Reducing Oracle Feedback with Vision-Language Embeddings for Preference-Based RL
Preference-based reinforcement learning can learn effective reward functions from comparisons, but its scalability is constrained by the high cost of oracle feedback. Lightweight vision-language embedding (VLE) models provide a cheaper alternative, b…
Authors: Udita Ghosh, Dripta S. Raychaudhuri, Jiachen Li
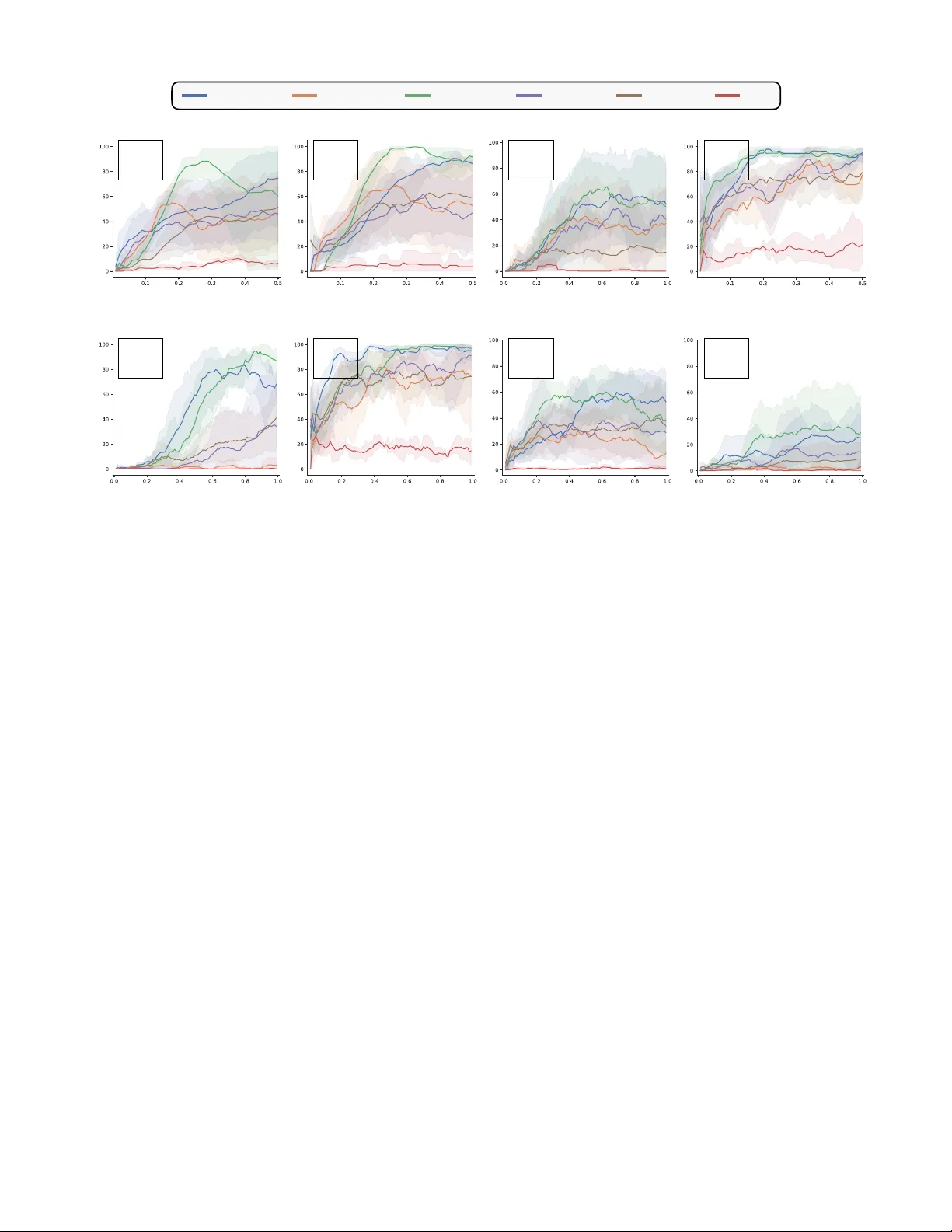
Reducing Oracle F eedback with V ision-Language Embeddings f or Pr eference-Based RL Udita Ghosh 1 ∗ , Dripta S. Raychaudhuri 2 , Jiachen Li 1 , K onstantinos Karydis 1 , Amit Roy-Cho wdhury 1 Abstract — Prefer ence-based reinf orcement lear ning can learn effective r eward functions fr om comparisons, but its scalability is constrained by the high cost of oracle feedback. Lightweight vision-language embedding (VLE) models pro vide a cheaper alternativ e, but their noisy outputs limit their effectiveness as standalone reward generators. T o address this challenge, we propose RO VED, a h ybrid framew ork that combines VLE-based supervision with targeted oracle feedback. Our method uses the VLE to generate segment-lev el preferences and defers to an oracle only for samples with high uncertainty , identified through a filtering mechanism. In addition, we introduce a parameter -efficient fine-tuning method that adapts the VLE with the obtained oracle feedback in order to impro ve the model over time in a synergistic fashion. This ensures the retention of the scalability of embeddings and the accuracy of oracles, while avoiding their inefficiencies. Across multiple robotic manipulation tasks, RO VED matches or surpasses prior prefer ence-based methods while reducing oracle queries by up to 80%. Remarkably , the adapted VLE generalizes across tasks, yielding cumulative annotation savings of up to 90%, highlighting the practicality of combining scalable embeddings with precise oracle supervision for prefer ence-based RL. Pr oject page: https://roved- icra- 2026.github.io/ I . I N T R O D U C T I O N When a robot manipulator is assigned a task, it must possess the necessary skills to complete it effecti vely . Acquiring such skills through reinforcement learning (RL) is challenging, primarily because designing a reward function that reliably guides the agent tow ard the desired behavior is difficult. Hand- crafted rewards often require significant domain expertise, risk unintended shortcuts or rew ard hacking, and struggle to capture complex task goals. A widely adopted alternative is preference-based RL (PbRL) [ 1 ], [ 2 ], where a reward function is inferred from human or oracle feedback in the form of comparisons between agent behaviors. This approach remov es the need for carefully engineered rew ard functions and provides a more direct w ay to align agent behavior with human intent. Howe ver , current PbRL methods typically demand large volumes of high-quality feedback, which is costly and time-consuming to obtain, thereby limiting their practicality and scalability . T o reduce human effort, recent w ork has explored vi- sion–language embedding (VLE) models such as CLIP [ 3 ], which enable zero-shot reward estimation from natural language descriptions ( e.g . , “open the door”) by mapping text and images into a shared representation space [ 4 ], [ 5 ], [ 6 ], [ 7 ]. While scalable, these VLE-based rewards are 1 Univ eristy of California, Riverside; 2 A WS AI Labs (W ork done outside A WS) * Corresponding author: ughos002@ucr .edu often coarse and noisy , limiting their utility in precise domains such as robotic manipulation [ 8 ]. More recently , large vision–language models (VLM) like Gemini-Pro [ 9 ] hav e been proposed as automated oracles for preference learning [ 10 ], replacing human annotators entirely . Although accurate, VLMs incur high query costs and suffer from slow , auto-regressiv e inference. This moti vates the need for a method that r etains the scalability of embedding based appr oaches and the accuracy of oracles, while avoiding their inefficiencies. T o wards this goal, we introduce R O VED: R educing O racle Feedback using V ision-language E mbed D ings, a framework for ef ficient PbRL that combines lightweight VLE models with targeted oracle feedback (where the oracle may be a human or a VLM). Prior approaches rely exclusi vely on either embeddings [ 4 ] or oracle comparisons [ 1 ], [ 10 ]. In contrast, R O VED adopts a hybrid strategy: the VLE generates segment-le vel preferences and defers to the oracle only when confidence is lo w . This creates a feedback loop where the VLE improv es from oracle supervision and becomes increasingly selectiv e in querying, thereby preserving annotation quality while substantially reducing query costs. T o the best of our knowledge, we are the first to exploit VLEs as a supplementary source of noisy labels to reduce dependence on high-quality oracle feedback. Our approach rests on two components. F irst , we improve the quality of scalable preference labels through a parameter-ef ficient fine- tuning scheme that combines an unsupervised dynamics-aw are objectiv e with sparse oracle feedback. Prior efforts hav e attempted to denoise embedding-based rewards using expert demonstrations or environment shaping [ 8 ], but demonstra- tions are costly to collect [ 11 ] and often suffer from domain gaps [ 12 ]. In contrast, preference feedback is lightweight, accessible, and more broadly applicable [ 13 ]. Second , to minimize oracle queries, we adopt robust confidence-aware training [ 14 ], [ 15 ]: by constraining the KL div ergence between the rew ard model and VLE predictions, the system automatically resolves confident cases and escalates only uncertain ones. T ogether , these mechanisms deliv er both efficienc y and precision in preference-based re ward learning. W e e valuate RO VED on robotic manipulation tasks from Meta-W orld [ 16 ] and demonstrate that it learns reward func- tions capable of training effecti ve policies. R O VED matches the performance of oracle-only methods while reducing annotation cost by 50-80% . Moreov er , a VLE fine-tuned on one task generalizes to related tasks with minimal additional supervision, yielding cumulative annotation savings of 75-90% . This cross-task generalization—absent in prior work—demonstrates that pairing scalable VLE models with selecti ve oracle feedback is a promising direction for practical and efficient PbRL. The main contributions of this work are: • W e present R O VED, a novel framework for ef ficient PbRL that combines the scalability of VLEs with the precision of selectiv e oracle supervision. • W e introduce two key techniques: (i) a parameter- efficient adaptation scheme that improv es noisy VLE preference labels with dynamics-aw are objecti ves and sparse oracle feedback, and (ii) an uncertainty-aware sample selection strategy that queries the oracle only for uncertain cases in an effort to reduce oracle feedback. • W e demonstrate that RO VED achiev es oracle-level performance on Meta-W orld tasks while cutting anno- tation cost by 50–80%, and further achieves 75–90% cumulativ e savings through cross-task generalization. I I . R E L A T E D W O R K Designing reward functions. T raditional methods for reward design often rely on manual trial-and-error , requiring sub- stantial domain expertise and struggling to scale to comple x, long-horizon tasks. In verse reinforcement learning of fers an alternati ve by attempting to infer rew ard functions from expert demonstrations [ 17 ]. Evolutionary algorithms hav e also been explored for automated reward function discovery [ 18 ]. More recently , foundation models hav e enabled re ward design from high-lev el task descriptions. Large language models (LLM) hav e been employed to deriv e reward functions directly from natural language task descriptions [ 19 ], [ 20 ], although these approaches assume access to the en vironment’ s source code. VLE models provide another path, aligning visual observations with textual descriptions to yield dense rew ard signals [ 4 ], [ 5 ], [ 6 ], [ 7 ]. These methods are fast and scalable, but VLE re wards are typically noisy and insufficiently precise for fine-grained control [ 8 ]. Prefer ence-based RL. Preference feedback has been widely explored across domains, including natural language process- ing [ 21 ] and robotics [ 2 ]. In RL, Christiano et al. pioneered the use of human trajectory comparisons [ 1 ], with subsequent works improving sample efficienc y and generalization. For instance, PEBBLE [ 2 ] combined human preferences with unsupervised exploration, SURF [ 22 ] augmented preference datasets using semi-supervised learning, and MRN [ 23 ] incorporated policy performance into reward model updates. These methods le verage the fact that relativ e judgments are easier for humans than explicit rew ard specification, but they remain constrained by costly human annotation. T o alle viate this bottleneck, recent work such as RL-VLM-F [ 10 ] uses large VLMs, such as Gemini-Pro, as preference oracles for preference learning. While promising in accuracy , this introduces ne w challenges: VLMs are expensiv e to query due to API costs and slo w because of their auto-regressi ve nature. Giv en these scalability challenges, we propose a hybrid framew ork that selectiv ely queries expensi ve oracles only when fast, automatic supervision is unreliable. Specifically , we use a lightweight VLE model to generate initial preference labels, deferring to the oracle based on a model uncertainty criterion. Unlike prior methods that fully commit to either oracle or automated feedback, our approach dynamically balances scalability and precision by allocating supervision where it is most needed, following principles from uncertainty- based active learning [ 24 ]. This targeted strategy substantially reduces annotation costs without sacrificing rew ard quality . Learning from noisy labels. The challenge of learning from noisy or imprecise labels has been extensi vely studied in supervised learning, particularly with the rise of machine- generated annotations [ 25 ]. Robust training methods tackle this issue through div erse strategies, including regularization techniques [ 26 ], [ 27 ], specialized loss functions [ 28 ], and sample-selection mechanisms [ 29 ]. In our framework, the preference labels generated by the VLE model may be noisy due to its inherent limitations. T o mitigate this, we adopt a sample-selection strategy inspired by RIME [ 15 ], which identifies confident labels for training while flagging uncertain samples for oracle refinement. This combination of robust training and targeted oracle feedback ensures that our rew ard model remains accurate while keeping preference learning efficient. I I I . P R E L I M I NA R I E S W e consider the standard RL setup [ 30 ], where an agent interacts with an environment in discrete time. At each timestep t , the agent observes a state s t and selects an action a t according to its policy π . The en vironment then provides a re ward r t and transitions the agent to the next state s t +1 . The return R t = P ∞ k =0 γ k r t + k represents the discounted sum of future rew ards starting at t , where γ ∈ [0 , 1) is the discount factor . The goal of RL is to maximize the expected return from each state s t . Prefer ence-based RL. In the PbRL setup, an oracle provides feedback in the form of preferences between trajectory segments of the agent. The agent uses these preferences to construct an internal reward model r θ . Formally , a trajectory segment σ is defined as a sequence of observations and actions: σ = { ( s 1 , a 1 ) , ( s 2 , a 2 ) , ..., ( s T , a T ) } . Given a pair of segments ( σ 0 , σ 1 ) , preferences are expressed as y ∈ { (0 , 1) , (0 . 5 , 0 . 5) , (1 , 0) } , where (1 , 0) indicates σ 0 ≻ σ 1 , (0 , 1) indicates σ 1 ≻ σ 0 , and (0 . 5 , 0 . 5) indicates a tie. Here, σ i ≻ σ j denotes that segment i is preferred to segment j . The probability of one segment being preferred ov er another is modeled via the Bradley-T erry model [ 31 ]: P θ [ σ 1 ≻ σ 0 ] = exp P t r θ ( s 1 t , a 1 t ) P i ∈{ 0 , 1 } exp P t r θ ( s i t , a i t ) . (1) T o train the re ward function r θ , we minimize the cross-entrop y loss between the predicted preferences P θ and the observed preferences y , L pref = − E ( σ 0 ,σ 1 ,y ) ∼ D y (0) P θ [ σ 0 ≻ σ 1 ]+ y (1) P θ [ σ 1 ≻ σ 0 ] . (2) The policy π ϕ and the rew ard function r θ are updated in an alternating fashion. First, the reward function is updated using the sampled preferences. Next, the policy is optimized to maximize the expected cumulati ve re ward under the learned rew ard function using standard RL algorithms. Fig. 1: Overview of our approach. Giv en a task description, R O VED iteratively updates the policy π ϕ via reinforcement learning using the reward model r θ . Trajectory segments from the replay buf fer are sampled and labeled with VLE-generated preferences. These samples are then classified as clean or noisy using thresholds τ upper and τ lower . A budgeted subset of noisy samples is sent for oracle annotation. The reward model is trained on both VLE and oracle-labeled preferences, while the VLE is fine-tuned using oracle annotations and replay buf fer samples. VLE as a reward model. VLE models comprise a language encoder F L and an image encoder F I , which map text and image inputs into a shared latent space respectively . Using contrasti ve learning on image-caption pairs, often augmented with task-specific or dynamics-aw are objectiv es [ 5 ], VLEs align textual and visual representations effecti vely . Giv en the image observation o t corresponding to a state s t , and the language description of the task l , most works [ 5 ], [ 7 ] define the rew ard as: r v le t = ⟨F L ( l ) , F I ( o t ) ⟩ ∥F L ( l ) ∥ · ∥F I ( o t ) ∥ . (3) While this rew ard captures some aspects of task progress, it is often too coarse for fine-grained tasks such as manipulation. Although higher rew ards tend to correspond to states closer to task completion, the signal is noisy and does not fully reflect nuanced progress [ 8 ]. This motiv ates our approach: VLEs provide a scalable starting point for generating preference labels, which can then be refined with targeted oracle supervision. By improving VLE accuracy selectiv ely , we reduce the need for expensi ve preference queries while maintaining high-quality rew ard signals. I V . M E T H O D In this section, we present R O VED, a frame work designed to minimize the reliance on expensi ve oracle supervision in preference-based RL by le veraging VLEs. W e first outline ho w VLEs are utilized to provide preference feedback for training a re ward model (Sec. IV -A ). Then, we address the limitations of directly applying VLEs to ne w environments and propose a data-efficient adaptation approach that combines self- supervised learning with minimal oracle feedback to align the VLE with the environment’ s dynamics (Sec. IV -B ). Finally , to ensure robust training in the presence of noisy machine- generated feedback, we introduce a filtering mechanism that identifies noisy VLE predictions and refines them with targeted oracle input - both to reduce annotation cost and to correct unreliable preference labels (Sec. IV -C ). Fig. 1 provides an overvie w of our approach. A. Scalable prefer ence generation using VLE T o lev erage VLEs for generating preference feedback, we begin by extracting image sequences corresponding to each trajectory segment. Specifically , for a giv en pair of segments ( σ 0 , σ 1 ) , we extract the image sequences ( O 0 , O 1 ) , where each sequence is defined as O i = { o i 0 , o i 1 , o i 2 , . . . , o i T } for i ∈ { 0 , 1 } . Here, o t represents the image observ ation of the state s t at the t -th time step. Using the language description of the task l , we compute the return for each segment as R i = P T t =0 r v le t , with r v le t the reward at time step t deriv ed from the VLE via Eq. 3 . Based on these returns, the preference label ˜ y is assigned as: ˜ y = (0 , 1) , if R 1 > R 0 , (1 , 0) , if R 1 < R 0 , (0 . 5 , 0 . 5) , otherwise . (4) These preferences are then used to train a reward model r θ ( s t , a t ) by minimizing the preference loss in Eq. 2 . The trained rew ard model can be integrated into a PbRL algorithm for policy optimization. In this work, we specifically lev erage PEBBLE [ 2 ], a PbRL frame work that combines unsupervised pre-training with off-policy learning using Soft Actor-Critic [ 32 ]. B. VLE adaptation to impro ve pr efer ence quality A key challenge in applying VLEs to downstream RL tasks is the domain gap between pretraining data and the target en vironment [ 33 ], [ 8 ], which often leads to noisy feedback. W e address this with a data-efficient adaptation strategy that aligns the VLE to en vironment dynamics using minimal oracle feedback and self-supervised learning. Window open/close Door open/close Drawer open/close Button press Sweep into Fig. 2: T asks. An illustration of the dif ferent manipulation tasks from Meta-W orld on which we ev aluate our approach. W e freeze the VLE and introduce two learnable layers, G L and G I , on top of the language and image embedding layers, respectiv ely . These layers are fine-tuned to adapt the VLE. The layer G L processes the language embedding F L ( l ) of the task description l and outputs an adapted text embedding, G L ◦ F L ( l ) . Similarly , for each image observation o t , the adapted image embedding is generated by G I ◦ F I ( o t ) . W ith these adapted embeddings, the reward for preference feedback is updated as: r v le t = ⟨G L ◦ F L ( l ) , G I ◦ F I ( o t ) ⟩ ∥G L ◦ F L ( l ) ∥ · ∥G I ◦ F I ( o t ) ∥ . (5) A small number of oracle-provided preferences are sampled to fine-tune the VLE using the preference loss in Eq. 2 . The dense rewards for training are deriv ed from the updated similarity measure (Eq. 5 ). The methodology for selecting oracle feedback samples is detailed in Sec. IV -C . W e also fine-tune the VLE using an unsupervised objectiv e designed to align the VLE embeddings with en vironment dynamics. Giv en the current observation o t , action a t , and the next observation o t +1 , we train the VLE to predict the action which leads to the transition between observations: ∥ f ( G I ◦ F I ( o t ) , G I ◦ F I ( o t +1 )) − a t ∥ 2 , (6) where f is a linear layer . This encourages the adapted embeddings to capture task-rele vant dynamics, improving the precision of preference feedback. C. Noise mitigation and targ eted oracle feedback The VLE generated preferences, while scalable, are prone to noise and lack the reliability afforded by oracle-pro vided annotations. T o ensure robust training, it is thus crucial to distinguish between accurate and noisy samples. This categorization not only improves the stability of the reward model training but also optimizes the use of oracle feedback by focusing on refining the noisy samples. Identifying noisy samples. Our approach builds on findings from noisy training [ 15 ], which show that deep networks fit clean samples before memorizing noisy labels. W e prioritize samples with lower training losses as clean, while treating high-loss samples as potential candidates for oracle revie w . Specifically , consider the preference loss defined in Eq. 2 for training the re ward model r θ . Assuming the loss for clean samples is bounded by ρ , Cheng et al. [ 15 ] show that the KL div ergence between the predicted preference distrib ution P θ and label ˜ y for a noisy sample ( σ 0 , σ 1 ) is lower bounded as: D K L ( ˜ y ∥ P θ ) ≥ − ln ρ + ρ 2 + O ( ρ 2 ) . (7) T o filter out unreliable samples based on Eq. 7 , we take a lower bound on the KL div ergence, τ base = − ln ρ + αρ , where ρ is the maximum loss calculated on the filtered samples from the latest update, and α ∈ (0 , 0 . 5] is a hyperparameter . T o ensure tolerance for clean samples under distribution shifts during policy learning, we introduce an additional uncertainty term in the lo wer bound, τ unc = β t · s K L , where s K L is the standard deviation of KL diver gence across encountered samples, and β t decays linearly over time. Specifically , β t = max( β min , β max − k t ) , where β min , β max , and k are hyperparameters controlling the decay . The final dynamic lower bound is given by τ lower = τ base + τ unc . This adaptive thresholding enables greater tolerance for noisy samples early in training, while becoming more conservati ve as learning progresses. Handling noisy samples. Samples with a KL di vergence below τ lower are considered clean and are incorporated into the rew ard model training: D τ l = { ( σ 0 , σ 1 , ˜ y ) : D K L ( ˜ y ∥ P θ ( σ 0 , σ 1 )) < τ lower } . (8) Con versely , samples with a KL div ergence exceeding a higher threshold τ upper are presumed to contain noisy labels with high certainty . T o preserve their utility , we relabel these samples by flipping their predicted labels and include them in a separate dataset: D τ u = { ( σ 0 , σ 1 , 1 − ˜ y ) : D K L ( ˜ y ∥ P θ ( σ 0 , σ 1 )) > τ upper } . (9) The remaining samples, with KL di vergence between τ lower and τ upper , are deemed uncertain , and we sample from them based on the av ailable oracle annotation b udget. These samples are particularly valuable, as both the VLE and rew ard model struggle to assign reliable labels. By focusing annotation on this subset, D o , we ensure that annotations address the most uncertain cases. T raining with selective feedback. The reward model is trained on N vle = |D τ l | + |D τ u | machine-labeled samples, supplemented by N oracle = |D o | oracle-labeled samples from uncertain cases. The N oracle samples are used to update the VLE. This targeted feedback mechanism improves the re ward model and the VLE while significantly reducing the overall annotation burden. Success rate Window Open Window Close Door Open Door Close Environment steps (1e6) Environment steps (1e6) Environment steps (1e6) Environment steps (1e6) Environment steps (1e6) Environment steps (1e6) Environment steps (1e6) Environment steps (1e6) Success rate Drawer Open Drawer Close Button Press Sweep Into x=1K y=1K z=2K x=1K y=1K z=2K x=1K y=1K z=2K x=1K y=1K z=2K x=1K y=1K z=2K x=5K y=15K z=25K x=1.5K y=2K z=4K x=10K y=15K z=30K ROVED (x) PEBBLE (y) PEBBLE (z) SURF (x) MR N (x) LIV Fig. 3: Improv ed feedback efficiency . R O VED consistently outperforms all baselines with minimal oracle feedback, matching or exceeding PEBBLE’ s performance while requiring 50%-80% fe wer annotations. At equal preference counts, RO VED also outperforms MRN and SURF . V ariables (x, y , z) denote the number of oracle preferences used. D. Overall algorithm R O VED proceeds by initializing the policy π ϕ , reward function r θ , and additional layers G on top of the VLE randomly . Giv en a task description l , the method iterati vely follows a structured cycle. First, the policy π ϕ is updated using the rew ard function r θ , interacting with the en vironment and storing observed trajectories in a buf fer . From this buf fer , trajectory segment pairs are sampled and assigned preferences using the VLE using Eq. 4 and Eq. 5 . These labeled pairs are then categorized into clean and noisy samples based on the filtering strategy outlined in Sec. IV -C . A subset of the noisy samples is sent for oracle annotation, subject to a predefined budget. The rew ard model is updated using the preference- labeled pairs ( VLE/oracle annotated) through Eq. 2 , while the VLE is fine-tuned using the oracle-annotated samples, following the adaptation strategy outlined in Sec. IV -B . V . E X P E R I M E N T S A. Experimental setup T asks. W e ev aluate RO VED on eight div erse manipulation tasks from Meta-W orld [ 16 ]: door-open , door-close , drawer - open , drawer-close , window-open , window-close , b utton- pr ess , and sweep-into . The tasks are visualized in Fig. 2 Implementation. W e use Soft Actor-Critic (SA C) [ 32 ] with state-based observations. Actor and critic models are MLPs (3 hidden layers, 256 units) trained with Adam using a learning rate (LR) of 1e − 4 ; the critic τ is set to the default value of 5e − 3 . The reward model is an ensemble of 3 MLPs (3 hidden layers, 256 units, Leaky ReLU; tanh output), trained with Adam (LR 3e − 4 , batch size 128) for 200 steps per iteration. The re ward model is trained on 30K preference samples in total, combining the allocated oracle preference budget with the remaining preferences generated by the VLE. W e collect 1K random interactions, followed by 5K unsupervised interactions using state-entropy maximization. Policy , reward model, and VLE training begin after these 6K steps. For initialization, 250 oracle feedback samples are used to train both the re ward model and the VLE. Subsequently , at e very 3K steps, N = 128 preference pairs are sampled using segments of length 50 from the SA C replay buf fer , following PEBBLE [ 2 ]. VLE labels for these pairs are added to the preference buffer B . From B , we sample D τ l and D τ u as described in Sec. IV -C . From the remaining uncertain pairs, up to 0 . 25 N are selected for oracle feedback. This procedure is repeated ev ery 3K steps until either the total preference budget or the oracle preference budget is exhausted. T o determine the oracle feedback budget, we first ran PEBBLE with v arying budgets (1K–30K) across tasks, and identified the minimum b udget to achiev e a reasonable success rate ( > 50% ) in each task. Although larger budgets generally improv e performance, our goal is to show that incorporating VLEs can substantially reduce the amount of oracle feedback needed to reach comparable results. W e set task-specific oracle budgets based on task complexity . W e experiment with both LIV [ 5 ] and DecisionNCE [ 7 ] as VLEs, and implement RO VED with LIV by default unless specified. The trainable layers, G L and G I , are 2-layer MLPs (256, 64, ReLU), while the in verse dynamics head f is a ROVED w/ knowledge transfer (w) ROVED (x) PEBBLE (y) PEBBLE (z) Success rate Drawer open (from Door open) Environment steps (1e6) w=2.5K x=5K y=15K z=25K Window open (from Window close) w=0.5K x=1K y=1K z=2K Environment steps (1e6) Fig. 4: Knowledge transfer across tasks. W ith knowledge transfer , R O VED matches or surpasses PEBBLE while reduc- ing annotation requirements by 75–90%. This demonstrates ef fectiv e transfer in both same task, differ ent object (left) and same object, differ ent task (right) settings. V ariables (w , x, y , z) denote the number of preferences used. 128–64–4 MLP with ReLU, with an LR of 3e − 4 . For label selection, we adopt RIME [ 15 ] hyperparameters: α = 0 . 5 , β min = 1 , β max = 3 , k = 1 / 300 , and τ upper = 3 ln(10) . VLM oracles. W e also ev aluate using a VLM-based oracle, following RL-VLM-F [ 10 ] with Gemini-Pro-1.5 [ 9 ]. Due to API costs 1 , results are reported on a subset of tasks. W e adopt the exact RL-VLM-F setup (segment length 1, two-step prompting, 20K budget), and additionally e valuate with a reduced budget of 10K. Note that RL-VLM-F requires more queries than PEBBLE as it operates on single-step segments. Baselines. W e compare RO VED against several baselines. PEBBLE [ 2 ] serves as a basic reference, learning a re ward function from human preference feedback and optimizing policies using SA C. SURF [ 22 ] and MRN [ 23 ] improv e prefer- ence learning ef ficiency via semi-supervised augmentation and policy-informed reward updates, respecti vely . For pure VLE- based approaches, we include LIV [ 5 ] and DecisionNCE [ 7 ]. Finally , RL-VLM-F [ 10 ] is ev aluated as a VLM-based oracle. All results are av eraged across fiv e random seeds. B. Main results Does RO VED improve oracle feedback efficiency? W e e valuate whether R O VED can achiev e high task performance with substantially less oracle feedback. Fig. 3 shows the learning curves comparing task success rates. R O VED is ev aluated using x oracle feedback samples, while PEBBLE, the baseline preference-based method, is assessed with y (similar or higher than x ) and z (significantly higher) samples to highlight the impact of feedback efficiency . Efficienc y- focused PbRL methods, SURF and MRN, are also e valuated using x oracle samples to examine the gains by RO VED. Across most tasks, R O VED matches PEBBLE’ s perfor- mance while requiring only 50% fewer oracle queries. For more challenging tasks ( e.g. , button-press, sweep-into, and drawer -open), the reduction increases to 63.5%, 66.6%, and 80%, respectiv ely . Standalone VLE-based rew ard models 1 https://ai.google.dev/gemini- api/docs/pricing# gemini- 1.5- pro Success rate Environment reward Success rate Environment reward (a) Door open (b) Drawer close Environment steps (1e6) Environment steps (1e6) Environment steps (1e6) Environment steps (1e6) RL-VLM-F (10K) RL-VLM-F (20K) ROVED (10K) Fig. 5: Experiments with VLM oracles. R O VED achieves comparable or better performance than RL-VLM-F while using 50% fewer oracle preferences (denoted by the number in brackets), demonstrating its ability to generalize across different PbRL algorithms. Experiments are reported on a subset of en vironments due to the high API cost of VLMs. (LIV and DecisionNCE) fail to achieve meaningful success due to noisy rew ards when applied without supervision (see Sec. III ), highlighting the need for minimal oracle feedback. While SURF and MRN show moderate gains over PEBBLE at reduced oracle budgets, they still lag behind R O VED across all tasks, emphasizing the effecti veness of our approach. Can RO VED transfer knowledge across tasks? A ke y objecti ve of R O VED is to refine the VLE with oracle feedback to reduce inherent noise. W e test whether an adapted VLE can generalize to related tasks with minimal additional supervision. T wo types of transfer are considered: (1) same task, differ ent object : “door-open” → “drawer -open”; (2) same object, differ ent task : “windo w-close” → “window-open”. In both cases, the VLE for the target task is initialized with weights from the source task, while the rest of the algorithm remains unchanged. Fig. 4 sho ws that R O VED with kno wledge transfer matches PEBBLE trained with 25K queries using as few as 2.5K, a 90% reduction in oracle queries. Even in the worst case, we observe at least 75% query reduction. This transferability enables cumulati ve annotation savings across tasks, a feature absent in existing methods. Is R O VED effective with large vision-language models as oracles? W e also evaluate R O VED in settings where large VLMs act as automated oracles, following the RL-VLM- F setup [ 10 ] with Gemini-Pro-1.5 [ 9 ]. As shown in Fig. 5 , R O VED reduces the number of oracle queries by 50% without compromising policy performance and improves cumulativ e Steps Adapted VLE reward Steps Unadapted VLE reward Door open Steps Steps Drawer close Fig. 6: Impact of VLE adaptation. VLE rew ard predictions on the door-open and drawer -close tasks before (top row) and after (bottom row) adaptation, averaged over the same 5 expert trajectories. After adaptation, the VLE aligns more closely with true task progress. episode re wards. Although VLMs provide accurate preference labels, they are slow ( ∼ 5s per query) and incur high API costs. R O VED leverages lightweight VLEs to automatically generate most preference labels, reserving expensi ve VLM queries for uncertain cases. This approach produces feedback in under 0.009s—ov er three orders of magnitude faster—while cutting reliance on costly oracle queries by at least 50%, demonstrating that VLEs are essential for efficient PbRL. C. Ablation study Impact of VLE adaptation. T o understand how oracle feedback impro ves the VLE, we analyze re ward outputs before and after adaptation. Fig. 6 shows VLE rew ard predictions on fiv e expert trajectories for the door-open and drawer -close tasks. Ideally , rewards should increase along the trajectory , reflecting progress toward task completion. As shown, the adapted VLE better aligns with ground-truth task progress, producing higher reward values to ward the end of successful trajectories without abrupt drops. This reduces reliance on expensi ve oracle feedback and enables the VLE to serve as a more effecti ve and generalizable prior . Consequently , fine- tuned VLEs transfer across tasks more robustly , compounding annotation savings ov er time (see Sec. V -B ). T o further analyze the impact of this adaptation, we trained only the rew ard model using feedback from the VLE and the oracle, while keeping the VLE fixed (Sec. IV -B ). As shown in Fig. 8 , although the success rate initially increases, it later drops, since the VLE does not incorporate oracle feedback, leading to increasingly misaligned rew ard signals. Robustness to choice of VLE. Our main experiments use LIV [ 5 ] as the default VLE, but we also e v aluate R O VED with DecisionNCE [ 7 ] to test sensitivity to the choice of VLE. As Environment steps (1e6) Success rate PEBBLE (15K) PEBBLE (30K) ROVED w/ DecisionNCE (10K) LIV ROVED w/ LIV (10K) DecisionNCE Fig. 7: Robustness to choice of VLE. R O VED maintains consistent performance (on the sweep-into task) across different VLE backbones, including LIV and DecisionNCE, highlighting robustness to the choice of embedding model. Success rate Environment steps (1e6) Environment steps (1e6) Door open Drawer close ROVED (1K) N o inverse dynamics N o selection N o VLE adaptation Fig. 8: Ablation study . Success rates when (i) removing the in verse dynamics loss from VLE adaptation, (ii) replacing selectiv e feedback with random sampling or (iii) removing VLE adaptation. All ablations show clear performance degra- dation, underscoring the importance of each component. sho wn in Fig. 7 on the sweep-into task, R O VED successfully lev erages stronger pre-trained VLEs: DecisionNCE slightly improv es performance over LIV . Importantly , DecisionNCE alone fails to solve these tasks without R O VED’ s uncertainty- aw are hybrid components, v alidating the necessity of selective adaptation and oracle-guided feedback. This shows that R O VED’ s benefits generalize across VLE backbones and makes the approach adaptable to stronger or more specialized VLEs in future work. Impact of in verse dynamics loss. T o ev aluate the ef ficacy of the self-supervised loss, we trained the VLE using only the preference loss in Eq. 2 . As shown in Fig. 8 , the success rate initially increases but later degrades. In the early stages, when oracle feedback is av ailable, the VLE performs well by leveraging reliable supervision. Howev er , without the in verse dynamics loss, its performance declines as the policy ev olves. This occurs because, while the VLE learns from oracle preferences, these preferences are deriv ed from samples of a suboptimal policy . As the policy improves and the data distribution shifts, the VLE struggles to generalize due to limited understanding of en vironment dynamics. Incorporating the in verse dynamics loss allows the VLE to adapt to distribution shifts, maintaining stable performance throughout. Impact of selective feedback. T o e valuate the efficac y of the selection strategy , we ev aluate a variant of R O VED where oracle feedback is collected on randomly selected pairs from the replay b uffer instead of using the noise mitigation and selection strate gy in Sec. IV -C . As sho wn in Fig. 8 , removing this selection achiev es reasonable performance and can ev en surpass PEBBLE with the same amount of feedback, but remains inferior to the full method. Random selection allows noisy labels to influence reward model training and introduces redundancy in oracle feedback, as uncertain segments for the VLE may not be prioritized. This shows the need of selective feedback in maximizing oracle efficienc y . V I . C O N C L U S I O N In this work, we introduced RO VED, a hybrid framework for PbRL that combines the scalability of VLEs with the precision of selecti ve oracle supervision. By lev eraging an uncertainty-aware sample selection strate gy and a parameter- efficient VLE adaptation mechanism, we reduce reliance on costly human or VLM feedback. Across several manipulation tasks, we achie ve comparable or superior policy performance while cutting annotation costs by 50–80%. Moreov er , our fine-tuned VLE transfers effecti vely across related tasks, enabling cumulative annotation savings of 75–90%. These results highlight R O VED as a practical step tow ard more efficient and scalable PbRL. Acknowledgement. This work was partially supported by NSF grants under A ward No. 2326309 and 2312395, and the UC Multi-campus Research Programs Initiativ e. R E F E R E N C E S [1] P . F . Christiano, J. Leike, T . Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences, ” NeurIPS , 2017. 1 , 2 [2] K. Lee, L. Smith, and P . Abbeel, “Pebble: Feedback-efficient interactive reinforcement learning via relabeling experience and unsupervised pre- training, ” arXiv preprint , 2021. 1 , 2 , 3 , 5 , 6 [3] A. Radford, J. W . Kim, C. Hallacy , A. Ramesh, G. Goh, S. Agarwal, G. Sastry , A. Askell, P . Mishkin, J. Clark, et al. , “Learning transferable visual models from natural language supervision, ” in ICML , 2021. 1 [4] J. Rocamonde, V . Montesinos, E. Nav a, E. Perez, and D. Lindner, “V ision-language models are zero-shot reward models for reinforcement learning, ” arXiv preprint , 2023. 1 , 2 [5] Y . J. Ma, V . Kumar , A. Zhang, O. Bastani, and D. Jayaraman, “Li v: Language-image representations and rewards for robotic control, ” in ICML , 2023. 1 , 2 , 3 , 5 , 6 , 7 [6] S. Sontakke, J. Zhang, S. Arnold, K. Pertsch, E. Bıyık, D. Sadigh, C. Finn, and L. Itti, “Roboclip: One demonstration is enough to learn robot policies, ” NeurIPS , 2024. 1 , 2 [7] J. Li, J. Zheng, Y . Zheng, L. Mao, X. Hu, S. Cheng, H. Niu, J. Liu, Y . Liu, J. Liu, et al. , “Decisionnce: Embodied multimodal representations via implicit preference learning, ” in ICML , 2024. 1 , 2 , 3 , 5 , 6 , 7 [8] Y . Fu, H. Zhang, D. Wu, W . Xu, and B. Boulet, “Furl: V isual-language models as fuzzy rewards for reinforcement learning, ” arXiv preprint arXiv:2406.00645 , 2024. 1 , 2 , 3 [9] G. T eam, P . Georgiev , V . I. Lei, R. Burnell, L. Bai, A. Gulati, G. T anzer, D. V incent, Z. Pan, S. W ang, et al. , “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context, ” arXiv preprint arXiv:2403.05530 , 2024. 1 , 6 [10] Y . W ang, Z. Sun, J. Zhang, Z. Xian, E. Biyik, D. Held, and Z. Erickson, “Rl-vlm-f: Reinforcement learning from vision language foundation model feedback, ” in ICML , 2024. 1 , 2 , 6 [11] B. Akgun, M. Cakmak, K. Jiang, and A. L. Thomaz, “Ke yframe-based learning from demonstration: Method and ev aluation, ” International Journal of Social Robotics , vol. 4, pp. 343–355, 2012. 1 [12] L. Smith, N. Dhawan, M. Zhang, P . Abbeel, and S. Levine, “ A vid: Learning multi-stage tasks via pixel-lev el translation of human videos, ” arXiv pr eprint arXiv:1912.04443 , 2019. 1 [13] D. J. Hejna III and D. Sadigh, “Few-shot preference learning for human-in-the-loop rl, ” in CoRL , 2023. 1 [14] H. Song, M. Kim, D. Park, Y . Shin, and J.-G. Lee, “Learning from noisy labels with deep neural networks: A survey , ” IEEE transactions on neural networks and learning systems , vol. 34, no. 11, pp. 8135–8153, 2022. 1 [15] J. Cheng, G. Xiong, X. Dai, Q. Miao, Y . Lv , and F .-Y . W ang, “Rime: Robust preference-based reinforcement learning with noisy preferences, ” arXiv pr eprint arXiv:2402.17257 , 2024. 1 , 2 , 4 , 6 [16] T . Y u, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine, “Meta-world: A benchmark and ev aluation for multi-task and meta reinforcement learning, ” in CoRL , 2020, pp. 1094–1100. 1 , 5 [17] J. Ho and S. Ermon, “Generative adversarial imitation learning, ” NeurIPS , 2016. 2 [18] H.-T . L. Chiang, A. Faust, M. Fiser, and A. Francis, “Learning navigation behaviors end-to-end with autorl, ” IEEE RA-L , vol. 4, no. 2, pp. 2007–2014, 2019. 2 [19] Y . J. Ma, W . Liang, G. W ang, D.-A. Huang, O. Bastani, D. Jayara- man, Y . Zhu, L. Fan, and A. Anandkumar, “Eureka: Human-le vel rew ard design via coding large language models, ” arXiv preprint arXiv:2310.12931 , 2023. 2 [20] R. W ang, D. Zhao, Z. Y uan, I. Obi, and B.-C. Min, “Prefclm: Enhancing preference-based reinforcement learning with crowdsourced large language models, ” IEEE RA-L , 2025. 2 [21] R. Rafailov , A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Y our language model is secretly a rew ard model, ” NeurIPS , 2024. 2 [22] J. Park, Y . Seo, J. Shin, H. Lee, P . Abbeel, and K. Lee, “Surf: Semi-supervised reward learning with data augmentation for feedback- efficient preference-based reinforcement learning, ” arXiv preprint arXiv:2203.10050 , 2022. 2 , 6 [23] R. Liu, F . Bai, Y . Du, and Y . Y ang, “Meta-reward-net: Implicitly differentiable reward learning for preference-based reinforcement learning, ” NeurIPS , vol. 35, 2022. 2 , 6 [24] D. Li, Z. W ang, Y . Chen, R. Jiang, W . Ding, and M. Okumura, “ A survey on deep active learning: Recent advances and new frontiers, ” T ransactions on Neural Networks and Learning Systems , 2024. 2 [25] Y . W ang, Y . Kordi, S. Mishra, A. Liu, N. A. Smith, D. Khashabi, and H. Hajishirzi, “Self-instruct: Aligning language models with self- generated instructions, ” arXiv preprint , 2022. 2 [26] M. Lukasik, S. Bhojanapalli, A. Menon, and S. Kumar, “Does label smoothing mitigate label noise?” in ICML , 2020. 2 [27] U. Ghosh, D. S. Raychaudhuri, J. Li, K. Karydis, and A. Roy- Chowdhury , “Robust offline imitation learning from diverse auxiliary data, ” Tr ansactions on Machine Learning Research , 2025. 2 [28] Z. Zhang and M. Sabuncu, “Generalized cross entropy loss for training deep neural networks with noisy labels, ” NeurIPS , 2018. 2 [29] W . W ang, F . Feng, X. He, L. Nie, and T .-S. Chua, “Denoising implicit feedback for recommendation, ” in Proceedings of the 14th ACM international conference on web sear ch and data mining , 2021, pp. 373–381. 2 [30] R. S. Sutton and A. G. Barto, Reinforcement learning: An intr oduction . MIT press, 2018. 2 [31] R. A. Bradley and M. E. T erry , “Rank analysis of incomplete block designs: I. the method of paired comparisons, ” Biometrika , vol. 39, no. 3/4, pp. 324–345, 1952. 2 [32] T . Haarnoja, A. Zhou, P . Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor , ” in ICML , 2018. 3 , 5 [33] D. S. Raychaudhuri, S. Paul, J. V anbaar, and A. K. Roy-Chowdhury , “Cross-domain imitation from observations, ” in ICML , 2021. 3
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment