X-OPD: Cross-Modal On-Policy Distillation for Capability Alignment in Speech LLMs
While the shift from cascaded dialogue systems to end-to-end (E2E) speech Large Language Models (LLMs) improves latency and paralinguistic modeling, E2E models often exhibit a significant performance degradation compared to their text-based counterpa…
Authors: Di Cao, Dongjie Fu, Hai Yu
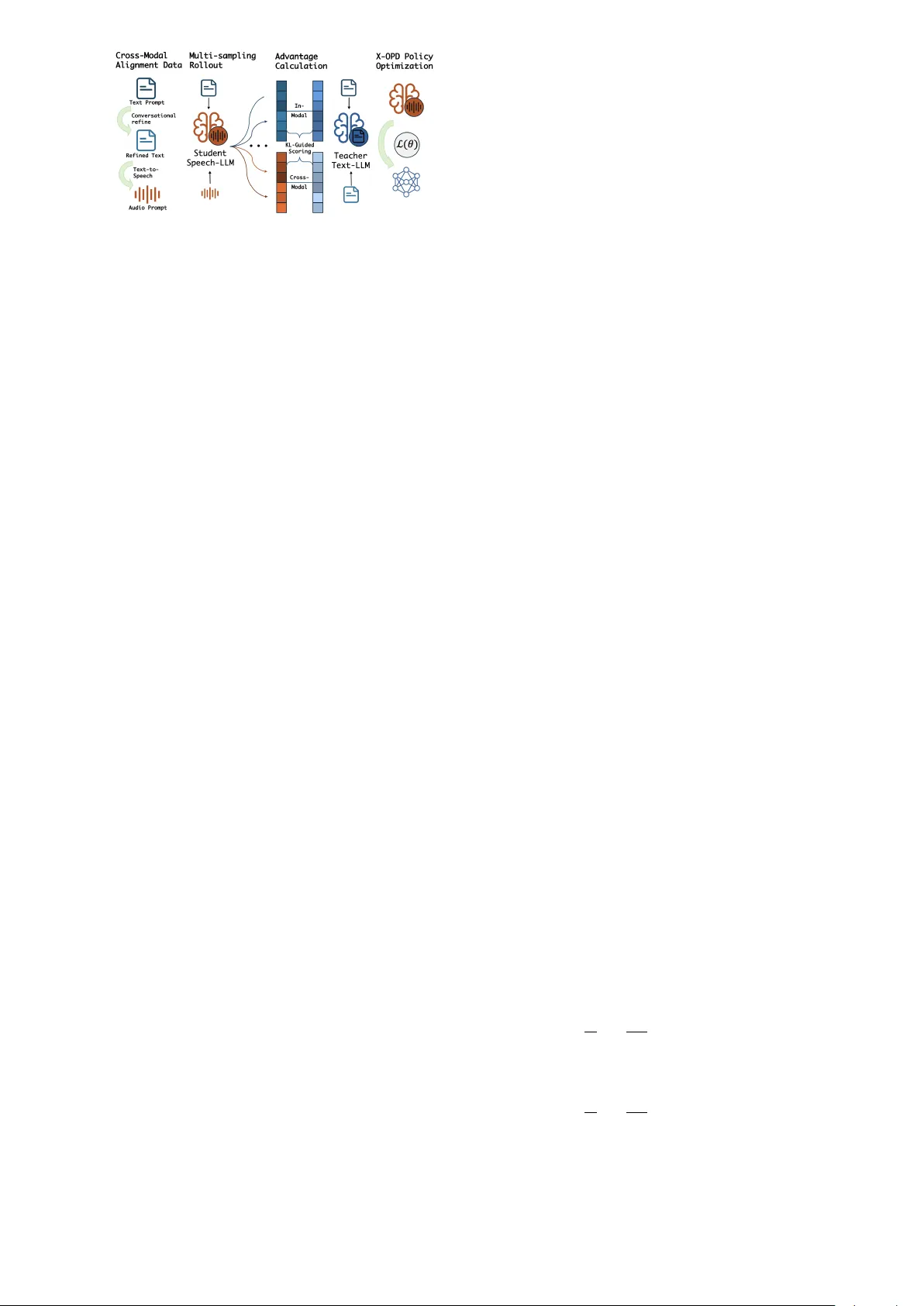
X-OPD: Cr oss-Modal On-P olicy Distillation f or Capability Alignment in Speech LLMs Di Cao 1 , ∗ , Dongjie Fu 1 , 2 , ∗ , Hai Y u 1 , Siqi Zheng 1 , Xu T an 1 , ∗∗ , T ao Jin 2 , ∗∗ 1 T encent Hunyuan 2 Zhejiang Uni versity Abstract While the shift from cascaded dialogue systems to end- to-end (E2E) speech Large Language Models (LLMs) im- prov es latency and paralinguistic modeling, E2E models often exhibit a significant performance degradation com- pared to their text-based counterparts. The standard Super- vised Fine-T uning (SFT) and Reinforcement Learning (RL) training methods fail to close this gap. T o address this, we propose X-OPD, a no vel Cross-Modal On-Policy Distilla- tion framework designed to systematically align the capa- bilities of Speech LLMs to their text-based counterparts. X-OPD enables the Speech LLM to explore its own dis- tribution via on-polic y rollouts, where a text-based teacher model ev aluates these trajectories and provides token-le vel feedback, effecti vely distilling teacher’ s capabilities into student’ s multi-modal representations. Extensiv e exper- iments across multiple benchmarks demonstrate that X- OPD significantly narro ws the gap in complex tasks while preserving the model’ s inherent capabilities. Index T erms : speech language model, on-policy distilla- tion, modality gap 1. Introduction As multimodal LLMs become increasingly popular , speech interaction is transitioning from traditional cascaded archi- tectures — typically comprising Automatic Speech Recog- nition (ASR), an LLM, and T e xt-to-Speech (TTS) — to- ward End-to-End (E2E) paradigms. By modeling directly within the continuous speech signal space, E2E models sig- nificantly reduce interaction latency and capture rich par- alinguistic information, such as intonation, emotion, and en vironmental context, thereby offering a user experience that is f ar more e xpressi ve and akin to human-to-human in- teraction. This potential is exemplified by recent flagship systems — including GPT -4o [1], Gemini 2.5 [2], Qwen3- Omni [3] and V oxtral [4] — which ha ve collectively rede- fined unified audio-text understanding. Howe v er , despite the superior interaction fluenc y of E2E architectures, the significant performance gap remains a barrier to their widespread deployment. Empirical studies [5, 6, 7, 8] indicate that these models frequently e xhibit sig- nificant degradation in complex instruction following, log- ical reasoning, or knowledge-intensi v e queries compared to their text-based counterparts. Consequently , while cas- caded systems may be slower , they remain the industrial se- lection due to the rob ust capabilities inherited from the un- derlying te xt LLM. This misalignment between modalities prev ents speech models from fully le veraging the cognitiv e power of their te xtual foundations. * These authors contributed equally . ** indicates the corresponding author . W e attribute this degradation primarily to two factors: the scarcity of high-quality , paired speech-reasoning data, and the inherent misalignment between continuous acoustic representations and the discrete logical space of te xt LLMs. As a result, the high-quality Supervised Fine-T uning (SFT) and Reinforcement Learning (RL) data in text LLM train- ing cannot be fully transferred into the training of a Speech LLM, resulting in the gap in standard SFT+RL training pipeline. Consequently , there is an urgent need for training paradigms that can align cross-modal capabilities without heavy reliance on static datasets. Some methods try to bridge this gap by performing of- fline distillation from a cascaded system. Howe ver , these methods often struggle with distrib ution shifts — known as the exposure bias problem — where the model’ s generation trajectory during inference div erges from the training dis- tribution. Furthermore, the accumulati ve errors in cascaded pipeline will also harm the performance. Addressing these challenges, we proposes X-OPD, a nov el Cross-Modal On-Policy Distillation framework de- signed to systematically bridge the intelligence gap be- tween Speech LLMs and their text-based counterparts. W e introduce a training strate gy that utilizes transcribed text as an alignment bridge. In our framew ork, the student model performs autonomous rollouts across both speech and text modalities. Simultaneously , a more capable text-based teacher model generates a reference distribution based on the synchronized text input. By lev eraging Kullback- Leibler (KL) div ergence, denoted as D KL ( P ∥ Q ) , for dy- namic credit assignment, we precisely distill the teacher’ s logical knowledge into the student’ s multimodal represen- tations. This approach offers three distinct advantages: it significantly enhances training ef ficiency; it eliminates the dependency on ground truth data, allowing for the utiliza- tion of open-source models where training data is undis- closed; and it minimizes the catastrophic forgetting of other acoustic capabilities. Through this framework, we aim to achieve a low-cost, high-efficiency alignment of cross- modal intelligence, paving the way for the next generation of smart, expressi ve spoken language agents. In this work we introduce X-OPD, a novel optimiza- tion strategy that achieves rob ust modality alignment while effecti vely preserving the pre-trained model’ s general pro- ficiency . W e demonstrate that X-OPD consistently outper- forms various training paradigms and distillation bench- marks, significantly narrowing the performance g ap. 2. Related works 2.1. Distillation in Speech LLMs Recent studies utilize distillation to bridge the performance gap in Speech LLMs. DeST A2.5-Audio [9] achie ves cross- modal alignment by emplo ying backbone LLM to generate Figure 1: Overview of the pr oposed Cr oss-Modal On-P olicy Distillation (X-OPD) frame work. responses from audio captions, which then serve as ground truth targets for SFT . SALAD [10] employs a two-stage approach, integrating cross-modal distillation with active data selection to achieve high sample efficienc y . W ang et al. [11] introduced a dual-channel distillation framew ork with logit-lev el supervision to transfer complex reasoning capabilities from text teachers. These methods are funda- mentally off-polic y , relying on static teacher trajectories or fixed targets rather than the model’ s own inference rollouts. This results in e xposure bias, as the model cannot learn to correct its own reasoning path upon de viation. Qwen3-Omni claimed to achieve state-of-the-art per- formance across multiple modalities [3], without cross- modality gap. Howe ver , when ev aluated on mainstream audio understanding benchmarks, such as Big Bench Au- dio and Audio Multi-Challenge, performance drops are ob- served, compared to the Qwen3 counterpart [12]. This result further suggests that standard SFT+RL training schemes are insufficient to close the g ap. 2.2. On-Policy Distillation T o address the exposure bias in off-policy distillation, some research has pi voted tow ards on-policy paradigms for gen- erativ e models. GKD [13] introduces Generalized Kno wl- edge Distillation, which addresses the distrib ution mis- match in auto-regressi ve models by training the student on its self-generated sequences using teacher feedback. MiniLLM [14] utilizes an on-policy distillation strategy with a rev erse KL diver gence objective to mitigate e xposure bias and improve generation calibration in smaller language models. In some recent works within the industry , Qwen3 [12, 3] introduces a strong-to-weak distillation framework to transfer reasoning capabilities from flagship teachers to smaller students with exceptional ef ficiency . Thinking Ma- chines Lab [15] explores on-policy distillation as a method combining the dense rewards of distillation with the on- policy relevance of RL, achieving massiv e compute effi- ciency gains o ver traditional RL. 3. Cross-Modal On-Policy Distillation The overall framew ork of our proposed Cross-Modal On- Policy Distillation (X-OPD) is shown in Figure 1. X-OPD lev erages on-policy sampling from student model across both modalities, guided by token-level scoring from the text-based teacher . Optimized by policy gradients, X-OPD ensures Speech LLMs ef ficiently inherit the teacher’ s capa- bilities through direct cross-modal alignment. 3.1. Cross-Modal Alignment Data T o enable ef fectiv e distillation, we define a parallel dataset D = { ( S i , T i ) } , consisting of paired speech and text prompts. The fundamental requirement for D is Semantic In variance: the acoustic signal S i and the textual instruc- tion T i must be strictly aligned in their logical intent. In practice, such alignment can be established by either syn- thesizing speech from textual instructions or transcribing existing audio prompts via speech recognition. 3.2. Robust Multi-sampling Rollout Single-sample rollouts often suffer from inherent stochas- ticity , yielding excessiv e variance in gradient estimation that can destabilize the training process. T o enhance op- timization robustness, the policy independently samples n candidate trajectories for each prompt. By marginaliz- ing the gradients across these multiple paths, we achiev e broader coverage of the policy space and significantly at- tenuate the high volatility characteristic of on-policy rein- forcement learning updates. 3.3. In-modal and Cross-modal Advantage Function T o ensure the student model π θ faithfully inherits the teacher’ s capabilities, we introduce a dual-advantage mech- anism. This framework first emplo ys an in-modal ad- vantage to stabilize the student’ s foundational proficiency within the textual domain, providing a consistent reference for cross-modal alignment. For a giv en trajectory y sampled from the student pol- icy π θ , let y t be the t -th token. The in-modal advantage A im ( y t ) measures the log-probability discrepancy between the teacher π ϕ and the student π θ when both are condi- tioned on the text prompt T : A im ( y t ) = log π ϕ ( y t | T , y 69% ). Notably , the text-only distilla- tion setting ( λ = 1 ) yields the highest retention at 70.7%, confirming that in-modal optimization imposes the least in- terference on pre-trained audio features. Even when incor- porating cross-modal objectives ( λ = 0 or 0 . 5 ), X-OPD consistently maintains a marginal decline compared to the baseline methods. This demonstrates that X-OPD’ s RL- style paradigm effecti vely regularizes the model’ s behav- ior , successfully balancing cross-modal alignment with the preservation of its original general capabilities. 5. Conclusion In this work, we propose X-OPD, a novel Cross-Modal On-Policy Distillation framework that ef fectiv ely aligns Speech LLMs with their text-based counterparts. Our ex- periments sho w that X-OPD significantly narro ws the per- formance gap between speech and text modalities while effecti vely mitigating catastrophic forgetting. Notably , X- OPD exhibits remarkable sample efficiency , achieving su- perior alignment and capability preservation with a mod- est dataset of only 27k samples. This establishes a ro- bust, data-efficient, and annotation-free pathway for foun- dational alignment in multimodal agents. 6. References [1] A. Hurst, A. Lerer, A. P . Goucher , A. Perelman, A. Ramesh, A. Clark, A. Ostrow , A. W elihinda, A. Hayes, A. Radford et al. , “Gpt-4o system card, ” arXiv preprint arXiv:2410.21276 , 2024. [2] G. Comanici, E. Bieber , M. Schaekermann, I. Pasu- pat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen et al. , “Gemini 2.5: Pushing the fron- tier with advanced reasoning, multimodality , long context, and next generation agentic capabilities, ” arXiv preprint arXiv:2507.06261 , 2025. [3] J. Xu, Z. Guo, H. Hu, Y . Chu, X. W ang, J. He, Y . W ang, X. Shi, T . He, X. Zhu et al. , “Qwen3-omni technical report, ” arXiv pr eprint arXiv:2509.17765 , 2025. [4] A. H. Liu, A. Ehrenberg, A. Lo, C. Denoix, C. Bar- reau, G. Lample, J.-M. Delignon, K. R. Chandu, P . von Platen, P . R. Muddireddy et al. , “V oxtral, ” arXiv pr eprint arXiv:2507.13264 , 2025. [5] K.-H. Lu, C.-Y . Kuan, and H. yi Lee, “Speech-IFEval: Eval- uating Instruction-Follo wing and Quantifying Catastrophic For getting in Speech-A ware Language Models, ” in Inter- speech 2025 , 2025, pp. 2078–2082. [6] Y . Chen, W . Zhu, X. Chen, Z. W ang, X. Li, P . Qiu, H. W ang, X. Dong, Y . Xiong, A. Schneider et al. , “ Aha: Aligning large audio-language models for reasoning hallu- cinations via counterfactual hard negatives, ” arXiv preprint arXiv:2512.24052 , 2025. [7] Y . F ang, H. Sun, J. Liu, T . Zhang, Z. Zhou, W . Chen, X. Xing, and X. Xu, “S2sbench: A benchmark for quantifying intelli- gence degradation in speech-to-speech large language mod- els, ” arXiv pr eprint arXiv:2505.14438 , 2025. [8] Y . Zhang, Y . Du, Z. Dai, X. Ma, K. Kou, B. W ang, and H. Li, “Echox: T owards mitigating acoustic-semantic gap via echo training for speech-to-speech llms, ” arXiv preprint arXiv:2509.09174 , 2025. [9] K.-H. Lu, Z. Chen, S.-W . Fu, C.-H. H. Y ang, S.-F . Huang, C.-K. Y ang, C.-E. Y u, C.-W . Chen, W .-C. Chen, C.-y . Huang et al. , “Desta2. 5-audio: T ow ard general-purpose large audio language model with self-generated cross-modal alignment, ” arXiv pr eprint arXiv:2507.02768 , 2025. [10] S. Cuervo, S. Seto, M. de Seyssel, R. H. Bai, Z. Gu, T . Likhomanenko, N. Jaitly , and Z. Aldeneh, “Closing the gap between text and speech understanding in llms, ” arXiv pr eprint arXiv:2510.13632 , 2025. [11] E. W ang, Q. Li, Z. T ang, and Y . Jia, “Cross-modal knowledge distillation for speech large language models, ” arXiv preprint arXiv:2509.14930 , 2025. [12] A. Y ang, A. Li, B. Y ang, B. Zhang, B. Hui, B. Zheng, B. Y u, C. Gao, C. Huang, C. Lv et al. , “Qwen3 technical report, ” arXiv pr eprint arXiv:2505.09388 , 2025. [13] R. Agarwal, N. V ieillard, Y . Zhou, P . Stanczyk, S. R. Garea, M. Geist, and O. Bachem, “On-policy distillation of lan- guage models: Learning from self-generated mistakes, ” in The twelfth international conference on learning r epresenta- tions , 2024. [14] Y . Gu, L. Dong, F . W ei, and M. Huang, “MiniLLM: Knowl- edge distillation of lar ge language models, ” in The T welfth In- ternational Confer ence on Learning Representations , 2024. [15] K. Lu and T . M. Lab, “On-policy distillation, ” Thinking Machines Lab: Connectionism , 2025, https://thinkingmachines.ai/blog/on-policy-distillation. [16] N. Lambert, J. Morrison, V . Pyatkin, S. Huang, H. Ivison, F . Brahman, L. J. V . Miranda, A. Liu, N. Dziri, X. Lyu, Y . Gu, S. Malik, V . Graf, J. D. Hwang, J. Y ang, R. L. Bras, O. T afjord, C. Wilhelm, L. Soldaini, N. A. Smith, Y . W ang, P . Dasigi, and H. Hajishirzi, “T ulu 3: Pushing frontiers in open language model post-training, ” in Second Conference on Language Modeling , 2025. [Online]. A vailable: https://openreview .net/forum?id=i1uGbfHHpH [17] W . Y uan, J. Y u, S. Jiang, K. Padthe, Y . Li, I. Kulikov , K. Cho, D. W ang, Y . Tian, J. E. W eston et al. , “Naturalreasoning: Reasoning in the wild with 2.8 m challenging questions, ” arXiv pr eprint arXiv:2502.13124 , 2025. [18] Z. Du, C. Gao, Y . W ang, F . Y u, T . Zhao, H. W ang, X. Lv , H. W ang, X. Shi, K. An et al. , “Cosyvoice 3: T ow ards in- the-wild speech generation via scaling-up and post-training, ” arXiv pr eprint arXiv:2505.17589 , 2025. [19] X. Lyu, Y . W ang, T . Zhao, H. W ang, H. Liu, and Z. Du, “Build llm-based zero-shot streaming tts system with cosyvoice, ” in ICASSP 2025-2025 IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2025, pp. 1–2. [20] K. An, Q. Chen, C. Deng, Z. Du, C. Gao, Z. Gao, Y . Gu, T . He, H. Hu, K. Hu et al. , “Funaudiollm: V oice un- derstanding and generation foundation models for natu- ral interaction between humans and llms, ” arXiv preprint arXiv:2407.04051 , 2024. [21] A. Sriv astav a, A. Rastogi, A. Rao, A. A. M. Shoeb, A. Abid, A. Fisch, A. R. Brown, A. Santoro, A. Gupta, A. Garriga- Alonso et al. , “Beyond the imitation game: Quantifying and e xtrapolating the capabilities of language models, ” arXiv pr eprint arXiv:2206.04615 , 2022. [22] M. Suzgun, N. Scales, N. Sch ¨ arli, S. Gehrmann, Y . T ay , H. W . Chung, A. Chowdhery , Q. Le, E. Chi, D. Zhou et al. , “Chal- lenging big-bench tasks and whether chain-of-thought can solve them, ” in Findings of the Association for Computa- tional Linguistics: ACL 2023 , 2023, pp. 13 003–13 051. [23] A. Gosai, T . V uong, U. T yagi, S. Li, W . Y ou, M. Bav are, A. Uc ¸ ar, Z. Fang, B. Jang, B. Liu et al. , “ Audio mul- tichallenge: A multi-turn ev aluation of spoken dialogue systems on natural human interaction, ” arXiv preprint arXiv:2512.14865 , 2025. [24] Y . Chen, X. Y ue, C. Zhang, X. Gao, R. T . T an, and H. Li, “V oicebench: Benchmarking llm-based voice assistants, ” arXiv pr eprint arXiv:2410.17196 , 2024. [25] F . Faisal, S. K eshava, M. M. I. Alam, and A. Anastasopou- los, “Sd-qa: Spoken dialectal question answering for the real world, ” in F indings of the Association for Computational Linguistics: EMNLP 2021 , 2021, pp. 3296–3315. [26] J. Zhou, T . Lu, S. Mishra, S. Brahma, S. Basu, Y . Luan, D. Zhou, and L. Hou, “Instruction-following e valuation for large language models, ” arXiv preprint , 2023. [27] A. Zou, Z. W ang, N. Carlini, M. Nasr , J. Z. Kolter , and M. Fredrikson, “Universal and transferable adversar - ial attacks on aligned language models, ” arXiv pr eprint arXiv:2307.15043 , 2023. [28] G. Sheng, C. Zhang, Z. Y e, X. W u, W . Zhang, R. Zhang, Y . Peng, H. Lin, and C. W u, “Hybridflow: A flexible and ef- ficient rlhf framework, ” in Proceedings of the T wentieth Eu- r opean Conference on Computer Systems , 2025, pp. 1279– 1297. [29] Y . Zhao, J. Huang, J. Hu, X. W ang, Y . Mao, D. Zhang, Z. Jiang, Z. W u, B. Ai, A. W ang et al. , “Swift: a scalable lightweight infrastructure for fine-tuning, ” in Pr oceedings of the AAAI Confer ence on Artificial Intelligence , vol. 39, no. 28, 2025, pp. 29 733–29 735. [30] Y . Li, X. Y ue, Z. Xu, F . Jiang, L. Niu, B. Y . Lin, B. Rama- subramanian, and R. Poovendran, “Small models struggle to learn from strong reasoners, ” in F indings of the Association for Computational Linguistics: ACL 2025 , 2025, pp. 25 366– 25 394. [31] Z. Xu, F . Jiang, L. Niu, B. Y . Lin, and R. Poovendran, “Stronger models are not stronger teachers for instruction tuning, ” arXiv pr eprint arXiv:2411.07133 , 2024. [32] Z. Ma, Y . Ma, Y . Zhu, C. Y ang, Y .-W . Chao, R. Xu, W . Chen, Y . Chen, Z. Chen, J. Cong et al. , “Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix, ” arXiv pr eprint arXiv:2505.13032 , 2025.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment