Physics-Guided Transformer (PGT): Physics-Aware Attention Mechanism for PINNs
Reconstructing continuous physical fields from sparse, irregular observations is a central challenge in scientific machine learning, particularly for systems governed by partial differential equations (PDEs). Existing physics-informed methods typical…
Authors: Ehsan Zeraatkar, Rodion Podorozhny, Jelena Tešić
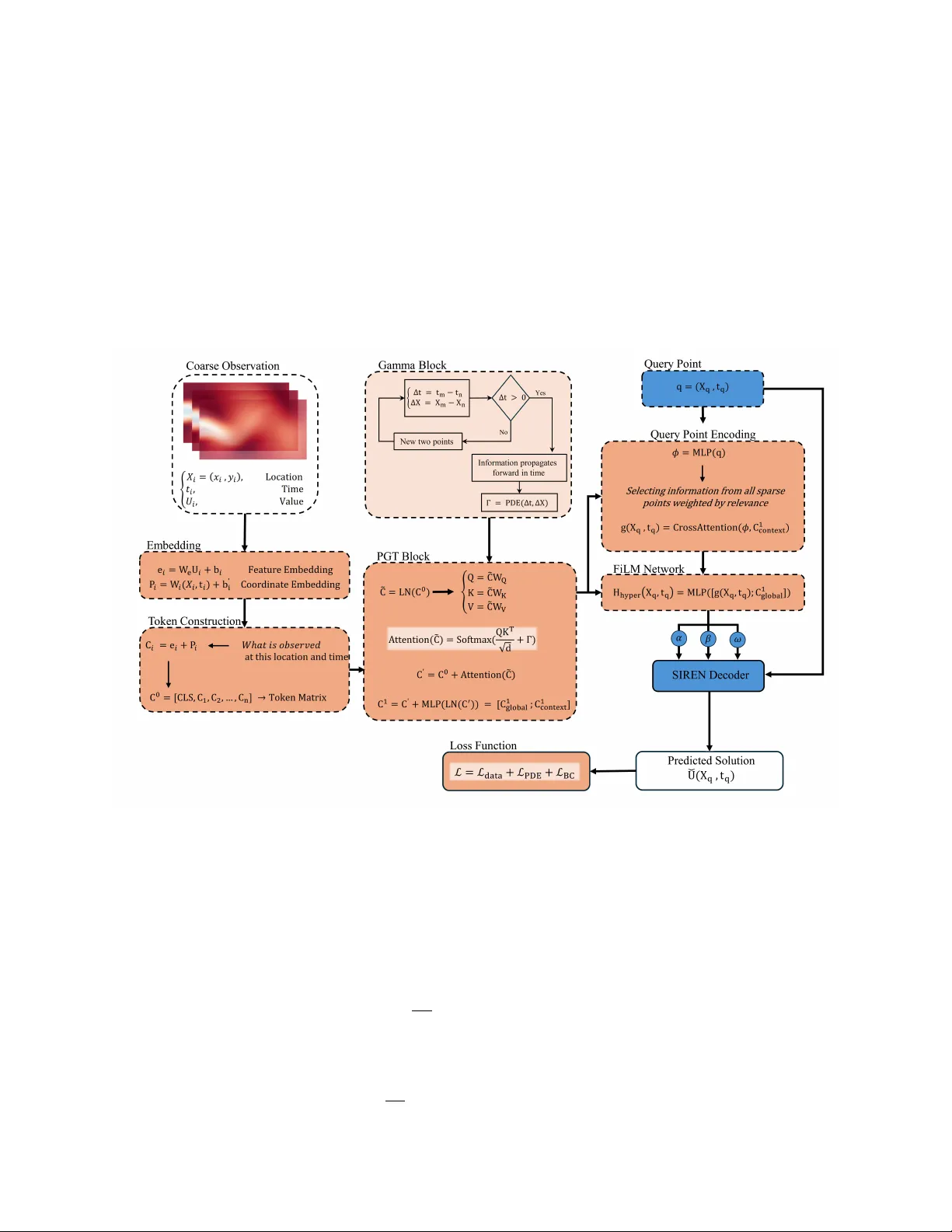
Ph ysics-Guided T ransformer (PGT): Ph ysics-A w are A tten tion Mec hanism for PINNs Ehsan Zeraatk ar* , Ro dion P o dorozhn y , Jelena T ešić Computer Scienc e, T exas State University, San Mar c os, T exas, US Abstract Reconstructing con tin uous ph ysical fields from sparse, irregular observ ations is a fundamen tal c hallenge in scien tific machine learning, particularly for nonlinear systems go verned b y partial differen tial equations (PDEs). Dominan t physics-informed approac hes enforce go v erning equations as soft p enalt y terms during optimization, a strategy that often leads to gradien t im balance, instability , and degraded physical consistency when measuremen ts are scarce. Here we in troduce the Ph ysics-Guided T ransformer (PGT) , a neural arc hitecture that mo v es b eyond residual regularization by embedding physical structure directly into the self-atten tion mec hanism. Sp ecifically , PGT incorp orates a heat-k ernel–derived additiv e bias into attention logits, endo wing the encoder with an inductive bias consistent with diffusion ph ysics and temporal causality . Query co ordinates attend to these ph ysics-conditioned context tokens, and the resulting features drive a FiLM-mo dulated sinusoidal implicit deco der that adaptively con trols spectral response based on the inferred global context. W e ev aluate PGT on tw o canonical b enchmark systems spanning diffusi on-dominated and con vection-dominated regimes: the one-dimensional heat equation and the tw o-dimensional incompressible Na vier–Stokes equations. In 1D sparse reconstruction with as few as 100 observ ations, PGT attains a relative L 2 error of 5 . 9 × 10 − 3 , representing a 38-fold reduction ov er ph ysics-informed neural net works and more than 90-fold reduction ov er sinusoidal implicit representations. In the 2D cylinder-wak e problem reconstructed from 1500 scattered spatiotemporal samples, PGT uniquely ac hieves strong p erformance on b oth axes of ev aluation: a gov erning-equation residual of 8 . 3 × 10 − 4 — on par with the b est residual-based metho ds — alongside a comp etitive o verall relativ e L 2 error of 0.034, substantially b elo w all metho ds that achiev e com- parable physical consistency . No individual baseline sim ultaneously satisfies these dual criteria. Conv ergence analysis further rev eals sustained, monotonic error reduction in PGT, in contrast to the early optimization plateaus observ ed in residual-based approaches. These findings demonstrate that structural incorp oration of physical priors at the representational level, rather than solely as an external loss p enalt y , substan tially impro ves b oth optimization stabilit y and physical coherence under data-scarce conditions. Ph ysics-guided atten tion pro vides a principled and extensible mechanism for reliable reconstruction of nonlinear dynamical systems go verned by partial differential equations. Keywor ds: ph ysics-informed neural netw orks, implicit neural representations, transformer architecture, ph ysics-guided attention, sparse reconstruction, Navier–Stok es equations, scientific machine learning, partial differen tial equations 1. In tro duction Scien tific systems go verned by partial differential equations (PDEs) describ e a wide range of natural and engineered phenomena, from heat diffusion and fluid transp ort to climate dynamics and material de- formation. A ccurately solving these equations is central to adv ancing predictiv e science and engineering. Ho wev er, traditional numerical solvers — finite difference, finite v olume, or sp ectral metho ds [17, 6] — of- ten require finely discretized spatiotemp oral grids to maintain stability and accuracy , leading to prohibitive computational costs for mo deling high-dimensional or multiscale systems. This motiv ates the growing field Email addr ess: ehsanzeraatkar@txstate.edu (Ehsan Zeraatk ar*) of Scientific Machine L e arning (SciML) [14, 4], which seeks to learn surrogate mo dels that embed ph ysical kno wledge into data-driven neural architectures, enabling efficient y et ph ysically c onsisten t approximations of PDE-go verned pro cesses. Among the early and influential developmen ts in SciML are Physics-Informe d Neur al Networks (PINNs) [25], whic h enforce PDE constraints as soft penalties within the loss function. Although conceptually elegant, PINNs exhibit well-kno wn challenges: gradien t pathologies in stiff or multiscale regimes, multiscale con- v ergence in high dimensions, and limited ability to represent oscillatory or high-frequency comp onents. T o o vercome these issues, sev eral op erator-learning frameworks, suc h as F ourier Neur al Op er ators (FNOs) [19], De epONets , and Galerkin T r ansformers [7], hav e b een prop osed to learn mappings b etw een function spaces rather than on discrete fields. Despite their success, these models often rely on purely sp ectral priors or dense F ourier con volutions, lacking explicit aw areness of underlying physical causality or PDE structure. In parallel, the T r ansformer arc hitecture [29] has rev olutionized sequence and vision mo deling by cap- turing long-range dep endencies through self-atten tion. Recent w orks ha ve adapted T ransformers to physical systems, demonstrating their p oten tial for spatiotemp oral forecasting and op erator learning. Y et, conv en- tional T ransformers are data-driven but not physics-driven — their attention w eigh ts are learned solely from data, without constraints that enforce ph ysical consistency , suc h as causality in time, lo calit y in diffusion, or conserv ation la ws. As a result, these mo dels ma y achiev e high predictive accuracy while violating funda- men tal PDE dynamics, particularly when training data are sparse or partially observed. T o bridge this gap, we introduce the Physics-Guided T ransformer (PGT) , a unified arc hitecture that couples T ransformer-based context mo deling with explicit ph ysical priors deriv ed from PDE theory . PGT em b eds the heat-kernel Green’s function [11] as an additive bias within the self-attention mechanism, enabling the mo del to resp ect the causal and diffusive structure of parab olic PDEs. Con textual patches extracted from lo w-resolution data are enco ded through this physics-guided attention, pro ducing a latent representation that captures b oth lo cal in teractions and physically meaningful dependencies. Query co ordinates ( x, t ) then attend to these enco ded context tokens to generate physics-c onditione d fe atur es , which are decoded by a FiLM-mo dulate d SIREN —an implicit neural representation that adaptiv ely adjusts its frequency resp onse based on the learned con text. Unlik e purely data-driven T ransformers or ph ysics-agnostic INRs, PGT in tegrates ph ysical reasoning directly in to the attention kernel while retaining the flexibilit y of neural implicit represen tations. The resulting mo del can infer contin uous spatiotemporal fields, satisfy gov erning PDEs via auto differen tiation, and integrate m ultiple sources of sup ervision, including high-resolution data, low-resolution av erages, and b oundary or initial constraints. The k ey contributions of this work are summarized as follows: • Physics-guided attention: W e form ulate an additive attention bias derived from the heat-kernel Green’s function, in tro ducing an inductive bias consistent with diffusion physics and temp oral causality . • Context-conditioned implicit deco ding: W e design a FiLM-mo dulated SIREN deco der that adap- tiv ely con trols sp ectral bias via frequency gating, enabling accurate reconstruction of high-frequency details. • Unified physics–data training framew ork: W e propose a comp osite uncertain t y-weigh ted loss com bining PDE residuals, b oundary/initial conditions, and data-fidelity terms. • Demonstration on canonical b enc hmarks: Through extensive exp eriments on 1D heat diffusion and 2D incompressible Navier–Stok es problems, PGT achiev es comp etitive reconstruction accuracy alongside markedly reduced gov erning-equation residuals compared to PINNs, FNOs, and T ransformer- based baselines. By integrating physical inductive biases into the T ransformer attention mechanism, PGT mov es b eyond blac k-b ox learning tow ard interpretable, generalizable, and computationally efficien t scientific mo dels. The framew ork is broadly extensible to other parab olic and h yp erb olic PDEs, laying the foundation for scalable ph ysics-aw are neural op erators across scientific domains. 2 2. Related W ork Scien tific mac hine learning has emerged as a framework for in tegrating data-driv en mo dels with gov erning ph ysical la ws [14, 4, 24]. A cen tral ob jective is to reconstruct or predict solutions of partial differen tial equations (PDEs) from limited observ ations while preserving physical consistency . Early efforts focused on embedding differential constrain ts directly into neural netw ork training, leading to the developmen t of Ph ysics-Informed Neural Netw orks (PINNs) [25, 26]. PINNs incorp orate PDE residuals as soft p enalties in the loss function and hav e been s uccessfully applied to diffusion, fluid dynamics, elasticity , and m ultiphysics systems [14, 21]. How ev er, optimization instabilit y , gradient im balance, and sp ectral bias often limit their p erformance under sparse or noisy sup ervision [16, 30]. T o address representational limitations, implicit neural represen tations (INRs) ha ve b een explored for mo deling contin uous ph ysical fields [27, 28, 22]. Sinusoidal activ ation functions [27] and F ourier feature em b eddings [28] mitigate sp ectral bias and enable improv ed reconstruction of high-frequency comp onents. INR-based approac hes hav e b een extended to scien tific computing tasks, including PDE solution appro xi- mation and sup er-resolution of physical fields [18]. Despite their expressiveness, pure INRs typically lack explicit ph ysical constraints unless combined with residual regularization. P arallel dev elopments in op erator learning aim to learn mappings b et ween function spaces rather than discrete solutions. DeepONet [20] and its physics-informed v ariants [13] approximate nonlinear op erators from data, while F ourier Neural Op erators (FNO) [19] leverage sp ectral con volution to mo del global interac- tions efficien tly . These operator-based mo dels scale fa vorably and ha v e demonstrated strong p erformance in parametric PDE settings [15]. Ho wev er, they often require extensive training data and may exhibit reduced robustness in sparse-measuremen t regimes. T ransformer arc hitectures ha v e recen tly b een in troduced into scientific machine learning to capture long- range dep endencies in spatiotemp oral systems [29, 1]. PINNsF ormer [32] extends classical PINNs by incor- p orating self-attention mechanisms to enhance global feature mo deling. T ransformer-based PDE solvers and neural op erators hav e also b een prop osed for fluid simulation and spatiotemp oral forecasting [32]. While these approac hes impro ve long-range interaction mo deling, they typically enforce ph ysics through residual p enalties rather than embedding physical structure directly into the attention mechanism. Recen t works ha ve explored incorp orating T ransformer architectures into ph ysics-informed learning, in- cluding T ransformer-based PINNs and attention-based neural op erators. In most of these approac hes, the atten tion mechanism itself remains purely data-driv en: p ositional information is t ypically enco ded via learned relativ e p osition biases or sin usoidal enco dings, while physical laws are enforced only through additional loss terms, suc h as PDE residual p enalties. In contrast, the prop osed Physics-Guided T ransformer (PGT) embeds ph ysics directly into the attention computation through a kernel-based bias term Γ . Rather than represen ting a generic distance-dep endent bias as in standard relative p osition enco dings, Γ is derived from PDE theory , sp ecifically the heat k ernel (Green’s function) of the diffusion op erator. This formulation encodes b oth tem- p oral causalit y and the spatial diffusion structure of the underlying physical pro cess. Consequently , PGT shifts the role of physics from an external regularization term to the attention logits themselves, thereb y shaping how contextual information propagates b etw een tokens b efore the softmax op eration. This design fundamen tally differs from prior T ransformer-based PINN formulations b y allowing the attention mechanism to follo w physically meaningful interaction patterns rather than learning them solely from data. Recen t studies highlight the imp ortance of architectural inductive biases in scien tific learning [2, 23]. Graph neural netw orks and message-passing frameworks enco de conserv ation laws and lo calit y constrain ts in to model structure [2]. Similarly , symmetry-preserving and equiv ariant netw orks incorp orate ph ysical priors at the representational level [9, 12]. These works collectively suggest that embedding physics into arc hitecture, rather than solely into the ob jective function, may improv e generalization and optimization stabilit y . Sparse reconstruction of fluid flows presen ts additional challenges due to nonlinear conv ection and pres- sure–v elo city coupling [3, 10]. Classical c ompressed sensing and reduced-order mo deling metho ds hav e b een widely studied [5, 31], but they often rely on linear subspace assumptions. Data-driven neural approaches pro vide greater flexibility but must reconcile data fidelity with physical constraints. Existing approac hes largely fall into tw o categories: residual-based physics enforcemen t (e.g., PINNs and PINNsF ormer) [32] and op erator-learning framew orks (e.g., DeepONet and FNO) [12, 20]. While these metho ds improv e either physical regularization or global mo deling capacit y , they t ypically treat gov erning 3 equations as external constraints added to the loss function. In contrast, Ph ysics-Guided T ransformers (PGT) integrate physical structure directly into the attention mechanism itself through a physics-guided bias term. This arc hitectural integration shifts physics from a p enalt y-based regularizer to an in trinsic comp onen t of represen tational in teractions. By coupling physics-guided attention with adaptive implicit deco ding, PGT unifies insights from PINNs, neural op erators, INRs, and T ransformer architectures while explicitly addressing optimization im balance and physical inconsistency under sparse sup ervision. 3. Metho dology 3.1. Pr oblem F ormulation W e consider a time-dep enden t physical system gov erned by a partial differential equation (PDE) F u ( x, t ) , ∇ x u ( x, t ) , ∂ t u ( x, t ); θ p = f ( x, t ) , ( x, t ) ∈ Ω × [0 , T ] , (1) where u ( x, t ) denotes the physical state v ariable of in terest, F is a differential op erator parameterized by ph ysical co efficients θ p , and f ( x, t ) is a known source or forcing term. The ob jective of the Physics-Guided T ransformer (PGT) is to learn a con tinuous mapping u Θ : ( x, t ) 7→ u ( x, t ) , (2) parameterized by Θ , such that the predicted solution satisfies the go v erning PDE while remaining consistent with av ailable observ ations. By mo deling the solution as an implicit function of contin uous co ordinates, PGT enables prediction at arbitrary spatial and temp oral lo cations. 3.2. Overview of the PGT Ar chite ctur e PGT combines a ph ysics-guided T ransformer enco der with an implicit neural representation deco der. Giv en a set of sparse or coarse observ ations, the encoder constructs a laten t token represen tation that captures b oth lo cal measurements and global system structure. F or an y query co ordinate ( x, t ) , the mo del retriev es relev an t con textual information through a cross-attention mechanism and conditions an implicit deco der to pro duce the solution v alue at that co ordinate. Figure 1 illustrates the ov erall architecture. 3.3. Physics-Guide d T r ansformer Enc o der Let { ( u i , x i , t i ) } P i =1 denote the av ailable spatiotemp oral observ ations. Each observ ation is em bedded into a laten t context token by linearly pro jecting b oth the observed v alue and its co ordinate, c i = W u u i + W p [ x i , t i ] + b , (3) where W u and W p are learnable pro jection matrices. In addition to these context tokens, a learnable global tok en c (0) glob is prep ended to the sequence. The resulting token matrix is C (0) = [ c (0) glob , c 1 , . . . , c P ] ∈ R ( P +1) × d model . (4) A stack of L ph ysics-guided T ransformer blo cks processes the token matrix. In each block, self-atten tion is mo dified by an additive physics-based bias Γ , A ttn ( Q , K , V ) = softmax QK ⊤ √ d k + Γ V , (5) where the bias matrix Γ enco des known physical relations b etw een spatiotemp oral lo cations. F or diffusion- t yp e systems, Γ is derived from the logarithm of the heat k ernel and enforces forward temp oral influence. The output of eac h blo ck is up dated using resi dual connections and a feed-forward netw ork, C ( l +1) = C ( l ) + Attn ( LN ( C ( l ) )) + MLP ( LN ( C ( l ) )) . (6) After L lay ers, the final token matrix C ( L ) is split by index into a global tok en c glob and context tokens C ctx . 4 3.4. Physics Guide d Bias Γ The physics-guided bias Γ is constructed from the Green’s function (fundamen tal solution) of the gov ern- ing PDE in Eq. (1). F or a pair of context tokens lo cated at spatiotemp oral co ordinates ( x i , t i ) and ( x j , t j ) , the bias en try is defined as Γ ij = log G ( x i − x j , t i − t j ; θ p ) , (7) where G is the Green’s function of the differen tial operator F and θ p are the physical parameters in tro duced in Eq. (1). T aking the logarithm maps the multiplicativ e k ernel structure of G to an additiv e logit bias, consisten t with the pre-softmax additive form in Eq. (5). En tries for which G = 0 — suc h as future tokens in causal problems or off-c haracteristic tokens in advection-dominated systems — are set to Γ ij = −∞ , so they receiv e exactly zero attention weigh t after the softmax op eration. This formulation is general across PDE families. F or p ar ab olic systems such as the heat equation ( ∂ t u = α ∇ 2 u ) , the Green’s function is the Gaussian heat kernel, giving Γ ij = − ∥ x i − x j ∥ 2 4 α ∆ t ij − d 2 log(4 π α ∆ t ij ) , ∆ t ij = t i − t j > 0 , (8) where d is the spatial dimension and α > 0 is the physical diffusivit y (e.g. thermal conductivity for the heat equation, kinematic viscosity ν for linearized viscous flow). The bias decays quadratically with spatial distance and logarithmically with elapsed time, encoding b oth diffusive lo calit y and strict temp oral causalit y . The effective spatial influence radius scales as σ = p 2 α ∆ t ij , matching the diffusion length of the underlying PDE. F or hyp erb olic systems (e.g. the wa ve equation ∂ tt u = c 2 ∇ 2 u ), G has compact supp ort on the ligh t cone, so Γ ij is finite only within the causal wa v efront ∥ x i − x j ∥ ≤ c ∆ t ij , imp osing finite-sp eed propagation directly in the attention computation. F or el liptic problems (e.g. Poisson or Laplace equations), G dep ends only on spatial separation and no temp oral causal mask is applied. In e ac h case, the physical parameters θ p — diffusivity , viscosit y , w av e sp eed, or b oundary geometry — enter Γ directly from the problem sp ecification, in tro ducing no additional architectural h yperparameters b eyond those already presen t in the go verning equation. In the limiting case where θ p driv es the kernel tow ard a uniform distribution (e.g. α → ∞ for diffusion), Γ approac hes a constant matrix and its effect on the softmax v anishes, recov ering a standard data-driven T ransformer. Conv ersely , as α → 0 , the Gaussian narrows tow ard a Dirac delta, restricting eac h token to attend only to its immediate spatial neighbor. Because the v anilla T ransformer is reco vered exactly in the former limit, PGT strictly contains standard atten tion as a sp ecial case: ph ysics-guided atten tion is a con tinuously tunable inductiv e bias that reduces to purely data-driven attention when physical information is absen t, and progressiv ely imposes PDE-consistent structure as the go verning parameters mov e tow ard the diffusion-dominated regime. 3.5. Query Conditioning via Cr oss-Attention T o ev aluate the solution at a query coordinate q = ( x, t ) , the co ordinate is first mapp ed to a laten t query em b edding using a small multila y er p erceptron, ϕ ( q ) = MLP q ( x, t ) . (9) The query em b edding attends to the enco ded con text tokens through cross-attention, g ( q ) = softmax ( W q ϕ )( W k C ctx ) ⊤ √ d k ( W v C ctx ) , (10) pro ducing a query-specific con text v ector that summarizes the most relev ant observ ations for the giv en lo cation. 3.6. FiLM-Mo dulate d Implicit De c o der The con tinuous solution is reconstructed using an implicit neural represen tation implemen ted as a si- n usoidal represen tation net work (SIREN). The deco der takes the raw query co ordinates ( x, t ) as input and computes h 1 = sin( ω 0 ( W 0 [ x, t ] + b 0 )) . (11) 5 T o adapt the deco der to lo cal and global physical con text, F eature-wise Linear Mo dulation (FiLM) is applied at eac h la yer. A h yp ernet work conditioned on the query-sp ecific context g ( q ) and the global tok en c glob generates mo dulation parameters, ( α l , β l , ω l ) = H ([ g ( q ) , c glob ]) , (12) whic h control amplitude, bias, and frequency at lay er l . Eac h hidden lay er is computed as h l +1 = sin ( ω l ⊙ ( α l ⊙ ( W l h l ) + β l )) . (13) The final prediction is obtained through a linear readout, u Θ ( x, t ) = W out h L + b out . (14) The o verall PGT architecture is illustrated in Figure 1. Figure 1: Overview of the PGT architecture. The physics-guided T ransformer enco der pro cesses sparse observ ations into latent context tok ens, whic h are then used to condition the FiLM-mo dulated SIREN decoder for contin uous field reconstruction. 3.7. T r aining Obje ctive PGT is trained by minimizing a comp osite loss that enforces b oth data fidelity and physical consistency across sources of sup ervision: observed data, PDE residuals, b oundary conditions, and initial conditions. The data loss p enalizes discrepancies b etw een predictions and av ailable observ ations at the sampled spatiotemp oral lo cations, L data = 1 N d N d X i =1 ∥ u Θ ( x i , t i ) − u obs i ∥ 2 2 . (15) Ph ysical consistency is enforced through the PDE residual loss , ev aluated at N r randomly sampled collo- cation p oin ts, L PDE = 1 N r N r X j =1 ∥F ( u Θ )( x j , t j ) − f ( x j , t j ) ∥ 2 2 , (16) 6 where F is the differential op erator defined in Eq. (1) and f is the known forcing term. The b oundary condition loss and initial condition loss enforce prescrib ed constraints on ∂ Ω and at t = 0 , resp ectiv ely , L BC = 1 N b N b X k =1 ∥ u Θ ( x k , t k ) − u bc k ∥ 2 2 , L IC = 1 N 0 N 0 X k =1 ∥ u Θ ( x k , 0) − u ic k ∥ 2 2 . (17) These four terms are com bined into the total training ob jective using uncertaint y-based weigh ting [8], L = 1 2 σ 2 data L data + 1 2 σ 2 PDE L PDE + 1 2 σ 2 BC L BC + 1 2 σ 2 IC L IC . (18) Here σ data , σ PDE , σ BC , σ IC > 0 are learnable scalar uncertain ty parameters, one p er loss term. Eac h w eight 1 / 2 σ 2 k ) is inv ersely prop ortional to the task-sp ecific noise v ariance σ 2 k : if a sup ervision signal is noisy or inconsistent, the mo del learns a larger σ k , automatically do wn-weigh ting that term. All four σ k are initialized to 1 and optimize d join tly with the net work parameters Θ via the same gradient-based up date step. The form ulation eliminates the need for manual loss-w eight tuning and allo ws PGT to adapt its sup ervision balance automatically as training progresses. 3.8. Gener ality of Physics-Guide d Attention The physics-guided atten tion formulation in Eq. (5) is inten tionally general. The bias matrix Γ ma y enco de diffusion kernels, transp ort directionalit y , or other problem-sp ecific relational priors. By incorp orating suc h a structure directly into the attention logits, PGT embeds domain knowledge into the T ransformer enco der while retaining the flexibility and scalability of mo dern attention-based architectures. 4. Exp erimen tal Results W e ev aluate the prop osed Physics-Guided T ransformer (PGT) on tw o canonical PDE-gov erned systems: (1) sparse scattered-data reconstruction for the 1D heat diffusion equation, and (2) reconstruction of 2D v elo city and pressure fields gov erned by the incompressible Navier–Stok es equations. Across b oth tasks, PGT is compared with state-of-the-art baselines, including FNO, PINN, PI-DeepONet, PINNsF ormer, SIREN, and WIRE, under matc hed sparse-sampling budgets. 4.1. 1D He at Equation: Sp arse R e c onstruction Analysis W e first ev aluate PGT on the 1D heat equation: ∂ t u − ν ∂ xx u = 0 , x ∈ [0 , 1] , t ∈ [0 , 1] , (19) with sin usoidal initial conditions u ( x, 0) = sin( nπ x ) , u ( x, t ) = e − ν ( nπ ) 2 t sin( nπ x ) . (20) The task is sparse reconstruction: given only M randomly sampled spatiotemp oral observ ations, the mo del must reconstruct the full solution field. W e v ary the num ber of sparse samples ( M = 100 , 200 , 500 ) to study robustness under differen t sup ervision levels. T able 1 reports the data loss, PDE residual loss, relativ e L 2 error, computational cost (FLOPs), training time, and parameter count for SIREN, PINN, and PGT. PGT achiev es dramatically low er data error and relativ e L 2 error across all different observ ation data p oints, M . F or example, at M = 100 , PGT reduces the relativ e L 2 error to 5 . 90 × 10 − 3 , compared to 2 . 26 × 10 − 1 for PINN and 5 . 40 × 10 − 1 for SIREN. The PGT error reduction is approximately a 38 × improv emen t o ver PINN and nearly 90 × improv emen t o v er SIREN . Ev en as the n umber of sparse p oin ts increases to M = 500 , PGT maintains relativ e errors on the order of 10 − 3 , while PINN and SIREN remain t wo orders of magnitude higher. Although PGT’s PDE residual loss remains around 6 . 6 × 10 − 2 , its significan tly smaller data loss indicates sup erior global field reconstruction accuracy . SIREN exhibits relatively high PDE residuals due to the absence of explicit physics enforcement. PINN reduces the PDE residual compared to SIREN, but struggles to ac hieve comparable reconstruction fidelity under sparse sup ervision. 7 T able 1: Comparison of SIREN, PINN, and PGT models across different v alues of M . Model Loss FLOPs T rain time Param Data PDE Rel L 2 (G) SIREN M = 100 0.063 0.18 0.54 6.5 126 s 26,419 M = 200 0.045 0.14 0.45 6.8 127 s M = 500 0.025 0.18 0.34 7.5 135 s PINN M = 100 0.026 0.12 0.226 1.69 65 s 66,500 M = 200 0.024 0.19 0.332 1.75 65.9 s M = 500 0.021 0.13 0.313 1.94 66.8 s PGT (ours) M = 100 0.000076 0.066 0.0059 116 9.5 min 4.05E+08 M = 200 0.000029 0.066 0.0028 132 13 min M = 500 0.000017 0.067 0.0026 190 27.5 min As the num b er of sparse observ ations increases, all mo dels b enefit from additional sup ervision. Ho w ever, the improv emen t for PGT is substantially more stable and consistent. Its relative L 2 error decreases from 5 . 90 × 10 − 3 at M = 100 to 2 . 60 × 10 − 3 at M = 500 , demonstrating robustness even in low-data regimes. In con trast, PINN and SIREN show less consistent trends and remain significantly less accurate. The improv ed accuracy of PGT comes at a higher computational cost. While PINN requires approxi- mately 1 . 7 – 1 . 9 GFLOPs and ab out 65 seconds of training time, PGT requires 116 – 190 GFLOPs and up to 1 . 67 × 10 3 seconds of training time. The parameter count is also substan tially larger for PGT. The trade-off highligh ts that PGT prioritizes reconstruction fidelit y and ph ysics-guided generalization ov er light weigh t deplo yment. Figure 2: T raining error conv ergence (relativ e L 2 ) for PINN, SIREN, and PGT on the 1D heat diffusion sparse reconstruction task ( M = 100 observ ations). PGT exhibits sustained monotonic decay , whereas PINN and SIREN plateau at muc h higher error levels. Figure 2 illustrates the evolution of the reconstruction error during training. Both SIREN and PINN sho w rapid initial error reduction, follow ed b y early stagnation at relatively high error levels around 10 − 3 . In contrast, PGT exhibits contin uous, sustained error decay throughout training, ultimately reac hing errors on the order of 10 − 7 . Thus, the PGT av oids the optimization plateaus observed in the baseline metho ds and con verges to a significantly more accurate solution. T o further analyze the training dynamics, Figure 3 (loss comp onen t contribution plot) sho ws the relativ e con tributions of the data, PDE, b oundary-condition (BC), and initial-condition (IC) losses within PGT. In the early stages of training, the IC loss contributes substantially , reflecting the mo del’s initial effort to satisfy the prescribed initial state. As training progresses, the relative contribution of the PDE loss increases, indicating a gradual shift tow ard enforcing the go verning ph ysical dynamics across the domain. Notably , the contribution of the data loss remains comparatively stable throughout training. The balanced evolution suggests that PGT effectively co ordinates data fitting and physics enforcement, progressively refining the 8 solution while main taining consistency with b oth observ ations and gov erning equations. (a) (b) Figure 3: (a) Error components breakdown. (b) Error comp onents con tribution analysis. Ov erall, the 1D exp erimen t demonstrates that incorp orating physics-guided attention and adaptive fre- quency mo dulation significan tly enhances sparse reconstruction accuracy . The controlled setting v alidates the effectiv eness of PGT b efore extending the comparison to more complex 2D nonlinear systems. 4.2. 2D Navier–Stokes R e c onstruction Under Sp arse Me asur ements W e next ev aluate PGT on the tw o-dimensional incompressible Navier–Stok es equations gov erning viscous flo w: ∂ u ∂ t + u ∂ u ∂ x + v ∂ u ∂ y = − ∂ p ∂ x + ν ∇ 2 u, (21) ∂ v ∂ t + u ∂ v ∂ x + v ∂ v ∂ y = − ∂ p ∂ y + ν ∇ 2 v , (22) ∂ u ∂ x + ∂ v ∂ y = 0 , (23) where ( u, v ) denote the v elo cit y comp onen ts, p is the pressure field, and ν = 1 / Re is the kinematic viscosit y . W e consider the canonical cylinder wak e dataset and p erform sparse reconstruction from N train = 1500 randomly sampled spatiotemp oral p oin ts. All mo dels are ev aluated on a full-resolution spatial snapshot at a fixed time index. T able 2 rep orts the final quan titative comparison across all seven metho ds, including total relative L 2 error, v ariable-wise errors for u , v , and p , the PDE residual, and computational cost. T able 2: Sparse reconstruction p erformance for the 2D Na vier–Stokes cylinder wak e at a fixed time snapshot ( N train = 1500 ). Best results are shown in b old . Arc hitecture family groups metho ds: operator-learning (FNO, PI-DeepONet), T ransformer- based (PINNsF ormer), implicit representation (SIREN, WIRE), classical PINN, and the proposed PGT. Model Params (M) FLOPs (G) T rain Time Rel- L 2 Rel- L 2 ( u ) Rel- L 2 ( v ) Rel- L 2 ( p ) PDE Residual T rain Error FNO 2.360 0.092 4.41 s 0.710 0.2200 1.4900 0.770 4 . 70 × 10 − 2 4 . 20 × 10 − 4 PI-DeepONet 0.215 176.12 36 s 0.095 0.0600 0.2300 0.210 4 . 20 × 10 − 1 3 . 90 × 10 − 3 PINNsF ormer 0.545 13.200 296 min 0.080 0.0400 0.0900 0.110 8 . 30 × 10 − 2 8 . 30 × 10 − 4 SIREN 0.264 1.310 2.5 min 0.690 0.3100 1.0000 0.770 3 . 90 × 10 − 4 5 . 50 × 10 − 2 WIRE 0.528 5.200 6.3 min 0.018 0.0041 0.0350 0.014 5 . 10 × 10 − 1 1 . 54 × 10 − 4 PINN 0.336 1.600 2.6 min 0.110 0.0400 0.1400 0.160 8 . 40 × 10 − 4 1 . 19 × 10 − 3 PGT (ours) 5.630 32.860 47 min 0.034 0.0160 0.0410 0.046 8 . 30 × 10 − 4 6 . 50 × 10 − 5 The results reveal imp ortant differences across mo del families. Among the ope rator-learning metho ds, FNO ac hieves the lo w est computational cost but yields the highest reconstruction error, with a relativ e L 2 error of 1.49 for the v ertical-velocity comp onent, indicating a near-complete failure to capture v ortex- shedding dynamics under sparse sampling. PI-DeepONet substan tially impro ves reconstruction accuracy , yet 9 its PDE residual remains large ( 4 . 2 × 10 − 1 ), indicating that the predicted fields do not satisfy the gov erning momen tum equations with adequate precision. Among implicit represen tation baselines, SIREN achiev es a low PDE residual ( 3 . 9 × 10 − 4 ). Stil l, it exhibits very p o or field reconstruction accuracy , with a relative L 2 error of 0.69 and a vertical v elo city error of 1.00, reflecting the absence of explicit physics enforcement in the reconstruction pro cess. WIRE presents an opp osing b eha viour: it attains the low est ov erall relativ e L 2 error (0.018). It excels on the horizon tal v elo city ( 0 . 0041 ) and pressure ( 0 . 014 ) comp onents. Y et, its PDE residual ( 5 . 1 × 10 − 1 ) is the highest among all metho ds, revealing that accurate data fitting do es not guarantee satisfaction of the gov erning equations. The classical PINN achiev es a PDE residual of 8 . 4 × 10 − 4 , comp etitive with PGT, but its reconstruction accuracy (o verall relative L 2 = 0 . 11 ) is substantially inferior, particularly for the vertical velocity and pressure fields. Figure 4: Qualitative comparison b etw een ground truth and PGT reconstruction for the 2D Navier–Stok es problem. Rows correspond to u , v , and p fields. Columns sho w ground truth, PGT prediction, and absolute error. PGT achiev es the strongest sim ultaneous balance b et ween reconstruction fidelit y and ph ysical consistency across all ev aluated metho ds. Its ov erall relative L 2 error of 0.034 is surpassed only by WIRE (0.018). Y et, PGT deliv ers a PDE residual of 8 . 3 × 10 − 4 — comparable to PINN and SIREN in residual magnitude, but accompanied by significantly sup erior reconstruction accuracy . V ariable-wise errors remain consistently low across u ( 0 . 016 ), v ( 0 . 041 ), and p ( 0 . 046 ), indicating balanced coupling b et ween the velocity and pressure comp onen ts, a property not ac hieved by any individual baseline. The combination — competitive data fidelit y with rigorous physical consistency — distinguishes PGT from all comparators and is precisely the regime that matters for scien tific reconstruction tasks. Figure 4 illustrates the qualitative reconstruction of u , v , and p . The predicted fields faithfully repro duce the dominant v ortex shedding structures and pressure gradien ts presen t in the ground truth. Absolute error maps confirm that residuals are primarily confined to regions of strong nonlinear interaction and high v orticity , while the global flow top ology is accurately preserved throughout the domain. The training conv ergence b ehavior is shown in Figure 5. PGT exhibits stable, monotonically decreasing error throughout optimization. In contrast, several baselines undergo rapid initial decay follo wed by early stagnation, a hallmark of optimization imbalance under sparse sup ervision. PGT’s sustained con vergence re- flects the stabilizing effect of embedding physics directly within the attention mechanism, whic h contin uously biases the mo del tow ard physically plausible solutions rather than relying on comp eting loss terms. Collectiv ely , the 2D results demonstrate that PGT uniquely addresses the fundamen tal tension b etw een 10 data fidelity and physical consistency that afflicts all baseline approac hes: pure data-fitting methods (WIRE, SIREN) ac hieve low reconstruction error at the exp ense of PDE compliance, while residual-based metho ds (PINN, PINNsF ormer) enforce physics at the cost of reconstruction accuracy . By em b edding physical pri- ors architecturally rather than as an external penalty , PGT sidesteps this trade-off and ac hieves strong p erformance on b oth axes simultaneously . Figure 5: T raining error conv ergence for PGT and baseline metho ds on the 2D Na vier–Stokes problem. 4.3. A blation Study T o rigorously attribute PGT’s p erformance to its individual design choices, we conduct a comprehensive ablation study on the 2D Na vier–Stokes cylinder wak e task ( N train = 1500 ). The study prob es three inde- p enden t axes of the arc hitecture: (i) the ph ysics-guided attention bias Γ and the PDE residual loss L PDE , whic h together constitute the ph ysics-in tegration mec hanisms in the enco der and training ob jective; and (ii) the deco der design, which isolates the con tribution of sinusoidal activ ations and FiLM-based con text conditioning within the implicit reconstruction head. All sev en configurations share the same encoder depth, em b edding dimension, optimizer, and training budget, and all retain the data loss L data throughout. Results are summarized in T able 3. T able 3: Ablation study on the 2D Navier–Stok es cylinder wak e ( N train = 1500 ). A ttn. bias Γ : heat-k ernel additive bias in self-attention logits (disabled in pure-transformer v ariants). PDE loss L PDE : momen tum and contin uit y residual terms. De c o der : FiLM-SIREN is the full deco der; SIREN (no FiLM) uses a plain SIREN with context concatenated at the input; MLP replaces sin usoidal activ ations with GELU; FiLM-MLP retains FiLM conditioning but uses GELU activ ations. ✓ activ e; ◦ disabled. Data loss is active in all rows. Best results in b old . V ariant Decoder A ttn. bias Γ PDE loss L PDE Reconstruction Error ↓ PDE Residual ↓ PGT (full) FiLM-SIREN ✓ ✓ 6 . 50 × 10 − 5 8 . 30 × 10 − 4 No PDE loss FiLM-SIREN ✓ ◦ 8 . 80 × 10 − 5 2 . 90 × 10 − 3 No attention bias FiLM-SIREN ◦ ✓ 3 . 00 × 10 − 4 1 . 30 × 10 − 2 No physics (data only) FiLM-SIREN ◦ ◦ 3 . 60 × 10 − 4 3 . 50 × 10 − 2 SIREN, no FiLM SIREN ✓ ✓ 1 . 83 × 10 − 4 1 . 10 × 10 − 3 FiLM-MLP FiLM-MLP ✓ ✓ 1 . 21 × 10 − 4 1 . 05 × 10 − 3 Plain MLP MLP ✓ ✓ 3 . 12 × 10 − 4 1 . 42 × 10 − 3 The results rev eal three distinct and complementary insights into the architectural design of PGT. The physics-guide d attention bias Γ is the dominant driver of r e c onstruction ac cur acy.. Comparing v arian ts that differ only in whether Γ is activ e, its effect is consistent and substantial. Without the ph ysics loss (“no PDE loss” vs. “no ph ysics”), activ ating Γ reduces the reconstruction error by approximately 4 × — from 3 . 60 × 10 − 4 to 8 . 80 × 10 − 5 — with no change to the training ob jectiv e. This gain arises purely from the structural inductive bias in tro duced at the attention lev el: by enco ding the heat-k ernel Green’s function into the atten tion logits, Γ directs the enco der to aggregate con text tokens according to physically meaningful 11 spatiotemp oral pro ximit y , enabling more coheren t field reconstruction ev en when no explicit PDE p enalt y is applied. The same pattern holds when the physics loss is active (“no attention bias” vs. “PGT full”): enabling Γ reduces the reconstruction error from 3 . 00 × 10 − 4 to 6 . 50 × 10 − 5 , a further 4 . 6 × improv emen t. Across b oth conditions, Γ is the single most impactful design choice for reconstruction fidelity . The PDE loss L PDE is essential for governing-e quation c omplianc e.. When Γ is active but L PDE is withheld (“no PDE loss”), the mo del achiev es strong reconstruction accuracy y et yields a PDE residual of 2 . 90 × 10 − 3 — approximately 3 . 5 × larger than the full mo del. Introducing L PDE reduces the residual to 8 . 30 × 10 − 4 , confirming that explicit residual sup ervision at collocation p oin ts is necessary to enforce momentum conserv ation and incompressibility throughout the domain. This effect also app ears in the absence of Γ : adding the ph ysics loss (“no atten tion bias” vs. “no ph ysics”) reduces the residual from 3 . 50 × 10 − 2 to 1 . 30 × 10 − 2 , a 2 . 7 × reduction. How ever, the residual achiev ed b y L PDE alone without Γ ( 1 . 30 × 10 − 2 ) remains more than an order of magnitude larger than that of the full mo del ( 8 . 30 × 10 − 4 ), confirming that the tw o mechanisms are c omplemen tary rather than substitutable. Structural physics priors shap e the represen tation. Explicit residual sup ervision enforces p oint wise compliance with the PDE. FiLM c onditioning and sinusoidal activations b oth c ontribute to de c o der quality, and their c ombination is ne c essary for optimal p erformanc e.. The bottom three rows of T able 3 isolate the deco der design while holding the enco der ( Γ active) and training ob jective ( L PDE activ e) fixed. R emoving FiLM while ke eping sinusoidal activations (SIREN, no FiLM) raises the reconstruction error from 6 . 50 × 10 − 5 to 1 . 83 × 10 − 4 , a degradation of 2 . 8 × , and mo destly worsens the PDE residual to 1 . 10 × 10 − 3 . Without FiLM, the deco der cannot adapt its frequency resp onse to the lo cal physical con text inferred by the cross-attention step. Instead, it receives the entire context v ector only at the first lay er, forcing a single fixed set of sinusoidal frequencies to represent all query lo cations equally . The resulting mo del still b enefits from the p eriodic activ ation’s sp ectral prop erties but loses the p er-query mo dulation that allows PGT to resolv e fine vortex-shedding structures and pressure gradients with v arying spatial complexity . R eplacing sinusoidal activations with GELU while r etaining FiLM (FiLM-MLP) yields a reconstruction error of 1 . 21 × 10 − 4 and a PDE residual of 1 . 05 × 10 − 3 . This is noticeably b etter than the SIREN-no-FiLM v arian t, indicating that deep, m ultilay er context conditioning contributes more to reconstruction quality than the choice of activ ation function alone. Nevertheless, the gap with the full FiLM-SIR EN mo del ( 6 . 50 × 10 − 5 ) confirms that GELU activ ations are insufficient to represent the smooth, oscillatory solution fields t ypical of conv ection-dominated flows. The absence of perio dic activ ations prev ents the deco der from efficiently enco ding the sp ectral con tent present in the cylinder w ake — a limitation that FiLM conditioning alone cannot o vercome. R emoving b oth FiLM and sinusoidal activations (plain MLP) pro duces the weak est deco der: reconstruc- tion error climbs to 3 . 12 × 10 − 4 and the PDE residual reaches 1 . 42 × 10 − 3 . The reconstruction error of this v arian t approaches that of the no-atten tion-bias v ariant ( 3 . 00 × 10 − 4 ), suggesting that a sub optimal decoder can negate the represen tational b enefit of physics-guided attention in the enco der. T ogether, thes e deco der results establish a clear p erformance hierarch y: FiLM-SIREN > FiLM-MLP > SIREN (no FiLM) > plain MLP . The hierarch y reveals that FiLM conditioning is the more critical of the t wo mechanisms: Its remo v al costs 2 . 8 × in reconstruction accuracy , whereas swapping sinusoidal activ ations for GELU cost only 1 . 9 × . Y et the combination uniquely achiev es the lo west error, confirming that b oth prop erties — p eriodic sp ectral represen tation and adaptive con text-driven mo dulation — are indep enden tly b eneficial and mutually reinforcing. The ful l mo del uniquely achieves str ong p erformanc e on b oth evaluation axes simultane ously.. Across all seven configurations, only the full PGT v ariant simultaneously attains the low est reconstruction error ( 6 . 50 × 10 − 5 ) and the lo west PDE residual ( 8 . 30 × 10 − 4 ). Disabling Γ primarily degrades reconstruction accuracy; disabling L PDE primarily degrades PDE compliance; degrading the deco der hurts b oth metrics in prop ortion to the sev erity of the simplification. The four-w ay ablation traces a clear Pareto fron t in the accuracy–consistency space: no simplified v arian t achiev es the Pareto fron tier of the full mo del. These findings pro vide mechanistic v alidation of ev ery ma jor design c hoice in PGT — ph ysics-guided attention, explicit PDE sup ervision, sin usoidal implicit deco ding, and FiLM-based context conditioning — and confirm that all four are necessary comp onen ts of the architecture. 12 4.4. R obustness to Me asur ement Noise Sensor noise is una voidable in exp erimental flow measurement. T o assess its impact, w e corrupt the u and v context observ ations with additiv e Gaussian noise at six relativ e levels, u noisy i = u i + ε i , ε i ∼ N (0 , σ 2 ) , σ = η · std( u train ) , for η ∈ { 0 , 0 . 01 , 0 . 02 , 0 . 05 , 0 . 10 , 0 . 20 } (clean to 20% of signal std). W e compare standard PGT (MSE data loss) against a v arian t, PGT-UW, that replaces the data loss with a heteroscedastic uncertaint y- w eighted negative log-likelihoo d, L UW data = 1 N d N d X i =1 " log σ 2 i + u Θ ( x i , t i ) − u obs i 2 σ 2 i # , (24) where σ 2 i is a per-token aleatoric v ariance predicted by a small auxiliary head on the cross-atten tion output. All other comp onen ts are identical b et ween the tw o v arian ts. Results are rep orted in T able 4 and Figure 6. T able 4: Noise robustness on the 2D Navier–Stok es cylinder wak e ( σ = η · std( u train ) ). PGT uses a standard MSE data loss; PGT-UW uses a heteroscedastic uncertain ty-w eigh ted loss. Best p er ro w in b old . A vg. Rel- ℓ 2 ( u, v ) ↓ PDE Residual ↓ η PGT PGT-UW PGT PGT-UW 0.00 0.0496 0.0410 1.61e-03 4.55e-03 0.01 0.0634 0.0861 1.99e-03 6.80e-03 0.02 0.0406 0.1054 1.86e-03 7.78e-03 0.05 0.0508 0.1102 1.49e-03 7.63e-03 0.10 0.0512 0.1551 1.92e-03 7.74e-03 0.20 0.0607 0.0400 1.82e-03 4.64e-03 Standard PGT is r emarkably stable : the av erage Rel- ℓ 2 error for u and v remains within [0 . 040 , 0 . 064] across all noise levels, and the PDE residual stays in the narrow band [1 . 5 , 2 . 0] × 10 − 3 throughout. This robustness is a direct consequence of the ph ysics-guided attention bias Γ : by con tinuously anc horing in ternal represen tations to the heat-kernel Green’s function, the architectural prior preven ts noise from propagating in to the reconstructed fields, acting as an implicit regularizer indep endent of the data loss. PGT-UW, by contrast, exhibits a non-monotone tra jectory: error rises steeply for intermediate noise lev els ( η = 0 . 01 – 0 . 10 ), p eaking at 0 . 155 b efore partially recov ering at η = 0 . 20 . PDE residuals follo w the same pattern, remaining 3 – 4 × higher than standard PGT across all in termediate lev els. The heteroscedastic head in tro duces optimisation complexit y that the fixed training budget cannot fully resolve; at very high noise, the large predicted v ariances effectively suppress the data loss, allowing the physics loss to comp ensate. These findings indicate that when a strong architectural ph ysics prior is present, an explicit aleatoric uncertaint y mec hanism offers limited benefit and ma y destabilise training. Standard PGT is therefore the recommended configuration for noisy measuremen t scenarios. 5. Discussion This study demonstrates that embedding physical structure directly in to the neural architecture, rather than solely as an external loss p enalty , can substantially improv e the reconstruction of nonlinear dynamical systems from sparse observ ations. Across both diffusion-dominated and conv ection-dominated regimes, PGT ac hieved strong physical consistency while main taining competitive reconstruction accuracy—a com bination that none of the individual baseline metho ds achiev ed simultaneously . The expanded 2D Navier–Stok es comparison reveals a clear structural dichotom y among existing meth- o ds. Pure data-fitting approaches (WIRE, SIREN) achiev e low reconstruction error but exhibit large PDE residuals, confirming that accurate interpolation of sparse observ ations do es not guarantee satisfaction of the underlying gov erning equations. Con versely , residual-based metho ds (PINN, PINNsF ormer) reduce the PDE residual at the cost of reconstruction accuracy , particularly for the vertical velocity and pressure fields where the effects of pressure–velocity coupling are most pronounced. Op erator-learning metho ds (FNO, PI-DeepONet) o ccupy a middle ground but fail to excel on either axis under the sparse measurement budget considered here. 13 Figure 6: Reconstruction error (left) and PDE residual (right) as a function of noise lev el η for PGT and PGT-UW on the 2D Navier–Stok es cylinder-wak e problem. PGT sidesteps this trade-off b y in tegrating ph ysical priors at the represen tational lev el. The heat- k ernel–derived atten tion bias con tinuously steers the model to ward ph ysically plausible solutions during optimization, without comp eting with data-fidelity terms as p enalt y-weigh ted losses do. This architectural constrain t app ears to stabilize training and promote globally coheren t solutions, esp ecially in nonlinear flow regimes where pressure–v elo city coupling is critical. The result is a mo del that sim ultaneously ac hieves reconstruction accuracy approac hing that of the best data-fitting baseline (WIRE) and a PDE residual comparable to that of the b est residual-based baseline (PINN). This outcome is structurally difficult to ac hieve through loss reweigh ting alone. The ablation study provides direct mechanistic evidence for this claim. Removing the physics-guided atten tion bias Γ while retaining the PDE loss degrades reconstruction error by more than an order of mag- nitude, confirming that the architectural bias — not the loss term — is the primary mechanism resp onsible for accurate field recov ery . Conv ersely , removing the PDE loss while retaining Γ lea ves reconstruction ac- curacy largely intact but causes the PDE residual to increase nearly sevenfold, demonstrating that explicit residual supervision remains necessary for gov erning-equation compliance. These t w o mec hanisms are there- fore non-redundant: Γ shap es the latent representation to ward physically coheren t solutions, while L PDE enforces point wise satisfaction of the differential constraints. Their com bination uniquely ac hieves strong p erformance on b oth ev aluation axes. PGT is deliberately more exp ensiv e than ligh t weigh t baselines suc h as PINN, SIREN, and FNO, as the quadratic self-attention ov er context tokens and the FiLM hypernetw orks are precisely the mechanisms that enable global propagation of sparse observ ations and adaptiv e spectral deco ding — capabilities that c heap er architectures forgo, at the cost of the large reconstruction and PDE-residual errors do cumen ted in T ables 1 and 2. View ed against ph ysics-aw are metho ds of comparable am bition, how ever, PGT is comp etitive: PINNsF ormer trains substan tially longer y et yields higher reconstruction error, and PI-DeepONet consumes far greater FLOPs while pro ducing a PDE residual orders of magnitude larger. The curren t cost is therefore an engineering constrain t of the protot yp e rather than a fundamental limit of physics-guided atten tion. The spatial lo cality of Γ — which decays rapidly b eyond a physically determined radius — motiv ates sparse or hierarc hical atten tion that would reduce complexity from O ( P 2 ) tow ard O ( P log P ) ; low-rank factorisation of the Gaussian bias matrix and mixed-precision training offer further reductions with no c hange to the underlying ph ysics prior. It is worth noting that sparse reconstruction differs fundamen tally from sup er-resolution: whereas sup er- resolution op erates on a dense lo w-resolution grid with uniform spatial co verage, sparse reconstruction m ust reco ver contin uous fields from scattered, unstructured samples, leaving large p ortions of the domain en tirely unobserv ed. This more ill-p osed setting makes architectural inductive biases and physics-based constraints corresp ondingly more critical, precisely the regime that PGT targets. More broadly , these findings suggest that future scien tific mac hine learning mo dels ma y b enefit from em- b edding gov erning principles at the representational lev el rather than relying solely on residual regularization. 14 Extending this framewor k to higher-dimensional, m ulti-physics, and turbulen t regimes — and quantifying its behaviour under v arying Reynolds num bers and noise levels — remains an imp ortan t direction for future researc h. 6. Conclusion W e hav e in tro duced a Physics-Guided T ransformer (PGT) for reconstructing partial differential equa- tion–go verned systems from sparse observ ations. By embedding physical structure directly in to the atten- tion mechanism and coupling it with an adaptive implicit decoder, the prop osed framework mov es b eyond residual-only ph ysics enforcement. Instead, it incorp orates gov erning principles at the architectural level. A cross diffusion and nonlinear flow problems, PGT achiev ed solutions that were b oth numerically accu- rate and strongly consistent with the underlying equations. A controlled ablation study further confirmed that the physics-guided attention bias Γ and the PDE residual loss L PDE op erate through distinct and complemen tary path wa ys: Γ is the primary driv er of reconstruction accuracy , while L PDE is essential for go verning-equation compliance. Only their com bination simultaneously minimizes b oth ob jectives, pro viding mec hanistic v alidation of the architectural design choices. While the approach incurs a higher computational cost than light w eigh t op erator-learning metho ds, it offers a meaningful trade-off b etw een efficiency and physical fidelity . More broadly , this w ork p oints tow ard a shift in scien tific machine learning: from treating gov erning equations as external constraints to incorp orating them as intrinsic comp onents of model design. Extending suc h ph ysics-guided attention mechanisms to higher-dimensional, multiscale, and multiph ysics systems ma y provide a path to reliable and interpretable data-driv en mo deling in science and engineering. References [1] Alexey Dosovitskiy , L.B., et. al., 2021. An image is worth 16x16 words: T ransformers for image recog- nition at scale. URL: , . [2] Brandstetter, J., W orrall, D., W elling, M., 2023. Message passing neural pde solvers. URL: https: //arxiv.org/abs/2202.03376 , arXiv:2202.03376 . [3] Brun ton, B.W., Brunton, S.L., Pro ctor, J.L., Kutz, J.N., 2016. Sparse sensor placement optimization for classification. SIAM Journal on Applied Mathematics 76, 2099–2122. doi: 10.1137/15M1036713 . [4] Brun ton, S.L., Noack, B.R., K oumoutsakos, P ., 2020. Machine learning for fluid mec hanics. Ann ual Review of Fluid Mec hanics 52, 477–508. [5] Candès, E.J., Romberg, J., T ao, T., 2006. Robust uncertaint y principles: Exact signal reconstruction from highly incomplete frequency information. IEEE T ransactions on Information Theory 52, 489–509. [6] Can uto, C., Quarteroni, A., 2017. Sp ectral Methods. John Wiley and Sons, Ltd. c hapter 5. pp. 1–16. URL: https://onlinelibrary.wiley.com/doi/abs/10.1002/ 9781119176817.ecm2003m , doi: https://doi.org/10.1002/9781119176817.ecm2003m , arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1002/9781119176817.ecm2003m . [7] Cao, S., 2021. Cho ose a transformer: F ourier or galerkin. . [8] Cip olla, R., Gal, Y., Kendall, A., 2018. Multi-task learning using uncertaint y to weigh losses for scene geometry and semantics, in: Pro ceedings of the IEEE Conference on Computer Vision and P attern, pp. 7482–7491. doi: 10.1109/CVPR.2018.00781 . [9] Cohen, T.S., W elling, M., 2016. Group equiv ariant conv olutional netw orks. . [10] Eric hson, N.B., Mathelin, L., Y ao, Z., Brunton, S.L., Mahoney , M.W., Kutz, J.N., 2020. Shallo w neural netw orks for fluid flow reconstruction with limited sensors. Pro- ceedings of the Roy al So ciety A: Mathematical, Physical and Engineering Sciences 476, 20200097. URL: https://doi.org/10.1098/rspa.2020.0097 , doi: 10.1098/rspa.2020.0097 , arXiv:https://royalsocietypublishing.org/rspa/article-pdf/doi/10.1098/rspa.2020.0097/637169/rspa.202 0.0097.pdf . 15 [11] Ev ans, L.C., 2010. Partial Differential Equations. volume 19 of Gr aduate Studies in Mathematics . 2 ed., American Mathematical So ciet y , Providence, RI. [12] Finzi, M., Stan ton, S., Izmailov, P ., Wilson, A.G., 2020. Generalizing conv olutional neural netw orks for e quiv ariance to lie groups on arbitrary contin uous data, in: Pro ceedings of the 37th International Conference on Machine Learning, PMLR. pp. 3165–3176. URL: https://proceedings.mlr.press/ v119/finzi20a.html . [13] Gosw ami, S., Bora, A., Y u, Y., Karniadakis, G.E., 2022. Physics-informed deep neural op erator net- w orks. URL: , . [14] Karniadakis, G.E., Kevrekidis, I.G., Lu, L., P erdik aris, P ., W ang, S., Y ang, L., 2021. Physics-informed mac hine learning. Nature Reviews Ph ysics 3, 422–440. [15] K ov achki, N., Li, Z., Liu, B., Azizzadenesheli, K., Bhattachary a, K., Stuart, A., Anandkumar, A., 2023. Neural op erator: learning maps b et ween function spaces with applications to pdes. The Journal of Mac hine Learning Research 24. [16] Krishnapriy an, A., Gholami, A., Zhe, S., Kirby , R., Mahoney , M.W., 202 1. Characterizing possible failure modes in ph ysics-informed neural net w orks, in: Adv ances in Neural Information Pro cessing Systems, Curran Asso ciates, Inc.. pp. 26548–26560. [17] Le V eque, R.J., 2007. Finite Difference Methods for Ordinary and P artial Differ- en tial Equations. So ciet y for Industrial and Applied Mathematics. URL: https: //epubs.siam.org/doi/abs/10.1137/1.9780898717839 , doi: 10.1137/1.9780898717839 , arXiv:https://epubs.siam.org/doi/pdf/10.1137/1.9780898717839 . [18] Li, Z., K o v ac hki, N., Azizzadenesheli, K., Liu, B., Bhattachary a, K., Stuart, A., Anandkumar, A., 2020a. Neural operator: Graph k ernel net w ork for partial differen tial equations. URL: https://arxiv. org/abs/2003.03485 , arXiv:2003.03485 . [19] Li, Z.Y., Ko v achki, N.B., Azizzadenesheli, K., Liu, B., Bhattac harya, K., Stuart, A.M., Anandkumar, A., 2020b. F ourier neural op erator for parametric partial differential equations. ArXiv abs/2010.08895. URL: https://api.semanticscholar.org/CorpusID:224705257 . [20] Lu, L., Jin, P ., Pang, G., Zhang, Z., Karniadakis, G.E., 2021a. Learning nonlinear operators via deep onet based on the universal appro ximation theorem of op erators. Nature Machine Intelligence 3, 218–229. [21] Lu, L., Meng, X., Mao, Z., Karniadakis, G.E., 2021b. Deep xde: A deep learning li- brary for solving differen tial equations. SIAM Review 63, 208–228. doi: 10.1137/19M1274067 , arXiv:https://doi.org/10.1137/19M1274067 . [22] Mildenhall, B., Sriniv asan, P .P ., T ancik, M., Barron, J.T., Ramamo orthi, R., Ng, R., 2020. Nerf: Represen ting scenes as neural radiance fields for view synthesis, in: V edaldi, A., Bischof, H., Brox, T., F rahm, J.M. (Eds.), Computer Vision – ECCV 2020, Springer, Cham. pp. 405–421. [23] Pfaff, T., F ortunato, M., Sanc hez-Gonzalez, A., Battaglia, P .W., 2021. Learning mesh-based sim ulation with graph net works. URL: , . [24] Rac k auc k as, C., Ma, Y., Martensen, J., W arner, C., Zub ov, K., Supek ar, R., Skinner, D., Ramadhan, A., Edelman, A., 2021. Universal differential equations for scientific machine learning. URL: https: //arxiv.org/abs/2001.04385 , arXiv:2001.04385 . [25] Raissi, M., Perdik aris, P ., Karniadakis, G., 2019. Ph ysics-informed neural netw orks: A deep learning framew ork for solving forw ard and inv erse problems inv olving nonlinear partial differential equations. Journal of Computational Ph ysics 378, 686–707. URL: https://www.sciencedirect.com/science/ article/pii/S0021999118307125 , d oi: https://doi.org/10.1016/j.jcp.2018.10.045 . 16 [26] Sirignano, J., Spiliop oulos, K., 2018. Dgm: A deep learning algorithm for solving partial differen tial equations. Journal of Computational Physics 375, 1339–1364. URL: https://www.sciencedirect.com/ science/article/pii/S0021999118305527 , doi: https://doi.org/10.1016/j.jcp.2018.08.029 . [27] Sitzmann, V., Martel, J.N.P ., Bergman, A.W., Lindell, D.B., W etzstein, G., 2020. Implicit neural represen tations with perio dic activ ation functions, in: Pro ceedings of the 34th In ternational Conference on Neural Information Pro cessing Systems, Curran Asso ciates Inc., Red Ho ok, NY, USA. pp. 7462–7473. [28] T ancik, M., Sriniv asan, P .P ., Mildenhall, B., F ridovic h-Keil, S., Raghav an, N., Singhal, U., Ramamo or- thi, R., Barron, J.T., Ng, R., 2020. F ourier features let net works learn high frequency functions in lo w dimensional domains. . [29] V asw ani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I., 2023. Atten tion is all you need. URL: , . [30] W ang, S., T eng, Y., Perdik aris, P ., 2021. Understanding and mitigating gradient pathologies in ph ysics- informed neural net works. SIAM Journal on Scientific Computing 43, A3055–A3081. [31] Willco x, K., P eraire, J., 2012. Balanced mo del reduction via the prop er orthogonal decomposition. AIAA Journal 40, 2323–2330. doi: doi.org/10.2514/2.1570 . [32] Zhao, Z., Ding, X., Prak ash, B.A., 2024. Pinnsformer: A transformer-based framew ork for ph ysics- informed neural net works. URL: , . 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment