HISA: Efficient Hierarchical Indexing for Fine-Grained Sparse Attention
Token-level sparse attention mechanisms, exemplified by DeepSeek Sparse Attention (DSA), achieve fine-grained key selection by scoring every historical token for each query using a lightweight indexer, and then computing attention only over the selec…
Authors: Yufei Xu, Fanxu Meng, Fan Jiang
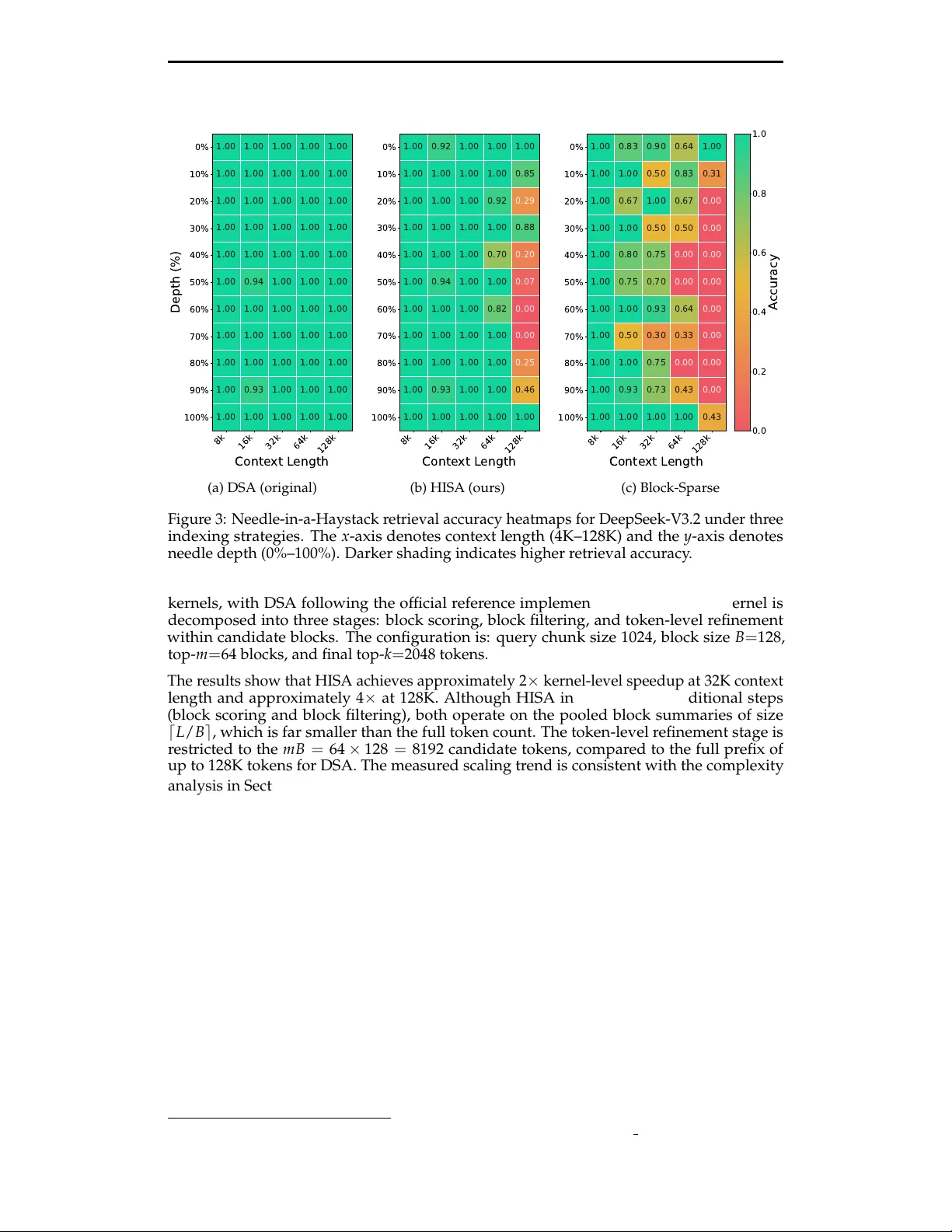
Preprint. Under review . HISA: Ef ficient Hierarchical Indexing for Fine-Grained Sparse Attention Y ufei Xu ∗ , Fanxu Meng ∗ , Fan Jiang, Y uxuan W ang, Ruijie Zhou, Jiexi W u, Zhixin Pan, Zhaohui W ang, Xiaojuan T ang, W enjie Pei, T ongxuan Liu, Di yin, Xing Sun, Muhan Zhang † Abstract T oken-level sparse attention mechanisms, exemplified by DeepSeek Sparse Attention (DSA), achieve fine-grained key selection by scoring every histor- ical token for each query through a lightweight indexer , then computing attention only on the selected subset. While the downstream sparse at- tention itself scales favorably , the indexer must still scan the entir e pr efix for every query , introducing an O ( L 2 ) per-layer bottleneck that gr ows pro- hibitively with context length. W e propose HISA ( H ierarchical I ndexed S parse A ttention), a dr op-in replacement for the indexer that r ewrites the search path fr om a flat token scan into a two-stage hierar chical pr ocedur e: (1) a block-level coarse filter that scores pooled block repr esentatives to prune irrelevant r egions, followed by (2) a token-level refinement that runs the original indexer only inside the surviving candidate blocks. HISA preserves the identical token-level top- k sparse pattern consumed by the downstream Sparse MLA operator and requir es no additional training. On kernel-level benchmarks, HISA achieves 2 × speedup at 32K context and 4 × at 128K. On Needle-in-a-Haystack and LongBench, we directly r eplace the indexer in DeepSeek-V3.2 with our HISA indexer , without any finetun- ing. HISA closely matches the original DSA in quality , while substantially outperforming block-sparse baselines. Moreover , the token selection sets of HISA and the original DSA exhibit a mean IoU gr eater than 99%, indicat- ing that this ef ficient design does not significantly af fect the final selected tokens. 1 Introduction Serving large language models (LLMs) over long contexts r emains a central systems chal- lenge. As context windows gr ow from 4K to 128K tokens and beyond—driven by demands for agentic multi-turn reasoning, long-document understanding, and native multimodal processing—the quadratic cost of self-attention becomes a dominant bottleneck in both prefill latency and memory consumption ( Dao et al. , 2022 ; Dao , 2023 ). A productive line of work addresses this challenge through sparse attention : rather than attending to all key–value pairs, each query selects a small subset of the most relevant tokens and computes attention only over that subset. Recent production-grade systems have converged on a token-level sparse attention paradigm, in which a lightweight indexer module scores every historical token for each query , selects the top- k highest-scoring keys, and passes only those keys to a downstr eam sparse attention operator (e.g., Sparse MLA). This design, which we refer to as DeepSeek Sparse Attention (DSA), has been adopted in DeepSeek-V3.2 ( DeepSeek-AI , 2025 ) and GLM-5 ( T eam , 2025 ), and offers strictly finer- grained selection than block-level methods such as MoBA ( Lu et al. , 2025 ) and Native Sparse Attention ( Y uan et al. , 2025 ). However , the token-level sparse paradigm intr oduces a subtler bottleneck. Although the downstream attention is sparse and cheap, the indexer itself must score every token in the ∗ Equal contribution. † Corresponding author: muhan@pku.edu.cn 1 Preprint. Under review . prefix for every query . Concretely , if the prefix length is L and the indexer runs once per query per layer , the per-layer indexing cost is O ( L 2 ) —the same asymptotic scaling as dense attention. As context lengths push toward 128K or 1M tokens, the indexer can transition from a negligible over head into the dominant cost component. This observation motivates a natural question: can we reduce the indexer ’ s search cost without changing the final sparse attention pattern it pr oduces? In other wor ds, can we r ewrite the sear ch path while preserving the sear ch r esult ? W e answer affirmatively with HISA (Hierar chical Indexed Sparse Attention). HISA replaces the flat, full-prefix token scan with a two-stage hierar chical sear ch: 1. Block-level coarse filtering. The prefix is partitioned into contiguous blocks of size B . A pooled repr esentative vector is computed for each block via mean pooling over its constituent indexing keys. The query scores all ⌈ L / B ⌉ block r epresentatives and retains only the top- m blocks, immediately pruning the majority of the prefix from further consideration. 2. T oken-level refinement. The token-level indexer then scores at most m B tokens from the selected blocks using the same scoring mechanism as the original DSA lighting indexer , with the only differ ence being that the candidate pool is restricted to these tokens in the selected blocks rather than the full set of L tokens considered in DSA. The token-level indexer subsequently assigns scor es to at most m B tokens drawn from the selected blocks, following the same scoring mechanism as the original DSA lighting indexer . Unlike DSA, which evaluates all L tokens, our approach only scores tokens within this r educed candidate pool. The final top-kkk token set is selected accordingly . The original DSA token-level indexer runs only inside the surviving candidate blocks , scoring at most m B tokens instead of L . The final top- k token set is selected from this r educed candidate pool. Crucially , the output of HISA is the same data structure as the output of the original DSA indexer: a per-query set of k token indices. The downstr eam Sparse MLA operator is entirely unmodified. HISA is therefor e a dr op-in replacement that requir es no r etraining, no architectural changes to the attention mechanism, and no modification to the KV cache layout. The per-query indexing complexity drops from O ( L ) to O ( L / B + m B ) , and the per -layer cost drops from O ( L 2 ) to O ( L 2 / B + L m B ) . When m ≪ ⌈ L / B ⌉ and B ≪ L —precisely the regime of inter est for ultra-long contexts—this r epresents a substantial r eduction. Our contributions are as follows: • W e identify the indexer as an emer ging bottleneck in token-level sparse attention systems and formalize the problem of sear ch-path optimization for sparse indexers. • W e propose HISA, a hierarchical block-to-token indexing strategy that is training- free, operator -compatible, and asymptotically faster than the flat indexer . • W e provide optimized T ileLang GPU kernel implementations for both stages of HISA and demonstrate 2–4 × kernel-level speedup at 32K–128K contexts. • W e validate empirically that HISA preserves selection quality ( > 99% mean IoU with original DSA) and downstream task performance on Needle-in-a-Haystack and LongBench benchmarks. 2 Related W ork Block-sparse attention. A family of methods reduces attention cost by restricting com- putation to selected blocks of contiguous tokens. Longformer ( Beltagy et al. , 2020 ) and BigBird ( Zaheer et al. , 2020 ) combine local sliding windows with sparse global tokens. Sparse T ransformers ( Child et al. , 2019 ) employ fixed strided patterns. More recently , 2 Preprint. Under review . MoBA ( Lu et al. , 2025 ) applies a mixture-of-experts-style gating to select the most relevant blocks per query , and Native Sparse Attention (NSA) ( Y uan et al. , 2025 ) proposes hardwar e- aligned block selection that is natively trainable. These methods are efficient but operate at block granularity: every token within a selected block participates in attention, sacrificing the ability to prune irr elevant tokens within an important block. HISA uses blocks only as an intermediate filtering device and preserves token-level selection. T oken-level sparse attention. At the other end of the granularity spectr um, token-level methods select individual keys for each query . DSA, deployed in DeepSeek-V3.2 ( DeepSeek- AI , 2025 ) and GLM-5 ( T eam , 2025 ), uses a lightweight multi-head indexer that scores every prefix token and selects the top- k per query . This yields fine-grained patterns that adapt to each query’s information need. However , the indexer itself requires a full prefix scan, creating a quadratic bottleneck. KV cache eviction strategies such as H 2 O ( Zhang et al. , 2024 ) and StreamingLLM ( Xiao et al. , 2024 ) permanently discard tokens, which can be viewed as a one-time coarse token selection but is irreversible and less flexible. QUEST ( T ang et al. , 2024 ) uses query-aware page selection to reduce KV cache reads but still operates at a page (block) granularity for the final attention computation. Hierarchical and multi-granularity attention. Several works explore multi-scale attention structur es. LongNet ( Ding et al. , 2023 ) uses dilated attention at exponentially increasing in- tervals. MInference ( Zhu et al. , 2024 ) dynamically selects among predefined sparse patterns (vertical, slash, block-sparse) per head. SqueezedAttention ( Li et al. , 2025 ) clusters keys offline and uses cluster centr oids to prune irrelevant gr oups at infer ence time, conceptually similar to our block pooling but requiring an offline clustering step. A distinct family of methods compresses each block’s tokens into a fixed number of summary vectors and computes attention over these summaries. The key distinction of HISA is that it uses the block hierarchy pur ely as a sear ch accelerator : blocks serve only to narrow the candidate set, and the final selection and attention computation r emain at token granularity . This design preserves full compatibility with existing Sparse MLA operators without any ar chitectural modification. Approximate nearest-neighbor search for attention. The coarse-to-fine strategy in HISA is reminiscent of inverted file indexing (IVF) in approximate near est-neighbor sear ch ( Johnson et al. , 2021 ) and locality-sensitive hashing in Reformer ( Kitaev et al. , 2020 ). Whereas these methods introduce appr oximation into the attention computation itself, HISA restricts the approximation to the indexer ’s search path and leaves the downstream attention kernel exact (over the selected tokens). 3 Preliminary 3.1 Background: T oken-Level Sparse Attention via DSA W e briefly recap the DSA indexing mechanism as used in DeepSeek-V3.2 ( DeepSeek-AI , 2025 ). Consider a single decoder layer . Let L denote the causal prefix length for a given query position t . The indexer maintains a set of lightweight indexing keys { k I s } L s = 1 alongside indexing queries { q I t , j } H I j = 1 across H I indexing heads, together with per-head gating weights { w I t , j } . The relevance scor e for query t and key s is: I t , s = H I ∑ j = 1 w I t , j · ReLU ( q I t , j ) ⊤ k I s . (1) The indexer selects T t = T opK ( I t ,: , k ) and passes this set to the Sparse MLA operator , which computes attention only over the k selected keys. The per-query cost of this scoring is O ( L ) (over the full prefix), leading to O ( L 2 ) per layer when summed across all queries. 3 Preprint. Under review . Indexer Key Indexer Query T op-k T okens Select top-k tokens (a) Original DSA: token-wise indexer . Indexer Query T op-k T okens T op-m Blocks Indexer Query Indexer Key Pooling Select top-m blocks Select top-k tokens (b) Our HISA: block-to-token indexer . Figure 1: Comparison of the DSA token-wise indexer (left) and our HISA hierarchical block-level coarse filter followed by token-level refinement (right). Both produce the same data structur e—a per-query set of k token indices—consumed by the downstr eam Sparse MLA operator . 4 Method 4.1 HISA: Hierarchical Indexed Sparse Attention HISA replaces the flat prefix scan with a two-stage coarse-to-fine sear ch. The final output remains an ident ical per-query token set T H t of size k , consumed by the unmodified Sparse MLA operator . Block partitioning and pooled keys. The prefix of length L is partitioned into M = ⌈ L / B ⌉ contiguous, causally valid blocks B 1 , B 2 , . . . , B M , where B is the block size. For each block, a repr esentative vector is constructed via mean pooling over its indexing keys: ˜ k I b = Pool n k I s | s ∈ B b o . (2) These pooled keys serve exclusively as coarse-grained proxies for the block-level scoring stage. They do not alter the token-level indexing keys or the KV states consumed by Sparse MLA. In practice, the pooled keys can be incrementally maintained alongside the KV cache with negligible overhead. Stage 1: Block-level coarse filtering. For query position t , HISA reuses the same indexing query repr esentations { q I t , j } and gating weights { w I t , j } as DSA, but scor es the pooled block keys instead of individual token keys: J t , b = H I ∑ j = 1 w I t , j · ReLU ( q I t , j ) ⊤ ˜ k I b . (3) The top- m blocks are retained: C t = T opK ( J t ,: , m ) , (4) and the candidate token set is the union of all tokens in the selected blocks: Ω t = [ b ∈ C t B b . (5) All block selections strictly respect the causal mask: only blocks preceding query position t are eligible. Following the design of MoBA ( Lu et al. , 2025 ), the first block and the last two blocks are always included in C t , as they typically contain globally important context (e.g., system prompts, r ecent tokens). This forced inclusion also simplifies boundary handling during batched prefill with packed sequences of varying lengths, where a single block may straddle the boundary of two sequences. 4 Preprint. Under review . Stage 2: T oken-level refinement. W ithin the r educed candidate set Ω t , the original DSA token-level scoring (Eq. 1 ) is applied: I H t , s = H I ∑ j = 1 w I t , j · ReLU ( q I t , j ) ⊤ k I s , s ∈ Ω t , (6) and the final token set is selected: T H t = T opK n I H t , s | s ∈ Ω t o , k . (7) The Sparse MLA operator executes identically to the original DSA, with T H t replacing T t . The feasibility constraint m B ≥ k must hold to ensur e that the candidate pool is large enough to select k tokens. Boundary behavior . Three regimes arise depending on the relationship between the effective pr efix length t , the candidate capacity m B , and the budget k : • When t ≤ k , all prefix tokens ar e selected and HISA is equivalent to dense attention. • When k < t ≤ m B , the coarse filter selects all blocks (since m ≥ M ), and Stage 2 reduces the set to k tokens. HISA is equivalent to the original DSA indexer . • When t > m B , the coarse filter genuinely prunes blocks, and HISA ’s hierarchical advantage is active. The third regime is precisely the long-context setting where HISA provides its efficiency gains. 4.2 Complexity Analysis Assuming the pooled block keys are maintained incrementally , the per-query indexing cost of HISA consists of scoring ⌈ L / B ⌉ block repr esentatives (Stage 1) and scoring at most m B candidate tokens (Stage 2): O L B + m B . (8) Summing over all L queries in a layer yields: O L 2 B + L m B , (9) compared to O ( L 2 ) for the original DSA indexer . The design introduces a clear trade-of f: larger B reduces the coarse-filter cost but makes each block a coarser proxy; smaller m improves efficiency but increases the risk of missing relevant blocks. When m ≪ M and B ≪ L —the regime of ultra-long contexts with a selective coarse filter—the reduction is substantial. Conversely , when m approaches M , HISA degrades gracefully toward the full-scan baseline. In today’s LLM landscape, where context windows of 128K or even 1M tokens are pur- sued for improved agent capabilities and native multimodal reasoning, HISA ’s asymptotic advantage translates directly into practical speedup. Algorithm 1 provides the complete pseudocode for the HISA indexer . 5 Experiments W e evaluate HISA along four axes: (1) kernel-level latency , (2) retrieval accuracy on Needle- in-a-Haystack, (3) downstream task quality on LongBench, and (4) selection consistency with the original DSA indexer via IoU analysis. Throughout, we compare three indexing strategies: 5 Preprint. Under review . Algorithm 1 HISA: Hierarchical Indexed Sparse Attention Require: Query indexing representations { q I t , j } , gating weights { w I t , j } , token indexing keys { k I s } L s = 1 , block size B , block budget m , token budget k Ensure: Selected token set T H t of size k 1: Partition prefix into M = ⌈ L / B ⌉ blocks B 1 , . . . , B M 2: for b = 1 to M do 3: ˜ k I b ← MeanPool ( { k I s | s ∈ B b } ) 4: end for 5: for each query position t do 6: // Stage 1: Block-level coarse filter 7: for b = 1 to M such that B b precedes t do 8: J t , b ← ∑ j w I t , j · ReLU ( ( q I t , j ) ⊤ ˜ k I b ) 9: end for 10: C t ← T opK ( J t ,: , m ) ∪ { first block, last two blocks } 11: Ω t ← S b ∈ C t B b 12: // Stage 2: T oken-level refinement 13: for s ∈ Ω t do 14: I H t , s ← ∑ j w I t , j · ReLU ( ( q I t , j ) ⊤ k I s ) 15: end for 16: T H t ← T opK ( { I H t , s | s ∈ Ω t } , k ) 17: end for 18: return T H t 8192 16384 32768 65536 Sequence L ength 0 1 2 3 4 5 6 7 8 T ime (ms) DS A (inde x) DS A (topk) HIS A Block (inde x) HIS A Block (topk) HIS A T ok en (inde x) HIS A T ok en (topk) Figure 2: Indexer kernel latency comparison between the original DSA (flat token scan) and HISA (hierarchical block-to-token). Query chunk size: 1024, block size B = 128, top- m = 64 blocks, top- k = 2048 tokens. HISA ’s advantage grows with context length, reaching ∼ 4 × at 128K. • DSA (original) : the full-prefix token-level indexer as described in Section 4 . • HISA : the hierarchical block-to-token indexer pr oposed in this work. • Block-Sparse : a block-level-only baseline that selects top- m blocks and attends to all tokens within those blocks (i.e., Stage 1 only , without token-level refinement). Both HISA and Block-Sparse are training-fr ee : they ar e applied at inference time by replacing the indexer module, with no fine-tuning or architectural modification. 5.1 Kernel-Level Speedup Figure 2 compar es the indexer kernel latency of the original DSA and HISA acr oss context lengths from 4K to 128K tokens. Both implementations use T ileLang ( Y e et al. , 2025 ) GPU 6 Preprint. Under review . 8k 16k 32k 64k 128k Conte xt L ength 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% Depth (%) 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.94 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.93 1.00 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.0 0.2 0.4 0.6 0.8 1.0 A ccuracy (a) DSA (original) 8k 16k 32k 64k 128k Conte xt L ength 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% Depth (%) 1.00 0.92 1.00 1.00 1.00 1.00 1.00 1.00 1.00 0.85 1.00 1.00 1.00 0.92 0.29 1.00 1.00 1.00 1.00 0.88 1.00 1.00 1.00 0.70 0.20 1.00 0.94 1.00 1.00 0.07 1.00 1.00 1.00 0.82 0.00 1.00 1.00 1.00 1.00 0.00 1.00 1.00 1.00 1.00 0.25 1.00 0.93 1.00 1.00 0.46 1.00 1.00 1.00 1.00 1.00 0.0 0.2 0.4 0.6 0.8 1.0 A ccuracy (b) HISA (ours) 8k 16k 32k 64k 128k Conte xt L ength 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% Depth (%) 1.00 0.83 0.90 0.64 1.00 1.00 1.00 0.50 0.83 0.31 1.00 0.67 1.00 0.67 0.00 1.00 1.00 0.50 0.50 0.00 1.00 0.80 0.75 0.00 0.00 1.00 0.75 0.70 0.00 0.00 1.00 1.00 0.93 0.64 0.00 1.00 0.50 0.30 0.33 0.00 1.00 1.00 0.75 0.00 0.00 1.00 0.93 0.73 0.43 0.00 1.00 1.00 1.00 1.00 0.43 0.0 0.2 0.4 0.6 0.8 1.0 A ccuracy (c) Block-Sparse Figure 3: Needle-in-a-Haystack retrieval accuracy heatmaps for DeepSeek-V3.2 under three indexing strategies. The x -axis denotes context length (4K–128K) and the y -axis denotes needle depth (0%–100%). Darker shading indicates higher retrieval accuracy . kernels, with DSA following the official reference implementation. 1 The HISA kernel is decomposed into three stages: block scoring, block filtering, and token-level refinement within candidate blocks. The configuration is: query chunk size 1024, block size B = 128, top- m = 64 blocks, and final top- k = 2048 tokens. The results show that HISA achieves approximately 2 × kernel-level speedup at 32K context length and approximately 4 × at 128K. Although HISA introduces two additional steps (block scoring and block filtering), both operate on the pooled block summaries of size ⌈ L / B ⌉ , which is far smaller than the full token count. The token-level refinement stage is restricted to the m B = 64 × 128 = 8192 candidate tokens, compared to the full prefix of up to 128K tokens for DSA. The measured scaling trend is consistent with the complexity analysis in Section 4.2 : as L grows, the O ( L 2 ) cost of the flat scan dominates, while HISA ’s O ( L 2 / B + L m B ) cost grows mor e slowly . W e emphasize that these are indexer kernel -level measurements and do not directly translate to end-to-end serving throughput, which also depends on the Sparse MLA operator , KV cache management, and other system components. 5.2 Needle-in-a-Haystack The Needle-in-a-Haystack (NIAH) test ( Kamradt , 2023 ) evaluates a model’s ability to re- trieve a specific fact (the “needle”) embedded at a controlled position within a long distractor context (the “haystack”). W e evaluate DeepSeek-V3.2 with its original DSA indexer r eplaced by HISA, without any additional training, acr oss context lengths from 4K to 128K tokens and needle insertion depths from 0% (beginning) to 100% (end). Figure 3 pr esents the r etrieval accuracy heatmaps. The original DSA achieves near-perfect retrieval across all positions and lengths (Figur e 3a ). HISA closely matches this performance (Figure 3b ), with only marginal degradation at extreme lengths and depths, confirming that the hierarchical coarse filter rarely discar ds blocks containing the target information. In con- trast, the Block-Sparse baseline (Figure 3c ) exhibits noticeable accuracy drops, particularly 1 https://github.com/tile- ai/tilelang/tree/main/examples/deepseek v32 7 Preprint. Under review . T able 1: LongBench results for DeepSeek-V3.2 under dif ferent indexing strategies. All sparse methods are applied at inference time without additional training. Scores are averaged across sub-tasks within each category . T ask abbreviations: SQA = Single-Document QA, MQA = Multi-Document QA, Sum = Summarization, FS = Few-shot Learning, Syn = Syn- thetic Retrieval. Model Indexer SQA MQA Sum FS Syn A vg. DeepSeek-V3.2 DSA 0.5089 0.5266 0.2211 0.6224 0.6983 0.5155 HISA 0.4917 0.5196 0.2213 0.6162 0.7083 0.5114 Block 0.4836 0.4976 0.2190 0.5945 0.6867 0.4963 when the needle falls in the middle of the context wher e block-level selection is least reliable. This gap illustrates the value of token-level refinement: even when both methods select the same blocks, HISA ’s second stage can further concentrate attention on the critical tokens, whereas Block-Sparse must attend uniformly to all tokens within selected blocks. 5.3 LongBench Evaluation LongBench ( Bai et al. , 2024 ) is a comprehensive benchmark for long-context understanding, spanning single-document QA, multi-document QA, summarization, few-shot learning, synthetic retrieval, and code completion tasks. W e evaluate DeepSeek-V3.2 ( DeepSeek- AI , 2025 ) under three configurations: the original DSA indexer , HISA, and Block-Sparse Attention. Both DSA, HISA, and Block-Sparse Attention ultimately r etain 2048 tokens for computation. Specifically , Block-Sparse Attention directly selects 16 blocks with a block size of 128 (i.e., 128 × 16 = 2048 tokens). HISA first selects 64 blocks with a block size of 128 (i.e., 128 × 64 = 8192 tokens), and then further performs token-level selection to reduce them to 2048 tokens. T able 1 reports the r esults. Across both models and all task categories, HISA achieves scores within a narr ow margin of the original DSA, confirming that the hierarchical sear ch path preserves the quality of token-level selection. The Block-Sparse baseline, which lacks token-level refinement, shows a mor e pronounced gap, particularly on tasks requiring precise information r etrieval (Single-Doc QA, Multi-Doc QA, Synthetic). Summarization tasks, which depend on more diffuse attention patterns, show smaller differ ences across all methods. These results demonstrate that HISA successfully maintains task quality while reducing indexer computation: the two-stage hierar chy prunes irr elevant blocks without losing the fine-grained selection capability that distinguishes token-level sparse attention from block-level methods. 5.4 Selection Consistency: IoU Analysis T o quantify the extent to which the hierarchical search path pr eserves the original indexer ’s token selection, we measure the Intersection-over -Union (IoU) between the token sets selected by HISA and the original DSA: IoU T H t , T t = T H t ∩ T t T H t ∪ T t . (10) Figure 4 reports the results on a DeepSeek-V2-Lite ( DeepSeek-AI , 2024 ) pr ototype evaluated on LongBench inputs. Figure 4a shows the per-layer statistics: the mean IoU is consistently above 99% acr oss all layers, indicating that the block-level coarse filter almost never excludes blocks containing the tokens that the original DSA indexer would have selected. The minor variation across layers suggests that certain layers exhibit slightly more diffuse attention patterns, where the block-level pr oxy is a mar ginally less faithful repr esentative. 8 Preprint. Under review . (a) IoU across layers. Each point represents the mean IoU for a single layer , aggregated over all queries and LongBench inputs. (b) IoU across context lengths. Each point repre- sents one input; the solid line shows the mean and the shaded region the min–max range. Figure 4: T oken selection overlap (IoU) between HISA and the original DSA indexer , measured on a DeepSeek-V2-Lite prototype with LongBench inputs. HISA maintains > 99% mean IoU across layers and lengths, with a conservative lower bound above 90%. Figure 4b presents the per -input statistics stratified by context length. The mean IoU remains above 99% even at the longest tested context lengths, while the lower bound (minimum IoU across queries for each input) stays above 90%. The conservative lower bound reflects occasional boundary cases where a semantically important token resides in a block whose pooled repr esentative does not sufficiently stand out—precisely the information loss discussed in Section 7 . Nevertheless, the high overlap confirms that HISA ’s search path, despite examining only a fraction of the prefix, recovers nearly the same evidence set as the exhaustive flat scan. 6 Hyperparameter Sensitivity W e investigate the sensitivity of HISA to its two key hyperparameters—block size B and block-level top- m —by comparing three HISA configurations that share the same candidate pool size m B = 8192 but differ in the coarse–fine balance: ( B = 64, m = 128 ) , ( B = 128, m = 64 ) , and ( B = 256, m = 32 ) . W e also include the original DSA as an upper bound and Block-Sparse ( B = 128, m = 16 ) as a lower bound. All configurations use k = 2048 for the final token selection. Results are evaluated on DeepSeek-V2-Lite acr oss five LongBench task categories. 0.48 0.49 0.50 0.51 0.52 Scor e 0.5089 0.4890 0.4917 0.4950 0.4836 Single-Doc QA 0.49 0.50 0.51 0.52 0.53 0.54 0.55 0.5266 0.5281 0.5196 0.5188 0.4976 Multi-Doc QA 0.216 0.218 0.220 0.222 0.224 0.2211 0.2169 0.2213 0.2206 0.2190 Summarization 0.59 0.60 0.61 0.62 0.63 0.64 0.6224 0.6160 0.6162 0.6080 0.5945 F ew-Shot 0.68 0.69 0.70 0.71 0.72 0.6983 0.7017 0.7083 0.7033 0.6867 Synthetic DS A HIS A (B=64, m=128) HIS A (B=128, m=64) HIS A (B=256, m=32) Block-Sparse (B=128, m=16) Figure 5: LongBench scor es under different indexer configurations on DeepSeek-V2-Lite. All three HISA variants use m B = 8192 candidate tokens with varying block size B and block top- m . Block-Sparse uses B = 128, m = 16 (candidate pool = 2048, no token-level refinement). T oken budget k = 2048 throughout. Figure 5 reveals several findings. First, all three HISA configurations closely track DSA performance across all five task categories, with scor e dif fer ences within 2% in most cases. This confirms that, as long as the candidate pool m B is sufficiently large r elative to k , the two-stage hierarchy r ecovers nearly the same token set as the exhaustive flat scan. 9 Preprint. Under review . Second, among the three HISA variants, the intermediate configuration ( B = 128, m = 64 ) achieves the best balance: it matches or exceeds the other two on Summarization and Synthetic tasks while remaining competitive on QA tasks. The fine-grained variant ( B = 64, m = 128 ) performs slightly better on Multi-Doc QA, where cross-document evidence is distributed across many small regions, while the coarse variant ( B = 256, m = 32 ) offers marginally higher Single-Doc QA scores, likely because larger blocks better preserve local context coherence. Third, Block-Sparse consistently underperforms all HISA configurations, with particularly notable gaps on Single-Doc QA ( − 1.1% vs. the best HISA) and Few-Shot ( − 2.2%). This gap underscores the importance of token-level refinement: even when operating on the same block selection mechanism, the ability to prune low-relevance tokens within selected blocks yields measurable quality gains. 7 Discussion and Limitations Relationship to block-sparse methods. HISA and block-sparse methods such as MoBA ( Lu et al. , 2025 ) and NSA ( Y uan et al. , 2025 ) share the block selection mechanism in Stage 1 but dif fer fundamentally in what follows. Block-sparse methods treat the selected blocks as the final attention scope: all tokens within selected blocks participate in attention computation, and no token-level pruning occurs. HISA treats block selection as an inter- mediate filtering step, followed by token-level r efinement that can discar d low-r elevance tokens even within high-r elevance blocks. This distinction means HISA preserves the full flexibility of token-level sparse attention while using blocks only to accelerate the sear ch. The cost of this flexibility is the additional token-scoring step (Stage 2), which is bounded by m B and is independent of the total prefix length L . Relationship to intra-block compression methods. An alternative hierarchical design compresses each block into a fixed number of summary vectors (e.g., via pooling or learned projection) and computes attention over these summaries. While superficially similar , this approach differs from HISA in a key aspect: it allocates the same “budget” (number of summary vectors) to every block, r egar dless of that block’s r elevance to the curr ent query . For highly relevant blocks, this budget may be insufficient to captur e the fine-grained token-level structur e; for irr elevant blocks, it is wasted entir ely . HISA instead exploits the observation that, in ultra-long contexts, the relevance distribution across blocks is highly non-uniform: most blocks are entirely irrelevant to any given query and can be pruned wholesale, while the few relevant blocks deserve full token-level scrutiny . W e plan to include direct experimental comparisons with r epr esentative intra-block compr ession methods in future work. Information loss in block coarse filtering. The coarse-filtering stage approximates token- level relevance with a single pooled vector per block. This approximation is faithful when the indexing keys within a block are semantically coherent, as the pooled vector then aligns well with the dominant direction in key space. However , when a block straddles a semantic boundary (e.g., a paragraph break or topic shift), the pooled vector may fail to represent the most important token within the block, leading to its exclusion. The lower-bound IoU of approximately 90% in Figure 4b likely reflects such boundary cases. Potential mitigations include overlapping blocks, adaptive block boundaries, or using max-pooling instead of mean-pooling to better preserve outlier dir ections. Kernel-level vs. end-to-end performance. The speedup reported in Section 5.1 is mea- sured at the indexer kernel level and does not account for other components of the inference pipeline, including the Sparse MLA operator itself, KV cache loading, and inter-layer com- munication. In a full serving system, the indexer is one of several contributors to overall latency , and the end-to-end speedup will be lower than the kernel-level figure. However , as context lengths continue to grow , the indexer ’s share of total latency increases, making HISA ’s contribution incr easingly material. Detailed end-to-end profiling is left for future work. 10 Preprint. Under review . Limitations and future directions. Several avenues r emain open: (1) T raining-aware HISA : while HISA currently operates as a training-fr ee inference-time r eplacement, jointly training the block scoring stage may improve the coarse filter ’s accuracy , particularly for boundary cases. (2) Adaptive block size : using a fixed block size B may be suboptimal when the semantic coherence of tokens varies across the context; learned or heuristic adaptive partitioning could improve both the coarse filter ’s fidelity and the overall efficiency . (3) End-to-end system integration : integrating HISA into a full inference serving stack (e.g., with continuous batching and speculative decoding) and measuring throughput and latency under realistic workloads. 8 Conclusion W e have identified the indexer as an emerging bottleneck in token-level sparse atten- tion systems: while the downstream attention is sparse, the indexer ’s exhaustive prefix scan reintr oduces quadratic scaling. HISA addresses this by restructuring the indexer ’s search path into a two-stage hierarchy—block-level coarse filtering followed by token-level refinement—without altering the final sparse attention operator or requiring additional training. Empirically , HISA achieves 2–4 × kernel-level speedup at 32K–128K contexts, maintains > 99% mean IoU with the original selection, and preserves competitive perfor- mance on Needle-in-a-Haystack and LongBench benchmarks. As LLMs continue to push toward million-token contexts for agentic and multimodal applications, the indexer ’s cost will grow incr easingly dominant, making search-path optimizations like HISA an essential complement to sparse attention operators. References Y ushi Bai, Xin Lv , Jiajie Zhang, Hongchang L yu, Jiankai T ang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. arXiv preprint , 2024. Iz Beltagy , Matthew E Peters, and Arman Cohan. Longformer: The long-document trans- former . In arXiv preprint , 2020. Rewon Child, Scott Gray , Alec Radford, and Ilya Sutskever . Generating long sequences with sparse transformers. arXiv preprint , 2019. T ri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691 , 2023. T ri Dao, Daniel Y Fu, Stefano Ermon, Atri Rudra, and Christopher R ´ e. Flashattention: Fast and memory-efficient exact attention with io-awareness. In Advances in Neural Information Processing Systems , volume 35, 2022. DeepSeek-AI. Deepseek-v2: A str ong, economical, and ef ficient mixture-of-experts language model. arXiv preprint , 2024. DeepSeek-AI. Deepseek-v3.2 technical report. arXiv preprint , 2025. Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, W enhui W ang, and Furu W ei. Longnet: Scaling transformers to 1,000,000,000 tokens. arXiv preprint arXiv:2307.02486 , 2023. Jeff Johnson, Matthijs Douze, and Herv ´ e J ´ egou. Billion-scale similarity sear ch with GPUs. IEEE T ransactions on Big Data , 7(3):535–547, 2021. Greg Kamradt. Needle in a haystack — pressur e testing llms. 2023. https://github.com/ gkamradt/LLMTest NeedleInAHaystack . Nikita Kitaev , Ł ukasz Kaiser , and Anselm Levskaya. Reformer: The efficient transformer . In International Conference on Learning Repr esentations , 2020. 11 Preprint. Under review . Coleman Li, Hanlin Cai, et al. Squeezedattention: Accelerating long context llm inference. arXiv preprint arXiv:2411.09688 , 2025. Enzhe Lu, Zhejun Jiang, Jingyuan Liu, Y ulun Du, T ao Jiang, Chao Hong, Shaowei Liu, W eiran He, Enming Y uan, Y uzhi W ang, et al. Moba: Mixture of block attention for long-context llms. arXiv preprint , 2025. Jiaming T ang, Y ilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. QUEST: Query-aware sparsity for ef ficient long-context llm inference. arXiv preprint arXiv:2406.10774 , 2024. GLM T eam. Glm-5 technical report. arXiv preprint , 2025. Guangxuan Xiao, Y uandong T ian, Beidi Chen, Song Han, and Mike Lewis. Efficient stream- ing language models with attention sinks. arXiv preprint , 2024. Lei Y e, Y ining W ang, Lianmin Zheng, Zihao Shi, Jilong He, and T ianqi Chen. T ilelang: A composable tile-based programming model for gpu kernels. arXiv preprint , 2025. Jingyang Y uan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Y uxing W ei, Lean W ang, Zhiping Xiao, et al. Native sparse attention: Hardware- aligned and natively trainable sparse attention. In Pr oceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers) , pp. 23078–23097, 2025. Manzil Zaheer , Guru Guruganesh, Kumar A vinava Dubey , Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan W ang, Li Y ang, et al. Big bir d: T ransformers for longer sequences. In Advances in Neural Information Processing Systems , volume 33, pp. 17283–17297, 2020. Zhenyu Zhang, Y ing Sheng, T ianyi Zhou, T ianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Y uandong T ian, Christopher R ´ e, Clark Barrett, et al. H 2 O: Heavy-hitter oracle for efficient generative infer ence of large language models. In Advances in Neural Information Processing Systems , volume 36, 2024. Huiqiang Zhu, Luo Li, Y uqing Y ang, Y ingfan Jiang, Jianfeng Qiu, et al. Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention. arXiv preprint arXiv:2407.02490 , 2024. 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment