Pre-Deployment Complexity Estimation for Federated Perception Systems
Edge AI systems increasingly rely on federated learning to train perception models in distributed, privacy-preserving, and resource-constrained environments. Yet, before training begins, practitioners often lack practical tools to estimate how diffic…
Authors: KMA Solaiman, Shafkat Islam, Ruy de Oliveira
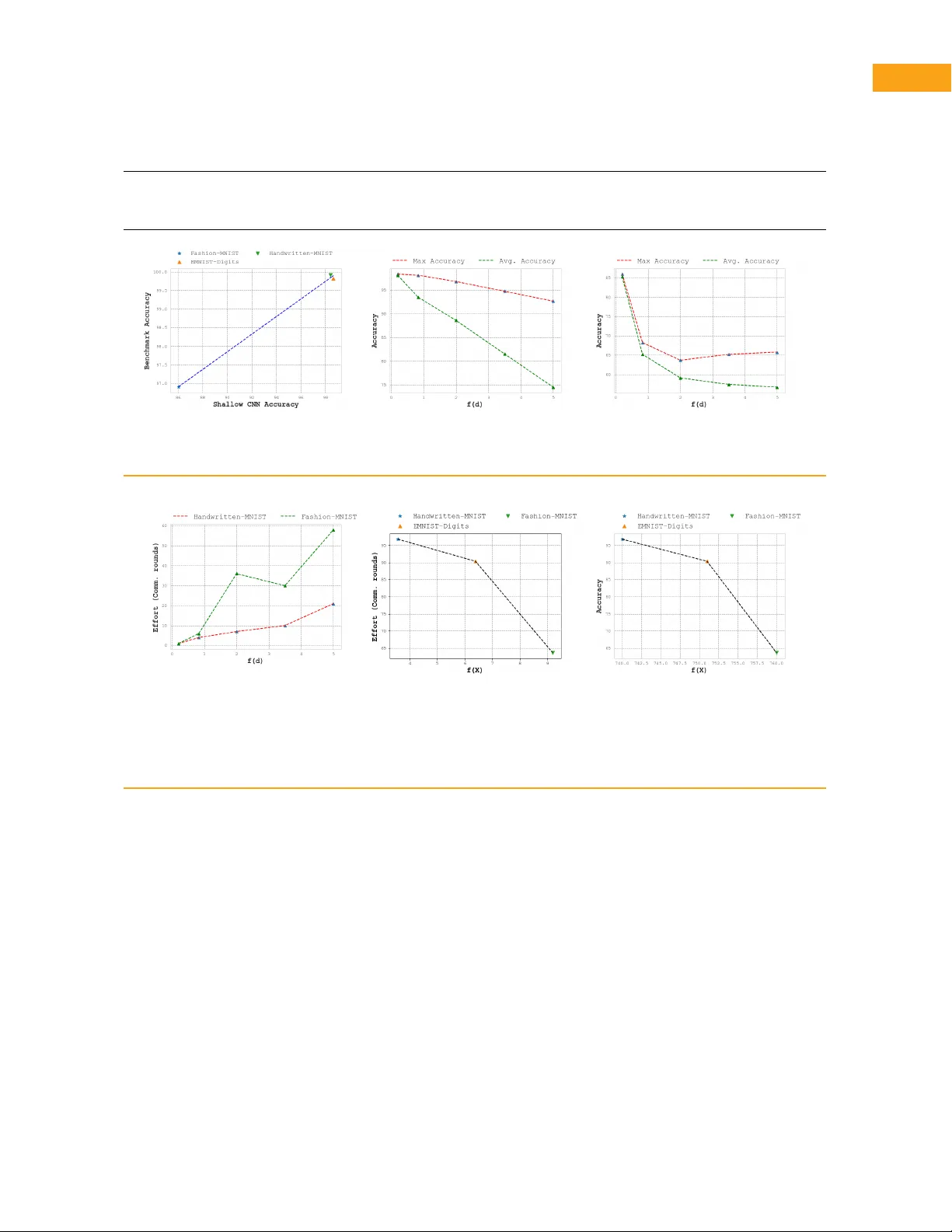
Ar ticle T ype: F eature Pre-Deplo yment Comple xity Estimation f or Federated P er ception Systems KMA Solaiman, ksolaima@umbc.edu, University of Maryland, Baltimore County , MD , USA Shafkat Islam, islam59@pnw .edu, Purdue Univ ersity Nor thwest, Hammond, IN, USA Ruy de Oliveir a, rdeolive@purdue .edu, Purdue University , W est Lafa y ette, IN, USA Bharat Bharga va, bbshail@purdue .edu, Purdue University , W est Laf ay ette, IN, USA Abstract—Edge AI systems increasingly rely on federated learning to train perception models in distributed, privacy-preserving, and resource-constrained environments . Y et, before training begins, practitioners often lack practical tools to estimate how difficult a feder ated lear ning task will be in ter ms of achie vab le accuracy and communication cost. This paper presents a classifier-agnostic, pre-deplo yment framework for estimating learning comple xity in f ederated perception systems by jointly modeling intrinsic proper ties of the data and characteristics of the distributed environment. The proposed complexity metric integrates dataset attributes such as dimensionality , sparsity , and heterogeneity with factors related to the composition of par ticipating clients. Using feder ated learning as a representative distributed training setting, we examine how learning difficulty varies across different feder ated configurations. Experiments on multiple variants of the MNIST dataset show that the proposed metr ic strongly correlates with federated learning performance and the communication effor t required to reach fix ed accuracy targets. These findings suggest that comple xity estimation can ser ve as a practical diagnostic tool for resource planning, dataset assessment, and feasibility e valuation in edge-deploy ed perception systems. Introduction Deplo ying perception models in edge environments introduces challenges that e xtend beyond model ac- curacy alone . Practical deplo yments must account f or communication limitations, constrained computation, and fragmented data ownership , particular ly when training data cannot be centraliz ed. Distr ibuted tr aining paradigms hav e theref ore become central to moder n Edge AI systems, motivating the need for tools that help practitioners reason about training feasibility and cost before large-scale learning is attempted. F ederated learning (FL) has emerged as a widely adopted framew or k for distributed and privacy- preser ving model training, especially in perception ap- plications [ 1 ]. While a substantial body of research has XXXX-XXX © 2026 IEEE Digital Object Identifier 10.1109/XXX.0000.0000000 f ocused on improving f ederated optimization strategies and conv ergence beha vior [ 2 ], [ 3 ], considerab ly less attention has been paid to understanding why cer tain f ederated lear ning tasks are inherently more difficult than others. In practice, f ederated tasks trained using identical models and algor ithms can exhibit mar kedly diff erent convergence r ates, communication costs, and final accuracy , differences that are often discov ered only after training has already begun. A k ey f actor underlying this v ariability is the intrinsic structure of the data and the characteristics of the distributed environment. Prior work has shown that proper ties such as dimensionality , sparsity , and het- erogeneity play a cr itical role in determining learning difficulty in perception domains [ 4 ], [ 5 ], [ 6 ]. Howe ver , most existing approaches assess complexity from the perspective of a single dataset or a centralized lear ning agent. Extending such analysis to distributed environ- ments remains challenging, as complexity in these Month Published by the IEEE Computer Society Publication Name 1 settings depends not only on local data proper ties but also on how data are par titioned across multiple entities. In this work, we adopt a measurement-oriented per- spective and address the problem of pre-deployment comple xity estimation for feder ated perception sys- tems. Rather than proposing a new lear ning algorithm or f ederated optimization policy , our objective is to quantify how difficult a federated lear ning task is likely to be based solely on intr insic data proper ties and distributed environment char acter istics. This diagnostic view complements existing work on feder ated opti- mization by providing insight into task difficulty prior to training. W e propose a classifier-agnostic comple xity es- timation framework that captures three intrinsic at- tributes of perception data—dimensionality , sparsity , and heterogeneity—and integr ates them with proper- ties of the federated environment, such as the num- ber and composition of par ticipating clients. F ederated learning is used as a representative distributed training paradigm, enabling the analysis of diff erent federated configurations without modifying the underlying lear n- ing process. The resulting complexity metric allows diff erent f ederated learning paths to be compared based on expected difficulty rather than obser ved per- f or mance. T o study the relationship between the proposed comple xity metric and feder ated learning behavior , we conduct controlled e xper iments on multiple variants of the MNIST dataset in distr ibuted settings. These e xper iments are designed to isolate comple xity effects and examine how intr insic and distr ibuted comple xity relate to f ederated accuracy and communication eff or t. The results demonstrate strong correlation between the proposed metric and both performance and training cost, suggesting that complexity estimation can ser ve as a practical diagnostic tool f or edge-deploy ed per- ception systems. Contributions The main contributions of this work are as follo ws: • We introduce an application-independent frame- work f or estimating intrinsic comple xity in per- ception datasets, based on dimensionality , spar- sity , and heterogeneity , without reliance on clas- sifier performance. • We propose a unified complexity metric f or feder- ated learning en vironments that integ rates intrin- sic data proper ties with distributed environment characteristics, enab ling compar ison of f eder- ated training configurations. • We empir ically ev aluate the proposed metric on multiple MNIST variants in distributed set- tings and demonstrate strong correlation with f ederated learning accuracy and communication eff or t. Backgr ound and Related W ork Comple xity Estimation in P erception Domains Estimating the complexity of perception datasets and learning tasks has been studied from se veral perspec- tives , including information theor y , uncer tainty estima- tion [ 7 ], [ 8 ], [ 9 ], and dataset organization. Prior w or k has shown that intr insic proper ties such as dimension- ality , sparsity , and heterogeneity play an impor tant role in deter mining learning difficulty in perception tasks. P ereyda et al. [ 5 ] proposed a theoretical frame- work for measuring domain comple xity and ev aluated it using approximations der ived from neural network models. Kr usinga et al. [ 6 ] inv estigated dataset com- ple xity by estimating probability densities of image distributions using gener ative adversarial networks, en- abling the detection of outliers and domain shifts at the cost of significant computational ov erhead. Schei- degger et al. [ 4 ] examined classification difficulty us- ing cluster ing-based metrics and lightweight neural probes, demonstrating that simple models can approx- imate dataset difficulty efficiently . While these approaches provide valuable insight into dataset complexity , they are typically de veloped f or centralized settings and often rely on classifier be- havior or learned representations. In contrast, our work f ocuses on estimating intrinsic complexity directly from data proper ties and extends the analysis to distr ibuted environments where data are par titioned across multi- ple entities. Distributed and F ederated Learning Context F ederated lear ning has emerged as a widely adopted frame work f or distributed and priv acy-preser ving model training [ 2 ]. A substantial body of research has f o- cused on improving f ederated optimization and conv er- gence behavior through methods such as FedA vg [ 2 ], F edAdaGrad [ 3 ] and F edY ogi [ 3 ]. These approaches aim to improv e training efficiency and robustness un- der heterogeneous data distributions and system con- straints. Howe v er , existing federated lear ning methods pr i- marily address how to train a model efficiently given a fixed task and dataset distribution. They do not e xplicitly estimate the intrinsic difficulty of a federated 2 Publication Title Month 2026 learning task pr ior to training, nor do they model how data complexity and distributed environment charac- teristics jointly influence lear ning difficulty . As a result, task f easibility and communication cost are typically discov ered only after training is underwa y . P ositioning of This W ork This wor k complements existing research by introduc- ing a classifier-agnostic , measurement-oriented frame- work for estimating learning comple xity in federated perception systems. By integrating intr insic dataset proper ties with distributed environment characteristics, the proposed approach provides a pre-deployment di- agnostic for assessing task difficulty . Federated lear n- ing is used as a representative distr ibuted training setting, and the proposed metric does not modify or optimize f ederated learning algor ithms. Instead, it aims to suppor t feasibility assessment and resource-aware planning prior to training. Complexity Estimation Framew ork Ov er view This section introduces the proposed complexity es- timation framew ork f or f ederated perception systems. The objectiv e of the fr amework is to provide a pre- deplo yment, classifier-agnostic diagnostic f or estimat- ing how difficult a f ederated lear ning task is likely to be, based solely on intr insic data proper ties and characteristics of the distr ibuted training environment. The frame work decomposes learning difficulty into two complementar y components. The first component captures the intrinsic comple xity of the data , reflecting structural proper ties of the perception domain that in- fluence lear nability regardless of model architecture or optimization strategy . The second component captures the complexity introduced by distr ibution , reflecting how data are par titioned across multiple entities in a f ederated lear ning environment. Intrinsic data complexity is character ized using three proper ties that ha ve been shown to pla y a critical role in perception tasks: dimensionality , sparsity , and heterogeneity . Dimensionality captures the size and structure of the feature space, sparsity reflects redun- dancy and effectiv e degrees of freedom in the data representation, and heterogeneity captures variability and diversity in the data distr ibution. These proper ties are computed directly from the data without reference to classifier performance or training dynamics. Distributed complexity is modeled using f ederated learning as a representative training paradigm. Feder- ated learning provides a concrete setting in which data are distr ibuted across multiple par ticipating entities, and lear ning proceeds through iterative communication rounds. Rather than modifying or optimizing the f eder- ated lear ning process, we use this setting to analyze how diff erent federated configurations influence ov erall learning difficulty when combined with intr insic data comple xity . The over all complexity of a feder ated lear ning task is expressed as a composite metric that integrates intrinsic data comple xity with distr ibuted environment characteristics. This formulation enables different f ed- erated training configurations to be compared in ter ms of expected difficulty , accuracy trends, and commu- nication eff or t, without requiring model training to be e xecuted in advance . Figure 1 illustrates how different subsets of par- ticipating clients across communication rounds give rise to multiple federated learning paths, motiv ating the need to characterize task difficulty at the le vel of f eder- ated configurations rather than individual datasets. In the subsequent subsections, we formalize the intr insic data complexity measures and define how the y are integrated with f ederated environment characteristics to obtain the proposed federated complexity metr ic. Intrinsic P erception Domain Comple xity Intrinsic comple xity ref ers to proper ties of the data distribution itself that influence learning difficulty , inde- pendent of any specific model architecture, training al- gorithm, or optimization procedure. In perception tasks, these proper ties arise from the structure, variability , and organization of the data and can be assessed prior to training. In this work, intrinsic complexity is characterized along three complementar y dimensions: dimensionality , sparsity , and heterogeneity . Dimensionality Dimensionality captures the size and structure of the feature space that a lear ning system must represent. F rom a classifier-agnostic perspective, an upper bound on the dimensional complexity of a perception dataset can be defined using two factors: the number of samples and the number of features . Let N s denote the number of samples and N d the number of f eature dimensions. For super vised datasets, the number of output classes N C is also in- cluded. An upper bound on en vironment dimensionality is given by EC upper = N s × N d + N C . (1) This upper bound reflects the maximum represen- tational space implied by the dataset, regardless of the learning model. T o refine this estimate, features Month 2026 Publication Title 3 FIGURE 1 . Illustration of federated learning paths across communication rounds. Each node represents an inter mediate training state obtained from a subset of par ticipating clients. Different paths correspond to distinct f ederated configurations, each associated with potentially diff erent lear ning difficulty . with zero variance across the dataset are remov ed, as they do not contribute to data v ariability . Let N r d denote the reduced number of features after removing zero-v ariance dimensions. The refined upper bound becomes EC upper = N s × N r d + N C . (2) While upper-bound dimensionality reflects worst- case representational requirements, real-world percep- tion data often lie on lower-dimensional manifolds . T o capture this str ucture, we estimate intrinsic dimension- ality (ID), defined as the minimum number of latent di- mensions required to represent the data without infor- mation loss. Intr insic dimensionality provides a lower- bound characterization of dimensional comple xity that is sensitive to non-linear str ucture. W e estimate intrinsic dimensionality using the max- imum likelihood estimator proposed in [ 10 ]. Giv en a dataset { x i } n i =1 , the estimator f or intrinsic dimensional- ity m based on k nearest neighbors is defined as m k ( x ) = 1 k − 1 k − 1 X j =1 log T k ( x ) T j ( x ) − 1 , (3) where T j ( x ) denotes the distance from sample x to its j -th nearest neighbor . This estimator provides a data- driven measure of latent dimensional structure without relying on class labels or classifier performance. Sparsity Sparsity characterizes the degree to which inf or mative str ucture in a dataset can be captured using a reduced set of components. In perception domains, sparsity reflects redundancy in feature rep- resentations and indicates how efficiently inf ormation can be compressed without significant loss. W e assess sparsity using unsuper vised dimension- ality reduction techniques that operate independently of class labels. Principal Component Analysis (PCA) [ 11 ] is used to quantify how much variance can be e xplained by a reduced number of linear components. A dataset that concentrates most of its variance in a small number of principal components is considered more sparse. T o capture non-linear str ucture, we additionally consider Isomap [ 12 ], a manif old lear ning method that preser ves geodesic distances between samples. Isomap provides complementary insight into sparsity when data lie on curved or non-linear manifolds . T o- gether , PCA and Isomap off er diagnostic indicators of how compactly a dataset can be represented, reflect- ing intrinsic sparsity in the perception domain. Heterogeneity Heterogeneity measures the diversity and variability present within a dataset. In perception tasks, heterogeneity ar ises from variations in pixel intensities, textures, shapes, and other low-lev el f ea- tures, and it directly influences lear ning difficulty . W e quantify heterogeneity using Shannon entropy [ 13 ], a standard inf or mation-theoretic measure of un- cer tainty . For gra yscale images, entropy is defined as H = − n − 1 X i =0 p i log p i , (4) 4 Publication Title Month 2026 where p i denotes the probability of obser ving gray le vel i and n is the n umber of possible gra y le vels . Higher entropy v alues indicate greater div ersity in pixel distributions and increased heterogeneity . T aken together , dimensionality , sparsity , and het- erogeneity provide complementar y , classifier-agnostic indicators of intr insic perception domain complexity . These measures are computed prior to training and ser v e as inputs to the feder ated complexity f ormulation described in the next subsection. F ederated Lear ning Comple xity Intrinsic data comple xity captures the difficulty of learn- ing from a single, local dataset, but it does not account f or additional challenges introduced when data are distributed across multiple entities. In f ederated lear n- ing, data are par titioned across par ticipating clients, and lear ning proceeds through iterative communication rounds. The distribution of data across entities and the patterns of participation dur ing training can sub- stantially influence learning behavior , e ven when the underlying model and optimization procedure remain fix ed. In this work, w e use f ederated learning as a rep- resentative distributed training paradigm to model and analyze the impact of distribution on lear ning difficulty . Rather than modifying the federated lear ning process or proposing a new training strategy , we f ocus on characterizing how intrinsic data comple xity interacts with distributed environment proper ties to influence task difficulty . W e represent a federated lear ning process as a conceptual tree, as illustrated in Figure 1 , where each path corresponds to a distinct sequence of par tici- pating entities across communication rounds. Diff erent paths represent diff erent feder ated configurations and ma y lead to diff erent lear ning outcomes due to vari- ations in data exposure and aggregation order . This representation is used solely as an analytical tool to enumerate and compare feder ated configurations, not as a mechanism for controlling or selecting training behavior . The over all complexity of a feder ated lear ning task is modeled as the combination of intr insic data com- ple xity and distr ibuted environment complexity . W e de- fine the feder ated complexity metric as F ( d , X ) = f ( X ) + f ( d ), (5) where f ( X ) captures intrinsic data complexity , com- puted from dimensionality , sparsity , and heterogeneity measures, and f ( d ) captures complexity ar ising from the distributed environment. Let X = [ x 1 , x 2 , ... , x n ] denote the vector of intr insic complexity components. The intrinsic complexity term is defined as f ( X ) = β ∥ X ∥ 2 = β q x 2 1 + x 2 2 + · · · + x 2 n , (6) where x i denotes the intrinsic comple xity of the local dataset associated with par ticipating entity i , n is the number of entities inv olved in a given f ederated con- figuration, and β is a normalization constant. T o characterize the complexity introduced by data distribution across entities, we define the distributed environment complexity as f ( d ) = 1 m 1 + 1 m 2 + · · · + 1 m d , (7) where d is the number of distinct entities in the f eder- ated environment and m j denotes the frequency with which entity j appears across feder ated configurations. This f ormulation reflects the degree of fr agmentation and imbalance in data distr ibution across entities, with higher values corresponding to more heterogeneous par ticipation patter ns. Combining these components yields the federated learning comple xity metric f or a given feder ated con- figuration: F ( d , X ) = β q x 2 1 + x 2 2 + · · · + x 2 n + 1 m 1 + 1 m 2 + · · · + 1 m d . (8) The proposed metric is used as a diagnostic in- dicator of learning difficulty . It enables comparison of diff erent f ederated configurations in ter ms of expected accuracy trends and communication effor t, without al- tering the learning algorithm or requir ing training to be e xecuted in advance . In the experimental section, we examine how this metr ic correlates with feder ated learning perf or mance and effort across controlled dis- tributed settings. Experimental Setup and Evaluation This section ev aluates whether the proposed comple x- ity framework provides a meaningful diagnostic signal f or federated learning difficulty in perception domains. Specifically , we examine the relationship between the proposed complexity measures and two obser vab le outcomes of federated learning: model accuracy and communication effort. The goal is not to optimize the f ederated lear ning process, but to assess whether comple xity estimated pr ior to training correlates with learning behavior obser ved during training. All experiments are conducted using Python 3.8 on a workstation equipped with an Intel Core i7 (8th Month 2026 Publication Title 5 generation) CPU and 16 GB of memor y . Standard open-source libraries are used throughout to ensure reproducibility . Datasets: W e e valuate the proposed frame work using three commonly used perception benchmarks: Handwritten-MNIST [ 14 ], F ashion-MNIST [ 15 ], and EMNIST -Digits [ 16 ]. These datasets provide controlled variations in visual complexity while maintaining iden- tical input resolution and label str ucture, making them suitable for comparativ e complexity analysis. Handwritten-MNIST and F ashion-MNIST each con- tain 70,000 gra yscale images, with 60,000 training samples and 10,000 test samples. EMNIST -Digits con- tains 280,000 digit images. All images are of size 28 × 28 pix els with pixel intensities in the range [0, 255]. Intrinsic Complexity Measurement: T o character- ize intrinsic dataset complexity , we compute the follow- ing measures for each dataset: (i) Shannon entrop y as a measure of heterogeneity , (ii) sparsity estimated via principal component analysis (PCA), (iii) environment comple xity based on feature variance thresholds, and (iv) intrinsic dimensionality (ID). Entrop y is computed using Scikit-image [ 17 ], PCA- based sparsity and environment complexity are com- puted using Scikit-learn [ 18 ], and intrinsic dimension- ality is estimated using the Scikit-dimension package [ 19 ]. T able 1 summar izes the resulting measurements. These values provide a relativ e ordering of dataset comple xity that serves as input to the intrinsic com- ple xity function f ( X ) descr ibed in Section 3. F ederated Lear ning Configuration F ederated learning experiments are conducted using a fix ed shallow convolutional neural network architecture across all settings. All clients emplo y identical model architectures and local training procedures. Model ag- gregation is performed using the FedA vg algorithm [ 2 ]. Unless otherwise stated, experiments use five fed- erated clients with non-identical local data distributions. Each client perf or ms a single local iteration per com- munication round, and all clients contain comparab le amounts of data. F or each configuration, training is run for 100 communication rounds. Federated test accuracy is e valuated on a held-out test set. Ev aluation Metr ics W e e valuate federated learning behavior using two obser v able quantities: accuracy and communication eff or t . Accuracy is repor ted both as the maximum test accuracy achiev ed ov er all communication rounds and as the av erage accuracy across rounds. Communi- cation effort is measured as the number of commu- nication rounds required to reach a fixed accuracy threshold, set to 60% across all datasets. T o assess the diagnostic value of the proposed comple xity metric, we analyze correlations between accuracy , effort, and the estimated complexity values. In par ticular, we examine how changes in f ederated environment complexity f ( d ) and intrinsic comple xity f ( X ) relate to obser ved learning behavior , and whether the combined complexity metric F ( d , X ) provides a stronger predictive signal than either component alone. Results and Anal ysis This section analyzes the relationship between the pro- posed complexity measures and obser ved feder ated learning behavior . The objective is to ev aluate whether intrinsic dataset proper ties and distributed environment characteristics provide a reliable diagnostic signal for f ederated learning difficulty , as reflected in accuracy and communication effor t. All results are repor ted us- ing the experimental setup described in Section 4. Intrinsic Complexity Across MNIST V ariants T able 1 summar izes the intrinsic complexity mea- surements for Handwr itten-MNIST , EMNIST -Digits , and F ashion-MNIST . Across all metr ics - heterogeneity , sparsity , environment comple xity , and intrinsic dimen- sionality , Handwritten-MNIST consistently exhibits the lowest complexity , while F ashion-MNIST exhibits the highest. EMNIST -Digits occupies an inter mediate po- sition. Although some metrics e xhibit minor order ing differ- ences (e .g., sparsity at higher variance thresholds), the ov erall trend is consistent. These results confir m that the selected intr insic measures capture meaningful diff erences in dataset str ucture, e ven among datasets derived from the same base domain. F ederated Environment Comple xity Figures 2(b) and 2(c) illustrate the relationship be- tween federated environment complexity f ( d ) and f ed- erated lear ning accuracy for Handwritten-MNIST and F ashion-MNIST , respectiv ely , with intrinsic complexity held fixed. As the number and diversity of par ticipating clients increase, both maximum and aver age accuracy e xhibit a decreasing trend. Figure 3(a) fur ther sho ws that comm unication eff or t increases monotonically with f ( d ) for both datasets. These results indicate that distr ibuted environment characteristics alone introduce measurable learning difficulty , independent of intrinsic dataset proper ties. 6 Publication Title Month 2026 T ABLE 1 . Heterogeneity , Sparsity , Environment Comple xity , and Intr insic Dimensionality Measurement Dataset Heterogeneity Sparsity ( r 2 = 80%) Sparsity ( r 2 = 95%) EC upper ( v θ = 0) EC upper ( v θ = 90) ID Handwritten-MNIST 1.60 740 629 717 530 13.368 EMNIST -digits 2.86 751 685 697 557 14.095 F ashion-MNIST 4.11 760 594 784 745 14.547 FIGURE 2 . (a) Shallow CNN accuracy vs. benchmark accuracy for F ashion-MNIST , Handwritten-MNIST and EMNIST -Digits, (b) Feder ated environment complexity f ( d ) vs. shallow federated lear ning accuracy for Handwritten-MNIST when f ( X ) is fixed, (c) Feder ated environment complexity f ( d ) vs. shallow federated lear ning accuracy for F ashion-MNIST when f ( X ) is fixed. FIGURE 3 . (a) Feder ated environment complexity f ( d ) vs. effort (communication rounds) for MNIST and F ashion-MNIST , (b) Feder ated accuracy vs. Federated intr insic function f ( X ), reflecting heterogeneity (entropy), for Fashion-MNIST , Handwritten- MNIST and EMNIST -Digits, with f ( d ) fixed at 2, (c) Federated accuracy vs. Feder ated intrinsic function f ( X ), reflecting sparsity (number of sparse components for e xplaining 80% of variance), for F ashion-MNIST , Handwritten-MNIST and EMNIST -Digits with f ( d ) fixed at 2. Impact of Intrinsic Complexity on F ederated Lear ning Figures 3(b) and 3(c) examine the relationship be- tween intrinsic complexity f ( X ) and feder ated accuracy while holding the feder ated environment complexity constant. As intr insic comple xity increases—whether due to higher heterogeneity or increased spar- sity—f ederated accuracy decreases. Similarly , Figure 4(a) shows that communication ef- f or t increases as intr insic complexity increases. These trends are consistent across all three MNIST variants, suggesting that intrinsic data proper ties directly influ- ence lear ning difficulty in distributed settings. Combined Comple xity Metr ic Figures 4(b) and 5 ev aluate the relationship between the combined complexity metric F ( d , X ) and feder- ated lear ning accuracy . A strong negative correlation is observed between comple xity and accuracy , with R 2 = 0.81 for maximum accuracy and R 2 = 0.85 for av erage accuracy . Notably , av erage accur acy e xhibits a slightly stronger correlation with the proposed complexity met- ric than maximum accuracy . This suggests that F ( d , X ) better reflects sustained lear ning behavior rather than isolated peak perf or mance, which is desirab le for pre- deplo yment assessment. Month 2026 Publication Title 7 FIGURE 4 . (a) F ederated intr insic function f ( X ) (reflecting heterogeneity) vs. effort (communication rounds), (b) Federated complexity F ( d , X ) vs. shallow Federated lear ning accuracy , considering maximum accuracy ( R 2 = 0.81). FIGURE 5 . Federated comple xity F ( d , X ) vs. shallow Feder- ated learning accuracy , consider ing av erage accuracy ( R 2 = 0.85). Summar y of Findings Across all experiments, intr insic complexity , f ederated environment comple xity , and their combination demon- strate consistent relationships with feder ated learning behavior . While neither intr insic nor distributed com- ple xity alone fully explains learning difficulty , their com- bination provides a stronger diagnostic signal. These results suppor t the use of complexity es- timation as a complementar y tool for understanding f ederated lear ning behavior prior to deployment, with- out modifying tr aining algorithms or requiring extensiv e training runs. Discussion The results presented in this paper demonstrate that learning difficulty in feder ated perception systems is influenced by both intr insic proper ties of the data and characteristics of the distributed training environment. By jointly modeling these factors , the proposed com- ple xity metric pro vides a practical diagnostic signal that correlates with federated lear ning beha vior , including achie vab le accuracy and communication effort. A key implication of this work is that federated learning difficulty is not determined solely by the choice of model architecture or optimization algorithm. Even when training configurations are held constant, v ar ia- tions in dataset structure and client composition lead to measurab le diff erences in con vergence behavior and training cost. The proposed framew ork makes these diff erences explicit prior to training, enabling compar- ison of feder ated configurations without requiring e x- tensive tr ial-and-error e xper imentation. F rom an edge AI perspectiv e, such pre-deplo yment comple xity estimation is par ticular ly valuable . Edge- deplo yed systems often operate under strict resource constraints, where communication budgets, energy consumption, and latency must be considered along- side accuracy . By providing an ear ly indication of e xpected learning difficulty , the proposed metric can suppor t feasibility assessment, dataset selection, and resource planning before committing to large-scale f ederated training. It is impor tant to emphasize that the proposed comple xity metric is intended as a diagnostic tool rather than an optimization mechanism. The framework does not prescribe client selection policies, training schedules, or model adaptations, nor does it modify 8 Publication Title Month 2026 the feder ated lear ning process itself. Instead, it com- plements existing f ederated optimization methods by characterizing task difficulty independently of training dynamics. This separation allows complexity estima- tion to be applied broadly , regardless of the specific learning algorithm used. The e xper imental e valuation is conducted using controlled perception benchmarks and simplified fed- erated configurations. While these settings are suffi- cient to v alidate the diagnostic relationship between comple xity and lear ning behavior , they do not capture the full diversity of real-world feder ated systems. In par ticular , f actors such as extreme data imbalance, heterogeneous client hardware, par tial par ticipation, and more complex data modalities are not explored in this study . These limitations suggest natural direc- tions for future work rather than shor tcomings of the proposed framew ork. Future e xtensions of this work ma y include e valuat- ing complexity estimation on larger and more diverse perception datasets, incorporating additional sources of heterogeneity common in real-world f ederated de- plo yments, and studying how diagnostic comple xity measures interact with adaptive training strategies. Impor tantly , such e xtensions can b uild upon the current frame work without alter ing its core objective: providing a principled, pre-deplo yment understanding of feder- ated lear ning difficulty in edge AI systems. Conclusion This paper introduced a diagnostic framew or k for es- timating learning complexity in federated perception systems pr ior to training. By combining intrinsic dataset proper ties—dimensionality , sparsity , and heterogene- ity—with characteristics of the distributed training envi- ronment, the proposed metric provides a unified mea- sure of feder ated learning difficulty that is independent of model architecture and optimization strategy . Using f ederated learning as a representative dis- tributed training paradigm, w e empirically e v aluated the relationship between the proposed complexity mea- sures and obser vable lear ning behavior . Exper iments on multiple MNIST v ar iants demonstrated consistent correlations between estimated complexity , federated accuracy , and communication effor t. In par ticular, the combined complexity metr ic showed strong correlation with both av erage and maximum federated accuracy , indicating its potential utility as a pre-deplo yment diag- nostic indicator . The proposed approach does not seek to optimize or control the f ederated lear ning process. Instead, it complements e xisting feder ated lear ning methods by providing insight into task difficulty before training begins. Such ear ly-stage complexity estimation can suppor t f easibility assessment, dataset comparison, and resource planning in edge-deplo yed perception systems, where training costs and communication con- straints are critical considerations. Future work will explore the applicability of the proposed frame work to more diverse and large-scale perception datasets, as well as federated settings with greater heterogeneity in data v olume, client a vailability , and system resources . These extensions aim to fur ther assess the generality of complexity estimation as a diagnostic tool f or f ederated lear ning in real-world edge AI environments . REFERENCES 1. T . Li, A. K. Sahu, A. T alwalkar , and V . Smith, “Fed- erated lear ning: Challenges, methods, and future di- rections, ” IEEE Signal Processing Magazine , vol. 37, no . 3, pp. 50–60, 2020. 2. H. B. McMahan, E. Moore, D . Ramage, S . Hampson, and B. A. y Arcas, “Communication-efficient lear ning of deep networks from decentralized data, ” in Proceedings of the 20th Inter national Conference on Ar tificial Intelligence and Statistics (AIST A TS) , 2017. [Online]. A vailab le: http://arxiv .org/abs/1602.05629 3. S. Reddi, Z. Charles, M. Zaheer , Z. Garrett, K. Rush, J. Kone ˇ cn ` y, S. Kumar , and H. B. McMa- han, “Adaptive federated optimization, ” arXiv prepr int arXiv:2003.00295 , 2020. 4. F . Scheidegger , R. Istrate, G. Mariani, L. Benini, C. Bekas, and C. Malossi, “Efficient image dataset classification difficulty estimation for predicting deep- learning accuracy , ” Vis. Comput. , vol. 37, no. 6, pp . 1593–1610, Jun. 2021. 5. C. Pere yda and L. B. Holder , “Measur ing the com- plexity of domains used to evaluate ai systems, ” ArXiv , vol. abs/2010.01985, 2020. 6. R. Kr usinga, S. Shah, M. Zwicker , T . Goldstein, and D . W . Jacobs, “Understanding the (un)inter pretability of natural image distributions using generativ e mod- els, ” ArXiv , vol. abs/1901.01499, 2019. 7. M. Batty , R. Morphet, P . Masucci, and K. Stanilov , “Entropy , comple xity , and spatial inf ormation, ” Journal of Geographical Systems , vol. 16, no. 4, pp. 363–385, Sep. 2014. [Online]. A vailable: https: //doi.org/10.1007/s10109- 014- 0202- 2 8. P . Langley , “Open-world lear ning for radically au- tonomous agents, ” Proc. Conf. AAAI Ar tif. Intell. , vol. 34, no. 09, pp. 13 539–13 543, Apr . 2020. 9. R. P . Cardoso, E. Har t, D . B. Kurka, and J. V . Pitt, “Using nov elty search to explicitly create diversity Month 2026 Publication Title 9 in ensemb les of classifiers, ” in Proceedings of the Genetic and Evolutionary Computation Conference . New Y ork, NY , USA: ACM, Jun. 2021. 10. E. Le vina and P . Bickel, “Maximum lik elihood esti- mation of intrinsic dimension, ” Adv ances in neural information processing systems , v ol. 17, 2004. 11. I. T . Jolliff e and J . Cadima, “Principal component analysis: a review and recent dev elopments, ” Philo- sophical transactions of the royal society A: Mathe- matical, Ph ysical and Engineering Sciences , vol. 374, no . 2065, p. 20150202, 2016. 12. J. B. T enenbaum, V . d. Silva, and J. C . Langf ord, “A global geometric framework for nonlinear dimen- sionality reduction, ” science , vol. 290, no. 5500, pp. 2319–2323, 2000. 13. C. E. Shannon, “A mathematical theor y of commu- nication, ” A CM SIGMOBILE mobile computing and communications re view , vol. 5, no . 1, pp . 3–55, 2001. 14. L. Deng, “The mnist database of handwr itten digit images for machine lear ning research, ” IEEE Signal Processing Magazine , vol. 29, no. 6, pp. 141–142, 2012. 15. H. Xiao, K. Rasul, and R. V ollgraf , “Fashion-mnist: a nov el image dataset for benchmarking machine learning algor ithms, ” 2017, cite arxiv:1708.07747Comment: Dataset is freely av ail- able at https://github.com/zalandoresearch/f ashion- mnist Benchmark is availab le at http://fashion- mnist.s3-website.eu-centr al-1.amazonaws .com/. [Online]. A vailab le: http://arxiv .org/abs/1708.07747 16. G. Cohen, S. Afshar , J. T apson, and A. van Schaik, “Emnist: an e xtension of mnist t o handwritten letters, ” 2017. [Online]. A vailab le: https://arxiv .org/abs/1702. 05373 17. S. van der W alt, J . L. Schönberger , J . Nunez-Iglesias, F . Boulogne, J. D . W arner, N. Y ager , E. Gouillar t, T . Y u, and the scikit-image contr ibutors , “scikit-image: Image processing in p ython, ” Peerj , 2014. 18. F . Pedregosa, G. V aroquaux, A. Gramfort, V . Michel, B. Thir ion, O . Grisel, M. Blondel, P . Prettenhof er , R. W eiss, V . Dubourg, J . V anderplas, A. P assos, D . Cour napeau, M. Brucher, M. Perrot, and E. Duch- esnay , “Scikit-learn: Machine lear ning in Python, ” Journal of Machine Lear ning Research , vol. 12, pp. 2825–2830, 2011. 19. J. Bac, E. M. Mir kes , A. N. Gorban, I. T yukin, and A. Zinovy ev , “Scikit-dimension: a python package for intrinsic dimension estimation, ” Entropy , vol. 23, no . 10, p. 1368, 2021. 10 Publication Title Month 2026
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment