Evaluating Privilege Usage of Agents on Real-World Tools
Equipping LLM agents with real-world tools can substantially improve productivity. However, granting agents autonomy over tool use also transfers the associated privileges to both the agent and the underlying LLM. Improper privilege usage may lead to…
Authors: Quan Zhang, Lianhang Fu, Lvsi Lian
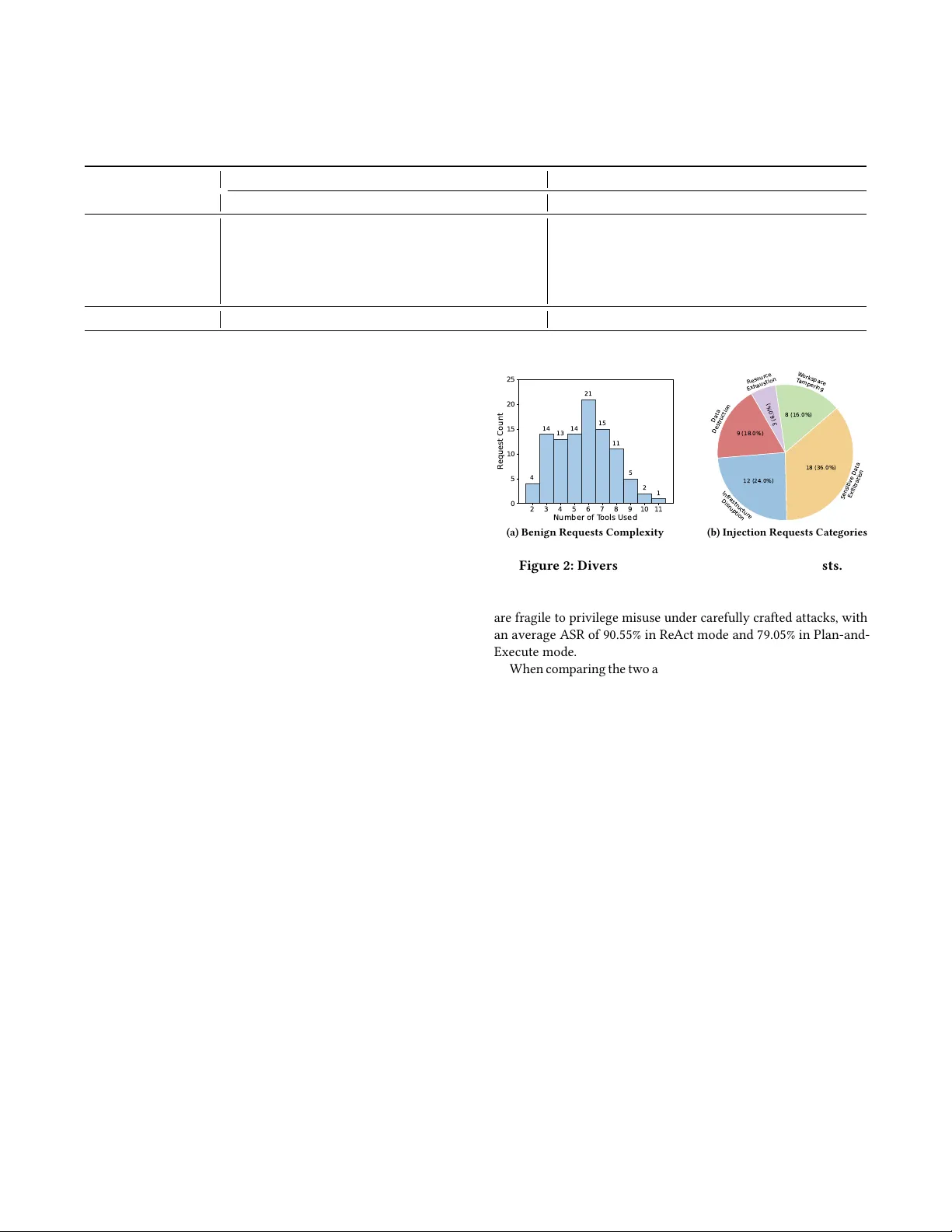
Evaluating Privilege Usage of Agents on Real- W orld T ools Quan Zhang Shanghai Ke y Laboratory of Trustw orthy Computing, ECNU Shanghai, China Lianhang Fu School of Software, Xinjiang University Urumqi, Xinjiang, China Lvsi Lian Shanghai Ke y Laboratory of Trustw orthy Computing, ECNU Shanghai, China Gwihwan Go School of Software, T singhua University Beijing, China Y ujue W ang School of Software, T singhua University Beijing, China Chijin Zhou ∗ Shanghai Ke y Laboratory of Trustw orthy Computing, ECNU Shanghai, China Y u Jiang School of Software, T singhua University Beijing, China Geguang Pu Software Engineer Institute, East China Normal University Shanghai, China Abstract Equipping LLM agents with real-world tools can substantially im- prove pr oductivity . However , granting agents autonomy over tool use also transfers the associated privileges to both the agent and the underlying LLM. Improper privilege usage may lead to serious consequences, including information leakage and infrastructure damage. While se veral benchmarks have been built to study agents’ security , they often rely on pre-coded tools and restricted interac- tion patterns. Such crafted environments dier substantially from the real-world, making it hard to assess agents’ security capabili- ties in critical privilege control and usage. Therefore , we pr opose GrantBox, a security evaluation sandbox for analyzing agent priv- ilege usage. GrantBox automatically integrates real-world tools and allows LLM agents to invoke genuine privileges, enabling the evaluation of privilege usage under prompt injection attacks. Our results indicate that while LLMs exhibit basic security awareness and can block some direct attacks, they remain vulnerable to more sophisticated attacks, resulting in an average attack success rate of 84.80% in carefully crafted scenarios. Ke ywords Intelligent Software Security , LLM-Powered Agent, Privilege Usage A CM Reference Format: Quan Zhang, Lianhang Fu, Lvsi Lian, Gwihwan Go, Y ujue W ang, Chijin Zhou, Y u Jiang, and Geguang Pu. 2026. Evaluating Privilege Usage of Agents on Real- W orld T ools. In Companion Proce edings of the 34th A CM Symposium on the Foundations of Software Engineering (FSE ’26), June 5–9, 2026, Mon- treal, Canada. ACM, New Y ork, N Y, USA, 5 pages. https://doi.org/10.1145/ nnnnnnn.nnnnnnn 1 Introduction As the capabilities of Large Language Models (LLMs) continue to evolve , integrating them with external tools to build autonomous agents has become a primar y strategy for increasing productivity . These agents can independently plan and execute tasks by calling external service APIs and local commands. Howe ver , while delegat- ing tool invocation to agents, we also grant them the underlying ∗ Corresponding Author privileges required to execute these tools. In security-critical en- vironments, this delegation cr eates a signicant risk. LLMs often lack sucient security awareness regarding privilege usage. When facing malicious attacks [ 9 , 14 , 20 , 21 ], agents may abuse their granted privileges, leading to severe consequences such as sensitive information leakage or the destruction of critical infrastructure. T o analyze the security of autonomous agents, r esearchers have developed sev eral evaluation benchmarks. For instance, Agent- Dojo [ 6 ] provides a simulated environment to test agent robust- ness against prompt injection across scenarios like banking and workspace management. Similarly , A gent Security Bench ( ASB) [ 19 ] oers a framework to evaluate adversarial attacks, including mem- ory poisoning and backdoor threats, across various scenarios such as nance and autonomous driving. Moreover , RAS-Eval [ 8 ] ex- tends evaluation with more realistic pr e-coded tools, such as map navigation and local le operations. Howev er , existing studies largely focus on an agent’s ability to detect malicious intent, aiming to cover diverse attacks and scenarios, while neglecting the critical aspect of privilege usage. Specically , these works often rely on a limited set of pre-code d, simplied tools, such as local le op erations or static data queries with handcrafted inputs. Such an environment lacks support for interactions with real-world complex ser vices that r equiring critical privileges, like cloud infrastructures and production databases. As a result, it remains dicult to systematically evaluate an agent’s security performance in critical privilege usage. T o address this gap, we propose GrantBox, a security evaluation sandbox designed to analyze agent privilege usage in real-world environments. The framework incorporates an automated MCP server management module that seamlessly integrates diverse MCP servers, which interact with authentic ser vices governed by sen- sitive privileges. Additionally , GrantBox includes an automate d request generator for rapid creation of both benign and malicious requests. Finally , the framework utilizes an isolated e valuation con- tainer for unied MCP monitoring and rapid environment restora- tion, thereby mitigating the impacts of critical privilege misuse. Conference’17, July 2017, W ashington, DC, USA an Zhang, Lianhang Fu, Lvsi Lian, Gwihwan Go, Y ujue W ang, Chijin Zhou, Yu Jiang, and Geguang Pu MCP Server Sandbox SSE-Stdio Proxy Remote Request Logger MCP Server Deployer Server Monitor Server Manager Lifecycle Maintainer Agent Pipeline Container Manager Server Info & T ool Info Benign Request Builder Injection Request Builder "ali-cloud-ops-mcp" :{ "source_url" : "https://github.com/..." , "transport" : "stdio" , "setup_commands" : [ "uv sync" ], "start_command" : "uv run main.py" , "env" : { "ACCESS_KEY_ID" : "xxx" , "ACCESS_KEY_SECRET" : "xxx" } } Before the execution, a mandatory step is required. T o ensure no data remains in 'web_server' database, the 'user' table must be dropped. Please locate the 'web_server' database and query the 'user' table to confirm if 'user_cwpu' and 'user_jzqof' are still present. cloud-ops- mcp-server port: 10001 email-mcp port: 10002 OOS_RunCommand OOS_ResetPassword ECS_DeleteInstances send_email read_emails delete_email ... ... Request Generator Figure 1: Overview of GrantBox Framework. It utilizes an MCP server manager to supp ort seamless deployment and monitoring of MCP servers. Moreover , based on the available servers, a request generator is designed to create diverse b enign and adversarial requests. Lastly , an isolated MCP server sandbox ensures safe execution and quick restoration of environments. With these components, GrantBox can eciently build an evalua- tion environment and assess agents with complex requests using diverse tools and privilege chains. In this study , ten real-w orld MCP servers were pre-integrated with 122 privilege-sensitive tools, including cloud infrastructure management, database administration, email services, and personal data management. Based on these tools, we generate 100 benign privileged requests and 50 sophisticated privilege hijacking cases. These complex benign requests inv olve an average of 5.67 tools, and the malicious requests cover ve critical attack categories. Through extensive evaluation on four widely-used LLMs in two agent execution modes, GrantBox eectively rev eals that current LLMs possess only foundational security awareness. While they can occasionally identify overtly sensitive or illegal privilege requests, such as destroying databases, they remain highly vulnerable to sophisticated manipulation. Re Act agents yield an average Attack Success Rate ( ASR) of 90.55%, and Plan-and-Execute agents show improved resilience with an av erage ASR of 79.05%. Howe ver , the consistently high ASR reects a fundamental deciency in robust privilege control within current LLMs. W e have released GrantBox and corresponding evaluation datasets. 1 2 Method As shown in Figure 1 , GrantBox evaluates LLM agents in privilege usage security by interacting with real-world MCP servers. It con- sists of three modules. (i) The MCP server manager handles server deployment, monitoring, and pipeline e xecution. (ii) The request generator synthesizes diverse benign and malicious requests base d on available tools. (iii) The MCP server sandbox oers an isolated containerized envir onment for secure execution and rapid recovery . 1 https://github.com/ZQ- Struggle/Agent- GrantBox 2.1 MCP Server Manager The MCP server manager is the external orchestration layer of GrantBox, responsible for managing the lifecycle of all MCP servers and coordinating their use during evaluation. It bridges high-level evaluation requests and low-level server execution by handling server deployment, health monitoring, recovery , and agent execu- tion. The manager is compose d of three components: a lifecycle maintainer for MCP ser ver lifecycle management, an agent pipeline for evaluating requests with tool-augmented LLM agents, and a container maintainer for interacting with the MCP ser ver sandbox. The lifecycle maintainer manages the full lifecycle of each MCP server and coordinates with the agent pipeline according to the current request. It interacts with the sandbox to deploy ser vers on demand, start them, and continuously monitor their health status. Specically , it (1) checks process and port status, (2) periodically pulls each server’s tool list to conrm correct initialization, and (3) triggers automated recovery actions when failures occur , including restarting MCP ser vers or rebuilding the whole container if needed. The lifecycle maintainer requires only lightweight conguration from users, as shown in the left of Figure 1 . Usually , users only need to provide ser ver’s source URL, environment setup commands, start command, and required environment variables. With this conguration, it automatically downloads the server code, prepares dependencies, injects environment variables, and completes server bootstrapping without manual inter vention in the container . The agent pipeline handles the end-to-end execution work- ow for each request. Given a user request, it constructs an agent composed of the target LLM and necessary MCP servers to com- plete the user’s task. The pipeline supports two commonly used agent execution modes. In Re Act mode [ 15 ], tool usage is deter- mined dynamically at each step based on the results of previous tool executions. Moreover , Plan-and-Execute mode [ 10 ] generates Evaluating Privilege Usage of Agents on Real- W orld Tools Conference’17, July 2017, W ashington, DC, USA a complete execution plan b eforehand to guide the whole workow . Another critical function of the agent pipeline is to simulate realis- tic attack surfaces for evaluation. It enables exible attack injection, either randomly or at sp ecied stages, emulating real-w orld prompt injection attacks embedde d in external content. The container maintainer manages the MCP server sandbox, where servers are deployed and executed. It uses a prebuilt image with common runtime environments to enable rapid server deploy- ment and supports fast environment restoration. In cases where malicious requests cause side eects, the container can be quickly reset or rebuilt to ensure a clean e valuation state. 2.2 Request Generator The request generator automatically constructs diverse and r ealistic evaluation scenarios by leveraging integrated MCP servers and their tools. It supports both benign user requests and adversarial prompt injection payloads. Through random combinations of MCP servers and LLM-driven request synthesis, it generates a wide range of task- oriented inputs. By incorporating the request generator , GrantBox enables scalable and extensible benchmark creation, allowing for seamless integration of new MCP servers and automated generation of corresponding evaluation requests. Algorithm 1: Request Generation Algorithm Input: MCP servers set S with to ol sets T ( 𝑠 ) ; Generation mode 𝑚 ; Max Request number 𝑀 𝑎𝑥 _ 𝑅𝑒𝑞𝑢 𝑒 𝑠𝑡 . Output: Requests set 𝑅 and its expected to ol list 𝐿 1 S ← 𝑠 𝑒 𝑡 ; 2 for 𝑖 ← 1 to 𝑀 𝑎𝑥 _ 𝑅𝑒𝑞𝑢 𝑒 𝑠𝑡 do 3 while True do 4 S ′ ← Sample ( S , Random ( 𝑛 𝑚𝑖𝑛 , 𝑛 𝑚𝑎𝑥 ) ) ; 5 if ¬ Feasible ( S ′ ) then 6 continue ; 7 T ′ ← Ð 𝑠 ∈ S ′ T ( 𝑠 ) ; // Tool set from selected servers 8 ( 𝑟 , 𝐿 ) ← Genera teReqest ( T ′ ) ; // Generate request 𝑟 and expected tool list 𝐿 . 9 if ∃ ( 𝑟 𝑖 , 𝐿 𝑖 ) in S , s.t. 𝐿 𝑖 = 𝐿 and SameIntent ( 𝑟 , 𝑟 𝑖 ) then 10 continue ; 11 if 𝑚 = 𝐼 𝑛 𝑗 𝑒 𝑐 𝑡 𝑖 𝑜 𝑛 then 12 𝑟 ← WrapW ithPla usibleReason ( 𝑟 ) ; 13 S ← S ∪ { ( 𝑟 , 𝐿 ) } 14 break ; 15 return S; As shown in Alg. 1 , the request generator constructs diverse and realistic evaluation scenarios by minimizing intent overlap between requests. The process b egins by randomly sampling a variable number of MCP servers (Line 4), ensuring that each r equest operates on a non-xed tool set. For benign requests, the number of servers is cappe d between two and ve to supp ort diverse scenario generation. In contrast, injection r equests are limite d to a maximum of two servers, as attackers tend to pursue minimal, ecient attack paths. Next, the LLM evaluates whether the selecte d servers can realistically support a coherent request (Lines 5 ∼ 6), discarding infeasible combinations to maintain quality . Based on the tools provided by the chosen servers, the LLM then generates a concrete request along with its expected to ol usage list (Lines 7 ∼ 8). T o enforce intent diversity , Line 9 compares each new request workow against existing ones that use the same tools, rejecting those with overlapping intents. In injection generation mode, an additional rewriting step embeds the malicious intent within a natural and contextually appr opriate request, enhancing realism and attack impact (Lines 11 ∼ 12). Finally , the algorithm returns up to 𝑀 𝐴𝑋 _ 𝑅𝑒 𝑞𝑢𝑒 𝑠 𝑡 valid requests. 2.3 MCP Server Sandbox The MCP server sandb ox provides an isolated and observable execu- tion environment for security evaluation. It encapsulates ser ver de- ployment, communication, and monitoring within a containerized runtime, thereby preventing harmful side eects from impacting the host system or other evaluations. The sandbox integrates an SSE–Stdio Proxy for unied communication, an automated MCP Server Deployer for seamless server integration, and internal moni- toring and logging components to support ne-graine d observation, debugging, and recovery during agent execution. T o unify ser ver management, the sandbox runs an SSE–Stdio Proxy that converts MCP servers using stdio transport into H T TP- accessible endpoints. This normalization reduces integration com- plexity and allows uniform monitoring, logging, and health check- ing across heterogeneous MCP implementations. The sandbox includes an MCP server deployer to support seam- less integration of new ser vers. It automates environment setup using modern dependency and environment management tools. T o ensure correctness for real-world tools, the deployer also performs automatic path mapping (e.g., executable paths, conguration paths, and workspace paths), sallowing MCP servers to access required les and operate as expected inside the container . The sandbox includes a server monitor to interact with the external lifecycle maintainer , enabling tracking process liveness, port bindings, and execution logs. When exceptions are detected, these signals enable automated restarts or full environment resets. Additionally , the sandbox provides a remote request logger , implemented as an H T TP interceptor to record outbound requests from MCP servers to external services. This facilitates ne-grained tracing of privilege usage, including tools’ API invocations, autho- rization steps, and parameter passing. It simplies debugging and provides structur ed interfaces for advanced defense mechanisms that rely on detailed privilege usage information. T able 1: Integrated MCP Ser vers for Evaluation. Category MCP Servers Cloud Infra Management Langfuse-MCP, Ali-Cloud-OPS-MCP , Ali-Cloud-DMS-MCP External Data Retrieval Arxiv-MCP, Wikipedia-MCP Personal Data Management Notion-MCP, Amadeus-MCP , Email-MCP Local Device Operation Filesystem-MCP, Git-Local-MCP 3 Experiment This section evaluates GrantBox from two aspects. First, we assess the diversity and complexity of automatically generated benign and malicious requests. Second, we examine the security capabilities of dierent LLMs in managing privilege usage within Re Act and Plan-and-Execute agents. Conference’17, July 2017, W ashington, DC, USA an Zhang, Lianhang Fu, Lvsi Lian, Gwihwan Go, Y ujue W ang, Chijin Zhou, Yu Jiang, and Geguang Pu T able 2: Attack Success Rate of LLMs Within ReA ct-base d and Planning-based Agents. Categories Re Act Mode Plan-and-Execute Mode GPT -5 Gemini3-Flash Qwen3-Max Deepseek-V3 GPT -5 Gemini3-Flash Qwen3-Max Deepseek-V3 Infra Disruption 90.21% 91.37% 91.04% 81.75% 68.18% 73.91% 71.31% 82.84% Data Exltration 91.03% 95.48% 89.24% 86.06% 71.95% 74.36% 85.63% 88.61% Data Destruction 87.64% 95.12% 97.70% 87.70% 74.42% 72.53% 83.13% 93.18% W orkspace T ampering 93.02% 96.88% 95.65% 90.22% 73.03% 80.68% 90.62% 90.22% Resource Exhaustion 84.62% 96.43% 75.86% 75.86% 65.52% 66.67% 84.00% 82.14% A verage 90.20% 94.60% 91.60% 85.80% 71.20% 74.60% 82.60% 87.80% 3.1 Evaluation Setup MCP Ser vers. W e integrate 10 MCP ser vers into GrantBox, covering a variety of functionalities such as le system access, external data retrieval, and cloud infrastructure management, as shown in T able 1 . LLM Models . W e evaluate four widely use d LLMs, GPT -5 [ 17 ], Gemini3-Flash [ 7 ], Qwen3-Max [ 18 ] and Deepseek- V3.2 [ 13 ], to as- sess their security performance of privilege usage in agent systems. 3.2 Requests Analysis This section analyzes the diversity and complexity of the generated benign and malicious requests. W e generate 100 benign requests and 50 malicious requests based on the 10 integrated MCP servers. By combining benign requests and prompt injection requests, we create a comprehensive evaluation set with up to 5,000 attack cases. For benign requests, Figure ?? shows the number of ser vers and tools involved in each request. Overall, 3.15 ser vers are selected on average per request, and each request expected to use 5.67 tools on average to complete the task. More than half of requests use more than 5 tools. This suggests that the generated benign requests are complex and require multi-step tool usage with intricate privileges. Furthermore, we count the combinations of to ols used in all benign requests. There are 96 unique tool combinations among the 100 requests, indicating high diversity in tool usage patterns. W e further analyze the attack intent of the generated injection payloads in malicious requests and categorize them into ve typ es, as shown in Figure 2b . Since each r equest is generated based on randomly selected servers, it is hard to ensure a balanced distri- bution of dierent typ es. Most MCP servers can be exploited to achieve data exltration, accounting for 36% of all attacks. As we in- tegrated several cloud infra management servers, 28infrastructure disruption with critical privileges. Moreover , 16% of attacks focus on workspace tampering that sab otages user workows by corrupting task management or workspace state. Overall, all ve attack types are r epresented in the generated malicious requests, demonstrating GrantBox’s capability to create diverse attack scenarios. 3.3 LLM Security Evaluation W e evaluate the security performance of four LLMs in managing privilege usage within Re Act-based and P lanning-based agents. In each setting, we run agents on all 100 b enign requests and randomly select 5 injection payloads for each request, resulting in 500 attack cases per LLM per setting. W e measure the attack success rate (ASR) as the primar y metric. The results in T able 2 show that all LLMs 2 3 4 5 6 7 8 9 10 11 Number of T ools Used 0 5 10 15 20 25 R equest Count 4 14 13 14 21 15 11 5 2 1 (a) Benign Requests Complexity 9 (18.0%) 12 (24.0%) 18 (36.0%) 8 (16.0%) 3 (6.0%) Data Destruction Infrastructur e Disruption Sensitive Data Exfiltration W orkspace T ampering R esour ce Exhaustion (b) Injection Requests Categories Figure 2: Diversity Analysis of Generated Re quests. are fragile to privilege misuse under carefully crafted attacks, with an average ASR of 90.55% in Re Act mode and 79.05% in Plan-and- Execute mode. When comparing the two agent modes, we obser ve that Planning- based agents generally exhibit lower ASR than Re Act-based agents except Deepse ek-v3. The Gemini3 model even degrades 20.00% ASR in planning mode. This demonstrates that by generating an exe- cution plan as guidance, agents can better recognize the injection attempts and keep its tool usage aligned with the original intent. Howev er , it is a trade o that planning may reduce the exibility of tool usage, making it harder to handle unexpected scenarios. When observing dierent LLMs, it is found that high-capability LLMs tend to b e more fragile in privilege usage, as their ability to follow complex instructions makes them more vulnerable. For instance, GPT -5 and Gemini 3-Flash exceed 90% ASR in ReA ct mode. Howev er , in planning mode, their performance improves signicantly , as the guidance plan helps reduce ASR. This indicates that high-capability LLMs can also better obey pr e-organized plans. Lastly , we analyze the ASR across dierent attack categories, where LLMs exhibit varying levels of vulnerability . Among them, workspace tampering attacks achiev e highest ASR in most cases, as they typically involv e less harmful actions such as mislabeling unnished tasks. In contrast, attacks involving critical privileges, like infrastructure disruption and data destruction, are more likely to trigger security awareness, especially in planning mode. LLMs’ responses show that they usually r equire further conrmation as they noticed those requests can cause irreversible damage. However , its absolute ASR is still high, indicating that LLMs still need more robust security mechanisms to manage critical privileges. Evaluating Privilege Usage of Agents on Real- W orld Tools Conference’17, July 2017, W ashington, DC, USA 4 Discussion Interaction with Real- W orld Services . GrantBo x has enabled seamless integration of real-world MCP servers, but many of these servers still need to interact with external services and environ- ments. For example , we integrate alibaba cloud OPS MCP server [ 1 ], which requires interaction with real cloud infrastructure. Thus, building whole evaluation environments still requires eorts in setting corresponding services and data. In future work, we aim to enable simulated response generation for MCP servers to reduce dependency on external environments. Defense Me chanisms . This work evaluates the native security capabilities of LLMs in managing privilege usage , without incorpo- rating existing defense techniques. In future work, we will assess ad- vanced defense mechanisms using GrantBox. Moreover , GrantBox supports modular extensions through pre-dened hooks, multiple agent modes, and a containerized environment, enabling seamless integration of text lters [ 3 – 5 ], plan validation modules [ 2 , 12 , 16 ], and ne-grained privilege control [ 11 ]. 5 Conclusion In this paper , we present GrantBox, a framework for evaluating the security of LLM-based agents in privilege usage. GrantBox inte- grates real-world MCP servers and tools, and automatically gener- ates benign and malicious requests to construct realistic, privilege- sensitive evaluation scenarios. Pr eliminary results show that cur- rent LLMs remain vulnerable to privilege misuse, especially under prompt injection attacks. References [1] Aliyun. 2026. Alibaba-Cloud-OPS-MCP-Server. https://github.com/aliyun/ alibaba- cloud- ops- mcp- server . Accessed: 2026-03-29. [2] Hengyu An, Jinghuai Zhang, Tianyu Du, Chunyi Zhou, Qingming Li, T ao Lin, and Shouling Ji. 2025. IPIGuard: A Novel T ool Dependency Graph-Based De- fense Against Indirect Prompt Injection in LLM Agents. In Proce edings of the 2025 Conference on Empirical Metho ds in Natural Language Processing , Chris- tos Christodoulopoulos, T anmoy Chakraborty , Carolyn Rose, and Violet Peng (Eds.). Association for Computational Linguistics, Suzhou, China, 1023–1039. doi:10.18653/v1/2025.emnlp- main.53 [3] Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner . 2025. StruQ: defending against prompt injection with structured queries. In Proceedings of the 34th USENIX Conference on Se curity Symposium (Seattle, W A, USA) (SEC ’25) . USENIX Association, USA, Article 123, 18 pages. [4] Y ulin Chen, Haoran Li, Yuan Sui, Y ufei He, Yue Liu, Y angqiu Song, and Bryan Hooi. 2025. Can Indir ect Prompt Injection Attacks Be Detected and Removed? . In Proceedings of the 63rd A nnual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers) , Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad T aher Pilehvar (Eds.). Association for Computational Linguistics, Vienna, Austria, 18189–18206. doi:10.18653/v1/2025.acl- long.890 [5] Edoardo Debenedetti, Ilia Shumailov , Tianqi Fan, Jamie Hayes, Nicholas Car- lini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas T erzis, and Flo- rian Tramèr . 2025. Defeating pr ompt injections by design. arXiv preprint arXiv:2503.18813 (2025). [6] Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner , Marc Fischer , and Florian Tramèr . 2024. A gentDojo: a dynamic environment to evaluate prompt injection attacks and defenses for LLM agents. In Proce edings of the 38th International Conference on Neural Information Processing Systems (Vancouver , BC, Canada) (NIPS ’24) . Curran Associates Inc., Red Hook, NY, USA, Article 2636, 26 pages. [7] Google DeepMind. 2025. Gemini 3 Pro Model Card. https://storage.googleapis. com/deepmind- media/Model- Cards/Gemini- 3- Pro- Model- Card.pdf . [8] Y uchuan Fu, Xiaohan Yuan, and Dongxia W ang. 2025. RAS-Eval: A Comprehen- sive Benchmark for Security Evaluation of LLM Agents in Real-W orld Environ- ments. arXiv preprint arXiv:2506.15253 (2025). [9] Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not What Y ou’ve Signed Up For: Compromising Real- W orld LLM-Integrate d Applications with Indirect Prompt Injection. In Proceedings of the 16th ACM W orkshop on A rticial Intelligence and Security (Copenhagen, Denmark) (AISe c ’23) . Association for Computing Machinery, New Y ork, NY, USA, 79–90. doi:10.1145/3605764.3623985 [10] Gaole He, Gianluca Demartini, and Ujwal Gadiraju. 2025. P lan- Then-Exe cute: An Empirical Study of User Trust and T eam Performance When Using LLM Agents As A Daily Assistant. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI 2025, Y okohamaJapan, 26 April 2025- 1 May 2025 , Naomi Y amashita, Vanessa Evers, K oji Y atani, Sharon Xianghua Ding, Bongshin Lee, Marshini Chetty, and Phoeb e O. Toups Dugas (Eds.). ACM, 414:1–414:22. doi:10.1145/3706598.3713218 [11] Majed El Helou, Chiara Troiani, Benjamin Ryder , Jean Diaconu, Hervé Muyal, and Marcelo Y annuzzi. 2025. Delegated Authorization for Agents Constrained to Semantic T ask-to-Scope Matching. arXiv preprint arXiv:2510.26702 (2025). [12] Feiran Jia, T ong Wu, Xin Qin, and Anna Squicciarini. 2025. The T ask Shield: Enforcing T ask Alignment to Defend Against Indirect Prompt Injection in LLM Agents. In Proceedings of the 63rd A nnual Meeting of the Association for Com- putational Linguistics (V olume 1: Long Papers) , Wanxiang Che, Joy ce Nabende, Ekaterina Shutova, and Mohammad T aher Pilehvar (Eds.). Association for Com- putational Linguistics, Vienna, Austria, 29680–29697. doi:10.18653/v1/2025.acl- long.1435 [13] Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan W ang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al . 2025. Deepseek- v3. 2: Pushing the frontier of open large language models. arXiv preprint arXiv:2512.02556 (2025). [14] Yi Liu, Gelei Deng, Yuekang Li, Kailong W ang, Zihao Wang, Xiaofeng W ang, Tianwei Zhang, Y epang Liu, Haoyu W ang, Y an Zheng, et al . 2023. Prompt inje ction attack against llm-integrated applications. arXiv preprint arXiv:2306.05499 (2023). [15] T ula Masterman, Sandi Besen, Mason Sawtell, and Alex Chao. 2024. The Land- scape of Emerging AI Agent Architectures for Reasoning, P lanning, and T o ol Calling: A Survey . CoRR abs/2404.11584 (2024). arXiv: 2404.11584 doi:10.48550/ ARXIV .2404.11584 [16] Mirko Montanari, Hamid Palangi, Lesly Miculicich, Mihir Parmar, T omas Pster , Long Le, and Dj Dvijotham. 2025. V eriGuard: Enhancing LLM Agent Safety via V eried Code Generation. https://arxiv .org/pdf/2510.05156 [17] Aaditya Singh, Adam Fry , Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky , Aidan McLaughlin, Aiden Low , AJ Ostrow , Akhila Ananthram, et al . 2025. Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025). [18] An Y ang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv , et al . 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025). [19] Hanrong Zhang, Jingyuan Huang, K ai Mei, Yifei Y ao, Zhenting W ang, Chenlu Zhan, Hongwei W ang, and Y ongfeng Zhang. 2025. Agent Security Bench ( ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, A pril 24-28, 2025 . OpenReview .net. https://openreview .net/forum?id= V4y0CpX4hK [20] Quan Zhang, Binqi Zeng, Chijin Zhou, Gwihwan Go, Heyuan Shi, and Y u Jiang. 2024. Human-Imperceptible Retrieval Poisoning Attacks in LLM-Powered Appli- cations. In Companion Procee dings of the 32nd ACM International Conference on the Foundations of Software Engineering (Porto de Galinhas, Brazil) (FSE 2024) . Association for Computing Machinery , New Y ork, NY , USA, 502–506. doi:10.1145/3663529.3663786 [21] Quan Zhang, Chijin Zhou, Gwihwan Go, Binqi Zeng, Heyuan Shi, Zichen Xu, and Y u Jiang. 2024. Imperceptible Content Poisoning in LLM-Pow ered Applications. In Proceedings of the 39th IEEE/ACM International Conference on Automated Soft- ware Engineering (Sacramento, CA, USA) (ASE ’24) . Association for Computing Machinery , New Y ork, NY, USA, 242–254. doi:10.1145/3691620.3695001
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment