1 /κ E logical . The key p oin t is that diminishing returns are not just a prop erty of curve shap e. They are a statement ab out escalating op erational burden. As target loss approaches the irreducible flo or, the logical compute requiremen t grows rapidly b ecause of the pow er la w, and the physical resource burden gro ws faster still when efficiency improv ements fail to k eep up. 5 This p ersp ectiv e also clarifies why progress in AI dep ends so strongly on systems and architecture. Ev en if the compute–loss relation remains unchanged, practical progress dep ends on how effectiv ely the training stac k con verts real resources into logical compute. Low er precision, b etter k ernels, improv ed communication patterns, and sparse architectures matter not b ecause they rewrite the classical la w, but b ecause they improv e the efficiency term that determines whether mov ement along it remains feasible. It also suggests a more concrete interpretation of the “race to efficiency .” T o sustain a roughly steady pace of impro vemen t, the supp ort system b ehind scaling must itself improv e recurren tly . That improv ement may come partly from larger clusters or higher p ow er budgets, but sustained progress b ecomes muc h easier when efficiency compounds as well. In this sense, the p ow er-law form do es more than describe diminishing returns; it structures the innov ation problem. It reveals why hardware, algorithms, and systems m ust search for rep eated gains in effectiv e efficiency . Systems such as DeepSeek-V3 or Kimi’s recent attention optimizations are therefore best understo od as resp onses to scaling pressure rather than exceptions to it [ 1 , 4 ]. 6 Brief Implications If scaling la ws abstract ov er realization details, then those details b ecome the margin of comp etition. Hard- w are efficiency , k ernels, quantization, sparsity , routing, and systems design matter because they improv e E logical , not b ecause each one requires a new theory of progress. The empirical law tells us what additional logical compute buys; the efficiency game changes what that compute costs. This also clarifies the pap er’s place in the larger four-pap er arc. The present pap er explains why AI scaling remains empirically active and economically meaningful despite diminishing returns: the law is stable at the level of logical compute, while the burden of realizing that compute is con tinually renegotiated by the efficiency stac k. The companion Amdahl paper explains ho w that p ersistent pressure reshap es arc hitecture b y raising the bar for sp ecialization and shifting optimal allo cation tow ard more programmable substrates. 7 Conclusion Classical AI scaling laws remain p ow erful b ecause they express a stable ratio relation b etw een loss and compute while abstracting a wa y from many realization details. That abstraction is the source of their unreasonable effectiv eness. It is wh y the law trav els across regimes, and why so m uch engineering effort can b e redirected in to the efficiency stack without destroying the la w’s usefulness. Once the compute v ariable is interpreted as logical compute, the practical meaning of diminishing returns c hanges. The cen tral problem is no longer only geometric flattening in a loss curv e. It is the rising op erational burden of realizing eac h further unit of useful progress. Con tinued AI scaling therefore depends join tly on the exp onent κ and on the rate at which the surrounding hardware, algorithmic, and systems stack can deliv er repeated efficiency doublings. Under that view, this pap er explains why scaling remains active: scaling la ws tra vel b ecause they abstract, and progress contin ues because efficiency compounds. The companion Amdahl pap er explains how that pressure reshap es arc hitecture. References [1] DeepSeek-AI. Deepseek-v3 technical rep ort. arXiv pr eprint arXiv:2412.19437 , 2024. doi: 10.48550/ arXiv.2412.19437. URL . [2] Jordan Hoffmann, Sebastian Borgeaud, Arth ur Mensc h, Elena Buchatsk ay a, T revor Cai, Eliza Ruther- ford, Diego de Las Casas, Lisa Anne Hendricks, Johannes W elbl, Aidan Clark, T om Hennigan, Eric Noland, Katie Millican, George v an den Driessche, Bogdan Damo c, Aurelia Guy , Simon Osindero, Karen Simon y an, Erich Elsen, Jack W. Rae, Oriol Vin yals, and Lauren t Sifre. T raining compute-optimal large language models. arXiv pr eprint arXiv:2203.15556 , 2022. doi: 10.48550/arXiv.2203.15556. URL 6 https://arxiv.org/abs/2203.15556 . [3] Jared Kaplan, Sam McCandlish, T om Henighan, T om B. Brown, Benjamin Chess, Rewon Child, Scott Gra y , Alec Radford, Jeffrey W u, and Dario Amo dei. Scaling laws for neural language mo dels. arXiv pr eprint arXiv:2001.08361 , 2020. doi: 10.48550/arXiv.2001.08361. URL 2001.08361 . [4] Kimi T eam. A ttention residuals. arXiv pr eprint arXiv:2603.15031 , 2026. doi: 10.48550/arXiv.2603. 15031. URL . [5] T anishq Kumar, Zachary Ankner, Benjamin F. Spector, Blake Bordelon, Niklas Muennighoff, Mansheej P aul, Cengiz P ehlev an, Christopher Re, and Aditi Ragh unathan. Scaling laws for precision. arXiv pr eprint arXiv:2411.04330 , 2024. doi: 10.48550/arXiv.2411.04330. URL 2411.04330 . [6] Jan Ludziejewski, Jakub Kra jewski, Kamil Adamczewski, Maciej Pi´ oro, Micha l Krutul, Szymon An to- niak, Kamil Ciebiera, Krystian Kr´ ol, T omasz Odrzyg´ o´ zd ´ z, Piotr Sanko wski, Marek Cygan, and Sebas- tian Jaszczur. Scaling laws for fine-grained mixture of experts. In Pr o c e e dings of the 41st International Confer enc e on Machine L e arning , volume 235 of Pr o c e e dings of Machine L e arning R ese ar ch , pages 33270–33288. PMLR, 2024. URL https://proceedings.mlr.press/v235/ludziejewski24a.html . [7] Jan Ludziejewski, Maciej Pi´ oro, Jakub Kra jewski, Maciej Stefaniak, Micha l Krutul, Jan Ma la ´ snicki, Marek Cygan, Piotr Sank owski, Kamil Adamczewski, Piotr Mi lo ´ s, and Sebastian Jaszczur. Join t MoE scaling la ws: Mixture of exp erts can b e memory efficien t. In Pr o c e e dings of the 42nd International Confer enc e on Machine L e arning , volume 267 of Pr o c e e dings of Machine L e arning R ese ar ch , pages 41056–41073. PMLR, 2025. URL https://proceedings.mlr.press/v267/ludziejewski25a.html . [8] Gordon E. Mo ore. Cramming more comp onents on to in tegrated circuits. Ele ctr onics , 38(8):114–117, 1965. URL https://www.cs.utexas.edu/ ~ fussell/courses/cs352h/papers/moore.pdf . [9] Nikhil Sardana, Jacob P ortes, Alexandre Doub ov, and Jonathan F rankle. Beyond chinc hilla-optimal: Accoun ting for inference in language mo del scaling laws. In Pr o c e e dings of the 41st International Confer- enc e on Machine L e arning , v olume 235 of Pr o c e e dings of Machine L e arning R ese ar ch , pages 45173–45226. PMLR, 2024. URL https://proceedings.mlr.press/v235/sardana24a.html . [10] Eugene P . Wigner. The unreasonable effectiv eness of mathematics in the natural sciences. Communi- c ations on Pur e and Applie d Mathematics , 13(1):1–14, 1960. doi: 10.1002/cpa.3160130102. 7
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment