FairGC: Fairness-aware Graph Condensation
Graph condensation (GC) has become a vital strategy for scaling Graph Neural Networks by compressing massive datasets into small, synthetic node sets. While current GC methods effectively maintain predictive accuracy, they are primarily designed for …
Authors: Yihan Gao, Chenxi Huang, Wen Shi
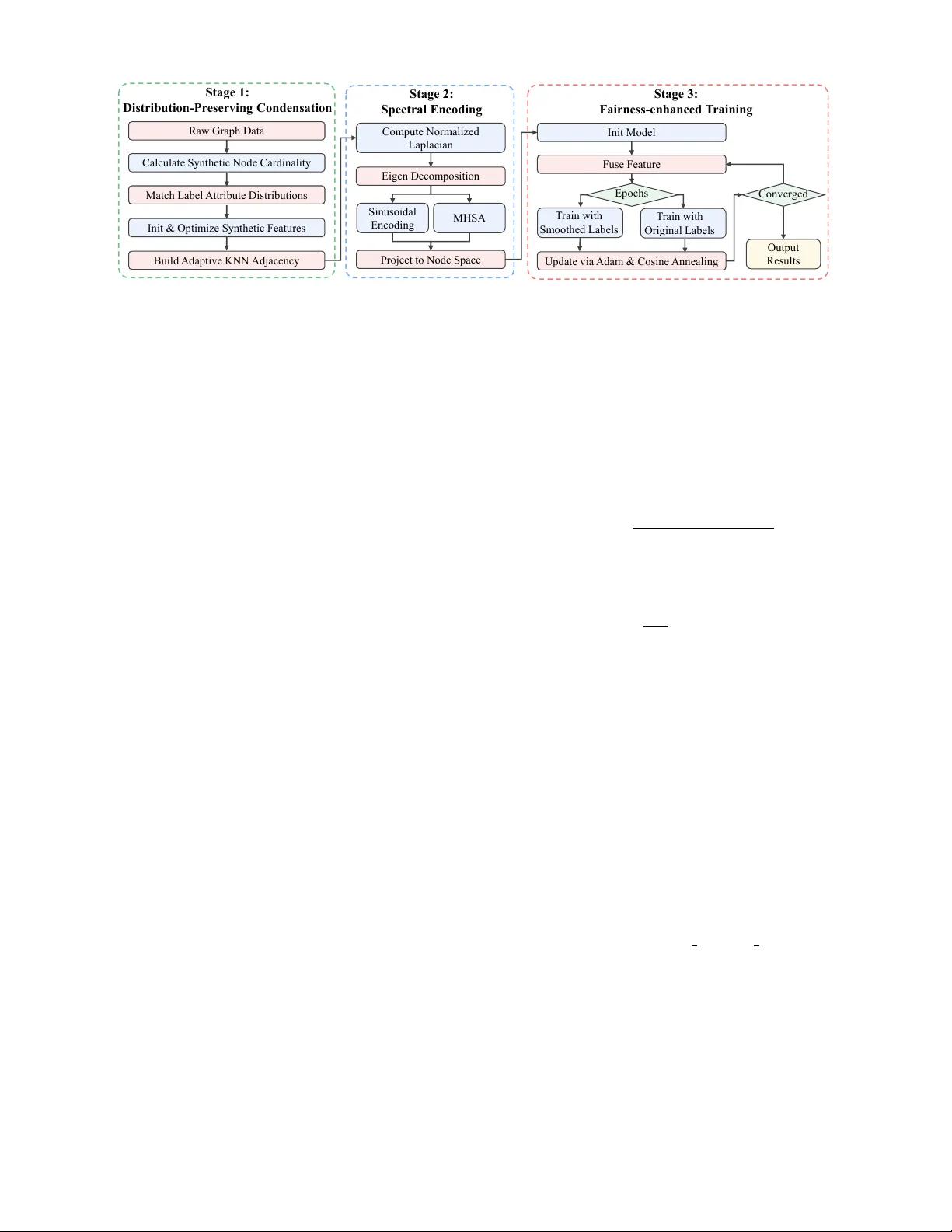
F airGC: F airness-a ware Graph Condensation Y ihan Gao 1 , Chenxi Huang 1 , W en Shi 1 , Ke Sun 2 , Ziqi Xu 3 , Xikun Zhang 3 , Mingliang Hou 4 , Renqiang Luo 1 * 1 College of Computer Science and T echnology , Jilin Univ ersity , Changchun, China 2 Ke y Laboratory of Advanced Design and Intelligent Computing, Dalian Univ ersity , Dalian, China 3 School of Computing T echnologies, RMIT University , Melbourne, Australia 4 Guangdong Institute of Smart Education, Jinan Univ ersity , Guangzhou, China Email: { gaoyh5523, huangcx5523, shiwen24 } @mails.jlu.edu.cn, sunke@dlu.edu.cn { ziqi.xu, xikun.zhang } @rmit.edu.au, teemohold@outlook.com, lrenqiang@jlu.edu.cn Abstract —Graph condensation (GC) has become a vital strat- egy for scaling Graph Neural Networks by compressing massive datasets into small, synthetic node sets. While current GC meth- ods effectively maintain predictive accuracy , they are primarily designed f or utility and often ignore fairness constraints. Because these techniques ar e bias-blind, they frequently capture and even amplify demographic disparities found in the original data. This leads to synthetic proxies that ar e unsuitable for sensiti ve applica- tions like credit scoring or social recommendations. T o solve this problem, we intr oduce FairGC, a unified framework that embeds fairness directly into the graph distillation pr ocess. Our appr oach consists of three key components. First, a Distrib ution-Preserving Condensation module synchronizes the joint distributions of la- bels and sensitive attributes to stop bias fr om spr eading. Second, a Spectral Encoding module uses Laplacian eigen-decomposition to preser ve essential global structural patterns. Finally , a Fair ness- Enhanced Neural Architectur e employs multi-domain fusion and a label-smoothing curriculum to produce equitable pr edictions. Rigorous evaluations on four real-world datasets, show that FairGC pro vides a superior balance between accuracy and fairness. Our results confirm that F airGC significantly r educes disparity in Statistical Parity and Equal Opportunity compared to existing state-of-the-art condensation models. The codes are av ailable at https://github .com/LuoRenqiang/FairGC. Index T erms —F airness, Graph neural networks, Graph con- densation I . I N T RO D U C T I O N Graph learning has become a fundamental framework for modeling complex interactions across v arious domains [1], [2], yet the rapid expansion of modern datasets has made training standard Graph Neural Netw orks (GNNs) increasingly dif ficult due to heavy memory and time costs [3]. T o overcome these computational barriers, graph condensation (GC) has emerged as a powerful paradigm that compresses massi ve, lar ge-scale graphs into a tiny set of synthetic nodes while ensuring that models trained on this compact proxy achie ve performance comparable to the original data [4]. This technique is currently finding widespread use in data-heavy applications, such as an- alyzing billion-scale social networks to map user connections or processing massiv e financial transaction graphs for real-time risk assessment [5]. Despite the technical maturity of mainstream GC paradigms, these frame works are primarily engineered to maximize pre- * Corresponding author Fig. 1. Fairness e valuation of GC methods on the Pokec-n-G dataset. Both vanilla GC methods (darker bars) and their fairness-enhanced versions integrated with FairGNN (lighter bars) exhibit worse fairness compared to our proposed FairGC. ∆ SP and ∆ EO are employed as fairness metrics (refer to Section III-B), where lower v alues represent better fairness. dictiv e utility while remaining largely indifferent to the under- lying fairness constraints [6]. Since these methods operate in a bias-blind manner , they often inadvertently capture and ev en amplify demographic disparities present in the original data, leading to synthetic surrogates that are unsuitable for socially sensitiv e applications [7]–[9]. In practical tasks like credit risk assessment or social friendship recommendation, this lack of fairness a wareness results in significant gaps in Statistical Parity ( ∆ SP ) [10] and Equal Opportunity ( ∆ EO ) [11], where protected groups may suffer from lower positive prediction rates or disproportionately higher misclassification errors. Ulti- mately , the f ailure to decouple predicti ve signals from sensiti ve attributes during the condensation process yields a biased proxy that fails to provide equitable decisions, highlighting a critical research gap in developing fairness-aw are data re- duction techniques. T o quantitatively demonstrate the fairness risks inherent in existing GC techniques, we e valuated six GC meth- ods (GCond [12], DosCond [13], SFGC [14], GCGP [15], GDCK [16], BiMSGC [17]) on the Pokec-n-G dataset. Our experimental setup follo wed established fair graph learning protocols, employing ∆ SP and ∆ EO to measure performance gaps across sensitive groups. The results rev eal that ev en when these frameworks are integrated with FairGNN [18], a widely used fairness-enhancing backbone, the y still e xhibit significantly higher disparities compared to our proposed FairGC. This empirical e vidence underscores a critical flaw: current methods treat data reduction and fairness as decoupled objectiv es, resulting in synthetic graphs that are fundamentally unsuitable for socially sensitive applications. Crucially , existing GC paradigms fail to fundamentally resolve fairness concerns, and e ven the integration of external fairness-aw are mechanisms often results in a degradation of ov erall performance rather than an impro vement [19]. This occurs because standard condensation algorithms are designed to maximize utility by matching gradients or distrib utions, which inadvertently discards the subtle structural dependencies and feature correlations essential for fairness constraints. Since the condensation process lacks the inherent capability to carry fairness properties through the data reduction phase, the result- ing synthetic nodes become biased proxies that downstream fair learners cannot rectify . These observ ations emphasize the urgent need for a unified framework that can integrate fairness as a core objective of the condensation process itself, ensuring that the compressed graph is both efficient and socially equitable. T o bridge this critical gap, we propose F airGC, a novel framew ork that first utilizes a Distribution-Preserving Con- densation module to synchronize label and sensitive attribute distributions, effecti vely preventing bias propagation during the data reduction phase. Subsequently , it incorporates a Spectral Encoding module that lev erages Laplacian eigen- decomposition and sinusoidal mapping to capture multi- scale topological footprints within the synthetic representation. These distilled spatial and spectral insights are then integrated through a F airness-Enhanced Neural Architecture that employs multi-domain fusion and a label-smoothing curriculum to ensure equitable downstream predictions. Extensiv e experi- mental ev aluations on diverse real-world datasets demonstrate that FairGC consistently achieves a superior balance between predictiv e utility and demographic fairness, significantly out- performing existing competitive GC paradigms. Our main contributions can be summarized as follows: • W e conduct an empirical study rev ealing that current GC methods amplify demographic bias and “crystallize” it within synthetic nodes, making it difficult for downstream models to fix. Our analysis proves that existing fairness- aware learners fail to rectify these disparities once the data reduction process is complete. • W e introduce FairGC, a unified framew ork that embeds fairness directly into the distillation pipeline through distribution-preserving condensation and spectral encod- ing. This design ensures synthetic graphs are both topo- logically accurate and socially equitable, balancing model utility with demographic fairness. • Extensi ve e valuations on real-world datasets like Credit and Pokec demonstrate that FairGC outperforms state-of-the- art baselines across various sensitive attributes. The results confirm our model achieves a superior trade-of f between classification accuracy and fairness metrics for responsible graph learning. I I . R E L A T E D W O R K A. Gr aph Condensation GC emerges as a piv otal technique to distill large-scale graph structures into a significantly smaller set of synthetic nodes, ensuring that models trained on this compact proxy achiev e comparable performance to those trained on the full dataset [20]–[22]. GDCK [16] accelerates graph distillation by lev eraging Neural T angent K ernels and kernel ridge regression, bypassing the need for expensi ve GNN training and nested optimization loops. GCGP [15] lev erages Gaussian Processes to estimate predictive posterior distributions, eliminating iter- ativ e GNN training and enabling efficient gradient-based opti- mization of discrete graph structures via Concrete relaxation. T raditional frameworks often maximize accuracy at the cost of exacerbating source graph biases, making their synthetic surrogates unsuitable for sensitive tasks. FairGC addresses this by coupling fairness with graph condensation. B. F airness-awar e GNNs Mitigating algorithmic bias in GNNs has become a cru- cial research frontier to pre vent discriminatory protected groups [23]. Pre-processing techniques [24], [25], aim to rectify data-le vel bias by generating de-biased graph augmen- tations. In contrast, in-processing methods integrate fairness constraints directly into the training objective. A seminal FairGNN, which le verages an adv ersarial debiasing framew ork to learn node representations that are in v ariant to sensitiv e attributes, ev en when such attributes are only partially ob- served. While other recent variants like FairSIN [26] and FMP [27] introduce sophisticated message-passing constraints, they are typically designed for static, full-scale graphs. These models often lack rob ustness for structural reduction, rev ealing a gap where fairness and data reduction are treated as isolated tasks. FairGC fills this void by intrinsically coupling graph compression with fairness preservation. I I I . P R E L I M I NA R I E S A. Notations Let G = ( V , E , X , y , s ) denote the original graph, where V is the set of n nodes, E is the edge set, X ∈ R n × d is the node feature matrix, y ∈ { 0 , 1 } n is the label vector , and s ∈ { 0 , 1 } n is the binary sensitive attribute vector . The condensed graph is denoted as G syn = ( V syn , E syn , ˜ X , ˜ y , ˜ s ) , where ˜ X ∈ R n syn × d , ˜ y ∈ { 0 , 1 } n syn , ˜ s ∈ { 0 , 1 } n syn , and E syn is represented by the adjacency matrix A syn ∈ { 0 , 1 } n syn × n syn . B. F airness Evaluation Metrics T o quantitativ ely ev aluate the fairness of our proposed FairGC, we focus on two widely recognized independence- based criteria: Statistical Parity and Equal Opportunity . In our notation, y ∈ { 0 , 1 } and ˆ y ∈ { 0 , 1 } represent the ground-truth and predicted labels, respectiv ely , while s ∈ { 0 , 1 } indicates the sensitive attrib ute (e.g., gender or age). Statistical Parity (SP) aims for an ideal state where the model’ s decision is decoupled from the sensitiv e group mem- bership [10]. A lower ∆ SP indicates that the model is more Raw G rap h D at a Stag e 1 : Distribution - Pr eserv ing Co ndensa tion Cal cu l at e Sy n t h et i c N o d e Card i n al i t y Stag e 2 : Spectral Enco ding Co m p u t e N o rm al i zed L ap l acian E i g en D eco m p o s i t i o n Stag e 3 : Fairnes s - enha nced T ra ining In i t Mo d el Mat ch L ab el A t t ri b u t e D i s t ri b u t i o n s Bui l d A d ap t i v e K N N A d j acency In i t & O p t i m i ze Sy n t h et i c Feat u res Si n u s o i d al E n co d i n g Pro j ect t o N o d e Sp ace Fu s e Feat u re U p d at e v i a A d am & Co s i n e A n n eal i n g O u t p u t Res u l t s Co n v er g ed MH SA E p o ch s T rai n w i t h Sm o o t h ed Lab el s T rai n w i t h O ri g i n al L ab el s Fig. 2. The illustration of FairGC. “group-blind” in its global outcome distrib ution. T o measure the deviation from this equilibrium, we define it as follows: ∆ SP = | P ( ˆ y = 1 | s = 0) − P ( ˆ y = 1 | s = 1) | . (1) Equal Opportunity (EO) provides a more nuanced perspec- tiv e by focusing on the fairness of qualified individuals [11]. ∆ EO ensures that the model does not disproportionately mis- classify positiv e instances from any specific protected group. Both metrics are computed based on the empirical probabilities observed in the test set. Formally , the disparity in equal opportunity is captured by the difference in TPRs: ∆ EO = | P ( ˆ y = 1 | y = 1 , s = 0) − P ( ˆ y = 1 | y = 1 , s = 1) | . (2) C. Gr aph Condensation GC aims to distill a massiv e source graph G into a compact, synthetic counterpart G syn that retains equiv alent training utility . Distinct from graph sparsification or coreset selection, which are constrained to a subset of existing nodes, GC generates entirely ne w feature matrices and connectivity pat- terns. This paradigm is typically formulated as an optimization problem intended to minimize the performance gap between models trained on original and synthetic data: min G syn D M ( G ; θ ) , M ( G syn ; ˜ θ ) , (3) where M ( · ) denotes a GNN-based learner, while θ and ˜ θ rep- resent the parameters optimized on G and G syn , respectively . I V . M E T H O D S A. Distrib ution-Preserving Condensation Module T o alleviate computational overhead while upholding fair - ness constraints, we condense graph G = ( X , y , s , E ) into a synthetic surrogate G syn = ( ˜ X , ˜ y , ˜ s , A syn ) . Giv en a budget ratio ρ ∈ (0 , 1) , the synthetic cardinality is defined as: n syn = max (10 , ⌊ ρ · n ⌋ ) . (4) 1) Multi-faceted Distrib ution Synchr onization: T o prevent bias propagation during condensation, we synchronize the marginal distributions of labels and sensiti ve attributes. Let p c and q a denote the empirical proportions of class c and sensitive group a in the training set. Node allocation is governed by: n c, syn = n syn × p c , n a, syn = n syn × q a . (5) This ensures that ˜ y and ˜ s replicate the source statistical properties: P ( ˜ y = c ) = P ( y = c ) , P ( ˜ s = a ) = P ( s = a ) . (6) For irregular sensiti ve attributes, randomized assignment is utilized to maintain distributional equilibrium. 2) F eatur e Distillation via Pr oxy Optimization: Synthetic features ˜ X are initialized via stratified sampling and stabilized through Z-score normalization: ˜ X (0) = X sampled − µ ( X sampled ) σ ( X sampled ) + ϵ , (7) where ϵ = 10 − 8 . W e optimize ˜ X as learnable parameters by minimizing the empirical risk of a proxy MLP g ϕ : L cond = − 1 n syn n syn X i =1 log[ g ϕ ( ˜ x i )] ˜ y i . (8) The optimization employs the Adam optimizer with gradient clipping to refine task-relev ant utility . 3) Hybrid Structural Reconstruction: The adjacency ma- trix A syn is reconstructed adapti vely . For large-scale settings ( n syn > 20 , 000 ), we implement a sparse k -nearest neighbor (kNN) graph based on cosine similarity to ensure memory effi- ciency . Con versely , smaller graphs adopt a denser connectivity strategy . This dual-track approach balances topological fidelity with scalability . B. Spectr al Encoding Module T o preserve multi-scale structural characteristics, we pro- pose a spectral encoding mechanism that captures global topological patterns. Given A syn , we derive the normalized Laplacian matrix: L syn = I − D − 1 2 A syn D − 1 2 , (9) where D and I represent the degree and identity matrices, respectiv ely . Eigendecomposition is performed to extract the leading K eigen values and eigen vectors: L syn = UΛU ⊤ , Λ = diag ( λ 1 , . . . , λ K ) . (10) The hyperparameter K is calibrated per dataset via pre- liminary inv estigations to balance information retention and computational tractability . Algorithm 1 Fair Graph Condensation (FairGC) Require: Original graph G = ( X , y , s , E ) , compression ratio ρ , spectral components K , fusion layers L Ensure: Compact surrogate G syn and fairness-enhanced model f θ 1: { Phase 1 : Distribution-Preserving Condensation } 2: Calculate n syn = max (10 , ⌊ ρ · n ⌋ ) ; 3: Compute p c , q a from y , s ; 4: Allocate ˜ y , ˜ s via n c, syn = n syn × p c , n a, syn = n syn × q a ; 5: Initialize ˜ X (0) = X sampled − µ ( X sampled ) σ ( X sampled )+ ϵ , where ϵ = 10 − 8 ; 6: while not conv erged do 7: Compute L cond = − 1 n syn P n syn i =1 log[ g ϕ ( ˜ x i )] ˜ y i ; 8: Update ˜ X via Adam with gradient clipping; 9: end while 10: Construct A syn via adaptive kNN (sparse if n syn > 20 , 000 , else dense); 11: { Phase 2 : Spectral Encoding } 12: Compute L syn = I − D − 1 2 A syn D − 1 2 ; 13: Eigendecompose L syn to get { λ i , u i } K i =1 ; 14: Generate E (0) via sinusoidal encoding of λ i ; 15: Refine E = LN E ′ + FFN ( LN ( E (0) + MHSA ( E (0) ))) ; 16: Project: z spec v = P K i =1 U vi E i ; 17: { Phase 3 : Fairness-Enhanced Training } 18: Initialize f θ with FULayers, ϵ = 0 . 1 ; 19: f or t = 1 to T do 20: Fuse H and Z spec ; 21: L = ( Smoothed NLL if t ≤ 40 Standard NLL otherwise 22: wher e ˜ y i = (1 − ϵ ) y i + ϵ C ; 23: Update θ via AdamW with cosine annealing; 24: Monitor ∆ SP , ∆ EO ; 25: end for 26: retur n G syn = ( ˜ X , ˜ y , ˜ s , A syn ) , f θ . 1) Sinusoidal Eigen value Encoding: T o transform discrete spectral values into a continuous space, we adopt a sinusoidal encoding scheme: PE ( λ i , 2 j ) = sin λ i 10000 2 j /d , PE ( λ i , 2 j + 1) = cos λ i 10000 2 j /d , (11) where j ∈ [0 , . . . , d/ 2 − 1] . This mapping encapsulates the frequency characteristics of the graph spectrum. 2) Attention-driven Spectral Refinement: T o model fre- quency dependencies, eigen value encodings E (0) are pro- cessed via a multi-head self-attention (MHSA) layer: E = LN E ′ + FFN ( LN ( E (0) + MHSA ( E (0) ))) , (12) where LN and FFN denote Layer Normalization and Feed- Forward Network, respecti vely . 3) Spectr al F eatur e Pr ojection: Refined embeddings are projected onto the node space via the eigen vector basis: z spec v = K X i =1 U v i E i . (13) This projection bridges macroscopic topology and micro- scopic node features, ensuring the latent space is structurally informativ e. C. F airness-Enhanced Neural Arc hitectur e W e design a specialized architecture centered on multi- domain fusion and fairness-aware regularization to leverage distilled spatial and spectral knowledge. 1) F eatur e Integr ation and Fusion: Initial node features are projected via a standardized encoder: H (0) = σ ( BN ( W 0 X )) . T o facilitate cross-domain interaction, we introduce Fairness- aware Unified Layers (FULayer): H ( l ) = Norm ( Dropout ( σ ( W ( l ) 1 H ( l − 1) + W ( l ) 2 Z spec ))) , (14) for l = 1 , . . . , L . This iterative additi ve fusion ensures the final representation H ( L ) incorporates global structural priors while maintaining node-level signals. 2) Optimization and F airness Alignment: T o balance utility and demographic alignment, we implement a Label Smoothing curriculum ( ϵ = 0 . 1 ) for the initial 40 epochs: ˜ y i = (1 − ϵ ) y i + ϵ C , (15) This soft-target approach encourages the learning of gen- eralized, non-discriminatory decision boundaries. Subsequent training utilizes standard neg ativ e log-likelihood (NLL). Final predictions ˆ y are generated via ˆ y = Softmax ( MLP ( H ( L ) )) . W e employ the AdamW optimizer with cosine annealing and monitor metrics to ensure demographic unbiasedness. V . E X P E R I M E N T S A. Datasets W e ev aluate the performance of FairGC using four diverse real-world graphs: Credit [28], Pokec-z, Pokec-n [29], and AMiner-L [30]. Credit is a financial transaction network where edges indicate spending similarities between users; binarized Age is utilized as the sensitive attribute for default risk prediction. Pokec-z and Pokec-n are social friendship networks from Slov akian regions, Zilinsky and Nitriansky . Follo wing common fairness benchmarks, we predict users’ employment categories while considering Gender (Pokec-z-G and Pokec- n-G) and Region (Pokec-z-R and Pokec-n-R) as sensitive features. AMiner-L is a large-scale co-authorship network where the task is to predict research fields, using Affiliation Continent as the protected attribute. All experiments were conducted on a w orkstation equipped with a server equipped with 3 × NVIDIA L 40 GPUs with the driv er version 580 . 95 . 05 . B. Baselines In our experiments, we compare FairGC against a com- prehensiv e set of SO T A baselines, which are categorized into two groups: 1) GC methods that focus on distilling large-scale graph structures into a significantly smaller set of synthetic nodes, and 2) f airness-aware GNNs that aim to mitig ate bias in graph learning. For the fairness-aw are GNNs, since they are not originally designed for GC, we adapt each model using the different GC framework, to enable a f air comparison un- der condensation scenarios, ensuring consistency in handling distilling requests. T ABLE I E X PE R I M EN TA L R E S U L T S O N D I FF E RE N T D A TA SE T S . ↑ D E N OT ES T H E L A R G ER , T H E B E TT E R ; ↓ D E N OT ES T H E O P P O SI T E . T H E B E ST R E S ULT S A R E R E D A N D B O LD - FAC ED . T H E RU N N ER - U P S A R E B L UE A N D U N D E RL I N ED . O O M M E A NS O U T - O F - M E M ORY . Pokec-n-G (r: 0.05) Pokec-n-R (r: 0.05) Pok ec-z-G (r: 0.05) Methods A CC(%) ↑ ∆ SP (%) ↓ ∆ EO (%) ↓ A CC(%) ↑ ∆ SP (%) ↓ ∆ EO (%) ↓ ACC(%) ↑ ∆ SP (%) ↓ ∆ EO (%) ↓ GCond (ICLR ’22) 69 . 36 ± 0 . 94 6 . 01 ± 2 . 39 7 . 59 ± 3 . 33 69 . 32 ± 0 . 81 3 . 81 ± 0 . 52 6 . 57 ± 1 . 01 63 . 21 ± 1 . 23 5 . 40 ± 1 . 05 5 . 90 ± 1 . 64 DosCond (KDD ’22) 68 . 83 ± 1 . 19 5 . 14 ± 0 . 97 8 . 91 ± 2 . 27 68 . 54 ± 1 . 62 6 . 14 ± 0 . 64 6 . 94 ± 2 . 60 64 . 30 ± 0 . 69 5 . 87 ± 1 . 29 5 . 60 ± 1 . 14 SFGC (NeurIPS ’23) 70 . 45 ± 1 . 24 5 . 01 ± 0 . 54 9 . 02 ± 2 . 01 69 . 82 ± 1 . 58 3 . 61 ± 0 . 86 1 . 83 ± 0 . 67 63 . 46 ± 1 . 57 1 . 47 ± 0 . 24 2 . 84 ± 1 . 46 GCGP (ArXiv ’25) 70 . 45 ± 0 . 95 6 . 96 ± 0 . 98 4 . 37 ± 0 . 43 70 . 39 ± 2 . 03 4 . 68 ± 0 . 08 3 . 28 ± 0 . 36 64 . 40 ± 0 . 49 10 . 86 ± 0 . 31 8 . 35 ± 0 . 25 GDCK (P AKDD ’25) 70 . 13 ± 0 . 54 3 . 01 ± 0 . 59 5 . 61 ± 0 . 83 70 . 31 ± 0 . 68 2 . 52 ± 0 . 57 2 . 97 ± 0 . 86 64 . 48 ± 0 . 34 2 . 47 ± 0 . 13 6 . 30 ± 0 . 17 BiMSGC (AAAI ’25) 69 . 53 ± 1 . 00 7 . 85 ± 1 . 72 5 . 32 ± 2 . 01 69 . 56 ± 1 . 25 1 . 49 ± 0 . 40 6 . 16 ± 2 . 10 63 . 48 ± 1 . 24 1 . 53 ± 0 . 14 4 . 86 ± 1 . 29 GCond +FairGNN 69 . 85 ± 0 . 56 5 . 96 ± 1 . 89 6 . 41 ± 3 . 27 69 . 75 ± 0 . 47 4 . 73 ± 0 . 81 6 . 19 ± 2 . 07 63 . 13 ± 0 . 64 6 . 72 ± 0 . 77 7 . 58 ± 1 . 24 DosCond +FairGNN 69 . 41 ± 0 . 18 6 . 21 ± 0 . 37 10 . 22 ± 2 . 15 69 . 15 ± 0 . 58 4 . 44 ± 1 . 51 3 . 26 ± 0 . 85 64 . 15 ± 0 . 67 7 . 73 ± 4 . 21 6 . 08 ± 5 . 11 FairGC 70 . 87 ± 0 . 28 0 . 40 ± 0 . 23 0 . 42 ± 0 . 11 70 . 47 ± 0 . 14 0 . 58 ± 0 . 08 0 . 84 ± 0 . 13 64 . 78 ± 0 . 28 0 . 82 ± 0 . 62 0 . 72 ± 0 . 51 Pokec-z-R (r: 0.05) Credit (r: 0.01) AMiner-L (r: 0.05) Methods A CC(%) ↑ ∆ SP (%) ↓ ∆ EO (%) ↓ A CC(%) ↑ ∆ SP (%) ↓ ∆ EO (%) ↓ ACC(%) ↑ ∆ SP (%) ↓ ∆ EO (%) ↓ GCond (ICLR ’22) 62 . 51 ± 1 . 41 3 . 35 ± 1 . 35 6 . 65 ± 0 . 88 77 . 77 ± 0 . 05 0 . 59 ± 0 . 27 0 . 73 ± 0 . 28 89 . 29 ± 0 . 28 8 . 06 ± 3 . 63 9 . 28 ± 1 . 09 DosCond (KDD ’22) 64 . 34 ± 0 . 66 4 . 12 ± 1 . 61 4 . 94 ± 2 . 19 77 . 74 ± 0 . 05 0 . 96 ± 1 . 14 1 . 11 ± 1 . 25 90 . 87 ± 0 . 24 10 . 80 ± 1 . 12 8 . 46 ± 2 . 06 SFGC (NeurIPS ’23) 64 . 35 ± 0 . 86 2 . 99 ± 1 . 53 10 . 58 ± 1 . 80 77 . 14 ± 1 . 26 6 . 14 ± 1 . 35 4 . 87 ± 1 . 32 90 . 30 ± 1 . 44 6 . 68 ± 1 . 32 8 . 35 ± 1 . 44 GCGP (ArXiv ’25) 64 . 35 ± 1 . 12 10 . 86 ± 1 . 79 8 . 35 ± 1 . 24 77 . 82 ± 0 . 76 6 . 82 ± 1 . 65 3 . 92 ± 0 . 04 OOM OOM OOM GDCK (P AKDD ’25) 64 . 07 ± 0 . 34 0 . 86 ± 0 . 53 2 . 57 ± 0 . 77 76 . 94 ± 2 . 16 6 . 03 ± 0 . 57 9 . 32 ± 1 . 60 OOM OOM OOM BiMSGC (AAAI ’25) 63 . 74 ± 0 . 76 1 . 91 ± 0 . 02 3 . 48 ± 1 . 02 78 . 13 ± 0 . 06 0 . 56 ± 0 . 02 1 . 61 ± 0 . 14 89 . 97 ± 1 . 43 8 . 58 ± 2 . 19 6 . 94 ± 2 . 15 GCond +FairGNN 63 . 21 ± 0 . 80 3 . 46 ± 2 . 68 8 . 39 ± 3 . 12 77 . 06 ± 0 . 63 0 . 87 ± 0 . 92 1 . 12 ± 1 . 36 86 . 21 ± 3 . 54 6 . 18 ± 6 . 98 9 . 40 ± 5 . 02 DosCond +FairGNN 64 . 09 ± 0 . 35 3 . 88 ± 2 . 64 4 . 90 ± 2 . 76 77 . 04 ± 0 . 38 3 . 24 ± 2 . 93 3 . 50 ± 3 . 69 90 . 66 ± 0 . 09 9 . 48 ± 1 . 27 5 . 88 ± 2 . 31 FairGC 64 . 62 ± 0 . 30 0 . 10 ± 0 . 09 0 . 29 ± 0 . 28 77 . 94 ± 0 . 10 0 . 20 ± 0 . 11 0 . 22 ± 0 . 06 90 . 80 ± 0 . 33 1 . 06 ± 0 . 71 3 . 28 ± 1 . 26 W e list six GC baselines: GCond [12], DosCond [13], SFGC [14], GCGP [15], GDCK [16], BiMSGC [17]. W e use one fairness-a ware GNN baseline with GC adaptation (some of them could not suit for fairness-aware controlling): FairGNN [18]. These baselines represent the current SOT A in GC and fairness-a ware graph learning. By adapting the FairGNN with GC capability , we ensure a comprehensive and fair ev aluation of FairGC against methods that address both fairness and condensation challenges. C. Comparison Results In this section, we present a comprehensive e valuation of FairGC ag ainst state-of-the-art GC baselines across se veral real-world datasets: Pok ec-n, Pok ec-z, Credit, and AMiner- L. The comparison focuses on the balance between predic- tiv e accuracy (A CC) and fairness metrics ( ∆ SP and ∆ EO ). The results, summarized in T able I, demonstrate that FairGC consistently achieves a superior trade-off between utility and fairness compared to all existing methods. Predicti ve Accuracy . FairGC maintains highly competitiv e node classification accuracy across all datasets, frequently achieving the best or second-best performance. For instance, on Pokec-n-G and Pokec-z-G, FairGC achie ves the highest accuracy ( 70 . 87% and 64 . 78% , respectiv ely), outperforming advanced baselines lik e BiMSGC and GCond. On the Credit and AMiner-L datasets, while FairGC’ s accuracy is marginally lower than the top-performing utility-centric methods (e.g., 90 . 80% vs. 90 . 87% for DosCond on AMiner-L), this minor difference is negligible. This indicates that our fairness-aw are condensation process preserves the essential informative fea- tures of the original graph without significant degradation in predictiv e power . Fair ness Perf ormance. F airGC significantly enhances fair- ness by dramatically reducing both statistical parity and equal opportunity disparities. Across all e valuated datasets, FairGC achiev es the lo west ∆ SP and ∆ EO values, often by a sub- stantial margin. For example, on Pok ec-n-G, F airGC reduces ∆ EO to 0 . 42% , a nearly 18x improv ement over the stan- dard GCond ( 7 . 59% ). Notably , even when baselines are aug- mented with f airness-aware backbones (e.g., GCond +FairGNN ), they still struggle to match FairGC’ s performance. On the Credit dataset, FairGC achiev es a ∆ EO of 0 . 22% , while most baselines fluctuate between 0 . 5% and 1 . 1% . These results underscore that FairGC effecti vely eliminates discriminatory patterns that traditional condensation methods often inadver - tently preserve or amplify . Collectiv ely , FairGC emerges as a robust solution that excels in both accuracy and fairness. Unlike utility-focused methods (e.g., DosCond, SFGC) that achieve high accuracy at the cost of high bias, or simple fairness-augmented base- lines that fail to achie ve optimal equity , FairGC provides a holistic frame work. It effecti vely addresses the challenges of preserving distribution-le vel fairness during graph reduction. The consistent gains across div erse datasets and condensation ratios validate FairGC’ s scalability and its practical value for socially sensitiv e applications where ethical considerations are as critical as model performance. D. Ablation Study T o ev aluate FairGC’ s components, we conduct an abla- tion study focusing on distribution-preserving condensation (FairGC w/o C) and fairness-enhanced architecture (FairGC w/o F), with results in T able II. The FairGC w/o F v ari- ant consistently exhibits the poorest fairness, as ∆ SP and T ABLE II A B LAT IO N S T UDY R E S U L T S F O R F A IR G C . “ P ” A N D “A M” D E N OT E T H E P O KE C A N D A M IN E R DAT A S E T S , R E S PE C T I VE LY . Dataset Metric FairGC FairGC w/o C F airGC w/o F P-n-G A CC (%) 70 . 87 ± 0 . 28 70 . 17 ± 0 . 05 69 . 36 ± 0 . 94 ∆ SP (%) 0 . 40 ± 0 . 23 0 . 48 ± 0 . 26 6 . 01 ± 2 . 39 ∆ EO (%) 0 . 42 ± 0 . 11 1 . 05 ± 0 . 85 7 . 59 ± 3 . 33 P-n-R ACC (%) 70 . 47 ± 0 . 14 70 . 23 ± 1 . 06 69 . 32 ± 0 . 81 ∆ SP (%) 0 . 58 ± 0 . 08 0 . 67 ± 0 . 25 3 . 81 ± 0 . 52 ∆ EO (%) 0 . 84 ± 0 . 13 1 . 06 ± 0 . 66 6 . 57 ± 1 . 01 P-z-G ACC (%) 64 . 78 ± 0 . 28 63 . 48 ± 0 . 97 63 . 21 ± 1 . 23 ∆ SP (%) 0 . 82 ± 0 . 62 2 . 23 ± 1 . 18 5 . 90 ± 1 . 64 ∆ EO (%) 0 . 72 ± 0 . 51 2 . 23 ± 1 . 18 5 . 90 ± 1 . 64 P-z-R A CC (%) 64 . 62 ± 0 . 30 63 . 44 ± 1 . 02 62 . 51 ± 1 . 41 ∆ SP (%) 0 . 10 ± 0 . 09 1 . 86 ± 1 . 03 3 . 35 ± 1 . 35 ∆ EO (%) 0 . 29 ± 0 . 28 4 . 23 ± 2 . 17 6 . 65 ± 0 . 88 Credit A CC (%) 77 . 94 ± 0 . 10 77 . 54 ± 0 . 14 77 . 77 ± 0 . 05 ∆ SP (%) 0 . 20 ± 0 . 11 0 . 42 ± 0 . 33 0 . 59 ± 0 . 27 ∆ EO (%) 0 . 22 ± 0 . 06 0 . 45 ± 0 . 30 0 . 73 ± 0 . 28 AM-L ACC (%) 90 . 80 ± 0 . 33 88 . 71 ± 0 . 58 89 . 29 ± 0 . 11 ∆ SP (%) 1 . 06 ± 0 . 71 1 . 56 ± 1 . 08 8 . 06 ± 3 . 63 ∆ EO (%) 3 . 28 ± 1 . 26 4 . 08 ± 2 . 15 9 . 28 ± 1 . 09 ∆ EO increase significantly across all datasets without explicit fairness-specific design. Similarly , the FairGC w/o C variant underscores the necessity of our condensation strategy; while traditional methods reduce graph size, they fail to preserve the nuanced statistical distributions required for fair do wnstream classification. In summary , the ablation study underscores that both the distribution-preserving condensation module and the fairness- enhanced neural architecture are indispensable. While replac- ing the fairness architecture may occasionally boost accuracy , it leads to unacceptable fairness degradation. Likewise, tradi- tional condensation fails to preserve the nuanced distributions necessary for fair representation. V I . C O N C L U S I O N In this paper , we address the critical research gap where existing GC methods prioritize predicti ve accurac y b ut inad- vertently amplify demographic biases during data reduction. W e propose FairGC, a nov el framew ork that integrates fair- ness as a core objective by combining distribution-preserving condensation, spectral encoding for structural fidelity , and a fairness-enhanced neural architecture. Through extensi ve em- pirical analysis on real-world datasets like Credit and Pokec-n, we demonstrate that FairGC effecti vely decouples predictive signals from sensitive attributes, prev enting the crystallization of bias in synthetic nodes. Our results confirm that FairGC achiev es a superior balance between training utility and demo- graphic equity , providing a robust and socially responsible so- lution for deploying graph intelligence in resource-constrained en vironments. A C K N O W L E D G M E N T S This w ork was supported by the National Natural Science Foundation of China (NSFC) under Grant No. 62406054 . R E F E R E N C E S [1] F . Xia, C. Peng, J. Ren et al. , “Graph learning, ” F oundations and Tr ends in Signal Processing , pp. 362–519, 2025. [2] X. Du, J. Li, D. Cheng et al. , “T elling peer direct effects from indirect effects in observational network data, ” in ICML , 2025. [3] R. Luo, H. Huang, L. Ivan et al. , “FairGP: A scalable and fair graph transformer using graph partitioning, ” in AAAI , 2025. [4] X. Gao, H. Y in, T . Chen et al. , “RobGC: T owards robust graph condensation, ” TKDE , pp. 4791–4804, 2023. [5] Q. Zhang, Y . Sun, C. Jin et al. , “Effectiv e policy learning for multi-agent online coordination beyond submodular objectives, ” in NeurIPS , 2025. [6] R. Luo, T . T ang, F . Xia et al. , “ Algorithmic fairness: A tolerance perspectiv e, ” , 2024. [7] Y . Dong, J. Ma, S. W ang et al. , “Fairness in graph mining: A survey , ” TKDE , pp. 10 583–10 602, 2023. [8] Z. Xu, Z. Xu, J. Liu et al. , “ Assessing classifier fairness with collider bias, ” in P AKDD , 2022. [9] B. Oldfield, Z. Xu, and S. Kandanaarachchi, “Revisiting pre-processing group fairness: A modular benchmarking framework, ” in CIKM , 2025. [10] C. Dwork, M. Hardt, T . Pitassi et al. , “Fairness through awareness, ” in ITCS , 2012. [11] M. Hardt, E. Price, and N. Srebro, “Equality of opportunity in supervised learning, ” in NeurIPS , 2016. [12] W . Jin, L. Zhao, S. Zhang et al. , “Graph condensation for graph neural networks, ” in ICLR , 2022. [13] W . Jin, X. T ang, H. Jiang et al. , “Condensing graphs via one-step gradient matching, ” in KDD , 2022. [14] X. Zheng, M. Zhang, C. Chen et al. , “Structure-free graph condensation: From large-scale graphs to condensed graph-free data, ” in NeurIPS , 2023. [15] L. W ang and Q. Li, “Efficient graph condensation via Gaussian process, ” arXiv:2501.02565 , 2025. [16] Y . Zhang, Z. Chen, Q. Liu et al. , “GDCK: Efficient large-scale graph distillation utilizing a model-free kernelized approach, ” in P AKDD , 2025. [17] X. Fu, Y . Gao, B. Y ang et al. , “Bi-directional multi-scale graph dataset condensation via information bottleneck, ” in AAAI , 2025. [18] E. Dai and S. W ang, “Learning fair graph neural networks with limited and pri vate sensitive attribute information, ” TKDE , pp. 7103–7117, 2023. [19] R. Luo, Z. Xu, X. Zhang et al. , “Fairness in graph learning augmented with machine learning: A survey , ” , 2025. [20] X. Zhang, D. Song, and D. T ao, “Sparsified subgraph memory for continual graph representation learning, ” in ICDM , 2022. [21] Q. Zhang, Z. W an, Y . Y ang et al. , “Near-optimal online learning for multi-agent submodular coordination: Tight approximation and commu- nication efficiency , ” in ICLR , 2025. [22] X. Zhang, D. Song, and D. T ao, “Ricci curvature-based graph sparsifi- cation for continual graph representation learning, ” TNNLS , 2023. [23] Z. Xu, S. Kandanaarachchi, C. S. Ong et al. , “Fairness ev aluation with item response theory , ” in WWW , 2025. [24] Z. Zhang, M. Zhang, Y . Y u et al. , “Endowing pre-trained graph models with provable fairness, ” in WWW , 2024. [25] Y . Zhu, J. Li, L. Chen et al. , “The devil is in the data: Learning fair graph neural networks via partial knowledge distillation, ” in WSDM , 2024. [26] C. Y ang, J. Liu, Y . Y an et al. , “FairSIN: Achie ving fairness in graph neural networks through sensitive information neutralization, ” in AAAI , 2024. [27] Z. Jiang, X. Han, C. Fan et al. , “Chasing fairness in graphs: A GNN architecture perspective, ” in AAAI , 2024. [28] C. Agarwal, H. Lakkaraju, and M. Zitnik, “T owards a unified framework for fair and stable graph representation learning, ” in UAI , 2021. [29] L. T akac and Z. Michal, “Data analysis in public social networks, ” in Pr oceedings of International Scientific Conference and International W orkshop Pr esent Day Tr ends of Innovations , 2012. [30] J. T ang, J. Zhang, L. Y ao et al. , “ Arnetminer: Extraction and mining of academic social networks, ” in KDD , 2008.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment