VulnScout-C: A Lightweight Transformer for C Code Vulnerability Detection
Vulnerability detection in C programs is a critical challenge in software security. Although large language models (LLMs) achieve strong detection performance, their multi-billion-parameter scale makes them impractical for integration into developmen…
Authors: Aymen Lassoued, Nacef Mbarek, Bechir Dardouri
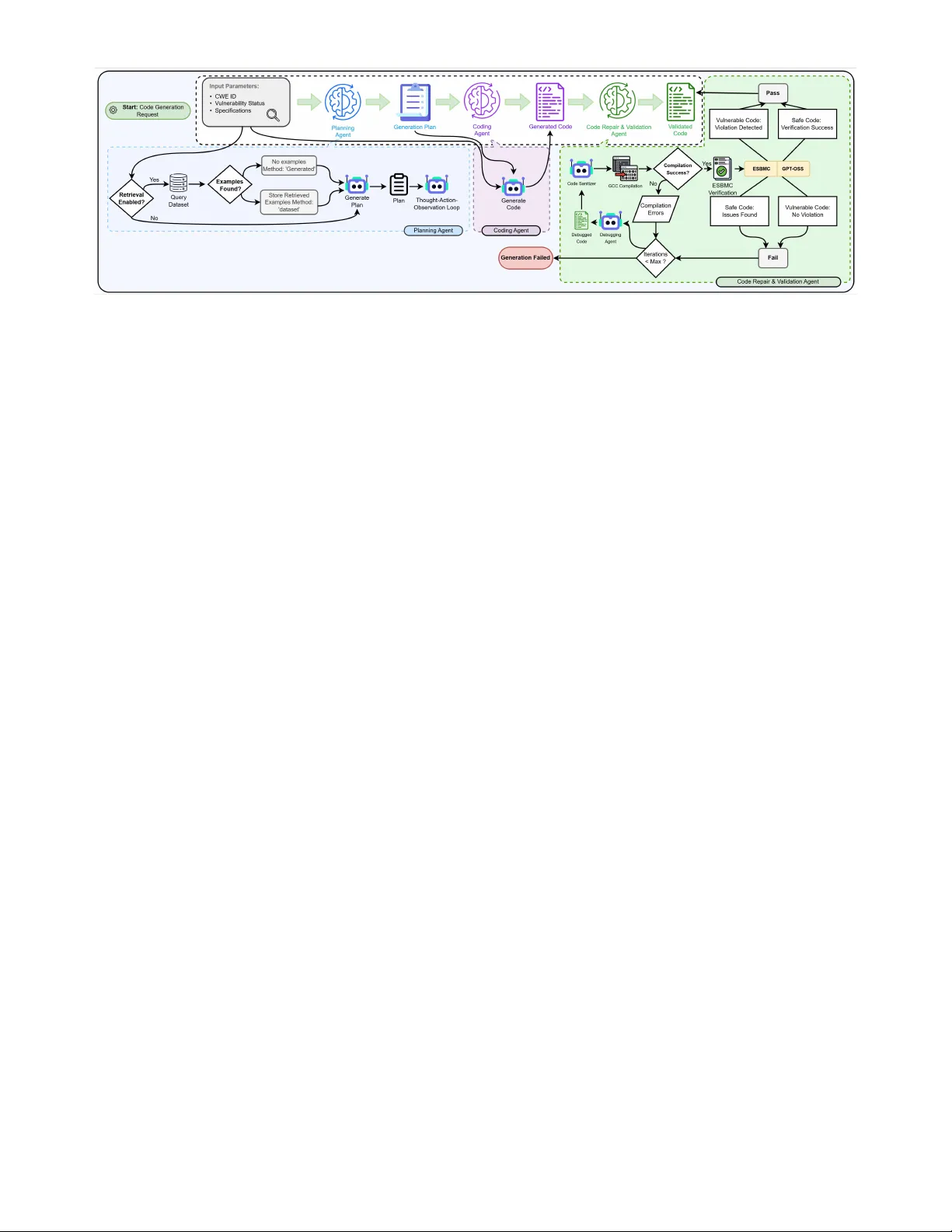
IEEE TRANSACTIONS ON DEPEND ABLE AND SECURE COMPUTING, V OL. XX, NO. X, MONTH 20XX 1 V ulnScout-C: A Lightweight T ransf or mer f or C Code V ulnerability Detection A ymen Lassoued ∗ , Nacef Mbarek ∗ , Bechir Dardouri ∗ , Bassem Ouni † , Qing Li ‡ , and F akhri Karra y § ✦ Abstract —V ulnerability detection in C programs is a cr itical challenge in software secur ity . Although large language models (LLMs) achiev e strong detection performance, their multi-billion-parameter scale makes them impractical for integration into dev elopment workflows requiring low latency and continuous analysis . We introduce V U L N S C O U T - C , a compact transf or mer architecture with 693M total parameters (353M activ e during inf erence), derived from the Qwen model f amily and optimized for C code vulnerability detection. Alongside the model, we present V U L N S C O U T , a new 33,565-sample curated dataset generated through a controlled multi-agent pipeline with formal v er ification, designed to fill cov erage gaps in e xisting benchmar ks across underrepresented CWE categor ies. Evaluated on a standard- ized C vulnerability detection benchmark, V U L N S C O U T - C outperforms all ev aluated baselines, including state-of-the-ar t reasoning LLMs and commercial static analysis tools, while offering a fraction of their infer- ence cost. These results demonstrate that task-specialized compact architectures can match or ev en outperf or m the detection capability of models orders of magnitude larger , making continuous, low-latency vulnerability analysis practical within real-world dev elopment workflows. Index T erms —V ulnerability Detection, Large Language Models, Mixture of Experts, Agentic AI, C Progr amming, Software Security , CWE Detec- tion, Deep Learning 1 I N T R O D U C T I O N S O F T W A R E vulnerabilities repr esent a persistent threat to system security , with memory-related errors in C/C++ programs accounting for a significant proportion of ex- ploitable weaknesses [1]. The MITRE Corporation’s annual ranking of the T op 25 Most Dangerous Softwar e W eaknesses consistently highlights critical issues such as buffer over- flows (CWE-121, CWE-122), out-of-bounds access (CWE- 787), use-after-free (CWE-416), and null pointer dereferences (CWE-476) [2]. T raditional approaches to vulnerability de- tection, including static analysis tools and formal verifica- tion methods, face inherent limitations in accuracy , false positive rates, and scalability [3]. Recent advances in large language models (LLMs) have opened new possibilities for automated vulnerability de- tection [4], [5]. Models such as GPT -4, DeepSeek R1, and Corresponding author: Bassem Ouni (bassem.ouni@ku.ac.ae). • ∗ Ecole Polytechnique de T unisie, La Marsa, T unisia. E-mail: {ay- men.lassoued, nacef.mbarek, bechir .dardouri}@ept.ucar .tn. • † Khalifa University, Abu Dhabi, UAE. E-mail: bassem.ouni@ku.ac.ae. • ‡ University of Groningen, The Netherlands. E-mail: qing.li@rug.nl. • § Mohamed bin Zayed University of Artificial Intelligence (MBZUAI), Abu Dhabi, UAE. E-mail: fakhri.karray@mbzuai.ac.ae. specialized variants have demonstrated strong capabilities in understanding code semantics and identifying security flaws. However , these models typically comprise billions of parameters, requiring substantial computational resour ces and incurring high inference costs that hinder practical deployment. For example, GPT -4 is estimated to contain approximately 1.76 trillion parameters [6], and most LLMs fine-tuned for vulnerability detection also operate at billion- parameter scales, leading to high memory consumption and significant computational overhead during inference. These limitations restrict their applicability for efficient large-scale vulnerability analysis and their integration into multi-agent systems, where each component is expected to perform tasks with low latency and high efficiency . This motivates the development of compact and efficient models that retain str ong vulnerability detection performance while substantially r educing inference cost and latency . This computational burden creates a critical gap be- tween the potential of LLM-based vulnerability detection and its practical deployment in software development en- vironments. The latency introduced by large-scale models fundamentally limits their integration into these workflows, particularly in resour ce-constrained environments or when analyzing lar ge codebases. 1.1 Motivation and Challenges The motivation for this work stems from thr ee key observa- tions: Accuracy vs. Efficiency T rade-off: While LLMs achieve superior detection rates compared to traditional static ana- lyzers [5], their computational requir ements make them un- suitable for integration into development tools that requir e sub-second response times. Static analysis tools, conversely , offer rapid analysis but suffer from high false positive rates (often exceeding 64%) [7] and limited understanding of contextual vulnerabilities. Parameter Redundancy: Analysis of existing LLM-based vulnerability detectors reveals that much of their parameter space contributes minimally to the specific task of vul- nerability identification. General-purpose language models contain extensive world knowledge and multi-domain capa- bilities that, while impressive, are unnecessary for focused vulnerability detection and particularly in this study for C code [8]–[10]. IEEE TRANSACTIONS ON DEPEND ABLE AND SECURE COMPUTING, V OL. XX, NO. X, MONTH 20XX 2 Dataset Quality and Diversity: Recent datasets such as FormAI-v2 [4] provide high-quality labeled examples with formal verification, yet existing models fail to fully leverage this structured knowledge due to their generic architectures optimized for broader language understanding tasks rather than specialized security analysis. 1.2 Our Contributions This paper presents V ulnScout-C, a lightweight neural ar- chitecture designed specifically for C code vulnerability detection. Our key contributions are as follows: 1) Compact and Efficient Architecture: W e design a cus- tom MoE-based transformer with 693M total parameters (353M active), derived from Qwen3-30B-A3B embed- dings. On the 250-sample CASTLE benchmark, this ar chi- tecture achieves a CASTLE score of 1068, a binary F1 of 85.4%, accuracy of 82.4%, recall of 86.0%, and precision of 84.9%, outperforming all evaluated baselines including GPT -o3 Mini (977), while processing samples at 4.97 ms each (batch size 32, 201.1 samples/s), significantly faster than 7B-scale generative LLMs and DeepSeek R1, en- abling r eal-time analysis in development workflows. 2) V U L N S C O U T Dataset: W e constr uct a new dataset of 33,565 labeled C code samples (19,239 vulnerable, 14,326 safe) spanning a wide range of CWE categories. Samples are generated through a multi-agent pipeline and re- tained only when a dual-verification protocol, combining ESBMC bounded model checking and a GPT -OSS-120B verifier , yields identical verdicts from both verifiers. Sam- ples on which the two verifiers disagree are discarded and the generation request is reissued. This conservative filtering addresses coverage gaps in existing benchmarks where several CWEs are sparsely represented or entirely absent. 3) Rank-A ware CWE Classification: W e propose a weighted BCE loss that prioritizes detection of high- severity CWEs according to the MITRE T op 25 ranking. The model is jointly optimized for binary vulnerability detection and 25-class CWE prediction, achieving a CWE classification accuracy of 90.0% on truly vulnerable sam- ples and an average per-CWE F1 of 84.6% across all 25 CASTLE categories, rising to 90.4% among the 8 CWEs shared with the MITRE T op 25 ranking (CWE-22, CWE- 78, CWE-89, CWE-125, CWE-416, CWE-476, CWE-770, CWE-787), including 100% F1 on CWE-78 and CWE-787 from the MITRE overlap, and additionally on CWE-327, CWE-362, CWE-522, and CWE-822 from the remaining CASTLE categories. 1.3 P aper Organization The remainder of this paper is organized as follows. Sec- tion 2 reviews related work on vulnerability detection, the use of large language models in security , and other relevant techniques. Section 3 provides background on C code vul- nerabilities and existing datasets. Section 4 introduces our newly created V U L N S C O U T dataset, describing its compo- sition, coverage, and role in enhancing model robustness. Section 5 presents the V ulnScout-C architecture, including its compact design and CWE-focused optimizations, as well as training methodology across multiple datasets. Section 6 describes the experimental setup and evaluation protocols. Section 7 reports performance on the CASTLE benchmark and compares it with state-of-the-art approaches. Section 8 presents compr ehensive ablation studies analyzing ar chitec- tural design choices and their impact on detection perfor- mance. Section 9 analyzes the results, highlights efficiency gains, discusses limitations, and outlines future work. Fi- nally , Section 10 concludes the paper . 2 R E L AT E D W O R K 2.1 T raditional V ulnerability Detection Approaches Static analysis tools have long been the primary method for automated vulnerability detection in C/C++ programs [3]. T ools such as Coverity , Fortify , and Cppcheck employ pat- tern matching, data flow analysis, and taint analysis to identify potential security flaws. However , these approaches face fundamental limitations in accuracy and coverage [11]. Empirical studies demonstrate false positive rates ranging from 60% to 90%, significantly impacting developer pr oduc- tivity and tool adoption [12]. Formal verification methods, including bounded model checking (BMC) and theorem proving, offer mathematically rigorous guarantees about program correctness [13]. T ools such as ESBMC [14] and CBMC [15] have demonstrated suc- cess in detecting memory-safety violations and undefined behavior . While these methods minimize false positives through counterexample generation, they face scalability challenges and cannot detect all vulnerability classes, par- ticularly those requiring semantic understanding beyond memory safety properties. 2.2 Machine Learning f or V ulnerability Detection Early machine learning approaches to vulnerability detec- tion employed traditional classifiers (SVM, Random For ests) with hand-crafted features extracted from source code [16]. These methods showed promise but required extensive fea- ture engineering and struggled with complex vulnerability patterns. Deep learning revolutionized this field with the intro- duction of code repr esentation learning. V ulDeePecker [17] pioneered the use of LSTMs for learning vulnerability patterns from code gadgets. Subsequent work introduced graph neural networks (GNNs) to capture control and data flow dependencies. Devign [18] demonstrated that GNN- based approaches could achieve superior performance on real-world vulnerabilities by modeling programs as graphs. The emergence of pr e-trained transformer models marked another paradigm shift. CodeBERT [19], trained on bimodal code-documentation pairs, showed that trans- fer learning from large code corpora significantly im- proved vulnerability detection. Subsequent models includ- ing GraphCodeBERT [20], CodeT5 [21], and V ulBERT a [22] refined this approach with specialized pre-training objec- tives and architectural modifications. 2.3 LLMs for Code Security Recent work has investigated the use of large-scale language models for security tasks. Several studies have evaluated IEEE TRANSACTIONS ON DEPEND ABLE AND SECURE COMPUTING, V OL. XX, NO. X, MONTH 20XX 3 GPT -4, GPT -3.5, and other commercial LLMs for vulner - ability detection, with mixed results [4]. Although these models exhibit strong zero-shot and few-shot capabilities, they face several limitations: (1) inconsistent performance across differ ent vulnerability types, (2) high computational and memory costs, (3) hallucinations that can pr oduce false positives, and (4) long inference times, which reduce their practicality in multi-stage or multi-agent workflows. The CASTLE benchmark [23] recently provided a stan- dardized evaluation framework, revealing that state-of-the- art LLMs still struggle with certain vulnerability classes. Despite these advances, few studies have explored ap- plying model compr ession techniques specifically to vulner - ability detection. Most existing approaches either fine-tune full-scale LLMs or rely on traditional machine learning with manual featur e engineering. In contrast, our work addresses this gap by designing a compact architecture from the ground up for vulnerability detection, leveraging insights from model compression research [8]–[10] to achieve both efficiency and high detection performance. 2.4 V ulnerability Detection Datasets The quality and diversity of training data critically impact model performance. Several datasets have been developed for C/C++ vulnerability detection: Synthetic Datasets: The Juliet test suite [24] contains over 64,000 test cases systematically covering 118 CWE cat- egories. While valuable for controlled evaluation, synthetic data may not fully captur e the complexity of real-world vulnerabilities. Real-W orld Datasets: BigV ul [25], DiverseV ul [26], and CVEFixes [27] extract vulnerabilities from GitHub com- mits. These datasets provide realistic examples but face challenges including mislabeling, data quality issues, and limited contextual information. Hybrid and AI-Generated Datasets: SecV ulEval [5] provides statement-level labels along with rich contextual information (function arguments, external functions, type definitions, globals, and execution environments) for real- world C/C++ vulnerabilities, addressing key limitations of earlier datasets such as coarse-grained labeling and lack of context. FormAI-v2 [4] consists of AI-generated C code labeled through formal verification using ESBMC, offering high-quality labels with minimal false positives and diverse vulnerability patterns. BenchV ul [28] specifically addresses these issues through manual curation, deduplication, NVD- based label standardization, and verification, resulting in a high-quality benchmark of over 2,500 self-contained func- tion samples focused on the MITRE T op 25 Most Dangerous CWEs, with strong r epresentation in C/C++. Our Contribution: T o complement existing datasets, we introduce V U L N S C O U T , a curated dataset of 33,565 C code samples generated through a controlled agentic system. V U L N S C O U T enhances coverage of underrepresented vul- nerability patterns, as we discovered that many CWEs are sparsely repr esented in existing datasets, and some do not appear at all. This provides additional high-quality data to improve model robustness and generalization. Our work leverages all four dataset types, enabling the model to learn from synthetic patterns, real-world examples, formally verified AI-generated code, and the additional coverage pr ovided by V U L N S C O U T . 3 B AC K G R O U N D 3.1 V ulnerability Detection Challenges V ulnerability detection in C code pr esents unique challenges due to the language’s low-level memory management, pointer arithmetic, and undefined behavior . The MITRE T op 25 CWEs encompass several critical vulnerability classes: Memory Corruption: Buffer overflows (CWE-121, CWE- 122, CWE-787) and out-of-bounds access (CWE-125) result from insufficient bounds checking. These vulnerabilities en- able attackers to corrupt memory , hijack control flow , and execute arbitrary code. Integer Errors: Integer overflow (CWE-190) and wraparound can lead to incorrect calculations, affecting security decisions and enabling secondary vulnerabilities such as buffer overflows when used in size calculations. Pointer Errors: Null pointer dereferences (CWE-476), use-after-fr ee (CWE-416), and double-free (CWE-415) errors compromise program stability and security . These issues often require understanding object lifetimes and control flow paths. Input V alidation: Improper input validation (CWE-20) and format string vulnerabilities (CWE-134) enable injection attacks and information disclosure. Detection requires un- derstanding how external data flows thr ough the program. Effective vulnerability detection faces several technical challenges, particularly in the context of C code: 1) Context Sensitivity: Many vulnerabilities manifest only under specific conditions, requiring analysis of control flow , data dependencies, and pr ogram state to accurately detect them. 2) Inter -Procedural Dependencies: V ulnerabilities often span multiple functions or modules, necessitating mod- els that can track relationships across function bound- aries and maintain contextual awareness. 3) Semantic Understanding: Differ entiating benign code from actual vulnerabilities requir es deep semantic com- prehension beyond simple syntactic pattern matching. 4) Balancing Accuracy and Reliability: High false posi- tive rates r educe tool usability . Effective models must carefully balance sensitivity and specificity to provide actionable vulnerability predictions. 3.2 Dataset Overview Our training methodology incorporates four complemen- tary datasets in addition to the V U L N S C O U T dataset that we intr oduced, each providing distinct advantages: 3.2.1 Juliet T est Suite The Juliet test suite [24] provides systematically constructed test cases covering 118 CWE categories. Each test case includes both vulnerable ("bad") and patched ("good") vari- ants, enabling models to learn discriminative features. The dataset’s synthetic nature ensures comprehensive coverage of vulnerability patterns but may not fully repr esent real- world code complexity . Key characteristics: IEEE TRANSACTIONS ON DEPEND ABLE AND SECURE COMPUTING, V OL. XX, NO. X, MONTH 20XX 4 • Systematic coverage of CWE categories • Compilable and executable test cases • Clear vulnerable/non-vulnerable labeling • Limited diversity in coding styles and patterns 3.2.2 SecV ulEv al Dataset SecV ulEval [5] addresses limitations of function-level datasets by providing statement-level vulnerability labels with rich contextual information. The dataset includes 25,440 functions from real-world C/C++ projects spanning 1999-2024, covering 5,867 unique CVEs across 5 context categories. Key characteristics: • Statement-level granularity for pr ecise localization • Contextual information (function arguments, external functions, type definitions, globals, execution environ- ments) • Real-world vulnerability patterns • Compr ehensive metadata including CWE types and CVE descriptions 3.2.3 F or mAI-v2 Dataset FormAI-v2 [4] comprises 331,000 compilable C programs generated by nine state-of-the-art LLMs and labeled through formal verification using ESBMC. The dataset provides high-quality labels with minimal false positives through counterexample generation. Key characteristics: • Lar ge-scale dataset with diverse code patterns • Formal verification for r eliable labeling • Coverage of 42 unique CWEs including MITRE T op 25 • AI-generated code mimicking common programming errors 3.2.4 BenchV ul Dataset BenchV ul [28] is a manually curated benchmark dataset specifically designed to evaluate the generalization of vul- nerability detection models across the MITRE T op 25 Most Dangerous CWEs. It aggregates and refines samples from multiple public vulnerability datasets, applying rigorous deduplication, label standardization using updated NVD recor ds, LLM-assisted filtering, and manual validation to ensure high quality and correctness. Key characteristics: • Focused exclusively on the MITRE T op 25 Most Danger - ous CWEs, with balanced representation but relatively low pr oportions. • High-quality curation through deduplication, NVD- based label correction, and manual verification • Self-contained function-level samples suitable for pre- cise evaluation • Real-world sourced data (aggregated from BigV ul, CVEfixes, DiverseV ul, etc.). 3.3 Evaluation Frame work: CASTLE Benchmark The CASTLE (CWE Automated Security T esting and Low- Level Evaluation) benchmark [23] provides a standardized framework for evaluating vulnerability detection tools. The benchmark consists of 250 hand-crafted micro-benchmarks covering 25 CWE categories, with 10 samples per CWE: 6 vulnerable and 4 non-vulnerable (150 vulnerable and 100 non-vulnerable in total). The CASTLE score incorporates several factors: • T rue positive detection with bonus points for high- severity CWEs (based on MITRE T op 25 ranking) • Penalty for false positives to encourage precision • Rewar d for correct identification of non-vulnerable code Formally , the CASTLE score for tool t over dataset d n is defined as: CASTLE ( t ) = n X i =1 s i (1) s i = 5 − | t ( d i ) | + 1 + B ( t cwe ) , v i ∈ t ( d i ) 2 , v i = t ( d i ) = ∅ −| t ( d i ) | , otherwise (2) where B ( t cwe ) repr esents the bonus for detecting CWEs in the MITRE T op 25, decreasing linearly with rank. This scoring mechanism ensures fair comparison across tools with differ ent sensitivity-specificity trade-offs while prioritizing detection of critical vulnerabilities. The CASTLE benchmark offers critical methodological advantages over lar ge-scale datasets such as BigV ul [25] and Devign [18]: Controlled Evaluation: CASTLE consists of 250 hand- crafted, compilable micro-benchmarks, each containing ex- actly zero or one vulnerability . This isolation provides pre- cise "unit tests" for model reasoning capabilities, eliminating the noise inherent in commit-based datasets where vul- nerable/safe distinctions are often ambiguous or context- dependent. False Positive A wareness: Unlike standard F1 scor es that treat false positives and false negatives symmetrically , the CASTLE score heavily penalizes false positives ( − 1 point per FP). This addresses a critical practical concern: in industrial security auditing, excessive false positives cause developer fatigue and tool abandonment, making precision equally important as recall. Compilation Requirement: Each CASTLE sample is compilable and self-contained, enabling direct comparison with formal verification tools and ensuring that detected vulnerabilities are contextually valid rather than artifacts of incomplete code snippets. 4 D AT A S E T This section introduces V U L N S C O U T , a curated dataset de- signed to address data sparsity and coverage limitations in existing C vulnerability benchmarks. The dataset is con- structed using a hybrid approach that combines existing labeled data with a controlled, multi-agent code generation pipeline, enabling balanced coverage across a wide range of CWEs. 4.1 Dataset Motivation and Overview Existing vulnerability datasets often suffer from skewed CWE distributions, limited coverage of certain weakness classes, and insufficient diversity within individual CWEs. IEEE TRANSACTIONS ON DEPEND ABLE AND SECURE COMPUTING, V OL. XX, NO. X, MONTH 20XX 5 Fig. 1. Overview of the multi-agent gener ation and validation pipeline used to construct the V U L N S C O U T dataset. While benchmarks such as SecV ulEval, BenchV ul, and the Juliet T est Suite provide valuable labeled samples, many CWEs are either sparsely represented or entirely absent from commonly used datasets. T o address these limitations, we construct V U L N S C O U T , a dataset consisting of 33,565 labeled C code samples (19,239 vulnerable, 14,326 safe). The dataset is designed to complement existing benchmarks by increasing coverage of underrepr esented CWEs, improving class balance, and introducing structurally diverse implementations validated by a consensus of two independent verifiers, ESBMC and a GPT -OSS-120B verifier , suitable for training and evaluating vulnerability detection models. 4.2 Source Corpus Construction The dataset construction process begins with the creation of a unified vulnerability corpus by combining SecV ulE- val [5], BenchV ul [28], and a selected subset of the Juliet T est Suite [24]. This selection is motivated by the fact that Juliet includes several CWE categories that are absent from other benchmarks, such as BenchV ul, thereby enabling broader and mor e comprehensive CWE coverage. From this merged corpus, we analyze the distribution of CWEs and identify vulnerability classes with limited repre- sentation. These CWEs are prioritized for data augmenta- tion to mitigate imbalance and impr ove model robustness. 4.3 CWE Distribution and Label Statistics Each sample in V U L N S C O U T is labeled as either vulnerable or safe and is associated with a corresponding CWE identifier . The final dataset consists of 33,565 samples used for training and analysis, with a relatively balanced label distribution. Specifically , 19,239 samples are labeled as vulnerable, while 14,326 samples are labeled as safe. The dataset spans all 25 CWE categories listed in T a- ble 2. The five most represented categories are CWE-617 (1,856 samples), CWE-22 (1,721), CWE-787 (1,673), CWE-835 (1,645), and CWE-843 (1,603), while the least represented are CWE-253 (974) and CWE-134 (1,003), which were the primary targets of the augmentation pipeline. While some CWEs remain more fr equent than others, the augmentation process significantly increases representation for previously sparse vulnerability classes, resulting in a more balanced and compr ehensive dataset. 4.4 Retriev al-Augmented Data Generation For CWEs with limited r epresentation in the source cor- pus, we employ a retrieval-augmented generation strategy . Samples are first grouped by (CWE, label) , where the label indicates whether the code is vulnerable or safe. When retrieval is enabled, the system randomly selects two examples fr om the corresponding group for each gener- ation request. These retrieved samples are injected into the planning and reasoning stages of the generation pipeline, providing contextual guidance while preserving diversity . This approach allows the system to generate realistic code that r eflects known vulnerability patterns without duplicat- ing existing samples. 4.5 Instruction-Only Generation f or Generalization T o encourage generalization beyond memorization, a subset of generation rounds is performed with retrieval disabled. In this mode, the system relies exclusively on high-level instructions derived from the CWE definition and user- specified constraints. This instruction-only setting forces the system to syn- thesize code that is structurally and semantically distinct from existing examples, r educing overfitting and promoting diversity . This strategy is particularly effective for generat- ing novel implementations within CWEs that are already present but poorly r epresented. For CWEs that are entirely missing from all source datasets, the system operates exclusively in this instruction- driven mode. 4.6 Generation Specifications Each generation request is parameterized by a set of explicit inputs, including: • The target CWE identifier • The desired vulnerability status (vulnerable or safe) • Optional constraints such as the number of functions, code length, and structural complexity These parameters allow fine-grained control over the generated samples and ensure diversity across implemen- tations. IEEE TRANSACTIONS ON DEPEND ABLE AND SECURE COMPUTING, V OL. XX, NO. X, MONTH 20XX 6 4.7 Multi-Agent Generation Pipeline The code generation process follows a multi-stage, agent- based workflow illustrated in Figure 1. Planning Agent: Given the CWE, vulnerability label, and optional specifications, the Planning Agent generates a detailed implementation plan outlining program struc- ture, contr ol flow , and vulnerability placement or mitigation strategy . Reasoning Agent (ReAct Loop): The system then enters a Thought, Action, Observation reasoning loop. When re- trieval is enabled, relevant dataset examples are analyzed to extract vulnerability patterns. Otherwise, reasoning is guided solely by CWE semantics and instructions. Coding Agent: Using the finalized plan and reasoning output, the Coding Agent produces a complete, compilable C pr ogram that adher es to the specified constraints and reflects realistic development practices. Code Repair and V alidation Agent: The generated code is sanitized and compiled using gcc . Samples that fail com- pilation are passed immediately to the Debugging Agent. Compilable samples enter a dual-verification stage executed in parallel: 1) ESBMC Formal V erification. The code is analysed with ESBMC [14] under the settings described in Section 4.10. ESBMC returns one of two ver dicts: V iolation Detected (counterexample pr oduced) or V erification Success (no property violation within the given bounds and timeout). 2) GPT -OSS-120B V erifier . The same source code, together with the intended CWE and vulnerability label, is sub- mitted to a GPT -OSS-120B model acting as a static rea- soning verifier . The model is prompted to return exactly one of four structured labels: • Vulnerable Code: Violation Detected • Safe Code: Verification Success • Safe Code: Issues Found • Vulnerable Code: No Violation Agreement Protocol. A sample is accepted only when both verifiers r each a consistent ver dict, defined as follows: • V ulnerable sample accepted: ESBMC returns V iolation Detected and the LLM verifier returns Vulnerable Code: Violation Detected . • Safe sample accepted: ESBMC returns V erification Success and the LLM verifier returns Safe Code: Verification Success . Any other combination including Safe Code: Issues Found (LLM identifies latent weaknesses in a nominally safe sample) or Vulnerable Code: No Violation (LLM cannot confirm the intended defect), is treated as a verification disagreement . Disagreements are not repairable by definition: they signal a fundamental inconsistency in the generated code’s security semantics. Such samples are discarded immediately , and a fresh end- to-end code generation request is issued to the pipeline. Samples that fail only because of ESBMC timeout or compilation err ors (i.e., neither verifier has yet render ed a verdict) are forwarded to the Debugging Agent, which iteratively repairs the code while preserving its intended security properties, repeating the dual-verification check after each r epair until both verifiers agree or the predefined iteration limit is reached. 4.8 Outcome and Dataset Quality Through this hybrid strategy combining retrieval- augmented generation, instruction-only synthesis, and dual verification (ESBMC bounded model checking cross- checked against a GPT -OSS-120B verifier), V U L N S C O U T provides high-quality , diverse, and consensus-verified C code samples. Only samples for which both verifiers independently reach the same verdict are admitted to the final dataset; disagreements trigger a fresh generation request. As a result, V U L N S C O U T serves as a robust dataset for training and evaluating vulnerability detection models, as well as for broader research in software security and formal verification. Its effectiveness is further demonstrated through the performance gains observed when training V ulnScout-C using this dataset. 4.9 Dataset Statistics and CWE Distribution T able 1 reports aggregate statistics for V U L N S C O U T . The dataset contains 33,565 samples spread across 25 CWE cat- egories, with a reasonable vulnerable/safe split (57.3% / 42.7%) to avoid severe class imbalance during training. T ABLE 1 V U L N S C O U T Dataset Aggregate Statistics. “Dual-V erified (pass)” counts samples accepted by both ESBMC and the GPT -OSS-120B verifier under the agreement protocol of Section 4. Property V alue T otal Samples 33,565 V ulnerable Samples 19,239 (57.3%) Safe Samples 14,326 (42.7%) Unique CWE Categories 25 A vg. T oken Length 412 Max T oken Length 1,024 (truncated) Median T oken Length 378 Initial Generated 52,714 Dual-V erified (pass) 33,565 (63.7%) V erifier Agreement Rate 63.7% Repair Iterations A vg. 1.8 T able 2 reports the per-CWE sample counts. CWEs present in the MITRE T op 25 are marked with ⋆ . The distribution highlights that CWE-617 (Reachable Assert.) and CWE-22 (Path T raversal) are the most repr esented, while CWE-253 and CWE-134 are the smallest categories; the augmentation pipeline specifically targeted these sparse categories. 4.10 Deduplication, Leakage Controls, and V erification Settings ESBMC Configuration. All ESBMC analyses were per- formed with ESBMC v7.8.1 using the following settings: 30-second per-sample timeout, unwind bound of 8, C99 language standard, and 32-bit memory model. For vulnerable samples, ESBMC must produce a counterexample ( V iolation Detected ); for safe samples, ESBMC must terminate without detecting a property violation ( V erification Success ). Samples where ESBMC times out befor e producing a verdict ar e forwarded to the Debugging Agent or discarded after ex- ceeding the repair limit. IEEE TRANSACTIONS ON DEPEND ABLE AND SECURE COMPUTING, V OL. XX, NO. X, MONTH 20XX 7 Fig. 2. Architecture of V ulnScout-C. The model employs a custom transformer architecture with Mixture-of-Exper ts (MoE) feed-f orward lay ers, Grouped Query Attention (GQA), and Rotar y Position Embeddings (RoPE) f or vulnerability detection in C code. GPT -OSS-120B V erifier Configuration. The LLM verifier is queried via a structured zero-shot prompt that supplies the C source code, the target CWE identifier , and the intended vulnerability label. The model is instr ucted to return exactly one of the four standardised verdict strings ( Vulnerable Code: Violation Detected , Safe Code: Verification Success , Safe Code: Issues Found , Vulnerable Code: No Violation ) and to provide a one-sentence justification. T emperature is set to 0 to maximise determinism. The verifier is queried independently of ESBMC and its output is compared only after both verdicts ar e available. Dual-V erification Outcome. Of 52,714 initially gener - ated samples, 33,565 (63.7%) were accepted under the agree- ment protocol: both ESBMC and the GPT -OSS-120B verifier returned consistent verdicts. The remaining 36.3% were either discarded due to verifier disagreement (the dominant failure mode), ESBMC timeout, or compilation failure, or were iteratively r epaired by the Debugging Agent (aver- age 1.8 repair rounds, maximum 5). V erifier disagreement accounted for approximately 18.4% of all generated candi- dates, confirming that the LLM verifier provides a mean- ingfully independent signal beyond what ESBMC alone captures. Deduplication. W e apply MinHash-based near- duplicate detection ( n -gram size 5, Jaccard threshold 0.85) within each (CWE, label) group. This removed 2,311 near-duplicates from the initial generated corpus, reducing within-group similarity and ensuring structural diversity . Leakage Prevention. T o prevent data leakage from the V U L N S C O U T training set into the CASTLE evaluation set, we applied the same MinHash similarity check across the merged training corpus and all 250 CASTLE sam- ples. No CASTLE sample exceeded a Jaccard similarity of 0.35 with any training sample, confirming the absence of near-duplicate leakage. W e further verified that no CAS- TLE sample appears verbatim or with minor renaming in V U L N S C O U T or the Juliet subset used in Stage 1. License and Release. V U L N S C O U T will be publicly re- leased under the CC BY 4.0 license upon paper acceptance. 5 M E T H O D O L O G Y 5.1 Arc hitecture Design V ulnScout-C adopts a custom transformer-based architec- ture inspired by the Qwen architectur e family , specifically designed for vulnerability detection in C code. Our de- sign philosophy prioritizes efficiency through Mixture-of- Experts (MoE) layers while maintaining the repr esenta- tional capacity needed for understanding complex security- relevant code patterns. IEEE TRANSACTIONS ON DEPEND ABLE AND SECURE COMPUTING, V OL. XX, NO. X, MONTH 20XX 8 T ABLE 2 P er-CWE Sample Distribution in V U L N S C O U T (exact counts). ⋆ = MITRE T op 25. Sor ted by total samples descending. CWE V uln. Safe T otal CWE-617 (Reachable Assert.) 973 883 1,856 CWE-22 ⋆ (Path T raversal) 1,092 629 1,721 CWE-787 ⋆ (OOB W rite) 927 746 1,673 CWE-835 (Infinite Loop) 930 715 1,645 CWE-843 (T ype Confusion) 885 718 1,603 CWE-761 (Free Non-Heap Ptr) 841 638 1,479 CWE-89 ⋆ (SQL Injection) 759 665 1,424 CWE-190 (Int. Overflow) 758 665 1,423 CWE-125 ⋆ (OOB Read) 783 636 1,419 CWE-415 (Double Free) 764 642 1,406 CWE-416 ⋆ (Use-After-Fr ee) 758 632 1,390 CWE-401 (Mem. Leak) 798 580 1,378 CWE-369 (Div-by-Zero) 658 656 1,314 CWE-798 (Hard-coded Cred.) 844 446 1,290 CWE-522 (Insuf. Credentials) 774 457 1,231 CWE-362 (Race Condition) 675 546 1,221 CWE-770 ⋆ (Uncontrolled Alloc.) 713 497 1,210 CWE-78 ⋆ (OS Cmd. Inj.) 758 449 1,207 CWE-476 ⋆ (Null Deref.) 686 510 1,196 CWE-674 (Uncontrolled Recursion) 753 416 1,169 CWE-327 (Broken Crypto) 656 459 1,115 CWE-822 (Untrusted Ptr Deref.) 690 421 1,111 CWE-628 (Incorrect Arg.) 645 462 1,107 CWE-134 (Fmt. String) 560 443 1,003 CWE-253 (Incorrect Return) 559 415 974 T otal 19,239 14,326 33,565 5.1.1 Overview The ar chitecture consists of four main components: 1) T oken Embedding Layer: Maps source code tokens to dense 2048-dimensional learned embeddings (from the larger model, in this work, Qwen3-30B-A3B [29]). These embeddings are then projected thr ough a linear layer to obtain 768-dimensional vector repr esentations. 2) Lightweight T ransformer Encoder: 8 transformer blocks with Grouped Query Attention and MoE feed- forward layers. 3) RMS Normalization: Applied after attention and feed- forward layers for training stability . 4) Classification Head: Predicts vulnerability presence and CWE categories using the final token repr esenta- tion. Novelty vs. Reuse. Several components in V ulnScout- C are directly derived from prior work and are r eused with- out modification: the BPE tokenizer and 2048-dimensional embedding matrix are taken from Qwen3-30B-A3B; the at- tention mechanism follows the GQA formulation of Ainslie et al. [30]; RoPE positional encoding follows Su et al. [31]; and the SwiGLU expert formulation follows Shazeer [32]. The novel contributions of this work are: (1) the 768- dimensional linear projection that adapts Qwen embed- dings to a smaller hidden dimension for efficient fine- tuning; (2) the reduced 8-layer , 693M-parameter MoE en- coder architectur e specifically sized for vulnerability de- tection tasks; (3) the rank-aware CWE-weighted BCE loss function; and (4) the multi-stage training strategy combining binary pre-training with CWE-specific fine-tuning. The em- pirical contribution is the demonstration that this compact, task-specialized design achieves state-of-the-art results on the CASTLE benchmark, surpassing models more than thr ee orders of magnitude lar ger . 5.1.2 T oken Embedding and P ositional Encoding W e employ byte-pair encoding (BPE) tokenization with a vocabulary size of 151,673 tokens, derived from the Qwen tokenizer . The vocabulary includes C language keywords, operators, common standard library functions, and security- relevant identifiers (e.g., malloc , free , strcpy , scanf ). Each token w i is mapped to a 768-dimensional embed- ding vector after passing through a learned embedding matrix E ∈ R | V |× 2048 followed by a linear projection layer with weights in R 2048 × d model , wher e | V | = 151 , 673 and d model = 768 . Unlike standard learned positional embeddings, we em- ploy Rotary Position Embeddings (RoPE) [31], which en- code positional information dir ectly into the attention mech- anism: RoPE( x, m ) = x · e imθ (3) where m is the position index and θ = 1 , 000 , 000 − 2 k/d for dimension k . RoPE provides better length extrapolation and relative position modeling compared to absolute positional encodings. 5.1.3 Lightweight T ransf or mer Encoder with MoE Our encoder consists of N = 8 transformer layers optimized for both efficiency and capacity . Each layer l implements: ˜ h ( l ) i = RMSNorm ( h ( l − 1) i ) (4) h ( l ) i = h ( l − 1) i + GQA ( ˜ h ( l ) i ) (5) ˆ h ( l ) i = RMSNorm ( h ( l ) i ) (6) h ( l ) i = h ( l ) i + MoE-FFN ( ˆ h ( l ) i ) (7) RMS Normalization: W e replace LayerNorm with Root Mean Square Layer Normalization (RMSNorm) [33], which normalizes using only the root mean square statistic: RMSNorm ( x ) = x q 1 d P d i =1 x 2 i + ϵ ⊙ γ (8) where γ is a learnable scale parameter and ϵ = 10 − 6 . RMSNorm provides comparable performance to Layer- Norm while reducing computational overhead. Grouped Query Attention (GQA): T o reduce the mem- ory footprint of key-value caches during inference, we im- plement Grouped Query Attention [30] with H = 12 query heads and G = 4 key-value groups: GQA ( Q, K, V ) = Concat ( head 1 , ..., head H ) W O (9) where each group of H /G = 3 query heads shares a single key-value head. Each head has dimension d k = 64 , yielding a total dimension of d model = 768 . This r educes KV cache size by 3× compared to standard multi-head attention while maintaining performance. Mixture-of-Experts Feed-Forward Network: W e employ sparse MoE layers with E = 25 experts and top- k = 1 IEEE TRANSACTIONS ON DEPEND ABLE AND SECURE COMPUTING, V OL. XX, NO. X, MONTH 20XX 9 routing, where each token is processed by a single expert selected via a learned gating network: g j = Softmax ( W g · x ) ∈ R E (10) e ∗ = arg max j g j (11) MoE-FFN ( x ) = g e ∗ · Expert e ∗ ( x ) + SharedExpert ( x ) (12) Each expert implements a SwiGLU activation [32]: Expert j ( x ) = W j 2 · ( SiLU ( W j 1 · x ) ⊙ W j 3 · x ) (13) where W j 1 , W j 3 ∈ R d model × d f f and W j 2 ∈ R d f f × d model with d f f = 768 . The SwiGLU activation provides superior performance compar ed to standard GELU or ReLU. Additionally , we include one shared expert that pro- cesses all tokens, ensuring a minimum level of cross-token information flow: SharedExpert ( x ) = W s 2 · ( SiLU ( W s 1 · x ) ⊙ W s 3 · x ) (14) This MoE design increases model capacity to approxi- mately 693M parameters while maintaining computational efficiency , as only 2 experts are active per token: 1 routed expert selected via top-1 gating from the 25 candidates, plus the 1 mandatory shared expert. Sequence Pooling: For classification, we extract the repr esentation of the last non-padded token from the final transformer layer: h pool = h ( N ) ℓ i (15) where ℓ i = P L j =1 ⊮ [ mask j = 1] is the position of the last unmasked token. T ask-Specific Classification Heads: The implementation supports both binary vulnerability detection and multi-class CWE classification through task-specific output heads: • Binary Classification: A linear projection W bin ∈ R d model × 2 maps the pooled repr esentation to binary logits for vulnerability presence prediction. • CWE Classification: For multi-class CWE prediction, the output head is expanded to W cwe ∈ R d model × C where C = 25 corresponds to the CWE categories present in the V U L N S C O U T and CASTLE datasets. Of these, 8 overlap with the current MITRE T op 25 rank- ing (CWE-22, CWE-78, CWE-89, CWE-125, CWE-416, CWE-476, CWE-770, CWE-787); the remaining 17 are security-relevant weaknesses pr esent in CASTLE but not in the current MITRE T op 25 list (e.g., CWE-190, CWE-362, CWE-617, CWE-798, CWE-822, CWE-843). The current implementation focuses on binary vulner- ability detection, with the architecture designed to accom- modate CWE-specific classification by simply adjusting the dimensionality of the final classification head. 5.2 T raining Strategy 5.2.1 Multi-Stage T raining Strategy W e employ a carefully structured multi-stage training pipeline that leverages high-quality token embeddings from a large teacher model for strong initialization, followed by progr essive specialization on vulnerability detection tasks. Stage 1 – Model Initialization During the initial phase of this stage, the binary classifi- cation head is trained to establish basic binary vulnerability detection capability (vulnerable vs. non-vulnerable) using the Juliet T est Suite. This serves as a foundational pre- training step, allowing the model to adapt the projected em- beddings from the larger model to the systematic synthetic vulnerability patterns and CWE-specific syntactic character- istics pr esent in Juliet. Stage 2 – Multi-Dataset Continual Pre-training In the second stage, we further refine the model’s general code understanding and robustness by training on a diverse corpus of more r ealistic vulnerability examples, including: • SecV ulEval [5], • FormAI-v2 [4], • V U L N S C O U T (our newly introduced dataset), • BenchV ul [28]. T raining at this stage focuses exclusively on binary vul- nerability classification. The goal is to enhance the model’s ability to handle real-world coding styles, project contexts, and diverse vulnerability manifestations. Stage 3 – CWE-specific Supervised Fine-tuning Once a robust binary classifier is obtained, we replace the classifi- cation head with a new multi-class head for predicting the CWEs. W e apply a differential learning rate schedule: • a significantly higher learning rate for the newly initial- ized CWE classification head, • a substantially lower learning rate for the backbone layers to preserve the general learned information and patterns. This final stage uses only datasets with fine-grained CWE annotations (primarily SecV ulEval, FormAI-v2, and V U L N S C O U T ). The training corpus contains approximately 53,349 samples with the following label distribution: 55.7% vulnerable (29,730 samples) and 44.3% non-vulnerable (23,619 samples). 5.2.2 Loss Function T o prioritize the detection of high-severity vulnerabilities according to the MITRE CWE T op 25 ranking, we propose a rank-aware weighted loss function for the CWE classifica- tion heads. This loss builds on binary cross-entropy (BCE) by incorporating a weighting scheme that assigns higher importance to more critical CWEs. The weighting factor is defined as follows: F ( r ) = ( 26 − r 25 , r ≤ 25 0 , r > 25 (16) w ( r ) = 1 + γ F ( r ) (17) where r is the rank of the CWE in the MITRE T op 25 (with r = 1 being the most dangerous), and γ is a hyperpa- rameter that controls the strength of the emphasis on high- ranking vulnerabilities ( γ = 2 . 0 in our experiments). Multi-label CWE formulation. Although each sample is primarily associated with a single CWE, a C function IEEE TRANSACTIONS ON DEPEND ABLE AND SECURE COMPUTING, V OL. XX, NO. X, MONTH 20XX 10 may simultaneously exhibit secondary weaknesses (e.g., a buffer overflow accompanied by an integer overflow in the size computation). W e therefore model CWE prediction as a multi-label problem: each of the 25 output logits is trained independently with a sigmoid activation, making BCE the appropriate per-class per-sample loss. Ground-truth labels are represented as binary vectors y i ∈ { 0 , 1 } 25 , where multiple entries may be set to 1 for samples exhibiting co-occurring weaknesses. The weighted loss for the CWE predictions is then: L CWE = 1 N N X i =1 C X c =1 w ( r c ) · BCE ( y i,c , ˆ y i,c ) (18) Here, N is the number of samples, C = 25 is the number of CWE classes, y i,c ∈ { 0 , 1 } is the ground-truth label for class c of sample i , ˆ y i,c is the corresponding sigmoid probability , and w ( r c ) is the rank weight for CWE class c . Per-class BCE is: BCE ( y i,c , ˆ y i,c ) = − [ y i,c log ˆ y i,c + (1 − y i,c ) log(1 − ˆ y i,c )] (19) This scheme ensures that higher-ranked (more critical) CWEs, which have lower r values, receive greater weight during training. For example, a CWE with rank r = 2 (e.g., Out-of-bounds W rite, CWE-787) receives w (2) = 1 + 2 . 0 × 24 25 = 2 . 92 , while one with r = 7 (e.g., Use After Free, CWE- 416) receives w (7) = 1 + 2 . 0 × 19 25 = 2 . 52 . CWEs outside the T op 25 r eceive the base weight of 1 . 0 . For the vulnerability detection head, we use a standard unweighted BCE loss, denoted L vul . The total loss is a weighted combination: L = W 1 · L vul + W 2 · L CWE (20) with W 1 = 10 and W 2 = 1 in our experiments. This higher weight on the vulnerability detection loss reflects its role as the primary task. T o focus CWE classification on confirmed vulnerable samples, we apply a confidence mask: the CWE loss con- tribution of sample i is zeroed when the vulnerability detec- tion pr obability falls below τ = 0 . 5 : L masked CWE ,i = ⊮ [ ˆ p vul ,i ≥ 0 . 5] · w ( r i ) · BCE ( y i , ˆ y i ) (21) so that the multi-label CWE head is not penalized for non- vulnerable samples, where no CWE label is applicable and y i = 0 . This rank-aware approach aligns the model’s optimiza- tion directly with established security priorities, allocating more learning capacity to the most prevalent and dangerous vulnerability types. 5.2.3 T raining Details T raining is performed on a single NVIDIA H100 80 GB GPU using mixed-precision BFloat16. W e use the AdamW optimizer [34] with ( β 1 , β 2 ) = (0 . 9 , 0 . 999) , weight decay λ = 10 − 2 , and gradient clipping at norm 1.0. The learning rate follows a cosine annealing schedule with a 500-step linear warm-up. Stage-specific hyperparameters ar e sum- marized in T able 3. All experiments use random seed 42. T ABLE 3 P er-stage T raining Hyper parameters. Hyperparameter Stage 1 Stage 2 Stage 3 LR (backbone) 5 × 10 − 4 1 × 10 − 4 1 × 10 − 5 LR (head) 5 × 10 − 4 1 × 10 − 4 5 × 10 − 4 Batch size 32 32 16 Grad. accumulation 1 2 4 Effective batch 32 64 64 Max seq. length 1024 1024 1024 Epochs 5 3 5 Dropout 0.1 0.1 0.1 Ckpt. selection val F1 val F1 CASTLE score T o assess result stability , we varied the binary classifica- tion threshold from 0.4 to 0.6: the CASTLE score changes by at most ± 12 points and binary F1 by at most ± 0.008, con- firming that reported r esults are not an artifact of threshold selection. 5.2.4 Data A ugmentation T o enhance model robustness and r educe overfitting, we fo- cus on cleaning potential data leakage that could artificially inflate performance metrics. This preprocessing ensures the model learns genuine vulnerability patterns rather than memorizing synthetic markers or documentation artifacts. V ariable Renaming: Randomly rename non-r eserved identifiers while maintaining consistency within each sam- ple. Equivalent Expression Substitution: Replace expres- sions with semantically equivalent alternatives (e.g., i++ ↔ i = i + 1 ). These augmentations are applied with probability p = 0 . 2 during training to prevent overfitting to specific syntac- tic patterns while preserving semantic vulnerability charac- teristics. 6 E X P E R I M E N TA L S E T U P 6.1 Implementation Details V ulnScout-C is implemented using PyT orch and the T rans- formers library . All experiments are conducted on a single NVIDIA H100 GPU (80GB VRAM). 6.2 Evaluation Metrics W e evaluate V ulnScout-C using multiple metrics: Standard Classification Metrics: • Accuracy: Overall correctness of predictions • Pr ecision: Ratio of true positives to predicted positives • Recall: Ratio of true positives to actual positives • F1-Scor e: Harmonic mean of precision and recall CASTLE Score: Primary evaluation metric on the CAS- TLE benchmark, accounting for severity-weighted detection and false positive penalties as defined in Section 3. It is important to note that CASTLE uses a CWE-hierarchy- aware matching scheme: a finding is counted as a true positive if the pr edicted CWE matches the gr ound-truth CWE or any of its parents/children in the CWE taxonomy . As a result, CASTLE TP/FP/FN counts differ from stan- dard binary classification counts and should not be used to IEEE TRANSACTIONS ON DEPEND ABLE AND SECURE COMPUTING, V OL. XX, NO. X, MONTH 20XX 11 derive F1, accuracy , or recall. Binary classification metrics (F1, accuracy , precision, recall) ar e computed independently using standard sklearn evaluation against the ground-truth vulnerable/non-vulnerable labels. Per-CWE Performance: Individual precision, recall, and F1-score for each of the T op 25 CWEs to assess model capabilities acr oss vulnerability types. 6.3 Baseline Models W e compare V ulnScout-C against several baseline ap- proaches: Static Analysis T ools: Cppcheck, Clang Static Analyzer as r epresentatives of traditional SAST tools. Formal V erification: ESBMC and CBMC as repr esenta- tives of formal methods. Large Language Models: GPT -4o, GPT -4o Mini, DeepSeek R1, and other state-of-the-art LLMs evaluated on the same benchmark (see T able 4). 7 R E S U LT S 7.1 Overall P erformance on CASTLE Benchmark T able 4 presents the CASTLE scores achieved by V ulnScout- C and baseline models on the benchmark dataset. V ulnScout-C achieves a CASTLE score of 1068, outper- forming GPT -4o (954) and surpassing reasoning-optimized models such as GPT -o1 (962) and GPT -o3 Mini (977). In standard binary vulnerability detection, the model achieves an F1 of 85.4%, accuracy of 82.4%, recall of 86.0% (129/150 truly vulnerable samples detected), and precision of 84.9% across the 250-sample benchmark. Under CASTLE’s CWE- hierarchy-awar e scoring, which counts a finding as correct if the predicted CWE matches via parent/child taxonomy relationships, the model registers 136 true positive findings and 77 true negatives, with only 16 false positive penalties and a bonus of 250 points for detecting high-severity CWEs. This dual performance demonstrates particularly strong re- sults on key MITRE T op 25 CWEs, including memory safety issues (CWE-787: 100% F1, CWE-125: 85.7% F1, CWE-416: 90.9% F1) and control-flow vulnerabilities (CWE-476: 83.3% F1), alongside a CWE classification accuracy of 90.0% on truly vulnerable samples. 7.2 Comparison with Fine-tuned Encoder Baselines T o contextualize V ulnScout-C’s performance, we fine-tuned three encoder-based models, CodeBER T , GraphCodeBER T , and V ulBERT a, on the V U L N S C O U T dataset. These results reveal critical ar chitectural limitations that persist even after task-specific fine-tuning: T oken Limit Constraints: Encoder models are funda- mentally limited by their 512-token context window [19], [20]. V ulnerabilities in C often require analyzing depen- dencies across many lines of code. When a vulnerability trigger (e.g., free() ) is separated from its allocation (e.g., malloc() ) by more than 512 tokens, encoders must trun- cate input, effectively becoming blind to the vulnerability . V ulnScout-C’s extended context capacity addresses this lim- itation. T ABLE 4 CASTLE Benchmark Results. TP/TN/FP/FN reflect CASTLE’ s CWE-hierarch y-aware matching and diff er from binar y classification counts. Under CASTLE’ s CWE-hierarch y-aware matching, a tool ma y repor t multiple CWE findings per sample; each finding is scored independently , so TP + FN can exceed the 150 vulnerab le samples and TN + FP can e xceed the 100 non-vulnerable samples in the benchmark. For V ulnScout-C, the 136 CASTLE true positives and 30 f alse negatives sum to 166, reflecting this m ulti-finding accounting; the binary classification counts (129 TP , 23 FP , 77 TN, 21 FN) used f or F1/accuracy/precision/recall computation are derived separately from the ground-truth vulnerable/non-vulner able labels (see Section 6). Model CASTLE Score TP TN FP FN Fine-tuned Encoder Baselines on V ulnScout CodeBER T -166 145 217 241 0 GraphCodeBER T -116 146 106 189 3 V ulBER T a -12 103 37 130 12 Static Analysis T ools CodeThreat -692 24 2 1101 126 Splint (3.1.2) -598 23 36 1027 127 Clang Analyzer (18.1.3) 381 13 99 2 137 GitLab SAST (15.2.1) 374 36 67 240 120 Cppcheck (2.13.0) 406 19 100 9 131 Coverity (2024.6.1) 425 31 86 62 119 Aikido 481 14 83 40 136 Jit 478 21 78 68 134 SonarQube (25.3.0) 511 43 68 135 107 CBMC (5.95.1) 536 18 100 0 132 Semgrep Code (1.110.0) 541 36 73 70 120 Snyk (1.1295.4) 552 26 82 42 124 GCC Fanalyzer (13.3.0) 559 41 76 93 109 CodeQL (2.20.1) 634 45 79 49 112 ESBMC (7.8.1) 661 53 91 32 97 Large Language Models LLAMA 3.1 (8B) 417 83 22 337 80 Gemma 2 (9B) 436 63 42 258 95 Mistral Ins. (7B) 446 63 23 215 91 Falcon 3 (7B) 521 30 76 76 124 GPT -4o Mini 761 134 27 263 43 QWEN 2.5CI (32B) 708 114 31 224 49 GPT -4o 954 136 45 116 43 DeepSeek R1 956 148 41 166 17 GPT -o1 962 128 56 90 35 GPT -o3 Mini 977 126 60 73 36 V ulnScout-C 1068 136 77 16 30 False Positive Problem: The TP/TN/FP/FN counts reported in T able 4 for the encoder models follow CAS- TLE’s CWE-hierarchy-aware multi-finding accounting (see the table caption). On the CASTLE benchmark, CodeBER T received a score of − 166 , exhibiting a strong prediction bias toward vulnerable, with near-perfect recall masked by ex- cessive false positives that the CASTLE scoring mechanism correctly penalizes. GraphCodeBER T (CASTLE=-116) and V ulBER T a (CASTLE=-12) showed progr essive impr ovement in false positive control but still received negative CASTLE scores, confirming that task-specific fine-tuning alone can- not overcome the 512-token context limitation of encoder architectur es when evaluating C vulnerabilities that span long code sequences. These findings confirm that even with task-specific fine- tuning, traditional encoder architectures with limited con- text windows cannot match the performance of our compact encoder architecture, which combines an extended context window with sparse mixture-of-experts feed-forwar d layers to achieve both breadth and depth in vulnerability pattern recognition. IEEE TRANSACTIONS ON DEPEND ABLE AND SECURE COMPUTING, V OL. XX, NO. X, MONTH 20XX 12 7.3 P er-CWE Detection P erformance T able 5 provides detailed metrics for the CWEs in the CASTLE dataset. T ABLE 5 Detailed P erformance on CWEs in CASTLE V alidation CWE Precision (%) Recall (%) F1-Score (%) CWE-22 85.7 100.0 92.3 CWE-78 100.0 100.0 100.0 CWE-89 100.0 83.3 90.9 CWE-125 75.0 100.0 85.7 CWE-134 100.0 83.3 90.9 CWE-190 100.0 66.7 80.0 CWE-253 100.0 66.7 80.0 CWE-327 100.0 100.0 100.0 CWE-362 100.0 100.0 100.0 CWE-369 100.0 83.3 90.9 CWE-401 75.0 100.0 85.7 CWE-415 100.0 83.3 90.9 CWE-416 100.0 83.3 90.9 CWE-476 83.3 83.3 83.3 CWE-522 100.0 100.0 100.0 CWE-617 100.0 50.0 66.7 CWE-628 83.3 83.3 83.3 CWE-674 100.0 33.3 50.0 CWE-761 75.0 50.0 60.0 CWE-770 100.0 66.7 80.0 CWE-787 100.0 100.0 100.0 CWE-798 100.0 66.7 80.0 CWE-822 100.0 100.0 100.0 CWE-835 100.0 33.3 50.0 CWE-843 83.3 83.3 83.3 The model demonstrates strong performance across all 25 CWE categories in the CASTLE benchmark, with each CWE evaluated on 6 vulnerable samples, achieving an av- erage F1 of 84.6% across all 25 CWEs. Among the 8 CWEs shared between CASTLE and the MITRE T op 25 ranking; CWE-22, CWE-78, CWE-89, CWE-125, CWE-416, CWE-476, CWE-770, and CWE-787; the model achieves an average F1 score of 90.4%, r eflecting particularly str ong performance on the most security-critical vulnerability classes. V ulnScout- C excels particularly on memory corruption vulnerabilities (CWE-787: 100% F1, CWE-416: 90.9% F1, CWE-125: 85.7% F1) and achieves perfect scor es on OS command injec- tion (CWE-78: 100% F1). Notably , the model also performs strongly on higher-level semantic vulnerabilities such as SQL injection (CWE-89: 90.9% F1) and path traversal (CWE- 22: 92.3% F1), demonstrating that the Mixture-of-Experts architectur e effectively captures both low-level memory pat- terns and high-level data flow semantics. The consistent high performance across these critical vulnerability types validates the effectiveness of our multi-dataset training strategy and specialized modeling choices in prioritizing detection of the most impactful security flaws. 8 A B L AT I O N S T U D I E S T o validate our ar chitectural design choices and identify the optimal configuration for vulnerability detection, we conducted systematic ablation studies examining the impact of expert granularity , expert width, and shared expert allo- cation on detection performance. 8.1 Experimental Setup All ablation experiments were conducted using the same training pipeline described in Section 5, with modifications only to the MoE layer configuration. Models were trained for 5 epochs on the combined dataset, and performance was evaluated using the CASTLE benchmark. W e r eport V ulnerability F1 (binary classification), V ulnerability Accu- racy , CWE Accuracy (multi-class classification), and CAS- TLE Scor e as our primary metrics. 8.2 Ablation Configurations W e evaluated thr ee distinct MoE architectures, progressively refining our design based on empirical results: Baseline Configuration: Our initial architectur e em- ployed 25 routed experts with hidden dimension 768, 1 shared expert, and top-1 r outing (1 active expert per token). This configuration served as the reference point for subse- quent experiments. Ablation 2 – Fine-Grained Specialization: Motivated by recent work on fine-grained MoE architectures [35], we hypothesized that increasing expert count while reducing individual expert width would improve CWE-specific pat- tern r ecognition. This configuration doubled the number of routed experts to 50, reduced expert width to 384 (50% reduction), increased active experts per token to 2, while maintaining 1 shared expert. Ablation 3 – Heavy Shared Backbone: Building on insights from Ablation 2, we tested whether aggressive compression of routed experts (hidden dimension 256, 66% reduction) combined with a substantial increase in shared experts (4 instead of 1) would allow the model to efficiently partition general code understanding and vulnerability- specific detection. This configuration used 25 r outed experts with 1 active per token and 4 shared experts. T able 6 summarizes these configurations. T ABLE 6 MoE Architecture Configurations f or Ablation Studies Hyperparameter Baseline Ablation 2 Ablation 3 Expert Hidden Dim 768 384 256 Num Routed Experts 25 50 25 Active Experts/T oken 1 2 1 Num Shared Experts 1 1 4 8.3 Results and Analysis T able 7 presents the performance of each configuration at their best checkpoint (selected based on validation CWE Accuracy and CASTLE Score). 8.3.1 Fine-Grained Specialization (Ablation 2) The fine-grained configuration with 50 experts achieved a CASTLE score of 1046 and CWE accuracy of 92.67%, repr esenting a 2.67 percentage point improvement in CWE accuracy over baseline. This validates the hypothesis that increased expert count enables better decomposition of vul- nerability patterns into specialized features. Each expert can focus on finer-grained aspects of specific CWE types (e.g., IEEE TRANSACTIONS ON DEPEND ABLE AND SECURE COMPUTING, V OL. XX, NO. X, MONTH 20XX 13 T ABLE 7 Ablation Study Results on CASTLE V alidation Set Configuration V uln F1 V uln Acc CWE Acc CASTLE Baseline 0.854 82.4% 90.0% 1068 Ablation 2 (Fine-Grained) 0.839 80.8% 92.67% 1046 Ablation 3 (Heavy Shared) 0.832 80.0% 92.0% 1028 boundary checking patterns vs. null pointer patterns). How- ever , this configuration shows a slight decrease in CASTLE score (1046 vs. 1068) compared to baseline, suggesting that while the increased specialization improves CWE classifica- tion, it may sacrifice some performance on other metrics. 8.3.2 Heavy Shared Backbone (Ablation 3) The heavy shared backbone configuration achieved a CAS- TLE score of 1028, which is lower than both baseline (1068) and Ablation 2 (1046). While this configuration achieves a CWE accuracy of 92.0%, the lower vulnerability F1 (0.832) and accuracy (80.0%) compared to baseline result in a reduced overall CASTLE score. This suggests that while aggressive compression of routed experts (768 → 256 di- mensions) combined with expanded shar ed capacity can improve CWE classification, it may sacrifice binary vulner- ability detection performance. Architectural Insight: V ulnerability detection r equires two distinct cognitive pr ocesses: (1) general code under - standing (parsing C syntax, tracking control flow , under- standing variable scopes), and (2) specific vulnerability pat- tern recognition (identifying missing bounds checks, rec- ognizing use-after-free patterns, detecting integer overflow conditions). By aggressively compressing routed experts to 256 dimensions while quadrupling shared experts, we attempted to partition these responsibilities. However , the reduced CASTLE score suggests that the 66% width reduc- tion in routed experts may have been too aggressive, lim- iting their capacity to learn nuanced vulnerability patterns despite the expanded shared backbone. Efficiency Analysis: Reducing expert width by 66% (768 → 256) while quadrupling shared experts resulted in a trade-off: improved CWE classification accuracy but re- duced overall CASTLE score. The 4 shared experts success- fully carried the computational load for general code under- standing, but the thin routed experts appear to have insuffi- cient capacity for complex vulnerability pattern recognition. This configuration demonstrates that extreme compression of routed experts, even with expanded shared capacity , can limit overall vulnerability detection performance. 8.4 Ke y Findings Our ablation studies yield several important insights: 1) Shared vs. Routed Expert T rade-off: While increasing shared expert capacity can improve CWE classification accuracy , aggressive compression of routed experts (66% width reduction) degrades overall CASTLE performance. This suggests that routed experts r equire suf ficient capac- ity for complex vulnerability pattern recognition, beyond lightweight task-specific transformations. 2) Expert Specialization: Fine-grained expert configura- tions (Ablation 2) achieve the highest CWE classification accuracy (92.67%) but lower overall CASTLE scores, sug- gesting a trade-off between specialized metric optimiza- tion and balanced multi-objective performance. 3) Parameter Efficiency: The baseline configuration with balanced expert allocation (25 routed experts at 768 dimensions, 1 shared expert) achieves the best overall CASTLE performance. Aggressive compression of r outed experts, even when combined with expanded shared capacity , reduces overall effectiveness despite improving specific metrics like CWE accuracy . Based on these findings, we adopt the baseline as our final V ulnScout-C architectur e, achieving the highest CAS- TLE score (1068) with strong balanced performance across all evaluation metrics. The ablation studies confirm that this configuration optimally balances expert specialization and model capacity . 8.5 Pre-T raining Stage Ablation T o assess the contribution of each training stage and the V U L N S C O U T dataset, we conducted a staged ablation in which we progr essively include training stages, measuring the impact on CASTLE and binary classification perfor- mance. All configurations use the same final architectur e (baseline MoE, 25 routed experts, 768 dim), and are evalu- ated on the full CASTLE test set. T ABLE 8 T raining Stage Ablation on CASTLE. Each ro w adds one component ov er the previous. CWE Acc is 0% f or configuration (A) as Stage 1 trains only a binary head with no CWE prediction capability . Configuration F1 Acc CWE Acc CASTLE (A) Stage 1 only (Juliet) 0.12 18.0% 0.0% 67 (B) Stages 1–2 w/o V ulnScout 0.33 28.0% 23.0% 420 (C) Stages 1–2 w/ V ulnScout 0.821 79.6% 85.4% 978 (D) Full (Stages 1–3) 0.854 82.4% 90.0% 1068 8.5.1 Eff ect of Each Stage Stage 1 Juliet Initialization (A): T raining exclusively on the Juliet T est Suite with a binary classification head yields an F1 of only 0.12, accuracy of 18.0%, and a CASTLE score of 67. The CWE accuracy is 0% by construction, as Stage 1 trains only a binary vulnerability head with no CWE prediction capability , making it impossible to accumulate any of CASTLE’s severity-weighted bonus points for correct CWE identification. Although Juliet’s systematic coverage of CWE-specific syntactic patterns provides a starting point for learning discriminative representations, the model severely overfits to Juliet’s uniform synthetic style and fails to gener - alize to the stylistically diverse CASTLE micro-benchmarks. Multi-Dataset Continual Pre-training without V ulnScout (B): Extending to real-world datasets (SecV ulEval, FormAI-v2, BenchV ul) adds +0.21 F1 , +10 pp accuracy , +23 pp CWE accuracy , and +353 CASTLE points over configuration (A). The emergence of non-zero CWE accuracy at this stage confirms that exposure to r ealistically annotated, stylistically diverse code is a prer equisite for IEEE TRANSACTIONS ON DEPEND ABLE AND SECURE COMPUTING, V OL. XX, NO. X, MONTH 20XX 14 the model to begin learning CWE-discriminative patterns beyond Juliet’s controlled templates but still cannot identify others due to the absence or scarcity of certain CWEs in the test set. Contribution of V ulnScout (C vs. B): Including V U L N S C O U T in Stage 2 adds +0.491 F1 , +51.6% accuracy , +62.4% CWE accuracy , and +558 CASTLE points over configuration (B), representing the single largest gain in the entir e ablation. This dramatic jump reflects the criti- cal coverage gaps that V U L N S C O U T fills: CWE categories that are sparse or entirely absent from the other three datasets (CWE-617, CWE-761, CWE-835, CWE-674, CWE- 822) receive the majority of their training signal exclusively from V U L N S C O U T . W ithout this coverage, the CWE classi- fication head cannot learn discriminative patterns for these categories, directly suppressing both CWE accuracy and the CASTLE severity bonus. CWE-Specific Fine-tuning (D vs. C): Stage 3 produces an additional +0.033 F1 , +2.8% accuracy , +4.6% CWE ac- curacy , and +90 CASTLE points . The rank-aware weighted loss and differential learning rate between backbone and classification head are jointly responsible for this improve- ment; without the differential learning rate, Stage 3 con- verges to a CASTLE score of 991 (vs. 1068), confirming the importance of preserving the binary detection repr esenta- tions learned in earlier stages while specializing only the classification head for CWE prediction. 8.5.2 Comparison: Without vs. With Full Pipeline The gap between Stage 1-only initialization (A, CAS- TLE = 67, F1 = 0.12) and the full pipeline (D, CASTLE = 1068, F1 = 0.854) amounts to +1001 CASTLE points and +0.734 F1 . This confirms that neither the Qwen token embeddings nor Juliet pre-training alone are sufficient: competitive vulnera- bility detection requir es the full progr essive curriculum of synthetic initialization, multi-source continual pre-training including V U L N S C O U T , and rank-aware CWE-specific fine- tuning. 9 D I S C U S S I O N 9.1 Ke y Findings Our results demonstrate that carefully designed compact architectur es can achieve competitive vulnerability detec- tion performance while offering practical deployment ad- vantages. Key findings include: Efficiency-Accuracy T rade-off: V ulnScout-C achieves a binary F1 of 85.4%, accuracy of 82.4%, recall of 86.0%, and precision of 84.9% on the 250-sample CASTLE benchmark (150 vulnerable, 100 non-vulnerable, 25 CWE categories), using only 693M total parameters (353M active). Under CASTLE’s CWE-hierarchy-aware scoring, the model reg- isters 136 true positive findings with only 16 false posi- tive penalties, yielding a final CASTLE score of 1068. The average per-CWE F1 reaches 84.6% across all 25 CASTLE categories and 90.4% among the 8 CWEs shared with the MITRE T op 25 ranking. CWE Coverage: The model successfully detects a ma- jority of vulnerabilities in the MITRE T op 25 CWEs, with particularly strong performance on memory safety vulnera- bilities (e.g., CWE-787, CWE-416). Dual-V erification Data Quality: The conservative agreement-based filtering applied during V U L N S C O U T con- struction (retaining only samples wher e ESBMC and the GPT -OSS-120B verifier agree) reduced the initial candidate pool by 36.3% but demonstrably improved downstream model quality: the staged ablation (T able 8) shows that including V U L N S C O U T in Stage 2 yields +0.491 F1 and +558 CASTLE points over the identical pipeline trained without it, suggesting that consensus-filtered data is a stronger train- ing signal than larger but noisier corpora. Real-T ime Capability: V ulnScout-C processes 250 sam- ples in 1.243 s (4.97 ms/sample, 201.1 samples/s at batch size 32 on a single H100 80 GB) enabling direct integration into IDEs, pre-commit hooks, and CI/CD pipelines without dedicated infer ence servers. 9.2 Future Directions Several pr omising directions emerge from this work: Explainability Enhancements: Developing attention vi- sualization and saliency mapping techniques to help devel- opers understand why code was flagged as vulnerable. Continuous Learning: Implementing mechanisms for the model to learn from new vulnerabilities discovered in production, creating a feedback loop that improves detec- tion over time. Cross-Language Extension: Adapting the architecture to other memory-unsafe languages like C++ or Rust, leverag- ing transfer learning from the C-trained model. 1 0 C O N C L U S I O N This paper presents V ulnScout-C, a lightweight neural ar- chitecture for C code vulnerability detection that addresses the critical gap between detection accuracy and deployment practicality . Thr ough car eful ar chitectural design inspir ed by state-of-the-art language models but drastically reduced in size, we demonstrate that compact models can achieve com- petitive vulnerability detection performance while offering significant practical advantages. Key contributions: 1) A compact MoE-based transformer (693M total / 353M active parameters) achieving a CASTLE score of 1068, binary F1 = 85.4%, accuracy = 82.4%, r ecall = 86.0%, and pr ecision = 84.9% on the 250-sample CASTLE bench- mark, with 136 CASTLE true positive findings and only 16 false positive penalties under CWE-hierarchy-awar e scoring, outperforming all evaluated LLM and static analysis baselines. 2) The V U L N S C O U T dataset: 33,565 C code samples spanning 25 CWE categories, generated through a multi-agent pipeline and retained only under a dual-verification agreement protocol combining ES- BMC v7.8.1 and a GPT -OSS-120B verifier . Both ver- ifiers must independently return consistent verdicts ( Vulnerable Code: Violation Detected or Safe Code: Verification Success ) for a sample to be admitted; disagreements discard the sample and trigger a fresh generation request. Of 52,714 initial candidates, 33,565 (63.7%) passed dual verification (average 1.8 re- pair rounds, maximum 5). The dataset addresses cov- erage gaps in CWE-617, CWE-761, CWE-835, CWE-674, IEEE TRANSACTIONS ON DEPEND ABLE AND SECURE COMPUTING, V OL. XX, NO. X, MONTH 20XX 15 and CWE-822, which are absent or underrepresented in SecV ulEval, FormAI-v2, and BenchV ul, and contributes +0.491 F1 and +558 CASTLE points when added to Stage 2 training (T able 8). V U L N S C O U T will be released under CC BY 4.0. 3) A rank-aware CWE-weighted BCE loss that prioritizes detection of high-severity CWEs according to the MITRE T op 25 ranking. Combined with a multi-stage training curriculum (synthetic initialization, multi-source contin- ual pre-training, and CWE-specific fine-tuning with dif- ferential learning rates), this achieves a CWE classifica- tion accuracy of 90.0% on truly vulnerable samples and an average per-CWE F1 of 84.6% across all 25 CASTLE categories. R E F E R E N C E S [1] MITRE Corporation, “Common W eakness Enumeration (CWE),” https://cwe.mitre.or g/, 2025. [2] ——, “2025 CWE T op 25 Most Dangerous Software W eaknesses,” https://cwe.mitre.or g/top25/, 2025, page last updated: December 15, 2025. [3] B. Chess and J. W est, Secure Programming with Static Analysis . Addison-W esley Professional, 2007. [4] N. T ihanyi, T . Bisztray , M. A. Ferrag, R. Jain, and L. C. Cordeiro, “How Secure is AI-Generated Code: A Large-Scale Comparison of Large Language Models,” Empirical Software Engineering , 2024, also available at [5] M. B. U. Ahmed, N. S. Harzevili, J. Shin, H. V . Pham, and S. W ang, “SecV ulEval: Benchmarking LLMs for Real-W orld C/C++ V ulner- ability Detection,” https://arxiv .org/abs/2505.19828, 2025. [6] D. Patel and G. W ong. (2023, Jul.) Gpt-4 architecture, infrastruc- ture, training dataset, costs, vision, moe. [Online]. A vailable: https: //www .semianalysis.com/p/gpt- 4- architectur e- infrastructure [7] K. Kuszczy ´ nski and M. W alkowski, “Comparative analysis of open-source tools for conducting static code analysis,” Sensors , vol. 23, no. 18, p. 7978, 2023. [Online]. A vailable: https://doi.org/10.3390/s23187978 [8] X. Men, M. Xu, Q. Zhang, B. W ang, H. Lin, Y . Lu, X. Han, and W . Chen, “Shortgpt: Layers in large language models are more redundant than you expect,” arXiv preprint , Mar . 2024. [9] W . Reda, A. Jangda, and K. Chintalapudi, “How many parameters does your task really need? task specific pruning with llm-sieve,” arXiv preprint arXiv:2505.18350 , May 2025. [10] P . V . Dantas, L. C. Cordeiro, and W . S. S. Junior , “A re view of state- of-the-art techniques for large language model compression,” Complex & Intelligent Systems , 2025. [Online]. A vailable: https: //link.springer .com/article/10.1007/s40747- 025- 02019- z [11] A. Habib and M. Pradel, “How Many of All Bugs Do W e Find? A Study of Static Bug Detectors,” in Pr oceedings of the 33rd IEEE/ACM International Conference on Automated Software Engineering (ASE) , 2018, pp. 317–328. [12] B. Johnson, Y . Song, E. Murphy-Hill, and R. Bowdidge, “Why Don’t Software Developers Use Static Analysis T ools to Find Bugs?” in Proceedings of the 35th International Conference on Software Engineering (ICSE) , 2013, pp. 672–681. [13] E. M. Clarke, T . A. Henzinger , H. V eith, and R. Bloem, Handbook of Model Checking . Springer , 2018. [14] M. R. Gadelha, F . R. Monteiro, J. Morse, L. C. Cordeir o, B. Fischer , and D. A. Nicole, “ESBMC 5.0: An Industrial-Strength C Model Checker,” in Proceedings of the 33rd ACM/IEEE International Confer- ence on Automated Software Engineering (ASE) , 2018, pp. 888–891. [15] D. Kroening and M. T autschnig, “CBMC - C Bounded Model Checker,” in Proceedings of the International Confer ence on T ools and Algorithms for the Construction and Analysis of Systems (T ACAS) , 2014, pp. 389–391. [16] G. Grieco, G. L. Grinblat, L. Uzal, S. Rawat, J. Feist, and L. Mounier , “T oward Large-Scale V ulnerability Discovery Using Machine Learning,” in Proceedings of the 6th ACM Conference on Data and Application Security and Privacy (CODASPY) , 2016, pp. 85–96. [17] Z. Li, D. Zou, S. Xu, X. Ou, H. Jin, S. W ang, Z. Deng, and Y . Zhong, “V ulDeePecker: A Deep Learning-Based System for V ulnerability Detection,” in Proceedings of the Network and Distributed System Security Symposium (NDSS) , 2018. [18] Y . Zhou, S. Liu, J. Siow , X. Du, and Y . Liu, “Devign: Effective V ulnerability Identification by Learning Comprehensive Program Semantics via Graph Neural Networks,” in Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS) , 2019, pp. 10 197–10 207. [19] Z. Feng, D. Guo, D. T ang, N. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T . Liu, D. Jiang, and M. Zhou, “CodeBER T : A Pre-T rained Model for Programming and Natural Languages,” in Findings of the Association for Computational Linguistics: EMNLP 2020 , 2020, pp. 1536–1547. [20] D. Guo, S. Ren, S. Lu, Z. Feng, D. T ang, S. Liu, L. Zhou, N. Duan, A. Svyatkovskiy , S. Fu, M. T ufano, S. K. Deng, C. Clement, D. Drain, N. Sundaresan, J. Yin, D. Jiang, and M. Zhou, “GraphCodeBER T: Pre-training code representations with data flow ,” in International Conference on Learning Representations (ICLR) , 2021. [Online]. A vailable: https://openreview .net/for um? id=jLoC4ez43PZ [21] Y . W ang, W . W ang, S. Joty , and S. C. H. Hoi, “Codet5: Identifier-awar e unified pre-trained encoder-decoder models for code understanding and generation,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , 2021, pp. 8696–8708. [Online]. A vailable: https://aclanthology .org/2021.emnlp- main.685 [22] H. Hanif and S. Maffeis, “V ulBER T a: Simplified Source Code Pre- T raining for V ulnerability Detection,” in Pr oceedings of the Interna- tional Joint Conference on Neural Networks (IJCNN) , 2022, pp. 1–8. [23] R. A. Dubniczky , K. Z. Horvát, T . Bisztray , M. A. Ferrag, L. C. Cordeir o, and N. T ihanyi, “CASTLE: Benchmarking Dataset for Static Code Analyzers and LLMs towards CWE Detection,” in Proceedings of the International Conference on Theoretical Aspects of Software Engineering (T ASE) . Springer , 2025, [24] T . Boland and P . E. Black, “Juliet 1.1 C/C++ and Java T est Suite,” IEEE Computer , vol. 45, no. 10, pp. 88–90, 2012. [25] J. Fan, Y . Li, S. W ang, and T . N. Nguyen, “A C/C++ Code V ulnerability Dataset with Code Changes and CVE Summaries,” in Proceedings of the 17th International Conference on Mining Software Repositories (MSR) , 2020, pp. 508–512. [26] Y . Chen, Z. Ding, L. Alowain, X. Chen, and D. W agner , “Diverse- V ul: A New V ulnerable Source Code Dataset for Deep Learning Based V ulnerability Detection,” in Proceedings of the 26th Inter- national Symposium on Research in Attacks, Intrusions and Defenses (RAID) , 2023, pp. 654–668. [27] G. Bhandari, A. Naseer , and L. Moonen, “CVEfixes: Auto- mated Collection of V ulnerabilities and Their Fixes from Open- Source Software,” in Proceedings of the 17th International Conference on Predictive Models and Data Analytics in Software Engineering (PROMISE) , 2021, pp. 30–39. [28] Y . Li, N. T . Bui, T . Zhang, C. Y ang, X. Zhou, M. W eyssow , J. Jiang, J. Chen et al. , “Out of distribution, out of luck: How well can LLMs trained on vulnerability datasets detect top 25 CWE weaknesses?” arXiv preprint arXiv:2507.21817 , 2025, accepted for publication at ICSE 2026. [Online]. A vailable: https://arxiv .org/abs/2507.21817 [29] A. Y ang, A. Li, B. Y ang, B. Zhang, B. Hui, B. Zheng, B. Y u, C. Gao, C. Huang, C. Lv , C. Zheng, D. Liu, F . Zhou, F . Huang, F . Hu, H. Ge, H. W ei, H. Lin, J. T ang, J. Y ang, J. T u, J. Zhang, J. Y ang, J. Y ang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Y ang, L. Y u, L. Deng, M. Li, M. Xue, M. Li, P . Zhang, P . W ang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T . Li, T . T ang, W . Y in, X. Ren, X. W ang, X. Zhang, X. Ren, Y . Fan, Y . Su, Y . Zhang, Y . Zhang, Y . W an, Y . Liu, Z. W ang, Z. Cui, Z. Zhang, Z. Zhou, and Z. Qiu, “Qwen3 technical report,” arXiv preprint , May 2025, qwen3 series including Qwen3-30B-A3B (MoE model). [Online]. A vailable: https://arxiv .or g/abs/2505.09388 [30] J. Ainslie, J. Lee-Thorp, M. de Jong, Y . Zemlyanskiy , F . Lebrón, and S. Sanghai, “GQA: T raining Generalized Multi-Query T ransformer Models fr om Multi-Head Checkpoints,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) . Association for Computational Linguistics, 2023, pp. 4895–4901. [Online]. A vailable: https://aclanthology .org/2023. emnlp- main.298 [31] J. Su, Y . Lu, S. Pan, A. Murtadha, B. W en, and Y . Liu, “RoFormer: Enhanced transformer with rotary position embedding,” https:// arxiv .org/abs/2104.09864, 2021. [32] N. Shazeer , “Glu variants improve transformer ,” arXiv preprint arXiv:2002.05202 , 2020. IEEE TRANSACTIONS ON DEPEND ABLE AND SECURE COMPUTING, V OL. XX, NO. X, MONTH 20XX 16 [33] B. Zhang and R. Sennrich, “Root mean square layer normalization,” in Advances in Neural Informa- tion Processing Systems 32 (NeurIPS 2019) , 2019, pp. 12 360–12 371, also available at arXiv:1910.07467. [On- line]. A vailable: https://proceedings.neurips.cc/paper/2019/ file/1e8a19426224ca89e83cef47f1e7f53b- Paper .pdf [34] I. Loshchilov and F . Hutter , “Decoupled weight decay regularization,” in International Conference on Learning Representations , 2019. [Online]. A vailable: https://openreview . net/forum?id=Bkg6RiCqY7 [35] DeepSeek-AI, “DeepSeek-V3 T echnical Report,” arXiv preprint arXiv:2412.19437 , 2025. Aymen Lassoued is a final-year engineer ing student at Ecole P olytechnique de T unisie, La Marsa, T unisia. He is also a Kaggle Competi- tions Master . His research interests lie at the intersection of software secur ity and machine learning, with a f ocus on efficient deep lear ning models f or code analysis and vulnerability detec- tion. Nacef Mbarek is currently an engineer ing stu- dent at Ecole Polytechnique de T unisie, La Marsa, T unisia. He is also a Kaggle Compe- titions Exper t and is currently conducting re- search at the KAUST Center of Excellence in Generativ e AI, Saudi Arabia. His research in- terests include deep lear ning, large language models, and computer vision. Bechir Dardouri is a second-year engineering student at Ecole P olytechnique de T unisie, La Marsa, T unisia. His research interests lie at the intersection of software secur ity and machine learning, with a f ocus on efficient deep lear ning models f or code analysis and vulnerability detec- tion. Bassem Ouni (Senior Member , IEEE) receiv ed the Ph.D . degree in computer science from the University of Nice Sophia Antipolis, Nice, France , in 2013. He has held research and academic po- sitions at Eurecom, the University of Southamp- ton, the F rench Atomic Energy Commission (CEA-LIST), the University of Paris Saclay , and the T echnology Innov ation Institute, Abu Dhabi. He is currently the AI Sector Lead (Provost Office) at Khalifa University , Abu Dhabi, UAE. He has managed industr ial collaborations with ARM, Airbus, Rolls Royce, Thales, and Continental. His research in- terests include Gen AI applications, T r ustwor thy AI, IoT Security , and Embedded Systems. IEEE TRANSACTIONS ON DEPEND ABLE AND SECURE COMPUTING, V OL. XX, NO. X, MONTH 20XX 17 Qing Li received the Ph.D . deg ree from the University of Stav anger, Norwa y . She also holds a master’ s degree in applied mathematics from South China University of T echnology . She is currently an Assistant Professor at the Univer- sity of Groningen, The Nether lands. Previously , she was a P ostdoctoral Researcher at Mohamed bin Zayed University of Ar tificial Intelligence (MBZU AI). Her research f ocuses on improving the inter pretability and tr ustworthiness of large language models. Fakhri Karray (Life Fello w , IEEE) received the Ph.D . degree from the University of Illinois at Urbana-Champaign (UIUC), USA. He is the in- augural co-director of the University of W ater- loo’ s Ar tificial Intelligence Institute and ser ved as the Lobla ws Research Chair in Ar tificial In- telligence in the Depar tment of Electrical and Computer Engineering. He is also a Prof essor of Machine Lear ning at Mohamed bin Zayed Uni- versity of Ar tificial Intelligence (MBZUAI), where he has ser ved as Provost. His research focuses on operational and generative AI, cognitive machines , and autonomous systems.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment