Voice-Controlled Scratch for Children with (Motor) Disabilities
Block-based programming environments like Scratch have become widely adopted in Computer Science Education, but the mouse-based drag-and-drop interface can challenge users with disabilities. While prior work has provided solutions supporting children…
Authors: Elias Goller, Gordon Fraser, Isabella Graßl
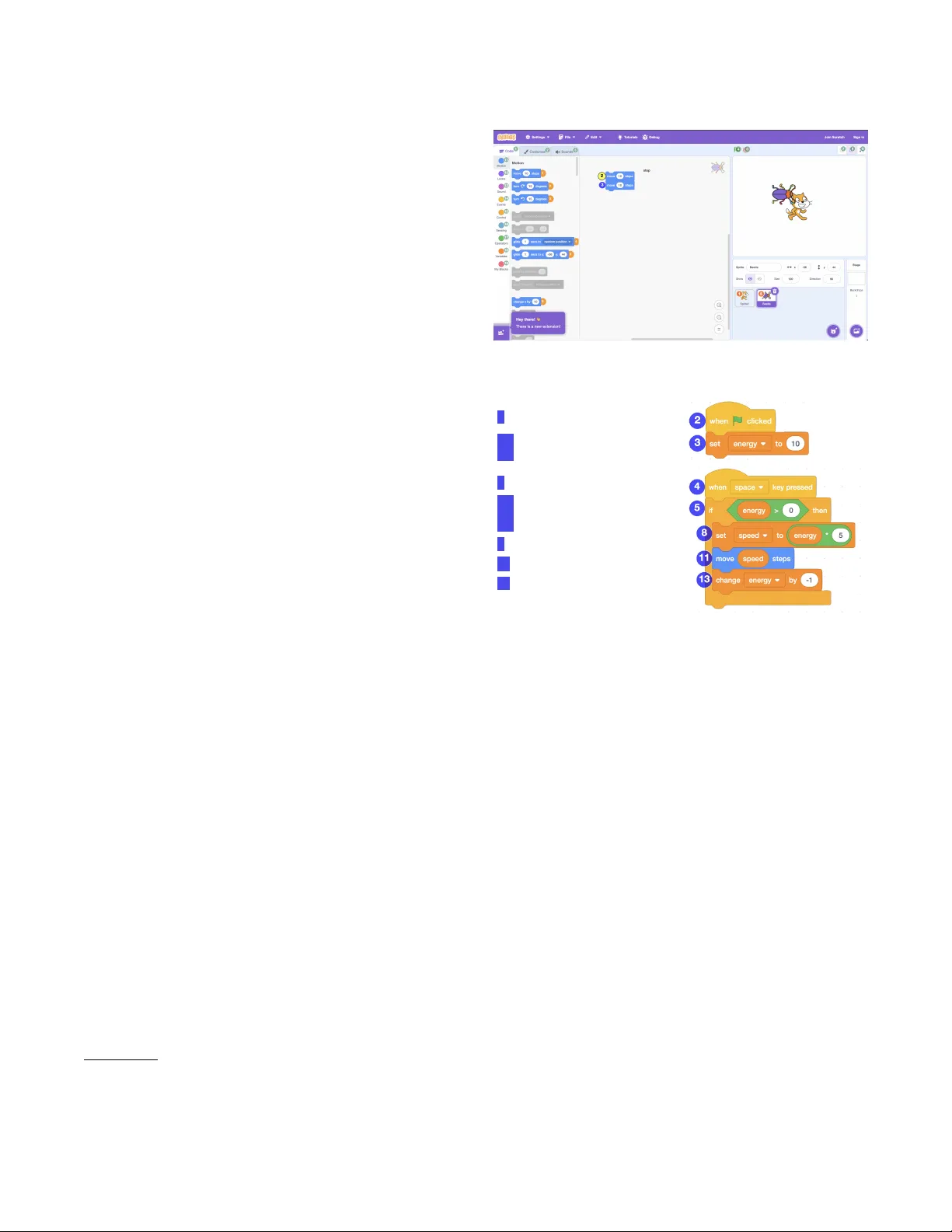
V oice-Controlled Scra t ch for Children with (Motor ) Disabilities Elias Goller elias.goller@uni- passau.de University of Passau Passau, Germany Gordon Fraser gordon.fraser@uni- passau.de University of Passau Passau, Germany Isabella Graßl isabella.grassl@tu- darmstadt.de T e chnical Univ ersity of Darmstadt Darmstadt, Germany Abstract Block-based programming envir onments like Scra t ch have be- come widely adopted in Computer Science Education, but the mouse-based drag-and-dr op interface can challenge users with disabilities. While prior work has provided solutions supporting children with visual impairment, these solutions tend to focus on making content perceivable and do not address the physical inter- action barriers faced by users with motor disabilities. T o bridge this gap, we introduce MeowCrophone , an approach that uses voice control to allo w editing co de in Scra tch . MeowCrophone supports clicking elements, placing blocks, and navigating the work- space via a multi-modal voice user interface that uses numerical overlays and lab el reading to bypass physical input entirely . As imperfect spe ech recognition is common in classrooms and for children with dysarthria, MeowCrophone employs a multi-stage matching pipeline using regular expressions, phonetic matching, and a custom grammar . Evaluation shows that while free speech recognition systems achieved a baseline success rate of only 46.4%, MeowCrophone ’s pipeline improved results to 82.8% o verall, with simple commands reaching 96.9% accuracy . This demonstrates that robust voice control can make Scrat ch accessible to users for whom visual aids are insucient. CCS Concepts • Applied computing → Education ; • Social and professional topics → Gender ; Cultural characteristics ; CS1 . Ke y w ords Scra tch , motor disabilities, inclusion, pr ogramming education. A CM Reference Format: Elias Goller, Gordon Fraser, and Isabella Graßl. 2026. V oice-Controlled Scra tch for Children with (Motor) Disabilities. In Proceedings of the 31th A CM Conference on Innovation and T echnology in Computer Science Education V . 1 (I TiCSE 2026), July 13–15, 2026, Madrid, Spain. A CM, New Y ork, N Y , USA, 7 pages. https://doi.org/XXXXXXX.XXXXXXX 1 Introduction Programming helps children build problem-solving skills and per- severance [ 3 ], yet many children with motor disabilities cannot fully participate in typical introductor y courses. Scra tch , the most Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for prot or commercial advantage and that copies bear this notice and the full citation on the rst page. Copyrights for components of this work owned by others than the author(s) must be honor ed. Abstracting with credit is permitted. T o copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specic permission and /or a fee. Request permissions from permissions@acm.org. I TiCSE 2026, Madrid, Spain © 2026 Copyright held by the owner/author(s). Publication rights licensed to A CM. ACM ISBN XXXXXXX.XXXXXXX https://doi.org/XXXXXXX.XXXXXXX widely use d visual programming to ol for children [ 34 ], relies on mouse-based drag-and-drop interactions, which is challenging for learners with limited ne motor control [ 45 ]. While accessibility has improved signicantly for users with visual impairments [ 21 , 28 , 43 ], students with motor disabilities have been largely overlooked. The fundamental interaction model of Scra tch , in which children have to use a mouse to drag and drop code blocks, requires ne motor skills that present a signicant barrier for children with con- ditions such as Cerebral Palsy [ 23 ]. Unlike te xt-based pr ogramming, which can often be adapted with standard assistive technologies, the specic physical requirements of a blo ck-based drag-and-drop interface render standard Scra t ch inaccessible for this user group. Enabling users with motor disabilities to use Scra t ch requires a voice user interface ( VUI ) [ 22 ], but to the best of our knowledge, there is no actively dev eloped and usable to ol available . Accessib- ility tools such as Myna [ 39 , 42 ] translated voice commands into Scra tch actions, but has not be en maintained since 2015 [ 31 ], does not supp ort Scra t ch 3.0, and is not practical for classroom use [ 40 , 41 ]. Existing work for Blockly [ 10 ] cannot access key parts of Scra tch such as stage and costume editors [24, 25]. W e therefore introduce MeowCrophone , a voice-controlled interface that runs in parallel to Scra tch , allowing users to oper- ate it entirely without physical input. Drawing inspiration from professional voice-coding tools like T alon [ 38 ] and Serenade [ 33 ], MeowCrophone acts as an assistive layer that translates spoken commands into actions within Scra tch . Users can place blo cks, ma- nipulate sprites, navigate menus, and manage variables entirely by voice. Since Meo wCrophone is a separate application, it is easier to maintain and ensures upgrade compatibility . Designing voice control for Scra t ch brings practical challenges: MeowCrophone must supp ort navigation, block creation and ma- nipulation, parameter setting, and object management, while also handling noisy environments and inaccurate transcripts. W e imple- mented a vertical slice that demonstrates feasibility across these core interactions. The tool includes conrmations for critical ac- tions, handles low-condence commands, and oers shortcuts and contextual commands to reduce frustration. Even though baseline sp eech recognition accuracy was low (46.4% overall and 27.1% for German), reecting authentic classroom conditions, our matching pipeline improved accuracy to 82.8% overall. Due to the explorative nature of this work, MeowCro - phone is evaluated against a set of 28 accessibility criteria based on W CAG [ 14 ], NAUR [ 44 ], and prior work [ 18 ] to validate its design foundations and support future studies with the target group. 2 Background and Relate d W ork 2.1 Scra t ch : Visual Programming Scra tch is the most widely adopted visual programming tool in education, particularly for children aged eight to sixteen [ 32 , 34 ]. I TiCSE 2026, July 13–15, 2026, Madrid, Spain Elias Goller, Gordon Fraser, and Isabella Graßl Learners create programs by assembling colourful, interlo cking blocks, a design that eliminates syntax errors and engages b eginners. Scra tch has been shown to eectively support interests among diverse learners as well as the development of problem-solving skills, computational thinking, and creative thinking. [5, 11, 17]. From a technical p erspective , Scrat ch 3.0 1 is built on the Scra tch Virtual Machine (VM) and Scra tch -Blocks (a fork of Google Blockly ). The VM manages the state of the Stage and sprites, and maps blocks to executable functions. Scra tch -Blocks renders the graphical in- terface, handling user interactions such as dragging, snapping, and deleting blocks. While this architecture provides a robust visual metaphor , it enforces a mouse-centric interaction model, as the VM relies on UI events trigger ed by the drag-and-drop interface. 2.2 Accessibility Barriers and Existing T o ols Since Scra t ch and similar blo ck-based programming environments rely heavily on visual cues and precise ne-motor control, they present signicant barriers for students with disabilities [ 23 , 36 ]. Children with motor impairments, such as those with cerebral palsy , often struggle with the sustained mouse control r equired to drag blocks across the screen [ 23 ]. Similarly , learners with learning or emotional disabilities as well as ADHD may nd the unstructured, cluttered interface overwhelming [8, 12, 26, 45]. Several voice-assisted tools have attempted to bridge this gap, though none provide a comprehensive solution for mo dern Scra tch : Okafor et al. [ 23 , 25 ] developed a voice-controlled system for Blockly that maps spoken commands to block actions. Howe ver , this tool is deeply integrated into the Blockly core and lacks supp ort for Scra tch -specic features, such as the Stage , costume editor , and sprite management, rendering it unsuitable for the full Scra tch curriculum. Myna [ 39 ] is a standalone voice bridge for Scra tch . While Myna successfully demonstrated that grid-based voice con- trol could mimic mouse actions, it was designed for Scra tch 1.4 and is incompatible with the Scra tch 3.0 web-based architecture, relies on outdated dependencies, and is no longer actively maintained. Consequently , there is currently no publicly available , classroom- ready VUI that supports Scra tch 3.0. A new solution is requir ed that operates in parallel with the modern Scra tch editor , handling not just code generation but also complex UI interactions such as sprite manipulation and stage management. 2.3 Speech Recognition for Children A utomatic spee ch r ecognition ( ASR ) accuracy is measured by w ord error rate ( WER ): Substitutions + Insertions + Deletions ) / T otalW ords × 100 . 2 Accuracy depends on factors such as background noise, audio quality , age, accent, speaking speed, and pronunciation. Streaming recognition is usually less accurate than batch processing. 3 Reliable voice control requires accurate ASR , yet commercial engines continue to underperform with children’s spee ch [ 4 ]. Key challenges include higher acoustic variability , shifting formant fre- quencies due to vocal tract development, and irr egular pronunci- ation [ 9 , 15 , 30 , 35 ]. These diculties are compounde d for users with motor disabilities; dysarthria (slurred or slo w spe ech) aects 1 https://github.com/scratchfoundation 2 https://www.assemblyai.com/blog/ho w- accurate- spe ech- to- text 3 https://voicewriter .io/speech- recognition- leaderboard Figure 1: Numeric overlay for the workspace. 2 Place when flag clicked 3.1 Create variable energy 3.2 Place set energy to 10 4 Place when key pressed 5.1 Place if 5.2 Place energy greater than zero 5.3 Attach six as condition of five 8 Place set speed to energy times five 1 1 Place move speed 13 Place change energy by minus one Figure 2: V oice commands mappe d to Scra tch blocks. up to 78% of children with cerebral palsy , reducing ASR accuracy to as low as 50–60% [2, 16, 19, 20]. T o mitigate transcription errors, raw ASR output often requires post-processing. Phonetic matching algorithms, such as Double Metaphone (for English) or Cologne Phonetics (for German), encode words into phonetic keys to identify intended commands despite mispronunciations [ 27 , 29 ]. Fuzzy matching utilises edit distance metrics (e.g., Levenshtein distance) to quantify string similarity , allowing recovering commands fr om imperfe ct transcripts [1, 6]. 3 Approach MeowCrophone is a V UI designed to run in parallel with the Scra tch editor , enabling users with motor impairments to con- trol the interface using spoken commands rather than mouse and keyboard interactions. It operates on a command-remainder ar- chitecture: the “command” captur es the user’s intent (e.g., “place ” , “delete ”), while the “remainder” supplies necessar y parameters ( e.g., “block 5” , “turn left”). T o ensure robustness against imp erfect spee ch recognition, MeowCrophone employs a multi-stage matching pipeline that validates transcripts against a xed vocabulary and block grammars. The architecture bridges the user’s voice input and the Scra t ch internals by interacting directly with the Scra tch VM and the Blockly rendering engine, ensuring that voice actions are reected accurately in the project state. V oice-Controlled Scra tch for Children with (Motor) Disabilities I TiCSE 2026, July 13–15, 2026, Madrid, Spain 3.1 Ke y Design Decisions The nal system architecture evolved through several iterations. Below , w e summarise the central engineering challenges and the design choices made to resolve them. Transition from Simulated Mouse Control to Programmatic Block Manipulation. Our initial prototype controlled Scra tch by simu- lating low-level mouse clicks and key pr esses via a browser auto- mation tool. While this conrmed the viability of the interaction concept, it proved fragile; UI automation br oke easily depending on screen resolution, zoom levels, and precise coordinate osets required for stacking blocks. Conse quently , we replaced simulated inputs with pr ogrammatic manipulation, utilising the internal APIs of Scra tch -Blocks ( Blockl y ) to create, connect, and delete blocks directly . This approach decoupled execution from visual layout, signicantly improving reliability . Adoption of the Scra tch VM as A uthoritative State. While ma- nipulating Blockly provided robust placement, we encountered synchronisation issues with shadow blocks. Shadow blocks are non-draggable placeholders that provide default values for block inputs (e .g., the number bubble inside a “move steps” block). W e dis- covered that when creating blocks programmatically via Blockl y , the properties of these shadow blocks did not reliably propagate to the Scra tch VM. As a result, shadow blocks would become de- tached or reset after project reloads or sprite switches. T o resolve this, we instantiate new blocks by manipulating the Scra tch VM directly , ensuring the authoritative state is correct, while Blockl y is retained to handle interactions with existing blocks. Robust Matching Pipeline. Early tests with the W eb Speech API 4 revealed that standard spee ch-to-te xt frequently returned inac- curate transcripts. T o mitigate this, we implemented a three-tier matching pipeline. MeowCrophone aggregates transcripts from interchangeable A utomatic Spee ch Recognition ( ASR) services and processes them through three stages: (1) Accurate Matching: Checks for exact command phrases. (2) Phonetic Matching: Uses algorithms like Double Metaphone to match similarly sounding words ( e.g., recovering “place ” from a transcript of “plays”). (3) Fuzzy Matching: Uses edit distance as a nal fallback for approximate matches. Hypotheses are scored and normalised into condence values. This allows MeowCrophone to prioritise high-condence commands while gracefully recovering from ASR err ors. Grammar-Based Block Specication. Users can place blocks by reading their text aloud ( e.g., “place turn left by 10 degrees”). Ini- tially , we used fuzzy matching for this, but it proved unreliable for complex blocks with multiple inputs. T o address scalability , we in- troduced a grammar-base d denition for all supp orted blo cks. Each block denes a grammar that expands into regular expressions, com- plete with metadata for input typ es ( e.g., variables, reporters). This trade-o adds implementation complexity but ensures lightweight and accurate denition of blo ck syntax, allowing MeowCrophone to distinguish between similar blocks eectively . 4 https://developer .mozilla.org/en- US/docs/W eb/API/W eb_Spe ech_API Interaction Modalities. T o accommodate dierent user nee ds, we moved beyond “always-listening” modes which were pr one to ac- cidental triggers. W e introduced Push-to- T alk and T oggle-to- T alk modes to give users explicit control over input timing. Furthermore, to support users who nd reading block text dicult, we use Nu- merical Overlays (e.g., Fig. 1, Fig. 2). These assign unique numbers to on-screen elements (blocks, sprites, UI buttons), allowing users to execute commands by saying “Click 1” or “Select 5” . W e imple- mented three overlay modes: Combined (the main mode), which supports both spoken commands such as “place mo ve tw enty steps” and numerical commands like “place 10”; Smart , which supports only spoken commands and was the original design; and Numer- ical , which supports only numbers and can improve recognition accuracy because commands are shorter . 3.2 Conceptual Model and Architecture The architecture of MeowCrophone consists of a command pro- cessing pipeline structured into distinct Layers and Domains. The Processing Pipeline. The pip eline driv es the state machine, transforming raw audio into actions. The primary states are: • Listening and Transcribing : A udio is captured and con- verted to text candidates. • Matching : The pip eline applies the three-tier matching strategy to extract a Command (intent) and a Remainder (parameters) from the transcript. • Processing : The matched command is routed to a specic handler . • Execution and Up date : The handler validates inputs, ex- ecutes the logic, and triggers updates to the Scra tch VM, Blockly workspace, or DOM. • Feedback : Visual conrmation is provided to the user . Layers and Domains. Rather than a strictly horizontal te chnical layering, the system uses a domain-driven structure: • Core Layer : Manages the global state, the matching pipeline, and the feedback system. • V oice Layer : Abstracts various ASR ser vices (e.g., W eb Sp eech API, V osk 5 ) into a unied interface. • Overlay Layer : Manages the injection of SVG o verlays into the DOM to render numeric labels on blocks and sprites. • Domain Layers : These contain the sp ecic logic for dif- ferent Scrat ch features. For example, the Block Domain handles block placement and connections, while the UI Do- main handles scrolling and button clicks. 4 Evaluation T o evaluate Meo wCrophone , we focused on three key dimensions: feasibility , accessibility , and transcription reliability: RQ1 : Can common Scra tch features be supported via a V UI ? RQ2 : Does the V UI comply with key accessibility standards? RQ3 : How accurate are voice transcription services for the VUI , and does our pipeline improve them? 5 https://www.assemblyai.com/blog/top- open- source- stt- options-for- voice- applications I TiCSE 2026, July 13–15, 2026, Madrid, Spain Elias Goller, Gordon Fraser, and Isabella Graßl 4.1 Procedure W e evaluated RQ1 and RQ2 using structured criteria derived from prior work and accessibility standards, and RQ3 using a controlled experiment with statistical analysis of real voice transcripts. 4.1.1 Feature Support and Accessibility (RQ1 & RQ2). T o assess feature support (RQ1), we systematically tested essential Scra tch actions such as block manipulation, sprite handling, and navigation, rating each as fully supporte d, partially supporte d, or not supporte d. For accessibility (RQ2), we developed a catalogue of 28 criteria based on the W eb Content Accessibility Guidelines (W CA G) [ 14 ] and the Natural Language Interface Accessibility User Re quir ements (NAUR) [ 44 ]. These criteria cover feedback, timing, command dis- coverability , and error handling. W e evaluated the system against these metrics using both manual insp ection and automated checks. 4.1.2 Transcription Reliability (RQ3). RQ3 examines whether our matching pipeline improves recognition ov er raw transcripts. Data Collection. W e designe d a dataset of 24 spoken commands varying in complexity ( length and structur e). These were recorded using two microphones, two transcription ser vices (V osk 6 and W eb Speech 7 in Chrome), and two languages (English and German), resulting in 192 trials. Re cor dings were made at natural volume from a distance of 50cm to simulate typical classroom conditions. Evaluation Conditions. T o measure the impact of our system, we compared the raw transcription output against the processed output of our pipeline. W e dened four evaluation conditions: Baseline- T op : A manual evaluation of the top hypothesis re- turned by the transcription ser vice. This establishes how a basic system would p erform without our pipeline. W e applie d lenient manual verication (e.g., accepting “5” and “v e” as equal) to ensure we tested recognition quality rather than strict string formatting. Baseline- Any : A manual evaluation checking if any alternative hypotheses returned by the ser vice contained the correct intent. This represents the theoretical maximum accuracy of the raw ASR. Pipeline- T op : The transcript is processed by our pipeline (in- cluding block grammar matching). W e count success if the system’s highest-condence candidate triggers correct execution. Pipeline- Any : The transcript is processe d by our pipeline. W e count a success if any of the ranked candidates generated by the pipeline would trigger the correct execution. W e enforce hierarchy constraints for data consistency: if a com- mand succeeds at Baseline- T op, it must succeed at Baseline- Any . The same applies to the Pipeline conditions. Statistical A nalysis. W e report success rates, absolute/relative gains, and Cohen’s ℎ to measure ee ct size (interpreted as small (0.2–0.5), medium (0.5–0.8) or large (above 0.8). T o determine statistical signicance, we use McNemar’s test for paired comparisons (counting cases where the pipeline succeeds but the baseline fails, versus the inverse). W e apply the Holm correction to control for multiple comparisons, setting 𝛼 < 0 . 05 . Finally , we employ a mixed-eects logistic regression model to analyse the 192 trials. This mo del estimates how factors like micro- phone quality , service choice, language, and command complexity 6 https://alphacephei.com/vosk/ 7 https://developer .mozilla.org/en-US/docs/W eb/API/W eb_Spe ech_API T able 1: Criteria of the evaluation categories (RQ1, RQ2). No. Name Source Pass Multi-Modal Input and Command Denition 1.1 Seamless Multi-Modal Interactions WCA G 2.1.1, NAUR 13c, 3 ✓ 1.2 Speech Recognition Adaptability NAUR 12b, [18] ✗ 1.3 Condence Thresholds and Conrmation NAUR 13a, 13b ✓ 1.4 Custom V ocabulary Support NAUR 18c ✓ 1.5 Use labels for unclear button names WCA G 1.1.1, 2.4.6, 2.5.3, 4.1.2 ( ✓ ) System Feedback and Error Handling 2.1 Multi-Modal Feedback NAUR 4 ✗ 2.2 Clear Error Communication WCA G 3.3.1, 3.3.3 ( ✓ ) 2.3 System Feedback Clearly Recognisable [18] ✓ 2.4 Undo and Redo Support WCA G 2.5.2 ✓ Timing and Flow of V oice Interaction 3.1 Adjustable Timing WCA G 2.2.1 ✓ 3.2 Pause and Resume Functionality WCA G 2.2.2 ✓ Command Design and Discoverability 4.1 Simple Command Structure NAUR 18b, [18] ( ✓ ) 4.2 Command Discovery and Help NAUR 16a, 16b, 16c ( ✓ ) 4.3 Multiple Command Phrasings NAUR 18a ✓ Focus Management and Input Compatibility 5.1 Visual Focus Indicators WCA G 2.4.7 ( ✓ ) 5.2 Screen Reader Compatibility NAUR 10c, WCA G ( ✓ ) 5.3 Keyboard Shortcut Compatibility NAUR 3, WCA G 2.1.1 ✓ Context Handling 6.1 Step-by-Step Guidance NAUR ✓ 6.2 Contextual Actions NAUR ✓ Personalisation and Adaptive Learning 7.1 User Prole Settings NAUR 18c, 15 ( ✓ ) 7.2 Multi-User Support NAUR 12b, 18c ✗ Privacy and Data Processing 8.1 Local Processing VOSK feasibility ✓ 8.2 Data Control Project constraint ✓ Accessibility and Cross-Platform Support 9.1 User T esting with Disabilities NAUR ✗ 9.2 Cross-Platform Compatibility NAUR ✓ Feature Coverage and Capability Levels 10.1 Core Feature Completion NAUR 5 ✓ 10.2 Advanced Feature Completion NAUR 5 ( ✓ ) 10.3 Expert Feature Completion NAUR 5 ✗ aect the odds of improvement. W e report odds ratios (values > 1 indicate improvement). W e intentionally omit interaction terms (e.g., Language × Service) to avoid unreliable estimates caused by small subgroup sizes (12 observations per cell). 4.2 Features (RQ1) and Accessibility (RQ2) Before conducting user studies with children, which pr esents signi- cant challenges [ 13 , 37 ], we needed to validate MeowCrophone against evaluation criteria found in accessibility research, most of which were derived from W CA G and NAUR. W e structured these criteria following W CA G’s format, describing expected b ehaviour and dening passing requirements. T able 1 pr esents our evaluation structured into ten categories, marking each criterion as passed, partial or failed . Importantly , using the voice interface does not prevent users from exploring Scra t ch ’s regular drag-and-drop controls or keyboard shortcuts, and vice versa. This allows teachers to assist children while they are using v oice commands [7]. Multi-modal input and command denition. W e success- fully implemented independent overlay updates for voice controls across sprites, blocks, library , and fullscreen states ( 1.1 , T able 1). W e built a condence and conrmation system with adjustable thresholds and thr ee tiers ( 1.3 ), and made command aliases, remain- ders, and block grammars congurable through external les ( 1.4 ). W e partially addr essed textual labelling by adding labels to clickable elements in smart and combined modes, though we encountered a known bug preventing labels from app earing on small buttons ( 1.5 ). Criterion 1.2 is outside our project scope. V oice-Controlled Scra tch for Children with (Motor) Disabilities I TiCSE 2026, July 13–15, 2026, Madrid, Spain System fe edback and error handling. The fee dback system clearly communicates errors, although MeowCrophone does not yet have voice output, audio cues, or x suggestions ( 2.1, 2.2 ). W e use color to highlight command names and numbers, and push-to- talk and tap-to-talk modes display a large red Recording indicator ( 2.3 ). W e maintained support for undo and redo functionality ( 2.4 ). Timing and interaction ow . W e made timers adjustable for conrmations, feedback, and sp eech recognition silence detection. Our push-to-talk and tap-to-talk modes help reduce time pressure ( 3.1 ), and we pro vide explicit start and stop commands that allow users to pause when needed ( 3.2 ). Command design and discoverability . W e generally kept commands simple or broke them into smaller steps, though some convenience options do add complexity; we have rated this as partial pending user testing ( 4.1 ). W e implemented tutorial systems but have not yet added a help command or contextual assistance ( 4.2 ). W e support multiple synonyms, exible word orders, and various parameter phrasings to make commands more natural ( 4.3 ). Focus management. Sprites and blocks are highlighted when selected, but we have not yet added highlighting for workspace and yout focus ( 5.1 ). W e designed the system to avoid interfering with Scra tch ’s scr een reader compatibility , though we have not tested this thoroughly ( 5.2 ). W e ensured our voice interface additions do not conict with Scra tch ’s e xisting keyboard shortcuts ( 5.3 ). Context handling. Our tutorial system guides users step by step through tasks ( 6.1 ). The system uses focus to determine scroll targets, selection to enable property setting, and librar y context to change how it interprets commands ( 6.2 ). Settings adjustable for personalisation. Settings can b e ad- justed, but currently need to be set in conguration les directly ( 7.1 ). W e have not yet implemented prole management, which would require manual conguration ( 7.2 ). Privacy criteria. W e met b oth by implementing V osk for local speech processing and supporting multiple ser vices ( 8.1, 8.2 ). Accessibility and cross-platform support. W e have not con- ducted a user study yet. One didactics expert on physical and motor disabilities provided expert feedback suggesting we show tutorial end results rst, break tutorials into smaller steps, add voice feed- back, and include supplementary keyb oar d controls ( 9.1 ). W e have veried the system works across multiple browsers and desktop operating systems using Play wright ( 9.2 ). Feature coverage. W e implemented all core features in Scra t ch except menubar elements, for which we created dedicated com- mands instead ( 10.1 , T able 1). W e have implemented most advanced features, though some remain limited by te chnical constraints ( 10.2 ). W e have not yet implemente d the features we categorised as op- tional enhancements ( 10.3 ). 4.3 Transcription (RQ3) T o ensure data integrity , we rst veried our dataset for hierarchy constraint violations. Acr oss all 192 trials, the “ Any” metrics con- sistently met or exceeded the “T op” metrics ( e.g., Pipeline- Any ≥ Pipeline- T op), conrming that our data is internally consistent and correctly labelled. Overall Performance Improvement. The pipeline in Meow - Crophone demonstrated a statistically signicant improvement in T able 2: Comparisons of metrics language , complexity , and ASR service (RQ3). Gain is shown in points. Metric Comparison Base (%) Impr (%) Gain Cohen’s ℎ McNemar 𝑝 Overall Performance Base-A ny vs Base-T op 46.4 68.2 +21.9 0.45 ( s ) 4.5e-13 Pipe-T op vs Base-T op 46.4 80.2 +33.9 0.72 ( m ) 3.4e-15 Pipe-A ny vs Base-Any 68.2 84.9 +16.7 0.40 ( s ) 4.4e-7 Pipe-A ny vs Base-T op 46.4 84.9 +38.5 0.85 ( l ) 2.0e-20 Language EN Base-A ny vs Base-T op 65.6 77.1 +11.5 0.25 ( s ) 9.8e-4 EN Pipe-T op vs Base-T op 65.6 84.4 +18.8 0.44 ( s ) 5.3e-4 EN Pipe-A ny vs Base-Any 77.1 87.5 +10.4 0.28 ( s ) 3.1e-2 EN Pipe-A ny vs Base-T op 65.6 87.5 +21.9 0.53 ( m ) 1.9e-5 DE Base-A ny vs Base-T op 27.1 59.4 +32.3 0.66 ( m ) 1.9e-9 DE Pipe-T op vs Base-T op 27.1 76.0 +49.0 1.02 ( l ) 2.4e-12 DE Pipe-A ny vs Base-Any 59.4 82.3 +22.9 0.51 ( m ) 6.0e-6 DE Pipe-A ny vs Base-T op 27.1 82.3 +55.2 1.18 ( l ) 4.4e-16 Complexity Simple Base-A ny vs Base-T op 62.5 89.1 +26.6 0.64 ( m ) 4.6e-5 Simple Pipe-T op vs Base-T op 62.5 89.1 +26.6 0.64 ( m ) 4.9e-4 Simple Pipe-A ny vs Base-Any 89.1 96.9 +7.8 0.32 ( s ) 0.070 Simple Pipe-A ny vs Base-T op 62.5 96.9 +34.4 0.96 ( l ) 9.5e-7 Medium Base-A ny vs Base-T op 42.2 60.9 +18.8 0.38 ( s ) 4.9e-4 Medium Pipe-T op vs Base-T op 42.2 84.4 +42.2 0.91 ( l ) 3.4e-7 Medium Pipe-A ny vs Base-Any 60.9 89.1 +28.1 0.68 ( m ) 3.6e-4 Medium Pipe-A ny vs Base-T op 42.2 89.1 +46.9 1.05 ( l ) 5.6e-9 Complex Base-A ny vs Base-T op 34.4 54.7 +20.3 0.41 ( s ) 4.9e-4 Complex Pipe-T op vs Base-T op 34.4 67.2 +32.8 0.67 ( m ) 3.9e-5 Complex Pipe-A ny vs Base-Any 54.7 68.8 +14.1 0.29 ( s ) 0.070 Complex Pipe-A ny vs Base-T op 34.4 68.8 +34.4 0.70 ( m ) 1.0e-5 Service V osk Base-A ny vs Base-T op 45.8 62.5 +16.7 0.34 ( s ) 3.1e-5 V osk Pipe-T op vs Base-T op 45.8 78.1 +32.3 0.68 ( m ) 7.3e-8 V osk Pipe-A ny vs Base-Any 62.5 82.3 +19.8 0.45 ( s ) 3.1e-4 V osk Pipe-A ny vs Base-T op 45.8 82.3 +36.5 0.79 ( m ) 5.5e-10 W eb Base-Any vs Base-T op 46.9 74.0 +27.1 0.56 ( m ) 6.0e-8 W eb Pip e- T op vs Base- Top 46.9 82.3 +35.4 0.76 ( m ) 7.3e-8 W eb Pip e- Any vs Base-A ny 74.0 87.5 +13.5 0.35 ( s ) 2.3e-3 W eb Pip e- Any vs Base- Top 46.9 87.5 +40.6 0.91 ( l ) 7.6e-11 command execution success. By moving from a baseline that relies solely on the top transcript to a pipeline that utilises any matched candidate, success rates rose from 46.4% to 84.9%. T able 2 details these comparisons across all categories. Impact of Language. While the pipeline b eneted both tested languages, the magnitude of impr ovement varied signicantly . Eng- lish showed a solid improv ement of 21.9 percentage points, rising from a baseline of 65.6% to 87.5% (medium eect size, ℎ = 0 . 53 ). German demonstrated the most dramatic gains. Starting fr om a low baseline of 27.1%, the pipeline boosted success to 82.3% (large eect size, ℎ = 1 . 18 ). A mixe d-eects model conrmed that language was the strongest predictor of success, with German commands showing 4.7 times higher odds of improvement (OR 4.72, 95% CI 4.70–4.75, 𝑝 < 0 . 001 ). This indicates the pipeline is particularly eective at compensating for languages where the baseline ASR performance is lower . Eect of Command Complexity . The pipeline proved eect- ive across all levels of command comple xity , though the “Medium” category saw the greatest relative benet: Simple commands im- proved from 62.5% to near-perfect execution at 96.9% (large eect, ℎ = 0 . 96 ). Medium commands achieved the largest gain in the study , doubling success rates from 42.2% to 84.4% (large eect, ℎ = 1 . 05 ). Complex commands improved from 34.4% to 68.8%. While this remains the most challenging category , the ee ct size was still medium ( ℎ = 0 . 70 ). ASR Ser vice Resilience. A key nding is that the pipeline eectively equalises performance between dierent ASR services. While the W eb Speech API provided b etter initial transcripts ( higher I TiCSE 2026, July 13–15, 2026, Madrid, Spain Elias Goller, Gordon Fraser, and Isabella Graßl baseline), our pipeline added signicantly more value to V osk’s output. Ultimately , both ser vices reached similar nal performance levels: V osk at 82.3% and W eb Speech at 87.5%. This suggests that our fuzzy matching and phonetic algorithms are particularly valuable when initial transcription quality is low er . Statistical analysis using a mixed-eects model found no signicant service eect on the nal outcome, conrming that MeowCrophone is robust regardless of the underlying speech engine. 5 Discussion This study demonstrates the technical feasibility of a voice-controlled interface for Scra t ch , conrming that major features can be ef- fectively supporte d through a multi-modal approach (RQ1). By implementing core functionalities, including block manipulation, sprite management, and variable handling, we met 15 of 28 standard accessibility criteria fully (RQ2). T echnical Feasibility and Interaction Design. The system’s success relied on integrating multiple interaction mechanisms: simulated mouse controls, Blockl y integration, and direct Scra t ch VM in- teractions. A key nding was the eectiveness of the multi-modal overlay system. By allowing users to refer ence visual elements via voice while preserving standard mouse and keyboard controls, the system enables seamless switching b etw een input methods. This is particularly valuable in classrooms, allowing teachers to inter v ene manually without disrupting the child’s voice workow [7]. Pipeline Performance and Reliability (RQ3). Our improved tran- scription pipeline signicantly outp erformed expectations, prov- ing that reliable execution is achievable even with free, privacy- preserving services. The pipeline raised overall execution success from a baseline of 46.4% to 84.9%. Improvements were most sig- nicant for German commands, where the pipeline compensated eectively for lower baseline transcription quality . The three-tier condence system successfully balanced safety and sp eed, request- ing conrmation only for uncertain matches while executing clear commands immediately . Push-to-talk and tap-to-talk modes pro ved more reliable than continuous listening, likely due to reduced back- ground noise interference Practical Implications. The obser v ed gain of 38.5 percentage points demonstrates that p ost-pr ocessing can compensate for poor ASR quality to a signicant degree when the domain grammar is known. Notably , simple commands reached 96.9% accuracy with the pipeline (up from a 62.5% baseline). While an 84.9% overall success rate might seem insucient for frustration-free usage, this gure includes complex commands. When resorting to the simpler numer- ical mode for block placement rather than complex block grammar , most commands fall into simple or medium complexity categor- ies, achieving 96.9% and 89.1% success respectively . Thus, practical success rates in a classroom setting could be substantially higher . Howev er , it must b e noted that children’s and dysarthric speech is challenging to transcribe, potentially pushing error rates higher than those observed in our controlled tests. Even at ∼ 89% accuracy , one in ten commands fails, which poses a risk of frustration. Challenges and T echnical Trade-os. Several approaches pro ved technically costly or less eective: While enabling users to “read code out loud” ( e.g., placing blocks and parameters in one utterance) worked in testing, it added substantial comple xity and p erformance overhead. W eak transcripts often contained unrecoverable errors; for example, “place glide ” was frequently transcrib ed as “plays slide” due to phonetic dissimilarity . Our initial reliance on Playwright for UI automation proved fragile, for cing a mid-project pivot to direct Scra tch VM interaction. Novelty . MeowCrophone distinguishes itself from v oice-only systems by maintaining a hybrid, multi-modal overlay system that works for non-English languages. Most importantly , we demon- strated that voice control for complex visual programming is feas- ible using free, locally-run services, r emoving the barrier of expens- ive cloud subscriptions for schools. Limitations. The primar y limitation of this work is the absence of user studies with children. T o avoid exposing the target demo- graphic to early-stage frustration [ 13 , 37 ], we opted for a criteria- based evaluation to conrm theoretical accessibility rst. Con- sequently , our performance data is derived fr om one sp eaker across 192 trials using two free services (V osk and W eb Speech), without evaluating premium providers or actual children’s speech. Further- more, operations r equiring op erating system control, such as le uploads, remain outside the system’s voice control capabilities Future Research. The most critical next step is user testing with children, particularly those with motor disabilities, to validate design decisions and assess the impact on motivation and learn- ing outcomes. Future technical work should focus on (1) Feature Expansion, such as adding support for costumes, sounds, and stand- ard tutorials to increase educational utility; (2) applying phonetic matching to remainder extraction and tuning aliases for common errors (like the “place glide” issue); (4) investigating whether chil- dren prefer the eciency of numerical overlays over the smart mode grammar , which could allo w for removing the complex grammar matching system entirely . 6 Conclusions By introducing MeowCrophone , this paper establishes that a voice- controlled interface for Scra tch is not only technically feasible but capable of supp orting complex programming tasks through a privacy-preserving, local architecture. By integrating a custom post-processing pipeline with the V osk engine, we demonstrated that free, oine ASR can be enhanced to pr ovide reliable command execution, oering a viable alternative to costly cloud-based ser- vices. The r esulting system is designed for the real-w orld classr oom. It complies with major accessibility standards (WCA G, NAUR) and adopts a multi-modal approach where voice o verlays coexist with traditional inputs. This exibility ensures that students with motor disabilities can participate in creative coding while allowing for seamless teacher assistance. While technical limitations remain regarding specic OS-level interactions, the foundation is laid. The critical next step is to transition from system validation to user evaluation. Future studies must assess the tool’s intuitive value for children with motor disabilities, validating its potential to make computing education genuinely inclusive. MeowCrophone is avail- able at https://github.com/se2p/MeowCrophone. V oice-Controlled Scra tch for Children with (Motor) Disabilities I TiCSE 2026, July 13–15, 2026, Madrid, Spain References [1] Ricardo Baeza- Y ates and Gonzalo Navarro. 1998. Fast approximate string match- ing in a dictionary . In Proceedings. String Processing and Information Retrieval: A South A merican Symposium (Cat. No. 98EX207) . IEEE, 14–22. [2] Fabio Ballati, Fulvio Corno, and Luigi De Russis. 2018. “Hey Siri, do you under- stand me?”: Virtual Assistants and Dysarthria. In Intelligent Environments 2018 . IOS Press, 557–566. [3] Emily C Bouck and Aman Y adav. 2022. Providing access and opportunity for com- putational thinking and computer science to support mathematics for students with disabilities. Journal of Special Education T echnology 37, 1 (2022), 151–160. [4] Holly Bradley , Madeleine E Y u, and Elizabeth K Johnson. 2025. V oice assistant technology continues to underperform on children’s speech. JASA Express Letters 5, 3 (2025). [5] Ünal Çakıroğlu and Emrah Muştu. 2025. Mathematical Thinking behind Co ding: Promoting Generalization Skills via Scratch. International Journal of Science and Mathematics Education (2025), 1–22. [6] Surajit Chaudhuri, Kris Ganjam, V enkatesh Ganti, and Rajeev Motwani. 2003. Robust and ecient fuzzy match for online data cleaning. In Proceedings of the 2003 ACM SIGMOD international conference on Management of data . 313–324. [7] W Catherine Cheung, Panpan Chen, and Michaelene M Ostrosky . 2025. T eachers’ perspectives on including childr en with disabilities in virtual motor play activities during online learning. British Journal of Special Education 52, 1 (2025), 27–36. [8] Christos Galeos, K ostas Karpouzis, and George T satiris. 2020. Developing an edu- cational programming game for children with ADHD. In 2020 15th International W orkshop on Semantic and Social Media Adaptation and Personalization (SMA . IEEE, 1–6. [9] M Gerosa, D Giuliani, and S Narayanan. 2006. Acoustic analysis and automatic recognition of spontaneous children’s speech. Training 1, T2 (2006), T1. [10] Google. 2025. Blockly: A visual programming editor . https://developers.google. com/blockly. Accessed: 2025-12-28. [11] Isabella Graßl and Gor don Fraser . 2022. Gender-dependent contribution, code and creativity in a virtual programming course. In Proceedings of the 17th W orkshop in Primary and Se condary Computing Education . 1–10. [12] Isabella Graßl and Gordon Fraser . 2024. Coding to cope: teaching programming to children with emotional and behavioral disorders. In Proceedings of the 46th International Conference on Software Engineering: Software Engine ering Education and Training . 127–138. [13] Ana O Henriques, Patricia Piedade, Filipa Rocha, Isabel Neto, and Hugo Nicolau. 2024. Ethical Concerns when W orking with Mixed-Ability Groups of Children. In Pr oce edings of the 26th International ACM SIGA CCESS Conference on Computers and Accessibility . 1–9. [14] Andrew Kirkpatrick, Joshue O Connor , Alastair Campbell, and Michael Cooper. 2018/2025. W eb Content Accessibility Guidelines (W CAG) 2.1. https://w ww .w3. org/TR/WCA G21/ [15] Sungbok Lee, Alexandros Potamianos, and Shrikanth Narayanan. 1999. Acoustics of children’s speech: Developmental changes of temporal and spectral parameters. The Journal of the Acoustical Society of America 105, 3 (1999), 1455–1468. [16] Tristan J Mahr, Paul J Rathouz, and Katherine C Hustad. 2020. Longitudinal growth in intelligibility of connected speech from 2 to 8 years in childr en with cerebral palsy: A novel Bayesian approach. Journal of Spe ech, Language, and Hearing Research 63, 9 (2020), 2880–2893. [17] Benjamín Maraza-Quispe, Ashtin Maurice Sotelo-Jump, Olga Melina Alejandro- Oviedo, Lita Marianela Quispe-F lor es, Lenin Henr y Cari-Mogrov ejo, W alter Cor- nelio Fernandez-Gambarini, and Luis Ernesto Cuadros-Paz. 2021. To wards the development of computational thinking and mathematical logic through scratch. International Journal of Advanced Computer Science and Applications 12, 2 (2021), 332–338. [18] Fabio Masina, Valeria Orso, Patrik Pluchino, Giulia Dainese, Stefania V olpato, Cristian Nelini, Daniela Mapelli, Anna Spagnolli, and Luciano Gamberini. 2020. Investigating the accessibility of voice assistants with impaired users: mixed methods study . Journal of medical Internet research 22, 9 (2020), e18431. [19] Mayo Clinic. 2024. D ysarthria - Symptoms and causes . https://www.may oclinic. org/diseases- conditions/dysarthria/symptoms- causes/syc- 20371994 Mayo Clinic - Diseases and Conditions. [20] Cristina Mei, Sheena Reilly , Molly Bickerton, Fiona Mensah, Samantha T urner , Dhanooshini Kumaranayagam, Lindsay Pennington, Dinah Reddihough, and Angela T Morgan. 2020. Spe ech in children with cerebral palsy . Developmental Medicine & Child Neurology 62, 12 (2020), 1374–1382. [21] Cecily Morrison, Nicolas Villar , Anja Thieme, Zahra Ashktorab, Eloise T aysom, Oscar Salandin, Daniel Cletheroe, Greg Saul, Alan F Blackwell, Darren Edge , et al . 2020. T orino: A tangible pr ogramming language inclusive of childr en with visual disabilities. Human–Computer Interaction 35, 3 (2020), 191–239. [22] Chelsea M Myers, Anushay Furqan, and Jichen Zhu. 2019. The impact of user characteristics and preferences on performance with an unfamiliar voice user in- terface. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems . 1–9. [23] Obianuju Okafor . 2022. Helping students with cerebral palsy program via voice- enabled block-based programming. ACM SIGACCESS Accessibility and Computing 132 (2022), 1–1. [24] Obianuju Okafor and Stephanie Ludi. 2022. V oice-enable d blockly: usability im- pressions of a speech-driven blo ck-based programming system. In Proceedings of the 24th International ACM SIGACCESS Conference on Computers and Accessibility . 1–5. [25] Obianuju Chinonye Okafor . 2022. Helping Students with Upper Limb Motor Impairments Program in a Block-Base d Programming Environment Using V oice . Dissertation. University of North T exas, Denton, T exas. https://digital.library . unt.edu/ark:/67531/metadc1985949/ Accessed May 26, 2025. [26] Rui Oliveira, Benjamim Fonseca, Paula Catarino, and Armando A Soar es. 2019. SCRA TCH: A study with students with learning diculties. In EDULEARN19 Proceedings . IA TED, 3947–3956. [27] Lawrence Philips. 2000. The double metaphone search algorithm. C/C++ Users J. 18, 6 (June 2000), 38–43. [28] Ana Cristina Pires, Filipa Ro cha, Antonio José de Barros Neto, Hugo Simão , Hugo Nicolau, and Tiago Guerreiro. 2020. Exploring accessible programming with educators and visually impaired children. In Proceedings of the Interaction Design and Children Conference . 148–160. [29] Hans Joachim Postel. 1969. Die kölner phonetik. ein verfahren zur identizierung von personennamen auf der grundlage der gestaltanalyse. IBM-Nachrichten 19 (1969), 925–931. [30] Alexandros Potamianos and Shrikanth Narayanan. 2004. Robust recognition of children’s speech. IEEE Transactions on speech and audio processing 11, 6 (2004), 603–616. [31] ProjectMyna. 2015. MynaMapper Combo. https://w ww .youtube.com/watch?v= 7wazaivuZgI [32] Peter J Rich, Samuel Browning, McKay Perkins, Timothy Shoop, Olga Beliko v , and Emily Y oshikawa. n.d.. Coding in K-8: Computational Practices in Primary Education from Around the W orld. (n.d.). [33] Serenade. 2025. Serenade: Code with voice. https://serenade.ai. Accessed: 2025-12-28. [34] Misbahu Sharfudde en Zubair , David Brown, Matthe w Bates, and Thomas Hughes- Roberts. 2020. Are visual programming tools for children designed with access- ibility in mind? . In Proceedings of the 12th International Conference on Education T echnology and Computers . 37–40. [35] Prashanth Gurunath Shivakumar and Panayiotis Georgiou. 2020. Transfer learn- ing from adult to children for speech recognition: Evaluation, analysis and re- commendations. Computer sp eech & language 63 (2020), 101077. [36] Andreas Stek, Willliam Allee, Gabriel Contreras, Timothy Kluthe, Ale x Ho- man, Brianna Blaser , and Richard Ladner . 2024. Accessible to whom? Bringing accessibility to blocks. In Proceedings of the 55th ACM T echnical Symp osium on Computer Science Education V . 1 (Portland OR USA). ACM, New Y ork, N Y , USA. [37] Boštjan Šumak, Katja Kous, Loïc Martínez-Normand, J ¯ anis Pekša, and Maja Pušnik. 2023. Identication of challenges and best practices for including users with disabilities in user-based testing. A pplied Sciences 13, 9 (2023), 5498. [38] T alon. 2025. T alon: Powerful hands-free input. https://talonvoice.com/. Accessed: 2025-12-28. [39] Amber Wagner . 2015. Programming by voice: A hands-free approach for motorically challenged children . Ph. D. Dissertation. The University of Alabama. [Accessed 19-12-2025]. [40] Amber W agner and Je Gray . 2025. Myna: Generalizing the Mapping of a Graph- ical User Interface to a V ocal User Interface. https://myna.cs.ua.edu/Prototype. html. Accessed: 2025-12-28. [41] Amber Wagner and Je Grey . [n. d.]. https://myna.cs.ua.edu/Prototypes/ Instructions.pdf [42] Amber W agner , Ramaraju Rudraraju, Srinivasa Datla, A vishek Banerjee, Mandar Sudame, and Je Gray . 2012. Programming by voice: A hands-free approach for motorically challenged children. In CHI’12 Extended Abstracts on Human Factors in Computing Systems . 2087–2092. [43] Zirui W ang and Amber Wagner . 2019. Evaluating a tactile approach to program- ming Scratch. In Proceedings of the 2019 ACM Southeast Conference . 226–229. [44] Jason White and Joshue O’Connor . 2022. Natural Language Interface Accessibility User Requirements. https://www.w3.org/TR/naur/ [45] Misbahu S Zubair , David Brown, Thomas Hughes-Roberts, and Matthew Bates. 2018. Evaluating the accessibility of scratch for children with cognitive impair- ments. In Univ ersal Access in Human-Computer Interaction. Methods, T echnologies, and Users: 12th International Conference, UAHCI 2018, Held as Part of HCI Interna- tional 2018, Las V egas, NV , USA, July 15-20, 2018, Procee dings, Part I 12 . Springer , 660–676.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment