FedDES: Graph-Based Dynamic Ensemble Selection for Personalized Federated Learning
Statistical heterogeneity in Federated Learning (FL) often leads to negative transfer, where a single global model fails to serve diverse client distributions. Personalized federated learning (pFL) aims to address this by tailoring models to individu…
Authors: Brianna Mueller, W. Nick Street
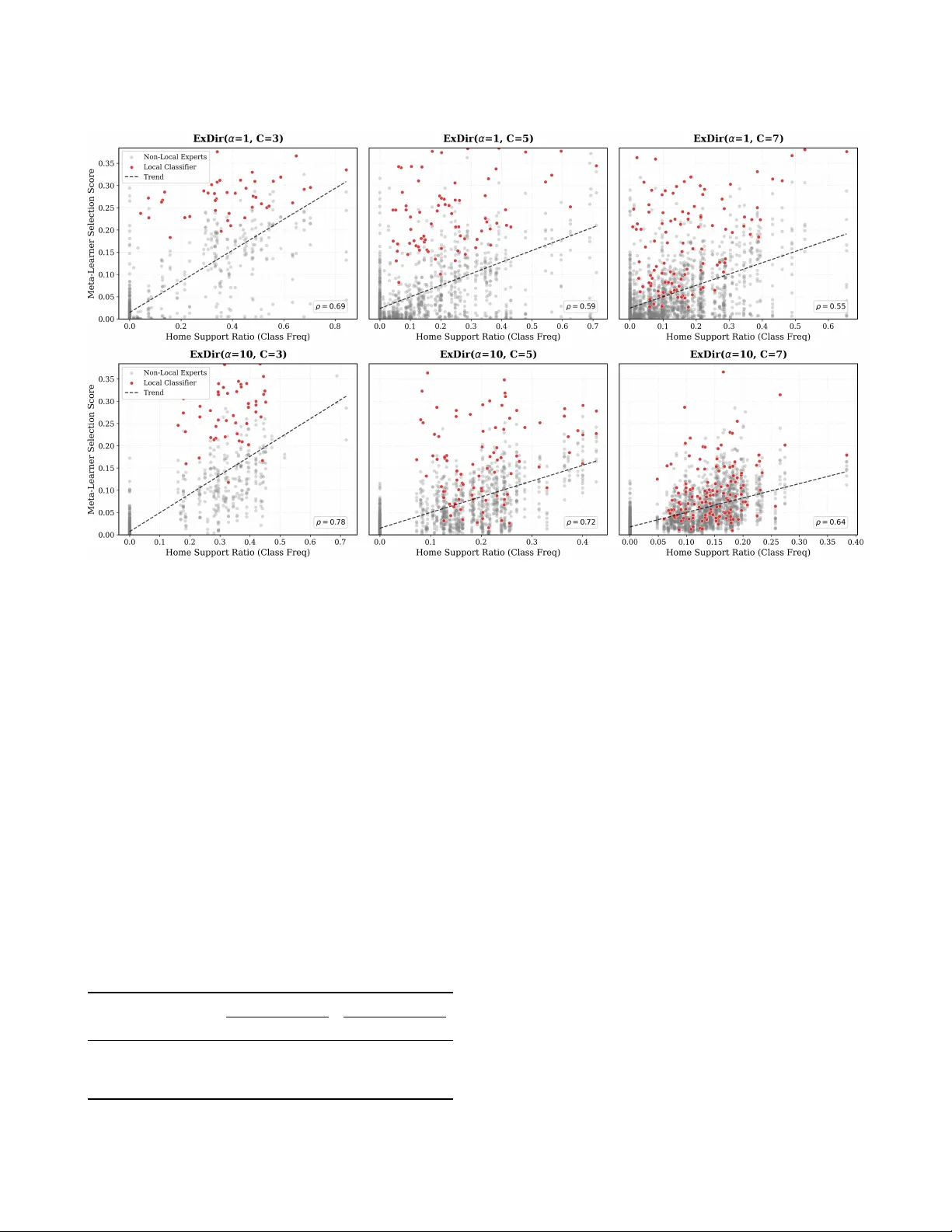
FedDES: Graph-Based Dynamic Ensemble Selection for Personalized Federated Learning Brianna Mueller University of Iowa Iowa City, Iowa brianna- mueller@uiowa.edu W . Nick Street University of Iowa Iowa City, Iowa nick- street@uiowa.edu Abstract Statistical heterogeneity in Federated Learning (FL) often leads to negative transfer , where a single global model fails to serve diverse client distributions. Personalized federated learning (pFL) aims to address this by tailoring mo dels to individual clients. However , under most existing pFL appr oaches, clients integrate peer client contributions uniformly , which ignor es the r eality that not all peers are likely to b e equally benecial. Additionally , the potential for personalization at the instance level remains largely unexplored, even though the reliability of dierent peer mo dels often varies across individual samples within the same client. W e introduce FedDES (Federated D ynamic Ensemble Selection), a decentralized pFL framework that achieves instance-level per- sonalization through dynamic ensemble selection. Central to our approach is a Graph Neural Network (GNN) meta-learner trained on a heterogeneous graph modeling interactions between data samples and candidate classiers. For each test query , the GNN dynamically selects and weights peer client mo dels, forming an ensemble of the most competent classiers while eectively suppr essing con- tributions from those that are irrelevant or potentially harmful for performance. Experiments on CIF AR-10 and real-world ICU health- care data demonstrate that FedDES outperforms state-of-the-art pFL baselines in non-IID settings, oering robust pr otection against negative transfer . 1 Introduction Federated Learning (FL) enables collaborative model training across distributed data sources without requiring data centralization. By keeping sensitive data localized, FL addresses privacy and regu- latory constraints in applications such as healthcare diagnostics, nancial fraud detection, and autonomous systems. Traditional federated learning approaches, exemplied by Federated A veraging (FedA vg) and its variants, train a single global model by iteratively aggregating local gradient updates from participating clients. How- ever , the assumption that a single shared model can adequately serve all clients often fails when clients possess signicantly dier- ent data distributions in practice. This statistical heterogeneity cre- ates a critical challenge: forcing diverse clients to converge toward a shared representation can result in negative transfer , degrading performance for individual participants. In response to the limitations of global model appr oaches, per- sonalized federated learning has emerge d as a pr omising research direction that aims to provide each client with a model tailored to its local data distribution while still beneting from collaborative learning. Existing pFL approaches use various strategies to balance global and local information. Methods like pFe dMe [ 27 ] and Ditto [16] use bi-level optimization to separate shared and personalized parameters. Meta-learning approaches such as Per-FedA vg [ 9 ] learn initialization points that can be quickly adapted to local data. Other works explore mixtures of global and local models [ 7 ], clustered federated learning [ 23 ],or personalized aggregation strategies that weight pe er models based on client similarity or local utility [ 12 , 37 ]. While these metho ds show improvements over purely global approaches, they share several fundamental limitations. First, many rely on centralized coordination through synchronous communica- tion rounds, creating bottlenecks and single points of failure. Recent decentralized approaches have addressed this by enabling direct peer-to-pe er collaboration without a central server [ 4 , 20 , 26 , 31 ]. Howev er , most metho ds, whether centralized or decentralized, still require homogeneous model architectures acr oss all clients. This constraint limits exibility for a federated network of clients with varying computational capabilities. W ork on model-heterogeneous FL has begun to relax this constraint through methods such as knowledge distillation [ 24 , 33 ] or sharing prototypes rather than gradients or mo del parameters. Despite these advances, the ma- jority of personalized federated learning approaches balance only "global" and "local" knowledge, treating all peer contributions uni- formly without the ability to identify when spe cic peer models help versus harm. While some personalized methods learn client- specic weights that can selectively emphasize individual peers, these approaches still require homogeneous mo del architectures to perform weighted averaging in parameter space. Moving be- yond selective peer contribution at the client level, we identify an opportunity for sample-level personalization. Ev en methods that successfully learn which pe er models to weight for each client apply those weights uniformly across all test samples. Within a single client’s data distribution, the optimal set of contributing peer clients may vary signicantly across individual test samples. A hospital’s patients matching its predominant demographic prole might be best predicted by local models, while patients from un- derrepresented populations could benet from models trained at institutions where those populations are better represented. In this work, we introduce FedDES (Federated D ynamic Ensem- ble Selection), a novel pFL approach that performs dynamic ensem- ble selection to achieve personalization at the instance level. FedDES inherits the decentralized framework of the FedP AE algorithm [ 21 ], where clients independently train heterogeneous base classiers and construct local model b enches thr ough asynchronous peer-to- peer model sharing. The key advancement is the replacement of FedP AE’s static ensemble selection (one ensemble per client) with a Graph Neural Network ( GNN) that learns to dynamically select models from the bench for each individual test sample. The foundation of this approach is a heter ogeneous graph that models relationships between data samples and classiers, with Brianna Mueller and W . Nick Street edges encoding their interactions base d on classier prediction patterns and sample similarity . The GNN processes this graph to produce sample emb eddings, which are then mapped to output weights that determine both classier selection and the relative strength of their contribution to the ensemble prediction. Through this process, the network learns to identify which classiers are competent in spe cic regions of the sample space. By assigning zero weights to peer classiers not estimated to contribute to a correct ensemble de cision, the GNN provides instance-level protection against negative transfer , ensuring external knowledge is integrated only when benecial. Our main contributions are summarized as follows: • A decentralized, model-heterogeneous framework : W e propose FedDES, a fully decentralized pFL framework that relies on peer-to-peer communication, replacing syn- chronous communication rounds facilitated by a central server . By aggregating client contributions in the output space (via ensembles) rather than the parameter space, Fed- DES supports complete model heterogeneity . • GNN-based dynamic ensemble selection for instance- level personalization : W e introduce a novel dynamic en- semble selection approach leveraging GNNs. By modeling the interactions between local data samples and candidate classiers, the GNN learns to estimate classier competence based on sample-specic characteristics. This enables Fed- DES to mov e beyond standard client-level weighting in pFL to personalization at the instance level. • Precise protection against negative transfer : By tailor- ing solutions to individual samples rather than clients, Fe d- DES eectively suppresses contributions from non-benecial peer clients even in scenarios where a peer client’s model is generally useful for the client’s local data distribution, but fails on specic cases. • Empirical validation : W e demonstrate the eectiveness of FedDES on benchmarks including image classication (CIF AR-10) and real-world distributed healthcare data (eICU). Our experiments show that FedDES outperforms state-of- the-art p ersonalized federated learning baselines in non-IID settings. In Section 2, w e revie w personalized federated learning, dynamic ensemble selection, and graph representation learning. W e describe the proposed method in Section 3. Exp eriments and results are presented in Sections 4 and 5, followed by discussion in Section 6 and conclusions in Section 7. 2 Related W orks 2.1 Personalized Fe derated Learning under Heterogeneity Standard federated learning methods such as FedA vg assume a single global model can ser v e all clients, but statistical heterogene- ity across client data distributions often causes this assumption to fail [ 17 ]. Personalize d federated learning (pFL) addresses this by tailoring models to individual clients while retaining the benets of collaboration. A range of personalization strategies hav e been proposed, including meta-learning approaches that learn shared initializations for rapid local adaptation [ 9 ], regularization meth- ods that penalize deviation from a global reference [ 16 , 27 ], and aggregation-based approaches that learn client-specic weighting of pe er models [ 12 , 37 ]. However , most pFL methods assume ho- mogeneous model architectures across clients, which is restrictive when clients have varying computational resources or proprietary model designs. Model-heterogeneous federate d learning (MHFL) relaxes this constraint through sev eral strategies. Model-splitting methods such as LG-FedA vg [ 19 ] and FedGH [ 35 ] partition the architecture into shared and personalized components, enabling heterogeneity in the personalized portion while maintaining a com- mon component for collaboration. Knowledge distillation metho ds such as FML [ 24 ] and FedKD [ 33 ] achieve full architectural exibil- ity by exchanging knowledge thr ough model outputs rather than parameters. Each client maintains a personalized model alongside a local copy of a shared auxiliary model, with bidirectional distillation providing the learning signal. Prototype-based methods such as FedProto [ 28 ] and FedTGP [ 36 ] communicate class-level feature rep- resentations rather than parameters or predictions, which FedTGP improves throug h adaptive-margin contrastive learning to address poor prototype separability under strong heterogeneity . While these methods vary in the degree of architectural exibility they sup- port, most still require some form of dimensionality alignment across clients. Model-splitting methods require matching output dimensions at the shared component boundary , prototype-based methods assume embe ddings ar e comparable across architectures, and distillation methods introduce a shared auxiliary model whose architecture must be xed across all clients. These constraints can degrade performance when heterogeneous backb ones pr oduce rep- resentations with dierent scales or dimensionalities. Be yond these structural constraints, existing MHFL methods personalize at the client level, learning a single model or set of aggregation weights applied uniformly across all test samples. FedDES addresses both limitations: by aggregating classier contributions in the output space, it requires only that classiers produce predictions over a common label set, and by selecting classiers per sample through a GNN meta-learner , it achieves instance-level personalization. 2.2 Dynamic Ensemble Selection Dynamic ensemble selection (DES) aims to improve classication performance by selecting, for each test sample , a subset of classiers from a larger pool to contribute to the prediction. The core intu- ition underlying DES is that classiers vary in competence across dierent regions of the sample space [ 14 ], such that selecting those estimated to be most competent in the local region of the query can outperform static ensemble selection or full-pool aggregation [ 5 ]. The standard DES pipeline procee ds in three phases: (1) Dening a region of competence (RoC) around the query , (2) estimating classi- er competence within that region, and (3) selecting the subset of classiers for the nal prediction. Region of competence construction. The RoC determines the local context for competence estimation. Most DES methods dene this region using 𝑘 -nearest neighbors in the feature space, drawn from a de dicated dynamic selection dataset (DSEL) [ 2 , 5 ]. Standard k- NN, however , is sensitive to noise, class overlap, and class imbalance, prompting renements such as adaptive neighborhoods, alternative FedDES: Graph-Based Dynamic Ensemble Selection for Personalized Federated Learning distance metrics, and class-balanced neighbor rules [ 8 ]. Decision- space approaches take a dierent persp ectiv e, representing each sample by its vector of classier outputs (hard labels or posterior scores) and determining neighbors based on similarity in this space rather than the original feature space [10, 13]. Competence estimation criteria. Individual-based compe- tence measures evaluate each classier independently , most com- monly through accuracy within the RoC [ 32 ]. In contrast, meta- learning frameworks estimate competence from meta-featur es en- coding classier behavior . MET A-DES, for instance , trains a meta- classier on features such as local accuracy , condence, and output entropy to predict whether each base classier should be included in the ensemble for a given query [ 6 ]. Group-based measures account for classier interactions by seeking complementar y error patterns [ 25 ], though some work suggests that the benets of ensemble diversity are more relevant for static selection and that actively promoting instance-level div ersity can be counterproductive [34]. Selection and aggregation. Selection strategies range from strict oracle-inspired rules that require (near-)perfect local accuracy to softer threshold-based criteria that retain any classier outper- forming random chance [ 14 ]. Rather than making binar y inclusion decisions, dynamic weighting approaches use competence scor es directly to modulate each classier’s inuence during aggregation. 2.3 Graph Representation Learning Graph neural networks (GNNs) learn node representations by it- eratively aggregating information from each no de ’s local neigh- borhood. At each layer 𝑙 , a no de 𝑣 updates its emb edding ℎ ( 𝑙 ) 𝑣 by combining its current representation with messages fr om its neigh- bors N ( 𝑣 ) : ℎ ( 𝑙 ) 𝑣 = Upda te ( 𝑙 ) ℎ ( 𝑙 − 1 ) 𝑣 , Aggrega te ( 𝑙 ) { ℎ ( 𝑙 − 1 ) 𝑢 : 𝑢 ∈ N ( 𝑣 ) } By stacking multiple layers, each node’s emb edding captures in- creasingly broad structural context. Graph Attention Networks (GA T s) [ 30 ] replace xed aggregation with a learned attention mechanism that assigns dierent importance weights to dier ent neighbors. However , Brody et al. [ 3 ] showed that standard GA T computes a global ranking of neighb or importance that is indepen- dent of the query node, a limitation termed static attention. Their proposed GA T v2 remedies this by reordering the nonlinearity in the attention computation, yielding dynamic attention where the ranking of neighbors is conditioned on the specic query node. This property makes GA Tv2 a natural t for FedDES, where the relevance of neighboring samples and classiers varies depending on the specic quer y instance . 3 Methodology FedDES op erates in a fully decentralized, p eer-to-peer setting in which each client performs three main operations locally: (1) train- ing a set of heterogeneous base classiers on its local data and exchanging the models with peers to obtain a shared pool of 𝑀 clas- siers; (2) evaluating all models in the shared pool on its lo cal data to construct a decision-space representation of samples and build a heterogeneous graph where nodes represent data samples and candidate classiers; (3) training a GNN meta-learner that produces sample-specic ensemble weights. Figure 1 pro vides an overview of the complete pipeline. 3.1 Stage 1: T raining Base Classiers and Decentralized Model Exchange. Each client partitions its private dataset D 𝑘 into three subsets: (i) a training set used to t the local base classiers and to supervise the GNN meta-learner , (ii) a validation set for early stopping during base model training and tuning GNN hyperparameters, and (iii) a test set reserved for nal performance evaluation. Clients train one or more models on their local data, producing model sets F 𝑘 with 𝑀 𝑘 = | F 𝑘 | classiers. These models may vary in architecture and are not limited to gradient-based methods. After training, clients exchange their classiers via P2P communication, so that each locally retains a copy of the full pool of 𝑀 = Í 𝑘 𝑀 𝑘 base classiers. 3.2 Stage 2: Decision-Space Representation and Graph Construction. After exchanging models, each client constructs a decision-space representation of its training data. Since the base classiers are trained on non-IID data using heter ogeneous architectures, their condence scores may not be directly comparable. Each client there- fore calibrates the received classiers using temperature scaling, aligning condence estimates with the local data distribution and preventing poorly calibrated classiers fr om distorting the decision- space representation. For each sample 𝑥 𝑖 , every classier 𝑓 𝑚 produces a probability vector 𝑝 𝑚 ( 𝑥 𝑖 ) ∈ R 𝐶 where 𝐶 is the number of classes. W e dene the projection function 𝜙 : X → R 𝑀 · 𝐶 which maps a sample into the decision space, the concatenated outputs of all 𝑀 classiers: 𝜙 ( 𝑥 𝑖 ) = 𝑝 1 ( 𝑥 𝑖 ) , 𝑝 2 ( 𝑥 𝑖 ) , . . . , 𝑝 𝑀 ( 𝑥 𝑖 ) ∈ R 𝑀 · 𝐶 . Let x 𝑖 : = 𝜙 ( 𝑥 𝑖 ) denote the decision-space embedding of sample 𝑥 𝑖 . Stacking these embeddings yields the decision-space matrix P 𝑘 ∈ R 𝑁 𝑘 × ( 𝑀 · 𝐶 ) . T o super vise the meta-learner , each client constructs a binary meta-label matrix Z 𝑘 ∈ { 0 , 1 } 𝑁 𝑘 × 𝑀 , where 𝑍 𝑖 , 𝑚 = 1 indicates that classier 𝑓 𝑚 correctly predicts the label of 𝑥 𝑖 . These meta-labels serve as targets for learning sample-specic ensemble weights. Each client then constructs a heter ogeneous graph over data samples and classiers, linke d by two edge types: sample-sample edges encoding decision-space similarity , and classier-sample edges encoding lo cal competence. Sample-sample e dges. These edges enco de similarity in the decision space. Instead of using standard global 𝑘 -NN, which is known to be sensitive to class imbalance, w e perform class-aware selection. For a target sample 𝑥 𝑗 , we identify the 𝑘 nearest neighbors from each class based on 𝐿 1 distance in the decision space, forming a class-balanced neighborhoo d: N ( 𝑥 𝑗 ) = 𝐶 − 1 Ø 𝑐 = 0 { 𝑥 𝑛 𝑐 , 1 , 𝑥 𝑛 𝑐 , 2 , . . . , 𝑥 𝑛 𝑐 , 𝑘 } , where 𝑛 𝑐 , 1 , . . . , 𝑛 𝑐 , 𝑘 index the selected neighbors from class 𝑐 . While class-stratied sampling ensures representation of minority classes for downstream GNN training, it introduces a tradeo: to meet per- class quotas, we may include neighbors that are r elatively distant from the target sample and therefor e provide less reliable signals. Brianna Mueller and W . Nick Street Figure 1: O v erview of FedDES. Stage 1: Clients independently train heterogeneous base classiers on their lo cal data and exchange models via pe er-to-peer communication, forming a shared classier pool. Stage 2: Each client evaluates the full classier pool on its local data to obtain decision-space representations P 𝑘 and meta-labels Z 𝑘 , and then constructs a heterogeneous graph in which sample nodes (circles) are linked by decision-space similarity and classier nodes (triangles) are connected to samples base d on local competence. Stage 3: A heterogeneous GA T v2 meta-learner is trained to map sample embeddings, rened through message passing over the graph, to per-classier competence scores. Inference: A new quer y 𝑥 𝑞 is projected into the de cision space, inserted into the graph, and processe d by the trained GNN. The resulting competence scores 𝜎 ( s 𝑖 ) determine which classiers are sele cted (scores above 0.5) and their relative voting strength in the nal weighted ensemble prediction ˆ 𝑦 𝑞 . More broadly , dynamic ensemble sele ction is inher ently sensitive to noise and class overlap near decision boundaries, which can distort the local context that guides ensemble selection. W e address this by assessing the stability of each class’s local structure ar ound 𝑥 𝑗 using Cumulative Mean Distance W eighting [ 1 ] and adjusting the inuence of neighbors accordingly . Classes whose neighb ors form compact, coherent clusters receive higher aggregate weight, while scattered or distant neighborho ods are downw eighted. Formally , neighbors are ordered by increasing distance and the class stability is quantied by the average drift of the cumulative neighborhood mean from the target: ¯ 𝑑 𝑐 = 1 𝑘 𝑘 𝑟 = 1 𝝁 𝑐 , 𝑟 − x 𝑗 1 , (1) where 𝝁 𝑐 , 𝑟 is the cumulative mean of the 𝑟 closest class- 𝑐 neigh- bors. Thus, smaller values of ¯ 𝑑 𝑐 indicate 𝑥 𝑗 lies within a reliable region of class 𝑐 , while large values suggest the nearest class- 𝑐 neighbors may be unrepresentative of the broader class distribu- tion. Finally , neighborho od inuence is distributed through a hier- archical weighting scheme. Class-level inuence is rst allocated as 𝜋 𝑐 ∝ 1 / ( ¯ 𝑑 𝑐 + 𝜀 ) , and then distributed among individual neighbors within each class through softmax over negative distances, yielding nal edge weights 𝑤 𝑖 𝑗 for each neighb or 𝑥 𝑖 ∈ N ( 𝑥 𝑗 ) , which sum to one across the entire neighborhood. Thus, edge weights reect both class stability and sample-level proximity . Classier-sample edges. These edges enco de classier compe- tence within the decision-space region local to the target sample. Given the weighted neighborhood N ( 𝑥 𝑗 ) , we evaluate each classi- er 𝑓 𝑚 by computing a gain score 𝐺 ( 𝑓 𝑚 , 𝑥 𝑗 ) , which quanties its performance relative to the pool average: 𝐺 ( 𝑓 𝑚 , 𝑥 𝑗 ) = 𝑥 𝑖 ∈ N ( 𝑥 𝑗 ) 𝑤 𝑖 𝑗 ( I ( 𝑓 𝑚 ( 𝑥 𝑖 ) = 𝑦 𝑖 ) − ¯ 𝑐 𝑖 ) (2) where 𝑤 𝑖 𝑗 are the sample-sample edge weights, I ( ·) is the indicator of correctness, and ¯ 𝑐 𝑖 = 1 𝑀 Í 𝑚 ′ I ( 𝑓 𝑚 ′ ( 𝑥 𝑖 ) = 𝑦 𝑖 ) represents the mean accuracy of the pool for neighb or 𝑥 𝑖 . By prioritizing marginal con- tribution over absolute accuracy , this metric identies local experts that succeed on dicult samples where the majority fail. T o r esolve ties where classiers achiev e identical gain, we use the w eighted log-loss over N ( 𝑥 𝑗 ) as a secondary criterion, favoring higher con- dence on correct predictions. W e sele ct the top- 𝑘 classiers ( 𝑘 = 5 ) and assign edge weights by normalizing their gain scores. Sample node features. Depending on the data modality and input dimensionality , sample node features may be the raw input features or a xed embedding of them. This pr ovides a complemen- tary signal to the decision-space representation, which captures only how classiers respond to a sample and discards input-le vel structure. Classier node features. While classier–sample edges cap- ture local, sample-sp ecic performance, the classier no de attributes characterize each model’s global b ehavior . Classier features in- clude per-class recall, the standard error of per-class recall, per-class condence, overall accuracy , and balanced accuracy . FedDES: Graph-Based Dynamic Ensemble Selection for Personalized Federated Learning 3.3 Stage 3: T raining meta-learner The objective of the meta-learner is to learn a sample repr esenta- tion that captures both local data context and classier behavior . Operating on the graph constructed in Stage 2, a heterogeneous GNN aggregates information from neighboring nodes to rene sample embeddings. Through iterative message passing over sam- ple–sample and classier–sample edges, each sample node incor- porates information about nearby samples and locally competent classiers. A nal linear projection maps each embe dding to an 𝑀 - dimensional vector of logits that quantify the pr edicted competence of each classier for the given sample. Specically , for sample 𝑥 𝑖 , the meta-learner takes the heteroge- neous graph as input and outputs a vector of logits s 𝑖 = ( 𝑠 𝑖 , 1 , . . . , 𝑠 𝑖 ,𝑀 ) ∈ R 𝑀 , where 𝑠 𝑖 , 𝑚 represents a scor e quantifying the predicted com- petence of classier 𝑓 𝑚 for sample 𝑥 𝑖 . Training is supervised using the meta-label matrix Z , where each entry 𝑍 𝑖 , 𝑚 ∈ { 0 , 1 } indicates whether classier 𝑓 𝑚 correctly predicts the label of sample 𝑥 𝑖 . Spe cif- ically , training minimizes L meta = 1 𝑁 train 𝑖 ∈ D train 1 𝑀 𝑀 𝑚 = 1 ℓ BCE _ logits ( 𝑠 𝑖 , 𝑚 , 𝑍 𝑖 , 𝑚 ) ! , (3) where ℓ BCE _ logits denotes the binar y cross-entropy loss with log- its. This training objective can be viewed as a multi-label learning problem at the sample level, wher e each sample may have multi- ple positive targets corresponding to the classiers that corr ectly predict its label. Notably , the loss is dened exclusively o ver sam- ple nodes. Classier nodes are not prediction targets and thus do not contribute directly to the loss, instead providing contextual information through classier–sample edges. At inference time, we apply the sigmoid function to map the raw logits to normalized competence scores in [ 0 , 1 ] , consistent with the binary cross-entropy training objective. Classiers with competence scores exceeding 0.5 are selected for the ensemble: 𝑞 𝑖 , 𝑚 = 𝜎 ( 𝑠 𝑖 , 𝑚 ) , 𝑤 𝑖 , 𝑚 = ( 𝑞 𝑖 , 𝑚 if 𝑞 𝑖 , 𝑚 > 0 . 5 0 otherwise (4) The competence scores of selected classiers are then normalized to sum to one across the sele cted subset. In cases where all classiers have competence scor es at or below 0.5 (i.e., no classier is deemed competent), the system falls back to uniform weighting across all classiers to ensure a valid prediction. The learne d weights serve a dual role: classiers with compe- tence score exceeding 0.5 are selecte d for the ensemble, while their normalized scores determine their voting strength. The nal pre- diction for 𝑥 𝑖 is obtained by aggregating the hard predictions of the selected classiers according to their normalized weights ˜ 𝑤 𝑖 , 𝑚 : ˆ 𝑝 ( 𝑦 | 𝑥 𝑖 ) = 𝑀 𝑚 = 1 ˜ 𝑤 𝑖 , 𝑚 1 { ˆ 𝑦 𝑚,𝑖 = 𝑦 } , ˆ 𝑦 𝑖 = arg max 𝑦 ˆ 𝑝 ( 𝑦 | 𝑥 𝑖 ) . (5) This competence-weighted voting mechanism enables FedDES to dynamically determine whether , and how much, each peer client contributes knowledge for each sample. 4 Experiments Datasets. Experiments are performed on CIF AR-10 [ 15 ], a widely- used image dataset, and real-world distributed healthcare datasets from the eICU Collaborative Research Database [22]. CIF AR-10. W e simulate a federation of 20 clients using the CIF AR- 10 dataset, consisting of 60,000 images across 10 classes. T o generate heterogeneous client data distributions, we use the Extended Dirich- let (ExDir) sampling strategy [ 18 ], which extends Dirichlet-based data partitioning [ 11 ] by rst randomly assigning a subset of class labels to each client before allocating samples to each client via a Dirichlet distribution. This strategy is denoted ExDir ( 𝐶, 𝛼 ) , where 𝐶 is the numb er of classes assigned to each client and 𝛼 is the Dirichlet concentration parameter . W e vary heterogeneity along two axes: the number of classes per client 𝐶 ∈ { 3 , 5 , 7 } and the Dirichlet concentration 𝛼 ∈ { 1 , 10 } , producing six experimental settings. Smaller values of 𝐶 restrict each client to fewer classes, creating label-distribution skew , while smaller values of 𝛼 produce more uneven sample allocations within the assigned classes, cre- ating quantity skew . T ogether , these two axes span a range from mild heterogeneity ( 𝐶 = 7 , 𝛼 = 10 ) to severe heterogeneity ( 𝐶 = 3 , 𝛼 = 1 ). eICU. The eICU Collab orativ e Research Database is a multi-center critical care dataset containing de-identie d health records from over 200 hospitals. Following the preprocessing pipeline and cohort denitions from T ang et al. [ 29 ], we use their extracted cohorts for two prediction tasks: cir culatory shock and in-hospital mortality . For both tasks, we use static features (age, demographics, past me di- cal history) and time-series features from the rst hours of ICU data (vital signs, laboratory values, medications, uid intake/output) to predict whether the patient will de velop the outcome. The obser- vation window is 4 hours for shock and 24 hours for in-hospital mortality . Shock is dened as the ne ed for vasopressor therapy during the remainder of the hospital stay , while in-hospital mor- tality corresponds to hospital discharge status as expired. Clients are naturally dened by hospital. W e select the 50 hospitals with the highest positive class prevalence among those with at least 150 ICU encounters. Baselines. W e include two reference baselines: (i) Local, where each client trains its o wn model( s) independently (a single classier for CIF AR-10, a uniform ensemble of locally trained classiers for eICU), and (ii) Global Ensemble, where all classiers in the shared pool are weighted equally . W e also compare FedDES against six state-of-the-art pFL methods that support mo del heterogeneity , spanning three categories: kno wledge distillation–based (FedKD, FML), model-splitting (LG-FedA vg, FedGH), and representation- based (FedProto , FedTGP). All methods use identical data partitions and architecture assignments, and w e adopt hyperparameters re- ported in the original papers. Model Heterogeneity . W e create model heterogeneity by den- ing a po ol of 𝐾 model architectures per dataset. For CIF AR-10, we use 𝐾 = 4 convolutional architectures: a custom 3-layer CNN, MobileNetV2, ResNet-18, and ResNet-34. For eICU , we use 𝐾 = 3 se- quence modeling architectur es: a T emporal Conv olutional Netw ork (TCN), a custom 1D CNN, and an LSTM-based recurrent mo del. Baseline methods assign each client a single architecture from the pool in a repeating sequence over the 𝐾 options. Since FedDES Brianna Mueller and W . Nick Street aggregates in the output space, it is not constrained to a single architecture per client. W e leverage this e xibility on eICU, wher e each client trains all 𝐾 = 3 architectures on its local data to increase pool diversity by capturing dierent inductiv e biases o ver the same data, producing three base classiers per hospital (150 classiers across the federation). For CIF AR-10, FedDES follows the same single-architecture assignment as baselines to ensure a controlled comparison, with the shared po ol containing 20 classiers ( one per client). T o minimize communication overhead during parameter trans- mission, distillation-based methods require compact auxiliary mod- els. W e therefore select the architecture with the few est parameters from each dataset’s model group to serve as the auxiliar y model for FedKD and FML. For model-splitting methods FedGH and LG- FedA vg, we introduce heterogeneity only in the feature extractor (backbone) while ke eping the classier head homogeneous across clients, as these methods rely on a shared component for collab- oration. Since heterogeneous backbones may output embeddings with dierent dimensionalities, representation-based methods that compare or aggregate embeddings (FedProto and FedTGP) are not directly applicable . W e therefore follow FedTGP and insert an adap- tive pooling layer after each backbone to standardize the emb edding dimension across clients. General implementation details. Each client’s lo cal data is divided into training and test sets following an 80/20 split, with 25% of the training data reserved for validation. W e report stan- dard accuracy for CIF AR-10 and balanced accuracy (the unweighted mean of p er-class recall) for eICU, where substantial class imbalance causes standard accuracy to be dominated by majority-class perfor- mance and can obscure meaningful dierences between methods. All methods use a client participation ratio of 1, learning rate 0.01, and train for up to 300 communication rounds. For each client, we report test performance from the round achie ving the best valida- tion accuracy (CIF AR-10) or validation balanced accuracy (eICU). Each round consists of 1 epoch of lo cal training with batch size 32. For eICU tasks, all methods use class-weighted cross-entropy loss to account for label imbalance, with w eights inversely proportional to class frequency . Method-specic hyperparameters are set according to their origi- nal publications. Knowledge distillation baselines use the following: FML employs 𝛼 = 0 . 5 and 𝛽 = 0 . 5 , while FedKD congures its aux- iliary model with learning rate 0.01 (matching client models) and temperature parameters 𝑇 start = 𝑇 end = 0 . 95 . Representation-based methods are congured as: FedProto with 𝜆 = 0 . 1 , and FedTGP with 𝜆 = 0 . 1 , margin threshold 𝜏 = 100 , and 𝑆 = 100 server epochs. FedDES implementation details. T o utilize all local data for both base classier training and graph construction without the optimistic bias from evaluating classiers on their own training data, we employ 5-fold cross-validation to generate out-of-fold pre- dictions for graph construction. Base classiers are then retrained on the complete training set using Adam (LR = 5e-4) for up to 300 epochs with early stopping based on validation balance d accuracy (eICU) or validation accuracy (CIF AR-10). Since classiers dier in both architecture and the data distributions they wer e trained on, their condence scores may not be directly comparable. Each client therefore calibrates all received models using temperature scaling to align condence estimates across the pool, preventing miscalibrated condence scores from distorting the decision-space representation. For building the heterogeneous graphs, we use 𝑘 = 5 neighbors per class for sample-sample edges and top- 𝑘 = 3 classiers for classier-sample e dges. The GNN meta-learner uses a two-layer heterogeneous GA T v2 architecture with hidden dimension 128 and four attention heads. The network is trained for up to 300 epochs using Adam (LR = 1e-3), with dropout 0.2, batch size 32, and early stopping based on validation loss with patience 20. 5 Results Overall Performance. T able 1 presents results on CIF AR-10 across six heterogeneity settings spanning two axes: the number of classes per client ( 𝐶 ∈ { 3 , 5 , 7 } ) and the Dirichlet concentration ( 𝛼 ∈ { 1 , 10 } ). FedDES achieves the highest mean accuracy in every set- ting, ranging from 85.7% ( 𝛼 = 1 , 𝐶 = 3 ) to 60.2% ( 𝛼 = 10 , 𝐶 = 7 ). The per- formance gap over the next-best method ranges from 1.9 points at 𝛼 = 1 , 𝐶 = 3 (vs. Local at 83.8%) to 4.7 points at 𝛼 = 1 , 𝐶 = 7 (vs. Local at 63.7%). FedDES also achieves the highest win rates across all settings (80–95%), meaning it improv es over local training for the T able 1: Performance comparison on CIF AR-10 across heterogeneity levels. Win rate indicates p er centage of clients where a method outperforms the local baseline. Mean accuracy (%) ± standard deviation computed across 20 clients. 𝛼 = 1 𝛼 = 10 𝐶 = 3 𝐶 = 5 𝐶 = 7 𝐶 = 3 𝐶 = 5 𝐶 = 7 Method Acc. Win% Acc. Win% Acc. Win% Acc. Win% Acc. Win% Acc. Win% FedDES 85.7 ± 6.0 90 74.2 ± 8.9 95 68.4 ± 7.3 95 81.9 ± 6.8 80 68.3 ± 10.5 90 60.2 ± 5.1 90 Local 83.8 ± 7.0 – 70.9 ± 10.5 – 63.7 ± 9.7 – 79.3 ± 7.2 – 64.0 ± 12.8 – 54.3 ± 7.7 – Global 44.5 ± 16.4 0 46.7 ± 8.5 0 51.1 ± 5.8 10 49.1 ± 18.5 0 49.5 ± 7.4 20 57.0 ± 3.8 60 FML 80.4 ± 7.0 30 67.8 ± 11.8 25 60.0 ± 10.0 25 75.5 ± 8.2 20 61.1 ± 12.4 40 48.4 ± 7.6 15 LG-FedA vg 81.1 ± 6.5 20 68.7 ± 10.7 20 60.9 ± 9.9 10 76.4 ± 7.0 20 61.8 ± 11.4 25 49.5 ± 6.1 20 FedTGP 76.3 ± 13.0 5 65.9 ± 12.2 5 58.0 ± 12.2 10 74.8 ± 11.6 20 59.8 ± 12.4 30 50.2 ± 8.2 25 FedKD 81.0 ± 7.5 25 69.2 ± 11.2 30 61.8 ± 9.8 35 76.0 ± 7.9 30 62.7 ± 11.9 45 51.0 ± 8.6 35 FedGH 81.3 ± 7.1 10 68.3 ± 11.3 15 60.1 ± 9.5 20 76.2 ± 7.1 15 61.3 ± 11.6 30 49.1 ± 6.9 10 FedProto 69.8 ± 19.9 5 57.4 ± 18.2 5 54.3 ± 12.9 10 68.1 ± 14.1 10 57.4 ± 15.1 20 45.9 ± 7.8 10 FedDES: Graph-Based Dynamic Ensemble Selection for Personalized Federated Learning T able 2: Performance comparison on eICU prediction tasks. Win rate indicates percentage of hospitals where a method outperforms the local baseline. Mean balanced accuracy (%) ± standard deviation computed across 50 hospitals. Shock Mortality Method Mean ± Std Win (%) Mean ± Std Win (%) FedDES 65.7 ± 8.6 70 71.9 ± 7.2 86 Local 61.1 ± 7.6 - 64.4 ± 8.3 - Global 60.1 ± 7.1 40 62.8 ± 7.2 36 LG-FedA vg 62.9 ± 9.2 64 68.1 ± 8.2 74 FedTGP 57.3 ± 9.8 30 61.1 ± 8.3 44 FedKD 63.2 ± 9.2 64 70.0 ± 8.5 82 FedProto 51.9 ± 5.4 12 54.5 ± 7.3 18 FML 63.4 ± 9.3 62 66.2 ± 9.1 60 FedGH 64.4 ± 9.0 76 66.8 ± 8.4 66 vast majority of clients. In contrast, competing fe derated meth- ods achieve win rates of only 5–45%, indicating that while they may help some clients, they hurt others. The global ensemble per- forms poorly under high heterogeneity (44.5% at 𝛼 = 1 , 𝐶 = 3 ; 49.1% at 𝛼 = 10 , 𝐶 = 3 ), conrming that uniform aggregation without person- alization causes severe negative transfer when client distributions diverge substantially . The one exception is 𝛼 = 10 , 𝐶 = 7 , where the global ensemble achieves 57.0% with a 60% win rate, outperforming all federated baselines except FedDES. The two heterogeneity axes produce distinct patterns. Across both 𝛼 values, the local baseline alone outp erforms most federated methods, and at 𝛼 = 10 the local baseline outp erforms e very person- alized federated metho d e xcept FedDES across all three 𝐶 settings. This observation is consistent with the nding from FedP AE [ 21 ] that local baselines in the pFL literature may b e underestimated when default training congurations are adopted without tuning for the local setting. T able 2 reports balanced accuracy on the eICU prediction tasks. On mortality prediction, FedDES achieves 71.9% balanced accuracy with an 86% win rate, improving ov er the local baseline (64.4%) by 7.5 points and outperforming all competing methods. The next-best method is FedKD (70.0%, 82% win rate), followed by LG-Fe dA vg (68.1%, 74%). On shock prediction, FedDES achieves 65.7% balanced accuracy with a 70% win rate, improving over the local baseline (61.1%) by 4.6 points. FedDES outperforms all baselines, with FedGH (64.4%, 76% win rate) and FML (63.4%, 62%) as the next-closest meth- ods. The global ensemble achieves 60.1% on sho ck and 62.8% on mortality , underperforming FedDES by 5.6 and 9.1 points respec- tively , conrming that uniform aggregation acr oss hospitals fails to account for distributional dierences between institutions. Representation-based methods (FedProto, FedTGP) show the weakest and most variable performance, with FedPr oto achieving only 51.9% balanced accuracy on eICU sho ck and high variance across CIF AR-10 settings. This instability likely reects the chal- lenge of aligning heterogeneous backbone emb eddings through adaptive pooling, which can produce poorly separated representa- tions when architectures dier substantially . Meta-Learner Selection Behavior . T o visualize the selection behavior of the GNN meta-learner , we group test samples by their true class label and compute, for each classier , the mean sele ction score across all test samples of that class. W e then plot this average selection score against the proportion of the target class in the classier’s home client’s training data (Figure 2). Each p oint in the gure represents one (classier , target class) pair , aggregated across all clients, with local classiers (those traine d at the same client as the test samples) highlighted in red. Across all heterogeneity settings, the meta-learner assigns higher selection scor es to classiers whose home clients had more training data for the target class. The strength of this relationship varies with both heterogeneity axes. Fixing the number of classes per client, 𝛼 = 10 yields stronger correlations than 𝛼 = 1 : at 𝐶 = 3 , 𝜌 = 0 . 78 for 𝛼 = 10 versus 𝜌 = 0 . 69 for 𝛼 = 1 ; at 𝐶 = 5 , 𝜌 = 0 . 72 versus 0 . 59 ; at 𝐶 = 7 , 𝜌 = 0 . 64 versus 0 . 55 . Fixing 𝛼 , the correlation decreases as 𝐶 increases (more classes per client). Under high label skew ( 𝐶 = 3 ), class frequencies are highly skewed and the meta-learner e xploits these distributional dierences more aggressively . In settings with lower label skew ( 𝐶 = 7 ), each client trains on a broader subset of classes, compressing the range of class fr equencies across clients and narrowing the resulting dier ences in selection scores. Classiers with near-zero home support for a given class gener- ally receive near-zero average selection scores across all settings, as the meta-learner learns to exclude classiers that lack relevant training experience. Conversely , classiers trained at clients with high class prevalence ar e preferentially selected, ev en when they originate from remote clients. Local classiers (red points in Fig- ure 2) tend to app ear ab ov e the trendline, and this local preference is most pronounced under high heterogeneity . At 𝐶 = 3 , lo cal classiers are clearly elevated above non-local classiers with comparable home support in both 𝛼 settings, while at 𝐶 = 7 the distinction is less pronounced. Under high heterogeneity , each client’s training distribution is more distinctive , so locally trained classiers are especially well-matched to local test samples. Nevertheless, non- local classiers with high home support still receive substantial selection scores across all settings, conrming that the meta-learner actively leverages peer classiers based on their rele vant training experience rather than defaulting to local models. This increasing selectivity is also reected in the ensemble size statistics (T able 3). The mean number of classiers selected per pre- diction decreases from 9.73 ( 𝛼 = 10 , 𝐶 = 7 ) to 4.36 ( 𝛼 = 1 , 𝐶 = 3 ), conrm- ing that the meta-learner identies fewer experts as heterogeneity increases. The eective ensemble size (ESS), which accounts for weight concentration among selected classiers, remains in a nar- rower range (3.71–4.71), indicating that ev en when more classiers are selected under mild heterogeneity , the meta-learner concen- trates weight on a small set. The ESS-to-size ratio decreases from 0.85 ( 𝛼 = 1 , 𝐶 = 3 ) to 0.48 ( 𝛼 = 10 , 𝐶 = 7 ): under high heterogeneity , se- lected classiers contribute more e qually , while under mild hetero- geneity the ensemble is larger but weight is concentrate d on few er members. 6 Discussion The consistent gap between FedDES and competing metho ds on CIF AR-10 (T able 1) illustrates a fundamental limitation of client- level p ersonalization. Methods such as FedKD, FML, and LG-FedA vg learn a single personalized model per client that applies the same Brianna Mueller and W . Nick Street Figure 2: Meta-learner selection scores vs. home client class frequency on CIF AR-10 across six heterogeneity settings. Each point represents one (classier , target class) pair averaged across all clients. Re d p oints indicate local classiers; gray points indicate non-local classiers. Dashed line shows linear trend. 𝜌 denotes Spearman correlation. T op row: 𝛼 = 1 ; bottom row: 𝛼 = 10 . Columns vary 𝐶 ∈ { 3 , 5 , 7 } . learned parameters to all test samples. When a client’s data spans multiple classes with varying representation, no single model can optimally handle all samples, a shortcoming that FedDES addresses by assembling a dierent ensemble for each test sample . The con- sistently high win rates across settings suggest that this per-sample adaptability provides broad benets across the federation rather than improvements concentrated on a few clients. Notably , the local baseline alone outperformed most federated methods on CIF AR-10. Fe dDES’s ensemble-base d design aords exibility not only in model architecture but also in training proce- dure. Because aggregation occurs in the output space , each client is T able 3: Fe dDES ensemble characteristics across heterogene- ity levels on CIF AR-10. Mean ensemble size is the average number of classiers selecte d (competence score > 0 . 5 ). Eec- tive ensemble size (ESS) measures the number of classiers meaningfully contributing to each prediction after account- ing for weight concentration. ESS/Size ratio indicates how evenly weight is distributed among selected classiers. 𝛼 = 1 𝛼 = 10 𝐶 = 3 𝐶 = 5 𝐶 = 7 𝐶 = 3 𝐶 = 5 𝐶 = 7 Mean Ensemble Size 4.36 5.44 7.07 4.96 7.58 9.73 Mean ESS 3.71 3.73 4.12 3.96 4.38 4.71 ESS / Ensemble Size 0.85 0.68 0.58 0.80 0.58 0.48 free to select the optimizer and training conguration best suited to its local setting. In our experiments, this meant training base classi- ers with Adam and early stopping, which pr oduced surprisingly strong local models. This raises the possibility that local baselines in the pFL literature may be underestimated when default training congurations are adopted without tuning for the local setting. The eICU results (T able 2) demonstrate that FedDES’s instance- level selection is eective beyond synthetic benchmarks. The im- provements over local training on both mortality and shock pre- diction are notable given that heterogeneity across hospitals arises naturally from dierences in patient p opulations, clinical proto- cols, and documentation practices rather than being synthetically induced. Beyond raw performance, FedDES’s selection mechanism of- fers insight into how collaboration emerges across clients. The strong correlation between selection scores and home client class frequency (Figure 2) supports our hypothesis that heterogeneity produces classiers with distinct areas of expertise, and a learned selection mechanism can route test samples to classiers with rele- vant training experience rather than defaulting to local models or treating all peers uniformly . The decreasing correlation strength as heterogeneity decreases highlights when federated collab oration is most valuable. Under high heterogeneity , clients produce highly specialize d classiers with concentrated expertise in a small numb er of classes, meaning that for any given target class, fe wer classiers in the global pool FedDES: Graph-Based Dynamic Ensemble Selection for Personalized Federated Learning possess relevant kno wledge and selective ensemble construction becomes critical. Conversely , under low heterogeneity , more classi- ers develop general knowledge, reducing the gap between strong and weak classiers for a given target class, which weakens the correlation. This suggests that FedDES is particularly well-suited to settings where data heterogeneity is a primary challenge, which is also where conventional federated methods struggle most. The mild selection preference for local classiers is also notewor- thy . This preference is most pronounced under high heterogeneity ( 𝐶 = 3 in both 𝛼 settings) where distribution-specic knowledge is most valuable. A lo cal classier that has se en even a modest number of examples from the same distribution oers an advantage that its class frequency alone does not capture. 7 Conclusion W e introduced FedDES, a p ersonalized federated learning frame- work that achie ves instance-lev el personalization through dynamic ensemble selection. By constructing heterogeneous graphs that model interactions between data samples and candidate classiers, and training a GNN meta-learner to pr edict per-sample classier competence, FedDES moves beyond the client-level p ersonaliza- tion oered by existing methods. The framework operates in a fully decentralized setting and supports complete model hetero- geneity by aggregating in the output space. On CIF AR-10, FedDES consistently outperforms all baselines across heterogeneity levels with 80–95% win rates, demonstrating that instance-level selection provides broad benets across the federation. On r eal-world eICU healthcare data, FedDES achiev es competitive performance on both mortality and shock prediction, improving over local training on both tasks. Our results suggest that routing samples to classiers with relevant training experience, rather than applying uniform client-level weights, is a particularly eective strategy when client data distributions are highly heterogeneous. References [1] Hassan I Abdalla, Ali A Amer , and Mohammad Nassef. 2025. New fuzzy K- nearest neighbor algorithms for classication performance impr ovement. Future Generation Computer Systems (2025), 108139. [2] Alceu S Britto Jr , Robert Sabourin, and Luiz ES Oliveira. 2014. Dynamic selection of classiers—a comprehensive r eview . Pattern recognition 47, 11 (2014), 3665– 3680. [3] Shaked Brody, Uri Alon, and Eran Yahav . 2021. How attentiv e are graph attention networks? arXiv preprint arXiv:2105.14491 (2021). [4] Wu Chen, Peilin Liu, Yida Bai, Jiamou Liu, Nianyu Li, Enhong Mu, and Mingyue Zhang. 2025. De centralized Federated Learning with Dynamic Neighbor Selec- tion and Condence-Based Aggregation. A vailable at SSRN 5560620 (2025). [5] Rafael MO Cruz, Robert Sabourin, and George DC Cavalcanti. 2018. Dynamic classier selection: Recent advances and perspectives. Information Fusion 41 (2018), 195–216. [6] Rafael MO Cruz, Robert Sab ourin, George DC Cavalcanti, and T sang Ing Ren. 2015. MET A-DES: A dynamic ensemble selection framework using meta-learning. Pattern recognition 48, 5 (2015), 1925–1935. [7] Y uyang Deng, Mohammad Mahdi Kamani, and Mehrdad Mahdavi. 2020. Adaptive personalized federated learning. arXiv preprint arXiv:2003.13461 (2020). [8] Luca Didaci and Giorgio Giacinto. 2004. Dynamic classier selection by adaptive k-nearest-neighbourhood rule. In International workshop on multiple classier systems . Springer , 174–183. [9] Alireza Fallah, Aryan Mokhtari, and Asuman Ozdaglar . 2020. Personalized federated learning with theoretical guarantees: A mo del-agnostic meta-learning approach. Advances in Neural Information Processing Systems 33 (2020), 3557– 3568. [10] Giorgio Giacinto and Fabio Roli. 2001. Dynamic classier sele ction based on multiple classier behaviour . Pattern Recognition 34, 9 (2001), 1879–1881. [11] Tzu-Ming Harry Hsu, Hang Qi, and Matthew Brown. 2019. Measuring the eects of non-identical data distribution for federated visual classication. arXiv Preprint arXiv:1909.06335 (2019). [12] Y utao Huang, Lingyang Chu, Zirui Zhou, Lanjun W ang, Jiangchuan Liu, Jian Pei, and Y ong Zhang. 2021. Personalized cross-silo federated learning on non-IID data. In Proceedings of the AAAI Conference on Articial Intelligence , V ol. 35. 7865–7873. [13] Y ea S Huang and Ching Y Suen. 1993. The behavior-knowledge space method for combination of multiple classiers. In IEEE computer society conference on computer vision and pattern recognition . Institute of Electrical Engineers Inc (IEEE), 347–347. [14] Albert HR Ko, Robert Sabourin, and Alceu Souza Britto Jr . 2008. From dynamic classier selection to dynamic ensemble selection. Pattern recognition 41, 5 (2008), 1718–1731. [15] Alex Krizhe vsky , Georey Hinton, et al . 2009. Learning multiple layers of features from tiny images . Technical Rep ort. Univ ersity of T oronto. [16] Tian Li, Shengyuan Hu, Ahmad Beirami, and Virginia Smith. 2021. Ditto: Fair and robust federated learning through personalization. In International Conference on Machine Learning . 6357–6368. [17] Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ame et Talwalkar , and Virginia Smith. 2020. Federate d optimization in heterogeneous networks. Proceedings of Machine Learning and Systems 2 (2020), 429–450. [18] Yipeng Li and Xinchen Lyu. 2023. Convergence analysis of sequential federated learning on heterogeneous data. Advances in Neural Information Processing Systems 36 (2023), 56700–56755. [19] Paul Pu Liang, Terrance Liu, Liu Ziyin, Nicholas B Allen, Randy P Auerbach, David Brent, Ruslan Salakhutdinov , and Louis-Philippe Morency . 2020. Think locally , act globally: Federate d learning with local and global representations. arXiv preprint arXiv:2001.01523 (2020). [20] I Lin, Osman Y agan, Carlee Joe-W ong, et al . 2024. Fedspd: A soft-clustering approach for personalized decentralized federate d learning. arXiv preprint arXiv:2410.18862 (2024). [21] Brianna Mueller , W Nick Street, Stephen Baek, Qihang Lin, Jingyi Yang, and Y ankun Huang. 2024. FedPAE: Peer- Adaptive Ensemble Learning for Asynchr o- nous and Model-Heterogeneous Federated Learning. In 2024 IEEE International Conference on Big Data (BigData) . IEEE, 7961–7970. [22] T om J Pollard, Alistair EW Johnson, Jesse D Raa, Leo A Celi, Roger G Mark, and Omar Badawi. 2018. The eICU Collaborative Research Database, a freely available multi-center database for critical care research. Scientic data 5, 1 (2018), 1–13. [23] Felix Sattler , Klaus-Robert Müller, and W ojciech Samek. 2020. Clustered feder- ated learning: Model-agnostic distributed multitask optimization under privacy constraints. IEEE T ransactions on Neural Networks and Learning Systems 32, 8 (2020), 3710–3722. [24] T ao Shen, Jie Zhang, Xinkang Jia, Fengda Zhang, Gang Huang, Pan Zhou, Kun Kuang, Fei Wu, and Chao W u. 2020. Federated mutual learning. arXiv preprint arXiv:2006.16765 (2020). [25] Rodrigo GF Soares, Alixandre Santana, Anne MP Canuto, and Marcílio Car- los Pereira de Souto. 2006. Using accuracy and diversity to select classiers to build ensembles. In The 2006 IEEE international joint conference on neural network proceedings . IEEE, 1310–1316. [26] Pedro Miguel Sánchez Sánchez, Enrique T omás Martínez Beltrán, Chao Feng, Gérôme Bovet, Gregorio Martínez Pérez, and Alberto Huertas Celdrán. 2025. S- V OTE: Similarity-based V oting for Client Selection in Decentralized Fe derated Learning. In International Joint Conference on Neural Networks . International Neural Network Society , 1–9. [27] Canh T Dinh, Nguyen Tran, and Josh Nguyen. 2020. Personalized federated learning with Moreau envelopes. Advances in Neural Information Processing Systems 33 (2020), 21394–21405. [28] Y ue Tan, Guodong Long, Lu Liu, Tianyi Zhou, Qinghua Lu, Jing Jiang, and Chengqi Zhang. 2022. Fedproto: Federated prototype learning across hetero- geneous clients. In Proceedings of the AAAI conference on articial intelligence , V ol. 36. 8432–8440. [29] Shengpu T ang, Parmida Davarmanesh, Y anmeng Song, Danai Koutra, Michael W Sjoding, and Jenna Wiens. 2020. Demo cratizing EHR analyses with FIDDLE: a exible data-driven preprocessing pipeline for structured clinical data. Journal of the A merican Medical Informatics Association 27, 12 (2020), 1921–1934. [30] Petar V eličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Y oshua Bengio. 2017. Graph attention networks. arXiv preprint arXiv:1710.10903 (2017). [31] Lin W ang, Yang Chen, Y ongxin Guo, and Xiaoying T ang. 2024. Smart sampling: Helping from friendly neighbors for decentralized federated learning. arXiv preprint arXiv:2407.04460 (2024). [32] Kevin W oods, W . Philip Kegelmeyer , and Kevin Bo wyer . 1997. Combination of multiple classiers using local accuracy estimates. IEEE transactions on pattern analysis and machine intelligence 19, 4 (1997), 405–410. [33] Chuhan Wu, Fangzhao W u, Lingjuan Lyu, Y ongfeng Huang, and Xing Xie. 2022. Communication-ecient federated learning via knowledge distillation. Nature Brianna Mueller and W . Nick Street communications 13, 1 (2022), 2032. [34] Şenay Y aşar Sağlam and W Nick Street. 2018. Distant diversity in dynamic class prediction. Annals of Operations Research 263, 1 (2018), 5–19. [35] Liping Yi, Gang W ang, Xiaoguang Liu, Zhuan Shi, and Han Yu. 2023. Fe dGH: Heterogeneous federated learning with generalized global header . In Proceedings of the 31st ACM International Conference on Multimedia . 8686–8696. [36] Jianqing Zhang, Y ang Liu, Y ang Hua, and Jian Cao. 2024. Fedtgp: T rainable global prototypes with adaptive-margin-enhanced contrastive learning for data and model heterogeneity in federated learning. In Proceedings of the AAAI conference on articial intelligence , V ol. 38. 16768–16776. [37] Michael Zhang, Karan Sapra, Sanja Fidler, Serena Y eung, and Jose M Alvarez. 2020. Personalize d federate d learning with rst order model optimization. arXiv preprint arXiv:2012.08565 (2020).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment