Bit-Identical Medical Deep Learning via Structured Orthogonal Initialization
Deep learning training is non-deterministic: identical code with different random seeds produces models that agree on aggregate metrics but disagree on individual predictions, with per-class AUC swings exceeding 20 percentage points on rare clinical …
Authors: Yakov Pyotr Shkolnikov
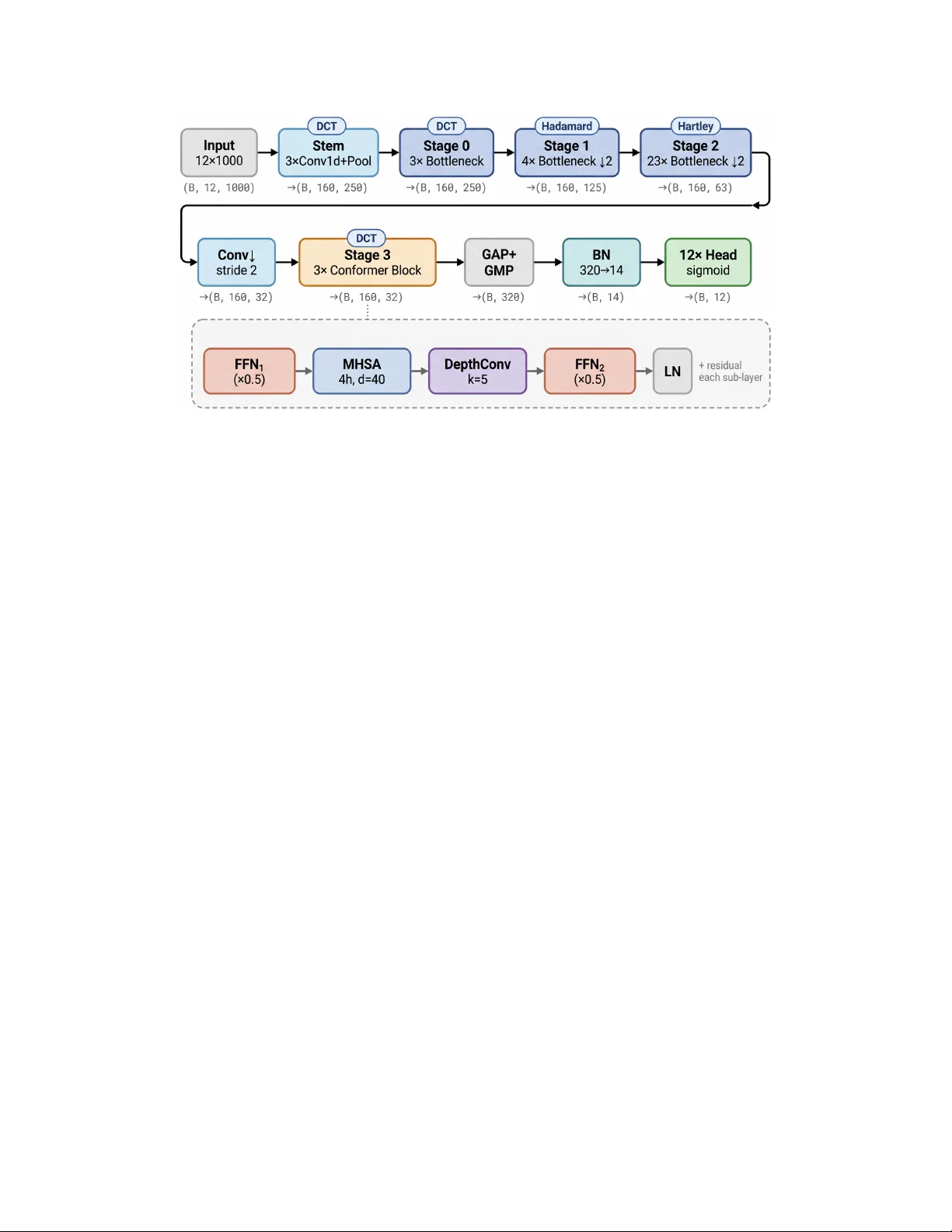
Bit-Iden tical Medical Deep Learning via Structured Orthogonal Initialization Y ak ov P . Shk olniko v Indep enden t Researc her, Mountain View, CA, United States yshkolni@gmail.com Abstract Deep learning training is non-deterministic: identical co de with different random seeds pro duces models that agree on aggregate metrics but disagree on individual predictions, with per-class AUC swings exceeding 20 p ercen tage p oin ts on rare clinical classes. W e presen t a framew ork for v erified bit-identical training that eliminates three sources of randomness: weigh t initialization (via structured orthogonal basis functions), batc h ordering (via golden ratio sc heduling), and non-deterministic GPU op erations (via arc hitecture selection and custom autograd). The pip eline pro duces MD5-v erified iden tical trained w eigh ts across independent runs. On PTB-XL ECG rhythm classification, structured initialization significantly ex- ceeds Kaiming across tw o architectures ( n = 20; Conformer p = 0 . 016, Baseline p < 0 . 001), reducing aggregate v ariance b y 2–3 × and reducing p er-class v ariability on rare rh ythms by up to 7 . 5 × (TRIGU range: 4.1pp vs 30.9pp under Kaiming, indep enden tly confirmed b y 3-fold CV). A four-basis comparison at n =20 shows all structured orthogonal bases pro duce equiv alent p erformance (F riedman p =0 . 48), es- tablishing that the contribution is deterministic structured initialization itself, not any particular basis function. Cross-domain v alidation on sev en MedMNIST b enchmarks ( n = 20, all p > 0 . 14) confirms no p erformance p enalty on standard tasks; p er-class analysis on im balanced tasks (ChestMNIST, RetinaMNIST) shows the same v ariance reduction on rare classes observ ed in ECG. Cross-dataset ev aluation on three external ECG databases confirms zero-shot generalization ( > 0.93 AFIB A UC). Keyw ords: deterministic training, repro ducibility , w eight initialization, structured orthog- onal initialization, medical image classification, ECG classification 1 In tro duction Deep learning for medical classification, including electro cardiogram (ECG) rhythm de- tection, histopathology tissue t yping, and dermatoscopic lesion classification, has ac hiev ed exp ert-lev el p erformance on b enchmark datasets [1 – 4]. Y et a barrier to clinical deploymen t p ersists: irrepro ducibilit y at the individual patient lev el. Standard deep learning training inv olves three sources of randomness, namely weigh t ini- tialization (Kaiming uniform sampling [5]), stochastic batc h ordering, and non-deterministic 1 Figure 1: Per-cl ass p erformance v ariability (Conformer, n = 20 seeds). (a) Kaiming initial- ization: SARRH ( n pos = 77) ranges 4.2pp across seeds despite b eing moderately represen ted. SV ARR ( n pos = 14) ranges 20.2pp; TRIGU ( n pos = 2) ranges 30.9pp. (b) Mixed-basis initial- ization: systematically tighter ranges. SARRH reduced from 4.2 to 2.5pp, SV ARR from 20.2 to 11.5pp, TRIGU from 30.9 to 4.1pp (7 . 5 × ). Green stars sho w the fully deterministic golden ratio run (zero v ariance by construction); golden falls within or ab ov e the seeded range for all classes. Thic k horizontal lines: mean; shaded regions: ± 1 std; thin whisk ers: full min– max range. T est-set p ositive counts (fold 10): SR 1674, AFIB 152, ST A CH 82, SARRH 77, SBRAD 64, P ACE 28, SV ARR 14, BIGU 8, AFL T 7, SVT AC 3, PSVT 2, TRIGU 2. GPU op erations (e.g., atomicAdd in p o oling backw ard passes). T ogether, these mean that running iden tical co de with different random seeds can pro duce mo dels that agree on ag- gregate metrics but disagree on whic h patien ts they misdiagnose. In our ECG exp erimen ts, Kaiming-initialized Conformers across 20 initialization seeds exhibit p er-class AUC swings of 20.2 p ercen tage p oints for suprav en tricular arrhythmia (SV ARR: 0.766–0.969, n pos = 14 test cases) and 11.8 p oints for paced rh ythm (P A CE: 0.861–0.979, n pos = 28), while aggregate macro A UC v aries b y only 4.1 p ercen tage p oints (Fig. 1). A clinician reviewing tw o mo dels trained from the same co de with different seeds w ould encounter differen t failure mo des: one mo del migh t miss SV ARR, another migh t miss P ACE, with no wa y to predict whic h patien ts are at risk from which mo del. P er-class instability of this magnitude is invisible in aggregate metrics. Repro ducibilit y is increasingly recognized as imp ortan t in medical AI developmen t. The FD A’s AI/ML Soft ware as a Medical Device Action Plan [6, 7] and the EU AI Act (Reg- ulation 2024/1689) [8] discuss repro ducibilit y and traceabilit y in their guidance on go o d mac hine learning practices. Deterministic training directly supports these goals by enabling v erifiable, auditable training pip elines, though the regulatory implications of algorithmic determinism ha ve not been formally ev aluated. Prior w ork on deterministic training has fo cused on GPU op eration determinism (PyT orch’s deterministic mo de [9]) or seed fixing, but these approaches merely make randomness repro ducible given a sp ecific seed, and they do not eliminate the seed dependence itself. Recen t w ork has established that structured initialization can match random Kaiming initialization [10, 11] (Section 2), confirming that random weigh ts are unnecessary . These metho ds do not address the remaining sources of non-determinism (batc h ordering and GPU op erations) that prev en t fully repro ducible train- ing. Our con tribution is a complete determinism framework that eliminates all three sources 2 sim ultaneously , not an y particular basis function. W e achiev e verified bit-iden tical deep learning training by systematically eliminating all three sources of randomness. W eight initialization uses structured orthogonal basis functions (DCT, Hadamard, Hartley) computed analytically , producing identical w eigh ts on every run without any random seed. Batc h ordering uses golden ratio sc heduling, a deterministic metho d requiring no random seed. Non-deterministic GPU op erations are eliminated b y arc hitectural choice (the Conformer uses deterministic implemen tations for all op erations) or custom autograd functions. T ogether, these comp onen ts yield trained mo dels with bit- iden tical weigh ts across indep endent runs on the same hardware, v erified b y MD5 hash comparison. Three levels of determinism are distinguished. Initialization determinism pro duces iden- tical weigh ts regardless of seed, and all architectures in this study attain it. F ul l tr aining determinism additionally requires deterministic batc h ordering and deterministic GPU op- erations. Only the Conformer with golden ratio batc h ordering attains full training deter- minism, pro ducing MD5-v erified bit-iden tical trained weigh ts. Infer enc e determinism , where the same trained mo del and input pro duce the same output, holds trivially for all mo dels. This pap er mak es fiv e con tributions: • MD5-verified bit-iden tical training on medical classification tasks in b oth 1D (ECG) and 2D (medical imaging). • V ariance decomposition separating initialization v ariance (eliminated by construction), batc h-ordering v ariance (std = 0.005), and fold/data v ariance (std = 0.012). • A four-basis comparison (DCT, Hadamard, Hartley , sinusoidal, n =20 eac h) demon- strating equiv alent mean performance (F riedman p =0 . 48), establishing that the contri- bution is deterministic structured initialization itself, not any particular basis function. • A 2 × 2 golden-seed design illustrating seed-dependent p er-class v ariation under Kaim- ing initialization (e.g., trigeminy A UC 0.781 vs 0.980 with structured init). • V alidation across t wo ECG arc hitectures, sev en MedMNIST medical image b enchmarks ( n =20 p er condition), CIF AR-100, and three external ECG databases. 2 Related W ork 2.1 W eigh t initialization Glorot and Bengio [12] deriv ed v ariance-preserving conditions for sigmoid/tanh activ ations. He et al. [5] extended this to ReLU net works with Kaiming initialization, now the default in most deep learning framew orks. Saxe et al. [13] sho wed that orthogonal w eigh t matrices en- able depth-indep endent learning dynamics and faithful gradient propagation. P ennington et al. [14] show ed that orthogonal initialization ac hiev es dynamic al isometry , the concentration of all singular v alues of the input-output Jacobian near unity , enabling deep signal propaga- tion through sigmoid net works. Xiao et al. [15] extended dynamical isometry to conv olutional net works, enabling training of 10,000-la yer v anilla CNNs with orthogonal initialization. Hu 3 et al. [16] pro vided the first prov able conv ergence b enefit for orthogonal initialization in deep linear netw orks, establishing that orthogonal weigh ts accelerate optimization, not merely preserv e signal norms. Mishkin and Matas [17] prop osed La yer-Sequen tial Unit-V ariance (LSUV) initialization, demonstrating that careful initialization can replace batch normaliza- tion [18]. Zhang et al. [19] introduced Fixup initialization, enabling stable training of very deep ResNets through residual branch rescaling. All of these metho ds remain sto chastic. Differen t random seeds produce differen t w eigh t matrices, even when v ariance is prop erly con trolled. 2.2 Deterministic and structured initialization Sev eral recent works hav e explored non-random initialization. Zhao et al. [10] prop osed ZerO initialization using Hadamard matrices to initialize netw orks with only zeros and ones, demonstrating on ImageNet that random weigh ts are unnecessary . F ernandez-Hernandez et al. [11] introduced sin usoidal initialization, matching Kaiming accuracy across CNNs and vision transformers with faster conv ergence. Agha jan yan [20] proposed con volution-a w are initialization b y constructing orthogonal filters in the F ourier domain and inv erting to stan- dard space, providing an early demonstration that exploiting con volution structure yields impro vemen ts ov er random initialization. Ulicny et al. [21] developed Harmonic Conv olu- tional Net w orks using DCT basis functions as preset sp ectral filters, demonstrating DCT energy compaction for netw ork compression. Our w ork differs from Ulicny et al. in that they replace conv olutional lay ers en tirely with fixed DCT filter banks that learn linear com bina- tions of basis functions, whereas we initialize standard con volutional lay ers with DCT-derived w eights that are then freely up dated b y gradien t descen t. Our approach differs from ZerO ini- tialization in using DCT bases (which provide smo oth frequency-domain structure suited to quasi-p erio dic signals lik e ECGs) rather than binary Hadamard patterns, and in supp orting m ultiple basis families (DCT, Hadamard, Hartley , sinusoidal) that can b e used individu- ally or combined across net work stages. T o our knowledge, Hartley basis functions hav e not previously b een used for neural netw ork w eight initialization. Pan et al. [22] prop osed IDInit using padded identit y-lik e matrices, demonstrating at ICLR 2025 that structured ini- tialization can ov ercome rank constrain ts in non-square weigh t matrices. IDInit fo cuses on initialization qualit y and do es not address batch ordering or GPU determinism. 2.3 ECG classification b enc hmarks The PTB-XL dataset [1] and its asso ciated b enc hmarks [2] established xresnet1d101 (0.957 macro A UC, rhythm classification) as a widely used reference. Mehari and Stro dthoff [23] demonstrated self-sup ervised pre-training for learning ECG represen tations from unlab eled data, achieving near-sup ervised p erformance with limited lab els. Hann un et al. [3] demon- strated cardiologist-level arrhythmia detection on ambulatory ECGs, and Rib eiro et al. [4] ac hieved exp ert-lev el 12-lead ECG classification at scale, motiv ating p otential clinical ap- plications. Li et al. [24] trained ECGF ounder on o ver 10 million ECGs with 150 lab el cat- egories, demonstrating large-scale foundation mo del approac hes to ECG analysis. None of these works address initialization-induced irrepro ducibility or pro vide deterministic training guaran tees. 4 2.4 Repro ducibilit y in clinical AI Semmelro c k et al. [25] survey ed repro ducibilit y barriers in ML-based researc h, finding that “man y papers are not ev en repro ducible in principle” due to sensitivity of training conditions. Desai et al. [26] prop osed a taxonomy distinguishing rep eatabilit y , repro ducibilit y , and repli- cabilit y in AI/ML researc h. McDermott et al. [27] found that ML for health consistently lags in repro ducibility , with fewer than half of surv eyed pap ers pro viding co de. Pineau et al. [28] in tro duced the ML Reproducibility Chec klist, raising co de a v ailability but not addressing algorithmic non-determinism. Bouthillier et al. [29] demonstrated that “v ariance due to data sampling, parameter initialization and h yp erparameter c hoice impact markedly the results” in ML b enchmarks, motiv ating proper v ariance accounting. Zh uang et al. [30] c haracterized the impact of tooling randomness on neural net work training, finding that while top-line metrics are minimally affected, p erformance on sp ecific data subgroups is highly sensitive, consisten t with the p er-class instability we observ e. Chen et al. [31] proposed systematic framew orks for training repro ducible deep learning mo dels, identifying weigh t initialization as one of sev eral reproducibility-critical random sources. Our approach eliminates this source at the algorithmic level. Xie et al. [32] in tro duced RepDL, a library ensuring bit-level repro ducibility across com- puting environmen ts. RepDL addresses hardw are-level non-determinism (floating-p oint as- so ciativit y , platform differences). Our work addresses algorithmic non-determinism (initial- ization, batc h ordering, GPU op erations). These approaches are complemen tary . 2.5 Neural collapse and classifier geometry P apy an et al. [33] disco vered that during terminal training, classifier weigh ts conv erge to a simplex Equiangular Tight F rame (ETF). Zhu et al. [34] prov ed that ETF geometry is the unique global minimizer under cross-en tropy loss with weigh t decay . Y ang et al. [35] sho wed that “feature learning with a fixed ETF classifier naturally leads to the neural collapse state ev en when the dataset is im balanced among classes,” motiv ating ETF initialization for imbalanced classification tasks. W e exploit this by initializing classification heads from the ETF directly , pro viding structured geometry from the start (used heuristically in our m ulti-lab el sigmoid setting; see Metho ds). 3 Metho ds 3.1 Arc hitectures 3.1.1 Conformer The Conformer (1.83M parameters), adapted from the sp eech recognition Conformer [36], com bines depthwise separable conv olutions with multi-head self-atten tion in a feed-forward– atten tion–conv olution–feed-forward (F ACF) blo ck structure (Fig. 2). Input 12-lead ECGs (1000 time steps at 100 Hz) are pro cessed through a conv olutional stem, follow ed by Con- former blo cks that alternate global self-atten tion (capturing inter-beat temp oral dep enden- cies) with depth wise conv olution (extracting local morphological features). The arc hitecture 5 Figure 2: ECG Conformer arc hitecture (1.83M parameters). The net work processes 12-lead ECG input (1000 samples at 100 Hz) through a con volutional stem (3 × Conv1d + AvgP o ol, outputting 160 c hannels), three bottleneck stages with progressiv e stride-2 do wnsampling (3, 4, and 23 blo c ks resp ectively), a stride-2 transition con v olution, and three Conformer blo c ks. Eac h Conformer blo ck follows a macaron structure: FFN 1 (feed-forw ard net work, × 0.5 resid- ual) → MHSA (multi-head self-atten tion, 4 heads, d = 40) → depth wise conv olution ( k = 5) → FFN 2 ( × 0.5 residual) → LN (la yer normalization), with residual connections around eac h sub-la yer. GAP (global av erage p ooling) and GMP (global max p ooling) are concatenated (320-d) and pro jected through a BN ( K + 2 information b ottleneck, 14-d) b efore 12 inde- p enden t sigmoid heads. Pill badges ab ov e each stage indicate the orthogonal basis used for w eight initialization in mixed-basis mo de. Color co ding: light cyan = stem/transition la y ers, ligh t blue = conv olutional b ottlenec k stages, light orange = Conformer blo c ks, light teal = information b ottlenec k, ligh t green = classification heads. uses 14-dimensional output features. Stride-2 skip connections in stages 1–2 use a deter- ministic adaptiv e av erage p o oling implemen tation (custom autograd with explicit gradient distribution, a voiding non-deterministic atomicAdd). Conformer blocks (stage 3) contain no p o oling op erations. All CUD A op erations are fully deterministic. Classification uses 12 indep enden t sigmoid heads. 3.1.2 Baseline CNN The baseline (1.65M parameters) follows an xresnet-style architecture [2, 37] with residual blo c ks at constant width, similar to the published xresnet1d101 but substantially smaller. It uses a 128-dimensional feature space with no intermediate b ottleneck. Skip connections use adaptive a verage p ooling for stride c hanges. Classification uses 12 indep enden t sigmoid heads. 6 3.2 Structured Orthogonal Initialization Algorithm 3.2.1 Orthogonal basis computation F or eac h conv olutional lay er Conv1d( C in , C out , K ), compute the DCT-I I matrix D of size C out × ( C in · K ). Eac h ro w is defined as: d i [ j ] = cos π i (2 j + 1) 2 C in K , i ∈ [0 , C out ) , j ∈ [0 , C in · K ) . (1) The resulting filters are near-orthogonal (worst-case maxim um pairwise cosine s imilarit y 0.138 for the stem lay er where C out > fan in ; most internal la yers ac hieve < 0 . 02 after global mean subtraction). F or 2D con volutions, the basis uses a separable construction: 1D DCT along input c hannels com bined with 2D DCT spatial basis functions ov er the k ernel, yielding n ch × n spatial unique basis vectors. In b ottleneck expand lay ers (1 × 1 Con v2d: d → C out , C out ≫ d ), only d unique basis vectors exist ( n spatial = 1). Excess filters cycle through the basis mo dulo d (e.g., with d = 14 and C out = 512, only 2.7% of filters are unique). Despite this low uniqueness ratio, v ariance matching ensures correct activ ation magnitudes, and gradien t descen t rapidly diversifies the cycled filters during training (see MedMNIST results in T able 6). 3.2.2 Fixup residual scaling The last conv olution in eac h residual branch (con v3) is scaled by α fixup = 0 . 01: w conv3 = 0 . 01 · D , ensuring eac h residual blo ck starts as near-identit y ( y = x + α · f ( x )), providing gradien t stabilit y through deep netw orks. F or orthonormal initialization ( κ ( W ) = 1), each residual branc h preserves input norms: ∥ f l ( x ) ∥ ≤ ∥ x ∥ . The forw ard pass after L blo c ks satisfies ∥ y L ∥ ≤ (1 + α ) L ∥ x 0 ∥ ≈ e αL ∥ x 0 ∥ , whic h remains b ounded when α L = O (1), i.e., α = O (1 /L ). F or L = 33 blo c ks, this giv es α ≈ 0 . 03. In contrast, Zhang et al. [19] deriv e α = L − 1 / (2 m − 2) for random initialization, where the sp ectral norm exceeds 1 due to the Marc henk o–Pastur distribution. F or L = 33 and m = 3 (b ottlenec k blocks), this giv es α ≈ 0 . 42. The key distinction is that orthonormal matrices preserv e norms exactly ( κ = 1), making residual accum ulation multiplicativ e rather than v ariance-additiv e, and requiring substan tially smaller scaling. The empirically optimal α = 0 . 01 is consistent with O (1 /L ) scaling. The additional reduction b elow 0.03 is attributable to GELU activ ation con traction ( E [GELU( x ) 2 ] < E [ x 2 ]), whic h we do not formally quantify . Ablation confirms the predicted ordering: α = 0 is to o conserv ativ e (0.946 A UC), α = 0 . 01 is empirically optimal (0.961), the Fixup-derived α = 0 . 42 is to o aggressiv e for orthonormal w eigh ts (0.928), and α = 1 . 0 causes gradien t explosion (0.462). 3.2.3 V ariance matc hing All w eigh ts are zero-meaned and scaled to a target standard deviation: σ = 1 √ 3 × fan in (2) 7 This gives v ariance 1 / (3 · fan in ), appro ximately 0 . 17 × the PyT orch kaiming uniform default (2 / fan in ). The reduced scale was selected empirically; orthonormal initialization ( κ =1) is less sensitive to the absolute v ariance scale than random initialization, b ecause gradien t flo w is well-conditioned regardless of magnitude, and the fixup residual scaling ( α =0 . 01) comp ensates for the smaller activ ation magnitudes. 3.2.4 ETF head geometry Classification head weigh ts (12 heads in 14-dimensional space) are initialized from the Equiangular Tigh t F rame (ETF), the unique configuration of K unit vectors in R D ( D ≥ K ) with minim um pairwise cosine similarit y − 1 / ( K − 1) [33, 34]. The ETF is computed via SVD of the centered iden tit y matrix: M ETF = SVD I K − 1 K 11 ⊤ . (3) ETF geometry is theoretically motiv ated by neural collapse under balanced softmax cross- en tropy with weigh t deca y [34]. Li et al. [38] recen tly extended neural collapse theory to m ulti-lab el settings with pic k-all-lab el loss, demonstrating that ETF geometry emerges as an optimal classifier structure even when m ultiple lab els are activ e simultaneously . Their form ulation uses summed softmax cross-entropies rather than our indep enden t sigmoid BCE, so the ETF is used heuristically as a structured initialization rather than as a con vergence target. The 14-dimensional b ottlenec k ( K + 2 = 12 + 2) provides the minimum represen ta- tion capacit y for K classes plus a margin for in ter-class separation, following the principle that useful representations require at least K dimensions for K -class discrimination plus additional dimensions for features not captured b y the class structure (e.g., OOD detection, calibration). The K + 2 choice w as v alidated empirically; other dimensionalities (e.g., K + 1 or K + 3) were not systematically compared. 3.2.5 Numerical consistency DCT and sin usoidal basis matrices are computed in float64 precision, cac hed, and conv erted to float32, eliminating floating-p oin t unit state leak age that could cause platform-dep enden t initialization differences. Hadamard matrices (binary ± 1 entries) are exact in an y precision; Hartley matrices are verified iden tical across tested platforms. 3.2.6 Mixed orthogonal bases An y orthonormal basis can replace DCT in the initialization algorithm ab o v e. Our framew ork supp orts four bases: DCT-I I (smo oth cosine patterns), Hadamard (binary ± 1 patterns), Hartley (real-v alued frequency decomp osition), and sin usoidal (DST-I I, sine patterns). Eac h basis can b e used uniformly across all stages, or different bases can b e assigned to different stages in a mixe d configuration. The default mixed configuration assigns DCT-I I to early stages, Hadamard to middle stages, Hartley to late stages, and DCT-I I to the final stage. This assignmen t was selected heuristically by matching basis sp ectral prop erties to exp ected feature complexit y at each 8 depth, v alidated by ablation (T able 2), not derived from theory . One motiv ation is in ter-stage decorrelation: for t w o orthonormal bases B 1 , B 2 in R n , the mutual coherence µ ( B 1 , B 2 ) = max i,j |⟨ b 1 ,i , b 2 ,j ⟩| satisfies µ < 1 when the bases differ, p otentially reducing cross-stage gradien t coupling. Ho wev er, the basis comparison exp erimen t at n =20 (Section 4.4) sho ws that no structured basis significantly outp erforms any other (F riedman p =0 . 48): all four single-basis configu- rations matc h Kaiming, with means ranging from 0.955 (Hadamard) to 0.959 (Hartley). The mixed configuration’s v ariance reduction (std from 0.012 to 0.003; T able 2) may reflect the inclusion of low-v ariance bases (Hartley std=0.006, sin usoidal std=0.005) in the largest stage (23 of 30 b ottlenec k blo cks) rather than inter-stage decorrelation p er se. Mixed-basis remains the recommended default as the most thoroughly v alidated configuration. This design builds on ZerO initialization’s [10] demonstration that Hadamard bases suffice for effectiv e initialization. Theoretical analysis of DCT initialization prop erties (energy preserv ation, condition num- b er optimality , and connection to optimal decorrelation for first-order Marko v pro cesses) is pro vided in App endix D. 3.3 T raining Proto col All exp eriments use PyT orch 2.12 (nightly , CUD A 13.0) with CUDA deterministic execution. All ECG mo dels are trained with Adam (lr=10 − 3 ) and cosine annealing LR deca y [39] ov er 85 ep o c hs, batch size 128. Image classification exp erimen ts (CIF AR-100, MedMNIST) use SGD (lr=0 . 1, momen tum 0 . 9, w eight deca y 5 × 10 − 4 ) with cosine annealing ov er 200 ep o chs. Binary cross-en trop y loss is used for multi-label ECG classification. The sqrt class-w eighted v arian t scales the p ositiv e-class weigh t for class k : w + k = r N N k (4) where N is the total num b er of training samples and N k is the n umber of p ositive training samples for class k . No morphing or activ ation annealing is used. Buffer dimensions b ey ond K classes are L2-regularized (w eight 0.01). Logits are clamp ed to [ − 50 , 50] b efore loss computation for n umerical stabilit y . V alidation A UC is ev aluated ev ery 10 epo chs and at the final ep o c h; the chec kp oin t with highest v alidation AUC is selected for test ev aluation. No- lab el samples (3.4% of training data) are excluded. Data augmen tation (random cropping, flipping) is not a source of non-determinism in this framework, as augmentation op erations are deterministic given a fixed random generator state seeded p er ep o c h. Batc h ordering uses one of t wo strategies. Se e de d shuffle ( torch.Generator with a sp ecified seed) is seed-dependent but data-indep endent: the p erm utation dep ends on the random seed, not on sample con ten t, and c hanging the seed pro duces a different training run. Golden r atio or dering is seed-free but data-dep endent: the p erm utation is computed from signal conten t via k ey[ i ] = hash( X [ i ]) + ep o c h · φ mo d 1 (5) where hash( X [ i ]) = P | X [ i ] | · φ mo d 1 and φ = ( √ 5 − 1) / 2 is the golden ratio conjugate. Because the ordering dep ends only on the data and epo ch index, it is fully deterministic 9 with no random seed; the same dataset alw ays pro duces the same batch sequence. Ap- pro ximately 4% of training records share float32 L1 norms (collision groups of size ≤ 4), pro ducing fixed relative orderings for those pairs; p ermutation en tropy loss is < 0 . 2%. The φ -rotation exploits equidistribution prop erties of irrational rotations [40], pro ducing a dif- feren t but equally-spaced p erm utation eac h ep o ch. Lo w-discrepancy sequences hav e been sho wn to impro v e deep net w ork training through more uniform input-space cov erage [41]; Bengio et al. [42] show ed that presentation order affects learning outcomes. Deterministic GPU execution uses torch.use deterministic algorithms(True) with the environmen t v ariable CUBLAS WORKSPACE CONFIG set to :4096:8 [9]. 3.4 Deterministic T raining V erification F or the Conformer, stride-2 skip connections use a custom deterministic adaptive av er- age p o oling implemen tation (explicit gradient distribution via autograd.Function , av oid- ing non-deterministic atomicAdd). Conformer blo cks (stage 3) con tain no p o oling, so all op erations are fully deterministic. F or the baseline CNN, the adaptive avg pool1d bac kward pass uses non-deterministic atomicAdd in stride-2 skip connections. A custom autograd.Function replaces the bac kw ard pass with an explicit determinis- tic lo op, adding approximately 1% training o verhead (compared to 20–30% for global torch.use deterministic algorithms [43]). Bit-identical training is v erified b y MD5 hash comparison of trained mo del parameters across indep enden t runs on the same hardware. The 2D CIF AR exp erimen ts v alidate initialization qualit y under standard training con- ditions (cuDNN auto-tuning enabled), comparing DCT vs. Kaiming with 20 seeds p er condition. F ull determinism is demonstrated on MedMNIST (b elo w). F or MedMNIST, w e enable full determinism: deterministic algorithms, deterministic cuBLAS workspace, disabled cuDNN b enc hmarking, single-threaded data loading, and p er-epo ch seeded aug- men tation. Under these conditions, the DCT golden configuration pro duces bit-iden tical trained mo dels, v erified by running each exp erimen t t wice and comparing MD5 hashes of all mo del parameters. Three representativ e datasets confirmed: PathMNIST ( 62e7d86bfb32 55c319f0efbbf95492cc ), DermaMNIST ( eff68238d9a791df4e628ed96893be8c ), Blo o dM- NIST ( e063461547d38d573cb7050b8f05a4ec ). The DCT initialization itself is fully deter- ministic: the same MD5 hash ( c64e66e8764d8b749eb794b79b11638c ) is produced across NVIDIA R TX 3080, R TX 5090, A100, and R TX Pro 6000 GPUs. 3.5 Metho dological Note: Multiple Comparisons Appro ximately 140 configurations w ere ev aluated on fold 10 during model developmen t. The fold-10 results should b e interpreted as developmen t metrics, not un biased estimates. Our primary claims are v alidated on gen uinely held-out data: (1) cross-dataset generalization on three external ECG databases (AFDB, CPSC2018, Chapman-Shaoxing) nev er used during mo del developmen t (Section 4.9), (2) cross-domain v alidation on sev en MedMNIST medical image benchmarks with n =20 seeds p er condition (Section 4.6), and (3) CIF AR-100 equiv a- lence testing with n = 20 seeds (Appendix A). The MedMNIST and CIF AR-100 experiments w ere conducted after all ECG architecture dev elopment and h yp erparameter selection were complete. These are confirmatory experiments on new domains and datasets, not additional 10 T able 1: Statistical p o wer analysis for primary comparisons. Observed Cohen’s d computed from p o oled standard deviation; p o wer estimated for tw o-sided indep endent t -test at α = 0 . 05; n 80% is the p er-group sample size required for 80% p o w er. Comparison n d P o wer n 80% TOST Conform. mixed vs Kaim. 20 0.82 ∼ 71% 25 p < 0 . 001 ( δ = 0 . 015) Baseline struct. vs Kaim. 20 1.60 > 99% 7 sup eriorit y ( p < 0 . 001) CIF AR-100 struct. vs Kaim. 20 0.24 11% a — p < 0 . 001 ( δ = 0 . 5pp) a Lo w superiority p ow er is expected: the observed difference is small ( d = 0 . 24) and the primary claim is equiv alence (TOST p < 0 . 001). comparisons within the dev elopmen t lo op, and are therefore not sub ject to the m ultiple comparisons concern. Note: fold 9 was used for v alidation during arc hitecture selection. Its inclusion as one of three CV test folds ma y slightly inflate the CV mean; folds 8 and 10 are uncon taminated. 3.6 Statistical P o w er Analysis T able 1 rep orts the statistical p o w er av ailable for each primary comparison. Both ECG comparisons reach statistical significance at n = 20: Conformer ( p = 0 . 016, 71% p o wer) and Baseline CNN ( p < 0 . 001, > 99% p o wer). The pap er’s primary claim is equiv alence of structured initialization to Kaiming. TOST equiv alence is confirmed for the Conformer ( p < 0 . 001 at δ = 0 . 015, c hosen as 1.5 × the Kaiming within-condition standard deviation, represen ting a difference smaller than natural seed-to-seed v ariation) and on CIF AR-100 ( p < 0 . 001 at δ = 0 . 5 p ercen tage p oin ts, n = 20; App endix A). Both ECG comparisons additionally reach significance for sup eriorit y: the Conformer adv antage (0.6 p ercen tage p oin ts) is clinically negligible for macro AUC, while the Baseline adv antage (0.9 percentage p oin ts, d = 1 . 60) reflects a large effect driven b y Kaiming’s 2 . 8 × higher v ariance. 3.7 Data 3.7.1 PTB-XL PTB-XL v1.0.3 [1]: 21,799 12-lead ECG recordings at 100 Hz, 10 seconds eac h. W e classify 12 rh ythm sup erclasses (SR, AFIB, ST A CH, SARRH, SBRAD, P ACE, SV ARR, BIGU, AFL T, SVT AC, PSVT, TRIGU) as a m ulti-lab el task. Class distribution is severely imbalanced: SR comprises 77.0% of training samples; six classes hav e few er than 200 training samples (P ACE: 237, SV ARR: 128, BIGU: 66, AFL T: 59, SVT AC: 21, PSVT: 19, TRIGU: 16). T est-set (fold 10) p ositiv e coun ts p er class: SR: 1674, AFIB: 152, ST ACH: 82, SARRH: 77, SBRAD: 64, P ACE: 28, SV ARR: 14, BIGU: 8, AFL T: 7, SVT AC: 3, PSVT: 2, TRIGU: 2. Appro ximately 96% of records ha ve a single rhythm lab el, and 3.4% ha v e no rh ythm lab el and are excluded from training. Data split follows [1, 2]: strat fold 1–8 train (17,418 records), fold 9 v alidation (2,183), fold 10 test (2,198). Z-normalization uses train-set statistics only . F or 6-lead cross-dataset exp erimen ts, w e use leads I, I I, I I I, aVR, aVL, aVF. 11 3.7.2 MIT-BIH AFDB MIT-BIH AFDB [44]: 25 long-term (10-hour) t wo-c hannel Holter recordings with b eat- lev el AFIB annotations, originally sampled at 250 Hz. W e anti-alias downsample to 100 Hz using a p olyphase FIR filter (Kaiser window, applied via scipy.signal.resample poly , deterministic, no data-dep endent parameters) and extract 84,334 non-ov erlapping 10-second windo ws. The t wo av ailable c hannels are mapp ed to leads I and I I, with leads II I, aVR, aVL, and aVF derived via Ein tho v en’s law and Goldberger’s equations, providing 6 lim b leads but no precordial information (a distribution shift from the 6-lead PTB-XL training data). No training is p erformed on AFDB; it is used exclusively for zero-shot cross-dataset ev aluation of AFIB detection. 3.7.3 CPSC2018 and Chapman-Shao xing The China Ph ysiological Signal Challenge 2018 dataset (CPSC2018) [45] (500 Hz, 12-lead) and the Chapman-Shaoxing 12-lead ECG database [46] (500 Hz, 12-lead) pro vide additional external v alidation. Both are anti-alias do wnsampled to 100 Hz using the same p olyphase FIR filter as AFDB. Both datasets con tain AFIB annotations and were never used during mo del dev elopment, arc hitecture selection, or hyperparameter tuning. F or 6-lead ev aluation, w e use the same lead subset as PTB-XL (I, I I, II I, aVR, aVL, aVF). All external datasets are normalized using PTB-XL training-set statistics only , prev en ting information leak age. 3.7.4 MedMNIST Sev en datasets from the MedMNIST v2 b enchmark [47] pro vide cross-domain medical image v alidation: Blo o dMNIST (17,092 blo o d cell images, 8 types), OrganCMNIST (23,583 ab- dominal CT slices, 11 organ classes), DermaMNIST (10,015 dermatoscopic images, 7 lesion categories), BreastMNIST (780 breast ultrasound images, 2 classes), RetinaMNIST (1,600 fundus images, 5 ordinal grades), ChestMNIST (112,120 c hest X-ra ys, 14 m ulti-lab el find- ings), and PathMNIST (107,180 colon pathology patches, 9 tissue t yp es). All images are 28 × 28 RGB. W e train ResNet-18 [48] with a mo dified stem (3 × 3 conv olution stride 1, no initial max p o oling) without an information b ottleneck. T raining uses SGD (lr=0 . 1, mo- men tum 0 . 9, weigh t decay 5 × 10 − 4 ) with cosine annealing o ver 200 ep o c hs and standard augmen tation (random crop, horizon tal flip). Eac h condition (DCT, Kaiming) uses 20 seeds plus one golden ratio deterministic run, totaling 42 runs p er dataset (294 total). 3.8 Ev aluation Metrics Primary metric: macro AUC (area under receiver op erating c haracteristic curv e, av eraged across 12 classes). All cross-v alidation standard deviations use the sample standard deviation (dividing by n − 1). Multi-seed standard deviations also use n − 1. Secondary metrics: effectiv e rank (eRank via SVD entrop y of feature matrix) and exp ected calibration error (ECE, 10 bins p er class). Cross-v alidation uses 3 folds (test on folds 10, 9, 8) with the standard training proto col. 12 T able 2: Ablation of structured initialization framew ork comp onen ts (Conformer architec- ture). “DCT-only” = single-basis DCT across all stages, no class w eighting. “Mixed” = DCT/Hadamard/Hartley p er stage. “cw” = sqrt class weigh ting. Standard deviations re- flect batch-ordering v ariance ( n = 5 batch seeds p er configuration); the Kaiming v alue differs from T able 3 ( n = 20 initialization seeds) b ecause it measures a different source of v ariance. Comp onen t T est A UC Delta DCT-only (fixup=0.01) 0 . 948 ± 0 . 012 baseline + mixed bases 0 . 951 ± 0 . 006 +0.003 + sqrt class weigh t 0 . 951 ± 0 . 006 +0.003 + mixed + cw (“Mixed”) 0 . 961 ± 0 . 003 +0.013 Kaiming (reference) 0 . 958 ± 0 . 002 — Kaiming + cw 0 . 960 ± 0 . 006 a +0.002 a Kaiming+cw: n =3 con verged of 5 launched; 2 seeds collapsed to < 0.60 AUC (0% failure rate for all structured configurations). DCT-only batch-ordering mean (0.948) reflects v ariance at n =5 batch seeds with fixed init; at n =20 init seeds (T able 4), DCT matches Kaiming (0.956 vs 0.953). 4 Results 4.1 Structured Initialization and the Com bined F ramew ork The structured initialization framew ork (Section 3.2) replaces random w eight sampling with analytically computed orthogonal basis functions, scaled to match Kaiming v ariance, with fixup residual scaling ( α = 0 . 01), mixed orthogonal bases across stages (for ECG), and ETF-initialized classification heads. Single-basis DCT initialization matc hes Kaiming in mean p erformance (0 . 956 vs 0 . 953 at n =20; T ables 3, 4) but shows higher batch-ordering sensitivity . T able 2 presents the comp onen t ablation. Plain DCT initialization pro duces higher batch-ordering sensitivity (std=0.012 vs Kaim- ing’s 0.002) b ecause all DCT filters are smo oth cosines that pro duce correlated gradients within each stage. Mixed orthogonal bases in tro duce gradien t diversit y across stages, and sqrt class w eighting amplifies signal from rare classes. Neither comp onent individually ex- ceeds Kaiming (0 . 951 ± 0 . 006 for each, vs Kaiming 0 . 958 ± 0 . 002), and their combination (0.961) numerically exceeds Kaiming (0.958) within the batch-ordering v ariance analysis ( n = 5). A t n =20 init seeds (T able 4), all single-basis structured initializations matc h Kaim- ing, confirming that batch-ordering sensitivit y (measured here) is distinct from initialization qualit y . A t n =20, sqrt class weigh ting do es not impro ve Kaiming (0 . 960 ± 0 . 006, n =3 con- v erged of 5, vs 0 . 953 ± 0 . 010 without cw) and 2 of 5 seeds collapsed to < 0.60 AUC (consistent with the n =20 result where 2 of 20 seeds collapsed). Throughout this pap er, ECG exp er- imen ts lab eled “Mixed” in tables use the combined framework (mixed-basis stages + sqrt class w eighting); MedMNIST and CIF AR exp erimen ts use single-basis DCT. “Structured initialization” refers to an y deterministic orthogonal basis (DCT, Hadamard, Hartley , or sin usoidal), in con trast to random Kaiming initialization. 13 Figure 3: Structured orthogonal initialization. (a) DCT-II basis matrix for a Conv1d(64, 64, 5) lay er: all 64 cosine basis v ectors spanning from DC ( k = 0, top) to near-Nyquist ( k = 63, b ottom). Each ro w is one deterministic filter; the structured frequency progression replaces random Kaiming w eights. Alternative bases (Hadamard, Hartley , sin usoidal) use analogous constructions. (b) Conv ergence comparison (Conformer, n = 20 seeds): mean ± 1 std bands. Mixed-basis initialization maintains higher v alidation AUC with low er v ariance from ep o c h 20 on ward. T est-set results in T able 3. 4.2 Conformer Multi-Seed V alidation Mixed-basis initialization was applied to a Conformer architecture (1.83M parameters) com- bining depth wise separable conv olutions with m ulti-head self-atten tion [36] (Fig. 3). The Conformer, adapted from sp eec h recognition, uses a custom deterministic adaptive av erage p o oling implemen tation in its stride-2 skip connections (stages 1–2), while Conformer blo cks (stage 3) con tain no p o oling operations. Com bined with deterministic GPU execution mo de, all CUD A op erations are fully deterministic. The Conformer with mixed-basis initialization yielded 0 . 959 ± 0 . 005 test macro AUC (20 batch seeds), exceeding the published xresnet1d101 benchmark (0 . 957, single seed, 9.0M parameters [2]) with 5 × fewer parameters (1.83M). Our repro duction of xresnet1d101 with 5 Kaiming seeds yields 0 . 947 ± 0 . 013, 1.0 p ercen tage p oint b elow the published result and 3 × the v ariance, illustrating the unreliabilit y of single-seed rep orting. Structured initializa- tion is statistically significan tly higher than Kaiming on the same Conformer architecture (0 . 959 ± 0 . 005 vs 0 . 953 ± 0 . 010, p = 0 . 016, W elch t -test; T able 3). Kaiming initialization ex- hibits t wice the v ariance of structured init (std 0.010 vs 0.005), with individual seeds ranging from 0.926 to 0.967. A fully deterministic v ariant (golden ratio batch ordering, zero random seeds at any stage, bit-iden tical mo del w eigh ts verified b y MD5 hash) reached 0.966 on the standard ev aluation fold (fold 10). Three-fold cross-v alidation with seeded batch ordering confirms stable p erformance (0 . 955 ± 0 . 012; folds: 0.942, 0.961, 0.963). The fully determinis- tic configuration (golden ratio batc hing) sho ws higher fold v ariance (0 . 941 ± 0 . 031), reflecting sensitivit y to fold-lev el data comp osition rather than initialization. The 0.966 single-fold golden result falls within the seeded CV fold range (0.942–0.963); the CV means of 0.941 (golden ratio) or 0.955 (seeded batc h ordering) provide more repre- sen tative estimates of exp ected p erformance. With n = 20 seeds p er condition, the 95% confidence in terv al for the mean difference is [0 . 001 , 0 . 011] A UC, excluding zero. Cohen’s d = 0 . 82 (95% CI [0 . 15 , 1 . 46]), a large effect driv en primarily b y Kaiming’s higher v ariance, not a large mean difference. Mixed-basis initialization is equiv alen t to Kaiming within the δ =0 . 015 margin (TOST p < 0 . 001). The 14 T able 3: Structured initialization across architectures (PTB-XL rh ythm classification, 12- class m ulti-lab el, macro AUC). “Det.” indicates determinism lev el. “Mixed” = mixed-basis initialization (DCT/Hadamard/Hartley p er stage); “DCT” = single-basis DCT initialization. Both use sqrt class weigh ting. MedMNIST cross-domain results in T able 6; CIF AR-100 in App endix A. Mo del Init Configuration T est A UC P arams Det. Conformer Mixed 20 batc h seeds 0 . 959 ± 0 . 005 1.83M Init Conformer Mixed golden ratio 0.966 a 1.83M F ull Conformer Kaiming 20 init seeds 0 . 953 ± 0 . 010 1.83M No Baseline CNN DCT 20 batc h seeds 0 . 956 ± 0 . 004 1.65M Init Baseline CNN Kaiming 20 init seeds 0 . 947 ± 0 . 007 1.65M No xresnet1d101 Kaiming 5 init seeds 0 . 947 ± 0 . 013 9.0M No xresnet1d101 [2] Kaiming published 0.957 9.0M No a Single fold 10. CV: 0 . 955 ± 0 . 012 (seeded batc h ordering), 0 . 941 ± 0 . 031 (golden ratio batch ordering). Initialization is deterministic in b oth cases; the v ariance reflects batc h ordering only . mean difference of 0.6 p ercentage points is statistically detectable ( p = 0 . 016) but clinically negligible for macro AUC. 4.3 V ariance Decomp osition T raining v ariance decomp oses into four indep enden tly addressable comp onen ts. Initialization varianc e is zero by construction, as structured orthogonal basis functions pro duce identical w eights on every run. Batch-or dering varianc e measured std=0.005 under seeded shuffle ( n = 20) and zero under golden ratio sc heduling. GPU op er ation varianc e is zero for the Conformer, which uses deterministic adaptiv e p o oling implementations; for the baseline CNN, non-deterministic atomicAdd in skip connections is addressed via custom autograd at 1% training ov erhead. F old/data c omp osition varianc e measured std=0.012 (3-fold CV, estimated from n = 3) and cannot b e eliminated as it reflects genuine data v ariation. The fold v ariance estimate dep ends on the batch ordering strategy: seeded sh uffle yielded fold std=0.012 while golden ratio yielded std=0.031, indicating interaction b etw een batch order- ing and fold/data v ariance. The decomp osition assumes approximate indep endence, and the sources do interact. The Conformer with golden ratio batch ordering eliminates all three controllable sources, ac hieving MD5-v erified bit-iden tical training across indep enden t runs. 4.4 Orthogonal Basis Comparison T o test whether the choice of orthogonal basis affects learned representations, w e trained the Conformer with four structured initializations (DCT, Hartley , Hadamard, and sinusoidal), eac h across 20 initialization seeds on the PTB-XL rhythm classification task (T able 4). Because the same 20 seeds are used across all bases (pro ducing iden tical batc h orderings), pairwise comparisons use paired t -tests. Kaiming+cw uses the same seed n um b ers, pro viding matc hed batc h orderings. 15 T able 4: Orthogonal basis comparison (Conformer, PTB-XL rhythm classification, n =20 seeds each). Each ro w uses a single basis uniformly across all stages with sqrt class w eigh ting. P aired t -tests (same seeds across bases). F riedman χ 2 =2 . 46, p =0 . 48: no significan t difference b et ween structured bases. All standard deviations use n − 1 (sample std). a Kaiming+cw: n =18 conv erged of 20 launc hed; 2 seeds (2, 7) collapsed to < 0.67 AUC (0% failure rate for all structured bases and Kaiming without cw). Basis (single, all stages) T est AUC (mean ± std) vs. DCT p (paired) Hartley-only 0 . 959 ± 0 . 006 0 . 253 Sin usoidal-only 0 . 956 ± 0 . 005 0 . 940 Hadamard-only 0 . 955 ± 0 . 008 0 . 751 DCT-only 0 . 956 ± 0 . 010 — Kaiming+cw 0 . 954 ± 0 . 012 a — A t n =20, no structured basis significantly outp erforms an y other (F riedman χ 2 =2 . 46, p =0 . 48). All four bases matc h Kaiming (individual paired comparisons: all p > 0 . 25), with means ranging from 0 . 955 (Hadamard) to 0 . 959 (Hartley). No pairwise comparison survives Holm–Bonferroni correction. The result establishes that the con tribution is deterministic structured initialization itself, not any particular basis function. The key finding is a varianc e gr adient across bases: DCT sho ws the highest structured training v ariance (std=0.010), follo wed b y Hadamard (0.008), Hartley (0.006), and sinusoidal (0.005), compared to Kaiming’s 0.010 (T able 3). Levene’s test shows no significant pairwise v ariance differences (all p > 0 . 72), but the monotonic ordering (smo oth p erio dic bases pro- ducing the low est v ariance, binary patterns intermediate, and purely cosine the highest) is consisten t with basis smo othness gov erning optimization stability . A largely concordant or- dering app ears in noise robustness (Appendix T able 10): Hartley > Hadamard > Sin usoidal > DCT across all three noise types (F riedman p =0 . 069 for electro de motion; sin usoidal and Hartley swap p ositions relativ e to the v ariance ranking). All structured bases exhibit equal or lo w er v ariance than Kaiming. P er-class analysis at n =20 shows one significan t class-level effect: atrial flutter (AFL T: F riedman p =0 . 046), where Hartley leads (0 . 917) and Hadamard trails (0 . 893). The aggre- gate p er-class pattern shows no single basis dominating: Hartley is b est on 5 of 12 classes, Hadamard on 3, sinusoidal on 2, and DCT on 2. 4.5 Golden Deterministic Baselines T o isolate the effect of initialization from batch ordering, w e trained b oth architectures with golden ratio deterministic batch ordering using mixed-basis and Kaiming initialization (T able 5). Mixed-basis initialization improv es ov erall AUC in b oth the Conformer (+3 . 1 p ercentage p oin ts versus Kaiming) and the Baseline (+1 . 0 pp). The Conformer–Kaiming combination illustrates a seed-dep endent p er-class failure on trigeminy (TRIGU AUC = 0 . 781 versus 0 . 980 with structured init, a 19.9 pp gap) and atrial flutter (AFL T: 0 . 855 vs. 0 . 951, 9.6 pp). While 16 T able 5: Golden-seed 2 × 2 design: architecture crossed with initialization, all using golden ratio batc h ordering. “Mixed” = mixed-basis (DCT/Hadamard/Hartley per stage) with sqrt class weigh ting. Per-class AUC sho wn for the three rhythms with the largest initialization effect. Eac h entry is a single deterministic run (MD5-verified for structured init). Caution: TRIGU ( n = 2 test p ositiv es), SV ARR ( n = 14), and AFL T ( n = 7) hav e small test-set sizes; p er-class A UC estimates carry substantial uncertain t y . Arc hitecture Init A UC TRIGU SV ARR AFL T Conformer Mixed 0 . 959 0 . 980 0 . 892 0 . 951 Conformer Kaiming 0 . 928 0 . 781 0 . 923 0 . 855 Baseline Mixed 0 . 950 0 . 906 0 . 870 0 . 963 Baseline Kaiming 0 . 940 0 . 891 0 . 814 0 . 941 TRIGU has only n =2 test p ositiv es in fold 10, this v ariabilit y is indep enden tly confirmed b y: (a) 3-fold CV, where each fold tests TRIGU on different samples (0 . 885 ± 0 . 167 under golden Conformer), and (b) the n =20 multi-seed distribution (TRIGU range: 30.9pp under Kaiming vs 4.1pp under structured init, Fig. 1). The Baseline–Kaiming mo del av oids such extreme failures (TRIGU = 0 . 891), indicating that the deep er Conformer is more sensitive to initialization qualit y for rare rhythms. Suprav entricular arrhythmia (SV ARR) sho ws a consisten t pattern across architectures: Kaiming drops to 0 . 814 in the Baseline v ersus 0 . 870 with structured initialization. 4.6 Cross-Domain Medical Image V alidation T o v alidate structured initialization b eyond 1D ECG signals, w e applied single-basis 2D-DCT initialization to ResNet-18 on seven MedMNIST medical image b enc hmarks [47] spanning sev en clinical domains (T able 6). MedMNIST uses single-basis DCT rather than mixed- basis b ecause ResNet-18 lacks the multi-stage b ottleneck structure that motiv ated mixed assignmen t in the ECG arc hitectures; golden runs with alternativ e bases confirm that basis c hoice has minimal impact on 2D imaging tasks (see b elo w). Eac h exp erimen t uses 20 random seeds per initialization metho d (DCT and Kaiming) plus one golden ratio deterministic run p er metho d, enabling prop er statistical comparison. Across all seven datasets, no statistically significant difference exists b et ween DCT and Kaiming initialization (all p > 0 . 14, Cohen’s d range: − 0.46 to +0.32). On saturated b enc hmarks (Blo o dMNIST AUC 0.999, OrganCMNIST 0.994, PathMNIST 0.990), b oth metho ds reach near-ceiling p erformance. On datasets with more headro om (ChestMNIST ∼ 0.75 A UC, RetinaMNIST ∼ 0.73, BreastMNIST ∼ 0.88), the difference remains negligible. All DCT golden results are bit-iden tical across indep endent runs (MD5 verified). MedMNIST exp erimen ts use a fixed architecture and h yp erparameter recip e transferred from the ECG pip eline without task-sp ecific optimization. They v alidate that DCT initialization generalizes across mo dalities without degrading p erformance, not that it achiev es state-of-the-art on eac h b enc hmark. Golden ratio deterministic runs with alternative bases (Hadamard, Hartley , Sin usoidal) 17 T able 6: MedMNIST cross-domain v alidation. ResNet-18, 200 ep o c hs, n =20 seeds p er initialization. DCT = single-basis 2D-DCT (no mixed bases, no class w eigh ting). p -v alues from W elc h’s t -test. No dataset shows a statistically significan t difference. Dataset DCT A UC Kaiming A UC ∆ p n train Blo odMNIST . 9986 ± . 0002 . 9987 ± . 0002 − . 0001 .65 11,959 OrganCMNIST . 9943 ± . 0006 . 9945 ± . 0004 − . 0002 .16 13,000 DermaMNIST . 9186 ± . 0062 . 9192 ± . 0048 − . 0006 .74 7,007 BreastMNIST . 878 ± . 032 . 877 ± . 030 + . 001 .96 546 RetinaMNIST . 729 ± . 016 . 734 ± . 014 − . 005 .26 400 ChestMNIST . 756 ± . 011 . 752 ± . 014 + . 004 .32 78,468 P athMNIST . 9903 ± . 0034 . 9899 ± . 0029 + . 000 .74 89,996 on DermaMNIST and RetinaMNIST confirm that basis choice has minimal impact on 2D imaging tasks: DermaMNIST golden AUCs cluster within 0.004 across all fiv e bases (DCT 0.915, Hadamard 0.914, Hartley 0.911, Sinusoidal 0.914, Kaiming 0.912). On RetinaMNIST, DCT leads (0.755) but three of four structured bases fall b elo w Kaiming (0.733): Hadamard (0.701), Hartley (0.711), and sin usoidal (0.717), consistent with the high-v ariance regime of this small dataset ( n train = 400). P er-class analysis on ChestMNIST (14 thorax diseases, m ulti-lab el, imbalanced) sho ws that the v ariance reduction observed in ECG generalizes to imbalanced imaging tasks (Fig. 4). DCT initialization produces a tigh ter p er-class AUC range than Kaiming in 11 of 14 disease classes, with an o verall mean p er-class range of 0.056 (DCT) vs 0.079 (Kaim- ing). The strongest stability adv antage app ears on uncommon conditions: Pneumothorax (Kaiming range 3.7 × DCT range, n pos = 1 , 089 test cases) and Emph ysema (2.4 × , n pos = 509). Unlik e the ECG rare classes where small test sets ( n pos ≤ 14) limit p er-class A UC precision, ChestMNIST has sufficien t test cases for reliable p er-class estimates. The rarest class (Her- nia, n pos = 42) exhibits high v ariance under b oth metho ds (range ∼ 0.19). These aggregate results complement the ECG findings (T ables 3, 4, 5) where struc- tured initialization provides significan t adv an tages at the macro level. T ogether, the results demonstrate a consisten t pattern across domains: on saturated b enc hmarks, initialization is irrelev ant; on im balanced clinical tasks, p er-class v ariance reduction emerges (ChestMNIST: 11 of 14 classes, Pneumothorax 3 . 7 × reduction) and reaches aggregate statistical significance on sp ecialist tasks (ECG: p =0 . 016). This pattern holds indep enden tly in 1D (ECG rhythm classification) and 2D (c hest X-ra y m ulti-lab el classification), confirming that the v ariance reduction is a prop erty of structured initialization, not task-sp ecific. 4.7 Arc hitecture Generalit y: Baseline CNN Matc hes Published SOT A T o establish that structured initialization generalizes b ey ond the Conformer, w e applied single-basis DCT initialization to a standard xresnet-st yle CNN (1.65M parameters, 128- dimensional feature space, no b ottlenec k, no self-attention). This arc hitecture is structurally similar to the published xresnet1d101 [2] but smaller (1.65M vs 9.0M parameters). W e also repro duce xresnet1d101 directly with 5 Kaiming initialization seeds, obtaining 0 . 947 ± 0 . 013 18 Figure 4: Per-class A UC v ariabilit y on ChestMNIST (ResNet-18, single-basis 2D-DCT, n = 20 seeds). (a) Kaiming initialization: Pneumothorax ( n pos = 1 , 089) ranges 0.130, Emph ysema ( n pos = 509) ranges 0.141. (b) DCT initialization: systematically tighter ranges in 11 of 14 classes (mean range 0.056 vs 0.079). Pneumothorax tightens 3 . 7 × (0.035 vs 0.130), Emph ysema 2 . 4 × . Green stars: DCT golden deterministic run. Thic k horizontal lines: mean; shaded regions: ± 1 std; thin whiskers: full min–max range. Compare with Fig. 1 for the analogous ECG pattern. test macro AUC, low er and more v ariable than the published single-seed 0.957, with an outlier (seed 1337: 0.927, 1 . 5 σ b elow mean) illustrating initialization instabilit y . DCT initialization pro duced 0 . 956 ± 0 . 004 macro AUC ( n = 20 batc h seeds), matc hing the published xresnet1d101 b enc hmark (0.957) with more than 5 × few er parameters (T able 3). DCT initialization significantly exceeds Kaiming on the same arc hitecture: 0 . 956 ± 0 . 004 vs 0 . 947 ± 0 . 007 ( p < 0 . 001, W elch t -test, n = 20 p er group; Cohen’s d = 1 . 60, 95% CI [0 . 89 , 2 . 31]). Kaiming v ariance is 2 . 8 × higher than DCT (std 0.007 vs 0.004), consistent with the Conformer pattern. 4.8 Cross-V alidation Three-fold cross-v alidation (folds 10, 9, 8 as test sets) w as p erformed on four configurations using strict determinism (T able 7, Fig. 5). All cross-v alidation standard deviations use the sample standard deviation ( n − 1 divisor). The Conformer combined with seeded batch ordering ac hieves 0 . 955 ± 0 . 012. The fully deterministic Conformer (golden ratio batching) drops to 0 . 941 ± 0 . 031, reflecting higher sensitivity to fold-sp ecific data comp osition when batc h ordering is data-dep enden t. P er-class CV analysis shows class-sp ecific architecture preferences. The Conformer sho wed the highest CV mean for SARRH (0.941 vs 0.835 for the Kaiming baseline), the class with the highest Kaiming seed v ariance. The baseline show ed the highest CV mean for P ACE (0.973 vs 0.944 for Conformer). No single arc hitecture dominates across all 12 classes. TRIGU ( n = 16 total samples, 2 per test fold) exhibits high fold v ariance (0 . 885 ± 0 . 167 for the fully deterministic Conformer), but this v ariance is v alidated across all three CV folds (eac h TRIGU sample tested exactly once) and confirmed by the 20-seed distribution on fold 10: TRIGU A UC range spans 30.9 p ercen tage p oin ts under Kaiming versus 4.1 under 19 Figure 5: Generalization v alidation. (a) Three-fold cross-v alidation macro AUC for four configurations; Conformer combined (0 . 955 ± 0 . 012) reac hes the highest mean with seeded batc h ordering. (b) Cross-dataset AFIB detection A UC on three external databases (AFDB, CPSC2018, Chapman-Shao xing): b oth arc hitectures exceed 0.93 transfer AUC. T able 7: Cross-v alidation results (3 folds, sample std). Each fold uses a single batc h seed; T able 3 m ulti-seed results av erage 20 batch orderings on fold 10. The golden fold 10 result (0.908) differs from T able 3 (0.966) b ecause CV golden uses a different v alidation fold for mo del selection, and golden ordering’s data-dep endence amplifies fold sensitivity (std=0.031 vs 0.012 for seeded). Configuration F10 F9 F8 Mean ± Std Conform. mixed (seeded) .942 .961 .963 . 955 ± . 012 Conform. mixed (golden) .908 .948 .968 . 941 ± . 031 Baseline mixed .927 .953 .934 . 938 ± . 013 Baseline Kaiming .923 .949 .941 . 938 ± . 013 structured initialization (Fig. 1). The high fold v ariance reflects genuine sensitivit y to data comp osition, not measuremen t noise. 4.9 Cross-Dataset V alidation Tw o mixed-basis-initialized architectures w ere v alidated on three gen uinely held-out external databases: the MIT-BIH Atrial Fibrillation Database (AFDB; 84,334 windo ws from long- term Holter recordings), the China Ph ysiological Signal Challenge 2018 dataset (CPSC2018), and the Chapman-Shaoxing 12-lead ECG database (T able 8). All mo dels were trained on PTB-XL using 6 common leads and ev aluated zero-shot for AFIB detection. None of these datasets w ere used during developmen t, architecture selection, or h yp erparameter tuning. Both arc hitectures ac hiev e > 0.93 AFIB A UC across all external databases, confirming generalization without data leak age. The baseline generalizes b est on AFDB (0.952 vs 0.932 for Conformer), attributable to the wider 128-dimensional represen tation. On CPSC2018 and Chapman-Shaoxing, b oth models exceed 0.97 AFIB A UC. The Conformer’s low er AFDB score (0.932) and more conserv ative prediction b eha vior (22.9% AFIB p ositive rate vs 34.1% for baseline) suggest that the self-atten tion mechanism may ov erfit to PTB-XL-sp ecific R- R in terv al distributions. 20 T able 8: Cross-dataset generalization (6-lead mo dels trained on 6 PTB-XL lim b leads: I, I I, I II, aVR, aVL, aVF). Eac h en try is a single golden deterministic chec kp oin t. All mo dels trained on PTB-XL with mixed-basis initialization and ev aluated zero-shot for AFIB detec- tion on three external databases. F or AFDB, 4 of 6 leads are deriv ed from 2 channels via Ein thov en’s la w (Section 3.7). These 6-lead models are distinct from the 12-lead mo dels used in all other exp eriments. Mo del AFDB CPSC2018 Chapman Params Baseline (xresnet) 0.952 0.979 0.991 1.65M Conformer 0.932 0.979 0.984 1.83M 5 Discussion Across t w o ECG architectures, structured orthogonal initialization significantly exceeds ran- dom Kaiming initialization ( n = 20 p er group): Conformer ( p = 0 . 016, d = 0 . 82) and Base- line CNN ( p < 0 . 001, d = 1 . 60), with Kaiming exhibiting 2–3 × the v ariance in b oth cases. The 2 × 2 golden-seed design (T able 5) isolates initialization from batc h ordering, illustrating that Kaiming exhibits seed-dep enden t p er-class v ariation on rare rh ythms: trigeminy AUC drops to 0.781 (v ersus 0.980 with structured init). The basis comparison at n =20 (T able 4) sho ws that basis choice do es not significantly affect mean p erformance (F riedman p =0 . 48); the practical distinction is training v ariance, with DCT showing the highest (std=0.010) and sinusoidal the low est (std=0.005). Any structured orthogonal basis pro duces Kaiming- equiv alent p erformance with deterministic weigh ts. The critical distinction is b etw een initialization determinism and full pip eline determin- ism. F or initialization alone, the price is zero: structured initialization matches or exceeds Kaiming on every arc hitecture and dataset tested, while providing seed-indep enden t w eigh ts. F or full pip eline determinism (including deterministic batc h ordering), the price is real: the golden ratio Conformer yielded CV 0 . 941 ± 0 . 031 ve rsus 0 . 955 ± 0 . 012 for seeded batc hing, a 1.4 p ercen tage p oint loss with higher v ariance. W e tested 11 seed-free batc h ordering strategies (App endix T able 11); the b est (class-guaranteed, 0.947) narrows the gap to 0.8 p ercen tage p oints v ersus seeded shuffle (0.955), but requires class-lab el calibration. The most consistent finding across all exp eriments is v ariance reduction, confirmed inde- p enden tly across domains. On ECG, structured initialization halves the aggregate v ariance (std 0.005 vs 0.010) and reduces p er-class v ariabilit y by up to 7 . 5 × (TRIGU range: 4.1pp vs 30.9pp, n pos = 2; SARRH: 2.5pp vs 4.2pp, n pos = 77; SV ARR: 11.5pp vs 20.2pp, n pos = 14). On ChestMNIST (14 thorax diseases, m ulti-lab el, im balanced), the same pattern emerges inde- p enden tly: DCT pro duces tigh ter p er-class ranges in 11 of 14 classes, with the strongest effect on uncommon conditions (Pneumothorax: Kaiming range 3 . 7 × DCT; Emphysema: 2 . 4 × ; Fig. 4). On balanced b enc hmarks (Blo o dMNIST, OrganCMNIST, P athMNIST, CIF AR- 100), structured initialization matches Kaiming with comparable v ariance. The pattern (v ariance reduction on im balanced tasks, equiv alence on balanced tasks) is confirmed inde- p enden tly in 1D (ECG) and 2D (c hest X-ra y), establishing that the b enefit is a prop ert y of structured initialization itself, not task-sp ecific. Cross-domain v alidation on seven MedMNIST benchmarks ( n =20 per condition, all p > 21 0 . 14; T able 6) further confirms the “no harm” conclusion: structured initialization introduces no p erformance p enalt y on standard imaging tasks. Jordan et al. [49] prov ed that test-set v ariance b et ween training runs is mathemati- cally inevitable for calibrated ensem bles, arguing it is “harmless” b ecause distribution-lev el metrics are stable. F rom the deep ensemble p ersp ectiv e, this in ter-run v ariance enables un- certain ty estimation and calibrated predictions. Our findings do not contradict this view. Ho wev er, they qualify it for safety-critical single-model deploymen t: while aggregate metrics (macro A UC) v ary by only 4.1 p ercentage p oin ts across 20 seeds, p er-class metrics for rare classes swing by ov er 20 p ercen tage p oin ts (Fig. 1). This v ariance is invisible in aggregate rep orting but consequential for sp ecific patien t populations. When regulatory or deplo ymen t constrain ts require a single deterministic model rather than an ensem ble, eliminating this v ariance b ecomes v aluable. The ablation (T able 2) measures batc h-ordering v ariance ( n =5 batc h seeds p er configura- tion) and should b e interpreted cautiously . The DCT-only batc h-ordering mean (0.948) falls within the DCT init-seed distribution (T able 4: 0 . 956 ± 0 . 010, n =20), confirming that DCT initialization matches Kaiming in mean p erformance. The combined framew ork (mixed + cw, 0.961) numerically exceeds Kaiming (0.958) but do es not reac h statistical significance at n = 5. A t n =20, sqrt class w eighting do es not improv e Kaiming: Kaiming+cw achiev es 0 . 954 ± 0 . 012 ( n =18 con verged of 20; 2 seeds collapsed to < 0.67) v ersus 0 . 953 ± 0 . 010 without cw ( p =0 . 82, W elc h t -test), while introducing a 10% training failure rate absent from b oth Kaiming alone and all structured bases (0/80 failures). The 2 × 2 golden design (T able 5), where b oth structured and Kaiming mo dels use iden tical sqrt class w eighting, sho ws a 3.1 p ercen tage-p oint gap (0.959 vs 0.928), though this is a single deterministic observ ation, not a statistical comparison. Structured initialization creates correlated gradien ts: all DCT filters are smo oth cosines, so similar inputs pro duce similar activ ations across filters within a stage. This correlation con tributes to DCT’s higher training v ariance (std=0.010, matc hing Kaiming’s 0.010, at n =20 init seeds). The n =20 basis comparison (T able 4) sho ws a v ariance gradien t across bases: DCT (0.010) > Hadamard (0.008) > Hartley (0.006) ≈ sinusoidal (0.005). While the pairwise v ariance differences do not reac h significance (Levene’s test, all p > 0 . 72), a largely concordan t ordering app ears in noise robustness rankings (App endix T able 10): Hartley > Hadamard > Sinusoidal > DCT across all three noise types (sinusoidal and Hartley swap b et ween v ariance and robustness rankings). The mixed-basis configuration reduces batch- ordering sensitivity by 4:1 (std 0.012 to 0.003, T able 2). Whether this reflects cross-stage decorrelation, prop erties of sp ecific bases, or the dominance of the 23-blo ck Hartley stage remains an op en question. Structured initialization maintains higher v alidation A UC with low er v ariance than Kaim- ing from ep o c h 20 onw ard (Fig. 3b), indicating that frequency-domain basis functions provide a more stable optimization tra jectory on p erio dic ph ysiological signals. The observ ation is consisten t with recen t findings by F ernandez-Hernandez et al. [11], who rep ort faster con- v ergence with sin usoidal initialization across multiple arc hitectures. Bey ond conv ergence sp eed, deterministic initialization guaran tees spatial attribution sta- bilit y: bit-iden tical w eights pro duce bit-iden tical gradien t-based explanations (e.g., Grad- CAM [50]), ensuring that spatial attributions are fixed and auditable across indep endent runs. 22 The practical implication is that deplo ymen t context should determine architecture c hoice. F or maximum cross-dataset transfer, the unconstrained baseline with structured initialization provides b oth determinism and generalization. The Conformer provides self- atten tion maps for rhythm-lev el interpretabilit y (which b eat-to-b eat interv als inform the prediction), though its cross-dataset p erformance (0.932 AFDB) trails the baseline (0.952). 5.1 Limitations Structured initialization has b een demonstrated on tw o conv olutional ECG arc hitectures and ResNet-18 on medical image b enc hmarks. T esting on non-conv olutional arc hitectures (RNNs, state space mo dels) and pre-trained mo dels w ould extend the generality claim. AFDB ev aluation uses 2-channel recordings with 6 lim b leads deriv ed via Ein tho ven’s law, a distribution shift from PTB-XL training since precordial lead information is absen t. The mixed-basis stage assignment w as selected heuristically; a systematic search o ver basis p er- m utations has not b een p erformed. All exp eriments use batch size 128; the interaction b et ween structured initialization’s correlated gradien ts and batc h size has not been explored. Structured initialization eliminates initialization randomness but not batch ordering ran- domness. Golden ratio ordering ac hieves full determinism at a p erformance cost: among 11 seed-free strategies ev aluated (App endix T able 11), the b est (class-guaranteed, 0.947) nar- ro ws the gap to 0.8 p ercen tage p oin ts versus seeded sh uffle (0.955) but requires class-lab el calibration. Closing this gap with a parameter-free metho d remains op en. Clinical v alidation requires prosp ectiv e studies with cardiologist-adjudicated outcomes, follo wing rep orting standards suc h as TRIPOD+AI [51]. Demographic subgroup analysis ( n =20 seeds, 9 rhythm classes ev aluable in b oth sex groups, excluding SVT AC, PSVT, and TRIGU with ≤ 2 test p ositiv es p er sex) shows no significant sex disparit y (p erm utation p = 0 . 85). Indep enden t repro duction by other groups is essential b efore any consideration for p oten tial clinical applications. 6 Conclusion W e ha ve presen ted a framework for v erified bit-iden tical deep learning training that sys- tematically eliminates three sources of non-determinism: weigh t initialization (via struc- tured orthogonal basis functions), batch ordering (via golden ratio batch ordering), and non-deterministic GPU op erations (via architecture selection). The framework pro duces trained mo dels with MD5-verified iden tical weigh ts across indep enden t runs. On PTB-XL ECG rhythm classification, structured initialization significan tly exceeds Kaiming on b oth architectures tested (T able 3): the Conformer ( p = 0 . 016, d = 0 . 82, n = 20) with Kaiming exhibiting twice the v ariance, and the baseline CNN ( p < 0 . 001, d = 1 . 60, n = 20) with Kaiming exhibiting 2 . 8 × the v ariance. A four-basis comparison at n =20 (T able 4) sho wed that all structured orthogonal bases pro duce equiv alen t mean p erformance (F riedman p =0 . 48), with the practical distinction among bases b eing training v ariance (DCT std=0.010, sinusoidal std=0.005), not mean p erformance. V ariance decom- p osition (Conformer) estimates initialization v ariance (zero by construction), batch-ordering v ariance (std = 0.005), and fold v ariance (std = 0.012), enabling quan tification of eac h source. 23 Cross-domain v alidation on seven MedMNIST b enc hmarks ( n = 20 p er condition, all p > 0 . 14; T able 6) confirms no p erformance p enalt y on standard tasks, while p er-class analysis on ChestMNIST indep enden tly replicates the ECG v ariance reduction pattern on rare classes (11 of 14 classes, Pneumothorax 3 . 7 × ). Structured initialization matters most on imbalanced tasks with rare classes, precisely where seed-dep enden t failures are clinically consequen tial. Cross-dataset ev aluation on three external ECG databases not used during mo del developmen t confirms generalization, with both arc hitectures exceeding 0.93 AFIB A UC (T able 8). The framew ork provides a metho dological tool for algorithmic repro ducibilit y in deep learning for medical applications. As regulatory frameworks increasingly v alue transparency and process do cumen tation for AI/ML-based medical devices [6, 8], metho ds that eliminate non-determinism at the algorithmic level, instead of merely fixing random seeds, facilitate v erifiable training pipelines. All code, ev aluation scripts, and exp erimen tal evidence are pub- licly av ailable. T rained chec kp oints are repro ducible from the released code b y construction. Declaration of comp eting in terests The author declares no comp eting interests. F unding This research did not receive an y sp ecific gran t from funding agencies in the public, com- mercial, or not-for-profit sectors. Ethics statemen t This study uses only publicly av ailable, de-identified datasets (PTB-XL, MIT-BIH AFDB, CPSC2018, Chapman-Shaoxing, MedMNIST, CIF AR) and does not inv olve h uman sub jects researc h. No ethics approv al was required. Declaration of generativ e AI and AI-assisted tec hnolo- gies in the man uscript preparation pro cess During the preparation of this w ork the author used Claude (An thropic) in order to assist with co de developmen t, manuscript drafting, and editorial revision. After using this to ol, the author review ed and edited the con ten t as needed and tak es full resp onsibilit y for the con tent of the published article. 24 Data and co de a v ailabilit y PTB-XL v1.0.3 is av ailable at PhysioNet [52] ( https://doi.org/10.13026/6sec- a640 ). The MIT-BIH A trial Fibrillation Database is a v ailable at PhysioNet ( https://doi.org/ 10.13026/C2FS0H ). The MIT-BIH Noise Stress T est Database is av ailable at PhysioNet ( https://doi.org/10.13026/C2HS- 1990 ). CPSC2018 [45] is av ailable at http://2018. icbeb.org/Challenge.html . Chapman-Shaoxing [46] is a v ailable at https://doi.org/ 10.6084/m9.figshare.c.4560497 . MedMNIST v2 [47] is a v ailable at https://medmnist. com/ . All datasets used in this study are publicly av ailable and require no access restrictions. All co de, ev aluation scripts, and exp erimental evidence are av ailable at https://github. com/yshk- mxim/repnet . References [1] P . W agner, N. Stro dthoff, R.-D. Bousseljot, et al., PTB-XL, a large publicly a v ailable electro cardiography dataset, Sci. Data 7 (2020) 154. doi:10.1038/ s41597- 020- 0495- 6 . [2] N. Stro dthoff, P . W agner, T. Schaeffter, W. Samek, Deep learning for ECG analysis: Benc hmarks and insigh ts from PTB-XL, IEEE J. Biomed. Health Inform. 25 (5) (2021) 1519–1528. doi:10.1109/JBHI.2020.3022989 . [3] A. Y. Hann un, et al., Cardiologist-lev el arrhythmia detection and classification in am- bulatory electrocardiograms using a deep neural netw ork, Nat. Med. 25 (2019) 65–69. doi:10.1038/s41591- 018- 0268- 3 . [4] A. H. Rib eiro, et al., Automatic diagnosis of the 12-lead ECG using a deep neural net work, Nat. Comm un. 11 (2020) 1760. doi:10.1038/s41467- 020- 15432- 4 . [5] K. He, X. Zhang, S. Ren, J. Sun, Delving deep in to rectifiers: Surpassing human- lev el p erformance on ImageNet classification, in: Pro c. IEEE In t. Conf. Comput. Vis. (ICCV), 2015, pp. 1026–1034. doi:10.1109/iccv.2015.123 . [6] U.S. F o o d and Drug Administration, Artificial in telligence/machine learning (AI/ML)- based soft w are as a medical device (SaMD) action plan, FDA (2021). [7] U.S. F o o d and Drug Administration, Artificial in telligence-enabled device soft ware func- tions: Lifecycle managemen t and mark eting submission recommendations (draft guid- ance), FD A (2025). [8] Europ ean P arliament and Council, Regulation (EU) 2024/1689 la ying do wn harmonised rules on artificial intelligence (Artificial In telligence Act), Off. J. EU (2024). [9] A. P aszke, et al., PyT orch: An imp erativ e st yle, high-p erformance deep learning library , in: Pro c. Adv. Neural Inf. Pro cess. Syst. (NeurIPS), V ol. 32, 2019. [10] J. Zhao, F. Sch¨ afer, A. Anandkumar, ZerO initialization: Initializing neural netw orks with only zeros and ones, T rans. Mac h. Learn. Res. (2022). 25 [11] A. F ernandez-Hernandez, J. I. Mestre, M. F. Dolz, J. Duato, E. S. Quin tana-Orti, Sin usoidal initialization, time for a new start, in: Pro c. Adv. Neural Inf. Pro cess. Syst. (NeurIPS), 2025. [12] X. Glorot, Y. Bengio, Understanding the difficult y of training deep feedforward neural net works, in: Pro c. Int. Conf. Artif. In tell. Statist. (AIST A TS), V ol. 9 of PMLR, 2010, pp. 249–256. [13] A. M. Saxe, J. L. McClelland, S. Ganguli, Exact solutions to the nonlinear dynamics of learning in deep linear neural net works, in: Proc. Int. Conf. Learn. Represent. (ICLR), 2014. [14] J. Pennington, S. S. Sc ho enholz, S. Ganguli, Resurrecting the sigmoid in deep learning through dynamical isometry: theory and practice, in: Pro c. Adv. Neural Inf. Pro cess. Syst. (NeurIPS), V ol. 30, 2017. [15] L. Xiao, Y. Bahri, J. Sohl-Dic kstein, S. S. Schoenholz, J. P ennington, Dynamical isom- etry and a mean field theory of CNNs: How to train 10,000-lay er v anilla con volutional neural netw orks, in: Pro c. In t. Conf. Mach. Learn. (ICML), V ol. 80 of PMLR, 2018, pp. 5393–5402. [16] W. Hu, L. Xiao, J. Pennington, Prov able b enefit of orthogonal initialization in optimiz- ing deep linear net works, in: Pro ceedings of the International Conference on Learning Represen tations, 2020. URL https://openreview.net/forum?id=rkgqN1SYvr [17] D. Mishkin, J. Matas, All y ou need is a go o d init, in: Pro c. In t. Conf. Learn. Represent. (ICLR), 2016. [18] S. Ioffe, C. Szegedy , Batch normalization: Accelerating deep net work training b y re- ducing internal cov ariate shift, in: Pro c. In t. Conf. Mach. Learn. (ICML), V ol. 37 of PMLR, 2015, pp. 448–456. [19] H. Zhang, Y. Dauphin, T. Ma, Fixup initialization: Residual learning without normal- ization, in: Pro c. Int. Conf. Learn. Represen t. (ICLR), 2019. [20] A. Agha jany an, Conv olution a w are initialization, arXiv preprin t (2017). [21] M. Ulicn y , V. A. Krylo v, R. Dah y ot, Harmonic con volutional netw orks based on discrete cosine transform, Pattern Recognit. 129 (2022) 108707. doi:10.1016/j.patcog.2022. 108707 . [22] Y. Pan, et al., IDInit: A universal and stable initialization metho d for neural netw ork training, in: Pro c. Int. Conf. Learn. Represen t. (ICLR), 2025. [23] T. Mehari, N. Stro dthoff, Self-sup ervised represen tation learning from 12-lead ECG data, Comput. Biol. Med. 141 (2022) 105114. doi:10.1016/j.compbiomed.2021. 105114 . 26 [24] J. Li, A. Aguirre, J. Moura, C. Liu, L. Zhong, et al., An electro cardiogram founda- tion mo del built on ov er 10 million recordings with external ev aluation across multiple domains, NEJM AI 2 (7) (2025) AIoa2401033. doi:10.1056/AIoa2401033 . [25] H. Semmelro c k, T. Ross-Hellauer, S. Kop einik, D. Theiler, A. Hab erl, S. Thalmann, D. Kow ald, Repro ducibility in mac hine learning-based research: Overview, barriers and driv ers, AI Magazine 46 (2) (2025) e70002. doi:10.1002/aaai.70002 . [26] A. Desai, M. Ab delhamid, N. R. P adalk ar, What is repro ducibility in artificial in- telligence and machine learning researc h?, AI Magazine 46 (2) (2025) e70004. doi: 10.1002/aaai.70004 . [27] M. B. A. McDermott, et al., Reproducibility in mac hine learning for health researc h: Still a w a ys to go, Sci. T ransl. M ed. 13 (2021) eabb1655. doi:10.1126/scitranslmed. abb1655 . [28] J. Pineau, et al., Improving repro ducibilit y in machine learning researc h, J. Mac h. Learn. Res. 22 (2021) 1–20. [29] X. Bouthillier, P . Delauna y , M. Bronzi, A. T rofimo v, B. Nich yp oruk, J. Szeto, N. Sepah, E. Raff, K. Madan, V. V oleti, S. E. Kahou, V. Mic halski, D. Serdyuk, T. Arb el, C. Pal, G. V aro quaux, P . Vincen t, Accoun ting for v ariance in machine learning b enchmarks, in: Pro c. Conf. Machine Learning and Systems (MLSys), 2021. [30] D. Zh uang, et al., Randomness in neural netw ork training: Characterizing the impact of to oling, in: Pro c. Mach. Learn. Syst. (MLSys), V ol. 4, 2022. [31] B. Chen, et al., T o w ards training repro ducible deep learning mo dels, in: Pro c. IEEE/A CM In t. Conf. Soft w. Eng. (ICSE), 2022, pp. 2202–2214. [32] P . Xie, X. Zhang, S. Chen, RepDL: Bit-level repro ducible deep learning training and inference, Preprin t at https://arxiv.org/abs/2510.09180 (2025). [33] V. P ap yan, X. Y. Han, D. L. Donoho, Prev alence of neural collapse during the terminal phase of deep learning training, Proc. Natl. Acad. Sci. 117 (40) (2020) 24652–24663. doi:10.1073/pnas.2015509117 . [34] Z. Zh u, et al., A geometric analysis of neural collapse with unconstrained features, in: Pro c. Adv. Neural Inf. Pro cess. Syst. (NeurIPS), V ol. 34, 2021. [35] Y. Y ang, S. Chen, X. Li, L. Xie, Z. Lin, D. T ao, Inducing neural collapse in im balanced learning: Do we really need a learnable classifier at the end of deep neural netw ork?, in: Adv ances in Neural Information Pro cessing Systems (NeurIPS), 2022. [36] A. Gulati, et al., Conformer: Con volution-augmen ted transformer for sp eech recog- nition, in: Pro c. Interspeech, 2020, pp. 5036–5040. doi:10.21437/interspeech. 2020- 3015 . 27 [37] J. How ard, S. Gugger, F astai: A la y ered API for deep learning, Information 11 (2) (2020) 108. doi:10.3390/info11020108 . [38] P . Li, X. Li, Y. W ang, Q. Qu, Neural collapse in multi-label learning with pic k-all-lab el loss, in: Pro ceedings of the 41st International Conference on Machine Learning, V ol. 235 of Pro ceedings of Machine Learning Researc h, PMLR, 2024, pp. 28060–28094. [39] I. Loshchilo v, F. Hutter, SGDR: Sto c hastic gradien t descent with w arm restarts, in: Pro c. In t. Conf. Learn. Represent. (ICLR), 2017. [40] L. Kuip ers, H. Niederreiter, Uniform Distribution of Sequences, Wiley-In terscience, New Y ork, 1974. [41] S. Mishra, T. K. Rusc h, Enhancing accuracy of deep learning algorithms b y training with lo w-discrepancy sequences, SIAM J. Numer. Anal. 59 (3) (2021) 1811–1834. [42] Y. Bengio, J. Louradour, R. Collob ert, J. W eston, Curriculum learning, in: Pro c. Int. Conf. Mac h. Learn. (ICML), 2009, pp. 41–48. doi:10.1145/1553374.1553380 . [43] S. Shanm ugav elu, A. P . Periy asamy , D. Graux, G. De Luca, On the impacts of py- torc h repro ducibilit y on the accuracy and p erformance of deep learning mo dels, in: Pro ceedings of the In ternational Conference on Softw are Engineering and Kno wledge Engineering, 2024. [44] G. B. Moo dy , R. G. Mark, A new metho d for detecting atrial fibrillation using R-R in terv als, in: Comput. Cardiol., V ol. 10, 1983, pp. 227–230. [45] F. Liu, et al., An op en access database for ev aluating the algorithms of electro cardiogram rh ythm and morphology abnormality detection, J. Med. Imaging Health Inform. 8 (7) (2018) 1368–1373. doi:10.1166/jmihi.2018.2442 . [46] J. Zheng, et al., A 12-lead electro cardiogram database for arrhythmia researc h cov ering more than 10,000 patients, Sci. Data 7 (2020) 48. doi:10.1038/s41597- 020- 0386- x . [47] J. Y ang, R. Shi, D. W ei, Z. Liu, L. Zhao, B. Ke, H. Pfister, B. Ni, MedMNIST v2 – a large-scale light w eight b enc hmark for 2D and 3D biomedical image classification, Sci. Data 10 (2023) 41. doi:10.1038/s41597- 022- 01721- 8 . [48] K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: Pro c. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2016, pp. 770–778. doi: 10.1109/cvpr.2016.90 . [49] K. Jordan, On the v ariance of neural net work training with resp ect to test sets and distributions, in: Pro c. Int. Conf. Learn. Represen t. (ICLR), 2024. [50] R. R. Selv ara ju, et al., Grad-CAM: Visual explanations from deep netw orks via gradient- based localization, in: Pro c. IEEE In t. Conf. Comput. Vis. (ICCV), 2017, pp. 618–626. doi:10.1109/iccv.2017.74 . 28 T able 9: CIF AR-100 image classification results (ResNet-18, 20 seeds). DCT = single-basis 2D-DCT initialization. TOST equiv alence confirmed at δ = 0 . 5 p ercentage p oin ts ( p < 0 . 001). Dataset Init Accuracy P arams CIF AR-100 DCT 2D 78 . 4 ± 0 . 3% 11.2M CIF AR-100 Kaiming 78 . 3 ± 0 . 4% 11.2M [51] G. S. Collins, et al., TRIPOD+AI statemen t: Up dated guidance for rep orting clinical prediction mo dels that use regression or mac hine learning metho ds, BMJ 385 (2024) e078378. doi:10.1136/bmj- 2023- 078378 . [52] A. L. Goldb erger, et al., Ph ysioBank, Ph ysioT o olkit, and PhysioNet: Comp onen ts of a new research resource for complex physiologic signals, Circulation 101 (23) (2000) e215–e220. doi:10.1161/01.cir.101.23.e215 . [53] G. B. Mo o dy , W. E. Muldrow, R. G. Mark, A noise stress test for arrhythmia detectors, Comput. Cardiol. 11 (1984) 381–384. [54] V. A. Marc henko, L. A. P astur, Distribution of eigenv alues for some sets of random matrices, Mat. Sb ornik 72 (4) (1967) 507–536. [55] K. R. Rao, P . Yip, Discrete Cosine T ransform: Algorithms, Adv antages, Applications, Academic Press, 1990. A CIF AR Image Classification Results T o v alidate DCT initialization b ey ond medical domains, we applied 2D-DCT initialization to ResNet-18 on CIF AR-100 image classification [48]. 2D-DCT initialization uses separable 2D-DCT basis functions computed ov er the ( k h , k w ) k ernel dimensions, with 1D-DCT for c hannel mixing. Data augmen tation uses p er-ep o c h seeding ( torch.manual seed(epoch × 1000) ), making all augmen tation op erations deterministic. Sample indices replace the signal hash for golden ratio ordering: k ey[ i ] = mo d( i · φ + ep o c h · φ, 1). With 20 seeds p er condition (T able 9), DCT and Kaiming are statistically equiv alent on CIF AR-100 (78 . 4 ± 0 . 3% vs 78 . 3 ± 0 . 4%; t = 0 . 77, p = 0 . 45; Cohen’s d = 0 . 24; 95% CI [ − 0 . 14 , +0 . 31] pp). TOST equiv alence testing confirms equiv alence at δ = 0 . 5 percentage p oin ts ( p < 0 . 001), pro viding definitive evidence that DCT initialization matches Kaiming on a standard b enchmark with prop er statistical p ow er. DCT also exhibits low er seed v ariance ( σ = 0 . 26 vs 0 . 42). MedMNIST medical image results (T able 6) further v alidate the approach on clinical imaging tasks. B Noise Robustness Details A t n =5, Hartley sho ws the lo w est noise degradation across all three noise types (T able 10). DCT sho ws the largest electro de motion drop (0 . 091 ± 0 . 017), while Hartley loses 0 . 057 ± 29 T able 10: Noise robustness b y orthogonal basis (Conformer, 12-lead PTB-XL, n =5 seeds p er basis, 0 dB SNR). Eac h column shows A UC drop from clean at the harshest noise lev el. F ried- man tests: baseline w ander p =0 . 18, m uscle artifact p =0 . 18, electro de motion p =0 . 069; none reac h significance at α =0 . 05, though the electro de motion ordering approac hes significance. Noise sources from the MIT-BIH Noise Stress T est Database [53]. Basis Clean A UC BW drop Muscle drop EM drop Hartley . 959 ± . 003 . 033 ± . 012 . 035 ± . 010 . 057 ± . 019 Hadamard . 957 ± . 008 . 041 ± . 019 . 046 ± . 023 . 070 ± . 022 Sin usoidal . 951 ± . 006 . 050 ± . 011 . 063 ± . 021 . 064 ± . 019 DCT . 951 ± . 005 . 054 ± . 009 . 063 ± . 017 . 091 ± . 017 T able 11: Seed-free batch ordering strategies (Conformer, mixed-basis init, PTB-XL fold 10, single run each). All seed-free metho ds pro duce deterministic batch sequences without an y random seed. Golden ratio was selected for simplicit y (no h yp erparameters, no class-lab el dep endence) despite lo w er AUC than class-guaran teed ordering. Metho d A UC Seed-free? Notes Seeded sh uffle (control) 0.955 No Upp er b ound Class guaran teed 0.947 Y es Highest seed-free; needs cali- bration Golden ratio 0.941 Y es Selected: parameter-free Sob ol sequence 0.939 Y es Quasi-random cov erage F eature-space div erse 0.883 Y es Rotating pro jection Stratified quan tile 0.579 Y es Loss-based, class-correlated Class div erse 0.559 Y es Class interlea ve Herding 0.522 Y es Static order, ov erfits Con ten t hash (SHA-256) 0.479 Y es Hash correlates with class P airBalance (GraB) 0.579 Y es Loss-based ordering Loss-rank ed 0.500 Y es Homogeneous batches In terlea ved loss-ranked 0.579 Y es Still class-correlated 0 . 019. F riedman tests show no significan t basis effect for baseline wander ( p =0 . 18) or m uscle artifact ( p =0 . 18), but electro de motion approaches significance ( χ 2 =7 . 08, p =0 . 069), where the Hartley > Hadamard > Sinusoidal > DCT ordering is most pronounced. The pattern is broadly consistent with the clean-AUC ranking (T able 4). Baseline wander (low-frequency drift), muscle artifact (high-frequency EMG con tamination), and electro de motion (abrupt signal discon tin uities) all sho w the same directional ordering. C Batc h Ordering Strategies Class-guaran teed ordering (0.947) outp erforms golden ratio (0.941) by A UC but requires sp ecifying a minim um p er-batc h class count, making it lab el-dep enden t and dataset-sp ecific. Golden ratio ordering w as selected for the main exp eriments b ecause it is entirely parameter- free: the p erm utation dep ends only on signal conten t and ep o c h index, requires no class lab els or calibration, and transfers directly to new datasets. Sob ol-sequence ordering p erforms 30 comparably (0.939). Loss-based metho ds (stratified quantile, PairBalance, loss-ranked, interlea v ed loss- rank ed) all fail catastrophically b ecause in m ulti-lab el ECG classification, loss correlates strongly with class mem b ership: the dominan t SR class (77% of samples) is consistently lo w-loss, while rare arrh ythmias are high-loss. An y loss-based ordering implicitly sorts by class, pro ducing homogeneous batc hes. The golden ratio metho d a voids this b y computing p erm utations from signal con ten t rather than training dynamics. D Theoretical Analysis of DCT Initialization This section analyzes the information-theoretic prop erties of DCT-initialized conv olutional la yers compared to random (Kaiming) initialization. The notation C k,n used b elow corre- sp onds to d i [ j ] in the implemen tation description (Eq. (1)). Consider a con volutional lay er y = Wx , where x ∈ R N is the input signal and W ∈ R M × N is the weigh t matrix. Definition (DCT-II W eigh t Matrix). The orthonormal DCT-I I matrix C ∈ R N × N has en tries C k,n = α k cos π ( n + 1 2 ) k N , α k = ( p 1 / N k = 0 p 2 / N k ≥ 1 (6) satisfying C ⊤ C = CC ⊤ = I N . F or a Conv1d( C in , C out , K ), we set W DCT to the first C out ro ws of the DCT-I I matrix in the ( C in · K )-dimensional space, scaled to match Kaiming v ariance. Prop osition 1 (Energy Preserv ation Bound). Let x ∈ R N b e an arbitrary signal and let W K consist of K ≤ N rows of the DCT-I I matrix. Then ∥ W K x ∥ 2 ∥ x ∥ 2 = P K − 1 k =0 |⟨ c k , x ⟩| 2 ∥ x ∥ 2 ≥ 1 − P N − 1 k = K | ˆ x k | 2 ∥ x ∥ 2 (7) where ˆ x k = ⟨ c k , x ⟩ are the DCT co efficients. F or the full matrix ( K = N ), P arsev al’s theorem giv es ∥ Cx ∥ 2 = ∥ x ∥ 2 exactly . F or Kaiming initialization W ∼ N ( 0 , 2 N I ), the exp ected energy ratio is E [ ∥ Wx ∥ 2 / ∥ x ∥ 2 ] = 2 K / N with v ariance 8 K/ N 2 . Pr o of. The b ound follows from Parsev al’s iden tity: ∥ x ∥ 2 = P N − 1 k =0 | ˆ x k | 2 . F or Kaiming, eac h W ij ∼ N (0 , 2 / N ), so ( Wx ) k ∼ N (0 , 2 ∥ x ∥ 2 / N ), giving a χ 2 K -distributed squared norm with the stated moments. □ Theorem 1 (Condition Number Bound). The DCT-II matrix satisfies κ ( C ) = 1 (all singular v alues equal 1). F or Kaiming W ∈ R N × N with i.i.d. N (0 , σ 2 ) entries, the Marc henko–P astur law [54] giv es: κ ( W ) → 1 + √ γ 1 − √ γ as N → ∞ , γ = M N . (8) F or square matrices ( γ = 1), κ → ∞ . Since ∇ x L = W ⊤ ∇ y L , gradient comp onent ratios are b ounded b y κ ( W ). Corollary (Band-Limited Signals). F or ECG signals sampled at f s = 100 Hz with diagnostic conten t b elo w 40 Hz ( B = 0 . 8), the first ⌈ 0 . 8 N ⌉ DCT co efficien ts capture > 99% of signal energy . In a Con v1d la yer with k ernel size K = 5, the full 5 × 5 DCT matrix captures all within-window energy with κ = 1. 31 Figure 6: Theoretical analysis of DCT vs. Kaiming initialization. (a) Energy capture ratio for band-limited signals ( N = 64): DCT with full rank preserves energy exactly; Kaiming has correct expectation but high v ariance. (b) Condition n umber: DCT is alw a ys 1 (optimal gra- dien t flo w); Kaiming gro ws with matrix dimension N . (c) Mutual information I ( x ; Wx ) for a dimensionality-reducing lay er ( M = N/ 4, N = 64, SNR = 10 dB) with T o eplitz-correlated input: for correlated signals ( ρ ≳ 0 . 3), DCT preserves more m utual information than Kaim- ing b y selecting the most informativ e sp ectral components; at lo w correlation, Kaiming’s higher p er-filter v ariance (fan-in scaling) comp ensates for its random pro jection directions. D.1 Connection to Optimal Decorrelation The DCT-I I is the asymptotically optimal transform for decorrelating first-order Marko v pro- cesses [55]. ECG signals are well-modeled as quasi-stationary with autoregressiv e structure, making the DCT a near-optimal linear transform in the Karhunen–Lo ` ev e sense: CΣ x C ⊤ ≈ diag( λ 0 , . . . , λ N − 1 ) . (9) This near-diagonalization means DCT initialization appro ximately whitens the input, ensur- ing eac h output channel captures an indep enden t sp ectral comp onen t (Fig. 6). 32
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment