CoE: Collaborative Entropy for Uncertainty Quantification in Agentic Multi-LLM Systems
Uncertainty estimation in multi-LLM systems remains largely single-model-centric: existing methods quantify uncertainty within each model but do not adequately capture semantic disagreement across models. To address this gap, we propose Collaborative…
Authors: Kangkang Sun, Jun Wu, Jianhua Li
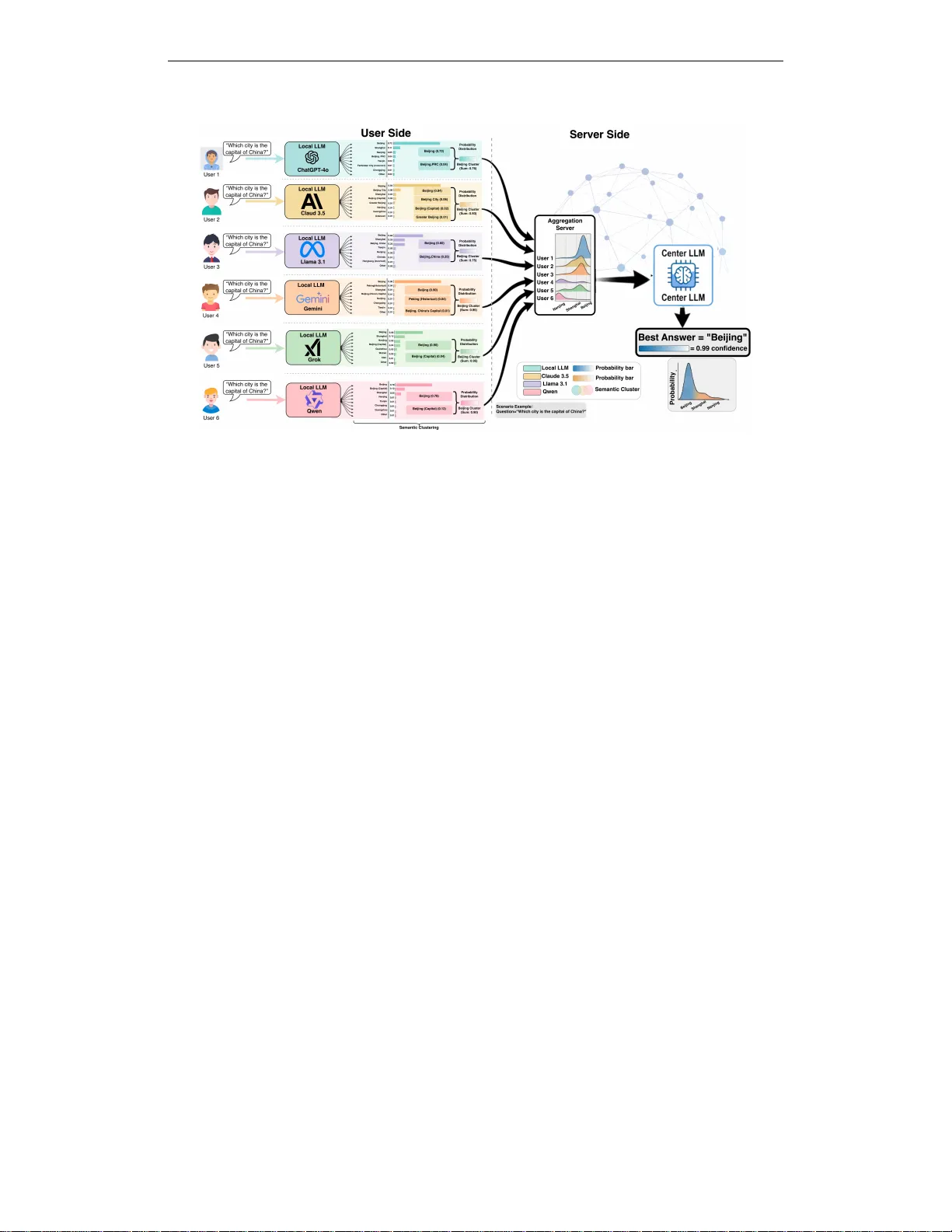
Published as a workshop paper at the workshop of “ Agentic AI in the W ild” in ICLR 2026 C O E : C O L L A B O R A T I V E E N T R O P Y F O R U N C E RT A I N T Y Q UA N T I FI C A T I O N I N A G E N T I C M U L T I - L L M S Y S T E M S Kangkang Sun, Jun W u, Jianhua Li, Minyi Guo, Xiuzhen Chen Shanghai Ke y Laboratory of Integrated Administration T echnologies for Information Security School of Computer Science Shanghai Jiao T ong University Shanghai, China { szpsunkk, junwuhn, lijh888, myguo, chenxz } @sjtu.edu.cn Jianwei Huang School of Science and Engineering The Chinese Univ ersity of Hong K ong, Shenzhen Shenzhen, China { jianweihuang } @cuhk.edu.hk A B S T R AC T Uncertainty estimation in multi-LLM systems remains largely single-model-centric: existing methods quantify uncertainty within each model but do not adequately capture semantic disagreement across models. T o address this gap, we propose Collaborativ e Entropy (CoE), a unified information-theoretic metric for semantic uncertainty in multi-LLM collaboration. CoE is defined on a shared semantic cluster space and combines two components: intra-model semantic entropy and inter-model div ergence to the ensemble mean. CoE is not a weighted ensemble predictor; it is a system-le vel uncertainty measure that characterizes collaborati ve confidence and disagreement. W e analyze sev eral core properties of CoE, including non-negati vity , zero-value certainty under perfect semantic consensus, and the be- havior of CoE when indi vidual models collapse to delta distrib utions. These results clarify when reducing per-model uncertainty is suf ficient and when residual inter- model disagreement remains. W e also present a simple CoE-guided, training-free post-hoc coordination heuristic as a practical application of the metric. Experiments on T riviaQA and SQuAD with LLaMA-3.1-8B-Instruct, Qwen-2.5-7B-Instruct, and Mistral-7B-Instruct sho w that CoE pro vides stronger uncertainty estimation than standard entropy- and div ergence-based baselines, with gains becoming larger as additional heterogeneous models are introduced. Ov erall, CoE offers a useful uncertainty-aware perspecti ve on multi-LLM collaboration. 1 I N T R O D U C T I O N Large language models (LLMs) ha ve demonstrated remarkable capabilities across natural language processing and decision-making tasks Chang (2024); Singhal et al. (2023), with systems such as GPT -4 Achiam et al. (2023), Gemini T eam et al. (2023), and DeepSeek Liu et al. (2024) achie ving strong performance on complex reasoning and question-answering benchmarks. Y et these models remain susceptible to hallucinations Fadee va et al. (2024), solution space bias Holtzman et al. (2019), and err or pr opagation Prystawski et al. (2023)—failure modes that are particularly consequential in high-stakes domains such as medicine and law , where unreliable outputs can cause serious harm. Agentic multi-LLM frame works have emerged as a principled response to these limitations. By allowing heterogeneous models to cross-check reasoning through structured interaction Knott & Vlugter (2008); Luo et al. (2025); Li et al. (2025); Ran et al. (2025), these systems le verage collecti ve intelligence to improve both accurac y and reliability . Empirical studies confirm that multi-LLM collaboration can reduce indi vidual model errors W ang et al. (2024); ho wev er , they also re veal that collaboration quality is highly uneven Cai et al. (2025); Cemri et al. (2025). A ke y obstacle is 1 Published as a workshop paper at the workshop of “ Agentic AI in the W ild” in ICLR 2026 semantic uncertainty : when models disagree at the le vel of meaning—not merely surface form—their outputs can conflict in w ays that degrade rather than impro ve system performance Abdelnabi et al. (2024); Chan et al. (2023); Li et al. (2023). Understanding and measuring this disagreement is therefore a prerequisite for reliable multi-LLM deployment. The measurement gap. Uncertainty Quantification (UQ) is well-established for individual LLMs. T oken-lev el entropy Geng et al. (2024), semantic entropy Farquhar et al. (2024); Kuhn et al. (2023), self-consistency Ri vera et al. (2024); Ling et al. (2024), reflection Self-Reflection (2024), and confor - mal prediction W ang et al. (2024) all provide principled estimates of a single model’ s confidence. Howe ver , none of these methods is designed to characterize uncertainty at the system lev el in a multi-LLM setting. The most natural extension—av eraging per-model semantic entropy across the ensemble—suf fers from two fundamental limitations. First, it treats all models as independent and interchangeable, ignoring the inter -model epistemic diver gence that arises when heterogeneous models (e.g., LLaMA, Qwen, Mistral), trained on distinct corpora and aligned via different proce- dures, disagree at the semantic lev el. Second, it conflates two qualitativ ely different uncertainty sources— intra-model aleatoric uncertainty (a single model’ s internal ambiguity over semantic clus- ters) and inter-model epistemic uncertainty (cross-model semantic disagreement)—into a single scalar , thereby discarding actionable diagnostic information about why the system is uncertain. This conflation is not merely a theoretical incon venience. In practice, the two components call for different interventions: high intra-model uncertainty suggests that individual models require more div erse sampling or better prompting, while high inter-model uncertainty signals that the models are each internally confident but semantically inconsistent with one another . A metric that collapses both into one number forecloses this distinction entirely . Collaborative Entropy . T o fill this gap, we propose Collaborative Entropy (CoE) , a unified information-theoretic metric for semantic uncertainty in agentic multi-LLM systems. CoE is defined ov er a shared semantic cluster space and decomposes system-le vel uncertainty into two interpretable components: U CoE ( K ) = 1 |K| X i ∈K S E ( x i ) | {z } intra-model (aleatoric) + X i ∈K w i · D KL ( p i ( ·| x ) ∥ ¯ p ( ·| x )) | {z } inter-model (epistemic) (1) where S E ( x i ) is the semantic entropy of model M i , p i ( ·| x ) is its cluster -lev el output distribution, and ¯ p ( ·| x ) = P i w i p i ( ·| x ) is the weighted ensemble mean. Crucially , CoE is not a weighted ensemble predictor or an output-scoring rule: it is a system-lev el uncertainty measure that characterizes collaborativ e confidence and cross-model semantic disagreement, independently of any do wnstream task objectiv e. W e analyze se veral core properties of CoE that formalize its beha vior as a metric. Non-Ne gativity (Theorem 1) establishes that CoE is a valid uncertainty measure bounded belo w by zero. Zer o V alue Certainty (Theorem 2) proves that U CoE = 0 if and only if all models place full probability mass on the same semantic cluster—i.e., perfect semantic consensus. Single-Model Ne gative Entr opy Maxi- mization (Theorem 3) characterizes the partial reduction achie vable through per -model uncertainty minimization: when each model collapses to a delta distribution, the aleatoric component van- ishes, but residual inter -model disagreement may persist, reflecting irreducible epistemic diver gence across heterogeneous models. T ogether , these results clarify when reducing per-model uncertainty is sufficient for system-lev el certainty , and when cross-model alignment is additionally required—a distinction in visible to single-model-centric metrics. As a practical application of the metric, we also present a simple CoE-guided, training-free post-hoc coordination heuristic that uses CoE-deriv ed signals to refine model weighting at inference time, without updating any model parameters. Contributions. The main contrib utions of this paper are as follows: • A unified system-level uncertainty metric for multi-LLM collaboration. W e propose Collabo- rativ e Entropy (CoE), an information-theoretic metric that quantifies semantic uncertainty jointly across a heterogeneous set of LLMs. CoE is defined over a shared semantic cluster space and decomposes uncertainty into tw o interpretable components: intra-model semantic 2 Published as a workshop paper at the workshop of “ Agentic AI in the W ild” in ICLR 2026 Figure 1: Overview of the proposed Collaborati ve Entropy (CoE) frame work for agentic multi-LLM uncertainty quantification. Each LLM generates candidate responses that are clustered semantically to form probability distributions, which are then aggre gated to minimize system-le vel collaborati ve entropy . dispersion and inter-model semantic disagreement. It is the first metric to jointly capture both sources at the system level, and it is distinct from weighted ensemble predictors or output scoring rules. • F ormal theoretical analysis of CoE. W e prov e three properties of CoE—Non-Negati vity , Zero V alue Certainty , and the behavior under per-model delta-distrib ution collapse—that collectiv ely characterize CoE’ s range, its ideal state, and the conditions under which per- model uncertainty reduction does or does not suf fi ce for system-le vel certainty . These results provide a principled foundation for interpreting CoE v alues in practice. • A CoE-guided post-hoc coor dination heuristic. As a lightweight practical application of the metric, we present a training-free inference-time heuristic that uses CoE-related signals to adjust model weights and refine ensemble coordination. This procedure should be understood as a direct application of the metric rather than a standalone algorithmic contribution. • Empirical validation as an uncertainty metric. Experiments on Tri viaQA and SQuAD with LLaMA-3.1-8B-Instruct, Qwen-2.5-7B-Instruct, and Mistral-7B-Instruct show that CoE provides stronger uncertainty estimation than standard entropy- and di vergence-based baselines in A UROC and A URA C, with gains that scale as additional heterogeneous models are introduced. The remainder of this paper is or ganized as follo ws. Section 2 revie ws related work on uncertainty quantification for LLMs and multi-LLM systems. Section 3 introduces the system model, the semantic entropy preliminaries on which CoE builds, and the formal definition of Collaborative Entropy together with its two-component decomposition. Section 4 interprets CoE through the lens of four qualitatively distinct uncertainty regimes on the ( U A , U E ) plane. Section 5 presents the experimental setup and results. Section 6 concludes the paper . Appendix A provides the formal theoretical analysis of CoE, including proofs of Non-Ne gativity , Zero V alue Certainty , and Delta- Distribution Beha viour , and describes the CoE-guided post-hoc coordination heuristic. 2 R E L A T E D W O R K UQ methods for LLMs span token-le vel entropy aggreg ation Geng et al. (2024), self-verbalized con- fidence Riv era et al. (2024), and semantic entropy Farquhar et al. (2024); Kuhn et al. (2023)—which 3 Published as a workshop paper at the workshop of “ Agentic AI in the W ild” in ICLR 2026 clusters generations via bidirectional entailment to provide paraphrase-in variant uncertainty esti- mates—as well as classical approaches such as Bayesian networks and deep ensembles Jospin et al. (2022) that scale poorly to modern LLMs. Benchmarks including LM-Polygraph Fadee va et al. (2023) and MA QA Y ang et al. (2025) reveal persistent calibration gaps Ling et al. (2024), while recent surve ys Shorinwa et al. (2025) cate gorize open challenges along input ambiguity , reasoning div ergence, and decoding stochasticity . Howe ver , all these methods are single-model-centric : they quantify uncertainty within one model and cannot characterize semanti c disagreement across a hetero- geneous ensemble. At the multi-LLM lev el, self-consistency Ri vera et al. (2024) treats cross-model agreement as a voting signal rather than a principled measure, and graph-structured approaches such as DEUP Lahlou et al. (2021) and T opologyUQ Da et al. (2025) propagate uncertainty through ensemble pipelines but do not define a closed-form metric over shared semantic clusters. The closest prior work, Kruse et al. (2025), applies information-theoretic reasoning to multi-LLM uncertainty b ut aggregates per -model entropy scores without decomposing aleatoric and epistemic components or providing formal metric guarantees. CoE addresses this gap by operating on a shared semantic cluster space—follo wing the framework of semantic entropy Farquhar et al. (2024); Kuhn et al. (2023)—and introducing an asymmetric KL div ergence term measured against the ensemble mean, a reference structure that is sensiti ve to directional epistemic di vergence in w ays that symmetric alternati ves (e.g., Jensen-Shannon) are not, as our experiments confirm. 3 M E T H O D O L O G Y W e begin by describing the multi-LLM collaborativ e system that motiv ates CoE (Sec. 3.1), and then introduce the semantic entropy (SE) preliminaries on which CoE is b uilt (Sec. 3.2). 3 . 1 S Y S T E M O V E RV I E W Figure 1 illustrates the proposed agentic multi-LLM collaborati ve system, which consists of two primary layers. • Local Inference and Clustering. Each LLM agent M i receiv es the same query x and independently generates a set of candidate responses. These responses are partitioned into semantic clusters { c j } via bidirectional entailment, yielding a cluster-le vel probability distribution p i ( c j | x ) that summarises the model’ s semantic confidence. • Central Aggregation. A central aggregator collects the cluster distributions from all agents and computes the system-le vel Collaborati ve Entropy (CoE). The aggre gator identifies the semantic cluster with the lowest associated CoE as the system’ s most reliable answer . This two-layer structure cleanly separates the per-model uncertainty estimation (intra-model) from the cross-model disagreement measurement (inter-model), corresponding directly to the tw o components of CoE defined in Sec. 3.3. 3 . 2 S E M A N T I C E N T RO P Y : S I N G L E - M O D E L U N C E RTA I N T Y B A S E L I N E Before defining CoE, we recall the semantic entropy (SE) metric of Farquhar et al. (2024), which serves as the intra-model component of CoE and as the primary single-model baseline in our experiments. Definition 1 (Semantic Entropy , Farquhar et al., 2024) . F or an LLM M and input x ∈ X , let { s (1) , . . . , s ( m ) } be m sampled output sequences, partitioned into l semantic clusters { c 1 , . . . , c l } ⊆ C via bidir ectional entailment. The semantic entropy of M on x is: S E ( x ) = − l X j =1 p ( c j | x ) log p ( c j | x ) , (2) wher e p ( c j | x ) = P s ( k ) ∈ c j p ( s ( k ) | x ) aggr e gates the length-normalized generation pr obabilities of all sequences assigned to cluster c j . SE measures how spread the model’ s probability mass is across semantically distinct answers: S E ( x ) = 0 when the model concentrates entirely on one semantic cluster, and S E ( x ) is maximised 4 Published as a workshop paper at the workshop of “ Agentic AI in the W ild” in ICLR 2026 when probability mass is distributed uniformly . SE is robust to surface paraphrase because it operates on semantic clusters rather than raw token sequences. Howe ver , as a single-model metric, SE cannot capture the disagreement that arises when multiple heterogeneous models each hav e lo w internal entropy yet commit to differ ent semantic clusters. Addressing this limitation is the central motiv ation for CoE. 3 . 3 C O L L A B O R AT I V E E N T RO P Y : D E C O M P O S I N G S Y S T E M - L E V E L U N C E RT A I N T Y W e now define CoE formally . Let K denote a set of K LLMs M = {M 1 , . . . , M K } and let { w 1 , . . . , w K } be non-negativ e ensemble weights satisfying P K i =1 w i = 1 . F or input x , each model M i generates m i sequences that are collecti vely partitioned into l shared semantic clusters { c 1 , . . . , c l } ⊆ C via bidirectional entailment. Let p i ( · | x ) denote the resulting cluster distrib ution of model M i , and let ¯ p ( · | x ) = P K i =1 w i p i ( · | x ) denote the weighted ensemble mean distribution. CoE decomposes system-lev el semantic uncertainty into two interpretable components: Intra-model aleatoric uncertainty U A . This term captures the av erage internal ambiguity of individual models: U A ( K ) = 1 K K X i =1 S E ( x i ) . (3) High U A indicates that individual models are themselves uncertain, re gardless of whether they agree with each other . Inter -model epistemic uncertainty U E . This term captures the semantic diver gence of each model’ s distribution from the ensemble consensus: U E ( K ) = K X i =1 w i · D ( p i ( · | x ) ∥ ¯ p ( · | x )) , (4) where D ( ·∥· ) is a distributional div ergence. In our primary formulation we use the asymmetric KL di vergence, D KL ( p i ∥ ¯ p ) = P l j =1 p i ( c j | x ) log p i ( c j | x ) ¯ p ( c j | x ) , whose reference-directed asymmetry is critical for capturing directional epistemic disagreement (see Sec. 5). W e also ev aluate symmetric alternativ es (JS, W asserstein, Hellinger) as ablations. High U E indicates that models disagree semantically ev en if each is individually confident. Collaborative Entr opy (CoE). Definition 2 (Collaborativ e Entropy) . The Collaborative Entropy of a multi-LLM system K on input x is: U C oE ( K ) = 1 K K X i =1 S E ( x i ) | {z } U A : intra-model + K X i =1 w i · D KL ( p i ( · | x ) ∥ ¯ p ( · | x )) | {z } U E : inter-model . (5) CoE is a measurement of system-lev el semantic uncertainty: it is not a task-specific scoring rule, a weighted ensemble predictor , or an output selector . Its two components are interpretable and actionable—high U A calls for improving per -model sampling or prompting, while high U E calls for inter-model alignment. The theoretical properties of CoE are analysed in Appendix A. 4 C O E D E C O M P O S I T I O N : T H E F O U R U N C E RTA I N T Y Q U A D R A N T S Figure 2 maps the four qualitativ ely distinct states of a multi-LLM system onto the ( U A , U E ) plane. 1. High U A + High U E — “W e do not know . ” Both intra-model ambiguity and inter-model disagreement are sev ere. CoE is maximally accumulated; Theorem 1 establishes that U C oE ≥ 0 holds as a global lo wer bound throughout this worst-case regime. 5 Published as a workshop paper at the workshop of “ Agentic AI in the W ild” in ICLR 2026 Figure 2: V isualization of the four CoE quadrants using Dirichlet distributions o ver three semantic clusters. Each simplex (colour intensity = probability density) and accompanying bar chart illustrates a characteristic combination of U A (horizontal axis) and U E (vertical axis). 2. Low U A + High U E — “Models are confident but disagree. ” Individual models hav e concentrated distributions (low internal entropy), yet they commit to differ ent semantic clusters. This is precisely Case B of Theorem 3: per-model entropy maximisation has eliminated U A , but residual epistemic di vergence U E > 0 persists and can only be reduced through inter-model alignment. 3. Low U A + Low U E — “W e are v ery sure. ” All models concentrate on the same cluster . By Theorem 2, U C oE = 0 ; this is the ideal state and the target of the CoE-guided coordination heuristic. 4. High U A + Low U E — “Multiple reasonable answers exist. ” Models broadly agree on the distribution o ver clusters but none is internally decisi ve. Per Theorem 3(i), driving each model tow ard its Delta distribution reduces U A and, if consensus is reached, eliminates U C oE entirely . 5 E X P E R I M E N T S 5 . 1 E X P E R I M E N TA L S E T U P Models. W e e valuate on three publicly available instruction-tuned LLMs: LLaMA-3.1-8B- Instruct (Dubey et al., 2024), Qwen-2.5-7B-Instruct (T eam et al., 2024), and Mistral-7B-Instruct (Jiang et al., 2024), abbreviated as Llama , Qwen , and Mistral throughout. All models are used without any fine-tuning or parameter modification. Experiments are conducted on the 7–8B parameter range to ensure reproducibility and to isolate the effect of multi-LLM collaboration from model-scale confounds; we discuss the implications of this choice in Sec. 6. Datasets. W e evaluate on two open-domain QA benchmarks. T riviaQA (Joshi et al., 2017) is a large-scale reading comprehension dataset requiring retriev al and compositional reasoning over noisy evidence documents. SQuAD (Rajpurkar et al., 2016) is an extracti ve QA dataset built on W ikipedia articles that demands precise context grounding. The two benchmarks present complementary chal- lenges: Tri viaQA fav ours broad factual recall, while SQuAD rewards fine-grained span identification. Both ev aluations use 200 samples drawn from the respectiv e validation splits. Detailed experimental results are provided in Appendix B.1. Evaluation metrics. Following F arquhar et al. (2024), we ev aluate uncertainty metrics along three complementary axes. AUR OC (McDermott et al., 2024): the area under the receiver -operating- characteristic curve, measuring ho w well the uncertainty score ranks correct answers above incorrect ones across all thresholds. A value of 1.0 indicates perfect discrimination; 0.5 corresponds to random 6 Published as a workshop paper at the workshop of “ Agentic AI in the W ild” in ICLR 2026 T able 1: Selecti ve prediction performance of uncertainty metrics in multi-LLM collaborati ve settings on T riviaQA (200 samples). For Semantic Entropy , Regular Entrop y , and P false , scores are reported as the arithmetic mean over constituent models. U A and U E are ablation baselines isolating each component of CoE. Bold denotes the best A UR OC in each configuration. Uncertainty Metric T wo LLMs (Llama + Qwen) Three LLMs (Llama + Qwen + Mistral) Rejection Accuracy A URA C A UR OC Rejection Accuracy A URA C A UR OC 80% 90% 95% 100% 80% 90% 95% 100% Semantic Entropy 0.625 0.583 0.579 0.575 0.176 0.670 0.394 0.416 0.468 0.375 0.123 0.687 Regular Entropy 0.562 0.583 0.605 0.575 0.175 0.475 0.342 0.333 0.343 0.375 0.103 0.416 P false 0.575 0.575 0.575 0.575 0.172 0.586 0.375 0.405 0.405 0.375 0.117 0.540 U E 0.625 0.583 0.589 0.575 0.177 0.661 0.368 0.388 0.437 0.375 0.116 0.716 U A 0.593 0.583 0.578 0.575 0.174 0.666 0.394 0.416 0.437 0.375 0.121 0.673 U C oE 0.593 0.583 0.578 0.575 0.174 0.683 ↑ 0.394 0.416 0.437 0.375 0.121 0.772 ↑ ranking. A URA C (Kuhn et al., 2023): the area under the rejection-accuracy curve, summarising how accuracy improv es as the most uncertain predictions are progressi vely abstained from. Higher values indicate better selecti ve prediction across all cov erage lev els. Rejection Accuracy (Nadeem et al., 2009): accuracy on the retained predictions at fixed retention le vels (80%, 90%, 95%, 100%), capturing the practical precision–cov erage trade-off at specific operating points. A UR OC and A URAC assess CoE as a ranking signal for uncertainty , while rejection accuracy assesses it as a thr eshold signal. T aken together , they provide a comprehensi ve picture of whether CoE reliably identifies which predictions to trust. 5 . 1 . 1 B A S E L I N E M E T H O D S Single-model uncertainty baselines. W e compare CoE against three standard single-model UQ methods. For multi-model settings, each baseline is reported as the arithmetic mean over all con- stituent models, i.e., 1 K P i metric ( M i , x ) . Semantic Entropy (SE) (Farquhar et al., 2024): partitions sampled responses into semantic clusters via bidirectional entailment and computes Shannon entropy ov er the cluster distribution. When av eraged uniformly over K models, this equals the aleatoric component U A of CoE (Eq. 3). The tw o are therefore numerically equiv alent under uniform weighting but dif fer in interpretation: S E treats models as independent, while U A is framed explicitly as one component of a joint decomposition. Regular Entropy (Farquhar et al., 2024): computes token-lev el entropy ov er the raw generation distribution, without semantic clustering. This metric is known to be misleading when semantically equiv alent answers receive dif ferent token sequences. P false (Madaan et al., 2023): the probability assigned by the LLM to the response “False” in a self-consistency judgment, used as a proxy for model-lev el uncertainty . W e additionally include U A and U E as ablation baselines to isolate the individual contrib ution of each CoE component. Diver gence measure ablations. T o assess the sensitivity of CoE to the choice of inter-model div ergence D ( ·∥· ) in Eq. (5), we ev aluate four instantiations that span a range of structural properties. KL diver gence D KL : asymmetric and unbounded; measures directed diver gence from each model’ s distribution to the ensemble mean. Jensen-Shannon div ergence D JS (Kruse et al., 2025): symmetric and bounded in [0 , log 2] ; the symmetrised average of two KL terms. W asserstein distance D W (Ar- jovsk y et al., 2017): geometry-aware optimal-transport distance between distrib utions ov er the cluster space. Hellinger distance D H (Beran, 1977): symmetric, bounded in [0 , 1] , based on the ℓ 2 distance between square-root densities. These four di vergences are asymmetric vs. symmetric, bounded vs. unbounded, and geometry-aware vs. geometry-agnostic, enabling a controlled comparison of which structural property matters most for CoE. 5 . 2 C O E A S A N U N C E RTA I N T Y M E T R I C Results on T riviaQA (T able 1). W e compare six uncertainty metrics across two ensemble configu- rations on T riviaQA (200 samples): two-model (Llama + Qwen) and three-model (Llama + Qwen + Mistral). In the two-model setting, CoE achiev es the highest A UR OC of 0.683 , surpassing Semantic Entropy (0.670), U A (0.666), U E (0.661), P false (0.586), and Regular Entropy (0.475). Rejection accuracy remains consistently abov e 0.58 across all retention levels, indicating well-calibrated se- lectiv e prediction e ven with limited inter -model diversity in a two-model ensemble. Notably , CoE 7 Published as a workshop paper at the workshop of “ Agentic AI in the W ild” in ICLR 2026 outperforms both of its indi vidual components ( U A and U E ) taken alone, confirming that the two uncertainty sources carry complementary information that is better captured jointly . As the ensemble scales to three models, CoE’ s advantage widens. It attains an A UR OC of 0.772 , a substantial improv ement over the strongest single-component baseline U E (0.716) and over Semantic Entropy (0.687). This scaling behaviour —where CoE’ s margin o ver baselines gro ws with ensemble size—is consistent with Theorem 3: as more heterogeneous models contribute, inter-model epistemic div ergence becomes an increasingly significant contributor to system uncertainty , and CoE’ s explicit modelling of this component yields proportionally larger gains. 6 C O N C L U S I O N W e have introduced Collaborati ve Entropy (CoE) , an information-theoretic metric for quantifying semantic uncertainty in agentic multi-LLM systems. CoE decomposes system-lev el uncertainty into two interpretable components—intra-model aleatoric uncertainty , captured by the mean semantic entropy across models, and inter-model epistemic uncertainty , captured by the weighted asymmetric KL diver gence from each model’ s cluster distribution to the ensemble mean—and provides three formal guarantees: Non-Negativity , Zero V alue Certainty , and a characterisation of the partial reductions achie vable through per -model entropy maximisation. These properties clarify precisely when individual-model certainty is sufficient for system-le vel certainty , and when residual inter-model disagreement persists as irreducible epistemic div ergence. Experiments on T riviaQA and SQuAD with three 7–8B instruction-tuned LLMs demonstrate that CoE consistently out performs single-model uncertainty baselines (semantic entropy , regular entropy , P false ) and single-component ablations ( U A , U E ) in A UR OC and A URA C, with gains that scale as additional heterogeneous models are introduced (A UROC 0 . 683 → 0 . 772 on T riviaQA; up to 0 . 878 on SQuAD). As a practical application of the metric, the CoE-guided coordination heuristic achie ves a +39 . 0% accuracy gain under asymmetric KL di ver gence, substantially exceeding symmetric alternati ves and validating the importance of reference-directed epistemic measurement. Limitations. W e acknowledge two theoretical limitations inherent to the aleatoric/epistemic decom- position adopted in CoE. First, intra-model semantic entrop y may conflate aleatoric and epistemic sources at the single-model lev el: an LLM that lacks kno wledge about a prompt may hallucinate div erse but factually incorrect answers across samples, artificially inflating SE beyond pure aleatoric uncertainty (Shorinwa et al., 2025). This epistemic contamination of SE is a known open problem in LLM uncertainty quantification and is orthogonal to the multi-LLM contribution of CoE. Second, inter-model KL div ergence may capture superficial stylistic differences between models—such as verbosity or formatting preferences induced by differing RLHF procedures—rather than genuine epistemic disagreement about the correct answer . Future work could incorporate a semantic normal- isation step (e.g., extracting canonical answer spans before clustering) to reduce the influence of stylistic variation on U E . Future directions. Sev eral extensions of CoE are natural. Scaling to larger models (e.g., 70B parameter LLMs) and to closed-source APIs—where token-le vel probabilities may be una vailable and generation frequency must serv e as a proxy for cluster probability—would broaden the applicability of the metric. Incorporating verbalized confidence (Riv era et al., 2024) or log-probability-based signals as additional uncertainty sources could further enrich the decomposition. Finally , applying CoE to sequential multi-agent settings, where models interact across multiple rounds, would test whether the metric’ s two-component structure remains informati ve when uncertainty accumulates ov er a reasoning trajectory . 7 A C K N O W L E D G M E N T This work is supported by the National Natural Science Foundation of China (Project 62271434, 62501397), Shenzhen Ke y Laboratory of Crowd Intelligence Empo wered Low-Carbon Energy Net- works (No. ZDSYS20220606100601002), the Shenzhen Stability Science Program 2023, Shenzhen Loop Area Institute, and Shenzhen Institute of Artificial Intelligence and Robotics for Society . 8 Published as a workshop paper at the workshop of “ Agentic AI in the W ild” in ICLR 2026 R E F E R E N C E S Sahar Abdelnabi, Amr Gomaa, Sarath Siv aprasad, Lea Sch ¨ onherr , and Mario Fritz. Cooperation, competition, and maliciousness: Llm-stakeholders interactiv e negotiation. Advances in Neural Information Pr ocessing Systems , 37:83548–83599, 2024. Josh Achiam, Stev en Adler , Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv pr eprint arXiv:2303.08774 , 2023. Martin Arjovsk y , Soumith Chintala, and L ´ eon Bottou. W asserstein generativ e adversarial networks. In International confer ence on machine learning , pp. 214–223. PMLR, 2017. Rudolf Beran. Minimum hellinger distance estimates for parametric models. The annals of Statistics , pp. 445–463, 1977. W eilin Cai, Juyong Jiang, F an W ang, Jing T ang, Sunghun Kim, and Jiayi Huang. A surv ey on mixture of experts in large language models. IEEE T ransactions on Knowledge and Data Engineering , 2025. Mert Cemri, Melissa Z Pan, Shuyi Y ang, Lakshya A Agrawal, Bha vya Chopra, Rishabh Tiw ari, Kurt Keutzer , Aditya Parameswaran, Dan Klein, Kannan Ramchandran, et al. Why do multi-agent llm systems fail? arXiv preprint , 2025. Chi-Min Chan, W eize Chen, Y usheng Su, Jianxuan Y u, W ei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chate val: T owards better llm-based e valuators through multi-agent debate. arXiv pr eprint arXiv:2308.07201 , 2023. Edward Y Chang. Evince: Optimizing multi-llm dialogues using conditional statistics and information theory . arXiv pr eprint arXiv:2408.14575 , 2024. Longchao Da, Xiaoou Liu, Jiaxin Dai, Lu Cheng, Y aqing W ang, and Hua W ei. Understanding the uncertainty of llm explanations: A perspecti ve based on reasoning topology . arXiv pr eprint arXiv:2502.17026 , 2025. Abhimanyu Dube y , Abhinav Jauhri, Abhina v Pande y , Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur , Alan Schelten, Amy Y ang, Angela Fan, et al. The llama 3 herd of models. arXiv e-prints , pp. arXiv–2407, 2024. Ekaterina Fadeev a, Roman V ashurin, Akim Tsvigun, Artem V azhentsev , Sergey Petrako v , Kirill Fedyanin, Daniil V asilev , Elizaveta Goncharova, Alexander Panchenko, Maxim Panov , et al. Lm-polygraph: Uncertainty estimation for language models. arXiv preprint , 2023. Ekaterina Fadee va, Aleksandr Rubashe vskii, Artem Shelmanov , Sergey Petrako v , Haonan Li, Hamdy Mubarak, Evgenii Tsymbalov , Gleb Kuzmin, Alexander Panchenko, Timothy Baldwin, et al. Fact-checking the output of large language models via token-lev el uncertainty quantification. arXiv pr eprint arXiv:2403.04696 , 2024. Sebastian Farquhar , Jannik K ossen, Lorenz Kuhn, and Y arin Gal. Detecting hallucinations in large language models using semantic entropy . Nature , 630(8017):625–630, 2024. Jiahui Geng, Fengyu Cai, Y uxia W ang, Heinz K oeppl, Preslav Nakov , and Iryna Gurevych. A survey of confidence estimation and calibration in large language models. In Pr oceedings of the 2024 Confer ence of the North American Chapter of the Association for Computational Linguistics: Human Language T ec hnologies (V olume 1: Long P apers) , pp. 6577–6595, 2024. Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Y ejin Choi. The curious case of neural text degeneration. arXiv preprint , 2019. Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Sav ary , Chris Bamford, Dev endra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts. arXiv preprint , 2024. 9 Published as a workshop paper at the workshop of “ Agentic AI in the W ild” in ICLR 2026 Mandar Joshi, Eunsol Choi, Daniel S W eld, and Luke Zettlemoyer . T riviaqa: A large scale distantly supervised challenge dataset for reading comprehension. In Pr oceedings of the 55th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pp. 1601– 1611, 2017. Laurent V alentin Jospin, Hamid Laga, F arid Boussaid, Wray Buntine, and Mohammed Bennamoun. Hands-on bayesian neural networks—a tutorial for deep learning users. IEEE Computational Intelligence Magazine , 17(2):29–48, 2022. Alistair Knott and Peter Vlugter . Multi-agent human–machine dialogue: issues in dialogue manage- ment and referring expression semantics. Artificial Intelligence , 172(2-3):69–102, 2008. Maya Kruse, Majid Afshar , Saksham Khatwani, Anoop Mayampurath, Guanhua Chen, and Y anjun Gao. Simple yet effecti ve: An information-theoretic approach to multi-llm uncertainty quan- tification. In Pr oceedings of the 2025 Conference on Empirical Methods in Natural Language Pr ocessing , pp. 30481–30492, 2025. Lorenz Kuhn, Y arin Gal, and Sebastian Farquhar . Semantic uncertainty: Linguistic in variances for uncertainty estimation in natural language generation. arXiv pr eprint arXiv:2302.09664 , 2023. Salem Lahlou, Moksh Jain, Hadi Nekoei, V ictor Ion Butoi, Paul Bertin, Jarrid Rector-Brooks, Maksym K orablyov , and Y oshua Bengio. Deup: Direct epistemic uncertainty prediction. arXiv pr eprint arXiv:2102.08501 , 2021. Huao Li, Y u Chong, Simon Stepputtis, Joseph P Campbell, Dana Hughes, Charles Le wis, and Katia Sycara. Theory of mind for multi-agent collaboration via lar ge language models. In Pr oceedings of the 2023 Confer ence on Empirical Methods in Natural Languag e Pr ocessing , pp. 180–192, 2023. Senyao Li, Haozhao W ang, W enchao Xu, Rui Zhang, Song Guo, Jingling Y uan, Xian Zhong, T ianwei Zhang, and Ruixuan Li. Collaborati ve inference and learning between edge slms and cloud llms: A surve y of algorithms, execution, and open challenges. arXiv pr eprint arXiv:2507.16731 , 2025. Chen Ling, Xujiang Zhao, Xuchao Zhang, W ei Cheng, Y anchi Liu, Y iyou Sun, Mika Oishi, T akao Osaki, Katsushi Matsuda, Jie Ji, et al. Uncertainty quantification for in-conte xt learning of large language models. In Pr oceedings of the 2024 Confer ence of the North American Chapter of the Association for Computational Linguistics: Human Language T echnologies (V olume 1: Long P apers) , pp. 3357–3370, 2024. Aixin Liu, Bei Feng, Bing Xue, Bingxuan W ang, Bochao W u, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv pr eprint arXiv:2412.19437 , 2024. Haoxiang Luo, Y inqiu Liu, Ruichen Zhang, Jiacheng W ang, Gang Sun, Dusit Niyato, Hongfang Y u, Zehui Xiong, Xianbin W ang, and Xuemin Shen. T oward edge general intelligence with multiple- large language model (multi-llm): architecture, trust, and orchestration. IEEE T ransactions on Cognitive Communications and Networking , 2025. Aman Madaan, Niket T andon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah W iegref fe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Y iming Y ang, et al. Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Pr ocessing Systems , 36:46534–46594, 2023. Matthew McDermott, Haoran Zhang, Lasse Hansen, Giov anni Angelotti, and Jack Gallifant. A closer look at auroc and auprc under class imbalance. Advances in Neural Information Pr ocessing Systems , 37:44102–44163, 2024. Malik Sajjad Ahmed Nadeem, Jean-Daniel Zuck er , and Blaise Hanczar . Accuracy-rejection curves (arcs) for comparing classification methods with a reject option. In Machine Learning in Systems Biology , pp. 65–81. PMLR, 2009. Ben Prystawski, Michael Li, and Noah Goodman. Why think step by step? reasoning emerges from the locality of experience. Advances in Neural Information Pr ocessing Systems , 36:70926–70947, 2023. 10 Published as a workshop paper at the workshop of “ Agentic AI in the W ild” in ICLR 2026 Pranav Rajpurkar , Jian Zhang, K onstantin Lopyrev , and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. arXiv preprint , 2016. Nian Ran, Zhongzheng Li, Y ue W ang, Qingsong Ran, Xiaoyuan Zhang, Shikun Feng, Richard Allmendinger , and Xiaoguang Zhao. Mcce: A framework for multi-llm collaborativ e co-ev olution. arXiv pr eprint arXiv:2510.06270 , 2025. Mauricio Ri vera, Jean-Fran c ¸ ois Godbout, Reihaneh Rabban y , and K ellin Pelrine. Combining con- fidence elicitation and sample-based methods for uncertainty quantification in misinformation mitigation. In Pr oceedings of the 1st W orkshop on Uncertainty-A war e NLP (UncertaiNLP 2024) , pp. 114–126, 2024. Standard Self-Reflection. Self-contrast: Better reflection through inconsistent solving perspecti ves. arXiv pr eprint , 2024. Claude E Shannon. A mathematical theory of communication. The Bell system technical journal , 27 (3):379–423, 1948. Ola Shorinwa, Zhiting Mei, Justin Lidard, Allen Z Ren, and Anirudha Majumdar . A survey on uncertainty quantification of large language models: T axonomy , open research challenges, and future directions. A CM Computing Surveys , 2025. Karan Singhal, Shekoofeh Azizi, T ao T u, S Sara Mahdavi, Jason W ei, Hyung W on Chung, Nathan Scales, Ajay T anwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowledge. Natur e , 620(7972):172–180, 2023. Gemini T eam, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Y u, Radu Soricut, Johan Schalkwyk, Andre w M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models. arXiv pr eprint arXiv:2312.11805 , 2023. Qwen T eam et al. Qwen2 technical report. arXiv preprint , 2(3), 2024. Qineng W ang, Zihao W ang, Y ing Su, Hanghang T ong, and Y angqiu Song. Rethinking the bounds of llm reasoning: Are multi-agent discussions the key? In Pr oceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long P apers) , pp. 6106–6131, 2024. Y ongjin Y ang, Haneul Y oo, and Hwaran Lee. Maqa: Evaluating uncertainty quantification in llms regarding data uncertainty . In Findings of the Association for Computational Linguistics: NAA CL 2025 , pp. 5846–5863, 2025. 11 Published as a workshop paper at the workshop of “ Agentic AI in the W ild” in ICLR 2026 A T H E O R E T I C A L A NA L Y S I S O F C O E A N D A C O E - G U I D E D C O O R D I NA T I O N H E U R I S T I C W e first establish three formal properties of CoE as an uncertainty metric (Sec. A.1), then present a lightweight coordination heuristic motiv ated by these properties (Sec. A.2). A . 1 T H E O R E T I C A L P RO P E R T I E S O F C O E Theorem 1 (Non-Ne gativity) . F or any input x and model set M = {M 1 , . . . , M K } , U C oE ( K ) ≥ 0 . Pr oof of Theorem 1 (Non-Ne gativity). The aleatoric term U A = 1 K P i S E i ( x ) ≥ 0 follows im- mediately from the non-negati vity of Shannon entropy: for any distribution over l clusters, − P j p ( c j ) log p ( c j ) ≥ 0 , since p ( c j ) ∈ [0 , 1] and u log u ≤ 0 for u ∈ (0 , 1] . The epistemic term satisfies K X i =1 w i D KL ( p i ∥ ¯ p ) = K X i =1 w i l X j =1 p i ( c j | x ) log p i ( c j | x ) ¯ p ( c j | x ) ≥ 0 , (6) by the non-negati vity of KL diver gence, with equality if f p i ( · | x ) = ¯ p ( · | x ) for all i . Since w i ≥ 0 and P i w i = 1 , the weighted sum is also non-negati ve. As U C oE is the sum of two non-negati ve terms, U C oE ( K ) ≥ 0 . Theorem 2 (Zero V alue Certainty) . U C oE ( K ) = 0 if and only if ther e exists a single semantic cluster c ∗ such that p i ( c ∗ | x ) = 1 for all i ∈ { 1 , . . . , K } , i.e., e very model places all its pr obability mass on the same semantic cluster . Pr oof of Theorem 2 (Zer o V alue Certainty). Suppose p i ( c | x ) = 1 for all i and some fixed cluster c . The ensemble mean then satisfies ¯ p ( c | x ) = P i w i · 1 = 1 and ¯ p ( c j | x ) = 0 for all j = c . The aleatoric term reduces to − l X j =1 ¯ p ( c j | x ) log ¯ p ( c j | x ) = − 1 · log 1 − X j = c 0 = 0 . For the epistemic term, since p i ( c | x ) = ¯ p ( c | x ) = 1 and p i ( c j | x ) = ¯ p ( c j | x ) = 0 for j = c , D KL ( p i ∥ ¯ p ) = 1 · log 1 1 + X j = c 0 = 0 ∀ i, so P i w i D KL ( p i ∥ ¯ p ) = 0 . Hence U C oE ( K ) = 0 . Con versely , if U C oE = 0 , then both terms v anish. U A = 0 requires each S E i ( x ) = 0 , i.e., e very p i is a Delta distribution. U E = 0 then requires D KL ( p i ∥ ¯ p ) = 0 for all i , i.e., p i = ¯ p for all i , which holds iff all Delta distrib utions concentrate on the same cluster . Remark 1 . Theorem 2 makes precise the ideal state of a multi-LLM system: CoE reaches its global minimum of zero only when all models are simultaneously internally certain and mutually consistent. Neither condition alone is sufficient. T o characterise the partial reductions of CoE achie vable through per-model optimisation, we introduce the following: Definition 3 (Delta Distribution) . The cluster distribution p i ( · | x ) of model M i is called a Delta distribution , written p ∗ i ( · | x ) , if there e xists a unique cluster c ∗ i such that p i ( c ∗ i | x ) = 1 and p i ( c j | x ) = 0 for all j = c ∗ i . Remark 2 . p ∗ i is the unique global maximiser of − S E i ( x ) ov er the probability simplex ∆ l − 1 , since S E i ( x ) ≥ 0 with equality if and only if p i is a Delta distribution (Shannon, 1948). Consequently , driving model M i tow ard p ∗ i eliminates its contribution to U A entirely , but does not by itself control U E . 12 Published as a workshop paper at the workshop of “ Agentic AI in the W ild” in ICLR 2026 Theorem 3 (Delta-Distribution Behaviour) . Let M = {M 1 , . . . , M K } with fixed non-ne gative weights { w i } satisfying P K i =1 w i = 1 , and let each p ∗ i ( c j | x ) be the Delta distribution of M i concentrating on cluster c j ∗ i . Suppose p i = p ∗ i for all i . Then: 1. Aleatoric minimum. U A = 0 . 2. Case A — Consensus. If j ∗ 1 = j ∗ 2 = · · · = j ∗ K =: j ∗ , then U E = 0 and U C oE ( K ) = 0 , the global minimum of Theor em 2. 3. Case B — Residual Disagreement. If ∃ i = k such that j ∗ i = j ∗ k , then U E > 0 and U C oE ( K ) = U E = K X i =1 w i · D KL ( p ∗ i ∥ ¯ p ∗ ) , (7) wher e ¯ p ∗ ( c j | x ) = P i w i 1 [ j = j ∗ i ] . Pr oof of Theorem 3 (Delta-Distrib ution Behaviour). Part (i): U A = 0 . Shannon entropy satis- fies S E i ( x ) ≥ 0 for any distribution ov er l clusters, with equality iff p i is a Delta distribu- tion (Definition 3). When every p i = p ∗ i (a Delta distribution), S E i ( x ) = 0 for all i , so U A = 1 K P i S E i ( x ) = 0 . Part (ii): Case A (Consensus). Suppose j ∗ 1 = · · · = j ∗ K = j ∗ , i.e., all Delta distributions concentrate on c j ∗ . The ensemble mean satisfies ¯ p ∗ ( c j ∗ | x ) = P i w i · 1 = 1 and ¯ p ∗ ( c j | x ) = 0 for j = j ∗ . For each model, D KL ( p ∗ i ∥ ¯ p ∗ ) = 1 · log 1 1 = 0 , so U E = P i w i · 0 = 0 and U C oE = 0 , consistent with Theorem 2. Part (iii): Case B (Residual Disagreement). Suppose ∃ i = k with j ∗ i = j ∗ k . Without loss of generality , let p ∗ 1 ( c ∗ 1 | x ) = 1 and p ∗ 2 ( c ∗ 2 | x ) = 1 with c ∗ 1 = c ∗ 2 . The ensemble mean satisfies ¯ p ∗ ( c ∗ 1 | x ) = w 1 > 0 and ¯ p ∗ ( c ∗ 2 | x ) = w 2 > 0 . For model M 1 , D KL ( p ∗ 1 ∥ ¯ p ∗ ) = 1 · log 1 w 1 = − log w 1 > 0 , since w 1 < 1 . Hence U E > 0 , and U C oE ( K ) = U A |{z} = 0 + U E = K X i =1 w i D KL ( p ∗ i ∥ ¯ p ∗ ) > 0 , where ¯ p ∗ ( c j | x ) = P i w i 1 [ j = j ∗ i ] . This residual CoE is irreducible by per-model optimisation alone and reflects genuine epistemic disagreement across heterogeneous models, corresponding to Quadrant II in Figure 2. Remark 3 . Theorem 3 reveals a fundamental asymmetry in how the two CoE components can be reduced. The aleatoric component U A can always be driv en to zero by per -model negati ve-entropy maximisation, independently of what other models do. The epistemic component U E , howe ver , cannot be controlled by any single model: it vanishes only when all models con verge to the same cluster (Case A), and persists otherwise as irreducible inter-model disagreement (Case B). This distinction is in visible to single-model UQ metrics and motiv ates the decomposed structure of CoE. Theorem 3 is stated ov er the semantic cluster distribution induced by sampling and does not imply deterministic token-le vel generation. A . 2 A C O E - G U I D E D P O S T - H O C C O O R D I N A T I O N H E U R I S T I C Theorems 1–3 characterise when and how CoE can be reduced. W e now describe a simple, training- free, post-hoc heuristic that operationalises this intuition at inference time. This procedure is best understood as a practical application of the CoE metric rather than a standalone algorithmic contribution: it uses CoE-derived signals to re weight the ensemble and refine model coordination, without updating any model parameters. Algorithm 1 gives the full procedure. W e describe its two stages below . 13 Published as a workshop paper at the workshop of “ Agentic AI in the W ild” in ICLR 2026 Algorithm 1 CoE-Guided Coordination Heuristic Require: Query x , model set M = {M 1 , . . . , M K } , con ver gence threshold ϵ > 0 , maximum iterations T max Ensure: Per-model output distributions { p ∗ 1 , . . . , p ∗ K } , final CoE value U ∗ C oE 1: Set t ← 0 2: Initialise weights uniformly: w (0) i ← 1 K for all i 3: f or i = 1 to K do 4: Sample m responses: S i ← { s i, 1 , . . . , s i,m } 5: Cluster S i via bidirectional entailment; compute p (0) i via Eq. (8) 6: end f or 7: Compute ensemble mean: ¯ p (0) ← P K i =1 w (0) i p (0) i 8: Compute initial CoE: U (0) C oE via Eq. (5) 9: while t < T max do 10: for i = 1 to K do 11: { Step 2a: greedy Delta-distribution approximation } 12: j ∗ i ← arg max j p ( t − 1) i ( c j | x ) 13: p ( t ) i ( c j | x ) ← 1 [ j = j ∗ i ] { Eq. (9) } 14: { Step 2b: entropy-proportional weight update } 15: ˜ w ( t ) i ← w ( t − 1) i 1 + P j p ( t ) i ( c j | x ) log p ( t ) i ( c j | x ) 16: end for 17: Normalise: w ( t ) i ← ˜ w ( t ) i / P K k =1 ˜ w ( t ) k 18: Update ensemble mean: ¯ p ( t ) ← P K i =1 w ( t ) i p ( t ) i 19: Recompute: U ( t ) C oE via Eq. (5) 20: if U ( t ) C oE − U ( t − 1) C oE < ϵ then 21: p ∗ i ← p ( t ) i for all i ; break 22: end if 23: t ← t + 1 24: end while 25: U ∗ C oE ← U ( t ) C oE Stage 1: Semantic clustering and initialisation (Lines 1–8). For each model M i , we draw m candidate responses and partition them into semantic clusters via bidirectional entailment scoring: two sequences s a , s b are assigned to the same cluster if each entails the other . The initial cluster probability is: p (0) i ( c j | x ) = X s ∈ c j p ( s | x ) X k X s ∈ c k p ( s | x ) , (8) where p ( s | x ) is the length-normalised generation log-probability of sequence s . Ensemble weights are initialised uniformly: w (0) i = 1 /K . Stage 2: Iterative r efinement (Lines 9–24). Step 2a — Greedy Delta-distribution appr oxima- tion (Lines 12–13). Motiv ated by Theorem 3 (i), each model’ s distribution is updated tow ard its Delta distribution by concentrating all probability mass on its currently most probable cluster: p ( t ) i ( c j | x ) = ( 1 if j = j ∗ i := arg max j p ( t − 1) i ( c j | x ) , 0 otherwise. (9) This greedy step is O ( l ) per model per iteration and requires neither gradient computation nor model retraining. Alternativ e solvers—gradient ascent on a softmax-parameterised distribution, genetic algorithms, or Bayesian optimisation over the cluster simplex—may be substituted at Line 11 when a smoother optimisation trajectory is preferred. Step 2b — Entropy-pr oportional weight update (Lines 14–17). After updating the distributions, ensemble weights are adjusted to giv e higher influence to models that have achie ved greater semantic 14 Published as a workshop paper at the workshop of “ Agentic AI in the W ild” in ICLR 2026 T able 2: The performance of dif ferent single LLMs on different dataset (200 samples) LLMs T riviaQA Dataset SQuAD Dataset Train Accuracy V alidation Accuracy Train Accuracy V alidation Accuracy Llama-3.1-8b-instruct 0.65 0.675 0.225 0.1 Qwen-2.5-7b-instruct 0.6 0.55 0.2 0.15 Mistral-7b-instruct 0.375 0.375 0.05 0.075 certainty: w ( t ) i = w ( t − 1) i 1 + P j p ( t ) i ( c j | x ) log p ( t ) i ( c j | x ) P K k =1 w ( t − 1) k 1 + P j p ( t ) k ( c j | x ) log p ( t ) k ( c j | x ) . (10) The numerator factor 1 + P j p log p equals 1 − S E ( t ) i , which lies in [0 , 1] and is maximised at 1 when p ( t ) i is a Delta distribution. The update thus implements a soft version of majority-weight assignment: models that have already con ver ged to a confident cluster receiv e proportionally larger weight, pulling the ensemble mean ¯ p ( t ) = P i w ( t ) i p ( t ) i tow ard the consensus. The CoE is then recomputed via Eq. (5), and con ver gence is declared when |U ( t ) C oE − U ( t − 1) C oE | < ϵ . B C O M P L E X I T Y A NA L Y S I S The total computational cost of Algorithm 1 decomposes into three stages. Stage 1: Sequence generation. Generating m candidate responses for each of the K models incurs O P K i =1 F ( M i ) , where F ( M i ) denotes the autoregressiv e inference cost of model i (typically O ( m · L max · d 2 ) for sequence length L max and hidden dimension d ). This is the dominant bottleneck. Stage 2: Semantic clustering. Partitioning the m K responses into semantic clusters via pairwise bidirectional entailment incurs O ( K · C cluster ) , where C cluster = O ( m 2 · C NLI ) and C NLI is the cost of a single NLI inference call. In practice, m is small ( m ≤ 10 ), so this term is modest relative to Stage 1. Stage 3: Iterative r efinement. Each of the T iterations performs a greedy Delta-distrib ution update ( O ( l ) per model) and a CoE recomputation ( O ( K · l ) ), gi ving O ( T · K · l ) in total. The ov erall complexity is therefore: O K X i =1 F ( M i ) + K · C cluster + T · K · l ! . (11) Since l ≤ 10 and T ≤ 10 in all our experiments, the T · K · l term is negligible relative to the generation cost. CoE thus adds minimal overhead to a standard multi-LLM inference pipeline: Stages 2 and 3 are plug-and-play post-processing steps that operate on already-generated outputs and do not require any model retraining or gradient computation. B . 1 D E TA I L E D E X P E R I M E N TA L R E S U LT S T riviaQA is a large-scale reading comprehension dataset containing over 950K question-answer pairs authored by tri via enthusiasts and scraped from the W eb, with distant supervision from 662K e vidence documents. Its questions are designed to be challenging and compositional, requiring models to handle long, noisy contexts and complex reasoning. SQuAD consists of 100K+ crowdsourced question-answer pairs on W ikipedia articles. The code will be released upon acceptance. T able 2 presents the performance of three instruction-tuned lar ge language models (Llama-3.1-8b- instruct, Qwen-2.5-7b-instruct, and Mistral-7b-instruct) on the T riviaQA and SQuAD machine reading comprehension datasets, ev aluated using a 200-sample subset. Performance is quantified by accuracy 15 Published as a workshop paper at the workshop of “ Agentic AI in the W ild” in ICLR 2026 ( a ) Llama ( b ) Qwen ( c ) Mistral ( d ) Llama + Qwen ( e ) Llama + Qwen + Mistral ( f ) 2Llama + 2Qwen + 2Mistral Figure 3: Performance comparison of CoE with different div ergence metrics on T riviaQA dataset (200 samples, KL div ergence). ( a ) Llama ( b ) Qwen ( c ) Mistral ( d ) Llama + Qwen ( e ) Llama + Qwen + Mistral ( f ) 2Llama + 2Qwen + 2Mistral Figure 4: Performance comparison of CoE with different di ver gence metrics on SQuAD dataset (200 samples, KL div ergence). on both training and validation splits, rev ealing that Llama-3.1-8b-instruct achieves the highest ov erall accuracy across both datasets: on T riviaQA , it scores 0.65 on the training set and 0.675 on the validation set, while on SQuAD , it attains 0.225 and 0.1 respectively . By contrast, Mistral-7b- instruct exhibits the lowest performance, with 0.375/0.375 accuracy on T riviaQA and 0.05/0.075 on SQuAD , and Qwen-2.5-7b-instruct yields intermediate results. These findings underscore the varying generalization capabilities of the models across dif ferent reading comprehension tasks, with Llama-3.1-8b-instruct demonstrating superior robustness, and all models sho wing a marked decline in accuracy when shifting from T riviaQA to SQuAD , suggesting dataset-specific task challenges. As shown in T able 1, CoE consistently outperforms existing metrics across various ensemble configu- rations. In a two-LLMs’ setup (Llama + Qwen), CoE achiev es an A UR OC of 0.683, significantly surpassing SE (0.670) and U E (0.661). This superiority becomes more pronounced as the ensemble scales: with three models, CoE attains an A UR OC of 0.772, a substantial gain ov er the strongest baseline U E (0.716). These results, further visualized in Figure 3, validate that CoE ef fectiv ely harnesses complementary signals from heterogeneous models by jointly minimizing intra-model uncertainty and maximizing beneficial inter-model di vergence. Figure 4 presents a parallel ev aluation on the SQuAD dataset, mirroring the structure of Figure 3. Subfigures ( a )-( c ) assess the same indi vidual models (Llama, Qwen, and Mistral), where Semantic Entropy again leads with the highest A UR OC and rejection accuracy , though overall scores are lo wer than on T riviaQA (e.g., A UR OC < 0 . 82 ), reflecting SQuAD ’ s emphasis on extracti ve reasoning and the models’ varying capabilities in handling context-heavy tasks. The limited improvements in rejection accuracy (typically < 0 . 2 at 80% retention) further expose single-model constraints in finer- grained uncertainty estimation. Subfigures ( d )-( f ) highlight multi-LLM gains, with CoE’ s superiority 16 Published as a workshop paper at the workshop of “ Agentic AI in the W ild” in ICLR 2026 Figure 5: Robustness of the CoE-reduction algorithm to the conv ergence threshold ϵ (Llama + Qwen ensemble on T riviaQA , 200 shots). ( a ) Different T emperatures ( b ) Different Generations Figure 6: Analysis of CoE-Reduction optimization algorithm under different sampling temperatures and generation counts (Llama + Qwen on T riviaQA dataset with 200 in-context examples). scaling ev en more prominently on SQuAD . In two-model ( d : Llama + Qwen), three-model ( e : Llama + Qwen + Mistral), and six-model ( f : 2Llama + 2Qwen + 2Mistral) setups, CoE consistently delivers the highest A UR OC (reaching 0 . 878 ↑ in three-model and 0 . 811 ↑ in six-model configurations) and competiti ve rejection accuracy , surpassing baselines by up to 20% in lar ger ensembles. This enhanced performance on SQuAD v alidates CoE’ s robustness across datasets, as it ef fectiv ely integrates inter - model div ergence to mitigate conte xt-specific hallucinations, outperforming methods like U A , U E , Semantic Entropy , Regular Entropy , and P f alse . The results reinforce CoE’ s design efficacy in capturing collaborativ e signals, enabling more accurate UQ and selectiv e prediction in div erse, real-world multi-LLM deployments for edge AI systems. Con vergence and Sensitivity Figure 5 ev aluates the rob ustness of the CoE-reduction algorithm with respect to the con vergence threshold ϵ on the T riviaQA dataset (200 shots, Llama + Qwen ensemble). In subplot (a), we observ e that the number of iterations required for con ver gence increases linearly from approximately 4.0 to 7.0 as ϵ decreases from 10 − 4 to 10 − 8 , demonstrating that stricter con ver gence criteria impose higher computational costs but do not prevent the algorithm from con ver ging. Subplot (b) rev eals that the ensemble accuracy remains relativ ely stable, fluctuating between 0.65 and 0.70 with a peak near ϵ = 10 − 6 , indicating that the final performance of the ensemble is insensitive to the choice of ϵ . Meanwhile, the optimized CoE decreases from 0.94 to 0.88 as ϵ becomes smaller, reflecting a trade-off between conv ergence stringency and the internal consistency of the ensemble. T ogether , these results confirm the robustness of the CoE-reduction algorithm: it maintains stable performance across varying con vergence thresholds while exhibiting predictable con ver gence behavior . Impact of T emperature and Sample V olume Figure 6 demonstrates that CoE optimization is highly robust to sampling temperature. While higher temperatures ( 0 . 8 → 1 . 0 ) naturally increase prediction div ersity , CoE-guided weighting ef fectively transforms this stochasticity into useful signals, maintaining stable ensemble accuracy (92%–95%). Furthermore, performance scales gracefully with the number of generations (Figure 6b); increasing samples from 4 to 8 per model yields a steady accuracy gain ( 81 . 9% → 96 . 0% ), indicating that CoE efficiently exploits av ailable diversity ev en with low computational o verhead. B . 2 A N A L Y S I S O F T H E C O E - G U I D E D C O O R D I NA T I O N H E U R I S T I C Effect of div ergence measure (Figur e 7). Figure 7 compares the four di ver gence instantiations of CoE on Tri viaQA (Llama + Qwen, 200 samples), reporting both initial and post-heuristic CoE 17 Published as a workshop paper at the workshop of “ Agentic AI in the W ild” in ICLR 2026 Figure 7: Accuracy gain and residual CoE after applying the CoE-guided coordination heuristic under four div ergence measures (Llama + Qwen on T riviaQA, 200 samples). Initial CoE (light bars) and optimised CoE (dark bars) are shown on the left axis; ensemble accuracy g ain is annotated on each bar . values and the resulting ensemble accuracy gain. The asymmetric KL div ergence is the only measure that drives CoE to approximately its theoretical lower bound, yielding a +39 . 0% accuracy gain . Symmetric alternativ es achiev e markedly smaller gains: JS div ergence ( +27 . 5% ), Hellinger distance ( +23 . 0% ), and W asserstein distance ( +20 . 5% ) all leave a substantially lar ger residual CoE. This result is consistent with the directional structure of inter -model epistemic di vergence. D KL ( p i ∥ ¯ p ) measures how far model i ’ s distribution departs from the ensemble consensus—a naturally asymmetric quantity , since the relev ant question is whether an individual model is an outlier relativ e to the group, not whether the group is an outlier relative to the indi vidual. Symmetric measures conflate these two directions and therefore underestimate the epistemic di ver gence of confident but dissenting models. W e use KL diver gence as the default in all CoE experiments. 18
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment