Kernel-Smith: A Unified Recipe for Evolutionary Kernel Optimization
We present Kernel-Smith, a framework for high-performance GPU kernel and operator generation that combines a stable evaluation-driven evolutionary agent with an evolution-oriented post-training recipe. On the agent side, Kernel-Smith maintains a popu…
Authors: He Du, Qiming Ge, Jiakai Hu
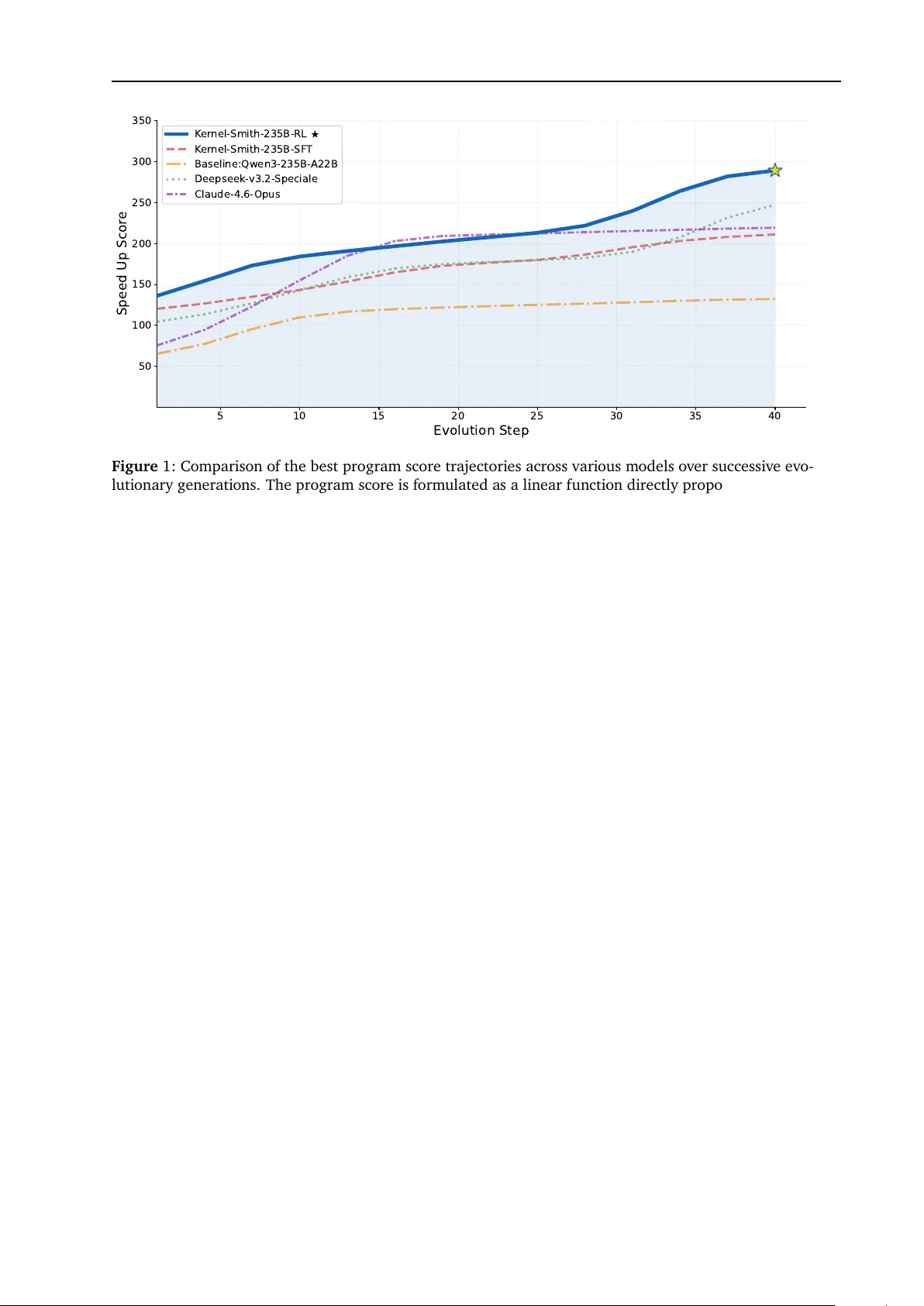
2026-3-31 K ern el-Smith: A U nifi ed R ecipe f or E v oluti o n ary K ern el Optimi z ati on He Du † 1,3 , Qiming Ge † 1 , Jiakai Hu 1 , Aijun Y ang 1 , Zheng Cai 1 , Zixian Huang 1 , Sheng Y uan 1 , Qinxiu Cheng 1 , Xinchen Xie 1 , Yicheng Chen 1,3 , Yining Li 1 , Jiaxing Xie 2 , Huan an Dong 2 , Y aguang Wu 2 , Xiang jun Huang 2 , Jian Y ang 2 , Hui W ang 1 , Bow en Zhou 1 , Bow en Li ‡ 1 , Qipeng Guo ‡ 1 and Kai Chen ‡ 1 1 Shanghai AI L aboratory , 2 MetaX, 3 Fudan Univ ersit y High-performan ce GPU kernel generati on is increasingly important for both l arge-model systems and broader scientific or ind ustrial workloads, yet current LLM-ba sed approaches still struggle to sustain reliab le optimization beyond one-shot code generation. W e present K ernel-Smith, a framew ork f or high- performan ce GPU kern el and operator generati on that combin es a stab le eva luation-driv en ev olutionary a gent with an evolutio n-oriented post-training recipe. On the a gent side, Kernel-Smith maintains a population o f executab le candidates and iterativ ely improv es them using an archiv e of top-perf orming and div erse programs together with stru ctured execution feed back on co mpil atio n, correctness, and s peedup. T o ma ke this search reli ab le, w e b uild backend-specific eva luation servi ces for T riton on NVI DIA GP U s and Maca on MetaX GP U s. On the training side, we con vert long-horizon evoluti on trajectories into step-centric supervisio n and reinf orcement learning signals by ret aining correctness-preserving, high-gain revisions, so that the model is optimiz ed as a strong loca l improv er inside the evoluti onary loop rather than as a on e-shot generator . Under a unifi ed evoluti onary protocol, Kern el-Smith-235B -RL achieves state-of -the-art o vera ll performance on KernelBen ch with Nvidia T riton backend, attaining the best av erage speed up rati o and outperf orming frontier propri et ary m odels including Gemini-3.0-pro and Claude-4.6-opus. W e further va lidate the framework on the Met aX MA C A backend, where our Kern el-Smith-MA CA-30B surpasses large-scale co unterparts such a s DeepSeek- V3.2-think and Qw en3-235B -2507-think, highlighting potential for seamless adaptatio n across heterogeneo us platforms. Beyo nd benchmark results, the same workfl ow prod uces upstream contrib uti ons to prod ucti on systems in cluding S GL ang and LMDeploy , dem onstrating that LLM-driv en kernel optimization can transfer from controll ed evaluati on to practi cal deployment. Project P age: https://chat.intern-ai.org.cn/kernel-smith * 1. Introd ucti on High-performan ce kernels are centra l to translating hardware capa bilit y into practica l throughput on m od- ern accelerators. Systems su ch as Megatron [ 22 ], XTuner [ 6 ], vLLM [ 9 ], S GL ang [ 34 ], and LMDeploy [ 5 ] hav e dem onstrated that caref ul kernel optimization can improv e large-model training and inference by large margins. This dependence on kern el engineering extends well beyond f oundati on models: scientific computing w orkloads in AI for S cien ce ( AI4S) [ 32 ] and deployment pipelines in div erse ind ustrial settings likewise rely on effi cient operator implementatio ns to realize the performance potenti al o f the underlying hardware. Although programming has beco me a represent ative ca pabilit y of m odern LLMs [ 3 , 21 ], recent studies suggest that high-perf ormance kern el generatio n remains far from solv ed [ 8 , 19 , 28 , 35 ]. In particular , achieving end-to-end autono mo us contrib utions to real prod ucti on repositori es is still highly chall enging. W e argue that ma king LLM-based kernel dev elopment practica l requires solving two coupl ed prob lems. First, effici ent kernels usua lly emerge only after searching ov er many implementatio n choices, including * The onlin e demo is powered by a customized versi on of the Intern-S1-Pro model [ 36 ]. † These authors contrib uted equally to this work. ‡ Corresponding a uthors: Bow en Li (libow en@pjlab.org.cn), Qipeng Guo (gu oqipeng@pjlab.org.cn) Kai Chen ( chenkai@pjlab.org.cn) Kern el-Smith : A Unifi ed R ecipe for Ev olutionary Kernel Optimi zation alternativ e f usi on patterns, tiling strategies, and rewrite directions. Existing systems in creasingly rely on m ulti-turn refinement or history-conditi oned a gent loops [ 1 , 7 , 10 , 14 , 27 , 33 ]. While usef ul for l ocalized deb ugging, these procedures can anchor later proposals to early decisi ons and limit expl oration di versit y . Second, f unctio nal correctness and high perf ormance are not the same ca pabilit y . The objectiv e is therefore not merely to generate on e correct and fast kernel in a single pass, b ut to sustain iterativ e optimiz atio n that keeps impro ving candidate programs and makes effectiv e use of additional test-time co mpute. T o address these challenges, w e propose Kernel-Smith, a unifi ed framew ork that combines a reliab le eva luation-driv en ev olutionary a gent with a training recipe t ailored to evolutio nary search through the identificati on o f key impro vement steps fro m evoluti on trajectori es. An o vervi ew of the full framework is sho wn in Figure 2 . The first design choi ce of Kernel-Smith lies in its agent framew ork. Ev olutionary search is a natural fit for kernel optimization because it maint ains a population o f executab le candidates and a llow s perf ormance gains to accum ul ate o ver m ultiple rounds o f search [ 18 ]. Ho wev er , this paradigm is highly sensitiv e to eva luation variance: when profiling noise is large, the search may preserve suboptimal kernels or eliminate genuin ely promising o nes, and su ch mist akes compound across generations. W e therefore center the agent design on kernel-specifi c evaluati on stabilit y , combining fixed computation graphs, repeated mea surements, and outli er remo va l to suppress timing no ise and preserve reli ab le search dyn amics. The second design choi ce of K ernel-Smith li es in its training recipe. Rather than optimi zing the m odel for one-shot kernel generati on, w e train it to act as a strong local impro v er inside the ev olutionary l oop. Concretely , w e transf orm long-horizon ev olutio n trajectories into step-centric training signals and retain only the high-gain revisi ons that mo ve a candidate to ward better correctness-preserving performance. This filtering strategy acts a s a form of trajectory compression: instead o f imit ating ev ery intermediate transition, the m odel learns the atomi c improv ements that contrib ute m ost to ev entual s peedup. W e apply the same principle in both supervised fine-tuning and reinf orcement learning, where carefully selected optimiz atio n steps provide more informati ve learning sign als than f ull trajectories that may cont ain redundant transitions or shortcut opportunities. As a result, Kernel-Smith improv es not only single-step edit qua lit y , but a lso the rate at which gains compound o ver su ccessive rounds of evolutio nary search. These two design choi ces translate into clear empirical gains. Under a unifi ed ev olutionary-a gent proto- col, Kern el-Smith-235B -RL achiev es state-of-the-art o vera ll performan ce on KernelBen ch [ 19 ], attaining the best av erage speed up ratio while maint aining strong correctness against competitiv e open-weights baselines as w ell as frontier proprietary models such a s Gemini-3.0-pro and Cl aude-4.6-opus. More importantly , Figure 1 sho ws that its best-score gro wth curve forms the upper envel ope o f competing m odels throughout the search process, indicating that our m odel benefits m ore effectiv ely from additi onal test-time compute. This result directly reflects the role of our t wo core compo nents: st ab le evaluatio n preserv es reliab le search dynamics, while ev olutio n-oriented post-training impro v es the qualit y o f each optimization step and all ows gains to compound ov er longer horizons. Beyo nd benchmark performan ce, we f urther va lidate the practical va lue o f Kernel-Smith thro ugh accepted pull requests to widely used inferen ce engines including S GLang [ 34 ] and LMDeploy [ 5 ], dem onstrating that the framework transf ers from controll ed evaluati on to real deployment settings. 2. R elated W ork 2.1. Benchmarks for LLM-Driv en Kern el Generation Benchmark design has become central to LLM-driv en kernel generatio n because pass rate alo ne does not capture whether a gen erated kernel is actua lly usef ul in practi ce. Kern elBench [ 19 ] estab lished the cano nical evaluatio n setting by form ulating the task as repl acing PyT orch reference implementations with faster GP U kernels and by introducing the fast p family of metri cs, which jo intly reflects correctness and speed up. Subsequent benchmarks extend this setup al ong compl ement ary axes rather than simply increa sing scale. MultiKern elBench [ 28 ] broadens evaluatio n bey ond a single hardware stack to study cross-platform kernel generatio n, CUDABen ch [ 35 ] expands the task scope to ward text-to-CUDA generatio n , and Trit onGym [ 8 ] focuses on benchmarking a gentic workfl ows for T riton code generation. T aken together , these benchmarks mo ve the field from an ecdot al ca se studies to ward reproducib le, executi on-grounded eva luation, while also underscoring that strong results o n st andardized t asks do not yet f ully resolv e the chall enges of heterogen eous and prod ucti on-facing kernel optimization. 2 Kern el-Smith : A Unifi ed R ecipe for Ev olutionary Kernel Optimi zation 5 10 15 20 25 30 35 40 Evolution Step 50 100 150 200 250 300 350 Speed Up Scor e K er nel-Smith-235B-RL K er nel-Smith-235B-SF T Baseline:Qwen3-235B- A22B Deepseek- v3.2-Speciale Claude-4.6- Opus Figure 1: Compariso n of the best program score trajectori es across v arious models o ver successiv e evo- lutio nary generatio ns. The program score is f orm ul ated a s a linear functio n directly proportio nal to the speed up, penalizing programs that f ail compilatio n or correctness checks by assigning them a ppropriately lo w scores. Throughout the evoluti on steps, our RL model (Kern el-Smith-235B -RL) exhibited superior effici ency for evoluti on and peak performance. 2.2. Agent Systems and Model Training for Kern el Generation A critical bottleneck in automating kernel generati on is the scarcit y o f human-optimiz ed, high-performance CUDA and T riton code, which limits st andard supervised fine-tuning. T o break this ceiling, recent ad- vancements utilize R einforcement L earning from V erifiab le R ewards (RL VR) [ 26 ]. For inst ance, AutoT riton [ 11 ] combin es an automated data distillation pipeline with Group R elativ e Policy Optimi zation ( GRPO), utilizing rule-ba sed and executio n-based rewards to specifi cally est ab lish foundati onal T riton programming capa bilities. Bey ond single-pa ss generation, m ulti-agent w orkflow s and multi-turn RL are designed to replicate the iterative deb ugging and tuning trajectori es of performance engineers. Frameworks su ch as Astra and CudaForge partitio n the cognitiv e load into specialized rol es, iterativ ely refining kernels based on feed back from pro filers like NVI D IA Nsight Compute (NCU) [ 27 , 33 ]. PRAGMA [ 10 ] f urther advances this by injecting fine-grain ed hardware metrics into a bottleneck-a ware reaso ning mod ule. Ho wev er , training m odels to natively perf orm this iterativ e optimiz ation introduces uni que RL cha llenges such a s context explosi on and sparse reward attributi on. Kevin [ 1 ] addresses these by f ormulating a m ulti-turn RL recipe that effectiv ely eva luates and attributes rewards to intermediate refinement turns. Dr . Kern el [ 14 ] f urther identifies gradi ent biases in m ulti-turn advantage estimati on and introd uces Turn-l evel R einf orce-L eav e- One-Out (TRLOO), al ongside Profiling-ba sed R ewards (PR) and R ejection Sampling (PRS) to mitigate preva lent issues like reward hacking and "lazy optimization" ( e.g., o nly f using trivial operati ons). S caling these concepts, CUD A Agent [ 7 ] proposes a comprehensiv e agenti c RL system featuring combinatorial data synthesis and st ab le m ulti-stage warm-up, achi eving subst antial s peedups o v er industria l compilers like T orchInd uctor acro ss varied diffi cult y levels. 2.3. Advanced Search and Ev olution Algorithms Because the GPU kernel optimi zation landscape is highly non-con v ex, recent work increa singly treats kernel gen eration a s a structured search prob lem rather than a pure on e-shot predicti on task. Kern elSkill addresses repetitiv e backtracking with a dua l-level memory architecture that retriev es previo usly v erified optimization skills [ 24 ]. KernelBand instead emphasizes exploratio n–exploitatio n balance, f ormulating optimization as a hierarchical multi-armed bandit that uses runtime behavi or to prune unpromising branches [ 20 ]. K -Search pushes this pers pective f urther by co-ev olving high-lev el algorithmi c planning and low-lev el implement atio n, replacing b lind code m ut atio n with search o ver a m ore expli cit w orld model o f hardware-so ft ware interaction [ 2 ]. Complementary lines of work mo v e this search process into the learning objectiv e itself . CUDA-L1 [ 12 ] introdu ces contra stive reinf orcement learning, conditi oning policy 3 Kern el-Smith : A Unifi ed R ecipe for Ev olutionary Kernel Optimi zation updates on multiple previously generated code variants and their measured speed ups so that the model can reaso n more expli citly about perf ormance trade-o ffs. CUDA-L2 [ 23 ] scal es this idea to l arge HGEMM optimization spaces and sho ws that reinf orcement learning can be used as a t argeted search proced ure o ver highly specialized kernel f amilies. At an even m ore aggressiv e end of the spectrum, T TT -Disco ver [ 31 ] performs reinf orcement learning only at test time f or a single prob lem, extending the search horizon for diffi cult scientific disco very tas ks. T aken together , these approaches suggest that progress in kernel generati on depends n ot only o n stronger ba se models or richer f eed back, but also on search algorithms that better organize exploratio n across candidate implementatio ns. 3. K ernel-Smith 3.1. Ov erview Our t as k is to generate high-performan ce GPU kernels fro m PyT orch reference operators. Giv en a PyT orch m odule together with its executio n interf ace and test inputs, Kernel-Smith produces candidate kernel implementations who se goal is not only to preserv e f unctio nal behavi or , b ut also to impro ve executio n effici ency on the t arget hardware. The target therefore combines three requirements: each candidate m ust compile su ccessf ully , match the numerica l output o f the PyT orch referen ce, and deliv er measura ble speed up o ver the ea ger-m ode baseline. T o address this objectiv e, Kern el-Smith adopts an evolv e-a gent framew ork rather than the conv enti onal m ulti-turn agent l oop used in pri or kernel optimization sy stems [ 10 , 27 , 33 ]. Instead of refining a single trajectory through sequential dial ogue, the system maint ains and ev olves a population o f candidate programs, which broadens explorati on o ver the kernel search space and better explo its test-time compute. This evoluti on process is paired with a comprehensiv e automated eva luation backend that executes generated kern els, returns structured feed back, and measures compilatio n, correctness, and speed up in a stabl e and reliab le manner . Initial Torch Module Initialization User - Defined Metrics Compilation Correctness Speed - Up Evolutionary Islands MAP - Elites Grid Evolution Management Programs Evaluation V a ri a n t V a ri a n t V a ri a n t V a ri a n t Variant Metric Assessment Program Save & Database Update Program Selection & Prompt Construction Error Messages Metrics LLM - Based Variation Code Mutations & Recombination Optimized Kernels Output Evolution Trajectory LLM Ensemble Best Evolution Steps Initial Policy Model SFT Best Evolution Steps Cold - start Data Inherits from nn.Module Cluster - Seeded Expert Data Rollout Program 1 Program 2 Program 3 Program 4 Validation Workers Validation Workers Speed - Up 1 2.19x Speed - Up 2 1.37x Speed - Up 3 0.97x Speed - Up 4 0.65x Speed - Up as Rewards Gradient Update Verify Compute Rewards Agent Framework Training Workflow Figure 2: An ov erview of the evoluti onary process of our proposed framework and the corresponding m odel training pipeline. 3.2. Agent Framework AlphaEv olv e form ulates code optimiz atio n as an evoluti onary search process o ver execut ab le programs: the m odel proposes candidate edits, an evaluator scores the resulting programs, and the search state is maintained in an archiv e that supports subsequent explorati on [ 18 ]. This perspectiv e is especia lly well 4 Kern el-Smith : A Unifi ed R ecipe for Ev olutionary Kernel Optimi zation suited to machine-v erifiab le t as ks such as kernel generatio n, where correctness and performance can both be measured automatica lly . More broad ly , the design is clo sely rel ated to island-ba sed evoluti onary algorithms, which preserve partially independent search trajectori es, and MAP -Elites, which maint ains div erse high-qu ality soluti ons across a feature space rather than colla psing the search to a single incumbent [ 17 , 29 ]. W e inst antiate this idea thro ugh OpenEv olve 1 , adapting an evoluti onary coding a gent to the setting o f high-performan ce GPU kern el generati on. In our setting, each search st ate corresponds to a backend- specific kernel candidate f or a fixed PyT orch reference m odul e. At each iteration, the agent is prompted with the referen ce implementation together with archived candidates sampl ed from both top-perf orming and diverse regions of the search space, and then proposes a new kernel implementation. F ollo wing our design, the archiv e is organized by a feature space that includes kernel complexit y and an ov erall score combining compilation, correctn ess, and speed up. Our main adaptatio n to kernel generation is a fine-grain ed execution feed back mechanism at ev ery ev olutio n step. Rather than returning only a scalar reward, the ev aluator produ ces stru ctured f eed back that in cludes co mpil atio n status, correctness outcomes, speed up, runtime measurements, hardware met adata, and error logs. These sign als are injected into the next iterati on together with archiv ed candidate programs, a llo wing the model to learn not only from strong soluti ons b ut a lso from inf ormative f ailure cases. As a result, the a gent performs iterative kern el optimization with explicit executio n evidence instead o f relying purely on con versati onal refin ement. A representative example of the system prompt, user prompt, and m odel generati on f or one ev olutio n step is pro vided in Appendix A . 3.3. Ev aluatio n Backends W e est ab lished a comprehensi ve aut omated eva luation system design ed to m ulti-dimensionally verif y the reliabilit y and accelerati on effects o f generated GP U operators in high-perf ormance computing scenario s. Ev aluatio n Service and Metrics A distrib uted API eva luation serv er wa s developed to provide distrib uted parall el evaluati on interfaces. In our current backends, the sy stem generates T rito n kernels f or NVI D IA GPU s and Maca kernels for Met aX GPU s. The core evaluati on metrics include: 1) Compilation, which v erifies whether the generated backend-specific code can be su ccessf ully compiled on the target hardware; 2) Correctness, whi ch examines the n umerical co nsistency bet ween the operator output and the PyT orch referen ce implement atio n; and 3) Speed up, which mea sures the performance impro vement o f the generated operators relative to the PyT orch ea ger mode. Stabilit y and Noise R ed ucti on In GP U enviro nments, the wall-cl ock time o f operator executio n exhibits no n-negligib le fluctuatio ns even when hardware and driver v ersions are fixed. For small-scal e input tensors, the kernel l aunch time accounts for an excessive proportion of tot al execution, leading to particularly pron ounced v olatilit y . T o mitigate these eff ects, we implemented the follo wing soluti ons: first, warm-up executio ns were perf ormed before timing to red uce initia li zation o v erhead and transient variance; seco nd, m ultiple measurements were co ndu cted to ca lculate the mean and exclude outliers; third, CUDA Graph technology wa s introdu ced to f urther stabilize the timing process. The impro ved evaluati on scheme successfully constrained executi on time flu ctuations to within 1% . Hacking Detection In automated generatio n tasks, models may circumvent backend-specific kernel generati on by directly calling n ativ e PyT orch operators, thereby fabricating a false "passed test" result with approximately 1x speed up. W e est ab lished a runtime detection mechanism to mandate the actual executio n of gen erated kernel code rather than falling back to PyT orch implementations. Beyond such automati cally detectab le ca ses, we a lso manua lly observed a failure m ode in strong closed-so urce models that w e refer to as adv anced hacking or trivial optimization . In these ca ses, the m odel appli es optimizations that satisf y compilatio n and correctness checks but offer little practi cal engineering va lue; rewriting simple element-wise additi ons in T riton or Maca is one representativ e example. This behavior is closely related to the lazy optimiz atio n phenomen on discussed in Dr . kernel [ 14 ]. Heterogeneo us Platf orms As illustrated in Figure 2 , our ev aluatio n backend f ollow s a backend-decoupl ed design that separates task specificati on, execution orchestration, and metric computation from device- specific compilation and runtime interfaces, rather than being ti ed to a single v endor-specifi c st ack. This all ows the same eva luation prot ocol to be reused across heterogeneo us accelerators while preserving a 1 https://github.com/algorithmicsuperintelligence/openevolve 5 Kern el-Smith : A Unifi ed R ecipe for Ev olutionary Kernel Optimi zation consistent optimiz atio n target f or the a gent. In the current implement atio n, w e inst antiate this design with T riton backends for NVIDIA GP Us and MAC A backends f or Met aX GPU s, both ev aluated under the same compilatio n, correctn ess, and speedup criteria. The same a bstractio n also provides a natural extensio n path to additio nal platforms, su ch as Hua wei NP Us, without changing the a gent-side optimiz ation objective. 4. Training R ecipe 4.1. Ov erview Our training recipe is designed to impro v e the model’s eff ectiv eness inside the ev olutionary a gent rather than optimize one-shot kernel generatio n in isolation. Starting from a curated corpus o f PyT orch m odules, we synthesize m ulti-step ev olutio n trajectories with stro ng teacher models and con v ert them into post-training signals at the level of individua l improv ement steps. This step-centric formulati on treats multi-ro und search a s a compositi on o f learna ble atomic revisi ons: supervised fine-tuning pro vides a cold st art from correctness- and speedup-filtered sampl es, while reinf orcement learning further sharpens the m odel on the m ost inf ormative high-gain steps. 4.2. Data Synthesis T orch Dat a Curatio n Existing work t ypically st arts from fixed benchmarks or a sma ll set of well-maintained libraries, and may f urther increase complexity by synthetically combining simple operators into f used tasks. These pipelines are effectiv e f or constructing training prob lems at sca le, but their seed distrib utio ns still remain biased tow ard cano nical operators and standardi zed repository structures, leaving limited co vera ge o f the div erse implementation patterns found in real-world codebases. T o address this ga p, we systematica lly crawl di verse GitHub repositori es and build an a utomated static-analysis pipeline to extract torch.nn.Module subclasses from wild code. More specifi cally , w e first filter high-qua lit y open-source GitHub repositories to obt ain a div erse pool o f PyT orch implementatio ns. W e then extract candidate nn.Module definitio ns and, rather than discarding incompl ete files, recursively resolv e intra-file dependenci es, inline essential compo nents, and infer the minimal PyT orch imports needed to make each example self-contained. After this normalization step, w e apply embedding- and gra ph-based ded uplicatio n to red uce near-d uplicate m od ules while preserving structura l div ersit y . W e f urther use LLM-a ssisted test generation to supplement missing test ca ses, f ollo wed by executio n-based filtering to remo v e examples that fail to run reli ab ly . Ultimately , this pipelin e yields 59k high-qualit y m odules spanning 20 f uncti onal families, f orming a robu st PyT orch dataset. Instructi on Data Synthesis W e lev erage o ur Kernel-Smith framework f or dat a synthesis to s pecifically address the challenges o f data diversit y and qualit y . Our synthesis process is divided into t wo primary compon ents: • Cold-st art Data : St arting from the curated PyT orch dataset, w e run K ernel-Smith with the open- source teacher model DeepS eek- V3.2-S peciale [ 13 ] to generate rollout trajectory data. W e then filter these trajectories using correctness and speed up metrics, retaining only samples that are both f uncti onally va lid and perf ormance-impro ving. • Cluster-Seeded Expert Data : T o raise the qualit y ceiling of the synthesiz ed data, w e first embed the curated dataset and then a pply H DBSC AN clustering [ 15 ] to identif y represent ativ e cluster centers for manual cleaning and expert annot atio n. W e then feed these expert-curated operators back into Kern el-Smith for additional roll out rounds, prod ucing higher-fidelit y trajectory data with stronger o vera ll performan ce. 4.3. Supervised Fine-tuning W e utilize seed-based synthetic dat a f or the SFT cold-st art pha se. Our pipeline is stru ctured around m ulti-turn agenti c evoluti on t as ks, where we preserve the historical st ate of each step and decompose m ulti-turn trajectories into single-turn training samples. Giv en that operator generatio n requires both f uncti onal correctn ess and performan ce gains, we impl ement the foll owing d ual-filtering strategi es: • Correctness-Oriented A ugmentation This stage f ocuses on the model’s f undament al generation 6 Kern el-Smith : A Unifi ed R ecipe for Ev olutionary Kernel Optimi zation accuracy . W e specifi cally filter the initial translati on step (PyT orch → T riton) and adopt a relaxed filtering policy to in clude all functio n ally correct outputs. This ensures the model’s pro ficien cy in basi c code translatio n. • Perf ormance-Ori ented Augmentatio n F or the iterativ e ev olutio n phase (T riton → T riton), w e enforce a more stringent filtering policy . Only samples that are both f uncti onally correct and achiev e a speed up ratio > 1.0 are selected, thereby enhancing the m odel’s iterativ e optimiz atio n capabiliti es. T o ensure a balanced training distrib utio n, we categorize operator difficult y using heuristic rules ba sed on the number and t ypes of m od ules inv olv ed. Finally , we perf orm balanced sampling across these categories, resulting in o ver 200k high-qu alit y single-turn sampl es for SF T training with a 64k context l ength. 4.4. R einforcement Learning The highly complex and no nlinear n ature of the entire ev olution process poses significant chall enges for end-to-end on-policy reinforcement learning training. Consequently , the core prob lem s hifts tow ard identif ying the mo st effectiv e single-step ev olutio n RL strategy to maximi ze genera li zation performance across the m ulti-round ev olutio n process during inf erence. W e inv estigated sev eral strategi es for selecting ev olution steps and derived the f ollo wing empirica l observatio ns: The incorporati on of a ll procedura l steps may facilit ate the emergence of s hortcuts deriv ed from informati on lea kage. Incorporating a ll steps from the ev olution process significantly expands the training set. How ev er , experiment al results indicate that in cluding both preceding and succeeding steps simultane- ously allo ws the model to exploit the presen ce of superior kernel examples within the input prompts o f later steps. Consequently , the m odel tends to memorize these high-qualit y references rather than acquiring genera liz ed optimiz atio n capa bilities. Although this leads to an ostensib ly f av orab le reward curv e, the actual learning efficacy remains marginal. Selecting only the initi al step of the ev olution process yields suboptimal perf ormance. O ur analysis suggests that the distributio n of the first step deviates subst antially from subsequent st ages, as the input consists solely of a PyT orch implementation without any optimi zed T riton kernels as exemplars. Furtherm ore, the primary objectiv e of the initial step is the f unctiona l migration from PyT orch to Trito n rather than achieving subst antial throughput accel eration. The inherent simplicit y of this tas k renders it unsuitabl e for eff ectiv e reinforcement learning. Selecting the best steps from the ev olution process results in a marked impro vement in perf ormance. The inclusio n o f best steps t ypically inv olves providing example code with a certain baselin e lev el of accelerati on. L evera ging such inputs to generate f urther optimi zed kernels ensures that the learning space for the model remains constrained while maintaining a sufficient lev el of challenge. During a single training iteration, the steady increa se in the reward curve indicates that the t as k complexit y is appropriately ca librated. Furthermore, consistent end-to-end performance impro vements observ ed across m ultiple rounds o f inference dem onstrate that the best step effecti vely represents the fundament al atomi c capa bilit y within the iterative evolutio nary process. As illustrated in Figure 2 , our methodology is based on Cluster-Seeded Expert Data, where each prob lem undergoes 40 iterations of ev olutionary refinement using Gemini-3.0-pro. From this process, the Best steps are selected to constru ct the fin al training set. A represent ativ e dat a sample comprises an input containing severa l high-performan ce kernels a s exemplars and a design ated parent code f or modifi cation. The m odel is then tasked with generating a m ore effici ent and optimized kernel ba sed on these inputs; the det ailed configurati ons are provided in the prompt template in Appendix A . W e employ the GRPO algorithm, sampling eight candidates per data entry and utilizing the speed up ratio relative to the parent code a s the reward signa l for training. The results presented in T a bl e 1 dem onstrate the effi cacy of our proposed training strategy . 5. Experiments 5.1. Ev aluatio n Protocol Models T o comprehensi vely ev aluate the effectiv eness o f our propo sed approach, w e cond uct a rigoro us comparison against a diverse set of state-of -the-art ba selines. F or the open-w eights baselin es, we select 7 Kern el-Smith : A Unifi ed R ecipe for Ev olutionary Kernel Optimi zation the recent reaso ning-focused Qw en3 series [ 30 ] (in cluding both Qwen3-235B-A22B -2507-think and Qw en3.5-397B -A17B -think) to assess performance acro ss varying parameter scal es. W e also include the highly competitiv e DeepSeek-v3.2-Specia le [ 13 ], al ongside recently open-so urced frontier models su ch as Kimi-K2.5 [ 25 ] and MiniMax-M2.5 [ 16 ]. Furtherm ore, to est ab lish the absolute perf ormance upper bound and ensure a holistic eva luation, w e additio nally benchmark a gainst leading propriet ary systems, specifica lly Claude-4.6-opus and Gemini-3.0-pro. Configuratio ns T o ensure a rigoro us and fair evaluatio n, we deploy all compared models within the same Kern el-Smith evoluti on-agent framew ork , ma king the agent system itself a controll ed constant across the entire co mparison. Under this unified protocol, w e condu ct 40 rounds o f iterative evoluti on for each model. F or text generatio n, the decoding parameters are set to a temperature of 0.6 and a top- 𝑝 o f 0.95. T o prevent context ov erflo w during extended interactions, we strictly cap both the input prompt and the maxim um output generati on at 32K tokens per round. Furthermore, to ensure a rigorous a ssessment of system stabilit y and mitigate v ariance, we execute independent unit tests 100 times f or each individ ual m odule and report the av erage performance. Metrics T o rigorously a ssess the perf ormance o f the generated operators, we eva luate the m odels based on three primary metrics: • Correctness ( corr) : Measures the va lidit y of the gen erated operators after the introdu ctio n of hack detectio n. An operator is considered correct only if its comput atio n al precisi on diff erence compared to the original impl ement atio n is strictly controll ed within an acceptabl e threshold. • F ast Proporti on ( fast p ) : Represents the percentage o f gen erated operators that successf ully achi eve executio n speed up (i.e., faster execution time) co mpared to the original ba seline operators. • A verage S peedup Ratio ( avg amsr) : Calculates the mean speed up ratio acro ss all operators within a specifi c difficult y lev el. Specifica lly , to emphasize accelerati on perf ormance, a ll inst ances where the speed up ratio w as less than 1 were a ssigned a score o f zero. This serv es as the core indi cator of the absolute performance gains deliv ered by the gen erated code. 5.2. R esults On Nvidia Backend T ab le 1 presents the performance of our proposed model alongside leading open-weights m odels and po werful proprietary baselin es. As expected, the highly optimized propri et ary m odel, Claude-4.6-opus, establis hes a perf ormance upper bo und in o vera ll correctness ( corr of 99.33) and first-pass speed ( fast 1 o f 0.77). How ev er , our approach demonstrates highly competitiv e accuracy , achieving an av erage corr o f 96.33 to effectiv ely outperform all other advanced ba selines, including Gemini-3.0-pro (94.33) and DeepSeek-v3.2-Special e (94.67). More import antly , our model estab lishes a new state-o f-the-art in o vera ll generati on qualit y and structura l stabilit y , recording the highest avg amsr of 3.70 across all difficult y lev els. This distinct advanta ge is particularly prono unced in the Level 2 subset, where our m odel deliv ers a remarkab le a vg amsr o f 7.77, substanti ally exceeding even Claude-4.6-opus (5.83). Furthermore, on the hardest tasks (Level 3), our m odel sustains a robust correctn ess rate of 94, surpa ssing Gemini-3.0-pro and all open-weights co unterparts by significant margins. These findings suggest that while ultra-large proprietary models may lead in ra w accuracy , our method successfully optimi zes for deeper reasoning ( avg amsr), o ffering an excepti onally rob ust a ltern ativ e for co mplex tasks. T ab le 1: Ben chmark R esults with Baselin es and Our Model. Best results are in bold, and second best are underlined. Models Level 1 ( Easy) Level 2 (Medium) Level 3 ( Hard) A VG Level-1/2/3 Corr F ast 1 A vg AMSR Corr F ast 1 A vg AMSR Corr F ast 1 A vg AMSR Corr F ast 1 A vg AMSR Baselines Qwen3-235B-2507-think 92 0.57 1.86 96 0.86 3.96 84 0.42 0.76 90.67 0.62 2.20 Qwen3.5-397B-think 89 0.55 2.00 90 0.72 3.86 74 0.38 0.61 84.33 0.55 2.16 Minimax-M2.5 70 0.49 2.39 91 0.77 1.06 56 0.30 0.36 72.33 0.52 1.27 Kimi-K2.5 89 0.55 2.00 90 0.72 3.86 74 0.38 0.61 84.33 0.55 2.16 DeepSeek-v3.2-Speciale 98 0.63 2.30 96 0.88 6.89 90 0.32 1.14 94.67 0.61 3.44 Gemini-3.0-pro 99 0.78 2.46 96 0.95 4.78 88 0.50 1.26 94.33 0.74 2.83 Claude-4.6-opus 100 0.70 2.14 100 0.99 5.83 98 0.62 2.02 99.33 0.77 3.33 Ours Kernel-Smith-235B-RL 97 0.70 2.30 98 0.93 7.77 94 0.46 1.02 96.33 0.70 3.70 8 Kern el-Smith : A Unifi ed R ecipe for Ev olutionary Kernel Optimi zation 5.3. R esults On MetaX Backend W e f urther validate our system on the MetaX pl atform. In this setting, the task f ormulatio n differs slightly from that on the NVIDIA platf orm: given a CUD A operator implementation, the sy stem is t asked to gen er- ate a corresponding high-performan ce MAC A implementation. W e construct an evaluati on benchmark consisting o f 45 co mmo n operators, categorized into fo ur groups: Activati on (15, e.g., R eL U, S o ftmax), Norma liz atio n (8, e.g., BatchNorm, GroupNorm), R ed uctio n&Aggregatio n (17, e.g., P ooling, Sum), and Loss Function (5, e.g., CrossEntropy , MSE). Each test sample includes a correctness-v erified CUDA im- plementation generated by an LLM, which serv es as the input f or ev olution and as the referen ce f or cal cul ating the s peedup rati o. Using a similar a gentic framew ork and ev aluatio n protocol, w e compare Kern el-Smith-MA CA-30B with multipl e baselines. Results are sho wn in T abl e 2 . Since the task input includes a correctness-v erified CUDA referen ce, all evaluated m odels exhibit stab le perf ormance on the corr and fast 1 metrics. On the a vg asmr metric, our Kernel-Smith-MA CA-30B outperf orms large-scale baselines such as DeepSeek-v3.2-think and Qw en3-235B -2507-think, and Kernel-Smith-MA CA-235B achiev es additio nal performan ce gains, highlighting the potential o f the proposed framew ork f or generating high-perf ormance operators across heterogeneous platforms. T ab le 2: E valuati on results on MAC A kernel gen eration t ask. Models Activatio n Normalization Red uctio n&Aggregation Loss Fun ction A VG Corr F ast 1 Avg AMSR Corr F ast 1 Avg AMSR Corr F ast 1 Avg AMSR Corr F ast 1 Avg AMSR Corr F ast 1 Avg AMSR Baselines GPT -OSS-20B 100 1.00 3.25 100 0.88 29.7 94.1 0.53 3.63 100 0.80 8.56 97.8 0.78 8.69 Qwen3-30B-A3B 100 1.00 9.03 100 1.00 7.03 100 0.71 17.44 100 0.80 5.67 100 0.87 11.48 Qwen3-235B-2507-think 100 1.00 14.55 100 0.75 35.18 100 0.59 1.36 100 1.00 6.12 100 0.80 12.30 DeepSeek-v3.2-think 100 1.00 10.09 100 0.88 6.06 94.1 0.47 8.60 100 0.60 2.89 97.8 0.73 8.01 Kimi-K2.5 100 1.00 12.62 100 1.00 29.37 100 0.65 5.11 100 0.60 2.21 100 0.82 11.60 Ours Kernel-Smith-MA CA-30B 100 1.00 13.61 100 0.88 36.03 100 0.71 4.69 100 0.40 5.02 100 0.80 13.27 Kernel-Smith-MA CA-235B 100 1.00 9.25 100 0.88 40.59 100 0.65 9.63 100 1.00 3.07 100 0.84 14.26 6. R ea l-w orld Applicatio ns Bey ond benchmark eva luation, w e are interested in whether the same optimiz ation w orkflo w can transfer to m ultiple realisti c deployment settings. W e therefore highlight three compl ement ary case t ypes. The LMDeploy and S GLang cases sho w that Kern el-Smith can contribute to produ ctio n inferen ce engines through merged upstream pull requests. The Engram case instead f ocuses on an up-to-date PyT orch m odule collected from the recent research from DeepSeek [ 4 ], which helps red uce the risk of ben chmark contamination whil e testing the method on a practi cally relev ant t arget. Across these cases, the workflo w is consistent. W e first extract the t arget PyT orch mod ule from an upstream repository and construct execut ab le testing utiliti es, using LLM assistance to compl ement test generati on when necessary . W e then run Kernel-Smith to search for backend-specific kernels under compilatio n, correctness, and s peedup feed back. Once a candidate achiev es mea surab le performan ce gains, w e integrate the generated kernel back into the original codebase by foll owing the repo sitory’s pull-requ est guidance, and w e add supplementary tests when needed. Figure 3 illustrates the speed up gro wth curv es associated with the deployment of o ur framework acro ss three distinct scenario s. 4 8 16 32 64 128 256 512 Iteration 1.0 2.0 3.0 4.0 5.0 Speedup ( a) S GL ang Normal Decode Set Meta 4 8 16 32 64 128 256 512 Iteration 1.0 2.0 3.0 4.0 5.0 Speedup ( b) LMDeploy DeepSeek MoE R outing 4 8 16 32 64 128 256 512 Iteration 5.0 10.0 15.0 Speedup ( c) Deepseek Engram Figure 3: The accelerati on curv es d uring the ev olutionary process o f applying Kernel-Smith to operators across three rea l-world scen ario s. 9 Kern el-Smith : A Unifi ed R ecipe for Ev olutionary Kernel Optimi zation T ab le 3: Isolated kernel benchmarking for the SGLang normal_decode_set_metadata f used T riton kernel, LMDepl oy f used MoE routing kern el and DeepSeek engram kernel on NV -H200. ( a) S GL ang kernel Setting V alu e Batch size 32 P a ge siz e 1 Max context l ength 8192 Max pool size 1024 Seq delt a 0 Iteratio ns 1000 R eported speed up 4 . 78 × (b) LMDeploy kernel Setting V alu e Batch size 512 Num experts 256 N group 8 T op-k group 4 T op-k 8 R outed sca ling f actor 2.5 R eported speed up 1 . 36 × ( c) DeepS eek Engram kern el Setting V alu e Engram hidden size 1024 Hidden size 1024 Kern el size 4 Dilation 3 Hc_m ult 4 Norm_eps 1e-5 R eported speed up 14 . 59 × 6.1. S GL ang In the S GLang serving stack [ 34 ], K ernel-Smith generated a f used T riton kern el for the met adata setup routine normal_decode_set_metadata , and this kernel wa s subsequently merged into the FlashAtten- tio n backend. 2 The upstream patch replaces a previ ously unfused sequence of operati ons with a custo m kernel that co vers both a specialized fast path for the co mmo n page_size=1 case without sliding-window attentio n and a more general path supporting pow er-of -t wo page si zes with optio nal sliding-window attentio n. T o ma ke the contrib ution accept ab le f or produ ction use, the PR also introd uced dedi cated unit tests across m ultiple batch sizes, sequen ce lengths, and routing settings. This case is therefore not only a microben chmark improv ement, b ut also a complete upstream integratio n exercise with implementatio n, va lidation, and deployment-f acing constraints. The t wo benchmarking tabl es highlight the expected gap bet ween operator-lev el and system-lev el gains. T ab le 3a reports a 4 . 78 × speed up for the f used kernel under the target configuratio n, sho wing that the met adat a update routine itself benefits subst antially from f usio n. T abl e 4 , how ev er , reports small er but m ostly positi ve latency impro vements in full serving runs. This difference is expected beca use normal_decode_set_metadata occupies only part of the end-to-end decoding pipeline, so even a large loca l optimiz ation is diluted o nce sched uling, model executi on, and other runtime o verheads are included. This example sho ws that the same search-and-integratio n workflo w can transfer to a mature inferen ce engine, where the bar is not just raw kernel speed but also correctness co vera ge, compatibilit y with existing execution m odes, and maintain ab le upstream code. In that setting, sub-percent end-to-end latency red uctio ns remain meaningful because they are obtained o n a real serving path and are backed by merged prod uctio n code rather than an isolated protot ype. 6.2. LMDeploy In LMDeploy [ 5 ], we apply K ernel-Smith to the forward ro uting mod ule in the MoE l ayer o f DeepS eek-family m odels. The resulting implementation fuses severa l routing-stage operati ons, including sigm oid activ ation, bias additio n, reshape, top-k selecti on, and masking, into a T riton kernel that was l ater merged into LMDeploy . 3 This case f ollo ws the same practica l workfl ow a s the SGLang example: Kernel-Smith searches for a backend-specific kernel, the candidate implementation is v alidated in the target codebase, and the final result is integrated upstream. The configuratio ns for isolated operator benchmarking are detailed in T ab le 3b . The merged kernel achieves more than 30% speed up in isolated operator benchmarking and a lso impro ves end-to-end throughput in practical DeepS eek-v3.2 inferen ce workl oads. The t wo t ab les a gain sho w the difference bet ween l ocal kernel improv ements and end-to-end system gains. T a bl e 3b reports about 1 . 36 × speed up for the fused routing kernel in isolated benchmarking, while T ab le 5 sho ws consistent throughput gains of ro ughly 1 . 85% to 3 . 00% in full DeepSeek-v3.2 inferen ce runs. This pattern is expected because the routing kern el is only one co mponent o f the f ull serving path, but the end-to-end impro vements remain meaningful because they are measured in a realisti c deployment setting. This ca se f urther sho ws that Kernel-Smith can generate code with direct engineering va lue f or a widely 2 https://github.com/sgl- project/sglang/pull/20778 3 https://github.com/InternLM/lmdeploy/pull/4345 10 Kern el-Smith : A Unifi ed R ecipe for Ev olutionary Kernel Optimi zation T ab le 4: End-to-end serving latency reported in the S GLang PR on NV -H200 using sglang.bench_serving with meta-llama/Meta-Llama-3.1-8B-Instruct . Max batch size Input l ength Output length Baselin e latency ( ms) PR latency ( ms) R el. gain (%) 16 64 64 251 . 20 249 . 87 0 . 53 16 128 128 430 . 46 427 . 80 0 . 62 16 256 256 794 . 13 787 . 26 0 . 87 16 512 512 1579 . 02 1569 . 09 0 . 63 16 1024 1024 3164 . 77 3147 . 41 0 . 55 16 2048 2048 7014 . 71 6978 . 49 0 . 52 32 64 64 301 . 44 302 . 48 − 0 . 35 32 128 128 513 . 51 504 . 52 1 . 75 32 256 256 916 . 67 911 . 05 0 . 61 32 512 512 1761 . 68 1751 . 12 0 . 60 32 1024 1024 3674 . 88 3655 . 83 0 . 52 32 2048 2048 8274 . 03 8239 . 82 0 . 41 64 64 64 394 . 45 392 . 46 0 . 50 64 128 128 653 . 04 647 . 54 0 . 84 64 256 256 1181 . 10 1173 . 95 0 . 61 64 512 512 2337 . 13 2321 . 75 0 . 66 64 1024 1024 4827 . 64 4813 . 91 0 . 28 64 2048 2048 11 689 . 43 11 662 . 33 0 . 23 128 64 64 485 . 51 480 . 58 1 . 02 128 128 128 916 . 92 913 . 92 0 . 33 128 256 256 1770 . 41 1761 . 12 0 . 52 128 512 512 3353 . 52 3337 . 89 0 . 47 128 1024 1024 7480 . 48 7472 . 00 0 . 11 128 2048 2048 19 039 . 06 19 017 . 41 0 . 11 used inferen ce engine rather than only for curated benchmark t as ks. More broad ly , it illustrates that the same search-and-integratio n workfl ow can prod uce upstream contrib uti ons for prod ucti on systems, where practica l impact depends o n both kernel effi ciency and successf ul adopti on in the surrounding software stack. 6.3. DeepSeek Engram U nlike the S GLang and LMDeploy ca ses, the Engram study does not begin from a prod ucti on inf erence engine. Instead, w e extract a recent PyT orch m od ule from the o fficia l Engram repository , 4 which acco m- panies DeepSeek’s co nditiona l-memory architecture for large language m odels [ 4 ]. This setup pro vides a practica lly relevant target that is both new er than st andard kernel benchmarks and closer to current research code, thereby redu cing the chance that the result is driv en by benchmark ov erlap rather than genuin e generalizatio n. The optimi zed Engram implementation repl aces Python-side control flow and redundant memory m ov ement with t wo specia lized T riton kern els that f use gate computation, RMS n ormalization, depthwise con voluti on, and resid ual updates into a m ore streamlined executi on path. By precomputing w eights and storing selected intermediates in half precisi on, the generated v ersion red uces both dispatch o v erhead and mem ory traffic, thereby impro ving GPU utili zation. As sho wn by the Engram curv e in Figure 3 , this ca se yields o ne o f the largest gains am ong the three a pplicati on studies: the best discov ered implementatio n achiev es a reported 14 . 59 × speed up in our l ocal eva luation, and the resulting Engram support was l ater merged into D LBl as. 5 The detailed configuratio n is given in T ab le 3c . This result is notab le not o nly for its ma gnitude, but a lso because it is obt ained on a fresh mod ule dra wn from a recent open-source research relea se rather than from a benchmark suite or a previou sly optimi zed serving st ack. The Engram case therefore complements the t wo upstream-engine examples by sho wing that Kern el-Smith can transfer effectiv ely to n ewly released research operat ors whose optimization opportuniti es remain l argely untapped. 4 https://github.com/deepseek- ai/Engram 5 https://github.com/DeepLink- org/DLBlas/pull/102 11 Kern el-Smith : A Unifi ed R ecipe for Ev olutionary Kernel Optimi zation T ab le 5: End-to-end DeepSeek-v3.2 inference throughput reported in the LMDeploy release n ote on NV -H200 with tensor parallelism degree 8. Max batch size Input length Output length Input thro ughput (tokens/s) Output throughput (tokens/s) Baselin e Generated kernel R el. gain (%) Baselin e Generated kernel R el. gain (%) 512 1K 4K 471 . 70 485 . 86 3 . 00 1886 . 78 1943 . 45 3 . 00 512 1K 8K 177 . 62 182 . 08 2 . 51 1420 . 97 1456 . 67 2 . 51 512 1K 16K 60 . 92 62 . 53 2 . 64 974 . 70 1000 . 45 2 . 64 512 4K 1K 3885 . 33 3972 . 52 2 . 24 971 . 33 993 . 13 2 . 24 512 8K 1K 3986 . 93 4067 . 89 2 . 03 498 . 37 508 . 49 2 . 03 512 16K 1K 3873 . 97 3945 . 79 1 . 85 242 . 12 246 . 61 1 . 85 7. Conclu sio n W e presented Kernel-Smith, a framework f or high-performan ce GPU kern el and operator generati on that combines a stabl e eva luation-driv en ev olutionary a gent with an evoluti on-oriented post-training recipe. Across Kern elBench, the Met aX backend, and rea l-world integratio ns su ch a s S GLang and LMDeploy , the results sho w that this combination improv es both search effecti ven ess and practica l transfer bey ond one-s hot code generati on. More broad ly , these findings suggest that reliab le execution feed back and step-centric training are key ingredients for turning LLM-based kernel optimization into a usab le systems w orkflow . Import ant future directions in clude extending the framew ork to m ore backends, aut omating m ore of the end-to-end pull-request process f or prod uctio n engines, and dev eloping m ore flexib le a gent w orkflow s with richer tools and adaptiv e search strategies. 12 Kern el-Smith : A Unifi ed R ecipe for Ev olutionary Kernel Optimi zation R ef erences [1] Carlo Baronio, P ietro Marsell a, Ben P an, Sim on Guo, and Sil as Alberti. Kevin: Multi-turn rl for generating cuda kern els, 2025. URL https://arxiv . org/abs/2507.11948 . 1 , 2.2 [2] Shiyi Cao, Ziming Mao, Joseph E Gonzalez, and Ion Stoica. K-search: Llm kernel generati on vi a co-ev olving intrinsic w orld model. arXiv preprint , 2026. 2.3 [3] Mark Chen et al. Evaluating large l anguage models trained on code. arXiv preprint , 2021. 1 [4] Xin Cheng, W angding Zeng, Damai Dai, Qinyu Chen, Bingxuan W ang, Zhenda Xie, Kezhao Huang, Xingkai Y u, Zhew en Hao, Y ukun Li, et a l. C onditi onal mem ory via sca l ab le l ookup: A new axis o f sparsit y for l arge langu a ge models. arXiv preprint , 2026. 6 , 6.3 [5] LMDeploy Contrib utors. Lmdeploy: A toolkit for compressing, deploying, and serving llm. https: //github.com/InternLM/lmdeploy , 2023. 1 , 6.2 [6] XTuner Contrib utors. Xtuner: A toolkit f or effici ently fine-tuning large m odels. https://github. com/InternLM/xtuner , 2023. 1 [7] W ein an Dai, H anlin Wu, Qiying Y u, Huan-ang Gao, Jiahao Li, Chengquan Jiang, W eiqiang L ou, Y ufan Song, Hongli Yu, Ji aze Chen, et al. Cuda a gent: L arge-scal e agenti c rl for high-performance cuda kernel gen eration. arXiv preprint , 2026. 1 , 2.2 [8] Y ue Guan, Y ichen Lin, Xu Zhao, Jianzhu Y ao, Xinw ei Qiang, Zhongkai Y u, Pramod Viswanath, Y ufei Ding, and Adnan Aziz. Trit ongym: A benchmark for agentic llm workfl ows in triton gpu code generati on. 1 , 2.1 [9] W oosuk Kw on, Zhuohan Li, Siyuan Zhu ang, Ying Sheng S heng, Lianmin Zheng, C ody Hao Y u, Jo seph E. Gonzal ez, Hao Z hang, and I on Stoi ca. Efficient mem ory management for large language m odel serving with pa gedattention. Proceedings of the A CM SIGO PS 29th Sympo sium on Operating Sy stems Principles , 2023. 1 [10] Kelun L ei, Hailong Y ang, Hu aitao Z hang, Xin Y ou, Kaige Zhang, Zhongzhi Luan, Y i Liu, and Depei Qian. Pragma: A profiling-rea soned m ulti-a gent framework f or automati c kernel optimiz atio n. arXiv preprint arXiv:2511.06345 , 2025. 1 , 2.2 , 3.1 [11] Shangzhan Li, Zef an W ang, Y e He, Yuxuan Li, Q i Shi, Ji anling Li, Y onggang Hu, W anxiang Che, Xu Han, Zhiyuan Liu, et al. A utotriton: A utomatic trito n programming with reinforcement learning in llms. arXiv preprint , 2025. 2.2 [12] Xiaoya Li, Xiao fei Sun, Albert W ang, Ji wei Li, and Chris Shum. Cuda-l1: Improving cuda optimization via contra stive reinforcement learning. arXiv preprint , 2025. 2.3 [13] Aixin Liu, Aoxu e Mei, Bangcai Lin, Bing Xue, Bingxuan W ang, Bingzheng Xu, Bochao Wu, Bo wei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: P ushing the fro ntier o f open l arge language m odels. arXiv preprint , 2025. 4.2 , 5.1 [14] W ei Liu, Ji aw ei Xu, Yingru Li, Longt ao Zheng, Tianjian Li, Qian Liu, and Junxian He. Dr . kernel: R einforcement learning done right for trito n kernel generations. arXiv preprint , 2026. 1 , 2.2 , 3.3 [15] Lel and McInnes, J ohn Hea ly , Steve Astels, et al. hd bscan: Hierarchica l densit y based clustering. J. Open Source So ft w. , 2(11):205, 2017. 4.2 [16] MiniMax. Minimax m2.5: Built for real-w orld prod uctivit y . https://www.minimax.io/news/ minimax- m25 , 2026. 5.1 [17] Jean-Baptiste Mouret and Jeff Clune. Illuminating search spaces by mapping elites. arXiv preprint arXiv:1504.04909 , 2015. 3.2 [18] Alexander No viko v , N gân V ˜ u, Marvin E isenberger , Emilien Dupont, Po-Sen Huang, Adam Zsolt W agner , Sergey Shiroboko v , Borislav Ko zlo vskii, Francisco JR Ruiz, Ab bas Mehrabian, et al. AlphaEv olve: A coding a gent for sci entific and algorithmi c discov ery . arXiv preprint , 2025. 1 , 3.2 13 Kern el-Smith : A Unifi ed R ecipe for Ev olutionary Kernel Optimi zation [19] Anne Ouyang, Simon Gu o, Simran Arora, Alex L Zhang, William Hu, Christopher Ré, and Azalia Mirhoseini. Kernelben ch: Can llms write efficient gpu kernels? arXiv preprint , 2025. 1 , 2.1 [20] Dezhi Ran, Shuxiao Xie, Mingf ang Ji, Ziyue Hua, Mengzhou Wu, Y uan Cao, Y uzhe Guo, Y u H ao, Linyi Li, Y it ao Hu, et al. Kernelband: Boosting llm-ba sed kernel optimiz atio n with a hierarchica l and hardware-a ware m ulti-armed bandit. arXiv preprint , 2025. 2.3 [21] Baptiste R ozi ere et al. Code ll ama: Open foundati on models f or code. arXiv preprint , 2023. 1 [22] Mohammad Shoeybi, Mosto fa P at wary , R ohan Puri, P atrick L eGresley , J ared Ca sper , and Bryan Catanz aro. Megatron-lm: T raining m ulti-billion parameter language m odels using model parallelism. arXiv preprint arXiv:1909.08053 , 2019. 1 [23] Songqiao Su, Xi ao fei Sun, Xiaoya Li, Albert W ang, Jiwei Li, and Chris Shum. Cuda-l2: Surpass- ing cub l as performan ce for matrix multipli cation through reinforcement learning. arXiv preprint arXiv:2512.02551 , 2025. 2.3 [24] Qitong Sun, Jun Han, Tianlin Li, Zhe T ang, Sheng Chen, F ei Y ang, Aishan Liu, Xianglo ng Liu, and Y ang Liu. Kern elskill: A multi-a gent framew ork for gpu kern el optimiz atio n, 2026. 2.3 [25] Kimi T eam, T ongtong Bai, Y ifan Bai, Yiping Bao, SH Cai, Y uan Cao, Y Charles, HS Che, Cheng Chen, Guandu o Chen, et al. Kimi k2. 5: Visual a gentic intelligence. arXiv preprint , 2026. 5.1 [26] Ali T ehrani, Y ahya Emara, Essam Wissam, W ojci ech P a luch, W aleed At allah, Mohamed S Abdelfattah, et al. Fine-tuning gpt-5 for gpu kernel gen eration. arXiv preprint arXi v:2602.11000 , 2026. 2.2 [27] Anjiang W ei, T ianran Sun, Y ogesh S eenichamy , Hang S ong, Anne Ouyang, Az alia Mirhoseini, Ke W ang, and Alex Aiken. Astra: A multi-a gent sy stem for gpu kernel performance optimi zation. arXiv preprint arXiv:2509.07506 , 2025. 1 , 2.2 , 3.1 [28] Zhongzhen W en, Yinghui Zhang, Zhong Li, Zhongxin Liu, Linn a Xie, and T ian Zhang. Multikernel- bench: A m ulti-platform benchmark for kernel generation. arXiv e-prints, pp. arXiv –2507 , 2025. 1 , 2.1 [29] Darrell Whitl ey , S oraya Ran a, and R obert B. Heckendorn. The island m odel genetic algorithm: On separabilit y , popul ation size and con vergence. Jo urnal of Computing and Informati on T echnology , 7(1):33–47, 1999. 3.2 [30] An Y ang, Anf eng Li, Baosong Y ang, Beichen Zhang, Binyu an Hui, Bo Zheng, Bow en Y u, Chang Gao, Chengen Huang, Chenxu L v , et al. Qw en3 technical report. arXiv preprint , 2025. 5.1 [31] Mert Y uksekgon ul, Daniel K oceja, Xinhao Li, F ederico Bianchi, Jed McCa leb, Xiaolong W ang, Jan Kautz, Y ejin Choi, James Zou, Carl os Guestrin, et a l. L earning to discov er at test time. arXiv preprint arXiv:2601.16175 , 2026. 2.3 [32] Jialing Z hang et a l. Scientific discov ery in the age of artifi cial intelligence. Nature , 620(7972):47–60, 2023. 1 [33] Zijian Zhang, R ong W ang, Shiyang Li, Y uebo Luo, Mingyi Ho ng, and Caiwen Ding. Cudaf orge: An agent framew ork with hardware feed back f or cuda kernel optimiz atio n. arXiv preprint arXiv:2511.01884 , 2025. 1 , 2.2 , 3.1 [34] Lianmin Zheng, Liangsheng Y in, Zhiqiang Xie, Jeff Huang, Chuyu e Sun, Cody Hao Y u, Shiyi Cao, Christos Kozyrakis, Ion Sto ica, J oseph E. Gonz al ez, et al. Sglang: Efficient execution o f stru ctured language m odel programs. arXiv preprint , 2023. 1 , 6.1 [35] Jiace Zhu, W ent ao Chen, Q i F an, Zhixing R en, Junying W u, Xing Z he Chai, Chotiwit R ungrueangwut- thino n, Y ehan Ma, and An Zou. Cudabench: Benchmarking llms for text-to-cuda generatio n. arXiv preprint arXiv:2603.02236 , 2026. 1 , 2.1 14 Kern el-Smith : A Unifi ed R ecipe for Ev olutionary Kernel Optimi zation [36] Y icheng Zou, Dongsheng Zhu, Lin Zhu, T o ng Z hu, Y unhua Z hou, Peiheng Zhou, Xinyu Z hou, Dongzhan Zhou, Zhiwang Zhou, Y uhao Zhou, Bo wen Zhou, Zhanping Zhong, Zhijie Zhong, Haiteng Zhao, Penghao Zhao, Xiaomeng Zhao, Z hiyuan Z hao, Y echen Zhang, Jin Zhang, W enw ei Zhang, Ho ng ji e Z hang, Zhuo Zhang, W enlong Zhang, Bo Z hang, Chao Z hang, Chen Zhang, Y uhang Zang, F ei Y uan, Jiakang Y uan, Jiashuo Y u, Jinhui Yin, Haochen Y e, Qian Y ao, Bow en Y ang, D anni Y ang, Kaichen Y ang, Ziang Y an, Jun Xu, Y icheng Xu, W anghan Xu, Xuenan Xu, Chao Xu, Ruiliang Xu, S huhao Xing, Long Xing, Xinchen Xie, Ling-I Wu, Zijian Wu, Zhenyu Wu, Lijun Wu, Y ue Wu, Jianyu Wu, W en W u, F an W u, Xilin W ei, Qi W ei, Bingli W ang, Rui W ang, Z iyi W ang, Zun W ang, Yi W ang, Haomin W ang, Y izhou W ang, Lint ao W ang, Yiheng W ang, L ong jiang W ang, Bin W ang, Jian T ong, Z hongbo T ian, Hu anze T ang, Chen T ang, Shixiang T ang, Y u Sun, Qiushi Sun, Xuerui Su, Qisheng Su, Chenlin Su, Demin Song, Jin Shi, Fukai S hang, Y uchen R en, Pengli R en, Xiaoye Qu, Y uan Qu, Jiantao Qiu, Y u Qiao, R unyu P eng, Tianshu o P eng, Jiahui P eng, Qizhi Pei, Zhuo shi P an, Linke Ouyang, W enchang Ning, Y ichuan Ma, Zerun Ma, Ningsheng Ma, R unyuan Ma, Chengqi L yu, Haijun Lv , Han Lv , Lindong Lu, K uikun Liu, Jiangning Liu, Y uhong Liu, Kai Liu, H ongw ei Liu, Zhoumianze Liu, Meng jie Liu, Ziyu Liu, W enran Liu, Y ang Liu, Liwei Liu, Kaiwen Liu, Junyao Lin, Junming Lin, T ianyang Lin, Da hua Lin, Jianz e Liang, Linyang Li, Peiji Li, Zonglin Li, Zehao Li, Pengze Li, Guoyan Li, Lingkai Kong, Linglin Jing, Zhenjiang Jin, F eifei Jiang, Qi an Jiang, Junhao Huang, Zixian Huang, Haian Huang, Zhouqi Hua, Han Hu, Linfeng Hou, Y inan He, Conghui He, T ianyao He, Xu Guo, Q ipeng Guo, Aijia Guo, Y uzhe Gu, Lixin Gu, Jingyang Gong, Qiming Ge, Jiaye Ge, So ngyang Gao, Jianfei Gao, Xinyu F ang, Caihua fan, Yu e F an, Y anhui Duan, Zichen Ding, Shengyuan Ding, Xuanlang Dai, Erfei Cui, Ganqu Cui, P ei Chu, T ao Chu, Gu angran Cheng, Y u Cheng, Kai Chen, Y ongkang Chen, Chiyu Chen, Guanzhou Chen, Qi aos heng Chen, Sitao Chen, Xin Chen, Haojiong Chen, Y icheng Chen, W eihan Cao, Y uhang Cao, Qinglong Cao, and Lei Bai. Intern-s1-pro: Scientific m ultim odal fo undation model at trillio n scale, 2026. (document) 15 Kern el-Smith : A Unifi ed R ecipe for Ev olutionary Kernel Optimi zation A. Example E v olution Prompt T o illustrate ho w the ev olv e-agent framew ork is instantiated for kern el generatio n, we provide a repre- sentative exampl e of o ne ev olutio n step belo w . The example is simplified f or presentation, b ut preserv es the core stru cture used by the system: a system prompt that specifies the optimizatio n objective, a user prompt that injects archiv ed programs and eva luator feed back, and a m odel generati on that propo ses the next candidate. System Prompt You are a Triton GPU kernel optimization engineer specializing in converting PyTorch reference implementations into fast, numerically-correct Triton kernels on NVIDIA GPUs. You are working in an evolving system that iteratively optimizes a Triton kernel. ==================== Context ==================== Input: You are given a PyTorch reference {reference code} Goal: You will generate functionally equivalent but faster Triton implementations {custom code} ==================== Backend Device ==================== {accelerator specs} ==================== Criteria ==================== 1. Compilation Pass: Make Triton code compile (performance irrelevant). 2. Numerical Correctness: Output must match PyTorch reference within float32 tolerance. 3. Performance Gain: Target more speedup than the reference code and previously generated code. The Evolution system will pass the EVOLVE-BLOCK from the previous version. Modify ONLY the Triton kernel source within this block - all other code is LOCKED. ==================== Constraints (MUST) ==================== NEVER change @triton.jit function signatures or parameter names. NEVER modify grid configuration, output tensor shapes, or PID logic. NEVER remove boundary checks or out-of-bound masks. NEVER introduce race conditions, uninitialized reads, or sync gaps. ==================== Output Format ==================== Return ONLY the complete updated code containing the EVOLVE-BLOCK comment marker in the Markdown format. See the example below: # ================== EVOLVE-BLOCK-START ================== # Your code here # =================== EVOLVE-BLOCK-END =================== The target module class to be optimized is named with the suffix "New" after the original module name. ==================== Optimization Tips ==================== 1. Minimize access to slow global memory. 2. Kernel fusion involves combining multiple separate computational steps. 3. Maximize Occupancy. Tune BLOCK_SIZE and num_warps. 4. Grouped gemm operations: Implement Persistent Kernels. 5. Increase Arithmetic Intensity. 6. Use TMA for perfect latency hiding on NVIDIA Hopper+. 7. Setting fast_math=True allows the compiler to reorder floating-point operations. 8. Multi-Level Compilation, Tiling Hints, and Warp-Level Primitives. 16 Kern el-Smith : A Unifi ed R ecipe for Ev olutionary Kernel Optimi zation 9. Advanced Tiling and Work Decomposition (SplitK and SplitM). User Prompt # Target Module Class ModelNew # Program Evolution History ## Previous Attempts {Previous Programs} ## Top Performing Programs {Top Performing Programs} # Current Program {current_program} # Current Program Information - Current performance metrics: - compiled: 1.0000 - correctness: 0.0000 - score: 5.0300 - Stage: runtime_error - Runtime Error Message: {error message} # Task Rewrite the program to improve its performance on the specified metrics. Provide the complete new program code. IMPORTANT: Make sure your rewritten program maintains the same inputs and outputs as the original program, but with improved internal implementation. 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment