Taming the Instability: A Robust Second-Order Optimizer for Federated Learning over Non-IID Data
In this paper, we present Federated Robust Curvature Optimization (FedRCO), a novel second-order optimization framework designed to improve convergence speed and reduce communication cost in Federated Learning systems under statistical heterogeneity.…
Authors: Yuanqiao Zhang, Tiantian He, Yuan Gao
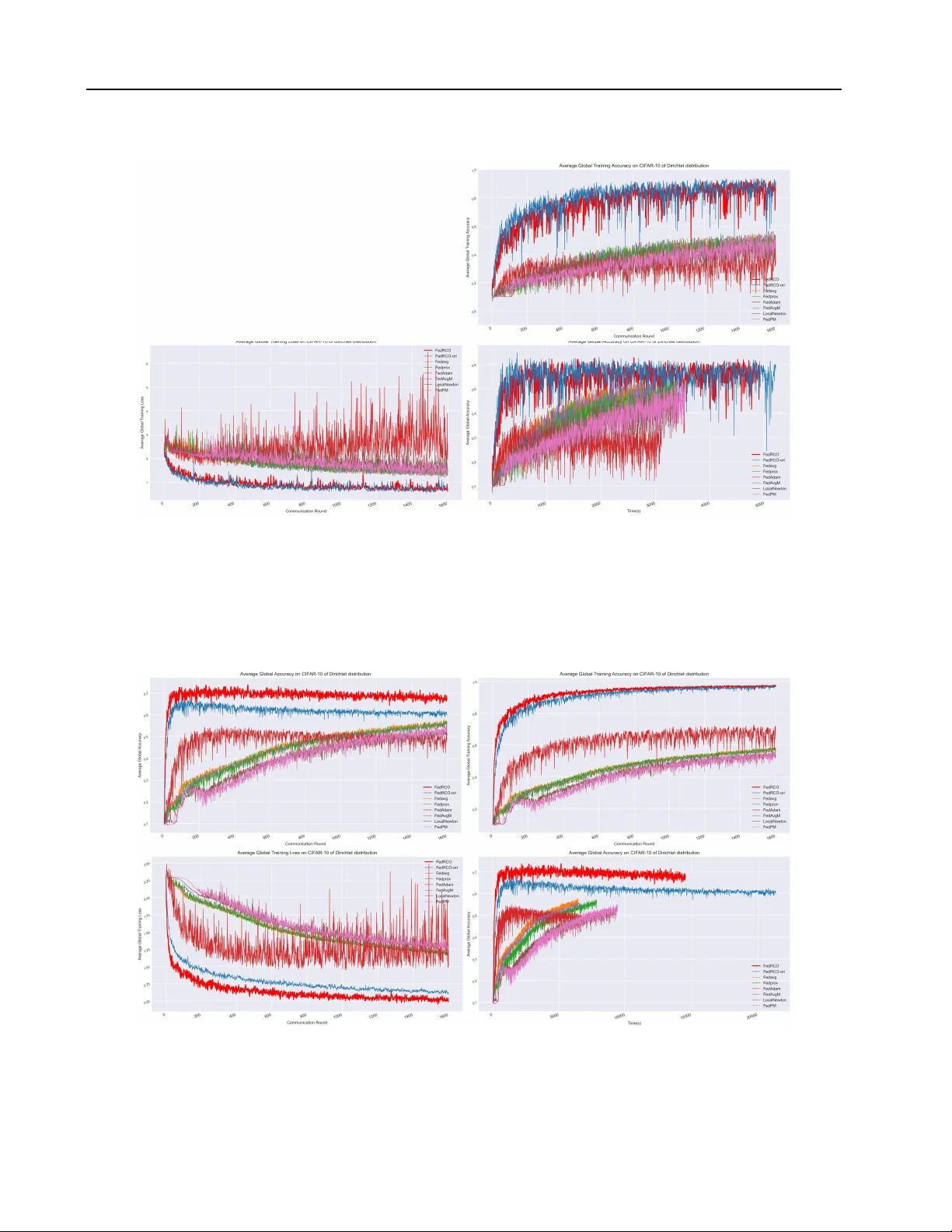
T aming the Instability: A Rob ust Second-Order Optimizer f or F ederated Lear ning ov er Non-IID Data Y uanqiao Zhang 1 2 3 Tiantian He 2 Y uan Gao 1 Y ixin W ang 1 Y ew-Soon Ong 2 4 Maoguo Gong 1 A.K. Qin 5 Hui Li 3 Abstract In this paper , we present Federated Robust Cur- vature Optimization (FedRCO), a no vel second- order optimization framew ork designed to im- prov e con ver gence speed and reduce communi- cation cost in Federated Learning systems under statistical heterogeneity . Existing second-order optimization methods are often computationally expensi v e and numerically unstable in distributed settings. In contrast, FedRCO addresses these challenges by integrating an ef ficient approxi- mate curv ature optimizer with a prov able stability mechanism. Specifically , FedRCO incorporates three k ey components: (1) a Gradient Anomaly Monitor that detects and mitigates exploding gra- dients in real-time, (2) a Fail-Safe Resilience pro- tocol that resets optimization states upon numer - ical instability , and (3) a Curv ature-Preserving Adaptiv e Aggre gation strategy that safely inte- grates global knowledge without erasing the local curvature geometry . Theoretical analysis sho ws that FedRCO can ef fectively mitigate instability and prev ent unbounded updates while preserving optimization efficiency . Extensiv e experiments show that FedRCO achie ves superior robustness against di verse non-IID scenarios while achie v- ing higher accuracy and faster con ver gence than both state-of-the-art first-order and second-order methods. 1 Ke y Laboratory of Collaborative Intelligence Systems of Ministry of Education, Xidian University , Xi’an, Shaanxi, China 2 Centre for Frontier AI Research, Institute of High Per- formance Computing, Agenc y for Science, T echnology and Research, Singapore 3 State Key Laboratory of ISN, School of Cyber Engineering, Xidian Univ ersity , Xi’an, Shaanxi, China 4 College of Computing and Data Science, Nanyang T echnological Uni versity , Singapore 5 Department of Comput- ing T echnologies, Swinburne Uni versity of T echnology , Mel- bourne, Australia. Correspondence to: Y uanqiao Zhang < zhangyuanqiao@xidian.edu.cn > , T iantian He < he tiantian@a- star .edu.sg > , Y ew-Soon Ong < asysong@ntu.edu.sg > , Maoguo Gong < gong@ieee.org > . Pr eprint. Mar ch 31, 2026. 1. Introduction W ith the rapid proliferation of Internet of Things (IoT) de- vices and mobile terminals, massiv e amounts of data are continuously generated at the network edge. Although such data are highly valuable for training machine learning mod- els, they often contain sensiti ve information, rendering cen- tralized data collection and training impractical or undesir - able. T o resolve the tension between data utilization and priv acy preserv ation, Google introduced Federated Learning (FL) ( McMahan et al. , 2016 ), a distrib uted machine learning paradigm that enables collaborativ e model training without requiring the sharing of raw data. In FL, clients perform local training on their priv ate datasets and communicate only model updates—such as parameters or gradients—to a central server for aggre gation, thereby ensuring data are kept confined to local de vices. Despite its growing success, FL still faces substantial op- timization challenges. Mainstream FL algorithms such as FedA vg ( McMahan et al. , 2016 ) and its v ariants are based on first-order Stochastic Gradient Descent (SGD). Although computationally efficient, these methods ignore curvature information in the loss landscape, often leading to slow con vergence and accordingly requiring a large number of communication rounds. This is particularly problematic in bandwidth-constrained edge en vironments. Moreov er , the inherent statistical heterogeneity of federated data, such as non-independent and identically distributed (non-IID) distribution, causes inconsistencies among local learning objectiv es, leading to client drift ( Karimireddy et al. , 2020 ) and further degrading con vergence stability or ev en causing div ergence. These challenges call for more principled and curvature-a ware optimization mechanisms. T o overcome these limitations, second-order optimization techniques hav e recently reg ained attention ( Abdulkadirov et al. , 2023 ). By exploiting curv ature information through Hessian or its approximations, these methods can adapti vely scale updates and potentially achiev e much faster conv er - gence. Among them, Kronecker -Factored Approximate Curvature (K-F A C) ( Martens & Grosse , 2015 ) has attracted significant attention for its ef ficient computational approx- imation. By approximating the large Fisher matrix as a 1 Submission and Formatting Instructions f or ICML 2026 layer-wise Kroneck er product, K-F A C makes second-order optimization feasible for deep neural networks. Howe ver , our analysis shows that directly applying second- order optimization in federated learning is highly nontrivial. First, the limited computational capacity of edge devices necessitates small local batch sizes, which often lead to a rank-deficient Hessian, thereby amplifying noise and pro- ducing extensi ve updates. Second, under non-IID data distri- butions, locally estimated curv ature can severely mismatch the global loss landscape, resulting in overly aggressive update steps that destabilize global optimization or even cause di ver gence. Therefore, a critical challenge is ho w to use the accelerated conv ergence brought by second-order optimization while taming its instability in the federated settings. T o address the aforementioned challenges, we propose Federated Robust Curvature Optimization (FedRCO), a second-order optimization frame work that enables stable and communication-efficient training under heterogeneous data distributions. T o the best of our kno wledge, this work presents the first comprehensi ve study that theoretically analyzes the instability of second-order optimization in fed- erated learning, providing both theoretical characterization and feasible solutions to address these challenges. Our main contributions are as follo ws. • W e rigorously analyze the fundamental causes of second-order optimization instability in federated learn- ing and demonstrate which factors lead to unbounded update norms. • W e dev elop FedRCO, a principled curv ature-adaptive federated optimization framework that prov ably con- trols update magnitudes and stabilizes second-order information under ill-conditioned and heterogeneous settings. • W e propose a simple yet effecti ve aggregation strat- egy tailored for non-IID scenarios. By safely fusing global knowledge without disrupting local geometry , our method supports robust second-order optimization with minimal computational and communication costs. • Extensi ve experiments on standard benchmarks demon- strate that FedRCO achieves consistently faster con- ver gence and improv ed final accuracy while signifi- cantly reducing communication rounds compared to both baseline first-order and state-of-the-art (SOT A) federated second-order methods. In addition to the background, motiv ations, methodology , analysis, and experiments presented in Sections 2-6 , we include an extensi ve theoretical and analytical treatment in the appendices. Appendices A-D respectively provide a detailed analysis of gradient instability in federated second- order optimization, the ef fectiveness of second-order opti- mization under federated and non-IID settings, the con ver - gence properties of second-order FL, and the deriv ations of the corresponding optimization bounds. Appendix E provides additional e xperimental setups and results 1 . 2. Related work 2.1. Federated Lear ning Federated Learning (FL) was pioneered by FedA vg ( McMa- han et al. , 2016 ), which minimizes a weighted global loss through periodic local SGD updates. Leaving θ denote the global model parameter and t ∈ { 0 , ..., T − 1 } denote the communication round, the parameter process on the client c can be described as: θ t +1 c = θ t c − η ∇L c ( θ t c ) , (1) where ∀ c ∈ { 1 , ..., C } is the index of the clients, η is the learning rate, and ∇L c ( θ t c ) denotes the gradient of the loss function L ( θ ) calculated on the local dataset. Thus, the global function L g lobal ( θ ) of FL can be denoted as: L g lobal ( θ t +1 ) = C X c =1 n c n L c ( θ t c ) , (2) where n c is the data v olume of client c , and n = P C c =1 n c . Howe ver , statistical heterogeneity resulting from non-IID data often leads to client drift ( Karimireddy et al. , 2020 ), where local optima diver ge from the global objective. T o address this, FedProx ( Li et al. , 2020 ) introduces a proximal regularization term to limit e xcessi ve local de viations. Lev eraging curvature information in FL offers the potential for faster conv ergence. Early approaches, such as Local- Newton ( Gupta et al. , 2021 ) and FedNL ( Safaryan et al. , 2021 ), utilize local Newton steps or require transmitting Hessians, incurring prohibitiv e communication and compu- tational ov erhead. Recent research, such as FedPM ( Ishii et al. , 2025 ), performs serv er-side aggre gation of cov ariance matrices to refine preconditioning with reduced costs. 2.2. Natural Gradient Descent Natural Gradient Descent (NGD) updates parameters via θ ← θ − η F − 1 ∇L ( θ ) , (3) where F is the Fisher Information Matrix (FIM) represent- ing the sensitivity of the model’ s output distribution. T o bypass the O ( d 3 ) in version bottleneck, Kronecker-F actored Approximate Curvature (K-F A C) ( Martens & Grosse , 2015 ) 1 Our code is av ailable in the Supplementary Material. 2 Submission and Formatting Instructions f or ICML 2026 approximates the layer-wise FIM as a Kroneck er product: F ( l ) ≈ Ω ( l ) ⊗ Γ ( l ) , (4) where l denotes the layer of the model, Ω ( l ) = E A ( l ) ( A ( l ) ) ⊤ and Γ ( l ) = E G ( l ) ( G ( l ) ) ⊤ denote the cov ariance of the input acti vation A ( l ) and the pre-activ ation gradient G ( l ) , respectiv ely . Lev eraging the in verse property of the Kronecker product ( Ω ⊗ Γ ) − 1 = Ω − 1 ⊗ Γ − 1 , K-F AC transforms the dense d × d in version into the in version of two much smaller matrices, significantly reducing computa- tional complexity ( T ang et al. , 2021 ). 3. Theoretical Moti vations T o date, the systematic and theoretical understanding of instability phenomena in FL, along with principled mecha- nisms to rectify them, remains largely une xplored. In this paper , we systematically initialize this analysis and propose principled mechanisms accordingly . 3.1. Gradient Instability Directly integrating second-order information into FL faces numerical instability . In this paper , we identify two critical failure modes: Rank Deficiency and Curvatur e Mismatch , and establish theoretical connections between the modes and numerical instability . Proposition 3.1. (Rank Deficiency) When batch size B ≪ d , the empirical FIM ˆ F c is rank-deficient, allowing sam- pling noise in the null space to induce unbounded updates (detailed in Appendix A.2 ). Proposition 3.2. (Curvature Mismatch) If local curvatur e under estimates global steepness under non-IID data, the global quadratic penalty becomes unbounded, leading to diver gence (detailed in Appendix A.3 ). 3.2. Advantages of Second-order Optimization Despite these risks, second-order methods of fer superior geometric robustness. While SGD suffers from slow con- ver gence as the condition number κ → ∞ , Fisher precondi- tioning ef fectively transforms the geometry into an isotropic shape (ideally κ → 1 ). The following two theorems sho w that adopting second-order optimization promises to dra- matically accelerate the con ver gence, if the previously men- tioned numerical instability can be effecti vely addressed. Proposition 3.3. (Impact of Condition Number .) SGD con vergence is bounded by κ − 1 κ +1 . In non-IID scenarios, κ → ∞ , causing slow con ver gence. (detailed in Appendix B.1 ) Proposition 3.4. (Affine In variance.) F isher precondi- tioning isotr opizes the parameter space, ideally achie ving κ → 1 r egar dless of the native landscape curvatur e (de- tailed in Appendix B.2 ). Remark. W ith Propositions 3.1 to 3.4 , we ha ve established a theoretical foundation for identifying k ey issues causing the unstable federated optimization and feasible solutions, which pav e the way for our approach. 4. Methodology In this section, we present our primary contribution: a robust second-order optimization framework for FL. In Section 4.1 , we first describe the client-side optimization procedure, where a block-diagonal approximation of Fisher is adopted. In Section 4.2 , we focus on ill-conditioned curvature esti- mates caused by rank deficiency and statistical staleness, and introduce a unified two-stage mechanism consisting of monitoring and resilience. Section 4.3 presents imple- mentation details, including an aggre gation strategy and a lazy in verse update strategy . All notation is described in Appendix A . 4.1. Block-Wise Cur vatur e Estimation via K-F A C T o make second-order optimization practical in the standard resource-limited en vironments ( T Dinh et al. , 2020 ), where each epoch only processes a single mini-batch of data, we adopt a block-diagonal approximation of FIM. The client- side learning process can be described as follows: θ t c = θ t c − η F − 1 ∇L c ( θ t c ) . (5) For a neural network layer, taking a fully connected layer l as an example, the corresponding FIM F ( l ) is approxi- mated as the Kronecker product of smaller matrices F ( l ) ≈ Ω ( l ) ⊗ Γ ( l ) . Since computing the natural-gradient update requires the inv erse of F , we lev erage a key property of the Kronecker product ( Ω ⊗ Γ ) − 1 = Ω − 1 ⊗ Γ − 1 , which enables the two factors to be in verted independently . T o fur- ther ensure numerical stability , we apply T ikhonov damping ( Martens & Grosse , 2015 ) with parameter ϵ together with the π -correction method to balance the relative scales of the two Kronecker f actors. Thus, the empirical statistics of the Kronecker factors can be defined as: [ b Ω ( l ) ] − 1 = ( Ω ( l ) t + π √ ϵ I ) − 1 , [ b Γ ( l ) ] − 1 = ( Γ ( l ) t + 1 π √ ϵ I ) − 1 , (6) where π = p tr ( A ) / tr ( G ) . For con volutional layers, we employ the unfold operation to reshape spatial features into two-dimensional matrices ( Grosse & Martens , 2016 ), enabling consistent co v ariance estimation across layers. Under this formulation, the Kro- necker factors are defined as: Ω ( l ) = E J A ( l ) KJ A ( l ) K ⊤ , Γ ( l ) = E G ( l ) G ( l ) ⊤ , where J · K denotes the operation that extracts local patches around each spatial location, stretches them into vectors, and stacks the resulting vectors into a 3 Submission and Formatting Instructions f or ICML 2026 matrix. Subsequent empirical covariance statistics b Ω and b Γ are computed in the same way as for fully connected layers. Since only a single mini-batch is processed per local epoch, we employ exponential moving averages (EMA) to miti- gate the stochastic noise inherent in small-batch training. Specifically , at the local epoch k , the updates are: ˆ A ( l ) k = α E [ A ( l − 1) A ( l − 1) ⊤ ] + (1 − α ) A ( l ) k − 1 , ˆ G ( l ) k = α E [ G ( l − 1) G ( l − 1) ⊤ ] + (1 − α ) G ( l ) k − 1 , (7) where α represents the hyperparameter to control the a ver- age ratio. W e substitute EMA to obtain b Ω and b Γ . Finally , the precon- ditioned natural gradient update for client c is: vec ( ˜ ∇ ( l ) θ ) = b Ω ( l ) − 1 ∇L c ( θ c ) b Γ ( l ) − 1 = ( Ω ( l ) + π √ ϵ I ) − 1 ∇L c ( θ c )( Γ ( l ) + √ ϵ π I ) − 1 . (8) 4.2. Gradient Anomaly Detection and Resilience One of the core contributions of our method is the ability to handle ill-conditioned curvature arising in non-IID fed- erated settings which is claimed in Section 2.3 and prov en in Appendix A . T o enable FedRCO to achiev e this, we pro- pose a two stage mechanism that stabilizes gradient updates while maintaining training efficienc y . 1) Look-Ahead Gradient Monitor First, we employ a real-time monitoring mechanism to in- spect the optimization trajectory . Specifically , we maintain a sliding-window history of preconditioned gradient norms, H = n ∥ ˜ g K − k ∥ , . . . , ∥ ˜ g K − 1 ∥ o , where ∥ · ∥ is the ℓ 2 -norm, and ˜ g k is the preconditioned gradient: ∥ ˜ g ( l ) k ∥ ≜ v u u t d out X i =1 d in X j =1 ( ˜ g ( l ) k,i,j ) 2 , ∥ ˜ g k ∥ = X l ∥ ˜ g ( l ) k ∥ , (9) where the parameters of a layer are typically represented as a matrix θ ( l ) ∈ R d out × d in . At epoch k , before applying the update, we calculate the anomaly score S k : S k = ∥ ˜ ∇ θ k ∥ mean ( H ) + ξ , (10) where, mean ( H ) = 1 K P K k =1 || ˜ g K − k || 2 serves as the base- line of e xpected update magnitude, and ξ is a small constant to pre vent di vision by zero. The score S k thus represents the relativ e div ergence of the current step compared to recent steps. Based on the anomaly score S k , we cate gorize potential fail- ures into two types. When S k > τ low ≈ 10 , this typically indicates a structural mismatch between the local curva- ture approximation and the underlying loss landscape. Such cases are classified as accumulated di vergence , which man- ifests as a gradual drift in the optimization trajectory . When S k > τ high ≈ 1000 , the FIM becomes nearly singular , caus- ing its in verse to excessi vely amplify gradients in arbitrary directions. These events are classified as sudden explosion , leading to impulsiv e noise in the updates. 2) Robust Resilience Protocol Upon detecting an anomaly , the client triggers a resilience protocol to safeguard both the local and global models. For cases of accumulated di ver gence, where τ low < S k < τ high , the instability arises from a gradual accumulation of curv a- ture mismatch, leading to steadily increasing gradients. In this regime, we adopt a soft rollback strate gy to stabilize the update: θ k +1 = ( θ k − η ˜ ∇ k , if S k ≤ τ low θ k − η ˜ ∇ stable , if τ low < S k < τ high (11) where ˜ ∇ stable is a stable gradient upper bound. If the anomaly score e xceeds the upper threshold S t > τ high , or remains above S t > τ low for multiple local epochs, the gradient is deemed to have caused an irrev ersible disruption to the optimization trajectory . In this case, a hard reset is performed. Specifically , all accumulated curvature statis- tics ( Ω , Γ ) and their corresponding in verses are discarded, the local model parameters are reset to the current global model, and the hyperparameters of both the optimizer and the preconditioner are re-initialized. This step is crucial, as a gradient explosion indicates that the current curv ature approximation is no longer geometrically valid. 4.3. Implementation Details 1) Curvature-Preserving Adaptive Aggregation Standard aggregation methods pose a risk of curv ature for - getting in second-order optimization, where forcibly ov er- writing local parameters with a global a verage disrupts the delicate geometric structure encoded by the local FIM. T o mitigate this in non-IID settings without incurring extra ov erhead, we introduce a lightweight interpolation strategy that preserves local curvature stability . Instead of a direct ov erwrite, the local model is updated as: θ new local = ( γ · θ g lobal + (1 − γ ) · θ old local , if Acc ′ > Acc θ g lobal , else (12) where Acc ′ and Acc denote the local accurac y and the global accuracy , respectiv ely , and γ is dynamically adjusted based 4 Submission and Formatting Instructions f or ICML 2026 on the confidence in the local representation: γ = Acc ′ Acc ′ + Acc . (13) This strategy serves as a stability filter for second-order updates. By prioritizing the local model when it significantly outperforms the global av erage, we prevent the curvature mismatch problem ( Proposition 3.2 ) where global drift erases the precise local directions computed by K-F A C. This ensures that the aggressi ve second-order steps remain valid throughout the training process. 2) Lazy In verse Update T o minimize computational overhead, the in verse matrices [ b Ω ( l ) ] − 1 and [ b Γ ( l ) ] − 1 are not recomputed at ev ery epoch. Instead, we define an inv ersion interv al T inv . The curvature factors Ω and Γ are accumulated continuously , b ut in version occurs sparsely . This update strategy actually acts as a regularizer against mini-batch noise. The discussion of the in version update frequency is gi ven in A ppendix A.4 . 5. Analysis W e present a rigorous theoretical analysis of FedRCO, estab- lishing con ver gence guarantees that effecti vely bound client drift under non-IID settings. Additionally , we show that our decoupled approximation and lazy updates achiev e lo w computational complexity and communication efficiency , ensuring edge feasibility . 5.1. Con vergence Analysis and Optimization Bounds W e present four theorems. Here, we first guarantee the con- ver gence beha vior of FedRCO from tw o perspecti ves: the local descent property on the client side and the con ver gence of the aggregated model on the serv er side. Theorem 5.1. (Local Descent with Preconditioning) F or a learning r ate η satisfying η ≤ λ min Lλ 2 max , the e xpected decr ease in the local objective L c for a single K-F A C step is lower bounded by (detailed in Appendix C.2 ): E [ L c ( θ t +1 c )] ≤ L c ( θ t c ) − η λ min 2 ∥∇L c ( θ t c ) ∥ 2 + η 2 Lλ 2 max σ 2 2 . (14) Theorem 5.2. (Server Con vergence Rate) Second-order federated optimization con ver ges to a neighborhood of the optimal solution θ ∗ . Specifically , for the global model θ t , the err or bound satisfies (detailed in Appendix C.3 ): E ∥ θ t +1 − θ ∗ ∥ 2 ≤ (1 − ρ ) E ∥ θ t − θ ∗ ∥ 2 + E . (15) Afterwards, we analyze the optimization bounds of the local drift and the final global con vergence bound. Theorem 5.3. (Client Drift Bound) The expected squar ed norm of the client drift after K local steps is bounded by (detailed in Appendix D.2 ): e drif t = E h θ t c,K − θ t 2 i ≤ 2 K 2 η 2 λ 2 max ( σ 2 + M 2 ) . (16) Theorem 5.4. After T ′ communication r ounds, the conver - gence of our method satisfies (detailed in Appendix D.4 ): E [ L ( θ T ′ ) − L ∗ ] ≤ (1 − ρ ) T ′ ( L ( θ 0 ) − L ∗ ) + LK η λ 2 max ( σ 2 + M 2 ) 2 µλ min . (17) Remark. Theorems 5.1 to 5.4 demonstrate that FedRCO achiev es conv ergence to a neighborhood of the optimal so- lution while ef fectiv ely bounding the client drift caused by data heterogeneity . T ogether with the remarkable empirical results in Section 6 , FedRCO is shown to be a novel and theoretically grounded approach to optimizing FL systems. 5.2. Computational Time Complexity W e address the computational ov erhead by comparing FedRCO against standard first-order methods and e xact second-order approaches. While exact methods incur a prohibitiv e O ( d 3 ) in version cost, FedRCO decouples this burden via Kroneck er factorization and lazy updates to ( d 3 in + d 3 out ) . By amortizing the periodic inv ersion cost ov er T in v steps, the per-step comple xity is reduced to: O ( d in d out ( d in + d out ) + d 3 in + d 3 out T inv ) , (18) where d in , d out , and d denote the input dimensions, out- put dimensions, and the total number of model parameters, O ( d in d out ( d in + d out )) is the cost of matrix-matrix multipli- cations described in Eq. 8 . As T in v increases, the additional term becomes marginal compared to the O ( d in d out ) complexity of SGD. Coupled with the linear O ( d ) cost of the gradient monitor , FedRCO enables efficient second-order optimization on edge devices with minimal latency o verhead. 5.3. Communication Time Complexity Unlike prior second-order methods that transmit heavy Hes- sian or cov ariance matrices, FedRCO maintains the same communication pattern as FedA vg, transmitting only the model parameter θ ∈ R d and a scalar accuracy . This results in a minimal per-round complexity of O ( d + 1) ≈ O ( d ) . 5 Submission and Formatting Instructions f or ICML 2026 By le veraging curv ature information to rectify local updates, FedRCO significantly accelerates con vergence, thereby re- ducing the total number of communication rounds. 6. Experiments 6.1. Experimental Setup Datasets and Baselines. W e conduct e xtensiv e experiments on two widely used federated learning benchmarks: CIF AR- 10 ( Krizhevsk y et al. , 2009 ) and EMNIST ( Cohen et al. , 2017 ). T o simulate non-IID data distributions, we choose Dirichlet ( Y urochkin et al. , 2019 ), Pathological ( Li et al. , 2022 ), and IID partitioning (Fig. 5 for details). Our realistic local training setup in volv es multiple epochs per round, with each epoch processing a single mini-batch of data. W e ev al- uate FedRCO across Dirichlet ( D ir ( α ) , α ∈ { 0 . 1 , 0 . 5 , 1 } ), Pathological { 2 , 5 } and { 10 , 30 } labels for CIF AR-10 and EMNIST , and IID to simulate di verse conditions. The exper - imental framew ork encompasses { 10 , 50 , 100 } clients with participation ratios in { 0 . 1 , 0 . 5 , 0 . 8 , 1 } , 1600 communica- tion rounds, and 20 local epochs per round. W e compare our method against sev eral first-order baseline methods and second-order SOT A methods: FedA vg ( McMahan et al. , 2016 ), FedA vgM ( Hsu et al. , 2019 ), FedProx ( Li et al. , 2020 ), FedAdam ( Reddi et al. , 2020 ), LocalNewton ( Gupta et al. , 2021 ), and FedPM ( Ishii et al. , 2025 ). Additional details about the model architecture and implementation are provided in A ppendix E . 6.2. Experimental Results As shown in T able 1 , FedRCO establishes a better perfor- mance lead across all datasets and settings, especially in ex- treme non-IID scenarios. FedRCO-ori refers to our method utilizing simple av eraging instead of the proposed aggrega- tion strategy . In the highly challenging Dirichlet α = 0 . 1 configuration on CIF AR-10, FedRCO achie ves a 78 . 8% accuracy , demonstrating significant improvement ov er stan- dard FedA vg and overcoming rob ust baselines by an ev en wider margin. Unlike naiv e second-order methods that fre- quently struggle with con vergence under high heterogene- ity , FedRCO effecti vely harnesses curv ature information to accelerate training without sacrificing stability . On the EMNIST dataset, our method maintains a decisi ve lead with 90 . 2% accuracy under α = 0 . 1 , conclusi vely v alidating its ability to neutralize local drift and handle se vere statistical heterogeneity where first-order baselines falter . The visualization of learning curves (Fig. 1 ) further con- firms that FedRCO significantly impro ves both con vergence speed and optimization stability . In scenarios with extreme data fragmentation, FedRCO quickly achiev es peak accu- racy , while first-order methods stagnate. While adaptiv e methods like FedAdam e xhibit erratic loss trajectories and LocalNewton suf fers from instability , FedRCO maintains a smooth and stable decreasing training loss, empirically proving that our robust gradient monitor successfully filters out the noise inherent in distributed second-order optimiza- tion. Furthermore, the notable performance improvement between FedRCO and FedRCO-ori highlights that our spe- cialized aggregation strategy successfully preserv es client- specific representations while enhancing global generaliza- tion, ensuring that FedRCO is not merely fitting local noise but learning a fundamentally superior global model. 6.3. Ablation Study 1) T ime Efficiency Analysis A common concern for second-order federated methods is the additional computational o verhead induced by curv ature estimation and matrix inv ersion. T o assess the practical efficienc y of FedRCO, we perform a comprehensive time analysis in Fig. 2 , cov ering both fine-grained time break- downs and wall-clock con vergence behavior . As shown in Fig. 2 (a), the matrix in version in FedRCO accounts for only 6.4% of the total training time, enabled by our efficient implementation and lazy in verse update strategy that amortizes the cost of expensi ve in versions across iter- ations. In contrast, FedPM spends 36.1% of its time on probabilistic computations, indicating a substantially higher computational burden. Moreover , the increased local compu- tation in FedRCO reduces the relati ve communication cost to 9.2%, compared to 19.5% for FedA vg, making FedRCO more computation-bound and well aligned with modern accelerator-equipped edge de vices. Importantly , this modest per-round o verhead translates into a decisi ve advantage in wall-clock performance. As shown in Fig. 2 (b), FedRCO reaches 70% accuracy within 1,000 seconds, while FedA vg and FedProx require over 10,000 seconds to approach com- parable performance. FedRCO also exhibits a steep initial accuracy rise and maintains stable con ver gence throughout training, unlike FedRCO-ori, which con verges quickly but degrades due to the absence of rob ust aggreg ation. Overall, these results demonstrate that FedRCO effecti vely breaks the con ventional trade-off between con vergence speed and computational cost, deliv ering both fast time-to-accuracy and consistently superior final performance in practice. 2) Impact of the In version F requency ( T inv ). Fig. 3 ev aluates the model’ s sensiti vity to the in version interval T inv across both communication rounds and wall- clock time. Contrary to the intuition that more frequent updates ( T inv = 20 or 50 ) would yield better results, the red curve ( T inv = 200 ) consistently achiev es the highest accuracy , which shows that v ery frequent updates result in lower steady-state accuracy . Meanwhile, excessi vely lazy updates lead to stale curv ature information that f ails to adapt to the changing loss landscape, causing sub-optimal con ver - 6 Submission and Formatting Instructions f or ICML 2026 T able 1. The experimental results on the Dirichlet-non, Pathological-non, and IID settings with client number 100, and the party ratio 0.8. CIF AR-10 EMNIST Method Dirichlet Pathological IID Dirichlet Pathological IID α = 0 . 1 α = 0 . 5 α = 1 2 5 \ α = 0 . 1 α = 0 . 5 α = 1 10 30 \ FedA vg 0.563 0.620 0.632 0.537 0.601 0.650 0.818 0.835 0.836 0.809 0.826 0.838 FedPr ox 0.553 0.628 0.637 0.530 0.616 0.631 0.817 0.831 0.833 0.801 0.822 0.839 FedAdam 0.557 0.639 0.610 0.439 0.623 0.619 0.845 0.856 0.859 0.804 0.837 0.864 FedA vgM 0.556 0.614 0.635 0.530 0.607 0.658 0.814 0.832 0.832 0.800 0.823 0.836 LocalNewton 0.509 0.613 0.621 0.492 0.598 0.626 0.804 0.818 0.817 0.800 0.809 0.819 FedPM 0.547 0.602 0.620 0.518 0.603 0.635 0.805 0.816 0.820 0.794 0.814 0.816 FedRCO-ori 0.695 0.713 0.727 0.612 0.712 0.725 0.854 0.869 0.871 0.851 0.859 0.871 FedRCO 0.788 0.742 0.730 0.753 0.751 0.719 0.902 0.886 0.881 0.882 0.890 0.870 F igure 1. The experimental results av eraged across all participating clients on test accuracy , training accuracy , and training loss on CIF AR-10 with Dir ( α ) = 0 . 1 , client number 100, party ratio 0.8. gence. In the time-accuracy plot, T inv = 200 reaches its peak accuracy faster than all other configurations. While T inv = 500 has theoretically lower amortized cost, its poor per-step progress results in a significantly longer time to reach target accuracy compared to T inv = 200 . The re- sults demonstrate that the Lazy In verse Update is not just a computational necessity but also a performance stabilizer . A moderate interv al ef fectiv ely suppresses curvature noise and minimizes the computational cost, achieving the best trade-off between ef ficiency and accuracy . 3) Stability Analysis of Gradient Anomaly Detection and Resilience T o ev aluate the effecti veness of the proposed gradient mon- itor , we visualize the temporal trajectory of the maximum gradient across layers during the training process in Fig. 4 . In the absence of our monitoring mechanism, the second- order optimization framework exhibits high numerical in- stability: one scenario leads to a sudden gradient explosion (orange line) early in training, while another triggers accu- mulated diver gence (blue line) in later rounds due to the noise amplification in the rank-deficient FIM. In contrast, our method, equipped with the gradient monitor (red line), successfully suppresses these extreme fluctuations and main- tains the gradient magnitude within a stable, bounded range throughout the entire communication rounds. This ablation result empirically validates that the Gradient Monitor is in- dispensable for rectifying curvature-induced instability and ensuring the robust con ver gence of FedRCO. 4) Impact of Client Number and P articipation Ratio W e demonstrate the exceptional scalability of FedRCO through extensi ve experiments varying client populations and participation ratios. The results are shown in T able 2 as well as Fig. 6 to Fig. 26 in Appendix E for details. Unlike baselines that stagnate or fluctuate as network com- plexity increases, FedRCO consistently dominates across all configurations. Notably , when scaling to 100 clients, our method achie ves a commanding 78 . 8% accuracy on CIF AR- 10—outperforming FedA vg and FedProx by a significant margin—while maintaining ov er 88% on EMNIST . Further- more, FedRCO prov es impervious to participation sparsity , maintaining a decisiv e lead from low ( 0 . 1 ) to full ( 1 . 0 ) par- ticipation rates. These results conclusiv ely validate that our robust curv ature correction ef fectiv ely neutralizes local drift, ensuring superior con ver gence and model quality in both massiv e, fragmented networks and stable, full-participation scenarios compared to all first-order and adaptive baselines. 7 Submission and Formatting Instructions f or ICML 2026 T able 2. The ablation experimental results about client number and participation ratio on the Dirichlet distribution with D ir ( α ) = 0 . 1 . For the client number part, the party ratio is set as 0.8, and for the party ratio part, the client number is set as 100. CIF AR-10 EMNIST Method Client Number Party Ratio Client Number Party Ratio 10 50 100 0.1 0.5 1 10 50 100 0.1 0.5 1 FedA vg 0.539 0.521 0.563 0.538 0.576 0.565 0.779 0.814 0.818 0.806 0.814 0.815 FedPr ox 0.557 0.573 0.553 0.540 0.575 0.554 0.781 0.810 0.817 0.807 0.819 0.815 FedAdam 0.456 0.539 0.557 0.397 0.549 0.525 0.795 0.834 0.845 0.840 0.847 0.846 FedA vgM 0.517 0.570 0.556 0.555 0.559 0.551 0.781 0.816 0.814 0.811 0.819 0.812 LocalNewton 0.495 0.559 0.509 0.512 0.534 0.538 0.758 0.791 0.804 0.798 0.806 0.802 FedPM 0.539 0.507 0.547 0.546 0.551 0.543 0.760 0.795 0.805 0.802 0.799 0.804 FedRCO-ori 0.622 0.609 0.695 0.650 0.675 0.662 0.805 0.839 0.854 0.853 0.853 0.853 FedRCO 0.743 0.786 0.788 0.630 0.737 0.764 0.885 0.908 0.902 0.856 0.887 0.910 F igure 2. (a), The proportion of time spent on Matrix In version and Communication relativ e to the total training time. (b) The experimental results on a verage global accuracy v ersus wall-clock time. The horizontal axis represents time. F igure 3. Impact results of Inv ersion Frequency ( T inv ) measured by communication round and time. 7. Conclusion W e introduced F edRCO , a no vel federated second-order op- timization method that stabilizes curvature estimation in the presence of data heterogeneity . FedRCO addresses the insta- bility through a robust correction mechanism and achie ves high computational efficienc y through a lazy update strat- egy . FedRCO dramatically accelerates conv ergence and accuracy across diverse non-IID settings, outperforming baselines with ne gligible overhead. The robustness and scal- 8 Submission and Formatting Instructions f or ICML 2026 F igure 4. V isualization of gradient stability . The plot compares the gradient trajectories with (red) and without (blue/orange) the Gradient Monitor . ability of FedRCO make it a promising solution for ef ficient federated learning on decentralized, resource-constrained devices. References Abdulkadirov , R., L yakhov , P ., and Nagornov , N. Survey of optimization algorithms in modern neural networks. Mathematics , 11(11):2466, 2023. Cohen, G., Afshar , S., T apson, J., and V an Schaik, A. Em- nist: Extending mnist to handwritten letters. In 2017 in- ternational joint confer ence on neural networks (IJCNN) , pp. 2921–2926. IEEE, 2017. Grosse, R. and Martens, J. A kronecker-factored approxi- mate fisher matrix for con volution layers. In International Confer ence on Machine Learning , pp. 573–582. PMLR, 2016. Gupta, V ., Ghosh, A., Derezinski, M., Khanna, R., Ram- chandran, K., and Mahoney , M. Localnewton: Reducing communication bottleneck for distributed learning. arXiv pr eprint arXiv:2105.07320 , 2021. Hsu, T .-M. H., Qi, H., and Bro wn, M. Measuring the ef fects of non-identical data distrib ution for federated visual clas- sification. arXiv pr eprint arXiv:1909.06335 , 2019. Ishii, H., Niwa, K., Sawada, H., Fujino, A., Harada, N., and Y okota, R. Fedpm: Federated learning using second- order optimization with preconditioned mixing of local parameters. arXiv pr eprint arXiv:2511.09100 , 2025. Karimireddy , S. P ., Kale, S., Mohri, M., Reddi, S., Stich, S., and Suresh, A. T . SCAFFOLD: Stochastic controlled av eraging for federated learning. In III, H. D. and Singh, A. (eds.), Pr oceedings of the 37th International Confer - ence on Machine Learning , volume 119 of Pr oceedings of Machine Learning Rese ar ch , pp. 5132–5143. PMLR, 13–18 Jul 2020. Krizhevsk y , A., Hinton, G., et al. Learning multiple layers of features from tiny images. 2009. Li, Q., Diao, Y ., Chen, Q., and He, B. Federated learning on non-iid data silos: An experimental study . In 2022 IEEE 38th international confer ence on data engineering (ICDE) , pp. 965–978. IEEE, 2022. Li, T ., Sahu, A. K., Zaheer, M., Sanjabi, M., T alw alkar , A., and Smith, V . Federated optimization in heterogeneous networks. Pr oceedings of Machine learning and systems , 2:429–450, 2020. Martens, J. and Grosse, R. Optimizing neural netw orks with kronecker -factored approximate curvature. In Interna- tional confer ence on machine learning , pp. 2408–2417. PMLR, 2015. McMahan, H. B., Moore, E., Ramage, D., Hampson, S., and y Arcas, B. A. Communication-efficient learning of deep networks from decentralized data. In International Confer ence on Artificial Intelligence and Statistics , 2016. Reddi, S., Charles, Z., Zaheer , M., Garrett, Z., Rush, K., K one ˇ cn ` y, J., Kumar , S., and McMahan, H. B. Adaptiv e federated optimization. arXiv pr eprint arXiv:2003.00295 , 2020. Safaryan, M., Islamo v , R., Qian, X., and Richt ´ arik, P . Fednl: Making ne wton-type methods applicable to federated learning. arXiv pr eprint arXiv:2106.02969 , 2021. T Dinh, C., T ran, N., and Nguyen, J. Personalized federated learning with moreau en velopes. Advances in neural information pr ocessing systems , 33:21394–21405, 2020. T ang, Z., Jiang, F ., Gong, M., Li, H., W u, Y ., Y u, F ., W ang, Z., and W ang, M. Skfac: T raining neural networks with faster kronecker -factored approximate curvature. In Pr o- ceedings of the IEEE/CVF Confer ence on Computer V i- sion and P attern Recognition , pp. 13479–13487, 2021. Y urochkin, M., Agarwal, M., Ghosh, S., Greenew ald, K., Hoang, N., and Khazaeni, Y . Bayesian nonparametric federated learning of neural networks. In International confer ence on machine learning , pp. 7252–7261. PMLR, 2019. 9 Submission and Formatting Instructions f or ICML 2026 A. Theoretical Analysis of Gradient Instability in F ederated Second-Order Optimization In this section, we provide a theoretical analysis of the numerical instability observed when applying second-order optimization methods in a federated learning setting. W e identify three primary sources of gradient explosion: (1) Rank deficiency due to small-batch approximation, (2) Curvature mismatch arising from non-IID data distrib utions, and (3) Error analysis caused by stale curvature information. First, we provide all the notation used in the main te xt and in the appendices. T able 3. Notations used in this paper Notation Description mainly used in the text θ Model parameter , θ ∈ R d . L ( θ ) , L c ( θ ) Global loss function, local loss function of client c . C, c T otal number of clients, client index. T , t T otal number of communication rounds, communication round index. K, k T otal number of local epochs, local epoch index. n, n c T otal data volume, local data v olume, n = P C c =1 n c . l Layer index of model. H , Hessian Matrix. F , ˆ F Fisher Information Matrix (FIM), the empirical FIM. A Input activ ation matrix. G Gradient matrix of the loss with respect to the layer’ s pre-activ ation outputs. Ω Cov ariance of A . Γ Covariance of G . D c Local dataset held by client c . g Stochastic gradient vector , g = ∇L ( θ ) . T inv Frequency of in version interv al. η Learning rate. π , ϵ, ξ , γ Parameters controlling Kronecker f actors, T ikhonov damping, anomaly score, and aggregation. Notation Description mainly used in the appendices B Local mini-batch size. λ, λ min , λ max Eigen values, minimum eigen value, maximum eigen value. v , δ Direction eigen vector , local curv ature. e, e dir , e drif t Error , error in the preconditioned update direction, expected squared norm of the client drift. κ ( H ) Condition number of the Hessian. L Lipschitz smoothness constant for assumption C.1 . µ Strong con vexity constant for assumption C.2 . σ V ariance constant assumption C.3 . M Gradient constant assumption C.4 . U t A veraged aggregate update for communication round t . θ ∗ , L ∗ Optimal model, global optimal value. ρ Effecti ve con vergence decay rate, ρ ≈ η E µλ min . 10 Submission and Formatting Instructions f or ICML 2026 A.1. Preliminaries and Notation Let L ( θ ) = E ( x,y ) ∼D [ l ( f ( x ; θ ) , y )] be the global loss function parameterized by θ ∈ R d . In Federated Learning, we hav e C clients, where the c -th client minimizes a local loss L c ( θ ) ov er a local dataset D c .The standard second-order update rule for client c in the communication round t is giv en by: θ t +1 = θ t − η ( ˆ F c + ϵ I ) − 1 ∇L c ( θ t ) , (19) where ˆ F c is the empirical Fisher Information Matrix (FIM) or Hessian approximation, ϵ is the damping factor , and η is the learning rate. A.2. Instability Induced by the Small-Batch Regime Proposition 3.1 . (Rank Deficiency) When the mini-batch size B is smaller than the model dimension d ( B ≪ d ), the empirical F isher Matrix ˆ F c becomes rank-deficient. W ithout sufficient damping, sampling noise within the null space of ˆ F c can lead to unbounded parameter updates. Pr oof. The empirical Fisher matrix computed on a mini-batch of size B is defined as: ˆ F c = 1 B B X i =1 ∇ log p ( y i | x i ; θ ) ∇ log p ( y i | x i ; θ ) ⊤ . (20) Let g i = ∇ log p ( y i | x i ; θ ) denote the gradient. ˆ F c is a sum of the B rank-1 matrices. Thus, rank ( ˆ F c ) ≤ B . Consider the spectral decomposition of ˆ F c : ˆ F c = d X j =1 λ j u j u ⊤ j , (21) where the eigen v alues λ 1 ≥ λ 2 ≥ · · · ≥ λ d ≥ 0 , and u j denote the eigen vectors. Since rank ( ˆ F c ) ≤ B , we hav e λ j = 0 for all j > B .The preconditioned gradient update ∆ θ = − ( ˆ F c + ϵI ) − 1 g c can be expanded on the eigenbasis: ∆ θ = − d X j =1 u ⊤ j g c λ j + ϵ u j . (22) Splitting this sum into the non-zero subspace and the null space: ∆ θ = − B X j =1 u ⊤ j g c λ j + ϵ u j | {z } Signal Component − d X j = B +1 u ⊤ j g c ϵ u j | {z } Noise/Null Component , ∥ ∆ θ ∥ 2 2 ≥ d X j = B +1 ( u ⊤ j g c ) 2 ϵ 2 . (23) The local stochastic gradient g c typically contains noise. In high-dimensional spaces, this noise vector is almost guaranteed to hav e a non-zero projection onto the null space of ˆ F c . For the null component, the scaling factor is 1 /ϵ . As ϵ → 0 , ∥ ∆ θ ∥ → ∞ . This confirms that in small-batch FL settings, the update v ector is dominated by noise in the unconstrained directions, causing the gradient explosion detected by our Look-Ahead Gradient Monitor . 11 Submission and Formatting Instructions f or ICML 2026 A.3. Div ergence due to non-IID Curv ature Mismatch Proposition 3.2 . (Curvature Mismatch) Let L c be the local objective and L g lobal be the global objective. If the local curvatur e underestimates the global curvatur e along the update dir ection, for example , the local landscape appears flatter while the global is steep, the quadratic penalty in the global objective can become unbounded, leading to diver gence. Pr oof. Consider the quadratic approximation of the global loss function at θ t : L g lobal ( θ t +1 ) ≈ L g lobal ( θ t ) + ∇L ⊤ g lobal ( θ t )(∆ θ ) + 1 2 (∆ θ ) ⊤ ∇ 2 L g lobal ( θ t )(∆ θ ) . (24) Substituting the local second-order step ∆ θ = − H − 1 c g c (assuming ϵ = 0 for simpl icity), the quadratic penalty term is: 1 2 (∆ θ ) ⊤ ∇ 2 L g lobal ( θ t )(∆ θ ) = 1 2 g ⊤ c H − 1 c C X c =1 n c n ∇ 2 L c ( θ t ) H − 1 c g k = 1 2 g ⊤ c H − 1 c H g lobal H − 1 c g c , (25) where n c is the data v olume of c clients n = P C c =1 n c , and H c and H g lobal denote the Hessian of the client c and global model, respecti vely . Let v be a direction eigen vector where data is sparse on client c but dense globally . Considering the local flatness, the client lacks information in direction v , so the local curv ature is small: v ⊤ H c v = δ ≈ 0 . Consequently , the in verse curvature is large: v ⊤ H − 1 c v ≈ 1 /δ . Considering the global sharpness, this direction is well-constrained: v ⊤ H g lobal v = Y ≫ 0 . Analyzing the matrix product H − 1 c H g lobal H − 1 c along direction v : v ⊤ H − 1 c H g lobal H − 1 c v ≈ 1 δ · Y · 1 δ = Y δ 2 . (26) The global loss increase is bounded by: L g lobal ( θ t +1 ) − L g lobal ( θ t ) ≳ − η ∥∇L g lobal ∥ · 1 δ + 1 2 η 2 Y δ 2 . (27) Since δ is in the denominator squared for the penalty term but linear for the descent term, for non-IID which represents sufficiently small δ , the quadratic penalty dominates: lim δ → 0 Y δ 2 = ∞ . (28) This proves that trusting a locally in verted Hessian on non-IID data can lead to catastrophic increases in global loss, necessitating the robust resilience mechanism proposed in our method. A.4. Perturbation Analysis of Stale Pr econditioners In our method, we update the in verse matrix ev ery T inv steps to reduce computational cost. Here we analyze the error introduced by this delay . Let F t be the true Fisher matrix at step t , and F old be the stale matrix computed τ steps ago. W e can model this as a perturbation: F old = F t + E , (29) 12 Submission and Formatting Instructions f or ICML 2026 where E is the error matrix due to the change in θ ov er τ steps. W e are interested in the error of the in verse ( F t + E ) − 1 . Using a first-order Neumann series expansion ( A + E ) − 1 ≈ A − 1 − A − 1 E A − 1 , the in verse of the stale matrix can be approximated as : ( F old ) − 1 ≈ F − 1 t − F − 1 t E F − 1 t . (30) As a result, the error in the preconditioned update direction can be expressed as e dir = ∆ θ stale − ∆ θ true ≈ η ( F − 1 t E F − 1 t ) ∇L , (31) T aking the spectral norm yields the bound: ∥ e dir ∥ ≤ η ∥ F − 1 t ∥ 2 ∥ E ∥∥∇L∥ . Use ∥ F − 1 t ∥ = 1 λ min ( F t ) for symmetric positiv e definite matrices. Thus: ∥ e dir ∥ ∝ 1 λ 2 min ∥ E ∥ . (32) This bound highlights that in ill-conditioned landscapes where λ min ( F t ) approaches zero, stale curv ature information can, in principle, lead to a large de viation in the update direction. Howe ver , this analysis characterizes a worst-case bias induced by delayed curv ature updates and does not account for the stochastic nature of mini-batch optimization. In FL settings with non-IID data and limited local computation, FIM estimates obtained from indi vidual mini-batches e xhibit high v ariance. Empirically , we observ e that excessi vely frequent curv ature in versions amplify this estimation noise: the preconditioner overfits to batch-specific fluctuations, resulting in unstable optimization trajectories. In contrast, updating the in verse curvature at a moderate interv al allows curv ature statistics to aggregate information across multiple steps, effecti vely acting as a temporal smoothing mechanism. This variance reduction often dominates the bias introduced by delayed updates, leading to more stable and efficient optimization in practice. Our experiments consistently show that a moderately large update interv al (e.g., T in v = 200 ) outperforms more frequent updates (e.g., T in v = 20 ), while simultaneously reducing computational ov erhead. These observations re veal a bias–v ariance trade-off in the choice of T in v , which our method exploits to achie ve both stability and efficienc y in federated second-order optimization. B. Theoretical J ustification for the Efficacy of Second-Order in F ederated Learning In this section, we provide the theoretical moti vation for employing K-F A C in federated settings. W e formally demonstrate that second-order preconditioning effecti vely mitigates the poor conditioning of the optimization landscape caused by data heterogeneity , leading to higher con vergence rates compared to first-order methods. B.1. The Conditioning Problem in F ederated Optimizations Consider the local objectiv e function L c ( θ ) for client c . In the quadratic approximation near a local minimum θ ∗ , the loss is gov erned by the Hessian matrix H = ∇ 2 L c ( θ ∗ ) : L c ( θ ) ≈ L c ( θ ∗ ) + 1 2 ( θ − θ ∗ ) ⊤ H ( θ − θ ∗ ) . (33) 13 Submission and Formatting Instructions f or ICML 2026 The conv ergence speed of first-order gradient descent is fundamentally limited by the condition number κ ( H ) of the Hessian: κ ( H ) = λ max ( H ) λ min ( H ) , (34) where λ max and λ min are the largest and smallest eigen values of H . Proposition 3.3 . (SGD Con vergence Rate) F or a con vex quadratic objective , the err or contraction of SGD with optimal learning rate is bounded by: ∥ θ t +1 − θ ∗ ∥ ≤ κ ( H ) − 1 κ ( H ) + 1 ∥ θ t − θ ∗ ∥ . (35) In FL, data heterogeneity induces highly skewed loss landscapes. For wxample, if a client only has examples of class A but not B, the curv ature along the B features is near zero, leading to λ min → 0 , while the A features are steep. This leads to κ ( H ) → ∞ . Consequently , the contraction factor κ − 1 κ +1 → 1 , meaning SGD con vergence becomes arbitrarily slo w . B.2. Geometric Correction via Fisher Pr econditioning K-F AC approximates the NGD update, which uses the Fisher Information Matrix F as a preconditioner . The update rule is ∆ θ = − η F − 1 ∇L . (36) Proposition 3.4 . (Affine In variance and Isotropization) Ideally , pr econditioning by the Hessian or the F isher transforms the geometry of the parameter space into an isotr opic sphere . Pr oof. Let the optimization landscape around a local optimum θ ∗ be approximated by a quadratic function. Consider a linear change of basis ϕ = F 1 / 2 ( θ − θ ∗ ) . In this transformed coordinate system, the Hessian of the loss L ( ϕ ) becomes: L ( ϕ ) ≈ 1 2 ϕ ⊤ ( F − 1 / 2 H F − 1 / 2 ) ϕ = 1 2 ϕ ⊤ ( ˜ H ) ϕ . (37) Under the standard assumption that the model distribution matches the data distribution near the optimum, we have H ≈ F . Consequently , the transformed Hessian approximates the identity matrix: ˜ H = F − 1 / 2 H F − 1 / 2 ≈ F − 1 / 2 F F − 1 / 2 = I . (38) The condition number of the identity matrix I is: κ ( ˜ H ) ≈ κ ( I ) = 1 (39) Substituting κ = 1 into the con ver gence bound from Proposition 3.3 : κ ( H ) − 1 κ ( H ) + 1 = 1 − 1 1 + 1 = 0 . (40) Ideally , second-order optimization achie ves quadratic con ver gence. In practice, K-F A C uses a block-diagonal approximation ˆ F , leading to the condition number κ new ≪ κ S GD . This implies that K-F AC can maximize the utility of each local training round, significantly reducing the required communication rounds. 14 Submission and Formatting Instructions f or ICML 2026 C. Con vergence Analysis of Second-order F ederated Learning In this section, we provide a detailed con ver gence analysis of the proposed FedRCO algorithm. W e analyze the con ver gence behavior from tw o perspecti ves: (1) the local descent property on the client side, showing ho w the second-order precondi- tioner accelerates local objecti ve minimization, and (2) the global con ver gence of the aggregated model on the serv er side, bounding the error accumulation caused by multiple local epochs and non-IID data. C.1. Problem Setup and Assumptions W e consider the following federated optimization problem: min θ ∈ R d L ( θ ) := c X c =1 n c n L c ( θ c ) , L c ( θ c ) = E ( x,y ) ∼D c [ l ( y | x ; θ )] , (41) where n c is the data volume of c clients n = P C c =1 n c , C is the number of clients, and D c is the local data distribution. Let ˆ F − 1 c ( θ ) denote the approximate in verse Fisher matrix for client c at parameters θ . The local update rule at communication round t on client c is: θ t +1 c = θ t c − η t ˆ F − 1 c ( θ t c ) ∇L c ( θ t c ) . (42) T o facilitate the analysis, we make the follo wing standard assumptions, which are widely used in the analysis of second-order and federated optimization methods. Assumption C.1. (L-Smoothness) Each local objecti ve function L c is L -smooth. For all θ 1 , θ 2 ∈ R d : L c ( θ 1 ) ≤ L c ( θ 2 ) + ∇L c ( θ 2 ) ⊤ ( θ 1 − θ 2 ) + L 2 ∥ θ 1 − θ 2 ∥ 2 . (43) Assumption C.2. ( µ -Str ong Con vexity) The global objectiv e function L is µ -strongly con ve x. For all θ 1 , θ 2 ∈ R d : L ( θ 1 ) ≥ L ( θ 2 ) + ∇L ( θ 2 ) ⊤ ( θ 1 − θ 2 ) + µ 2 ∥ θ 1 − θ 2 ∥ 2 . (44) Assumption C.3. (Unbiased Gradient and Bounded V ariance) For any client c , the stochastic gradient g c ( θ ) is an unbiased estimator of the local full-batch gradient ∇L c ( θ ) , and its v ariance is bounded by σ 2 : E [ g c ( θ )] = ∇L c ( θ ) , E [ | g c ( θ ) − ∇L c ( θ ) | 2 ] ≤ σ 2 . (45) Assumption C.4. (Bounded Gradients) The expected squared norm of stochastic gradients is bounded: E [ ∥∇L c ( θ ) ∥ ] ≤ M 2 . (46) Assumption C.5. (Bounded Pr econditioner Spectrum) The approximate in verse Fisher matrix ˆ F − 1 c ( θ ) used in K-F AC satisfies the following eigen v alue bounds for all c, θ : λ min I ⪯ ˆ F − 1 c ( θ ) ⪯ λ max I . (47) where λ max and λ min are the largest and smallest eigen values which ha ve 0 < λ min ≤ λ max . 15 Submission and Formatting Instructions f or ICML 2026 C.2. Client-Side Analysis: Local Descent Lemma First, we prov e that the second-order update ensures a suf ficient decrease in the local objecti ve function v alue, ef fectiv ely accelerating con vergence compared to SGD. Theorem 5.1 (Local Descent with Preconditioning) Under Assumptions C.1 and C.5 , for a learning rate η satisfying η ≤ λ min Lλ 2 max , the expected decr ease in the local objective L c for a single K-F AC step is lower bounded by: E [ L c ( θ t +1 c )] − L c ( θ t c ) ≤ − η λ min 2 ∥∇L c ( θ t c ) ∥ 2 + η 2 Lλ 2 max σ 2 2 . (48) Pr oof. From the L -smoothness of L c : L c ( θ t +1 ) ≤ L c ( θ t ) + ∇L c ( θ t ) ⊤ ( θ t +1 − θ t ) + L 2 ∥ θ t +1 − θ t ∥ 2 . (49) Substitute the second-order update rule θ t +1 − θ t = − η ( ˆ F t ) − 1 g t , where g t is the stochastic gradient: L c ( θ t +1 ) ≤ L c ( θ t ) − η ∇L c ( θ t ) ⊤ ( ˆ F t ) − 1 g t + Lη 2 2 ∥ ( ˆ F t ) − 1 g t ∥ 2 . (50) T aking the expectation ov er the stochastic noise and taking E [ g t ] = ∇L c ( θ t ) : E [ L c ( θ t +1 )] ≤ L c ( θ t ) − η ∇L c ( θ t ) ⊤ ( ˆ F t ) − 1 ∇L c ( θ t ) + Lη 2 2 E [ ∥ ( ˆ F t ) − 1 g t ∥ 2 ] . Using Assumption C.5 , ( ˆ F t ) − 1 ⪰ λ min I and ∥ ( ˆ F t ) − 1 ∥ ≤ λ max , the quadratic term can be described as: ∇L c ( θ t ) ⊤ ( ˆ F t ) − 1 ∇L c ( θ t ) ≥ λ min ||∇L c ( θ t ) || 2 . (51) And the variance term can be described as: E [ ∥ ( ˆ F t ) − 1 g t ∥ 2 ] ≤ λ 2 max E [ ∥ g t ∥ 2 ] = λ 2 max ( ∥∇L c ( θ t ) ∥ 2 + σ 2 ) . (52) Substituting the variance term and the quadratic term: E [ L c ( θ t +1 )] ≤ L c ( θ t ) − η λ min ∥∇L c ( θ t ) ∥ 2 + Lη 2 λ 2 max 2 ( ∥∇L c ( θ t ) ∥ 2 + σ 2 ) . (53) Regrouping the terms in volving gradient norm: E [ L c ( θ t +1 )] ≤ L c ( θ t ) − η λ min − η Lλ 2 max 2 ∥∇L c ( θ t ) ∥ 2 + Lη 2 λ 2 max σ 2 2 . (54) Since we choosing η ≤ λ min Lλ 2 max and λ min ≤ λ max , we ensure the descent term is neg ativ e. Specifically , setting η suf ficiently small such that λ min − η Lλ 2 max 2 ≥ λ min 2 , we obtain: E [ L c ( θ t +1 )] ≤ L c ( θ t ) − η λ min 2 ∥∇L c ( θ t ) ∥ 2 + Lη 2 λ 2 max σ 2 2 . (55) This lemma pro ves that on the client side, second-order optimization guaranties a descent proportional to λ min . The standard SGD is a special case where λ min = λ max = 1 . Second-order provides a significant advantage when the geometry is ill-conditioned, standard SGD would struggle with a large Lipschitz constant L , but our method effecti vely rescales the space. 16 Submission and Formatting Instructions f or ICML 2026 C.3. Server -Side Global Con vergence Theorem W e now employ the local descent to pro ve the con ver gence of the global model θ t after T ′ communication rounds. Theorem 5.2 (Global Con vergence Rate of F edRCO) Under Assumptions C.1 - C.5 , second-or der federated optimization con verg es to a neighborhood of the optimal solution θ ∗ . Specifically , for the global model θ t , the err or bound satisfies: E ∥ θ t +1 − θ ∗ ∥ 2 ≤ (1 − ρ ) E ∥ θ t − θ ∗ ∥ 2 + E , (56) wher e ρ ≈ η µK λ min , and E r epr esent noise and hetero geneity terms. Pr oof. The global model update rule at round t after k local steps aggregating updates from C clients is: θ t +1 = θ t − η 1 C C X c =1 K − 1 X k =0 ( ˆ F t c,k ) − 1 g t c,k . (57) Let U t = 1 C P C c =1 P K − 1 k =0 ( ˆ F t c,k ) − 1 g t c,k be the av eraged aggreg ate update. W e analyze the distance to the optimum θ ∗ : ∥ θ t +1 − θ ∗ ∥ 2 = ∥ θ t − η U t − θ ∗ ∥ 2 = ∥ θ t − θ ∗ ∥ 2 − 2 η ⟨ θ t − θ ∗ , U t ⟩ + η 2 ∥U t ∥ 2 . (58) First, we analyze the bounding of the e xpectation of the contraction term. W e focus on the term − 2 η E ⟨ θ t − θ ∗ , U t ⟩ . The aggregate update U t essentially approximates the descent direction. Ideally , we want U t ≈ K · F − 1 ∇L ( θ t ) . Howe ver , gradients are computed at local perturbed points θ t c,k . U t = 1 C C X c =1 K − 1 X k =0 ( ˆ F t c,k ) − 1 ( ∇L c ( θ t ) + ∇L c ( θ t c,k ) − ∇L c ( θ t ) | {z } Drift Error + g t c,k − ∇L c ( θ t c,k ) | {z } Noise ) . (59) T o rigorously bound the contraction term ⟨ θ t − θ ∗ , ( ˆ F t c,k ) − 1 ∇L c ( θ t ) ⟩ , we apply the Mean V alue Theorem. Specifically , we can express the gradient dif ference as ∇L c ( θ t ) − ∇L c ( θ ∗ ) = ˜ H ( θ t − θ ∗ ) , where ˜ H = ∇ 2 L c ( ˜ θ ) is the Hessian ev aluated at some interpolation point. Assuming ∇L c ( θ ∗ ) ≈ 0 , the term becomes a quadratic form: ⟨ θ t − θ ∗ , ( ˆ F t c,k ) − 1 ∇L c ( θ t ) ⟩ = ⟨ θ t − θ ∗ , ( ˆ F t c,k ) − 1 ˜ H ( θ t − θ ∗ ) ⟩ (60) Since both the preconditioner ( ˆ F t c,k ) − 1 and the Hessian ˜ H are positive definite matrices (Assumption C.2 and C.5 ), the product matrix has positi ve eigen values. W e can thus lower bound this term using the minimum eigen value of the product matrix: ⟨ θ t − θ ∗ , ( ˆ F t c,k ) − 1 ∇L c ( θ t ) ⟩ ≥ λ min ( ˆ F t c,k ) − 1 ˜ H ∥ θ t − θ ∗ ∥ 2 ≥ λ min µ ∥ θ t − θ ∗ ∥ 2 (61) Summing ov er c where P ∇L c = ∇L and k : E ⟨ θ t − θ ∗ , U t ⟩ ≥ K λ min µ ∥ θ t − θ ∗ ∥ 2 . (62) Thus, the contraction term becomes: − 2 η E ⟨ θ t − θ ∗ , U t ⟩ ≤ − 2 η µK λ min ∥ θ t − θ ∗ ∥ 2 . (63) 17 Submission and Formatting Instructions f or ICML 2026 Then we analyze the bounding of the quadratic term. W e bound η 2 E ∥U t ∥ 2 . Using the Cauchy-Schwarz inequality ∥ P n i =1 x i ∥ 2 ≤ n P n i =1 ∥ x i ∥ 2 , we hav e: E ∥U t ∥ 2 = 1 C C X c =1 K − 1 X k =0 ( ˆ F t c,k ) − 1 g t c,k 2 ≤ K K − 1 X k =0 ( ˆ F t c,k ) − 1 g t c,k 2 . (64) By the definition of the induced matrix norm, ∥ Ax ∥ ≤ ∥ A ∥ 2 ∥ x ∥ , where ∥ A ∥ 2 corresponds to the largest singular v alue or eigen value for symmetric matrices. Per Assumption C.5 , ∥ ( ˆ F t c,k ) − 1 ∥ 2 ≤ λ max , we hav e ( ˆ F t c,k ) − 1 g t c,k 2 ≤ ∥ ( ˆ F t c,k ) − 1 ∥ 2 2 ∥ g t c,k ∥ 2 ≤ λ 2 max ∥ g t c,k ∥ 2 . (65) Substituting this back and taking the expectation: η 2 E ∥U t ∥ 2 ≤ η 2 K K − 1 X k =0 λ 2 max E ∥ g t c,k ∥ 2 . (66) Using Assumption C.4 , where E [ ∥∇L c ( θ ) ∥ ] ≤ M 2 . : η 2 E ∥U t ∥ 2 ≤ η 2 K K − 1 X k =0 λ 2 max M 2 = η 2 K · ( K λ 2 max M 2 ) = η 2 K 2 λ 2 max M 2 . (67) Last, we combine the contraction term and quadratic term into the main equation: E ∥ θ t +1 − θ ∗ ∥ 2 ≤ ∥ θ t − θ ∗ ∥ 2 − 2 η K µλ min ∥ θ t − θ ∗ ∥ 2 + η 2 K 2 λ 2 max M 2 . (68) Let ρ = 2 η K µλ min . Note that λ min accelerates con vergence compared to first-order methods, where implicitly λ min = 1 . E ∥ θ t +1 − θ ∗ ∥ 2 ≤ (1 − ρ ) E ∥ θ t − θ ∗ ∥ 2 + O ( η 2 K 2 ) . (69) Applying this recursion ov er T ′ communication rounds: E ∥ θ T ′ − θ ∗ ∥ 2 ≤ (1 − ρ ) T ′ ∆ 0 + O ( η 2 K 2 ) ρ . (70) The first term decays linearly to zero, while the second term represents the residual error floor due to stochastic noise and non-IID drift. The preconditioner λ min in ρ effecti vely improv es the condition number , leading to faster con ver gence than SGD. D. Detailed Deri vation of Optimization Bounds In this section, we rigorously derive the error bounds for both the client-side local updates and the server -side global aggregation. Our analysis explicitly incorporates the second-order preconditioner matrix, demonstrating how second-order information impacts the con vergence trajectory compared to standard SGD. 18 Submission and Formatting Instructions f or ICML 2026 D.1. Pr eliminaries W e retain the standard Assumptions from Appendix C , and we e xplicitly define the properties of the K-F A C preconditioner . Let F − 1 c,k be the K-F AC preconditioner for client c at step k . The local update rule is: θ t c,k +1 = θ t c,k − η F − 1 c,k ∇L c ( θ t c,k ) , (71) where t index es the communication round and k indexes the local epoch ( k ∈ { 0 , . . . , K − 1 } ). D.2. Client-Side Bound: Analyzing Local Drift A key challenge in FL is the client drift caused by performing se veral local steps before aggregation. W e define the drift at step t within communication round E as ∆ t c = θ t c − θ t , where θ t is the virtual global model. The Client Drift measures how far the local model de viates from the global model after K steps of local training. This drift is the primary source of noise in Federated Learning. Theorem 5.3 (Client Drift Bound) Under Assumptions C.1 , C.3 , C.4 and C.5 , the expected squar ed norm of the client drift after K local steps is bounded by: e drif t = E h θ t c,K − θ t 2 i ≤ 2 K 2 η 2 λ 2 max σ 2 + 2 K 2 η 2 λ 2 max M 2 . (72) Pr oof. The accumulated parameter change after K steps is the sum of local updates: θ t c,k − θ t = − K − 1 X k =0 η ( F t c,k ) − 1 ∇L c ( θ t c,k ) . (73) T aking the squared norm and expectation: E h θ t c,k − θ t 2 i = η 2 E K − 1 X k =0 ( F t c,k ) − 1 ∇L c ( θ t c,k ) 2 . (74) Using the Jensen’ s inequality ∥ P n i =1 x i ∥ 2 ≤ n P n i =1 ∥ x i ∥ 2 : E h θ t c,k − θ t 2 i ≤ η 2 K K − 1 X k =0 E h ( F t c,k ) − 1 ∇L c ( θ t c,k ) 2 i . (75) Now we apply the bound on the preconditioner F − 1 . Since ∥ F − 1 v ∥ ≤ ∥ F − 1 ∥ 2 ∥ v ∥ ≤ λ max ∥ v ∥ : E h θ t c,k − θ t 2 i ≤ η 2 K λ 2 max − 1 X k =0 E h ∇L c ( θ t c,k ) 2 i . (76) W e decompose the stochastic gradient into the true gradient and variance: E [ ∥ g ∥ 2 ] = E [ ∥ g − ∇L + ∇L∥ 2 ] ≤ 2 E [ ∥ g − ∇L∥ 2 ] + 2 ∥∇L∥ 2 ≤ 2 σ 2 + 2 M 2 . (77) Substituting this back: 19 Submission and Formatting Instructions f or ICML 2026 e drif t ≤ η 2 K K − 1 X k =0 λ 2 max (2 σ 2 + 2 M 2 ) = 2 K 2 η 2 λ 2 max ( σ 2 + M 2 ) . (78) This result explicitly sho ws that the drift is proportional to λ 2 max . Suppose the Hessian approximation becomes singular , where very small eigen values → huge in verse eigen v alues λ max , the drift explodes quadratically , which mathematically justifies the gradient normalization and robust resilience in FedRCO. D.3. Ser ver -Side Bound: One-Round Conv ergence Guarantee Now we analyze ho w the global loss decreases after one round of aggregation. Theorem D.1. (One-Round Descent) Let the global aggr egation be θ t +1 = θ t + ∆ θ , where ∆ θ = 1 C P c ( θ t c,K − θ t ) . Under L-smoothness, the global objective impr oves as: E [ L ( θ t +1 )] ≤ L ( θ t ) − 2 η K µλ min | {z } Effective Decay ( L ( θ t ) − L ∗ ) + L 2 e drif t | {z } Drift Err or , (79) wher e L ∗ is the global optimal value. Pr oof. By L -smoothness of the global objectiv e L : L ( θ t +1 ) ≤ L ( θ t ) + ∇L ( θ t ) ⊤ ( θ t +1 − θ t ) + L 2 ∥ θ t +1 − θ t ∥ 2 . (80) Let the aggregated update be ¯ ∆ = 1 C P c P K − 1 k =0 − η ( F t c,k ) − 1 g t c,k . L ( θ t +1 ) ≤ L ( θ t ) − η ∇L ( θ t ) ⊤ E [ ¯ ∆] | {z } T 1 + L 2 E [ ∥ ¯ ∆ ∥ 2 ] | {z } T 2 . (81) First, we analyze the bounding of the Descent T erm T 1 . Ideally , we want the update to align with the gradient. T 1 ≈ − η K ∇L ( θ t ) ⊤ 1 C X c F − 1 c ∇L c ( θ t ) ! . (82) Using the preconditioner property v ⊤ Gv ≥ λ min ∥ v ∥ 2 and strong con vexity: T 1 ≤ − η K λ min ∥∇L ( θ t ) ∥ 2 . (83) Using the Polyak-Lojasiewicz condition: ∥∇L ( θ ) ∥ 2 ≥ 2 µ ( L ( θ ) − L ∗ ) : T 1 ≤ − 2 η K µλ min ( L ( θ t ) − L ∗ ) . (84) 20 Submission and Formatting Instructions f or ICML 2026 As λ min for K-F AC is much lar ger than standard SGD, it allows for a steeper descent. Second, we analyze the bounding of the term T 2 . T 2 is essentially the av erage drift error . Using con ve xity of norms: ∥ ¯ ∆ ∥ 2 = 1 C X c ( θ t c,K − θ t ) 2 ≤ 1 C X c ∥ θ t c,K − θ t ∥ 2 = e drif t L 2 E [ ∥ ¯ ∆ ∥ 2 ] ≤ L 2 e drif t . (85) Combining T 1 and T 2 E [ L ( θ t +1 ) − L ∗ ] ≤ (1 − 2 η K µλ min )( L ( θ t ) − L ∗ ) + L 2 e drif t . (86) Substituting the drift bound from Theorem 5.3 : E [ L ( θ t +1 ) − L ∗ ] ≤ (1 − ρ )( L ( θ t ) − L ∗ ) + LK 2 η 2 λ 2 max ( σ 2 + M 2 ) , (87) where ρ = 2 η K µλ min . D.4. Final Global Con vergence Bound Theorem 5.4 Recur sively applying Theor em D.1 leads to the final con verg ence rate . After T ′ communication r ounds, the con verg ence of our method satisfies: E [ L ( θ T ′ ) − L ∗ ] ≤ (1 − ρ ) T ′ ( L ( θ 0 ) − L ∗ ) | {z } Linear Decay + LK η λ 2 max ( σ 2 + M 2 ) 2 µλ min | {z } Asymptotic Error Floor . (88) For the linear decay speed ρ , the rate is governed by ρ ∝ λ min . In ill-conditioned problems, FedRCO ensures λ min is bounded away from zero, while in SGD it can be arbitrarily small. This proves f aster con vergence. For the error floor , the final error depends on the ratio λ 2 max λ min . If the preconditioner is unstable ( λ max → ∞ ), the error floor explodes. Our method proposes the Gradient Monitor and Robust Resilience, which effecti vely clips λ max , keeping the ratio λ 2 max λ min small and controlled. This theoretically proves why our method achie ves lo wer final loss. E. Experimental Details Here, we introduce all other details used in this paper . W e used four NVIDIA 3090 GPUs with 96GB of memory , Intel(R) Xeon(R) Gold 6226R CPU at 2.90GHz with 16 cores, and 128GB of RAM. The software en vironment includes Python 3.9.2, Pytorch 2.7.1+cu126, and CUD A 12.2. E.1. Model Structure T o simulate realistic resource-constrained federated learning en vironments, we employ a lightweight Con volutional Neural Network (CNN) architecture for both datasets. This streamlined design ensures that the model can be deployed on edge de vices with limited computational po wer and memory while maintaining suf ficient representati ve capacity for the classification tasks. CIF AR-10 Model: For the 3-channel color images, the architecture be gins with a conv olutional layer featuring 16 filters and a 3 × 3 kernel, follo wed by a 2 × 2 max-pooling layer to reduce spatial dimensions. A second conv olutional layer with 21 Submission and Formatting Instructions f or ICML 2026 F igure 5. The distribution example. The first figure is the Dirichlet distribution on 100 clients with D ir ( α ) = 0 . 1 , and the second figure is the Pathological distrib ution on 100 clients with 2 classes per client. 32 filters and a 3 × 3 kernel is then applied. The resulting feature maps are flattened and passed through tw o successi ve fully connected layers with 32 and 256 neurons, respecti vely . Finally , a softmax output layer is used to produce the probability distribution o ver the 10 cate gories. EMNIST Model: : T o maintain consistency in computational complexity across different data modalities, we adopt a mirrored structure for the EMNIST dataset. The input grayscale images are processed through the same configuration of two con volutional layers (16 and 32 filters) and max-pooling, followed by the two-tier linear layers (32 and 256 neurons). The output layer is adjusted to 62 units to accommodate the character and digit classes in the EMNIST dataset. Implementation Details: Throughout the network, we use the Rectified Linear Unit (ReLU) as the acti v ation function for all hidden layers to mitigate the vanishing gradient problem and accelerate con ver gence. No batch normalization is used to av oid the synchronization overhead and potential instability caused by non-IID data in federated settings. This minimalist design allows us to focus on evaluating the effecti veness of our proposed FedRCO in optimizing curvature information under strict resource constraints. E.2. Data Distribution T o comprehensiv ely ev aluate the robustness of FedRCO against statistical heterogeneity , we employ two widely used non-IID data partitioning strategie s: the Dirichlet-based distribution and the Pathological distrib ution. The distribution is shown in Fig. 5 . Dirichlet-based Non-IID Distribution The Dirichlet-based partitioning simulates a realistic scenario where the label distributions across clients are unbalanced. Specifically , for each class k , we sample a distribution vector q k ∼ D ir ( α ) and allocate a proportion of samples from class k to client i according to q k,i . The concentration parameter α controls the degree of non-IID. W e utilize α ∈ { 0 . 1 , 0 . 5 , 1 . 0 } . A smaller α indicates a more extreme sk ewness, where most samples of a specific class are concentrated on only a few clients. 22 Submission and Formatting Instructions f or ICML 2026 Pathological Non-IID Distribution The P athological partitioning mimics a scenario where each client only has access to a limited subset of the total classes. This creates the situation where certain features or labels are entirely missing from most local datasets. Each client is randomly assigned a fixed number of unique labels. The samples belonging to these labels are then e venly distrib uted among the assigned clients. For CIF AR-10, we test with 2 and 5 classes per client. For EMNIST , due to the large number of 62 categories, we set each client to ha ve 10 or 30 categories. The Pathological-2 setting on CIF AR-10 is particularly challenging, as local models tend to ov erfit to their o wn class sets, which may lead to drifting. E.3. Other ablation results Here we will sho w all the experimental results. For the Dirichlet setting, we sample client data from D ir ( α ) with α ∈ { 0 . 1 , 0 . 5 , 1 } . In the pathological setting, each client is restricted to a small subset of labels; specifically , clients are assigned { 2 , 5 } labels in CIF AR-10 and { 10 , 30 } labels in EMNIST . The number of clients varies in { 10 , 50 , 100 } , and the percentage of client participation per communication round is set to { 0 . 1 , 0 . 5 , 0 . 8 , 1 } for comparison. The communication round is set as 1600, and the local epoch is set as 20. The learning rate is set as 0.00625, batch size 32, EMA parameter α = 0 . 95 , ˜ ∇ stable is set as 10, and damping ϵ = 0 . 03 for all second-order methods. The parameters of comparison methods are all set to their optimal values. The results displayed below from Fig. 6 to Fig. 26 are calculated on the av erage of all participants’ clients. The upper left is the test accuracy , the upper right is the train accuracy , the lower left is the train loss, and the lower right is the test accurac y measured in real-time. F igure 6. Dataset: EMNIST , Data distribution: Dirichlet 0.1, Party ratio: 0.1, Number clients: 100. 23 Submission and Formatting Instructions f or ICML 2026 F igure 7. Dataset: EMNIST , Data distribution: Dirichlet 0.1, Party ratio: 0.5, Number clients: 100. F igure 8. Dataset: EMNIST , Data distribution: Dirichlet 0.1, Party ratio: 0.8, Number clients: 100. 24 Submission and Formatting Instructions f or ICML 2026 F igure 9. Dataset: EMNIST , Data distribution: Dirichlet 0.1, Party ratio: 1, Number clients: 100. F igure 10. Dataset: EMNIST , Data distribution: Dirichlet 0.1, Party ratio: 0.8, Number clients: 10. 25 Submission and Formatting Instructions f or ICML 2026 F igure 11. Dataset: EMNIST , Data distribution: Dirichlet 0.1, Party ratio: 0.8, Number clients: 50. F igure 12. Dataset: EMNIST , Data distribution: Dirichlet 0.5, Party ratio: 0.8, Number clients: 100. 26 Submission and Formatting Instructions f or ICML 2026 F igure 13. Dataset: EMNIST , Data distribution: Dirichlet 1, Party ratio: 0.8, Number clients: 100. F igure 14. Dataset: EMNIST , Data distribution: Pathological 10, Party ratio: 0.8, Number clients: 100. 27 Submission and Formatting Instructions f or ICML 2026 F igure 15. Dataset: EMNIST , Data distribution: Pathological 30, Party ratio: 0.8, Number clients: 100. F igure 16. Dataset: EMNIST , Data distribution: iid, Party ratio: 0.8, Number clients: 100. 28 Submission and Formatting Instructions f or ICML 2026 F igure 17. Dataset: CIF AR-10, Data distribution: Dirichlet 0.1, Party ratio: 0.1, Number clients: 100. F igure 18. Dataset: CIF AR-10, Data distribution: Dirichlet 0.1, Party ratio: 0.5, Number clients: 100. 29 Submission and Formatting Instructions f or ICML 2026 F igure 19. Dataset: CIF AR-10, Data distribution: Dirichlet 0.1, Party ratio: 1, Number clients: 100. F igure 20. Dataset: CIF AR-10, Data distribution: Dirichlet 0.1, Party ratio: 0.8, Number clients: 10. 30 Submission and Formatting Instructions f or ICML 2026 F igure 21. Dataset: CIF AR-10, Data distribution: Dirichlet 0.1, Party ratio: 0.8, Number clients: 50. F igure 22. Dataset: CIF AR-10, Data distribution: Dirichlet 0.5, Party ratio: 0.8, Number clients: 100. 31 Submission and Formatting Instructions f or ICML 2026 F igure 23. Dataset: CIF AR-10, Data distribution: Dirichlet 1, Party ratio: 0.8, Number clients: 100. F igure 24. Dataset: CIF AR-10, Data distribution: Pathological 2, Party ratio: 0.8, Number clients: 100. 32 Submission and Formatting Instructions f or ICML 2026 F igure 25. Dataset: CIF AR-10, Data distribution: Pathological 5, Party ratio: 0.8, Number clients: 100. F igure 26. Dataset: CIF AR-10, Data distribution: iid, Party ratio: 0.8, Number clients: 100. 33
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment