Variational Neurons in Transformers for Language Modeling
Transformers for language modeling usually rely on deterministic internal computation, with uncertainty expressed mainly at the output layer. We introduce variational neurons into Transformer feed-forward computation so that uncertainty becomes part …
Authors: Yves Ruffenach
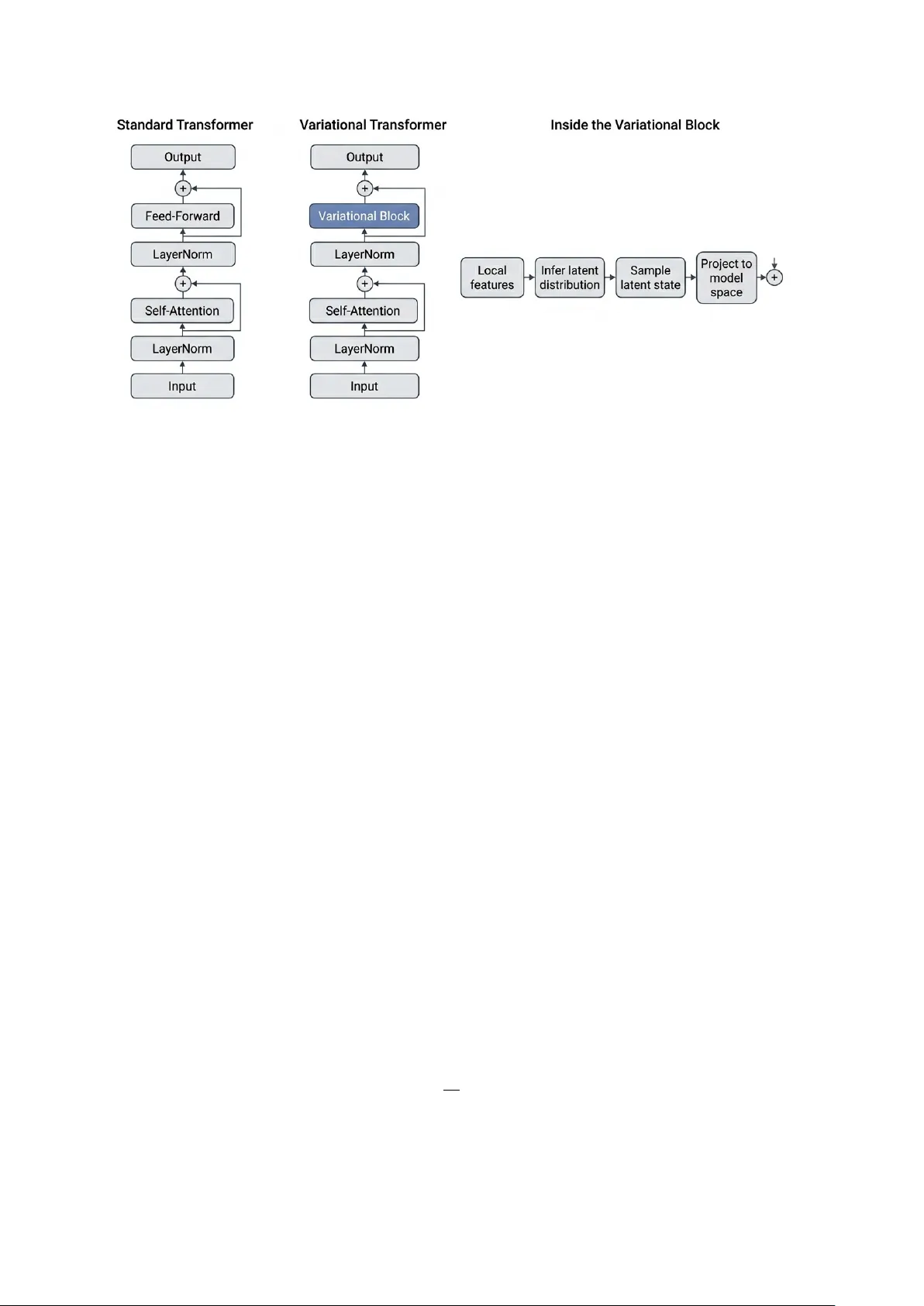
V ariational Neurons in T ransformers for Language Mo deling Y v es R uffenac h Conserv atoire National des Arts et Métiers Strasb ourg, F rance yves@ruffenach.net Abstract T ransformers for language mo deling usually rely on deterministic in ternal computation, with uncertaint y expressed mainly at the output lay er. W e introduce v ariational neurons in to T ransformer feed-forw ard computation so that uncertaint y b ecomes part of the in ternal computation itself. Concretely , we replace deterministic feed-forw ard units with local v ariational units based on EVE while preserving the ov erall T ransformer backbone. W e ev aluate this design in compact next-token language-mo deling settings. W e compare deterministic and v ariational v ariants with both predictive and probabilistic criteria. Along- side negativ e log-lik eliho o d, perplexity and accuracy , w e analyze calibration, conditional v ariance, m utual information and latent-usage statistics. The resulting picture is clear. V ari- ational neurons in tegrate stably in to T ransformers, preserve strong predictive p erformance and pro duce informative uncertain t y signals. The experiments also show that task quality , useful depth and internal stability are distinct prop erties. These results establish v ariational T ransformers as a practical form of uncertain t y- a ware language modeling. They show that T ransformers can predict with an explicit in ternal structure of uncertaint y , which supp orts stronger probabilistic ev aluation and a more informativ e analysis of mo del b ehavior. 1 In tro duction T ransformer language mo dels are strong predictors, but their in ternal computations are usually deterministic [ 8 , 10 ]. In most current practice, uncertain ty is read from the final predictive distribution or reco vered through external procedures suc h as ensem bles, drop out, or post-ho c calibration [ 1 , 3 , 4 , 7 ]. This leav es an imp ortan t question op en. Can uncertain ty b ecome part of the computation itself, rather than a quantit y observ ed only at the output? This question is esp ecially relev ant for language mo deling. Next-tok en prediction is inherently m ulti-v alued and many contin uations can b e plausible. A mo del that represents uncertain t y only at the last la yer can still predict well, but it pro vides limited access to how uncertaint y is formed, propagated an d used inside the net work. W e study a complementary design in which uncertain t y is in tro duced directly in to the in termediate computation. Our goal is not only to predict what comes next, but to predict with an explicit in ternal structure of uncertain ty . Our approach builds on EVE, a local v ariational neuron with a learned p osterior, a learned lo cal prior and an explicit con trol regime for latent activit y . W e instan tiate these neurons inside the feed-forward computation of compact T ransformer blo c ks for next-tok en language mo deling. This preserves the o v erall T rans former bac kb one while replacing deterministic in termediate computation with local v ariational inference. The resulting model com bines self-attention with neuron-lev el sto c hastic computation, laten t-state con trol and measurable internal uncertaint y signals during training. This design gives us a clean setting to study a practical question. Do es local v ariational computation impro v e mo del behavior b eyond p oint prediction? T o answer this, w e compare deterministic and v ariational T ransformers in compact language mo deling exp erimen ts with frozen 1 GPT-st yle embeddings and teac her-forcing windows built from prompt–story pairs. Alongside negativ e log-likelihoo d, perplexity and accuracy , w e track calibration, m utual information, conditional v ariance, laten t activity and related internal diagnostics. This lets us ev aluate not only predictive qualit y , but also how uncertain ty is represen ted and used during computation. Our contributions are threefold. First, we in tro duce a T ransformer language mo del whose feed-forw ard computation is carried by lo cal v ariational neurons. Second, w e pair this architecture with an explicit latent-con trol mechanism that k eeps the sto chastic path active and n umerically stable. Third, w e pro vide an uncertaint y-centered ev aluation proto col for compact next-tok en language mo deling, with metrics that exp ose b oth predictiv e b eha vior and in ternal laten t usage. 2 Related W ork T ransformers, uncertain t y and latent v ariables. T ransformers are the standard architec- ture for language mo deling b ecause self-atten tion supp orts strong con text modeling and efficient parallel training [ 10 ]. A utoregressiv e mo dels such as GPT-2 established next-tok en prediction as a simple and effectiv e training paradigm [ 8 ]. W e sta y in this setting and c hange not the task, but the in ternal feed-forw ard computation. A large literature studies uncertaint y in neural netw orks through Ba y esian or appro ximate Ba y esian methods, including v ariational w eight inference, Mon te Carlo drop out and deep ensem bles [ 1 , 3 , 7 ]. These metho ds impro v e calibration and predictive confidence estimation, whic h is imp ortant b ecause mo dern neural netw orks are often miscalibrated [ 4 ]. In parallel, laten t-v ariable mo dels for text ha ve long aimed to capture uncertaint y , div ersity and higher-level structure, while also highlighting the c hallenge of posterior collapse [ 2 , 5 , 6 ]. Most of this w ork uses sequence-level or sentence-lev el laten t v ariables. Our p osition. Recen t work has also explored uncertain ty-a ware T ransformers through Bay esian drop out v arian ts and T ransformer-specific appro ximate inference schemes [ 9 , 11 ]. Our w ork is complemen tary but operates at a differen t lev el. Rather than attaching uncertain t y to w eigh ts, reco v ering it only at the output, or in tro ducing a single global laten t co de, w e place explicit lo cal v ariational neurons inside T ransformer feed-forw ard blo c ks. This mak es uncertain t y part of the forw ard computation itself and mak es latent usage observ able throughout the net w ork. 3 Metho d 3.1 Ov erview W e study language mo deling with T ransformers whose feed-forward computation uses local v ariational neurons. Our starting p oin t is EVE, a neuron-level latent-v ariable compute primitive. Eac h neuron maintains a lo cal p osterior, a lo cal prior and an explicit in ternal control regime. W e instantiate this primitiv e inside T ransformer blocks for next-tok en prediction. The result is a language model in which uncertain ty is part of the internal computation, not only a property of the output distribution. Figure 1 summarizes the arc hitectural c hange studied in this pap er. The T ransformer bac kb one is preserved, while the deterministic feed-forward computation is replaced b y a local v ariational blo ck. 3.2 Lo cal v ariational neuron Let x denote the curren t neuron input and h its lo cal memory state. F ollo wing the EVE form ulation, each neuron defines a lo cal p osterior q ϕ ( z | x, h ) = N µ q ( x, h ) , diag( σ 2 q ( x, h )) , 2 Figure 1: Standard and v ariational T ransformer blocks. The o verall T ransformer bac kb one is unc hanged. Only the feed-forward computation is replaced by a v ariational blo c k that infers a lo cal latent distribution, samples a latent state and pro jects it to mo del space b efore the residual up date. and a local prior p ψ ( z | h ) = N µ p ( h ) , diag ( σ 2 p ( h )) . The latent state is sampled through the standard reparameterization z = µ q + σ q ⊙ ϵ, ϵ ∼ N (0 , I ) , and deco ded into an activ ation y = g θ ( z ) . This is the k ey difference with a deterministic neuron. A deterministic neuron emits an activ ation directly from a hidden transformation. Our neuron emits an activ ation from a lo cally inferred latent state. The neuron therefore carries its own probabilistic internal regime. 3.3 Lo cal objective, con trol, and prior Eac h neuron contributes a lo cal v ariational ob jectiv e that combines a task term, a lo cal KL term, and an internal control term: L local = L task + β KL( q ϕ ( z | x, h ) ∥ p ψ ( z | h )) + L control . In our setting, L task is induced by next-tok en prediction. The KL term aligns the lo cal p osterior with the lo cal prior. The control term keeps the neuron in a useful op erating regime. This ob jectiv e supp orts b oth learning and interpretation b ecause it regularizes the latent state while shaping the neuron’s internal b ehavior. A central con trol v ariable is the laten t energy µ 2 = 1 d z d z X j =1 µ 2 q ,j , whic h measures the a v erage squared p osterior mean across latent dimensions. V ery lo w laten t activit y weak ens the sto c hastic path, whereas v ery high activit y destabilizes it. W e therefore regulate the neuron around a target latent-energy regime. At a high level, the neuron is 3 encouraged to remain near µ 2 target and inside an admissible band around that target. This yields explicit internal statistics such as inside-band mass, fraction to o low, fraction too high, and target gap. In practice, our T ransformer implemen tation uses homeostatic regulation and band-based monitoring of latent activity . This k eeps the latent path activ e and makes its regime directly measurable during training. The neuron also main tains a lo cal autoregressive prior, which giv es temp oral contin uity to the latent state and turns the prior into a learned exp ectation rather than a fixed isotropic reference. At a high lev el, the prior mean evolv es as µ ( t ) p = f AR µ ( t − 1) p , z ( t − 1) , with an analogous up date for the prior scale when used. This giv es the neuron a short in ternal memory and lets the curren t posterior b e compared to its o wn recen t laten t trajectory . The result is a lo cal sto c hastic computation with explicit laten t dynamics rather than a static random activ ation. 3.4 T ransformer instan tiation for language mo deling W e instan tiate these lo cal v ariational neurons inside a compact T ransformer for next-token prediction. Let X = ( x 1 , . . . , x T ) b e an input token sequence. T okens are mapp ed to em b eddings and pro cessed b y a stac k of T ransformer blo cks. Self-attention remains standard. The feed-forw ard computation is replaced b y lo cal v ariational neurons. F or blo c k ℓ , let H ( ℓ ) denote the tok en represen tations at the input of the block. W e first apply self-attention: e H ( ℓ ) = H ( ℓ ) + MHA LN( H ( ℓ ) ) . W e then form a blo c k-lev el hidden representation u ( ℓ ) and pass it through a bank of lo cal v ariational neurons. F or neuron i , q ( ℓ,i ) ϕ ( z ( ℓ ) i | u ( ℓ ) , h ( ℓ ) i ) = N µ ( ℓ ) q ,i , diag (( σ ( ℓ ) q ,i ) 2 ) , p ( ℓ,i ) ψ ( z ( ℓ ) i | h ( ℓ ) i ) = N µ ( ℓ ) p,i , diag (( σ ( ℓ ) p,i ) 2 ) , and z ( ℓ ) i = µ ( ℓ ) q ,i + σ ( ℓ ) q ,i ⊙ ϵ i , ϵ i ∼ N (0 , I ) . The sampled laten t activ ations are then decoded and pro jected back to the model space to pro duce the feed-forw ard up date. This preserv es the ov erall T ransformer backbone while making the intermediate computation lo cally v ariational. 3.5 Prediction head The final hidden representation is mapp ed to next-tok en logits through a standard language- mo del head. In the v ariational mo del, prediction is ev aluated through Mon te Carlo av eraging o v er sto chastic forward passes. Let { y ( m ) } M m =1 denote the logits obtained from M sto c hastic samples and let p ( m ) = softmax( y ( m ) ) . 4 The Monte Carlo predictive distribution is ¯ p = 1 M M X m =1 p ( m ) . All probabilistic ev aluation metrics, including Monte Carlo predictive NLL, are computed from this predictive distribution. This Mon te Carlo view lets us ev aluate b oth predictiv e qualit y and uncertain t y-a ware b ehavior. 3.6 Global training ob jectiv e A t the mo del level, training combines the language-modeling objective with the lo cal v ariational and control terms accumulated across units and lay ers: L = L LM + β L KL + L control + α AR L AR , where L LM is the next-token prediction loss, L KL aggregates the lo cal KL terms and L AR is presen t when the autoregressive prior is activ e. This objective k eeps the language-mo deling task cen tral while preserving explicit control ov er laten t activit y and laten t dynamics. 3.7 Deterministic baseline and ev aluation T o test whether local v ariational computation is gen uinely useful, we compare the v ariational T ransformer to a deterministic baseline built from the same o v erall architecture. The comparison is therefore not b et w een unrelated mo dels. It isolates the effect of replacing deterministic feed-forw ard neurons with lo cal v ariational neurons. W e ev aluate b oth mo dels on standard predictive metrics, including negative log-lik eliho od, p erplexit y and accuracy . W e complement these with uncertaint y-centered metrics such as calibration, conditional v ariance, mutual information and in ternal laten t diagnostics. This matc hes the goal of the pap er. W e do not only ask whether the mo del predicts w ell. W e ask whether it predicts with a useful internal structure of uncertain ty . 4 Exp erimen ts 4.1 Exp erimen tal scop e and proto cols W e rep ort four controlled exp erimental blo cks on W ritingPr ompts-Filter e d . The first blo ck is the 19.9k-example setting, with ab out 17.9k training examples and 2.0k v alidation examples, used for Run A and Run B and for the task-qualit y versus useful-depth comparison. The second blo c k is the 10.0k-example setting, with about 8.0k training examples and 2.0k v alidation examples, used for the v23 versus v22 stabilization comparison. The third blo c k is a dedicated matched deterministic-v ersus-v ariational comparison on 2.0k examples. The fourth block is a separate matc hed EVE-versus-DET comparison on an approximately 19,925-ra w-example proto col with val_frac=0.2 . A cross all blo cks, self-attention and the language-mo del head are k ept fixed. The comparison isolates the effect of replacing deterministic feed-forward computation with lo cal v ariational computation and, where stated, stabilization patc hes. 4.2 Ev aluation logic W e ev aluate the runs along four complemen tary axes: language-mo deling qualit y , probabilis- tic quality , effective depth usage and internal stability . W e distinguish three metric sources throughout the section. Final v alidation reports the optimization ob jectiv e ( loss ) together 5 T able 1: 19.9k-example setting. Final-v alidation ob jectiv e and task metrics, together with extended-v alidation probabilistic metrics. Run B is slightly stronger on task-level metrics, while R un A preserv es the stronger deep latent regime. R un Loss ↓ CE ↓ PPL ↓ A cc ↑ MC NLL ↓ ECE ↓ MI Flip R un A (19.9k) 4.8118 4.7370 114.10 0.2293 4.8164 0.0445 0.1188 0.2757 R un B (19.9k) 4.7950 4.7217 112.36 0.2307 4.8286 0.0457 0.1168 0.2549 T able 2: 19.9k-example setting in ternal diagnostics. R un A keeps a genuinely activ e second laten t lay er, whereas Run B almost collapses the deep er lay ers. R un w 1 w 2 w 3 KL 1 KL 2 KL 3 µ 2 1 µ 2 2 µ 2 3 A (19.9k) 0.9120 0.0438 0.0442 0.1608 0.1920 ∼ 1 . 6 × 10 − 5 0.1551 0.0911 ∼ 1 . 5 × 10 − 5 B (19.9k) 0.9171 0.0462 0.0367 0.1636 2 . 0 × 10 − 5 1 . 47 × 10 − 5 0.1522 1 . 94 × 10 − 5 1 . 33 × 10 − 5 with standard task metrics ( ce , ppl , acc ). Because loss ma y include regularization and con- trol terms, task-level comparisons rely primarily on CE, p erplexit y and accuracy . Extended v alidation rep orts uncertaint y-aw are probabilistic metrics, including Mon te Carlo predictive NLL ( nll ), ece , mutual_information , conditional_variance_mc , top1_flip_rate_mc and cvar_nll . Internal diagnostics report la y er weigh ts and laten t statistics, including per-lay er KL and laten t energy µ 2 . 4.3 19.9k-example setting: task qualit y and useful depth R un A on the 19.9k-example setting is a strong run. In final v alidation , it reac hes loss = 4 . 8118 , CE = 4 . 7370 , p erplexity = 114 . 10 and accuracy = 0 . 2293 . F or task-lev el comparisons, w e primarily in terpret CE, perplexity and accuracy . In extended v alidation , the run remains gen uinely probabilistic, with Monte Carlo predictive NLL = 4 . 8164 , ECE = 0 . 0445 , mutual information = 0 . 1188 , conditional v ariance = 0 . 00209 , top-1 flip rate = 0 . 2757 and CV aR-NLL = 11 . 72 . In in ternal diagnostics , the head is almost entirely dominated b y the first la y er, with learned lay er w eights 0 . 9120 / 0 . 0438 / 0 . 0442 . The laten t statistics rev eal a more subtle picture: la y er 2 is still gen uinely activ e in laten t terms, with KL 2 = 0 . 1920 and µ 2 2 = 0 . 0911 , while la y er 3 is essen tially dead, with KL 3 ≈ 1 . 6 × 10 − 5 and µ 2 3 ≈ 1 . 5 × 10 − 5 . Run A therefore activ ates a meaningful second laten t lay er, although most final-head usage remains concentrated in lay er 1. R un B on the 19.9k-example setting sligh tly improv es the task-level metrics. In final v alidation , it reac hes loss = 4 . 7950 , CE = 4 . 7217 , p erplexity = 112 . 36 and accuracy = 0 . 2307 . In extended v alidation , it remains probabilistic, with Monte Carlo predictive NLL = 4 . 8286 , ECE = 0 . 0457 , mutual information = 0 . 1168 , conditional v ariance = 0 . 00173 , top-1 flip rate = 0 . 2549 and CV aR-NLL = 11 . 82 . The internal diagnostics , ho wev er, are muc h more concentrated than in R un A. The head b ecomes even more lay er-1 dominated, with w eigh ts 0 . 9171 / 0 . 0462 / 0 . 0367 and the deep er lay ers become nearly inactiv e: KL 2 = 2 . 0 × 10 − 5 , µ 2 2 = 1 . 94 × 10 − 5 , KL 3 = 1 . 47 × 10 − 5 and µ 2 3 = 1 . 33 × 10 − 5 . The active laten t fractions are also extremely small, with only 0 . 0059 active fraction in la y er 2 and 0 . 0010 in lay er 3. Run B therefore highlights a clear task–depth trade-off: it brings a small task-lev el gain while sharply reducing useful deep latent computation. 4.4 10.0k-example setting: ra w LM quality and stabilization The 10.0k-example blo ck serves a different purp ose. Here, the key comparison is b etw een the ra w tw o-phase run v23 and the stabilized lay er3aux run v22. In final v alidation , v23 remains sligh tly ahead on ra w language-mo deling metrics, with CE = 4 . 8157 , p erplexit y = 123 . 44 and 6 T able 3: 10.0k-example setting. Final-v alidation task metrics and in ternal diagnostics. v23 is sligh tly b etter on ra w LM metrics, while v22 is substantially cleaner internally . R un CE ↓ PPL ↓ A cc ↑ µ 2 ev al ↓ µ 2 std ↓ µ 2 3 ↓ v23 (10.0k) 4.8157 123.44 0.2256 1.5313 53.45 550.82 v22 (10.0k) 4.8208 124.06 0.2264 0.2119 2.94 13.78 T able 4: Low er-budget matc hed deterministic-v ersus-v ariational comparison on the dedicated 2.0k-example setting. The same o v erall pattern already app ears at this scale: EVE is stronger on final-v alidation task metrics and on extended-v alidation probabilistic metrics. Final v alidation Extended v alidation Mo del CE ↓ PPL ↓ A cc ↑ MC NLL ↓ ECE ↓ MI Flip CV aR ↓ DET 5.5417 255.12 0.1525 5.6673 0.0603 ≈ 0 0 13.51 EVE 5.2896 198.26 0.1752 5.4709 0.0444 0.1830 0.3288 12.51 accuracy = 0 . 2256 . In in ternal diagnostics , ho w ev er, its deep regime is m uc h less con trolled: µ 2 ev al = 1 . 5313 , µ 2 std,ev al = 53 . 45 and the third la y er reac hes µ 2 3 = 550 . 82 . Th us, v23 pro vides the strongest ra w CE/PPL p oin t in this setting, while its in ternal laten t regime remains substan tially less controlled. By contrast, v22 gives up only a negligible amoun t of ra w LM quality . In final v alidation , it reaches CE = 4 . 8208 , p erplexit y = 124 . 06 and accuracy = 0 . 2264 . In extended v alidation , its probabilistic b eha vior remains informative, with ECE = 0 . 0535 , mutual information = 0 . 1687 , top-1 flip rate = 0 . 2852 , σ mean = 0 . 8866 , active unit fraction = 1 . 0 and effectiv e active dimensions = 1024 . In in ternal diagnostics , the head is still strongly la yer-1 dominated, with w eigh ts 0 . 9128 / 0 . 0425 / 0 . 0447 , so the result is not one of balanced depth usage. But the stabilization effect is substantial: µ 2 ev al drops to 0 . 2119 , µ 2 std,ev al drops to 2 . 94 and the third-la y er laten t energy drops from 550 . 82 in v23 to 13 . 78 in v22. The residual excess shifts mostly to lay er 2, where µ 2 2 = 37 . 43 , while the most severe third-lay er instabilit y is strongly reduced. Ov erall, v23 pro vides the b est raw LM metrics in this setting, whereas v22 provides the cleanest stabilized v ariational regime. 4.5 Matc hed deterministic-versus-v ariational comparison on appro ximately 19,925 ra w examples A low er-budget matched comparison already p oin ts in the same direction. On the dedicated 2.0k- example setting, both run_variational and run_deterministic are enabled, the v ariational mo del uses the lay er-3 auxiliary patch, and c heckpoint selection uses select_by="ce" . In final v alidation , EVE reaches CE = 5 . 2896 , p erplexit y = 198 . 26 , and accuracy = 0 . 1752 , whereas DET reac hes CE = 5 . 5417 , p erplexit y = 255 . 12 , and accuracy = 0 . 1525 . EVE also shows cleaner early learning dynamics, with v alidation CE impro ving from 5 . 4466 to 5 . 3315 to 5 . 2859 o v er the first three epo c hs, whereas DET p eaks earlier. In extended v alidation , EVE reaches Mon te Carlo predictiv e NLL = 5 . 4709 , ECE = 0 . 0444 , mutual information = 0 . 1830 , conditional v ariance = 0 . 00144 , top-1 flip rate = 0 . 3288 , and CV aR-NLL = 12 . 51 . DET reac hes NLL = 5 . 6673 , ECE = 0 . 0603 , and CV aR-NLL = 13 . 51 , with m utual information ≈ 0 , conditional v ariance = 0 , and top-1 flip rate = 0 . The internal EVE diagnostics remain interpretable, with la y er w eights 0 . 6184 / 0 . 1911 / 0 . 1905 , per-lay er KL 0 . 2145 / 0 . 0587 / 0 . 0258 , and latent energies µ 2 = 0 . 1425 / 0 . 0163 / 0 . 0235 . This compact matc hed result reinforces the same pattern that app ears in the larger comparison below. W e next rep ort the main matc hed deterministic-versus-v ariational comparison on ab out 7 Figure 2: V alidation CE across ep o c hs on the matched appro ximately 19,925-ra w-example proto col. EVE impro ves steadily across th e full 5-ep och run, whereas DET reaches its b est p oint at ep o c h 3 and then rises. 19,925 raw examples from W ritingPr ompts-Filter e d , with GPT-2 tokenization, val_frac=0.2 , batc h size 48, and 5 training ep o c hs. In final v alidation , E VE is stronger on all task metrics. EVE selects ep och 5 and reac hes CE = 4 . 6572 , p erplexit y = 105 . 34 , and accuracy = 0 . 2402 , whereas DET selects ep o c h 3 with CE = 4 . 7795 , p erplexit y = 119 . 04 , and accuracy = 0 . 2264 . This corresp onds to gains of 0 . 1223 in CE, 13 . 70 p erplexit y p oin ts, and ab out 1 . 38 accuracy p oints in fa v or of EVE. The learning dynamics are also cleaner for EVE. Its final-v alidation CE improv es steadily from 4 . 8864 to 4 . 6572 across the full 5-ep o c h run, while DET reac hes its b est p oin t at ep o c h 3 and then rises to 4 . 8626 at ep och 4 and 5 . 0190 at ep och 5, as shown in Figure 2. EVE shows sustained v alidation impro v emen t, whereas DET p eaks early and then mov es aw ay from its best point. The extended-v alidation comparison is also fa vorable to EVE. EVE reac hes Mon te Carlo predictiv e NLL = 4 . 6749 versus 4 . 8116 for DET, and it exhibits a gen uine epistemic signal, with m utual information = 0 . 1362 , top-1 MC flip rate = 0 . 2454 , and epistemic ratio = 2 . 81% , whereas DET remains near zero on these axes. Calibration is more nuanced. DET achiev es the low er ECE, 0 . 03546 versus 0 . 05110 , while EVE ac hieves the lo w er CV aR-NLL, 11 . 8202 versus 12 . 1441 . This gives EVE the stronger tail-risk profile in this matc hed setting. Figure 3 makes the probabilistic gap explicit. EVE pro duces non-zero sampling-based epistemic signals, whereas the deterministic baseline remains degenerate on these quantities under rep eated deterministic forw ard ev aluation. F rom a mo deling p ersp ectiv e, this matc hed comparison sho ws b oth stronger predictiv e qualit y and ric her uncertaint y estimates for EVE. In this setting, latent usage remains primarily concen trated in the first la yer, with final lay er weigh ts 0 . 9351 / 0 . 0329 / 0 . 0320 , la y er-1 KL = 0 . 18846 , and lay er-2 and la y er-3 KL v alues near 9 . 4 × 10 − 6 . Both runs are numerically clean, with finite_ok=true and zero skipp ed batches, and EVE retains an activ e homeostatic con troller whose final band o ccupancy remains selectiv e. 8 Figure 3: Sampling-based epistemic metrics for EVE an d the matc hed deterministic baseline. Mutual information, conditional Mon te Carlo v ariance, top-1 Monte Carlo flip rate, and epistemic ratio are clearly non-zero for EVE, whereas they remain at zero or near-zero v alues for DET under rep eated deterministic forw ard ev aluation. The vertical axis is logarithmic; exact zeros for DET are displa yed with a tin y visualization floor only for plotting. Ov erall, on this matc hed ∼ 19,925-example proto col, EVE is stronger on final-v alidation CE, p erplexity , and accuracy , stronger on extended-v alidation Mon te Carlo predictive NLL and CV aR-NLL, and it provides non-zero epistemic uncertain t y . DET retains the low er ECE. EVE therefore combines the stronger task profile with the ric her uncertaint y-aw are profile in this setting. 5 Discussion Our results supp ort a clear conclusion. Lo cal v ariational neurons in tegrate w ell in to T ransformer feed-forw ard computation. They preserve strong next-token language-mo deling p erformance and add informativ e uncertain ty signals, including m utual information, conditional v ariance, and Monte Carlo flip rate. The exp erimen ts separate three useful prop erties: task qualit y , useful depth, and internal stabilit y . These prop erties are related, but they are not the same and should be ev aluated separately . In the 19.9k-example setting, R un B is slightly stronger than Run A on CE, perplexity , and accuracy . Run A, ho wev er, retains the ric her second-la yer latent regime. This sho ws that stronger task metrics do not automatically mean stronger useful depth. It also sho ws that latent activit y and head usage remain distinct. A laten t lay er can sta y genuinely active ev en when the final head is dominated by shallow er computation. In the 10.0k-example setting, v23 giv es the strongest ra w language-mo deling point, while v22 gives the cleaner v ariational regime at essen tially no meaningful task-level cost. Relative to v23, v22 reduces µ 2 ev al from 1 . 5313 to 0 . 2119 , µ 2 std,ev al from 53 . 45 to 2 . 94 , and third-la y er latent energy from 550 . 82 to 13 . 78 , while keeping CE at 4 . 8208 , perplexity at 124 . 06 , and accuracy at 0 . 2264 . This is a strong practical result. The v ariational regime can b e made m uch cleaner while remaining competitive on predictive metrics. 9 The matched deterministic comparisons reinforce the same p oin t. On the dedicated 2.0k- example setting, EVE impro v es CE from 5 . 5417 to 5 . 2896 , p erplexit y from 255 . 12 to 198 . 26 , and accuracy from 0 . 1525 to 0 . 1752 , while also producing non-zero epistemic structure under Mon te Carlo ev aluation. On the matc hed ∼ 19,925-example proto col, EVE improv es CE from 4 . 7795 to 4 . 6572 , p erplexit y from 119 . 04 to 105 . 34 , accuracy from 0 . 2264 to 0 . 2402 , and Mon te Carlo predictive NLL from 4 . 8116 to 4 . 6749 . These results show that v ariational T ransformers can improv e task quality while enriching probabilistic b eha vior. Ov erall, v ariational T ransformers already work w ell at controlled budget. They combine strong language-mo deling b eha vior with explicit internal uncertain ty and measurable laten t dynamics. This giv es a stronger basis for probabilistic ev aluation and a practical path tow ard uncertain t y-a ware language mo deling. 6 Conclusion W e introduced a T ransformer language mo del in which deterministic feed-forward units are replaced by lo cal v ariational neurons. The T ransf ormer bac kb one remains unc hanged, while the in ternal computation becomes explicitly uncertaint y-aw are. A cross compact next-token language-mo deling exp eriments, the mo del remains trainable, n umerically stable, and probabilistically informative. It preserv es strong task performance, pro duces informative Monte Carlo uncertain ty metrics, and exp oses in ternal latent diagnostics that make depth usage and stability directly measurable. The main empirical result is direct. Useful uncertain ty in language mo dels can be built into the computation itself. V ariational T ransformers therefore pro vide a practical path b eyond p oin t prediction, to ward language mo dels with explicit internal uncertaint y structure and stronger probabilistic analysis. References [1] Charles Blundell, Julien Cornebise, K ora y Ka vuk cuoglu, and Daan Wierstra. W eight uncertain t y in neural net w ork. In Pr o c e e dings of the 32nd International Confer enc e on Machine L e arning , v olume 37 of Pr o c e e dings of Machine L e arning R ese ar ch , pp. 1613–1622, 2015. [2] Sam uel R. Bowman, Luke Vilnis, Oriol Viny als, Andrew M. Dai, Rafal Jozefo wicz, and Sam y Bengio. Generating sen tences from a contin uous space. In Pr o c e e dings of the 20th SIGNLL Confer enc e on Computational Natur al L anguage L e arning , pp. 10–21, 2016. [3] Y arin Gal and Zoubin Ghahramani. Drop out as a Ba yesian appro ximation: Representing mo del uncertaint y in deep learning. In Pr o c e e dings of the 33r d International Confer enc e on Machine L e arning , v olume 48 of Pr o c e e dings of Machine L e arning R ese ar ch , pp. 1050–1059, 2016. [4] Ch uan Guo, Geoff Pleiss, Y u Sun, and Kilian Q. W ein b erger. On calibration of modern neural netw orks. In Pr o c e e dings of the 34th International Confer enc e on Machine L e arning , v olume 70 of Pr o c e e dings of Machine L e arning R ese ar ch , pp. 1321–1330, 2017. [5] Junxian He, Daniel Sp oko yny , Graham Neubig, and T aylor Berg-Kirkpatric k. Lagging inference netw orks and p osterior collapse in v ariational auto enco ders. In International Confer enc e on L e arning R epr esentations , 2019. [6] Diederik P . Kingma and Max W elling. Auto-encoding v ariational ba yes. In International Confer enc e on L e arning R epr esentations , 2014. 10 [7] Bala ji Lakshminara y anan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictiv e uncertaint y estimation using deep ensem bles. In A dvanc es in Neur al Information Pr o c essing Systems , volume 30, 2017. [8] Alec Radford, Jeffrey W u, Rew on Child, David Luan, Dario Amo dei, and Ily a Sutsk ev er. Language mo dels are unsup ervised multitask learners. T echnical rep ort, Op enAI, 2019. URL https://cdn.openai.com/better- language- models/language_ models_are_unsupervised_multitask_learners.pdf . [9] Karthik Abinav Sankararaman, Sinong W ang, and Han F ang. Bay esformer: T ransformer with uncertaint y estimation. CoRR , abs/2206.00826, 2022. URL 2206.00826 . [10] Ashish V aswani, Noam Shazeer, Niki Parmar, Jakob Uszk oreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. A tten tion is all you need. In A dvanc es in Neur al Information Pr o c essing Systems , volume 30, 2017. [11] Tim Z. Xiao, Aidan N. Gomez, and Y arin Gal. W at zei je? detecting out-of-distribution translations with v ariational transformers. CoRR , abs/2006.08344, 2020. URL https: //arxiv.org/abs/2006.08344 . 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment