From Independent to Correlated Diffusion: Generalized Generative Modeling with Probabilistic Computers
Diffusion models have emerged as a powerful framework for generative tasks in deep learning. They decompose generative modeling into two computational primitives: deterministic neural-network evaluation and stochastic sampling. Current implementation…
Authors: Nihal Sanjay Singh, Mazdak Mohseni-Rajaee, Shaila Niazi
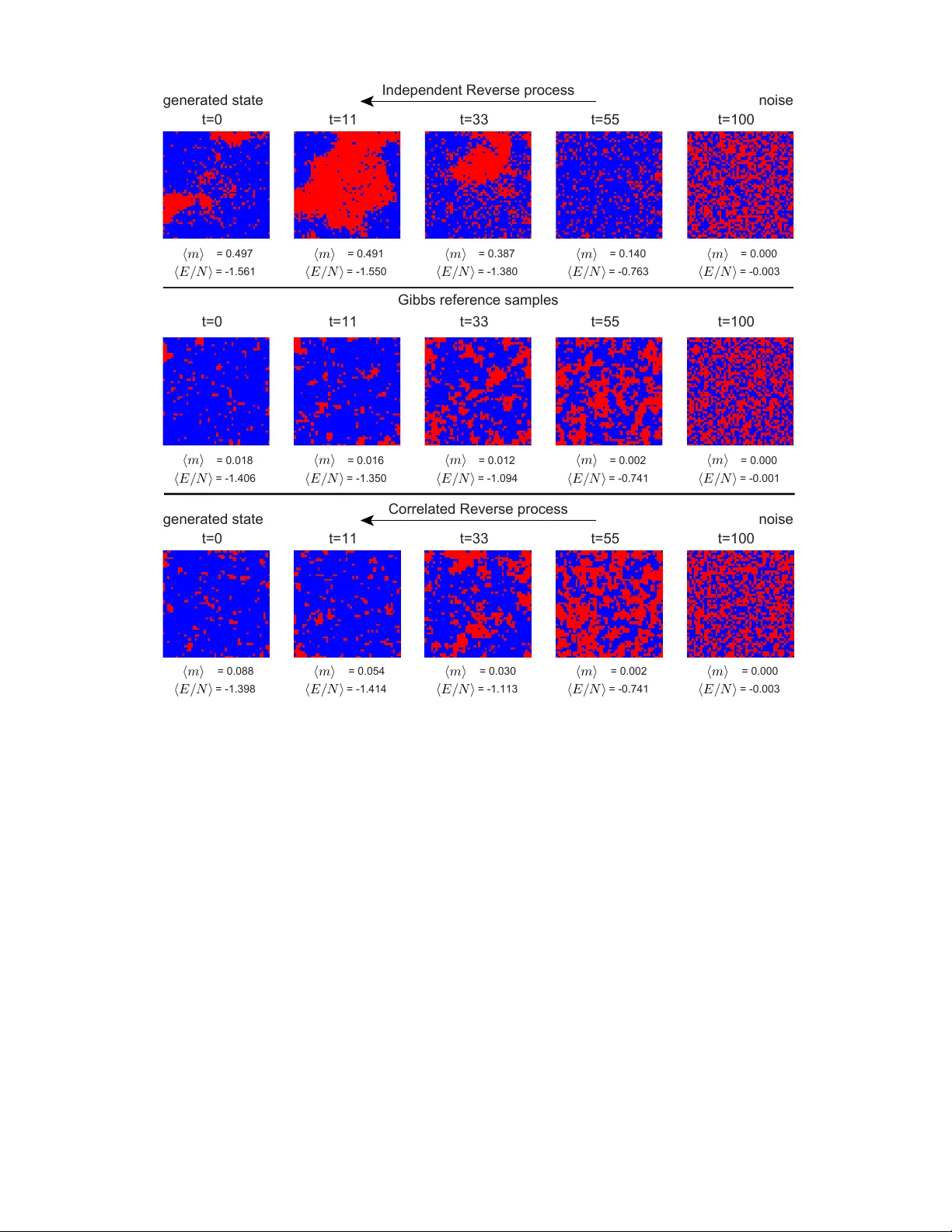
From Independent to Corr elated Diffusion: Generalized Generative Modeling with Pr obabilistic Computers Nihal Sanjay Singh, 1 , ∗ Mazdak Mohseni-Rajaee, 1 Shaila Niazi, 1 and Kerem Y . Camsari 1 , † 1 Department of Electrical and Computer Engineering, University of California, Santa Barbara, Santa Barbara, CA, 93106, USA Diffusion models hav e emerged as a po werful frame work for generativ e tasks in deep learning. They decompose generative modeling into two computational primitives: deterministic neural-network e valuation and stochastic sampling. Current implementations usually place most computation in the neural network, but diffusion as a framew ork allows a broader range of choices for the stochastic transition kernel. Here, we generalize the stochastic sampling component by replacing independent noise injection with Markov chain Monte Carlo (MCMC) dynamics that incorporate known interaction structure. Standard independent diffusion is recov ered as a special case when couplings are set to zero. By explicitly incorporating Ising couplings into the diffusion dynamics, the noising and denoising processes exploit spatial correlations representative of the target system. The resulting frame work maps naturally onto probabilistic computers (p-computers) built from probabilistic bits (p-bits), which provide orders-of-magnitude advantages in sampling throughput and energy efficienc y ov er GPUs. W e demonstrate the approach on equilibrium states of the 2D ferromagnetic Ising model and the 3D Edwards-Anderson spin glass, showing that correlated diffusion produces samples in closer agreement with MCMC reference distributions than independent dif fusion. More broadly , the framew ork sho ws that p-computers can enable new classes of diffusion algorithms that exploit structured probabilistic sampling for generativ e modeling. I. INTR ODUCTION Diffusion models are a class of generativ e models inspired by non-equilibrium thermodynamics [ 1 ]. They operate through a forward stochastic noising process that progressiv ely corrupts data, a training phase in which a neural netw ork learns to rev erse this corruption, and infer ence , in which new samples are generated by iteratively applying learned, stochastic denoising transitions [ 2 , 3 ]. The probabilistic nature of dif fusion models means the y are inherently composed of two computational components: deterministic neural-network e valuation (a conditional estimator) and stochastic sampling (a transition kernel that realizes the next state). A central but often ov erlooked aspect of diffusion models is that their algorithmic structure imposes no fundamental constraint on ho w computational effort is divided between these two components. In current practice, the widespread av ailability of GPUs has pushed most of the cost into the neural-network e valuation, which is well matched to dense linear algebra, while the stochastic sampling is typically kept lightweight to fit what this hardware makes easiest to ex ecute [ 4 ]. This is a hardware-contingent design choice rather than a property of the dif fusion frame work, and it lea ves underexplored a complementary regime in which the sampling step is fast enough to justify richer , more informativ e transition kernels. Probabilistic computers (p-computers) built from probabilistic bits (p-bits) [ 5 , 6 ] and their Gaussian counterparts (g-bits) provide e xactly this capability . These p-bits are binary stochastic units that naturally sample from Ising-type energy landscapes, and networks ∗ nihalsingh@ece.ucsb .edu † camsari@ece.ucsb .edu of p-bits implement Gibbs sampling of distributions defined by programmable couplings and biases. They thus constitute a form of Ising machine [ 7 , 8 ]: hardware designed to minimize Ising Hamiltonians, but extended here to support controllable stochastic sampling rather than energy minimization alone. Probabilistic computers built from p-bits ha ve demonstrated strong performance in combinatorial optimization and machine learning [ 9 – 11 ], with native hardware implementations on FPGAs and projected stochastic magnetic tunnel junction (sMTJ) devices of fering orders-of-magnitude advantages in sampling throughput and energy efficienc y over con ventional GPU- based implementations [ 10 ] (quantified in Section II , T able I ). The mapping of diffusion onto p-computers is particularly relev ant because recent proposals for energy-based candidate selection [ 12 ] and Monte Carlo tree search [ 13 , 14 ] during inference further increase the demand for fast, efficient probabilistic sampling. For physical systems governed by kno wn interactions, such as Ising models with coupling coef ficients J ij , there is a further opportunity: the sampling distributions within diffusion can be constructed directly from the correlations of the underlying system. Rather than sampling from independent noise at each diffusion step, the stochastic component can perform structure-aware Gibbs dynamics that respect the physical couplings. W e show that allowing dif fusion to sample from these physically motiv ated distributions improv es the accuracy of generated samples, and that independent diffusion is recovered as a special case when the couplings are set to zero ( J ij = 0 ). For systems with kno wn couplings, direct MCMC sampling is av ailable but can require prohibitiv ely long chains to decorrelate, particularly near phase transitions or in frustrated systems. Correlated dif fusion of fers an alternativ e route: once trained, the hybrid neural-network/Gibbs re verse process can generate decorrelated approximate samples intended to match 2 Probabilistic Computer Neural Network (GPU) p-bit p-bit p-bit p-bit ..... p-bit local field Gibbs sampling for next state estimate clean state denoised estimate current noisy state Fig. 1 . Hybrid p-computer/GPU inference loop for corr elated diffusion. System-le vel vie w of one rev erse-diffusion iteration. The current noisy configuration ( s t ) is passed from the probabilistic computer to the neural network on the GPU, which produces per -site denoising probabilities p = f θ ( s t ) . A binary clean-state estimate ˆ s 0 is then sampled from these probabilities and sent back to the probabilistic computer , where it initializes an ensemble of forward Gibbs chains under the known couplings J ij and the scheduled inv erse temperatures. Each chain produces a candidate for s t − 1 , and the candidates are reweighted by the one-step likelihood P ( s t | s t − 1 ) before one is sampled to continue the rev erse trajectory . Repeating this procedure produces successive re verse states s t → s t − 1 → · · · → s 0 , yielding the final sample s 0 . the target distribution without requiring long equilibrium chains at inference time. In this sense, the framework is analogous to a Boltzmann generator [ 15 ] for discrete systems, where the neural network proposes global denoising moves and the p-bit sampler enforces local consistency . Recent work on augmenting MCMC with learned proposals [ 16 ] demonstrates the value of this approach; correlated dif fusion extends it by embedding the physical structure directly into the generativ e dynamics. In this work, we formulate a generalized dif fusion framew ork that incorporates Ising-structured Gibbs dynamics into both the forward noising and rev erse inference processes. The framework naturally maps onto a hybrid architecture (Fig. 1 ) in which p-computers handle the stochastic sampling and GPUs handle the neural-network-based conditional estimation. More broadly , any Ising machine capable of controllable stochastic sampling (e.g., Ref. [ 7 , 17 – 20 ]) can serve as the sampling backend in this framew ork. W e introduce the probabilistic computing primiti ves, p-bits and g-bits (Fig. 2 ), that implement these dynamics, and quantify their sampling ef ficiency relative to GPUs (T able I ). W e demonstrate the approach on two benchmark systems: the 2D ferromagnetic Ising model and the 3D Edw ards-Anderson spin glass, showing that correlated diffusion produces samples that align more closely with MCMC reference distributions of equilibrium observables. II. PR OBABILISTIC COMPUTING PRIMITIVES: P-BITS AND G-BITS Before de veloping the diffusion framework, we introduce the probabilistic computing primitiv es on which it is built. The p-bit [ 5 , 6 ] is a binary stochastic unit whose output s i ∈ {− 1 , +1 } is sampled according to s i = sgn tanh( β I i ) + rand( − 1 , 1) (1) where rand( − 1 , 1) denotes a uniform random number on ( − 1 , 1) and β is the inv erse temperature controlling the degree of stochasticity . The local field I i seen by each p-bit is determined by its neighbors through I i = X j J ij s j + h i (2) where J ij are pairwise couplings and h i is an external bias. A network of p-bits connected by couplings J ij samples from the Ising energy E ( s ) = − X i 0 . T o perform noising or re verse annealing, during the forw ard process, as we mov e from s 0 to s t , we decrease the v alue of beta to allow for a steady de gradation of the state to noise. A standard Gibbs sampling update for spin i gi ven the other spin j is: Pr( s ′ i = +1 | s j ) = 1 + tanh( β J s j ) 2 = 1 + s j tanh( β J ) 2 . (S.39) So, if the neighbor is +1, Pr( s ′ i = +1) = q and Pr( s ′ i = − 1) = p . Similarly , if the neighbor is -1, Pr( s ′ i = +1) = p and Pr( s ′ i = − 1) = q . Now , we form a full step as first updating s 1 giv en s 2 , then updating s 2 giv en the possibly changed s 1 . (For setting the matrix, let ro ws and columns go (-1,-1), (-1,+1), (+1,-1), (+1,+1), with MSB being s 1 and LSB being s 2 .) First, we update s 1 giv en s 2 : W ( β ) 1 ← 2 = q 0 q 0 0 p 0 p p 0 p 0 0 q 0 q . (S.40) Next, we update s 2 giv en s 1 : W ( β ) 2 ← 1 = q q 0 0 p p 0 0 0 0 p p 0 0 q q . (S.41) Now , to ev aluate the composite transition matrix across both update steps, we get W ( β ) Gibbs as follows. W ( β ) Gibbs = W ( β ) 2 ← 1 W ( β ) 1 ← 2 (S.42) 18 W ( β ) Gibbs = q 2 pq q 2 pq pq p 2 pq p 2 p 2 pq p 2 pq pq q 2 pq q 2 . (S.43) The forward process is defined using the diffusion-timestep-dependent W Gibbs (note that timestep dependence is equiv alent to β dependence, since the β schedule varies with time): s 0 is the initial 2-spin state , v 0 = onehot ( s 0 ) For t = 1 , 2 , . . . , T − 1 : π t = W Gibbs ( β t − 1 ) v t − 1 v t ∼ π t (S.44) B. One-Step Reverse P osterior for Corr elated Noising W e use the standard one-step Bayes formula to ev aluate the posterior . Pr( s t − 1 | s t , s 0 ) = Pr( s t | s t − 1 ) Pr( s t − 1 | s 0 ) Pr( s t | s 0 ) . (S.45) Pr( s t − 1 | s t , s 0 ) = ℓ s t ◦ π t − 1 Z . (S.46) Now , with the determined W ( β ) Gibbs we can look at how we compute the dif ferent terms in the Bayes formulation. W e can denote the likelihood by selecting the ro w from W ( β ) Gibbs corresponding to the s t value that we start the re verse process with. This gi ves us the likelihood of the observ ed s t from some s t − 1 . L s t = W ( β t − 1 ) Gibbs [ s t , :] (S.47) Pr( s t | s t − 1 ) = ℓ s t = L T s t (S.48) The prior is π t − 1 obtained by pushing the giv en s 0 through the forward chain for t − 1 steps. This forms our belief for s t − 1 only gi ven s 0 and the forward noising schedule. v 0 in this case is the one-hot encoded version of s 0 and has dimension of 4 × 1 , and since our transition matrix is 4 × 4 , the dimensions work out. Pr( s t − 1 | s 0 ) = π t − 1 = W ( β t − 2 ) Gibbs × W ( β t − 3 ) Gibbs . . . × W ( β 1 ) Gibbs × W ( β 0 ) Gibbs v 0 (S.49) The normalization is the total probability of seeing the current state s t under the forward model and our belief about s 0 . Pr( s t | s 0 ) = [ π t ] s t = [ W ( β t − 1 ) Gibbs × W ( β t − 2 ) Gibbs . . . × W ( β 1 ) Gibbs × W ( β 0 ) Gibbs v 0 ] s t (S.50) The normalization factor can also be determined by the dot product of the pre vious two terms calculated, as sho wn below . Z = L s t · π t − 1 = W ( β t − 1 ) Gibbs [ s t , :] · π t − 1 (S.51) So the final expression for the posterior can be gi ven by the follo wing: Pr( s t − 1 | s t , s 0 ) = W ( β t − 1 ) Gibbs [ s t , :] T ◦ π t − 1 W ( β t − 1 ) Gibbs [ s t , :] · π t − 1 (S.52) 19 Mean energy per spin vs time Absolute Mean Magnetization vs time Mean energy per spin vs time Absolute Mean Magnetization vs time Independently noised states Diffusion generated states Independently noised states Diffusion generated states MCMC physical states Diffusion generated states MCMC physical states Diffusion generated states (a) (b) (c) (d) Fig. S1 . Energy and magnetization across diffusion timesteps f or generated Ising states. Mean energy per spin ⟨ E ⟩ / N and absolute mean magnetization |⟨ m ⟩| versus dif fusion timestep t . (a,b) Independent noising: reverse-generated states (orange/red) are compared with forward samples from the factorized noising kernel (blue/green). Energy appears broadly similar under a chosen schedule (a), but magnetization differs strongly (b), showing that independent noising suppresses long-range order too rapidly . (c,d) Correlated noising: reverse-generated states (orange/red) are compared with interaction-respecting MCMC reference states (blue/green). Both ⟨ E ⟩ / N and |⟨ m ⟩| track the reference more closely ov er t , consistent with the preservation of spatial correlations in the forward kernel. XIV . NETWORK AND TRAINING DET AILS 2D F err omagnetic Ising Model: Equilibrium configurations for the 50 × 50 ferromagnetic Ising model were generated via single-spin-flip Gibbs sampling. For each independent trial, the p-bit weights were first set to β = 0 (effecti vely randomizing the initial state), then updated to the critical inv erse temperature and e volved for 10 5 Gibbs sweeps, after which a single configuration was read out. The 10,000 configurations used as the training dataset were collected from independent trials at the critical point. 3D Edwards-Ander son Spin Glass: Reference configurations for the 3D Edwards-Anderson spin glass were generated via single-spin-flip Gibbs sampling. All chains were initialized in the uniform s i = +1 state. Equilibration consisted of 10 6 sweeps ramping linearly from β = 0 to the critical inv erse temperature of the disorder instance, follo wed by 9 × 10 6 sweeps at the critical point. Final configurations after 10 7 total sweeps at the critical point were used as the 20,000 training configurations referenced in the main text. XV . 2D FERROMA GNETIC ISING MODEL: EXTENDED RESUL TS Fig. S1 extends the snapshot comparison in Fig. 5 by plotting ⟨ E ⟩ / N and |⟨ m ⟩| across the full rev erse trajectory . Under independent noising, the energy trajectory roughly tracks the forward reference (Fig. S1 a), but the magnetization dev elops a strong bias at small t that is absent in the forward process (Fig. S1 b). Under correlated noising, both observables track the MCMC reference closely across all timesteps (Fig. S1 c,d). T ABLE S2. Architecture and training hyperparameters for the conditional estimator f θ , used identically for the 2D ferromagnetic Ising model and the 3D spin glass. Architectur e T raining Input / output size N Loss Binary cross-entropy Hidden layers 2 Optimizer Adam Hidden units per layer 1024 Learning rate 10 − 6 Activ ation ReLU W eight decay None Dropout None Batch size 512 Layer normalization None Epochs 4500 Early stopping patience 180
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment