MOSS-VoiceGenerator: Create Realistic Voices with Natural Language Descriptions
Voice design from natural language aims to generate speaker timbres directly from free-form textual descriptions, allowing users to create voices tailored to specific roles, personalities, and emotions. Such controllable voice creation benefits a wid…
Authors: Kexin Huang, Liwei Fan, Botian Jiang
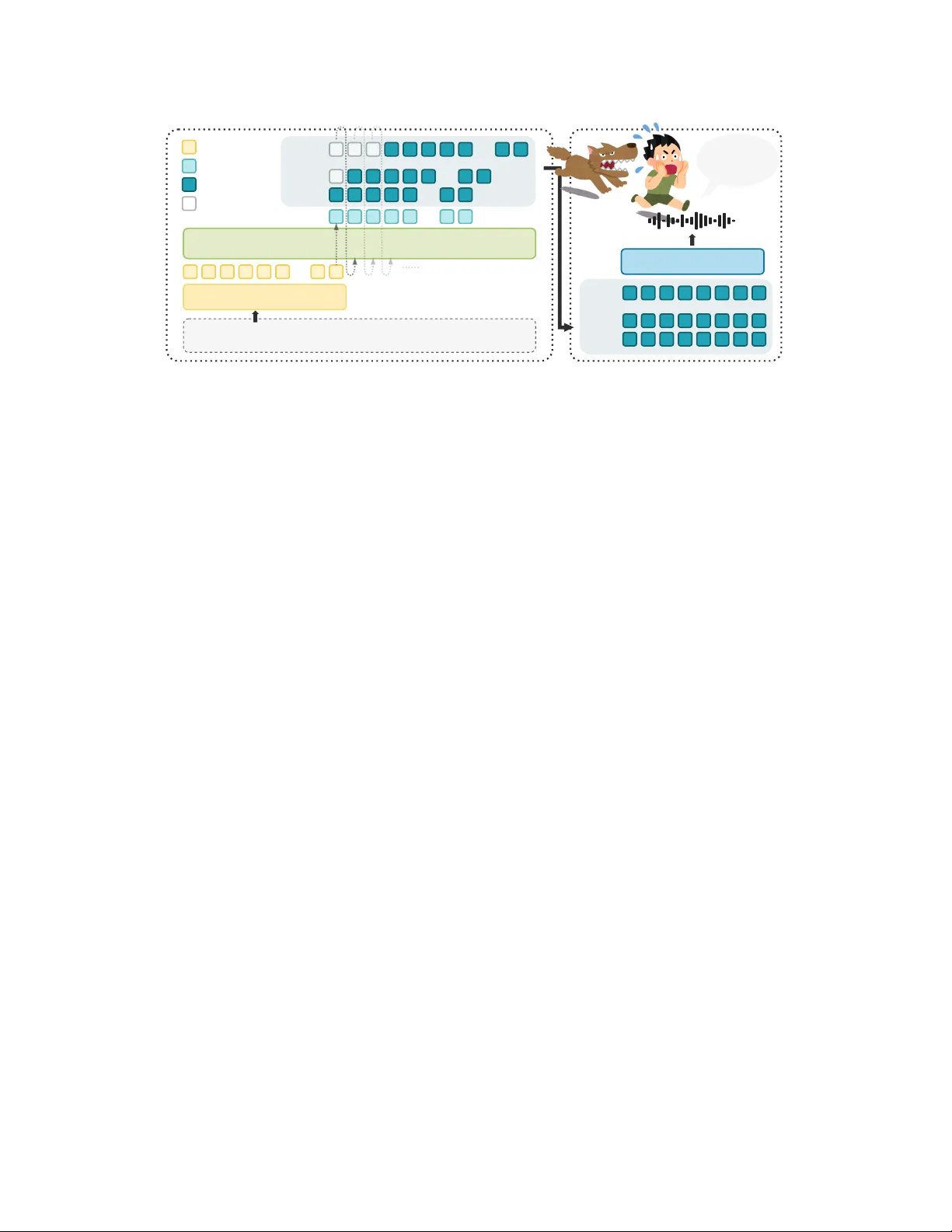
OpenMOSS MOSS- V oiceGenerator : Create Realistic V oices with N atural Languag e Descr iptions SII-OpenMOSS T eam * Abstract V oice design from natur al language aims t o generate speaker timbres directly from free-form textual descriptions, allowing users to create v oices tailored to specific roles, personalities, and emotions. Such controllable voice creation benefits a wide range of do wnstream applications—including st or ytelling, game dubbing, role-play ag ents, and conv ersational assistants, making it a significant task for modern T ext-to-Speech models. How ev er , existing models are larg el y trained on carefully recorded studio data, which produces speech t hat is clean and w ell-articulated, y et lacks t he lived-in qualities of real human v oices. T o address t hese limitations, w e present MOSS- V oiceGenerator , an open-source instruction-driv en v oice gener ation model t hat creates new timbres directly from natural language promp ts. Motiv ated by the h ypothesis that exposure to real-w orld acoustic variation produces more perceptuall y natural v oices, w e train on larg e-scale expressive speech data sourced from cinematic content. Subjective preference studies demonstrate its superiority in ov er all performance, instruction-follo wing, and naturalness compared to other v oice design models. Homepage: https://mosi.cn/models/moss- voice- generator Online Demo: https://huggingface.co/spaces/OpenMOSS- Team/MOSS- VoiceGenerator Hugging Face: https://huggingface.co/OpenMOSS- Team/MOSS- VoiceGenerator GitHub: https://huggingface.co/collections/OpenMOSS- Team/moss- tts 1 Introduction In recent y ears, T ext-to-Speech (TTS) systems ha v e progressed from merely producing natural and high-fidelity speech t ow ard supporting controllable and expressiv e speech generation [ 1 – 4 ]. These advances enable a shift from traditional TTS or voice-cloning (V C) to natural language–based instruction follo wing task. By allo wing users to control v ocal characteristics, such as emotion, speaking sty le, and character persona, through free-form text descriptions, t his paradigm substantially lo wers the barrier to voice cust omization for non-expert users, which broadens the applicability of TTS to downs tream scenarios such as audiobook s, game dubbing, role-pla y agents, and conv ersational assistants. A g rowing body of wor k has explored instruction-driv en v oice g eneration, y et current approaches differ considerabl y in their degree of controllability , generalizability , and dependence on reference audio. Ear ly efforts in this direction still rely on reference speakers to anchor t he generated timbre. Y ang et al. [ 5 ] introduces natural language sty le promp ts for expressive TTS, but the model is still trained on a closed set of speakers, limiting generalization and prev enting open-set timbre design. A udiobox [ 6 ] lev erag es pretrained CLAP [ 7 ] embeddings to condition audio g eneration on text descriptions; how ev er , CLAP models are typicall y trained ‗ Full contributors can be found in the Contributors section. 1 on coarse-g rained descriptions and struggle to capture fine-g rained timbre nuances. V oxInstruct [ 8 ] and EmoV oice [ 9 ] lev erage LLM understanding b y concatenating sty le descriptions with synthesis text for fine- grained control, but still require reference speaker audio rather than generating timbres from scratch. Moving to war d fully reference-free gener ation, V oiceSculptor [ 10 ] takes a step further by integ rating instruction-based v oice design with high-fidelity v oice cloning in a unified framew or k, enabling controllable timbre gener ation from natural language descriptions with iterativ e refinement via Retriev al- Augmented Generation (RA G). MIMO- A udio [ 11 ] enhances controllability t hrough massiv e pretraining follow ed by instruction tuning, demonstr ating the promise of t he LLM-based paradigm for open-domain voice design. The Qw en3- TTS famil y [ 12 ] also introduces models f ocused on v oice design, furt her advancing the field and offering additional options for expressiv e and customizable speech synthesis. On t he commercial side, sev eral APIs—including Elev enlabs, MiniMax, GPT -4o- TTS, and Gemini—ha ve begun offering v oice design or editing functionalities, reflecting growing mark et demand for instruction-driv en timbre gener ation and customizable voice synthesis. Despite significant recent prog ress in controllable speech synt hesis, man y existing models rel y on studio- recorded high-quality audio, resulting in v oices that sound clean and polished but lack the "liv ed-in" realism of ev eryday speech. The subtle imperfections of real speech, such as natural breat h patterns, rh yt hmic irregularity , and spontaneous emotional coloring, remain largel y absent, lea ving a perceptible gap betw een synthesized v oices and aut hentic human expression. T o address this, w e introduce MOSS- V oiceGenerator , a fully open-source instruction-driv en TTS model t hat generates realistic and expressiv e speech directly from natural language descriptions, without requiring an y reference audio. By lev eraging large-scale in-the-wild cinematic data and the strong instruction-f ollowing capabilities of decoder-onl y language models, MOSS- V oiceGenerat or produces v oices wit h g reater naturalness and div ersity . Our main contributions are as follo ws: • W e present MOSS- V oiceGenerator , a fully open-source instruction-driv en TTS model that gener ates realistic and expressiv e speech directly from natural language descriptions, wit hout requiring an y reference audio. • W e construct a data pipeline suitable for instruction-based task s, along wit h a richly annotated dataset sourced from cinematic content. Our dev eloped embedding model and annotation model can effectiv el y enable cost-effectiv e data augmentation. • Extensiv e evaluations show that MOSS- V oiceGenerator performs ex ceptionall y well in subjective ev aluations and achiev es competitiv e performance in objectiv e ev aluations. 2 MOSS- V oiceGenerator 2.1 Model Architecture As illustrated in Fig. 1 , t he architecture of MOSS- V oiceGenerat or follow s the design of MOSS- TTS [ 13 ] wit h the dela y patter n and utilizes t he MOSS- A udio- T okenizer [ 14 ] for audio tokenization. In our implementation, w e only use t he first 16 la yers of t he R VQ codebook s for training. The voice description and synthesis text are concatenated and input into the language model (LM). During inference, a time-dela y shif t is applied, where each codebook la yer’ s tokens are shif ted forw ard b y 𝑗 − 1 frames relativ e to t he first la yer . Af ter generating output until the end-of-sequence (EOS) token, t he audio tokens are decoded into t he final wa v eform. This discrete autoregressive architecture offers sev eral key benefits for the task. It unifies speech generation with language modeling as a sequence prediction task, allowing for t he direct reuse of LLM training paradigms and inference frame w orks. A utoregressive modeling naturally captures long-range dependencies, ensuring global prosody and timbre consistency . Additionall y , the discrete framew or k eliminates t he need for iterativ e inference, unlike diffusion or flow -matching models, leading to simpler and more efficient deplo yment. Finall y , t he shared sequence space for both speech and text tokens makes joint instruction-speech modeling more seamless, enhancing the model’s instruction-follo wing capabilities. 2 Autoregr essive Model T ext T okenizer T ext: "Run! It's gaining on us! Don't look back, just run!" Instruction: "Breathless, terrified scream, deliver edwith extreme urgency ." ...... Audio DeT okenizer Run! It's gaining on us!Don't look back, just run! RVQ0 RVQ15 RVQ1 RVQ0 RVQ1 RVQ15 ...... Input T ext T oken Speech T oken Output T ext T oken Pad T oken . . . . . . ... ... ... ... ... Figure 1 Illustration of t he MOSS- V oiceGenerator inference. The v oice description and text are concatenated and fed into a causal language model wit h dela y-pattern generation; t he output audio tokens are decoded by MOSS-A udio- T okenizer . 2.2 Data Collection As shown in Fig. 2 , the data collection process includes two phases: Phase 1: Collection and Annotation of Cinematic Data Motiv ated b y t he h ypothesis t hat exposure to real-w orld acoustic variation produces more perceptuall y natural speech, w e adopt a bottom-up approach in collecting audio from movies, TV dramas, and episodic series, as opposed to rel ying on scripted studio recordings. This type of content inherently offers diverse scenes, characters, and expressiv e speaking sty les, providing a richer source of acoustic variation than controlled recording en vironments. The data processing pipeline inv olv es t he following stag es: • Speaker Diarization : W e adopt DiariZen [ 15 – 17 ] to identify and segment audio by different speakers. • Denoising and Quality Filter ing : W e apply MossF or mer2_SE_48K [ 18 ] for noise reduction and use DNSMOS [ 19 ] to filter out low -quality audio. MossFormer2_SE_48K is particularl y effectiv e at extracting clean speech from challenging acoustic conditions, including significant background noise, music tracks, and speech-ov erlaid BGM, making it particularl y suited for processing noisy and music-infused audio sources. T o ensure t he quality of the audio data, w e set a DNSMOS t hreshold of ≥ 3.0 for quality filtering. Cinematic data often contains substantial background noise, and without denoising, onl y around 5% of the samples meet the DNSMOS 3.0 threshold. Af ter applying MossFormer2_SE_48K for denoising, t he retention rate increases to approximatel y 45%–50%. Although this denoising process ma y result in minor quality loss (e.g., occasional breath noises or slight loss of high-frequency details), our priority is to maximize sample retention and preser v e the div ersity of speech, particular ly giv en t he scarcity of high-quality cinematic data. • Single Speaker Filter ing : Given the potential inaccuracies in diarization, especially in distinguishing speakers with similar v oices (e.g., speakers of the same gender), w e lev erag e MOSS- T ranscribe- Diarize [ 20 ], which ex cels at producing accurate per -speaker transcrip tions in multi-speaker con v ersa- tions, to identify and retain only single-speaker segments. This ensures t hat t he model does not learn to gener ate inconsistent v oice tones during speech synt hesis. • ASR T ranscr iption : Through multiple iterations of ASR models, w e ev entually select Qw en3-Omni- 30B- A3B-Instruct [ 21 ] for transcription. This model performs well in recognizing numbers, symbols, and standard punctuation, which is essential for capturing the emotional nuances in speech. W e also apply sim ple r ule-based filtering to remov e em pty and duplicate entries, which are usually caused by 3 Film & Drama Phase1: Collection and Annotation Phase2: Augmentation (1)Speaker Diarization (2)Denoising and Quality Filtering (3)Single Speaker Filtering ✔ ✘ (4)ASR T ranscription SpeechCaption Instruction Generation DNSMOS≥ 3.0 T rain Caption Model' Speech-T ext Embedding Model' Retrieve T raining Corpus T rain TTS Data ... Undergo Phase 1 Instruction T ext Speech Figure 2 Data collection pipeline for MOSS- V oiceGenerator . Phase 1 annotates cinematic audio via speaker diarization, denoising and quality filtering, single-speaker filtering, and ASR transcrip tion, follow ed b y speech captioning and timbre instruction generation. Phase 2 augments the cor pus by training a speech-text embedding model for retriev al from internal TTS data and a fine-tuned cap tion model for scalable annotation. pure music or noise, leading to model collapse. Given that t he corpus primaril y consists of Chinese and English audio, we use Whisper-larg e-v3 [ 22 ] to filter out non-Chinese and non-English languages. This decision is driv en by t he need for the model to effectiv ely learn from a focused dataset, as introducing additional languag es could compromise the quality and accuracy of transcrip tions in the current scope. While our focus is on Chinese and English, we are committed to expanding this capability in the future to support low -resource languages, aiming to impro ve inclusivity and model robustness in TTS models. The resulting dataset consists of appro ximately 5,000 hours of audio, which w e t hen annotate using Gemini-2.5 Pro [ 23 ] to gener ate detailed captions. These captions are con verted into natural language timbre instructions using Qwen3-32B- A3B-Instruct [ 24 ]. Phase 2: Data A ugmentation In Phase 2, we scale up the dataset through tw o complementary strategies: • Fine- T uning a Speech Caption Model : W e fine-tune Qw en3-Omni-30B-A3B- Thinking [ 21 ] on t he Phase 1 data to train a dedicated speech caption model, which will be used for automatic annotation of larg e-scale audio in t he next steps. • Sty le-Guided Audio Mining : W e also train a speech-text alignment embedding model [ 25 ], which maps style instructions and speech audio into a shared embedding space, enabling text-based retriev al of audio clips that match a giv en sty le description. Because much of our inter nal TTS base training corpus consists of relativel y neutral speech (e.g., audiobook narration), directly sampling from it would yield predominantly flat, expressivel y homogeneous data. W e furt her lev erag e GPT -5 [ 26 ] to gener ate a div erse set of sty listicall y rich text-based timbre instructions. By using these sty le-oriented instructions as queries agains t t he shared embedding space, we can surface recordings t hat exhibit salient expressiv e characteris tics from within this other wise neutral collection. For each instruction, w e retriev e the top 50 matches ranked b y cosine similarity and immediately remov e them from the candidate pool before processing t he next instruction, ensuring that no audio clip is selected more t han once across different queries. This targeted mining adds approximatel y 10,000 hours of sty listically div erse audio data that complements the cinematic sources in Phase 1. The newl y matched audio is processed follo wing t he same steps as Phase 1, excep t t hat for cost efficiency , w e replace t he captioning model with t he internal, custom-tr ained caption model developed during t he fine-tuning process. T o further supplement cov erag e, we incor porate additional data from other internal sources, mainly crowdsourced dubbing recordings, annotated using t he same custom-trained caption model, yielding t he final dataset of appro ximately 25,000 hours. 4 Figure 3 A snapshot of t he training corpus profiled along three perceptual dimensions based on the caption results. The distributions reveal broad, naturalistic cov erage of ev er yda y speaking styles. Dataset S tatistics The final dataset comprises approximatel y 25,000 hours of unique audio across Chinese (18,025 hours) and English (7,047 hours). T o better understand t he composition of our cor pus, we uniformly sample 150K utterances from each language and profile t hem along three perceptual dimensions: speaker age, emotion/tone, and voice texture, as illustrated in Fig. 3 . The resulting slices confir m t hat the data captures a naturall y div erse range of ev eryday speaking characteris tics—skewing tow ard young-adult and middle-aged speakers, predominantly neutral-to-positiv e tones, and a broad palette of v oice textures. 2.3 T raining Strategy MOSS- V oiceGenerator starts from t he Qwen3 [ 24 ] checkpoint weights, and is trained end-to-end on our curated instruction-text-speech dataset. The model receiv es a structured input composed of a natural language timbre instruction and a target transcript, concatenated via a fixed chat template and encoded by the LLM’s nativ e text tokenizer . The training objectiv e is standard next-token prediction loss ov er the codec token sequence, conditioned on the text input. All model parameters are updated during training; w e do not apply parameter -efficient methods such as LoRA. Model Scale W e compare the 1.7B and 8B backbone sizes under t he same training recipe. The 1.7B model achiev es comparable instruction-follo wing quality to the 8B model, while demonstr ating better generation div ersity . W e suspect that the data v olume might not ha v e been sufficient, and t hus, we attemp ted to mix in appro ximately 10,000 hours of TTS-base data (without instructions, pure text-speech pairs). How ev er , we observed no significant gain in eit her objectiv e benchmar k s or human ev aluation. As a result, we decided to adopt the 1.7B model, trained exclusiv ely on instruction data, as t he final released configuration. Eng lish Prosody Augmentation Due to t he limited scale of t he English subset ( ∼ 7,047 hours vs. ∼ 18,025 hours for Chinese), earl y checkpoints exhibited unstable English prosody characterized by frequent unnatural pauses. T o address this, we apply instruction rewriting to all English samples: for each audio clip, w e gener ate tw o semantically equiv alent but lexically distinct instruction v ariants, t hereb y doubling the effectiv e English training signal without requiring additional audio collection. This augmentation substantiall y im prov es English prosody stability in the final model. 3 Evaluation 3.1 Objectiv e Evaluation W e ev aluate MOSS- V oiceGenerator on InstructTTSEval [ 27 ], a public benchmark designed to assess TTS models’ ability to follo w complex natural-languag e style instructions. InstructTTSEv al comprises 6,000 test cases (3 task s × 2 languages × 1,000 samples) dra wn from movies, TV dramas, and v ariety show s, each paired with a reference audio clip. The benchmark defines three ev aluation tasks of increasing abstraction: • APS (Acoustic-Parameter Specification): Instructions explicitly specify all 12 acoustic attributes (pitch, speed, emotion, gender , age, clarity , fluency , accent, texture, tone, volume, personality), testing direct fine-grained control. 5 T able 1 Instruction-following accuracy (%) on InstructTTSEv al. Model InstructTTSEval-EN InstructTTSEval-ZH APS DSD RP APS DSD RP Gemini- TTS-Pro 87.6 86.0 67.2 89.0 90.1 75.5 GPT -4o-mini- TTS 76.4 74.3 54.8 54.9 52.3 46.0 V oxIns tr uct 54.9 57.0 39.3 47.5 52.3 42.6 V oiceSculptor - VD - - - 75.7 64.7 61.5 MIMO- A udio-7B-Instruct 80.6 77.6 59.5 75.7 74.3 61.5 Qw en3- TTS- VD 78.4 78.8 72.0 84.3 82.9 77.4 MOSS- V oiceGenerator 68.2 82.0 68.7 78.0 80.0 74.0 • DSD (Descr iptive-S tyle Directiv e): APS instructions are rewritten by an LLM into free-form natural language descriptions with random attribute omissions, testing generalization to incomplete and unstructured inputs. • RP (Role-Play): Instructions provide abstract role and scenario descriptions (e.g., “a nervous inter view applicant”), requiring the model to infer appropriate v ocal characteristics from context. T o prev ent test-set contamination, we ensure that our training corpus does not ov er lap with the InstructTTSEval ev aluation set. A dditionally , we perform fuzzy matching on each tr anscript in the InstructTTSEval set to ensure t hat no test data from InstructTTSEv al appears in our training data. W e compare against gemini-2.5-pro-preview -tts (hereaf ter referred to as Gemini- TTS-Pro), GPT -4o-mini- TTS, V oxIns tr uct, MIMO-A udio-7B-Instruct, V oiceSculptor , and Qw en3- TTS- VD. No te that Gemini- TTS-Pro and GPT -4o-mini- TTS only support fixed voice editing rather t han free-form instruction-driv en v oice design, and V oxIns tr uct requires reference audio. Results for Gemini- TTS-Pro, GPT -4o-mini- TTS, and V oxIns tr uct are taken directly from the InstructTTSEval benchmark paper , while results for V oiceSculp tor , MIMO- A udio- 7B-Instruct, and Qw en3- TTS- VD are sourced from their respectiv e technical reports. As sho wn in T ab. 1 , MOSS- V oiceGenerat or demonstrates competitiv e performance wit hin t he open-source landscape. 3.2 Subjectiv e Evaluation For subjectiv e ev aluation, w e conduct a pair wise preference study on the same 100 instruction–speech pairs (50 Chinese, 50 English) dra wn from an inter nal test set distinct from InstructTTSEv al, cov ering diverse sty les and roles. For each pair , human listeners are presented with the outputs of MOSS- V oiceGener ator and a baseline model generated from t he same instruction, with audio presentation order randomized; listeners are blind to which model produced each output. They indicate t heir preference on t hree dimensions: Over all P erformance, Instruction F ollowing, and Natur alness. These dimensions are selected for their relev ance to real-w orld use cases and are critical for evaluating the quality of t he generated v oices: • Overall P er for mance : Given two audio outputs gener ated from the same instruction, which one would you ultimatel y pref er? This dimension reflects the holistic quality of the audio, encompassing factors such as human-likeness, emotional expressiv eness, audio fidelity , naturalness of prosody , clarity of articulation, speaker consistency , and o ver all listening experience. • Instruction Follo wing : Which output better follow s the instruction? Instructions ma y specify attributes such as gender , age, v oice characteristics, emotion, accent, etc. F or instructions inv olving specific characters or scenarios, t his dimension also considers whether the v oice matches your subjective expectation of that character or scene. • N aturalness : Which output sounds more like real human speech? This dimension ev aluates how closely the generated audio resembles natural human speech in ter ms of rh yt hm, pacing, intonation, and con versational quality . 6 0 20 40 60 80 100 Percentage (%) vs Qwen3-TTS-vd vs MiniMax V oice Design vs MiMo-Audio-7B-Instruct 61.9% 5.0% 33.1% 61.9% 6.9% 31.2% 63.1% 10.0% 26.9% Overall Performance 0 20 40 60 80 100 Percentage (%) 53.1% 11.2% 35.6% 55.0% 10.6% 34.4% 60.0% 10.0% 30.0% Instruction Following 0 20 40 60 80 100 Percentage (%) 57.5% 7.5% 35.0% 50.3% 13.2% 36.5% 59.4% 7.5% 33.1% Naturalness Win Tie Lose Figure 4 P air wise preference results (Win / Tie / Lose) of MOSS- V oiceGenerator agains t t hree baselines across t hree ev aluation dimensions. Each bar reports the percentage of comparisons won, tied, or lost. MOSS- V oiceGener ator consistentl y wins on all three dimensions against all baselines. Each item is annotated b y three independent cro wdsourced w orkers (100–300 items per w ork er , 1 RMB per item); the final label is determined by majority v ote. For each pair , each annotator scores onl y one of the dimensions to ensure focus and minimize bias. This approach allow s for a t horough and unbiased ev aluation of each dimension independentl y . W e compare against Qw en3- TTS- VD, MiniMax V oice Design, and MiMo- Audio-7B-Ins tr uct—models t hat provide publicly accessible v oice design interfaces, suitable for pair wise listening studies. W e exclude Gemini- TTS-Pro and GPT -4o-mini- TTS from the preference study , as these models offer preset voices rather than free-form v oice design, which makes a direct comparison in valid. For Qw en3- TTS- VD and MiniMax, w e use t heir respective APIs, wit h all models set to t heir default configurations, aside from the input v oice descriptions and text. Similar ly , MIMO- A udio-7B-Instruct is evaluated using the default settings as specified in its official tutorial. All models are evaluated with a single inference r un. As sho wn in F ig. 4 , MOSS- V oiceGenerator outperforms all t hree baselines across the three evaluation dimensions. In our analysis, MOSS- V oiceGenerator excels at gener ating ev er yda y con versational v oices that exhibit natural pauses, hesitations, and rh ythmic v ariations, clearl y dis tinguishing t hem from the steady , broadcast-s tyle delivery typical of new sreader speech. Further more, t he model con vincingly reproduces a wide range of aut hentic vocal traits—from the voices of t he elderl y and children to laughter , sobbing, a wkwar dness, and anger—deliv ering a lev el of realism t hat feels genuinel y spontaneous rather than studio- recorded. These capabilities make MOSS- V oiceGenerator particular ly well-suited for applications that demand expressiv e and immersiv e speech, such as audiobook narration, film dubbing, and emotionally nuanced voice assistants. 4 Conclusions W e presented MOSS- V oiceGenerator , an open-source instruction-driv en TTS model that synt hesizes realistic, expressiv e speech directly from natural language descriptions, without relying on any reference audio. T o train this model, we carefully source speech data from TV dramas and films, and construct a larg e-scale in-t he-wild corpus with fine-grained annotation, capturing a remarkabl y div erse rang e of speaker identities, emotions, and acoustic conditions. Benefiting from t his expressiv e and diverse training cor pus, MOSS- V oiceGenerator demonstr ates strong voice design capabilities, and excels in subjectiv e ev alutaion, including ov erall quality , instruction-follo wing accuracy , and speech naturalness. W e fully open-source our model, data pipeline, and ev aluation toolkit, and hope t his wor k provides the community wit h a practical and extensible foundation for adv ancing controllable, expressiv e TTS research. 5 Limitations MOSS- V oiceGenerator has sev eral limitations. Firs t, the language cov er age is currentl y limited to Chinese and English. While the model performs w ell on these languages, extension to low -resource languages remains a 7 focus for future wor k. Second, while t he English training corpus is sizable, it is still substantiall y smaller t han the Chinese corpus. Despite using instruction rewriting augmentation, this discrepancy can sometimes result in weak er prosody in certain English-speaking styles, highlighting t he need for furt her cor pus expansion. Third, our denoising-before-filtering pipeline, while increasing data retention, ma y introduce mild artifacts, such as residual breath noise or high-frequency smoothing. These artifacts can deg rade performance in certain cases, t hough disentangling t heir perceptual impact from model capacity effects remains challenging. Finall y , t he model’s output can occasionally lack stability . W e plan to enhance robustness in future v ersions to ensure more consistent and reliable gener ation across a wider range of inputs. Contributor s Contributor s : Kexin Huang ∗ , Liw ei Fan, Botian Jiang, Y aozhou Jiang, Qian T u, Jie Zhu, Y uqian Zhang, Yiw ei Zhao, Chenchen Y ang, Zhao y e Fei, Shimin Li, Xiaogui Y ang, Qin yuan Cheng Advisors : Xipeng Qiu § Affiliations : Shanghai Innov ation Institute MOSI Intelligence Fudan U niversity ∗ Project lead: kxhuang24@m.fudan.edu.cn . § Corresponding author: xpqiu@fudan.edu.cn . 8 Ref erences [1] Chengyi W ang, Sanyuan Chen, Y u W u, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Y anqing Liu, Huaming W ang, Jinyu Li, et al. Neural codec language models are zero-shot text to speech synthesizers. arXiv preprint arXiv :2301.02111 , 2023. [2] Philip Anastassiou, Jia w ei Chen, Jitong Chen, Y uanzhe Chen, Zhuo Chen, Ziyi Chen, Jian Cong, Lelai Deng, Chuang Ding, Lu Gao, et al. Seed-tts: A family of high-quality v ersatile speech gener ation models. arXiv preprint arXiv :2406.02430 , 2024. [3] Siyi Zhou, Yiquan Zhou, Yi He, X un Zhou, Jinchao W ang, W ei Deng, and Jingchen Shu. Indextts2: A break - through in emotionall y expressive and duration-controlled auto-regressiv e zero-shot text-to-speech. arXiv preprint arXiv :2506.21619 , 2025. [4] Zhihao Du, Y uxuan W ang, Qian Chen, Xian Shi, Xiang Lv , Tian yu Zhao, Zhifu Gao, Y exin Y ang, Changfeng Gao, Hui W ang, et al. Cosyvoice 2: Scalable s treaming speech synt hesis with larg e languag e models. arXiv preprint arXiv :2412.10117 , 2024. [5] Dongchao Y ang, Songxiang Liu, Rongjie Huang, Chao W eng, and Helen Meng. Instructtts: Modelling expressiv e tts in discrete latent space wit h natural language sty le prompt. IEEE/A CM T ransactions on Audio, Speech, and Language Processing , 32:2913–2925, 2024. [6] Apoorv V yas, Bo wen Shi, Matt hew Le, Andros Tjandra, Yi-Chiao W u, Baishan Guo, Jiemin Zhang, Xinyue Zhang, Robert Adkins, W illiam Ngan, et al. A udiobo x: Unified audio gener ation wit h natural language prompts. arXiv preprint arXiv:2312.15821 , 2023. [7] Y usong Wu, Ke Chen, Tian yu Zhang, Y uchen Hui, T a ylor Berg-Kir kpatrick, and Shlomo Dubnov . Larg e-scale contras tiv e language-audio pretraining with f eature fusion and keyw ord-t o-caption augmentation. In ICASSP 2023-2023 IEEE Int ernational Confer ence on Acoustics, Speech and Signal Processing (ICASSP) , pag es 1–5. IEEE, 2023. [8] Yixuan Zhou, Xiaoyu Qin, Zeyu Jin, Shuoyi Zhou, Shun Lei, Songtao Zhou, Zhiy ong W u, and Jia Jia. V o xinstruct: Expressiv e human instruction-to-speech gener ation with unified multilingual codec language modelling. In Proceedings of the 32nd ACM International Confer ence on Multimedia , pages 554–563, 2024. [9] Guanrou Y ang, Chen Y ang, Qian Chen, Ziyang Ma, W enxi Chen, W en W ang, Tianrui W ang, Yifan Y ang, Zhikang Niu, W enrui Liu, et al. Emov oice: Llm-based emotional text-to-speech model with freesty le text promp ting. In Proceedings of the 33rd A CM International Conference on Multimedia , pages 10748–10757, 2025. [10] Jingbin Hu, Huakang Chen, Linhan Ma, Dake Guo, Qirui Zhan, W enhao Li, Haoyu Zhang, Kangxiang Xia, Ziyu Zhang, W enjie T ian, et al. V oicesculp tor: Y our voice, designed by you. arXiv preprint , 2026. [11] Dong Zhang, Gang W ang, Jinlong X ue, Kai F ang, Liang Zhao, Rui Ma, Shuhuai Ren, Shuo Liu, T ao Guo, W eiji Zhuang, et al. Mimo-audio: A udio language models are few -shot learners. arXiv preprint , 2025. [12] Hangrui Hu, Xinfa Zhu, Ting He, Dake Guo, Bin Zhang, Xiong W ang, Zhifang Guo, Ziyue Jiang, Hongkun Hao, Zishan Guo, Xin yu Zhang, P ei Zhang, Baosong Y ang, Jin X u, Jing ren Zhou, and Jun yang Lin. Qwen3-tts technical report. arXiv preprint arXiv :2601.15621 , 2026. [13] Yitian Gong, Botian Jiang, Yiw ei Zhao, Y ucheng Y uan, K uangwei Chen, Y aozhou Jiang, Cheng Chang, Dong Hong, Mingshu Chen, R uixiao Li, Yiy ang Zhang, Y ang Gao, Hanfu Chen, Ke Chen, Songlin W ang, Xiaogui Y ang, Y uqian Zhang, Kexin Huang, ZhengY uan Lin, Kang Y u, Ziqi Chen, Jin W ang, Zhao y e Fei, Qin yuan Cheng, Shimin Li, and Xipeng Qiu. Moss-tts technical report, 2026. URL . [14] Yitian Gong, K uangw ei Chen, Zhaoy e F ei, Xiaogui Y ang, K e Chen, Y ang W ang, Kexin Huang, Mingshu Chen, R uixiao Li, Qingyuan Cheng, Shimin Li, and Xipeng Qiu. Moss-audio-tokenizer: Scaling audio tokenizers for future audio foundation models, 2026. URL . [15] Jiangyu Han, P etr Pálka, Marc Delcroix, F ederico Landini, Johan Rohdin, Jan Cer nock ` y, and L ukáš Burget. Efficient and generalizable speaker diarization via structured pr uning of self-super vised models. arXiv preprint arXiv :2506.18623 , 2025. 9 [16] Jiangyu Han, Federico Landini, Johan Rohdin, Anna Silnov a, Mireia Diez, Jan Cernocky , and L ukas Burg et. F ine-tune before structured pruning: T ow ards compact and accurate self-super vised models for speaker diarization. arXiv preprint arXiv:2505.24111 , 2025. [17] Jiangyu Han, F ederico Landini, Johan Rohdin, Anna Silnov a, Mireia Diez, and L ukáš Burget. Lever aging self- supervised lear ning for speaker diarization. In ICASSP 2025-2025 IEEE Int ernational Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pages 1–5. IEEE, 2025. [18] Shengkui Zhao, Y ukun Ma, Chongjia Ni, Chong Zhang, Hao W ang, T rung Hieu Nguy en, K un Zhou, Jiaqi Yip, Dian wen Ng, and Bin Ma. Mossformer2: Combining transformer and rnn-free recurrent netw ork for enhanced time-domain monaural speech separation, 2023. [19] Chandan KA Reddy , Vishak Gopal, and Ross Cutler . Dnsmos: A non-intr usiv e perceptual objectiv e speech quality metric to ev aluate noise suppressors. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages 6493–6497. IEEE, 2021. [20] MOSI. AI, :, Donghua Y u, Zhengyuan Lin, Chen Y ang, Yiy ang Zhang, Hanfu Chen, Jingqi Chen, Ke Chen, Liwei F an, Yi Jiang, Jie Zhu, Muchen Li, W enxuan W ang, Y ang W ang, Zhe X u, Yitian Gong, Y uqian Zhang, W enbo Zhang, Songlin W ang, Zhiyu W u, Zhaoy e F ei, Qinyuan Cheng, Shimin Li, and Xipeng Qiu. Moss tr anscribe diarize technical report, 2026. URL . [21] Jin X u, Zhifang Guo, Hangrui Hu, Y unf ei Chu, Xiong W ang, Jinzheng He, Y uxuan W ang, Xian Shi, Ting He, Xinfa Zhu, Y uanjun Lv , Y ongqi W ang, Dake Guo, He W ang, Linhan Ma, P ei Zhang, Xinyu Zhang, Hongkun Hao, Zishan Guo, Baosong Y ang, Bin Zhang, Ziyang Ma, Xipin W ei, Shuai Bai, K eqin Chen, X uejing Liu, P eng W ang, Mingkun Y ang, Dayiheng Liu, Xingzhang Ren, Bo Zheng, Rui Men, Fan Zhou, Bow en Y u, Jianxin Y ang, Le Y u, Jingren Zhou, and Jun yang Lin. Qwen3-omni technical report. arXiv preprint , 2025. [22] Alec Radford, Jong W ook Kim, T ao X u, Greg Brockman, Christine McLea ve y , and Ily a Sutskev er . Robus t speech recognition via larg e-scale weak super vision, 2022. URL . [23] Gheorghe Comanici, Eric Bieber , Mike Schaekermann, Ice P asupat, No veen Sachdev a, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing t he frontier wit h advanced reasoning, multimodality , long context, and next generation agentic capabilities. arXiv pr eprint arXiv :2507.06261 , 2025. [24] Qwen T eam. Qw en3 technical report, 2025. URL . [25] Liw ei F an, Chenchen Y ang, Kexin Huang, Jun Zhan, Zhaoy e F ei, Shimin Li, Qinyuan Cheng, Y aqian Zhou, and Xipeng Qiu. Speech-clap: T o war ds sty le-aw are speech representation. [26] Aaditya Singh, Adam Fry , A dam P erelman, A dam T art, A di Ganesh, Ahmed El-Kishky , Aidan McLaughlin, Aiden Low , AJ Ostro w , Akhila Anant hram, et al. Openai gpt-5 system card. arXiv preprint arXiv :2601.03267 , 2025. [27] Kexin Huang, Qian T u, Liw ei F an, Chenchen Y ang, Dong Zhang, Shimin Li, Zhaoy e Fei, Qin yuan Cheng, and Xipeng Qiu. Instructttsev al: Benchmarking com plex natural-language instruction following in text-to-speech systems. arXiv preprint arXiv:2506.16381 , 2025. 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment