Differentiable Power-Flow Optimization
With the rise of renewable energy sources and their high variability in generation, the management of power grids becomes increasingly complex and computationally demanding. Conventional AC-power-flow simulations, which use the Newton-Raphson (NR) me…
Authors: Muhammed Öz, Jasmin Hörter, Kaleb Phipps
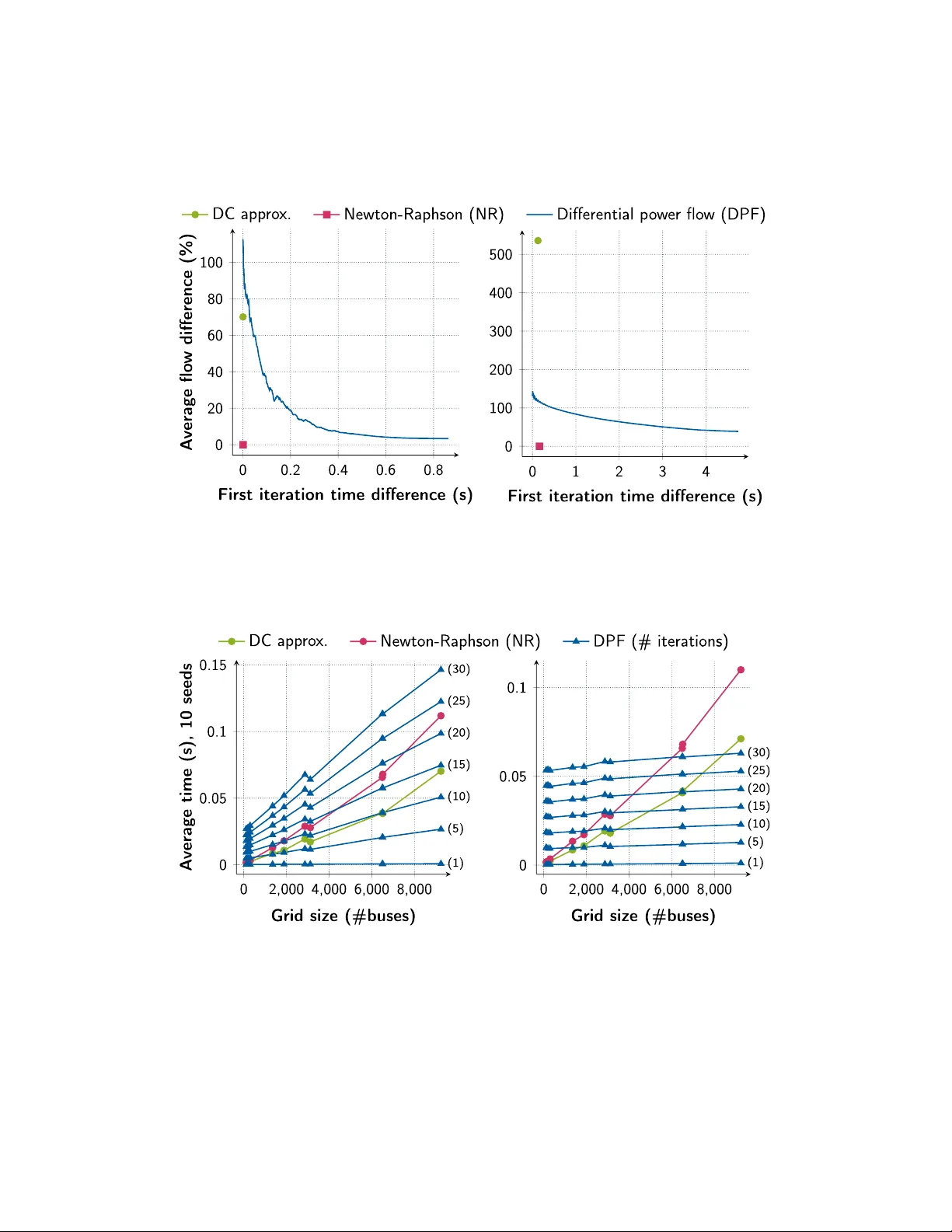
Graphical Abstract Differen tiable P o w er-Flo w Optimization Muhammed Öz, Jasmin Hörter, Kaleb Phipps, Charlotte Debus, A c him Streit, Markus Götz Highligh ts Differen tiable P o w er-Flo w Optimization Muhammed Öz, Jasmin Hörter, Kaleb Phipps, Charlotte Debus, A c him Streit, Markus Götz • W e use the concept of differentiable sim ulations on AC-pow er-flo w op- timizations. • Our Differ entiable Power-flow (DPF) metho d is scalable in terms of run time and memory usage. • The calculation of m ultiple p o w er-flo ws can b e accelerated via the GPU, making use of sparse tensors and batc hing. • When calculating p o w er-flo ws for time series, DPF is able to effectiv ely reuse previous solutions for faster con v ergence. • DPF can b e used as a fast screening metho d whic h can b e accelerated b y early stopping. • Easy implemen tation using common automatic differen tiation libraries lik e PyT orc h. Differen tiable P o w er-Flo w Optimization Muhammed Öz a, ∗ , Jasmin Hörter a , Kaleb Phipps a , Charlotte Debus a , A c him Streit a , Markus Götz a,b, ∗ a Scientific Computing Center (SCC), Karlsruhe Institute of T e chnolo gy (KIT), 76344 Eggenstein-L e op oldshafen, Germany b Helmholtz AI, Karlsruhe Abstract With the rise of renewable energy sources and their high v ariabilit y in genera- tion, the management of pow er grids b ecomes increasingly complex and com- putationally demanding. Con v entional A C-p o wer-flo w simulations, which use the Newton-Raphson (NR) metho d, suffer from p oor scalability , making them impractical for emerging use cases such as join t transmission–distribution mo deling and global grid analysis. A t the same time, purely data-driv en surrogate models lac k ph ysical guaran tees and may violate fundamen tal con- strain ts. In this w ork, w e prop ose Differ entiable Power-Flow (DPF) , a re- form ulation of the AC p o w er-flow problem as a differen tiable sim ulation. DPF enables end-to-end gradient propagation from the physical p o w er mis- matc hes to the underlying sim ulation parameters, thereby allo wing these parameters to b e identified efficien tly using gradient-based optimization. W e demonstrate that DPF pro vides a scalable alternativ e to NR b y lev eraging GPU acceleration, sparse tensor represen tations, and batc hing capabilities a v ailable in mo dern machine-learning framew orks such as PyT orc h. DPF is esp ecially suited as a to ol for time-series analyses due to its efficien t reuse of previous solutions, for N-1 con tingency-analyses due to its abilit y to pro cess cases in batches, and as a screening to ol by leveraging its sp eed and early stopping capabilit y . The co de is a v ailable in the authors’ co de rep ository . ∗ Please address corresp ondence to Muhammed Öz or Markus Götz Email addr esses: muhammed.oez@kit.edu (Muhammed Öz), jasmin.hoerter@kit.edu (Jasmin Hörter), kaleb.phipps@kit.edu (Kaleb Phipps), charlotte.debus@kit.edu (Charlotte Debus), achim.streit@kit.edu (A chim Streit), markus.goetz@kit.edu (Markus Götz) Keywor ds: Energy Grid, P o wer-flo w, Optimization, Sto chastic Gradient Descen t, Automatic Differen tiation 1. In tro duction Energy grids are among the most critical infrastructures of mo dern so- ciet y and the economy . They m ust b e contin uously monitored and actively managed to deliv er electricity reliably while main taining system stabilit y . A t the same time, p o w er grids are inheren tly fragile: the failure of a single com- p onen t can trigger cascading effects, as the redistribution of electrical flo ws ma y o v erload other parts of the netw ork ( Cam us , 2021 ; Emma P inedo and Latona , 2025 ; Lemos et al. , 2021 ). One example of an o v erload-induced cas- cade is the recen t black out that affected parts of F rance, Spain, and Portugal on April 28 th 2025 ( Emma Pinedo and Latona , 2025 ). Main taining grid stability b ecomes particularly challenging due to the enormous scale of mo dern p ow er systems. The North American p o wer grid alone encompasses more than 600,000 miles of transmission lines and 5.5 mil- lion miles of distribution lines ( Orf , 2023 ). Benc hmark transmission mo dels illustrate this complexity: the Europ ean transmission net work represented b y the c ase9241p e gase test case con tains roughly ten thousand high-voltage buses ( Josz et al. , 2016 ), while the North American Eastern Interconnec- tion comprises appro ximately eigh ty thousand buses ( Birc hfield and Ov erby e , 2023 ). These figures represen t only the transmission la y er. When distribu- tion netw orks are included, whic h is increasingly necessary due to the gro wing p enetration of distributed renew able generation, the scale increases dramat- ically . F or example, T exas alone i s estimated to contain roughly 46 million electrical no des when distribution-lev el infrastructure is considered as well ( Mateo et al. , 2024 ). T o ensure reliable op eration of suc h large systems, grid op erators must k eep transmission line flo ws within thermal limits, maintain stable frequen- cies, and ensure that voltages remain within sp ecified b oundaries while con- tin uously balancing electricity supply and demand ( Donnot et al. , 2017 ). A c hieving this b ecomes increasingly difficult as p ow er systems grow in size and complexity and as uncertain ty rises, for example due to w eather-dep endent renew able generation ( Hamann et al. , 2024 ). Sim ulation to ols play a crucial role in the decision-making pro cess b y en- abling the ev aluation of different grid states in near real time. F rameworks 2 suc h as Grid2Op ( Donnot , 2020a ) and Pandapower ( Thurner et al. , 2018 ) p erform AC-pow er-flow sim ulations to assess system stability . These sim- ulations enable sev eral imp ortant applications: F or example, grid op erators p erform N-1 c ontingency analyses ( Mitra et al. , 2016 ) to v erify that the grid remains stable if a comp onen t suc h as a transmission line or substation fails. Similarly , time-series simulations are used to ev aluate grid stability under c hanging demand and generation conditions throughout the day . T o sup- p ort suc h applications in op erational settings, p ow er-flow simulations must b e computationally efficien t. Most existing simulation framew orks rely on numerical metho ds suc h as Newton-R aphson (NR) ( Tinney and Hart , 1967 ) to solv e the non-linear A C p o wer-flo w equations. While NR remains the state-of-the-art metho d due to its high accuracy , its computational cost grows rapidly with system size. As a result, NR is not suitable for tackling emerging c hallenges suc h as the global grid ( Chatziv asileiadis et al. , 2013 ) or in tegrated transmission–distribution systems ( Idema et al. , 2013 ) and it is not sui table for expanding contingency analyses b ey ond N-1. Mac hine-learning approac hes ha ve therefore b een explored to accelerate p o wer-flo w computations. A common strategy is to train surrogate mo d- els that approximate the ph ysical simulation directly from data ( Fikri et al. , 2018 ). Such models can pro vide substan tial computational speedups by elim- inating the need to rep eatedly solv e the p o wer-flo w equations. How ever, b ecause they replace the underlying physical mo del with a learned appro x- imation, they may violate fundamental physical constrain ts and struggle to generalize reliably outside the training distribution. T o address these limitations, more recent work seeks to com bine mac hine learning with physical laws rather than replacing the sim ulation en tirely . One prominen t approac h is to incorp orate physical laws directly in to neural- net w ork arc hitectures, resulting in ph ysics-informed neural netw orks ( Donon et al. , 2020 ; Böttcher et al. , 2023 ; Dogoulis et al. , 2025 ). These mo dels im- pro v e ph ysical consistency compared to purely data-driv en surrogates. Nev- ertheless, they still rely on learned approximations of the system dynamics and therefore do not fully preserv e the original ph ysical consistency . This highlights a remaining gap b et ween traditional sim ulation metho ds and mo dern mac hine-learning approac hes. What is needed is a framework that preserves the physical equations without relying on learned appro xima- tions, scales fa vorably to systems with millions of no des, and preferably lev er- ages mo dern hardware capabilities such as GPU acceleration, batc hing, and 3 sparse op erations, and integrates seamlessly with existing mac hine-learning infrastructure. Rather than learning appro ximations of the physical system, one wa y to address these requiremen ts is to mak e the simulation itself compatible with modern machine-learning metho ds ( Barati , 2025 ; Okh uegb e et al. , 2024 ; Costilla-Enriquez et al. , 2020 ). Differen tiable simulations ( Liang and Lin , 2020 ; Barati , 2025 ) reform ulate the simulation pip eline in a fully differen- tiable manner, enabling gradien ts to b e computed throughout the en tire pro cess via automatic differentiation. This preserves the underlying phys- ical equations while enabling the use of efficien t gradient-based optimization algorithms such as A dam ( Kingma and Ba , 2017 ) or sto c hastic gradient de- scen t ( Ruder , 2017 ). In the context of p o w er netw orks, the p ow er-flow prob- lem can therefore b e solved by minimizing violations of the p ow er-balance equation deriv ed from Kirc hhoff ’s curren t law and Ohm’s la w (see Equa- tion ( 1 )). Compared to classical second-order metho ds such as NR , gradien t- based optimization av oids the explicit construction and in version of large Jacobian matrices and therefore scales more fav orably with system size (see Section 5.2 ). At the same time, differen tiable sim ulations retain ph ysical con- sistency , while naturally leveraging mo dern machine-learning infrastructure, including GPU acceleration, batching of m ultiple sim ulations, and sparse tensor represen tations. In this w ork, we prop ose Differ entiable Power-Flow (DPF) , a reform ula- tion of the AC p o wer-flo w problem as a differentiable sim ulation. This for- m ulation enables end-to-end gradient propagation from the physical p ow er mismatc hes to the underlying simulation parameters, thereby allo wing these parameters to b e iden tified efficiently using gradien t-based optimization. W e mak e the follo wing contributions: 1. W e introduce DPF , applying the concept of differen tiable sim ulations to A C p ow er-flow calculations. Using synthetic grid data, we analyze the scaling b eha vior of DPF compared to the classical NR solv er and show that DPF ac hiev es fav orable runtime and memory scaling on large grids. 2. W e ev aluate the accuracy of DPF on standard test systems b y comparing it to NR , a highly accurate second-order solv er, and to the DC p ower-flow appr ox- imation ( Qi et al. , 2012 ), whic h is computationally efficien t but less accurate. Our results sho w that th e solution qualit y of DPF lies b etw een the high ac- curacy of NR and the DC approximation. 3. W e demonstrate the practical applicabilit y of DPF for op erational grid analyses, fo cusing on time-series sim ulations. T o fully leverage the strengths of differen tiable simulations, our 4 Figure 1: Schematic view of the components of the energy grid and the curren t applications of p ow er flow calculations. implemen tation supp orts batching, GPU acceleration, w arm-start initializa- tion from previous solutions, and sparse tensor representations, whi c h can b e naturally integrated using mo dern machine-learning frameworks such as PyT or ch ( Paszk e et al. , 2019 ). 2. Bac kground This section provides the foundations for our approac h. First, we describ e the classical p ow er-flow equations and show how they can b e expressed as an optimization problem in Section 2.1 . Next, w e briefly introduce gradien t- based optimization and automatic differen tiation, which enable efficien t gra- dien t computation in differentiable simulations in Section 2.2 , and finally , w e motiv ate the use of differentiable sim ulation tec hniques for p ow er-flow calculations in Section 2.3 . 2.1. Pr oblem F ormulation The pow er grid is a complex system connecting generation and consump- tion through transmission and distribution la yers as illustrated in Figure 1 . It consists of N buses, or nodes, connected via transmission lines represented in the sparse admittance matrix Y bus . Y bus,ij represen ts the admittance, i.e., the 5 recipro cal of the imp edance, b et ween bus i and bus j . S bus,i = P i + iQ i ∈ C , with P i , Q i ∈ R , denotes the complex no dal p ow er injections at bus i . Using the complete AC-pow er-flow mo del, the goal of p ow er-flow sim- ulations is to determine the complex voltages V = | V | ∗ e iθ ∈ C N suc h that the sp ecified complex no dal injections S bus and the calculated injections S calc = V I ∗ = V ( Y bus V ) ∗ matc h. This leads to the non-linear p o wer-balance equation 1 : S bus ! = S calc = V I ∗ = V ( Y bus V ) ∗ . (1) There are three differen t bus t yp es in a grid: PV-buses (generators), PQ- buses (loads) and the slack bus (generator with adaptable generation such that the p o wer-balance equation is solv able). Dep ending on the bus type, differen t v ariables among {| V | , θ , P , Q } are sp ecified at bus i : PV-bus: activ e p ow er P i and v oltage magnitude | V i | PQ-bus: activ e p ow er P i and reactiv e p ow er Q i Slac k bus: v oltage V i Computing the missing v ariables is the purp ose of AC-pow er-flo w solvers, while the sp ecified v ariables should not change. Equation ( 2 ) shows the problem without v oltage b oundary conditions: Find { V , P , Q } such that P i = P calc i ∀ i ∈ pv ∪ pq , Q i = Q calc i ∀ i ∈ pq , | V i | = | V i | set ∀ i ∈ pv , θ slack = 0 , V slack = V set slack . (2) This can b e form ulated as an optimization problem: min | V | pq ,θ pv,pq || F ( V ) || 2 = || S bus − V ( Y bus V ) ∗ || 2 s.t. | V i | = | V i | set ∀ i ∈ pv , θ slack = 0 , (3) V slack = V set slack . There is a v ariety of differen t approaches to solve the optimization problem as listed in Section 3 . One p ossible w a y is to use gradien t-based optimization. 1 See matp ow er-manual , sections 3.6 and 4.1. 6 2.2. Gr adient Desc ent Optimization Optimization problems are commonly expressed as the minimization of an ob jective function f ( θ ) with parameters θ ∈ Θ . The goal is to find a mini- mizer θ ∗ = ar g min θ ∈ Θ f ( θ ) . A common approach to do this is to use gradien t descen t ( Andrycho wicz et al. , 2016 ). Starting from an initial parameter vec- tor θ 0 , v anilla gradien t descent iteratively up dates the parameters by mo ving to w ards the negative gradient with a learning rate η : θ t +1 = θ t − η ∇ f ( θ t ) (4) Differen t metho ds exist to calculate the gradien t ∇ f ( θ t ) , ranging from exact calculations (manual, symbolic and automatic differentiation) to numerical appro ximations ( K omarov et al. , 2025 ; Baydin et al. , 2018 ). Sym b olic differentiation w orks on expression trees or expression forests b y applying the rules of calculus, suc h as the p o w er rule, pro duct rule, and c hain rule, to obtain its deriv atives ( Zhang , 2025 ). It can suffer from "expres- sion sw ell" generating unnecessarily large expressions ( Zhang , 2025 ; Corliss , 1988 ), but this can b e a voided b y allowing common sub expressions ( Laue , 2022 ). A con v enient and efficient wa y of utilizing symbolic differentiation is au- tomatic differentiation (auto diff ). Auto diff follo ws the idea that all numer- ical computations are ultimately comp ositions of a finite set of elementary op erations for which deriv ativ es are known. These op erations form a com- putational graph in which deriv atives can b e systematically obtained using the chain rule. The essen tial algorithmic principle is dynamic programming: partial deriv atives are stored at each no de and reused, thereby a v oiding re- dundan t computations. T w o main ev aluation strategies exist: forward mo de and rev erse mo de auto diff ( Ba ydin et al. , 2018 ). In forw ard mo de, deriv ativ es are propagated alongside the function ev aluation from inputs to outputs. In rev erse mo de, the function is first ev aluated in a forward pass, after whic h partial deriv atives are propagated backw ard from the output to the inputs. The accumulation direction is relev ant. F or ob jective functions with many parameters and a scalar output, rev erse mo de auto diff is particularly efficien t b ecause in termediate partial deriv atives can b e reused during the bac kw ard pass. This prop ert y mak es reverse mo de auto diff w ell suited for large-scale optimization problems and forms the basis of differen tiable programming framew orks suc h as PyT orch. As an example for reverse mo de auto diff (similar to Flügel et al. ), con- sider the ob jective function y = f ( x 1 ; x 2 ) = g 3 ( g 2 ( g 1 ( x 1 , x 2 ))) ∈ R with the 7 in termediate scalar v alues h i = ( g i ◦ g i − 1 ◦ · · · ◦ g 1 )( x 1 , x 2 ) ∈ R , g i : R → R up to index i ∈ N . Then the partial deriv ative of y with regards to x 1 is ∂ y ∂ x 1 = ∂ y ∂ h 2 ∂ h 2 ∂ h 1 ∂ h 1 ∂ x 1 In a computational graph represen tation, the v ariables h 2 and h 1 corresp ond to internal no des, each holding their partial deriv atives ∂ y ∂ h 2 and ∂ y ∂ h 1 . The key adv an tage of storing the v ariables is the reusability . First ∂ y ∂ h 2 is calculated, then ∂ y ∂ h 1 using the previously stored deriv ative from h 2 . Calculating ∂ y ∂ x 2 afterw ards b ecomes trivial as ∂ y ∂ h 1 is already stored inside the inner no de and only one lo cal m ultiplication is required. 2.3. Differ entiable Simulations Ph ysical sim ulations are a prime use cases for reverse mo de auto diff, esp e- cially for industrial, design, engineering, and rob otics applications ( Newbury et al. , 2024 ). When simulations are expressed in a differentiable w a y , they are called differen tiable simulations. F ormulating a problem in this w a y can accelerate sim ulations, but also unlo ck new applications, e.g., learning un- kno wn system parameters or ev aluating their influence on the sim ulation result b y solving an inv erse problem ( F an et al. , 2020 ). A ccording to Liang and Lin , a goo d differen tiable sim ulator should b e v ectorization friendly (not con tain fragmen ted op erations during the forw ard pass), GPU friendly , and supp ort sparse op erations due to the lo cality of man y ph ysical computations. F or p o w er flo w sim ulations, all of these criteria are satisfied with the help of automatic differen tiation to ols such as PyT orch. 3. Related W ork A wide range of solutions has b een prop osed to p erform p ow er-flo w cal- culations ( Ala wneh et al. , 2023 ; Sauter et al. , 2017 ). Existing approaches can broadly be categorized in to direct methods, iterativ e numerical metho ds, and data-driv en metho ds. 2 Should be faster than NR in theory and can b e used for screening and large grids but in LightSim2Grid NR using a KLU-solv er is faster due to implementation reasons . 8 T able 1: P o wer-flo w solution metho ds. Abbreviations: DC: DC- Appro ximation, HELM: Holomorphic Embedding Load Flow Metho d, GS: Gauß-Seidel, SA: Successiv e Approximation, NR: Newton-Raphson, FDLF: F ast Decoupled Load Flow, DPF: Differentiable Po wer-Flo w, GNS: Graph Neural Solv er, K CLNet: Kirc hhoff Curren t La w Net work. Name Description Usage Dir e ct metho ds DC approx. ( Qi et al. , 2012 ) Remo ve nonlinearities and solv e linear system Screening HELM ( T rias , 2012 ) Em b ed p ow er-flow equation in to holomorphic function Guaran teed solution Iter ative metho ds b ase d on fix-p oint-iter ations GS ( Grainger , 1999 ) Rewrite pow er equation as a fix-point iteration and up- date buses sequentially Educational SA ( Giraldo et al. , 2022 ) Rewrite p o wer equation as fix-p oin t iteration and up- date buses simultaneously Educational Iter ative metho ds b ase d on line arization NR ( Tinney and Hart , 1967 ) Jacobian-in version through matrix decomp ositions Op erational FDLF ( Stott and Alsac , 2007 ) Simplifies NR b y remo ving off-diagonal blo cks from Ja- cobian Screening 2 DPF ( Barati , 2025 ) and us Gradien t-based optimiza- tion, corresp onds to NR with Jacobian-transp ose for squared loss function and simple gradient descen t Screening, large grids Data-driven metho ds - ( Fikri et al. , 2018 ) Multi-la yer perceptron F ast GNS ( Donon et al. , 2020 ) GNN F ast, accurate - ( Böttcher et al. , 2023 ) GNN F ast, accurate K CLNet ( Dogoulis et al. , 2025 ) GNN w. hard constraints F ast, physical 9 3.1. Dir e ct Metho ds Direct metho ds compute the solution voltage in one iteration. The most widely used direct metho d is the DC-approximation ( Qi et al. , 2012 ) which simplifies the AC p o wer-flo w equations to a linear problem by neglecting re- activ e p o wer effects, voltage magnitude v ariations, and line resistances. Due to its computational efficiency it is commonly used for screening applications suc h as contingency analysis, although the resulting pow er-flow estimates ma y deviate significan tly from the AC solution, with t ypical errors on the order of 20% ( Stott et al. , 2009 ). A more accurate no v el metho d is the Holomorphic Em b edding Load Flow (HELM) metho d ( T rias , 2012 ). It embeds the p ow er equation into a holo- morphic function, constructs and solv es a holomorphic p ow er series, and then ev aluates the series to get the resulting v oltages. While HELM is v ery sta- ble and can b e very accurate, it needs a significant amoun t of time to reach accurate results comparable to NR ( Sauter et al. , 2017 ). As a result, HELM in its base form is to o slow to b e used as a screening metho d, for decision to ols and for N − 1 analyses. Other v arian ts such as FFHE ( Chiang et al. , 2017 ) in com bination with NR can achiev e a b etter p erformance ( Huang and Sun , 2023 ), but it remains to b e seen whether a comp etitiv e implementation of HELM can outp erform NR . 3.2. Iter ative Numeric al Metho ds Iterativ e metho ds solv e the pow er-flow equation through rep eated up- dates until conv ergence in con trast to direct or data-driven metho ds. They can use other metho ds as an initialization for b etter stabilit y ( Costilla- Enriquez et al. , 2020 ; Okh uegb e et al. , 2024 ). They can also reuse solutions of similar problems. F or example, Grid2Op reuses previous solutions in time series analyses ( Donnot et al. , 2017 ). The iterative metho ds are based on one of t w o broader concepts: fix-point iterations or linearization. The metho ds based on fix-p oint-iterations are Gauß-Seidel (GS) ( Grainger , 1999 ) and the Successiv e Approximation (SA) metho d ( Giraldo et al. , 2022 ). Both rewrite the p ow er equation as a fix-p oint iteration to rep eatedly up- date v oltages. They differ in their up date order. GS up dates the volt- ages sequentially , bus by bus, and uses the up dated v alues to up date the remaining v oltages, while the Successiv e Appro ximation Metho d up dates the v oltages for all buses in parallel using the old voltage v alues. Both metho ds are rather conceptional and less practically relev an t as they are 10 m uc h slo wer than linearization-based metho ds ( Donnot , 2020b ), esp ecially for larger grids ( Sauter et al. , 2017 ). Linearization-based metho ds approximate the nonlinear equations locally and solve a linear system at eac h iteration. They include Newton-Raphson (NR), F ast Decoupled Load Flow (FDLF) and gradient-based metho ds. The standard op erational approac h is the NR metho d ( Tinney and Hart , 1967 ). In eac h iteration of NR , a linear system ∆ V = J − 1 ( − F ( V )) ⇔ J ∆ V = − F ( V ) is solved. In practice, NR conv erges to accurate solutions in a few itera- tions (lo w single digit) because of its quadratic conv ergence ( Overton , 2017 ). Ho w ever, it can b e slo w when applied to large grids. T o sp eed up NR , it is p ossible to further simplify the Jacobian. The FDLF metho d remov es the off-diagonal blo c ks. The k ey idea is that the v oltage angle is strongly coupled with the real p o wer and the voltage magnitude is coupled with reactiv e pow er while the cross-couplings are w eak. As a result, not muc h information is lost with the simplification. FDLF is suitable as a fast screening metho d. Ho w- ev er, w e do not consider this approach in our comparison as the rep orted times in the LightSim2Grid b enchmark for FDLF are slightly w orse than NR ( Donnot , 2020b ). 3.3. Data-Driven Metho ds Recen t researc h has explored the use of machine learning to appro ximate p o wer-flo w solutions. Early approac hes emplo y ed m ulti-lay er p erceptrons to directly map system states to v oltage solutions ( Fikri et al. , 2018 ). More re- cen t work lev erages graph neural net w orks (GNNs), whic h b etter capture the top ology of p o wer systems ( Donon et al. , 2020 ; Böttcher et al. , 2023 ). The main adv an tage of these models is their low inference time once trained. But they usually ha v e lo w er accuracy and sometimes output ph ysically implau- sible predictions ( Dogoulis et al. , 2025 ). T o prev en t this to a certain degree, ph ysics-informed neural netw orks can b e employ ed to p enalize the physical violations in the loss function (soft-constraints) and pro ject the solutions to ph ysically viable planes (h ard-constrain ts) ( Dogoulis et al. , 2025 ). Ho w ev er, the authors do not rep ort the additional training time for hard-constrain t enforcemen t via pro jections. 11 3.4. Gr adient-b ase d Appr o aches Gradien t-based methods represent an alternativ e class of iterative solvers that ha v e received comparatively limited attention in the p ow er-flow litera- ture. Unlike Newton-based metho ds, gradient-based optimization do es not require explicit Jacobian factorization and therefore yields computationally inexp ensiv e iterations. Ho wev er, they t ypically exhibit linear con v ergence rates ( Garrigos and Gow er , 2024 ), in contrast to the quadratic conv ergence of NR ( Ov erton , 2017 ). Previous w ork has explored gradien t-based tec hniques primarily as auxil- iary to ols, for example to impro v e the robustness of Newton-based solv ers or escap e lo cal minima using sto chastic optimization ( Costilla-Enriquez et al. , 2020 ). More recen tly , Barati ( 2025 ) prop osed a gradien t-based form ulation of the p o w er-flow problem. While their work provides a detailed theoret- ical analysis, the rep orted implemen tations op erate at significan tly larger run times (seconds instead of milliseconds for small grids suc h as the case- 118 grid) than optimized p ow er-flo w solv ers. W e b elieve that a fair ex- p erimen t m ust compare the metho ds in their optimal state. In this work, w e inv estigate gradien t-based p o w er-flow optimization within a differen tiable sim ulation framew ork and ev aluate its practical p erformance using a highly optimized Newton–Raphson implemen tation from LightSim2Grid ( Donnot , 2020b ) as a baseline. Our goal is to identify application scenarios in which dif- feren tiable pow er flo w can complement or outp erform state-of-the-art solvers. 4. The Differen tiable P o w er-Flo w Metho d W e prop ose the DPF metho d, whic h formulates the A C p o w er-flow prob- lem as a differentiable simulation. The k ey idea is to express the p o w er- flo w equations as a differentiable computational graph, enabling the use of gradien t-based optimization to compute the voltage solution while preserving the underlying ph ysical equations. Differen tiable sim ulations are constructed such that ev ery step of the nu- merical computation is differen tiable ( Pargmann et al. , 2024 ; Newbury et al. , 2024 ). This allows gradien ts of the simulation output with resp ect to in ter- nal parameters to b e computed efficiently using automatic differen tiation. Mo dern machine-learning frameworks such as PyT orch ( P aszk e et al. , 2019 ) pro vide built-in supp ort for this paradigm and enable scalable implementa- tions that leverage GPU acceleration, batc hing, and sparse tensor op erations. 12 Figure 2: The figure depicts the op erational graph of the p o wer balance equation. The calculated p ow er S calc (dep ending on the current voltage v ector) and the actual p o wer S bus are formed and their active/reactiv e comp onen ts are used in y calc and y to create the loss function. The green colored v ariables, namely the v oltage magnitude of PV-buses and the voltage angle of PV and PQ buses, are trainable and are used as the voltage solution after training. 13 An illustration of using this approac h on p ow er-flow sim ulations is de- picted in Figure 2 . Using the paradigm of differen tiable sim ulations in p o w er- flo w studies can b e done in the follo wing wa y: The p o w er-balance equation (Equation ( 1 )) defines the forward simulation. The complex bus v oltages are represen ted in p olar form as V = | V | e iθ . The unkno wn voltage magnitudes and phase angles are treated as optimiza- tion v ariables, while grid-sp ecific parameters suc h as the sparse admittance matrix Y bus remain fixed. The ob jective function measures the mismatch b et ween the sp ecified and calculated p o wer injections, L ( V ) = 1 N ∥ S bus − V ( Y bus V ) ∗ ∥ 2 , whic h corresp onds to the mean squared violation of the p ow er-balance equa- tion. Minimizing this loss therefore yields v oltages that satisfy the A C pow er- flo w equations. Starting from an initial voltage estimate, the metho d iter- ativ ely performs forw ard and backw ard passes through the computational graph. During the forward pass, PyT orch constructs a dynamic computa- tional graph that records all tensor operations. By inv oking backpropagation in the bac kw ard pass, PyT orch then applies reverse-mode automatic differen- tiation to tra v erse this graph and compute gradien ts of the loss with resp ect to the trainable voltage v ariables. These gradien ts are subsequently used b y an optimizer to up date the voltage v ector. Detailed pseudo co de for our approac h can b e found in the app endix (Algorithm 1 ). This approac h, by design, follo ws the characteristics of a go o d simulator as defined b y Liang and Lin ( 2020 ): it is vectorization friendly , it is GPU- friendly and it supp orts sparse op erations. 4.1. Implementation Details In our DPF implemen tation (see 1 in the App endix) w e mak e use of the classical PyT orch training lo op 3 . In each iteration, w e conduct a for- w ard pass, calculate the resulting loss, and finally use PyT orch’s automatic differen tiation functionalit y to calculate gradients (using the reverse mo de to calculate partial deriv atives in the computational graph) and up date the 3 https://docs . pytorch . org/tutorials/beginner/introyt/trainingyt . html 14 learnable comp onen ts of the complex v oltage (in p olar form) using an opti- mizer and a sc heduler. It should b e noted that the admittance matrix Y bus is stored in sparse compressed ro w storage format (CSR) and that all v ariables can b e easily b e placed on the GPU. In applications in volving rep eated sim- ulations on the same grid (e.g., time-series analyses), grid-sp ecific quantities suc h as Y bus and bus-t yp e indices can b e reused across iterations. 4.2. Batche d Computation An imp ortan t adv antage of the differentiable formulation is the ability to solv e m ultiple p ow er-flow problems simultaneously using batching. This is particularly relev an t for applications suc h as time-series sim ulations or con tingency analyses. T o enable batc hing while preserving the original computational structure, the system matrices and v ectors of individual sim ulations are concatenated. Sp ecifically , the admittance matrices are combined in to a block-diagonal ma- trix Y bus = blo ckdiag ( Y ( i ) bus ) , while v oltage v ectors | V | and θ and the other v ectors S calc , out and tar g et are stac k ed accordingly . The corresp onding bus indices are shifted by batch _ num ∗ N to reflect the extended system size. This formulation allo ws m ultiple p o wer-flo w problems to b e solved in parallel using a single forw ard and back- w ard pass, enabling efficien t utilization of mo dern hardware accelerators. 5. Theoretical Ev aluation In this section, we compare DPF to NR from a theoretical standp oint. W e sho w ho w they are related in Section 5.1 and compare them with resp ect to time (Section 5.2 ), memory (Section 5.3 ) and stabilit y (Section 5.4 ). 5.1. R elation to the Jac obian DPF and NR b oth use the Jacobian matrix in differen t wa ys. The Ja- cobian is defined as all first-order partial deriv atives of the complex p ow er mismatc h F ( V ) = S calc ( V ) − S bus : J = J ( V ) = ∂ F ( V ) ∂ V = ∂ P ∂ θ ∂ P ∂ ∥ V ∥ ∂ Q ∂ θ ∂ Q ∂ ∥ V ∥ ! (5) 15 It is a linear appro ximation of how the p ow er c hanges with respect to c hanges in the v oltage. NR uses the Jacobian to find the voltage up date that pro duces a p ow er equal to the negativ e p o wer mismatch. This is done by solving the linear system ∆ V = J − 1 ( − F ( V )) ⇔ J ∆ V = − F ( V ) (6) The in v ersion is usually done with sparse LU -decomp ositions. The new fac- tors L and U can hav e a larger amount of non-zero elements than the Jacobian due to the fill-in. In contrast, gradien t-based metho ds do not jump to wards the solution im- mediately but up date the v oltage along the direction of the steep est descen t. Since a scalar loss is used instead of a full mismatc h v ector and the corre- sp onding Jacobian matrix, gradient-based metho ds use less information p er iteration. F or regular gradient descent with the squared error loss function L ( V ) = 1 2 ∥ F ( V ) ∥ 2 = 1 2 F ( V ) T F ( V ) (7) the v oltage up date vector is ∆ V = − η ∂ ( L ( V )) ∂ V = − η J T F ( V ) (8) This can b e understo o d as pro jecting the p ow er mismatch F ( V ) back in to v oltage space through J T (instead of the inv erse J − 1 in NR ). This appro xi- mation has the adv antage that the Jacobian’s sparsit y can b e used effectively without any fill-in. The do wnside is that the up date v ector is less accurate and needs to b e con trolled by a learning rate η . 5.2. R un-time and Conver genc e NR is w ell kno wn to conv erge lo cally quadratically ( Overton , 2017 ) while gradien t descent sho ws global linear con v ergence ( Garrigos and Go wer , 2024 ). This, ho wev er, comes with a cost. NR repeatedly solv es a linear system using a large Jacobian matrix. T o do this, an LU -decomp osition can be used ( Donnot , 2020b ). While the w orst case run time for standard LU - decomp ositions is cubic, it is p ossible to exploit the sparsit y of the Jacobian to impro v e run times, e.g., using KLU ( Da vis and P alamadai Natara jan , 2010 ). The actual run time dep ends on the fill-in (additional numb er of non- zer o entries (nnz) in the decomp osition compared to the sparse Jacobian). 16 If no fill-in is presen t ( meaning that nnz ( J ) = nnz ( L ) + nnz ( R ) ), then an iteration of NR is in O ( nnz ( J )) as only nnz ( J ) op erations are needed to create the factorization and to solv e the system. In comparison, DPF do es not ha v e to solv e a linear system. F or standard gradien t descen t with a squared loss function the gradient can b e form ulated as ∂ L ( V ) ∂ V = J T F ( V ) . So the cost is dominated by a matrix vector m ultiplica- tion with no fill-in with an asymptotic run time of O ( nnz ( J )) = O ( nnz ( Y bus )) , whic h is linear for p ow er grids. Ov erall the total runtime is a tradeoff b etw een the num b er of iterations needed and the time p er iteration. Since this analysis do es not accoun t for differen t optimizers and loss functions, and since the fill-in is unclear, w e ev aluate the run time exp erimentally in Section 6 . 5.3. Memory Usage In the following, as defined previously , let N b e the n umber of busses (no des) and M the n umber of connections in the grid (edges). Aside from existing inputs (admittance matrix Y bus , injections S bus and indices pv , pq and sl ack and the voltage vector for the solution) DPF needs to store the com- plex gradient v ector ∂ L ( V ) ∂ V = J T F ( V ) consisting of δ LO S S δ ∥ V ∥ and δ LO S S δ θ , and the complex output vector created from indexing S calc . By using reverse-mode AD it is not necessary to fully store the Jacobian as a matrix. Instead, the partial deriv atives are applied directly in matrix-vector m ultiplication. In to- tal, additional memory of 2 N complex num b ers is required while temp orarily partial deriv ativ es of size M are used but not stored. As a comparison, NR has to store the Jacobian consisting of the partial deriv ativ es δ P δ ∥ V ∥ , δ P δ θ , δ Q δ ∥ V ∥ and δ Q δ θ ( 4 M real num b ers as eac h partial deriv ative mirrors the sparsit y pattern of the admittance matrix), the LU -factorization of the Jacobian (dep ends on the fill-in) and the complex mismatch v ector ( N complex num b ers). W e can further simplify this by assuming M ≈ 3 N . This is the case b ecause nodes in the grid (substations) are connected lo cally and ha v e only few connections. Doing this, NR needs to store a total of ab out 12 N complex num b ers as well as the fill-in from the LU -decomp osition. Ov erall, DPF needs ab out one sixth of the additional memory NR do es with no fill-in. Ho w ever, with fill-in, the additional memory of NR can b e O ( N 2 ) . 17 5.4. Stability NR can b e problematic when the starting p oin t is badly chosen or when the metho d gets stuck in lo cal minima. Costilla-Enriquez et al. solv e these problems for very small grids b y using stochastic gradien t descent for the initialization and for cases where NR gets stuc k in lo cal minima. They argue that, even though the Jacobian in NR can lose its full rank, it is often still close to its full rank, whic h means that the gradient can still pro vide a useful direction ( Costilla-Enriquez et al. , 2020 ). 6. Exp erimen tal Ev aluation In this section, we ev aluate the prop osed DPF metho d with a fo cus on its scalability and p erformance in large-scale settings. W e consider t w o sce- narios: (i) p o w er-flow computations on increasingly large grids to analyze scaling behavior, and (ii) time series sim ulations, where w e demonstrate ho w DPF b enefits from solution reuse and batching. W e explain the exp erimental setting in Section 6.1 and Section 6.2 and w e compare it to established metho ds in Section 6.4 . 6.1. Simulation F r amework and Dataset W e use the simulation framew ork Grid2Op and its back end LightSim2Grid ( Donnot , 2020b ) to represen t pow er grids and conduct pow er-flow simulations via NR. The grid sizes range from 118 buses with the IEEE-118 grid mo delling the old American p ow er system ( P ena et al. , 2017 ) to 9,241 buses with the case9241p egase grid mo deling the Europ ean system ( Josz et al. , 2016 ) similar to the b enchmark exp eriments in LightSim2Grid 4 (see table A.4 for a table with the used grids). The dataset w e use is the L e arning Industrial Physic al Simulation b enchmark suite (LIPS) ( Leyli Abadi et al. , 2022 ) for the 118- bus grid. It con tains a data-set of differen t grid states suited for ev aluating differen t p ow er-flow tec hniques, esp ecially data-driven approac hes. F or the other grids w e use the synthetic data as used in the b enchmark exp eriments. 6.2. Har dwar e and Softwar e Envir onment Our differen tiable simulation is implemented in PyT orc h ( Paszk e et al. , 2019 ), a p opular deep learning framework, including PyT orch’s sparse library 4 h ttps://lightsim2grid . readthedocs . io/en/latest/b enchmarks_grid_sizes . h tml 18 T able 2: Hyp erparameters for DPF on the small 118-bus and the large 9,241- bus grid. IEEE118 Case9241p egase Optimizer A dam Optimizer parameters lr ( η ) 0 . 0034 0 . 0001 deca y ( β ) (0 . 979 , 0 . 963) Sc heduler Reduce lr on plateau Sc heduler parameters factor 0 . 547 patience 41 threshold 0 . 0673 co oldo wn 97 Maxim um iterations 1 , 000 to represen t admittance matrices in a sparse compressed ro w storage (csr) format. The exp erimen ts w ere conducted on a gpu4-no de with four NVIDIA A100-40 GPUs with 40GB VRAM and dual so c ket In tel Xeon Platinum 8,368 CPUs. W e utilized CUD A 12.4 ( Nic k olls et al. , 2008 ), NVIDIA’s parallel computing platform, and PyT orch 2.6 ( Paszk e et al. , 2019 ) to lev erage GPU acceleration for faster sim ulations. 6.3. Hyp erp ar ameters T o find suitable hyper-parameters on the 118-bus-grid, we used Optuna ( Ak- iba et al. , 2019 ). W e considered the optimizers Adam ( Kingma and Ba , 2017 ), SGD ( Ruder , 2017 ) and RMSprop ( Hinton , 2012 ) and the learning rate schedulers constan t, step-lr, reduce-lr-on-plateau, and m ulti-step-lr with their resp ectiv e h yp er-parameters and conducted 100 trials for each com bi- nation. All three optimizers achiev e comparable losses. So we w en t ahead with A dam with a reduce-lr-on-plateau scheduler. W e noticed that the 9,241- bus-grid needs a smaller learning rate and manually lo wered it. F or the time series setting on the large grid, we conducted another h yp erparameter searc h. T able 2 and T able 3 show the hyperparameters used in a static setting and for time series. F or time series, while reusing previous solutions, w e noticed that the solutions are already close and a smaller learning rate is sufficient to learn the delta b et ween time steps. 19 T able 3: Hyperparameter settings for Time Series on IEEE118 with time step t . IEEE118 t = 0 IEEE118 t > 0 Optimizer A dam Optimizer parameters lr ( η ) 0 . 03564 0 . 00027 deca y ( β ) (0 . 9802 , 0 . 9440) (0 . 7847 , 0 . 6624) Sc heduler Step lr Reduce lr on plateau Sc heduler parameters step 100 γ 0 . 773 factor 0 . 8 patience 2 threshold 0 . 0388 co oldo wn 4 Maxim um iterations 1 , 000 300 6.4. Comp arison In this section, we compare our DPF to NR and the DC appr oximation . W e test the metho ds for different use-cases, in particular on individual grids in Section 6.4.1 and on the time series application in Section 6.4.2 . W e further compare the scalabilit y of DPF and NR in Section 6.4.3 ev aluating the approaches for relev ant sizes needed in larger continen tal transmission grids and join t transmission-distribution systems. 6.4.1. Single-Step Optimization W e b egin with the standard setting of solving individual p o wer-flo ws on small test grid cases. While this scenario fav ors second-order metho ds such as NR due to their fast lo cal con v ergence, it provides a useful baseline to analyze the b ehavior and prop erties of DPF . Here, the traditional NR ap- proac h w orks b est (see Figure 3 ). While our approach conv erges to a solution that is b etw een NR and the DC-appro ximation in terms of quality , it takes ab out 1,000 iterations (ab out 0 . 8 s for the IEEE-118 and ab out 5 s for the larger 9,241-bus grid) on CPU, which is longer than the runtime of NR and DC. Despite the longer runtime for small grids, the runtime for larger grids c hanges in fa vor of DPF . This is more apparen t when lo oking at differen t grid sizes. Figure 4 sho ws the scaling b ehavior of our approach compared to NR and DC. The larger 20 Figure 3: Comparison of our Differen tiable Sim ulation (blue), NR (red) and the DC- appro ximation (green) on CPU without data loading time. Left: the IEEE-118 grid, righ t: case9241pegase grid. In both cases our differentiable simulation is slow er than NR but the solution quality lies betw een NR and DC. Figure 4: Scaling b ehavior of DPF (braces show the num b er of iterations), NR and DC. While on CPU (left) the scaling seems similar betw een the differen t approac hes, on GPU (righ t) the b etter scaling b eha vior b ecomes apparen t. Y et for a grid size of 9,241 NR is still faster, as our gradient-based approac h needs ab out 1,000 iterations in its base form for conv ergence. 21 Figure 5: Solution distance of previous solutions (or initialization) to the solution of the next time step for the IEEE-118 grid. Subsequent time-steps ha ve v ery similar grids, and as a result, very similar solutions. the grid, the more iterations of our differen tiable simulation are p ossible. Ho w ever, even for the largest a v ailable grid in the LightSim2grid b enchmark tests ( case9241pegase ), NR is still faster. T o utilize the scaling b ehavior more effectively , it is p ossible to consider multiple p ow er-flow simulations at the same time. 6.4.2. Time Series Optimization One use-case where DPF shows adv an tages o ver NR is the time series setting with fixed grids and changing injections. The adv antage of DPF is the reusability of approximate solutions, e.g., pow er-flo w solutions of previous time steps. While b oth NR and DPF are iterative metho ds, NR cannot fully utilize previous solutions as it still has to calculate the Jacobian matrix. On the other hand, DPF uses many smaller steps to conv erge to a solution, whic h can b e accelerated with a go o d initial solution. The grid states of subsequen t time steps are similar, and as a consequence, the solutions are close to each other, as shown in Figure 5 . Using the simi- larit y of solutions from subsequent time-steps w e can reduce the num b er of iterations needed from ab out 1,000 to 100 iterations in Figure 6 . Another adv an tage of DPF that can b e used in a time-series setting but is not exclusive to is the abilit y to use batc hing. While NR b e used to 22 Figure 6: T raining curves for a time series application use case for the IEEE-118 grid. The first time step (left) needs a full fitting of roughly 1,000 iterations. Alb eit slow, needs to b e p erformed only once p er grid and can p ossibly b e replaced by Newton-Raphson. Subsequen t time steps (righ t), using the first as initial guess, only require 100 iterations to reach a plateau in solution quality . iterativ ely solve the subsequent p ow er-flows one b y one (and making use of information from previous time steps such as a similar admittance matrix and a similar Jacobian to reduce the calculation time), DPF uses batching as in Section 4.2 to calculate m ultiple pow er-flows at once. Using batc hing on the 9,241 bus grid we improv e the time p er p o wer-flo w from 2 ms to 0 . 45 ms as sho wn in Figure 7 for a batc h size of 64. Comp arison to NR. F or the time series setting we hav e sho wn that batc hing and reusing previous solutions impro v es the simulation speed for our metho d. But we cannot mak e a fair comparison to NR as LightSim2Grid do es not supp ort batc hing. What w e can do, how ever, is to compare our metho d to the most optimized version of NR used on time series 5 . W e ran the exp eri- men t on our device and found that the optimized v ersion NR for time series for the case9241pegase grid needs 12 . 37 ms . This means that by the time NR is finished, our differen tiable sim ulator has finished ab out 28 iterations, whic h is not enough to con verge. Ev en for c hanging grids (and th us chang- ing admittance matrices which DPF can handle as easily as fixed admittance 5 h ttps://lightsim2grid . readthedocs . io/en/latest/b enchmarks_grid_sizes . h tml 23 Figure 7: Normalized time p er p o wer-flo w using batching on the case9241pegase grid. Without batching, a time of ab out 2 ms p er iteration and p o wer-flo w is needed while a time of 0 . 45 ms p er iteration and p o wer-flo w is achiev ed at a batch size of 64. matrices) NR needs 26 . 06 ms which is still faster than DPF (DPF can do ab out 58 out of 100 iterations in that time). 6.4.3. Sc aling Behavior on Synthetic Data The av ailable grids w e used (see Section 6.1 ) are limited to 9,241 or less busses. On these grids, NR outp erforms DPF but the scaling app ears to b e in fav or of our approach (see Figure 4 ). T o shed ligh t on this, w e compare b oth metho ds using synthetic data. In Figure 8 we analyze no de and edge scaling. F or the no de scaling exp erimen t, we increase the grid size by cop ying the case9241pegase grid and adding a few random connections to connect them. F or the edge scal- ing exp eriment, w e add an increasing amount of random connections to the case9241pegase grid. Both exp eriments give a similar result: NR scaling app ears to b e close to quadratic while DPF scales linearly with the num b er of no des and edges. T ogether with the observ ation that the solution quality at eac h iteration is similar (not w orse) for larger grid sizes, the no de and edge scaling b eha vior makes DPF a scalable approach. 24 Figure 8: Scaling behavior with resp ect to grid c haracteristics. F or no de scaling (left), w e increase the num b er of no des in the grid b y copying the case9241pegase grid and making few ( 20 ∗ # copies ) random connections throughout the combined grid. In case of edge scaling (right), we insert an increasing amoun t of random connections to the case9241pegase grid, adding t wo new non-zero entries (due to symmetry) per connection in to the Y bus matrix consisting of 37 , 655 non-zero entries. DPF is almost unaffected (rises from 4 . 7 s to 5 . 2 s ) while the run time of NR increases significantly . 25 6.5. Discussion With a differen tiable simulation of the p ow er-flow equations, gradient- based optimization tec hniques can b e applied directly to the ph ysical sim- ulation. The primary adv antage of DPF lies in its scalability . While NR remains highly efficient for small and medium-sized grids, the computational and memory requiremen ts associated with constructing and solving large Ja- cobian matrices increase with system size. In contrast, DPF av oids these exp ensiv e matrix factorizations and shows fa vorable scaling b ehavior in large net w orks. As demonstrated in our exp erimen ts, DPF ev en tually surpasses NR in conv ergence sp eed for sufficien tly large systems while maintaining ac- ceptable solution qualit y . Although classical high-v oltage transmission net works alone are often too small to fully exploit this scaling adv antage, the situation c hanges when considering broader system p ersp ectives. The Europ ean transmission net- w ork, for example, con tains roughly ten thousand buses as represen ted by the case9241pegase b enchmark grid, while the North American Eastern In- terconnection con tains appro ximately eigh t y thousand buses ( Birc hfield and Ov erb ye , 2023 ). At this scale, NR remains highly efficient. Our results indi- cate that netw orks with on the order of millions of buses are required for DPF to outp erform NR on the first run, although this threshold could decrease with further optimization of the metho d. Suc h system sizes b ecome realistic when transmission and distribution netw orks are mo deled jointly . This p er- sp ectiv e is increasingly relev ant in the con text of the renew able energy tran- sition, where distributed generation, electrification, and weather-dependent fluctuations b enefit from more detailed system representations. In these set- tings, netw ork sizes can reac h tens of millions of no des. F or example, the electrical netw ork in T exas has b een estimated to contain appro ximately 46 million electrical no des ( Mateo et al. , 2024 ), well within the regime where scalable approaches suc h as DPF b ecome adv antageous. P ossible future work in this direction is to app ly DPF in a fully optimized, parallelized and p er- haps distributed manner on larger realistic systems. Bey ond its scalability , DPF also offers additional practical b enefits. Be- cause the formulation is em b edded in a differentiable programming frame- w ork, it can naturally exploit GPU acceleration and batc hing of m ultiple grid states. This mak es the approach particularly suitable for applications that require solving many related p o w er-flow problems, suc h as time-series sim ulations or N − 1 contingency analyses. While our curren t implemen- tation do es not yet outp erform the optimized time-series implemen tation of 26 LightSim2Grid for small grids, the observ ed p erformance gap is relativ ely small, suggesting that impro ved implementations could become comp etitiv e. F u rthermore, gradient-based approaches can con tribute to improving the robustness of traditional solv ers. NR is known to occasionally fail to con verge ev en with go o d initialization ( Okhuegbe et al. , 2024 ). In suc h cases, gradient- based metho ds can serve as stabilizing or initialization pro cedures, as ex- plored in h ybrid approaches com bining b oth techniques ( Costilla-Enriquez et al. , 2020 ). F u ture work should therefore fo cus on optimizing the implementation of DPF , including improv ed exploitation of sparsity structures, more suitable optimizers and hyperparameters, early stopping strategies, and tighter inte- gration with existing sim ulation framew orks such as LightSim2Grid . A d- ditionally , large-scale exp erimen ts on realistic transmission–distribution sys- tems could further demonstrate the adv an tages of the approach. 7. Conclusion This work demonstrates that the differentiable simulation paradigm can b e successfully applied to p ow er-flow calculations through the prop osed DPF form ulation. The metho d preserv es the underlying ph ysical equations while enabling gradien t-based optimization within mo dern machine-learning frame- w orks. The main strength of DPF lies in its scalabilit y . By a voiding explicit Jacobian construction and matrix factorization, the metho d exhibits fav or- able scaling b ehavior as net w ork size increases. While NR remains the most efficien t solv er for small and medium-sized transmission grids, DPF b ecomes increasingly attractiv e for v ery large systems where the computational and memory requiremen ts of traditional metho ds b ecome limiting. This scalabil- it y is particularly relev an t for emerging applications that require large and detailed system mo dels, such as join t transmission–distribution simulations. In suc h contexts, netw ork sizes can reac h millions of no des, making scalable solution approac hes essen tial. Bey ond scalability , DPF offers additional practical adv antages. The dif- feren tiable form ulation allo ws seamless integration with modern mac hine- learning infrastructure, including GPU acceleration, batc hing across m ultiple sim ulations, and automatic differen tiation framew orks suc h as PyT orch. This mak es the metho d w ell suited for applications in v olving man y related p o wer- flo w computations, suc h as time-series simulations and N − 1 -con tingency 27 analyses. Moreov er, DPF can provide intermediate appro ximate solutions that are more accurate than the widely used DC appro ximation, enabling efficien t screening applications where full con vergence is not required. Ov erall, DPF provides a scalable alternative to classical p o wer-flo w solvers. F u ture w ork should fo cus on impro ving the efficiency and con vergence behav- ior of the metho d, exploring optimized implementations, and deploying it on large realistic p o w er-system mo dels using parallel and distributed computing arc hitectures. A c kno wledgemen ts This w ork is supp orted by the Helmholtz AI platform gran t and the Helmholtz Asso ciation Initiative and Netw orking F und on the HAICORE@KIT partition. W e credit Assia Benk erroum from flaticon.com for pro viding the icons in Figure 1 . Declaration of generativ e AI and AI-assisted tec hnologies in the writing pro cess. Statemen t: During the preparation of this work, the author(s) used Chat- GPT to assist in the co ding pro cess and sparingly to refine the language in the do cumen t for unclear parts and explicitly not to generate new conten t. After using this tool/service, the author(s) review ed and edited the con ten t as needed and take(s) full responsibility for the con tent of the published article. 28 References T akuya Akiba, Shotaro Sano, T oshihiko Y anase, T ak eru Oh ta, and Masanori K o yama. Optuna: A next-generation hyperparameter optimization frame- w ork. In Pr o c e e dings of the 25th A CM SIGKDD international c onfer enc e on know le dge disc overy & data mining , pages 2623–2631, 2019. doi: 10 . 1145/3292500 . 3330701 . Shadi G Ala wneh, Lei Zeng, and Seyed Ali Arefifar. A review of high- p erformance computing metho ds for p ow er flo w analysis. Mathematics , 11(11):2461, 2023. doi: 10 . 3390/math11112461 . Marcin Andryc howicz , Misha Denil, Sergio Gomez, Matthew W. Hoffman, Da vid Pfau, T om Sc haul, Brendan Shillingford, and Nando de F reitas. Learning to learn by gradien t descent by gradient descent, 2016. URL https://arxiv . org/abs/1606 . 04474 . Masoud Barati. Enhancing acpf analysis: In tegrating newton-raphson metho d with gradient descen t and computational graphs. IEEE T r ansac- tions on Industry Applic ations , 61, 2025. doi: 10 . 1109/TIA . 2025 . 3571862 . A tilim Gunes Ba ydin, Barak A. P earlmutter, Alexey Andrey evich Radul, and Jeffrey Mark Siskind. Automatic differentiation in machine learning: a surv ey , 2018. URL https://arxiv . org/abs/1502 . 05767 . A dam B Birc hfield and Thomas J Overb ye. A review on pro viding real- istic electric grid simulations for academia and industry . Curr ent Sus- tainable/R enewable Ener gy R ep orts , 10(3):154–161, 2023. doi: 10 . 1007/ s40518- 023- 00212- 7 . Luis Böttcher, Hinrikus W olf, Bastian Jung, Philipp Lutat, Marc T rageser, Oliv er Pohl, Xiaohu T ao, Andreas Ulbig, and Martin Grohe. Solving ac p ow er flow with graph neural n et w orks under realistic constrain ts. In 2023 IEEE Belgr ade PowerT e ch , pages 1–7. IEEE, 2023. doi: 10 . 1109/p o wertec h55446 . 2023 . 10202246 . Claire Camus. Outage of frenc h-spanish interconnection on 24 july 2021, 2021. URL https://www . entsoe . eu/news/2021/08/20/outage- of- french- spanish- interconnection- on- 24- july- 2021- update/ . ac- cessed: 2025-08-20. 29 Sp yros Chatziv asileiadis, Damien Ernst, and Göran Andersson. The global grid. R enewable Ener gy , 57:372–383, 2013. doi: 10 . 1016/ j . renene . 2013 . 01 . 032 . Hsiao-Dong Chiang, T ao W ang, and Hao Sheng. A nov el fast and flexible holomorphic embedding p o wer flo w method. IEEE T r ansactions on Power Systems , 33(3):2551–2562, 2017. doi: 10 . 1109/TPWRS . 2017 . 2750711 . George F. Corliss. Applic ations of differ entiation arithmetic , page 127–148. A cademic Press Professional, Inc., USA, 1988. ISB N 0125056303. Nap oleon Costilla-Enriquez, Y ang W eng, and Baosen Zhang. Com bining newton-raphson and sto c hastic gradien t descent for p ow er flo w analysis. IEEE T r ansactions on Power Systems , 36(1):514–517, 2020. doi: 10 . 1109/ TPWRS . 2020 . 3029449 . Timoth y A Da vis and Ek anathan P alamadai Natara jan. Algorithm 907: Klu, a direct sparse solv er for circuit simulation problems. A CM T r ans- actions on Mathematic al Softwar e (TOMS) , 37(3):1–17, 2010. doi: 10 . 1145/1824801 . 1824814 . P an telis Dogoulis, Karim Tit, and Maxime Cordy . Kclnet: Physics-informed p o wer flo w prediction via constraints pro jections. In Joint Eur op e an Con- fer enc e on Machine L e arning and Know le dge Disc overy in Datab ases , pages 95–110. Springer, 2025. doi: 10 . 1007/978- 3- 032- 06129- 4_6 . Benjamin Donnot. Grid2op-a testb ed platform to mo del sequential decision making in p o wer systems, 2020a. URL https://github . com/Grid2Op/ grid2op . Benjamin Donnot. Ligh tsim2grid - A c++ bac kend targeting the Grid2Op platform, 2020b. URL https://GitHub . com/Grid2Op/lightsim2grid . Benjamin Donnot, Isab elle Guyon, Marc Sc ho enauer, P atric k P anciatici, and An toine Marot. In tro ducing mac hine learning for p o w er system op eration supp ort, 2017. doi: 10 . 48550/arXiv . 1709 . 09527 . Balthazar Donon, Rém y Clémen t, Benjamin Donnot, An toine Marot, Isabelle Guy on, and Marc Schoenauer. Neural net w orks for p o wer flow: Graph neural solv er. Ele ctric Power Systems R ese ar ch , 189:106547, 2020. doi: 10 . 1016/j . epsr . 2020 . 106547 . 30 Catarina Demon y Emma Pinedo and David Latona. P o wer b egins to return after huge outage hits spain and p ortugal, 2025. URL https://www . reuters . com/world/europe/large- parts- spain- portugal- hit- by- power- outage- 2025- 04- 28/ . accessed: 2025-05- 09. Tiffan y F an, Kailai Xu, Ja y Pathak, and Eric Darve. Solving inv erse problems in steady-state navier-stok es equations using deep neural netw orks, 2020. URL https://arxiv . org/abs/2008 . 13074 . Meriem Fikri, T ouria Haidi, Bouchra Cheddadi, Omar Sabri, Meriem Ma- jdoub, and Ab delaziz Belfqih. P o w er flo w calculations b y deterministic metho ds and artificial intelligence metho d. Int J A dv Eng R es Sci , 5: 148–152, 2018. doi: 10 . 22161/ijaers . 5 . 6 . 25 . Katharina Flügel, Daniel Co quelin, Marie W eiel, Charlotte Debus, A chim Streit, and Markus Götz. Beyond bac kpropagation: Optimization with m ulti-tangen t forward gradien ts. In 2025 International Joint Confer enc e on Neur al Networks (IJCNN) , page 1–8. IEEE, June 2025. doi: 10 . 1109/ ijcnn64981 . 2025 . 11227446 . Guillaume Garrigos and Rob ert M. Gow er. Handb o ok of conv ergence theorems for (sto chastic) gradien t metho ds, 2024. doi: 10 . 48550/ arXiv . 2301 . 11235 . Juan S Giraldo, Oscar Danilo Monto ya, P edro P V ergara, and F ederico Mi- lano. A fixed-p oint current injection p ow er flo w for electric distribution systems using laurent series. Ele ctric Power Systems R ese ar ch , 211:108326, 2022. doi: 10 . 1016/j . epsr . 2022 . 108326 . John J Grainger. Power system analysis . McGra w-Hill, 1999. ISBN 1259008355. Hendrik F. Hamann, Blazhe Gjorgiev, Thomas Bruns c h wiler, Leonardo S.A. Martins, Alban Puec h, Anna V arb ella, Jonas W eiss, Juan Bernab e- Moreno, Alexandre Blondin Massé, Seong Lok Choi, Ian F oster, Bri- Mathias Ho dge, Rishabh Jain, Kibaek Kim, Vincen t Mai, F rançois Mi- rallès, Martin De Montign y , Octavio Ramos-Leaños, Hussein Suprême, Le Xie, El-Nasser S. Y oussef, Arnaud Zinflou, Alexander Belyi, Ricardo J. Bessa, Bishnu Prasad Bhattarai, Johannes Schm ude, and Stanisla v 31 Sob olevsky . F oundation mo dels for the electric p ow er grid. Joule , 8(12): 3245–3258, 2024. ISSN 2542-4351. doi: 10 . 1016/j . joule . 2024 . 11 . 002 . Geoffrey Hin ton. rmsprop: Divide the gradien t b y a running av erage of its recen t magnitude, 2012. URL https://www . cs . toronto . edu/~tijmen/ csc321/slides/lecture_slides_lec6 . pdf . Kaiy ang Huang and Kai Sun. A review on applications of holomor- phic embedding methods. IEner gy , 2(4):264–274, 2023. doi: 10 . 23919/ IEN . 2023 . 0037 . Reijer Idema, Georgios P apaefthymiou, Domenico Lahay e, Cornelis V uik, and Lou v an der Sluis. T ow ards faster solution of large p o wer flow prob- lems. IEEE T r ansactions on Power Systems , 28:4918–4925, 2013. doi: 10 . 1109/TPWRS . 2013 . 2252631 . Cédric Josz, Stéphane Fliscounakis, Jean Maegh t, and P atric k P anciatici. Ac p o wer flo w data in matp ow er and qcqp format: itesla, rte snapshots, and p egase, 2016. doi: 10 . 48550/arXiv . 1603 . 01533 . Diederik P . Kingma and Jimm y Ba. Adam: A metho d for sto chastic opti- mization, 2017. doi: 10 . 48550/arXiv . 1412 . 6980 . P a vel K omaro v, Floris v an Breugel, and J. Nathan Kutz. A taxonomy of n umerical differentiation metho ds, 2025. URL https://arxiv . org/abs/ 2512 . 09090 . So eren Laue. On the equiv alence of automatic and symbolic differen tiation, 2022. URL https://arxiv . org/abs/1904 . 02990 . Gerardo Lemos, Ana Melgar, Mauricio T orres, and Michael Rios. State of emergency declared after black out plunges most of chile into darknes, 2021. URL https://edition . cnn . com/2025/02/25/americas/chile- blackout- 14- regions- intl- latam . accessed: 2025-08-20. Milad Leyli Abadi, Antoine Marot, Jérôme Picault, Da vid Danan, Mouadh Y agoubi, Benjamin Donnot, Seif A ttoui, Pa vel Dimitro v, Asma F arjallah, and Clement Etienam. Lips-learning industrial physical simulation b enc hmark suite. A dvanc es in Neur al Information Pr o c essing Sys- tems , 35:28095–28109, 2022. URL https://proceedings . neurips . cc/ 32 paper_files/paper/2022/hash/b3ac9866f6333beaa7d38926101b7e1c- Abstract- Datasets_and_Benchmarks . html . Jun bang Liang and Ming C Lin. Differentiable physics simulation. In ICLR 2020 workshop on inte gr ation of de ep neur al mo dels and differ ential e qua- tions , 2020. URL https://openreview . net/pdf?id=p- SG2KFY2 . Carlos Mateo, F ernando Postigo, T arek Elgindy , Adam B Birc hfield, P ablo Dueñas, Bry an Palmin tier, Nadia P anossian, T omás Gómez, F ernando de Cuadra, Thomas J Ov erby e, et al. Building and v alidating a large- scale com bined transmission & distribution synthetic electricity system of texas. International Journal of Ele ctric al Power & Ener gy Systems , 159: 110037, 2024. doi: 10 . 1016/j . ijep es . 2024 . 110037 . P arag Mitra, Vijay Vittal, Brian Keel, and Jeni Mistry . A systematic ap- proac h to n-1-1 analysis for p ow er system securit y assessment. IEEE Power and Ener gy T e chnolo gy Systems Journal , 3(2):71–80, 2016. doi: 10 . 1109/JPETS . 2016 . 2546282 . Rh ys Newbury , Jac k Collins, Kerry He, Jiahe Pan, Ingmar Posner, Da vid Ho w ard, and Ak ansel Cosgun. A review of differentiable simulators. IEEE A c c ess , pages 97581–97604, 2024. doi: 10 . 1109/A CCESS . 2024 . 3425448 . John Nick olls, Ian Buc k, Mic hael Garland, and Kevin Sk adron. Scalable parallel programming with cuda: Is cuda the parallel programming mo del that application dev elop ers ha v e been w aiting for? Queue , 6(2):40–53, 2008. doi: 10 . 1145/1401132 . 1401152 . Sam uel N Okhuegbe, Adedasola A Ademola, and Yilu Liu. A mac hine learn- ing initializer for newton-raphson ac pow er flo w conv ergence. In 2024 IEEE T exas Power and Ener gy Confer enc e (TPEC) , pages 1–6. IEEE, 2024. doi: 10 . 1109/TPEC60005 . 2024 . 10472261 . Darren Orf. The p o w er grid is the largest mac hine in the w orld, and our nation’s greatest engineering achiev ement, 2023. URL https://www . popularmechanics . com/science/energy/a44067133/ how- does- the- power- grid- work/ . accessed: 2024-07-29. Mic hael Overton. Quadratic con vergence of newton’s metho d. T ec hnical rep ort, New Y ork Univ ersit y , 2017. URL https://cs . nyu . edu/~overton/ NumericalComputing/newton . pdf . 33 Max P argmann, Jan Eb ert, Markus Götz, Daniel Maldonado Quin to, Rob ert Pitz-P aal, and Stefan Kesselheim. Automatic heliostat learning for in situ concen trating solar p o w er plan t metrology with differen tiable ra y trac- ing. Natur e Communic ations , 15(1):6997, 2024. doi: 10 . 1038/s41467- 024- 51019- z . A dam P aszk e, Sam Gross, F rancisco Massa, Adam Lerer, James Bradbury , Gregory Chanan, T revor Killeen, Zeming Lin, Natalia Gimelshein, Luca An tiga, Alban Desmaison, Andreas Kopf, Edw ard Y ang, Zachary De Vito, Martin Raison, Alykhan T ejani, Sasank Chilamkurthy , Benoit Steiner, Lu F ang, Junjie Bai, and Soumith Chin tala. Pytorch: An imp erativ e style, high-p erformance deep learning library . In A dvanc es in Neur al Information Pr o c essing Systems , volume 32. Curran Asso ciates, Inc., 2019. Iv onne P ena, Carlo Brancucci Martinez-Anido, and Bri-Mathias Ho dge. An extended ieee 118-bus test system with high renewable p enetra- tion. IEEE T r ansactions on Power Systems , 33(1):281–289, 2017. doi: 10 . 1109/TPWRS . 2017 . 2695963 . Yingying Qi, Di Shi, and Daniel T yla vsky . Impact of assumptions on dc p o wer flo w mo del accuracy . In 2012 North Americ an Power Symp osium (NAPS) , pages 1–6. IEEE, 2012. doi: 10 . 1109/NAPS . 2012 . 6336395 . Sebastian Ruder. An ov erview of gradient descen t optimization algorithms, 2017. P atric k S Sauter, Christian A Braun, Mathias Kluw e, and Soren Hohmann. Comparison of the holomorphic em b edding load flow metho d with estab- lished p o wer flo w algorithms and a new h ybrid approac h. In 2017 Ninth A nnual IEEE Gr e en T e chnolo gies Confer enc e (Gr e enT e ch) , pages 203–210. IEEE, 2017. doi: 10 . 1109/GreenT ec h . 2017 . 36 . Brian Stott and Ongun Alsac. F ast decoupled load flo w. IEEE tr ans- actions on p ower app ar atus and systems , pages 859–869, 2007. doi: 10 . 1109/TP AS . 1974 . 293985 . Brian Stott, Jorge Jardim, and Ongun Alsaç. Dc p ow er flo w revisited. IEEE T r ansactions on Power Systems , 24(3):1290–1300, 2009. doi: 10 . 1109/ TPWRS . 2009 . 2021235 . 34 Leon Thurner, Alexander Scheidler, Florian Sc häfer, Jan-Hendrik Menke, Ju- lian Dollichon, F riederike Meier, Steffen Meinec ke, and Martin Braun. pan- dap o wer—an op en-source python to ol for conv enient mo deling, analysis, and optimization of electric p ow er systems. IEEE T r ansactions on Power Systems , 33(6):6510–6521, 2018. doi: 10 . 1109/TPWRS . 2018 . 2829021 . William. F. Tinney and Clifford E. Hart. P o w er flow solution b y newton’s metho d. IEEE T r ansactions on Power App ar atus and Systems , P AS-86 (11):1449–1460, 1967. doi: 10 . 1109/TP AS . 1967 . 291823 . An tonio T rias. The holomorphic embedding load flow method. In 2012 IEEE p ower and ener gy so ciety gener al me eting , pages 1–8. IEEE, 2012. doi: 10 . 1109/PESGM . 2012 . 6344759 . He Zhang. Higher-order automatic differentiation using sym b olic differen tial algebra: Bridging the gap b etw een algorithmic and symbolic differentia- tion, 2025. URL https://arxiv . org/abs/2506 . 00796 . 35 T able A.4: LightSim2Grid times on our device in ms . Compared are times of p o wer-flo ws for c hanging grids with and without recycling (RC), p ow er-flo ws for fixed grids on time series (TS) and times for contingency analysis (TS). The runtime scaling app ears to b e betw een linear and quadratic. The fastest times are achiev ed for time series as the grid (and therefore the admittance matrix and the sparsity structure of the Jacobian) stays the same and can b e reused. P o w er-flo w times using NR in ms Grid Size R C No RC TS CA case14 14 0.0204 0.0491 0.00790 0.0171 case118 118 0.1180 0.3206 0.0506 0.0746 case_illinois200 200 0.2447 0.5842 0.1032 0.1705 case300 300 0.4501 0.9606 0.2521 0.3341 case1354pegase 1,354 2.3303 4.0754 1.2324 1.5423 case1888rte 1,888 3.6692 5.9012 1.6169 2.059 case2848rte 2,848 5.6715 9.093 2.447 3.1987 case2869pegase 2,869 5.4858 9.443 2.9107 3.42051 case3120sp 3,120 6.371 10.155 2.307 3.5356 case6495rte 6,495 17.6517 25.9042 7.53377 8.6814 case6515rte 6,515 20.3695 28.8332 7.3132 8.77377 case9241pegase 9,241 26.0554 41.0947 12.3748 14.0037 App endix App endix A. Baseline T able A.4 sho ws the p ow er-flow runtime using the NR baseline when running Ligh tSim2Grid co de . It is notable that the run time app ears to b e b et ween linear and quadratic and not cubic. App endix B. Pseudo co de of DPF and NR Algorithm 1 and Algorithm 2 show pseudo-co de for our metho d ( DPF ) and the baseline metho d NR as it is implemen ted. 36 Algorithm 1 Pseudo co de for our DPF metho d. Lines 22-26 calculate a loss from the p ow er-balance equation which is used to up date the v oltages at lines 27-29 b y using an optimizer and sc heduler. 1: Hyp erparameters 2: optimiz er optimizer with own h yp erparameters 3: schedul er scheduler with o wn hyperparameters 4: l oss loss function 5: 6: Inputs 7: n n umber of active buses 8: V ∈ C n v oltages V = | V | ∗ e iθ with θ , | V | ∈ R n 9: Y bus ∈ C nxn A dmittance Matrix 10: S bus ∈ C n Injection V ector 11: p v index list of PV-buses 12: p q index list of PQ-buses 13: slac k index of slack bus 14: tol tolerance for conv ergence c hec k 15: 16: Start 17: V = | V | e iθ ← ones ▷ Initialization 18: | V | lear nable = | V | [ pq ] 19: θ lear nable = θ [ pv , pq ] 20: 21: for i=1 until max_iter do 22: | S calc = P calc + iQ calc ← V ( Y bus V ) ∗ 23: | out = [ P calc [ pv , pq ] , Q calc [ pq ]] ▷ F orward P ass 24: | tar g et = [ P [ pv , pq ] , Q [ pq ]] 25: | 26: | l oss = M S E ( out, tar g et ) 27: | l oss.back w ar d () ▷ Only up date learnable parameters 28: | optimiz er.step () 29: | schedul er.step () 30: | if l oss < tol then 31: | | return | V | e iθ 32: | end if 33: end for 34: return | V | e iθ 37 Algorithm 2 NR metho d for p o w er-flow calculations (Ligh tSim2Grid ( Don- not , 2020b )). Every iteration a linearization is done with the Jacobian (line 22) con taining the partial deriv ativ es (lines 20-21). If the p o wer mismatch is to o large (lines 13-16, 26-29), the voltage vector is up dated b y the v oltage delta that creates a p o wer delta (under the Jacobian) to balance out the p o wer mismatch (line 23). 1: Inputs 2: n n umber of active buses 3: V ∈ C n v oltages V = | V | ∗ e iθ with angles and magnitudes θ, | V | ∈ R n 4: Y bus ∈ C nxn A dmittance Matrix 5: S bus ∈ C n Injection V ector 6: p v index list of PV-buses 7: p q index list of PQ-buses 8: slac k index of slack bus 9: tol tolerance for conv ergence c hec k 10: 11: Start 12: V = | V | e iθ ← DC-p ow er-flow ▷ Initialization 13: S calc ← V ( Y bus V ) ∗ 14: P calc , Q calc ← Re ( S calc ) , I m ( S calc ) 15: f ( | V | , θ ) ← [( P calc − P )[ pv pq ] , ( Q calc − Q )[ pq ]] T ▷ Ev aluate p o wer mismatc h 16: if f ( | V | , θ ) < tol then ▷ Up date lo cal best solution 17: | return V 18: end if 19: for i=1 until max_iter do 20: | ∂ S calc i ∂ | V | j ← V i Y ∗ bus ij V ∗ j | V j | , for i = j V i | V i | I ∗ i + V i Y ∗ bus ij V ∗ j | V j | , for i = j ▷ Partial deriv atives 21: | ∂ S calc i ∂ θ j ← ( − iV i Y ∗ bus ij V ∗ j , for i = j iV i I ∗ i − iV i Y ∗ bus ij V ∗ j , for i = j ) 22: | J f ← ∂ P calc ∂ θ [ pv pq , pv pq ] ∂ P calc | V | [ pv pq , pq ] ∂ Q calc ∂ θ [ pq , pv pq ] ∂ Q calc | V | [ pq , pq ] ! ▷ Determine Jacobian 23: | θ [ pv pq ] | V | [ pq ] ← θ [ pv pq ] | V | [ pq ] − J − 1 f f ( | V | , θ ) ▷ Newton-step using linear solver 24: | S calc ← V ( Y bus V ) ∗ 25: | P calc , Q calc ← Re ( S calc ) , I m ( S calc ) 26: | f ( | V | , θ ) ← [( P calc − P )[ pv pq ] , ( Q calc − Q )[ pq ]] T ▷ Po wer mismatc h 27: | if f ( | V | , θ ) < tol then ▷ Up date lo cal best solution 28: | | return V = | V | e iθ 29: | end if 30: end for 31: return V = | V | e iθ 38
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment