CiQi-Agent: Aligning Vision, Tools and Aesthetics in Multimodal Agent for Cultural Reasoning on Chinese Porcelains
The connoisseurship of antique Chinese porcelain demands extensive historical expertise, material understanding, and aesthetic sensitivity, making it difficult for non-specialists to engage. To democratize cultural-heritage understanding and assist e…
Authors: Wenhan Wang, Zhixiang Zhou, Zhongtian Ma
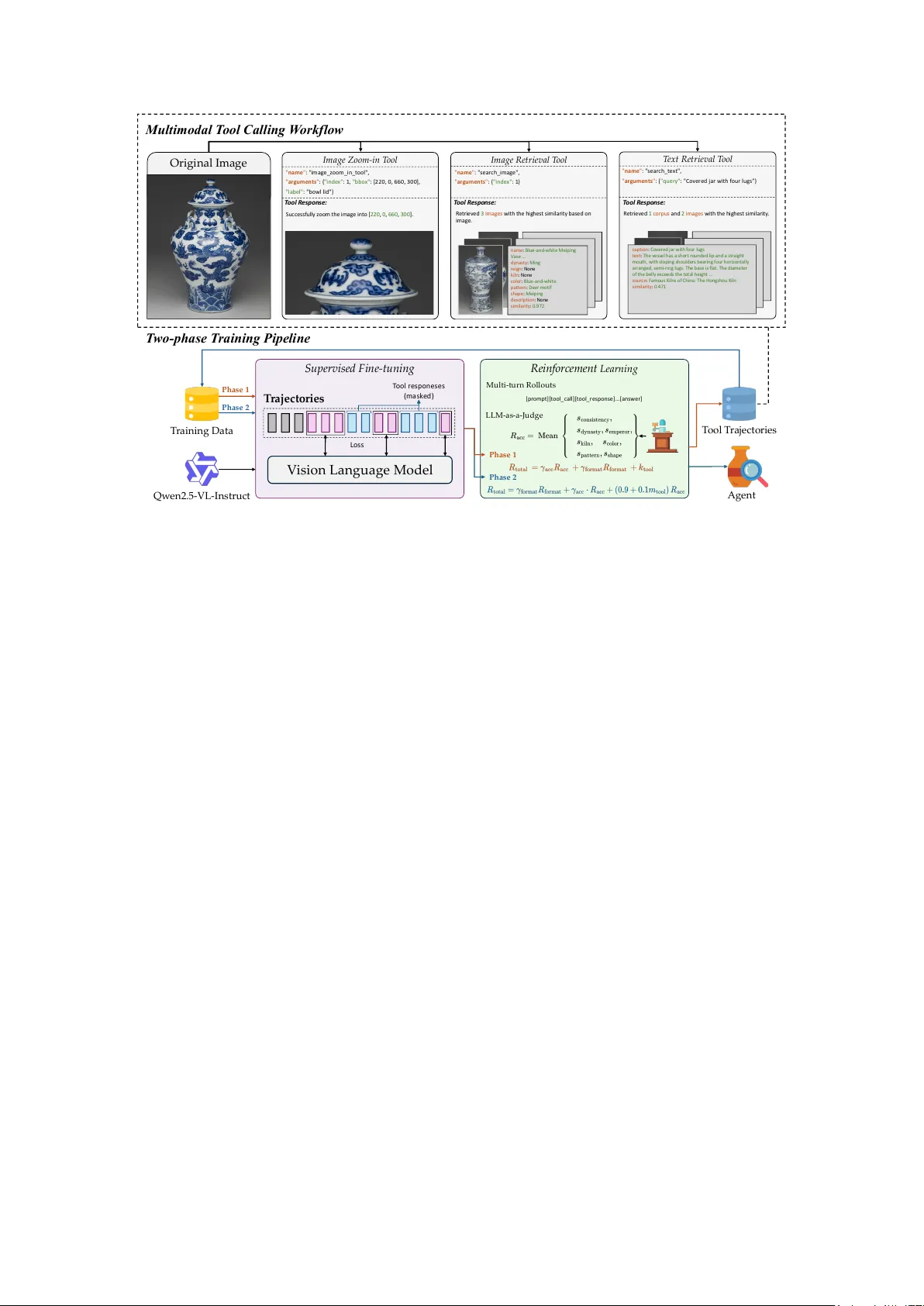
CiQi-Agen t: Aligning Vision, T o ols and Aesthetics in Multimo dal Agen t for Cultural Reasoning on Chinese P orcelains W enhan W ang ∗ , 1 Zhixiang Zhou ∗ , 1 Zhongtian Ma ∗ , 2 Y anzh u Chen 1 Ziyu Lin 1 Hao Sheng 1 P engfei Liu 1 Honglin Ma 3 W enqi Shao † , 1 Qiaosheng Zhang † , 1 , 2 Y u Qiao 1 , 2 1 Shanghai Inno v ation Institute 2 Shanghai AI Lab oratory 3 Shaanxi Academ y of Cultural Relics Conserv ation Abstract The connoisseurship of an tique Chinese porcelain demands extensiv e historical exp ertise, material understanding, and aesthetic sensitivity , making it difficult for non-sp ecialists to engage. T o demo cratize cultural-heritage understanding and assist exp ert connoisseurship, w e introduce CiQi-Agent —a domain-sp ecific Porcelain Connoisseurship Agen t for in telligent analysis of antique Chinese p orcelain. CiQi-Agen t supp orts multi-image p orce- lain inputs and enables vision to ol inv o cation and m ultimo dal retriev al-augmented gen- eration, p erforming fine-grained connoisseurship analysis across six attributes : dynasty , reign p eriod, kiln site, glaze color, decorativ e motif, and vessel shap e. Bey ond attribute classification, it captures subtle visual details, retrieves relev an t domain kno wledge, and in tegrates visual and textual evidence to produce coherent, explainable connoisseurship de- scriptions. T o achiev e this capabilit y , we construct a large-s cale, exp ert-annotated dataset CiQi-V QA , comprising 29,596 p orcelain sp ecimens, 51,553 images, and 557,940 visual question–answ ering pairs, and further establish a comprehensive b enc hmark CiQi-Benc h aligned with the previously mentioned six attributes. CiQi-Agen t is trained through sup er- vised fine-tuning, reinforcement learning, and a to ol-augmen ted reasoning framework that in tegrates tw o categories of to ols: a vision to ol and multimodal retriev al to ols. Experimen- tal results show that CiQi-Agent (7B) outp erforms all comp etitiv e op en- and closed-source mo dels across all six attributes on CiQi-Bench, achieving on a verage 12.2% higher accu- racy than GPT-5. The mo del and dataset hav e b een released and are publicly av ailable at https://huggingface.co/datasets/SII- Monument- Valley/CiQi- VQA . 1 In tro duction Cultural relics are in v aluable carriers of h uman civilization, encapsulating b oth artistic creation and historical ev olution. The connoisseurship and authentication of artifacts require deep ex- p ertise—com bining historical knowledge, p erceptual exp erience, and material understanding. Consequen tly , professional barriers hav e long restricted public engagement in cultural heritage connoisseurship. With the rapid progress of artificial in telligence (AI) metho ds, esp ecially large language mo dels (LLMs) and multimodal large language mo dels (MLLMs) [ 18 , 20 , 43 , 4 ], new opp ortunities ha ve emerged to demo cratize artifact understanding. By join tly mo deling vision, language, and reasoning, MLLMs enable in teractive, explainable, and scalable analysis of visual art and historical ob jects [ 14 , 26 , 2 , 51 ]. In this w ork, w e fo cus on An tique Chinese Porce- lain , one of the most represen tative yet tec hnically challenging categories of cultural relics, as our en try p oin t for AI-driven artifact connoisseurship. ∗ Equal contribution. † Corresp onding to: W enqi Shao ( weqish@gmail.com ), Qiaosheng Zhang ( zhangqiaosheng@p jlab.org.cn ). 1 Reasoning It’s a blue - and - white vase. Let me refi ne my answer. Zoom & Search Scrolling lotus … Ming Dynasty … What is this ? It’s a vase. Answer - Only Final Answer This is a Ming Dynasty blue - and - white vase with a lotus scroll design . Ground Truth: Celadon Fl attened Flask wi th Handles, Guan ware, Song Dynasty ( 宋 官窑青釉贯耳扁瓶 ) Based on its form and glaze characteristics, this porcelain piece can be identified as : Southern Song Dynas ty , Longquan ware , Celadon Cong - shaped Vas e . Key Points of Identification: • Dynasty : Southern Song Dynasty The smooth and lustrous glaze … • Kiln Site : Longquan Kiln Longquan celadon is renowned for its jade- like texture and subtle tones of fenqing (powder blue) and meiziqing (plum green). • Glaze : Celadon Glaze The visible crackle pattern (known as kaipian or crackle lines) is a typical characteristic of Longquan celadon. • Shape : Cong - shaped Vase The form derives from the ancient jade cong , symbolizing “the square within the circle .” The vessel is … Baseline (GPT - 5): CiQi - Agent: Based on visual observation, t his porcelain piece is a flattened fl ask with loop handles . The vessel exhibits…— features characteri stic of Song Dyn asty Guan ware . The body lines … More over, the loop - handle design is also a common decorative elemen t in Guan war e porcelain of the Song period . To further verify its provenance and detailed attributes, I plan to invoke t he search_image tool and input the image index 1 to retrieve the most similar records from the database. {"name":"search_image","arguments":{"index": 1 }} According to the information returned by the tool, this flattened flask with loop handles exhibits typical styli stic traits of Song Dynasty Guan ware, as seen in its form, glaze color, and crackle pattern . In particular, the celadon tone and naturally developed crackl es further confirm its identity as a product of the official kilns . Combined with its loop - handle design and overall shape, it can be identified as an authentic work of the Song Dynasty official kiln system . To obtain more pre cise details regarding its chronological period, kiln site, and exact des ignation, I plan to i nvoke the search_text tool to retrieve detailed artifact records. {"name": "search_text", "arguments": {"query": " Song Dynasty; Guan ware; celadon; vase with loop handles; crackle glaze "}} Vases with loop handles ( guan’er ping) can already be found among bronze vessels from the Spring and Autumn and Warring States periods, where they served as wine containers . In the Song dynasty, such shapes became popular … Based on the analysis, … All the se features conform to the craftsmanship standards of the official kilns of the Song period . The glaze …, typical of decorative vessels used in the imperial court of the Song Dynasty . {"name": "image_zoom_in_tool", "arguments": {"index": 1 , "bbox_2d": [ 223 , 223 , 670 , 670 ], "label": " vase with loop handles "}} According to the localized image analysis returned by the tool, this flattened flask … detailed obs ervation reveals the distinctive feature of “ purple mou th and iron foot ”. These attribut es further verify that it is a product of the Song offic ial kilns . Considering its form and glaze characteristics, the piece can be identified as : Song Dynasty , Guan ware, Celadon Flattened Flask with Loop Handles . Name : Song Dynasty, Guan ware, Celadon Vase with String - Pattern and Loop Handles Description : The form imitates a bronze vessel. It has a slightly contracting mouth with rolled rim, a long neck … Name : Qing Dynasty, Imitation Song Guan ware, Octagonal Vase with Loop Handles Description : The vessel is flattened and octagonal in form, with a flared mouth and slightly rolled lip, constricted neck … Name : Qing Dynasty, Yongzheng mark, Milk - glazed Double - spouted Vase Description : The vase is of flattened square form, modeled after the shape of an ancient bronze fang hu vessel … Name : Southern Song Dynasty, Longquan ware, Celadon Mallet - shaped Vase Description : The vessel has a disk - shaped mouth with a copper rim, a long neck, slanted shoulders leading to a broad … (b) CiQi -Agent (Ours) (a) General-purpose MLLM . . . Figure 1: Comparison betw een (a) General-purp ose MLLM and (b) CiQi-Agent. (a) Con ven tional MLLMs rely on single-p ass answering , directly outputting a lab el leading to super- ficial or inaccurate iden tifications. (b) The prop osed CiQi-Agent introduces T o ol-Augmente d R e asoning , enabling multi-step p orcelain analysis through image zo om-in, image/text retriev al. This iterativ e pro cess yields more reliable final answ ers aligned with exp ert connoisseurship reasoning. Existing approac hes to p orcelain connoisseurship remain limited in several k ey asp ects. In most computer vision (CV) studies, p orcelain connoisseurship is simplified as a fine-grained recognition task [ 22 , 21 , 19 , 12 ], fo cusing mainly on visual classification without incorp orating language-based reasoning or interactiv e explanation. Moreo ver, general-purp ose MLLMs p er- form p oorly in this sp ecialized domain due to the scarcit y of p orcelain-related data, leading to w eak generalization, unstable judgmen ts, and the absence of a unified ev aluation standard, resulting in outputs that are often incomplete and lacking in professionalism. These limitations highligh t the need for a dedicated p or c elain c onnoisseurship agent that in tegrates p erception, reasoning, and cultural in terpretation. Building suc h an agent presents several unique challenges. First, the n umber of v aluable p orcelain artifacts is inherently limited, making high-qualit y data collection extremely difficult. Second, accurate annotation and description of p orcelain piec es require deep domain exp ertise in art history and craftsmanship, whic h mak es large-scale lab eling b oth costly and inconsisten t. Third, there is no unified ev aluation standard for p orcelain connoisseurship, leaving MLLMs without reliable metrics to assess their p erformance. Finally , the essence of p orcelain connois- seurship lies in fine-gr aine d r e c o gnition , which demands precise identification of features such as v essel shap e, glaze color, decorative motifs, and historical p eriod—a task that remains highly c hallenging even for human exp erts. T o ov ercome these c hallenges, we propose CiQi-Agen t , the first Chinese p orcelain connois- seurship agent that integrates domain-grounded data curation, a t wo-phase training paradigm com bining sup ervised fine-tuning (SFT) and reinforcement learning (RL), and to ol-augmen ted 2 reasoning in to a unified framework (as shown in 1 ). CiQi-Agen t supp orts multi-image input and p erforms fine-grained connoisseurship ov er six attributes (dynast y , reign p erio d, kiln site, glaze color, decorativ e motif and vessel shap e) by nativ ely integrating vision to ol inv o cation and multimodal retriev al-augmen ted generation (RA G) as essen tial reasoning capabilities, and can optionally output the top- k visually similar p orcelains to facilitate h uman in terpretation and reference. Sp ecifically , our con tributions are as follows: • W e construct CiQi-VQA , a large-scale dataset for ancien t Chinese p orcelain connois- seurship, with 29 , 596 original artifacts from 20+ dynasties (2nd c. BCE–19th c. CE), co vering 100+ v essel shap es, 200+ glaze colors, and 200+ decorative motifs. T o sup- p ort multimodal model training, we further expand it to ov er 500K high-quality visual question answering (V QA) pairs via a h ybrid pip eline com bining exp ert annotation and LLM-assisted cleaning. • W e establish CiQi-Bench , an exp ert-aligned b enchmark for Chinese p orcelain connois- seurship, comprising 775 high-qualit y sp ecimens and tw o complemen tary ev aluation pro- to cols: (1) a fine-grained m ultiple-choice setting cov ering six attributes and standardized naming, and (2) a free-form generation setting assessed via LLM-based attribute-wise similarit y scoring. • W e prop ose a t wo-phase iterative training framew ork for CiQi-Agen t: Phase I uses GRPO- based RL with a large tool-calling rew ard to rapidly b ootstrap to ol-calling skills and gen- erate syn thetic tra jectories; Phase I I integrates these tra jectories back into SFT, follow ed b y RL with a reweigh ted, accuracy-conditioned rew ard that join tly optimizes tool-calling proficiency and connoisseurship accuracy , thereby aligning CiQi-Agent’s to ol-calling ca- pabilit y with its domain exp ertise. • CiQi-Agen t incorp orates b oth visual and retriev al-based to ols, including an image zoom- in tool and image/text retriev al to ols to enable m ultimo dal RAG. The retriev al database is primarily built from the CiQi-V QA dataset, consisting of 8 , 161 curated p orcelain pieces with 16 , 380 images, supplemented b y 49 , 606 cleaned plain-text en tries from professional articles. • The proposed CiQi-Agen t, built upon the Qw en2.5-VL-7B-Instruct, ac hieves sup erior per- formance on our b enc hmark, consistently outperforming all mainstream op en- and closed- source m ultimo dal mo dels across all ev aluation attributes. 2 Related W ork Classical AI Metho ds for P orcelain Connoisseurship. Early attempts at automating p orcelain connoisseurship treated it as a fine-grained image classification problem. T radi- tional CV metho ds relied on hand-crafted features (e.g., color, texture descriptors) combined with classifier such as supp ort vector mac hine (SVM), ac hieving mo derate success on small datasets [ 45 , 33 ]. With the rise of deep learning, conv olutional neural net w ork (CNN)-based approac hes hav e shown improv ed accuracy by automatically learning visual features lik e glaze color and v essel shap e [ 22 , 21 ]. Researc hers ha ve also explored m ulti-task mo dels to jointly classify attributes suc h as dynast y , kiln, and glaze t yp e. F or instance, Ling et al. present a deep-learning framew ork for four attributes (dynast y , glaze, ware, t yp e) on Song/Y uan p orce- lain [ 19 ]. Nonetheless, these classification-driv en works are limited to predefined lab els and cannot perform the ric her, explanatory reasoning that true connoisseurship demands. They also t ypically treat artifact analysis as one-shot classification, rather than interactiv e or multi-step reasoning [ 25 , 5 , 7 ]. In summary , classical AI methods underline the need for larger high-qualit y 3 Figure 2: Visualization of the four key attributes in p orcelain connoisseurship. Sho wn are the distributions of dynasty , glaze color, v essel shap e, and decorativ e motif in the ra w p orcelain dataset. F or eac h attribute, the top 10 most frequent categories are presen ted. datasets and for moving b ey ond one-shot classification tow ard in teractive, knowledge-ric h anal- ysis. MLLMs and Domain-Sp ecific Multimo dal Systems. General-purp ose m ultimo dal LLMs suc h as BLIP-2 [ 18 ] and LLaV A [ 20 ] bridge image and text understanding, but t ypically op erate in a single-pass manner without iterative p erception or external-knowledge integration [ 39 , 11 , 13 ]. Recen t visual-agen t systems address these limitations b y enabling multi-step p erception and to ol-based reasoning [ 46 , 50 , 34 , 6 ]. In parallel, domain-adapted m ultimo dal mo dels hav e emerged in medicine [ 28 , 27 , 42 ], remote sensing [ 44 , 16 ], and cultural heritage analysis suc h as V aseV QA [ 8 , 36 , 24 ]. How ever, these systems primarily p erform single-step pr e diction and do not supp ort to ol-augmen ted reasoning. This gap underscores the need for domain-sp ecific visual agen ts capable of multi-step p erception and knowledge-grounded decision making. 3 Dataset and Benc hmark 3.1 CiQi-V QA dataset Ra w Data Collection. W e first collect raw an tique Chinese p orcelains from multiple publicly accessible sources, including w eb-based searc hes, op en-access digital m useum collections, and digitized scholarly b ooks. F rom these sources, we curate a dataset of 29 , 596 unique sp ecimens spanning 38 dynasties, 42 reign p erio ds, 246 glaze colors, 248 decorative motif categories, and 158 vessel shap es. T o the b est of our kno wledge, this is the most comprehensive dataset for p orcelain appreciation currently a v ailable. ∗ Eac h p orcelain sp ecimen is asso ciated with at least one high-quality image and a standardized name that explicitly enco des four key attributes : dynasty , glaze c olor , vessel shap e , and de c or ative motif . In addition, a p ortion of the sp ecimens further sp ecifies t wo additional attributes — r eign p erio d and kiln origin . A complete example with all six attributes would b e: “Qing Dynast y , Kangxi p eriod (1662–1722 CE), Jingdezhen kiln, Blue-and-white, Cloud-and-dragon motif, Bowl ( 清 康 熙 景 德 镇 青 花 云 龙 纹 碗 ).” Figure 2 visualizes the distribution across the four key attribute dimensions, sho wing the top-10 most frequen t categories in each. F rom this collection, w e later select 775 pieces to construct CiQi-Bench for ev aluation, while the remaining 28 , 821 pieces are used to build the CiQi-V QA training set. Metadata Enric hmen t. ∗ A comparison with existing p orcelain-related datasets is provided in the supplementary materials. 4 Figure 3: Examples from CiQi-VQA dataset. The figure illustrates annotations across four k ey attributes: dynasty , glaze color, decorativ e motif and vessel shap e. W e further extract and clean descriptive texts related to p orcelain connoisseurship from the raw sources and align them with each sp ecimen. How ever, a substan tial p ortion of the collected p orcelains only provides standardized names without detailed narrative descriptions. T o address this issue, we invite h uman exp erts to participate in the metadata enrichmen t pro cess. Sp ecifically , for 61.18% of the specimens that lack detailed descriptions, the exp ert team comp oses complementary connoisseurship descriptions based on the sp ecimen images and the av ailable source metadata. In addition, to improv e the reliability of the dataset, the exp erts review and correct the naming accuracy of the standardized names for all collected sp ecimens, ensuring that the enco ded attribute information is consistent and prop erly formatted. The exp ert team is led by a senior researcher with more than 20 y ears of exp erience in p orcelain iden tification and connoisseurship researc h, and includes four graduate students from related disciplines who contribute to description completion and naming verification under the leader’s sup ervision. Finally , we feed the standardized names, enriched descriptiv e texts, and raw images in to MLLMs to pro duce a p olished connoisseurship description for each sp ecimen, whic h is structured in six paragraphs corresp onding to six connoisseurship attributes. V QA Data Generation. W e leverage MLLMs to generate specialized V QA pairs targeting the four key attributes, dynasty , glaze c olor , de c or ative motif , and vessel shap e , as illustrated in Figure 3 . W e fo cus on these four rather than the full six b enc hmark attributes b ecause they are most central to con- noisseurship; the remaining tw o are treated as more adv anced refinemen ts and are emphasized at the RL stage. F or each p orcelain sp ecimen, the holistic description is also conv erted into a V QA format, giving five VQA training samples p er item. T o further diversify linguistic expression, we adopt a light w eight augmentation strategy instead of multi-epo c h training on identical samples. F or eac h of the five V QA samples, we prompt the LLM to generate four additional v ariants that preserve the semantics but differ in phrasing and style. The final CiQi-VQA training set thus contains 20 stylistically div erse yet seman tically consistent V QA samples per specimen † , and we p erform SFT for a single epo ch on this augmen ted dataset. † F or a small subset of sp ecimens (e.g., mono c hrome wares), only 15 questions are av ailable b ecause these ob jects inherently lack decorativ e motifs. 5 T able 1: Ov erall statistics of CiQi-VQA dataset and CiQi-Bench. P orcelains Images Questions A ttributes V QA Multiple-c hoice SFT 28,821 50,675 557,165 — RL ∗ 10,275 10,275 10,275 — dynast y , reign, kiln, color, motif, shap e Ev aluation 775 878 775 5,425 T otal 29,596 51,553 557,940 5,425 dynast y , reign, kiln, color, motif, shap e ∗ The raw p orcelain data used for RL is a subset of that used for SFT. 3.2 CiQi-Benc h F or the b enc hmark, we curated a set of 775 p orcelain sp ecimens and designed tw o ev aluation proto cols. Multiple-Choice Questions. The first proto col adopts a multiple-choic e format. F or each sp ecimen, w e construct seven questions cov ering the four key attributes, tw o additional at- tributes (reign p eriod and kiln origin), and the full standardized name. W e use GPT-5 to automatically generate the multiple-c hoice questions: given the image and the ground-truth annotation as input, the mo del is instructed to pro duce plausible y et challenging distractor options. Mo del p erformance is then quan tified by the answer accuracy ov er all questions. F ree-F orm Questions. The second proto col fo cuses on fr e e-form gener ation . In this setting, the mo del is prompted to pro duce a holistic textual description of eac h p orcelain sp ecimen. An LLM-based ev aluator is subsequently employ ed to compare the generated description with the ground-truth text and assign six separate similarity scores—one for eac h of the four k ey attributes and the t wo additional attributes. ‡ T able 1 summarizes the ov erall statistics of the p orcelain dataset and b enc hmark. The raw p orcelain data used for RL is a subset of that used for SFT. 4 T raining F ramew ork of CiQi-Agen t In this section, w e present the ov erall architecture of our proposed CiQi-Agen t, which em ulates the reasoning pro cess of h uman experts by combining visual p erception, retriev al-augmented kno wledge access with reinforcement-driv en tool-calling. As illustrated in Figure 4 , the agent autonomously analyzes visual details, retrieves multimodal evidence, and generates context- a ware judgments through the co ordinated use of sp ecialized to ols. 4.1 T o ol Design T o enable more flexible and interpretable reasoning, a suite of external to ols is provided, which can b e autonomously selected and executed by CiQi-Agen t during inference. Each to ol inv o- cation is encapsulated within a standardized {"name": "search_image", "arguments": {"index": 1}} User: Succe ssfully found the following conten t: 1 Image searc h results: - Name: Ming W anli W ucai Garlic-Mouth V ase with Dragon, Flow ers and Birds - Dynast y: Ming - Reign: W anli - Glaze Color: W ucai (Fiv e-color) - Decoration: Dragon with flo wers and birds - F orm: Garlic-mouth v ase - Description: The slightly con tracted mouth forms a garlic shap e, with a long neck, sw ollen b elly , and shallow fo otring. The en tire v essel is thick and heavy . It was made b y forming separate sections and then joining them, therefore five seam lines app ear on the mouth, neck, and b elly . Both the inner fo otring and base are unglazed, with areas stained b y dripp ed glaze. The clay bo dy is coarse and ric h in iron, causing unglazed parts to fire in to an orange tone with iron sp ec kles. The whole surface is cov ered with a white glaze; in addition to underglaze-blue linear decoration, further scrolls, ent wined flo wers, freehand birds, and angular patterns are applied in m ulticolored lo w-temp erature enamels including red, yello w, orange, green, and black. The main motif is a dragon striding among flow ers on the b elly . F our dragons with large round eyes app ear as if dancing and grabbing p earls, their strange and exaggerated shap es carrying a carto on-lik e app eal. A six-character k aish u mark “Made in the W anli p eriod of the Great Ming Dynasty” is written in underglaze blue on the mouth rim. The use of man y lo w-temp erature o verglaze colors b egan in the Xuande reign, and by the Jia jing and W anli p erio ds, p otters applied v arious glazes onto complex patterns to create a lively and vibrant visual effect. - Source: National P alace Museum, T aip ei - Similarit y: 0.935499 — Image searc h results: - Name: Ming W anli W ucai Garlic-Mouth V ase with Dragon, Flow ers and Birds - Dynast y: Ming - Reign: W anli - Glaze Color: W ucai (Fiv e-color) - Decoration: Dragon with flo wers and birds - F orm: Garlic-mouth v ase - Description: Same as ab o ve. - Source: National P alace Museum, T aip ei - Similarit y: 0.93520796 — Image searc h results: - Name: Qing Qianlong F amille-Rose V ase with Floral Pho enix Motif and Ruyi Handles - Dynast y: Qing - Reign: Qianlong - Glaze Color: F amille-rose - Decoration: Floral motifs 2 - F orm: V ase - Description: Celestial-glob e form with flared mouth, long neck, rounded shoulders, and sw ollen b elly , with a pair of ruyi-shap ed handles on the sides of the neck. Flat base, out ward-turned fo otring, and gold-pain ted rim. The b ody is decorated in famille-rose enamels ov er a white ground. Below the rim is a p omegranate motif; the neck sho ws lotus, bats, and ancien t b ells linked together, interspersed with floral scrolls. Two gilt string bands encircle the shoulder, framing m ulticolored patterns and leading to a ruyi- cloud b order. The ruyi handles are link ed with w an symbols and p endan t ribb ons attached to the shoulders. The b elly features paired pho enixes b etw een m usical stones and lotus flo wers, surrounded b y dense floral scrolls. Near the bottom is a st ylized lotus-p etal band, ab o v e a ruyi-cloud border and a string line encircling the foot. A square six-c haracter seal mark “Made in the Qianlong p erio d of the Great Qing Dynasty” is written in underglaze blue. - Source: National Palace Museum, T aip ei - Similarit y: 0.9320861 Assistan t: According to the results returned by the to ol, the shap e, decorative motifs, glaze color, and reign mark of this blue-and-white figure-decorated flared-rim b o wl all corresp ond to t ypical c haracteristics of the Kangxi p eriod of the Qing dynasty . It can b e clearly distinguished from p orcelain pro duced during the Xuande, Jia jing, and W anli p eriods of the Ming dynasty , particularly in terms of the h ue of the cobalt blue, the refinemen t of the painting, and the prop ortional maturit y of the vessel form. These features reflect the highly adv anced craftsmanship of Kangxi p orcelain. Based on the narrativ e figure motif and the ov erall v essel shap e, it can b e confirmed as a w ork from the Kangxi imp erial kilns. Next, I in tend to inv oke the search text to ol and input a detailed description of this b o wl to further compare it with t ypical features of Kangxi blue-and-white p orcelain, in order to v erify its p erio d attribution and standardized name. {"name": "search_text", "arguments": {"query": "Qing Kangxi blue-and-white figure- → decorated flared-rim bowl"}} User: Succe ssfully found the following conten t: T ext search results: - T ext: F o ot diameter 2.7 cm. The center of the b o wl is decorated with a T aiji (yin–y ang) motif. The depiction of the yin–yang fishes is similar to the piece mentioned ab o v e, but the painting is less refined. The outer ring’s clo c kwise thin line is relativ ely smo oth. The cobalt-blue color is rich. Within the double circles at the base cen ter is an unrecognizable grass-st yle mark. - Title: F ragment of a green-glazed exterior b o wl with blue-and-white in terior, Qing Kangxi - Source: Authentication of Ming and Qing Porcelain Motifs — Decorativ e Motifs V olume - Similarit y: 0.8 — T ext search results: 3 - T ext: Flared rim, deep b elly , and fo otring. A band of floral motifs is pain ted along the inner rim. Inside the double blue rings at the cen ter is a painting of ro c ks, flo wers, and birds. The exterior wall depicts egrets in a lotus p ond, with luxurian t lotuses rendered in clear la yers. The lotus leav es show a sense of front-and-bac k yin–y ang shading. The fine lines outline flo wing water gracefully . Nine egrets, each in a different p ose, are accurately dra wn; light cobalt w ashes outside the outlines enhance expression with an elegant touc h. The b o dy is thin and fine, the glaze glossy and evenly applied. Within the double blue circles at the base is the k aishu mark “Made in the Jia jing p erio d of the Great Ming,” y et it is a refined work from Kangxi folk kilns. - Title: Flared-rim deep-b elly b o wl with fo otring - Source: Complete Collection of Porcelain Collected in Jiangxi — Qing Dynasty , V olume I - Similarit y: 0.7787347755736039 — Image searc h results: - Name: Blue-and-white b o wl with “banana leav es and ladies comp osing p o etry” and Xuande reign mark, Ming - Dynast y: Ming - Reign: Xuande - Glaze Color: Blue-and-white - Decoration: Ladies - F orm: Bo wl - Description: A band of scroll motifs is pain ted around the fo otring. Six cobalt-blue lines are added b et ween the rim and the fo ot. The cobalt blue is heavy , with bro wnish-green sp ec kles. The b o dy is thick, fine, white, and compact, with iron sp ots of different sizes. The base b ears a tw o-column six-c haracter k aishu mark “Made in the Xuande p erio d of the Great Ming,” enclosed b y double circles. The theme of this b owl is “lady with banana lea ves comp osing p oetry .” Due to somewhat thick brushw ork, the lady app ears with b old eyebro ws and a full face, lac king delicate elegance, yet the painting is still fine and remains a high-qualit y work. - Source: National P alace Museum, T aip ei - Similarit y: 0.19999999999999996 Assistan t: Based on the analysis, this blue-and-white flared-rim b o wl with figure deco- ration is a t ypical p orcelain piece from the Kangxi p eriod of the Qing dynasty . Its v essel form, decorativ e motifs, glaze color, and reign mark are all consistent with the c harac- teristics of imp erial-kiln wares from that p erio d. In conclusion, it should b e identified as “Qing Kangxi Blue-and-White Flared-Rim Bo wl with Narrative Figure Decoration.” {"name": "image_zoom_in_tool", "arguments": {"index": 1, "bbox_2d": [112, 114, 826, → 781], "label": "narrative figure motif"}} User: Successfully zo omed in on the image to the region lab eled “narrative figure motif” at [112, 114, 826, 781]. 4 Assistan t: Based on the analysis, this p orcelain piece is a typical work from the Kangxi p eriod of the Qing dynast y . Its vessel form, decorativ e motifs, glaze color, and reign mark all conform to the c haracteristics of imp erial-kiln wares from this p erio d. It should therefore b e iden tified as “Qing Kangxi Blue-and-White Flared-Rim Bo wl with Figure Decoration.” Qing Kangxi Blue-and-White Flared-Rim Bowl with Figure Decoration 5 White-Glazed Standing Guan yin, Dehua Kiln, Ming Dynasty ( 明 德 化 窑 白 釉 观 音 立 像 ) User: Please pro vide a standardized name for this p orcelain piece. After your analysis, c ho ose to either inv ok e a to ol or respond directly , and place the final iden tification result within the {"name": "search_image", "arguments": {"index": 1}} User: Succe ssfully found the following conten t: 6 Image searc h results: - Name: Qing Deh ua Kiln Guanyin - Dynast y: Qing - Glaze Color: White glaze - F orm: Guan yin figure - Description: Guan yin, “White-Robed Guan yin,” coated in white glaze, hollo w inside. The face is o v al like a go ose egg, with delicate features. W earing a white rob e, a chest nec klace, and a white ho o d, seated in a relaxed p ose. - Source: National P alace Museum, T aip ei - Similarit y: 0.9279872 — Image searc h results: - Name: 16th–18th Cen tury White-Porcelain Arhat Figure - Glaze Color: White p orcelain - F orm: Arhat figure - Description: The glaze is ivory-white with a sligh tly yello w tint, with m ultiple pinholes across the surface. The figure is modeled seated by the w ater, with a bald head, long ears, and bare feet. Drap ed in a rob e exp osing the chest, the folds are fluen tly sculpted. The relaxed p ose shows the left hand holding a sutra scroll and the right hand tuck ed within the sleev e. The face features pronounced bro ws and nose ridge, expressing con templation. Accompanied b y a woo den base. - Source: National P alace Museum, T aip ei - Similarit y: 0.8567522 — Image searc h results: - Name: T ang P ainted Grey-T erracotta F emale Figure - Dynast y: T ang - Glaze Color: P ainted - Decoration: Lady motif - F orm: T omb figure - Description: The pain ted garmen t on this grey terracotta female figure has mostly flaked a wa y , y et the form still fully expresses the features of T ang court women—“large hair buns, lo ose rob es,” and a plump figure. She stands uprigh t with head raised, long ey es and small mouth, wearing a lo ose, p oin ted-collar rob e draping from the neck. The ligh tly incised sleev e and fold lines resemble expressiv e ink strok es, accentuating the rounded b o dy . The hem reac hes the ground, with pointed shoes p eeking out. The righ t arm lifts a wide sleev e 7 to the chest, with the left hand dropping sligh tly , and the calm expression enhances the graceful b earing. The full face framed by a double-bun hairst yle embo dies the T ang ideal of b eaut y . The era fav ored full-b o died women with confident, healthy elegance, a trend that con tinued into the Late T ang and Fiv e Dynasties. - Source: National P alace Museum, T aip ei - Similarit y: 0.84899557 Assistan t: Based on the analysis, the c haracteristics of this p orcelain piece closely match the t ypical glaze tone, v essel form, and craftsmanship of Dehua w are. F urther verification through to ol results confirms that its style, glaze, and pro duction techniques are consistent with those of Deh ua kilns from the Ming dynasty . {"name": "search_text", "arguments": {"query": "Ming dynasty Dehua kiln white-glazed → standing Guanyin figure"}} User: Succe ssfully found the following conten t: T ext search results: - T ext: Ming, 17th cen tury , Deh ua white-glazed seated Guanyin figure, sho wing a Guanyin statue with hands hidden within the folds of her rob e. - Title: Ming, 17th Cen tury Dehua White-Glazed Seated Guanyin Figure - Source: Christie’s 2015 Spring Auction Catalogue — Imp ortan t Chinese Ceramics - Similarit y: 0.8 — T ext search results: - T ext: White p orcelain from the Dehua kilns of the Ming dynast y is distinctive, esp ecially the religious sculptures of Guan yin, Bo dhidharma, and other figures created b y the master sculptor He Chaozong. - Title: White P orcelain of the Ming Dynasty Dehua Kilns - Source: P alace Museum Ceramic Encyclop edia - Similarit y: 0.6398200054682729 — Image searc h results: - Name: Qing Deh ua Kiln Guanyin - Dynast y: Qing - Glaze Color: White glaze - F orm: Guan yin figure - Description: Guan yin, “White-Robed Guan yin,” coated in white glaze, hollo w inside. The face is o v al like a go ose egg, with delicate features. W earing a white rob e, a chest 8 nec klace, and a white ho o d, seated in a relaxed p ose. - Source: National P alace Museum, T aip ei - Similarit y: 0.19999999999999996 Assistan t: Based on the information returned b y the tool, this porcelain piece is a white- glazed standing Guan yin figure from the Dehua kilns of the Ming dynasty . Its glaze, form, and workmanship are consisten t with the t ypical characteristics of this p eriod. It can therefore b e identified as “Ming Dehua Kiln White-Glazed Standing Guanyin Figure.” I will no w further zo om in on the details for confirmation. {"name": "image_zoom_in_tool", "arguments": {"index": 1, "bbox_2d": [112, 114, 670, → 1004], "label": "Guanyin"}} User: Succe ssfully zo omed in on the region lab eled “Guanyin” at [112, 114, 670, 1004]. Assistan t: Based on the analysis of the p orcelain and the verification through the to ol results, this piece is a white-glazed standing Guanyin figure produced by the Deh ua kilns in the Ming dynasty . It exhibits the typical glaze tone, v essel form, and craftsmanship asso ciated with that p erio d, and th us corresp onds to the standard designation “Ming Deh ua Kiln White-Glazed Standing Guanyin Figure.” Ming Dehua Kiln White-Glazed Standing Guanyin Figure 9 T endrilled Lotus Patternp ( 缠 枝 莲 纹 ) User: Please determine the decorativ e motif of this antique. After your analysis, c ho ose to either inv ok e a to ol or respond directly , and place the final iden tification result within the {"name": "search_image", "arguments": {"index": 1}} User: Succe ssfully found the following conten t: 10 Image searc h results: - Name: Qing Y ongzheng Imitation Longquan Kiln Pho enix-T ail V ase - Dynast y: Qing - Reign: Y ongzheng - Glaze Color: Celadon glaze - Decoration: T endrilled floral motif - F orm: V ase - Description: Flared mouth with straight nec k, sw ollen b o dy tapering do wnw ard and flaring out ward at the fo ot. The entire vessel is coated in a celadon glaze. Sev eral string lines encircle the mouth rim. The neck and b elly are each decorated with floral blossoms and tendrilled scroll motifs, with a band of c hrysanthem um-p etal pattern around the lo wer b elly . The glaze tone is pale and evenly applied. Inside the fo otring is a six-character, three-column seal-script mark: “Made in the Y ongzheng p eriod of the Great Qing.” - Source: National P alace Museum, T aip ei - Similarit y: 0.9185529 — Image searc h results: - Name: Qing Y ongzheng Win ter-Green Celadon V ase with Incised Decoration - Dynast y: Qing - Reign: Y ongzheng - Glaze Color: Win ter-green glaze - Decoration: Incised motif - F orm: V ase - Description: Flared mouth with straight nec k, sw ollen b o dy tapering do wnw ard and flaring out ward at the fo ot. The entire vessel is coated in a celadon glaze. Sev eral string lines encircle the mouth rim. The neck and b elly are each decorated with floral blossoms and tendrilled scroll motifs, with a band of c hrysanthem um-p etal pattern around the lo wer b elly . The glaze tone is pale and evenly applied. Inside the fo otring is a six-character, three-column seal-script mark: “Made in the Y ongzheng p eriod of the Great Qing.” - Source: National P alace Museum, T aip ei - Similarit y: 0.9150853 — Image searc h results: - Name: Qing Y ongzheng Win ter-Green Celadon V ase with Incised Decoration - Dynast y: Qing - Reign: Y ongzheng 11 - Glaze Color: Win ter-green glaze - Decoration: Incised motif - F orm: V ase - Description: Flared mouth with straight nec k, sw ollen b o dy tapering do wnw ard and flaring out ward at the fo ot. The entire vessel is coated in a celadon glaze. Sev eral string lines encircle the mouth rim. The neck and b elly are each decorated with floral blossoms and tendrilled scroll motifs, with a band of c hrysanthem um-p etal pattern around the lo wer b elly . The glaze tone is pale and evenly applied. Inside the fo otring is a six-character, three-column seal-script mark: “Made in the Y ongzheng p eriod of the Great Qing.” - Source: National P alace Museum, T aip ei - Similarit y: 0.9142115 Assistan t: Based on the results returned b y the to ol, the decorative motif on this p orce- lain piece is indeed a tendrilled lotus pattern. Its st ylistic features closely corresp ond to those found on imp erial w ares from the Y ongzheng p erio d of the Qing dynast y , further substan tiating the accuracy of its p erio d attribution and craftsmanship. {"name": "image_zoom_in_tool", "arguments": {"index": 2, "bbox_2d": [112, 114, 888, → 987], "label": "tendrilled lotus pattern"}} User: Successfully zo omed in on the region lab eled “tendrilled lotus pattern” at [112, 114, 888, 987]. Assistan t: The decorativ e motif of this p orcelain piece is a typical tendrilled lotus pat- tern. The scrolling lines are graceful and fluent, and the lotus blossoms are rendered with delicate precision, fully reflecting the refined craftsmanship and aesthetic pursuit of imp erial p orcelain from the Y ongzheng p erio d of the Qing dynasty . Tendrilled lotus pattern 12 9 Prompts 9.1 Prompt for Metadata Enric hmen t Listing 1: Prompt for generating m ultiple-choice options Please describe the Chinese porcelain shown in the image: . Then revise the description according to the human experts annotation:. The final description should comprehensively cover six attributes: dynasty, reign period, → kiln site, glaze color, decorative motif, and vessel shape. 9.2 Prompt for VQA Data Generation Listing 2: Prompt for generating m ultiple-choice options Given the expert-enhanced description of a porcelain artifact: Your task is to extract four categories of information from this description: (1) Dynasty, (2) Vessel Shape, (3) Glaze Color, and (4) Decorative Motifs. Construct one QA pair at a time. For the current step, answer **only one** of the four categories. Format: Q: A question that asks specifically about one category (e.g., dynasty, vessel shape, → glaze color, or decorative motifs). A: A concise but complete answer extracted from the description, including all relevant → descriptive details. Do not include information from the other three categories in the answer. Do not infer beyond the given description; extract only what is stated. Generate the QA pair for the following category: 9.3 Prompt for Generating Multiple-c hoice Options Listing 3: Prompt for generating m ultiple-choice options You are an expert in porcelain-related question design. Below is a porcelain- → related question and its correct answer. Please transform this question into a → multiple-choice question with four options, where one option is correct and the → other three are plausible but incorrect. Please output strictly in the following format: Content of option A Content of option B Content of option C Content of option D Letter of the correct option Notes: - The options must be relevant to the given question and answer. - The incorrect options should be misleading but distinguishable from the correct one. - Do not add any other text or explanations outside the specified format. 13 9.4 Prompt for LLM-as-a-Judge in Ev aluation Listing 4: Prompt for LLM-as-a-Judge in Ev aluation You are an expert reviewer in the field of antique Chinese porcelain, specialized in → evaluating the accuracy of model identification results. Please compare the following "reference answer" and "model output" and produce a → comprehensive evaluation according to the rules below across 6 dimensions. --- ### Scoring requirements: For each of the seven dimensions listed below, assign an individual score between 0 and 1. → Adopt a conservative scoring style. ### Detailed scoring rules: 1.**Dynasty accuracy** Whether the output mentions and correctly states the dynasty to which the porcelain → belongs, and whether the provided dynasty information is sufficiently precise. 2.**Reign period accuracy** Whether the output mentions and correctly states the imperial reign (e.g., Kangxi, → Qianlong); note any deviation or omission. 3.**Kiln site accuracy** Whether the output mentions and correctly states the kiln site characteristics (e.g., → Jingdezhen, Ru Kiln); note any deviation or omission. 4.**Glaze color accuracy** Whether the output mentions and correctly states the glaze/color characteristics (e.g., → blue-and-white, famille-rose, red-ground with green enamels); note any deviation or → omission. 5.**Decoration / Motif accuracy** Whether the output correctly describes the decorative motifs or subjects (e.g., dragons → and phoenixes, floral patterns, human figures, cloud patterns), and whether the → motif matches the stylistic expectations of the claimed period. 6.**Form / Vessel-type accuracy** Whether the output reasonably identifies and describes the vessel form, and whether this → conforms with the reference answer. Note: If a particular dimension is absent in the reference answer, mark it with -1 to → indicate missing data. Please first provide the reasoning for each score, and then place the final numeric scores → inside the following tags in order: ... ... ... ... ... ... For example: 1.0 0.6 -1.0 1.0 0.0 0.8 Reference answer: {ground_truth} Model output: {prediction} 14 9.5 Prompt for LLM-as-a-Judge in T raining The training-time LLM-as-a-Judge prompt is largely aligned with the ev aluation-time version; the only difference is the addition of a Format consistency criterion to mitigate p oten tial reward hac king during reinforcement learning. Listing 5: Prompt for LLM-as-a-Judge in T raining You are an expert reviewer in the field of antique Chinese porcelain, specialized in → evaluating the accuracy of model identification results. Please compare the following "reference answer" and "model output" and produce a → comprehensive evaluation according to the rules below across seven dimensions. --- ### Scoring requirements: For each of the seven dimensions listed below, assign an individual score between 0 and 1. → Adopt a conservative scoring style. ### Detailed scoring rules: 1.**Format consistency** Whether the output strictly follows the naming order: "Dynasty", "Reign period", "Kiln → site", "Glaze color", "Decoration motif", "Vessel shape". Some elements may be → missing, but the order must not be disrupted. The model output must contain only a → single standard name; it must not include any explanatory, descriptive, or other → additional text. If the order is correct but some fields are missing, 1 score may → still be given. 2.**Dynasty accuracy** Whether the output mentions and correctly states the dynasty to which the porcelain → belongs, and whether the provided dynasty information is sufficiently precise. 3.**Reign period accuracy** Whether the output mentions and correctly states the imperial reign (e.g., Kangxi, → Qianlong); note any deviation or omission. 4.**Kiln site accuracy** Whether the output mentions and correctly states the kiln site characteristics (e.g., → Jingdezhen, Ru Kiln); note any deviation or omission. 5.**Glaze color accuracy** Whether the output mentions and correctly states the glaze/color characteristics (e.g., → blue-and-white, famille-rose, red-ground with green enamels); note any deviation or → omission. 6.**Decoration / Motif accuracy** Whether the output correctly describes the decorative motifs or subjects (e.g., dragons → and phoenixes, floral patterns, human figures, cloud patterns), and whether the → motif matches the stylistic expectations of the claimed period. 7.**Form / Vessel-type accuracy** Whether the output reasonably identifies and describes the vessel form, and whether this → conforms with the reference answer. Note: If a particular dimension is absent in the reference answer, mark it with -1 to → indicate missing data. Please first provide the reasoning for each score, and then place the final numeric scores → inside the following tags in order: ... ... ... 15 ... ... ... ... For example: 1.0 1.0 0.6 -1.0 1.0 0.0 0.8 Reference answer: {ground_truth} Model output: {prediction} 10 Detailed Configurations SFT Setup. W e conducted SFT using the ms-swift [ 49 ] framework for 1 ep o c h with a learning rate of 1 × 10 − 5 , a batch size of 16, and gradient accum ulation o ver 4 steps. W e used the default AdamW optimizer and set the maxim um sequence length to 8192. RL Setup. During the RL training, we use the AdamW with a learning rate of 1 × 10 − 6 , a batc h size of 128 with 16 rollouts for each prompt, and a KL co efficient of β = 0. T o ol Setup. The size of the initial image sent to the agen t is set to b e maxim um 313 , 600 pixels. F or the image zo om-in to ol, the zo om-in op eration is performed on the initial image by mapping the bbox back to the original image size. W e set k = 3 for b oth searc h image and searc h text, and the co efficient α is set as 0 . 2. The maxim um n umber of to ol inv o cations p er query is set to 4 to balance b et w een reasoning depth and computational efficiency . 11 Comparison with Existing Datasets Belo w, we presen t a comparison b et ween our prop osed CiQi-V QA dataset and several existing p orcelain-related datasets, as shown in T able 6 . W e rep ort the num b er of p orcelain sp ecimens included in each dataset, as well as the n umber of categories cov ered under six attributes. A “—” indicates that the dataset do es not provide statistics for that attribute. As shown in the comparison, our dataset contains the largest scale and offers the most fine-grained attribute co verage among all datasets. T able 6: Dataset Comparison. Datasets P orcelain Sp ecimens Dynasties Reigns Kilns Colors Motifs Shapes Ling et al. [ 19 ] 5,993 2 — 10 8 — 12 Ma et al. [ 23 ] 5,624 — — — — — 7 Sun et al. [ 38 ] 232 3 — — — — 1 Y ang et al. [ 48 ] 2,750 — — — 7 — — Hu et al. [ 12 ] 8,213 6 — — 20 6 7 CiQi-V QA (Ours) 29,596 38 42 43 246 248 158 16 T able 7: Comparativ e exp erimen ts on the Hu et al. [ 12 ] dataset. Mo del Glaze/Kiln Shape W eighted Avg. † GPT-5 [ 30 ] 86.9 91.4 88.1 GPT-4.1 [ 31 ] 86.4 88.6 87.0 GPT-4o [ 29 ] 86.4 91.4 87.7 o3 [ 32 ] 86.9 91.4 88.1 Claude Opus 4 [ 1 ] 84.4 90.0 85.9 Qw en2.5-VL-72B-Instruct [ 35 ] 82.4 88.6 84.0 GLM-4.5V (106B) [ 9 ] 85.4 91.4 87.0 In ternVL3.5-241B-A28B-Flash [ 15 ] 74.4 90.0 78.4 Kimi-VL-A3B-Instruct (16B) [ 17 ] 74.9 85.7 77.7 Hu et al. [ 12 ] — — 70.0 CiQi-Agen t (Ours, 7B) 87.4 92.9 88.9 † W eighted by item counts: w G = 199 / 269, w S = 70 / 269. 12 Additional Comparativ e Exp erimen ts W e conducted additional comparative exp erimen ts using the op en-source dataset provided by Hu et al. [ 12 ]. In their w ork, Hu et al. [ 12 ] p erformed ob ject detection and recognition tasks on Chinese p orcelains, defining three attributes for recognition: vessel shap e, glaze color/kiln site (treated as a single attribute in their pap er), and decorative motif. Each ma jor attribute con tains multiple sub-attributes (see T able 6 for details). In our comparative study , b ecause the released dataset is incomplete and the test set lacks annotations, we conducted the comparison using their v alidation set. W e consider this compar- ison still meaningful b ecause the pap er states that b oth the v alidation set and the test set w ere obtained by randomly sampling 20% and 10% of the full dataset, resp ectiv ely . Therefore, the results rep orted on the test set in the original pap er are also informative for the v alidation set and should not deviate significan tly . Additionally , in the open-source dataset, the decorativ e motif attribute is not represented by images of Chinese p orcelains; therefore, w e restricted our exp erimen ts to the glaze color/kiln site and v essel shap e attributes. W e generated multiple-c hoice questions for these tw o attributes, with the options corre- sp onding to all sub-attributes under each attribute (20 for glaze color/kiln site and 7 for v essel shap e). Sp ecifically , the glaze color/kiln site attribute included 199 questions, while the vessel shap e attribute contained 70 questions. W e ev aluated CiQi-Agent alongside nine MLLMs— including the GPT series, Claude, and others. The exp erimen tal results are summarized in T able 7 . The exp erimen tal results show that on the op en-source dataset pro vided by Hu et al. [ 12 ], our CiQi-Agent consistently outp erforms all baseline mo dels. Moreo ver, its fine-grained classi- fication capability significantly surpasses the approach describ ed in Hu et al. [ 12 ], achieving an a verage accuracy impro vemen t of 18 . 9%. The small p erformance gap b et ween our mo del and the other MLLMs is largely due to the simplicity of this dataset, which includes only 7 v essel- shap e categories and 20 glaze categories. In contrast, our constructed dataset includes 100+ of categories for b oth vessel shap es and glazes, making the task substantially more challenging. 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment