Courtroom-Style Multi-Agent Debate with Progressive RAG and Role-Switching for Controversial Claim Verification
Large language models (LLMs) remain unreliable for high-stakes claim verification due to hallucinations and shallow reasoning. While retrieval-augmented generation (RAG) and multi-agent debate (MAD) address this, they are limited by one-pass retrieva…
Authors: Masnun Nuha Chowdhury, Nusrat Jahan Beg, Umme Hunny Khan
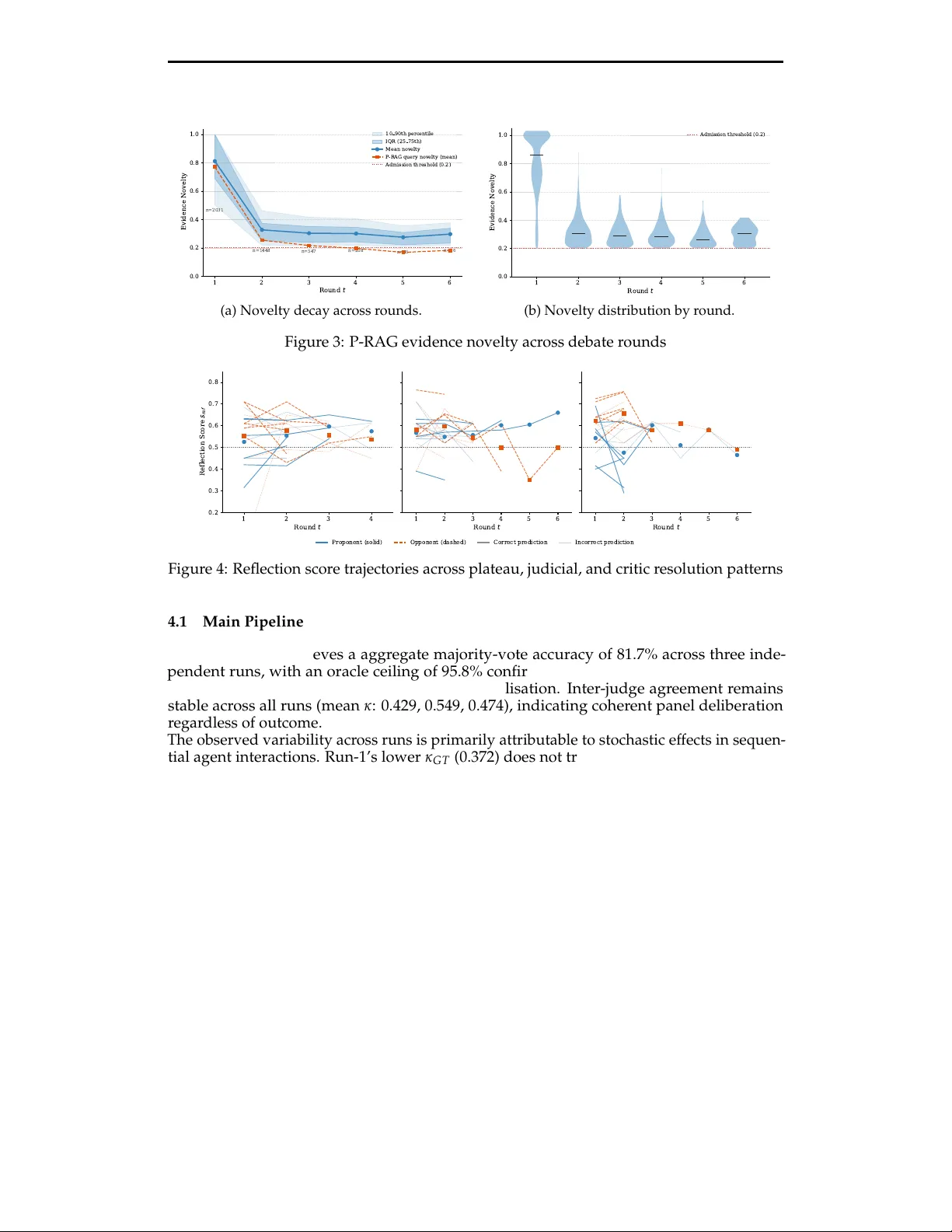
Preprint. Under review . Courtroom-Style Multi-Agent Debate with Progressive RAG and Role-Switching for Controversial Claim V erification Masnun Nuha Chowdhury † Nusrat Jahan Beg † Umme Hunny Khan Syed Rifat Raiyan ‡ Md Kamrul Hasan Hasan Mahmud Systems and Software Lab (SSL), Department of Computer Science and Engineering Islamic University of T echnology , Dhaka, Bangladesh † Equal contribution ‡ Corresponding author: rifatraiyan@iut-dhaka.edu Abstract Large language models (LLMs) remain unreliable for high-stakes claim verification due to hallucinations and shallow reasoning. While retrieval- augmented generation (RAG) and multi-agent debate (MAD) address this, they are limited by one-pass retriev al and unstructur ed debate dynamics. W e propose a courtroom-style multi-agent framework, P R O C L A I M , that reformulates verification as a structured, adversarial deliberation. Our approach integrates specialized roles ( e.g. , Plaintiff, Defense, Judge) with Progr essive RAG (P-RAG) to dynamically expand and r efine the evidence pool during the debate. Furthermore, we employ evidence negotiation, self-reflection, and heter ogeneous multi-judge aggr egation to enfor ce cali- bration, robustness, and diversity . In zero-shot evaluations on the Check- COVID benchmark, P R O C L A I M achieves 81.7% accuracy , outperforming standard multi-agent debate by 10.0 per centage points, with P-RAG driving the primary performance gains (+7.5 pp). W e ultimately demonstrate that structural deliberation and model heterogeneity effectively mitigate sys- tematic biases, providing a robust foundation for reliable claim verification. 1 Introduction LLMs have demonstrated str ong zero-shot performance on reasoning-intensive tasks, yet their reliability in high-stakes domains, such as claim verification, remains limited. Despite fluent generation, LLMs frequently exhibit hallucinations, shallow reasoning, and over con- fident predictions when evaluating evidence-dependent claims ( Huang et al. , 2025 ). RAG partially addresses these issues by gr ounding responses in external corpora ( Lewis et al. , 2020 ). Still, standard pipelines rely on static, single-pass retrieval ( Gao et al. , 2024 ) and lack mechanisms for iterative reasoning, often r esulting in incomplete or biased conclusions. T o impr ove rel iability , recent work has explor ed Multi-Agent Debate (MAD), wher e multiple LLM instances iteratively argue and refine answers ( Du et al. , 2024 ; Liang et al. , 2024 ; Han et al. , 2025 ). While promising, prior studies show that unstructur ed debate often leads to prematur e conver gence, shared bias r einfor cement, and limited evidence exploration ( Smit et al. , 2023 ; W u et al. , 2025 ). In particular , agent agreement is frequently misinterpr eted as correctness, even when gr ounded in insufficient or biased evidence. In this work, we pr opose a courtroom-style multi-agent deliberation framework P R O - C L A I M ( P rogr essive R etrieval O rchestrated multi-agent framework for Claim verification) that reformulates claim verification as a structured, adversarial r easoning process. Inspired by legal systems and recent agent-based simulations ( Chen et al. , 2025 ), our approach introduces explicit roles (Plaintiff, Defense, Judge, Critic, and Expert W itness), evidence admission protocols, and multi-stage deliberation. Central to the framework is Progres- sive Retrieval-Augmented Generation (P-RAG), which performs iterative, query-adaptive retrieval to continuously expand and r efine the evidence pool during debate. Contributions. W e pr esent a unified framework where structured deliberation outper- forms standard multi-agent debate, achieving a +10.0 pp accuracy gain and validating a courtroom-style ar chitecture. Dynamic retrieval via P-RAG is the primary driver , adding 7.5 points while pr eventing evidence stagnation. W e further show that model diversity is 1 Preprint. Under review . crucial: heterogeneous LLMs exhibit complementary errors that offset each other , outper- forming any single model. P R O C L A I M also demonstrates strong zero-shot, domain-agnostic performance. Beyond gains, our analysis reveals deeper insights into multi-agent reasoning: • Breaking the epistemic bubble , r emoving dynamic retrieval (P-RAG) increases inter - judge agreement ( ¯ κ = 0.468 → 0.599) while reducing accuracy by 7.5 pp , revealing confident convergence on incorr ect conclusions. • Acting as a logic-level lie detector , incorrect predictions exhibit unstable reasoning trajectories with oscillating self-reflection scor es, showing that reasoning dynamics are more informative than final confidence . • Enabling synthetic wisdom through diversity , heterogeneous LLMs exhibit complemen- tary error profiles ( e.g. , over -refutation vs. cautious abstention) whose combination yields a 3.3 pp accuracy gain over single-judge panels. • Serving as an economic governor , self-reflection reduces debate rounds by 29% (7.06 → 5.47) and token usage by 17% while maintaining accuracy within 0.8 pp . • Demonstrating the butterfly effect of argument framing , small biases in premise decom- position propagate and significantly impact outcomes , as seen in Run-2 where κ G T drops to 0.384 (down from 0.423 in Run-0) despite stable inter -judge κ . • Revealing structural negativity bias , LLM judges over -produce REFUTE verdicts relative to ground truth and converge faster on such claims (0.2 rounds in primary and 0.3 in role-switched debates), indicating inher ent conservatism shaped by their training data. T ogether , these findings reframe LLM reasoning as a dynamic process, where reliability arises from the structur e, diversity , and evolution of deliberation, not just final answers; see Appendices A for context with prior work. W e provide our code and data in the following GitHub repository: https://github.com/mnc13/PROClaim . 2 Methodology W e propose a courtroom-inspir ed pipeline for zero-shot, evidence-grounded fact-checking of COVID-19-related claims. Each claim is treated as a legal case, wher e a Plaintiff Counsel argues for the claim, a Defense Counsel argues against it, and an independent judicial panel deliberates toward a verdict — imposing disciplined adversarial structure over the reasoning process rather than relying on single-pass LLM inference. Figure 1 provides a high-level overview , with the full evaluation cycle formalised in Algorithm F . 2.1 Argument Mining S h ar ed Evi d e n c e P ool & P R A G N e goti ati on Prepr ocessing & Retrieval Layer Claim Load i n g & No r mal i z ati on RAG Retrieval (F AISS / PubMed) LLM-Based Argument Mining (Premise Decomposition) Shared Evidence Pool & Evidence Negotiation Evaluation & Decision Layer Multi-Judge Scoring (Logic · Evidence · Accuracy) Output: Final V erdict & Confidence Score Self-Reflection & Confidence Penalty + Majority V oting Role Switching & Consistency Audit (Plaintiff ↔ Defense) Bias & Contradiction Detection Data Layer Check-COVID Claims Dataset V ector Index & Metadata Store (F AISS) PubMed Biomedical Literature Corpus Dynamic Persona Assignment Reasoning & V erification Layer (Cor e) Plaintiff Counsel Defense Counsel Critic Expert Witness PRAG Query Expert T estimony Self Reflection Critique A r gu me n ts Arguments The Court Judicial Oversight & Query Refinement Multi-Agent Debate · Adversarial Pr oceedings Progressive RAG Feedback Loop - Adaptive · Novel Queries Each Round V erification & Bias Control Debate Claim Loading Figure 1: Overview of the pipeline Before r etrieval, the raw claim is decom- posed into atomic, independently testable premises ( Hu et al. , 2025a ; Lawr ence & Reed , 2017 ). This serves two purposes: first, de- composing complex claims allows the re- trieval system to cast a wider and more tar - geted net; second, the resulting premises act as an explicit checklist for scoring ar- gument completeness during self-r eflection and critic evaluation (Section 2.6 ). The out- put is a list of premise strings propagated to all downstream phases. Formally , given a claim c , the miner pr oduces a premise set P = { p 1 , . . . , p k } where each p i encodes a single verifiable proposition. The number of premises k is not fixed, allowing the agent to produce as many non-redundant premises as the claim’s semantic content warrants. 2 Preprint. Under review . 2.2 Initial Evidence Retrieval Relevant evidence is retrieved from COVID-19 PubMed abstracts (2020–2024) corpus, con- structed for this study , using dense vector embeddings to measure semantic similarity ( Gao & Callan , 2021 ). Claims and abstract chunks are mapped into a 384-dimensional embedding space using the all-MiniLM-L6-v2 bi-encoder ( Reimers & Gurevych , 2019 ), and the most semantically similar chunks are selected as the seed evidence pool with sour ce and year pre- served for provenance. The detailed embedding normalization and similarity computation are pr ovided in Appendix L . 2.3 Evidence Negotiation and Judicial Arbitration Inspired by the pre-trial discovery phase in legal proceedings, this stage constructs an admissibility-weighted evidence pool befor e the debate begins, drawing on r ecent works ( Jeong et al. , 2026 ; Hu et al. , 2025b ), proceeding in four steps. Premise-grounded shared retrieval: The F AISS index is queried once per decomposed premise, pr oducing a shared pool of retrieved evidence. Stance-conditioned retrieval: An LLM generates two distinct queries — one optimised to surface supporting evidence (for Plaintiff Counsel) and one for challenging evidence (for Defense Counsel) — yielding a proponent pool and opponent pool respectively . This asymmetric retrieval prevents the “Echo Chamber ” effect common in T op-K RAG, where the engine retrieves only the most statistically frequent papers, often ignoring marginalized but critical counter-evidence ( W u & Saxena , 2025 ), ensuring the evidence pool is adversarially balanced from Round 0. Negotiation injection: Both sides are exposed to each other ’s discovery pools via struc- tured LLM pr ompts, simulating the disclosure and challenge pr ocess. Rather than merely retrieving mor e data, agents actively refine the search space based on their legal strategy — a form of metacognitive evidence curation. Admissibility scoring: Each candidate is scored on two dimensions: Relevance r ∈ [ 0, 1 ] , the degree to which the evidence pertains to the specific claim, and Credibility c ∈ [ 0, 1 ] , the scientific rigour and sour ce quality . The admissibility weight is w = r × c . Items with w > 0.5 are admitted, 0.1 < w ≤ 0.5 are flagged as disputed , and w ≤ 0.1 are discarded. Admitted items are ranked in descending or der of w and passed to the debate orchestrator (see Appendix H.2 ). This mechanism operationalises a principle from both legal theory and fact-checking re- search: evidence quality and provenance matter beyond surface-level relevance, especially under conflicting sources ( Ge et al. , 2025 ). It mirrors the Daubert Standard ( Legal Infor- mation Institute , 2024 ) used in r eal-world expert testimony , excluding “scientific hearsay” before it can pollute agent deliberation. 2.4 Progressive Retrieval-Augmented Generation (P-RAG) Static, one-time retrieval is ill-suited to adversarial debate as new evidential gaps emerge as arguments evolve. Unlike prior iterative approaches that query solely from the previous gen- eration ( Shao et al. , 2023 ; T rivedi et al. , 2023 ), P-RAG concatenates three sour ces: (i) the last four messages of the rolling debate context, (ii) the agent’s self-identified evidential gap, and (iii) reflection-driven discovery needs fr om the prior round (Section 2.6 ) —into one prompt with the Judge refining each query befor e execution (see App. I for full logic and prompts). T o prevent redundant retrieval, each candidate item is scored against the existing pool: Criterion Threshold Rationale Novelty filter < 0.20 Rejects near-duplicates Redundancy ratio > 70% Indicates saturation Relevance gain < 0.05 Diminishing returns Iteration cap 10 Limits compute cost T able 1: P-RAG stopping criteria. novelty ( d ) = 1 − max p ∈ P cos ( e d , e p ) (1) where P is the current pool and e · de- notes an L2-normalised embedding. Un- like global diversity metrics such as the V endi Scor e ( Rezaei & Dieng , 2025 ), our novelty filter operates iteratively , rejecting near-duplicates at each r ound. 3 Preprint. Under review . Role Model Prov . T . Premise Decomp. deepseek-r1 OR 0.7 Plaintiff Counsel gpt-5-mini OA 0.5 Defense Counsel deepseek-v3.2 OR 0.5 The Court qwen3-235b OR 0.2 Expert W itness hermes-3-llama-405b OR 0.5 Critic Agent deepseek-r1 OR 0.3 Consistency Anal. deepseek-v3.2 OR 0.3 Judge 1 deepseek-r1 OR 0.3 Judge 2 hermes-3-llama-405b OR 0.3 Judge 3 Qwen3-235B-A22B OR 0.3 T able 2: Role-wise models. Providers (Prov .): OR =OpenRouter , OA =OpenAI. T .=T emperature. Only items with novelty ≥ 0.20 are admitted. This thr eshold is selected as a Redundancy-Noise T rade-off Heuristic; values below 0.15 allow near-duplicates, while values above 0.30 prematur ely dis- card nuanced but critical evidence. Retrieval terminates early under the adaptive stopping criteria in T a- ble 1 . 2.5 Multi-Agent Debate (MAD) Orchestration The multi-agent debate is the central r easoning engine of the pipeline involving five adjudication r oles—Plaintiff Counsel, Defense Counsel, and thr ee Judges—each assigned to a dif ferent underlying model (T able 2 ). Heterogeneous assignment serves to prevent collusion fr om shared repr esentations, introduce authentic disagreement, and improve argument diversity across rounds, as homogeneous agents cannot reliably improve over majority vote, while diversity in agent capabilities is critical for ef fective deliberation ( Zhang et al. , 2026 ; Zhu et al. , 2026 ). Each debate round executes five steps: (1) Evidence discovery: Both agents independently identify an evidential gap and propose a targeted query , which the Judge refines before execution via P-RAG, with novel results admitted to the shared pool. (2) Argument genera- tion: Each agent produces a structured legal argument grounded in the current evidence pool and debate history . (3) Expert witness testimony: Either side may request a domain expert; if granted by the Judge, a domain-specific persona is dynamically generated to pro- vide targeted testimony . This mechanism enables access to specialized knowledge without predefining expert domains. (4) Self-reflection: Each agent critiques its own performance, with identified gaps injected into the next round’s P-RAG query (Section 2.6 ). (5) Critic evaluation: The Critic Agent independently scores both sides and signals early termination if all key premises have been addr essed. The debate runs for up to max rounds = 10 but terminates early when any of the following conditions are met: (i) Reflection plateau: | ∆ total reflection score | < 0.05 for two consec- utive rounds; (ii) Critic resolution: debate resolved=True ; (iii) Novelty exhaustion: average novelty < 0.10 over two consecutive P-RAG calls; or (iv) Judicial signal: the Court agent affirms r eadiness to deliberate. 2.6 Self-Reflection and Critic Evaluation Per-agent self-reflection. After each round, each counsel performs a structured self-critique ( Madaan et al. , 2023 ; Shinn et al. , 2023 ) acr oss three dimensions: logic l ∈ [ 0, 1 ] (inferential validity), novelty n ∈ [ 0, 1 ] (new information intr oduced), and rebuttal b ∈ [ 0, 1 ] (engagement with the opposing side). Logical validity is weighted highest (0.4) as the core requir ement for inferential integrity , with novelty and rebuttal balanced equally (0.3 each) to maintain adversarial accountability without compromising factual grounding. They’re aggr egated as: s ref = 0.4 l + 0.3 n + 0.3 b , (2) and mapped to a symmetric confidence adjustment used in the final verdict (Section 2.8 ): δ ref = ( s ref − 0.5 ) × 0.6 ∈ [ − 0.30, + 0.30 ] . (3) The 0.6 multiplier scales the centered r eflection score to a range of ± 0.30. This allows the winning counsel’s self-critique to exert a significant, yet non-dominant, influence on the baseline consensus confidence ( c base ≈ 0.8), maintaining the supremacy of the judicial panel’s verdict. The self-reflection output also surfaces a discovery need —a description of missing evidence—which is included with the subsequent round’s P-RAG query . Independent Critic Agent. An independent Critic Agent, distinct from both debating agents, evaluates each r ound, leveraging prior findings that dedicated critics outperform 4 Preprint. Under review . self-critique( Li et al. , 2025b ). It scores both sides on logic, evidence coverage, and rebuttal; identifying unaddressed pr emises from Section 2.1 ; providing actionable recommendations; and issuing the debate resolved signal. Using an architecturally distinct model prevents both debaters from conver ging on a shared but potentially erroneous position. 2.7 Role-Switching Consistency T est T o pr obe whether arguments are genuinely evidence-grounded rather than position- anchored, we introduce a role-switching consistency test . Unlike prior work that uses role-switching to mitigate bias ( Jin et al. , 2025 ) or elicit uncertainty ( Liu et al. , 2025 ), we employ it as a consistency diagnostic. After the primary debate, Plaintif f and Defense Counsel swap roles, with the or chestrator resetting all state and re-running the full debate under the switched configuration. This is analogous to requiring legal counsel to argue the opposing brief: if arguments are evidence-driven, a capable agent should construct comparably strong ar guments from either position. A separate LLM then analyses both transcripts, assessing whether the logic in the switched debate contradicts the agent’s original position and whether evidence is marshalled con- sistently or opportunistically , producing a consistency score for each agent. The score is incorporated into the final confidence weighting (Section 2.8 ). 2.8 Judicial Panel Evaluation and Final V erdict The complete case record—both debate transcripts, admitted evidence, P-RAG retrieval histories, critic evaluations, and per-round self-r eflection scores—is submitted to a three- member Judicial Panel of independent LLM judges, each assigned a different model to prevent corr elated errors ( V erga et al. , 2024 ). Each judge independently evaluates the case through six stages: (1) case reconstr uction, (2) evidence Strength, (3) argument V alidity , (4) source Reliability , (5) discovery rigour and P-RAG query evolution, and (6) a final verdict of S U P P O R T E D , N O T S U P P O R T E D , or I N C O N C L U S I V E . The independent evaluations of the three judges ar e aggregated using a majority-vote mechanism to determine the final verdict. Appendix N . The confidence score is computed in two stages: Base confidence: c base = 0.8 σ + 0.3 q , (4) where σ = winning votes / total votes is the consensus str ength and q = ( ¯ s ev + ¯ s val + ¯ s rel ) / 30 is the mean judge quality score. The 30 divisor normalizes the three 10-point qualitative metrics into a unit interval [ 0, 1 ] for mathematical consistency with σ . (Certainty buffer detailed in Appendix M.1.3 ) The weights were determined using a 5-fold cross-validation grid sear ch (range [0.5, 0.9]) to minimize Expected Calibration Err or (ECE) on a held-out development subset, following best practices for calibrating LLM-based evaluators ( Gu et al. , 2025 ). Our final test set calibration yielded a near-optimal ECE of 0.034 (see Appendix M.1 ), representing a 5x improvement over standard averaging ( W = 0.6, ECE = 0.18). This high weighting ( W consensus = 0.8) is empirically justified as judge agreement proved the str ongest predictor of accuracy . Adjustment: c final = clamp c base + δ rs + δ ref , 0, 1 , (5) where δ rs is the role-switch adjustment scalar (Details in Appendix M.2 ), and δ ref is the winning side’s final self-reflection adjustment. While the agent’s raw self-reflection score ranges from [ − 0.30, + 0.30 ] (Eq. 3 ), the framework applies a strict floor ( δ ref = max ( − 0.15, raw score ) ) to ensure that self-critiques mathematically refine—but do not unilaterally overturn—the established judicial consensus (see Appendix M.3 ). After clamp- ing, if ≥ 2/3 judges agree, confidence is lower -bounded at 0.10 to prevent near-zer o scores under clear , majority agreement. 5 Preprint. Under review . 3 Experimental Setup Reflection Plateau Judicial Signal Critic Resolution Novelty Stabilization 0 100 200 179 (49.7%) 147 (40.8%) 23 (6.4%) 11 (3.1%) Number of Debates Debate T ermination Reasons (a) Debate termination reasons. GT = SUPPOR T GT = REFUTE 0 1 2 3 4 3 2.8 2.9 2.6 Rounds to Consensus (mean ± 95% CI) Primary debate Role-switched (b) Rounds to consensus by ground-truth label. Figure 2: T ermination distribution and con- vergence speed acr oss 360 debate instances. Dataset. T o evaluate the framework’s capac- ity for adversarial resolution, we focus on the subset of the Check-COVID ( W ang et al. , 2023a ) test set possessing definitive binary ground-tr uths (SUPPOR T or REFUTE). This task formulation, which we term Adversar- ial Resolution of Hard-Binary Claims , ensur es that the system is tested on its ability to navi- gate conflicting evidence toward a definitive truth, rather than defaulting to an uninfor- mative ‘Not Enough Information’ label com- mon in standard model outputs. Retrieval Corpus. Retrieval is performed over a static corpus of COVID-19 abstracts from PubMed (2020–2024), constructed for this study . Abstracts are encoded using all-MiniLM-L6-v2 , a Sentence-BERT model ( Reimers & Gurevych , 2019 ), and indexed with F AISS ( Douze et al. , 2025 ). Source meta- data, including PMID, title, journal, and pub- lication year , are stor ed alongside each pas- sage to support provenance tracking. Configuration and Metrics. T able 2 sum- marizes the heterogeneous LLM assignment, where agent r oles are partitioned across dis- tinct architectur es based on their functional capacity (deliberative vs. evaluative) and cognitive profile, utilizing moderate temperatures for adversarial advocacy and lower temperatures for rigor ous judicial evaluation (details in Appendix B.3 ). Key retrieval hy- perparameters are a novelty thr eshold τ = 0.20, per-r ound top- k = 3, and admissibility floor w > 0.5; full settings are in Appendix B.4 . W e evaluate classification performance (accuracy , macro F1), inter-judge reliability (Cohen’s κ , unanimity/split rates), confidence stability via the Kolmogorov–Smirnov statistic across rounds (App. E ), and efficiency (token usage, debate r ounds, evidence pool size). 4 Results and Discussion T able 3 reports Check-COVID performance across three independent runs, utiliz- ing majority voting for aggr egate results. Cr ucially , our framework enforces an adversarial ‘Burden of Refutation’. Mirroring legal systems where defendants are Run Acc m-F1 ¯ κ Agr . Unan. Split Run-0 0.950 0.950 0.429 0.617 0.442 0.558 Run-1 0.817 0.817 0.549 0.700 0.558 0.442 Run-2 0.790 0.790 0.474 0.652 0.496 0.504 W . T otal 0.841 0.841 0.484 0.656 0.499 0.501 Maj. V ote 0.817 0.817 0.468 0.648 0.489 0.511 Oracle 0.958 0.958 0.438 0.622 0.450 0.550 T able 3: Performance statistics. m-F1 : MacroF1. ¯ κ : Mean κ . Agr . : Raw Agreement. Unan. : Unanimity (3-0 consensus). Split : Divided vote. W. T otal: W eighted T otal. Oracle : Best-of-3. Per-judge κ GT in App. D . formally presumed intact unless definitively proven otherwise, we evaluate claims based strictly on adversarial survival. If a claim withstands rigorous deliberation and the panel fails to reach a definitive Refute consensus— instead returning an Inconclu- sive ver dict due to insufficient opposing evidence—the claim is formally classified as Supported. This strictly aligns our evaluation metrics with established court- room logic (see Appendix C ). 6 Preprint. Under review . 1 2 3 4 5 6 R o u n d t 0.0 0.2 0.4 0.6 0.8 1.0 Evidence Novelty n=2031 n=1448 n=547 n=208 n=85 n=26 Novelty Decay Across Debate Rounds 10 90th percentile IQR (25 75th) Mean novelty P -RAG query novelty (mean) Admission threshold (0.2) (a) Novelty decay across r ounds. 1 2 3 4 5 6 R o u n d t 0.0 0.2 0.4 0.6 0.8 1.0 Evidence Novelty Novelty Distribution by Round Admission threshold (0.2) (b) Novelty distribution by round. Figure 3: P-RAG evidence novelty across debate r ounds 1 2 3 4 R o u n d t 0.2 0.3 0.4 0.5 0.6 0.7 0.8 R e f l e c t i o n S c o r e s r e f Reflection Plateau 1 2 3 4 5 6 R o u n d t Judicial Signal 1 2 3 4 5 6 R o u n d t Critic Resolution Representative reflection score trajectories (n 10 per panel, all runs) Proponent (solid) Opponent (dashed) Correct prediction Incorrect prediction Figure 4: Reflection score trajectories acr oss plateau, judicial, and critic resolution patterns 4.1 Main Pipeline Performance This framework achieves a aggregate majority-vote accuracy of 81.7% across three inde- pendent runs, with an oracle ceiling of 95.8% confirming that near-optimal performance is structurally attainable under favourable initialisation. Inter-judge agreement remains stable across all runs (mean κ : 0.429, 0.549, 0.474), indicating coherent panel deliberation regar dless of outcome. The observed variability across runs is primarily attributable to stochastic ef fects in sequen- tial agent interactions. Run-1’s lower κ G T (0.372) does not translate to equivalent accuracy loss (0.817), as its errors r emain class-balanced. Run-2, however , exhibits class-asymmetric degradation: retrieval bias introduced during stochastic premise decomposition suppr esses REFUTE recall and propagates through deliberation, dr opping κ G T to 0.384 while inter-judge κ holds stable at 0.474 — confirming the panel converged confidently on systematically biased verdicts rather than br eaking down structurally . 4.2 Debate Dynamics and Adaptive Stopping T ermination distribution: Figure 2a shows that most debates self-terminate thr ough reflection-driven signals: Reflection Plateau and Judicial Signal. Reflection Plateau enforces adaptive halting once marginal argumentative gains diminish, mitigating cir cular r easoning. The low incidence of Novelty Stabilization (3.1%) further suggests that termination is driven by argumentative saturation rather than corpus insuf ficiency . Convergence speed: Figure 2b shows that REFUTE claims converge faster than SUPPOR T claims in both the primary (0.2 rounds faster) and role-switched debates (0.3 rounds faster), consistent with the LLM negativity bias documented in Section 4.5 . Evidence novelty decay: Figur es 3a – 3b confirm that P-RAG sustains genuine evidential discovery across all active rounds , with query novelty approaching the threshold from round 4 onward. The narrowing violin distributions from round 3 indicate pool satura- tion, empirically validating the 0.20 novelty threshold as the natural boundary between productive and redundant retrieval , justifying the adaptive stopping design. 7 Preprint. Under review . System Acc MacroF1 ∆ Acc ¯ κ A vg. Rounds Ev T ok (K) P R O C L A I M (Ours) 0.8167 0.8165 — 0.468 5.47 67.5 210.9 w/o P-RAG 0.7417 0.7408 − 7.5 pp 0.599 6.00 37.5 188.9 w/o Role-Switching 0.7750 0.7750 − 4.2 pp 0.513 2.88 54.0 147.3 w/o Three-Judge Panel 0.7833 0.7818 − 3.3 pp – 5.29 68.8 195.9 w/o Self-Reflection 0.8083 0.8080 − 0.8 pp 0.591 7.06 81.5 247.3 Standard MAD 0.7167 0.7068 − 10.0 pp – 2.00 12.1 18.9 T able 5: Ablation results on 120 claims. ∆ Acc is measured r elative to the full P R O C L A I M pipeline. Ev denotes the average evidence pool size. Each round count r eflects the sum of primary and role-switched debate r ounds per claim. Reflection trajectories: Figure 4 stratifies trajectories by termination condition, r evealing distinct convergence behaviours: Reflection Plateau yields rapid stabilisation within 3–4 rounds, Judicial Signal extends deliberation for contested claims, and Critic Resolution ex- hibits higher variance. Across all conditions, incorr ect predictions display greater trajectory instability , indicating a behavioural signature of err oneous outcomes. 4.3 Comparison with Baselines System Acc MacroF1 avg ev Single-call GPT -5-mini + RAG 0.8583 0.8571 19.3 Single-call DeepSeek-v3.2 + RAG 0.8000 0.7972 18.5 Standard MAD 0.7167 0.7068 5.0 P R O C L A I M (Majority V ote) 0.8167 0.8165 67.5 T able 4: P R O C L A I M vs. baselines. avg ev denotes average evidence pool size. While monolithic models like GPT -5- mini achieve strong point-estimate ac- curacy (85.8%), they lack Deliberative T raceability and Adversarial Robust- ness . Their predictions rely on single- pass, instruction-conditioned inference over a fixed evidence set, with no mech- anisms for iterative r efinement or con- sistency verification. Our Role-Switching Case Study ( Appendix K ) demonstrates that such models construct plausible ar guments for opposing conclusions based solely on task framing, revealing sensitivity to positional prompts rather than evidence-grounded r eason- ing. P R O C L A I M prioritizes Deliberative Resilience : variance in judge scores and agent consistency surfaces a T rajectory Instability Signal—a “Logic Lie Detector ” for contested claims inherently absent in single-call black-box models. The 95.8% Oracle ceiling further establishes a higher achievable performance bound than the monolithic baseline. Against Standard MAD (71.7%)—a two-agent, single-judge RAG-based debate without our en- hancements—our full pipeline achieves a +10.0 pp improvement, isolating the collective contribution of P-RAG, self-reflection, r ole-switching, and structured judicial evaluation. 4.4 Ablation Study W e conduct four ablation experiments, each excluding a single subsystem, evaluated on the same 120 claims. T able 6 summarises component activation across all configu- rations. P-RAG is the most impactful component ( ↓ 7.5 pp): without it, the evidence pool nearly halves (37.5 vs. 67.5), debates run longer (6.00 vs. 5.47) on weaker evidence, Component Full A1 A2 A3 A4 Evidence Negotiation ✓ ✓ ✓ ✓ ✓ P-RAG ✓ ✓ ✓ × ✓ Expert W itnesses ✓ ✓ ✓ ✓ ✓ Self-Reflection ✓ ✓ ✓ ✓ × Reflection → P-RAG ✓ ✓ ✓ × × Critic Agent ✓ ✓ ✓ ✓ ✓ Adaptive Convergence ✓ ✓ ✓ × Partial Role-Switching ✓ × ✓ ✓ ✓ 3-Judge Panel ✓ ✓ × ✓ ✓ Reflection Confidence Adj. ✓ ✓ ✓ ✓ × Max Rounds 10 10 10 3 10 T able 6: Component ablation matrix. ✓ = active; × = disabled. and inter-judge agreement rises to κ = 0.599—a negative signal of convergence with- out correctness ( epistemic bubble ). Role- switching contributes − 4.2 pp and r educes the evidence pool by 20%, confirming the second pass surfaces missed evidence rather than serving as a mer e consistency check. A single judge costs 3.3 pp , directly quantify- ing the benefit of heterogeneous adjudication (Sec. 2.8 ). Self-reflection has minimal accu- racy impact ( − 0.8 pp) but drives ef ficiency , reducing r ounds (7.06 → 5.47) and token us- age by 17%, providing the early-stopping sig- nal that makes the pipeline cost-effective. 8 Preprint. Under review . A full token usage breakdown and analysis ar e provided in Appendix P . 4.5 Judicial Panel: Reliability and Negativity Bias Inter-judge agr eement ( κ mean = 0.468, 48.9% unanimous) indicates heter ogeneous panels produce genuine disagr eement in 51.1% of cases, underscoring the need for diversity . Indi- vidual judges exhibit distinct biases: DeepSeek-R1 aggressively refutes (high REFUTE recall but false-refutes SUPPOR T), Hermes-3-405B cautiously abstains (frequent I N C O N C L U S I V E on SUPPOR T), and Qwen3-235B-A22B remains most calibrated (highest SUPPOR T recall, balanced abstention). All overproduce REFUTE or I N C O N C L U S I V E , reflecting structural negativity bias from epistemic caution induced by training corpora, yet their errors (com- mission, omission, calibration) dif fer such that disagr eements correct rather than compound mistakes. Consequently , the majority-vote panel achieves balanced judge–GT agr eement ( κ GT ∈ [ 0.431, 0.468 ] , mean 0.450), confirming that heter ogeneous voting improves reliability over homogeneous panels by mitigating shared biases. 4.6 Generalization to External Datasets Dataset Claim Acc F1 T ok(K) HealthV er 100 0.720 0.713 223 FEVEROUS 60 0.783 0.772 236 Check-COVID 120 0.817 0.817 211 T able 7: Generalization results (single run) HealthV er . ( Sarrouti et al. , 2021 ) W e evalu- ate on a 100-claim sample from HealthV er , achieving 72.0% accuracy . FEVEROUS. ( Aly et al. , 2021 ) W e evaluate on a 60-claim sample fr om FEVEROUS with a W ikipedia-based retriever , achieving 78.3% accuracy , within ∼ 3 pp of the Check-COVID result. Rather than exhaustive evaluations, these experiments serve as proof-of-concept robustness checks on randomly sampled subsets. Accuracy remains within 9 pp across domains, suggesting performance gains stem from the domain-agnostic nature of the deliberative framework rather than domain-specific tuning (see Appendix G for details). 4.7 Sycophancy and Argument Integrity Sycophancy—the tendency of agents to yield to opposing arguments ( Malmqvist , 2025 )—is low overall, with role-play consistency (Plaintiff: 7.80/10; Defense: 6.22/10) showing mild asymmetry as Defense “leaks” prior-role reasoning during r ole switches, producing weaker adversarial arguments. Concession rates are minimal (Plaintiff: 0.03; Defense: 0.01 per 1,000 words), with slightly higher Plaintiff rate reflecting greater argumentative friction in claim support, consistent with the negativity bias (Section 2.8 ). The reflection plateau averages 0.3823 per round, well above the 0.05 stagnation threshold, confirming agents actively push novel reasoning rather than resting on prior ar guments. Judicial conformity (Fleiss’ κ = 0.4513) further indicates moderate inter-judge agr eement—an alignment level that affirms independent evaluation while precluding the algorithmic enmeshment and absolute conformity ( κ → 1.0) symptomatic of systemic sycophancy (Appendix O ). 5 Conclusion P R O C L A I M shows that courtroom-style deliberation yields a claim verification system that is accurate, interpretable, and auditable. The framework establishes that reliability in multi- agent LLM systems emer ges from deliberative architectur e rather than individual model capability , and that the courtroom pr ovides a principled, empirically validated template for building such systems. Despite strong empirical performance, the pipeline has several limitations. Computational cost is high due to argument mining, multi-round debate, role-switching, and repeated judicial evaluations, and run-level variance remains notable despite majority voting. KS stability relies on final confidence scores as a proxy for per-round distributions, limiting insight into intra-claim dynamics. Future work includes extending r etrieval to live PubMed queries, applying the framework to other high-stakes domains such as scientific claim verification and r egulatory compliance, and reducing token usage via early-exit mechanisms, retrieval filtering, and model distillation. 9 Preprint. Under review . References Rami Aly , Zhijiang Guo, Michael Sejr Schlichtkrull, James Thorne, Andreas Vlachos, Christos Christodoulopoulos, Oana Cocarascu, and Arpit Mittal. FEVEROUS: Fact extraction and VERification over unstructur ed and structured information. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks T rack (Round 1) , 2021. URL https://openreview.net/forum?id=h- flVCIlstW . Guhong Chen, Liyang Fan, Zihan Gong, Nan Xie, Zixuan Li, Ziqiang Liu, Chengming Li, Qiang Qu, Hamid Alinejad-Rokny , Shiwen Ni, et al. Agentcourt: Simulating court with adversarial evolvable lawyer agents. In Findings of the Association for Computational Linguistics: ACL 2025 , pp. 5850–5865, 2025. Jon Chun, Kathrine Elkins, and Y ong Suk Lee. Agenticsimlaw: A juvenile courtroom multi-agent debate simulation for explainable high-stakes tabular decision making. arXiv preprint arXiv:2601.21936 , 2026. Y ihan Dong and T akayuki Ito. Multi-agent systems and credibility-based advanced scoring mechanism in fact-checking. Scientific Reports , 2026. Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jef f Johnson, Gergely Szilvasy , Pierre- Emmanuel Mazar ´ e, Maria Lomeli, Lucas Hosseini, and Herv ´ e J ´ egou. The faiss library , 2025. URL . Y ilun Du, Shuang Li, Antonio T orralba, Joshua B T enenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. In Forty-first international conference on machine learning , 2024. W ei Fan, JinY i Y oon, and Bo Ji. imad: Intelligent multi-agent debate for efficient and accurate llm inference. arXiv preprint , 2025. Luyu Gao and Jamie Callan. Condenser: a pre-training ar chitecture for dense retrieval, 2021. URL . Y unfan Gao, Y un Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Y uxi Bi, Y i Dai, Jiawei Sun, Meng W ang, and Haofen W ang. Retrieval-augmented generation for large language models: A survey , 2024. URL . Ziyu Ge, Y uhao W u, Daniel W ai Kit Chin, Roy Ka-W ei Lee, and Rui Cao. Resolving conflicting evidence in automated fact-checking: A study on r etrieval-augmented llms, 2025. URL . Shuzhi Gong, Richard O Sinnott, Jianzhong Qi, Cecile Paris, Pr eslav Nakov , and Zhuohan Xie. Multi-sourced, multi-agent evidence retrieval for fact-checking. arXiv preprint arXiv:2603.00267 , 2026. Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang T an, Xuehao Zhai, Chengjin Xu, W ei Li, Y inghan Shen, Shengjie Ma, Honghao Liu, Saizhuo W ang, Kun Zhang, Y uanzhuo W ang, W en Gao, Lionel Ni, and Jian Guo. A survey on llm-as-a-judge, 2025. URL https: //arxiv.org/abs/2411.15594 . Chen Han, W enzhen Zheng, and Xijin T ang. Debate-to-detect: Reformulating misinforma- tion detection as a real-world debate with large language models. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pp. 15125–15140, 2025. Khandakar Shakib Al Hasan, Syed Rifat Raiyan, Hasin Mahtab Alvee, and W ahid Sadik. Circuitlm: A multi-agent llm-aided design framework for generating circuit schematics from natural language pr ompts. arXiv preprint , 2026. Haorui He, Y upeng Li, Dacheng W en, Y ang Chen, Reynold Cheng, Donglong Chen, and Francis Lau. Debating truth: Debate-driven claim verification with multiple large lan- guage model agents. arXiv preprint , 2025. 10 Preprint. Under review . Qisheng Hu, Quanyu Long, and W enya W ang. Decomposition dilemmas: Does claim decomposition boost or burden fact-checking performance?, 2025a. URL https://arxiv. org/abs/2411.02400 . W entao Hu, W engyu Zhang, Y iyang Jiang, Chen Jason Zhang, Xiaoyong W ei, and Li Qing. Removal of hallucination on hallucination: Debate-augmented rag. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers) , pp. 15839–15853, 2025b. Zhe Hu, Hou Pong Chan, Jing Li, and Y u Y in. Debate-to-write: A persona-driven multi- agent framework for diverse argument generation. In Proceedings of the 31st International Conference on Computational Linguistics , pp. 4689–4703, 2025c. Zhengyu Hu, Jianxun Lian, Zheyuan Xiao, Max Xiong, Y uxuan Lei, T ianfu W ang, Kaize Ding, Ziang Xiao, Nicholas Jing Y uan, and Xing Xie. Population-aligned persona generation for llm-based social simulation. arXiv preprint , 2025d. Lei Huang, W eijiang Y u, W eitao Ma, W eihong Zhong, Zhangyin Feng, Haotian W ang, Qianglong Chen, W eihua Peng, Xiaocheng Feng, Bing Qin, and T ing Liu. A survey on hallucination in lar ge language models: Principles, taxonomy , challenges, and open questions. ACM T ransactions on Information Systems , 43(2):1–55, January 2025. ISSN 1558-2868. doi: 10.1145/3703155. URL http://dx.doi.org/10.1145/3703155 . Seyeon Jeong, Y eonjun Choi, JongW ook Kim, and Beakcheol Jang. T ool-mad: A multi-agent debate framework for fact verification with diverse tool augmentation and adaptive retrieval. arXiv preprint , 2026. W eiqiang Jin, Dafu Su, T ao T ao, Xiujun W ang, Ningwei W ang, and Biao Zhao. Courtroom- fnd: a multi-role fake news detection method based on argument switching-based courtroom debate. Journal of King Saud University - Computer and Information Sci- ences , 37(3):33, 2025. doi: 10.1007/s44443- 025- 00038- x. URL https://doi.org/10.1007/ s44443- 025- 00038- x . John Lawrence and Chris Reed. Mining argumentative str ucture fr om natural language text using automatically generated premise-conclusion topic models. In Ivan Habernal, Iryna Gurevych, Kevin Ashley , Claire Car die, Nancy Green, Diane Litman, Georgios Petasis, Chris Reed, Noam Slonim, and V ern W alker (eds.), Proceedings of the 4th Workshop on Argument Mining , pp. 39–48, Copenhagen, Denmark, September 2017. Association for Computational Linguistics. doi: 10.18653/v1/W17- 5105. URL https://aclanthology. org/W17- 5105/ . Legal Information Institute. Daubert standard. https://www.law.cornell.edu/wex/ daubert standard , 2024. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K ¨ uttler , Mike Lewis, W en-tau Y ih, T im Rockt ¨ aschel, et al. Retrieval- augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems , 33:9459–9474, 2020. Baiyang Li, Xiaosong Li, Y aY ue Zhao, Anqi Zhuo, Y ingxiao Zhao, and Shanhong T ang. A multi-agent debate approach based on large language models for scientific misinformation detection, 2025a. Jiazheng Li, Y uxiang Zhou, Junru Lu, Gladys T yen, Lin Gui, Cesare Aloisi, and Y ulan He. T wo heads are better than one: Dual-model verbal reflection at inference-time, 2025b. URL . Maoyuan Li, Zhongsheng W ang, Haoyuan Li, and Jiamou Liu. R-debater: Retrieval- augmented debate generation through argumentative memory . arXiv preprint arXiv:2512.24684 , 2025c. 11 Preprint. Under review . T ian Liang, Zhiwei He, W enxiang Jiao, Xing W ang, Y an W ang, Y ujiu Y ang, Shuming Shi, and Zhaopeng T u. Encouraging divergent thinking in large language models through multi-agent debate. In Proceedings of the 2024 conference on empirical methods in natural language processing , pp. 17889–17904, 2024. T ongxuan Liu, Xingyu W ang, W eizhe Huang, W enjiang Xu, Y uting Zeng, Lei Jiang, Hailong Y ang, and Jing Li. Groupdebate: Enhancing the efficiency of multi-agent debate using group discussion. arXiv preprint , 2024. Zixuan Liu, Siavash H Khajavi, Guangkai Jiang, and Xinru Liu. Uncertainty-aware role- switching debate: Improving truthfulness in lar ge language models. In Open Conference of AI Agents for Science 2025 , 2025. Jiatong Ma, Linmei Hu, Rang Li, and W enbo Fu. Local: Logical and causal fact-checking with llm-based multi-agents. In Proceedings of the ACM on W eb Conference 2025 , pp. 1614–1625, 2025. Aman Madaan, Niket T andon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah W iegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Y iming Y ang, et al. Self-refine: Iterative refinement with self-feedback. Advances in neural information processing systems , 36:46534– 46594, 2023. Lars Malmqvist. Sycophancy in large language models: Causes and mitigations. In Intelligent Computing-Proceedings of the Computing Confer ence , pp. 61–74. Springer , 2025. Onat Ozer , Grace W u, Y uchen W ang, Daniel Dosti, Honghao Zhang, and V ivi De La Rue. Mar: Multi-agent reflexion improves reasoning abilities in llms. arXiv pr eprint arXiv:2512.20845 , 2025. Minbae Park, Hyemin Y ang, Jeonghyun Kim, Kunsoo Park, and Hyunjoon Kim. Prograg: Hallucination-resistant pr ogressive retrieval and reasoning over knowledge graphs, 2025. URL . Salman Rahman, Sheriff Issaka, Ashima Suvarna, Genglin Liu, James Shiffer , Jaeyoung Lee, Md Rizwan Parvez, Hamid Palangi, Shi Feng, Nanyun Peng, et al. Ai debate aids assessment of controversial claims. arXiv preprint , 2025. Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks, 2019. URL . Mohammad Reza Rezaei and Adji Bousso Dieng. V endi-rag: Adaptively trading-off diver - sity and quality significantly impr oves retrieval augmented generation with llms, 2025. URL . Mourad Sarrouti, Asma Ben Abacha, Y assine Mrabet, and Dina Demner -Fushman. Evidence- based fact-checking of health-related claims. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott W en-tau Y ih (eds.), Findings of the Association for Computational Linguistics: EMNLP 2021 , pp. 3499–3512, Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.findings- emnlp. 297. URL https://aclanthology.org/2021.findings- emnlp.297/ . Zhihong Shao, Y eyun Gong, Y elong Shen, Minlie Huang, Nan Duan, and W eizhu Chen. Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy . In Houda Bouamor , Juan Pino, and Kalika Bali (eds.), Findings of the Association for Computational Linguistics: EMNLP 2023 , pp. 9248–9274, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings- emnlp.620. URL https://aclanthology.org/2023.findings- emnlp.620/ . Noah Shinn, Federico Cassano, Edwar d Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Y ao. Reflexion: Language agents with verbal reinfor cement learning, 2023. URL . 12 Preprint. Under review . Oshayer Siddique, J. M Areeb Uzair Alam, Md Jobayer Rahman Rafy , Syed Rifat Raiyan, Hasan Mahmud, and Md Kamrul Hasan. PhysicsEval: Inference-time techniques to improve the reasoning proficiency of large language models on physics problems. In Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguis- tics , pp. 738–760, Mumbai, India, December 2025. The Asian Federation of Natural Language Processing and The Association for Computational Linguistics. ISBN 979-8- 89176-303-6. doi: 10.18653/v1/2025.findings- ijcnlp.43. URL https://aclanthology.org/ 2025.findings- ijcnlp.43/ . Andries Smit, Paul Duckworth, Nathan Grinsztajn, Thomas D Barrett, and Arnu Pretorius. Should we be going mad? a look at multi-agent debate strategies for llms. arXiv preprint arXiv:2311.17371 , 2023. Harsh T rivedi, Niranjan Balasubramanian, T ushar Khot, and Ashish Sabharwal. Interleaving retrieval with chain-of-thought r easoning for knowledge-intensive multi-step questions, 2023. URL . Pat V erga, Sebastian Hofstatter , Sophia Althammer , Y ixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky , Minjie Xu, Naomi White, and Patrick Lewis. Replacing judges with juries: Evaluating llm generations with a panel of diverse models, 2024. URL https: //arxiv.org/abs/2404.18796 . Gengyu W ang, Kate Harwood, Lawrence Chillrud, Amith Ananthram, Melanie Subbiah, and Kathleen McKeown. Check-covid: Fact-checking covid-19 news claims with scientific evidence, 2023a. URL . Haotian W ang, Xiyuan Du, W eijiang Y u, Qianglong Chen, Kun Zhu, Zheng Chu, Lian Y an, and Y i Guan. Apollo’s oracle: Retrieval-augmented reasoning in multi-agent debates. arXiv preprint arXiv:2312.04854 , 1, 2023b. Haotian W ang, Xiyuan Du, W eijiang Y u, Qianglong Chen, Kun Zhu, Zheng Chu, Lian Y an, and Y i Guan. Learning to br eak: Knowledge-enhanced reasoning in multi-agent debate system. Neurocomputing , 618:129063, 2025. Hao W u and Prateek Saxena. Bias injection attacks on rag databases and sanitization defenses, 2025. URL . Haolun W u, Zhenkun Li, and Lingyao Li. Can llm agents really debate? a controlled study of multi-agent debate in logical reasoning. arXiv preprint , 2025. Miao Zhang, Junsik Kim, Siyuan Xiang, Jian Gao, and Cheng Cao. Dynamic role assignment for multi-agent debate. arXiv preprint , 2026. Xinping Zhao, Y an Zhong, Zetian Sun, Xinshuo Hu, Zhenyu Liu, Dongfang Li, Baotian Hu, and Min Zhang. Funnelrag: A coarse-to-fine progr essive retrieval paradigm for rag. In Findings of the Association for Computational Linguistics: NAACL 2025 , pp. 3029–3046, 2025. Xiaochen Zhu, Caiqi Zhang, Y izhou Chi, T om Stafford, Nigel Collier , and Andreas Vlachos. Demystifying multi-agent debate: The role of confidence and diversity . arXiv preprint arXiv:2601.19921 , 2026. A Related W ork Retrieval-Augmented Generation. RAG enhances factual grounding in large language models by incorporating external knowledge at inference time ( Lewis et al. , 2020 ; Gao et al. , 2024 ). Recent work improves retrieval quality thr ough structured pipelines such as coarse-to-fine retrieval ( Zhao et al. , 2025 ) and retrieval with reasoning ( Park et al. , 2025 ), helping mitigate hallucinations ( Huang et al. , 2025 ). Hybrid approaches further embed retrieval into multi-agent and iterative reasoning systems, including debate-augmented RAG ( Hu et al. , 2025b ), T ool-MAD ( Jeong et al. , 2026 ), R-Debater ( Li et al. , 2025c ), CircuitLM 13 Preprint. Under review . ( Hasan et al. , 2026 ), and multi-source retrieval frameworks ( Gong et al. , 2026 ), underscoring the need for adaptive evidence acquisition under conflicting or noisy conditions ( Ge et al. , 2025 ). However , most approaches rely on pr e-collected evidence pools or limited iterative mechanisms, lacking retrieval continuously driven by structur ed deliberation. Recent work also shows that claim decomposition’s benefits in fact-checking depend on how sub-claims are constructed ( Hu et al. , 2025a ), motivating its reuse as a means of extracting pr emise-level units to guide targeted r etrieval. Multi-Agent Debate. MAD has emerged as an effective paradigm for improving r easoning, factuality , and robustness in LLM outputs ( Du et al. , 2024 ), with variants spanning group- based discussions ( Liu et al. , 2024 ), ef ficiency-oriented architectures ( Fan et al. , 2025 ), and fact-checking frameworks ( Han et al. , 2025 ; Ma et al. , 2025 ; He et al. , 2025 ). Extensions incorporating credibility scoring and evidence aggregation further improve performance in high-stakes verification tasks ( Dong & Ito , 2026 ; Li et al. , 2025a ; Rahman et al. , 2025 ). By enabling agents to critique and refine each other ’s reasoning, debate reduces hallucinations and improves consensus quality . However , controlled analyses reveal persistent limitations including prematur e convergence, conformity bias, and sensitivity to agent configuration ( W u et al. , 2025 ; Zhu et al. , 2026 ; Smit et al. , 2023 ), motivating more structured debate protocols. Agent Coordination and Learning Dynamics. T o address these limitations, recent work explores impr oved coordination mechanisms in multi-agent systems, including dynamic role assignment ( Zhang et al. , 2026 ), uncertainty-aware role switching ( Liu et al. , 2025 ), and self-reflection frameworks such as Self-Refine ( Madaan et al. , 2023 ) and MAR ( Ozer et al. , 2025 ; Siddique et al. , 2025 ). Diversity and reasoning coverage ar e further improved through persona-based debate ( Hu et al. , 2025c ; d ) and divergent thinking strategies ( Liang et al. , 2024 ), while knowledge-enhanced and tool-augmented systems incorporate external signals to strengthen r easoning ( W ang et al. , 2025 ; Jeong et al. , 2026 ). Despite these advances, existing methods tr eat these components as independent objectives, wher eas P R O C L A I M repurposes them within a unified pipeline — wher e role-switching serves as a consistency diagnostic and self-reflection actively drives subsequent evidence r etrieval. Structured Deliberation and Courtroom Simulation. Structured debate frameworks in- troduce stronger inductive biases to stabilize multi-agent reasoning. Courtroom-style simulations such as AgentCourt ( Chen et al. , 2025 ) and AgenticSimLaw ( Chun et al. , 2026 ) demonstrate the effectiveness of explicit roles and adversarial interaction in high-stakes decision-making, while recent systems combine debate with retrieval for multi-round verifi- cation ( W ang et al. , 2023b ; Hu et al. , 2025b ). While these approaches impr ove robustness, they typically lack tightly integrated, dynamic retrieval mechanisms that evolve alongside the debate process, limiting their applicability to open-domain fact verification. Overall, prior work largely tr eats retrieval, debate, and coordination as separate or loosely coupled components. P R O C L A I M advances this line of research by tightly integrating progr essive retrieval, structur ed courtr oom-style deliberation, and multi-level judicial evalu- ation within a single unified framework, where evidence acquisition is continuously guided by the evolving ar gumentation process, addressing key limitations in evidence evolution, reasoning stability , and decision r eliability . B Reproducibility W e provide the repository containing the full implementation of our framework, including all configurations, prompts, and evaluation scripts. Source Code: https://anonymous.4open.science/r/PROClaim- 2535/ B.1 Software Environment and Dependencies All experiments wer e conducted utilizing Python 3.8+. W e isolated our reasoning engine using external API calls to language models, but local orchestration r elies on a strict set of dependencies. The core local libraries encompass: 14 Preprint. Under review . • Deep Learning Framework: PyT orch v1.7.0 • V ector Search Engine: faiss-cpu (configured with IndexFlatIP for inner-pr oduct cosine similarity searches) • T ext Embedding & Processing: transformers v3.4.0 and sentence-transformers • Numerical Operations: NumPy v1.19.1 B.2 Data Processing and Corpus Assumptions Input Dataset. W e evaluate our framework on the Check-COVID dataset, focusing on claims from the test split with definitive labels (SUPPOR TED or REFUTED). Claims are passed to the extraction agents without lexical normalization or stemming, pr eserving full linguistic semantics. Knowledge Corpus External knowledge is provided via a subset of PubMed abstracts related to COVID-19 (2020–2024). Offline processing embeds these abstracts into a 1.4 GB F AISS continuous vector index utilizing the 384-dimensional all-MiniLM-L6-v2 model with normalized embeddings. B.3 Agent Configurations Our framework adopts a deliberate separation between ar gumentative and evaluative components to ensure reliable adjudication. Adversarial debate is conducted between heterogeneous models ( GPT -5 mini and DeepSeek-V3.2 ), introducing diversity in reasoning styles and reducing the likelihood of homogeneous ar gument patterns. Evaluation is performed by a multi-model judicial panel, which includes DeepSeek-R1 alongside other independent large language models. Final decisions are determined via majority voting, ensuring that no single model exerts dispr oportionate influence over the outcome. Importantly , we enforce ar chitectural separation between generation and evaluation stages: models used for advocacy ( e.g. , DeepSeek-V3.2 ) ar e distinct from those used for judgment ( e.g. , DeepSeek-R1 ). This design ensures that argument construction and adjudication are carried out by systems with differing training paradigms and inference characteristics, thereby pr omoting more balanced and independent evaluation. The exact model mappings and generation sampling temperatures ( T ) defined for each architectural r ole are as follows: • Plaintiff Counsel (Proponent): gpt-5-mini ( T = 0.5) • Defense Counsel (Opponent): deepseek-v3.2 ( T = 0.5) • The Court: qwen3-235b-a22b-2507 ( T = 0.2) • Judicial Panel (Final Evaluation): A tripartite system combining deepseek-r1 , hermes-3-llama-3.1-405b , and qwen3-235b-a22b-2507 (all strictly set to T = 0.3 for highly deterministic arbitration). • Support Agents: Expert W itnesses are dynamically generated utilizing hermes-3-llama-3.1-405b ( T = 0.5), while the Critic, Argument Miner , and Consis- tency Analyzer rely on deepseek-r1 ( T = 0.3). B.4 Hyperparameters The novelty threshold τ was selected via grid search over { 0.10, 0.15, 0.20 } on a held-out development subset of 20 claims, optimising for the tradeoff between evidence diversity and retrieval pr ecision. Full settings are listed in T able 8 . 15 Preprint. Under review . Hyperparameter V alue Max debate rounds 10 Initial retrieval top- k 5 Per-r ound retrieval top- k 3 Novelty threshold 0.20 Admissibility floor > 0.5 admitted, > 0.1 disputed Redundancy similarity threshold 0.85 Redundancy ratio threshold 0.70 Relevance gain threshold 0.05 T able 8: Debate and retrieval hyperparameters. C The ‘Burden of Refutation’ Standard The framework’s structural decision to formally classify ‘Inconclusive‘ judicial panel verdicts as ‘SUPPOR T‘ is derived directly from the foundational legal concept of the burden of pr oof , which functions analogously to the presumption of innocence (“innocent until proven guilty”). In a traditional courtr oom, a defending party does not need to absolutely guarantee their innocence to survive a trial; rather , the prosecution bears the strict burden of definitively proving guilt. If the prosecution’s evidence is ambiguous, contr oversial, or broadly insuffi- cient, the presiding jury is legally obligated to return a “Not Guilty” ver dict, even if they remain partially unsur e. Our multi-agent debate architecture mirr ors this exact decision-making protocol. When ver- ifying controversial claims, the refuting agent mathematically functions as the pr osecution. If the refuting agent fails to successfully furnish enough concr ete, high-quality evidence to convince the judicial panel to issue a definitive ‘Refute‘ consensus, the panel will naturally return an ‘Inconclusive‘ stance. Under the burden of proof, this ‘Inconclusive‘ ruling means the prosecution completely failed to meet its evidentiary thr eshold. Consequently , the original claim legally and logically survives the adversarial trial, defaulting to ‘Supported.‘ This standard is a cor e necessity of the framework’s design. It actively prevents the multi- agent system from stalling on highly ambiguous cases and faithfully operationalizes the adversarial mechanics utilized to evaluate the Check-COVID dataset. D Per-Judge Ground-T ruth Agreement ( κ GT ) While the main r esults table (T able 3 ) reports inter-judge agreement ( ¯ κ )—the degree to which the three judges agr ee with each other —it does not capture how well each individual judge aligns with the ground truth. W e define κ GT (Judge-vs-Ground-T ruth Cohen’s κ ) as the Cohen’s κ computed between a single judge’s verdict and the ground-truth label, measured independently for each judge across all claims in a r un. The distinction between ¯ κ and κ GT is analytically important: a panel can exhibit high inter-judge agreement while simultaneously producing systematically biased verdicts, a failure mode we term the epistemic bubble ef fect (Section 4.1 ). T able 9 reports the per -judge κ GT across all runs and judge identities. The individual judge pr ofiles corroborate the qualitative bias characterisation in Section 4.5 : DeepSeek-R1 (J1) consistently achieves the highest κ GT across runs, Hermes-3-LLaMA-405B (J2) yields the lowest κ GT owing to fr equent INCONCLUSIVE abstentions on SUPPOR T claims, and Qwen3-235B-A22B (J3) occupies an intermediate position. Crucially , despite these individual biases, their error pr ofiles are complementary —such that majority voting corrects rather than compounds them. 16 Preprint. Under review . Run κ GT (J1) κ GT (J2) κ GT (J3) Mean κ GT DeepSeek-R1 Hermes-3-405B Qwen3-235B Run-0 0.442 0.413 0.414 0.423 Run-1 0.402 0.367 0.347 0.372 Run-2 0.452 0.353 0.348 0.384 Majority V oting 0.452 0.431 0.468 0.450 T able 9: Per-judge ground-tr uth agreement ( κ GT ) across runs and aggr egation modes. Mean κ GT is the unweighted average across the thr ee judges. E Kolmogorov–Smirnov (KS) Stability Analysis The KS statistic measures the maximum divergence between the sequential per-round confidence distribution and the final empirical consensus distribution. As established in Section 4.4 , the aggregate round index r tracks the continuous trajectory across both the primary debate phase (typically 2–3 rounds) and the subsequent r ole-switched debate phase (an additional 2–3 rounds). A decaying D r value across this combined trajectory indicates that the multi-agent system successfully resolves uncertainty and converges towar d a stable epistemic state, rather than oscillating randomly . T able 10 reports the average D r values across the first eight aggregate rounds for all three independent runs, alongside the weighted average total. Run D 1 D 2 D 3 D 4 D 5 D 6 D 7 D 8 A vg. Stop Round Run-0 1.142 0.027 0.333 0.242 0.097 0.129 0.104 -0.008 5.65 Run-1 1.131 0.017 0.455 0.347 0.178 0.138 0.127 -0.013 5.53 Run-2 1.137 0.018 0.590 0.287 0.226 0.197 0.131 0.038 5.36 T able 10: Kolmogorov–Smirnov (KS) stability statistics ( D r ) across debate rounds. V alues closer to zero indicate incr easing alignment with the final confidence distribution. Discussion of Convergence T rends. As observed in T able 10 , initial divergence is pre- dictably high ( D 1 ≈ 1.14), as the agents generate their initial arguments fr om the zero-shot discovery pool during the primary debate. Interestingly , we observe a sharp, transient mathematical alignment at Round 2 ( D 2 ≈ 0.02) before diverging again in Round 3 and Round 4 ( D 3 ≈ 0.46). This divergence pattern pr ecisely mirrors the structural orchestration of P R O C L A I M . Be- cause the primary debate phase averages 2–3 r ounds before triggering the role-switch configuration, D 3 and D 4 repr esent the peak of deliberative friction. At this thr eshold, agents are for ced to reverse their advocacy positions and process newly surfaced counter- evidence, intentionally fracturing any pr emature consensus established during the initial phase. Following this controlled disruption, the D statistic exhibits a steady , monotonic decay across all structural runs. This robust decay pr ovides quantitative validation of the framework’s adversarial resilience: as the role-switched agents engage in P-RAG discovery and self- reflection, the system’s internal confidence state steadily recoups and stabilizes. By the time the aggregate debate appr oaches its average stopping point ( ∼ 5.5 total rounds), the divergence is minimal ( D 5 ≈ 0.16), confirming that the adaptive stopping criteria ef fectively halt generation just as the role-switched epistemic state converges. Thus, while the KS metric remains a macr o-level temporal proxy , it mathematically corr oborates the necessity of role-switching and the framework’s ultimate capacity for evidence-driven r esolution. 17 Preprint. Under review . F Pseudo-code Algorithm 1 One Claim Evaluation Cycle of the PRAG Multi-Agent Debate Framework Require: claim c , PubMed F AISS index D , LLM agents { Proponent, Opponent, Judge, Critic } Ensure: final verdict v ∈ { SUPPORT, REFUTE, INCONCLUSIVE } 1: Mine atomic premises P = { p 1 , . . . , p k } using Argument Miner 2: Retrieve initial evidence E 0 ← R E T R I E V E ( c , D ) Evidence Negotiation & Arbitration 3: E 0 ← premise-gr ounded retrieval using P 4: E 0 ← stance-conditioned retrieval for supporting and r efuting evidence 5: E 0 ← LLM admissibility scoring (Relevance × Credibility) 6: Initialize debate state S 0 ← ( P , E 0 ) 7: for round t = 1 to T do 8: E t ← P R A G ( P , S t − 1 , D ) ▷ progr essive novelty-filtered retrieval 9: Pr oponent generates argument a + t from E t 10: Opponent generates counterar gument a − t from E t 11: Call Expert W itness to produce testimony τ t 12: Compute self-r eflection scores r + t , r − t 13: Critic evaluates ar guments and updates debate state 14: S t ← U P D AT E S TAT E ( S t − 1 , a + t , a − t , τ t ) 15: if evidence novelty < ϵ or debate convergence r eached or t = T then 16: break 17: end if 18: end for 19: Swap roles of Proponent and Opponent 20: Re-run debate with swapped roles to obtain consistency recor d S sw a p 21: Send debate records { S T , S sw a p } to judicial panel { J 1 , J 2 , J 3 } 22: for each judge J i do 23: v i ← J i ( c , S T , S sw a p ) 24: end for 25: v ← M A J O R I T Y V O T E ( v 1 , v 2 , v 3 ) 26: return v G External Dataset Details HealthV er . HealthV er is a benchmark dataset of health-related claims annotated for factu- ality , with a str ong focus on COVID-19 misinformation. Claims are paired with evidence and labelled as supported and refuted. In our evaluation, we sample 100 claims uniformly at random. Since the dataset operates within the biomedical domain, we retain the same PubMed-based retrieval backend used for Check-COVID. FEVEROUS. FEVEROUS is a W ikipedia-based fact verification dataset that extends FEVER by requiring evidence from both unstr uctured text and semi-structured tables. Claims are annotated with supporting or r efuting evidence from W ikipedia. For our experiments, we sample 60 claims and r eplace the retrieval module with a W ikipedia-based backend while keeping all other components unchanged. H Prompt T emplates All prompts ar e reproduced verbatim fr om the pipeline source code. V ariables enclosed in { braces } are filled at r untime. Each agent runs at the temperatur e listed in its slot definition. 18 Preprint. Under review . H.1 Premise Decomposition Prompt Agent: DeepSeek-R1 Given the following claim, decompose it into its core logical premises and sub-arguments that need to be verified. Claim: { claim text } List each premise as a separate numbered point. Be thorough and identify both explicit and implicit assumptions that must hold for the claim to be true. Focus on scientific and medical aspects. H.2 Admissibility Scoring Prompt The Judicial Arbiter evaluates the admissibility of evidence using a joint weighting equation that enforces a distinction between r elevance and scientific credibility: w = relevance ( q , e ) × credibility ( e ) . (6) Items with w > 0.5 are automatically admitted, while items with 0.1 < w ≤ 0.5 are flagged as disputed . This product-based scoring ensur es that ”scientific hearsay” (high relevance but low credibility) is ef fectively excluded. Arbiter Prompt The exact zero-shot pr ompt used by the arbiter to generate these scores is provided below: Evaluate the scientific relevance and credibility of the following evidence for the claim. CLAIM: {claim} EVIDENCE: {evidence_text} Provide an evaluation based on: 1. Relevance: How directly does this evidence address the premises of the claim? (0.0 - 1.0) 2. Credibility: Does the evidence come from a reliable scientific context or contain high-quality data? (0.0 - 1.0) H.3 Plaintiff Counsel Prompt Agent: GPT -5-mini System Prompt: You are the Plaintiff Counsel in a legal proceeding. Your role is to present arguments supporting the claim, interpret evidence favorably, challenge opposing arguments, and conduct examination of expert witnesses. Maintain a professional legal advocacy tone. Per-turn Argument Generation Prompt: You are participating in a structured legal proceeding. - Maintain a professional, factual, and strictly evidence-based tone. - Focus on proving or refuting the claim using the provided evidence and expert witness testimony. - State your arguments clearly and concisely as you would in a courtroom. - DIRECT OUTPUT ONLY: Do not reveal your internal thought process, scratchpad, or "thinking" steps. Output only your final argument. Claim: { claim.text } Your Role: Plaintiff Counsel Instruction: As Plaintiff Counsel, present your case in SUPPORT of the claim. Use evidence and expert testimony to persuade the Court. Available Evidence: { evidence text } Recent Debate History: { history text } Provide your statement (2-3 paragraphs, cite evidence by source ID) H.4 Defense Counsel Prompt Agent: DeepSeek-V3.2 System Prompt: 19 Preprint. Under review . You are the Defense Counsel in a legal proceeding. Your role is to challenge the claim, identify weaknesses in arguments, contest evidence interpretation, and cross-examine expert witnesses. Maintain a professional legal defense tone. Per-turn Argument Generation Prompt: Identical structure to Plaintif f Counsel above, with the role instr uction replaced by: Instruction: As Defense Counsel, present your case AGAINST the claim. Identify flaws and challenge the plaintiff’s evidence and witnesses. H.5 The Court (Presiding Judge) Prompt Agent: Qwen3-235B-A22B ( openrouter ) System Prompt: You are The Court presiding over a legal proceeding. Your role is to oversee the case, ensure professional conduct from all counsels, and determine when sufficient evidence and expert testimony have been presented for deliberation. Query Refinement Prompt: As the Court, you must maintain the quality and focus of evidence discovery. A counsel has proposed the following search query to retrieve additional exhibits: Proposed Query: " { original query } " Context of proceedings: { debate context } Refine this query to be more precise, narrow the scope if necessary, and ensure it follows scientific rigor. Respond ONLY with the refined query string. Debate Completion Check Prompt: As the Court, review the proceedings. Have both counsels had sufficient opportunity to present their evidence and arguments? Record Summary: { history summary } Should the proceedings continue or should we move to final deliberation? Respond ’Wait’ to continue or ’Close’ to finish. Expert W itness Admissibility Prompt: { requester } has requested to call an expert witness: { expert type } Reasoning: { reasoning } As the Court, is this expert witness necessary for the thorough resolution of this case? Respond only with ’Granted’ or ’Denied’ followed by a brief reason. H.6 Critic Agent Prompt Agent: DeepSeek-R1 ( openrouter ) System Prompt: You are the Independent Critic Agent. Your role is to evaluate the debate rounds for logical coherence, evidence coverage, and rebuttal quality. Round Evaluation Prompt: You are the Critic Agent observing a courtroom-style scientific debate. Claim: { claim } Round: { round num } Recent Proceedings: { history summary } Analyze both the Plaintiff and Defense Counsel’s performance in this round. 20 Preprint. Under review . Score each side (0.0 to 1.0) on: 1. Logical Coherence: Argument flow and structure. 2. Evidence Coverage: How well they used admitted exhibits. 3. Rebuttal Coverage: Did they address the opponent’s strongest points? Identify any premises that remain "unresolved" or under-supported. Provide actionable recommendations for both sides to improve their discovery and arguments. Respond ONLY in valid JSON format: { "plaintiff": { "logic": 0.0, "evidence": 0.0, "rebuttal": 0.0, "reasoning": "..." }, "defense": { "logic": 0.0, "evidence": 0.0, "rebuttal": 0.0, "reasoning": "..." }, "unresolved_premises": ["...", "..."], "recommendations": { "plaintiff": ["...", "..."], "defense": ["...", "..."], "queries": ["suggested search query 1", "..."] }, "debate_resolved": false } H.7 Self-Reflection Prompt Issued to: Plaintiff Counsel and Defense Counsel after each round. You are the { job title } ( { side } Counsel). You have just completed Phase { round num } of the proceedings. CLAIM: { claim } YOUR ARGUMENTS SO FAR: { my args[-2:] } { OPP SIDE } COUNSEL’S CHALLENGES: { opponent args[-2:] } Perform a strictly professional self-audit: 1. Logical Coherence: Evaluate the flow and structural integrity of your arguments. 2. Evidence Novelty: Have you introduced truly new information or just repeated old points? 3. Rebuttal Coverage: How effectively did you address the { opp side } counsel’s latest points? Identify: - Critical gaps in your current evidence base. - Premises you haven’t sufficiently supported. Respond ONLY in valid JSON format: { "scores": { "logic": 0.0-1.0, "novelty": 0.0-1.0, "rebuttal": 0.0-1.0 }, "flaws_identified": ["...", "..."], "discovery_need": "Specific evidence lookup query to fill a gap (1 sentence)", "refined_stance": "Summary of your improved position" } Note: The following aggregation and termination logic is executed programmatically by the or ches- trator script and is strictly hidden from the LLM agents to pr event strategic manipulation of debate 21 Preprint. Under review . length. The weighted convergence score is calculated as: S total = 0.4 · logic + 0.3 · novelty + 0.3 · rebuttal . Debate terminates when the absolute change satisfies | ∆ S total | < 0.05 across consecutive rounds. H.8 Expert W itness Prompt Agent: Hermes-3-LLaMA-3.1-405B ( openrouter ) System Prompt: You are a scientific expert witness. Provide technical analysis based on your expertise. The expert’s role instr uction within the argument pr ompt is: Instruction: As an Expert Witness ( { job title } ), provide your unbiased professional testimony regarding: { expertise list } . Expert Request Proposal Prompt (counsel-side): Based on the current state of the proceedings, do you need to call an expert witness to clarify a specific point? Recent Proceedings: { history summary } If yes, specify the type of expertise needed and why. If no, say ’None’. Format: { "expert type": "...", "reasoning": "..." } or "None" H.9 Judicial Panel Prompt Agents: Three independent judges—DeepSeek-R1, Hermes-3-LLaMA-3.1-405B, Qwen3- 235B-A22B Shared System Prompt: You are an independent appellate judge presiding over a legal proceeding. Your role is to perform a comprehensive holistic evaluation of the case, focusing on evidence admissibility, logical coherence of advocacy, and scientific accuracy of expert testimonies. Full Evaluation Prompt (6-stage): You are an appellate judge evaluating the following proceedings for fact-checking. PROCEEDINGS RECORD: CLAIM: { claim } PLAINTIFF COUNSEL’S ARGUMENTS: { proponent args } DEFENSE COUNSEL’S ARGUMENTS: { opponent args } ADMITTED EVIDENCE & EXPERT TESTIMONIES: { evidence summary } ROLE-SWITCH HISTORY (ADVERSARY CONSISTENCY): { role switch summary } EVIDENCE DISCOVERY METRICS (PRAG EVOLUTION): { prag metrics } INDEPENDENT CRITIC EVALUATIONS (PROCESS INTEGRITY): { critic evaluations } AGENT SELF-REFLECTION TRENDS: { reflection history } Perform the following evaluation stages: STAGE 1 -- CASE RECONSTRUCTION Identify: Core claim; main supporting arguments from Plaintiff; main counterarguments from Defense. STAGE 2 -- EVIDENCE & TESTIMONY WEIGHTING Score: Evidence Strength (0--10) 0--3: Weak/irrelevant/unreliable. 4--6: Moderate with limitations. 7--10: Strong, credible, highly relevant. STAGE 3 -- LOGICAL COHERENCE ANALYSIS Detect logical contradictions, fallacies, misuse of evidence. Score: Argument Validity (0--10). STAGE 4 -- SCIENTIFIC/TECHNICAL CONSISTENCY 22 Preprint. Under review . Check alignment with consensus. Score: Scientific Reliability (0--10). STAGE 5 -- DISCOVERY RIGOR & TRANSPARENCY Analyze PRAG metrics: query evolution, evidence novelty, judicial refinement impact. STAGE 6 -- JUDICIAL VERDICT Determine: SUPPORTED / NOT SUPPORTED / INCONCLUSIVE. Respond ONLY in valid JSON format: { "claim_summary": "...", "evidence_strength": 0, // 0-10 "argument_validity": 0, // 0-10 "scientific_reliability": 0, // 0-10 "verdict": "SUPPORTED", // or "NOT SUPPORTED" or "INCONCLUSIVE" "reasoning": "..." } Note on V erdict Label Mapping: While the judicial panel is prompted to output S U P P O R T E D , N O T S U P P O R T E D , or I N C O N C L U S I V E , these are programmatically mapped to the canonical Check-COVID dataset labels ( S U P P O R T and R E F U T E ) for all result logging and metric calculations. This terminology difference is a deliberate design decision: the judicial prompt uses N O T S U P P O RT E D to evoke a legal and scientific ”burden of proof” framework. In practice, given our focus on adversarial resolution of binary claims (Section 3 ), a finding of N O T S U P P O RT E D after rigorous advocacy against the claim—including a r ole-switching consistency pass—is functionally equivalent to a R E F U T E verdict. I P-RAG Query Construction T o address the challenge of merging heter ogeneous sources into a coher ent search strategy , P-RAG does not issue multiple separate queries. Instead, it concatenates the three sour ces into a single directed pr ompt, formulates an initial query via a lightweight LLM, and passes it to the presiding Judge for rigor ous refinement. This guarantees a single, highly targeted natural-language query is executed against the vector corpus per agent, per round. Step 1: Gap Proposal (Counsel) Each counsel identifies a discovery need from the curr ent debate state: As { job title } , analyze the current proceedings and identify a critical gap in the available exhibits. What specific evidence do you need to request to strengthen your case or challenge the opposition? Context: { debate context } Propose exactly one specific evidence need (1 sentence): Concatenation of Sources: The agent’s newly identified evidential gap (Source 2) and any unresolved discovery need generated during the prior round’s self-reflection (Sour ce 3) are concatenated into a single agent request string: { gap proposal } . Focus also on: { reflection discovery need } This combined agent request is then injected alongside the last four messages of the debate history ( debate context , Source 1) into the formulation pr ompt below . Step 2: Query Formulation (P-RAG Engine) The combined discovery prompt is passed to the P-RAG LLM: Based on the following proceedings context and legal request, formulate a precise search query to retrieve relevant exhibits and evidence. Debate Context: { debate context } 23 Preprint. Under review . Agent Request: { agent request } Generate a concise search query (1--2 sentences) that will retrieve the most relevant evidence Step 3: Judicial Query Refinement (The Court) Before retrieval executes, the formulated query is reviewed and refined by the presiding judge (The Court, Qwen3-235B-A22B): As the Court, you must maintain the quality and focus of evidence discovery. A counsel has proposed the following search query: Proposed Query: " { original query } " Context of proceedings: { debate context } Refine this query to be more precise, narrow the scope if necessary, and ensure it follows scientific rigor. Respond ONLY with the refined query string. Novelty Scoring and Stopping Criteria Retrieval applies the refined query to the F AISS index ( all-MiniLM-L6-v2 embeddings). Each retrieved document d receives a novelty scor e: η ( d ) = 1 − max e ∈ P cos ( v d , v e ) , where P is the curr ent evidence pool. Documents with η < 0.2 are rejected. The retrieval terminates early if any of the following criteria are met: (i) redundancy ratio > 0.70, (ii) relevance gain < 0.05 vs. the previous round, or (iii) r ound counter ≥ 10. J Example Full Debate T ranscript W e present a representative complete execution for claim 6063931df9b9e03ea4d8e441 0 : Claim: “Heart muscle cell damage is not an associated condition among hospitalized COVID-19 patients.” Ground T ruth: REFUTE Pipeline V erdict: REFUTE Correct: ✓ Confidence: 0.902 Premise Decomposition (Argument Mining) The Argument Miner (DeepSeek-R1) decomposed the claim into: 1. Hospitalized COVID-19 patients have detectable levels of cardiac biomarkers in- dicative of heart muscle cell damage. 2. The prevalence of elevated cardiac biomarkers in hospitalized COVID-19 patients is comparable to a control gr oup without COVID-19. 3. Incidence rates of heart muscle cell damage in hospitalized COVID-19 patients are not higher than in patients with other viral respiratory infections. 4. Clinical studies on hospitalized COVID-19 patients do not report significant occur - rences of heart muscle cell damage. 5. There is no statistical association between COVID-19 infection severity and markers of heart muscle cell damage in hospitalized patients. 6. Autopsy findings of deceased hospitalized COVID-19 patients do not show evidence of heart muscle cell damage. 7. Hospitalized COVID-19 patients with pre-existing car diac conditions do not have higher rates of heart muscle cell damage compar ed to those without pre-existing conditions. 24 Preprint. Under review . Evidence Negotiation & Admission Initial RAG retrieved 5 candidate documents; negotiation and arbitration admitted 21 ex- hibits (weights ranging 0.54–0.81), including: Source 32517963 ( Journal of the American College of Cardiology , highest weight 0.81), Source 37600048 ( Frontiers in Cardiovascular Medicine , weight 0.80), Source 33994028 ( Curr ent Cardiology Reports , 2022), and Source 35387441, among others. T wo items were flagged for dispute. Proceedings — Phase 1 Discovery (Plaintiff Counsel). Plaintiff pr oposed a need for controlled studies comparing myocardial injury biomarker rates in COVID-19 versus non-COVID critically ill cohorts. The Court refined the query to: “Retrieve individual participant data (IPD) from published meta-analyses and prospective cohort studies of hospitalized adult patients with confirmed COVID-19 that report myocardial injury defined by elevated cardiac troponin levels (above the 99th percentile upper refer ence limit) with concurrent assessment of car diomyocyte damage, while adjusting for pr e-existing cardiovascular disease, iatr ogenic expo- sures, and other potential confounders, to evaluate the independent association between SARS-CoV -2 infection and myocardial injury . . . ” 3 new exhibits admitted. Argument — Plaintiff Counsel (GPT -5-mini, T = 0 . 5): Y our Honor , the evidence does not establish that heart muscle cell damage is an associated condition specific to hospitalized COVID-19 patients. Numerous high-quality investigations and meta-analyses document that cardiac biomarker elevations ( e.g. , troponin) occur in more severely ill patients and predict worse outcomes, but they do so as non-specific indicators of systemic illness rather than as proof of SARS-CoV -2-caused myocardial cell injury (Sources 3, 6, 2, 4, 18). Moreover , studies find myocardial injury detected at a similar rate in patients with and without COVID-19 admitted to the same hospital setting, and it predicts short-term mortality to a comparable degr ee in both gr oups (Sources 12, 13). [. . . ] The record supports the conclusion that true heart muscle cell damage is not an established associated condition of hospitalization for COVID-19 but rather a non-specific marker of severe systemic disease. Discovery (Defense Counsel). Defense proposed production of all patient-level data from cited meta-analyses to independently verify the control for confounding variables. The Court refined the query to target prospective cohort studies with troponin-defined myocardial injury and histopathologic confirmation. 3 new exhibits admitted. Argument — Defense Counsel (DeepSeek-V3.2, T = 0 . 5): Y our Honor , opposing counsel’s argument fundamentally mischaracterizes the extensive body of evidence. Direct pathological evidence confirms SARS-CoV -2 can cause cardiac cell damage. Autopsy studies have documented myocardial injury , including myocyte necrosis and myocarditis, providing definitive histological proof of heart muscle cell damage attributable to the infection (Sources 14, 15). Furthermore, elevated cardiac troponin is consistently linked to dramatically worse in-hospital outcomes including incr eased mortality , need for life-sustaining treatment, and longer hospitalization (Sources 1, 5, 16, 18). [. . . ] The weight of evidence from direct tissue analysis to large-scale clinical cohorts conclusively demonstrates that heart muscle cell damage is a significant and associated condition in hospitalized COVID-19 patients. Expert W itness — Phase 1. Plaintiff requested a car diologist with expertise in myocarditis and clinical epidemiology of infectious diseases. Granted by The Court. Expert testimony (Hermes-3-LLaMA-405B): [. . . ] the evidence strongly supports the conclusion that heart muscle cell damage is indeed an associated condition among hospitalized COVID-19 patients. Autopsy 25 Preprint. Under review . studies have provided direct histological proof of myocardial injury , including myocyte necrosis and myocarditis, in COVID-19 patients (Sources 14, 15). This is not merely a biomarker corr elation; it is direct anatomical evidence of SARS-CoV - 2 causing cardiac cell damage. [. . . ] The plaintiff ’s claim that heart muscle cell damage is not an associated condition among hospitalized COVID-19 patients is not supported by the preponderance of the evidence pr esented. Self-Reflection Scores — Phase 1. Agent Logic Novelty Rebuttal T otal Discovery Need (summary) Plaintiff 0.78 0.45 0.62 0.633 Controlled studies comparing myocarditis rates in COVID-19 vs. non-COVID respiratory illness Defense 0.70 0.50 0.40 0.550 Studies demonstrating SARS-CoV -2 viral presence in car diomyocytes Critic Recommendations — Phase 1. • Plaintiff: Introduce studies comparing troponin elevations in COVID-19 vs. other severe infections ( e.g. , sepsis) to demonstrate non-specificity; challenge statistical significance of autopsy findings. • Defense: Provide epidemiological data linking autopsy-pr oven cardiac injury rates to hospitalization cohorts; address biomarker non-specificity by distinguishing acute myocardial injury patterns. Convergence delta: ∆ S = 1.183 (debate continues). Proceedings — Phase 2 Argument — Plaintiff Counsel: [. . . ] The medical literature does not establish heart muscle cell damage as a condi- tion specifically associated with hospitalization for COVID-19. Robust systematic reviews and meta-analyses consistently show that elevated cardiac biomarkers correlate with overall disease severity and worse prognosis but are non-specific markers of critical systemic illness rather than definitive evidence of SARS-CoV - 2-mediated myocyte necrosis (Sources 33086028, 34416596, 33994028, 35691587, 32589258). Comparative cohort analyses report myocardial injury at similar fre- quencies and with similar prognostic significance in patients with and without COVID-19 admitted to the same institutions (Sour ces 32921872, 33144126). Autopsy and pooled post-mortem studies show heterogeneous cardiac findings without consistent, SARS-CoV -2-specific myocyte necrosis (Sources 34273507, 35339672). Argument — Defense Counsel: [. . . ] Multiple high-quality systematic reviews and meta-analyses demonstrate a consistent and significant association between COVID-19 severity and biomarkers of myocardial injury (Source 3, 6, 2). The plaintiff ’s reliance on non-specificity of biomarkers ignores their established r ole as direct serological evidence of myocar - dial injury—a consistent, graded relationship between biomarker elevation and worse prognosis is confirmed across global cohorts (Sources 3, 6, 16). Crucially , autopsy and histopathologic analyses have identified myocarditis and other SARS- CoV -2-related cardiac pathologies in subsets of decedents, providing tissue-level corroboration beyond biomarker surr ogates (Source 14, 15, 25). Self-Reflection Scores — Phase 2. Agent Logic Novelty Rebuttal T otal Plaintiff 0.85 0.60 0.70 0.730 Defense 0.70 0.30 0.60 0.550 26 Preprint. Under review . Convergence delta: ∆ S = 0.097 > 0.05, debate continues. Phase 3 proceeded similarly; in Phase 3 the Court signalled sufficient evidence and invoked adaptive termination. Final Judicial Panel V erdict Judge Model Ev . Str . Arg. V al. V erdict Judge 1 DeepSeek-R1 7 8 NOT SUPPORTED Judge 2 Hermes-3-LLaMA-405B 7 6 SUPPOR TED Judge 3 Qwen3-235B-A22B 8 7 NOT SUPPORTED Majority V erdict: NOT SUPPOR TED Final pipeline verdict: REFUTE (confidence 0.902). Ground truth: REFUTE. ✓ T oken usage: 441,109 total tokens. Retrieval calls: 40. Evidence pool: 124 documents. K Role-Switching Case Study The same claim ( 6063931df9b9e03ea4d8e441 0 ) is used to illustrate the role-switching mech- anism. Mechanism After Phase 3, the orchestrator invokes RoleSwitcher.switch roles() . The model previ- ously acting as Plaintiff Counsel (GPT -5-mini, originally arguing S U P P O R T ) is reassigned the Defense role and vice versa. All debate state is reset; evidence pool is restor ed to the 21 originally admitted exhibits. A fresh debate runs for up to 2 adaptive r ounds. Original Argument (Agent A as Plaintiff Counsel, Pro-Support) Y our Honor , the evidence does not establish that heart muscle cell damage is an associated condition specific to hospitalized COVID-19 patients. Meta-analyses and systematic reviews show a correlation between elevated cardiac biomarkers and COVID-19 severity and mortality , but explicitly characterize these biomarkers as prognostic markers of critical illness rather than definitive evidence of direct myocardial cell damage attributable to COVID-19 (Sources 3, 6, 2, 4, 18). Studies find myocardial injury detected at a similar rate in patients with and without COVID-19 admitted to the same hospital setting, and it predicts mortality to a comparable degree in both groups (Sources 12, 13). [. . . ] The record supports the conclusion that heart muscle cell damage has not been established as an associated condition among hospitalized COVID-19 patients. Switched Argument (Agent A as Defense Counsel, Anti-Support) After the role swap, the same model (GPT -5-mini) now argues A G A I N S T the claim: Y our Honor , the claim that heart muscle cell damage is “not an associated condition” is definitively refuted by clinical, biochemical, and pathological data. Elevated cardiac tr oponin—a direct marker of cardiomyocyte damage—is a powerful and independent predictor of sever e outcomes including mortality , prolonged hospital- ization, and need for advanced life support in COVID-19 patients (Sources 1, 5, 18). The consistent, graded relationship between the degree of biomarker elevation and worse pr ognosis across global cohorts (Sources 3, 6, 16) confirms that this is a central feature of the disease’s pathophysiology , not an incidental finding. Furthermore, au- topsy studies provide incontrovertible histological pr oof of SARS-CoV -2-associated cardiac damage, documenting myocyte necrosis and myocarditis (Sour ces 14, 15, 31). [. . . ] W e therefor e ask the Court to reject the claim. 27 Preprint. Under review . Consistency Analysis Output The consistency analyzer (DeepSeek-v3.2, T = 0.3) evaluated both sets of arguments and returned: Agent A (GPT -5-mini) Consistency: Agent A maintains logical consistency when switching roles. As Plaintiff Counsel, they focused on biomarker non-specificity and comparable injury rates in non- COVID populations to argue against a unique association. As Defense Counsel, they shifted focus to the graded prognostic relationship between biomarker elevation and outcomes and to direct histopathological evidence to argue for association. The core ar guments ar e not contradictory but rather emphasize differ ent aspects of the evidence depending on their r ole. Agent A adapts their stance to align with their new position without internal inconsistency . Consistency: 9/10. Agent B (DeepSeek-V3.2) Consistency: Agent B maintains logical consistency when switching r oles. As Defense Counsel, they asserted biomarker elevation was pr oof of injury; as Plaintiff Counsel, they now ar gue it is mer ely correlative. While the conclusions flip, the underlying logic— demanding rigorous causal links—remains stable. Agent B consistently applies scrutiny to the opposition’s claims that they previously defended against. The arguments ar e opposing but not internally inconsistent. Consistency: 8/10. Contradictions Found: There ar e no direct contradictions in the ar guments of either Agent A or Agent B when switching r oles. Both agents adapt their arguments to align with their new positions by emphasizing different aspects of the evidence—for example, recontex- tualizing the same autopsy findings (Sour ces 14, 15) as either “heter ogeneous and non-specific” (Plaintif f r ole) or “direct tissue-level corroboration” (Defense role). The arguments ar e opposing but not contradictory . Overall Consistency Score: Consistency Score = 8.5 /10 Both agents demonstrate high logical consistency when switching roles (Agent A: 9/10; Agent B: 8/10). The score is not 10/10 because while the arguments are logically consistent, they are inherently opposing, and minor inconsistencies—such as Agent B’s shift fr om treating biomarkers as “definitive” (Defense) to “surrogate markers” (Plaintif f)—reflect the inherent tension in adversarial r ole design rather than true internal contradiction. Interpretation The role-switching experiment confirms that the LLMs are not simply “parroting” their initial stance due to anchoring bias. When forced to argue the opposite position with identical evidence, both agents successfully construct valid, evidence-grounded ar guments for the opposing side—without contradicting their prior reasoning. This provides empirical evidence that the agents ar e selectively marshaling evidence based on task instruction rather than hallucinating or pattern-matching their first output. The high consistency scor e (8.5/10) also validates the adversarial structure: the same body of cardiac injury literature genuinely supports multiple framings— association versus non-specificity , biomarker surrogacy versus histopathologic corroboration—and the final verdict depends on the judicial panel’s holistic synthesis rather than counsel advocacy alone. L Embedding Normalization and Similarity Computation For embedding-based similarity computation used in the evidence retrieval. Each claim q and abstract chunk d is mapped to a 384-dimensional vector v using the all-MiniLM-L6-v2 bi-encoder from the sentence-transformers framework ( Reimers & Gurevych , 2019 ). T o 28 Preprint. Under review . ensure that similarity depends only on semantic orientation, raw embeddings are L2- normalized: ˆ v = v ∥ v ∥ 2 = v q ∑ 384 i = 1 v 2 i . (7) The similarity between a query embedding ˆ v q and a chunk embedding ˆ v d is computed as their inner product, which is equivalent to cosine similarity for unit vectors: sim ( q , d ) = ˆ v q · ˆ v d = cos ( θ ) . (8) The most semantically similar chunks ar e selected as the seed evidence pool, with sour ce journal and publication year preserved for pr ovenance context in subsequent deliberation. M Confidence Score: Calibration and Adjustment Details M.1 Confidence Calibration Analysis T o ensure that the confidence scores produced by P R O C L A I M reflect empirical accuracy , we performed a post-hoc calibration of the consensus weighting parameter ( W consensus ). The calibration aims to minimize the Expected Calibration Error (ECE), defined as: ECE = M ∑ m = 1 | B m | N | acc ( B m ) − conf ( B m ) | , (9) where N is the total number of samples, B m is a bin of predictions within a specific confidence range, and acc ( B m ) and conf ( B m ) are the observed accuracy and mean confidence of that bin, respectively . M.1.1 Methodology W e conducted an exhaustive grid search over W consensus ∈ [ 0.5, 0.9 ] with a step size of 0.1. T o prevent test-set leakage, the optimal weights were determined via 5-fold cr oss-validation across the experimental metadata. The values for c base were then adjusted by the secondary refinements ( δ rs and δ ref ). M.1.2 Results T able 11 summarizes the comparison between the baseline equal-weighting variant ( W = 0.6) and our final calibrated model ( W = 0.8). The 0.8 weighting achieved a near -optimal ECE of 0.0340, representing a significant reduction in over-confidence compared to the experimental variant. V ariant N Accuracy ECE W consensus = 0.6 118 95.76% 0.1802 W consensus = 0.8 (Final) 118 95.76% 0.0340 T able 11: Impact of Consensus W eighting on Calibration Error . The bucket analysis for the final model (T able 12 ) shows that the generated confidence scores closely align with observed accuracy , particularly in the high-certainty bins wher e the system’s majority-vote consensus is strongest. M.1.3 Confidence Aggregation and the Certainty Buf fer The coefficients in Equation 4 are purposefully scaled to provide a theoretical maximum greater than 1.0 (specifically 0.8 + 0.3 = 1.1) to establish a mathematical “certainty buffer ” that ensures the framework’s practical r obustness. Epistemologically , confirming a contr o- versial claim with definitive certainty should not necessitate absolute flawlessness across every granular adversarial sub-metric. By allowing the unadjusted calculation to exceed 1.0 29 Preprint. Under review . Confidence Bin N Observed Acc. Mean Conf. [ 0.6, 0.7 ) 4 75.00% 0.6685 [ 0.7, 0.8 ) 4 100.00% 0.7365 [ 0.8, 0.9 ) 20 95.00% 0.8639 [ 0.9, 1.0 ] 90 96.67% 0.9768 T able 12: Bucket Analysis for W consensus = 0.8. prior to final metric clamping, the system guarantees that a unanimously supported claim (a 3-0 consensus) can safely absorb minor downstream penalties—such as a slightly imperfect role-switch or a pedantic self-r eflection critique—without artificially degrading its definitive 1.0 confidence score. Conversely , this weighted structure simultaneously acts as a strict safeguard against divided outcomes: in a “split court” scenario (a 2-1 vote), the consensus multiplier drops fr om 1.0 to 0.67, immediately pulling the base confidence calculation down to a heavily constrained 0.53 baseline (0.67 × 0.8). This intentional, dual-bounded design ensures that while inconsequential metric noise cannot derail a truly unanimous factual consensus, absolute high-confidence ratings remain mathematically inaccessible for any claim that fails to convince the entire adjudicating panel. M.2 Role-Switch Consistency Mapping ( δ rs ) T o ensure complete repr oducibility , the mapping from the role-switch consistency score ( γ ∈ [ 0, 10 ] ) to the adjustment scalar ( δ rs ) is defined as a discrete piecewise threshold function: δ rs ( γ ) = + 0.10 if γ ≥ 7, 0.0 if 5 ≤ γ < 7, − 0.05 if γ < 5. (10) Semantically , γ is not computed per-agent; rather , it serves as an aggregated, holistic metric that evaluates the stability of the entire debate’s logical trajectory before and after the r ole exchange. The threshold boundaries of 5 and 7 are defined to logically partition the 10-point scale into distinct qualitative strata: γ ≥ 7 demarcates definitively str ong consistency deserving of a positive scalar rewar d, operations between [ 5, 7 ) repr esent ambiguous or neutral role- switching performance where the baseline consensus r emains unadjusted (0.0), and strictly γ < 5 signifies a clear adversarial dialogue breakdown warranting a penalty . Furthermore, we intentionally employ this asymmetric mapping—of fering a larger + 0.10 rewar d versus a smaller − 0.05 penalty . Because LLM agents face inher ent structural diffi- culties in strictly preserving complex persona states across continuous extended context windows, achieving high consistency ( γ ≥ 7) is actively rewar ded as a strong marker of r eli- ability . Conversely , slight structural drift during r ole-switching is expected, so the penalty is constrained to − 0.05 to strictly ensur e that a failed r ole-switch does not excessively override the primary evidentiary consensus. M.3 Self-Reflection Asymmetric Bounding ( δ ref ) During the self-reflection phase, the winning agent generates a raw confidence adjustment scalar , denoted here as δ raw ∈ [ − 0.30, + 0.30 ] (derived from Eq. 3 ). However , to maintain the structural supremacy of the judicial panel over the individual debating agents, the framework limits the overall mathematical damage that an agent’s post-hoc self-critique can inflict upon a finalized consensus. T o achieve this, the final self-reflection adjustment ( δ ref ) is subjected to an explicit, asymmet- ric floor function: δ ref = max − 0.15, δ raw (11) 30 Preprint. Under review . Consequently , the effective operative range of the adjustment is bounded to [ − 0.15, + 0.30 ] . This ensures that while exceptional self-validation can significantly boost the final confidence score (up to + 0.30), extreme self-doubt is structurally constrained to a maximum penalty of − 0.15. The specific threshold of − 0.15 was explicitly defined to cap the penalty at exactly half the magnitude of the theoretical maximum rewar d. This structural boundary intuitively ensures that while a reflective self-critique is incorporated into the final metric, a single agent’s post-hoc self-doubt mathematically lacks the weight to unilaterally veto or completely overturn the established multi-agent majority vote. N Consensus Edge-Cases Consensus Edge-Cases. While the multi-agent panel primarily operates on a standard majority-vote consensus, a statistically rare edge-case may occur when all three evalu- ating judges return completely separate and distinct verdicts (e.g., one agent concludes ’SUPPOR T ,’ another ’REFUTE,’ and the thir d ’INCONCLUSIVE’). In such highly disputed scenarios, the framework structurally defers to the judge DeepSeek-R1. DeepSeek-R1 was strategically designated as the Chief Justice because its specialized capabilities in deep Chain-of-Thought (CoT) reasoning provide unparalleled fidelity in tracing complex logical deductions and identifying fallacies during debate evaluation. Because it is established as the most analytically rigor ous model on the panel, its initial independent evaluation is granted ’Chief Justice’ priority-weighting to automatically break the deadlock. This ensures that in moments of complete ambiguity , the final determination safely relies on the panel’s highest-quality reasoning trajectory without forcing an arbitrary or redundant meta-r eview cycle. O Sycophancy and Argument Integrity Metrics T o rigorously evaluate the framework’s susceptibility to sycophancy—where agents prema- turely yield to opposition, abandon their persona, or collude without sufficient evidence ( Malmqvist , 2025 )—we track four quantitative metrics from the execution logs. 1. Role-Play Consistency (0–10) During the r ole-switching consistency test (Section 2.7 ), an independent consistency ana- lyzer evaluates whether an agent successfully argues the opposing position using identical evidence without logically contradicting its prior arguments. The score reflects adher ence to the persona constraints on a 10-point scale; lower scores indicate “leakage” or positional sycophancy where an agent is unable to fully adopt the adversarial stance. 2. Concession Rate W e programmatically track explicit linguistic markers of concession and conversational yielding (e.g., “I concede,” “you make a good point,” “I partially agree” ) within the counsel transcripts. T o normalize for varying debate lengths, the metric is reported as the frequency of such triggers per 1,000 generated words. A near-zer o rate indicates high adversarial retention. 3. Reflection Plateau ( ∆ S ) It is computed as the average absolute change in the cumulative self-reflection score ( S total ) between consecutive debate rounds: ∆ S = | S ( t ) total − S ( t − 1 ) total | For a given round, the maximum possible change is ∼ 1.0 (depending on reflection ad- justments). The early-stopping criterion conservatively halts the debate if ∆ S < 0.05 (stagnation). In the context of sycophancy , an average ∆ S ≈ 0.3823 is high relative to the stopping threshold. It empirically demonstrates that the agents maintain robust adversarial 31 Preprint. Under review . divergence and continually push the boundaries of their logic rather than comfortably colluding into a plateau. 4. Judicial Conformity (Fleiss’ κ ) T o measure whether the three structurally heter ogeneous LLM judges exhibit “rubber - stamping” or independent evaluation, we calculate Fleiss’ Kappa ( κ ) over their final ver dicts (SUPPOR TED, NOT SUPPORTED, INCONCLUSIVE). A κ ≈ 0.4513 indicates moderate, au- thentic agreement. While confirming they reach consensus on clear-cut cases, this moderate value confirms they ar e not trapped in systemic conformity bias ( κ → 1.0), independently evaluating the nuanced shortcomings of contested claims. P Computational Cost and Scalability Analysis T oken Usage Overview . T able 13 reports token consumption across system configurations. The full P R O C L A I M pipeline consumes an average of 210,900 tokens per claim. This fig- ure r eflects the cumulative cost of primary debate, r ole-switched debate, and thr ee-judge panel evaluation—the three structurally essential components. For context, Standard MAD consumes only 18,900 tokens per claim, making P R O C L A I M appr oximately 11 × more token- intensive. However , as the ablation demonstrates, each high-cost component corresponds directly to a measurable accuracy contribution: P-RAG ( + 7.5 pp), role-switching ( + 4.2 pp), and the thr ee-judge panel ( + 3.3 pp). The one component that does not contribute pr opor- tionally to accuracy — self-reflection—is also the one that r educes token usage: disabling it increases consumption fr om 210,900 to 247,300 tokens ( + 17%) while recovering only 0.8 pp, confirming that self-reflection functions as an economic governor rather than a performance driver . System A vg T okens/Claim (K) 120 Claims (M) 1K Claims (M) 10K Claims (B) Acc. Standard MAD 18.9 2.3 18.9 0.19 71.7% P R O C L A I M w/o Self-Refl. 247.3 29.7 247.3 2.47 80.8% P R O C L A I M w/o Role-Switch 147.3 17.7 147.3 1.47 77.5% P R O C L A I M w/o P-RAG 188.9 22.7 188.9 1.89 74.2% P R O C L A I M (Full) 210.9 25.3 210.9 2.11 81.7% T able 13: T oken usage per claim across system configurations and pr ojected totals at scale. Projections assume linear scaling with no batching discount. Cost-Accuracy T rade-off as a Pareto Front. Figure 5 situates P R O C L A I M r elative to its ablated variants on the accuracy–token-cost plane. Although the full pipeline is not the cheapest configuration, it occupies the Par eto-optimal frontier: no single-ablation variant achieves equal or higher accuracy at lower cost. Notably , removing P-RAG saves only 22,000 tokens per claim ( − 10% ) while costing 7.5 accuracy points , the worst trade-off of any ablation; the evidence pool nearly halves (37.5 vs. 67.5 documents), and the saved tokens are consumed by longer debates on weaker evidence (6.00 vs. 5.47 rounds on average). By contrast, self- reflection of fers the most favourable trade: it consumes a disproportionately small share of total tokens while cutting rounds by 29% (7.06 → 5.47) and token usage by 17%, positioning it as the primary cost-control lever in any r esource-constrained deployment. P .1 When Is the Cost Justified? Use-case determines the cost threshold. T oken expenditure should be evaluated relative to the downstream cost of an incorr ect verdict, not in isolation. In the Check-COVID setting, a false-refutation of an evidence-backed health claim may lead practitioners to dismiss clinically valid guidance; a false-support of a misinformation claim may propagate harmful advice at scale. Regulatory and public-health domains place the cost of an erroneous verdict in the range of reputational, legal, and human-welfar e consequences that dwarf any inference budget. Under this framing, P R O C L A I M ’s 11 × token overhead over Standard MAD is best read as a 17.4 pp accuracy uplift (71.7% → 81.7%) at a marginal token surchar ge, not as a raw cost increase. 32 Preprint. Under review . 0 50 100 150 200 250 70 72 74 76 78 80 82 84 A vg. T okens per Claim (K) Accuracy (%) Standard MAD w/o Role-Switch w/o P-RAG w/o Self-Refl. P R O C L A I M (Full) Figure 5: Cost–accuracy Pareto front acr oss system configurations. P R O C L A I M (Full) lies on the efficient fr ontier; the dashed line traces Pareto-optimal points. w/o P-RAG is strictly dominated: it saves fewer tokens than w/o Role-Switch while incurring a larger accuracy penalty . Auditability has a value that accuracy alone does not capture. A black-box verdict of fers no mechanism for human reviewers to interrogate why a claim was accepted or rejected, which evidence was admitted, whether the opposing case was meaningfully considered, or whether the system’s confidence is calibrated. P R O C L A I M produces a structur ed case recor d—comprising admitted evidence with admissibility weights, per-round argument transcripts, self-reflection trajectories, critic evaluations, role-switch consistency scores, and a six-stage judicial opinion for each judge—that dir ectly supports post-hoc audit. In regulated domains such as healthcar e, finance, or legal proceedings, this deliberative traceability is not merely desirable but is increasingly mandated by emer ging AI governance frameworks. T rajectory instability as a reliability signal. Section 4.2 documents that incorrect predictions exhibit oscillating self-reflection trajectories , a behavioural signature absent from confident correct pr edictions. This instability signal is entirely invisible in single-call pipelines, where confidence is reported as a single scalar that correlates poorly with calibrated accuracy (ECE = 0.18 for na ¨ ıve averaging vs. 0.034 for P R O C L A I M ; Appendix J). The multi-round deliberation pr ocess is thus a prer equisite for generating the per-r ound evidence fr om which this diagnostic is derived, meaning the additional token cost is precisely what enables reliability estimation beyond the final answer . Heterogeneous adjudication and the value of diversity . Section 4.5 establishes that het- erogeneous judicial panels produce genuine disagreement in 55.8% of cases, and that disagreements correct rather than compound individual judge errors. A homogeneous single-judge panel sacrifices 3.3 pp of accuracy by amplifying shared biases (e.g., the struc- tural negativity bias documented for DeepSeek-R1, which over-pr oduces R E F U T E verdicts). The additional inference cost of thr ee independent judges is thus the mechanism by which systematic model bias is suppressed—an ef fect that cannot be replicated by calling a single, larger model. P .2 Pathways to Cost Reduction P R O C L A I M ’s deliberative architectur e is not inherently incompatible with cost ef ficiency; rather , its current implementation prioritises corr ectness and interpretability over through- put. As noted in Section 5 , several avenues exist to reduce token usage without sacrificing the core deliberative pr operties of the framework. Early-exit mechanisms beyond the curr ent reflection plateau could further r educe average rounds; retrieval filtering via tighter admis- sibility thresholds could shrink evidence pools; and model distillation could r eplace large- parameter role assignments (e.g., Hermes-3-LLaMA-405B) with smaller task-specialised models. 33
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment