Efficient Inference of Large Vision Language Models
Although Large Vision Language Models (LVLMs) have demonstrated impressive multimodal reasoning capabilities, their scalability and deployment are constrained by massive computational requirements. In particular, the massive amount of visual tokens f…
Authors: Surendra Pathak
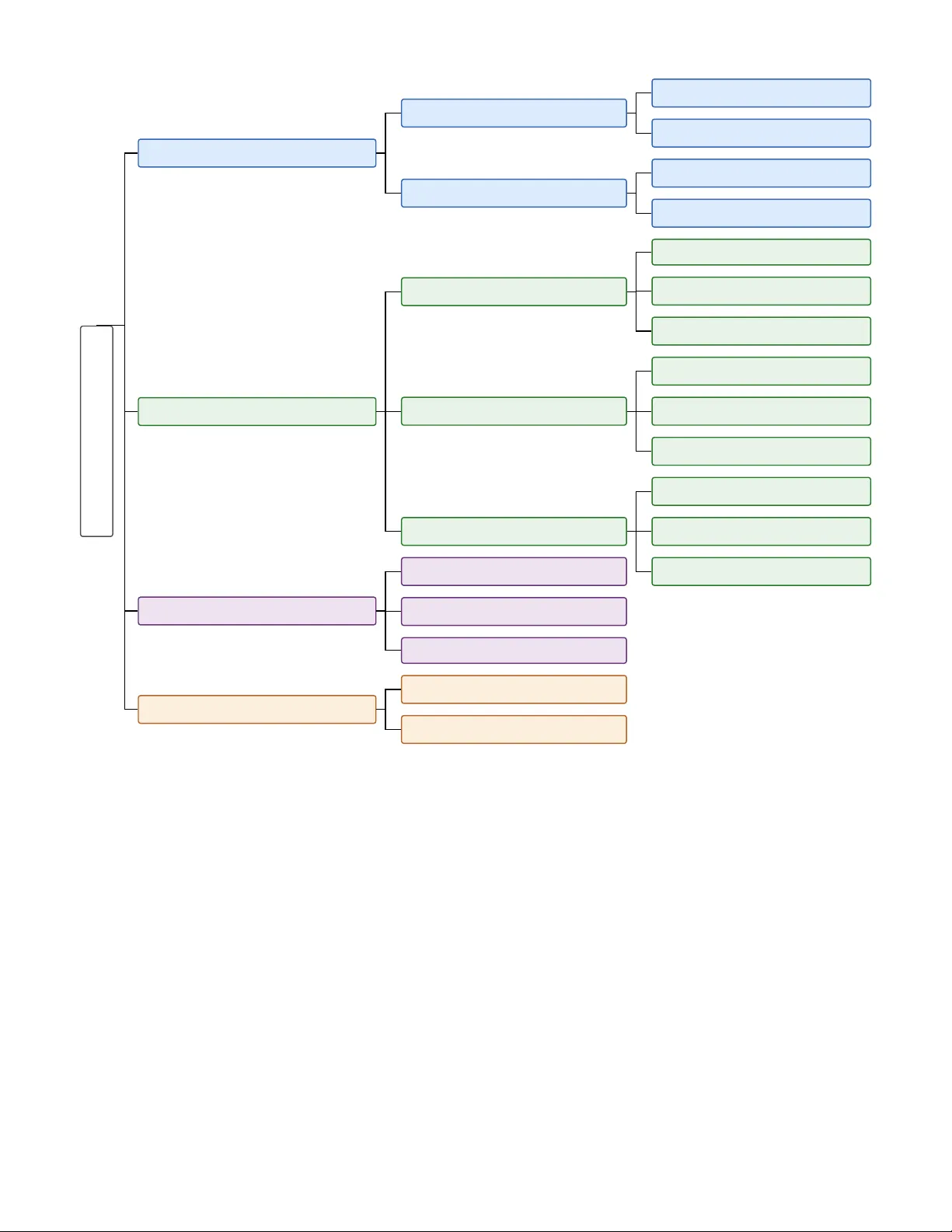
Ef ficient Inference of Lar ge V ision Language Models Surendra Pathak Computer Science Department Geor ge Mason University Fairfax, V A - 22030, USA spathak8@gmu.edu Abstract —Although Large V ision Language Models (L VLMs) hav e demonstrated impressiv e multimodal reasoning capabilities, their scalability and deployment are constrained by massi ve computational requir ements. In particular , the massive amount of visual tokens from high-resolution input data aggra vates the situation due to the quadratic complexity of attention mech- anisms. T o addr ess these issues, the resear ch community has developed several optimization frameworks. This paper pr esents a comprehensi ve survey of the current state-of-the-art techniques for accelerating L VLM inference. W e intr oduce a systematic taxonomy that categorizes existing optimization framew orks into four primary dimensions: visual token compression, memory management and serving, efficient architectural design, and advanced decoding strategies. Furthermor e, we critically examine the limitations of these curr ent methodologies and identify critical open problems to inspire future resear ch directions in efficient multimodal systems. Index T erms —Large Vision Language Models, Efficient In- ference, V isual T oken Compr ession, KV Cache Management, Memory Management, Efficient Attention, Efficient Decoding I . I N T RO D U C T I O N Large Language Models (LLMs) have emer ged as the domi- nant paradigm for a wide range of natural language processing tasks, demonstrating remarkable capabilities in reasoning, gen- eration, and understanding [4, 57]. This success has catalyzed a shift tow ard the development of multimodal systems such as Large V ision Language Models (L VLMs)[5, 38, 39]. By integrating visual encoders with LLM backbones, L VLMs hav e achiev ed unprecedented performance on challenging vision-and-language tasks, including visual question answer- ing (VQA), image captioning, and multimodal reasoning. Howe ver , the adoption of these models is constrained by their enormous computational demands. For instance, the length of visual tokens increases drastically in L VLMs, introducing a computational burden that scales quadratically with token length. Similarly , the massi ve influx of visual input sequences from high-resolution images and long videos increases the KV cache footprint. This scenario worsens during the decode phase, where the model repeatedly reads large context from the Ke y V alue (KV) cache, incurring a large latency . Thus, mit- igating these memory and computational bottlenecks through efficient inference optimizations has become imperativ e to enable scalable and real-time application of L VLMs. In response to these critical bottlenecks, the research com- munity has explored dif ferent mechanisms to utilize compute resources ef ficiently . These strategies encompass algorithmic enhancements, such as visual token compression, as well as system-lev el optimizations like KV cache management and L VLM serving. This work presents a comprehensiv e explo- ration of the frame works proposed by the research community to address these challenges. The major contrib ution of this work is to present the current state of visual reasoning inference acceleration paradigms. For that, this re view paper systematically outlines effecti ve mech- anisms to alleviate computational and memory constraints. In particular , the frameworks are categorized into the follow- ing: input context’ s algorithmic optimizations, system-level enhancements, architectural and structural framew orks, and advanced decoding strategies. Furthermore, these categories are divided into subcate gories, as sho wn in Figure 2, for better readability . In addition to discussing current approaches, this paper points out their limitations. Finally , this work outlines open problems in the visual context inference domain to inspire future research directions. The remainder of the paper is organized as follows: The preliminaries of the surve y are presented in Section II. The area taxonomy categorizing the optimization framew orks is presented in Section III. After that, the taxonomy-based survey is presented in Section IV. Then, open problems in the domain’ s current literature are presented Section V. Finally , the concluding remarks are presented in Section VI. I I . P R E L I M I NA R I E S A. Lar ge V ision Language Models A standard L VLM[5, 38, 39] consists of a vision encoder, a vision-language projector, a text encoder , and a backbone language model. A representative schematic of a standard L VLM model is presented in Figure 1. A vision encoder g compresses an input image X v into patch features Z v , mathematically defined as Z v = g ( X v ) . The most popular vision encoders used in L VLMs are CLIP [45], SigLIP [74], and InternV iT [11]. Since these encoders constitute a relativ ely minor portion of a multimodal model’ s total parameters, the advantages of optimization in this portion of L VLMs are less pronounced. A vision-language projector P is a bridge that projects embedded visual patches Z v into visual embeddings H v such that H v = P ( Z v ) to align the feature space of the language Fig. 1. Schematic of a standard Large Vision Language Model (L VLM) architectur e. The vision encoder and text encoder conv ert the visual and text inputs to corresponding tokens. V ision tokens further transform through the projector before being fused with the text tokens. The aggregated tokens are then passed to the backbone language model for autoregressi ve generation. model. An efficient vision projector must be adaptable to a variable number of input visual tokens and preserve local spatial context with minimal computational overhead. These projected visual representations H v are concatenated with the encoded textual tokens to form a unified multimodal input sequence, which is passed to the LLM backbone for inference. The LLM backbone is usually a large pre-trained transformer model, which serves as the core reasoning engine of the L VLM. During inference, the model is ex ecuted in two stages, namely prefill and decode. Prefill is a compute-bound phase that ingests the entire input sequence in parallel to populate the initial KV cache. Alternatively , the decode phase is a memory- bound, autoregressiv e process that generates the subsequent output tokens sequentially and is constrained by the latency of repeatedly reading the growing KV cache memory . B. Self-Attention in Lar ge Language Models The backbone LLM [4, 12, 27, 57, 58] consists of multiple decoder layers that compute causal self-attention values. The input sequence X to each layer consists of system, image, and text tokens gi ven by X = [ x sys ; x img ; x txt ] ∈ R L × D , where L is the total input length and D is the hidden dimension. Three weight matrices W Q , W K , W V ∈ R D × D are used to compute the query Q , key K , and value V as: Q = X W Q , K = X W K , V = X W V Then, attention value A is computed as: A ( Q, K ) = Softmax QK T + M √ D , O = AV . where Q ∈ R L × D and K ∈ R L × D . A lower triangular causal mask M ∈ R L × L is applied to ascertain each token to attend to only the previous tokens and itself. Self-attention in transformer -based L VLMs enables these models to capture a wide range of visual contexts and nuances. Howe ver , the quadratic complexity O ( N 2 ) of the attention block to compute attention values during training and inference has become a critical computational bottleneck [59], necessitating the adoption of optimizations to reduce computational demands. I I I . A R E A T A X O N O M Y T o systematically present the e xisting work on the efficient inference of L VLMs, an area taxonomy is presented in Fig- ure 2. The first category , visual tok en compression, tar gets the massiv e influx of input tokens in image and video inferences, addressing the prefill phase’ s bottleneck. The second category , memory management and serving, comprises system-le vel op- timizations such as KV cache management and disaggreg ated scheduling framew orks that address the memory-bandwidth constraints of visual workloads. The third category , efficient architectural design, explores the model’ s structural optimiza- tions, including cross-modal projectors, sparse Mixure-of- Experts (MoE), and hardware-aware attention mechanisms. Finally , advanced decoding strategies consist of frameworks to accelerate the autoregressiv e generation process with strate- gies such as multimodal speculative decoding and adaptive computation. In summary , while this classification provides a structure for exploring the current inference optimization strategies, it also pro vides a framework for identifying the open problems to inspire future research directions. I V . T A X O N O M Y - B A S E D S U R V E Y A. V isual T oken Compr ession The primary motiv ation behind token compression is the inherent feature redundancy observed in visual data. Unlike text, where each word has a distinct role in the sentence, an image may consist of multiple patches that do not hav e a unique visual feature. For instance, though an image may contain multiple visual patches to represent a sky or a wall, these patches contribute negligible unique semantic value. Howe ver , retaining such redundant patches has massiv e com- putational implications, especially during the computation of self-attention values. Since standard L VLMs use transformers’ self-attention mechanism, which has quadratic computational complexity , retaining such uninformati ve tokens creates a massiv e, unnecessary computational bottleneck. The primary objectiv e of visual token compression is to identify and drop/merge such tokens as early as possible to alle viate the computational ov erhead, while retaining the model’ s perfor- mance. 1) Image T oken Compression: Image T oken Compression can be classified into image token pruning and image token merging. a) Image T oken Pruning: Image token pruning in L VLMs was introduced by the seminal work FastV [10]. FastV aggressiv ely discarded visual tokens with low attention scores after the second decoder layer of the backbone LLM. Even though FastV achieves massiv e computational savings, it occasionally discards visual patches critical for certain fine- grained user prompts due to its task-agnostic mechanism. T o address this task-agnostic limitation, subsequent works pi voted tow ards query-based cross-modal token pruning strategies. For instance, SparseVLM [77] ev aluates the relev ance of visual Efficient L VLM Inference Strategies V isual T oken Compression Image Compression T oken Pruning T oken Merging V ideo Compression Spatiotemporal Merging Dynamic Multi-granular Merging Memory & Serving KV Cache Management KV Cache Selection KV Cache Budget Allocation KV Cache Merging Memory Management and Paging Block-wise Memory Allocation Prefix-A ware Caching T iered Heterogeneous Storage L VLM Serving Frameworks Continuous Batching Prefill-Decode Disaggregation Distributed and Sequence Parallelism Architectural Design Cross-Modal Projector & Resampler Sparse Mixture-of-Experts (MoE) Hardware-A ware Attention Advanced Decoding Speculativ e Decoding Early Exit & Layer Skipping Fig. 2. T axonomy of Ef ficient Inference Strategies for Large V ision-Language Models (L VLMs). tokens to the user query , retaining task-critical visual patches. Similarly , TRIM [54] uses a CLIP metric-based cross-modal pruning strategy to retain tokens based on the user query . In addition to the attention-based approaches, alternati ve strategies that use similarity-based methods to preserve feature div ersity ha ve been introduced. For instance, Di vprune [3] formulates token pruning as a “Max-Min Diversity Problem” (MMDP) to select a subset of visual patches that maximizes feature distance. It finds a subset of patches among all possible subsets that has the maximum minimum distance between its elements. Similarly , CDPruner [76] uses a determinantal point process (DPP) to maximize the conditional diversity of visual features by maintaining a list-wise div ersity based on the pairwise similarity of visual features and user instructions. These approaches discard identical textures, ensuring a di- verse, representati ve set of visual patches is retained for further computation. Another frontier of research explores alternativ e techniques to address the limitations of attention-based or div ersity-based strategies. For instance, Pyramidrop [69] proposed progres- siv ely dropping tokens across multiple stages rather than an aggressiv e, single-stage drop. Similarly , encoder -side meth- ods such as PruMerge [49] and V isionZip [70] implement attention-based reduction directly within the visual encoder, eliminating the token sequence e ven before it reaches the backbone LLM. b) Image T oken Mer ging: While token pruning provides efficienc y by permanently eliminating visual information, to- ken merging offers an alternative by consolidating redundant features. The seminal work in this domain was T oken Merging (T oMe) [6], which introduced bipartite soft matching to fuse similar visual points within V ision T ransformers. Similar ap- proaches were later adopted for L VLMs in frameworks such as V isionZip [70], which consolidate visual information directly within the visual encoder . Furthermore, hybrid strategies such as PuMer [9], ASAP [43], and V isPruner [76] fuse pruning and merging operations by first pruning uninformati ve patches and then iteratively consolidating the remaining patches, re- taining a condensed visual representation. By aggregating the recurring patterns, such as sky or wall, within an image, these frame works maintain a feature-dense set for subsequent processing. 2) V ideo T oken Compression: The transition from image to video L VLMs introduced a quadratic increase in computational ov erhead. For instance, a 10-minute video, though sampled at only 1 FPS, generates a token sequence that rapidly o verflo ws the conte xt windo w of standard L VLMs. Apart from that, video-based token aggregation poses distinct challenges com- pared to the prior image-based approaches. F or instance, while images contain spatial redundancy , videos further introduce temporal redundancy , necessitating more robust strategies to address this complexity . Initial techniques extended image token consolidation strate- gies into the temporal dimension. Then, more dynamic, multi- granular strategies were proposed to address the heterogeneous nature of videos. a) Spatiotemporal Merging: The early framew orks’ prominent strategy was to extend existing image-based tech- niques to the temporal dimension. For instance, Chat- UniV i [28] pooled each frame by applying the K-Nearest Neighbor-based Density Peak Clustering algorithm, i.e., DPC- KNN, to group temporally adjacent frames before merging tokens based on spatial features. Similarly , LLaMA-VID [33] consolidated each video frame into two tokens, i.e., one global conte xt token and one local content token, representing temporal and visual cues, respectiv ely . While these foundational works successfully prevented Out- of-Memory (OOM) errors, they suffered from se veral lim- itations. While relying on single-frame clustering represen- tations misses subtle temporal dynamics, fixed-rate merging algorithms make the approach brittle to the di verse complexity of underlying videos. b) Dynamic, Multi-Granular , and T ask-A ware Compres- sion: The literature quickly recognized the inherent hetero- geneity of the underlying videos, such that processing a static frame of a mountain requires less compute than processing a complex action sequence. Subsequent works moved to wards this paradigm, presenting dynamic, multi-granular , and task- aware compression frameworks. T o address the limitations of DPC-KNN, HoliT om [50] in- troduced a holistic token condensation approach framing tem- poral redundancy as a global optimization problem across mul- tiple video frames, rather than a limited local inter -frame issue. Additionally , FastVID [51] redefined density-based pruning by dynamically clustering adjacent frames to merge visual patches on-the-fly , while DyCoke [56] and Dynamic-VLM [61] pro- posed techniques to flexibly adjust the compression ratio based on the complexity of the video frame sequences. Furthermore, Multi-Granular Spatio-T emporal T oken Merging [24] main- tained a multi-le vel quadtree of video frame patches, which was subsequently used to perform pairwise temporal merging, allowing models to retain patches for complex features while heavily compressing static backgrounds. One of the prominent shifts in the domain was the cross- modal inte gration of user prompts and video patches during the consolidation. Such cross-modal approaches were pioneered in LongVU [52] and FlexSelect [73]. Particularly , FlexSelect employed a trained lightweight selector network to mimic the attention weights of a large L VLM, eliminating query- irrelev ant visual features before heavy multimodal reasoning occurs. Similarly , LangDC [62] lev eraged a lightweight lan- guage model to generate captions from video clips to aid in selecting key visual cues for downstream inference. These cross-modality techniques incorporated textual cues during aggregation to make informed, contextual decisions. In addition to these approaches, a few other works present new strate gies. For instance, FrameFusion [17] presented a hy- brid prune-mer ge technique that consolidates identical patches and eliminates unimportant features. Similarly , VQT oken [75] lev eraged neural discrete representation learning via vector quantization to map continuous video embeddings into a highly compact feature space, achie ving a massive reduction of the visual representation. B. KV Cache & Memory Management While optimizing the prefill phase via token consolidation addresses the compute bottlenecks, the memory-bound decode phase remains a significant hurdle for real-time autoregressiv e generation. The implications for L VLM remain critical because high-resolution images and video sequences inject thousands of dense visual tokens into the prefill stage. Consequently , the resulting KV Cache gro ws linearly when generation pro- gresses, rapidly consuming the GPU High Bandwidth Mem- ory (HBM). This massiv e memory footprint may lead to the infamous OOM errors, which compromise the model’ s functionality . Thus, ef ficient strategies are necessary to address the growing memory footprint. 1) Algorithmic KV Cache Management: Algorithmic KV cache management can be further categorized into KV cache selection, budget allocation, and merging. a) KV Cache Selection: Algorithmic KV Cache selection strategies that minimize GPU HBM memory consumption by retaining the most critical visual tokens can be categorized into static and dynamic approaches. Static KV Cache selection techniques execute a one-time compression immediately fol- lowing the L VLMs’ prefill phase. For instance, SnapKV [34] employs an observation window to determine important fea- tures, retaining only the critical contextual tokens. Similarly , L2Compress [15] establishes a strong correlation between lo w L2 norms in ke y embeddings and high attention scores, and compresses the KV Cache based on this observation. Unlike the static approach’ s single selection during prefill, dynamic selection continuously updates the KV Cache dur- ing the decoding phase. StreamingLLM [68], one of the pioneering works in this cate gory , presented the “attention sink” phenomenon, where initial sequence tokens are vital for model stability regardless of their semantic v alue. Lev eraging this observation, StreamingLLM incorporates attention sink positions with recent context for efficient processing. Building on the “attention sink” phenomenon, H2O [78] dynamically tracked and retained “Heavy Hitters” - tokens that accumulate high attention scores over time - while permanently evicting unimportant tokens to enforce a feature-dense KV Cache. While permanent eviction effecti vely reduces GPU HBM usage, it irre versibly eliminates information, degrading the model’ s performance on long contexts. T o mitigate this, a subset of dynamic selection approaches avoids permanent eviction by utilizing multi-tier hierarchical storage systems. For instance, InfLLM [67] maintains the most critical con- versational context in GPU HBM while of floading the less- frequently accessed bulk of KV cache to the host CPU. The of floaded cache is organized with advanced indexing for low-latenc y retriev al and transfer back to the GPU. For instance, PQCache [55] organizes offloaded cache into block- lev el representations and uses product quantization codes and centroids to identify important tokens during retriev al. Simi- larly , SqueezedAttention [21] employs K-means clustering to group semantically related k eys on the of floaded cache. During the autoregressiv e generation loop, query-matching algorithms like SparQ [47] dynamically identify and retrie ve only the specific top-k relev ant KV blocks needed for the current computational step. Such query-matching strate gies accelerate the model’ s access to infinite context without incurring huge latency . b) KV Cache Budget Allocation: Due to the hierarchical architecture of L VLMs, the KV Cache of different layers uniquely contributes to model performance. In that regard, applying a uniform cache compression ratio often becomes suboptimal. T o maximize memory utilization while retaining prediction accuracy , KV cache budget allocation strategies distribute memory resources based on the component’ s im- portance. These allocation frameworks can be categorized into two le vels of granularity: layer-wise and head-wise KV cache budget allocation. In contrast to con ventional methods that enforce a uniform compression ratio across the entire model, layer-wise budget allocation applies different compression ratios across model layers. PyramidKV [8] is a seminal work in this category that implements a pyramid-shaped allocation strategy , i.e., allocating more cache budget in shallow layers and less in the deeper ones. Furthermore, DynamicKV [82] expanded be- yond static architectural heuristics to introduce a task-adaptive framew ork that distributes the memory budget proportionally based on the computed attention-scores of recent and prior tokens across the model layers. Other frameworks utilize advanced scoring mechanisms to dictate layer budgets. For instance, CAKE [44] frames memory allocation as a “cake- slicing” problem, adaptively allocating layer-specific cache sizes based on both the spatial and temporal dynamics of attention. c) KV Cache Mer ging: T o address the growing size of the KV cache as token generation progresses, several merging strate gies consolidate similar information. KV Cache aggregation can be done within a layer or across multiple layers. Intra-layer merging combines representations within indi- vidual decoder layers, utilizing either supervised strategies or training-free techniques. Supervised approaches train the model to effecti vely condense conv ersation history . For in- stance, CCM [31] and LoMA [63] introduce special indicator tokens into the input sequence, e.g., 〈 COMP 〉 in CCM, acting as checkpoints which are lev eraged to compress past key-v alue pairs in each layer into a compact memory space. Similarly , DMC [42] employs a learned variable to dynamically decide whether a new KV pair should be added to the cache or mer ged into an existing KV representation. Alternativ ely , training-free methods rely on inherent struc- tural observations to mer ge tokens without requiring parameter updates. For instance, D2O [60] aggregates the ke y/value of an evicted token with a retained one using the cosine-similarity- based threshold. Furthermore, CHAI [1] noted that sev eral heads in multi-head attention that produce correlated atten- tion values can be clustered. Subsequently , CHAI computed attention for only a representativ e head for each cluster and shared the values across all heads within the group, eventually reducing memory implications. 2) Memory Management and P aging: L VLMs need so- phisticated system-le vel memory management techniques to accommodate the massiv e influx of visual tokens in mod- ern multimodal architectures. Recent works in this domain generally fall into three key categories: block-wise memory allocation to eliminate fragmentation, prefix-aware caching to reuse shared multimodal contexts, and tiered heterogeneous storage for capacity expansion. a) Block-wise Memory Allocation: The foundational ar- chitecture for resolving memory fragmentation during infer- ence is vLLM [32], which introduced PagedAttention mecha- nism. Drawing analogy from operating system virtual memory , PagedAttention partitions the KV cache into fixed-size logical blocks and maintains a corresponding block table. The block table maps the continuous sequence tokens to non-contiguous physical blocks in GPU memory . Due to this approach, vLLM can dynamically allocate memory block as per demand rather than pre-allocating maximum possible sequence blocks. Con- sequently , this strategy eliminates both external fragmentation and the internal memory waste, drastically impro ving memory utilization and enabling processing more request concurrency without out-of-memory errors. b) Pr efix-A war e Caching: Beyond minimizing memory fragmentation within individual requests, advanced memory management framew orks address the huge computational re- dundancy inherent in L VLM inferences via prefix caching. In a multi-turn question answering setup, multiple requests may share identical high-resolution images or system prompts. T o exploit the inherent redundancy , prefix caching frameworks or - ganize paged KV blocks into hierarchical structures, enabling dynamic lookup and fetch operations for recurring multimodal data. A leading paradigm in this domain is SGLang [79], which introduced RadixAttention that enables the reuse of precomputed context across multiple generation calls. Radix- Attention maintains a Least Recently Used (LR U) cache using a radix tree structure that prioritizes requests based on matched prefix lengths. This is complemented by a strict reference counting mechanism that protects activ ely used cache entries from premature e viction during continuous batching. Building upon these tree-based data structures, ChunkAttention [71] enables the dynamic detection and sharing of common prompt prefixes during runtime by partitioning monolithic KV cache tensors into smaller, organized chunks. Furthermore, frame- works like BatchLLM [80] enhance system efficienc y by co- scheduling requests that share the same KV cache context to maximize cache reuse. Additionally , MemServe [22] scales these locality-aware prefix policies across distributed en viron- ments by pooling CPU and GPU memory across multiple instances to optimize global KV cache sharing. c) T ier ed Hetero geneous Storag e: Even after implement- ing efficient paging and prefix sharing techniques, ultra-long visual data, such as very long videos, inevitably exhaust the av ailable capacity of the GPU High Bandwidth Memory . T o address these storage constraints, tiered memory manage- ment extends the effecti ve KV cache capacity by offload- ing sequence context to the host CPU DRAM and NVMe SSDs, treating them as secondary storage layers. For instance, FlexGen [53] and InfLLM [67] implement this frame work by continuously monitoring memory states and proacti vely offloading inacti ve or historically distant context to the high- capacity secondary storage layers. Finally , to alleviate the considerable latenc y bottlenecks caused by PCIe data transfers, these systems employ asynchronous prefetching techniques that ov erlap cross-de vice communication with ongoing GPU computation. 3) L VLM Serving: While memory management and paging framew orks effecti vely resolv e the storage constraints of mas- siv e visual contexts, scheduling the computational resources for these requests presents a unique challenge. T o address these new challenges, modern L VLM serving systems intro- duce sophisticated scheduling mechanisms such as continuous batching, disaggregated execution, and sequence parallelism. a) Continuous Batching Strate gies: T o overcome the constraints of static batching prev alent in prior works, multiple framew orks proposed batching strategies to maximize GPU utilization. For instance, Orca [72] pioneered the continuous batching paradigm where job requests can be dynamically added or remov ed from a running batch iteratively rather than waiting for the completion of the entire batch. The continuous scheduling strategy was extended by vLLM [32], that integrated iteration-level scheduling with PagedAttention to eliminate memory fragmentation while enabling the concur- rent ex ecution of div erse-length job requests within a single batch. Furthermore, FastServe [65] addressed the inherent div erse request lengths by introducing a skip-join Multi-Level Feedback Queue (MLFQ). The MLFQ employs an dynamic scheduling policy that prioritizes shorter requests while demot- ing hea vier long-running requests across multiple priority tiers. This preempti ve multi-tier approach minimizes average job completion time while prev enting the head-of-line blocking common to static batching pipelines. Building upon these mechanics, Sarathi-Serve introduced chunked prefill, which splits massive compute request sequences into smaller units. It further co-schedules the prefill chunks alongside decoding jobs within a single batch to effecti vely saturate compute resources. b) Pr efill-Decode Disaggr e gation: Although pre vious batching mechanisms enabled efficient resource utilization, the inherent prefill and decode stages during autoregressi ve generation pose distinct challenges. Prefill-Decode disaggrega- tion paradigms separate the compute-bound prefill phase and memory-bound decode phase into separate GPU pools, further optimizing GPU usage. Distserve [81], a seminal framework in this domain, disaggregates these phases to meet distinct Ser- vice Lev el Objectives (SLOs), including T ime-to-First-T oken and Time-per -Output-T okens, by of floading them to individual computing resources. Furthermore, ShuffleInfer [23] adopted this two-lev el decoupled scheduling strategy , incorporating a component that predicts hardw are resource utilization to optimize the allocation of disaggregated workloads. It employs LLM-based prediction to speculate the length of generated tokens of decode requests and schedules them accordingly . Additionally , Infinite-LLM [36] decouples LLM’ s attention layers across a pooled GPU memory , facilitating resource sharing to maximize both memory and compute utilization. By analyzing the computational characteristics of dynamic length LLM workloads, Infinite-LLM proposes a mechanism to saturate both compute and memory utilization. c) Distributed and Sequence P arallelism: For massive multimodal inputs, the workload may exceed a single GPU’ s capacity , necessitating a distributed workflo w to partition the compute across multiple compute devices. In that regard, distributed and sequence parallelism enable processing ultra- long contexts, unlike the traditional strategies. For instance, DeepSpeed-FastGen [20] and DeepSpeed-MoE [46] employ expert parallelism along with Dynamic SplitFuse [20] to optimize throughput and resource utilization for large-scale deployments. Similarly , RingAttention [37] and StripeAtten- tion [7] distribute self-attention blocks across a ring of GPUs, ov erlapping cross-de vice computation and communication, enabling high throughput and low communication overhead. Additionally , an elastic sequence framework was introduced in LoongServe [64] that dynamically determines and allocates the GPU count required for a job sequence based on the real- time workload’ s compute demands. C. Efficient Arc hitectural Design The architectural components of L VLMs present several opportunities for inference optimization. By redefining the interaction between the vision and language components of the L VLM network, such optimizations can reduce inherent com- putational o verhead, ultimately enhancing resource utilization. 1) Cr oss-Modal Projector & Resampler Optimization: Cross-modal projectors and resamplers act as a semantic bottleneck, compressing the massi ve quantity of visual to- kens into a smaller sized latent tokens before passing them to the LLM backbone. Flamingo [2], a seminal work in this domain, introduced the “perceiver resampler” that maps variable-length visual patches into fix ed-sized visual “queries” via a cross-attention mechanism. More recently , NVILA [40] implemented an optimization strategy that processes high- resolution images and videos at full detail initially and then aggressiv ely compresses them into a minimal token set. 2) Sparse Mixtur e-of-Experts (MoE) for L VLMs: Sparse MoE strate gies allo w models to increase their parameter count while keeping the token computational cost constant. Specifically , sparse MoE architectures maintain multiple “ex- perts” and employ a dynamic routing approach, acti v ating only a subset for any giv en input sequence rather than using the entire network for ev ery request. In particular, MoE- LLaV A [35], a seminal framew ork, established that sparse L VLMs could increase parameter count to model complex visual reasoning capabilities while maintaining the FLOPs count of a smaller model. Additionally , DeepSeek-VL2 [66] introduced advanced MoE paradigms with fine-grained e xpert separation and shared experts, enhancing the compute-sa ving capabilities of MoE architectures. Similarly , the MM1 family of models [41] v alidated the ef fectiveness of these strategies at a massive scale by establishing the comprehensi ve multimodal scaling laws. By dynamically routing multimodal inputs only to the relev ant networks, these MoE-paradigm-based L VLMs support advanced visual reasoning while strictly bounding computational ov erhead. 3) Har dware-A ware Attention Optimization: The standard self-attention mechanism is highly memory-bound as it re- peatedly writes and reads the intermediate attention matrices to and from GPU HBM. FlashAttention [14] addressed this bottleneck by introducing an exact attention algorithm that utilizes tiling and forward-pass recomputation to keep the data within on-chip SRAM. Furthermore, FlashAttention-2 [13] optimized the attention computation by partitioning it between different thread blocks and warps on the GPU, improving parallel occupancy and further reducing the number of non- matmul FLOPs. In addition, FlashAttention-3 [48] decreases attention computation time on NVIDIA Hopper GPUs by exploiting the compute node’ s architecture. It does so by ov erlapping the computation with data movement via wrap- specialization and interleaving block-wise matmul and softmax operations. Overall, the iterations of FlashAttention are the critical hardware-lev el engine that make processing a massiv e quantity of high-resolution visual tokens computationally vi- able. D. Advanced Decoding Strate gies After generating the first token in the prefill phase, the L VLM generation transitions to the decode phase, where the subsequent output sequence is generated. At this stage, operations are primarily memory-bound, since the model loads precomputed weights from HBM, often causing a high-latency model pass. T o alleviate these limitations, sev eral advanced decoding strategies are introduced. 1) Multimodal Speculative Decoding: Multimodal specula- tiv e decoding often employs the “draft-then-verify” paradigm, which parallelizes output generation to alleviate the limitations of the memory-bound autoregressi ve phase. By extending the existing text-only speculativ e decoding paradigms, a few works hav e proposed corresponding workflo ws for multi- modal tasks. For instance, Gagrani et al. [18] demonstrated that language-only models can effecti vely verify multimodal workflo ws using a 115M language model as a draft for a lar ger LLaV A 7B L VLM. Additionally , LANTERN [25] acknowledges the “token selection ambiguity” inherent in visual autoregressi ve models, where models uniformly assign low probabilities to token sequences. LANTERN subsequently mitigates the phenomenon by introducing a relaxed acceptance condition that permits the interchange of semantically similar latent tok ens, thereby im proving speculati ve decoding through- put. Furthermore, SpecVLM [26] extends speculativ e decoding to video workloads by introducing a training-free paradigm that prunes redundant video patches to minimize the draft model’ s KV cache footprint. Similarly , V iSpec [29] employs a tin y vision adaptor to aggregate thousands of redundant visual patches into a compact, representativ e unit for the draft model, enabling huge throughput gains while maintain- ing output accuracy . Additionally , DREAM enhances visual speculativ e decoding by adopting an entropy-adaptiv e cross- attention fusion mechanism, which injects target model fea- tures into the draft model, thereby enhancing representation alignment and achieving massiv e inference speedups. These framew orks demonstrate that addressing the specialized multi- modal context during the drafting process ef fectively mitigates the memory-bandwidth bottleneck inherent in L VLMs. 2) Early Exit & Layer Skipping: Adapti ve computation strategies, such as early exit and layer skipping, ha ve emer ged to address the inherent computational redundancy in L VLMs. Such methods le verage observed token-le vel complexity vari- ance, where “easy” tokens (e.g., punctuation and syntax) can be effecti vely predicted using only a fraction of the model’ s layers, whereas “hard” tokens require full utilization of the network layers. One prominent paradigm of this v ariance is confidence- based early exits, which introduce internal classifiers to predict the maturity of the token’ s representation. Such approaches are employed in recent works, such as AdaInfer [16], which uti- lizes statistical features and classifiers, like SVM and CRF , to terminate computation early for high-confidence predictions. By skipping layers for simple tasks, this strategy can save a large number of computational FLOPs. V . O P E N - P R O B L E M S The research community has presented sev eral solutions to address the growing multimodal input context, mem- ory requirements, and inefficient architectural designs in the L VLM generation scenario. Consequently , these approaches hav e reduced inference latency and memory footprint, while simultaneously maximizing the model throughput and efficient GPU utilization. Ho wever , these works overlook the dynamic shift in the domain towards continuous video streaming, multi- image processing, and real-time agent applications. This sec- tion presents such une xplored avenues to define the upcoming research frontiers in vision-language computing efficienc y . While the existing visual compression strategies hav e suc- cessfully mitigated the quadratic complexity of the self- attention block, these approaches are often heuristic-based. Particularly , many of these techniques use attention values, which are susceptible to the decay artifact of rotary po- sitional embedding. Additionally , after the introduction of div ersity-based approaches, there is an importance-di versity dilemma on whether to use high-salience important patches or a comprehensiv e set of div erse patches during complex visual reasoning tasks. Furthermore, the transition to streaming- video-based workloads has presented unique challenges. The liv e video setup restricts access to future video patches, fundamentally making temporal redundanc y elimination a challenging objectiv e. Furthermore, the infinite context length of these inferences becomes a se vere memory bottleneck as the KV cache grows linearly with autoregressiv e generation. Similarly , a visual context eliminated at the current time can eventually be relev ant in the future. Since the visual information is already discarded, the model can hallucinate in such circumstances. Designing frameworks that address the importance-div ersity dilemma, while maintaining memory- constrained spatial-temporal aggre gation in live video streams, remains a critical open challenge for visual token compression. Although PagedAttention and continuous batching ap- proaches addressed the memory fragmentation for text-based inferences, visual workloads pose distinct challenges. Current KV cache compression techniques often require full attention matrices before deciding which tokens to e vict. Ho wever , such an approach for high frame rate and long videos results in mas- siv e computational waste while computing attention v alues. An alternativ e proxy for token salience can be introduced to a void expensi ve attention computation. Similarly , existing prefill- decode disaggre gation strate gies suf fer from se veral limitations for long video or streaming video inferences. While sepa- rating the compute-bound prefill and memory-bound decode phases optimizes GPU utilization, transferring the massi ve visual cache for an inference across the network may incur substantial latency . Due to this, the latency gains from the disaggregation may be diminished. Thus, devising strategies that av oid expensi ve attention computation and mitigate the ov erhead of transferring multimodal conte xts across disag- gregated nodes remains a critical open challenge for scaling L VLM serving systems. Though the inference efficienc y of multimodel LLMs has in- creased due to the inte gration of cross-modal projectors, sparse MoE, and hardware-aw are attention, several limitations still exist. For instance, the routing algorithm in MoE often routes visual context to a small subset of “popular” experts, failing to distribute the tasks across different experts. Consequently , other experts are underutilized, and the model stops function- ing like a true mixture of experts. Additionally , ev en though FlashAttention[13, 14, 48] optimizes attention for hardware, the underlying mechanism is still O ( N 2 ) complexity , which becomes critical while processing high-resolution images or long videos. While some alternative strategies, such as state- space models [19] and linear attention [30], mitigate this issue, they suffer from limited expressivity compared to standard attention. These techniques often lose the fine-grained details of the visual content that leads to inadequate performance in complex visual question answering tasks. V I . C O N C L U S I O N S As Large V ision Language Models (L VLMs) handle high- resolution images and continuous video streams, their compu- tational and memory demands become a primary bottleneck for real-world deployment. This paper presents a compre- hensiv e survey of L VLM inference acceleration, organizing existing approaches into four dimensions: visual token com- pression, memory management and serving, ef ficient architec- tural design, and advanced decoding strate gies. While current methods have made significant progress in mitigating the quadratic complexity of self-attention and the linear growth of the KV cache, se veral open challenges exist. In particular , the shift tow ard continuous video streaming demands sophis- ticated solutions beyond static heuristics. By identifying these limitations and outlining open problems, this surv ey offers a roadmap for future research toward scalable, efficient, and robust multimodal systems. R E F E R E N C E S [1] Agarwal, S., Acun, B., Hosmer , B., Elhoushi, M., Lee, Y ., V enkataraman, S., Papailiopoulos, D., W u, C.J.: Chai: clustered head attention for efficient llm inference. In: Proceedings of the 41st International Conference on Machine Learning. pp. 291–312 (2024) [2] Alayrac, J.B., Donahue, J., Luc, P ., Miech, A., Barr , I., Hasson, Y ., Lenc, K., Mensch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural information processing systems 35 , 23716–23736 (2022) [3] Alv ar , S.R., Singh, G., Akbari, M., Zhang, Y .: Di- vprune: Di versity-based visual token pruning for large multimodal models. In: Proceedings of the Computer V ision and Pattern Recognition Conference. pp. 9392– 9401 (2025) [4] Bai, J., Bai, S., Chu, Y ., Cui, Z., Dang, K., Deng, X., Fan, Y ., Ge, W ., Han, Y ., Huang, F ., et al.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023) [5] Bai, J., Bai, S., Y ang, S., W ang, S., T an, S., W ang, P ., Lin, J., Zhou, C., Zhou, J.: Qwen-vl: A frontier large vision- language model with versatile abilities. arXiv preprint arXiv:2308.12966 1 (2), 3 (2023) [6] Bolya, D., Fu, C.Y ., Dai, X., Zhang, P ., Feichtenhofer, C., Hoffman, J.: T oken merging: Y our vit but faster . arXiv preprint arXiv:2210.09461 (2022) [7] Brandon, W ., Nrusimha, A., Qian, K., Ankner , Z., Jin, T ., Song, Z., Ragan-K elley , J.: Striped attention: Faster ring attention for causal transformers. arXiv preprint arXiv:2311.09431 (2023) [8] Cai, Z., Zhang, Y ., Gao, B., Liu, Y ., Li, Y ., Liu, T ., Lu, K., Xiong, W ., Dong, Y ., Hu, J., Xiao, W .: PyramidKV : Dynamic KV cache compression based on p yramidal information funneling. In: Second Conference on Lan- guage Modeling (2025), https://openrevie w .net/forum? id=ayi7qezU87 [9] Cao, Q., Paranjape, B., Hajishirzi, H.: Pumer: Pruning and mer ging tok ens for efficient vision language models. arXiv preprint arXiv:2305.17530 (2023) [10] Chen, L., Zhao, H., Liu, T ., Bai, S., Lin, J., Zhou, C., Chang, B.: An image is worth 1/2 tok ens after layer 2: Plug-and-play inference acceleration for large vision- language models. In: European Conference on Computer V ision. pp. 19–35. Springer (2024) [11] Chen, Z., W u, J., W ang, W ., Su, W ., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Intern vl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24185–24198 (2024) [12] Chiang, W .L., Li, Z., Lin, Z., Sheng, Y ., W u, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y ., Gonzalez, J.E., et al.: V icuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality . See https://vicuna. lmsys. org (accessed 14 April 2023) 2 (3), 6 (2023) [13] Dao, T .: Flashattention-2: Faster attention with better parallelism and work partitioning. In: The T welfth Inter- national Conference on Learning Representations (2024), https://openrevie w .net/forum?id=mZn2Xyh9Ec [14] Dao, T ., Fu, D., Ermon, S., Rudra, A., R ´ e, C.: Flashat- tention: Fast and memory-efficient exact attention with io-awareness. Advances in neural information processing systems 35 , 16344–16359 (2022) [15] De voto, A., Zhao, Y ., Scardapane, S., Minervini, P .: A simple and ef fectiv e l 2 norm-based strategy for kv cache compression. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 18476–18499 (2024) [16] Fan, S., Jiang, X., Li, X., Meng, X., Han, P ., Shang, S., Sun, A., W ang, Y .: Not all layers of llms are necessary during inference. In: Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, IJCAI-25. pp. 5083–5091 (2025) [17] Fu, T ., Liu, T ., Han, Q., Dai, G., Y an, S., Y ang, H., Ning, X., W ang, Y .: Framefusion: Combining similarity and importance for video token reduction on lar ge vision language models. In: Proceedings of the IEEE/CVF International Conference on Computer V ision (ICCV). pp. 22654–22663 (October 2025) [18] Gagrani, M., Goel, R., Jeon, W ., Park, J., Lee, M., Lott, C.: On speculative decoding for multimodal large language models. In: Proceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition. pp. 8285–8289 (2024) [19] Gu, A., Dao, T .: Mamba: Linear-time sequence model- ing with selectiv e state spaces. In: First conference on language modeling (2024) [20] Holmes, C., T anaka, M., W yatt, M., A wan, A.A., Rasley , J., Rajbhandari, S., Aminabadi, R.Y ., Qin, H., Bakhtiari, A., Kurilenko, L., et al.: Deepspeed-fastgen: High-throughput te xt generation for llms via mii and deepspeed-inference. arXiv preprint arXi v:2401.08671 (2024) [21] Hooper , C.R.C., Kim, S., Mohammadzadeh, H., Mah- eswaran, M., Zhao, S., Paik, J., Mahoney , M.W ., Keutzer , K., Gholami, A.: Squeezed attention: Accelerating long context length llm inference. In: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers). pp. 32631–32652 (2025) [22] Hu, C., Huang, H., Hu, J., Xu, J., Chen, X., Xie, T ., W ang, C., W ang, S., Bao, Y ., Sun, N., et al.: Mem- serve: Context caching for disaggre gated llm serving with elastic memory pool. arXiv preprint (2024) [23] Hu, C., Huang, H., Xu, L., Chen, X., W ang, C., Xu, J., Chen, S., Feng, H., W ang, S., Bao, Y ., et al.: Shuffle- infer: Disaggreg ate llm inference for mixed downstream workloads. ACM Transactions on Architecture and Code Optimization 22 (2), 1–24 (2025) [24] Hyun, J., Hwang, S., Han, S.H., Kim, T ., Lee, I., W ee, D., Lee, J.Y ., Kim, S.J., Shim, M.: Multi-granular spatio- temporal token merging for training-free acceleration of video llms. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer V ision. pp. 23990–24000 (2025) [25] Jang, D., Park, S., Y ang, J.Y ., Jung, Y ., Y un, J., Kundu, S., Kim, S.Y ., Y ang, E.: LANTERN: Accelerating vi- sual autoregressi ve models with relaxed speculativ e de- coding. In: The Thirteenth International Conference on Learning Representations (2025), https://openre vie w .net/ forum?id=98d7DLMGdt [26] Ji, Y ., Zhang, J., Xia, H., Chen, J., Shou, L., Chen, G., Li, H.: Specvlm: Enhancing speculati ve decoding of video llms via verifier -guided token pruning. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 7216–7230 (2025) [27] Jiang, A., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D., Casas, D., Bressand, F ., Lengyel, G., Lam- ple, G., Saulnier , L., et al.: Mistral 7b . arxiv 2023. arXiv preprint arXiv:2310.06825 (2024) [28] Jin, P ., T akanobu, R., Zhang, W ., Cao, X., Y uan, L.: Chat-univi: Unified visual representation empowers large language models with image and video understanding. In: Proceedings of the IEEE/CVF Conference on Computer V ision and P attern Recognition. pp. 13700–13710 (2024) [29] Kang, J., Shu, H., Li, W ., Zhai, Y ., Chen, X.: V is- pec: Accelerating vision-language models with vision- aware speculative decoding. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025), https://openrevie w .net/forum?id=x2BsIdJJJW [30] Katharopoulos, A., Vyas, A., Pappas, N., Fleuret, F .: T ransformers are rnns: Fast autoregressi ve transformers with linear attention. In: International conference on machine learning. pp. 5156–5165. PMLR (2020) [31] Kim, J.H., Y eom, J., Y un, S., Song, H.O.: Com- pressed context memory for online language model in- teraction. In: The T welfth International Conference on Learning Representations (2024), https://openre vie w .net/ forum?id=64kSvC4iPg [32] Kwon, W ., Li, Z., Zhuang, S., Sheng, Y ., Zheng, L., Y u, C.H., Gonzalez, J., Zhang, H., Stoica, I.: Efficient mem- ory management for large language model serving with pagedattention. In: Proceedings of the 29th symposium on operating systems principles. pp. 611–626 (2023) [33] Li, Y ., W ang, C., Jia, J.: Llama-vid: An image is worth 2 tokens in large language models. In: European Confer - ence on Computer V ision. pp. 323–340. Springer (2024) [34] Li, Y ., Huang, Y ., Y ang, B., V enkitesh, B., Locatelli, A., Y e, H., Cai, T ., Le wis, P ., Chen, D.: Snapkv: Llm kno ws what you are looking for before generation. Advances in Neural Information Processing Systems 37 , 22947– 22970 (2024) [35] Lin, B., T ang, Z., Y e, Y ., Huang, J., Zhang, J., Pang, Y ., Jin, P ., Ning, M., Luo, J., Y uan, L.: Moe-llav a: Mixture of experts for large vision-language models. IEEE T ransactions on Multimedia (2026) [36] Lin, B., Zhang, C., Peng, T ., Zhao, H., Xiao, W ., Sun, M., Liu, A., Zhang, Z., Li, L., Qiu, X., et al.: Infinite-llm: Ef- ficient llm service for long context with distattention and distributed kvcache. arXiv preprint arXi v:2401.02669 (2024) [37] Liu, H., Zaharia, M., Abbeel, P .: Ringattention with blockwise transformers for near -infinite context. In: The T welfth International Conference on Learning Representations (2024), https://openre view .net/forum? id=WsRHpHH4s0 [38] Liu, H., Li, C., Li, Y ., Lee, Y .J.: Impro ved baselines with visual instruction tuning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26296–26306 (2024) [39] Liu, H., Li, C., W u, Q., Lee, Y .J.: V isual instruction tun- ing. Advances in neural information processing systems 36 , 34892–34916 (2023) [40] Liu, Z., Zhu, L., Shi, B., Zhang, Z., Lou, Y ., Y ang, S., Xi, H., Cao, S., Gu, Y ., Li, D., et al.: Nvila: Efficient frontier visual language models. In: Proceedings of the IEEE/CVF Conference on Computer V ision and Pattern Recognition. pp. 4122–4134 (2025) [41] McKinzie, B., Gan, Z., Fauconnier , J.P ., Dodge, S., Zhang, B., Dufter , P ., Shah, D., Du, X., Peng, F ., Belyi, A., et al.: Mm1: methods, analysis and insights from multimodal llm pre-training. In: European Conference on Computer V ision. pp. 304–323. Springer (2024) [42] Nawrot, P ., Ła ´ ncucki, A., Chochowski, M., T arjan, D., Ponti, E.M.: Dynamic memory compression: retrofitting llms for accelerated inference. In: Proceedings of the 41st International Conference on Machine Learning. pp. 37396–37412 (2024) [43] Pathak, S., Han, B.: Asap: Attention-shift-aware pruning for efficient lvlm inference. arXiv preprint arXiv:2603.14549 (2026) [44] Qin, Z., Cao, Y ., Lin, M., Hu, W ., Fan, S., Cheng, K., Lin, W ., Li, J.: CAKE: Cascading and adaptiv e KV cache e viction with layer preferences. In: The Thirteenth International Conference on Learning Representations (2025), https://openrevie w .net/forum?id=EQgEMAD4kv [45] Radford, A., Kim, J.W ., Hallacy , C., Ramesh, A., Goh, G., Agarwal, S., Sastry , G., Askell, A., Mishkin, P ., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) [46] Rajbhandari, S., Li, C., Y ao, Z., Zhang, M., Aminabadi, R.Y ., A wan, A.A., Rasley , J., He, Y .: Deepspeed-moe: Advancing mixture-of-experts inference and training to power ne xt-generation ai scale. In: International con- ference on machine learning. pp. 18332–18346. PMLR (2022) [47] Ribar , L., Chelombie v , I., Hudlass-Galley , L., Blake, C., Luschi, C., Orr , D.: Sparq attention: bandwidth-efficient llm inference. In: Proceedings of the 41st International Conference on Machine Learning. pp. 42558–42583 (2024) [48] Shah, J., Bikshandi, G., Zhang, Y ., Thakkar , V ., Ramani, P ., Dao, T .: Flashattention-3: Fast and accurate attention with asynchrony and low-precision. Advances in Neural Information Processing Systems 37 , 68658–68685 (2024) [49] Shang, Y ., Cai, M., Xu, B., Lee, Y .J., Y an, Y .: Llava- prumerge: Adaptive token reduction for efficient large multimodal models. In: Proceedings of the IEEE/CVF In- ternational Conference on Computer V ision. pp. 22857– 22867 (2025) [50] Shao, K., T ao, K., Qin, C., Y ou, H., Sui, Y ., W ang, H.: Holitom: Holistic token merging for fast video large lan- guage models. arXiv preprint arXiv:2505.21334 (2025) [51] Shen, L., Gong, G., He, T ., Zhang, Y ., Liu, P ., Zhao, S., Ding, G.: Fastvid: Dynamic density pruning for fast video large language models. arXiv preprint arXiv:2503.11187 (2025) [52] Shen, X., Xiong, Y ., Zhao, C., W u, L., Chen, J., Zhu, C., Liu, Z., Xiao, F ., V aradarajan, B., Bordes, F ., et al.: Longvu: Spatiotemporal adaptiv e compression for long video-language understanding. In: International Confer- ence on Machine Learning. pp. 54582–54599. PMLR (2025) [53] Sheng, Y ., Zheng, L., Y uan, B., Li, Z., Ryabinin, M., Chen, B., Liang, P ., R ´ e, C., Stoica, I., Zhang, C.: Fle xgen: High-throughput generative inference of large language models with a single gpu. In: International Conference on Machine Learning. pp. 31094–31116. PMLR (2023) [54] Song, D., W ang, W ., Chen, S., W ang, X., Guan, M.X., W ang, B.: Less is more: A simple yet effecti ve token reduction method for ef ficient multi-modal llms. In: Proceedings of the 31st International Conference on Computational Linguistics. pp. 7614–7623 (2025) [55] T ang, J., Zhao, Y ., Zhu, K., Xiao, G., Kasikci, B., Han, S.: Quest: query-aware sparsity for efficient long-context llm inference. In: Proceedings of the 41st International Con- ference on Machine Learning. pp. 47901–47911 (2024) [56] T ao, K., Qin, C., Y ou, H., Sui, Y ., W ang, H.: Dycoke: Dynamic compression of tokens for fast video large language models. In: Proceedings of the Computer V ision and Pattern Recognition Conference. pp. 18992–19001 (2025) [57] T ouvron, H., Lavril, T ., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T ., Rozi ` ere, B., Goyal, N., Hambro, E., Azhar , F ., et al.: Llama: Open and efficient foundation language models. arXi v preprint arXiv:2302.13971 (2023) [58] T ouvron, H., Martin, L., Stone, K., Albert, P ., Alma- hairi, A., Babaei, Y ., Bashlyko v , N., Batra, S., Bharga va, P ., Bhosale, S., et al.: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint (2023) [59] V aswani, A., Shazeer, N., Parmar , N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: At- tention is all you need. Advances in neural information processing systems 30 (2017) [60] W an, Z., W u, X., Zhang, Y ., Xin, Y ., T ao, C., Zhu, Z., W ang, X., Luo, S., Xiong, J., W ang, L., Zhang, M.: $ \ te xt { D } { 2 }\ text { O } $: Dynamic discriminativ e operations for efficient long-context inference of large language models. In: The Thirteenth International Con- ference on Learning Representations (2025), https:// openrevie w .net/forum?id=HzBfoUdjHt [61] W ang, H., Nie, Y ., Y e, Y ., W ang, Y ., Li, S., Y u, H., Lu, J., Huang, C.: Dynamic-vlm: Simple dynamic vi- sual tok en compression for videollm. In: Proceedings of the IEEE/CVF International Conference on Computer V ision. pp. 20812–20823 (2025) [62] W ang, X., Zhang, J., W ang, T ., Zhang, H., Zheng, F .: Seeing more, saying more: Lightweight language experts are dynamic video token compressors. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 541–558 (2025) [63] W ang, Y ., Xiao, Z.: Loma: Lossless compressed memory attention. arXiv preprint arXiv:2401.09486 (2024) [64] W u, B., Liu, S., Zhong, Y ., Sun, P ., Liu, X., Jin, X.: Loongserv e: Efficiently serving long-conte xt lar ge language models with elastic sequence parallelism. In: Proceedings of the A CM SIGOPS 30th Symposium on Operating Systems Principles. pp. 640–654 (2024) [65] W u, B., Zhong, Y ., Zhang, Z., Liu, S., Liu, F ., Sun, Y ., Huang, G., Liu, X., Jin, X.: Fast distributed infer- ence serving for large language models. arXiv preprint arXiv:2305.05920 (2023) [66] W u, Z., Chen, X., Pan, Z., Liu, X., Liu, W ., Dai, D., Gao, H., Ma, Y ., W u, C., W ang, B., et al.: Deepseek-vl2: Mixture-of-experts vision-language mod- els for advanced multimodal understanding. arXi v preprint arXiv:2412.10302 (2024) [67] Xiao, C., Zhang, P ., Han, X., Xiao, G., Lin, Y ., Zhang, Z., Liu, Z., Sun, M.: Infllm: Training-free long-context extrapolation for llms with an ef ficient context memory . Advances in neural information processing systems 37 , 119638–119661 (2024) [68] Xiao, G., T ian, Y ., Chen, B., Han, S., Lewis, M.: Efficient streaming language models with attention sinks. In: The T welfth International Conference on Learning Representations (2024), https://openre vie w .net/ forum?id=NG7sS51zVF [69] Xing, L., Huang, Q., Dong, X., Lu, J., Zhang, P ., Zang, Y ., Cao, Y ., He, C., W ang, J., W u, F ., et al.: Pyramid- drop: Accelerating your lar ge vision-language models via pyramid visual redundancy reduction. arXiv preprint arXiv:2410.17247 (2024) [70] Y ang, S., Chen, Y ., T ian, Z., W ang, C., Li, J., Y u, B., Jia, J.: V isionzip: Longer is better but not necessary in vision language models. In: Proceedings of the Computer V ision and Pattern Recognition Conference. pp. 19792– 19802 (2025) [71] Y e, L., T ao, Z., Huang, Y ., Li, Y .: Chunkattention: Efficient self-attention with prefix-aware kv cache and two-phase partition. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguis- tics (V olume 1: Long Papers). pp. 11608–11620 (2024) [72] Y u, G.I., Jeong, J.S., Kim, G.W ., Kim, S., Chun, B.G.: Orca: A distributed serving system for { T ransformer- Based } generative models. In: 16th USENIX symposium on operating systems design and implementation (OSDI 22). pp. 521–538 (2022) [73] Y unzhuzhang, Lu, Y ., W ang, T ., Rao, F ., Y ang, Y ., Zhu, L.: Fle xselect: Flexible token selection for efficient long video understanding. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025) [74] Zhai, X., Mustafa, B., K olesnikov , A., Beyer , L.: Sigmoid loss for language image pre-training. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11975–11986 (2023) [75] Zhang, H., Fu, Y .: Vqtoken: Neural discrete token repre- sentation learning for extreme token reduction in video large language models. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025) [76] Zhang, Q., Cheng, A., Lu, M., Zhang, R., Zhuo, Z., Cao, J., Guo, S., She, Q., Zhang, S.: Beyond text- visual attention: Exploiting visual cues for ef fective token pruning in vlms. In: Proceedings of the IEEE/CVF In- ternational Conference on Computer V ision. pp. 20857– 20867 (2025) [77] Zhang, Y ., F an, C.K., Ma, J., Zheng, W ., Huang, T ., Cheng, K., Gudovskiy , D., Okuno, T ., Nakata, Y ., Keutzer , K., et al.: Sparsevlm: V isual token sparsifica- tion for ef ficient vision-language model inference. arXiv preprint arXiv:2410.04417 (2024) [78] Zhang, Z., Sheng, Y ., Zhou, T ., Chen, T ., Zheng, L., Cai, R., Song, Z., Tian, Y ., R ´ e, C., Barrett, C., et al.: H2o: Heavy-hitter oracle for ef ficient generati ve inference of large language models. Adv ances in Neural Information Processing Systems 36 , 34661–34710 (2023) [79] Zheng, L., Y in, L., Xie, Z., Sun, C., Huang, J., Y u, C.H., Cao, S., K ozyrakis, C., Stoica, I., Gonzalez, J.E., et al.: Sglang: Ef ficient ex ecution of structured language model programs. Advances in neural information processing systems 37 , 62557–62583 (2024) [80] Zheng, Z., Ji, X., F ang, T ., Zhou, F ., Liu, C., Peng, G.: Batchllm: Optimizing large batched llm inference with global prefix sharing and throughput-oriented token batching. arXiv preprint arXiv:2412.03594 (2024) [81] Zhong, Y ., Liu, S., Chen, J., Hu, J., Zhu, Y ., Liu, X., Jin, X., Zhang, H.: { DistServe } : Disaggregating prefill and decoding for goodput-optimized large language model serving. In: 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). pp. 193–210 (2024) [82] Zhou, X., W ang, W ., Zeng, M., Guo, J., Liu, X., Shen, L., Zhang, M., Ding, L.: DynamicKV : T ask-aware adaptiv e KV cache compression for long context LLMs. In: Find- ings of the Association for Computational Linguistics: EMNLP 2025. pp. 8042–8057 (2025)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment