Varuna: Enabling Failure-Type Aware RDMA Failover
RDMA link failures can render connections temporarily unavailable, causing both performance degradation and significant recovery overhead. To tolerate such failures, production datacenters assign each primary link with a standby link and, upon failur…
Authors: Xiaoyang Wang, Yongkun Li, Lulu Yao
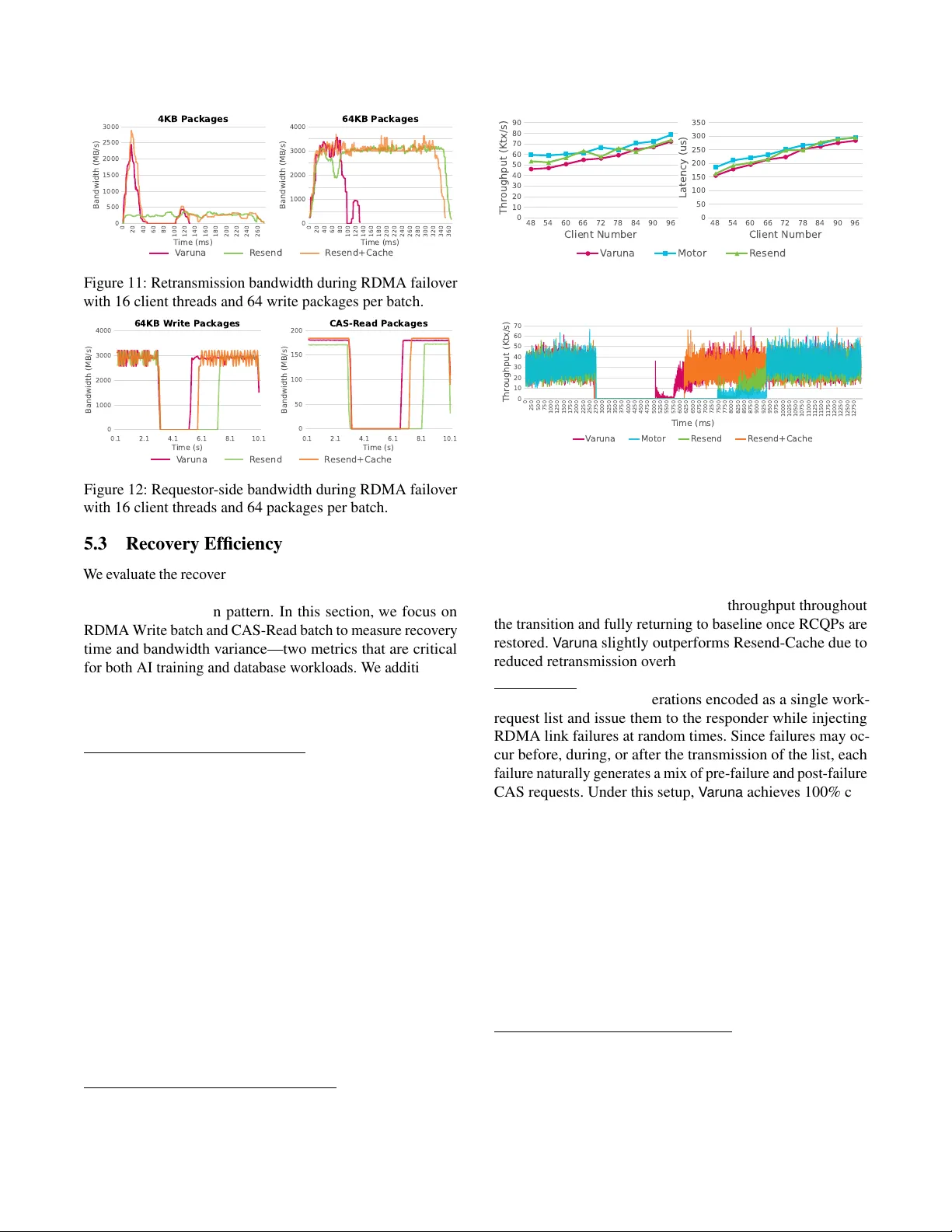
V aruna: Enabling F ailur e-T ype A ware RDMA F ailo ver Xiaoyang W ang 1 , Y ongkun Li 1 ∗ , Lulu Y ao 2 , Guoli W ei 1 , Longcheng Y ang 1 , Y inlong Xu 1 W eiqing Kong 3 , W eiguang W ang 3 , Peng Dong 3 , Bingyang Liu 3 1 University of Science and T echnolo gy of China 2 Ningbo University 3 Huawei Abstract RDMA link failures can render connections temporarily unav ailable, causing both performance degradation and signif- icant recovery o verhead. T o tolerate such failures, production datacenters assign each primary link with a standby link and, upon f ailure, uniformly retransmit all in-flight RDMA request ov er the backup path. Ho wev er , we observe that such blan- ket retransmission is unnecessary . In-flight requests can be split into pre-failure and post-failure categories depending on whether the responder has already e xecuted. Retransmit- ting post-failure requests is not only redundant—consuming bandwidth—but also incorrect for non-idempotent operations, where duplicate ex ecution can violate application semantics. W e present V ar una , a failure-type-a ware RDMA recov ery mechanism that enables correct retransmission and µs-le vel failov er . V aruna piggybacks a lightweight completion log on ev ery RDMA operation; after a link failure, this log deter- ministically reveals which in-flight requests were executed (post-failure) and which were lost (pre-failure). V ar una then retransmits only the pre-failure subset and fetches/recovers the return values for post-failure requests. Evaluated using synthetic microbenchmarks and end-to-end RDMA TPC-C transactions, V ar una incurs only 0.6–10% stea dy-state latenc y ov erhead in realistic applications, eliminates 65% of reco very retransmission time, preserves transactional consistency , and introduces zero connectivity reb uild ov erhead and negligible memory ov erhead during RDMA failov er . 1 Introduction The growing prev alence of big data and large-scale AI models has driven a critical need for high-throughput, low-latency networks in data centers and distributed clusters to enable ef- ficient data communication [ 19 , 25 ]. RDMA ( R emote D irect M emory A ccess) [ 32 ], with its high bandwidth, ultra-lo w la- tency , and minimal CPU overhead, has thus become essential infrastructure for building modern distributed systems such as key-v alue stores [ 35 , 41 ] and AI applications [ 16 , 30 , 31 ]. By employing mechanisms including CPU bypass, k ernel bypass, zero-copy operations, and direct remote memory access, the latest NICs can deliver bandwidths of up to 800 Gbps and nanosecond-scale latency [ 28 ]. Despite these advantages, RDMA deployments increas- ingly suf fer from single-point RDMA failures—including 1 Y ongkun Li is the corresponding author . link failures and link flappings—as application and cluster scales continue to gro w . Link flapping, in particular , has be- come common: when a link flaps, it repeatedly goes down and typically recov ers only after sev eral seconds [ 12 , 16 , 30 ]. Operational reports highlight the severity of the problem. For example, Alibaba observes 5,000-60,000 link flaps per day in a cluster with 15,000 GPUs, while the monthly link failure rate reaches 0.057%. In another 3,000-GPU cluster , a single link failure can incur losses of up to 30,000 dollars [ 30 ]. As a result, RDMA failures increasingly de grade applica- tion performance at scale [ 12 , 16 , 20 – 23 , 30 , 31 ]. For transac- tional services such as ke y-value stores, RDMA f ailures can significantly reduce throughput when certain nodes become temporarily unav ailable, and may even lead to data inconsis- tency [ 10 , 41 ]. For highly parallel tasks like AI training, a single RDMA failure may cause an entire job to abort. T o recov er from RDMA network errors, applications typically rely on software-lev el strategies such as checkpointing, appli- cation migration, or log replay . Howe ver , these approaches are costly—often taking from seconds to hours—and they fundamentally cannot address the temporary unav ailability of RDMA-attached resources, leading to extended do wntime and resource underutilization [ 20 , 30 , 37 ]. T o address RDMA failures, datacenters deploy hardware- le vel redundancy—such as multiple netw ork ports [ 30 ], NICs [ 20 , 31 , 42 ], and switches [ 30 ]—to pro vide alternativ e trans- mission links. These backup RDMA paths can handle both persistent link failures and transient link flapping, thereby reducing the ov erall effect of RDMA failure. In practice, whether the failure is a hard link outage or a brief flap, the common recovery strategy is to switch traffic to a standby link and retransmit the in-flight RDMA requests. Ho wev er , link-switcho ver–based retransmission is far from a silver b ullet. A closer examination of RDMA link f ailures rev eals that not all failed requests actually require retransmis- sion. W e find that in-flight requests naturally fall into two categories depending on whether the responder has already ex ecuted them: pr e-failur e requests, which were lost before reaching the responder and must be retransmitted, and post- failur e requests, whose responses were lost after the responder completed the operation. Blindly retransmitting post-failure requests is problematic for two reasons. First, it wastes external bandwidth by redun- dantly resending data that has already been applied at the remote end. More critically , it jeopardizes data correctness for non-idempotent operations. An in-flight non-idempotent 1 verb (e.g., Write, Compare-and-Sw ap, Fetch-and-Add) may hav e completed on the responder e ven though its acknowledg- ment was lost. Retransmitting such an operation to the backup NIC re-e xecutes it and corrupts remote state. Our experiments show that under high-bandwidth conditions, blanket retrans- mission can increase end-to-end transmission time by approx- imately 182.1%, and retransmissions of post-failure requests can cause up to 83.9% of transactional inconsistencies. Furthermore, multi-link failover suffers from a fundamental performance–space trade-off. Re-establishing communication contexts (e.g., Reliable Connection Queue P airs or RCQPs) for the backup link incurs substantial computation and multi- second stalls, whereas pre-allocating these contexts for f ast failov er doubles QP memory consumption in practice. Both options impose significant ov erheads on modern deployments. W e propose V aruna , a failure-type–aware RDMA recov ery mechanism that ensures correct retransmission and low-cost, fast failover . V ar una piggybacks a lightweight completion log on ev ery RDMA operation; upon a link failure, this log deterministically identifies which in-flight requests were exe- cuted (post-failure) and which were lost (pre-failure). V ar una retransmits only the pre-failure subset and retrieves the re- turn v alues of post-failure requests to avoid redundant or incorrect re-ex ecution. T o minimize failover latenc y , V ar una instantiates Dynamic Connection Queue Pairs (DCQPs) on standby links and introduces a high-performance, application- transparent RCQP–DCQP co-working link-switch framework that integrates lightweight failure coherenc y and recovery . Specifically , the design of V aruna is as follo ws: 1) Log-based Fail Recognition. T o distinguish between different types of failures, V ar una maintains logs on both the requester and the responser sides. In particular , for each non - idempotent operation, the requester writes to its local log and simultaneously appends a compact completion record using an inline one - sided RDMA write to a small log entry on the remote peer . The completion state is recorded indepen- dently of RDMA request acknowledgments, thus V aruna can consult these logs after a failov er to determine exactly which requests ex ecuted and which must be retransmitted. 2) Extended Status in Post Failur e. T o guarantee the data correctness of post failure, V aruna carries a unique per - operation identifier (UID) and the operation’ s result is recorded alongside that UID for each request. V aruna uses UIDs to deterministically detect whether a given atomic oper - ation completed during reco very and to reco ver its outcome without ambiguity . 3) Lightweight F ast reco very . V ar una maintains a small, configurable pool of lightweight DCQPs on each NIC that can be shared across endpoints on the same host to differ - ent targets. When a link fails, traffic is redirected to DC- QPs on a standby link so communication can resume within milliseconds. All RCQPs are rebuilt asynchronously and swapped in later, avoiding the memory blo wup associated with pre - caching RCQPs on ev ery link to enable lightweight fast recov ery . W e ev aluate V aruna on multi - NIC servers using represen- tativ e microbenchmarks and end - to - end RDMA transactions with TPC-C workloads. V aruna incurs 0.6%-10% steady-state latency overhead, eliminates 65% of retransmission traffic, preserves consistency transactional with zero connectivity rebuild o verhead and ne gligible memory overhead. The rest of the paper is organized as follo ws. W e first ex- amine the limitations of existing RDMA failo ver mechanisms (Sec. 2 ), then describe the design of V aruna and implementa- tion (Secs. 3 , 4 ), and e valuate its reco very performance using benchmarks and end-to-end applications (Sec. 5 ). W e discuss limitations and potential extensions (Sec. 6 ), revie w related work (Sec. 7 ), and conclude (Sec. 8 ). The implementation of V aruna is av ailable at GitHub 1 . 2 Background and Moti vation 2.1 RDMA with F ailure Effectiveness of RDMA. RDMA has become the de facto communication primitive for high - performance datacenter services. By exposing RDMA v erbs and Queue Pairs (QPs), it supports one - sided operations (READ, WRITE, and atomic operations) as well as two - sided send/recei ve semantics that bypass the kernel and avoid extra data copies. The result is microsecond - lev el latencies, low CPU utilization, and near line - rate throughput—properties that make RDMA central to systems such as distrib uted key - value stores [ 35 ], remote memory/disaggregation platforms [ 1 , 9 , 34 ], and large - scale AI training [ 30 ] and serving [ 31 ]. RDMA failure. As application scales continuous gro w , an increasing number of hosts are connected with RDMA to ex ecute distributed tasks, which in turn raises the risk of single - point RDMA failures [ 12 , 16 , 20 – 23 , 30 , 31 ]. The single- point RDMA failures primarily include the following three categories: link failure, link flapping, and NIC failure. (i) Link failure refers to the physical link of an RDMA network card re- maining persistently and stably in the "DOWN" state, unable to establish a physical connection. (ii) Link flapping refers to the frequent, intermittent switching of the physical link (e.g., Ethernet or InfiniBand port) of an RDMA between the "UP" (connected) and "DO WN" (disconnected) states, such as several times per second or per minute. (iii) NIC failure refers to the RDMA network card itself exhibiting functional abnormalities or a complete failure, which extends beyond the scope of a single port. Impact of RDMA failure. In pursuit of extreme perfor- mance, RDMA sacrifices the resilience and buf fering layers of the traditional network stack, shifting the complexity of network reliability from software to hardware and physical infrastructure. Consequently , the cost and impact of RDMA 1 https://github .com/Plasticinew/V aruna 2 failures far e xceed those of traditional TCP/IP networks. For transactional applications (such as key-v alue stores), RDMA failures typically se verely degrade their performance, lead to service unav ailability , and may even compromise data con- sistency . Like Motor and uKharon [ 10 , 41 ], when network failures occur , they assume that RDMA failures are detected and resolved by data center administrators. According to the CAP theorem [ 4 , 7 ], either av ailability or consistency cannot be fully guaranteed. For highly parallel tasks, such as high performance computing and AI training/inference, RDMA failures can range from causing performance degradation to rendering training unav ailable. For example, in Alibaba clusters, 5,000 to 60,000 occurrences of link flapping happen daily , resulting in temporary performance degradation [ 30 ]. 2.2 Recovery T echniques of RDMA failure Recovery with A pplication A ware. Current distributed ap- plications typically employ fault recovery and fault toler- ance to address network failures. F ault r ecovery mechanisms for applications often utilize techniques such as checkpoint- ing [ 6 , 14 , 27 , 37 , 39 ] or logging [ 24 , 29 , 38 ] to restore failed ap- plications and minimize overhead. Howe ver , these approaches not only introduce additional storage overhead b ut also incur computational costs and latency due to log replay or check- point recov ery , thereby increasing costs [ 36 , 40 ]. F ault tolerance in applications primarily aims to prevent the failure of a single worker—often caused by network is- sues—from rendering the entire application unav ailable. It’ s typically achieved by replacing the faulty node with a new one [ 5 , 15 , 44 ]. For instance, in distrib uted key-v alue stor- age systems, when the primary node responsible for write operations becomes unav ailable, the system must undergo a multi-step process: leader election, link restoration, log replay , and resumption of new write operations. This significantly de- grades both the av ailability of the service and the performance of the application. While implementing fault recovery and fault tolerance mechanisms at the application layer mitigate the a vailability impact caused by RDMA failures, it inevitably incurs signifi- cant performance overhead, making it dif ficult for the system to meet predefined service lev el objects (SLOs) requirements. Recovery with RDMA Link-switcho ver . T o better address RDMA failures, modern data centers widely adopt a multi- path redundant, high-av ailability network architecture. By deploying multiple physical links between serv ers and config- uring them to serve as mutual backups, rapid link-switchover can be achieved in the event of link or switch failures [ 20 ]. The link-switchov er strategy typically relies on servers equipped with multiple network ports, multiple NICs, or multiple switches. Currently , such RDMA reco very design based on link-layer redundancy and fast rerouting has become an in- frastructure standard for data center networks [ 2 , 8 , 11 , 13 , 30 ]. In practice, regardless of whether a failure is a hard link Requestor Responder Send Execute Completion Pre-Failure Post-Failure × × Figure 1: T ransmission Stages and Failure T ypes: If a net- work failure occurs before ex ecution, the entire request is considered un-ex ecuted (pre-failure). Otherwise, the request ex ecution is completed at the responder , but the A CK may be lost (post-failure), and no retransmission is required. drop or a brief disruption, the prev ailing recovery strategy is to shift traffic onto a standby path (or backup path) and retransmit all in-flight RDMA requests. Throughout this pa- per , we use backup link as an umbrella term encompassing a variety of redundancy architectures, including multi-port bonding, multi-NIC configurations (within a single node or pooled across nodes via CXL like Oasis [ 42 ] discussed), and multi-plane RDMA switch fabrics. The link-switch and retransmission–based RDMA failover framew ork—ex emplified by LubeRDMA [ 20 ] and Moon- cake T ransfer Engine [ 31 ]—operates at the RDMA net- work–library layer , between the application and the NIC hard- ware. This placement allows the framework to maintain a global vie w of multiple links and to support a wide range of applications. Upon a link failure, the frame work consults its local list of in-flight RDMA requests and uniformly retrans- mits all of them to the responder . 2.3 Link-switchover -based Retransmission This subsection aims to conduct an in-depth analysis of re- transmission mechanisms based on link switchover . Exist- ing strategies typically adopt an indiscriminate and blind re- transmission pattern, lacking precise aw areness of the spe- cific transmission stage in which a failure occurs. T o address this, we systematically analyze the actual transmission stages where retransmission operations take effect and, based on this, redefine a more targeted design space for retransmission. As shown in Fig. 1 , an RDMA request proceeds through a simple pipeline according to RDMA specifications. (i) The requester generates packets according to its work request and transmits them to the responder . (ii) After recei ving and verify- ing the complete packet sequence, the responder executes the RDMA operation. (iii) The responder returns an acknowledg- ment (ACK) once the operation finishes, signaling completion to the requester . A critical point in this pipeline is the e xecution commit at the responder . Execution is assumed atomic—once started, it cannot be partially applied. Therefore, from the requestor’ s perspecti ve, an RDMA request can be di vided into two stages: i) Send Stage: packets are in flight and the responder has not yet executed the request. ii) Completion Stage: the respon- der has executed the request and is sending the ACK back. 3 Requestor Responder QP 1 Recieved PSN history (1-k) QP 2 Recieved PSN history (empty) QP 1 Work Requests QP 2 Work Requests Link 1 PSN 1-n Link 2 Retransmit PSN 1-n Retransmission at the backup QP In-consistency PSN history Redundant Execution! Figure 2: Retransmission Flow: When retransmitting using a backup link with a backup QP , the standard RDMA re- transmission detection mechanism is bypassed. As a result, previously transmitted requests may be applied ag ain at the receiv er, leading to redundant e xecution. 8 16 24 32 40 48 56 64 Batch number 0.0 0.2 0.4 0.6 0.8 1.0 P ost-F ailur e R atio 64B- W rite 4KB- W rite 64KB- W rite CAS (a) Post-Failure Ratio. 0 1000 2000 3000 4000 0 50 100 150 200 250 300 350 Bandwidth (MB/s) Time (ms) Pre-Failure Resend Uniform Resend 0 1 0 0 0 2 0 0 0 3 0 0 0 4 0 0 0 0 2 0 4 0 6 0 8 0 1 0 0 1 2 0 1 4 0 1 6 0 1 8 0 2 0 0 2 2 0 2 4 0 2 6 0 2 8 0 3 0 0 3 2 0 3 4 0 B a n d w i d t h ( M B / s ) T i m e ( m s ) 6 4 B - P a c k a g e 4 K B - P a c k a g e 6 4 K B - P a c k a g e (b) Uniform Resend Overhead. Figure 3: Post-Failure in RDMA: (a) Post-failure occurrences are unpredictable across different w orkloads. (b) Identifying post-failure requests reduces unnecessary resend ov erhead. If an RDMA failure occurs during the Send Stage, the re- quest has not been executed; we classify this as pr e-failur e . If the failure occurs after the responder has fully received and executed the request—whether before or during the A CK transmission—the requester will still observ e the request as incomplete, but the operation has already tak en effect at the responder . W e classify this scenario as post-failure . In summary , from the requestor’ s viewpoint, both cases look identical—no A CK returned. Howe ver , the responder’ s ex ecution state distinguishes non-executed (pre-f ailure) from already executed (post-failure). Misclassifying post-failure requests leads to duplicate ex ecution on retransmission. 2.4 Limitations with Retransmission In general, RDMA ’ s history packet sequence numbers (PSNs) record and ACK-b uffer design can suppress duplicate ex e- cution within the same QP by re- emitting cached A CKs for repeated PSNs. Howe ver , if the recovery mechanism focuses on a more general scenario where the original QP may be unusable after a failure and the backup link may reside on another port or e ven another NIC with a fresh new QP . In such cases, the built-in RDMA retransmission mechanism is insuf ficient, as illustrated in Fig. 2 . In particular , blind retrans- mission strategies has se veral limitations: 1) Significant redundant r etransmission overhead. Blind retransmission resend e very in-flight request, ev en though only the pre-failure subset actually requires retransmission. This leads to unnecessary bandwidth consumption and ex- tended recov ery latency . T o quantify the necessity of distin- guishing pre- and post-failure requests, we ev aluate RDMA one-sided operations using 16 client threads against a sin- gle server , covering a range of payload sizes—from an 8 B Compare-and-Swap (CAS), to a 64 B small write, to a 4 KB write, to a 64 KB lar ge write. W e vary the send-batch size (i.e., the number of packets aggregated before generating one com- pletion) and inject failures by manually bringing the RDMA NIC port down. As shown in Fig. 3 (a), across dif ferent operations and batch sizes, a substantial fraction (up to 83.9%) of RDMA re- quests become post-failure—i.e., they ha ve already ex ecuted at the responder when the failure occurs. Moreover , in a high- throughput setting where 16 clients continuously transfer 64 KB objects in batches of 64 (4 MB per request), uniform retransmission results in a 2.8× longer failo ver than retrans- mitting only the pre-failure subset (Fig. 3 (b)). This redundant traffic directly inflates f ailov er latency . 2) Duplicate execution and semantic violations. Blindly resending post-failure requests causes the responder to ex- ecute them twice. This jeopardizes applications relying on one-sided semantics. For example, consider a database client updating a value from A → B using an RDMA write, followed by another client modifying the v alue from B → C. If the first client experiences a post-f ailure and blindly retransmits, the stale write B may overwrite the correct value C, violating transactional correctness. 2.5 F ailure-type A ware Retransmission T o be practical at datacenter scale, a failure-type–aw are RDMA failov er mechanism is needed to address both the cor- rectness and efficienc y shortcomings of blind retransmission. Achieving this goal requires ov ercoming three key challenges: C1. Corr ectly recognizing completion without hard- ware changes. In RDMA, the canonical signal that an opera- tion has completed is an A CK from the responder . Howe ver , commodity NICs do not expose historical A CK state to soft- ware. Thus the requester must maintain additional comple- tion metadata in software (or piggybacked on requests) that faithfully reflects the responder’ s commit point — without modifying hardware, while keeping the metadata’ s runtime and memory ov erheads minimal and ensuring metadata con- sistency with actual e xecution. C2. Reconstructing post-failure return values. Some post-failure requests (those already executed by the respon- der) have no A CK visible to the requester , yet their return values are necessary for correctness—for example, a success- ful CAS must return the v alue that was present at the instant of the atomic operation. Reconstructing those return v alues 4 Requestor Responder Applications RDMA Programming Interface Open Device Create QP/CQ Post Send NIC 1 NIC n NIC 2 ... vQP Link Topology RCQP DCQPs Backup DCQPs Multiple RDMA NICs Read Request List Work Request Applications RDMA Interface Open Device Create QP/CQ NIC 1 NIC n ... vQP RCQP DCQPs Backup DCQPs Multiple RDMA NICs Request 1 ... Request 3 Completion Log Request 1 ... Request 3 Async. Worker Write Atomics Log-Write or Extended Status Figure 4: V aruna Overvie w: Completion logs and extended status provide durable evidence of RDMA failures, and vQPs backed by lightweight DCQPs enable immediate failo ver . is harder than tracking simple completion: CAS is atomic, so ordinary reads before or after the CAS cannot re veal the value at the CAS ex ecution point. The requester therefore needs a lightweight, externally visible mechanism to retrieve the exact post-failure result of atomic/non-idempotent operations. C3. F ast, resour ce-efficient failover (time–space trade- offs). Failo ver requires mo ving outstanding traffic to a backup path. Existing approaches either pre-allocate RCQPs on standby NICs (sacrificing memory and initialization cost) or create RCQPs on demand (incurring ms-scale stalls). Lu- beRDMA [ 20 ] reserv es a pool of pre-allocated RCQPs across all av ailable links to ensure fast switcho ver , whereas Moon- cake [ 31 ] restricts the number of active RCQPs and creates new RCQPs on demand when a link switch occurs. Both ap- proaches, howe ver , either incur substantial memory overhead or suffer from increased f ailov er latency . 3 V aruna Design V aruna is a runtime RDMA f ailov er framew ork designed to solve three challenges from Sec. 2 . In this section we will gi ve a architecture ov ervie w and detailed explanation of three key mechanisms that together solv e these challenges: Com- pact Completion Logging for failure type identifying (C1), Extended Status for deterministic recovery of post-failures (C2), and DCQP Pools for immediate failov er (C3). 3.1 Architectur e V aruna is implemented as an RDMA netw ork programming library that sits between applications and the RDMA verbs layer , exposing a standard RDMA API and requiring minimal application changes. Internally (Fig. 4 ), V ar una comprises three core components: a) a logical-to-physical connection ta- ble that maps each virtual QP (vQP) to one primary RCQP and multiple backup DCQPs across primary and standby links; b) per-connection request-log and completion-log regions main- Algorithm 1 Post_Send 1: pr ocedure P O S T _ S E N D (vqp, input_wr) 2: qp ← vqp.get_current_qp() 3: if qp.status == CONNECTING then 4: qp ← vqp.get_dcqp() 5: end if 6: wr ← WR_Logging(input_wr) 7: wr ← WR_Extension(wr) 8: result ← Ra w_Post_Send(qp, wr) 9: if result == error then 10: S W I T C H _ V Q P (vqp) 11: R E C O V E RY (vqp) 12: end if 13: vqp.append_log(input_wr) 14: end pr ocedure tained across the requestor and responder; and c) extended completion records that track per -operation execution status for correct recov ery . V aruna supports common RDMA programming abstrac- tions—including QP management, protection-domain and memory-region management, connection setup, post send, post batch, poll, and others—while transparently integrating its failo ver mechanisms. It augments RDMA work requests with lightweight completion logging and ex ecution status, dispatches them through a v ailable RDMA paths, and automat- ically triggers failov er procedures when detecting failures. Algorithms 1 and 2 illustrate the simplified w orkflows of V aruna ’ s two fundamental APIs and highlight the core design principles of the system. In Algorithm 1 , when the application issues a vQP and a set of work requests, V ar una first resolves the currently acti ve physical QP; if the RCQP is under going (re)connection, V aruna temporarily falls back to the associ- ated DCQP (Sec. 3.4 ). It then augments the application’ s work requests with e xternal completion logging and extended ex ecution status for failure-type identification (Sec. 3.2 ) and return-v alue recov ery (Sec. 3.3 ), before in voking the raw post- send operation. After the post-send/poll stage, the post (Alg. 1 ) and poll (Alg. 2 ) workflo ws share a common structure: both check the returned status, trigger link switching upon detecting failures (Sec. 3.4 ), perform recovery for in-flight requests (Sec. 3.2 and Sec. 3.3 ), and finally update the local request log by inserting or removing entries as needed. In the follo wing sections, we detail V ar una ’ s designs for completion logging, execution-status e xtensions, and DCQP- acceleration fast failo ver . 3.2 Log-based F ail Recognition V aruna le verages a dual-log design—a request log on the re- questor and completion log on the responder—to precisely determine each requests’ f ailure type. Realizing this design re- 5 Algorithm 2 Poll_CQ 1: pr ocedure P O L L _ C Q (vqp) 2: Raw_Poll_CQ(vqp.cq, completion) 3: if completion.status == error then 4: S W I T C H _ V Q P (vqp) 5: R E C O V E RY (vqp) 6: end if 7: vqp.remov e_log_by_id(completion.id) 8: end pr ocedure quires addressing three key challenges: 1) ho w to identify and reload request contents under constrained request-log space, 2) ho w to maintain a correct responder -side completion-log with minimal performance ov erhead, and 3) how to correctly handle a batch of RDMA operations when a link f ailure oc- curs in the middle of the request sequence. 1) Unified request identification with r equest storage. V aruna allocates two per-vQP logs—a request log on the requestor and a completion log on the responder . Both logs share the same 8-byte entry format (Fig. 5 ). Before posting a request to the NIC, V aruna first cre- ates a full copy of the request’ s metadata (i.e., its struct ibv_send_wr) and stores the pointer to this copy in the lo wer 48 bits of the request-log entry . The remaining bits encode a 15-bit timestamp and a 1-bit finished flag. After appending the log entry , V aruna posts the original request as usual. Upon receiving a successful completion ev ent, the re- questor scans the request log, matches the completed request ID with the corresponding log entry , marks the entry as fin- ished, and frees the copied work request. For applications that do not supply unique request IDs (e.g., al ways using 0), V aruna uses the 8-byte log entry itself as a unified request identifier , combining its wr_addr and timestamp. During recovery , V aruna scans the entire request log and matches each unfinished local entry with its counterpart in the remote completion log. This unified identification relies on comparing the timestamp and the pointer-encoded request metadata. If the timestamps match, the request must have completed before the failure; if they differ , the request was not finished and must be retransmitted. For each unfinished entry , V aruna retrie ves the sa ved ib v_send_wr via the stored pointer and resends the corresponding operation. 2) Compacted and lightweight completion-log design. V aruna allocates a responder-side completion log for each vQP , which is updated exclusiv ely by the requestor via one-sided RDMA writes. For ev ery work request issued by the application, V ar una ap- pends a one-sided inline write that updates the corresponding completion-log entry with the same timestamp and request- metadata pointer recorded in the request log. T o maintain a sin- gle completion e vent per request, V ar una reuses the original request’ s ID for the inline write and transfers the completion- signaling flag from the original operation to the log-write. Requestor Responder target mem block Write: new_val@target Write request_log @offset Write new_val @target Request 1 ... Request 3 Timestamp (15bit) Wr_addr (48bit) Finished (1bit) offset Request 1 ... Request 3 Request List Completion Log vQP Figure 5: Completion Log: V ar una records a log at the respon- der for each request to distinguish pre-failure operations. Thus, only the log-write is configured to generate a comple- tion ev ent. The correctness of the completion log is guaranteed in two cases. First, f or pre-failur e requests , the completion-log write is nev er executed. Because the inline write is ordered immediately after the actual operation, any failure that in- terrupts the original request will also prevent its log-write from reaching the responder . As a result, the corresponding completion-log entry remains empty , allowing the reco very process to correctly categorize the request as unex ecuted and safely retransmit it. Second, for post-failure requests , the completion-log write is successfully executed before the failure, ensuring that the request is recorded as completed. A rare corner case exists where the original operation succeeds b ut the inline log-write fails. W e treat this as a lo w-probability ev ent in practice: the inline write is only 8 bytes and its send window is significantly shorter than the end-to-end execution windo w of the actual operation. Moreo ver , once the corner case hap- pened, only one operation will be influenced and it will be treated as a retransmit request, falling back to basic methods. The overhead of the completion-log writes is negligible. They share the same doorbell with the original send requests, incur no additional round-trips, and can be issued in parallel with application requests, becoming sequential only during NIC e xecution to keep correctness. When failure happens, the whole completion-log can be fetched by one RDMA read as the size of completion-log is also small (8B per entry). 3) Batch operations and asynchronous transport. RDMA applications commonly issue multiple work requests in a single linked list, or dispatch requests asynchronously with- out waiting for completions—often polling completions in a background thread. V aruna fully supports both batching and asynchronous transports. For a batch of w ork requests, V aruna first iterates through the linked list, replicates each work request, and appends a completion-log write after ev ery request. Each request in the batch is inserted into both the request log and the completion log independently , as link failures may occur in the middle of the batch. During recovery , V ar una replays the batch in the 6 Requestor Responder Content (64) Addr (48) Time (15) Fin (1) new_val target time 0 CAS Buffer@buffer_addr target stage 1: UID (buffer_addr) stage 2: new_val CAS: old_val --> new_val@target CAS old_val --> UID @target Write new_val, target, time, 0 @buffer_addr Stage 1 (occupy) CAS UID --> new_val @target CAS Finish bit: 0 --> 1 @buffer_addr Stage 2 (async confirm, no retry) worker (Async scan and confirm) UID: buffer_addr (48bit) + QP ID (16bit) Figure 6: Extended Status: V ar una implements traceable two- stage atomic operations to replace the original. order of originally posted, starting from the first pre-failure request, ensuring consistent semantics. Asynchronous transports are naturally supported because the request log already records all in-flight requests. V ar una exposes completion-queue polling interfaces that allo w appli- cations to filter by request ID. And the recovery procedure can be triggered after a poll-completion failure detected. T o further reduce logging overhead, V aruna logs only non-idempotent operations by default (e.g., WRITE, CAS, F AA), as resending these operations incorrectly can violate RDMA semantics. Finally , V ar una pro vides a pre-allocated work-request pool, allo wing applications to directly issue re- quests using these managed objects without additional mem- ory copies— V aruna safely manages their lifetimes. 3.3 Post-F ailure Recov ery via Extended Status W ith the completion-log mechanism, V ar una can identify post- failure requests—operations that have already executed on the responder NIC but whose return v alues are lost (mani- festing as retry errors or timeouts). This enables V ar una to provide return-v alue recov ery , which is particularly important for CAS operations. CAS return values determine whether a lock acquisition or a transaction commit succeeds, and incor- rect duplication can break application semantics. T o support correct recovery , V aruna extends CAS work requests with ad- ditional status information and restructures atomic ex ecution into two stages (Fig. 6 ). 1) Step 1—Occupy . For each CAS operation, the requestor first writes the operation’ s payload (the “swap value”), to- gether with the completion-log, into a small per-vQP CAS buf fer at the responder . It then constructs a 64-bit UID from the buf fer’ s address and the requestor’ s QP ID (e.g., 48-bit buf fer address || 16-bit QP ID). The CAS instruction uses this UID as the swap v alue instead of the actual value. A success- ful CAS installs this UID at the target location, making the operation globally unique and unambiguously recoverable: anyone seeing the UID can decode it to locate the buf fer and retriev e the actual value and recorded status. 2) Step 2—Confirm. After a successful CAS, the requestor asynchronously resolves the UID by reading the b uffer , mark- ing the operation as finished in the local/remote metadata, and replacing the UID in the target with the actual v alue via another CAS. T o accelerate cleanup, the responder runs a lightweight background worker that scans the CAS buf fer and automatically resolves an y unflushed completion operations. 3) Recovery . Upon failure, V aruna determines the outcome of a CAS by inspecting the target and its metadata: pres- ence of a UID (or a completion record) indicates that the CAS ex ecuted and returned success; presence of an unfinished com- pletion record without a UID indicates the CAS executed b ut returned false; absence of both indicates the operation does not executed and is safe to retransmit. This two-stage pat- tern (b uffer → UID → final v alue) ensures that e very successful CAS is prov ably traceable with metadata compact. 4) Correctness. Different from completion-log writes, CAS operations with extended status pro vide stronger consistency guarantees. V ar una first writes the swap v alue and the as- sociated completion log, and only then performs the CAS commit point. This ordering ensures that, if the CAS request is not ex ecuted or fails, its log entry remains in an unfinished state, prompting the requestor to safely resend the operation. Con versely , if the CAS executes successfully , the correspond- ing log entry is marked as finished, which reliably prev ents any further retransmission. As a result, the extended-status CAS enables V aruna to achiev e absolute correctness in distin- guishing pre-failure requests (which must be replayed) from post-failure requests (which must not be repeated). V aruna also exposes an interf ace that lets applications dis- able the extended-status mechanism when unnecessary—for example, when applications use globally unique swap-v alues or when only a single writer can commit the CAS. In these cases, V aruna can simply re-read the target value and compare it to the swap-v alue to determine the correct return value. Beyond CAS, V aruna handles other post-failure operations as follows: Reads : safely re-issued, since the y are idempotent; Writes : no action required, as the y hav e already completed; Fetch-and-Add : re written into a read+CAS sequence by de- fault, and applications may optionally declare them idempo- tent for blind retransmission; T wo-sided Operations : treated as non-idempotent with no reco verable return v alue, and ap- plications may mark them idempotent if retransmission is safe. 3.4 Lightweight F ast Failo ver Finally , V ar una assembles a complete failov er pipeline us- ing the failure-recognition and recov ery mechanisms de- scribed abov e. This section addresses a fundamental perfor - mance trade-off in RDMA failover: recreating thousands of per - connection RCQPs on standby links prolongs re- covery , whereas fully pre - caching RCQPs on every link consumes excessive host memory and initialization time . V aruna resolves this tension by e xploiting hardware support for Dynamic Connected QPs (DCQPs). A small, bounded 7 DCQP pool serves as a set of lightweight, shared failover channels, as illustrated in Fig. 7 . 1) Failo ver with DCQP P ools. Upon detecting a NIC fail- ure, V aruna atomically remaps the logical → physical QP ta- ble so that affected vQPs redirect to av ailable DCQPs on a healthy RDMA link. The current selection polic y assigns DC- QPs at random—achieving near-uniform sharing under steady load without enforcing strict fairness. Because DCQPs are pre - allocated and the remapping is a purely local, in - memory operation that can be paralleled, traffic resumes within mil- liseconds rather than waiting for new RCQP establishment. The DCQP pool size is a tunable operator parameter that bal- ances steady - state resource usage against transient contention during failov er . DCQP sharing introduces a temporary performance penalty—indi vidual vQP bandwidth may drop and contention may rise—but V aruna confines this bounded de gradation to the brief interval required for asynchronous RCQP reconstruc- tion. Once RCQPs are rebuilt, V aruna switches vQP map- pings back to dedicated RCQPs, restoring full per-connection throughput. During this swap-back, in-flight requests issued on a DCQP continue to complete on that DCQP and deli ver acknowledgments/results to its CQ, while new requests are posted on the rebuilt RCQP and use its o wn CQ. 2) Failo ver Pr ogress Summary . Building on the mecha- nisms mentioned above, V ar una ’ s recov ery proceeds in three phases: normal operation, immediate failo ver (Alg. 3 ), and in-flight request recov ery (Alg. 4 ). During normal operation, each vQP is bound to its ded- icated RCQP . V ar una issues completion-log writes and extended-status metadata only for non-idempotent operations, keeping the common-case ov erhead minimal. Upon detecting an RDMA failure—via dri ver or firmware callbacks, link-state notifications, completion-queue errors, or heartbeat timeouts— V aruna triggers an atomic, batched remapping of all vQPs associated with the failed link to their corresponding DCQPs on a standby link. Because the logi- cal → physical mapping table is updated in one coherent step, applications ne ver observe partially switched or inconsistent states. T raffic resumes immediately ov er the pre-allocated DCQPs. Concurrently , an asynchronous repair process re- constructs each vQP’ s RCQP on the standby link, including address e xchange and QP state transitions, as shown in Alg. 3 . Once reconstruction completes, V ar una atomically redirects each vQP from the shared DCQP to its ne wly established RCQP , restoring full per-connection throughput. During immediate failov er , V aruna also initiates recov- ery logic that inspects responder -side completion logs to de- termine which in-flight requests require retransmission and which require return-value fetching, as illustrated in Alg. 4 . After recov ery completes, the system transparently resumes normal request processing without any application-visible disruption or modification. Algorithm 3 Switch_VQP 1: pr ocedure S W I T C H _ V Q P(vqp) 2: link_id ← vqp.ne xt_av ailable_link() 3: vqp.create_qp_async(link_id) 4: vqp.change_current_qp(link_id) 5: end pr ocedure Algorithm 4 Recov ery 1: pr ocedure R E C OV E RY (vqp) 2: Read(vqp, vqp.remote_log_addr , remote_log) 3: for i = vqp.log_start to vqp.log_end do 4: if remote_log[i] == local_log[i] then 5: CAS_Recov ery(local_log[i]) 6: else 7: P O S T _ S E N D (vqp, *local_log[i].wr) 8: end if 9: vqp.remov e_log(i) 10: end for 11: end pr ocedure 请 求 侧 响 应 侧 创 建 R C Q P 连 接 N I C 1 N I C 2 . . . R D M A 单 边 请 求 ( R C Q P ) R e t r y t i m e o u t R e c r e a t e R C Q P s R e s e n d i n - f l i g h t r e q u e s t s 问 题 1 恢 复 性 能 P r o b l e m 2 R e c o v e r y C o n s i s t e n c y C A S 0 - - > 1 r e t u r n 0 C A S 0 - - > 1 r e t u r n 1 v a l u e = 0 v a l u e = 1 v a l u e = 1 Requestor Responder Create RCQP Connection NIC1 NIC2 ... RDMA Requests via RCQP RDMA Requests via DCQP Fetch Completion Log Resend Requests Asynchronous RCQP Creation Retry time out Figure 7: Failo ver T imeline: V ar una first uses DCQPs as temporary connections to fetch logs and retransmit pre-f ailure requests, while rebuilding RCQPs in the background. 4 Implementation This section describes our V aruna prototype, highlighting integration points and the engineering choices we made to keep the runtime minimally inv asive and compatible with RDMA hardware, dri vers and applications. Integration. V aruna is a runtime layer that intercepts connec- tion management and the RDMA send path while preserving the standard verbs API so existing applications require lit- tle source code changes. The layer can be deployed as a user - space library wrapper (we tar get a shim for libib verbs) or , when tighter integration is desired, as a thin kernel module or dri ver . V aruna relies only on standard RDMA primitiv es, libibv erbs, and unmodified kernel dri vers. Failur e Detection. V aruna aggregates failure notifications from multiple complementary sources. Firmware- and driv er- lev el events, along with RDMA completion errors, provide the primary detection signals, while a lightweight control- channel heartbeat offers a rob ust fallback path. The detection policy—heartbeat interval, retry thresholds, and related param- eters—is fully configurable. V ar una also e xposes interfaces 8 that allo w user-defined failure detectors to update link status or explicitly trigger and re voke failo ver actions. Link Selection. V aruna reads user-defined configuration files that specify the primary and backup RDMA links, as well as the policy for selecting reco very paths. Upon a primary-link failure, V aruna selects backup links in the order defined by the configuration—similar to prior RDMA transfer engines [ 31 ]. When the primary link later recov ers, V aruna rebuilds RCQPs on that link and transparently migrates subsequent transmissions back to the primary path. DCQP Management. At startup V aruna pre - allocates a small DCQP pool on each NIC; the pool size is configurable, the prototype uses a practical default of 1 per NIC, but operators can increase this to tens depending on workload, or setting the DCQP number auto-scaling with a DCQP-RCQP ratio, e.g., 1:8 means adding 1 more DCQP after 8 RCQP created. Before a DCQP can be used to communicate with a remote endpoint, V aruna must resolve and obtain an Address Handle (AH) for that endpoint. Creating an AH is relativ ely expensi ve, so V ar una generates AHs lazily the first time an RCQP to that endpoint is established and then caches the AH for subsequent use by DCQPs or newly created RCQPs. Memory Management. V aruna uses a simple but effecti ve memory - registration polic y to support multi - NIC access. For each application memory region, the runtime registers the region on each acti ve NIC and records the resulting per - NIC MR and rkey . These per - NIC rkeys are stored in a small lookup table index ed by (region id, NIC id). When a respon- der shares access information with a requester (for example, during connection setup), it includes the set of per - NIC rke ys; the requester keeps this rkey set and selects the appropriate rkey when sending requests via a particular NIC. This ap- proach lets V aruna transparently target dif ferent remote NICs without re-registering memory at failo ver time. 5 Evaluation W e ev aluate the performance and resource overhead of V aruna , benchmarking RDMA applications using V ar una against leading state-of-the-art solutions. Our ev aluation is structured to address the following k ey questions: • Steady-state perf ormance: How does V aruna operate when no failures occur? What is the runtime cost of maintaining completion logs and extended-status meta- data? • Recovery efficiency: Ho w does V aruna perform during RDMA failures? What are the impacts on bandwidth due to retransmission and RCQP reconstruction? • T ransactional integration: Ho w does V aruna affect end- to-end performance for representative RDMA transac- tional workloads (e.g., TPC-C)? 5.1 Experimental Setup Our testbed consists of 4 servers with 16 - core CPUs, 128GB RAM, and dual 25 Gbps RDMA NICs ov er PCIe 4.0. The 4 servers connect with each other in via two Ethernet switches, thus they hav e two links to connect to each other . The software stack uses Linux kernel 5.4.0 and latest RDMA NIC dri ver . W e compare V ar una against three baselines from state-of- the-art work designs and implement these policies in V ar una code framew ork to keep performance consistency . No-backup. represents standard RDMA usage without any recov ery support, and without external mechanisms such as request logs or completion logs. Resend. maintains a local request log, synchronously rebuilds all affected RCQPs on a standby NIC after a failure, and blindly retransmits all in-flight requests. Resend-cache. is similar to Resend in that it uses a local request log, b ut it pre-establishes and maintains duplicate RC- QPs on both the primary and backup links to avoid reconstruc- tion delays. W e only show this baseline at recovery-related ev aluations, other cases it is the same with Resend. Our ev aluation consists of two parts: multi-to-one inbound microbenchmarks and multi-node cluster experiments for end- to-end RDMA transaction performance. In the microbench- marks, the requestor side send up to 16 clients issuing one- sided RDMA operations of v arying request sizes to a single server node. For end-to-end e valuation, we b uild an 4-node RDMA transaction system atop Motor’ s three-replica RDMA transaction framew ork [ 41 ] and use TPC-C as the workload. 5.2 Steady-state Perf ormance W e characterize the steady-state performance of RDMA trans- port adapting V ar una and other baseline methods, to show the normal influence of V aruna ’ design with no RDMA failure happens, which is a more common cases in datacenters. W e ev aluate V aruna along se veral dimensions: (i) how its performance scales with different transport payload sizes, and (ii) how it beha ves under varying de grees of concurrency . W e measure both latenc y and bandwidth under two request pat- terns—synchronous and batched—while varying the number of concurrent clients. In the synchronous mode, each client issues a single request at a time and w aits for its completion before issuing the next. In the batched mode, multiple opera- tions are aggregated into a single w ork-request list, generating one completion entry per batch; this reduces posting ov erhead while preserving ordering semantics. W e use a batch size of 64 packets, a common configuration in AI data-transfer en- gines [ 31 ] and database systems [ 35 ]. Unless otherwise stated, all experiments use inbound workloads where multiple clients issue one-sided RDMA operations to a single server . Perf ormance under Ranging Payloads. First, we ev aluate V aruna using one-sided RDMA writes with payload sizes ranging from 16B to 1MB (Fig. 8 ). All three configurations 9 0 1000 2000 3000 4000 Bandwidth (MB/s) 1 10 100 1000 10000 Latency (us) Sync. W rite 0 1000 2000 3000 4000 Bandwidth (MB/s) 0 1 10 100 1000 10000 Latency (us) Batch W rite V aruna R aw-RDMA R esend Figure 8: Synchronous and batched writes with payload sizes ranging from 16B to 1MB, using 16 client threads and 64 packages per batch. reach approximately 25Gbps bandwidth at a 4KB payload size, with comparable latencies. Beyond 4 KB, the average latency increases roughly linearly with payload size. Batched writes achieve lower latency than synchronous writes due to reduced posting overhead, and the two modes conv erge in both latency and bandwidth once payloads exceed 4 KB. V aruna maintains similar external latency across payload sizes, adding only 1 µs compared to the resend and no-backup baselines—primarily due to log writes. This overhead is largely hidden under batched writes or larger payload sizes. V aruna also sustains the same peak bandwidth as the baselines, e ven though its internal log-write bandwidth is not counted in the reported throughput. Ov erall, for payloads larger than 4 KB—which are common in RDMA deployments, especially when batching is enabled— V aruna incurs at most a 4.7% external latency ov erhead and a 2.5% external bandwidth ov erhead. Perf ormance under Ranging Concurrency . Next, we e val- uate V ar una using 4 KB writes and 8 B CAS operations under varying concurrency le vels, scaling up to 16 clients. For the synchronous pattern, we measure V ar una across two types of one-sided operations—write and CAS—as shown in Fig. 9 . W e omit RDMA read results because V ar una behav es simi- larly to the baselines for reads. V aruna introduces negligible latency and bandwidth overhead for 4 KB writes across all thread counts. In contrast, synchronized CAS operations e x- hibit relativ ely higher ov erhead, as CAS has a very small payload and is executed serially at the responder . Howe ver , in real transactional workloads, CAS is typically issued to- gether with one-sided reads in batched form. Accordingly , we present batched-operation ev aluations next, where this ov erhead is largely amortized. For the batched pattern, we e valuate V aruna using two types of RDMA batch requests: (i) batches of 4 KB writes, and (ii) batches combining an 8 B CAS follo wed by three read operations (reflecting typical RDMA transactional locking behavior [ 41 ]), as sho wn in Fig. 10 . Under batching, V ar una achiev es latency and bandwidth nearly identical to both t he No-backup and Resend baselines. The batching optimization in RDMA ef fectiv ely amortizes the ov erhead of V aruna ’ s log writes, making the added cost almost in visible. Batch execu- 0 500 1000 1500 2000 2500 3000 Bandwidth (MB/s) 0 5 10 15 20 25 Latency (us) Sync. W rite 0 500 1000 1500 2000 2500 3000 3500 Thr oughput (r eq/s) 0 2 4 6 8 10 Latency (us) Sync. CAS V aruna R aw-RDMA R esend Figure 9: Performance of synchronous RDMA one-sided Write and CAS operations with 1–16 client threads. 2000 2500 3000 3500 4000 Bandwidth (MB/s) 0 5 10 15 20 25 Latency (us) Batch W rite 0 500 1000 1500 2000 Thr oughput (r eq/s) 0 5 10 15 20 Latency (us) Batch CAS V aruna R aw-RDMA R esend Figure 10: Performance of Write and CAS-Read batches (1:3 ratio) with 1–16 client threads and 64 packages per batch. tion is pre valent in RDMA-based systems—for e xample, AI data-transfer engines commonly use batch sizes of 128 with 64 KB payloads [ 31 ], and transactional workloads frequently issue batches combining one CAS with sev eral reads [ 41 ]. These characteristics further reinforce that V ar una ’ s overhead remains negligible in realistic deployment scenarios. Overhead Drill-down. Breaking down the ex ecution path of a one-sided RDMA write, the pipeline consists of four stages: copying the work request, enqueueing it onto the send queue, transmitting the request together with the in-line log entry , and finally polling for completion. As sho wn in Fig. 8 – 10 , the memory-copy and queue-management stages contrib ute negligibly compared to the transmission stage. This is re- flected in the nearly identical performance of the Resend and No-backup baselines, where Resend performs only local log recording without remote log writes. The dominant source of additional latency in V ar una comes from its in-line log write: the NIC must complete the log write before issuing the corresponding A CK, extending end-to-end request latency by approximately 1 µs. Memory overheads. V aruna incurs a lo w steady-state mem- ory overhead through its memory-efficient use of DCQPs, comparable to the no-cache baselines (No-backup and Re- send). In contrast, Resend-Cache roughly doubles memory usage due to RCQP duplication. For example, with 4,096 QPs, Resend-Cache consumes nearly twice the memory of V ar una (3,000 MB vs. 1,500 MB). On the other hand, V aruna ’ s request and completion logs add only modest over - head—approximately 1 KB per QP—amounting to about 4 MB out of the 1,500 MB total at 4,096 QPs. 10 0 20 40 60 80 100 120 140 160 180 200 220 240 260 T ime (ms) 0 500 1000 1500 2000 2500 3000 Bandwidth (MB/s) 4KB P ackages 0 20 40 60 80 100 120 140 160 180 200 220 240 260 280 300 320 340 360 T ime (ms) 0 1000 2000 3000 4000 Bandwidth (MB/s) 64KB P ackages V aruna R esend R esend+Cache Figure 11: Retransmission bandwidth during RDMA failov er with 16 client threads and 64 write packages per batch. 0.1 2.1 4.1 6.1 8.1 10.1 T ime (s) 0 1000 2000 3000 4000 Bandwidth (MB/s) 64KB W rite P ackages 0.1 2.1 4.1 6.1 8.1 10.1 T ime (s) 0 50 100 150 200 Bandwidth (MB/s) CAS-Read P ackages V aruna R esend R esend+Cache Figure 12: Requestor-side bandwidth during RDMA failo ver with 16 client threads and 64 packages per batch. 5.3 Recovery Efficiency W e e valuate the recovery ef ficiency of V aruna and the baseline mechanisms by injecting random RDMA failures under the batch communication pattern. In this section, we focus on RDMA Write batch and CAS-Read batch to measure reco very time and bandwidth variance—two metrics that are critical for both AI training and database workloads. W e additionally ev aluate RDMA CAS operations to verify correctness under failure, ensuring that V aruna ’ completion log and external state tracking correctly prev ent duplicate execution. Recovery Band width Consuming. First, we ev aluate the re- cov ery bandwidth consumption of resend-based approaches, using 4KB/64 KB payloads and a batch size of 64—an AI- style transmission pattern similar to the Mooncake engine [ 31 ]. W e compare two retransmission baselines (Resend and Resend-cache) against V ar una . As shown in Fig. 12 , V aruna reduces recov ery time by 52.2% / 64.5% compared to resend- based mechanisms, which must retransmit all in-flight pack ets ov er the backup path, regardless of whether RCQPs are pre- cached. When accounting for total data transferred during failov er , V aruna sends only 25.4% of the data required by Resend and Resend-cache at 64KB packages, since it retransmits only pre- failure requests. Under batched and large-payload workloads, failed requests often span the middle of a batch list, meaning that only part of the batch was actually transmitted before the failure. V ar una a voids retransmitting the already-completed portion, further reducing recov ery bandwidth. Bandwidth V ariance during Recov ery . Figure 12 shows a representativ e throughput time series during failov er for both Write and CAS-Read batches (64 packages per batch). Before 48 54 60 66 72 78 84 90 96 Client Number 0 10 20 30 40 50 60 70 80 90 Thr oughput (Ktx/s) 48 54 60 66 72 78 84 90 96 Client Number 0 50 100 150 200 250 300 350 Latency (us) V aruna Motor R esend Figure 13: A verage latency and throughput of RDMA T rans- action Motor [ 41 ] running TPC-C. 0 250 500 750 1000 1250 1500 1750 2000 2250 2500 2750 3000 3250 3500 3750 4000 4250 4500 4750 5000 5250 5500 5750 6000 6250 6500 6750 7000 7250 7500 7750 8000 8250 8500 8750 9000 9250 9500 9750 10000 10250 10500 10750 11000 11250 11500 11750 12000 12250 12500 12750 T ime (ms) 0 10 20 30 40 50 60 70 Thr oughput (Ktx/s) V aruna Motor R esend R esend+Cache Figure 14: Throughput of Motor under network failure. the injected fault, all systems operate at the same baseline throughput. At the moment of failure, the Resend baseline drops near zero while RCQPs are rebuilt, whereas Resend- Cache maintains throughput close to baseline. V ar una imme- diately remaps vQPs to DCQPs and reconciles state in the background, sustaining near-baseline throughput throughout the transition and fully returning to baseline once RCQPs are restored. V aruna slightly outperforms Resend-Cache due to reduced retransmission ov erhead. Correctness. T o ev aluate correctness under f ailure, we con- struct batches of CAS operations encoded as a single work- request list and issue them to the responder while injecting RDMA link failures at random times. Since failures may oc- cur before, during, or after the transmission of the list, each failure naturally generates a mix of pre-failure and post-failure CAS requests. Under this setup, V ar una achie ves 100% cor - rectness. Its two-step CAS protocol, together with extended completion-status tracking, guarantees that all successful CAS operations are reliably recorded and recoverable, without risk- ing duplicate ex ecution. 5.4 T ransaction Integration Finally , we inte grate V aruna and other baselines into Motor , an RDMA-based distrib uted transaction with three memory node replicas. This integration modifies the calling of network interfaces in Motor , with less than 100 LoC modification. T ransaction execution performance. As shown in Fig. 13 , we e valuate V ar una against other baselines using the TPC-C workload. V ar una achie ves nearly identical throughput com- pared to the baselines, indicating that its failo ver -related mech- anisms introduce 1.7%-13.9% bandwidth and 0.6%-10% a v- erage latency o verhead in real application scenarios. 11 The low overhead primarily stems from the fact that V ar una does not introduce log-writing operations for RDMA reads, which constitute a lar ge fraction of network requests in Mo- tor’ s transaction processing. For RDMA writes and CAS op- erations, the additional log-writing overhead is minimal with batch optimization in Motor . Moreover , the overhead of CAS can be further reduced by Motor’ s unified CAS-value modifi- cation in its lock design, which naturally amortizes the extra operations required by V aruna . T ransaction failover progr ess. W e inject external failures using the same methodology as in prior e xperiments (Fig. 14 ). V aruna achiev es rapid throughput recovery , comparable to both Resend and Resend-cache. By contrast, the Resend base- line suffers additional delay due to RCQP reconstruction. For comparison, we also e v aluate Motor’ s recovery beha vior under a network switch failure—where no packet retransmis- sion occurs and recovery is handled solely at the applica- tion layer . W e emulate Motor’ s external detection delay by inserting a zero-bandwidth interval equiv alent to Resend’ s failure-detection and RCQP-rebuild time. Motor e xperiences an ev en longer recovery period because it relies entirely on application-lev el mechanisms and must additionally wait for external failure detection before resuming e xecution. T ransaction recovery corr ectness. Finally , in transaction failov er ev aluations, V aruna achie ves a 100% correct resub- mission success rate with no consistency errors, stalls, or crashes, matching the reliability of application-level reco very . 6 Discussion While V aruna improv es recov ery performance and determin- istic correctness, our design has sev eral limitations: 1) Overhead of completion logs and atomic UIDs. Com- pletion logging and per - operation UID tracking introduce additional metadata writes. In our measurements these costs are microsecond - scale per logged request, but workloads dom- inated by non - idempotent or atomic operations could incur higher ov erhead. Adaptiv e batching, asynchronization, or se- lecti ve logging policies can reduce this cost in practice. Look- ing ahead, offloading log persistence to a programmable NIC could further eliminate these costs from the host datapath. 2) Background RCQP reconstruction. DCQPs enable immediate failov er , yet rebuilding full RCQPs in the back- ground consumes CPU and driver resources. In en vironments with v ery frequent NIC churn, a non - tri vial fraction of system resources may be de voted to RCQP reconstruction; admission or backof f policies may be required to bound reconstruction effort under pathological churn. 3) Multi-path selection and load balancing. V aruna adopts a simple backup-link selection strategy: it parses a user-pro vided configuration file to determine the primary and standby links. In practice, deployments may offer multiple candidate paths—for example, a CXL-based NIC pool as dis- cussed in Oasis [ 42 ]—allowing more sophisticated selection or dynamic load balancing. Extending V ar una with adapti ve multi-path scheduling and real-time load balancing is an im- portant direction for future work. 7 Related W ork V aruna intersects multiple areas: RDMA recovery and reliability , multipath and redundant RDMA systems, and RDMA-based database recov ery . Redundant RDMA systems. Besides previous multi-path [ 23 , 30 ] and multi-NIC [ 3 , 33 ] researches in RDMA, recent work lik e Oasis [ 42 ] designs a multi-NIC pool based on CXL, lev eraging idle NICs in existing clusters as backup devices. Howe ver , Oasis targets general-purpose network traf fic and cannot directly support RDMA semantics. In contrast, V aruna combines a small pool of dynamic connection QPs with per- operation completion logging, enabling immediate continuity and deterministic recov ery for RDMA workloads. RDMA reco very and r eliability . At the link layer , many mechanisms provide reliability [ 18 , 26 ], but they cannot handle seamless failover in scenarios inv olving multiple NICs, multiple paths, or multiple cards. Libraries such as LubeRDMA [ 20 ] and Mooncake [ 31 ] provide recovery to support most cases of multiple links at the network program- ming layer; howe ver , as noted earlier , their retransmission is not strictly correct and may lead to duplicate ex ecution for non-idempotent operations. V aruna dif fers by pro viding de- terministic classification of in-flight requests into pre-failure and post-failure, enabling correct retransmission and µs-level failov er across multiple NICs and paths. RDMA-based application-lev el recov ery . Systems such as Motor [ 41 ] and FUSEE [ 35 ] implement application-layer error recov ery for RDMA-based disaggregated databases. In parallel, designs based on multi-node memory replicas or era- sure coding [ 17 , 43 ] lev erage RDMA to ensure fault tolerance. While effecti ve, these approaches typically incur recov ery delays on the order of hundreds of milliseconds and cannot av oid the bandwidth collapse that arises when memory nodes become temporarily unreachable. V ar una complements these systems by enabling fine-grained, microsecond-scale failov er , eliminating redundant retransmissions and sustaining high throughput during link outages. 8 Conclusion W e present V aruna , a failure-type aware RDMA recov ery frame work with correct retransmission and microsecond-level failov er . By introducing completion logs and extended status, V aruna ensures correctness for non-idempotent operations, while provides immediate f ailov er with minimal DCQP pre- caching. Our e valuation show that V ar una reduces recovery la- tency to milliseconds, sustains high bandwidth during failover , and guarantees transactional correctness. 12 References [1] Emmanuel Amaro, Christopher Branner -Augmon, Zhi- hong Luo, Amy Ousterhout, Marcos K Aguilera, Aurojit Panda, Sylvia Ratnasamy , and Scott Shenker . Can far memory improv e job throughput? In Eur osys 20 , pages 1–16, 2020. [2] W ei Bai, Shanim Sainul Abdeen, Ankit Agraw al, Kris- han K umar Attre, Paramvir Bahl, Ameya Bhagat, Gowri Bhaskara, T anya Brokhman, Lei Cao, Ahmad Cheema, et al. Empo wering azure storage with { RDMA } . In 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23) , pages 49–67, 2023. [3] Deepak Bansal, Gerald DeGrace, Rishabh T ew ari, Michal Zygmunt, James Grantham, Silvano Gai, Mario Baldi, Krishna Doddapaneni, Arun Selv arajan, Arunk- umar Arumugam, Balakrishnan Raman, A vijit Gupta, Sachin Jain, Dev en Jagasia, Ev an Langlais, Pranjal Sri- vasta va, Rishiraj Hazarika, Neeraj Motwani, Soumya T iwari, Ste wart Grant, Ran veer Chandra, and Srikanth Kandula. Disaggregating stateful netw ork functions. In 20th USENIX Symposium on Networked Systems De- sign and Implementation (NSDI 23) , pages 1469–1487, Boston, MA, April 2023. USENIX Association. [4] Eric A. Brewer . T owards rob ust distributed systems (ab- stract). In Pr oceedings of the Nineteenth Annual A CM Symposium on Principles of Distributed Computing , page 7. Association for Computing Machinery , 2000. [5] Jiangfei Duan, Shuo Zhang, Zerui W ang, Lijuan Jiang, W enwen Qu, Qinghao Hu, Guoteng W ang, Qizhen W eng, Hang Y an, Xingcheng Zhang, et al. Efficient training of large language models on distrib uted infras- tructures: a survey . arXiv pr eprint arXiv:2407.20018 , 2024. [6] Assaf Eisenman, Kiran Kumar Matam, Ste ven Ingram, Dheev atsa Mudigere, Raghuraman Krishnamoorthi, Kr- ishnakumar Nair , Misha Smelyanskiy , and Murali An- nav aram. Check-N-Run: a checkpointing system for training deep learning recommendation models. In 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22) , pages 929–943. USENIX Association, April 2022. [7] Seth Gilbert and Nancy L ynch. Bre wer’ s conjecture and the feasibility of consistent, av ailable, partition-tolerant web services. SIGA CT News , 33(2):51–59, June 2002. [8] Phillipa Gill, Nav endu Jain, and Nachiappan Nagappan. Understanding network failures in data centers: mea- surement, analysis, and implications. In Pr oceedings of the A CM SIGCOMM 2011 Conference , pages 350–361, 2011. [9] Juncheng Gu, Y oungmoon Lee, Y iwen Zhang, Mosharaf Chowdhury , and Kang G Shin. Efficient memory disag- gregation with infinisw ap. In NSDI 17 , pages 649–667, 2017. [10] Rachid Guerraoui, Antoine Murat, Javier Picorel, Athanasios Xygkis, Huabing Y an, and Pengfei Zuo. uKharon: A membership service for microsecond appli- cations. In 2022 USENIX Annual T echnical Confer ence (USENIX A TC 22) , pages 101–120, Carlsbad, CA, July 2022. USENIX Association. [11] Chuanxiong Guo, Haitao W u, Zhong Deng, Gaurav Soni, Jianxi Y e, Jitu Padhye, and Marina Lipshteyn. Rdma ov er commodity ethernet at scale. In Pr oceedings of the 2016 ACM SIGCOMM Confer ence , pages 202–215, 2016. [12] Shixian Guo, Kefei Liu, Y ulin Lai, Y angyang Bai, Zi- wei Zhao, Songlin Liu, Jianghang Ning, Gen Li, Jian- wei Hu, Y ongbin Dong, Feng Luo, Sisi W en, Qi Zhang, Y uan Chen, Jiale Feng, Y ang Bai, Chengcai Y ao, Zhe Liu, Xin Hu, Y ang Lv , Zhuo Jiang, Jiao Zhang, and T ao Huang. Bytetracker: An agentless and real-time path- aware network probing system. In Pr oceedings of the A CM SIGCOMM 2025 Confer ence , SIGCOMM ’25, page 541–553, New Y ork, NY , USA, 2025. Association for Computing Machinery . [13] Qinghao Hu, Zhisheng Y e, Zerui W ang, Guoteng W ang, Meng Zhang, Qiaoling Chen, Peng Sun, Dahua Lin, Xi- aolin W ang, Y ingwei Luo, et al. Characterization of large language model de velopment in the datacenter . In 21st USENIX Symposium on Network ed Systems Design and Implementation (NSDI 24) , pages 709–729, 2024. [14] Zimeng Huang, Hao Nie, Haonan Jia, Bo Jiang, Junchen Guo, Jianyuan Lu, Rong W en, Biao L yu, Shunmin Zhu, and Xinbing W ang. Flowcheck: Decoupling checkpoint- ing and training of lar ge-scale models. In Pr oceedings of the T wentieth Eur opean Conference on Computer Systems, Eur oSys 2025 , pages 1334–1349. ACM, 2025. [15] Insu Jang, Zhenning Y ang, Zhen Zhang, Xin Jin, and Mosharaf Chowdhury . Oobleck: Resilient distributed training of large models using pipeline templates. In Pr oceedings of the 29th Symposium on Oper ating Sys- tems Principles , pages 382–395, 2023. [16] Ziheng Jiang, Haibin Lin, Y inmin Zhong, Qi Huang, Y angrui Chen, Zhi Zhang, Y anghua Peng, Xiang Li, Cong Xie, Shibiao Nong, Y ulu Jia, Sun He, Hongmin Chen, Zhihao Bai, Qi Hou, Shipeng Y an, Ding Zhou, Y iyao Sheng, Zhuo Jiang, Haohan Xu, Haoran W ei, Zhang Zhang, Pengfei Nie, Leqi Zou, Sida Zhao, Liang Xiang, Zherui Liu, Zhe Li, Xiaoying Jia, Jianxi Y e, Xin 13 Jin, and Xin Liu. MegaScale: Scaling large language model training to more than 10,000 GPUs. In 21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24) , pages 745–760, Santa Clara, CA, April 2024. USENIX Association. [17] Y oungmoon Lee, Hasan Al Maruf, Mosharaf Chowd- hury , Asaf Cidon, and Kang G Shin. Hydra: Resilient and highly av ailable remote memory . In 20th USENIX Confer ence on F ile and Storag e T echnologies (F AST 22) , pages 181–198, 2022. [18] W enxue Li, Xiangzhou Liu, Y unxuan Zhang, Zihao W ang, W ei Gu, T ao Qian, Gaoxiong Zeng, Shoushou Ren, Xinyang Huang, Zhenghang Ren, et al. Re visiting rdma reliability for lossy fabrics. In Proceedings of the A CM SIGCOMM 2025 Confer ence , pages 85–98, 2025. [19] Shengkai Lin, Qinwei Y ang, Zengyin Y ang, Y uchuan W ang, and Shizhen Zhao. Luberdma: A fail-safe mech- anism of rdma. In Pr oceedings of the 8th Asia-P acific W orkshop on Networking , pages 16–22, 2024. [20] Shengkai Lin, Qinwei Y ang, Zengyin Y ang, Y uchuan W ang, and Shizhen Zhao. Luberdma: A fail-safe mech- anism of rdma. In Pr oceedings of the 8th Asia-P acific W orkshop on Networking , APNet ’24, page 16–22, New Y ork, NY , USA, 2024. Association for Computing Ma- chinery . [21] Kefei Liu, Jiao Zhang, Zhuo Jiang, Haoran W ei, Xiao- long Zhong, Lizhuang T an, T ian Pan, and T ao Huang. Di- agnosing end-host network bottlenecks in rdma servers. IEEE/A CM T ransactions on Networking , 32(5):4302– 4316, 2024. [22] Kefei Liu, Jiao Zhang, Zhuo Jiang, Xuan Zhang, Shix- ian Guo, Y angyang Bai, Y ongbin Dong, Zhang Zhang, Xiang Shi, Lei W ang, Haoran W ei, Zicheng W ang, Y ongchen Pan, Tian Pan, and T ao Huang. Hostmesh: Monitor and diagnose networks in rail-optimized roce clusters. In Proceedings of the 8th Asia-P acific W ork- shop on Networking , APNet ’24, page 122–128, New Y ork, NY , USA, 2024. Association for Computing Ma- chinery . [23] Y uanwei Lu, Guo Chen, Bojie Li, Kun T an, Y ongqiang Xiong, Peng Cheng, Jiansong Zhang, Enhong Chen, and Thomas Moscibroda. Multi-Path transport for RDMA in datacenters. In 15th USENIX Symposium on Networked Systems Design and Implementation (NSDI 18) , pages 357–371, Renton, W A, April 2018. USENIX Associa- tion. [24] Xuhao Luo, Ramnatthan Alagappan, and Aishwarya Ganesan. Splitft: Fault tolerance for disaggregated dat- acenters via remote memory logging. In Proceedings of the Nineteenth Eur opean Conference on Computer Systems , pages 590–607, 2024. [25] Shaonan Ma, T eng Ma, Kang Chen, and Y ongwei W u. A Survey of Storage Systems in the RDMA Era . IEEE T ransactions on P arallel & Distrib uted Systems , 33(12):4395–4409, 2022. [26] Rui Miao, Lingjun Zhu, Shu Ma, Kun Qian, Shu- jun Zhuang, Bo Li, Shuguang Cheng, Jiaqi Gao, Y an Zhuang, Pengcheng Zhang, et al. From luna to solar: the evolutions of the compute-to-storage networks in alibaba cloud. In Proceedings of the A CM SIGCOMM 2022 Confer ence , pages 753–766, 2022. [27] Jayashree Mohan, Amar Phanishayee, and V ijay Chi- dambaram. CheckFreq: Frequent, Fine-Grained DNN checkpointing. In 19th USENIX Confer ence on F ile and Storage T echnolo gies (F AST 21) , pages 203–216. USENIX Association, February 2021. [28] NVIDIA ConnectX-8 SuperNIC User Manual. https://docs.nvidia.com/networking/display/ nvidia- connectx- 8- supernic- user- manual.pdf. Accessed: 3-December-2025. [29] Sheng Qi, Haoyu Feng, Xuanzhe Liu, and Xin Jin. Ef- ficient fault tolerance for stateful serverless computing with asymmetric logging. ACM T ransactions on Com- puter Systems , 43(1-2):1–43, 2025. [30] Kun Qian, Y ongqing Xi, Jiamin Cao, Jiaqi Gao, Y ichi Xu, Y u Guan, Binzhang Fu, Xuemei Shi, Fangbo Zhu, Rui Miao, Chao W ang, Peng W ang, Pengcheng Zhang, Xianlong Zeng, Eddie Ruan, Zhiping Y ao, Ennan Zhai, and Dennis Cai. Alibaba hpn: A data center network for large language model training. In Proceedings of the A CM SIGCOMM 2024 Confer ence , A CM SIGCOMM ’24, page 691–706, New Y ork, NY , USA, 2024. Associ- ation for Computing Machinery . [31] Ruoyu Qin, Zheming Li, W eiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Y ongwei W u, W eimin Zheng, and Xinran Xu. Mooncake: Trading more storage for less computation — a KVCache-centric architecture for serving LLM chatbot. In 23rd USENIX Confer- ence on File and Stora ge T echnologies (F AST 25) , pages 155–170, Santa Clara, CA, February 2025. USENIX Association. [32] Remote Direct Memory Access (RDMA) - W ikipedia. https://en.wikipedia.org/ wiki/Remote_direct_memory_access#:~: text=In%20computing%2C%20remote%20direct% 20memory, in%20massively%20parallel% 20computer%20clusters. Accessed: 1-December- 2024. 14 [33] Zhenghang Ren, Y uxuan Li, Zilong W ang, Xinyang Huang, W enxue Li, Kaiqiang Xu, Xudong Liao, Y i- jun Sun, Bowen Liu, Han T ian, et al. Enabling effi- cient { GPU } communication over multiple { NICs } with { FuseLink } . In 19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25) , pages 91–108, 2025. [34] Y izhou Shan, Y utong Huang, Y ilun Chen, and Y iying Zhang. Legoos: A disseminated, distributed OS for hardware resource disaggregation. In OSDI 18 , pages 69–87, 2018. [35] Jiacheng Shen, Pengfei Zuo, Xuchuan Luo, T ianyi Y ang, Y uxin Su, Y angfan Zhou, and Michael R L yu. FUSEE: A fully Memory-DisaggregatedK ey-V alue store. In F AST 23 , pages 81–98, 2023. [36] John Thorpe, Pengzhan Zhao, Jonathan Eyolfson, Y i- fan Qiao, Zhihao Jia, Minjia Zhang, Ravi Netra vali, and Guoqing Harry Xu. Bamboo: Making preemptible in- stances resilient for affordable training of lar ge { DNNs } . In 20th USENIX Symposium on Networked Systems De- sign and Implementation (NSDI 23) , pages 497–513, 2023. [37] Borui W an, Mingji Han, Y iyao Sheng Y anghua Peng, Haibin Lin, Mofan Zhang, Zhichao Lai, Menghan Y u, Junda Zhang, Zuquan Song, Xin Liu, and Chuan W u. Bytecheckpoint: A unified checkpointing system for large foundation model de velopment. In 22nd USENIX Symposium on Networked Systems Design and Imple- mentation, NSDI 2025 , pages 559–578. USENIX Asso- ciation, 2025. [38] Stephanie W ang, John Liagouris, Robert Nishihara, Philipp Moritz, Ujval Misra, Ale xe y T umanov , and Ion Stoica. Lineage stash: fault tolerance off the critical path. In Tim Brecht and Carey W illiamson, editors, Pr oceedings of the 27th ACM Symposium on Operating Systems Principles, SOSP 2019 , pages 338–352. A CM, 2019. [39] Zhuang W ang, Zhen Jia, Shuai Zheng, Zhen Zhang, Xin- wei Fu, T . S. Eugene Ng, and Y ida W ang. GEMINI: fast failure reco very in distrib uted training with in-memory checkpoints. In Pr oceedings of the 29th Symposium on Operating Systems Principles, SOSP 2023, K oblenz, Germany , October 23-26, 2023 , pages 364–381. A CM, 2023. [40] Mengwei Xu, Dongqi Cai, W angsong Y in, Shangguang W ang, Xin Jin, and Xuanzhe Liu. Resource-efficient algorithms and systems of foundation models: A survey . A CM Computing Surveys , 57(5):1–39, 2025. [41] Ming Zhang, Y u Hua, and Zhijun Y ang. Motor: Enabling Multi-V ersioning for distributed transactions on disag- gregated memory . In 18th USENIX Symposium on Op- erating Systems Design and Implementation (OSDI 24) , pages 801–819, Santa Clara, CA, July 2024. USENIX Association. [42] Y uhong Zhong, Daniel S Berger , Pantea Zardoshti, En- rique Saurez, Jacob Nelson, Dan RK Ports, Antonis Psis- takis, Joshua Fried, and Asaf Cidon. Oasis: Pooling pcie devices o ver cxl to boost utilization. In Pr oceedings of the ACM SIGOPS 31st Symposium on Operating Sys- tems Principles , pages 101–119, 2025. [43] Y ang Zhou, Hassan MG W assel, Sihang Liu, Jiaqi Gao, James Mickens, Minlan Y u, Chris K ennelly , Paul T urner , David E Culler , Henry M Levy , et al. Carbink: { Fault- T olerant } far memory . In 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22) , pages 55–71, 2022. [44] Siyuan Zhuang, Zhuohan Li, Danyang Zhuo, Stephanie W ang, Eric Liang, Robert Nishihara, Philipp Moritz, and Ion Stoica. Hoplite: efficient and fault-tolerant collec- tiv e communication for task-based distributed systems. In Pr oceedings of the 2021 ACM SIGCOMM 2021 Con- fer ence , pages 641–656, 2021. 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment