HeteroHub: An Applicable Data Management Framework for Heterogeneous Multi-Embodied Agent System
Heterogeneous Multi-Embodied Agent Systems involve coordinating multiple embodied agents with diverse capabilities to accomplish tasks in dynamic environments. This process requires the collection, generation, and consumption of massive, heterogeneou…
Authors: Xujia Li, Xin Li, Junquan Huang
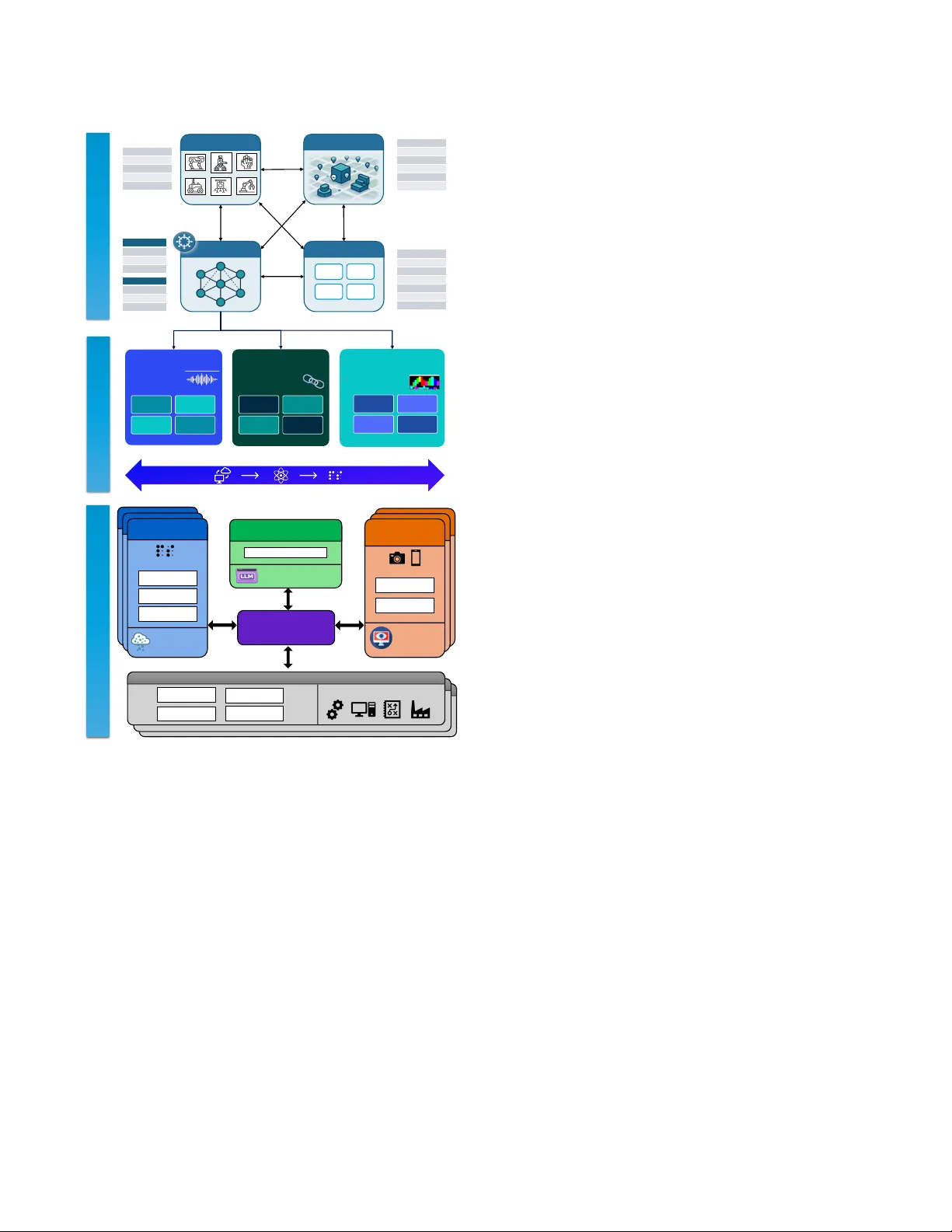
HeteroHub: An Applicable Data Management Framew ork for Heterogeneous Multi-Emb odied Agent System Xujia Li leexujia@ust.hk HKUST Hong Kong SAR, China Xin Li xli494@connect.hkust- gz.edu.cn HKUST (GZ) GuangZhou, China Junquan Huang junquan@m.scnu.edu.cn HKUST (GZ) GuangZhou, China Beirong Cui bcui472@connect.hkust- gz.edu.cn HKUST (GZ) GuangZhou, China Zibin W u zwu945@connect.hkust- gz.edu.cn HKUST (GZ) GuangZhou, China Lei Chen leichen@cse.ust.hk HKUST (GZ) & HK UST GuangZhou, China ABSTRA CT Heterogeneous Multi-Embodied Agent Systems involve coordinat- ing multiple embodied agents with diverse capabilities to accom- plish tasks in dynamic environments. This process requires the collection, generation, and consumption of massive , heterogeneous data, which primarily falls into three categories: static knowledge regarding the agents, tasks, and environments; multimodal train- ing datasets tailored for various AI models; and high-frequency sensor streams. Howe ver , existing frameworks lack a unied data management infrastructure to support the real-world deployment of such systems. T o address this gap, we present HeteroHub , a data-centric framework that integrates static metadata, task-aligned training corpora, and real-time data streams. The frame work sup- ports task-aware model training, context-sensitive execution, and closed-loop control driven by real-w orld feedback. In our demon- stration, HeteroHub successfully co ordinates multiple embo died AI agents to execute complex tasks, illustrating how a robust data management framework can enable scalable, maintainable, and evolvable embodied AI systems. 1 IN TRODUCTION Heterogeneous Multi-Embodied Agent Systems are poised to b e- come integral to daily life such as buying coee, colle cting de- liveries, cleaning homes, and conducting security patrols [ 1 , 5 ]. Howev er , enabling seamless collaboration among diverse hardware devices while coordinating various task-specic AI models creates a critical demand for a robust, applicable data management frame- work. Specically , managing the vast amounts of heterogeneous data raises signicant challenges [ 2 , 9 ]. The r elated data spans three primary categories: static knowledge regarding agent proles and task descriptions, dynamic sensor streams, and adequate training datasets for AI models. Beyond handling diverse data types, this eective data management framework also supports the entire oper- ational lifecycle: maintaining static metadata, facilitating AI model training, and processing real-time data during task execution [ 10 ]. In this demo, we pr esent Heter oHub, a comprehensive data man- agement solution designed to orchestrate the lifecycle of data in embodied intelligent systems. HeteroHub is composed of three in- terconnected layers: (1) Static Knowledge Management , which ∗ HKUST is the abbre viation for The Hong Kong University of Science and T echnology . includes detailed proles of agents, a task graph representing ex- ecutable workows, a model library housing AI algorithms, and environment information; (2) Training Data Fabric , which fo- cuses on collecting and organizing multimodal datasets for training perception, reasoning, and interaction models; and (3) Real- Time Sensor Stream Management , which handles the ingestion, pro- cessing, and routing of sensor data during task execution. At the core of HeteroHub is a task-aligned data structure that ensures all data elements are semantically linke d to spe cic tasks. This alignment enables precise querying and retrieval of r elevant data, facilitating ecient training and deployment of AI models. An- other key innovation is its adaptability to new scenarios. When a new device, capability , or model is introduced, the system can generate synthetic workows, augment the training set, and per- form lightweight ne-tuning. This ensur es that the system remains aligned with evolving operational requirements and learns from every interaction. T o demonstrate the eectiveness of HeteroHub, we deploy it in a smart campus logistics scenario . Specically , we orchestrate heterogeneous embodied agents to collaborate on complex tasks, including cross-oor and indo or-outdoor navigation, as well as autonomous pickup and delivery . Our demonstration highlights how HeteroHub manages the entire data lifecycle from initial data collection and model training to real-time task planning and exe- cution. By presenting HeteroHub, w e aim to illustrate the critical role of robust data management in enabling adaptable and scalable embodie d AI systems . W e believe this work will in- spire further resear ch into data-centric approaches for embodied AI, fostering innovations that bridge the gap between theoreti- cal advancements and practical applications. The demo video is available on https://youtu.be/rXEKhaa7W y0. 2 FRAMEW ORK O VERVIEW 2.1 Embodie d Agent Static Information Hub In Fig. 1, we present the Static Information Hub (SI-Hub), which is a structured data management framework designed to organize and serve the static knowledge required by heterogeneous embodied agent systems. SI-Hub consists of four interlinked modules: The Agent Proles mo dule maintains a registry of all embodied agents, capturing their physical specications, such as degrees of freedom, sensor suites, functional capabilities, and supp orted tasks. … capability hardware_specs status agent_id Task node requirement success_flag task_id Edge to_task_id edge_type from_task_id … I/ O_modality bound_tasks metrics model_id artifact _uri dependencies … map_type data_uri assciated_agent env_id last_updated Agen t Profile Ta s k Gr a ph Model Library VLA CV GNN NLP Audio files Transcripts Environme nts … Goals Negative Samples CoTs … Reasoning - based Wor k fl ow Dataset RGBs Semantic labels Segmentat ions … Vision - Centric Perc ep t io n Da ta se t linked - task - id Collection Annotation Deployment Context - Aware Ta s k Monito r Con t e x t - Aw a r e St r e a m Ro u t e r Real - time Executive Plan Poi nt Cloud St ream LiDAR/depth camera Active obstac le avoidance Semantic segmentation Automatic navigation V is io n S t r e a m Manag e r Vision Stream Segmentation Edge inference bindings RGB - event camera Dynamics & Proprioc eption S tream Robot joint control Hight - frequency data processing Safety monitoring Rule - based control policies Semantic signal Location signal Scenarios s ignal Ta s k - Aligned Speech Corpus Tra in i n g Static Informa tion Hub (SI - Hub) Tra i n i n g Data Fab ri c (E TDF ) Execution Da ta Stream Manager (EDSM) Posture signal Natural La ngu age Stream Point - cloud Model - SAM 3, Open3D… Vision Model - Yolo v8… Large Reasoning Model - Gemini 3 Cerebellum Models Environment Information Figure 1: HeterHub for Multi-agent Embodied AI Systems. Each agent is assigned a globally unique URI, allowing unambiguous reference across the system. The T ask Graph encodes the space of executable tasks as a directed property graph. Nodes represent atomic or composite tasks annotated with input and output schemas, required capabilities, and success criteria. Edges mo del sequential, parallel, or conditional dependencies between tasks. This graph enables high-level task planning and compatibility checks against agent capabilities. The Model Library catalogs all AI models used for p erception, planning, control, or language grounding. For each model, we store metadata including modality of input abnd output data, perfor- mance metrics, version, and the relations to one or mor e tasks in the T ask Graph. Model artifacts themselves are stored externally with only URIs retained in the registry to ensure scalability . Finally , the Environment Information module stores digital representations of operational environments, such as point clouds, occupancy grids, or semantic maps. Each environment entry in- cludes metadata ab out static objects, dynamic zones, and associated agents, along with a reference to the actual map le . Environments are also linked to tasks commonly executed within them, facilitating context-aware deployment. All four modules are interconnected through standardized URI- based references. For example, an agent prole references task IDs and a task node references model IDs. This design enables rich cross-module queries. For instance, "Which agents in environ- ment 𝐸 1 can execute task 𝑇 1 , and which models should b e loaded?" , while maintaining loose coupling for independent up dates. SI-Hub thus provides a scalable , queryable, and extensible foundation for managing the static knowledge backb one of multi-agent embo died intelligence systems. 2.2 Embodie d AI Training Data Fabric (ETDF) ETDF is a multimo dal data storage for the entire model training lifecycle, spanning data collection, annotation, training, and de- ployment. ETDF is grounded in the principle of task-centric data curation , which means every training sample is e xplicitly linked to a node in the T ask Graph. ETDF currently comprises three core components. The rst mod- ule, the T ask-Aligned Spee ch Corpus , manages voice interaction data collected in context-specic scenarios. Each entr y consists of a recorded audio utterance, a corresponding human-veried transcript, and an intent representation (e .g., grasp(object="mug")). This corpus directly supports ne-tuning automatic speech recog- nition and natural language understanding models that map user commands to actionable system intents. The se cond module, Reasoning-Based W orkow Dataset , captures high-level planning knowledge by pairing LLM-generated Chains of Thought (Co T s) with both awless multi-agent trajecto- ries and deliberately awed plans [ 7 ]. Each entry includes a natural- language goal, e.g., "Transport equipment to E4" , a step-by-step reasoning trace, and machine-readable action sequences. T o en- sure strict adherence to physical and morphological constraints, its training leverages the Reasoning-Based W orko w Dataset rather than relying solely on successful demonstrations. Crucially , the rejected plans are injected with compound errors, such as a drone navigating indoors or a legge d robot attempting to open a door . The training data consists of r easoning-augmented preference tuples: (task context, chosen awless plan, rejected awed plan, penalty score). These preference pairs are generate d through our auto- mated three-phase pipeline: (1) extracting localized subgraphs to provide high-density physical contexts without attention dilution; (2) probabilistic injection of compound errors, including capability mismatches and co ordination failures, to construct highly deceptive negative samples; and (3) rigorous evaluation via a hybrid symbolic- semantic validator to compute a quantitative penalty score based on error severity , instead of simple binary success or failure labels. The third module, the Vision-Centric Perception Dataset , stores annotate d visual data, including RGB, semantic labels for training specic perception mo dels. Annotations are all aligned with the object v ocabulary dened in the corresponding task scop e. Images and annotations are organized hierar chically by task and object class, and exporte d in standard formats compatible with mainstream computer vision frameworks [ 4 ]. Critically , camera intrinsics and scene context are preserved to support ge ometry- aware training and domain adaptation. 2.3 Execution Data Stream Manager T o close the perception–decision–action loop during task execu- tion, we introduce the Execution Data Stream Manager (EDSM). Unlike traditional data logging systems that tr eat sensors as passive sources [ 8 ], EDSM treats sensor data as task-driven semantic signals, dynamically activating processing pipelines based on the current executable plan derived from the high-level r easoning module. EDSM manages three primar y modalities. The point cloud stream , derived from 3D data collected by LiDARs or depth cam- eras, undergoes real-time preprocessing on the robot edge using the known environment map from the Static Knowledge Hub. Fol- lowing the processing on the e dge, the real-time status of agent, specically location signals in this demo, is fed back to the central task monitor to verify the completion status of the current sub- task. Simultaneously , the point cloud data is processed on-device by SLAM algorithms to enable autonomous navigation and active obstacle avoidance for the embo died agent. Secondly , the visual data stream is transmitted to lightweight, task-specic trained vision mo dels on the edge, e.g., Y OLO for detection or DINOv2 for feature extraction. T o optimize bandwidth, only frames con- taining scenario-relevant content trigger a upload to the central task monitor . Visual detections are fused with point cloud data to rene spatial understanding for more eective sub-task execution. For instance, by projecting 2D bounding b oxes into 3D space to guide grasp planning—thereby enabling more ee ctive sub-task execution. The dynamics and proprioception data stream cap- tures high-frequency signals from joint encoders, IMUs, and force or torque sensors. This data is primarily processed in real-time on the edge by diverse cerebellar control models to perform state estimation and continuously monitor safety constraints, such as joint torque limits and balance stability . When an executable plan species a control policy , the EDSM dynamically invokes the corre- sponding cerebellum, fee ding it real-time proprioceptive data with the task goal. The policy then generates low-level commands. The central Context-A ware T ask Monitor primarily aggre- gates and analyzes processe d signals from various local data streams to assess the completion status of each sub-task. It aligns this progress with the r eal-time executive plan generated by the large reasoning model. If deviations or errors are detected, the monitor triggers the reasoning large model to regenerate the w ork execu- tion plan. Upon receiving an up dated executable plan, the Monitor redistributes sub-tasks to the local embodie d agents. 3 DEMONSTRA TION PROPOSAL This demo focuses on logistics transp ortation tasks within a campus and consists of two main parts. The rst part involves using ETDF in HeteroHub to train de ep learning models tailored to specic logistics tasks. The second part leverages the trained brain and cerebellum models to interact in real time with static information from SI-Hub and dynamic signals from EDSM, enabling embodied agents to execute tasks ee ctively . 3.1 Model Training Demonstration W e will demonstrate the data sample, training implementations, and training result of following models using HeteroHub . 3.1.1 Scenario 1: Training the Brain for Campus Logistics . The "brain" , which is a ne-tune d large reasoning model, is respon- sible for translating abstract user goals, such as "Buy me a cup of coee from Starbucks" , into concrete execution plans. Training proceeds in two stages. First, sup ervised ne-tuning teaches the model to map spatial contexts and goals to executable plans using chain-of-thought prompting. This phase establishes the founda- tional reasoning steps required to generate valid structur ed outputs. Second, we apply Direct Preference Optimization (DPO ) to rene the p olicy . This ne-grained penalty feedback directly enables DPO , where the alignment margin is scaled proportionally to the exe- cution violation [ 3 ]. DPO utilizes the penalty scores computed by the hybrid validator to dynamically scale the alignment margin. This forces the optimization landscape to aggressively penalize severe physical violations, e.g., a drone navigating indoors, while applying softer corrections to minor coordination ineciencies. By grounding every preference pair in explicit physical constraints, this module ensures the planner generates only feasible, execution- consistent strategies. 3.1.2 Scenario 2: Training the Cerebellums for T ask-Sp ecific Perception . In this demo, two cerebellum models are trained using ETDF, r esponsible for spe ech understanding and visual perception. For speech , the T ask- Aligne d Spee ch Corpus provides audio- transcript-intent triples annotated with task context. W e train a compact Whisper variant for ASR and a BERT -base d intent parser whose output space is dynamically constraine d by the active task’s object vocabulary . This ensures the NLU module ignores out-of- scope commands, thereby improving robustness. For vision , the Vision-Centric Perception Dataset supplies RGB- Depth images and annotations organized by task and object class. Models like YOLOv8 or Segment Anything are ne-tuned exclu- sively on data relevant to active tasks. Multi-task learning is em- ployed when object categories ov erlap across tasks. For example, we jointly train the policies for "pressing the elevator button" and "grasping a coee cup" on the same r obotic arm and camera suite, sharing a common backbone to improve sample eciency . 3.2 T ask Exe cution Demonstration T o demonstrate the integration of HeteroHub with heterogeneous embodied agents, we show the full execution pr ocess for a repr e- sentative task: " Grab a coee from the Starbucks . " This demo seamlessly orchestrates static knowledge, trained models, r eal-time sensing, and physical actuation thr ough ve successive scenarios . 3.2.1 Scenario 1: T ask Reception and W orkf low Planning . The interaction begins when a human issues a spoken command. The audio stream is captured by the microphone array and routed to the T ask-Aligned Speech Corpus. The spe ech model transcribes the utterance and parses it into a structured intent. Because this is a natural-language goal rather than a low-level instruction, it is directly for warded to the brain. Upon receiving the intent, the brain consults the T ask Graph to decomp ose the goal into executable sub- tasks. Leveraging its training on reasoning-augmented w orkows, Ta s k Reception Wor k fl ow Planning Sub - Tas k 1 : Move to elevator Sub - Tas k 2 : Call and take the elevator Sub - Tas k 3 : Navigate to Starbuck Sub - Tas k 4 : Grab the coffee Sub - Tas k 5 : Hand over to roboti c dog Sub - Tas k 6: Delivery Demo Wo r k f l ow Embodied AI Age nt s Natur al Lang uag e Str eam Poi n t - cloud Stream Vision Stream Dyna. & Proprio . Stream Static Information Hub (SI - Hub) E D S M Data Flow Figure 2: Orchestrating Multi- Agent Embodie d AI: A Data-Driven W orkow for "Bring Me a Coee from Starbucks" it generates a context-aware plan grounded in the system’s capa- bilities. T o ensure feasibility , each subtask is bonded to a specic agent and a model registered in the Model Library . 3.2.2 Scenario 2: Autonomous Navigation . The T ask Monitor dispatches the plan generated in Scenario 1 step-by-step. First, it activates the Chassis Agent ( 𝑎𝑔𝑒𝑛𝑡 : // 𝑐 ℎ𝑎𝑠 𝑠 𝑖 𝑠 / 01 ) and instructs it to navigate to the elevator . During navigation, the chassis agent retrieves the static map ( 𝑒 𝑛𝑣 : // 5 𝑡 ℎ _ 𝑓 𝑙 𝑜 𝑜 𝑟 ) from SI-Hub and si- multaneously performs real-time environmental perception using LiD AR and proprioceptive sensors managed by the EDSM mod- ule. It then uses a SLAM algorithm to localize and navigate to the destination of the rst sub-task [6]. 3.2.3 Scenario 3: Vision-base d Control . Up on reaching the elevator , the Task Monitor invokes the visual perception model ( 𝑚 𝑜𝑑 𝑒𝑙 : // 𝑦𝑜 𝑙 𝑜 _ 𝑒𝑙 𝑒 𝑣 𝑎𝑡 𝑜 𝑟 / 01 ) deployed on the edge compute unit to perform semantic segmentation of the visual input. The Arm Agent then performs real-time detection of the elevator buttons on the wall using the live Vision Stream. Upon successful dete ction, the system triggers the next action: the me chanical arm ( 𝑎𝑔𝑒𝑛𝑡 : // 𝑎𝑟 𝑚 / 02 ) is activated to press the designated elevator button. Sim- ilar vision-base d control mechanisms also app ear in other sub-tasks within this demo, including recognizing visual cues outside the ele- vator to help the chassis identify the current oor , and performing semantic segmentation on images of coee bags to determine pre- cise grasping points for the robotic arm. These sub-tasks require ne-grained control, which is achieved through trained cerebellum models in conjunction with the vision streams managed by EDSM. 3.2.4 Scenario 4: Collaboration among Multiple Agents . T o demonstrate Hetero-Hub ’s capability in supporting collaborative tasks among a group of embo died agents, our demo features a cooperation scenario involving the chassis agent, the arm agent, and a robot dog. They jointly transport a coee bag through han- dover and ultimately deliv er it to a conned oce ar ea. Leveraging the T ask Monitor’s sche duling capability for both tasks and data streams, the three agents concurrently access dierent modalities of data from Hetero-Hub: point-cloud streams for navigation, and vision signals for robotic arm control and vision-based navigation in narrow spaces. 3.2.5 Scenario 5: Real- Time Fe edback and Plan Refinement . After each subtask completes or fails, the agent sends a structured status report back to the brain. If a step fails, e.g., grasp unsuccess- ful due to slippage, the failure signal includes diagnostic metadata ( 𝑒 𝑣 𝑒 𝑛𝑡 : // 𝑙 𝑜 𝑤 _ 𝑓 𝑜 𝑟 𝑐 𝑒 _ 𝑟 𝑒 𝑎𝑑𝑖 𝑛𝑔 ) . The brain can then trigger a local retry , like reposition and re-grasp, or trigger a fall back to an alter- native workow branch dened in the T ask Graph, e.g., "ask user for help" . This closed-lo op fee dback ensures robustness while simul- taneously enriching the Reasoning- A ugmented W orkow Dataset with real-world experience, thereby closing the cycle between task execution and system continual learning. 4 CONCLUSION HeteroHub demonstrates that robust embodied intelligence funda- mentally relies on principled data management. By unifying static knowledge, training data, and real-time sensor streams within a task-centric framew ork, Heter oHub enables traceable, scalable, and adaptive robot systems. Our demo illustrates how this framew ork are not just supportive but essential to coordinating heter ogeneous agents in dynamic environments. As embo died AI scales to real- world deployments, w e hope this demo inspires deeper collabora- tion between the database and robotics communities. REFERENCES [1] Junting Chen, Checheng Y u, et al . 2025. EMOS: Embodiment-aware Heteroge- neous Multi-robot Operating System with LLM Agents. In ICLR 2025 . [2] Timo Eckmann and Carsten Binnig. 2026. A Vision for Autonomous Data Agent Collaboration: From Query-by-Integration to Quer y-by-Collaboration. In Conference on Innovative Data Systems Research, CIDR. ww w . cidrdb. org . [3] W enfei Fan, Xiao yu Han, W eilong Ren, and Zihuan Xu. 2025. Data Enhancement for Binary Classication of Relational Data. Proc. ACM Manag. Data (2025). [4] Ricardo Garcia, Shizhe Chen, and Cordelia Schmid. 2025. T owards Generalizable Vision-Language Robotic Manipulation: A Benchmark and LLM-Guided 3D Policy . International Conference on Rob otics and Automation (ICRA) (2025). [5] Kehui Liu, Zixin T ang, et al . 2025. COHEREN T: Collab oration of Heterogeneous Multi-Robot System with Large Language Models. In ICRA 2025 . [6] Andréa Macario Barros, Maugan Michel, Y oann Moline, and Gwenolé Corre. 2022. A Comprehensive Survey of Visual SLAM Algorithms. Robotics (2022). [7] James Pan and Guoliang Li. 2025. Database Perspective on LLM Inference Systems. Procee dings of the VLDB Endowment (2025). [8] Ties Robroek, Neil Kim Nielsen, and Pınar Tözün. 2025. TensorSocket: Shared Data Loading for Deep Learning Training. Proc. ACM Manag. Data (2025). [9] Jun Song, Jingyi Ding, Irshad Kandy , et al . 2025. Magnus: A Holistic Approach to Data Management for Large-Scale Machine Learning W orkloads. Procee dings of the VLDB Endowment (2025). [10] Tingting W ang, Shixun Huang, Zhifeng Bao , J Shane Culpepper , V olkan Dedeoglu, and Reza Arablouei. 2024. Optimizing data acquisition to enhance machine learning performance. Procee dings of the VLDB Endowment (2024).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment