Quid est VERITAS? A Modular Framework for Archival Document Analysis
The digitisation of historical documents has traditionally been conceived as a process limited to character-level transcription, producing flat text that lacks the structural and semantic information necessary for substantive computational analysis. …
Authors: Leonardo Bassanini, Ludovico Biancardi, Alfio Ferrara
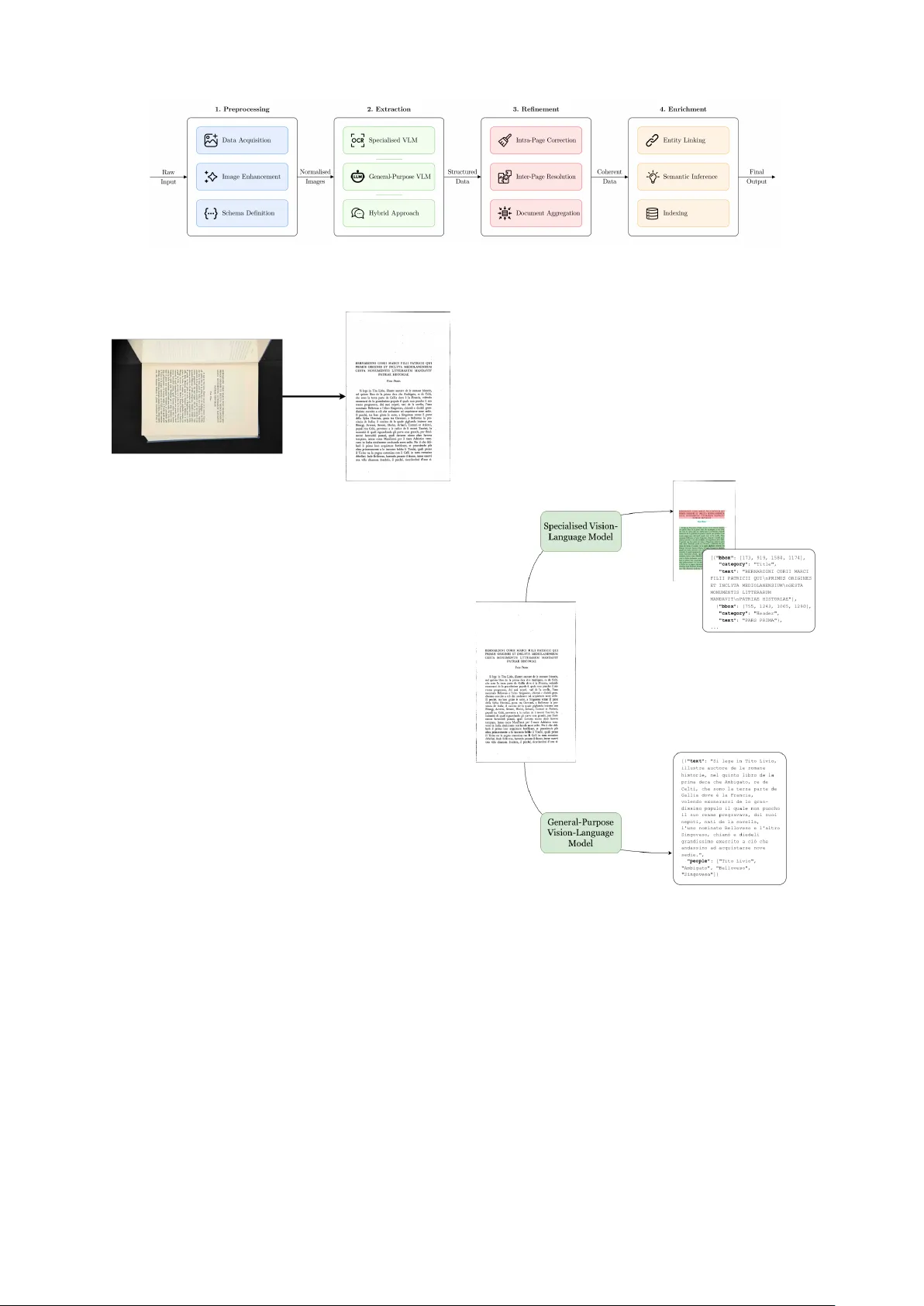
Quid est VERIT AS? A Modular F ramework f or Archival Document Analy sis Leonardo Bassanini 1 , Ludo vico Biancardi 1 , Alfio Ferrara 2 , Andrea Gamberini 3 , Sergio Picascia 4 ∗ , Folco V aglienti 3 1 Università degli Studi di Milano, University Library Ser vice Via Santa Sofia, 7/9 - 20122 Milano (Italy) leonardo.bassanini@unimi.it, ludovico.biancardi@unimi.it 2 Università degli Studi di Milano, Depar tment of Literary Studies, Philology and Linguistics Via Festa del P erdono, 7 - 20122 Milano (Italy) alfio.ferrara@unimi.it 3 Università degli Studi di Milano, Depar tment of Historical Studies Via Festa del P erdono, 7 - 20122 Milano (Italy) andrea.gamberini@unimi.it, folco.vaglienti@unimi.it 4 Università degli Studi di Milano, Depar tment of Computer Science Via Celoria, 18 - 20133 Milano (Italy) sergio.picascia@unimi.it Abstract The digitisation of historical documents has traditionally been conceiv ed as a process limited to character -lev el transcription, pr oducing flat te xt that lacks the structur al and semantic information necessary for substantiv e computational analysis. W e present VERIT AS (Vision-Enhanced R eading, Interpretation, and T ranscription of Archival Sources), a modular , model-agnostic framework that reconceptualises digitisation as an integrated workflow encompassing tr anscription, la yout analy sis, and semantic enrichment. The pipeline is organised into four stages—Preprocessing, Extraction, Refinement, and Enrichment—and em plo ys a schema-driven architecture that allows researchers to declarativel y specify their extr action objectives. We evaluat e VERIT AS on the critical edition of Bernardino Corio’ s Storia di Milano , a Renaissance chronicle of over 1,600 pages. Results demonstrate that the pipeline achiev es a 67.6% relative reduction in word error rate compared to a commercial OCR baseline, with a threefold reduction in end-to-end processing time when accounting for manual correction. We fur ther illustrate the downstream utility of the pipeline’s output by quer ying the transcribed corpus through a retriev al-augmented generation system, demonstrating its capacity to suppor t historical inq uiry . Ke ywords: vision language models, document layout analysis, historical document digitisation, digital hu- manities 1. Introduction The digitisation of historical documents has long been conceived as a process whose primar y ob- jective is the faithful transcription of textual content into machine-readable form. Under this paradigm, the output is flat te xt : a character sequence suit- able for keyword search but lac king the structural, semantic, and relational information necessar y for substantive scholarly inquir y . This limitation stems from an entrenched architectural assum ption that semantic enrichment constitutes a separate, down- stream task. In practice, this separation means that the majority of digitised collections nev er re- ceive such enrichment, as the resources required to revisit already-processed materials and ex ecute enrichment pipelines are rarely av ailable. The con- sequence is a widening gap between the volume of digitised material and the volume that is gen- uinely searchable, interoperable, and amenable to computational analysis. W e argue that o ver coming this gap requir es reconceptualising digitisation itself: rather than treating semantic enrichment as optional post- processing, it should be an int egral component of the digitisation workflow , producing structured, semantically annotated digital objects. The feasi- bility of this shift is enabled by recent advances in foundation models, par ticularly vision-language models (VLMs) and large language models (LLMs). Unlike traditional OCR systems, which operate at the character lev el with no aw areness of document semantics, VLMs can jointly process visual and te x- tual information, performing lay out analysis, tran- scription, and content interpretation within a unified infer ence pass. LLMs, in turn, can be lev eraged for downstream semantic tasks pre viously requiring dedicated, task -specific systems. T ogether , these technologies make it viable to construct pipelines trav ersing the full arc from raw image to semanti- cally enriched digital object in a single automated workflow . In this paper , we present VERIT AS (Vision- Enhanced Reading, Interpretation, and T ranscrip- tion of Archival Sources), a modular framework that operationalises this integrat ed approach. VERIT AS is organised into four seq uential stages, each con- stituting a self-contained module with well-defined inputs and outputs. The framework is model- agnostic: individual components can be substituted as newer models become av ailable without archi- tectural modifications. A schema-driven extr action process allows researchers to configure the target data structure according to their analytical objec- tives. We ev aluate VERIT AS on Bernardino Corio’ s St oria di Milano , a Renaissance chronicle of ov er 1,600 pages, demonstrating substantial impro ve- ments o ver a commercial OCR baseline in bot h transcription accuracy and processing efficiency . F ur thermore, we illustrate downstream utility by submitting the complete transcription to a retrie val- augmented generation (RAG) syst em and posing historically motiv ated research questions. 2. Related W ork The automated processing of historical documents has attracted growing attention at the intersection of computer science and the digital humanities. W e re view the relev ant literature across two areas: tran- scription technologies and integrat ed digitisation pipelines. 2.1. T ranscription of Historical Documents The transcription of historical documents has ev olved through sev eral technological paradigms. Commercial OCR engines such as T esser - act ( Smit h , 2007 ) have long served as default tools; howe ver , their reliance on charact er -lev el pattern matching renders them ill-suited to the de- graded image quality , irregular lay outs, and ar - chaic typographic conv entions of historical materi- als. Deep learning substantially improv ed capabili- ties for such documents. T ranskribus ( Kahle et al. , 2017 ; Muehlberger et al. , 2019 ), developed within the EU-funded READ project, became one of the most widely adopted platforms for automatic te xt recognition in the humanities. In parallel, eScrip- torium ( Kiessling et al. , 2019 ) extended recogni- tion to non-Latin and bidirectional writing systems. While both platforms significantly lowered the bar - rier of entr y , they remain primarily interactiv e tools requiring manual ground-truth preparation, model training, and post-hoc correction. Generative AI has opened new a venues for his- torical document transcription. One line of re- search e xplores LLMs as post-OCR correctors: Thomas et al. ( 2024 ) demonstrated that instruction- tuned Llama 2 models can achieve a 54.5% reduc- tion in character error rate on 19th-century British newspapers, though subseq uent studies repor ted mix ed r esults in multilingual conte xts ( Kanerva et al. , 2025 ; Boros et al. , 2024 ). A more recent line of research has shif ted focus to direct tran- scription through vision-l anguage models (VLMs), which jointly process visual and te xtual information end-to-end without a separate OCR stage. Sev - eral ev aluations demonstrate that VLMs can match or surpass dedicated OCR systems: Humphries et al. ( 2024 ) reported character error rates of 5– 7% on 18th–19th century English manuscripts, Kim et al. ( 2025 ) f ound general-purpose VLMs outperforming traditional OCR on historical tab- ular documents, and Le vchenk o ( 2025 ) bench- marked 12 multimodal LLMs on 18th-century Rus- sian te xts, highlighting both promise and pitfalls such as ov er -hist oricisation . On the specialised side, CHURR O ( Semnani et al. , 2025 ), a 3B- paramet er VLM fine-tuned on 155 historical cor - pora spanning 46 language clusters, demonstrated that targeted training yields accuracy superior to commercial alternatives at a fraction of the cost. VERIT AS builds on this latter paradigm, employing VLMs as its primar y extr action mechanism while retaining flexibility for LLM-based refinement. 2.2. Integrated Digitisation Pipelines While significant progress has been made on indi- vidual components, few er effor ts have addressed their integration into end-to-end pipelines. The OCR-D project ( Neudec k er et al. , 2019 ) developed a modular framework for OCR processing of histor - ical printed documents in German libraries, empha- sising interoperability t hrough standardised formats, though its scope does not extend to semantic en- richment. The DAHN project ( Chiffoleau , 2024 ) pro- posed a TEI-centred pipeline comprising six stages, lev eraging eScriptorium for HTR and TEI Publisher for dissemination, representing an impor tant step but remaining oriented tow ards digital scholarly edi- tions rather than flexible data extraction. At larger scales, SocF ace ( Boillet et al. , 2024 ) demonstrated end-to-end pipelines for F rench censuses, and Con- stum et al. ( 2024 ) proposed an approach for hand- written Parisian marriage records. These effor ts, howe ver , tend to be tightly coupled to specific doc- ument genres. VERIT AS ext ends this body of work in several respects. Unlik e inter active platforms such as T ran- skribus and eScriptorium, it operates as a fully auto- mated, configurable pipeline. Unlike OCR-focused frameworks such as OCR-D, it ext ends bey ond transcription to encompass semantic enrichment, entity linking, and structured data inde xing. Its model-agnostic architecture provides fle xibility ab- sent from existing designs. Finally , by demonstrat- ing downstr eam utility for LLM-assisted scholarly inquir y (Section 5 ), we address a gap where evalua- tion typically stops at transcription accuracy without assessing usability for substantive research. 3. Methodology VERIT AS (Vision-Enhanced Reading, Int erpreta- tion, and T ranscrip tion of Archiv al Sources) is designed to transform raw historical documents into structured, semantically enriched, machine- readable data. By lev eraging VLMs and LLMs, the pipeline e xtends digitisation be yond character -lev el transcription towards com prehensiv e document un- derstanding. The architecture is model-agnostic, al- lowing practitioners to substitute models optimised for par ticular languages or document types with- out architectural modifications. Combined with schema-driven extraction, this ensures broad ap- plicability across diverse archival collections. The pipeline comprises four sequential stages—Preprocessing, Extraction, Refinement, and Enrichment—each a self-contained module with well-defined inputs and standardised out- puts (Figure 1 ). Individual components can be activat ed, bypassed, or substituted according to project requirements. Throughout this section, we illustrate operations using pages from the case study in Section 4 : the critical edition of Bernardino Corio’ s Storia di Milano (1978), a Renaissance chronicle of ov er 1,600 pages. 3.1. Pr eprocessing The Preprocessing stage transforms het eroge- neous raw inputs into a standardised format suit- able for automat ed analysis through three opera- tions. Data Conversion . The pipeline accepts input for - mats commonly encounter ed in archival research, e.g. digitised PDFs, individual page scans (TIFF , JPEG, PNG), and photogr aphs captured with hand- held devices, and converts them into a uniform rep- resentation, ensuring that all subseq uent pipeline stages operate on a homogeneous, high-quality image format. Each input is rendered as a high- resolution raster image normalised to a consistent colour space and resolution. Image Enhancement . Optional computer vi- sion techniques ma y be applied to the normalised images: deske wing (correcting rotational misalign- ment), denoising (remo ving noise, stains, or scan- ning ar tifacts), binarisation (converting to black - and-white to increase te xt-background contrast), and page detection (isolating the document area from extraneous background elements). The spe- cific enhancement operations applied are config- urable based on the quality and characteristics of the source materials. Figure 2 shows the result of these operations conducted on an image from the proposed case study . Schema Definition . This operation constitutes the critical inter face between scholarly intent and machine-processable output: analytical require- ments are formalised into a structured specification determining what information the pipeline extracts and in what form. The schema, typically e xpressed in JSON Schema, defines the semantic fields to populate for each document element, and det er - mines the tools employ ed in subsequent stages. Its design is a collaborativ e e xer cise between domain experts, who ar ticulate driving research questions, and technical personnel, who translate these into formal specifications. Below is an illustrativ e e xam- ple. { "type": "object", "properties": { "bbox": { "type": "array", "items": { "type": "integer" } }, "category": { "type": "string", "enum": ["title", "text", "header", "footnote", "figure", "table"] }, "text": { "type": "string" }, "speaker": { "type": "string" }, "date": { "type": "string" }, "place": { "type": "string" }, "entities": { "type": "array", "items": { "type": "object", "properties": { "mention": { "type": "string" }, "type": { "type": "string", "enum": ["person", " institution", "place"] }}}}}, "required": ["bbox", "category", "text"] } 3.2. Extr action The Extraction stage constitutes the core of the pipeline, per forming the transformation of visual information into machine-readable structured data. This stage is designed with high modularity , offering three distinct processing paths that can be selected based on project requirements, available compu- tational infrastructur e, and the com ple xity of the target extraction tasks. • Specialised Vision-Language Models . Com- pact, resource-efficient VLMs optimised for document analysis, achieving high accuracy in la yout det ection, te xt localisation, reading order determination, and transcription. Their advantage lies in computational efficiency and transcription fidelity; howev er , they operate ac- cording to a fix ed output schema and cannot Figure 1: VERIT AS architectur e diagram illustrating the four stages and their inputs and outputs. Figure 2: Prepr ocessing operations applied to a page from the critical edition of Corio ’s Storia di Milano . Left: the original colour scan, captured in landscape orientation with por tions of the adjacent page visible. Right: the result af ter rotation cor - rection, page detection, gra yscale conversion, and adaptive thresholding. accommodate arbitrar y user -defined instruc- tions. • General-Purpose Vision-Language Mod- els . Large-scale VLMs capable of process- ing both visual and te xtual information. While potentiall y exhibiting marginally lower per - formance on specialised document analysis benchmarks compared to the previous mod- els, their strengt h resides in flexibility : user s provide natural language instructions to guide extr action towards specific information needs bey ond conventional transcription. • Multi-Step Hybrid Approach . Combines both approaches through a two-phase process: a specialised VLM per forms foundational la yout detection and transcription, then a general- purpose LLM or VLM refines and enhances extr action according to user -specified instruc- tions. This path suits complex documents re- quiring both accurate transcription and sophis- ticated semantic interpretation. The selection among these paths is determined by the interpla y of sever al factors, including the av ailable com putational resources, the quality and complexity of the source documents, and the depth of semantic analysis required. F or projects priori- tising transcription accuracy with minimal compu- tational overhead, the first path offer s an efficient solution. For projects requiring flexible, instruction- guided extraction or semantic infer ence, the sec- ond and third path are more appropriate. Figure 3 contrasts the predefined output of a specialised VLM against the more flexible output of a general- purpose VLM per forming semantic infer ence. Figure 3: The difference in output between the Spe- cialised Vision-Language Model and the General- Purpose Vision-Language Model processing paths. 3.3. Refinement The Refinement stage transforms the collection of page-lev el extraction outputs into a single, coherent document representation through a series of clean- ing, consolidation, and aggregation operations. Intra-Page Corr ection . This operation ad- dresses ar tifacts and inconsistencies within individ- ual page outputs. T ypical corrections include the reconstruction of h yphenated w ords split across line breaks, normalisation of typographic conventions (e.g., unifying quotation mark styles, standardising whitespace), and validation of the extract ed data against the defined schema to ensure structural integrity . Inter -Page Resolution . This operation resolves dependencies and continuities that span page boundaries. In historical documents, content units frequently ext end across multiple pages, e.g a newspaper ar ticle beginning on one page and con- cluding on another , or a parliamentar y speech span- ning several folios. Inter -page resolution ensures that such fragmented content is correctly identified and linked, and that metadata is propagated appro- priately across page breaks. Document Aggregation . The refined page- lev el outputs are merged into a unified data struc- ture representing the complete source document. This aggregation produces a single coherent object that ser ves as input to the subsequent Enrichment stage. 3.4. Enrichment The Enrichment stage enhances the value of the structured data by connecting it to e xternal knowl- edge sources, obtaining additional semantic in- sights, and preparing it for storage and downstream analysis. Entity Linking . Named entities identified within the transcribed te xt—such as per sons, organisa- tions, and locations—are disambiguated and linked to canonical identifiers in e xternal knowledge bases (e.g., Wikidata, VIAF , or domain-specific authority files). This process not only resolves ambiguities (e.g., distinguishing between individuals sharing the same name) but also situates the document within a broader knowledge graph, enabling cross- refer encing and relational queries. Semantic Inference . This operation lev erages LLMs to perform advanced analytical tasks and in- fer information not explicitly present in the source te xt. Depending on the research objectiv es, such tasks may include topic classification, sentiment analysis, event extraction, temporal reasoning, named entity recognition for domain-specific entity types, or abstractive summarisation. The schema- driven architectur e of the pipeline allows these in- ferred annotations to be sys tematically incor po- rated into the structured output. These operations can be also performed with general-purpose VLMs during the Extraction stage. Indexing . The inde xing operation formats the enriched data according to established standards appropriate to the target research community and loads it into suitable storage syst ems. For human- ities scholarship, standard serialisation formats such as XML - TEI (T e xt Encoding Initiative) facili- tate interoperability with existing digital humanities infrastructures. For quantitative analysis, tabular formats (e.g., CS V) or integration with database syst ems (e.g., relational databases, full-text search engines, vect or or graph databases) enable effi- cient quer ying and statistical processing. Figure 4 shows different ex amples of Enrichment operations: through semantic inference we can ex- tract named entities, e.g. people and places; an encoder can com put e the embedding of a te xtual el- ement to index it for semantic search; we can match the entities within the te xt with ext ernal knowledge bases. Figure 4: Examples of Enrichment operations. 4. Evaluation T o assess the effectiveness of the VERIT AS pipeline, we conducted an em pirical ev aluation on a representativ e historical document collection. This ev aluation focused on two primary dimensions: (i) transcription accuracy , measured through standard OCR quality metrics, and (ii) computational effi- ciency , assessed via processing time analysis. Ad- ditionally , we evaluat ed the pipeline ’s capacity for accurate lay out analysis and element extraction. 4.1. Case Study The evaluation was conducted on the Storia di Mi- lano ( Hist ory of Milan ), a Renaissance chronicle authored by Bernardino Corio (1459–c. 1519). The digitisation of this work was undertaken as par t of a broader interdisciplinary project at our univer - sity , bringing together historians, computational lin- guists, and computer scientists with the shared objective of making this primary source accessi- ble for large-scale computational analysis. Corio ’s work constitutes one of the most significant sources for the histor y of the Duchy of Milan, spanning from antiquity to the late fifteenth centur y . For this study , we employed the critical edition curated by Anna Morisi Guerra, published by UTET (T urin) in 1978 as par t of the Classici della St oriogr afia series ( Corio , 1978 ). The edition com prises two volumes totalling 1,688 pages. Although this critical edition employ s modern ty- pography , thereb y avoiding the challenges posed by historical typefaces or manuscrip t hands, it nonetheless presents a rich varie ty of difficulties for automated processing that motiv ated its selection as an e valuation testbed. The text alternat es be- tween vernacular and modern Italian, requiring the extr action syst em to handle two distinct languages within a single document flow . The page lay outs are heterogeneous, com prising dense prose, e xten- sive footnot es, illustrative figures, tables, indices, and front matter , each demanding correct identi- fication and classification by the layout analysis component. 4.2. Evaluation Methodology Ground T ruth Construction . A subset of 100 pages was selected from the corpus using strati- fied sampling to ensure adequate representation of the diverse page lay outs present in the edition (e.g., pages with dense prose, pages with exten- sive footno tes, title pages, and pages containing illustrations or tables). Three domain e xper ts, work - ing from a shared set of transcription guidelines, manually transcribed these pages to establish a ref- erence ground truth. Additionally , the structural ele- ments identified by the vision-language model (te xt, headers, foo tnotes, etc.) were manually v erified and correct ed by the same annotators to pro vide ground truth for lay out analysis evaluation. Baseline . T o conte xtualise the per formance of the VERIT AS pipeline, we compared it against AB- B YY FineReader , a widely adopted commercial OCR solution that is also the standard digitisation tool currently employ ed by our university librar y . The sof tware was ex ecuted with default configura- tion settings, which is appropriate given that the critical edition employ s modern typefaces that do not require specialised historical document profiles. Pipeline Configuration . For this ev aluation, the VERIT AS pipeline was configured as follows. In the preprocessing stage, several image normalisation operations were applied to address ar tifacts intro- duced during digitisation. The original scans were captured in landscape orientation with por tions of adjacent pages par tially visible in the frame; fur - thermore, the scans were acquired in colour . T o prepare the images for extraction, we applied ro- tation correction to restor e por trait orientation, em- ploy ed an object detection model to identify and isolate the region of inter est corresponding to the target page ( Boillet et al. , 2021 ), and converted the images to gra yscale. Additionally , adaptiv e thresh- olding techniques were applied to enhance te xt- background contrast and improv e content legibility . For the extr action stage, the pipeline was config- ured to use P ath A (Specialised Vision-Language Models), employing a document-specialised VLM, specifically , dots.ocr ( Li et al. , 2025 ), followed by minimal post-processing operations consisting of end-of-line hyphenation correction and output format normalisation (remov al of mar kdown ar te- facts). Metrics . T r anscription quality was assessed us- ing two standard metrics: Word Error Rate (WER), defined as the minimum number of word-lev el in- ser tions, deletions, and substitutions required to transform the pr edicted transcription into t he ground truth, normalised by the total number of words in the refer ence; and Character Error Rate (CER), anal- ogously defined at the character lev el, pro viding a finer-gr ained assessment of transcription fidelity . Both metrics wer e computed at the corpus level, i.e., ov er the concatenat ed te xt of all evaluat ed pages, to av oid potential bias introduced by page-length vari- ability . T o isolate substantive transcription errors from superficial formatting differences, we repor t results under two conditions: Ra w (no normalisa- tion) and Normalised (text conv er ted to lowercase with punctuation removed). We also ev aluated el- ement extraction computing the F1 Score: an ex- tracted element w as considered a true positive if it matched a ground-truth element in both spatial location (bounding box ov erlap) and semantic la- bel; false positives comprised spurious detections or incorrect label assignments; false negatives rep- resented missed elements. 4.3. Results T able 1 presents the corpus-lev el transcription error rates for both sys tems. The results demonstrat e that the VLM-based approach employ ed in VERI- T AS consistently outper forms the commercial base- line across all metrics and normalisation conditions. Under normalised ev aluation, VERIT AS achiev es a WER of 1.1% and a CER of 0.7%, repr esenting relativ e improv ements of 67.6% and 50.0%, respec- tively , compared to ABB YY FineReader . The per - formance gap is even more pronounced under raw ev aluation conditions. ABB YY VERIT AS T ext WER CER WER CER Ra w 0.142 0.031 0.055 0.013 Normalised 0.034 0.014 0.011 0.007 T able 1: Corpus-level transcription error rates com- puted o ver the concatenated te xt of all 100 ev al- uated pages. Low er values indicate better per for - mance. Regarding processing efficiency , while the VLM- based approach incur s substantially higher compu- tational cost per page when processed individually (46 seconds versus 4 seconds for ABB YY), modern inference framew orks enable efficient concurrent processing through automatic request batching. In our experimental configuration, we employ ed vLLM ( Kwon et al. , 2023 ), a high-throughput ser v- ing framework that dynamically batches incoming requests and optimises GPU memor y utilisation. Using one third of the memory allocation of a sin- gle Nvidia H100 NVL 94Gb GPU, vLLM’s contin- uous batching mechanism reduced the effectiv e per -page processing time to 0.89 seconds, a 4.5 × improv ement ov er the commercial solution. Bey ond automated processing time, howe ver , the practical impact of the pipeline must also account for the manual effor t required to correct its output. The domain e xper ts recorded the time needed to cor - rect the ABB YY FineReader transcriptions, yielding a mean correction time of 2 minutes and 15 sec- onds per page. Extrapolated to the full 1,688-page corpus, this amounts to approximat ely 63 hours of manual post-correction labour . Since VERIT AS reduces the normalised WER by 67.6% relative to ABB YY , a proportional reduction in correction effor t can be reasonably assumed, bringing the es- timated per -page correction time to approximat ely 44 seconds and the projected cor pus-le vel total to roughly 20 hour s, a saving of ov er 40 hours of ex- per t labour . Combining automated processing and manual correction, the total estimated time for pro- ducing a verified transcription of the full edition de- creases from approximatel y 65 hours with ABBYY to approximat ely 21 hours with VERIT AS, a three- fold reduction in end-to-end effor t. These gains should, howev er , be interpret ed in light of the com- putational profile of the selected extr action model. While concurrent infer ence substantially lowers ef- fectiv e per -page latency , VLM-based processing remains more demanding than conventional OCR in terms of GPU memory , ser ving infrastructure, and energy consumption. Finally , the element extraction performance of the VLM-based approach confirms its reliability for lay out analysis, with the model achieving an F1 Score of 0 . 966 . These results indicate that the spe- cialised VLM reliably identifies and correctly classi- fies the structural elements present in the document pages, a capability essential for the subsequent re- finement and enrichment stages of the pipeline, as accurate element extraction enables proper content aggregation and semantic annotation. 5. Downstream Application The preceding ev aluation demonstrat es that the VERIT AS pipeline achieves high-fidelity transcrip- tion and reliable lay out analysis. Howe ver , the ulti- mate value of a digitisation framework for the hu- manities resides not merely in the accuracy of its output, but in the degree to which that output can suppor t substantive scholarly inquir y . T o illustrate this potential, we conducted an e xploratory study in which the complete transcribed te xt of the Sto- ria di Milano , produced by the VERIT AS pipeline, was ingest ed into a re triev al-augmented generation (RA G) syst em, and a set of historically motivat ed research questions was posed to the model. 5.1. Setup On top of the indexing results of the Enrichment phase of VERIT AS, we developed a dedicated RA G pipeline tailored to the structure of Corio’ s chroni- cle. The 1,688 digitised pages were processed by a custom ingestion module that annotates each page with temporal and structural metadata and groups them into chronologically coherent chunks aligned with the chronicle’s year markers and chapters di- visions. The resulting corpus comprises appro x- imately 1,331 content chunks and 200 footnot es, embedded using BAAI/bge-m3 1 ( Chen et al. , 2024 ) and index ed in a ChromaDB collection with cosine distance. At quer y time, an embedding-based router clas- sifies each question as either specific (targeting ev ents, persons, or dates) or gener al (spanning themes, style, or interpre tive questions). Specific queries trigger year -filtered semantic search with footno te augmentation, while general q ueries em- ploy Maximal Marginal Rele vance (MMR) reranking to ensure temporal and thematic diversity across re- triev ed chunks. Retriev ed passages are then fed to a generative model, GLM-4.7-Flash 2 ( et al. , 2025 ), with prompt templates that enforce grounding in the source material and instruct the model to match the quer y language. A panel of historians formulated a set of research questions spanning diverse analytical dimensions: factual retrie val, interpretiv e analysis, thematic syn- thesis, prosopographic reconstruction, and cross- refer encing of events and actors. These questions were designed to reflect the types of inquiry that scholars would naturally pursue when working with this primary source. From this set, we selected three representativ e q uestions for detailed discus- sion, each e x emplifying a distinct mode of historical inquir y . 5.2. Repr esentative Queries Factual Entity Extraction. The question “Who wer e the ducal secret aries and chancellors during 1 https://huggingface.co/BAAI/bge- m3 2 https://huggingface.co/zai- org/GLM- 4. 7- Flash the Sforza era?” requires the model to identify spe- cific individuals and their institutional roles from mentions disper sed across the chronicle. The sys- tem produced a well-organised response grounded in the retriev ed passages. It correctly identified Cicco Simonetta as general secretary , citing the chronicle’ s account of his formal appointment fol- lowing the death of Galeazzo Maria Sforza in 1477, and described his sweeping administrativ e author - ity over both domestic and foreign affairs. The re- sponse fur ther retriev ed Giovanni F rancesco Mar - liano, appointed as jurist and go vernor during Lu- dovico Sforza’ s depar ture from Italy in 1499, as well as peripheral figures such as Bernardino Cur tio and his brother Iacopo, named prefect and captain of the Milanese fortresses during the Duke ’ s illness in 1489. Notably , the syst em also reconstruct ed the institutional reorganisation into two senates de- scribed in the chronicle: one for civil affairs in the Cor te dell’ Arenga and another for state delibera- tions in the castle, where Simonetta and his asso- ciates ex ercised decisive influence. This response demonstrates the syst em’s capacity to aggregate factual information scatt ered across hundreds of pages into a structured outcome, a task that would require considerable manual effor t if conduct ed through traditional close reading alone. Interpretive Stance Detection. The question “Does the author rev eal his political sympathies?” demands a qualitatively different analytical opera- tion: the model must synthesise evidence of autho- rial bias across the entire work and ar ticulate an in- terpretiv e judgment. The system’ s response identi- fied a multi-lay ered political stance that ev olves o ver the course of the chronicle. It recognised Corio’ s e xplicit loyalty to the Sforza dynasty . The response detect ed an early apologetic posture, ex emplified by the author’s praise of F rancesco Sforza’ s restora- tion of Milan’ s for tifications and his justification of ducal authority as a bulwark against popular dis- order . Howev er , the syst em also identified a pro- gressiv e disenchantment in the later por tions of the work: Corio’ s depiction of Giov anni Galeazzo Maria as a ruler corrupt ed by ministerial av arice, and his characterisation of hybris as the root cause of the Sforza downf all, rev eal a capacity for self- critical judgment regarding his own patrons. This response illustrates the syst em’s ability to move bey ond literal extraction tow ard historical interpre- tation, identifying ideological tensions within the source. Thematic Synthesis and Causal Reasoning. The question “Which epidemics does t he author record and what sanitary measures were tak en to limit contagion?” requires the model to identify a recurring thematic thread across several centuries of narrativ e and, for each instance, link the event to any associated policy response. The system iden- tified multiple epidemic events, most prominently the peste acerrima of 1485, which Corio describes as having driven him into rural retreat and which directly motivated the composition of the chroni- cle, and the pestilence of 1450, reported to hav e caused approximat ely thir ty thousand deaths and sev erely disrupted the Jubilee. F or each event, the model pro vided contextual details drawn from the source te xt, including Corio’ s autobiographical account of fleeing to the countr yside. Regarding sanitary measures, the response correctly noted that the chronicle reflects predominantly reactive and informal responses: rural withdraw al as a form of quarantine, obligations placed on rulers such as Em peror Henr y VII to maintain urban infrastruc- ture at their own e xpense (bridges, roads), and the role of civic assemblies ( Credentia ) in coordinating crisis management. This response demonstrat es the system’ s capacity for multi-hop reasoning: e x- tracting thematically related passages distributed across the chronicle and synthesising them into a coherent analytical account. 5.3. Discussion The explorat or y results presented abov e suggest that RAG-based LLM systems, when pro vided with high-quality transcriptions produced by the VERI- T AS pipeline, can ser ve as effective tools for pre- liminary historical analysis. Howev er , while these results are encouraging, they should be interpret ed with appropriate caution. The responses hav e not been subjected to systematic validation, and RAG- based systems remain susceptible to hallucination, par ticularly when queries require infer ence beyond what is e xplicitly stated in the source material. A rigorous evaluation of factual accuracy and interpre- tive validity , conducted in collaboration with domain historians, constitutes an essential direction for fu- ture work. Notwit hstanding these limitations, this demonstration highlights the potential of integrating high-fidelity transcription pipelines with LLM-based quer ying systems to lower the barrier of entr y for large-scale historical document analysis, enabling scholars to formulate and explor e research hypot he- ses across ext ensive corpora more efficiently than traditional manual methods would allow . 6. Conclusion W e hav e presented VERIT AS, a modular , model- agnostic framew ork that reconceptualises historical document digitisation as an integrated process en- compassing transcription, structural analysis, and semantic enrichment within a unified pipeline. The framework’ s schema-driven architecture allows re- searchers to declarativ ely specify their extraction objectives, ensuring that the pipeline’s outputs are tailored to the analytical needs of diverse scholarly communities. Our evaluation on the critical edition of Corio ’s St oria di Milano demonstrat es that a VLM-based extr action pipeline can substantially outper form a commercial OCR baseline, achieving a 67.6% rel- ative reduction in word error rate under normalised conditions, while concurrent inference reduces ef- fectiv e per -page processing time b y a f actor of 4.5. When accounting for the manual correction effor t that remains indispensable in an y digitisa- tion workflow , these improv ements translate into an estimat ed threef old reduction in end-to-end pro- cessing time for the com plet e 1,688-page corpus. The downstr eam application of the pipeline ’s output through a RAG-based system fur ther illustrates that high-fidelity , structured transcriptions can directly suppor t substantive historical inquir y , from factual entity extraction to interpretive stance detection. Sev eral directions for future work remain. First, a syst ematic ev aluation of the Enrichment stage, in- cluding entity linking accuracy and the reliability of LLM-based semantic infer ence on historical te xts, is needed to validate the full pipeline beyond its transcription capabilities. Second, the downstream RA G-based analysis presented here is e xploratory; a rigorous assessment of factual accuracy and in- terpretiv e validity , conducted in collaboration with domain historians, is essential. Third, we intend to evaluat e VERIT AS on document collections that pose great er palaeographic challenges, such as manuscript sources and early printed books with non-standard typefaces, to assess the generalis- ability of the approach. Finally , we plan to release the framework as an open-source toolkit to facilitate adoption and community-driven ext ension across the digital humanities. Bibliographical References Mélodie Boille t, Solène T arride, Y oann Schnei- der , Bastien Abadie, Lionel Keszt enbaum, and Christopher Kermorvant. 2024. The socface project : Large-scale collection, processing, and analysis of a century of french censuses. In Document Analy sis and Recognition - ICD AR 2024 , pages 57–73, Cham. Springer Nature Switzerland. Mélodie Boillet, Christ opher Kermorvant, and Thierry P aquet. 2021. Multiple Document Datasets Pre-training Im pro ves T e xt Line Detec- tion With Deep Neural Networks . In 2020 25th Inter national Confer ence on P attern Recognition (ICPR) , pages 2134–2141. Emanuela Bor os, Maud Ehrmann, Matt eo R o- manello, Sven Najem-Mey er , and Frédéric Ka- plan. 2024. Pos t-correction of historical te xt transcripts with large language models: An ex- ploratory study . In Proceedings of the 8th Joint SIGHUM Work shop on Computational Linguis- tics for Cultural Heritage, Social Sciences, Hu- manities and Lit eratur e (LaT eCH-CLfL 2024) , pages 133–159, St. Julians, Malta. Association for Computational Linguistics. Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. Bge m3-embedding: Multi-lingual, multi-functionality , multi-granularity text embeddings through self- knowledge distillation . Floriane Chiffoleau. 2024. Keeping it open: A tei-based publication pipeline for historical doc- uments . Journal of the T e xt Encoding Initiativ e , Issue 15. Thomas Constum, Lucas Preel, Théo Larcher , Pier - rick T r anouez, Thierr y Paquet, and Sandra Brée. 2024. End-to-end information e xtraction in hand- written documents: Understanding paris mar - riage records from 1880 to 1940 . Bernardino Corio. 1978. Storia di Milano . Classici della Storiografia. Unione Tipografico-Editrice T orinese, T orino. Critical edition of Hist oria patria . GLM T eam et al. 2025. Glm-4.5: Agentic, reason- ing, and coding (arc) foundation models . Mark Humphries, Lianne C. Leddy , Quinn Down- ton, Meredith Legace, John McConnell, Isabella Murra y , and Elizabeth Spence. 2024. Unlocking the archives: Using large language models to transcribe handwritten historical documents . Philip Kahle, Sebastian Colutto, Günter Hackl, and Günter Mühlberger . 2017. T ranskribus - a ser - vice platform for transcription, recognition and re- triev al of historical documents . In 2017 14th IAPR Inter national Conf erence on Document Analysis and Recognition (ICD AR) , volume 04, pages 19– 24. Jenna Kaner va, Cassandra Ledins, Siiri Käpyaho, and Filip Ginter . 2025. OCR error post- correction with LLMs in historical documents: No free lunches . In Proceedings of the Third W orkshop on Resour ces and Representations for Under -Resour ced Languages and Domains (RESOURCEFUL -2025) , pages 38–47, T allinn, Estonia. University of T ar tu Librar y , Estonia. Benjamin Kiessling, Robin Tissot, Pet er Stokes, and Daniel Stökl Ben Ezra. 2019. escriptorium: An open source platform for historical document analysis . In 2019 International Confer ence on Document Analysis and Recognition W orkshops (ICD ARW) , volume 2, pages 19–19. Seorin Kim, Julien Baudru, W outer Ry ckbosch, Hugues Bersini, and Vincent Ginis. 2025. Early evidence of how llms outper form traditional sys- tems on ocr/htr tasks for historical records . W oosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Y u, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Ef- ficient memor y management for large language model ser ving with pagedattention. In Proceed- ings of the A CM SIGOPS 29th Symposium on Operating Sys tems Principles . Maria Levchenk o. 2025. Evaluating llms for histori- cal document ocr: A methodological framew ork for digital humanities . Y umeng Li, Guang Y ang, Hao Liu, Bowen W ang, and Colin Zhang. 2025. dots.ocr : Multilin- gual document lay out parsing in a single vision- language model . Guenter Muehlberger , Louise Seaward, Melissa T err as, Sofia Ares Oliveir a, Vicente Bosch, Max- imilian Br yan, Sebastian Colutto, Hervé Dé- jean, Markus Diem, Stefan Fiel, Basilis Gatos, Alber t Greinoecker , T obias Grüning, Guent er Hackl, Vili Haukko vaar a, Gerhard Hey er , Lauri Hir vonen, T obias Hodel, Matti Jokinen, Philip Kahle, Mario Kallio, F rederic Kaplan, Florian Kleber , Roger Labahn, Eva Maria Lang, Sören Laube, Gundram Leifer t, Georgios Louloudis, Rory McNicholl, Jean-Luc Meunier , Johannes Michael, Elena Mühlbauer , Nathanael Philipp, Ioannis Pratikakis, Joan Puigcer v er Pérez, Han- nelore Putz, George Retsinas, V erónica Romero, Robert Sablatnig, Joan Andreu Sánchez, Philip Schofield, Giorgos Sfikas, Christian Sieber , Niko- laos Stamatopoulos, T obias Strauß, T amara T erbul, Alejandro Héctor T oselli, Ber thold Ulre- ich, Mauricio Villegas, Enrique Vidal, Johanna W alcher , Max W eidemann, Herber t W urster , and K onstantinos Zagoris. 2019. T r ansforming schol- arship in the archives through handwritten te xt recognition: T ranskribus as a case study . Journal of Documentation , 75(5):954–976. Clemens Neudecker , K onstantin Baierer , Maria Federbusch, Matthias Boenig, Ka y-Michael Würzner , V olker Har tmann, and Elisa Herrmann. 2019. Ocr -d: An end-to-end open source ocr framework for historical printed documents . In Proceedings of the 3rd International Conference on Digital A ccess t o T e xtual Cultural Heritage , D A T eCH2019, page 53–58, New Y ork, NY , US A. Association for Computing Machiner y . Sina J. Semnani, Han Zhang, Xiny an He, Merve T ek g"urler , and Monica S. Lam. 2025. CHURRO: Making histor y readable with an open-w eight large vision-language model for high-accuracy , low-cost historical te xt recognition. In Proceed- ings of the 2025 Confer ence on Empirical Meth- ods in Natur al Language Processing (EMNLP 2025) . R. Smith. 2007. An ov er view of the tesseract ocr engine . In Ninth Int ernational Conf erence on Doc- ument Analysis and Recognition (ICD AR 2007) , volume 2, pages 629–633. Alan Thomas, Rober t Gaizauskas, and Haiping Lu. 2024. Lever aging LLMs for post-OCR correction of historical newspapers . In Proceedings of the Third W orkshop on Language T echnologies for Hist orical and Ancient Languages (L T4HALA) @ LREC-COLIN G-2024 , pages 116–121, T orino, Italia. ELRA and ICCL.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment