The Scaffold Effect: How Prompt Framing Drives Apparent Multimodal Gains in Clinical VLM Evaluation
Trustworthy clinical AI requires that performance gains reflect genuine evidence integration rather than surface-level artifacts. We evaluate 12 open-weight vision-language models (VLMs) on binary classification across two clinical neuroimaging cohor…
Authors: Doan Nam Long Vu, Simone Balloccu
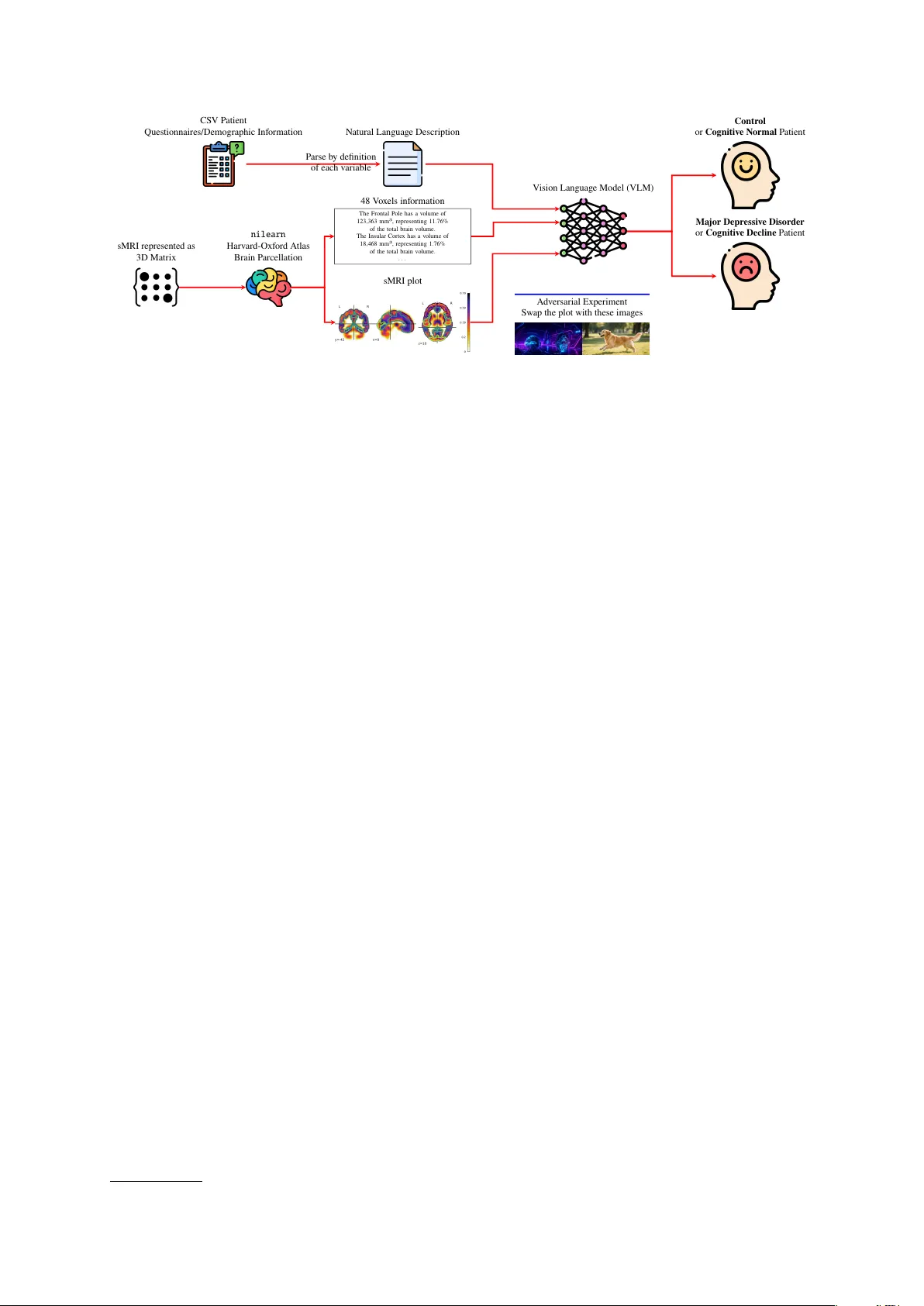
The Scaff old Effect: How Pr ompt Framing Driv es A pparent Multimodal Gains in Clinical VLM Evaluation Doan Nam Long V u, Simone Balloccu Natural Language Processing for Expert Domains (ExpNLP), T echnical Uni versity of Darmstadt Abstract T rustworthy clinical AI requires that perfor- mance gains reflect genuine evidence inte gra- tion rather than surface-lev el artifacts. W e ev al- uate 12 open-weight vision-language models (VLMs) on binary classification across two clin- ical neuroimaging cohorts, F O R 2 1 0 7 (affec- tiv e disorders) and OA S I S - 3 (cognitive de- cline). Both datasets come with structural MRI data that carries no reliable indi vidual- lev el diagnostic signal. Under these condi- tions, smaller VLMs exhibit gains of up to 58% F1 upon introduction of neuroimaging context, with distilled models becoming com- petitiv e with counterparts an order of magni- tude larger . A contrasti ve confidence analysis rev eals that merely mentioning MRI a v ailabil- ity in the task prompt accounts for 70-80% of this shift, independent of whether imaging data is present, a domain-specific instance of modal- ity collapse we term the scaffold ef fect . Expert ev aluation re veals fabrication of neuroimaging- grounded justifications across all conditions, and preference alignment, while eliminating MRI-referencing behavior , collapses both con- ditions to ward random baseline. Our findings demonstrate that surface ev aluations are in- adequate indicators of multimodal reasoning, with direct implications for the deployment of VLMs in clinical settings 1 . 1 Introduction The application of vision-language models to clin- ical decision-making has attracted growing inter - est, with recent work exploring their potential for diagnostic classification from multimodal patient data ( Moor et al. , 2023 ; Singhal et al. , 2023 ; Li et al. , 2023 ). A natural expectation is that pro- viding richer inputs should impro ve model perfor - mance, but only insof ar as the additional modalities supply r elevant diagnostic e vidence. While spuri- ous correlations and hallucination in VLMs hav e 1 https://github.com/long21wt/scaffold- effect recei ved growing attention ( Zhong et al. , 2024 ; Ho ward et al. , 2025 ), to our kno wledge no prior work has directly examined ho w models respond when a clinically r elated b ut diagnostically uninfor - mative modality is introduced alongside structured tabular data. This distinction matters: a model changing its beha viour upon receiving an uninfor- mati ve modality is not integrating evidence but responding to context, a failure mode that standard multimodal benchmarks are not designed to de- tect. W e inv estigate this using two clinical cohorts where prior w ork has established that neuroimaging markers carry no reliable indi vidual-lev el diagnos- tic signal ( W inter et al. , 2022 , 2024 ), and where we further exclude tri vially discriminati ve features in consultation with domain experts, ensuring models must reason rather than exploit shortcuts. Across 12 open-weight VLMs, smaller models exhibit substantial genuine, calibrated performance gains upon introduction of neuroimaging conte xt, with Qwen2.5-VL-3B ( Xu et al. , 2025 ) improving up to 58% F1 score, with distilled models becom- ing competitiv e with counterparts an order of mag- nitude larger . Y et these gains carry no diagnostic grounding: the overwhelming majority of the shift is dri ven by the te xtual mention of MRI av ailabil- ity alone, persisting e ven when the MRI visual- ization is replaced by an unrelated out-of-domain image. W e characterize this as a scaffold ef fect , a domain-specific instance of modality collapse ( Sim et al. , 2025 ; Parcalabescu and Frank , 2023 ) arising from a con v ergence of prompt sensiti vity ( Lu et al. , 2024 ; Ismithdeen et al. , 2025 ) and the priming ef- fect ( Jones and Steinhardt , 2022 ; Y oshida et al. , 2025 ) that produces confident, evidence-styled jus- tifications decoupled from actual diagnostic inputs. Critically , this vulnerability persists across model families and resists correction via preference align- ment, suggesting it reflects a structural property of ho w these models process domain-specific multi- modal prompts rather than an incidental artifact of 1 any single architecture. Our contributions are: • A systematic e valuation of 12 open-weight VLMs on F O R 2 1 0 7 ( Kircher et al. , 2019 ) and OA S I S - 3 ( LaMontagne et al. , 2019 ) across five input conditions, rev ealing genuine calibrated gains of up to 58% F1 gains not attributable to benchmark memorization. • A contrasti ve confidence analysis sho wing ≈ 70– 80% of the performance shift stems from textual priming, characterized as a scaf fold effect via phrase-le vel probe and false-modality ablation. • An e xpert case study with a clinical psychologist, sho wing that multimodal context measurably im- prov es reasoning trace quality , yet faithfulness remains belo w acceptable thresholds, indicating that gains are partly dri ven by confidence rather than e vidence-grounded inference. • Evidence that preference alignment via MPO which suppresses MRI-referencing behavior b ut induces symmetry-without-r ecovery , collapsing both conditions tow ard random baseline rather than selecti vely removing modality dependence. Our findings re veal the vulnerabilities in the relia- bility of VLMs for clinical diagnosis. W e demon- strate that surface ev aluations are fragile indicators of genuine multimodal reasoning and can exagger - ate a model’ s diagnostic ability . 2 Related W orks W e revie w related work on prompt sensiti vity , the priming effect and modality collapse in vision- language models (VLMs). 2.1 Prompt Sensiti vity in VLMs While prompt sensiti vity has been extensi vely stud- ied in large language models (LLMs) ( Ishibashi et al. , 2023 ; Lu et al. , 2024 ), it remains under- explored in VLMs. T o the best of our kno wl- edge, only Ismithdeen et al. ( 2025 ) hav e explicitly demonstrated that VLMs suf fer from sev ere prompt sensiti vity , a vulnerability that leads to inconsis- tent classification performance and a concerning reliance on language priors. In healthcare, sensiti vity to instruction phras- ing can se verely impact reliability: prompt v ari- ations cause F1 fluctuations of up to 0.25 in LLMs ( Ceballos-Arroyo et al. , 2024 ) and accu- racy variations of up to 6% in VLMs on health benchmarks ( Ismithdeen et al. , 2025 ). 2.2 Priming Effect in VLMs The priming effect is a cognitive phenomenon in which prior exposure to a stimulus influences sub- sequent judgments or behaviors, often without con- scious aw areness ( Meyer and Schv anev eldt , 1971 ). Rather than altering decision-making through ex- plicit alternati ve descriptions, priming operates by acti vating related concepts, associations, or re- sponse tendencies that shape how later inputs are interpreted ( K oo et al. , 2024 ). In the context of VLMs, priming in vision- language models refers to ho w prompts, both te x- tual and visual cues, shape model outputs, mirror - ing the priming concept from cogniti ve science. Y oshida et al. ( 2025 ) directly in v estigate this phe- nomenon in large-scale VLMs, demonstrating that model responses systematically shift in the direc- tion intended by an accompanying image, suggest- ing that VLMs activ ely incorporate visual informa- tion into language processing rather than treating it as incidental. Recent research has further re- vealed both the po wer and limitations of priming in adapting VLMs to ne w tasks and domains ( Jones and Steinhardt , 2022 ; K oo et al. , 2024 ). As these models increasingly incorporate multimodal inputs, such priming effects can be further intensified by interactions between te xtual and visual signals ( Gu- lati et al. , 2025 ; Zhang et al. , 2026 ). For instance, Zhang et al. ( 2026 ) sho w that in fact-checking set- tings, VLMs may fa vor pre viously introduced tex- tual conte xt o ver salient visual evidence, and re- lated behaviors have been observ ed in general VQA tasks ( Shu et al. , 2025 ). 2.3 Modality Collapse in VLMs Modality collapse refers to the phenomenon whereby a unimodal model achiev es comparable ac- curacy to a multimodal model on a vision-language task, rev ealing that one modality is not meaning- fully utilized ( Javalo y et al. , 2022 ; Parcalabescu and Frank , 2023 ). A recent survey by Sim et al. ( 2025 ) provides a systematic taxonomy of con- tributing f actors, including dataset bias, model be- havior , lack of fine-grained supervisory signal, and task setup, and re views methods for quantifying modality contribution and cross-modal interaction. A consistent finding across this literature is that the text modality dominates, with visual input failing to influence predictions e ven when it is ostensibly required by the task ( Zhu et al. , 2022 ). Our work moves from detection to diagnosis. 2 CS V P atient Ques tionnaires/Demog raphic Inf or mation nilearn Har v ard-Oxf ord A tlas Brain P arcellation sMRI represented as 3D Matr ix sMRI plot The Frontal P ole has a v olume of 123,363 mm ³ , representing 11.76% of the total brain v olume. The Insular Cor te x has a v olume of 18,468 mm ³ , representing 1.76% of the total brain v olume. . . . 48 V o x els inf or mation A dv ersar ial Exper iment Sw ap the plot with these imag es N atural Languag e Descr iption P arse b y definition of eac h v ar iable V ision Languag e Model (VLM) Contr ol or Cognitiv e N ormal P atient Ma jor Depr essiv e Disor der or Cognitiv e Decline P atient Figure 1: Ov erview of the proposed VLM pipeline. On F O R 2 1 0 7 and OA S I S - 3 we only change the label from MDD to Cognitiv e Decline and Control to Cogniti ve Normal. Prior modality collapse work establishes that te xt dominates, we instead identify whic h part of the tex- tual input triggers the collapse in a clinical setting, and sho w that con ventional suppression strate gies cannot disentangle the trigger from the model’ s broader inferential capacity . 3 Methodology Figure 1 illustrates our pipeline, inte grating two pri- mary data modalities: tabular clinical data (pro- vided in CSV format) and structural brain MRI (sMRI) scans. It comprises three sequential phases: (i) Clinical T abular Data Serialization, (ii) sMRI Information Extraction, and (iii) Multimodal Pre- diction, each described belo w . Clinical T abular Data Serialization W e seri- alize patient-lev el, which comes in CSV format, into natural language by mapping each v ariable’ s v alue to its corresponding clinical description. This tabular -to-text transformation has been shown to substantially improv e comprehension and reason- ing in language models ( He gselmann et al. , 2023 ; V u et al. , 2025 ). sMRI Information Extraction T1-weighted sMRI scans are typically stored as 3D volumes in .nii or .nii.gz format, with common dimen- sions of 256 × 256 × 176 - 208 vox els. W e utilize nilearn 2 , a widely used Python package for neu- roimaging research ( Kapoor and Egger , 2025 ; Gal- teau et al. , 2025 ), to both visualize these v olumes and extract re gional anatomical measurements via brain parcellation. W e extract re gional brain mea- surements using the Harv ard-Oxford probabilistic 2 https://github.com/nilearn/nilearn cortical atlas ( Rushmore et al. , 2022 ), which delin- eates 48 anatomical regions of interest. Per-re gion volumetric measurements are serialized into de- scripti ve text following the same approach as the tabular data. For visualization, we render three orthogonal slices (sagittal, coronal, axial) anno- tated with MNI coordinates, hemisphere labels, and vox el contour ov erlays. Multimodal Prediction The serialized text, par - cellation descriptions, and MRI visualizations are aggregated into a structured chat template and for - warded through a VLM for binary classification. The pipeline supports dynamic modality selection, enabling arbitrary combinations of input compo- nents to be included or ablated at inference time. W e ev aluate fi ve such configurations as described in Section 4 , with the full prompt template in Ap- pendix A . 4 Experiment Datasets W e e v aluate our pipeline on two clinical neuroimaging datasets: F O R 2 1 0 7 ( Kircher et al. , 2019 ) and O A S I S - 3 ( LaMontagne et al. , 2019 ), both of which provide paired structured clinical records and structural brain MRI. F O R 2 1 0 7 is a German multicenter cohort study focused on the neurobiology of affecti ve disor - ders ( Kircher et al. , 2019 ). It comprises pa- tients with Major Depressiv e Disorder (MDD) and matched healthy controls, with deep phenotyp- ing spanning structural MRI, clinical assessments, neuropsychological testing, and demographic in- formation. Prior work on this cohort using clas- sical ML pipelines found classification accura- cies of only 54–56% with univ ariate neuroimag- 3 Label Condition aCRF Pr ompt(MRI) Par cel. Image Image T ype C1 T E X T ( A R C F ) ✓ C2 T E X T ( A R C F ) + P RO M P T ( M R I ) ✓ ✓ C3 T E X T ( A R C F ) + P RO M P T ( M R I ) + P L OT ( M R I ) ✓ ✓ ✓ nilearn brain plot C4 T E X T ( A R C F , PA R C E L ) + P R O M P T ( M R I ) + P L O T ( M R I ) ✓ ✓ ✓ ✓ nilearn brain plot C5 T E X T ( A R C F , PA R C E L ) + P R O M P T ( M R I ) + P L O T ( S W A P ) ✓ ✓ ✓ ✓ OOD image (ablation) T able 1: Experimental conditions and their input components. Dataset Group / Status # Samples FOR2107 Activ e MDD 701 Control 1,071 O ASIS-3 Cognitiv e Decline 487 Cognitiv e Normal 849 T able 2: Class distrib ution of the clinical subsets used in this work. ing markers ( Winter et al. , 2022 ), and no infor- mati ve individual-le vel biomarker ev en under e x- tensi ve multi v ariate optimization across 4 million models ( W inter et al. , 2024 ), establishing that F O R 2 1 0 7 represents a genuinely hard classifi- cation problem where apparent VLM gains war- rant scrutiny . Our binary classification task distin- guishes active MDD from healthy contr ols . OA S I S - 3 is an open-access longitudinal dataset compiled from the W ashington University Knight Alzheimer Disease Research Center ( LaMontagne et al. , 2019 ). It includes participants ranging from cogniti vely normal adults to indi viduals at various stages of cognitiv e decline, accompanied by multi- modal MR sessions and clinical assessments. Our binary classification task distinguishes cognitive decline from cognitively normal participants. Both datasets are governed by strict data-use agreements prohibiting redistrib ution and requiring formal application for access. T o our kno wledge, neither has appeared in any NLP or VLM publi- cation, making contamination highly unlikely , a stronger control than benchmarks such as the 86- 160 sample subsets of Ceballos-Arroyo et al. ( 2024 ) or the 197 Health and Medicine examples ev aluated by Ismithdeen et al. ( 2025 ). Clinical v ariables are drawn from multiple CSV files, retaining the most recent value per participant. In consultation with domain experts in clinical psychology , we were suggested to exclude trivially discriminativ e fea- tures (e.g. suicidal thoughts) as they are strongly discriminati ve features that would make the task tri vial for the model. By removing them, we ensure that tested models must reason rather than pattern- match. T able 2 summarizes class distrib utions. W e refer to the full v ariable list in Appendix D . Models W e test 12 popular open weight V ision-Language Models: InternVL3.5-4B and 14B ( W ang et al. , 2025 ), GLM-4.1V-9B thinking ver- sion ( Hong et al. , 2025 ), GLM-4.6V-Flash ( Zeng et al. , 2025 ), LLaVA-OV-1.5-4B instruction ver - sion ( Li et al. , 2025 ), Ministral-3-3B and 14B instruction version ( Liu et al. , 2026 ), Qwen2.5-VL-3B , 32B and 72B instruction v er- sion ( Xu et al. , 2025 ), Qwen3-VL-2B and 32B ( Bai et al. , 2025 ). W e use all models implementation in HuggingFace T ransformers ( W olf et al. , 2020 ). For the checkpoints detail name, we refer to T a- ble 7 in the Appendix. In our experimental setup, we set do_sample=False to ensure deterministic, reproducible outputs across runs. T o contextualize model performance we report a stratified random baseline on F O R 2 1 0 7 and O A S I S - 3 . The deriv a- tion of random baseline is provided in Appendix F . Naming Scheme W e e v aluate fi ve conditions that progressi vely incorporate multimodal neuroimag- ing information into the pipeline, summarized in T able 1 . T E X T ( A R C F ) 3 consists of a te xtual repre- sentation of the patient metadata, usually collected in repeated sessions with the client by the clinical expert and used for diagnosis; P RO M P T ( M R I ) adds a mention of MRI data (brain parcellation volume, visualization of brain regions) in the used prompt; T E X T ( PA R C E L ) includes a te xtual representation of the brain parcellation data; P L OT ( M R I ) adds the MRI plot as image modality; P L OT ( S W A P ) replaces the brain plot with an out-of-distrib ution image (a dog photograph or styled sci-fi brain scan) to ablate whether performance depends on image content or image presence alone. 4.1 Experiments Results Figure 2 reports the F1 scores across all models and input conditions on OA S I S - 3 and F O R 2 1 0 7 . Se veral models fail to e xceed the random baseline 3 A R C F stands for "Annotated Case Report Forms", which are used in FOR2107. T o simplify the notation, we also adopted it for O ASIS-3 to describe the CSV -to-text baseline. 4 0 . 00 0 . 25 0 . 50 0 . 75 1 . 00 O ASIS-3 / F1 Score GLM-4.1V-9B GLM-4.6V-Flash LLaVA-OV-1.5-4B Ministral-3-14B Ministral-3-3B Qwen2.5-VL-32B Qwen2.5-VL-3B Qwen2.5-VL-72B Qwen3-VL-2B Qwen3-VL-32B InternVL3.5-14B InternVL3.5-4B 0 . 00 0 . 25 0 . 50 0 . 75 1 . 00 FOR2107 / F1 Score T E XT ( A R C F ) T E XT ( A R C F ) + P RO M P T ( M R I ) T E XT ( A R C F ) + P RO M P T ( M R I ) + P L OT ( M R I) T E XT ( A R C F , P A R C EL ) + P RO M P T ( M R I ) + P L OT ( M R I) T E XT ( A R C F , P A R C EL ) + P RO M P T ( M R I ) + P L OT ( S W A P ) Random baseline Figure 2: F1 Score on 2 datasets O ASIS-3 and FOR2107 ov er 5 dif ferent modes. Model δ T E XT ( A R C F ) + P RO M P T ( M R I ) ← TE X T ( A R C F ) δ T E XT ( A R C F , PA R C E L )+ P R OM P T ( M R I ) + P LO T ( MR I ) ← TE X T ( A R C F ) δ T E XT ( A R C F , PA R C E L )+ P R OM P T ( M R I ) + P LO T ( MR I ) ← TE X T ( A R C F ) + PR O M PT ( M R I ) Qwen2.5-VL-3B + 0 . 458 ± 0 . 379 + 0 . 636 ± 0 . 322 + 0 . 178 ± 0 . 277 Ministral-3-3B +0 . 215 ± 0 . 243 +0 . 295 ± 0 . 310 +0 . 080 ± 0 . 278 T able 3: Per -patient confidence shift δ in ˆ P ( MDD ) (mean ± std). Higher v alues indicate greater shift toward the correct MDD label. Bold indicates the best score. threshold under the T E X T ( A R C F ) condition, most strikingly on F O R 2 1 0 7 where Ministral-3-3B (0.064) and Qwen2.5-VL-3B (0.153) fall far belo w it, indicating that raw textual features alone are apparently insufficient for reliable diagnosis classi- fication in these models. Larger models dominate under text-only condi- tions, with Qwen2.5-VL-72B achie ving 0.786 and 0.849 F1 on OA S I S - 3 and F O R 2 1 0 7 respecti vely . This narrati ve in v erts once multimodal context en- ters: smaller models respond most dramatically , with Qwen2.5-VL-3B and Ministral-3-3B gain- ing +0 . 58 and +0 . 66 F1 on F O R 2 1 0 7 , while larger counterparts barely move. Larger models, already well-calibrated on tabular e vidence, appear less susceptible to framing effects. The swap image condition confirms this directly: replacing the MRI plot with an unrelated image preserv es the perfor- mance gain. Qualitativ e inspection further re veals that lar ger models also pr oduce MRI-r efer encing justifications despite stable F1, decoupling fabrica- tion from the performance signal entirely . 5 Confidence Estimation T o analyze this phenomenon beyond surface-le vel scores, we analyze the two models exhibiting the highest gains on F O R 2 1 0 7 : Qwen2.5-VL-3B and Ministral-3B . Since the two class labels di ver ge at the first generated token ( Major vs. Contr ol ), we extract the softmax probability at this single-token branching point to obtain a normalized confidence score ˆ P ( MDD ) for each patient, following the label-token probability e xtraction approach ( Zhao et al. , 2021 ; Geng et al. , 2024 ) (formal definition in Appendix I ). W e define the per-patient confi- dence shift δ between conditions as the dif ference in ˆ P ( MDD ) , enabling a contrastiv e analysis that disentangles prompt framing from actual MRI con- tent contribution. T able 3 reports the mean δ across both models. For both Qwen2.5-VL-3B and Ministral-3-3B , introducing the MRI prompt header alone already produces a substantial positiv e shift ( +0 . 458 and +0 . 215 respecti vely), indicating that the model’ s confidence in the MDD label increases before any 5 T E XT ( A R C F ) T E XT ( A R C F ) + P RO M P T ( M R I ) T E XT ( A R C F , PA R C E L ) + P RO M P T ( M R I ) + P L OT ( M R I ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 ˆ P ( MDD ) ± 1 SD Group mean Decision boundary (0.5) (a) Qwen2.5-VL-3B T E XT ( A R C F ) T E XT ( A R C F ) + P RO M P T ( M R I ) T E XT ( A R C F , PA R C E L ) + P RO M P T ( M R I ) + P L OT ( M R I ) 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 ˆ P ( MDD ) ± 1 SD Group mean Decision boundary (0.5) (b) Ministral-3-3B Figure 3: Group mean ˆ P ( MDD ) across the three input conditions. The black line and mark ers sho w the group mean per condition. The shaded band indicates ± 1 STD. The dashed line marks the decision boundary at 0 . 5 . imaging data is provided. Adding the full imag- ing content further increases this shift ( +0 . 636 and +0 . 295 ), though the mar ginal gain attrib utable to the MRI data itself remains modest ( +0 . 178 and +0 . 080 ). Qwen2.5-VL-3B exhibits a consis- tently larger response across all conditions, sug- gesting greater sensiti vity to both prompt framing and imaging content. In both models, the prompt framing ef fect accounts for the majority of the to- tal shift, approximately 70%, raising the question of whether the observed confidence gains reflect primarily a response to contextual priming. Figure 3 confirms this pattern. For Qwen2.5-VL-3B , mean baseline confidence is near zero and both subsequent conditions produce a sharp monotonic increase, with a narro w standard-de viation band indicating consistency across patients rather than outlier-dri ven shift. Ministral-3B-Instruct sho ws the same direc- tional trend with wider spread, consistent with its smaller δ v alues. 6 Expert Case Study of Reasoning T races T o assess whether the large F1 gains from multi- modal context reflect genuine clinical understand- ing or priming-induced confabulation, we con- ducted a human expert case study of reasoning traces generated by Qwen2.5-VL-3B , the model ex- hibiting the most dramatic performance shift. Evaluation protocol W e sampled 12 predic- tions per class (MDD vs. Control) from the F O R 2 1 0 7 dataset under two conditions: the base- line T E X T ( A R C F ) , which receives only the serial- ized clinical record, and the full multimodal con- dition T E X T ( A R C F , PA R C E L ) + P R O M P T ( M R I ) + P L O T ( M R I ) , which additionally incorporates brain parcellation text and a nilearn -generated MRI vi- sualization, yielding 24 reasoning traces per con- dition (48 total). A clinical psychologist ev aluated each trace on three criteria (F aithfulness, Clinical Accuracy & Safety , Diagnostic Reasoning) on a 4- point Lik ert scale. W e refer to the full rubric scores in Appendix H . Results T able 4 reports results for each criterion across the four ev aluated groups. The traces pro- duced under the full multimodal condition (Groups 2 and 3) consistently score higher across all three dimensions compared to the baseline condition (Groups 0 and 1), suggesting that the additional neuroimaging context does contrib ute to more co- herent and clinically grounded outputs. Notably , Control predictions under the full multimodal con- dition (Group 2) achiev e the highest faithfulness ( 2 . 79 ± 0 . 98 ) and diagnostic reasoning ( 2 . 96 ± 0 . 91 ) scores, while MDD predictions under the baseline (Group 1) receive the lo west scores o verall ( 2 . 08 , 2 . 17 , and 2 . 17 respecti vely), showing that with- out neuroimaging context, the model struggles to produce meaningful justifications for the more di- agnostically complex class. Critically , ev en the best-scoring groups remain belo w 3 . 0 on average across all criteria. Faith- fulness in particular shows moderate fabrication across all conditions, indicating that the model of- ten introduces un verified clinical details into its reasoning traces e ven when multimodal conte xt is av ailable. This finding tempers the interpretation of the large F1 gain: while richer inputs produce mea- surably better reasoning quality , the gap between human-rated faithfulness and classification perfor - mance suggests that a portion of the impro vement may still be attrib utable to priming-induced confi- dence rather than e vidence-grounded inference. 6 Grp. Cond., Class Faith. ↑ Clin. Acc. ↑ Reasoning ↑ 0 C1, Control 2 . 17 ± 1 . 09 2 . 25 ± 0 . 90 2 . 46 ± 1 . 10 1 C1, MDD 2 . 08 ± 0 . 88 2 . 17 ± 0 . 92 2 . 17 ± 0 . 92 2 C4, Control 2 . 79 ± 0 . 98 2 . 63 ± 0 . 82 2 . 96 ± 0 . 91 3 C4, MDD 2 . 83 ± 0 . 92 2 . 46 ± 0 . 83 2 . 83 ± 0 . 87 T able 4: Expert scores (Mean ± Std) of Qwen2.5-VL-3B reasoning traces rated by a clinical psychologist on a 4-point Likert scale ( n = 12 per group, F O R 2 1 0 7). Bold indicates the best score and underlined indicates the worst score in each metric column. See T able 1 for notation description. 7 Scaff old Effect While modality collapse is well documented ( Sim et al. , 2025 ), we did not find work in literature exploring the specific trigger mechanism we ob- served. Section 5 shows that prompt framing ac- counts for the majority of the observed perfor- mance shift. W e now ask what class of inputs is sufficient to trigger this effect, and whether it is specific to the e xact preamble wording used in our pipeline. W e first characterize the effect on Qwen2.5-VL-3B from F O R 2 1 0 7 , then v alidate the findings on Ministral-3-3B and O A S I S - 3 via an ablation. For formal details we refer to Appendix J . Phrase probe W e construct a set of candidate preamble phrases spanning six semantic cate gories: MRI/neur oimaging , gener al clinical, authoritative framing , neutr al, structural/format, and ne gation (full list in T able 8 of Appendix J ), and ev alu- ate each as a probe replacement for the original P R O M P T ( M R I ) on F O R 2 1 0 7 MDD patients using Qwen2.5-VL-3B , measuring ho w much each phrase shifts ˆ P ( MDD ) relati ve to the T E X T ( A R C F ) base- line. T o characterize alignment with the original preamble ef fect in the model’ s internal representa- tions, we additionally compute the cosine similarity of each phrase’ s induced hidden-state shift to that of the original MRI preamble. Figure 4 plots both quantities jointly . The relationship can be described approximately by an in verse sigmoid curve (Ap- pendix J ), consistent with the ef fect operating as a linear of fset in representation space passed through the model’ s output nonlinearity . MRI and neuroimaging phrases cluster strongly in the top-right quadrant, confirming that the ef- fect is reliably activ ated by neuroimaging-adjacent language. Phrases outside this category , includ- ing authoritative framings and explicit pathology primes, fall near or below zero on both axes, in- dicating that the trigger is specific to the modality − 0 . 6 − 0 . 4 − 0 . 2 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 Cosine similarity to scaffold direction − 0 . 2 − 0 . 1 0 . 0 0 . 1 0 . 2 0 . 3 δ MRI / neuroimaging Neutral / unrelated General clinical Structural / format Authoritative framing Figure 4: Cosine similarity to the scaffold direction vs. δ T E X T ( A R C F ) + P RO M P T ← T E X T ( A R C F ) for candidate phrases across se- mantic categories, e v aluated on Qwen2.5-VL-3B ov er the F O R 2 1 0 7 cohort. Phrases in the top-right quad- rant acti v ate the same residual-stream direction as T E X T ( A R C F ) + P R O M P T ( M R I ) without providing any imaging data. announcement r e gister rather than to clinical au- thority or symptom description in general. F alse-modality ablation T o confirm that the trig- ger is purely surface-le vel and generalizes be- yond the model and dataset used in the phrase probe, we construct two conditions: a factually false fMRI a v ailability without providing any imag- ing, and a semantically irrelev ant weather con- text preamble serving as a non-clinical null con- dition. W e e v aluate both on Qwen2.5-VL-3B and Ministral-3-3B across both F O R 2 1 0 7 and OA S I S - 3. T able 5 sho ws that on F O R 2 1 0 7 , the fMRI preamble alone achiev es F1 = 0.702 and 0.361 for Qwen2.5-VL-3B and Ministral-3-3B respecti vely , recov ering most of the gain observed under the full multimodal condition, while the weather preamble collapses performance to near or belo w the text-only baseline (0.056 and 0.031). The contrast replicates on OA S I S - 3, where the weather condition consistently underperforms the fMRI preamble across both models. This confirms that the effect generalizes across model families and clinical domains: models acquired a strong prior associating neuroimaging a vailability announce- ments with a shifted pathway , which is entirely absent when the preamble is clinically irrelev ant, regardless of whether imaging data is pro vided. 8 Prefer ence Lear ning The model frequently grounded predictions in MRI- deri ved or brain-parcellation features e ven when those features were absent or uninformativ e, a fail- ure mode confirmed by domain experts. T o sup- press this behavior , we apply alignment via Direct 7 Mode Input Condition F O R 2 1 0 7 OA S I S - 3 Qwen2.5-VL-3B Ministral-3B Qwen2.5-VL-3B Ministral-3B C1 T E X T ( A C R F ) 0.153 0.064 0.262 0.504 C2 T E X T ( A C R F ) + P RO M P T ( M R I ) 0.728 0.480 0.589 0.541 C2 † T E X T ( A C R F ) + P RO M P T ( F M R I ) 0.702 0.361 0.379 0.569 C2 ‡ T E X T ( A C R F ) + P RO M P T ( W E AT H E R ) 0.056 0.031 0.148 0.425 T able 5: Scaf fold ablation F1 scores across conditions. Bold indicates best score per model per cohort. Condition Befor e MPO ↑ After MPO ↑ C1 0.153 0.459 C2 0.728 0.496 C4 0.728 0.477 T able 6: F1 of Qwen2.5-VL-3B on F O R 2 1 0 7 before and after MPO. Random baseline F1 = 0.52. Bold indi- cates the best score. See T able 1 for notation description. Preference Optimization (DPO) ( Rafailov et al. , 2023 ) in its multimodal e xtension, Mixed Prefer- ence Optimization (MPO) ( W ang et al. , 2024 ). Dataset construction W e construct a preference dataset from the OA S I S - 3 using the outputs of the 12 models described in Section 4 . Each sample belongs to one of three input modes: T E X T ( A R C F ) , T E X T ( A R C F ) + P R O M P T ( M R I ) , T E X T ( A R C F , PA R - C E L ) + P R O M P T ( M R I ) + P L O T ( M R I ) . For ev- ery subject, we define the c hosen response as the T E X T ( A R C F ) mode output of any model that pre- dicted the correct label, and the r ejected response as any output, from any mode, whose te xt explic- itly mentions MRI findings, brain parcellation, or related neuroimaging language. The final dataset comprises 17202 preference pairs balanced across the two tar get classes: Cognitive Normal and Cog- nitive Decline ( ≈ 50% each). Fine-tuning W e fine-tune Qwen2.5-VL-3B using MPO, training detailed are reported in Appendix K . Parameter -ef ficient fine-tuning is performed via Lo w-Rank Adaptation (LoRA) ( Hu et al. , 2022 ), targeting all attention projection and feed-forward layers. T raining ran for approximately 12 hours on a single NVIDIA H200 GPU. Evaluation and Results W e ev aluate the trained models on F O R 2 1 0 7 to av oid contamination and nai ve improv ements deri ving from finetuning, as the preference dataset was constructed from OA S I S - 3 outputs. T able 6 compares pre- and post-alignment F1 on F O R 2 1 0 7 . Preference align- ment has opposite effects on the two ev aluation modes. In the text-only setting, performance im- prov es substantially ( 0 . 153 → 0 . 459 , +0 . 306 ). In the full multimodal setting, performance drops ( 0 . 728 → 0 . 477 , − 0 . 251 ). This pattern is consis- tent with the prompt-conditioned reasoning mode identified in our contrasti ve analysis: the unaligned model’ s strong multimodal performance was pri- marily dri ven by the preamble-acti vated deeper inference pathway , not by genuine inte gration of neuroimaging e vidence. Preference alignment sup- presses this pathway by collapsing both conditions to ward a common lev el rather than selectively re- moving the dependence on irrele v ant modalities. Crucially , the aligned model no longer produces outputs that reference MRI findings or brain par- cellation, satisfying the primary objecti ve of this intervention. Ho wev er , both modes con v erge near the random baseline of 0.52 F1, exhibiting what we term a symmetry-without-r ecovery ef fect: the modality gap closes not by lifting the weaker condi- tion but by suppressing the stronger one. This sug- gests that the prompt-conditioned reasoning mode is entangled with the model’ s capacity for care- ful clinical inference, and lightweight preference alignment cannot disentangle the two. 9 Conclusion W e have shown that clinical neuroimaging clas- sification via VLMs exhibits a domain-specific instance of modality collapse: they achiev e gen- uine, calibrated performance gains upon introduc- tion of multimodal context. The improvement is attributable to a scaffold effect : a learned sur- face trigger specific to neuroimaging language acti vates a shifted inference pathway . This hap- pens regardless of whether imaging data is present, confirmed through a phrase-le v el probe and false- modality ablation across model families and clini- cal domains. Expert ev aluation re veals fabrication of neuroimaging-grounded justifications across all conditions. Preference alignment via MPO, while eliminating MRI-referencing behavior , col- 8 lapses both conditions to ward chance le vel rather than selecti vely remo ving modality dependence, a symmetry-without-r ecovery ef fect suggesting the scaf fold is entangled with the model’ s inferential capacity . These findings call for ev aluation pro- tocols that explicitly probe the causal relationship between input content and model outputs before VLMs are deployed in high-stakes clinical settings. Limitations Due to data gov ernance constraints, our experi- ments are limited to open-weight models with a maximum of 72 billion parameters, and we bench- mark only 12 models across tw o binary classifica- tion datasets. This may limit generalizability to closed systems, lar ger scales, and multi-class set- tings. While the two cohorts span distinct clinical domains, af fectiv e disorders and cognitiv e decline, both in volve binary classification o ver structured tabular records paired with structural MRI, and it remains an open question whether the scaf fold ef- fect generalizes to other imaging modalities, such as fMRI or PET , or to tasks with richer label spaces where the decision boundary is less discrete. Our contrasti v e confidence analysis is conducted on the two models e xhibiting the highest gains on F O R 2 1 0 7 , and the 70-80% estimate of prompt framing contrib ution should be interpreted in this context, as it may not hold uniformly across the full model set. Furthermore, F1 differences between conditions are not accompanied by significance tests, and future work should establish whether the observed margins are statistically reliable across repeated sampling and dataset splits. Our expert case study relies on a single clinical psychologist. Recruiting qualified annotators for this task is non-tri vial: ev aluating VLM reasoning traces against patient-le vel clinical records requires both domain expertise and familiarity with the spe- cific instruments used in F O R 2 1 0 7 , a combina- tion that se verely constrains the a v ailable annotator pool. W e therefore treat Section 6 as a qualitati ve expert case study rather than a definitive quanti- tati ve ev aluation. While the directional patterns across conditions are consistent and interpretable, the absolute scores should be re garded as indicati v e rather than definiti ve, and future work with multi- ple independent raters w ould be needed to establish reliable ef fect sizes for reasoning trace quality . Our preference alignment via MPO successfully suppresses MRI-referencing behavior b ut does not produce factually correct reasoning traces. Con- structing a preference dataset that rewards gen- uinely e vidence-grounded inference would require annotated traces from clinical psychologists, which is costly and not yet av ailable at the scale needed for robust fine-tuning. More fundamentally , the re- sults suggest that the ef fect is deeply entangled with the model’ s broader inferential capacity , and that lightweight post-hoc alignment cannot disentangle the two. Whether alternativ e strategies, such as su- pervised in v ariance training, modality dropout dur- ing pretraining, or causal intervention objectiv es, could decouple the scaf fold trigger from genuine multimodal reasoning remains an open question. Finally , while we take care to exclude tri vially discriminati ve features in consultation with domain experts, the serialization of tabular clinical records into natural language may itself introduce subtle presentation biases that influence model beha vior . The interaction between tabular serialization format and prompt framing effects is not systematically explored here and warrants dedicated in v estigation. Ethics Statement This study uses two clinical datasets go verned by strict data-use agreements. F O R 2 1 0 7 data access was granted under the consortium’ s institutional re view protocol, which requires formal applica- tion and prohibits redistribution to third parties. OA S I S - 3 is av ailable through a controlled-access application process administered by the W ashing- ton Uni versity Knight ADRC, subject to a data-use agreement that similarly prohibits redistribution. No indi vidually identifiable patient information is presented in this work. All reported results are aggregate statistics computed o ver the full cohort. The study on reasoning traces was conducted by a qualified clinical psychologist who re vie wed only model-generated outputs. No patient-facing clinical decisions were made on the basis of model predictions, and no real patient data w as exposed beyond what is already accessible under the rele- v ant data-use agreements. W e emphasize that the VLM outputs analyzed in this study are not suitable for clinical deplo yment. Models achiev e genuine performance gains that nonetheless carry no diagnostic grounding, fabri- cate neuroimaging-grounded justifications with per- sistent regularity , and cannot be straightforwardly corrected through preference alignment without collapsing overall predicti ve capacity . The gap 9 between surface classification performance and e vidence-grounded inference is precisely the vul- nerability this work seeks to expose. Any future application of VLMs in clinical psychiatry or neu- rology must incorporate rigorous prospecti ve v al- idation by domain experts, with ev aluation proto- cols that explicitly probe the causal relationship between input e vidence and model outputs, before any patient-f acing use is considered. Acknowledgments This work is funded by LOEWE Center D YNAMIC as part of the Hessian pro- gram for the promotion of cutting-edge re- search LOEWE under the grant number of LOEWE1/16/519/03/09.001(0009)/98. W e thank our colleagues at UKPLab, TU Darmstadt for the technical discussion at AI4Psych, SIG Clinical/Psych, SIG Multimodal, SIG F oundation Models, SIG LLM Understanding and Inter- pretability meetings, and colleagues from the Uni versity of Marburg and colleagues from the Uni versity of Frankfurt for the clinical discussion. References Shuai Bai, Y uxuan Cai, Ruizhe Chen, K eqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, W ei Ding, Chang Gao, Chunjiang Ge, and 1 others. 2025. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 . Alberto Mario Ceballos-Arroyo, Monica Munnangi, Ji- uding Sun, Karen Zhang, Jered McInerney , Byron C. W allace, and Silvio Amir . 2024. Open (clinical) LLMs are sensiti ve to instruction phrasings . In Pr o- ceedings of the 23rd W orkshop on Biomedical Nat- ural Language Pr ocessing , pages 50–71, Bangkok, Thailand. Association for Computational Linguistics. Marie E. Galteau, Margaret Broadwater , Y i Chen, Gabriel Desrosiers-Gregoire, Rita Gil, Johannes Kaesser , Eugene Kim, Pervin Kırya ˘ gdı, Henriette Lambers, Y anyan Y . Liu, Xavier López-Gil, Eilidh MacNicol, Parastoo Mohebkhodaei, Ricardo X.N. De Oli veira, Carolina A. Pereira, Henning M. Reimann, Alejandro Riv era-Olvera, Erw an Selingue, Nikoloz Sirmpilatze, and 32 others. 2025. Ac- tiv ation mapping in multi-center retrospecti ve rat sensory-ev oked functional mri datasets using a uni- fied pipeline . Imaging Neur oscience , 3:IMA G.a.157. Jiahui Geng, Fengyu Cai, Y uxia W ang, Heinz K oeppl, Preslav Nako v , and Iryna Gurevych. 2024. A sur - ve y of confidence estimation and calibration in large language models . In Pr oceedings of the 2024 Con- fer ence of the North American Chapter of the Asso- ciation for Computational Linguistics: Human Lan- guage T echnolo gies (V olume 1: Long P apers) , pages 6577–6595, Mexico City , Mexico. Association for Computational Linguistics. Mor Gev a, A vi Caciularu, Ke vin W ang, and Y oav Gold- berg. 2022. Transformer feed-forward layers build predictions by promoting concepts in the vocab ulary space . In Pr oceedings of the 2022 Conference on Empirical Methods in Natural Language Pr ocess- ing , pages 30–45, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics. Aditya Gulati, Moreno D’Incà, Nicu Sebe, Bruno Lepri, and Nuria Oliv er . 2025. Beauty and the bias: Explor- ing the impact of attracti veness on multimodal lar ge language models . Pr oceedings of the AAAI/ACM Confer ence on AI, Ethics, and Society , 8(2):1154– 1168. Stefan He gselmann, Alejandro Buendia, Hunter Lang, Monica Agra wal, Xiaoyi Jiang, and David Sontag. 2023. T abllm: Fe w-shot classification of tabular data with large language models. In International Confer ence on Artificial Intelligence and Statistics , pages 5549–5581. PMLR. W enyi Hong, W enmeng Y u, Xiaotao Gu, Guo W ang, Guobing Gan, Haomiao T ang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, and 1 others. 2025. Glm-4.5 v and glm-4.1 v-thinking: T ow ards versatile multi- modal reasoning with scalable reinforcement learn- ing. arXiv preprint . Phillip How ard, Kathleen C. Fraser , Anahita Bhiwandi- walla, and Sv etlana Kiritchenko. 2025. Uncovering bias in large vision-language models at scale with counterfactuals . In Pr oceedings of the 2025 Confer - ence of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language T echnologies (V olume 1: Long P apers) , pages 5946–5991, Albuquerque, Ne w Mexico. Asso- ciation for Computational Linguistics. Edward J Hu, yelong shen, Phillip W allis, Zeyuan Allen- Zhu, Y uanzhi Li, Shean W ang, Lu W ang, and W eizhu Chen. 2022. LoRA: Low-rank adaptation of large language models . In International Confer ence on Learning Repr esentations . Y oichi Ishibashi, Danushka Bollegala, Katsuhito Su- doh, and Satoshi Nakamura. 2023. Evaluating the robustness of discrete prompts . In Pr oceedings of the 17th Confer ence of the Eur opean Chapter of the As- sociation for Computational Linguistics , pages 2373– 2384, Dubrovnik, Croatia. Association for Computa- tional Linguistics. Mohamed Insaf Ismithdeen, Muhammad Uzair Khattak, and Salman Khan. 2025. Promptception: How sen- sitiv e are large multimodal models to prompts? In F indings of the Association for Computational Lin- guistics: EMNLP 2025 , pages 23950–23985, Suzhou, China. Association for Computational Linguistics. Adrian Jav aloy , Maryam Meghdadi, and Isabel V alera. 2022. Mitigating modality collapse in multimodal 10 V AEs via impartial optimization. In Pr oceedings of the 39th International Confer ence on Machine Learning , volume 162 of Pr oceedings of Machine Learning Resear ch , pages 9938–9964. PMLR. Erik Jones and Jacob Steinhardt. 2022. Capturing fail- ures of large language models via human cognitiv e biases . In Advances in Neural Information Pr ocess- ing Systems . Shreya Kapoor and Bernhard Egger . 2025. Computer graphics from a neuroscientist’ s perspecti ve . In Second W orkshop on Representational Alignment at ICLR 2025 . T ilo Kircher , Markus Wöhr , Igor Nenadic, Rainer Schwarting, Gerhard Schratt, Judith Alferink, Carsten Culmsee, Holger Garn, T im Hahn, Bertram Müller-Myhsok, Astrid Dempfle, Maik Hahmann, Andreas Jansen, Petra Pfefferle, Harald Renz, Mar- cella Rietschel, Stephanie H Witt, Markus Nöthen, Axel Krug, and Udo Dannlowski. 2019. Neurobiol- ogy of the major psychoses: a translational perspec- tiv e on brain structure and function—the FOR2107 consortium. Eur opean Ar chives of Psychiatry and Clinical Neur oscience , 269(8):949–962. Ryan K oo, Minhwa Lee, V ipul Raheja, Jong Inn P ark, Zae Myung Kim, and Dongyeop Kang. 2024. Bench- marking cogniti ve biases in large language models as ev aluators . In F indings of the Association for Com- putational Linguistics: ACL 2024 , pages 517–545, Bangkok, Thailand. Association for Computational Linguistics. Lorenz Kuhn, Y arin Gal, and Sebastian Farquhar . 2023. Semantic uncertainty: Linguistic in variances for un- certainty estimation in natural language generation . In The Eleventh International Confer ence on Learn- ing Repr esentations . Pamela J. LaMontagne, T ammie LS. Benzinger, John C. Morris, Sarah Keefe, Russ Hornbeck, Chengjie Xiong, Elizabeth Grant, Jason Hassenstab, Krista Moulder , Andrei G. Vlassenko, Marcus E. Raichle, Carlos Cruchaga, and Daniel Marcus. 2019. Oasis- 3: Longitudinal neuroimaging, clinical, and cogni- tiv e dataset for normal aging and alzheimer disease . medRxiv . Bo Li, Y uanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Y an- wei Li, Ziwei Liu, and Chunyuan Li. 2025. LLaV A- onevis ion: Easy visual task transfer . T ransactions on Machine Learning Resear c h . Chunyuan Li, Cliff W ong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Y ang, Tristan Nau- mann, Hoifung Poon, and Jianfeng Gao. 2023. LLaV A-med: T raining a large language-and-vision assistant for biomedicine in one day . In Thirty- seventh Confer ence on Neur al Information Pr ocess- ing Systems Datasets and Benchmarks T rack . Alexander H Liu, Kartik Khandelwal, Sandeep Sub- ramanian, V ictor Jouault, Abhinav Rastogi, Adrien Sadé, Alan Jef fares, Albert Jiang, Alexandre Cahill, Alexandre Ga v audan, and 1 others. 2026. Ministral 3. arXiv preprint . Sheng Lu, Hendrik Schuf f, and Iryna Gure vych. 2024. How are prompts different in terms of sensiti vity? In Pr oceedings of the 2024 Confer ence of the North American Chapter of the Association for Computa- tional Linguistics: Human Language T echnologies (V olume 1: Long P apers) , pages 5833–5856, Mexico City , Mexico. Association for Computational Lin- guistics. David E. Me yer and Roger W . Schvane veldt. 1971. Fa- cilitation in recognizing pairs of words: evidence of a dependence between retrie val operations. Journal of experimental psyc hology , 90 2:227–34. Michael Moor , Oishi Banerjee, Zahra Shakeri Hossein Abad, Harlan M. Krumholz, Jure Leskovec, Eric J. T opol, and Prana v Rajpurkar . 2023. Foundation mod- els for generalist medical artificial intelligence . Na- tur e , 616(7956):259–265. Letitia Parcalabescu and Anette Frank. 2023. MM- SHAP: A performance-agnostic metric for measur- ing multimodal contributions in vision and language models & tasks . In Pr oceedings of the 61st Annual Meeting of the Association for Computational Lin- guistics (V olume 1: Long P apers) , pages 4032–4059, T oronto, Canada. Association for Computational Lin- guistics. Rafael Rafailo v , Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Y our language model is secretly a re ward model . In Thirty-seventh Confer ence on Neural Information Pr ocessing Sys- tems . R. Jarrett Rushmore, K yle Sunderland, Holly Carring- ton, Justine Chen, Michael Halle, Andras Lasso, G. Papadimitriou, N. Prunier , Elizabeth Rizzoni, Brynn V essey , Peter W ilson-Braun, Y ogesh Rathi, Marek Kubicki, Sylvain Bouix, Edw ard Y eterian, and Nikos Makris. 2022. Anatomically curated segmen- tation of human subcortical structures in high resolu- tion magnetic resonance imaging: An open science approach . F r ontiers in Neur oanatomy , V olume 16 - 2022. Y an Shu, Hangui Lin, Y exin Liu, Y an Zhang, Gangyan Zeng, Y an Li, Y u ZHOU, Ser-Nam Lim, Harry Y ang, and Nicu Sebe. 2025. When semantics mislead vi- sion: Mitigating lar ge multimodal models hallucina- tions in scene text spotting and understanding . In The Thirty-ninth Annual Conference on Neur al Infor- mation Pr ocessing Systems . Mong Y uan Sim, W ei Emma Zhang, Xiang Dai, and Biaoyan F ang. 2025. Can VLMs actually see and read? a surve y on modality collapse in vision- language models . In F indings of the Association for Computational Linguistics: ACL 2025 , pages 24452–24470, V ienna, Austria. Association for Com- putational Linguistics. 11 Karan Singhal, Shekoofeh Azizi, T ao T u, S. Sara Mahdavi, Jason W ei, Hyung W on Chung, Nathan Scales, Ajay T anwani, Heather Cole-Le wis, Stephen Pfohl, Perry Payne, Martin Seneviratne, Paul Gam- ble, Chris Kelly , Abubakr Babiker , Nathanael Schärli, Aakanksha Cho wdhery , Philip Mansfield, Dina Demner-Fushman, and 13 others. 2023. Large lan- guage models encode clinical kno wledge . Natur e , 620(7972):172–180. Doan Nam Long V u, Rui T an, Lena Moench, Svenja Jule Francke, Daniel W oiwod, Florian Thomas-Odenthal, Sanna Stroth, T ilo Kircher , Chris- tiane Hermann, Udo Dannlowski, and 1 others. 2025. Roleplaying with structure: Synthetic therapist-client con versation generation from questionnaires. arXiv pr eprint arXiv:2510.25384 . W eiyun W ang, Zhe Chen, W enhai W ang, Y ue Cao, Y angzhou Liu, Zhangwei Gao, Jinguo Zhu, Xizhou Zhu, Lewei Lu, Y u Qiao, and 1 others. 2024. En- hancing the reasoning ability of multimodal large language models via mixed preference optimization. arXiv pr eprint arXiv:2411.10442 . W eiyun W ang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang W ei, Zhaoyang Liu, Linglin Jing, Shenglong Y e, Jie Shao, and 1 others. 2025. In- tern vl3. 5: Adv ancing open-source multimodal mod- els in versatility , reasoning, and efficienc y . arXiv pr eprint arXiv:2508.18265 . Nils R W inter , Julian Blanke, Ramona Leenings, Jan Ernsting, Lukas Fisch, K elvin Sarink, Car- lotta Barkhau, Daniel Emden, Katharina Thiel, Kira Flinkenflügel, Ale xandra W inter , Janik Goltermann, Susanne Meinert, Katharina Dohm, Jonathan Rep- ple, Marius Gruber , Elisabeth J Leehr , Nils Opel, Dominik Grotegerd, and 26 others. 2024. A system- atic ev aluation of machine Learning-Based biomark- ers for major depressi ve disorder . J AMA Psychiatry , 81(4):386–395. Nils R W inter , Ramona Leenings, Jan Ernsting, K elvin Sarink, Lukas Fisch, Daniel Emden, Julian Blanke, Janik Goltermann, Nils Opel, Carlotta Barkhau, Su- sanne Meinert, Katharina Dohm, Jonathan Repple, Marco Mauritz, Marius Gruber, Elisabeth J Leehr , Dominik Grotegerd, Ronn y Redlich, Andreas Jansen, and 12 others. 2022. Quantifying deviations of brain structure and function in major depressiv e disorder across neuroimaging modalities. JAMA Psyc hiatry , 79(9):879–888. Thomas W olf, L ysandre Debut, V ictor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pier- ric Cistac, T im Rault, Remi Louf, Mor gan Funto wicz, Joe Davison, Sam Shleifer , P atrick von Platen, Clara Ma, Y acine Jernite, Julien Plu, Canwen Xu, T e ven Le Scao, Sylvain Gugger , and 3 others. 2020. T rans- formers: State-of-the-art natural language processing . In Pr oceedings of the 2020 Confer ence on Empirical Methods in Natural Language Pr ocessing: System Demonstrations , pages 38–45, Online. Association for Computational Linguistics. Y iheng Xu, Peng W ang, Hang Zhang, Pengfei W ang, Shuai Bai, Shijie W ang, Junyang Lin, T ianbao Xie, Y uanzhi Zhu, Zhibo Y ang, W ei Ding, Xi Zhang, Jianqiang W an, Jun T ang, Haiyang Xu, Jiabo Y e, Keqin Chen, Xuejing Liu, Jialin W ang, and 8 oth- ers. 2025. Qwen2.5-vl technical report . Pr eprint , Daiki Y oshida, Haruki Sakajo, Kazuki Hayashi, Y usuke Sakai, Hidetaka Kamigaito, Katsuhiko Hayashi, and T aro W atanabe. 2025. V isual priming ef fect on large- scale vision language models . In Pr oceedings of the 15th International Conference on Recent Advances in Natural Language Pr ocessing - Natural Languag e Pr ocessing in the Generative AI Era , pages 1385– 1395, V arna, Bulgaria. INCOMA Ltd., Shoumen, Bulgaria. Aohan Zeng, Xin Lv , Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang W ang, Da Y in, Hao Zeng, Jiajie Zhang, and 1 others. 2025. Glm-4.5: Agentic, reasoning, and coding (arc) foundation mod- els. arXiv preprint . Chi Zhang, W enxuan Ding, Jiale Liu, Mingrui W u, Qingyun W u, and Ray Moone y . 2026. Do images speak louder than words? in v estigating the effect of textual misinformation in vlms. arXiv pr eprint arXiv:2601.19202 . Zihao Zhao, Eric W allace, Shi Feng, Dan Klein, and Sameer Singh. 2021. Calibrate before use: Improv- ing fe w-shot performance of language models . In Pr oceedings of the 38th International Confer ence on Machine Learning , v olume 139 of Pr oceedings of Machine Learning Resear ch , pages 12697–12706. PMLR. W eihong Zhong, Xiaocheng Feng, Liang Zhao, Qim- ing Li, Lei Huang, Y uxuan Gu, W eitao Ma, Y uan Xu, and Bing Qin. 2024. In vestigating and miti- gating the multimodal hallucination sno wballing in large vision-language models . In Pr oceedings of the 62nd Annual Meeting of the Association for Compu- tational Linguistics (V olume 1: Long P apers) , pages 11991–12011, Bangkok, Thailand. Association for Computational Linguistics. W anrong Zhu, Y uankai Qi, Pradyumna Narayana, Ka- zoo Sone, Sugato Basu, Xin W ang, Qi W u, Miguel Eckstein, and W illiam Y ang W ang. 2022. Diagnosing vision-and-language navigation: What really matters . In Pr oceedings of the 2022 Confer ence of the North American Chapter of the Association for Computa- tional Linguistics: Human Language T echnologies , pages 5981–5993, Seattle, United States. Association for Computational Linguistics. A Prompt Prompts that are used in our paper (Figure 5 , 6 for F O R 2 1 0 7 ), (Figure 7 , 8 for O ASIS-3) 12 Abbr eviation Checkpoint (Link to HF) GLM-4.1V-9B zai-org/GLM-4.1V-9B-Thinking GLM-4.6V-Flash zai-org/GLM-4.6V-Flash LLaVA-OV-1.5-4B lmms-lab/LLaVA-OneVision-1.5-4B-Instruct Ministral-3-3B mistralai/Ministral-3-3B-Instruct-2512-BF16 Ministral-3-14B mistralai/Ministral-3-14B-Instruct-2512-BF16 Qwen2.5-VL-3B Qwen/Qwen2.5-VL-3B-Instruct Qwen2.5-VL-32B Qwen/Qwen2.5-VL-32B-Instruct Qwen2.5-VL-72B Qwen/Qwen2.5-VL-72B-Instruct Qwen3-VL-2B Qwen/Qwen3-VL-2B-Instruct Qwen3-VL-32B Qwen/Qwen3-VL-32B-Instruct InternVL3.5-4B OpenGVLab/InternVL2.5-4B InternVL3.5-14B OpenGVLab/InternVL2.5-14B T able 7: Abbre viation used in this work and Hyperlinked Checkpoint P aths Prompt Y ou are given patient clinical inf ormation Classify the patient into one of the f ollowing cate- gories: - Major Depressive Disorder - Control (no disorder detected) Return your ans wer as a JSON object with two fields: - "categor y": the chosen category (exactly one of the two abov e) - "e xplanation": a shor t reasoning f or the choice Figure 5: T E X T ( A R C F ) prompt for F O R 2 1 0 7 B Par cellation in details Parcellation is performed using the Harvard- Oxford probabilistic atlas ( Rushmore et al. , 2022 ), which delineates the cerebral corte x into 48 anatom- ically defined regions of interest (R OIs; e.g., Insu- lar Corte x, T emporal Pole). The atlas was con- structed by spatially normalizing manually labeled T1-weighted scans of healthy adults into MNI (Montreal Neurological Institute) space and com- puting v oxelwise label probabilities across subjects. W e apply the cortical component of this atlas to ex- tract per -region v olumetric measurements, which are then serialized into descriptiv e text following the same approach as the tabular data. MRI visualization For each scan, we render three orthogonal slices, sagittal, coronal, and ax- ial, annotated with crosshairs at MNI coordinates ( x, y , z ) , hemisphere labels (L/R), voxel contour ov erlays, and a zero-anchored colormap to enhance tissue contrast. Prompt Y ou are giv en patient clinical information and their MRI data (brain parcellation v olume, vi- sualization of brain regions) Classify the patient into one of the f ollowing cate- gories: - Major Depressive Disorder - Control (no disorder detected) Return your ans wer as a JSON object with two fields: - "categor y": the chosen category (exactly one of the two abov e) - "e xplanation": a shor t reasoning f or the choice Figure 6: T E X T ( A R C F ) + P R O M P T ( M R I ) prompt for F O R 2 1 0 7. Bold text denotes the component that cause performance boost. C Models in details T able 7 sho ws the abbreviations and checkpoints of the models we used in this work. D F O R 2 1 0 7 V ariables V ariables that we used to con vert to text (T a- ble 13 , 14 , 15 , 16 , 17 , 18 ). T able D illustrates the token distribution of input in F O R 2 1 0 7 , divided to Major Depressi ve Disorder/Control P atient. W e use tiktoken 4 to do tokenization. E OA S I S - 3 V ariables V ariables that we used to con vert to text (T a- ble 21 , 22 24 , 23 ). T able E illustrates the token distribution of input in O A S I S - 3 , di vided to Cog- 4 https://github.com/openai/tiktoken 13 Prompt Y ou are given patient clinical inf ormation Classify the patient into one of the f ollowing cate- gories: - Cognitive Normal - Cognitive Decline Return your ans wer as a JSON object with two fields: - "categor y": the chosen category (exactly one of the two abov e) - "e xplanation": a shor t reasoning f or the choice Figure 7: T E X T ( A R C F ) prompt for O A S I S - 3 Prompt Y ou are giv en patient clinical information and their MRI data (brain parcellation v olume, vi- sualization of brain regions) Classify the patient into one of the f ollowing cate- gories: - Cognitive Normal - Cognitive Decline Return your ans wer as a JSON object with two fields: - "categor y": the chosen category (exactly one of the two abov e) - "e xplanation": a shor t reasoning f or the choice Figure 8: T E X T ( A R C F ) + P R O M P T ( M R I ) prompt for OA S I S - 3. Bold text denotes the component that cause performance boost. niti ve Normal/Cogniti ve Decline Patient. W e also use tiktoken for tokenization. F Random Baseline T o contextualize model performance, we report a random baseline corresponding to a stratified random classifier that predicts each class with a probability equal to its prior . For a binary classi- fication task with class proportions p and 1 − p , the expected weighted F1 score of such a classi- fier is: F 1 random = p 2 + (1 − p ) 2 , where p is the proportion of the minority class. G Full Results on F O R 2 1 0 7 and OA S I S - 3 G.1 F O R 2 1 0 7 - P er -Condition Results T able 9 reports the complete ev aluation results on the F O R 2 1 0 7 dataset across all fi ve input condi- tions and all twelve models. Metrics are F1, Preci- sion (P), Recall (R), and Accuracy (A CC). Baseline text-only performance (C1) Under the text-only condition T E X T ( A R C F ) , performance is highly model-dependent. Large-scale models such as Qwen2.5-VL-72B and GLM-4.6V-Flash achie ve competiti ve F1 scores of 0.828 and 0.795, respecti vely , while se veral smaller models fail to discriminate the positi ve class meaningfully ( InternVL3.5-4B : F1 = 0 . 000 ; Ministral-3-3B : F1 = 0 . 064 ; Qwen2.5-VL-3B : F1 = 0 . 153 ). In these failure cases, precision is either undefined or inflated at 1.000 while recall collapses near zero, indicating a systematic bias to ward predicting the negati v e class. Preamble-only framing (C2) Adding the MRI av ailability mention to the prompt preamble without providing any image produces dra- matic gains for models that previously failed. Qwen2.5-VL-3B rises from F1 = 0 . 153 to 0 . 728 ( +0 . 575 ); Ministral-3-3B from 0 . 064 to 0 . 480 ( +0 . 416 ); and InternVL3.5-4B from 0 . 000 to 0 . 255 ( +0 . 255 ). Gains for already-strong models are more modest, confirming that the preamble scaf- fold disproportionately unlocks latent capacity in smaller models. Across the board, recall increases substantially while precision is slightly tempered, suggesting the preamble prompts the models to be more willing to predict the positi ve class. Effect of the actual MRI image (C3) Provid- ing the actual neuroimaging plot alongside the multimodal preamble yields further , though gener - ally smaller , improv ements ov er C2 for most mod- els. The largest additional gains are observed in Ministral-3-3B ( 0 . 480 → 0 . 723 , +0 . 243 ) and Qwen3-VL-2B ( 0 . 281 → 0 . 447 , +0 . 166 ), suggest- ing that some models are capable of extracting useful signal from the MRI plot when primed by the preamble. Howe ver , se veral strong models plateau or mar ginally decline ( InternVL3.5-14B : 0 . 729 → 0 . 540 ), indicating that visual grounding does not uniformly improv e performance and may e ven introduce noise for certain architectures. Effect of par cellation features (C4) Augment- ing the text input with parcellation-deriv ed fea- tures alongside the MRI plot, yields results broadly comparable to C3, with no consis- tent improvement. Most models change by less than ± 0 . 02 F1 relative to C3. Notably , Qwen2.5-VL-3B and Qwen2.5-VL-32B sho w slight declines ( − 0 . 046 and − 0 . 041 respecti vely), while InternVL3.5-14B recov ers somewhat ( 0 . 540 → 14 0 1000 2000 3000 4000 5000 6000 Number of T okens 0 50 100 150 Number of Files (a) Major Depressiv e Disorder Patient 0 1000 2000 3000 4000 5000 6000 Number of T okens 0 100 200 300 Number of Files (b) Control Patient Figure 9: Distrib ution of input tokens in F O R 2 1 0 7 dataset 0 . 587 ). The absence of a clear benefit from par- cellation features suggests that models do not reli- ably integrate the additional structural neuroimag- ing statistics when image-lev el features are already present. Counterfactual image swap (C5) Replacing the subject-specific MRI plot with an unrelated image, while retaining the multimodal preamble produces performance largely indistinguishable from C4. For e xample, Qwen2.5-VL-72B scores F1 = 0 . 849 in C4 and 0 . 849 in C5; Qwen3-VL-32B scores 0 . 835 and 0 . 822 ; GLM-4.6V-Flash scores 0 . 791 and 0 . 788 . This near-equi valence between C4 and C5 provides the strongest evidence that models are not extracting diagnostically meaningful content from the provided image. Instead, performance gains attrib utable to the visual modality are driv en almost entirely by the preamble framing that an MRI is present, rather than by processing the im- age itself, the central scaf fold ef fect demonstrated in this work. G.2 OA S I S - 3 - P er -Condition Results T able 10 reports the complete e v aluation results on the O A S I S - 3 dataset across all fi ve input con- ditions. O A S I S - 3 presents a markedly dif fer- ent challenge from F O R 2 1 0 7 : the class distrib u- tion is more balanced, the clinical domain dif fers (Alzheimer’ s disease vs. depression), and se veral models exhibit notably diff erent beha vioral pat- terns, including near-total recall collapse or ex- treme precision inflation. Baseline text-only performance (C1) Perfor- mance under T E X T ( A R C F ) is more heteroge- neous than on F O R 2 1 0 7 . Strong models such as InternVL3.5-14B (F1 = 0 . 773 ) and Qwen2.5-VL-72B (F1 = 0 . 786 ) perform well, while sev eral models exhibit sev ere class imbal- ance artefacts. Qwen3-VL-2B nearly abstains from positi ve predictions (F1 = 0 . 090 , R = 0 . 047 ), and GLM-4.1V-9B like wise shows high precision but near-zero recall ( 0 . 278 , R = 0 . 164 ). Con versely , InternVL3.5-4B ov er-predicts the positiv e class (R = 0 . 893 , P = 0 . 470 ), and Qwen2.5-VL-32B produces a pathological output (R = 0 . 963 , P = 0 . 374 , A CC = 0 . 400 ), suggesting near-constant positi ve prediction. Scaff old effect: preamble-only framing (C2) Unlike F O R 2 1 0 7 , where the MRI preamble pro- duced consistent gains, O A S I S - 3 shows a more mixed picture under C2. Sev eral models that per- formed well in C1 de grade : InternVL3.5-14B drops from F1 = 0 . 773 to 0 . 584 ( − 0 . 189 ), and Qwen3-VL-32B from 0 . 582 to 0 . 767 represents one of the fe w clear gains. Qwen3-VL-2B collapses fur- ther (F1 = 0 . 028 ), and Qwen2.5-VL-32B remains degenerate (R = 1 . 000 , P = 0 . 365 ). This instabil- ity under preamble framing on OA S I S - 3 , where the C1 baseline is already competiti ve for strong models, is consistent with the negati ve transfer h y- pothesis: the multimodal scaffold was optimized implicitly for the F O R 2 1 0 7 clinical domain and disrupts well-calibrated text-only beha vior on out- of-domain data. Effect of the actual MRI image (C3) Pro viding the MRI plot (C3) yields the most consistent im- prov ements on O A S I S - 3 , with se veral models re- cov ering from C2 degradation. InternVL3.5-14B recov ers to F1 = 0 . 731 ( +0 . 147 ov er C2), GLM-4.6V-Flash improv es to 0 . 705 ( +0 . 239 ov er C2), and Ministral-3-14B climbs to 0 . 652 ( +0 . 097 ). Ho we ver , Qwen3-VL-2B remains es- sentially non-functional (F1 = 0 . 008 ), and 15 Qwen2.5-VL-32B remains degraded relati ve to its C1 baseline despite partial reco very . The over - all pattern suggests that on O A S I S - 3 , the im- age provides more disambiguating signal than the preamble alone, the in verse of what is observed on FOR2107. Effect of parcellation features (C4) Adding parcellation-deri ved features (C4) produces modest and inconsistent changes relativ e to C3. InternVL3.5-4B improv es slightly ( 0 . 634 → 0 . 656 ), and Ministral-3-14B im- prov es ( 0 . 652 → 0 . 675 ), while GLM-4.1V-9B declines ( 0 . 608 → 0 . 455 ). The best-performing model under C4 is Qwen2.5-VL-72B (F1 = 0 . 775 ), unchanged from C3 ( 0 . 776 ), confirming that parcellation features add no reliable signal on this dataset either . Counterfactual image swap (C5). The swap condition on O ASIS-3 closely mirrors C4 for most models, further supporting the scaffold ef- fect interpretation. Qwen2.5-VL-72B is identi- cal across C4 and C5 (F1 = 0 . 778 in both); GLM-4.6V-Flash scores 0 . 659 (C4) vs. 0 . 696 (C5); InternVL3.5-14B scores 0 . 738 (C4) vs. 0 . 683 (C5). The near-equi v alence of subject- specific MRI and an unrelated image, replicating the F O R 2 1 0 7 finding on an entirely different clin- ical population and MRI protocol, provides strong cross-dataset evidence that preamble framing rather than image content driv es apparent multimodal gains. H Case Study - Score Rubric in Details • F aithfulness : whether the output strictly adheres to the input context without adding un verified information (1 = sev ere fabrication; 4 = perfectly faithful). • Clinical Accuracy & Safety : whether the con- clusions are correct, safe, and aligned with clin- ical standards (1 = completely inaccurate or un- safe; 4 = perfectly accurate and safe). • Diagnostic Reasoning : whether the reasoning behind the diagnosis is clearly and logically ex- plained (1 = poor; 4 = excellent). I Confidence Estimation in Details W e analyze the two models e xhibiting the highest performance gains on F O R 2 1 0 7 : Qwen2.5-VL-3B and Ministral-3B . T o quantify model confi- dence during inference, we extract per-token log- probabilities from the decoder using greedy decod- ing with output_scores=True , which provides the full v ocabulary distrib ution at each generation step. Since the two class labels di ver ge at the first generated token, Major and Contr ol , the model’ s decision reduces to a single-tok en fork. W e there- fore extract the softmax probability directly at that branching point, which is both suf ficient and unam- biguous for this binary classification setting. This av oids the structural length bias that would arise from comparing ra w joint probabilities across se- quences of unequal length, while remaining more interpretable than sampling-based approaches such as semantic entropy ( Kuhn et al. , 2023 ), which require stochastic decoding and multiple forward passes. Formally , let s denote the generation step at which the label token is produced. For each class ℓ ∈ { MDD , ctrl } , the raw softmax probability at step s is: p ℓ = softmax( z s ) t ℓ 1 , (1) where z s is the logit vector at step s and t ℓ 1 is the first token of label ℓ . The normalized confidence score is then: ˆ P c ( ℓ | x ) = p ℓ p MDD + p ctrl + ϵ , (2) where ϵ = 10 − 12 for numerical stability and c denotes the input condition. The predicted class is ˆ y = arg max ℓ ˆ P c ( ℓ | x ) . W e use ˆ P c ( ℓ | x ) as the basis for a contrastiv e analysis designed to disentangle the respecti ve con- tributions of prompt framing and actual MRI con- tent. Specifically , we e v aluate each patient under three conditions and define the per-patient confi- dence shift as: δ cond ← base ( x i ) = ˆ P cond ( ℓ | x i ) − ˆ P base ( ℓ | x i ) , (3) where ℓ = MDD . A positi ve δ indicates that the condition increases the model’ s confidence in the MDD label relati ve to the baseline. J Scaff old Effect: Formal Details J.1 Scaffold Dir ection Let M be a decoder-only vision-language model with L layers and hidden dimension d . Let h ( l ) c ( x ) ∈ R d denote the residual-stream hidden state at layer l , extracted at the label tok en decod- ing step for patient record x under input condition c . W e denote the target positiv e class as ℓ + (the 16 condition of interest in the binary classification task). For brevity we write c 0 = T E X T ( A R C F ) and c 1 = T E X T ( A R C F ) + P RO M P T ( M R I ) . Gi ven a set of N patient records { x i } N i =1 , we define the scaff old direction at layer l ∗ as: d = 1 N N X i =1 h ( l ∗ ) c 0 ( x i ) − 1 N N X i =1 h ( l ∗ ) c 1 ( x i ) , (4) with unit-normalized form u = d / ∥ d ∥ 2 . Intu- iti vely , u captures the direction in residual-stream space that the MRI preamble injects to shift the model’ s final-layer classification routing to ward ℓ + . The target layer l ∗ . The target layer l ∗ is selected per model as the layer immediately preceding the earliest layer at which ˆ P c 1 ( ℓ + | x ) departs substan- tially from the c 0 baseline, as identified via a logit lens sweep ov er the label token. J.2 Phrase Probe Pr ocedure For a candidate preamble phrase p , we define its induced hidden-state shift as: ∆ h ( l ∗ ) p ( x i ) = h ( l ∗ ) p ( x i ) − h ( l ∗ ) c 0 ( x i ) , (5) where h ( l ∗ ) p ( x i ) is obtained by replacing the task preamble with p while keeping all other inputs fixed. W e quantify each candidate phrase along two ax es: Scaff old alignment The mean cosine similarity between the induced hidden-state shift and the scaf- fold direction: cos-sim ( p ) = 1 N N X i =1 ∆ h ( l ∗ ) p ( x i ) ∥ ∆ h ( l ∗ ) p ( x i ) ∥ 2 · u . (6) A v alue near +1 indicates that p shifts the residual stream in the same direction as the original MRI preamble; a v alue near − 1 indicates the opposite. Confidence shift The mean per-patient shift in ˆ P c ( ℓ + | x ) relativ e to c 0 , follo wing Equation ( 3 ): δ c 0 + p ← c 0 = 1 N N X i =1 ˆ P p ( ℓ + | x i ) − ˆ P c 0 ( ℓ + | x i ) . (7) Figure 4 plots cos-sim ( p ) against δ c 0 + p ← c 0 for all can- didate phrases. J.3 Scaffold Response Cur ve The two quantities defined in Equations ( 6 ) and ( 7 ) are not independent. Since the residual stream architecture of transformer-based models propa- gates information written at any layer additively to all subsequent layers ( Ge v a et al. , 2022 ), the hidden-state shift induced at l ∗ reaches the final layer approximately as: h ( L ) p ( x ) ≈ h ( L ) c 0 ( x ) + α · cos - sim( p ) · v , (8) for some propagated direction v ∈ R d and scalar α ∈ R , where cos-sim ( p ) is as defined in Equa- tion ( 6 ) . The binary confidence from Equation ( 2 ) then reduces to ˆ P c ( ℓ + | x ) = σ (∆ w ⊤ h ( L ) c ( x )) , where ∆ w = w ℓ + − w ℓ − is the LM head con- trast vector . Substituting Equation ( 8 ) and setting a = α · ∆ w ⊤ v ∈ R and b = ∆ w ⊤ h ( L ) c 0 ( x ) gi ves: ˆ P p ( ℓ + | x ) = σ b + a · cos - sim( p ) . (9) Subtracting the baseline ˆ P c 0 ( ℓ + | x ) = σ ( b ) and follo wing Equation ( 7 ) gi ves the scaf fold response curve: δ c 0 + p ← c 0 = σ a · cos - sim( p ) + b − σ ( b ) . (10) Equation ( 10 ) carries a direct mechanistic in- terpretation: the scaffold ef fect operates as a lin- ear offset in r epr esentation space passed thr ough the model’ s fixed output nonlinearity . The sen- siti vity parameter a quantifies per-model suscep- tibility to the scaffold trigger . W e would ex- pect a to be larger for Qwen2.5-VL-3B than for Ministral-3-3B , consistent with its systemati- cally larger δ c 0 + p ← c 0 v alues in T able 3 . The false- modality ablation further follows as a direct pre- diction: “fMRI data is included. ” achiev es high cos-sim ( p ) , so Equation ( 10 ) predicts a lar ge ˆ δ , which T able 5 confirms. In practice, a and b are estimated per model by minimizing mean squared error ov er P : ( a ∗ , b ∗ ) = arg min a, b 1 |P | X p ∈P δ c 0 + p ← c 0 − ˆ δ ( p ) 2 . (11) J.4 Phrase Probe In v entory T able 8 lists the full in v entory of phrase probes with their scores. For this work, we applied the logit lens 5 to all layers and found that the di ver - gence signal between MDD and control emerges at layer 33. W e then sampled 71 participants from FOR2107 for the probe experiment. 5 https://www.lesswrong. com/posts/AcKRB8wDpdaN6v6ru/ interpreting- gpt- the- logit- lens 17 400 450 500 550 600 650 700 750 Number of T okens 0 20 40 60 80 Number of Files (a) Cognitiv e Decline Patient 550 600 650 700 750 800 Number of T okens 0 20 40 60 80 Number of Files (b) Cognitiv e Normal Patient Figure 10: Distrib ution of input tokens in O A S I S - 3 dataset # Category Phrase cos ↑ δ ↑ 1 • MRI / neuroimaging Brain MRI findings ar e available . +0.43 +0.02 2 • General clinical Diagnostic r esults ar e available. +0.24 +0.02 3 • MRI / neuroimaging Brain scans have been performed. +0.23 -0.01 4 • Structural / format Classification r esult: +0.00 -0.02 5 • General clinical A clinical diagnosis has been established. -0.07 -0.01 6 • Structural / format The answer is: -0.25 -0.09 7 • Structural / format Output: {"cate gory": -0.32 -0.08 8 • Neutral / unrelated This is a test of the system. -0.32 -0.04 9 • General clinical Clinical evaluation is complete . -0.32 -0.06 10 • Neutral / unrelated Answer the following question car efully . -0.38 -0.05 11 • Authoritativ e framing As a medical pr ofessional, r evie w the following. -0.39 -0.04 12 • Neutral / unrelated Please pr ocess the following information. -0.43 -0.04 13 • General clinical The patient has been e valuated by a specialist. -0.45 -0.06 14 • Authoritativ e framing Y ou have extensive e xperience in psychiatric diagnosis. -0.48 -0.08 15 • Structural / format Return your answer as JSON. -0.48 -0.07 16 • Authoritativ e framing Y ou ar e an expert clinical psyc hiatrist. -0.49 -0.07 17 • Structural / format Respond only with a JSON object. -0.49 -0.09 18 • General clinical The patient has been assessed for a psychiatric disor der . -0.49 -0.11 19 • Neutral / unrelated Y ou are a helpful assistant. -0.53 -0.08 T able 8: Numbered phrases from Figure 4 . cos : cosine similarity to scaffold direction and δ K Prefer ence Lear ning in details W e use MPO for preference finetuning which com- bines three complementary loss signals: L MPO = w σ L sigmoid + w bco L bco_pair + w sft L sft , (12) where L sigmoid is the standard DPO preference loss, L bco_pair is a binary quality signal penalising re- jected responses, and L sft is a generation loss on the chosen response that prev ents degenerate out- put collapse. The LoRA configuration is giv en in T able 11 . T able 12 depicts all hyperparameters used in our DPO training. 18 Model F1 P R A CC C1: T E X T ( A R C F ) InternVL3.5-4B 0.000 0.000 0.000 0.604 InternVL3.5-14B 0.559 0.946 0.397 0.752 GLM-4.1V-9B 0.521 0.958 0.358 0.740 GLM-4.6V-Flash 0.795 0.896 0.715 0.854 LLaVA-OV-1.5-4B 0.663 0.954 0.508 0.796 Ministral-3-3B 0.064 1.000 0.033 0.617 Ministral-3-14B 0.588 0.983 0.419 0.768 Qwen2.5-VL-3B 0.153 1.000 0.083 0.637 Qwen2.5-VL-32B 0.749 0.900 0.642 0.830 Qwen2.5-VL-72B 0.828 0.853 0.805 0.868 Qwen3-VL-2B 0.546 0.869 0.398 0.738 Qwen3-VL-32B 0.744 0.928 0.621 0.831 C2: T E X T ( A R C F ) + PR O M P T ( M R I ) InternVL3.5-4B 0.255 0.963 0.147 0.660 InternVL3.5-14B 0.729 0.884 0.621 0.818 GLM-4.1V-9B 0.640 0.915 0.492 0.781 GLM-4.6V-Flash 0.802 0.847 0.760 0.851 LLaVA-OV-1.5-4B 0.592 0.980 0.424 0.769 Ministral-3-3B 0.480 0.720 0.360 0.691 Ministral-3-14B 0.680 0.961 0.526 0.804 Qwen2.5-VL-3B 0.728 0.876 0.623 0.816 Qwen2.5-VL-32B 0.820 0.897 0.756 0.869 Qwen2.5-VL-72B 0.844 0.804 0.889 0.870 Qwen3-VL-2B 0.281 0.966 0.164 0.667 Qwen3-VL-32B 0.823 0.900 0.758 0.871 C3: T E X T ( A R C F ) + PR O M P T ( M R I ) + M R I P L O T InternVL3.5-4B 0.296 0.992 0.174 0.673 InternVL3.5-14B 0.540 0.981 0.372 0.749 GLM-4.1V-9B 0.733 0.887 0.625 0.820 GLM-4.6V-Flash 0.794 0.875 0.728 0.851 LLaVA-OV-1.5-4B 0.713 0.937 0.575 0.817 Ministral-3-3B 0.723 0.851 0.628 0.809 Ministral-3-14B 0.710 0.948 0.568 0.817 Qwen2.5-VL-3B 0.680 0.878 0.555 0.794 Qwen2.5-VL-32B 0.820 0.840 0.802 0.861 Qwen2.5-VL-72B 0.846 0.795 0.903 0.870 Qwen3-VL-2B 0.447 0.908 0.297 0.710 Qwen3-VL-32B 0.846 0.827 0.866 0.875 Model F1 P R A CC C4: T E X T ( A R C F , PAR C E L ) + PR O M P T ( M R I ) + M R I PL OT InternVL3.5-4B 0.252 0.990 0.144 0.661 InternVL3.5-14B 0.587 0.913 0.432 0.759 GLM-4.1V-9B 0.720 0.916 0.593 0.818 GLM-4.6V-Flash 0.791 0.848 0.740 0.845 LLaVA-OV-1.5-4B 0.603 0.975 0.437 0.773 Ministral-3-3B 0.677 0.903 0.542 0.796 Ministral-3-14B 0.680 0.966 0.525 0.805 Qwen2.5-VL-3B 0.723 0.633 0.845 0.744 Qwen2.5-VL-32B 0.779 0.896 0.689 0.845 Qwen2.5-VL-72B 0.845 0.798 0.897 0.870 Qwen3-VL-2B 0.347 0.974 0.211 0.686 Qwen3-VL-32B 0.835 0.865 0.806 0.874 C5: T E X T ( A R C F , PAR C E L ) + PR O M P T ( M R I ) + S WAP I M AG E InternVL3.5-4B 0.399 0.972 0.251 0.701 InternVL3.5-14B 0.703 0.902 0.576 0.808 GLM-4.1V-9B 0.732 0.888 0.622 0.819 GLM-4.6V-Flash 0.788 0.864 0.725 0.846 LLaVA-OV-1.5-4B 0.540 0.992 0.371 0.750 Ministral-3-3B 0.675 0.759 0.608 0.769 Ministral-3-14B 0.698 0.955 0.549 0.812 Qwen2.5-VL-3B 0.728 0.666 0.803 0.763 Qwen2.5-VL-32B 0.780 0.902 0.686 0.847 Qwen2.5-VL-72B 0.849 0.838 0.859 0.879 Qwen3-VL-2B 0.365 0.935 0.227 0.688 Qwen3-VL-32B 0.822 0.893 0.762 0.870 T able 9: Full results on F O R 2 1 0 7 across all five input conditions (C1–C5) and all twelv e models. Metrics are F1, Precision (P), Recall (R), and Accuracy (A CC). Best F1 per condition is bolded . Left panel: text-only and preamble/image conditions (C1–C3). Right panel: parcellation-augmented and counterf actual swap conditions (C4–C5). 19 Model F1 P R A CC C1: T E X T ( A R C F ) InternVL3.5-4B 0.616 0.470 0.893 0.594 InternVL3.5-14B 0.773 0.865 0.698 0.850 GLM-4.1V-9B 0.278 0.909 0.164 0.689 GLM-4.6V-Flash 0.359 0.901 0.224 0.708 LLaVA-OV-1.5-4B 0.680 0.591 0.799 0.725 Ministral-3-3B 0.504 0.692 0.396 0.716 Ministral-3-14B 0.602 0.878 0.458 0.779 Qwen2.5-VL-3B 0.262 0.961 0.152 0.689 Qwen2.5-VL-32B 0.539 0.374 0.963 0.400 Qwen2.5-VL-72B 0.786 0.927 0.682 0.865 Qwen3-VL-2B 0.090 0.920 0.047 0.651 Qwen3-VL-32B 0.582 0.945 0.421 0.780 C2: T E X T ( A R C F ) + PR O M P T ( M R I ) InternVL3.5-4B 0.636 0.509 0.848 0.646 InternVL3.5-14B 0.584 0.421 0.953 0.505 GLM-4.1V-9B 0.397 0.696 0.277 0.692 GLM-4.6V-Flash 0.465 0.835 0.322 0.730 LLaVA-OV-1.5-4B 0.615 0.464 0.912 0.584 Ministral-3-3B 0.541 0.425 0.745 0.540 Ministral-3-14B 0.555 0.387 0.982 0.426 Qwen2.5-VL-3B 0.589 0.910 0.435 0.778 Qwen2.5-VL-32B 0.534 0.365 1.000 0.365 Qwen2.5-VL-72B 0.778 0.902 0.684 0.858 Qwen3-VL-2B 0.028 1.000 0.014 0.641 Qwen3-VL-32B 0.767 0.887 0.676 0.850 C3: T E X T ( A R C F ) + PR O M P T ( M R I ) + M R I P L O T InternVL3.5-4B 0.634 0.502 0.860 0.638 InternVL3.5-14B 0.731 0.726 0.735 0.802 GLM-4.1V-9B 0.608 0.827 0.481 0.774 GLM-4.6V-Flash 0.705 0.915 0.573 0.825 LLaVA-OV-1.5-4B 0.620 0.468 0.920 0.589 Ministral-3-3B 0.592 0.498 0.729 0.633 Ministral-3-14B 0.652 0.522 0.867 0.662 Qwen2.5-VL-3B 0.501 0.885 0.349 0.746 Qwen2.5-VL-32B 0.688 0.625 0.766 0.747 Qwen2.5-VL-72B 0.776 0.828 0.731 0.846 Qwen3-VL-2B 0.008 1.000 0.004 0.636 Qwen3-VL-32B 0.713 0.641 0.803 0.764 Model F1 P R A CC C4: T E X T ( A R C F , PAR C E L ) + PR O M P T ( M R I ) + M R I PL OT InternVL3.5-4B 0.656 0.563 0.784 0.699 InternVL3.5-14B 0.738 0.783 0.698 0.819 GLM-4.1V-9B 0.455 0.867 0.308 0.730 GLM-4.6V-Flash 0.659 0.836 0.544 0.795 LLaVA-OV-1.5-4B 0.681 0.570 0.844 0.711 Ministral-3-3B 0.563 0.521 0.612 0.653 Ministral-3-14B 0.675 0.670 0.680 0.761 Qwen2.5-VL-3B 0.595 0.799 0.474 0.765 Qwen2.5-VL-32B 0.712 0.889 0.593 0.825 Qwen2.5-VL-72B 0.775 0.878 0.694 0.853 Qwen3-VL-2B 0.004 1.000 0.002 0.636 Qwen3-VL-32B 0.728 0.860 0.630 0.828 C5: T E X T ( A R C F , PAR C E L ) + PR O M P T ( M R I ) + S WAP I M AG E InternVL3.5-4B 0.675 0.594 0.782 0.725 InternVL3.5-14B 0.683 0.658 0.711 0.759 GLM-4.1V-9B 0.522 0.900 0.368 0.754 GLM-4.6V-Flash 0.696 0.813 0.608 0.806 LLaVA-OV-1.5-4B 0.677 0.579 0.815 0.716 Ministral-3-3B 0.568 0.556 0.581 0.678 Ministral-3-14B 0.736 0.781 0.696 0.818 Qwen2.5-VL-3B 0.619 0.833 0.493 0.779 Qwen2.5-VL-32B 0.713 0.870 0.604 0.822 Qwen2.5-VL-72B 0.778 0.902 0.684 0.858 Qwen3-VL-2B 0.008 1.000 0.004 0.636 Qwen3-VL-32B 0.667 0.860 0.544 0.801 T able 10: Full results on O A S I S - 3 across all fiv e input conditions (C1–C5) and all twelve models. Metrics are macro-av eraged F1, Precision (P), Recall (R), and Accuracy (A CC). Best F1 per condition is bolded . Left panel: text-only and preamble/image conditions (C1–C3). Right panel: parcellation-augmented and counterfactual swap conditions (C4–C5). Note that Qwen3-VL-2B produces near-de generate outputs across all conditions on this dataset, and Qwen2.5-VL-32B under C1–C2 exhibits near -constant positi ve prediction (A CC ≈ 0.40, R ≈ 1.00), reflecting calibration failure rather than discriminati ve ability . 20 Hyperparameter V alue Rank ( r ) 64 Alpha ( α ) 128 Dropout 0.05 Bias none T arget modules q, k, v, o, gate, up, down_proj T able 11: LoRA adapter configuration. Hyperparameter V alue MPO losses Loss types sigmoid, bco_pair , sft Loss weights 0.8, 0.2, 1.0 KL penalty ( β ) 0.1 Optimisation Learning rate 5 × 10 − 5 LR scheduler Cosine W armup steps 100 Epochs 3 Ef fectiv e batch size 16 Per-de vice batch size 1 Gradient accumulation 16 Har dwar e & pr ecision Precision BF16 + TF32 Gradient checkpointing ✓ GPU 1 × H200 T raining time ≈ 12 h Sequence truncation None (image-safe) T able 12: MPO training hyperparameters. 21 Name Description Proband T est subject Datum_Interview Date interview as stated on the intervie w form Datum_Fragebogen Date of the questionnaire Geburtsjahr Y ear of birth Alter Age Geschlecht Gender Bildungsjahre Y ear of education Bildungsjahre_V ater Y ear of education father Bildungsjahre_Mutter Y ear of education mother BMI Body mass index BMI_category Body mass index cate gory UrbanicityScore Urbanity score AlterMutterBeiGeburt Mom age at birth AlterV aterBeiGeburt Dad age at birth Spezifische_Phobie_T ypus What type of phobia is present Spezifische_Phobie_T ypus2 What type of phobia is present? If more than one, found here Group Patient grouping or diagnosis Specific_phobia_current Is the patient currently suf fering from a specific phobia? Specific_phobia_lifetime Is the patient suffering from a specific phobia in his lifetime? Eating_Disorder_current Is the patient currently suffering from an eating disorder? Eating_Disorder_lifetime Is the patient suffering from an eating disorder in his lifetime? Alcohol_Use_Disorder_Current Is the patient currently suffering from an alcohol use disorder? Alcohol_Use_Disorder_Lifetime Is the patient suffering from an alcohol use disorder in his lifetime? T able 13: F O R 2 1 0 7 - Demographics and Clinical Information. Name Description RS-25: Resilience Scale RS251 If I hav e plans, I follow them through. RS252 I usually manage ev erything somehow . RS253 I can rely on myself rather than on others. RS254 It is important for me to stay interested in many things. RS255 If I hav e to, I can be alone. RS256 I am proud of what I hav e already achiev ed. RS257 I’m not easily thrown of f track. RS258 I like myself. RS259 I can manage sev eral things at the same time. RS2510 I am determined. RS2511 I rarely ask myself questions about meaning. RS2512 I take things as they come. RS2513 I can get through difficult times because I kno w I ha ve done it before. RS2514 I hav e self-discipline. RS2515 I stay interested in many things. RS2516 I often find something to laugh about. RS2517 My belief in myself helps me ev en in hard times. RS2518 I can be relied on in emergencies. RS2519 I can usually see a situation from sev eral perspectiv es. RS2520 I can also ov ercome myself to do things that I don’t really want to do. RS2521 My life has a purpose. RS2522 I don’t insist on things that I can’ t change. RS2523 When I’m in a difficult situation, I usually find a w ay out. RS2524 I hav e enough energy to do e verything I ha ve to do. RS2525 I can accept it if not ev eryone likes me. PSS: Per ceived Str ess Scale PSS1sf - PSS3sf In the last month, ho w often did you feel upset/unable to control things/nervous? PSS4sf - PSS6sf In the last month, ho w often were you able to successfully handle problems/changes? PSS7sf - PSS9sf In the last month, ho w often did you feel things were going your way/could not fulfill responsibilities? PSS10sf - PSS12sf In the last month, how often did you feel on top of things/upset about uncontrolled things? PSS13sf - PSS14sf In the last month, how often were you able to decide ho w to spend time/feel dif ficulties piling up? T able 14: F O R 2 1 0 7 - Items for the Resilience Scale (RS-25) and Perceived Stress Scale (PSS). 22 Name Description FSozU1 I hav e people who can look after my home (flo wers, pets) when I’m not there. FSozU2 There are people who accept me for who I am. FSozU3 It is important for my friends/relati ves to kno w my opinion on certain things. FSozU4 I would like more understanding and care from others. FSozU5 I hav e a very trusted person whose help I can al ways count on. FSozU6 I can borro w tools and food if necessary . FSozU7 I hav e friends/relati ves who can listen when I need to talk. FSozU8 I hardly kno w anyone I like to go out with. FSozU9 I hav e friends/relati ves who can gi ve me a hug. FSozU10 If I am ill, I can ask friends/relati ves to do important things (e.g. shopping). FSozU11 If I’m really depressed, I kno w who I can go to. FSozU12 I often feel like an outsider . FSozU13 There are people who share my joys and sorro ws. FSozU14 W ith some friends/relati ves, I can also be quite relax ed. FSozU15 I hav e a trusted person who I feel very comfortable around. FSozU16 I hav e enough people who really help me when I get stuck. FSozU17 There are people who stick by me e ven when I make mistak es. FSozU18 I would like more security and closeness. FSozU19 There are enough people with whom I hav e a really good relationship. FSozU20 There is a community of people (circle of friends, clique) that I feel drawn to. FSozU21 I often get good tips from my circle of friends and acquaintances. FSozU22 There are people to whom I can show all my feelings without it being embarrassing. T able 15: F O R 2 1 0 7 - Questionnaire on Social Support (FSozU) Items. 23 Name Description LEQ_pn1 / LEQ1 Health: Serious illness of one’ s own (T ype of influence / Influence on life) LEQ_pn2 / LEQ2 Health: Major change in eating habits LEQ_pn3 / LEQ3 Health: Major change in sleeping habits LEQ_pn4 / LEQ4 Health: Significant change in the type or amount of leisure acti vities LEQ_pn5 / LEQ5 Health: Major dental procedure LEQ_pn6 / LEQ6 Health: Pregnanc y LEQ_pn7 / LEQ7 Health: Miscarriage or abortion LEQ_pn8 / LEQ8 Health: Onset of menopause LEQ_pn9 / LEQ9 Health: Major dif ficulties with contraceptiv e aids LEQ_pn10 / LEQ10 W ork: Difficulties in finding work LEQ_pn11 / LEQ11 W ork: T aking up work outside the home LEQ_pn12 / LEQ12 W ork: Changing to a new type of work LEQ_pn13 / LEQ13 W ork: Changing your working hours or conditions LEQ_pn14 / LEQ14 W ork: Changing your job responsibilities LEQ_pn15 / LEQ15 W ork: Difficulties at work with your emplo yer or other employees LEQ_pn16 / LEQ16 W ork: Major company reorg anisations LEQ_pn17 / LEQ17 W ork: Being dismissed or laid off from work LEQ_pn18 / LEQ18 W ork: Ending your working life LEQ_pn19 / LEQ19 W ork: Learning at home or distance learning LEQ_pn20 / LEQ20 School/Education: Starting or ending a school or training program LEQ_pn21 / LEQ21 School/Education: Changing schools or training programs LEQ_pn22 / LEQ22 School/Education: Changing a career goal or major in college LEQ_pn23 / LEQ23 School/Education: Problems in a school or training program LEQ_pn24 / LEQ24 Residence: Difficulties in finding accommodation LEQ_pn25 / LEQ25 Residence: Moving within the same to wn or city LEQ_pn26 / LEQ26 Residence: Moving to another to wn, state, or country LEQ_pn27 / LEQ27 Residence: Significant changes to your living circumstances LEQ_pn28 / LEQ28 Lov e/Partnership: Beginning of a ne w , close, personal relationship T able 16: F O R 2 1 0 7 - Life Experiences Questionnaire (LEQ) Part 1. Note: ’pn’ designates T ype of Influence, while the number alone designates Influence on Life. 24 Name Description LEQ_pn29 / LEQ29 Lov e/Partnership: Entering into an engagement LEQ_pn30 / LEQ30 Lov e/Partnership: Problems with boyfriend or girlfriend LEQ_pn31 / LEQ31 Lov e/Partnership: Separation from boyfriend/girlfriend or breaking engage- ment LEQ_pn32 / LEQ32 Lov e/Partnership: Pregnanc y of wife or girlfriend LEQ_pn33 / LEQ33 Lov e/Partnership: Miscarriage or abortion of wife or girlfriend LEQ_pn34 / LEQ34 Lov e/Partnership: Marriage or domestic partnership LEQ_pn35 / LEQ35 Lov e/Partnership: Change in closeness to partner LEQ_pn36 / LEQ36 Lov e/Partnership: Infidelity LEQ_pn37 / LEQ37 Lov e/Partnership: Conflict with in-laws LEQ_pn38 / LEQ38 Lov e/Partnership: Separation from spouse or partner due to arguments LEQ_pn39 / LEQ39 Lov e/Partnership: Separation from spouse/partner due to work, tra vel, etc. LEQ_pn40 / LEQ40 Lov e/Partnership: Reconciliation with spouse or partner LEQ_pn41 / LEQ41 Lov e/Partnership: Div orce LEQ_pn42 / LEQ42 Lov e/Partnership: Changes in spouse/partner’ s acti vities outside the home LEQ_pn43 / LEQ43 Family/Friends: Addition of a ne w family member LEQ_pn44 / LEQ44 Family/Friends: Moving out of a child or f amily member LEQ_pn45 / LEQ45 Family/Friends: Major changes in health/behavior of family member or friend LEQ_pn46 / LEQ46 Family/Friends: Death of a spouse or partner LEQ_pn47 / LEQ47 Family/Friends: Death of a child LEQ_pn48 / LEQ48 Family/Friends: Death of a family member or close friend LEQ_pn49 / LEQ49 Family/Friends: Birth of a grandchild LEQ_pn50 / LEQ50 Family/Friends: Changes in your parents’ marital status LEQ_pn51 / LEQ51 Parenting: Changes in childcare arrangements LEQ_pn52 / LEQ52 Parenting: Conflicts with spouse or partner ov er parenthood LEQ_pn53 / LEQ53 Parenting: Conflicts with child’ s grandparents o ver parenthood LEQ_pn54 / LEQ54 Parenting: T aking on the responsibilities of being a single parent LEQ_pn55 / LEQ55 Parenting: Custody disputes with former spouse or partner T able 17: F O R 2 1 0 7 - Life Experiences Questionnaire (LEQ) Part 2. 25 Name Description LEQ_pn56 / LEQ56 Personal/Social: Greater personal achiev ement LEQ_pn57 / LEQ57 Personal/Social: Important decision regarding your immediate future LEQ_pn58 / LEQ58 Personal/Social: Changes in your personal habits (clothing, lifestyle, hob- bies) LEQ_pn59 / LEQ59 Personal/Social: Changes in your religious beliefs LEQ_pn60 / LEQ60 Personal/Social: Changes in your political views LEQ_pn61 / LEQ61 Personal/Social: Loss or damage to your personal property LEQ_pn62 / LEQ62 Personal/Social: Gone on a vacation LEQ_pn63 / LEQ63 Personal/Social: T aking a trip for non-recreational purposes LEQ_pn64 / LEQ64 Personal/Social: Changes in family gatherings LEQ_pn65 / LEQ65 Personal/Social: Changes in your social activities (clubs, e vents, visits) LEQ_pn66 / LEQ66 Personal/Social: Beginning of ne w friendships LEQ_pn67 / LEQ67 Personal/Social: End of a friendship LEQ_pn68 / LEQ68 Personal/Social: Acquisition or loss of a pet LEQ_pn69 / LEQ69 Money: Significant change in your financial situation LEQ_pn70 / LEQ70 Money: Moderate financial commitment (TV , car , etc.) LEQ_pn71 / LEQ71 Money: Large financial commitment or mortgage LEQ_pn72 / LEQ72 Money: Cancellation of a mortgage or loan LEQ_pn73 / LEQ73 Money: Dif ficulties with creditworthiness LEQ_pn74 / LEQ74 Crime/Legal: V ictim of theft or identity theft LEQ_pn75 / LEQ75 Crime/Legal: V ictim of a violent crime (rape, assault, etc.) LEQ_pn76 / LEQ76 Crime/Legal: In v olvement in an accident LEQ_pn77 / LEQ77 Crime/Legal: In v olvement in a le gal dispute LEQ_pn78 / LEQ78 Crime/Legal: In v olvement in a misdemeanor (tick ets, disturbing the peace) LEQ_pn79 / LEQ79 Crime/Legal: T rouble with the law resulting in arrest or detention LEQ_pn80 / LEQ80 Other recent experiences ha ving an impact on life (1) LEQ_pn81 / LEQ81 Other recent experiences ha ving an impact on life (2) LEQ_pn82 / LEQ82 Other recent experiences ha ving an impact on life (3) T able 18: F O R 2 1 0 7 - Life Experiences Questionnaire (LEQ) Part 3. Name Description SozDemo1 – SozDemo5 Current living, w ork situation, occupation, social contacts Haushaltu14 / Haushaltab14 People in the household under/ov er 14 years Haushaltsnetto Household net income Schulabschluss Highest educational qualification achie ved by subject Schule_V ater / Schule_Mutter Highest educational qualification achie ved by father / mother GebJahr_Mutter / GebJahr_V ater Mother’ s / Father’ s year of birth Immigration Own immigration or parents’? Kinder Do you hav e children? Soehne_leibl (_age) Number (and age) of biological sons T oechter_leibl (_age) Number (and age) of biological daughters Soehne_adopt (_age) Number (and age) of adopted sons T oechter_adopt (_age) Number (and age) of adopted daughters Geschwister Do you hav e siblings? Brueder_GE (_age) Number (and age) of brothers (parents shared) Schwestern_GE (_age) Number (and age) of sisters (parents shared) Halbbrueder / Halbschwestern Number (and age) of half-brothers / half-sisters Stiefbrueder / Stiefschwestern Number (and age) of step-brothers / step-sisters Zwillinge_Famil / Zwilling_selbst Are there twins in your first degree f amily? / Are you a twin? SS_Stadt / SS_Bundesland City/State mother li ved during pre gnancy SS_Risiken1 – SS_Risiken7 Pregnanc y risks (infection, alcohol, drugs, malnutrition, smoking) Geburtsk omplikationen1 – 4 Birth complications (forceps, vacuum, cesarean, other) Geburtsge wicht / SSW_Geburt Birth weight in grams / W eek of birth T able 19: F O R 2 1 0 7 - Socio-Demographics, Family Composition, and Pregnanc y V ariables. 26 Name Description FzT : Drinking Habits FzT1 – FzT5 Questions on frequenc y and quantity of alcohol consumption (no w/past). FzT6 – FzT9 Questions on binge drinking (6+ drinks) and inability to stop (no w/past). FzT10 – FzT13 Failing e xpectations due to alcohol; morning drinking (no w/past). FzT14 – FzT17 Guilt, remorse, and memory loss due to alcohol (no w/past). FzT18 – FzT20 Injuries, advice to reduce, and professional help sought for alcohol. T able 20: F O R 2 1 0 7 - Alcohol Use (FzT). Name Description Subject Demographics & F amily O ASISID O ASIS subject ID GENDER Subject’ s gender RA CE Subject’ s race HAND Subject’ s Handedness TWIN Is this a ne w informant? (Note: Label suggests ’T win’ but description asks about ne w informant status) SIBS Ho w many full siblings does the subject ha ve? KIDS Ho w many biological children did the subject ha ve? Living Situation & Independence LIVSIT What is the subject’ s living situation? LIVSITU A Living situation (detailed categorization) INDEPEND What is the subject’ s le v el of independence? RESIDENC What is the subject’ s primary type of residence? MARIST A T Subject’ s current marital status T able 21: O ASIS-3 - Subject Demographics, Family , and Living Situation. Name Description INSEX Informant’ s sex INHISP Does informant report being of Hispanic/Latino ethnicity? INHISPOR If yes, what are the informant’ s reported origins? INRA CE What does informant report as his/her race? INRASEC What additional race does informant report? INRA TER What additional race, beyond what was indicated abov e, does informant report? INEDUC Informant’ s years of education INREL TO What is informant’ s relationship to subject? INLIVWTH Does the informant liv e with the subject? INVISITS If no, approximate frequency of in-person visits INCALLS If no, approximate frequency of telephone contact INREL Y Is there a question about the informant’ s reliability? T able 22: O ASIS-3 - Informant Demographics and Contact Frequency . 27 Name Description General Medical History HYPER TEN Hypertension HYPERCHO Hypercholesterolemia DIABETES Diabetes B12DEF B12 deficiency THYR OID Thyroid Disease CV AFIB Atrial fibrillation CVCHF Congesti ve heart failure CV ANGIO Angioplasty/endarterectomy/stent CVBYP ASS Cardiac bypass procedure V itals WEIGHT Subject W eight (lbs) HEIGHT Subject Height (inches) BPSYS Subject Blood Pressure (sitting) (systolic) BPDIAS Subject Blood Pressure (sitting) (diastolic) HRA TE Subject resting heart rate (pulse) T able 23: O ASIS-3 - Subject Medical History , Cardiov ascular Conditions, and V itals. Name Description Lifestyle, Sleep & T rauma TOB A C100 Smoked more than 100 cigarettes in life? SMOKYRS T otal years smoked ALCOHOL Substance abuse - alcohol (clinically significant o ver a 12 month period) TRA UMEXT Traumatic brain injury with e xtended loss of consciousness ( ≥ 5 minutes) TRA UMCHR T raumatic brain injury with chronic deficit or dysfunction APNEA Sleep apnea INSOMN Hyposomnia/insomnia Sensory & Cognition VISION W ithout correcti ve lenses, is the subject’ s vision functionally normal? VISCORR Does the subject usually wear correcti ve lenses? VISWCORR Is the subject’ s vision functionally normal with correcti ve lenses? HEARING W ithout a hearing aid(s), is the subject’ s hearing functionally normal? HEARAID Does the subject usually wear a hearing aid(s)? HEAR W AID Is the subject’ s hearing functionally normal with a hearing aid(s)? T able 24: O ASIS-3 - Lifestyle Factors, Sensory Capabilities. 28
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment