Beyond Dataset Distillation: Lossless Dataset Concentration via Diffusion-Assisted Distribution Alignment
The high cost and accessibility problem associated with large datasets hinder the development of large-scale visual recognition systems. Dataset Distillation addresses these problems by synthesizing compact surrogate datasets for efficient training, …
Authors: Tongfei Liu, Yufan Liu, Bing Li
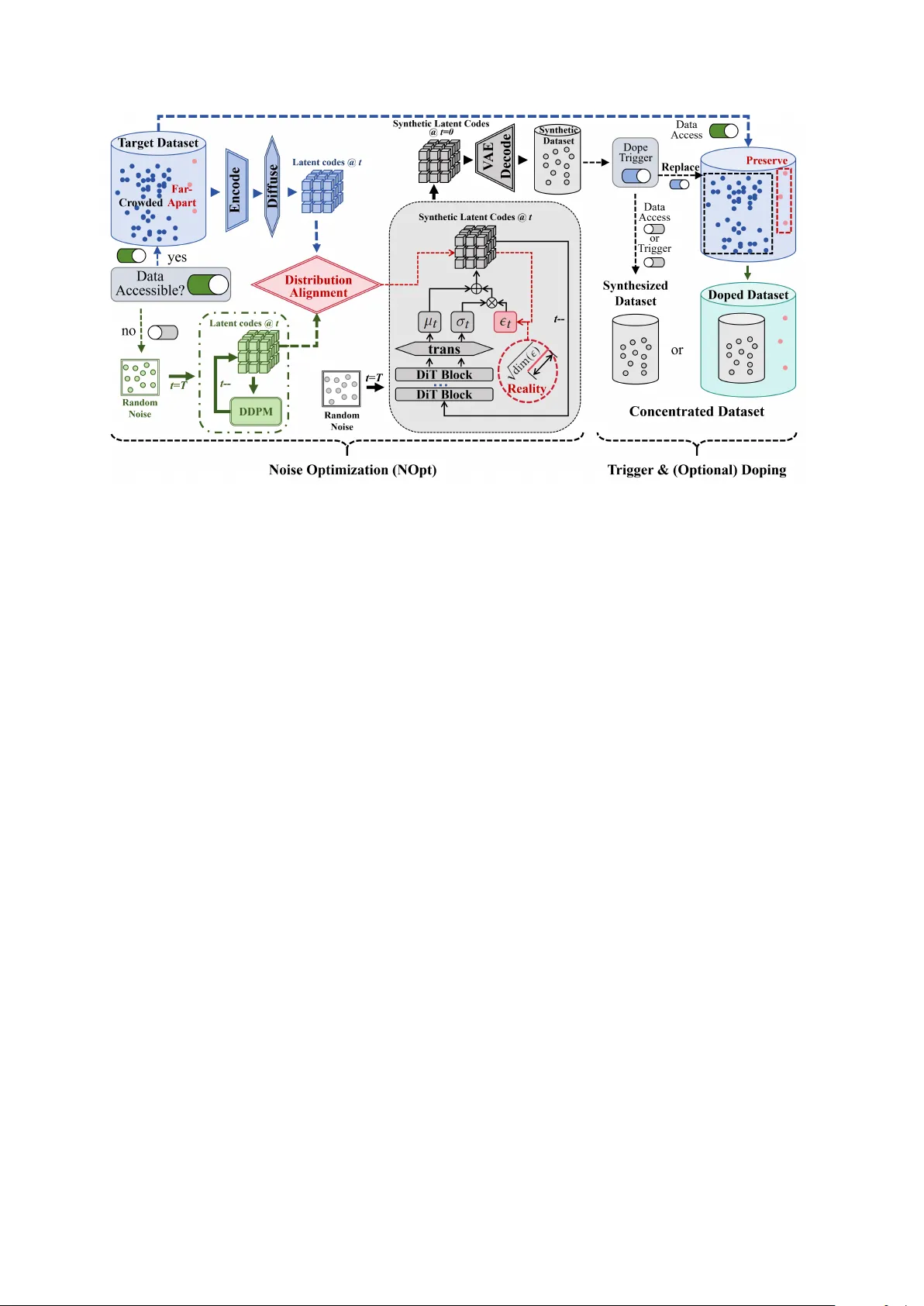
Bey ond Dataset Distillation: Lossless Dataset Concen tration via Diffusion-Assisted Distribution Alignmen t T ongfei Liu 1,2 † , Y ufan Liu 1,2* † , Bing Li 1,3* , W eiming Hu 1,2,4 1* State Key Lab oratory of Multimodal Artificial Intelligence Systems, Institute of Automation, Chines Academ y of Sciences, 95 Zhongguancun East Road, Beijing, 100190, Beijing, China. 2 Sc ho ol of Artificial In telligence, Universit y of Chinese Academ y of Sciences, 1 Y anqihu East Road, Beijing, 101408, Beijing, China. 3 P eopleAI, Inc., 68 Zhich un Road, Beijing, 100098, Beijing, China. 4 Sc ho ol of Information Science and T ec hnology , ShanghaiT ec h Univ ersit y , 393 Huaxia Middle Road, Shanghai, 201210, Shanghai, China. *Corresp onding author(s). E-mail(s): yufan.liu@ia.ac.cn ; bli@nlpr.ia.ac.cn ; Con tributing authors: liutongfei22@mails.ucas.ac.cn ; wmhu@nlpr.ia.ac.cn ; † These authors con tributed equally to this work. Abstract The high cost and accessibility problem asso ciated with large datasets hinder the dev elopment of large-scale visual recognition systems. Dataset Distillation addresses these problems by synthesiz- ing compact surrogate datasets for efficien t training, storage, transfer, and priv acy preserv ation. The existing state-of-the-art diffusion-based dataset distillation metho ds face three issues: lack of theoret- ical justification, po or efficiency in scaling to high data volumes, and failure in data-free scenarios. T o address these issues, w e establish a theoretical framew ork that justifies the use of diffusion mo d- els b y proving the equiv alence betw een dataset distillation and distribution matching, and reveals an inheren t efficiency limit in the dataset distillation paradigm. W e then prop ose a Dataset Concen tra- tion (DsCo) framew ork that uses a diffusion-based Noise-Optimization (NOpt) method to synthesize a small yet represen tative set of samples, and optionally augmen ts the synthetic data via ”Doping”, whic h mixes selected samples from the original dataset with the synthetic samples to o vercome the efficiency limit of dataset distillation. DsCo is applicable in b oth data-accessible and data-free sce- narios, achieving SOT A p erformances for lo w data volumes, and it extends w ell to high data volumes, where it nearly reduces the dataset size by half with no p erformance degradation. Keyw ords: Generative Models, Diffusion Mo dels, D a taset Condensation, Dataset Distillation, Data Augmentation 1 In tro duction The establishmen t of large-scale visual recognition systems requires a large amoun t of high-fidelity data. Ho wev er, the excessively large datasets incur prohibitiv e costs in mo del training and data stor- age, and their accessibilit y is often limited by transfer ov erhead and the growing priv acy and 1 securit y regulations. T o address these problems, Dataset Distillation (W ang, 1811 [ 1 ]) (DD, also kno wn as Dataset Condensation, DC) has emerged as a promising solution tow ards secure and effi- cien t data utilization. It aims to synthesize an extremely small surrogate dataset for the orig- inal large target dataset while preserving its essen tial information. This significantly reduces the resource demands asso ciated with training, storage, and transfer. Moreov er, it also enables a priv acy-preserving data-sharing paradigm b y releasing a synthetic dataset instead of the orig- inal target dataset that ma y con tain sensitiv e information, circumv enting the data accessibility problem. Among existing dataset distillation methods, diffusion-mo del-based dataset distillation meth- o ds (Abbasi, 2024 [ 2 ]; Su, 2024 [ 3 ]; Du, 2023 [ 4 ]; Chen, 2025 [ 5 ]) that syn thesize samples with pre-trained diffusion mo dels (Rombac h, 2022 [ 6 ]) ha ve demonstrated state-of-the-art (SOT A) train- ing p erformances and remark able distillation effi- ciency on large-scale, high-resolution datasets, suc h as the image classification b enc hmark, ImageNet-1k (Deng, 2009 [ 7 ]). F or instance, the Minimax-IGD (Chen, 2025 [ 5 ]) method has dis- tilled the ImageNet-1k dataset into a syn thetic dataset of 50 items p er class (IPC), reducing ab out 95% of the data with a performance degradation of no more than 10% on the ResNet-18 (He, 2016 [ 8 ]) mo del. Despite the great success of the dataset distil- lation metho ds in reducing costs asso ciated with large datasets and impro ving data accessibilit y , there remain some limitations in these metho ds. Firstly , the curren t dataset distillation metho ds t ypically work under extremely small surrogate set sizes of no more than 100 items p er class (IPC) on large-scale datasets such as the ImageNet-1k due to increasing synthesis costs. It is unclear whether the dataset distillation paradigm can b e extended to high-IPC settings on large-scale, high-resolution datasets, raising concerns ab out its consistency and reliability across different data regimes. Secondly , most metho ds require full access to the target dataset, failing in data-free scenarios where the target data is inaccessible for priv acy or safety reasons. Thirdly , while the cur- ren t SOT A metho ds use a pre-trained diffusion mo del to syn thesize samples, the motiv ation for the use of diffusion mo dels is based on heuris- tics and not analytically justified, raising doubts regarding the reliabilit y and trustw orthiness of the metho ds. This w ork addresses these limitations b y estab- lishing a theoretical framew ork to analyze the dataset distillation task. The framework demon- strates that the dataset distillation task is equiv- alen t to a distribution matc hing problem under mild conditions. Since the diffusion model is trained for distribution alignmen t, the motiv ation for using diffusion mo dels to syn thesize surrogate datasets is justified. The theoretical analysis fur- ther reveals an inherent random sampling bias in diffusion-based sampling that causes a distribu- tion misalignmen t that cannot be mitigated via guidance functions or fine-tuning. Moreo ver, an illustrativ e analysis under the prop osed frame- w ork reveals a fundamental efficiency b ottlenec k in the dataset distillation paradigm that stems from the presence of ”far-apart” samples in the target dataset, making it inefficient to extend the dataset distillation metho ds to high-IPC settings. In light of these theoretical insigh ts, w e pro- p ose a D ata s et Co ncentration (DsCo) framework. It syn thesizes a small dataset via a diffusion- based Noise-Optimization (NOpt) method with mitigated random sampling bias, whic h is applica- ble in b oth data-accessible and data-free scenarios. T o o vercome the fundamental efficiency limit of the dataset distillation paradigm, DsCo option- ally augments the synthetic samples with selected ”far-apart” samples from the target dataset via a ”Doping” procedure, which is con trolled by a ”Dop e T rigger”. The adaptability of the DsCo framew ork ensures robust performance across v ar- ious data v olumes and v arious accessibility condi- tions. Exp erimen ts across multiple datasets demon- strate that DsCo achiev es state-of-the-art p erfor- mance across multiple datasets and settings, and a cost analysis is p erformed to demonstrate the sup erior efficiency of DsCo compared to existing op en-source diffusion-based methods in b oth high- IPC and low-IPC regimes. F urther, the extended high-IPC exp erimen ts demonstrate that the con- cen trated datasets achiev e lossless dataset con- cen tration p erformances even when reducing the dataset b y half, demonstrating strong reliabil- it y for the large-scale compression. In data-free scenarios, it outp erforms all existing data-free 2 dataset distillation metho ds, offering a practi- cal path to learning from inaccessible data while safeguarding priv acy . Bey ond technical metrics, this work has a sig- nifican t broader impact: it enables efficient mo del training with reduced energy consumption, facil- itates priv acy-complian t data sharing while keep- ing the sensitiv e original dataset inaccessible, and enables effectiv e surrogate dataset syn thesis in the absence of the original dataset, contributing to global data accessibilit y . This work substantially extends our previous w ork: Noise-Optimized Distribution Distillation for Datase t Condensation (Liu, 2025 [ 9 ]), whic h is published in Pro ceedings of the 33rd A CM In ternational Conference on Multimedia. The pre- vious w ork identified the random sampling bias and prop osed the Noise-Optimization framew ork to mitigate it in the data-free scenario. The data- free Noise-Optimization metho d w as termed the ”NODD” metho d in our previous w ork. In this w ork, w e mak e the following extensions in theory , metho dology , and exp eriments: • W e establish a new theoretical framework to analyze the task of dataset distillation, justify- ing the use of diffusion mo dels by proving the equiv alence of dataset distillation to distribu- tion matc hing, identifying an inherent random sampling bias in diffusion synthesis, and pro v- ing a fundamen tal efficiency limit in dataset distillation. • W e propose a unified DsCo framework that encloses the NODD prop osed in our previ- ous work (Liu, 2025 [ 9 ]) along with the newly prop osed NOpt, Doping, and Dop e T rigger to handle data-accessible and data-free scenarios under both high-IPC and lo w-IPC regimes. • W e p erform extensive ev aluation and ablation exp erimen ts to demonstrate the high-IPC scala- bilit y , sup erior concentration performance, and comp elling cost-efficiency of the DsCo frame- w ork. 2 Related W ork 2.1 Diffusion Mo del The diffusion mo del is a generative mo del that syn thesizes samples b y rev ersing a diffusion pro- cess, whic h degenerates the samples in a tar- get dataset into random noise. The pro cess is called ”denoising”. It was first proposed by Sohl-Dic kstein (2015 [ 10 ]) and improv ed by Ho (2020 [ 11 ]) to generate samples of high quality . The mo dern laten t diffusion mo dels are prop osed b y Rom bach (2022 [ 6 ]), which enco des the high- resolution samples into compressed latent co des with a pre-trained V AE (Kingma, 2013 [ 12 ]), so that the diffusion mo del is trained in the latent space and synthesizes the small-scale latent co des instead of the high-resolution samples, signifi- can tly reducing its training and syn thesis costs. T o control the sample synthesis pro cess, the classifier guidance (Dhariw al, 2021 [ 13 ]) and classifier-free guidance (Ho, 2022 [ 14 ]) metho ds ha ve b een proposed to steer the sample synthesis in the denoising pro cess. These metho ds modify the transformation from the diffusion mo del out- puts to the mean and standard deviations of the denoised samples at eac h denoising step by adding a guidance term to the transformation, thus mo d- ifying the step-wise denoised sample statistics to the desired directions. In particular, the classifier- free guidance method has b een widely used in mo dern text-to-image tasks. In this work, we p erform a theoretical analy- sis to demonstrate that diffusion mo dels naturally fulfill a dataset distillation ob jective that aims to syn thesize informativ e surrogate samples for a tar- get dataset, and an improv ed Noise-Optimization metho d is proposed to improv e their p erformance on this task. 2.2 Dataset Distillation The task of Dataset Distillation (DD) aims to syn thesize a small surrogate dataset for the given target dataset, so that the do wnstream mo del trained on the surrogate dataset demonstrates as strong a performance as p ossible on the do wn- stream task. Based on the main idea, the dataset distillation metho ds can b e categorized into fiv e broad categories: direct meta-learning metho ds, 3 surrogate meta-learning methods, distribution- matc hing metho ds, patc hw ork metho ds, and gen- erativ e metho ds. Dir e ct Meta-L e arning In the early days, the dataset distillation task was form ulated into a meta-learning problem, which optimizes the p erformance of downstream mo d- els trained on the synthetic dataset. A line of w ork uses the direct meta-learning techniques to resolv e the meta-learning problem. These meth- o ds iterativ ely optimize the synthetic dataset. A t eac h iteration, the synthetic dataset is used to train a specific do wnstream mo del for a few steps with the training tra jectory preserved, and the trained do wnstream mo del is used to com- pute a meta-loss on the target dataset, which is the classification loss of the mo del. The gradient of the meta-loss is back-propagated through the training tra jectory via the classical Bac kpropaga- tion Through Time (BPTT) technique (Rumel- hart, 1986 [ 15 ]). The original dataset distillation metho d (W ang, 1811 [ 1 ]) firstly introduced this paradigm up on the introduction of the dataset distillation task, but the training tra jectories are confined to only a few steps, inducing p oor dis- tillation p erformances. The LinBa metho d (Deng, 2022[ 16 ]) further extended this method to long tra jectories by reconstructing the training tra jec- tories with stored model c hec kp oin ts. RaT-BPTT (F eng, 2023 [ 17 ]) prop osed a Random T runcated Windo w BPTT metho d that improv es the distil- lation p erformance while reducing the syn thesis costs. This line of work has successfully synthe- sized informativ e datasets, but the prohibitiv e computational resource requiremen t for the rep et- itiv e unrolling of training tra jectories limits their applicabilit y in larger datasets. Surr o gate Meta-L e arning A series of works hav e prop osed a range of surrogate methods to substitute the computa- tionally cumbersome meta-learning techniques. The tra jectory-matc hing metho ds (Cazenav ette, 2022 [ 18 ]; Cui, 2023 [ 19 ]; Du, 2023 [ 20 ]; Li, 2024 [ 21 ]) prop ose a surrogate meta ob jective for the synthetic dataset, which aligns the train- ing tra jectories of the same model trained on the target dataset and the syn thetic dataset b eing optimized. The gradient of the meta loss is then bac k-propagated to the syn thetic dataset b y BPTT, or through a linearized substitute tra jec- tory (Li, 2024 [ 21 ]). Another line of works termed gradien t-matching methods (Zhao, 2021 [ 22 ]; Zhao, 2021 [ 23 ]; Kim, 2022 [ 24 ]; Liu, 2023 [ 25 ]) prop ose another surrogate meta ob jective, whic h aligns the training gradients of the mo del snap- shots on its training tra jectory on the target dataset with the training gradients on the syn- thetic dataset. These metho ds can b e view ed as a one-step v ariant of the tra jectory matching metho ds. Apart from these metho ds, the linear metho ds (Nguy en, 2020 [ 26 ]; Loo, 2022 [ 27 ]; Zhou, 2022 [ 28 ]; Y u, 2024 [ 29 ]) substitute the length y training tra jectories b y linearized appro ximations, suc h as the k ernel ridge regression (Nguyen, 2020 [ 26 ]) and T aylor-expanded tra jectories (Y u, 2024 [ 29 ]). These surrogate metho ds reduced the syn thesis cost significantly compared to the direct meta-learning metho ds, but the meta-learning nature of these metho ds results in strong archi- tecture o verfitting, suc h that the distilled dataset demonstrates degraded p erformances on arc hi- tectures that are unseen during the distillation pro cess. Distribution Matching Another line of work reform ulates the dataset distillation task as a distribution matching task. These metho ds are termed distribution-matching metho ds (Zhao, 2023 [ 30 ]; W ang, 2022 [ 31 ]; Zhang, 2024 [ 32 ]; Yin, 2023 [ 33 ]; Yin, 2023 [ 34 ]). They align the feature distributions of the synthetic dataset to that of the target dataset, with v ar- ious kinds of features used in the alignment, suc h as the NNGP-kernel asso ciated random fea- tures (Zhao, 2023 [ 30 ]), the v arious features extracted by classifiers on their training tra jec- tories (W ang, 2022 [ 31 ]; Zhang, 2024 [ 32 ]), and the Batch-Normalization statistics stored in pre- trained classifiers (Yin, 2023 [ 33 ]; Yin, 2023 [ 34 ]; Shao, 2024 [ 35 ]; Zhou, 2024 [ 36 ]; Shao, 2024 [ 37 ]; Shen, 2025 [ 38 ]). These metho ds further reduce the synthesis costs as they do not require bac k- propagation through training tra jectories, while ac hieving comparable p erformances to contempo- rary w orks. So far, all the metho ds discussed abov e adopt a pixel-lev el optimization paradigm, which ini- tializes the syn thetic dataset and optimizes it 4 through an iterative optimization pro cedure. Since the pixel-level optimization mak es no constraints on the joint distribution of pixels, the pixels tend to be indep enden tly optimized, resulting in high-frequency noises in the synthesized samples that impair the generalization performance of the syn thesized samples. Patchwork Metho ds Recen tly , a series of dataset distillation works ha ve prop osed to crop imp ortan t patc hes from the target dataset and stitch those patches in to new samples while discarding the unimp ortan t patc hes left. RDED (Sun, 2024 [ 39 ]) firstly pro- p osed this cropping-and-stitching paradigm, and DDPS (Zhong, 2024 [ 40 ]) further dev elop ed this tec hnique with the help of diffusion mo dels to demonstrate impro ved p erformances. These meth- o ds are significan tly faster than all previous metho ds b ecause no optimization is required in them, and they demonstrate satisfactory distilla- tion p erformances with the help of the relab eling tec hnique. Ho wev er, their p erformances are sub- optimal compared to a series of recent w orks discussed below. Gener ative Metho ds A line of work has explored the p ossibilit y of uti- lizing generative mo dels in the dataset distillation task. Some early works (Zhao, 2023 [ 41 ]; W ang, 2023 [ 42 ]; Huang, 2021 [ 43 ]; Li, 2024 [ 44 ]) replace the synthetic datasets with generative mo dels, and some other metho ds (Cazena v ette, 2023 [ 45 ]; Moser, 2024 [ 46 ]) optimize the latent co des of the generativ e mo dels to synthesize informative sam- ples. These methods adopt a ”generate-optimize” paradigm where the whole synthetic dataset is rep etitiv ely generated and used in the compu- tation of classical dataset distillation ob jectives of meta-learning or distribution-matching dataset distillation metho ds. The rep etitiv e syn thesis of the samples incurs a prohibitiv e syn thesis cost in these metho ds, making them unsuitable for large-scale datasets. In con trast to previous generative metho ds, a recent line of works (Abbasi, 2024 [ 2 ]; Su, 2024 [ 3 ]; Y uan, 2023 [ 47 ]; Du, 2023 [ 4 ]; Chen, 2025 [ 5 ]) use the denoising process of a pre- trained diffusion mo del to synthesize informative syn thetic samples. In these metho ds, the syn- thesized samples are only synthesized once in a single denoising process, significan tly b oosting the syn thesis efficiency . Among these metho ds, the Minimax (Du, 2023 [ 4 ]) metho d fine-tunes a pre- trained diffusion mo del for improv ed distribution alignmen t and syn thesizes samples with random noise. IGD (Chen, 2025 [ 5 ]) prop oses an influence guidance function that stems from the classi- cal gradient-matc hing method, which steers the denoising pro cess of diffusion mo dels to synthe- size training-effectiv e samples. OT (Cui, 2025 [ 48 ]) metho d prop oses to solve an optimal transp ort problem at each denoising step and incorp orate the solution into the guidance function of the step, and design sp ecific soft lab els for the synthesized samples to b o ost the distillation p erformance. These metho ds hav e demonstrated state-of-the- art (SOT A) dataset distillation p erformances on high-resolution datasets such as the ImageNet-1k and its tw o subsets, ImageNette and ImageW o of (Jerem y , 2019 [ 49 ]), with satisfactory distillation costs. 3 Theoretical Analysis This section establishes a theoretical frame- w ork to analyse the dataset distillation prob- lems. Section 3.1 illustrates the general theoret- ical framew ork and the key assumption made in the analysis. Section 3.2 demonstrates that the dataset distillation task is equiv alent to solving the distribution matc hing problem in this framew ork. Then, Section 3.3 illustrates that the distribution matc hing ob jective can b e naturally fulfilled by generativ e diffusion mo dels (Rombac h, 2022 [ 6 ]). Subsequen tly , Section 3.4 demonstrates that there exists a random sampling bias in the DDPM denoising pro cess commonly adopted by existing diffusion-based dataset distillation metho ds. F ur- ther, Section 3.5 unco vers an inheren t limitation of the curren t dataset distillation paradigm that lim- its its efficiency in scaling to high surrogate data v olumes. 3.1 The Memorize-Generalize Picture This work studies a general task of comp osing a small surrogate dataset for a given target dataset, 5 so that a downstream mo del trained on the sur- rogate dataset p erforms as well as one trained on the target dataset when applied to the down- stream task. Sp ecifically , the theoretical analysis in this w ork inv olv es three comp onen ts: a tar- get sample set of N T samples, denoted as T ≡ { x τ } τ = N T τ =1 , x τ ∈ R d , with sample indices τ = 1 , . . . , N T ; a surrogate sample set of N S samples, denoted as S ≡ { x s } N S s =1 , x s ∈ R d , with sample indices s = 1 , . . . , N S ; a model Φ that memo- rizes S through training to make predictions for T , whic h represents the neural netw ork used in the downstream task. If Φ mak es a correct pre- diction for x τ after memorizing S , we say that Φ recognizes x τ . F e atur e Dissimilarity and Kernel F unction Consider an arbitrary positive-definite symmetric k ernel function k ( x a , x b ) for t wo arbitrary samples x a , x b ∈ R d . According to the Mo ore-Aronsza jn Theorem, the k ernel function is asso ciated with a pro jection ψ that pro jects arbitrary samples x a , x b in to features f a , f b = ψ ( x a ) , ψ ( x b ) in a Repro duc- ing Kernel Hilb ert Space (RKHS) H of dimension d ′ → ∞ , which satisfies k ( x a , x b ) = ⟨ f a , f b ⟩ H . (1) That is, the inner pro duct ⟨· , ·⟩ H of the pro jected features in the RKHS equals the kernel function. Consequen tly , the L-2 distance betw een f a and f b can be formulated as || f a − f b || 2 H = k ( x a , x a ) + k ( x b , x b ) − 2 k ( x a , x b ) . (2) If the kernel function is shift-inv ariant (i.e., k ( x a , x b ) is solely determined by ( x a − x b )), k ( x, x ) is a constan t for any x . Therefore, the feature distance can be reformulated as || f a − f b || 2 H = Constan t − 2 k ( x a , x b ) . (3) Hence, for t wo arbitrary samples x a , x b , their fea- ture dissimilarit y , as measured b y the L-2 distance b et ween their pro jected features f a , f b , monoton- ically decreases with the kernel function k ( x a , x b ). Chanc e of R e c o gnition When the model Φ memorizes a surrogate sample x s through training, its generalization capabil- it y enables it to recognize a target sample x τ Fig. 1 The graphical illustration of the target features and surrogate features plotted in the RKHS. that b ears a certain degree of feature similarity to x s . The greater the feature similarity b et ween x τ and x s , the more likely x τ is recognized b y memorizing x s . Therefore, denoting the c hance of recognizing x τ b y memorizing x s as p rec ( x τ | x s ), it is reasonable to assume p rec ( x τ | x s ) > p rec ( x τ ′ | x s ) ⇐ ⇒ k ( x s , x τ ) > k ( x s , x τ ′ ) , (4) where x s ∈ S , and x τ , x τ ′ ∈ T . Equiv alently , the corresponding L-2 distances of features in the RKHS, denoted as d 2 ( f s , f τ ) and d 2 ( f s , f τ ′ ) with f s , f τ , f τ ′ = ψ ( x s ) , ψ ( x τ ) , ψ ( x τ ′ ), satisfy p rec ( x τ | x s ) > p rec ( x τ ′ | x s ) ⇐ ⇒ d 2 ( f s , f τ ) < d 2 ( f s , f τ ′ ) . (5) Summary and Il lustr ation In summary , the ab o ve construction can b e refor- m ulated into an assumption: Assumption 1 F or a mo del Φ whic h makes predic- tions on T b y memorizing samples in S , we assume that there exists a shift-inv ariant positive-definite k er- nel function k ( · , · ), suc h that the c hance of recognizing (i.e., making a correct prediction on) a sample x τ ∈ T b y memorizing x s ∈ S monotonically increases with increasing kernel function v alue k ( x τ , x s ). Under this assumption, the Reproducing Ker- nel Hilb ert Space (RKHS) asso ciated with k ( · , · ) 6 can b e describ ed by the memorize-generalize pic- ture, which is illustrated graphically by Figure 1 . In the figure, the pro jected features of the tar- get set T and the surrogate set S in RKHS are scattered and denoted as the cyan and red dots, resp ectiv ely . The fading pink region around each red dot denotes the chance of recognition asso- ciated with the corresp onding surrogate sample, whic h fades aw ay as the distance from the corre- sp onding surrogate feature increases. The dashed circles indicate the maximal distance from the surrogate feature, b ey ond which the chance of recognizing a target sample by memorizing the corresp onding surrogate sample is negligible. The picture provides an in tuitiv e exposition of the relationship betw een the surrogate set, the target set, and the mo del, incentivizing the subsequent analysis. 3.2 Dataset Distillation as a Distribution Matching Problem As defined in the previous literature [ 1 ], the task of dataset distillation is to synthesize a small set of samples that can replace the target dataset to train a downstream mo del to achiev e a high p erformance on the downstream task. In the Memorize-Generalize picture, this task can be reform ulated into synthesizing a surrogate dataset S so that as many samples from T as p ossible can b e recognized by memorizing S . As previously demonstrated, the chance of rec- ognizing a target sample x τ b y memorizing a surrogate sample x s monotonically decreases with the L-2 distance d 2 ( f s , f τ ). Considering the whole surrogate set, the chance of x τ b eing recognized can be formulated as p rec ( x τ |S ) = h N S X s g ( || f τ − f s || 2 ) ! , (6) where g ( · ) : R + → R + is an arbitrary monoton- ically decreasing function, h ( · ) : R + → R + is a normalizing function that normalizes the sum in to the range (0 , 1). Consider the conti nuous proba- bilit y distribution of T and S , denoted as P T ≡ p T ( x τ ) and P S ≡ p S ( x s ), resp ectiv ely . Their corresp onding feature distributions in RKHS are expressed as p f T ( f τ ) and p f S ( f s ), with p f T d f τ = p T dx τ and p f S d f s = p S dx s . Adopting this contin- uous expression and substituting the samples with the features in the RKHS, the exp ected chance of recognition in T is thus expressed as E x τ ∼ P T [ p rec ( x τ |S )] = Z R d ′ p f T ( f τ ) · h Z R d ′ g ( || f τ − f s || ) p f S ( f s ) d f s d f τ . (7) The task of dataset distillation is equiv alent to maximizing the ab o ve exp ected chance with resp ect to P RKHS S ≡ p f S ( f s ) under the constraint R p f S ( f s ) d f s = 1 and p f S ( f s ) ≥ 0. Denoting the ab o ve exp ected chance as J ( p f S ), The correspond- ing functional w ith Lagrangian m ultiplier λ is th us L [ p f S ] = J ( p f S ) + λ (1 − Z p f S ( f s ) d f s ) . (8) Setting its v ariational deriv ative with resp ect to p f S to 0, the maximal chance of recognition is attained when the follo wing condition is satisfied: Z R d ′ p f T ( f τ ) h ′ ( g ∗ p f S )( f τ ) g ( || f τ − f s || ) d f τ = λ, ∀ f s ∈ supp( P RKHS S ) , (9) where g ∗ p f S is the conv olution b et ween g ( · ) and p f S ( · ). The normalizing function h ( · ) can be linear. In this case, the condition is simplified to ( g ∗ p f T )( f s ) = Constan t( λ ) ∀ f s ∈ supp( P RKHS S ) . (10) F urther, as g ( || f s − f τ || ) is shift-in v ariant in RKHS, the ab o ve condition can b e satisfied iff p f S ( f ) ∝ p f T ( f ) , ∀ f ∈ R d ′ . F or the tw o probability densit y functions, this indicates that p f S ( f ) = p f T ( f ) ∀ f ∈ R d ′ . (11) That is, the feature probabilit y of S m ust b e aligned with that of T to maximize the exp ected c hance of recognition. In this case, E [ f s ] = E [ f τ ], th us the Maximal Mean Discrepancy asso ciated with the k ernel k ( · , · ) b et ween S and T is 0. This indicates that P S = P T in the sample space R d . T o summarize, under Assumption 1 , the dataset distillation task is equiv alent to solving a distribution matc hing problem. Therefore, the 7 ob jective of dataset distillation can b e reformu- lated into syn thesizing a surrogate dataset to maximize the distribution alignment betw een the surrogate set and the target dataset. F ormally , this conclusion can be formulated as follows: Prop osition 1 F or a mo del Φ which makes pr e dic- tions on T by memorizing samples in S , if Assump- tion 1 holds, the maximization of the total expe cte d chanc e of r e c o gnition of the samples in T is e quiva- lent to the minimization of the c ontinuous distribution discr epancy b etwe en S and T . In Appendix A , this prop osition is extended to apply under a broader condition: Prop osition 2 F or a mo del Φ which makes pr e dic- tions on T by memorizing samples in S , if ther e exists an invertible tr ansformation that maps the samples into a fe atur e sp ac e, in which ther e exist a shift- invariant p ositive-definite kernel function whose value monotonic al ly incr e ases with the chance of r e co gniz- ing a tar get sample x τ ∈ T by memorizing a surr o gate sample x s ∈ S , the maximization of the total exp e cte d chanc e of r e c o gnition of the samples in T is e quiva- lent to the minimization of the c ontinuous distribution discr e p ancy b etwe en S and T . This is equiv alen t to stating that the dataset distillation task is essen tially resolving a distribu- tion matc hing problem. 3.3 Generativ e Diffusion Mo del for Distribution Matching Consider an arbitrary sample set X ≡ { x n } N n =1 of N samples. A pre-trained auto encoder enco des the samples to latent co des Z ≡ { z n } N n =1 of reduced dimension, z n ∈ R C,H,W , whic h can b e deco ded bac k to X via the deco der. The enco ded latent co des can b e diffused via an iterative diffusion pro- cess, so that at step t of the diffusion process, the diffused latent code z t for an arbitrary latent code z 0 is z t = √ α t z 0 + √ 1 − α t ϵ, ϵ ∼ N (0 , I ) , (12) where α t s are the sc heduling coefficients for differ- en t t . At the last step T of diffusion, the diffused laten t code follo ws the Gaussian distribution, z T ∼ N (0 , I ). A latent diffusion model denoted as Ψ learns to rev erse the diffusion pro cess, so that an arbi- trary noise z T ∼ N (0 , I ) can b e mapp ed to a denoised latent co de z 0 via a series of denoising steps, t = T , . . . , 0. At a single denoising step t , giv en the denoised sample z t +1 from the previous step, the diffusion mo del Ψ predicts the mean µ t and standard deviation σ t of the denoised sample z t via a non-linear transformation, formulated as ( µ t , σ t ) = trans(Ψ( z t +1 , t )) , (13) where trans maps the output of the diffusion mo del to the statistics of z t . After that, a random noise ϵ t ∼ N (0 , I ) is sampled from the Gaussian distribution to predict z t as follo ws: z t = µ t + σ t · ϵ t . (14) T o analyze the diffusion mo del in the memorize-generalize picture, consider a latent dif- fusion model Ψ T trained on Z T ≡ { z τ } N T τ =1 . Giv en a set of M noise tensors, Z T ≡ { z m T } M m =1 , z m T ∼ N (0 , I ), the denoising pro cess of Ψ consecutively maps the set of tensors into a set of denoised latent co des, Z 0 ≡ { z m 0 } M m =1 . In the contin uous limit, the probabilit y distributions of the t wo sets Z T and Z 0 can be form ulated as p Z T ( z τ ) and p Z 0 ( z m 0 ). As demonstrated b y the previous literature [ 11 ], Ψ T minimizes the discrepancy b etw een the tw o dis- tributions by minimizing the distribution discrep- ancy b et ween the denoised and diffused samples at each denoising and diffusion step t . Therefore, the distribution discrepancy b et w een the samples T and X 0 deco ded from the laten t co des Z , Z 0 is minimized for a fixed deco der. In summary , the deco ded denoised sample set X 0 of a latent diffusion mo del Ψ T trained on the laten t code set Z T enco ded from T has a probabil- it y distribution with minimized discrepancy from that of X . Hence, X 0 naturally fulfills the equiv a- len t dataset distillation ob jective in the memorize- generalize picture, serving as an effectiv e surrogate set S . 3.4 The Random Sampling Bias The previous analysis theoretically demonstrates that a diffusion model Ψ T trained on the target dataset T naturally generates effective surrogate samples for T , fulfilling the dataset distillation 8 ob jective. How ever, in practice, when the size of the surrogate set is limited, the alignment is sub-optimal, resulting in reduced training p erfor- mance. T o analyze the misalignment, consider a par- ticular step t in the denoising process that gener- ates a laten t surrogate set Z S 0 ≡ { z s 0 } N S s =1 of size N S . At step t , a latent co de denoted as z τ t is dif- fused from its corresp onding target latent co de, z τ ∈ Z T , using Equation 12 , and a denoised co de z s t is computed with Equation 14 : z s t = µ s t + σ s t · ϵ s t . (15) Therefore, the probabilit y distribution of z s t in the con tinuous limit, denoted as p ( z s t ), satisfies the follo wing relationship: p ( z s t ) dz s t = p ( µ s t , σ s t , ϵ s t ) dµ s t dσ s t dϵ s t = p ( µ s t , σ s t ) p ( ϵ s t ) dµ s t dσ s t dϵ s t (16) Hence, p ( z s t ) is indep enden tly determined by the join t distribution of ( µ s t , σ s t ) and the distribution of ϵ s t . Ideally , ϵ s t strictly follows the Gaussian dis- tribution N (0 , I ), and ( µ s t , σ s t ) follo w an ideal distribution denoted as p ∗ ( µ t , σ t ), so that p ( z s t ) strictly aligns to the diffused laten t co de probabil- it y p ( z τ t ). How ever, in practice, b oth distributions can b e compromised. The statistics distribution p ( µ s t , σ s t ) may deviate from the ideal p ∗ ( µ t , σ t ) due to systematic bias, and the noise distribution may deviate from N (0 , I ) due to random errors. In light of Equation 13 , the systematic bias in p ( µ s t , σ s t ) stems from three sources: the bias in the denoised sample distribution from the pre- vious step p ( z τ t +1 ), the inherent bias of the dif- fusion mo del Ψ T , and the bias in the mapping function trans( · ). Previous works on diffusion- based dataset distillation hav e attempted to mit- igate the bias in Ψ T b y a Minimax fine-tuning (Gu, 2024 [ 4 ]) and calibrate trans( · ) by mo dify- ing its guidance function (Chen, 2025 [ 5 ]; Chen, 2025 [ 48 ]). How ever, even if the systematic bias in p ( µ s t , σ s t ) has b een mitigated, the random sam- pling bias in ϵ s t p ersists due to the random noise sampling, as illustrated in App endix B through a simple Monte-Carlo exp erimen t. Therefore, the denoised latent co de distribution p ( z s t ) still differs from the target diffused latent co de probability p ( z τ t ) regardless of the calibration prop osed by previous works. In the subsequent denoising step t − 1, the bias in p ( z s t ) results in a distribution bias in ( µ t − 1 , σ t − 1 ), which colludes with the ran- dom sampling bias in ϵ t − 1 to pro duce even more biased denoised laten t co de distribution p ( z s t − 1 ). The accum ulation of the distribution bias results in a biased sampling of Z S 0 , resulting in p er- formance degradations of the deco ded surrogate dataset S . In summary , the random noise sampling at eac h step of the denoising process of a diffu- sion mo del results in a bias in the step-wise denoised latent co de distribution that accumulates across the denoising pro cess, resulting in impaired training performance of the synthesized surro- gate dataset. In order to mitigate this problem, this work prop oses a Noise-Optimization frame- w ork to manually align the denoised latent co de distribution with the diffused target probability distribution, as detailed in Section 4.1 . 3.5 The F ar-Apart Samples In the memorize-generalize picture, the chance of recognition monotonically decreases with the L-2 distance b et w een the pro jected features in RKHS. In this case, we can define a sp ecific recognition threshold r rec asso ciated with the do wnstream mo del in the RKHS, as illustrated by the dashed rings in Figure 1 . F or a surrogate feature f s , if a target feature f τ lies further aw ay from it than r rec , the corresp onding target sample x τ is very unlik ely to b e recognized by memorizing x s . The recognition threshold is a direct indicator of the generalization capabilit y of the mo del, as mo d- els with larger r rec could recognize more target samples b y memorizing few er surrogate samples. F or a mo del with recognition threshold r rec , consider a sp ecial kind of target samples whose feature distances from their nearest neighbors in the target set in RKHS are greater than 2 × r rec . In this work, these samples are termed ”far- apart samples”. A key property that distinguishes these samples from other ordinary target sam- ples is that, for an arbitrary surrogate sample, there can be at most one far-apart sample that is recognized by memorizing the surrogate sample. This is b ecause the recognition threshold around an arbitrary surrogate feature in the RKHS can accommo date at most one far-apart sample. The existence of far-apart samples results in a natural limitation in the dataset distillation 9 paradigm, which synthesizes surrogate samples to maximize the exp ected chance of recognition of the target dataset. That is, when all the non-far- a wa y samples hav e been recognized b y memorizing the surrogate dataset, the num b er of extra tar- get samples recognized by synthesizing one extra surrogate sample cannot exceed one. In this case, since the cost of syn thesizing one surrogate sam- ple is significantly greater than directly sampling a target sample, it is no longer efficient to synthe- size more surrogate samples. Instead, the far-a wa y samples should b e directly sampled to complement the syn thesized samples. In this work, we term this impro ved strategy b ey ond dataset distillation as ”Doping”. 4 Metho d As indicated by the theoretical analysis, the state-of-the-art diffusion-based dataset distillation paradigm has tw o fundamen tal limitations: the p ersisten t random sampling bias present in denois- ing synthesis and the inefficiency in syn thesizing surrogate samples for far-apart samples. More- o ver, in practice, the target dataset can b e inac- cessible due to v arious reasons, such as safety , priv acy , cop yright, and transfer costs. The inac- cessibilit y renders the ma jority of existing dataset distillation metho ds inapplicable, and the appli- cable ones (SRe 2 L and v anilla DiT) suffer from sub-optimal training performances. In this w ork, we propose a D ata s et Co ncen tration (DsCo) framework to resolv e these problems. The DsCo framework is illustrated in Figure 2 . As illustrated in the figure, for a tar- get dataset, DsCo firstly synthesizes a compact and informativ e sample set using an inno v a- tiv e diffusion-based N oise- Opt imization (NOpt) metho d that mitigates the sampling bias and enforces a step-wise distribution alignment b y optimizing the random noise tensors up on gen- erating synthetic samples through the denoising pro cess of the diffusion mo del. In particular, the distribution alignment can b e enforced in both data-accessible and data-free scenarios, where the target distribution information is obtained either b y enco ding and diffusing the accessi- ble target samples or by generating step-wise laten t co des using the denoising pro cess of the diffusion mo del pre-trained on the inaccessible target dataset. After the denoising pro cess, the denoised synthetic latent co des are decoded into syn thetic samples with a deco der. Subsequently , if the samples hav e reac hed the efficiency limit of the synthesis paradigm (indicated by the ”Dop e T rigger” in the figure), the far-apart samples in the target dataset are iden tified and selected to complement the syn thesized sample set. This pro cess is termed Doping. It effectively replaces the crowded samples (denoted by the blue dots in the figure) that can be represented by the syn- thetic samples with the set of synthetic samples (denoted b y the gra y cylinder), and preserv es the far-apart samples denoted b y the pink dots. The Doping pro cess enables the extension of the surrogate dataset to high IPCs that are b ey ond the extensibility of the curren t dataset distilla- tion metho ds. In the end, the DsCo framework comp oses a surrogate dataset for the target dataset under b oth data-accessible and data-free scenarios. If Doping is triggered and the target data can b e accessed, the concentrated dataset is a mixture of selected far-apart target samples and the synthetic samples generated with data- accessible distribution alignment. Otherwise, the concen trated dataset is the set of synthetic sam- ples generated by NOpt with data-accessible or data-free distribution alignmen t. 4.1 The Noise-Optimization F ramew ork In ligh t of the theoretical analysis in Section 3.4 , a generativ e diffusion mo del is trained so that its denoising pro cess generates samples whose distribution in the contin uous limit aligns with the target sample distribution. Hence, a diffusion mo del can b e used to generate a set of surrogate samples to replace the target sample set to train do wnstream mo dels while preserving the mo del p erformance. How ev er, there exist m ultiple biases in the denoising pro cess, including the systematic biases in the diffusion mo del and the denoising transformation, and the random bias incurred b y random noise sampling at eac h denoising step. The biases impair the distribution alignmen t, resulting in sub-optimal training p erformance of the sur- rogate set. Among the biases, the random bias stemming from random noise sampling cannot be mitigated by mo difying the diffusion mo del or the denoising transformation. Therefore, this w ork prop oses the N oise- Opt imization (NOpt) method 10 Fig. 2 The Dataset Concentration framework. Enclosed in the gray region is the iterative denoising pro cess of NOpt; the dashed red arrows indicate the gradient flow during each noise-optimization. that enforces distribution alignment by optimizing the noise tensors in the denoising pro cess. The left of Figure 2 illustrates the prop osed Noise-Optimization (NOpt) metho d. It is an impro ved DDPM denoising pro cess that synthe- sizes the set of synthesized latent co des Z S ≡ { z s } N S s =1 through iterative denoising steps with optimized noise tensors, where s is the sample index. Sp ecifically , the gray region enclosed by the dashed black lines illustrates the denoising steps of NOpt in detail. A t each step t , the diffu- sion mo del predicts the set of sample-wise means and standard deviations of the denoised samples, { ( µ s t , σ s t ) } N S s =1 from the denoised samples from the previous step, denoted as Z S t +1 . Meanwhile, a set of Gaussian noise tensors denoted as E S t ≡ { ϵ s t } N S s =1 is sampled randomly . After that, the noise ten- sors are optimized to enforce feature distribution alignmen t under a reality constrain t. A t each step of the optimization of the noise tensors, the set of denoised samples, Z S t , are computed with Equation 13 from E S t and { ( µ s t , σ s t ) } N S s =1 , and pro- jected into features with a random pro jector. The set of features is denoted as F S t . Subsequently , it enforces the distribution alignment constraint under either data-accessible or data-free scenario, as detailed in Section 4.1.3 and 4.1.4 . Meanwhile, a realit y constraint applies a geometric regulariza- tion on the noise tensors, E S t . The noise tensors are then optimized to minimize the feature distribu- tion dissimilarity and the reality constraint. After the noise optimization, the final denoised latent co des computed from the optimized noise tensors are passed in to the next denoising step t − 1. 4.1.1 Realit y Constraint The Noise-Optimization framew ork optimizes the set of noise tensors E S t to minimize the feature dis- tribution dissimilarit y b et ween the denoised and diffused samples. Ho wev er, as the optimization pro ceeds, the noise tensors may deviate signifi- can tly from the Gaussian distribution, resulting in out-of-distribution denoised samples. T o a void this issue, w e prop ose a realit y constraint that regular- izes the noise to follow the Gaussian distribution. F or illustration, consider an arbitrary d - dimensional noise sample u = ( u 1 , . . . , u d ) T ∈ R d from the d -dimensional Gaussian distribution. Eac h element, u i , independently follo ws the stan- dard normal distribution, u i ∼ N (0 , 1). The L-2 11 norm of u , denoted as norm( u ), can be reformu- lated as norm( u ) = v u u t d X i ( u i − 0) 2 = p d · V ar( ˆ u ) , (17) where V ar( ˆ u ) is the sample v ariance of d sam- ples { ˆ u } independently sampled from N (0 , 1). As d increases, the law of large num b ers ensures that V ar( ˆ u ) → 1, hence norm( u ) → √ d . Therefore, the norm of a sample from the high-dimensional standard normal distribution is almost surely close to √ d . Since the high-dimensional standard normal distribution is spherically homogeneous, w e argue that an y d -dimensional tensor u with norm( u ) ≈ √ d is very likely to b e sampled from the d -dimensional normal distribution. The ab o ve analysis indicates that we can reg- ularize any noise tensor ϵ t ∈ R d to follow the d -dimensional Gaussian distribution by minimiz- ing the discrepancy b et ween its norm and √ d . F or fast conv ergence, we adopt the ”absolute and square” function, defined as absn 2 ( x ) ≡ | x | + x 2 , ∀ x ∈ R , (18) whic h provides non-diminishing gradient at all x except for x = 0 (where its gradien t is set to 0). In summary , for the set of noise tensors, E S t = { ϵ s t } , ϵ s t ∈ R C,H,W , the realit y constrain t is L t real ≡ N S X s =1 absn 2 (norm( ϵ s t ) − √ C H W ) . (19) . 4.1.2 Random F eature Pro jection As prop osed b y [ 50 ], a key c haracteristic of visual features is the spatial shift-in v ariance. That is, the spatial shift of a visual feature con tributes little to the identification of the feature. Latent DD [ 51 ] has demonstrated that this prop ert y is also present in the enco ded latent space of V AE. Therefore, the latent denoised samples also p ossess this property of shift-inv ariance. Conse- quen tly , the v ariation in the exact lo cation of a visual feature in a denoised latent co de z t con- tributes little to the information capacity of the laten t co de. When the num b er of samples in the condensed set is limited, the v ariations in the spa- tial lo cations of the visual features in the target dataset impose an extraneous spatial distribution constrain t that detrimentally in terferes with the information capacit y of the syn thesized samples. T o mitigate this problem, this w ork proposes to pro ject each latent co de, z t ∈ R C,H,W , into a feature of significan tly reduced spatial dimen- sions ( K ≪ H , L ≪ W ) and increased channel dimension J ≫ C , denoted as f t ∈ R J,K,L . The pro jection is conducted with a randomly initial- ized 3-la y er Con volutional Neural Net work (CNN) arc hitecture similar to the enco der architecture used in the small-scale V AE (Kingma, 2013 [ 12 ]), as detailed in App endix C . In particular, to sav e computational cost in feature pro jection, w e adopt the grouped conv olutional la yers (Krizhevsky , 2012 [ 52 ]) in the pro jector, making it equiv alent to multiple random pro jectors that indep enden tly and simultaneously pro ject the latent codes into a concatenated set of indep enden t random features. The b enefit of pro jecting the laten t codes in to features using a randomly initialized conv olutional neural netw ork is b ey ond the mitigation of spatial redundancy . In fact, it also facilitates the subse- quen t distribution alignment b y decoupling the en tangled laten t co de distribution in to a series of c hannel-wise feature distributions that are nearly indep enden t. As demonstrated b y the previous lit- erature (Nov ak, 2018 [ 53 ]), for a single la yer of a conv olutional neural netw ork with m channels, the correlation b et ween different c hannels of its output diminishes at the sp eed of O (1 / √ m ) as m increases. Since the pro jector used in this work is wide, with J ≫ C , the correlation betw een differen t channels of f t is strongly suppressed. Therefore, the pro jected feature f t can be viewed as J independent features concatenated together. 4.1.3 Data-Accessible Distribution Alignmen t As illustrated in Section 3.4 , the random sam- pling bias results in an accumulating distribution mismatc h b et ween the denoised latent co des and the diffused latent co des at each step. Therefore, the distribution of the denoised latent co des at eac h step is biased. T o mitigate this problem, this w ork prop oses to manually align the denoised and diffused latent co de distributions at each step t b y minimizing a distribution alignmen t loss L t align , 12 whic h enforces the distribution alignmen t betw een the tw o sets of pro jected features of the denoised and diffused laten t codes. Diffuse d L atent Co de Distribution The diffused target latent co des are obtained by diffusion. F or eac h latent co de z τ with index τ in the set of target laten t co des Z T , we com- pute its corresp onding diffused latent co de with Equation 12 with random noise for at least five times, and we group all the diffused target latent co des to form a set, denoted as Z Diff t ≡ { z τ ′ t } N Diff τ ′ =1 . N Diff denotes the total num b er of diffused latent co des in Z Diff t , which is automatically adjusted to the minimal v alue that satisfies N Diff mo d N S = 0 and N diff / N S ≥ 5 to facilitate the subsequen t dis- tribution alignment. τ ′ denotes the index of the diffused laten t co de. Channel-Wise Distribution Alignment As previously argued in Section 4.1.2 , the t wo sets of latent codes are pro jected into feature tensors, F S t ≡ { f s t } s = N S s =1 and F Diff t ≡ { f τ ′ t } τ ′ = N Diff τ ′ =1 , with f s t , f τ ′ t ∈ R J,K,L . The correlation b et ween the c hannels of the features is strongly suppressed b y the random pro jector. Therefore, the feature dis- tribution alignmen t can b e enforced in a c hannel- wise manner, where each channel of the tw o sets of features is indep enden tly aligned. F or simplicit y , w e further reduce the spatial dimensions of the features to (1 , 1) with a Global Av erage Pooling (Lin, 2013 [ 54 ]) lay er, so that eac h channel has only one dimension. F urther, the tw o sets of p ooled features are normalized by the element-wise mean and standard deviation of the p ooled features of Z Diff t for scale-inv ariance. The p ooled and normalized features are denoted as ˆ F S t ≡ { ˆ f s t } N S s =1 and ˆ F Diff t ≡ { ˆ f τ ′ t } N Diff τ ′ =1 , where ˆ f s t , ˆ f τ ′ t ∈ R J . The t wo sets of j -th elemen ts of the normalized features are denoted as ˆ F S ,j t ≡ { ˆ f s,j t } N S s =1 and ˆ F Diff ,j t ≡ { ˆ f τ ′ ,j t } N Diff τ ′ =1 . F or each channel j , the alignment is enforced b y minimizing the discrepancy b et ween each ˆ f s,j t and its corresp onding in terp olated percentile in ˆ F Diff ,j t , which is the solution to the one- dimensional optimal transp ort problem (Villani, 2021 [ 55 ]). In practice, ˆ F Diff ,j t is sorted in ascend- ing order and subsequently ch unked into N S groups of equal size, N ch unk = N Diff / N S , which is b ound to b e an integer as N Diff mo d N S = 0. Subsequen tly , eac h p ercen tile corresponding to the resp ectiv e ˆ f s,j t is computed by taking the a v erage of ˆ f τ ′ ,j t s in the corresp onding group. Finally , the c hannel-wise distribution alignment for c hannel j is enforced b y minimizing the follo wing loss: L t ch ,j = N S N S X s =1 absn 2 ( ˆ f s,j t − P s × N ch unk τ ′ =( s − 1) × N ch unk ˆ f τ ′ ,j t N ch unk ) , (20) where the extra N S corrects for the v ariation in the loss v alue with N S . A lignment Enfor c ement In summary , the feature distribution alignmen t is enforced b y minimizing the following distribution alignmen t loss: L t align ≡ λ align J X j L t ch ,j . (21) The λ align is a hyperparameter determining the strength of feature distribution alignment relative to the realit y constrain t. 4.1.4 The Data-free Distribution Alignmen t In the data-free scenario, a data-free version of the distribution alignment is enforced without access to the target dataset. Since the samples in the tar- get dataset cannot b e accessed, the diffused laten t co des at t cannot b e prop erly acquired. T o resolve this problem, w e approximate the feature distri- bution of the diffused target latent co des using the statistics of the features of the denoised latent co des, and apply data-free distribution alignmen t b y maximizing the spatial o ccupation of the syn- thesized sample features under regularization of the appro ximated feature distribution. Distribution Appr oximation In order to appro ximate the diffused distribution, w e generate a random template set of latent codes via the DDPM denoising process of the pre-trained diffusion model. The set of template denoised laten t co des at step t is denoted as Z temp t ≡ { z i t } N temp i =1 , where N temp is the num b er of template samples. 13 Subsequen tly , we pro ject the template denoised latent co des Z temp t in to features, F temp t ≡ { f i t } N temp i =1 , f i t ∈ R J,K,L , with the previ- ously mentioned random pro jector, and calculate the first tw o statistics (i.e., the mean and stan- dard deviation) of the set of pro jected template features. In particular, to remov e the extraneous spatial information, the statistics are computed in a channel-wise manner. F or an arbitrary set of N features F ≡ { f i } N i =1 with shap e f ∈ R J,K,L , elemen t indices j, k , l , and feature index i , the c hannel-wise mean (mean ch ( F ) ∈ R J ) and stan- dard deviation (std ch ( F ) ∈ R J ) are computed as follo wing: mean ch ( F ) j ≡ 1 N K L N , K,L X i,k,l f i j,k,l , (22) std ch ( F ) j ≡ v u u t 1 N K L N ,K,L X i,k,l [ f i j,k,l − mean ch ( F ) j ] 2 . (23) F urther, for tw o arbitrary sets of features, F ≡ { f i } N i =1 , f i ∈ R J,K,L and F ′ ≡ { f m ′ } N ′ m ′ =1 , f m ′ ∈ R J,K,L , we define a channel- wise cross-normalization function that normalizes a sample f i with elemen t indices j, k, l in F by the c hannel-wise statistics of F ′ , normalize( f i , F ′ ) j,k,l ≡ f i j,k,l − mean ch ( F ′ ) j std ch ( F ′ ) j . (24) Thereafter, we cross-normalize the pro jected fea- tures of the surrogate laten t co des, F S t , with the pro jected template features, F temp t , to com- pute the data-free distribution alignment loss. The set of cross-normalized pro jected laten t fea- tures is denoted as F S t ≡ { f s t } N S s =1 . In prac- tice, the distribution alignment is enforced by a maximal-o ccupation loss under the constraint of a c hannel-wise feature statistics regularization. Maximal Oc cup ation The maximal o ccupation loss maximizes the spa- tial o ccupation of each cross-normalized pro jected feature, f s t , in the pro jected feature space R J,K,L . The motiv ation is t w ofold. Firstly , maximizing the spatial o ccupation of each pro jected feature mit- igates the sample o verlapping problem illustrated in Section 3.4 . Secondly , as demonstrated in the previous literature (Gu, 2024 [ 4 ]), a generative dif- fusion mo del trained on the target dataset tends to generate representativ e samples that reside in the dense regions of the target sample distribu- tion, leading to insufficient diversit y . Maximizing the spatial occupation of eac h latent co de feature impro ves the diversit y b y increasing the feature dissimilarit y among the samples. In practice, the Maximal Occupation loss max- imizes the cosine distance d cos of each cross- normalized surrogate feature f s t from its nearest neigh b or in F S t , where d cos ( u, v ) ≡ − ( u · v / | u || v | ) for any u, v ∈ R d . F or a generic sample u of arbi- trary shap e from a set U , its nearest neigh b or nn( u ) is nn( u ) ≡ arg min u ′ ∈U ,u ′ = u D cos ( u, u ′ ) . (25) Therefore, the maximal-occupation loss, denoted as L t maxoc , is L t maxoc ≡ − N S X s d cos ( f s t , nn( f s t )) . (26) F e atur e Statistics R e gularization While the maximal o ccupation loss impro ves the feature diversit y in the surrogate sample, exces- siv e div ersity results in a distribution mismatch b et ween the surrogate set and the target dataset, as demonstrated in the previous literature (Gu, 2024 [ 4 ]). T o a void this problem, we enforce a distribution regularization on the statistics of the surrogate features, explicitly aligning the c hannel- wise mean and standard deviation of the set of surrogate features to those of the template features, which serve as appro ximations to the fea- ture statistics of the diffused laten t co des from the target dataset. Since the surrogate features ha ve been cross-normalized b y the statistics of the template features, the regularization is enforced b y minimizing the discrepancy of the channel- wise mean and standard deviation of the set of cross-normalized features from 0 and 1, resp ec- tiv ely . Therefore, the feature statistics regulariza- tion term of the data-free distribution alignment 14 loss is L t stats ≡ J X j absn 2 mean ch ( F S t ) j − 0 + J X j absn 2 std ch ( F S t ) j − 1 . (27) A lignment Enfor c ement In summary , the data-free distribution alignment loss can be formulated as L t align ≡ λ stats L t stats + λ maxoc L t maxoc , (28) where λ stats and λ maxoc are the resp ectiv e hyper- parameters regularizing the relativ e strengths of the t wo terms. In particular, the λ maxoc is fixed to the maximal v alue that enables the synthesis of visually sensible samples when λ stats is 0. F or all exp erimen ts presen ted in this work, this v alue is 10.0. 4.1.5 The Noise-Optimization Ob jective In light of the abov e form ulation, at each denoising step t , the Noise-Optimization metho d optimizes the noise tensors to minimize a combined noise- optimization loss L NOpt , whic h is defined as L t NOpt ≡ L t real + L t align , (29) where L t real is defined in Equation 19 , and the data-accessible and data-free v ersions of L t align are defined in Equation 21 and Equation 28 , resp ectiv ely . 4.2 Dop e T rigger and Doping In light of the analysis in section 3.5 , the far- apart samples are special samples whose nearest neigh b ors in the target dataset are b ey ond the generalization capabilit y of the classifier. F or these samples, it is uneconomic to synthesize represen- tativ e samples, bec au se one syn thesized sample can cov er at most one far-apart sample, yet syn- thesizing a surrogate sample incurs extra costs compared to directly sampling the exact target sample. Instead, this work proposes to identify and sample these samples to mix them up with the previously synthesized represen tative samples, forming a mixed dataset. How ever, there are tw o problems to be resolv ed: When to switch from syn- thesis to sampling? Ho w to sample the far-apart samples? 4.2.1 The Dop e T rigger The Dop e T rigger describ es a criterion on the n umber of samples synthesized, which determines when the switching from synthesis to sampling o ccurs. The criterion is deduced based on the reasoning below. In ligh t of the theoretical analysis, the distilled syn thetic samples are syn thesized to maximize the num b er of samples recognized by the mo del b y minimizing their distribution discrepancy from the target dataset. In the RKHS picture, as illus- trated in Figure 1 , the synthetic samples need to enclose as many target samples as p ossible into their recognition thresholds to increase the num- b er of target samples recognized. Therefore, these syn thetic samples tend to concentrate around the high-densit y regions of the target distribution. As the n umber of syn thetic samples increases, the new syn thetic samples tend to occupy the previ- ously uno ccupied regions with the highest target sample densit y . Therefore, the num b er of addi- tional target samples recognized by the addition of synthetic samples monotonically decreases as the n umber of synthetic samples increases. Denot- ing a synthetic dataset of M samples as S M , and the corresp onding num b er of target samples rec- ognized as N M , the marginal gain of increasing the num ber of synthetic samples from M 1 to M 2 can be defined as ∆ N ∆ M ≡ N M 2 − N M 1 M 2 − M 1 , (30) whic h monotonically decreases as M 1 increases. When ∆ N ∆ M > 1, the syn thetic dataset has not fully cov ered the crowded samples, th us the Dop e T rigger is off. When ∆ N ∆ M ≤ 1, adding one syn- thetic sample results in the recognition of at most one target sample, thus all the crowded samples ha ve been recognized, and the unrecognized target samples are all far-apart samples. In summary , the Dop e T rigger is essen tially the condition that ∆ N ∆ M ≤ 1. When the Dope T rigger is on, the Doping metho d is adopted to incorp orate the far-apart samples into the surrogate dataset. 15 4.2.2 Doping Giv en a designated size of surrogate set measured in the n umber of items per class (IPC), the Dop e T rigger determines whether the synthetic dataset has cov ered the cro wded regions in the target sam- ple distribution, and the Doping metho d identifies the far-apart samples to b e selected. Since the c hance of a target sample b eing recognized b y a mo del diminishes as its RKHS feature distance from its nearest surrogate neighbor increases, the more confused the mo del is ab out the target sam- ple, the further it is from the crowded region of the target sample, the more lik ely it is a far-apart sample. Hence, w e can iden tify the far-apart sam- ples b y assessing the degree to which the mo del trained on the syn thesized represen tative samples is confused ab out them, which is measured in the confusion score. The confusion score is determined as follows. Firstly , a do wnstream mo del, ϕ S is trained with the previously syn thesized small dataset S and the corresp onding labels provided b y a mo del ϕ T pre-trained on the target dataset. Subsequently , a confusion score is computed for each sample in the target dataset based on the predictions made by b oth mo dels. The confusion score mea- sures the degree to whic h the decision made b y ϕ S differs from ϕ T . F or a training sample x i ∈ T , the mo dels trained on the target dataset and the syn thesized dataset make p ost-softmax predictions, p T ( x i ) = ( p 1 T ( x i ) , . . . , p C T ( x i )) T and p S ( x i ) = ( p 1 S ( x i ) , . . . , p C S ( x i )) T , resp ectiv ely . The prediction made b y ϕ T is c T ≡ argmax c p c T . The confusion score measures the degree to which ϕ S disagrees with this prediction: Conf ≡ p c T S − max c = c T p c S . (31) If a sample has a prediction made by ϕ S that disagrees with that made by ϕ T , it is b ound to ha ve p ositiv e confusion scores, and those with unanimous hard predictions hav e negative confu- sion scores. This gives the samples with erroneous predictions a higher priorit y compared to those that hav e been correctly classified. In practice, the samples with the highest confusion scores are selected to complemen t the syn thetic sample set. 5 Exp erimen ts 5.1 Exp erimen tal Setup 5.1.1 Datasets W e follow previous diffusion-based dataset con- densation metho ds to ev aluate the proposed framew ork on the ImageNet-1K (Deng, 2009 [ 7 ]) dataset and its tw o representativ e subsets, Ima- geNette and ImageW o of, prop osed in (Jerem y , 2019 [ 49 ]). The ImageNet-1K dataset is a large- scale image classification dataset with 1000 classes of images, with at most 1300 training images and 50 test images in eac h class. The ImageNette and ImageW o of datasets are tw o representativ e subsets of ImageNet-1K. ImageNette is a simple subset that consists of 10 very dissimilar classes, while ImageW o of consists of ten dog breeds bear- ing significant visual similarity , making it difficult for classification tasks. All images are resized to 224 × 224 upon training classifiers. 5.1.2 Ev aluation Metrics This w ork follows previous literature in diffusion- based DD to ev aluate the condensed or con- cen trated datasets with the top-1 classification accuracies of a v ariety of model arc hitectures trained on the corresp onding datasets. The archi- tectures include Con vNet-6 (LeCun, 2002 [ 50 ]), ResNet-AP10 (He, 2016 [ 8 ]), ResNet-18, ResNet- 34, ResNet-101, Efficien tNet-B0 (T an, 2019 [ 56 ]), MobileNet-V2 (Sandler, 2018 [ 57 ]), and DenseNet- 121 (Huang, 2017 [ 58 ]). Unless otherwise sp eci- fied, the mo dels are trained on the concentrated dataset fiv e times, and the a verage ev aluation p er- formances are rep orted with the corresp onding standard deviations. 5.1.3 Implemen tation Details F or the Dataset Concen tration framework under b oth data-accessible and data-free scenarios, we follo w previous diffusion-based DD metho ds to use a publicly av ailable latent DiT (William, 2022 [ 59 ]) mo del pre-trained on ImageNet-1K as the bac kb one diffusion mo del, whic h is av ailable for do wnload in the co de repository asso ciated with the DiT pap er; the images are enco ded and deco ded with a pre-trained V AE model from Sta- ble Diffusion (Robin, 2021[ 60 ]). F or the ev aluation of the comp osed or distilled surrogate sets, the 16 training settings of the mo dels are the same as in (Chen, 2025 [ 5 ]), where all the models are trained with the AdamW (Loshchilo v, 2017 [ 61 ]) optimizer, unless otherwise sp ecified. The detailed implemen tations of the training of the mo dels are sp ecified in App endix D . The use of the rela- b eling technique that provides informativ e soft lab els for the distilled or composed samples using a pre-trained ResNet-18 model, whic h is com- monly adopted in the Dataset Distillation litera- ture (Yin, 2023 [ 33 ]; Yin, 2023 [ 34 ]; Sun, 2024 [ 39 ]; Chen, 2025 [ 5 ]), is sp ecified in the corresp onding analyses where applicable. The specific implemen- tations of NOpt, Dop e T rigger, and Doping are detailed below. NOpt Implementation Details In the Noise-Optimization (NOpt) stage of datasets concentration, the surrogate noises, ϵ s t s, are optimized for 200 steps by an SGD optimizer with a learning rate of 0.1 and a momentum of 0.9. The encoder-like feature pro jector is detailed in Appendix C . F or the data-free distribution alignmen t, 200 random denoised template sam- ples are used to compute the feature statistics. The adjustable h yp erparameters for the data- accessible and data-free distribution alignmen t, λ align and λ stats , are set to 0.0005 and 0.001 for all the exp erimen ts in this w ork except in the abla- tion studies, where they are tuned to analyze the h yp erparameter sensitivit y . Dop e T rigger and Doping In this w ork, the Dop e T rigger is determined by assessing the marginal gain of increasing the n um- b er of synthesized samples, ∆ N ∆ M ≡ N M 2 − N M 1 M 2 − M 1 . The synthetic dataset size M is incremen ted in a sc hedule of (10IPC, 50IPC, 100IPC, 150IPC), and the corresp onding marginal gains are com- puted to determine the Dop e T rigger. F or the ImageW o of and IMageNette, ∆ N ∆ M > 0 for 10IPC, 50IPC, and 100IPC, hence the Doping is triggered when the designated surrogate size is greater than 100IPC. F or ImageNet-1k, Doping is triggered for surrogate sizes greater than 50IPC. The Doping in this work is p erformed by sampling the sam- ples with the highest confusion scores, which are computed with the resp ectiv e ev aluation mo dels, unless otherwise sp ecified in the corresponding exp erimen t. Fig. 3 ResNet-18 Accuracy vs IPC for ImageNet-1k. The sub-figure enclosed in the ma jor figure depicts the 10IPC and 50IPC p erformances, which are commonly rep orted in the dataset distillation literature. 5.1.4 Baselines W e compare the DsCo framew ork with a v ariety of existing dataset distillation metho ds, includ- ing the traditional DD methods (DM(Zhao, 2023 [ 30 ]), IDC(Kim, 2022 [ 24 ]), SRe 2 L(Yin, 2023 [ 33 ]), CDA (Yin, 2023 [ 34 ]), EDC (Shao, 2024 [ 37 ]), G-VBSM (Shao, 2024 [ 35 ]), SC-DD [ 36 ] (Zhou, 2024 [ 36 ]), CV-DD (Cui, 2025 [ 62 ]), patch- w ork methods (RDED (Sun, 2024 [ 39 ]), DDPS (zhong, 2024 [ 40 ])), and the diffusion-based gen- erativ e DD metho ds (D 3 MAbbasi, 2024 [ 2 ],D 4 M (Su, 2024 [ 3 ]), TDSDM (Y uan, 2023 [ 47 ]), DiT (William, 2022 [ 59 ]), Minimax (Gu, 2024 [ 4 ]), IGD (Chen, 2025 [ 5 ]), and OT (Chen, 2025 [ 48 ])). In particular, for fair comparison, we repro duce the samples for DiT using the publicly av ailable DiT c heckpoint and rep ort the repro duced ev aluation p erformances. W e label the repro duced DiT base- line with a † sign for identification. Besides, it is w orth noting that EDC and OT use sp ecifically tailored soft lab els instead of the commonly used ResNet-18 soft lab els for the ImageNet-1k exp er- imen ts; thus, the tw o metho ds are not presented as baselines in the corresp onding tables to a void misleading comparisons. 17 T able 1 Performance comparison on ImageNette under low-IPC setting. Best p erformances are denoted in b old . ImageNette Mo del Con vNet6 ResNetAP-10 ResNet-18 F ull 94.3 ± 0.5 94.6 ± 0.5 95.3 ± 0.6 IPC 10 50 100 10 50 100 10 50 100 Data-Accessible Random 46.0 ± 0.5 71.8 ± 1.2 79.9 ± 0.8 54.2 ± 1.2 77.3 ± 1.0 81.1 ± 0.6 55.8 ± 1.0 75.8 ± 1.1 82.0 ± 0.4 DM 49.8 ± 1.1 70.3 ± 0.8 78.5 ± 0.8 60.2 ± 0.7 76.7 ± 1.1 80.9 ± 0.7 60.9 ± 0.7 75.0 ± 1.0 81.5 ± 0.4 IDC-I 48.2 ± 1.2 72.4 ± 0.7 80.6 ± 1.1 60.4 ± 0.6 77.4 ± 0.7 81.5 ± 1.2 61.0 ± 1.8 77.5 ± 1.0 81.7 ± 0.8 Minimax 58.2 ± 0.9 76.9 ± 0.8 81.1 ± 0.3 63.2 ± 1.0 78.2 ± 0.7 81.5 ± 1.0 64.9 ± 0.6 78.1 ± 0.6 81.3 ± 0.7 DiT-IGD 61.9 ± 1.9 80.9 ± 0.9 84.5 ± 0.7 66.5 ± 1.1 81.0 ± 1.2 85.2 ± 0.8 67.7 ± 0.3 80.4 ± 0.8 84.4 ± 0.8 Minimax-IGD 58.8 ± 1.0 82.3 ± 0.8 86.3 ± 0.8 63.5 ± 1.1 82.3 ± 1.1 86.1 ± 0.9 66.2 ± 1.2 82.0 ± 0.3 86.0 ± 0.6 OT 67.0 ± 0.9 83.1 ± 1.0 86.5 ± 0.5 68.0 ± 0.3 83.8 ± 0.6 86.4 ± 0.6 69.1 ± 1.9 84.6 ± 0.4 85.9 ± 0.2 DsCo(ours) 65.7 ± 0.8 83.2 ± 0.6 86.9 ± 0.2 69.8 ± 1.1 84.0 ± 0.7 86.9 ± 0.8 70.3 ± 0.1 83.4 ± 0.9 86.5 ± 0.9 Data-F ree DiT † 61.5 ± 0.9 74.3 ± 0.9 79.1 ± 1.1 64.8 ± 0.3 75.5 ± 0.6 80.5 ± 0.7 64.2 ± 0.9 74.9 ± 0.1 78.2 ± 0.7 DFDsCo(ours) 63.0 ± 1.2 80.3 ± 0.2 82.2 ± 0.4 67.0 ± 1.7 81.8 ± 0.9 81.6 ± 1.1 67.5 ± 0.8 81.0 ± 0.9 79.0 ± 1.0 T able 2 Performance comparison on ImageW o of under low-IPC setting.Best p erformances are denoted in b old . ImageW o of Mo del Con vNet6 ResNetAP-10 ResNet-18 F ull 85.9 ± 0.4 87.2 ± 0.6 89.0 ± 0.6 IPC 10 50 100 10 50 100 10 50 100 Data-Accessible Random 25.2 ± 1.1 41.9 ± 1.4 52.3 ± 1.5 31.6 ± 0.8 50.1 ± 1.6 59.2 ± 0.9 30.9 ± 1.3 54.0 ± 0.8 63.6 ± 0.5 DM 27.6 ± 1.2 43.8 ± 0.8 50.1 ± 0.9 29.8 ± 1.0 47.8 ± 1.2 59.8 ± 1.3 30.2 ± 0.6 53.9 ± 0.7 64.9 ± 0.7 IDC-I 34.1 ± 0.8 42.6 ± 0.9 51.0 ± 1.1 38.5 ± 0.7 49.3 ± 0.9 56.4 ± 0.5 36.7 ± 0.8 54.5 ± 1.0 57.7 ± 0.8 Minimax 33.5 ± 1.4 50.7 ± 1.8 57.1 ± 1.9 39.6 ± 1.2 59.8 ± 0.8 66.8 ± 1.2 42.2 ± 1.2 60.5 ± 0.5 67.4 ± 0.7 DiT-IGD 35.0 ± 0.8 54.2 ± 0.7 61.1 ± 1.0 41.0 ± 0.8 62.7 ± 1.2 69.7 ± 0.9 44.8 ± 0.8 62.0 ± 1.1 70.6 ± 1.8 Minimax-IGD 36.2 ± 1.6 55.7 ± 0.8 63.0 ± 1.8 43.3 ± 0.3 65.0 ± 0.8 71.5 ± 0.8 47.2 ± 1.6 65.4 ± 1.8 72.1 ± 0.9 DsCo(ours) 37.9 ± 0.5 53.7 ± 0.7 63.0 ± 1.5 47.1 ± 0.3 65.3 ± 0.7 71.2 ± 0.3 45.2 ± 1.0 65.5 ± 0.2 72.7 ± 1.0 Data-F ree DiT † 33.3 ± 0.3 47.9 ± 1.0 54.5 ± 1.0 39.7 ± 0.9 57.1 ± 0.6 63.1 ± 1.4 41.1 ± 1.1 57.5 ± 1.7 62.2 ± 0.9 DFDsCo(ours) 34.9 ± 1.3 51.5 ± 0.9 57.6 ± 0.6 41.0 ± 2.2 59.8 ± 0.7 66.6 ± 1.1 43.3 ± 2.1 59.9 ± 1.2 61.2 ± 1.0 T able 3 V alidation Accuracy vs IPC for Dataset Concentration on ImageNette. Dataset ImageNette IPC 200 300 400 700 1000 1300 F ull Ratio% 15.5 23.3 31.0 54.3 77.6 100.8 Mo del Con vNet6 Random 92.6 ± 0.8 92.6 ± 1.1 93.1 ± 0.7 94.7 ± 0.4 95.9 ± 0.2 96.5 ± 0.2 96.5 ± 0.2 DsCo 94.0 ± 0.7 94.2 ± 0.5 94.5 ± 0.6 95.7 ± 0.5 96.5 ± 0.2 96.6 ± 0.2 Mo del ResNetAP-10 Random 92.7 ± 1.1 94.4 ± 0.8 94.5 ± 0.9 96.5 ± 0.4 96.5 ± 0.3 96.8 ± 0.3 96.8 ± 0.3 DsCo 93.5 ± 0.5 94.0 ± 0.6 95.4 ± 0.5 97.2 ± 0.3 97.1 ± 0.1 97.1 ± 0.3 Mo del ResNet-18 Random 95.1 ± 0.7 95.6 ± 0.9 96.1 ± 0.9 97.0 ± 0.4 97.1 ± 0.3 97.8 ± 0.1 97.8 ± 0.1 DsCo 96.0 ± 0.5 96.1 ± 0.4 96.9 ± 0.5 97.9 ± 0.1 97.8 ± 0.3 98.0 ± 0.2 18 T able 4 V alidation Accuracy vs IPC for Dataset Concentration on ImageW oof. Dataset ImageW o of IPC 200 300 400 700 1000 1300 F ull Ratio% 16.0 24.1 32.1 56.2 80.3 104.4 Mo del Con vNet6 Random 80.2 ± 1.0 80.1 ± 1.0 83.1 ± 0.5 87.4 ± 0.6 87.4 ± 0.1 88.3 ± 0.3 88.3 ± 0.3 DsCo 81.0 ± 0.5 82.7 ± 0.5 84.0 ± 0.7 88.4 ± 0.4 88.3 ± 0.4 88.3 ± 0.2 Mo del ResNetAP-10 Random 83.1 ± 0.6 83.1 ± 0.3 86.0 ± 0.2 88.4 ± 0.5 88.0 ± 0.2 90.2 ± 0.3 90.2 ± 0.3 DsCo 85.9 ± 0.6 85.8 ± 0.7 87.4 ± 0.5 88.9 ± 0.3 90.0 ± 0.5 90.4 ± 0.2 Mo del ResNet-18 Random 88.5 ± 0.5 88.0 ± 0.6 88.6 ± 0.4 90.1 ± 0.2 90.5 ± 0.3 91.0 ± 0.3 91.0 ± 0.3 DsCo 89.0 ± 0.4 89.4 ± 0.5 89.3 ± 0.5 91.0 ± 0.2 91.2 ± 0.3 91.1 ± 0.3 T able 5 Low-IPC Performance comparison on ImageNet-1k. The b est p erformances are denoted in b old . Metho d ResNet-18 MobileNet-V2 Efficien tNet-B0 IPC10 IPC50 IPC10 IPC50 IPC10 IPC50 Data-Accessible RDED 42.0 ± 0.1 56.5 ± 0.1 40.4 ± 0.1 53.3 ± 0.2 31.0 ± 0.1 58.5 ± 0.4 DiT-IGD 45.5 ± 0.5 59.8 ± 0.3 39.2 ± 0.2 57.8 ± 0.2 47.7 ± 0.1 62.0 ± 0.1 Minimax-IGD 46.2 ± 0.6 60.3 ± 0.4 39.7 ± 0.4 58.5 ± 0.3 48.5 ± 0.1 62.7 ± 0.2 DsCo(ours) 47.0 ± 0.2 60.4 ± 0.1 42.3 ± 0.2 59.0 ± 0.2 50.9 ± 0.1 63.0 ± 0.1 Data-F ree SRe 2 L 21.3 ± 0.6 46.8 ± 0.2 10.2 ± 2.6 31.8 ± 0.3 11.4 ± 2.5 34.8 ± 0.4 DFDsCo(ours) 43.3 ± 0.1 58.2 ± 0.2 40.6 ± 0.2 57.4 ± 0.1 49.1 ± 0.1 61.8 ± 0.2 5.2 P erformance Analysis 5.2.1 Dataset Concen tration on ImageNette and ImageW o of T able 1 and T able 2 rep ort the performance of the prop osed Dataset Concentration (DsCo) metho d with v ery small surrogate set sizes (10IPC, 50IPC, and 100IPC) on the ImageNette and ImageW o of datasets, resp ectiv ely . F ollowing previous litera- ture [ 4 , 5 , 48 ], the accuracies rep orted in the table are the a verage ev aluation p erformances of the corresp onding architectures trained on the con- cen trated (or condensed) datasets with one-hot hard lab els ov er five training pro cesses. Under the low-IPC setting, the concentrated dataset is solely syn thesized. As illustrated in the table, our concen trated dataset demonstrates strong train- ing p erformances across b oth datasets. It achiev es SOT A performances in most scenarios, esp e- cially for the ResNetAP-10, 10IPC experiment on ImageW o of, surpassing the previous SOT A by 3 . 8%. On ImageNette, it demonstrates compara- ble p erformances to previous SOT A, surpassing it by 1 . 8% for the 10IPC, ResnetAP-10 setting. In particular, it consistently demonstrates sup e- rior performance compared to the V anilla DiT, esp ecially under 100IPC setting, where it demon- strates a 10 . 5% improv emen t. The strong p er- formances of the low-IPC concentrated datasets, whic h are all synthesized via the NOpt metho d, demonstrate that mitigating the random sampling bias results in significant p erformance impro ve- men t, providing an empirical v alidation for the effectiv eness of the proposed NOpt metho d. In T able 3 and T able 4 , we present the dataset concen tration p erformance in high-IPC settings. F or the high-IPC concentrated datasets that con- tain b oth synthesized samples and selected real samples, w e adopt the relab eling technique with ResNet-18 soft lab els. Since no previous Dataset Distillation works hav e rep orted their high-IPC p erformances due to the prohibitive generation costs, the high-IPC performance is compared 19 against random sampling (Random). As outlined in the table, the concentrated dataset demon- strates sup erior p erformances compared to ran- dom sampling, achieving lossless p erformances at 700IPC for b oth datasets when ev aluated on strong models such as ResNetAP-10 and ResNet- 18, where the full dataset training accuracies are within or b elo w the error ranges of the DsCo meth- o ds, reaching lossless data concen tration rates of 54 . 3% and 56 . 2%. 5.2.2 Dataset Concen tration on ImageNet-1k T able 5 presents the training p erformances of a series of mo dels (ResNet-18, ResNet- 101, MobileNet-V2, and EfficientNet-B0) for the dataset concentration metho d in the low-IPC set- ting. The concen trated datasets in the lo w-IPC setting are all syn thesized with the NOpt metho d. F or all ImageNet-1k exp erimen ts, we follow the previous literature to use the relab eling tech- nique with ResNet-18 soft lab els, and compare the concentrated dataset with the rep orted v al- ues in the corresp onding literature of RDED, IGD, and SRe 2 L. The table shows that the con- cen trated dataset achiev es SOT A p erformances among existing dataset distillation metho ds on all arc hitectures for 10IPC and 50IPC settings. T o assess the performance of DsCo under extended conditions with a broad range of syn the- sis IPC conditions, we further plot the ResNet-18 v alidation accuracy against the dataset size for the concentrated dataset as well as all av ailable rep orted performances of a v ariet y of baseline metho ds in Figure 3 . T o the b est of our kno wledge, no previous works in the dataset distillation litera- ture hav e rep orted more than 50IPC performance on ImageNet-1k under the present ev aluation set- ting with ResNet-18 relabeling, p oten tially due to the prohibitive cost of synthesizing more than 50,000 high-resolution images, nor ha ve lossless p erformances b een reported on ImageNet-1k or its subsets. In contrast, the DsCo metho d easily scales to high-IPC settings, and it demonstrates lossless p erformance from 700IPC, achieving a lossless compression rate of 53%, almost reducing the c hallenging ImageNet-1k dataset by half with no performance degradation. T able 6 ImageNet-1k cross-architecture p erformance of the 700IPC concentrated dataset on ResNet-18, ResNet-34, ResNet-101, EfficientNet-B0, and DenseNet-121. Model DsCo Accuracy F ull Accuracy ResNet-18 69.0 ± 0.1 69.0 ± 0.1 ResNet-34 69.1 ± 0.1 69.1 ± 0.2 ResNet-101 70.1 ± 0.1 70.1 ± 0.1 EfficientNet-B0 66.4 ± 0.2 66.8 ± 0.3 DenseNet-121 67.2 ± 0.2 67.6 ± 0.2 Moreo ver, in T able 6 , we rep ort the cross- arc hitecture training p erformance of the 700- IPC synthetic dataset, whose confusion score is computed with the ResNet-18 architecture. The mo dels are trained with the soft-lab el relab el- ing tec hnique with ResNet-18 soft lab els. As demonstrated in the table, the 700-IPC concen- trated dataset demonstrates the same perfor- mance as the full ImageNet-1k dataset on ResNet- 18, ResNet-34, and ResNet-101. On EfficientNet- B0 and DenseNet-121, the concentrated dataset demonstrates minor p erformance degradations of 0 . 4% on both architectures. In summary , the concen trated dataset demonstrates strong cross- arc hitecture transferability . 5.2.3 P erformance in Data-F ree Scenarios In the data-free scenario, the data-free dataset concen tration metho d syn thesizes an informa- tiv e surrogate dataset for the inaccessible target dataset. As the real target data is inaccessi- ble, all the samples are syn thesized in this case. Consequen tly , the generation cost mak es it dif- ficult to scale to high-IPC settings. W e rep ort the lo w-IPC p erformances of the data-free dataset concen tration metho d (denoted as ”DFDsCo”) on ImageNet-1k and its subsets (ImageNette and ImageW o of ) in T able 5 , T able 1 , and T able 2 , resp ectiv ely . Remark ably , the data-free dataset concen tration method outp erforms a series of metho ds that require data access, generally out- p erforming Random Sampling, DM, and IDC-I on ImageNette and ImageW o of. Its p erformances are similar to those of Minimax on the t wo datasets. On ImageNet-1k, it consisten tly outp er- forms RDED on all architectures and both 10IPC and 50IPC settings. F urther, among existing data- free metho ds, the data-free dataset concen tration 20 T able 7 Comp onen t ablation analysis for low-IPC Dataset Concentration Components ImageNette, ResNetAP-10 L align L real Acc@10 Acc@50 Acc@100 × × 64.8 75.5 80.5 × ✓ 64.6 75.6 81.1 ✓ × 68.9 81.4 85.5 ✓ ✓ 69.8 84.0 86.9 metho d ac hieves SOT A p erformance, significantly surpassing its counterpart (SRe 2 L) by 22 . 0% and 11 . 4% under 10IPC and 50IPC settings. In sum- mary , the data-free dataset concen tration metho d syn thesizes informativ e surrogate datasets for the target dataset when the target dataset is inacces- sible, making a great contribution to information freedom. 5.3 Ablation 5.3.1 Comp onen t Ablation Analysis Data-A c c essible L ow-IPC A blation In the low-IPC setting with data access, the sam- ples are solely synthesized by the NOpt method with data-accessible distribution alignment. In T able 7 , we analyze the imp ortance of the tw o noise-optimization comp onen ts, namely , the dis- tribution alignmen t loss and the realit y constraint. As illustrated in the table, eliminating either comp onen t results in degraded distillation perfor- mances. Therefore, both comp onen ts are vital for the mitigation of the random sampling bias. In particular, the distribution alignment loss makes a great contribution to the p erformance of the syn thesized dataset, as it leads to significant p erformance improv ements for all IPC settings. Mean while, the reality constraint provides vital complemen tary information for the dataset to b e b oth informative and authentic. Data-A c c essible High-IPC Ablation Under high-IPC settings, the concentrated dataset is a combination of the samples synthesized with the Noise-Optimization (NOpt) metho d and the samples selected from the target dataset via Dop- ing. T o analyze the contributions of the tw o stages, w e conduct a component ablation analysis on Ima- geNette, where w e indep enden tly eliminate the T able 8 Stage ablation analysis for high-IPC Dataset Concentration Components ImageNette, ResNet-18 NOpt Doping 200 300 400 700 × × 95.1 95.6 96.1 97.0 × ✓ 95.5 95.4 96.4 97.3 ✓ × 95.4 95.5 96.4 97.2 ✓ ✓ 96.0 96.1 96.9 97.9 t wo stages and replace the corresp onding elim- inated samples with randomly selected samples from the original dataset. When the NOpt sam- ples are replaced b y random samples, but Doping p ersists, we recompute the confusion scores using the random samples for the subsequen t Doping. The ResNet-18 ev aluation accuracies are outlined in T able 8 . As indicated b y the table, eliminating either stage results in globally degraded p erfor- mances across all IPC settings. Therefore, b oth stages pla y a vital role in the Dataset Concentra- tion metho d. Notably , the tw o stages contribute join tly to the p erformance of the concentrated dataset, as the p erformance degradations caused b y the elimination of either stage are similar. Data-F r e e A blation When the target dataset is inaccessible, w e can synth esize a small and informativ e surro- gate dataset with the data-free v arian t of noise- optimization. T o ev aluate the effect of each com- p onen t in the data-free dataset concentration, w e indep enden tly eliminate the three losses, L stats , L maxoc , and L real (with t dropp ed for clarit y), and w e ev aluate the generated surrogate datasets of ImageNette with ResNetAP-10. Specifically , the mo del is trained on the corresp onding datasets with the SGD (Bottou, 2018 [ 63 ]) optimizer. T able 9 shows that removing any comp onen ts degrades the performance, esp ecially under 10IPC. The results indicate that optimal data-free dataset concen tration p erformance requires the synergistic use of all three constraints. 5.3.2 Robustness Analysis Data-A c c essible Dataset Conc entr ation The data-accessible dataset concentration frame- w ork has b een established with great robustness, suc h that there is only one h yp erparameter that requires adjustmen t. That is, the relative strength 21 T able 9 Comp onen t ablation analysis of Data-F ree Dataset Concentration. In this exp erimen t, the ev aluation model is trained with the SGD [ 63 ] optimizer. Components ImageNette, ResNetAP-10 L stats L maxoc L real Acc@10IPC Acc@50IPC ✓ × × 60.3 76.2 × ✓ × 61.7 74.1 × × ✓ 58.5 74.5 × ✓ ✓ 61.5 74.9 ✓ × ✓ 60.9 74.6 ✓ ✓ × 61.9 76.2 ✓ ✓ ✓ 65.0 78.7 T able 10 Hyp erparameter sensitivity analysis for low-IPC Dataset Concentration λ align ImageNette, ResNetAP-10 Acc@10 Acc@50 Acc@100 5e-2 58.6 80.8 80.6 5e-3 66.6 81.6 86.2 5e-4 69.8 84.0 86.9 5e-5 69.0 83.0 85.8 5e-6 67.8 78.4 82.2 of the distribution alignment loss compared to the reality constraint, λ align . The p erformance of the dataset concentration framework under low- IPC setting with v arying hyperparameter λ align is listed in T able 10 . As outlined in the table, the lo w-IPC p erformance is robust against v ariation in λ align on a logarithmic scale, with a minor p erfor- mance degradation of 1% on a verage when divid- ing λ align b y 10 from 5e-4 to 5e-5. In this work, the same optimal λ align w orks for all datasets and all IPC settings. F or high-IPC settings, the condensed dataset is synthesized with the opti- mal λ align and subsequently participates in the doping pro cess with no further hyperparameter adjustmen ts. Data-F r e e Dataset Conc entr ation In the data-free dataset concentration framework, as indicated by Equation 28 and Equation 29 , the balance b et ween L stats , L maxoc , and L real determines the concentrated dataset that is solely generated with the Noise-Optimization pro cess. As previously argued, L real has a fixed weigh t of 1.0 as optimization is scale-in v ariant to the sum of losses. The weigh t of L real is fixed to the maximal T able 11 Hyp erparameter sensitivity analysis for low-IPC Dataset Concentration in data-free scenario (DFDsCo). In this exp erimen t, the models are trained with the SGD [ 63 ] optimizer. λ stats ImageNette, ResNetAP-10 Acc@10 Acc@50 1.0 58.4 72.0 0.1 61.0 73.9 0.01 64.6 78.2 1e-3 65.0 78.7 1e-4 63.8 76.1 1e-5 60.9 75.0 v alue that enables the synthesis of visually rec- ognizable samples in the absence of L stats , whic h can b e easily determined with a visual assess- men t, and is fixed to 10.0 for all exp erimen ts in this w ork. Therefore, only L stats requires empirical adjustmen t. The p erformances of the data-free- concen trated dataset under different strengths of L stats are listed in T able 11 . As indicated b y the table, the data-free dataset concentration metho d is robust to hyperparameter v ariation on a log- arithmic scale, as m ultiplying λ stats b y 10 only degrades the performance by 0 . 5%. 5.3.3 Cost Analysis T o ev aluate the cost of comp osing the concen- trated dataset, we separately perform cost analy- ses in the low-IPC and high-IPC settings. L ow-IPC Synthesis Cost Under low-IPC setting, all the samples are syn- thesized. W e presen t the total synthesis cost (including preparation cost and generation cost) of the prop osed framework under data-accessible and data-free scenarios (DsCo and DFDsCo) in T able 12 , with recent op en-source repro ducible diffusion-based metho ds (Minimax, IGD-DiT) as baselines. The costs are measured in the maxi- mal memory requiremen t and the running time on NVIDIA R TX-2080Ti GPUs to synthesize 10IPC, 50IPC, and 100IPC datasets for ImageNet-1k. F or the Minimax, IGD-DiT, DsCo, and DFDsCo metho ds, the preparation stages are fine-tuning DiT, training the classifier, encoding samples, and generating template samples, resp ectiv ely . Note that the GPU running time for IPC100 of DsCo 22 is for illustration only , as the Doping has b een triggered at 100IPC for ImageNet-1k. As illustrated by the table, among all repro- ducible diffusion-based methods, DsCo and DFD- sCo demonstrate high synthesis efficiency under lo w-IPC settings, with the low est total synthesis times and p eak memory requirements. Their low memory requirements allow them to b e run on a single NVIDIA GeF orce R TX2080 Ti GPU, while the Minimax and DiT-IGD metho ds require at least 2 suc h GPUs. High-IPC Synthesis Cost Figure 4 plots the total syn thesis cost for the Min- imax, DiT-IGD, DsCo, and DFDsCo metho ds for extended IPC settings. In particular, the costs for Minimax, DiT-IGD, and DFDsCo beyond 100IPC are an ticipated v alues obtained through linear extrap olation, th us expressed in dashed lines. The extrap olation w orks b ecause their synthesis costs scale linearly to the num b er of samples. In con- trast, as illustrated in the figure, the synthesis cost of DsCo ceases to increase after 100IPC, where the doping has been triggered. This is b ecause the cost of Doping is fixed to the constant cost of training the mo del on the syn thesized dataset, lab eling the target dataset with the model, computing the con- fusion score, and sorting the samples according to their confusion scores. It do es not dep end on the n umber of samples to b e selected. Therefore, the DsCo framew ork enjo ys sup erior extensibilit y o ver other diffusion-based dataset distillation metho ds. 5.3.4 Visualization L ow-IPC Visualization Under lo w-IPC settings, the Doping is not trig- gered, and all the samples are synthesized using the corresp onding Noise-Optimization metho ds with or without data access. Presen ted in Figure 5 is the visualization of random real samples (left), DiT-generated samples (middle left), the DsCo samples (middle righ t), and the data-free concen- trated samples (right) in the lo w-IPC setting of the ’Ch urch’ class of ImageNette. As illustrated b y the images, all samples enjoy great authenticit y , demonstrating the b enefit of syn thesizing images with pre-trained diffusion mo dels. Figure 6 depicts the t-SNE (Laurens, 2008 [ 64 ]) lo w-dimensional sample distribution of the syn- thesized latent co des plotted on top of that of the Fig. 4 Syn thesis costs, measured in running time on NVIDIA GeF orce R TX 2080 Ti GPUs, plotted against IPC for contemporary open-source diffusion-based dataset dis- tillation or concentration metho ds. The dashed lines are estimated costs obtained through linear extrap olation. Fig. 5 Visualization of the real samples (left), DiT syn- thetic samples (middle left), DsCo synthetic samples (mid- dle right), and the DFDsCo synthetic samples (right) of the Churc h class of the ImageNette dataset. 23 T able 12 Low-IPC synthesis cost analysis of ImageNet-1k on NVIDIA GeF orce R TX2080 Ti GPUs. Metho d Preparation Generation T otal P eak Memory IPC10 IPC50 IPC100 IPC10 IPC50 IPC100 Minimax 253h 7h 35h 70h 260h 288h 323h 14.8G DiT-IGD 124h 69h 347h 694h 193h 471h 818h 13.2G DsCo 14h 28h 62h 119h 42h 76h 133h 4.3G DFDsCo 142h 15h 53h 106h 157h 195h 247h 4.7G Fig. 6 The t-SNE distribution visualization for the ’ch urc h’ (left) and ’parach ute’ (right) classes of Ima- geNette. The latent co des of the synthetic samples are compressed to 2-D and plotted on top of the compressed latent co des of real samples. The synthetic samples are synthesized with DiT (top), DFDsCo (middle), and DsCo (bottom). V AE-encoded latent co des of the target dataset of the ’ch urch’ and ’parac hute’ classes of Ima- geNette. F or visual comparison, the v anilla DiT laten t co des are compared against DFDsCo and DsCo laten t codes. As illustrated in the figure, the DiT samples tend to concen trate in dense regions of the target dataset distribution, as observed in previous literature (Gu, 2024 [ 4 ]). It concentrates to o muc h on the densest area, and thus cannot co ver other dense regions of low er concentration. Both DFDsCo and DsCo demonstrate improv ed co verage, with their synthesized latent codes scat- tered in multiple dense areas. Since DFDsCo does not access the target dataset, its capability to find the dense regions indicates that the correct distribution has b een memorized b y the diffusion mo del, and that the proposed method is capa- ble in uncov ering this hidden memory . Among the three metho ds, DsCo generally p erforms b etter than its tw o counterparts, o ccup ying more clus- tered regions than DFDsCo and DiT, esp ecially for the ’parac h ute’ class. Visualization for high-IPC settings A visualization analysis is p erformed for the samples sampled with the doping metho d under high IPC settings. Figure 7 displays the target samples with increasing confusion scores of the ’c hurc h’ and ’parac hute’ classes of ImageNette. As illustrated b y the figure, the visual dissimilarit y b et ween the target samples in the same group increases as the confusion score increases, and the high-confusion samples are v ery dissimilar from the lo w-confusion samples. This substan tiates the previous argument that a high confusion score is asso ciated with high dissimilarit y of the sample to its neighbors, which indicates a high c hance of b eing a far-apart sample. F urther, the av erage in tra-class laten t-space m utual L-2 distances of the groups of samples with increasing confusion scores for the Ima- geNette dataset are visualized in the heatmap in Figure 8 . The samples in ImageNette are sorted b y their confusion scores in descending order, and the first 1000 × 10 samples are ev enly separated in to 5 groups, (1 , 2 , 3 , 4 , 5), with descending con- fusion scores. The heatmap presen ts the av erage in tra-class latent-space m utual L-2 distances of all com binations of the five groups. The laten t co des are enco ded with the V AE from stable-diffusion (Robin, 2021 [ 60 ]). As indicated b y the figure, there is a significant leap in the a v erage mutual L- 2 distance within the same group of samples (i.e., the diagonal v alues) b et w een groups (0 , 1 , 2) to groups (3 , 4 , 5), which substantiates the assump- tion that samples with high confusion scores are 24 Fig. 7 The real samples with increasing confusion scores for the ’c hurc h’ and ’parach ute’ classes of the ImageNette dataset. Fig. 8 The a verage intra-class laten t-space nearest- neighbor mutual L-2 distance for five groups of target samples of descending confusion scores computed within each group (diagonal) and b etw een different groups (off- diagonal). lik ely to b e far-apart samples. F urther, the av er- age mutual distances b et ween group 0 and groups 1,2,3,4,5 monotonically increases (the combina- tion is denoted as (0; 1 , 2 , 3 , 4 , 5), where the groups after the semicolon are listed in ascending order of av erage latent-space L-2 distances from sam- ples in group 0.), and the same tendency go es for the group combinations (1; 3 , 2 , 4 , 5), (2; 3 , 4 , 5), (3; 4 , 5 , 6), and (4; 5 , 6). This indicates that the prop osed confusion score is p ositiv ely asso ciated with the degree to which a sample is far aw ay from the ma jority of samples. Therefore, the confusion score serves as a go od indicator of the degree to whic h a sample is b oth far-a wa y and far-apart from other samples. 6 Conclusion In this work, we hav e addressed three critical limitations in dataset distillation: the lack of a theoretical foundation, the inefficiency in high- IPC settings, and the inability to op erate with- out access to the original data. Firstly , we ha ve established a theoretical framework to analyze the dataset distillation problem. The theoreti- cal analysis demonstrates that dataset distillation is equiv alent to a distribution matching prob- lem, justifying the use of diffusion mo dels in the dataset distillation task. Through further analy- sis, we hav e identified a random bias impairing the training p erformance of diffusion-syn thesized samples, and revealed a fundamental efficiency limit inherent to the dataset distillation paradigm stemming from the far-apart samples in tar- get datasets, pro viding a theoretical explanation for the difficult y in scaling dataset distillation metho ds to large data volumes. In light of the analysis, we prop osed the Dataset Concen tration (DsCo) framew ork, which adopts a diffusion-based Noise-Optimization (NOpt) metho d applicable 25 under both data-accessible and data-free scenar- ios to syn thesize informativ e samples through the denoising pro cess with mitigated random sampling biases. DsCo further incorp orates an optional ”Doping” pro cess for high data volumes, whic h samples the far-apart samples in the tar- get dataset to o vercome the efficiency limitation of data synthesis. Extensive exp erimen ts demon- strate that DsCo achiev es state-of-the-art p erfor- mance under m ultiple settings on v arious datasets. Crucially , it nearly reduces the dataset size by half with no p erformance degradation, proving its sup erior scalability . F urthermore, in the chal- lenging data-free setting, DsCo outp erforms all existing metho ds, offering a practical solution for priv acy-sensitive applications. In summary , this w ork adv ances dataset distillation by pro viding a solid theoretical ground, an efficient and adapt- able concen tration framework, and substan tial empirical v alidation, pa ving the w a y for more trust worth y and practical data-efficien t learning. Supplemen tary information. If your article has accompan ying supplemen tary file/s please state so here. Authors rep orting data from electrophoretic gels and blots should supply the full unpro cessed scans for k ey as part of their Supplemen tary infor- mation. This may b e requested by the editorial team/s if it is missing. Please refer to Journal-level guidance for any sp ecific requirements. Declarations • F unding This w ork w as supported b y Bei- jing Natural Science F oundation (JQ24022), the National Natural Science F oundation of China (No. 62192785, No. 62372451, No. 62372082, No. 62272125, No. 62306312, No. 62036011, No. 62192782), CAAI-Ant Group Researc h F und (CAAI-MYJJ 2024-02), Y oung Elite Scientists Sp onsorship Program b y CAST (2024QNR C001), the Pro ject of Beijing Sci- ence and technology Committee (Pro ject No. Z231100005923046). • Comp eting interests The authors hav e no comp eting interests to declare that are relev ant to the con ten t of this article. • Ethics appro v al and consen t to partici- pate Not Applicable. • Consen t for publication All authors hav e appro ved the submission of this manuscript for publication. • Data a v ailability The datasets used to syn thesize the concentrated datasets in this study are publicly av ailable, as cited in the pap er. The concentrated datasets for ImageNet-1k under 10IPC and 50IPC set- tings in data-accessible and data-free scenarios are a v ailable at the following repository: h ttps://pan.baidu.com/s/1WyR47H- cG06Zm3WfLpFm7Q with the access code 1234, and the complementary real samples can b e sampled from the publicly av ailable dataset using the co de pro vided b elo w. The authors are willing to provide any additional data up on request. • Materials av ailability Not Applicable. • Co de a v ailability The implemen ta- tion co de for this study is a v ailable at https://gith ub.com/kkkkqq/Dataset- Concen tration • Author contribution All authors contributed to the study conception and design. Material preparation, data collection and analysis were p erformed by T ongfei Liu and Y ufan Liu. The first draft of the manuscript was written b y T ongfei Liu, and all authors commented on pre- vious versions of the manuscript. All authors read and appro v ed the final man uscript. App endix A Applicabilit y of the Theoretical F ramew ork In Section 3.2 , we theoretically prov ed Prop o- sition 1 , whic h states that dataset distillation is a distribution matching task under Assump- tion 1 . F or a particular tuple of (Φ , T , S ), Assump- tion 1 assumes that there exists a shift-inv ariant p ositiv e-definite kernel function k ( x τ , x s ) that monotonically increases with the c hance of recog- nizing x τ b y memorizing x s . Under this formula- tion, it is unclear as to how likely this assumption can b e met. In this section, we develop a gener- alized prop osition asso ciated with Prop osition 1 under a looser assumption. 26 A.0.1 Extended Prop osition F or the tuple of (Φ , T , S ), consider an arbitrary in vertible transformation χ ( · ), which maps x τ ∈ T and x s ∈ S into χ ( x τ ) and χ ( x s ). With a slight abuse of notation, we denote the pro jected sam- ples as χ τ and χ s , respectively . If there exists a shift-inv ariant p ositiv e-definite kernel function k χ ( χ τ , χ s ) in this pro jected space, which mono- tonically increases with the chance of recognizing x τ b y memorizing x s , then we can immediately pro ve that the exp ected chance of recognition is maximized when P χ S = P χ T in the space pro jected b y χ by simply replacing the x b y χ ( x ) in the anal- ysis presented in Section 3.2 . Since p χ ( χ ) dχ = p ( x ) dx , and the reversibilit y of χ ( · ) ensures that | dχ | | dx | = 0, w e then deduce that p χ T ( χ ) = p χ S ( χ ) ∀ χ ⇐ ⇒ p T ( x ) = p S ( x ) ∀ x. (A1) Therefore, w e ha ve pro v ed Prop osition 2 . App endix B Mon te-Carlo Illustration of Random Bias This section presents a simplified Monte-Carlo exp erimen t to illustrate the effect of randomness. As argued in Section 3.4 , for a high-dimensional Gaussian distribution, the norms of the random Gaussian noises are very close to the square ro ot of their dimension. Therefore, we can ignore the v ariation in the norms of the noises and only con- sider the angular distribution. In this case, since the spherical surface is measurable, the surface can b e divided in to regions of equal area. The spheri- cal homogeneit y of the Gaussian distribution then dictates that a random Gaussian noise tensor has an equal chance to fall in to any region. Therefore, w e can reformulate this Gaussian noise sampling in to a simple arrangemen t problem. F or a set of N random Gaussian noise tensors, with the spherical surface divided into N equally-sized regions, the ideal sampling is when each region has one sam- ple, in which case the sample distribution of noise tensors closely aligns with the contin uous theoret- ical distribution. How ev er, the c hance of ac hieving this ideal sampling can b e analytically computed to b e N ! N N , which monotonically decreases with N . T able B1 The means and standard deviations of the num ber of occupied regions. N 10 50 100 mean 6.5 31.7 63.4 std 1.0 2.2 3.2 In practice, we can estimate the av erage n um- b er of regions o ccupied by at least one random noise by a simple Monte-Carlo exp erimen t using the PyT orch pack age (P aszke, 2019) through the follo wing command: import torch def average_occupation_rate( n_exp, n_smps ): rands=torch.randint( n_smps, (n_exp, n_smps) )[:,None,:] bins=torch.arange( n_smps )[None,:,None] noempty=(rands==bins).sum(2)>0 return noempty.sum(1).to( torch.float).mean() The mean and standard deviations of the num- b er of occupied regions is listed in T able B1 with n exp = 500. As illustrated in the table, no less than 35% of the regions are uno ccupied, demonstrating a significant distribution deviation resulting from random sampling bias. App endix C F eature Pro jector The feature pro jector used in this work adopts an enco der-lik e architecture that is built up on the ”v anilla V AE” architecture in the publicly a v ail- able implementation of V AE from Subramanian (2020 [ 65 ]). W e made a few key mo difications to adapt this small enco der into a feature pro jec- tor. Firstly , w e remov ed the final linear lay er as it breaks the spatial shift-in v ariance by assign- ing different weigh ts to different spatial lo cations. Secondly , w e remo ved all the batc h normalization la yers to av oid mutual interference of features. 27 Thirdly , the hidden dimensions of the encoder la y- ers are set to (256, 512, 1024, 2048), and the first conv olutional lay er has a smaller stride of 1. Finally , the fully connected conv olutional lay ers are replaced b y the group ed conv olutional la y- ers with 16 indep enden t groups to reduce the computational cost in feature pro jection. App endix D Ev aluation Implemen tations In this section, we provide the implemen tation details of the ev aluation metho ds. D.1 Hard-Lab el lo w-IPC T raining on ImageW o of and ImageNette In T able 1 and T able 2 , the 10IPC, 50IPC, and 100IPC syn thetic samples are used to train a series of mo dels (Convnet6, ResNet-AP10, ResNet-18) for 2000, 1500, and 1000 ep o c hs, resp ectiv ely . The mo dels are trained with the concentrated or syn- thesized datasets with one-hot hard labels using an AdamW optimizer with learning rate 0.001, b etas (0.9, 0.999), epsilon 1e-8, and w eight deca y 0.01. A StepLR sc heduler with tw o milestones at 2 / 3 and 5 / 6 of the total training ep o c hs is applied with gamma=0.2. During training, a RandomRe- sizedCrop (Lee, 2022 [ 66 ]) of scale (0.5,1.0), a RandomHorizon talFlip of chance 0.5, a ColorJit- ter of (0 . 4 , 0 . 4 , 0 . 4), and a Ligh tning augmentation (Cubuk, 2019 [ 67 ]) are applied on the dataset with a subsequent cutmix augmen tation (Y un, 2019 [ 68 ]) applied at a chance of 1.0, with its b eta v alue set to 1.0 as w ell. Mean while, the batch size of training is universally set to 64. D.2 High-IPC training with relab eling tec hnique on ImageW o of and ImageNette F or the high-IPC setting, we adopt the relab el- ing technique with the soft labels pro vided by the official pre-trained ResNet-18 model from the T orchVision (2016 [ 69 ]). The soft-label training temp erature is set to 20 . 0, and the total n um- b er of epo c hs is 1000 and 500 for datasets of no more than 200IPC and those with more data, resp ectiv ely . In high-IPC settings, the same aug- men tation and optimizer as in App endix D.1 is applied on the datasets, and it uses a default CosineAnnealingLR scheduler from PyT orc h with T max equal to t wice the total n um b er of ep o c hs. D.3 ImageNet-1k training with relab eling tec hnique The ImageNet-1k training setting for lo w-IPC is the same as the setting in Appendix D.2 , but the ColorJitter and Lightning are remo ved from the training, and the training ep ochs is fixed to 300 for both 10IPC and 50IPC. Moreo ver, the adamW learning rate increases to 0.002 and 0.0025 up on training the Efficien tNet-B0 and MobileNet-V2. The high-IPC training on ImageNet-1k trains the mo dels by 100 ep ochs, using a different sched- uler that linearly increases the learning rate in the first ten ep o c hs of training, starting from 0.1, and subsequen tly decreases the learning rate to 0 in 90 steps using CosineAnnealingLR. Other settings are the same as the low-IPC setting. References [1] W ang, T., Zhu, J.-Y., T orralba, A., Efros, A.A.: Dataset distillation. arXiv preprin t arXiv:1811.10959 (2018) [2] Abbasi, A., Shahbazi, A., Pirsiav ash, H., Kolouri, S.: One category one prompt: Dataset distillation using diffusion mo dels. arXiv preprin t arXiv:2403.07142 (2024) [3] Su, D., Hou, J., Gao, W., Tian, Y., T ang, B.: Dˆ 4: Dataset distillation via disen- tangled diffusion mo del. In: Pro ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5809– 5818 (2024) [4] Gu, J., V ahidian, S., Kungurtsev, V., W ang, H., Jiang, W., Y ou, Y., Chen, Y.: Efficien t dataset distillation via minimax diffusion. In: Pro ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15793–15803 (2024) [5] Chen, M., Du, J., Huang, B., W ang, Y., Zhang, X., W ang, W.: Influence-guided dif- fusion for dataset distillation. In: The Thir- teen th International Conference on Learning Represen tations (2025) 28 [6] Rombac h, R., Blattmann, A., Lorenz, D., Esser, P ., Ommer, B.: High-resolution image syn thesis with laten t diffusion mo dels. In: Pro ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10684–10695 (2022) [7] Deng, J., Dong, W., So c her, R., Li, L.-J., Li, K., F ei-F ei, L.: Imagenet: A large-scale hierarc hical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255 (2009). Ieee [8] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Pro ceedings of the IEEE Conference on Com- puter Vision and P attern Recognition, pp. 770–778 (2016) [9] Liu, T., Liu, Y., Li, B., Hu, W., Li, Y., Ma, C.: Noise-optimized distribution distillation for dataset condensation. In: Pro ceedings of the 33rd A CM International Conference on Multimedia, pp. 10352–10360 (2025) [10] Sohl-Dickstein, J., W eiss, E., Mah- esw aranathan, N., Ganguli, S.: Deep unsup ervised learning using nonequilibrium thermo dynamics. In: International Confer- ence on Machine Learning, pp. 2256–2265 (2015). pmlr [11] Ho, J., Jain, A., Abb eel, P .: Denoising diffu- sion probabilistic mo dels. Adv ances in neural information processing systems 33 , 6840– 6851 (2020) [12] Kingma, D.P ., W elling, M.: Auto- enco ding v ariational bay es. arXiv preprin t arXiv:1312.6114 (2013) [13] Dhariwal, P ., Nic hol, A.: Diffusion mo dels b eat gans on image synthesis. Adv ances in neural information pro cessing systems 34 , 8780–8794 (2021) [14] Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint (2022) [15] Rumelhart, D.E., Hinton, G.E., Williams, R.J.: Learning represen tations b y back- propagating errors. nature 323 (6088), 533– 536 (1986) [16] Deng, Z., Russako vsky , O.: Remem b er the past: Distilling datasets in to addressable memories for neural net works, v ol. 35, pp. 34391–34404 (2022) [17] F eng, Y., V edantam, S.R., Kempe, J.: Embar- rassingly simple dataset distillation. In: W orkshop on Adv ancing Neural Netw ork T raining: Computational Efficiency , Scalabil- it y , and Resource Optimization (W ANT@ NeurIPS 2023) [18] Cazenav ette, G., W ang, T., T orralba, A., Efros, A.A., Zhu, J.-Y.: Dataset distillation b y matching training tra jectories. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4750–4759 (2022) [19] Cui, J., W ang, R., Si, S., Hsieh, C.-J.: Scaling up dataset distillation to imagenet-1k with constan t memory . In: International Confer- ence on Machine Learning, pp. 6565–6590 (2023). PMLR [20] Du, J., Jiang, Y., T an, V.Y., Zhou, J.T., Li, H.: Minimizing the accumulated tra jec- tory error to improv e dataset distillation. In: Pro ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3749–3758 (2023) [21] Liu, D., Gu, J., Cao, H., T rinitis, C., Sch ulz, M.: Dataset distillation by automatic train- ing tra jectories. In: Europ ean Conference on Computer Vision, pp. 334–351 (2024). Springer [22] Zhao, B., Mopuri, K.R., Bilen, H.: Dataset condensation with gradient matching. In: Nin th International Conference on Learning Represen tations 2021 (2021) [23] Zhao, B., Bilen, H.: Dataset condensation with differentiable siamese augmentation. In: In ternational Conference on Mac hine Learn- ing, pp. 12674–12685 (2021). PMLR 29 [24] Kim, J.-H., Kim, J., Oh, S.J., Y un, S., Song, H., Jeong, J., Ha, J.-W., Song, H.O.: Dataset condensation via efficient synthetic- data parameterization. In: International Con- ference on Machine Learning, pp. 11102– 11118 (2022). PMLR [25] Liu, Y., Gu, J., W ang, K., Zh u, Z., Jiang, W., Y ou, Y.: Dream: Efficient dataset distillation b y representativ e matc hing. In: Pro ceedings of the IEEE/CVF International Conference on Computer Vision, pp. 17314–17324 (2023) [26] Nguyen, T., Chen, Z., Lee, J.: Dataset meta- learning from kernel ridge-regression. In: In ternational Conference on Learning Repre- sen tations [27] Lo o, N., Hasani, R., Amini, A., Rus, D.: Effi- cien t dataset distillation using random fea- ture approximation, v ol. 35, pp. 13877–13891 (2022) [28] Zhou, Y., Nezhadary a, E., Ba, J.: Dataset dis- tillation using neural feature regression, vol. 35, pp. 9813–9827 (2022) [29] Y u, R., Liu, S., Y e, J., W ang, X.: T eddy: Efficien t large-scale dataset distillation via ta ylor-approximated matching. In: European Conference on Computer Vision, pp. 1–17 (2024). Springer [30] Zhao, B., Bilen, H.: Dataset condensation with distribution matching. In: Pro ceedings of the IEEE/CVF Win ter Conference on Applications of Computer Vision, pp. 6514– 6523 (2023) [31] W ang, K., Zhao, B., Peng, X., Zhu, Z., Y ang, S., W ang, S., Huang, G., Bilen, H., W ang, X., Y ou, Y.: Cafe: Learning to condense dataset b y aligning features. In: Pro ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12196–12205 (2022) [32] Zhang, H., Li, S., Lin, F., W ang, W., Qian, Z., Ge, S.: Dance: dual-view distribution alignmen t for dataset condensation. In: Pro- ceedings of the Thirty-Third International Join t Conference on Artificial Intelligence, pp. 1679–1687 (2024) [33] Yin, Z., Xing, E., Shen, Z.: Squeeze, recov er and relab el: Dataset condensation at ima- genet scale from a new p erspective, vol. 36, pp. 73582–73603 (2023) [34] Yin, Z., Shen, Z.: Dataset distillation in large data era. arXiv preprint (2023) [35] Shao, S., Yin, Z., Zhou, M., Zhang, X., Shen, Z.: Generalized large-scale data condensa- tion via v arious bac kb one and statistical matc hing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 16709–16718 (2024) [36] Zhou, M., Yin, Z., Shao, S., Shen, Z.: Self- sup ervised dataset distillation: A go od com- pression is all you need. arXiv preprint arXiv:2404.07976 (2024) [37] Shao, S., Zhou, Z., Chen, H., Shen, Z.: Elu- cidating the design space of dataset con- densation. Adv ances in Neural Information Pro cessing Systems 37 , 99161–99201 (2024) [38] Shen, Z., Sherif, A., Yin, Z., Shao, S.: Delt: A simple div ersity-driv en earlylate training for dataset distillation. In: Proceedings of the Computer Vision and Pattern Recognition Conference, pp. 4797–4806 (2025) [39] Sun, P ., Shi, B., Y u, D., Lin, T.: On the div ersity and realism of distilled dataset: An efficient dataset distillation paradigm. In: Pro ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024) [40] Zhong, X., Sun, S., Gu, X., Xu, Z., W ang, Y., Zhang, M., Chen, B.: Efficient dataset dis- tillation via diffusion-driv en patch selection for impro ved generalization. arXiv preprint arXiv:2412.09959 (2024) [41] Zhao, B., Bilen, H.: Synthesizing informative training samples with gan. In: NeurIPS 2022 W orkshop on Syn thetic Data for Empow ering ML Researc h (2023) 30 [42] W ang, K., Gu, J., Zhou, D., Zhu, Z., Jiang, W., Y ou, Y.: Dim: Distilling dataset in to generativ e mo del. arXiv preprint arXiv:2303.04707 (2023) [43] Huang, C., Zhang, S.: Generative dataset distillation. In: 2021 7th International Con- ference on Big Data Computing and Com- m unications (BigCom), pp. 212–218 (2021). IEEE [44] Li, L., Li, G., T ogo, R., Maeda, K., Ogaw a, T., Hasey ama, M.: Generative dataset distil- lation: Balancing global structure and lo cal details. In: Pro ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7664–7671 (2024) [45] Cazenav ette, G., W ang, T., T orralba, A., Efros, A.A., Zh u, J.-Y.: Generalizing dataset distillation via deep generativ e prior. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3739–3748 (2023) [46] Moser, B.B., Raue, F., P alacio, S., F rolov, S., Dengel, A.: Latent dataset distilla- tion with diffusion mo dels. arXiv preprint arXiv:2403.03881 (2024) [47] Y uan, J., Zhang, J., Sun, S., T orr, P ., Zhao, B.: Real-fake: Effective training data syn- thesis through distribution matching. arXiv preprin t arXiv:2310.10402 (2023) [48] Cui, X., Qin, Y., Zhou, W., Li, H., Li, H.: Optimizing distributional geometry align- men t with optimal transport for gener- ativ e dataset distillation. arXiv preprint arXiv:2512.00308 (2025) [49] How ard, J.: Imagenette: A Smaller Subset of 10 Easily Classified Classes from Imagenet. h ttps://github.com/fastai/imagenette [50] LeCun, Y., Bottou, L., Bengio, Y., Haffner, P .: Gradient-based learning applied to do c- umen t recognition. Pro ceedings of the IEEE 86 (11), 2278–2324 (2002) [51] Duan, Y., Zhang, J., Zhang, L.: Dataset distillation in latent space. arXiv preprin t arXiv:2311.15547 (2023) [52] Krizhevsky , A., Sutskev er, I., Hinton, G.E.: Imagenet classification with deep conv olu- tional neural netw orks. Adv ances in neural information processing systems 25 (2012) [53] Nov ak, R., Xiao, L., Lee, J., Bahri, Y., Y ang, G., Hron, J., Ab olafia, D.A., P en- nington, J., Sohl-Dickstein, J.: Ba yesian deep con volutional net works with many c han- nels are gaussian processes. arXiv preprint arXiv:1810.05148 (2018) [54] Lin, M., Chen, Q., Y an, S.: Netw ork in net- w ork. arXiv preprint arXiv:1312.4400 (2013) [55] Villani, C.: T opics in Optimal T ransp orta- tion v ol. 58. American Mathematical So c., ??? (2021) [56] T an, M., Le, Q.: Efficientnet: Rethink- ing mo del scaling for conv olutional neural net works. In: In ternational Conference on Mac hine Learning, pp. 6105–6114 (2019). PMLR [57] Sandler, M., How ard, A., Zhu, M., Zhmogi- no v, A., Chen, L.-C.: Mobilenetv2: Inv erted residuals and linear b ottlenec ks. In: Proceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4510– 4520 (2018) [58] Huang, G., Liu, Z., V an Der Maaten, L., W einberger, K.Q.: Densely connected con- v olutional net works. In: Pro ceedings of the IEEE Conference on Computer Vision and P attern Recognition, pp. 4700–4708 (2017) [59] Peebles, W., Xie, S.: Scalable diffusion mo dels with transformers. arXiv preprin t arXiv:2212.09748 (2022) [60] Rombac h, R., Blattmann, A., Lorenz, D., Esser, P ., Ommer, B.: High-Resolution Image Syn thesis with Laten t Diffusion Models (2021) [61] Loshchilo v, I., Hutter, F.: Decoupled w eight decay regularization. arXiv preprin t arXiv:1711.05101 (2017) 31 [62] Cui, J., Li, Z., Ma, X., Bi, X., Luo, Y., Shen, Z.: Dataset distillation via committee voting. arXiv preprin t arXiv:2501.07575 (2025) [63] Bottou, L., Curtis, F.E., No cedal, J.: Opti- mization methods for large-scale machine learning. SIAM review 60 (2), 223–311 (2018) [64] Maaten, L., Hinton, G.: Visualizing data using t-sne. Journal of Machine Learning Researc h 9 (86), 2579–2605 (2008) [65] Subramanian, A.K.: PyT orch-V AE. GitHub (2020) [66] Lee, M.S., Han, S.W.: Duetnet: Dual enco der based transfer net work for thoracic dis- ease classification. P attern Recognition Let- ters 161 , 143–153 (2022) h ttps://doi.org/10. 1016/j.patrec.2022.08.007 [67] Cubuk, E.D., Zoph, B., Mane, D., V asude- v an, V., Le, Q.V.: Autoaugment: Learning augmen tation strategies from data. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 113–123 (2019) [68] Y un, S., Han, D., Oh, S.J., Ch un, S., Cho e, J., Y o o, Y.: Cutmix: Regulariza- tion strategy to train strong classifiers with lo calizable features. In: Pro ceedings of the IEEE/CVF International Conference on Computer Vision, pp. 6023–6032 (2019) [69] maintainers, T., contributors: T orc hVision: PyT orch’s Computer Vision Library . If you find T orchVision useful in your work, please consider citing this. h ttps://github.com/ p ytorch/vision 32
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment