Decoupling Exploration and Policy Optimization: Uncertainty Guided Tree Search for Hard Exploration
The process of discovery requires active exploration -- the act of collecting new and informative data. However, efficient autonomous exploration remains a major unsolved problem. The dominant paradigm addresses this challenge by using Reinforcement …
Authors: Zakaria Mhammedi, James Cohan
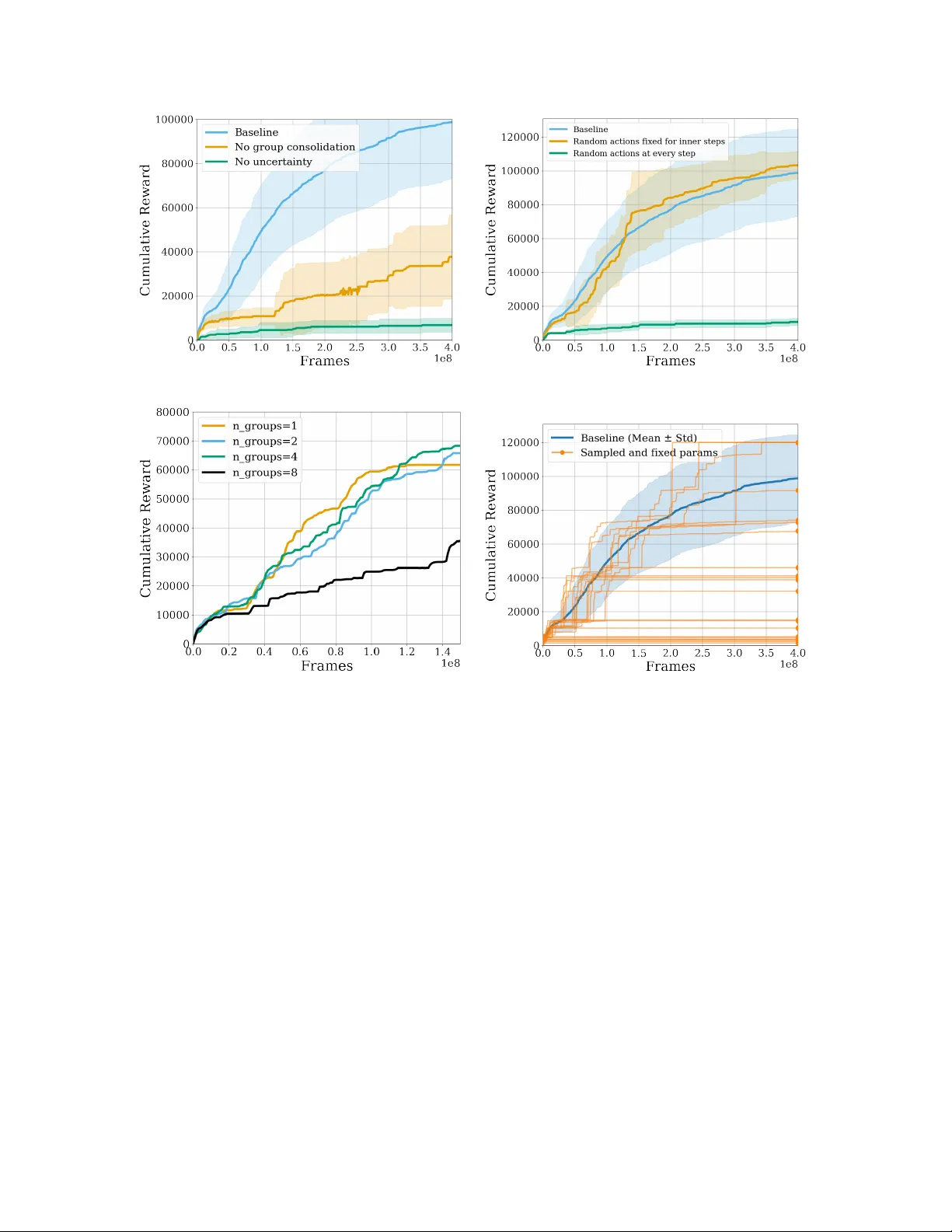
Decoupling Exploration and P olicy Optimization: Uncertain t y Guided T ree Searc h for Hard Exploration Zak aria Mhammedi Go ogle Research, NYC mhammedi@google.com James Cohan Go ogle Research, NYC jamesfcohan@google.com Marc h 31, 2026 Abstract The pro cess of disco very requires activ e exploration—the act of collecting new and informative data. Ho wev er, efficient autonomous exploration remains a ma jor unsolved problem. The dominant paradigm addresses this challenge b y using Reinforcement Learning (RL) to train agen ts with intrinsic motiv ation, maximizing a comp osite ob jectiv e of extrinsic and intrinsic rewards. W e suggest that this approach incurs unnecessary o verhead: while p olicy optimization is necessary for precise task execution, employing such mac hinery solely to expand state cov erage ma y b e inefficient. In this pap er, we prop ose a new paradigm that explicitly separates exploration from exploitation and bypasses RL during the exploration phase. Our metho d uses a tree-search strategy inspired by the Go-With-The-Winner algorithm, paired with a measure of epistemic uncertaint y to systematically drive exploration. By remo ving the ov erhead of p olicy optimization, our approach explores an order of magnitude more efficien tly than standard intrinsic motiv ation baselines on hard A tari b enc hmarks. F urther, we demonstrate that the discov ered tra jectories can b e distilled into deploy able p olicies using existing sup ervised backw ard learning algorithms, achieving state-of-the-art scores b y a wide margin on Montezuma’s R evenge , Pitfal l! , and V entur e without relying on domain-sp ecific knowledge. Finally , we demonstrate the generalit y of our framework in high-dimensional con tinuous action spaces by solving the MuJoCo Adroit dexterous manipulation and AntMaze tasks in a sparse-r ewar d setting, directly from image observ ations and without exp ert demonstrations or offline datasets. T o the b est of our knowledge, this has not b een achiev ed b efore for the Adroit tasks. 1 In tro duction Reinforcemen t learning (RL) is a cornerstone of mo dern artificial intelligence, enabling breakthroughs in complex autonomous systems and, more recen tly , the p ost-training and alignmen t of Large Language Mo dels (LLMs) ( Mnih et al. , 2015 ; Silv er et al. , 2016 , 2018 ; Ouyang et al. , 2022 ; Rafailov et al. , 2023 ). How ever, these successes often rely on rich feedback, suc h as exp ert demonstrations in rob otics or preference lab els in language mo del alignment ( Christiano et al. , 2017 ; Hester et al. , 2018 ; Brohan et al. , 2022 ). In the settings w e study , where guidance is scarce, rew ards sparse, or the goal is surpassing human p erformance, learning m ust go b ey ond imitation to autonomously generate quality data ( Silver et al. , 2016 ; Ecoffet et al. , 2021 ). This requires active explor ation : an algorithmic pro cess that delib erately collects informativ e exp erience ( Sh yam et al. , 2019 ; Sek ar et al. , 2020 ; Eysen bach et al. , 2018 ). In the hardest cases, this amounts to “finding a needle in a haystac k,” where a single rare tra jectory is the key that unlo c ks learning. In structured settings lik e tw o-play er games, self-pla y facilitates exploration ( Silver et al. , 2016 ). As the agen t improv es, it probes the boundary of its current p olicy , gradually expanding its cov erage of relev ant strategies. Outside of this self-pla y regime, driving exploration is significantly harder. Ev en in simple 2D en vironments, current metho ds often fail to explore efficiently without domain engineering; Montezuma’s R evenge and Pitfal l! remain standard b enchmarks that stress-test systematic exploration ( Ecoffet et al. , 2019 ; Badia et al. , 2020a , b ; Guo et al. , 2022 ). These failures suggest that we still lack a robust understanding of systematic exploration in data-sparse domains. Progress in this area has implications well b eyond games; efficien t exploration is a prerequisite for discov ery in complex scien tific domains. 1 Historically , the primary approach to exploration relies on training agents with intrinsic motivation ( Sc hmid- h ub er , 1991 ; Oudeyer et al. , 2007 ; Barto , 2012 ; Houtho oft et al. , 2016 ; Stadie et al. , 2015 ). In this paradigm, the agen t is trained to maximize a comp osite ob jective consisting of the extrinsic reward and an intrinsic b on us designed to encourage visiting no vel states. In high-dimensional spaces, these b onuses typically use pro xies for “visitation frequency ,” suc h as the error of Random Netw ork Distillation ( RND ) or the prediction error of a dynamics mo del ( Burda et al. , 2018 ; Pathak et al. , 2017 , 2019 ). While accurate uncertain ty estimation is crucial, we argue that driving exploration by maximizing these signals via RL incurs unnecessary complexit y; iteratively up dating a p olicy to reach nov el states is inherently sample-inefficient, as it requires constan tly tracking a non-stationary intrinsic reward signal. Con tributions. • W e prop ose a new paradigm for autonomous exploration in sparse-reward settings that b ypasses intrinsic- rew ard policy optimization. Our framework pairs a tree-search strategy , inspired by the Go-With-The- Winner ( GWTW ) algorithm ( Aldous and V azirani , 1994 ), with epistemic uncertain ty ( Dep ew eg et al. , 2018 ) to drive exploration; the approach is mo dular and agnostic to the sp ecific uncertaint y metric. The metho d relies on the ability to r eset the environmen t to previously visited states in order to redistribute computational effort tow ard the most promising frontiers. By replacing intrinsic-rew ard p olicy optimization with uncertaint y-guided tree search, our metho d disco vers high-reward tra jectories using an order of magnitude fewer environmen t in teractions than standard intrinsic m otiv ation baselines on hard-exploration b enc hmarks. • W e show that sup ervised backw ard learning algorithms (e.g., Salimans and Chen ( 2018 )) can distill the generated tra jectories into robust, high-scoring p olicies. In particular, we achiev e state-of-the-art results b y a wide margin on Montezuma’s R evenge , Pitfal l! , and V entur e when not relying on domain-specific kno wledge. • W e demonstrate the generalit y of our framew ork by applying it to high-dimensional contin uous action spaces, solving the MuJoCo Adroit dexterous manipulation and AntMaze navigation tasks from pixel observ ations in a sp arse-r ewar d setting without relying on exp ert demonstrations or offline datasets. T o the b est of our kno wledge, this has not b een previously achiev ed for the Adroit tasks. In b oth cases, the final distilled p olicies op erate directly from image observ ations, without accessing privileged state information. Outline. The remainder of this pap er is organized as follows. Section 2 presents the related work and con textualizes our approach within the literature on separating exploration from exploitation and the usage of environmen t resets. Section 3 formalizes the problem setting and introduces core comp onents, including the uncertaint y estimator and the reset mechanism. Section 4 details our uncertaint y-driv en tree-search algorithm for exploration, Go-With-Uncer t ainty ( GowU ). Section 5 presents implementation details, including a distributed architecture for scalable exploration and the sp ecific instantiations of the uncertaint y estimator and particle p olicies. Finally , Section 6 ev aluates the metho d on hard-exploration Atari games and c hallenging MuJoCo contin uous-control tasks, showing efficient exploration and successful policy distillation across all en vironments. 2 Related W ork Efficien t exploration remains a central c hallenge in reinforcement learning. Below w e situate our approach within the broader landscap e of exploration metho ds. In trinsic motiv ation and latent predictiv e mo dels. A dominant approach to exploration in deep RL is to train a p olicy to maximize an intrinsic motiv ation signal that encourages the agent to visit nov el s tates ( Stadie et al. , 2015 ; Bellemare et al. , 2016 ; Pathak et al. , 2019 ; Badia et al. , 2020a ). In high-dimensional settings, these signals are often defined using proxies for nov elty such as prediction error ( Pathak et al. , 2017 ), pseudo-coun ts ( Bellemare et al. , 2016 ), Random Netw ork Distillation ( Burda et al. , 2018 ), or information gain o ver a learned dynamics mo del ( Houtho oft et al. , 2016 ). Recent metho ds such as BYOL-Explore ( Guo et al. , 2022 ) contin ue this line by defining the in trinsic signal through the error in predicting future latent represen tations, an elegan t wa y to measure nov elty in high-dimensional observ ations. BYOL-Hindsight ( Jarrett et al. , 2023 ) extends this approach to b etter handle stochastic en vironments. These methods are 2 among the strongest intrinsic-motiv ation baselines on hard-exploration b enc hmarks, yet even they remain limited on the hardest sparse-reward problems (such as Montezuma’s R evenge and Pitfal l! ), esp ecially once sto c hasticity is in tro duced. This s upports the view that maximizing in trinsic motiv ation signals through standard p olicy optimization may b e fundamentally inefficient for hard exploration. Separating exploration from exploitation. An alternativ e line of w ork separates exploration and do wnstream task optimization into distinct phases. In the empirical literature, this p ersp ective app ears in rew ard-free or unsup ervised RL setups such as URLB ( Laskin et al. , 2021 ), where an agent first p erforms task-agnostic pre-training and is only later adapted to downstream rewards. Metho ds suc h as APT ( Liu and Abb eel , 2021 ) and Plan2Explore ( Sek ar et al. , 2020 ) allo cate this pre-training phase to broad state disco very using intrinsic ob jectiv es such as state cov erage or mo del uncertaint y , while skill-discov ery methods suc h as V ariational Intrinsic Control ( Mohamed and Jimenez Rezende , 2015 ) and DIA YN ( Eysenbac h et al. , 2018 ) learn div erse b ehaviors before task rewards are introduced. This persp ective also app ears in the theoretical literature. A canonical early example is E 3 ( Kearns and Singh , 2002 ), which formalizes an explicit explore-or-exploit strategy . The reward-free exploration framew ork of Jin et al. ( 2020 ) go es further b y showing that a pure exploration phase can suffice for efficient downstream planning in tabular MDPs. Subsequent w ork studies related ideas in ric h-observ ation settings with discrete ( Misra et al. , 2020 ; Mhammedi et al. , 2023b ) and low-rank transition structure ( Mhammedi et al. , 2023a ). Relativ e to these lines of work, the main distinction in our setting is not the use of a separate exploration phase itself, but the mechanism used within that phase: in the approaches ab ov e, exploration is still typically driv en by optimizing an explicit exploration ob jective. Exploration without p olicy optimization. Some approaches a v oid p olicy optimization during exploration en tirely . The closest conceptual anteceden t to our work is Go-Explore ( Ecoffet et al. , 2019 , 2021 ), which separates exploration from do wnstream rew ard maximization and av oids p olicy optimization during the exploration phase. W e follo w a similar high-level philosophy: exploration is treated as a search problem rather than as the optimization of an intrinsic reward. How ever, our exploration mechanism is fundamentally differen t. Instead of maintaining an arc hive ov er discretized cells and repeatedly returning to archiv ed states, w e use a particle-based tree-search pro cedure guided by an epistemic uncertaint y signal. A k ey difference from Go-Explore is that our metho d do es not rely on hand-designed observ ation discretization for archiv e construction or on deterministic exploration dynamics. 1 This makes our metho d more naturally suited to high-dimensional and sto chastic environmen ts. Despite these differences, b oth approac hes serve a similar high-lev el role: they generate suc cessful tra jectories that can later b e con verted into executable policies, for example through bac kward learning or reverse-curriculum metho ds ( Florensa et al. , 2017 ; Salimans and Chen , 2018 ; Ecoffet et al. , 2019 ). Lev eraging resets as a computational primitive. Both Go-Explore and our approac h rely on a shared computational primitive: the ability to reset the en vironment to a previously visited state. This capability is also central to search-based methods suc h as Monte Carlo T ree Search (MCTS), whic h rep eatedly branch from sim ulator states during planning ( Kocsis and Szep esvári , 2006 ; Coulom , 2006 ). While arbitrary resets are often impractical on physical systems ( Eysenbac h et al. , 2017 ; Gupta et al. , 2021 ), they are readily a v ailable in simulation, where muc h of modern RL training already tak es place ( Zhao et al. , 2020 ; Aljalb out et al. , 2025 ). Our work treats resets as a training-time to ol for exploration: they allow the algorithm to rep eatedly redirect computation to ward promising frontier states, without requiring simulator access at inference time. Relationship to Mon te Carlo T ree Search. Our metho d is also related to search-based planning metho ds. Both GowU and MCTS build search trees using simulator access, but they differ substantially in purp ose and mec hanism. MCTS is primarily a planning algorithm: it incremen tally expands a search tree for action selection, typically at inference time, by aggregating rollout statistics ov er no des ( Kocsis and Szep esvári , 2006 ; Coulom , 2006 ). In contrast, GowU is a training-time, p opulation-based exploration algorithm inspired by the 1 Latent Go-Explore ( Gallouédec and Dellandréa , 2023 ) addresses the first issue b y replacing manual discretization with a learned latent represen tation. How ever, learning such a represen tation itself requires sufficiently rich exploration data, creating a potential chic ken-and-egg issue. Moreov er, the metho d is ev aluated only in terms of exploration p erformance, where it slightly improv es ov er Go-Explore on Montezuma’s Revenge and Pitfal l! . It remains unclear whether this cell-free v ariant also supports the subsequent policy-learning stage needed to obtain a deploy able p olicy . 3 Go-With-The-Winner principle ( Aldous and V azirani , 1994 ). A p opulation of particles evolv es concurrently through the state space, with explicit cloning, pruning, and winner-selection op erations that ha ve no direct analogue in standard MCTS. The relationship b etw een MCTS and GowU is analogous to the relationship b et ween classical graph searc h algorithms and evolutionary or particle-based search—both explore a tree, but the searc h strategy is fundamentally different. The tw o metho ds also differ in how search is guided and in the kinds of action spaces they most naturally accommo date. Standard MCTS is usually guided b y v alue estimates or visit counts, whereas GowU uses epistemic uncertaint y as a primary signal for redistributing exploration effort. Recent work on Epistemic MCTS augments MCTS with epistemic uncertaint y for deep er exploration ( Oren et al. , 2022 ), but remains a non-particle-based search metho d. In addition, standard MCTS most naturally fits dis crete action spaces, while contin uous-action v arian ts typically require extra machinery such as progress iv e widening ( Couëtoux et al. , 2011 ). Go wU do es not en umerate actions at tree no des in this wa y: particles can execute rollouts using arbitrary p olicies, which allows the framework to accommo date contin uous actions more directly . Ev olutionary and population-based methods. A broader alternative paradigm driv es exploration through ev olutionary and p opulation-based search. F oundational approaches such as Nov elty Search, MAP- Elites, and the quality-div ersity literature maintain diverse sets of candidate solutions and reward b eha vioral no velt y or cov erage ( Lehman and Stanley , 2011 ; Mouret and Clune , 2015 ; Pugh et al. , 2016 ). More recent h ybrids combine such diversit y mechanisms with deep RL and p olicy-gradien t up dates ( Conti et al. , 2018 ; P arker-Holder et al. , 2020 ; W ang et al. , 2025 ). A key distinction is that these metho ds t ypically search in the parameter space of a controller or p olicy , generating b ehavioral diversit y by p erturbing mo del parameters. In contrast, our metho d searches directly in s tate space: it reallo cates particles b y resetting them to states o ccupied by existing particles, selected based on reward progress and epistemic uncertaint y . 3 Preliminaries W e consider the problem of exploration in a stochastic episo dic Marko v Decision Pro cess (MDP) defined b y the tuple M = ( X , A , 𝑃 , 𝑅 ) . Here, X and A are potentially high-dimensional state and action spaces, resp ectiv ely; 𝑃 : X × A → Δ ( X ) the transition dynamics, and 𝑅 : X × A → R a deterministic reward function. Surviv al and failure. Episo dic MDPs define termination conditions that mark the end of a tra jectory . F or instance, in games like Atari, an episo de typically ends after al l lives are lost. Our framework allows for distinguishing b etw een this standard termination and a stricter notion of failur e w e use for early episo de truncation. In the A tari context, for example, w e may treat the loss of a single life as a failure even t; similarly , in contin uous control, a state from whic h further progress is imp ossible (e.g., a quadrup ed flipping upside do wn in the AntMaze environmen t) can b e treated as a failure, even if the environmen t do es not formally terminate the episo de. W e demonstrate that using this flexibility can significantly improv e exploration efficiency . T o formalize this, we partition the state space into tw o disjoint sets: viable states, denoted Alive , and failure states, denoted Dead . A particle is considered “aliv e” if 𝑠 𝑡 ∈ Alive . W e further define the set of Doom states, X Doom ⊂ Alive , as the set of viable states from which entry into Dead is inevitable, regardless of the p olicy . Ideally , an exploration algorithm should b e able to backtrac k from these dead-end states to preserve the p otential for future rewards. Our approach is designed for settings where progress—accumulating rew ards or task comp letion—remains feasible from any non- Doom viable state. The goal of the exploration phase is to find tra jectories with high cumulativ e rewards. W e use an uncertaint y- guided tree-searc h based on the GWTW principle ( Aldous and V azirani , 1994 ) to find suc h tra jectories. Go-With-The-Winner. Originally prop osed for randomized search and sampling, GWTW is esp ecially effectiv e at finding deep no des in im balanced trees—a task where naive approaches lik e Depth-First or Breadth-First search can be computationally inefficien t (see App endix A for a concrete example). The algorithm op erates by maintaining a p opulation of 𝑁 particles starting at the ro ot. A t eac h step, every particle adv ances one lev el by following a random edge. Crucially , particles that reach a leaf are pruned and replaced b y clones of particles that reached non-leaf nodes, designated as “winners.” Theoretical guarantees 4 for reac hing a target depth in GWTW worsen gracefully with a measure of tree imbalance ( Aldous and V azirani , 1994 ). Our approach builds on this principle by viewing exploration in an MDP as a search for “deep” no des, where depth is characterized by high cum ulative reward and epistemic uncertaint y . T o adapt GWTW for exploration, we map “leav es” to Dead states and redefine “winners” as states combining high accum ulated reward and epistemic uncertaint y . Uncertain ty oracle. Epistemic uncertaint y represents the lack of knowledge resulting from limited data, as distinct from the inherent sto chasticit y of the environmen t ( Osband et al. , 2018 ; Kendall and Gal , 2017 ; Burda et al. , 2018 ). In the context of exploration, this reflects the scarcity of observ ations for sp ecific states or transitions. Our framework assumes access to an uncertaint y estimator, 𝑈 , which provides a measure of this uncertain ty for a given state. W e rely on this estimator to up date online: as states are visited, the asso ciated uncertain ty should decrease. Our framework is agnostic to the sp ecific implemen tation of 𝑈 (though in our exp erimen ts, we op erationalize 𝑈 using RND prediction error as a proxy). Reset oracle. T o enable cloning and redistribute computational effort (like GWTW ), we require ov erwriting one particle’s state with another’s. W e formalize this through a reset primitive, Reset ( 𝑝 target , 𝑝 source ) , which sets the internal state of 𝑝 target to match 𝑝 source . This allows 𝑝 target to resume tra jectory generation from the state of 𝑝 source . This oracle is a training-time primitive for data collection only; it is not required for the final p olicy’s execution or ev aluation. P article p olicies. Our framework is agnostic to the mechanism each particle uses to select actions. While our approach co ordinates the redistribution of computational effort across the population, it does not dictate ho w individual particles choose their mov es, ensuring the framework remains general. In our experiments, we emplo y reward-free diversit y p olicies based on b o otstrapp ed zero-target netw orks, as describ ed in Section 5 . Bac kward algorithm. The tra jectories disco vered during exploration can b e used in a second phase to learn high-scoring p olicies. Although these tra jectories may contain redundancies or sub optimal lo ops, they serv e as self-generated demonstrations for sup ervised bac kward learning algorithms ( Salimans and Chen , 2018 ; Ecoffet et al. , 2019 ). This class of algorithms b egins training near the end of a demonstration and progressiv ely mov es the starting state back along the demonstration as the agent masters each suffix segment. This creates a natural curriculum that significan tly simplifies the reinforcement learning problem. In our exp erimen ts, we use this framework to obtain high-scoring p olicies across all ev aluated environmen ts. Notation. W e define the lexicographic order ≻ lex o ver tuples such that ( 𝑏 , 𝑐 ) ≻ lex ( 𝑏 ′ , 𝑐 ′ ) if and only if 𝑏 > 𝑏 ′ or ( 𝑏 = 𝑏 ′ and 𝑐 > 𝑐 ′ ). Accordingly , for any tw o functions 𝑓 and 𝑔 , w e use the notation lex-argmax 𝑢 ( 𝑓 ( 𝑢 ) , 𝑔 ( 𝑢 ) ) to denote the argument 𝑢 that maximizes the vector ob jective with resp ect to ≻ lex . This op erator prioritizes maximizing the first comp onent 𝑓 ( 𝑢 ) , using the second comp onent 𝑔 ( 𝑢 ) strictly as a tie-breaker. 4 Metho d: Uncertaint y-Guided Exploration Building on the primitives in Section 3 , w e prop ose Go-With-Uncer t ainty ( GowU ), a tree-search metho d decoupling exploration from p olicy optimization. Our approac h adapts the GWTW principle by maintaining a p opulation of particles that explore the state space in parallel. At fixed interv als, the algorithm identifies “winners”—those in states with high cumulativ e reward and epistemic uncertaint y . Using the reset oracle, it redistributes computational effort by cloning winners and removing dead particles. W e first describ e the state-lineage tree, whic h tracks particle history and enables p opulation management. W e then detail particle evolution and the winner selection scoring function, referencing the pseudo-algorithms Algorithms 1 and 2 along the wa y . 4.1 The State Lineage T ree T o manage p opulations, GowU maintains a global state-line age tr e e . Eac h no de in this tree represents a v alid, chec kp oin ted state of the environmen t. F ormally , a tree no de 𝑣 is a tuple ( 𝑠 𝑣 , 𝑅 𝑣 , 𝑢 𝑣 ) , where 𝑠 𝑣 is the compact state representation (e.g., simulator snapshot); 𝑅 𝑣 is the cumulativ e extrinsic reward achiev ed by the agen t up to state 𝑠 𝑣 ; and 𝑢 𝑣 is a p oin ter to the p arent no de. 5 Roo t p 1 p 2 p 3 p 1 p 2 p 3 p 1 p 2 p 3 ALIVE S ta t e DEAD S ta t e Max Unc er tain ty S ta t e F ailur e Rese t G r oup Consolida tion Rese t p 1 p 2 p 3 Max Rewar d S ta t e Figure 1: Sc hematic ov erview of GowU with a single group of particles. The algorithm maintains a p opulation of particles ( 𝑝 1 , 𝑝 2 , 𝑝 3 ) that explore the state space via multi-step rollouts. During an outer step, if a particle reac hes a dead state (e.g., 𝑝 2 on level one), it is pruned and its state is reset via a R eset to the winner—the alive no de maximizing accumulated reward, with epistemic uncertain ty used as a tie-breaker. After 𝐾 outer steps, a Gr oup Consolidation R eset syncs all particles, including alive particles, to the current winner. This structure allo ws the algorithm to track the history of every particle. T o manage memory , no des are pruned when they are no longer o ccupied by an active particle or referenced by any descendant. This ensures that the storage requirements scale with the set of active lineages rather than the cumulativ e history of the searc h. 4.2 P article Ev olution W e now describ e the search pro cedure, which implements our adaptation of GWTW to drive exploration using a group of 𝑁 particles (e.g., 𝑁 = 32 for some of our exp erimen ts). The search pro ceeds in discrete iterations. Algorithm 1 details the execution of a single iteration, whic h consists of a sequence of 𝐾 outer steps , follow ed by a sync hronization phase, where 𝐾 is sampled uniformly from [ 𝐾 min , 𝐾 max ] at the start of eac h iteration. Ev olutionary rollout. During an outer step, ev ery alive particle interacts with its own instance of the en vironment for a random n umber of simulation steps ( inner steps ) sampled indep endently for each particle from the range [ 𝑇 min , 𝑇 max ] (see Algorithm 1, Line 4 ). During these steps, the uncertain ty estimator 𝑈 ma y up date based on newly collected observ ations (recall from Section 3 that our framework is agnostic to the sp ecific choice of lo cal p olicy). If a particle receives a p ositive reward, the rollout is terminated immediately ( Algorithm 1, Line 8 ); this secures the reward for the subsequen t winner selection, as further steps may lead to a dead state. If a particle completes the rollout without entering a dead state, the algorithm creates a new c hild no de in the lineage tree ( Algorithm 1, Line 11 ). The rollout length range controls a key trade-off: o verly short rollouts limit state diversit y , while ov erly long ones increase the frequency of dead states. (In our exp erimen ts, 𝑇 min and 𝑇 max are set b et ween 3 and 20 .) 6 F ailure reco v ery via rollbac k. If the entire p opulation enters a Dead state during a rollout, the algorithm p erforms a collective rollba ck . Every particle trav erses the lineage tree via parent pointers 𝑢 𝑣 to a randomly selected ancestor b etw een 𝑘 min and 𝑘 max generations prior ( Algorithm 1, Line 17 ). This restores the particles to v alid anteceden t states, allo wing exploration of alternative tra jectories around obstacles. A sufficiently large 𝑘 max allo ws particles to escap e do om states (e.g., irreversible falls), while a low 𝑘 min main tains proximit y to difficult obstacles, enabling alternative tra jectory attempts ( 𝑘 min , 𝑘 max ∈ [ 1 , 20 ] in our exp eriments). Winner selection and particle redistribution. When at least one particle survives the inner steps rollout, the algorithm redistributes computational effort by identifying “winners.” 1. Winner sele ction: The algorithm identifies the alive particles with the maximum accumulated reward. Among these, it selects the particle with the highest epistemic uncertaint y 𝑈 ( 𝑠 ) ( Algorithm 1, Line 20 ). This prioritizes high-v alue, under-explored states; in environmen ts with sparse rewards (like the ones in our exp erimen ts), uncertaint y is often the primary criterion for selection. 2. Pruning: All dead particles are immediately reset to the winner’s state ( Algorithm 1, Line 23 ). This prunes failed branches and redirects those resources to the current frontier. Non-winner alive particles con tinue indep endent tra jectories to maintain lo cal diversit y . Group consolidation. A t the conclusion of the 𝐾 outer steps , the algorithm p erforms an additional sync hronization to consolidate progress. W e identify a single p opulation winner based on accumulated reward and uncertaint y as described in Item 1 . Unlik e the mid-iteration particle redistribution (i.e., after the inner steps ) where only dead particles are redistributed, this phase resets the entire p opulation to the state of this single winner ( Algorithm 1, Line 30 ). This collapses the group to the most promising node found during the iteration, ensuring subsequent search b egins from the frontier of discov ered states. 4.3 P arallel Groups and Population Sync hronization T o div ersify the search and accelerate disco very , Go wU runs 𝑀 groups in parallel; see Algorithm 2 (e.g., 𝑀 = 4 for our atari exp eriments). While these groups ma y execute rollouts indep enden tly , our framew ork allo ws the groups to share a centralized uncertaint y estimator. This enables implicit co ordination: up dates from one group discourage others from revisiting the same states, pushing the collective p opulation to ward globally nov el regions. T o further prev ent groups from stagnating in explored regions, the algorithm emplo ys a global synchronization mechanism at the start of eac h iteration. W e identify a single “global winner” across all 𝑀 groups based on the rew ard-uncertaint y criterion in Item 1 ( Algorithm 2, Line 16 ). The algorithm then compares each group’s maximum reward to the global winner’s. If a group’s b est reward is strictly low er, all its particles are reset to the global winner ( Algorithm 2, Line 10 ). If equal, the group con tinues its search indep enden tly . This mechanism balances diversit y with efficiency: it allows comp etitiv e groups to explore unique tra jectories while propagating breakthrough discov eries across the entire p opulation. 5 Go wU Implemen tation Details This section describ es our implementation of the framework presented in Section 4 . W e use a distributed arc hitecture to enable scalable exploration ( Section 5.1 ), then describ e the uncertaint y estimator used to guide particle synchronization ( Section 5.2 ) and the reward-free particle p olicies that driv e lo cal action selec tion ( Section 5.3 ). 5.1 Distributed Arc hitecture T o scale GowU to high-dimensional en vironments, we employ a distributed co ordinator-work er architecture that decouples environmen t simulation, p opulation management, and parameter optimization. The system consists of three comp onents: • Centr al c o or dinator. Manages the global population state, including the 𝑀 groups of 𝑁 particles eac h (see Section 4 ), the ir environmen t chec kp oints, cumulativ e rewards, and surviv al status. It also maintains the state-lineage tree ( Section 4.1 ). The co ordinator drives the GowU lo op: it dispatches rollout requests to 7 Algorithm 1 Evol veGr oup input: P opulation 𝑃 = { 𝑝 1 , . . . , 𝑝 𝑁 } , lineage tree T , uncertaint y 𝑈 params: outer steps , inner steps , and rollba ck ranges: [ 𝐾 min , 𝐾 max ] , [ 𝑇 min , 𝑇 max ] , [ 𝑘 min , 𝑘 max ] 1: Sample outer steps 𝐾 ∼ Unif ( 𝐾 min , 𝐾 max ) 2: for 𝑘 = 1 , . . . , 𝐾 do 3: for eac h particle 𝑝 𝑖 ∈ 𝑃 do 4: Sample inner steps 𝑇 𝑖 ∼ Unif ( 𝑇 min , 𝑇 max ) 5: /* Rollout particle and update uncertainty */ 6: for 𝑡 = 1 , . . . , 𝑇 𝑖 do 7: 𝑈 ← 𝑝 𝑖 . Step ( 1 , 𝑈 ) // Execute one step 8: if 𝑝 𝑖 is dead or 𝑝 𝑖 . 𝑅 increased then break // Halting on reward does not kill the particle 9: end for 10: if 𝑝 𝑖 is alive then 11: T . AddChild ( 𝑝 𝑖 ) // Expand tree for surviving particles 12: end if 13: end for 14: if All 𝑝 𝑖 ∈ 𝑃 are Dead then 15: /* Failure recovery via rollback */ 16: 𝑣 𝑖 , anc ← 𝑝 𝑖 . GetAncestor ( 𝑘 min , 𝑘 max ) , ∀ 𝑖 // Pick 𝑘 𝑖 th ancestor of 𝑝 𝑖 with 𝑘 𝑖 ∼ Unif ( 𝑘 min , 𝑘 max ) , ∀ 𝑖 17: 𝑃 ← { Reset ( 𝑝 𝑖 , 𝑣 𝑖 , anc ) | ∀ 𝑖 } // Restore all particles to ancestor checkpoints 18: else 19: /* Uncertainty-aware redistribution */ 20: 𝑝 winner ← lex-argmax 𝑝 ∈ 𝑃 , 𝑝 . alive ( 𝑝 . 𝑅 , 𝑈 ( 𝑝 ) ) // Best alive: max reward, break ties by uncertainty 21: for eac h 𝑝 𝑖 ∈ 𝑃 do 22: if 𝑝 𝑖 is Dead then 23: Reset ( 𝑝 𝑖 , 𝑝 winner ) // Prune & respawn; 𝑝 𝑖 becomes alive after the reset 24: end if 25: end for 26: end if 27: end for 28: /* Group consolidation (lexicographic ranking) */ 29: 𝑝 winner ← lex-argmax 𝑝 ∈ 𝑃 ( 𝑝 . 𝑅 , 𝑈 ( 𝑝 ) ) 30: 𝑃 ← { Reset ( 𝑝 𝑗 , 𝑝 winner ) | ∀ 𝑗 } // Reset all particles to winner’s checkpoint 31: return 𝑃 , T , 𝑈 , 𝑝 winner the w orker p o ol, aggregates results, queries the uncertaint y estimator 𝑈 ( Section 5.2 ) to score states, and executes the winner-selection, pruning, and group-sync hronization logic describ ed in Sections 4.2 and 4.3 . • Distribute d r ol lout workers. Stateless execution no des that receiv e an environmen t chec kp oint and p olicy parameters—indexed by group and ensemble member—from the co ordinator. Each work er restores the sim ulator state, executes a rollout b y sampling actions from the designated p olicy , and returns the resulting tra jectory and endp oint chec kp oin t for tree expansion. • Asynchr onous le arning no des. Dedicated pro cesses that contin uously consume transitions from the replay buffers and up date mo del parameters (uncertaint y estimator and particle p olicies) via gradient descen t, broadcasting up dated weigh ts for subsequent rollouts. This architecture enables high-throughput exploration with minimal idle time. F urther implementation details are provided in App endix F , and wall-clock runtime and computational resource requirements are rep orted in Section F.4 . Repla y buffers. Eac h group maintains a replay buffer of capacity 128 , 000 that stores transitions. Eac h en try has the form ( 𝑠 , 𝑎 , 𝑚 ) , where 𝑠 is the observ ation, 𝑎 the action, and 𝑚 ∈ { 0 , 1 } a b o otstrap mask drawn indep enden tly at collection time. W orkers stream transitions into these buffers, from whic h the asynchronous learning no des sample mini-batches contin uously . 8 Algorithm 2 GowU : Go-With-Uncer t ainty input: En v. E , iterations 𝑁 iter , n umber of groups 𝑀 , and num b er of particles p er group 𝑁 1: Initialize lineage tree T with ro ot no de 𝑠 0 (initial state) 2: Initialize groups { 𝐺 1 , . . . , 𝐺 𝑀 } , each with 𝑁 particles, all starting at 𝑠 0 3: Initialize shared uncertaint y estimator 𝑈 4: Initialize 𝑝 winner at state 𝑠 0 with cum ulative reward 0 5: for 𝑖 = 1 , . . . , 𝑁 iter do 6: for eac h Group 𝐺 𝑚 in parallel do 7: /* Global synchronization */ 8: 𝑝 𝑚 ← lex-argmax 𝑝 ∈ 𝐺 𝑚 ( 𝑝 . 𝑅 , 𝑈 ( 𝑝 ) ) 9: if 𝑝 𝑚 . 𝑅 < 𝑝 winner . 𝑅 then 10: Reset 𝐺 𝑚 to the state of 𝑝 winner // Restore all particles to global winner’s checkpoint 11: end if 12: /* Evolve group */ 13: 𝐺 𝑚 , T , 𝑈 , 𝑝 𝑚 ← Ev ol veGr oup ( 𝐺 𝑚 , T , 𝑈 ) // Algorithm 1 14: end for 15: /* Update global winner */ 16: 𝑝 winner ← lex-argmax 𝑝 ∈ { 𝑝 1 , . .. , 𝑝 𝑀 , 𝑝 winner } ( 𝑝 . 𝑅 , 𝑈 ( 𝑝 ) ) 17: end for Lineage tree. Recall from Section 4.1 that GowU relies on a state lineage tree for p opulation managemen t. W e implement this using a TreeNode class that stores the en vironment chec kp oin t, cumulativ e reward, and a parent p ointer. T o extract a demonstration path for Phase I I, we select the highest-reward leaf and trav erse the paren t p ointers upw ard, collecting the environmen t chec kp oin t and cumulativ e rew ard at each no de. 5.2 Uncertain t y Estimation Using RND The Go wU algorithm relies on an uncertaint y score 𝑈 ( 𝑠 ) to rank particles and sel ect winners ( Section 4.2 ). T o instan tiate this estimator, we use standard RND ( Burda et al. , 2018 ), whose predictor is trained async hronously by a dedicated learning no de ( Section 5.1 ). At a high level, RND quantifies no velt y via the prediction error of a trained netw ork against a fixed, random target. W e choose RND for its scalability and efficiency compared to other metho ds that appro ximate epistemic uncertaint y suc h as ensemble metho ds ( Osband et al. , 2016 ; Lakshminaray anan et al. , 2017 ). F ormally , the mo dule consists of a fixed tar get network and a trainable pr e dictor network . Both use standard Atari conv olutional torsos ( Mnih et al. , 2015 ) follo wed b y MLP heads consisting of t wo 1024-unit linear lay ers separated by a ReLU activ ation. W e use orthogonal initialization for the torso weigh ts and normalize inputs (running mean/std) clipp ed to [ − 5 , 5 ] , consistent with standard RND implementations ( Burda et al. , 2018 ). The predictor is trained to minimize the Mean Squared Error (MSE) against the target embedding. As describ ed in Section 5.1 , the predictor is trained asynchronously by a dedicated learning node that con tinuously samples mini-batches from the replay buffers of all 𝑀 groups, ensuring that the uncertain ty estimate reflects collectively disco vered states. W e use a batc h size of 128 and train using Adam with a learning rate of 3 × 10 − 4 . 5.3 P article Beha vior and A ction Selection The final comp onent of GowU is the lo cal p olicy that each particle uses to select actions during rollouts. Recall from Section 4 that our exploration framework is agnostic to particle behavior. Consequently , one could simply use random l ocal p olicies, mirroring the random edge selection of the original GWTW algorithm or the random action strategy of Go-Explore . Ho wev er, uniform random action selection is w ell known to pro duce jittery , oscillatory b ehavior, causing particles to frequently revisit nearby states instead of making sustained progress through the state space. T o mitigate this, we equip each particle with a simple learned p olicy that yields temp orally consistent lo cal b ehavior and promotes b ehavioral diversit y across particles, all 9 without using any environmen t reward signal. The sp ecific p olicy architecture differs b et ween discrete and con tinuous action spaces, as detailed b elow; see App endix E for the full training ob jectives. A tari (Discrete Actions). Each particle within a group maintains its own netw ork 𝑓 𝜓 that maps state-action pairs ( 𝑠 , 𝑎 ) to scalar predictions. The environmen t reward is discarded entirely; it plays no role in training these netw orks. Instead, eac h netw ork is trained by minimizing the mean squared error (MSE) against a constan t zero target, using only a random subset of the group’s experience determined b y a binary bo otstrap mask (see App endix E for the training loss). This mechanism is conceptually related to Bo otDQN ( Osband et al. , 2016 ), except that the targets carry no reward information. Because each net work trains on a differen t mask ed subset of data, they develop different prediction landscap es, and the arg max actions differ across particles, yielding diverse tra jectories. Given a state 𝑠 , eac h particle selects 𝑎 = arg max 𝑎 ∈ A 𝑓 𝜓 ( 𝑠 , 𝑎 ) (ties brok en uniformly at random) with probability 1 − 𝜀 , and a uniform random action with probability 𝜀 = 0 . 2 . Remark 5.1. Be c ause the ensemble value functions ar e tr aine d with identic al ly zer o tar gets, they quickly c onver ge towar d zer o. However, this do es not r e duc e the ensemble to pur ely r andom action sele ction: in pr actic e, exact numeric al ties acr oss actions ar e r ar e b e c ause the differ ent maske d tr aining subsets induc e smal l but p ersistent differ enc es in the pr e dicte d values. As a r esult, the arg max stil l pr o duc es a deterministic, temp or al ly c onsistent action for e ach state r ather than sampling uniformly. MuJoCo (Con tinuous Actions). F or contin uous action spaces, each particle main tains a Soft Actor- Critic (SA C) mo dule with a double critic and entrop y-regularized p olicy . As in the discrete case, the en vironment reward is discarded: the critics are trained tow ard zero targets, and diversit y across particles arises from b o otstrap masking com bined with entrop y regularization. During rollouts, actions are sampled from the learned (sto chastic) p olicy , pro viding inherent exploration noise without requiring explicit 𝜀 -greedy randomization. T o ensure temp orally consistent b ehavior within eac h rollout segment, we fix the random seed for action sampling at the start of each inner steps block; this prev ents the stochastic p olicy from pro ducing jittery , incoherent tra jectories. See App endix E for the complete training ob jectives. As with the uncertain ty estimator, particle p olicies are trained asynchronously by dedicated learning no des ( Section 5.1 ). Unlike RND , ho wev er, eac h group’s ensemble trains on group-sp ecific data only , preserving b eha vioral diversit y across groups. W e use the Muon optimizer with learning rate 10 − 4 and batch size 𝑛 = 128 . Remark 5.2. Although our exp eriments employ these le arne d ensemble p olicies, the ablation study in Se ction 6.3 demonstr ates (for the discr ete-action setting) that a simpler alternative—sampling a single r andom action p er p article and holding it fixe d for the dur ation of the inner steps —p erforms on p ar with the le arne d ensemble. This c onfirms that the ensemble p article p olicies ar e not essential: the explor ation p ower of Go wU lies in the p opulation management me chanisms (winner sele ction, pruning, and r ol lb ack), not in the individual p article p olicies. W e exp e ct that simpler heuristics for p article p olicies c ould also work in c ontinuous domains; we adopt the ensemble SAC appr o ach her e primarily to maintain a mor al ly similar structur e to the discr ete setting. 6 Exp erimen ts W e ev aluate GowU on tw o families of hard-exploration b enchmarks spanning b oth discrete and contin uous action spaces: Atari games ( Montezuma’s R evenge , Pitfal l! , and V entur e ) and MuJoCo contin uous-control tasks (An tMaze and Adroit dexterous manipulation). Our exp eriments are designed to answer the following researc h questions: • R Q1 (Explor ation efficiency): Can GowU efficiently discov er high-reward and task-completing tra jectories across b oth discrete and contin uous domains? • R Q2 (Quality of explor atory data): Can the discov ered tra jectories b e distilled into deploy able p olicies that ac hieve high scores (Atari) or high success rates (MuJoCo)? 10 (a) Montezuma’s Revenge (b) Pitfal l! (c) V entur e Figure 2: F ully rendered observ ations from the three hard-exploration Atari games used in our ev aluation. (a) door-v0 (b) hammer-v0 (c) relocate-v0 (d) An tMaze Figure 3: MuJoCo contin uous-control tasks used in our ev aluation. (a–c) A droit dexterous manipulation tasks using the 24-DoF ShadowHand. (d) AntMaze navigation task (top-down view). 6.1 Exp erimen tal Setup A tari en vironments. W e ev aluate on Montezuma’s R evenge , Pitfal l! , and V entur e —three of the most c hallenging exploration benchmarks in the Arcade Learning Environmen t (ALE) Bellemare et al. ( 2013 ); Mac hado et al. ( 2018 ). Montezuma’s R evenge requires long-horizon planning across multiple ro oms, while Pitfal l! presen ts a distinct challenge due to its v ery sparse rewards and visually similar ro oms. Notably , Pitfal l! remains largely unsolved without human demonstrations or domain knowledge ( Ecoffet et al. , 2021 ) when using sticky actions. V entur e requires the agent to enter ro oms, collect treasure, and escap e b efore a pursuing enemy catches up; any delay in locating or reac hing the treasure allows the enem y to close the gap, making the task a test of not just exploration but fast exploration under time pressure. MuJoCo en vironments. T o ev aluate GowU on contin uous action spaces, we consider tw o families of tasks that require d eep exploration from visual observ ations: • AntMaze ( antmaze-large-diverse-v0 ): A quadruped ant must navigate a large maze to reac h a goal p osition. The en vironment provides only a sparse terminal reward up on reaching the goal (the default setting), requiring sustained exploration through extended corridors and dead ends. • A dr oit ( door-v0 , hammer-v0 , relocate-v0 ): Dexterous manipulation tasks using the 24-degree-of-freedom Shado wHand ( Ra jesw aran et al. , 2017 ). door-v0 requires op ening a do or by its handle, hammer-v0 requires pic king up a hammer and driving a nail, and relocate-v0 requires grasping a ball and mo ving it to a target lo cation. The high dimensionality of the action space and the precision required for manipulation mak e these tasks extremely c hallenging. W e enable the sparse_reward flag, which replaces the default dense rew ard shaping with a single task-completion reward. Although the MuJoCo dynamics are deterministic, task configurations are randomized across seeds, prev enting the p olicy from memorizing a fixed action sequence. F or AntMaze, the target location is sligh tly randomized around the top-right corner of the maze. F or door-v0 , the p osition of the do or and handle are p erturb ed across episo des; similarly , the nail p osition v aries in hammer-v0 . F or relocate-v0 , the randomization is more substan tial: b oth the ball and target locations change significantly b etw een seeds. W e aim to solve all MuJoCo tasks fr om images : the final distilled p olicy receives only visual observ ations, not privileged state information. 11 F rame − 3 F rame − 2 F rame − 1 F rame 0 F rame top door hammer relocate antmaze Figure 4: Pro cessed visual observ ations as seen by the agen t for each MuJoCo task. Eac h column shows a frame in the observ ation stack, from the oldest (F rame − 3 ) to the most recent (F rame 0 ). F or AntMaze, the “F rame top” column sho ws the global top-down view of the maze; during Phase I (exploration), only this top-do wn view is used. See Section 6.1 for an ov erview and App endix C for full details on the observ ation pro cessing pip eline. Observ ation pro cessing. All environmen ts pro duce grayscale, frame-stack ed visual observ ations. F or Atari, w e follo w the standard pip eline ( Mnih et al. , 2015 ): frames are temporally max-p o oled ov er the last 2 of ev ery 4 rep eated frames, conv erted to gra yscale, and resized to 84 × 84 pixels. The final observ ation stacks the 4 most recen t pro cessed frames, yielding a tensor of shape 84 × 84 × 4 . F or V entur e , we additionally apply 2 × 2 spatial max-p o oling b efore resizing to preserve small game sprites that would otherwise v anish under bilinear in terp olation. F or Phase I I (backw ard learning) on Montezuma’s R evenge , a fifth frame is app ended corresponding to the most recent reward observ ation—i.e., the frame at which the agent last receiv ed a reward (see App endix G for details). F or the Adroit tasks, w e render directly at 120 × 120 pixels via a hardware-accelerated MuJoCo camera with a task-specific fixed viewpoint (detailed in Appendix C ), con vert to grayscale, and stack 4 frames ( 120 × 120 × 4 ). F or AntMaze, we render tw o complementary views at 120 × 120 : a global top-down map of the full maze (with a goal mark er injected in to the scene) and a third-p erson ego centric view tracking the agent. During Phase I (exploration), only the global view is used ( 120 × 120 × 1 ); during Phase I I (p olicy distillation), the global frame is stack ed with 4 historical ego centric frames ( 120 × 120 × 5 ). All pixel v alues are normalized to [ 0 , 1 ] . F ull pip eline details (camera p oses, resampling metho ds, rendering configuration) are provided in App endix C . A dditional environmen t settings. F or the A tari environmen ts, we run both the exploration phase ( Go wU ) and the p olicy distillation phase using sticky actions : the previous action rep eats with probability 0 . 25 , in tro ducing aleatoric uncertain ty . W e use the standard action rep eat of 4, where the selected action is applied 4 times; thus, each environmen t step consumes four game frames ( Machado et al. , 2018 ). F or AntMaze, we similarly apply an action rep eat of 4 ov er the physics steps. Adroit tasks use no action rep eat owing to the precision required for dexterous manipulation. Unlike Montezuma’s R evenge and V entur e , Pitfal l! includes a t wen ty-min ute termination timer; w e disable this timer to allo w for non-episo dic exploration with GowU (see App endix B ), but final p olicies are ev aluated with the standard timer activ e. 12 Exploration signals (Phase I). During the exploration phase (Phase I), GowU leverages easily accessible signals to iden tify dead states, guiding particle redistribution across all environmen ts. • Atari: F or all three games, a loss of life—detected via a discoun t factor of zero—triggers a dead state designation. A dditionally , in Pitfal l! , an y negativ e rew ard (e.g., from touc hing a rolling barrel) also constitutes a dead state, as it signals an unreco verable p enalty . F or Montezuma’s R evenge , we also detect and prev ent exploitation of a newly discov ered en vironment bug in the middle ro om (see App endix H ). • A ntMaze: Flipping o ver constitutes a loss of life (i.e., the particle is marked as dead ), since the ant b ecomes irreco verably stuck. See App endix D for details on how this condition is extracted. • A dr oit: F or each task, we additionally define a single in termediate reward based on contact with the target surface. A reward of + 1 is assigned when the hand first makes contact with the relev ant ob ject—the do or handle ( door-v0 ), the hammer ( hammer-v0 ), or the ball ( relocate-v0 ). If contact with the target surface is subsequen tly lost, this constitutes a loss of life and the particle is marked as dead . W e emphasize that these signals are straightforw ardly extracted from readily av ailable state information and are far from the heavy reward shaping t ypically required b y standard RL algorithms. Nevertheless, they in teract with Go wU in a non-trivial wa y . P ositive even ts serve as milestones that mark progress to ward the goal, while dead state even ts signal a critical setback. P olicy distillation (Phase II). F ollo wing the exploration phase, we distill the discov ered tra jectories in to deploy able p olicies using only the original environmen t rewards (the additional exploration signals from Phase I are not used). F or each GowU run, w e extract the highest-rew ard tra jectory from the lineage tree ( Section 5.1 ) and use it as a demonstration for a backw ard learning curriculum ( Salimans and Chen , 2018 ). The agent is initialized near the end of the demonstration and trained using PPO ( Sch ulman et al. , 2017 ) to maximize cumulativ e reward from that p oint forward; as it masters the task, the initialization is progressiv ely mov ed backw ard to ward the start of the episo de. F or Atari, we decomp ose each demonstration in to 10 segments delineated by rew ard even ts, training on all segments simultaneously; this decomp osition breaks the long-horizon problem into manageable sub-tasks. F or MuJoCo, no segmentation is applied and the goal lo cation is held fixed to the one used during exploration while the curriculum progresses backw ard along a given demonstration. Once the curriculum reaches the initial state, the goal (i.e., the randomized target lo cation and ob ject placemen t describ ed ab ov e) is allow ed to v ary across episo des, training the p olicy to generalize; using 10 demonstrations p er Phase I I run, eac h corresp onding to a different goal configuration, pro vides initial diversit y across goals. Throughout training, a background ev aluator p erio dically fetches the latest p olicy weigh ts and tracks the b est-performing chec kp oint. After training is complete, this c heckpoint is ev aluated on 500 rollouts to pro duce the final p olicy score. See App endix G for additional details on the curriculum strategy , environmen t-sp ecific configurations, and ev aluation pro cedures. Resets. Both Phase I and Phase I I rely on environmen t resets to restore particles or training episo des to previously visited states. Reconstructing the environmen t mid-tra jectory requires chec kp oin ting b oth the sim ulator’s physical state and the agent’s observ ation history (e.g., frame stacks). The mechanism differs across en vironment families: • A tari: W e extract and restore the in ternal ALE emulator state along with the frame stac ker’s observ ation history , following the implementation of Yin et al. ( 2023 , Page 21). • A droit: W e chec kp oin t the MuJoCo ph ysics state (joint p ositions and v elo cities), the random seed (which determines the randomized ob ject and target p ositions), and task-sp ecific state v ariables (e.g., whether con tact with the target surface has b een established). • An tMaze: In addition to the MuJoCo physics state, we sav e the random seed (which determines the randomized goal co ordinates) and the pixel observ ation stack from the third-p erson camera renders. In all cases, the frame stack is replaced with the one sav ed at chec kp oint time. Hyp erparameters. T able 1 summarizes the main p opulation management hyperparameters introduced in Section 4 . Baselines. F or Atari, we compare against Go-Explore (no domain knowledge) ( Ecoffet et al. , 2021 ), which 13 T able 1: Population management hyperparameters for Go wU . The MuJoCo column applies to all con tinuous- con trol tasks (AntMaze and Adroit). P arameter Montezuma Pitf all Venture MuJoCo Gr oups ( 𝑀 ) 4 4 4 16 P ar ticles per group ( 𝑁 ) 32 32 32 8 outer steps range ( [ 𝐾 min , 𝐾 max ] ) [ 10 , 20 ] [ 10 , 20 ] [ 6 , 16 ] [ 20 , 40 ] inner steps range ( [ 𝑇 min , 𝑇 max ] ) [ 5 , 15 ] [ 10 , 20 ] [ 10 , 20 ] [ 3 , 4 ] r ollback range [ 𝑘 min , 𝑘 max ] [1, 3] [1, 4] [1, 12] [1,20] represen ts the current state of the art on hard-exploration games, and three intrinsic motiv ation metho ds: RND ( Burda et al. , 2018 ), MEME ( Kapturowski et al. , 2022 ) ( Agent57 ’s successor ( Badia et al. , 2020a )), and BYOL-Hindsight ( Jarrett et al. , 2023 ). The latter tw o are among the strongest intrinsic motiv ation approac hes for hard-exploration games. F or the MuJoCo tasks, direct baselines are una v ailable. F or A droit, recen t visual RL metho ds such as DrM ( Xu et al. , 2023 ) and MENTOR ( Huang et al. , 2025 ) solv e door and hammer from pixels without demonstrations, but rely on dense reward shaping. With privileged state observ ations, W ang and Zhao ( 2024 ) solve door and hammer using sparse rew ards and mo del-based intrinsic motiv ation, but do not use pixels. T o the b est of our knowledge, no existing metho d solves these tasks from pixel observations in the sparse-rew ard setting without exp ert demonstrations or offline datasets. The relocate task, in particular, remains unsolved from pixels even with dense rewards; with state observ ations, it has b een solved using dense rew ard shaping ( Ra jesw aran et al. , 2017 ). W e note that our Phase I exploration do es augment the sparse en vironment reward with a single intermediate reward signal and a dead-state condition, b oth derived from privileged state information (see the exploration signals paragraph ab ov e and App endix D for details); these are far simpler than the dense reward shaping required b y standard RL metho ds, but they do go b eyond a purely sparse rew ard signal. F or AntMaze, Director ( Hafner et al. , 2022 ) solves an ego cen tric an t maze from first-p erson pixel inputs with sparse rew ards, but their custom maze is smaller than ours ( antmaze-large-diverse-v0 ) and uses uniquely colored w alls as navigation landmarks. Several goal-conditioned RL metho ds ( Bortkiewicz et al. , 2024 ; Kim et al. , 2021 ) achiev e mo derate success rates on AntMaze b enc hmarks using the JaxGCRL framework (e.g., ∼ 65% on AntMaze-large), but op erate from state observ ations with fixed start and goal lo cations. In contrast, our setup learns entirely from images with randomized goal lo cations. 2 6.2 Results Phase I: Exploration. W e run GowU for 400M game frames p er seed to ev aluate exploration efficiency on the Atari b enchmarks (100 seeds for Montezuma’s R evenge , 50 for Pitfal l! and V entur e ). T able 2 summarizes the a verage cumulativ e reward at the end of exploration alongside the baselines, and Figure 5 compares the Go wU and Go-Explore ( Ecoffet et al. , 2021 ) exploration curves on each game. A cross all three games, Go wU discov ers high-scoring tra jectories substantially faster: it reaches higher cum ulative rewards within a fraction of the frames required by Go-Explore . W e next ev aluate whether this efficiency extends to contin uous control. As discussed in Section 6.1 , no existing metho d solves the Adroit tasks from pixel observ ations in the sparse-reward setting without demonstrations or offline data. T able 3 rep orts statistics on the num b er of environmen t frames required for Go wU to discov er a task-completing tra jectory across 100 Phase I seeds for eac h MuJoCo task. All tasks are solved reliably: hammer requires only ∼ 26 K frames on av erage, while relocate —the hardest Adroit task—has a median of ∼ 86 K frames despite high v ariance. AntMaze requires ∼ 10 M frames on av erage (already accounting for the action rep eat of 4 ). 2 W e note, howev er, that our training uses the default en vironment randomization, where the target lo cation is slightly perturb ed around a fixed p oint across seeds. This differs from the D4RL-style “diverse” setting ( F u et al. , 2020 ), where tra jectories span substantially differen t start and goal configurations, requiring greater generalization. 14 T able 2: Comparison of GowU against baselines on hard-exploration Atari games. F or GowU , we rep ort the av erage cumulativ e reward along the discov ered demonstrations across exploration seeds after 400M frames p er seed ( Explor ation ; 100 seeds for Montezuma’s R evenge , 50 for Pitfal l! and V entur e ) and the a verage p olicy score across 10 Phase I I runs ( R obustific ation ; see T able 4 for details). All Go wU results use stic ky actions ( 𝑝 = 0 . 25 ). RND , MEME , and BYOL-Hindsight results are rep orted with sticky actions. Go-Explore uses a deterministic (non-sticky) environmen t for exploration but ev aluates its distilled p olicies with stic ky actions. Baseline num b ers are taken from the resp ectiv e pap ers. ∗ BYOL-Hindsight v alues are appro ximate, extracted visually from Figure 19 in the original pap er. Game Go wU (ours) Go-Explore RND MEME BYOL-Hind. Explora tion Robustifica tion Montezuma 98,753 182,672 43,791 8,152 9,429 ∼ 14 , 517 ∗ Pitf all 60,600 97,980 6,945 − 3 7,821 ∼ 16 , 211 ∗ Venture 3,330 5,190 2,281 1,859 2,583 ∼ 2 , 328 ∗ (a) Montezuma’s Revenge (b) Pitfal l! (c) V entur e Figure 5: Phase I exploration on A tari: GowU vs. Go-Explore ( Ecoffet et al. , 2021 ). Mean cumulativ e rew ard ( ± std) across 100 seeds as a function of game frames. Go-Explore curves are appro ximated from Extended Data Fig. 2 in ( Ecoffet et al. , 2021 ). Go wU discov ers high-scoring tra jectories substantially faster across all three games. Ov erall, these results confirm that decoupling exploration from p olicy optimization yields substantial b enefits across b oth discrete and contin uous domains. Phase I I: Policy distillation. F ollowing the exploration phase, we distill the disco vered tra jectories into deplo yable p olicies via the bac kward learning curriculum describ ed in Section 6.1 . F or each task, we conduct 10 Phase I I runs, where each run trains on a unique set of demonstrations extracted from the state lineage tree (10 demonstrations p er run for Montezuma’s R evenge and MuJoCo, 5 for Pitfal l! and V entur e ). Eac h run is rep eated with 5 random seeds. W e note that unlike the demonstrations used for backw ard learning in ( Salimans and Chen , 2018 ; Ecoffet et al. , 2021 ), which consist of a chec kp oint at ev ery en vironment step, ours consist of c heckpoints spaced inner steps apart, since we only expand the tree at the end of each rollout (see Algorithm 1 ). Despite the gaps b etw een chec kp oints, the backw ard algorithm successfully learns high-p erforming p olicies. F or A tari, the robustification column of T able 2 reports the av erage p olicy scores, and T able 4 pro vides detailed statistics (standard deviation, median, worst-run, and b est-run) across the 10 Phase I I runs. Go wU ’s distilled p olicies surpass all baselines on ev ery game by a wide margin. Notably , even the worst-run scores across all games remain substantially ab ov e the b est baseline. Remark 6.1. In the Montezuma’s R evenge c ase, some of the highest-sc oring distil le d p olicies exploit a known fe atur e of the game, pr eviously do cumente d by Salimans and Chen ( 2018 ): the key in the first r o om r esp awns after a sufficient amount of time has elapse d. R ather than tr aveling to distant r o oms to c ol le ct keys, these 15 T able 3: MuJoCo Phase I exploration efficiency: num b er of environmen t frames until a task-completing tra jectory is first disco vered, across 100 GowU seeds. F or AntMaze, raw step counts are multiplied by 4 to accoun t for the action rep eat. T ask Mean Std Median Min Max Hammer 25,731 11,468 24,797 5,577 62,180 Door 218,123 143,297 198,984 20,627 902,163 Reloca te 246,436 766,929 86,336 1,727 7,460,062 AntMaze 9,966,117 4,991,098 9,394,478 3,688,488 28,081,212 T able 4: Detailed Phase I I robustification statistics for GowU on Atari. W e conduct 10 Phase I I runs p er game, where each run trains on a unique set of demonstrations (10 demonstrations for Montezuma’s R evenge , 5 for Pitfal l! and V entur e ). Each run is rep eated with 5 random seeds. W e report the mean, standard deviation, median, w orst-run, and b est-run p olicy scores ac ross the 10 runs, where each run’s score is the a verage ov er its 5 seeds. Game Mean Std Median W orst-Run Best-R un Montezuma 182,672 73,150 177,476 89,172 337,835 Pitf all 97,980 1,800 98,295 94,898 101,027 Venture 5,190 608 5,201 4,470 6,362 p olicies le arn to move b ack and forth b etwe en the first r o om and an adjac ent r oom, waiting for the key to r e app e ar. By c ol le cting keys without tr aversing the ful l level, the agent c an sometimes c omplete levels faster, le ading to the esp e cial ly high sc or es observe d for the b est runs. However, this is a fe atur e of the game, not a bug; in fact, waiting for the key to r esp awn is sometimes ne c essary, as c ertain levels r e quir e the first r o om’s key multiple times to advanc e. F or the MuJoCo tasks, we ev aluate the distilled p olicies b y their success rate ( T able 5 ). Go wU achiev es near-p erfect success rates on the Adroit tasks: 99 . 9% on hammer , 96 . 4% on door , and 93 . 9% on relocate . On An tMaze, the mean success rate is 86 . 3% , with the b est run reaching 95 . 1% . These results confirm that our approac h of explicitly separating exploration from exploitation is also effective in contin uous-control domains. T o the b est of our knowledge, no prior metho d has achiev ed such high success rates on these tasks from pixel observ ations with sparse rewards, without exp ert demonstrations. 6.3 Ablation Study T o v alidate the design choices underlying Go wU , w e conduct a series of ablation exp erimen ts on Montezuma’s R evenge . Unless stated otherwise, we rep ort the mean cumulativ e reward (with standard deviation) along the exploration path as a function of game frames. All ablations are conducted on Montezuma’s R evenge with 8 seeds p er v arian t (the baseline uses 100 seeds; see ab o ve). Figure 6 presents the results across four exp eriments. Comp onen t ablation. W e disable individual comp onents of GowU while keeping everything else fixed ( Figure 6 a). Removing the uncertaint y estimator (selecting the winner uniformly at random among surviving particles instead) causes exploration to fail; the v arian t do es not complete the first level. This confirms that epistemic uncertain ty is critical for directing the search tow ard under-explored regions. Disabling the group consolidation step ( Algorithm 1, Line 30 ) also degrades p erformance: while the v ariant even tually completes the first level, it do es so slow er than the baseline. This indicates that p erio dically collapsing the p opulation to the group’s most uncertain state accelerates progress. An additional b enefit of group consolidation is that it results in more frequent pruning, keeping the lineage tree smaller and reducing memory usage. Random actions. W e compare the baseline ensem ble particle p olicies against tw o random-action v ariants ( Figure 6 b): (i) purely random actions sampled indep endently at every step, and (ii) a single random action 16 T able 5: Phase I I success rate statistics for MuJoCo tasks. W e conduct 10 Phase I I runs p er task, where eac h run trains on a unique set of 10 demonstrations and is rep eated with 5 random seeds. W e rep ort the mean, standard deviation, median, worst-run, and b est-run success rates across the 10 runs, where each run’s success rate is av eraged ov er its 5 seeds. T ask Mean Std Median W orst-Run Best-R un Hammer 0.999 0.002 1.000 0.994 1.000 Door 0.964 0.060 0.986 0.794 0.993 Reloca te 0.939 0.059 0.965 0.818 0.977 AntMaze 0.863 0.086 0.893 0.715 0.951 sampled once p er particle and held fixed for the duration of the inner steps (with a differen t random action play ed with probability 0 . 2 at each step, matc hing the ensemble metho d’s epsilon). Purely random actions p erform p o orly due to the jitter phenomenon; without temp oral consistency , the particles fail to make sustained directional progress. Surprisingly , the fixed random action v ariant p erforms on par with the learned ensem ble p olicies. This indicates that the ensemble particle p olicies describ ed in Section 5.3 are not essential for exploration: the system do es not rely on any deep-exploration effect akin to BootDQN. This affirms that the p opulation management mechanisms of Go wU —winner selection, pruning, and rollbac k—are what drive exploration, not the individual p olicies. Effect of group size. W e v ary the num b er of parallel groups 𝑀 ∈ { 1 , 2 , 4 , 8 } while keeping the total num b er of particles fixed at 64 (i.e., 𝑁 = 64 / 𝑀 p er group) ( Figure 6 c). Using 𝑀 = 4 groups p erforms sligh tly b etter, but the differences b etw een 𝑀 ∈ { 1 , 2 , 4 } are mo dest. Performance deteriorates with 𝑀 = 8 groups, b ecause the num b er of particles p er group drops to 8 , making it harder to leverage the particle management logic (winner selection, pruning, and rollback) to navigate around obstacles. Robustness to h yp erparameter randomization. In our standard configuration, the p opulation manage- men t hyperparameters ( 𝐾 , 𝑇 , and rollbac k depth) are sampled uniformly from their resp ective ranges at each iteration. T o test robustness, we run an alternative proto col with 20 seeds in which a single draw from each range is fixed for the entire run; different seeds th us corresp ond to different fixed hyperparameter settings ( Figure 6 d). Per-iteration randomization yields consistently strong p erformance, whereas the fixed-dra w proto col pro duces high v ariance across seeds. This demonstrates that randomization pro vides inheren t robustness: sampling from a reasonable range at each step is sufficient, without needing to identify a single optimal setting. 6.4 Discussion and F uture W ork Our findings suggest that GWTW -st yle particle-based tree search guided by a me asure of uncertaint y is a highly promising paradigm for solving hard-exploration tasks. The mo dular design underlying our approach could naturally extend b ey ond the environmen ts considered here. One p ossible direction is complex reasoning, where particles would correspond to LLM instances exploring differen t reasoning chains. Indeed, particle-based metho ds are indep endently gaining traction in the LLM setting: recent work ( Golowic h et al. , 2026 ) studies Sequen tial Monte Carlo for inference-time steering of language mo dels, maintaining a p opulation of partial generations that are resampled based on reward-model scores. While the goal there is different, this shares the same core particle -managemen t primitives as our framework: replication, pruning, and the adaptive allo cation of computation across a population. Notably , the LLM setting is esp ecially w ell-suited to our framew ork’s reset primitiv e, since the “environmen t” is a tok en sequence and resetting merely entails restoring a con text window ( F oster et al. , 2025 ; Chang et al. , 2024 ). In another direction, by b ypassing the need for shap ed rewards or exp ert demonstrations, Go wU could op en the do or to scaling up op en-ended rob otic learning in simulation, where a broad range of sparse- rew ard manipulation and lo comotion tasks could be solv ed autonomously ( T eam et al. , 2021 ). In such applications, resets are readily a v ailable, and leveraging them effectiv ely is crucial. More broadly , resets remain a computational primitive that is underutilized in exploration. While resets are sometimes view ed as infeasible for physical rob ots ( Eysenbac h et al. , 2017 ; Gupta et al. , 2021 ), this view o verlooks the cen tral role 17 (a) Comp onen t ablation (b) Random actions (c) Effect of group size (d) Fixed vs. randomized hyperparameters Figure 6: Ablation studies on Montezuma’s R evenge . Mean cumulativ e reward ( ± std) across seeds. (a) Dis- abling uncertaint y-based winner selection causes exploration to fail; disabling group consolidation degrades p erformance. (b) Fixed random actions match learned ensem ble p olicies; purely random actions fail. (c) Per- formance is stable across 1 – 4 groups but degrades at 8 due to fewer particles p er group. (d) Per-iteration h yp erparameter randomization yields robust p erformance without tuning. of simulation in mo dern AI training. Ev en for physical applications, p olicies are increasingly pre-trained in sim ulation, from robotic manipulation to autonomous driving ( Qassem et al. , 2010 ; Bo jarski et al. , 2016 ; T obin et al. , 2017 ; Akk ay a et al. , 2019 ; Bansal et al. , 2018 ). In these settings, ignoring the capability to reset is a missed opp ortunity ( Mhammedi et al. , 2024 ). Recen t theoretical w ork further shows that lo cal simulator access enables efficient learning in settings where standard online RL is prov ably inefficient ( Li et al. , 2021 ; Yin et al. , 2023 ; Mhammedi et al. , 2024 ), and the empirical success of planning algorithms suc h as AlphaZero ( Silv er et al. , 2016 , 2018 ) provides additional evidence for the p ow er of this primitive. On the methodological side, an imp ortant direction for future w ork is the design of more principled uncertaint y measures. RND is scalable and effective in our setting, and was sp ecifically designed to av oid the noisy-TV problem by using a deterministic target netw ork ( Burda et al. , 2018 ). How ever, Mav or-Park er et al. ( 2022 ) sho w that RND can still assign p ersisten tly high no velt y to sto chastic observ ations, pro ducing misleading signals that can trap the agent. Promising alternatives include the learned representations used in BYOL- Hindsight ( Jarrett et al. , 2023 ), which explicitly disentangle aleatoric and epistemic uncertaint y , as well as temp oral contrastiv e features ( My ers et al. , 2024 ; Mohamed et al. , 2026 ; Liu et al. , 2024 ), which capture 18 temp oral structure and may provide a stronger basis for planning-aw are and noise-robust exploration. 19 A c kno wledgmen ts W e thank Ark anath Pathak for discussions during the early stages of this pro ject. References Ilge Akk a ya, Marcin Andrycho wicz, Maciek Chociej, Mateusz Litwin, Bob McGrew, Arthur Petron, Alex P aino, Matthias Plapp ert, Glenn Po w ell, Raphael Ribas, et al. Solving rubik’s cub e with a rob ot hand. arXiv pr eprint arXiv:1910.07113 , 2019. Da vid Aldous and Umesh V azirani. “go with the winners” algorithms. In Pr o c e e dings 35th A nnual Symp osium on F oundations of Computer Scienc e , pages 492–501. IEEE, 1994. Elie Aljalb out, Jiaxu Xing, Angel Romero, Iretiay o Akinola, Caelan Reed Garrett, Eric Heiden, Abhishek Gupta, T uck er Hermans, Y ashra j Narang, Dieter F ox, et al. The realit y gap in rob otics: Challenges, solutions, and b est practices. Annual R eview of Contr ol, R ob otics, and Autonomous Systems , 9, 2025. A drià Puigdomènech Badia, Bilal Piot, Stev en Kapturowski, P ablo Sprechmann, Alex Vitvitskyi, Zhao- han Daniel Guo, and Charles Blundell. Agen t57: Outp erforming the atari h uman b enc hmark. In International c onfer enc e on machine le arning , pages 507–517. PMLR, 2020a. A drià Puigdomènech Badia, Pablo Sprechmann, Alex Vitvitskyi, Daniel Guo, Bilal Piot, Steven Kapturowski, Olivier Tieleman, Martín Arjovsky , Alexander Pritzel, Andew Bolt, et al. Nev er give up: Learning directed exploration strategies. arXiv pr eprint arXiv:2002.06038 , 2020b. Ma yank Bansal, Alex Krizhevsky , and Abhijit Ogale. Chauffeurnet: Learning to drive by imitating the b est and syn thesizing the worst. arXiv pr eprint arXiv:1812.03079 , 2018. Andrew G Barto. Intrinsic motiv ation and reinforcemen t learning. In Intrinsic al ly motivate d le arning in natur al and artificial systems , pages 17–47. Springer, 2012. Marc Bellemare, Sriram Sriniv asan, Georg Ostrovski, T om Schaul, David Saxton, and Remi Munos. Unifying coun t-based exploration and intrinsic motiv ation. A dvanc es in neur al information pr o c essing systems , 29, 2016. Marc G Bellemare, Y a v ar Naddaf, Jo el V eness, and Michael Bowling. The arcade learning environmen t: An ev aluation platform for general agents. Journal of artificial intel ligenc e r ese ar ch , 47:253–279, 2013. Mariusz Bo jarski, Da vide Del T esta, Daniel Dworak owski, Bernhard Firner, Beat Flepp, Praso on Goy al, La wrence D Jack el, Mathew Monfort, Urs Muller, Jiak ai Zhang, et al. End to end learning for self-driving cars. arXiv pr eprint arXiv:1604.07316 , 2016. Mic hał Bortkiewicz, Władysła w Pałuc ki, Vivek My ers, T adeusz Dziarmaga, T omasz Arczewski, Łuk asz Kuciński, and Benjamin Eysenbac h. Accelerating goal-conditioned rl algorithms and research. arXiv pr eprint arXiv:2408.11052 , 2024. An thony Brohan, Noah Brown, Justice Carba jal, Y evgen Cheb otar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Rob otics transformer for real-w orld control at scale. arXiv pr eprint arXiv:2212.06817 , 2022. Y uri Burda, Harrison Edwards, Amos Storkey , and Oleg Klimov. Exploration by random netw ork distillation. arXiv pr eprint arXiv:1810.12894 , 2018. Jonathan D Chang, W enhao Zhan, Owen Oertell, Kianté Brantley , Dip endra Misra, Jason D Lee, and W en Sun. Dataset reset p olicy optimization for rlhf. arXiv pr eprint arXiv:2404.08495 , 2024. P aul F Christiano, Jan Leike, T om Brown, Miljan Martic, Shane Legg, and Dario Amo dei. Deep reinforcement learning from human preferences. A dvanc es in neur al information pr o c essing systems , 30, 2017. 20 Edoardo Con ti, V ashish t Madhav an, F elipe Petroski Such, Joel Lehman, Kenneth O. Stanley , and Jeff Clune. Impro ving exploration in evolution strategies for deep reinforcement learning via a p opulation of no velt y-seeking agents. In A dvanc es in Neur al Information Pr o c essing Systems , 2018. A drien Couëtoux, Jean-Baptiste Ho o ck, Nataliya Sokolo vsk a, Olivier T eytaud, and Nicolas Bonnard. Con tin- uous upp er confidence trees. In International c onfer enc e on le arning and intel ligent optimization , pages 433–445. Springer, 2011. Rémi Coulom. Efficien t selectivity and bac kup op erators in monte-carlo tree search. In International c onfer enc e on c omputers and games , pages 72–83. Springer, 2006. Stefan Dep ew eg, Jose-Miguel Hernandez-Lobato, Finale Doshi-V elez, and Steffen Udluft. Decomp osition of uncertain ty in bay esian deep learning for efficient and risk-sensitiv e learning. In International c onfer enc e on machine le arning , pages 1184–1193. PMLR, 2018. A drien Ecoffet, Jo ost Huizinga, Jo el Lehman, Kenneth O Stanley , and Jeff Clune. Go-explore: a new approac h for hard-exploration problems. arXiv pr eprint arXiv:1901.10995 , 2019. A drien Ecoffet, Joost Huizinga, Joel Lehman, Kenneth O Stanley , and Jeff Clune. First return, then explore. Natur e , 590(7847):580–586, 2021. Lasse Esp eholt, Hub ert Soy er, Remi Munos, Karen Simony an, Vlad Mnih, T om W ard, Y otam Doron, Vlad Firoiu, Tim Harley , Iain Dunning, et al. Impala: Scalable distributed deep-rl with imp ortance weigh ted actor-learner architectures. In International c onfer enc e on machine le arning , pages 1407–1416. PMLR, 2018. Benjamin Eysenbac h, Shixiang Gu, Julian Ibarz, and Sergey Levine. Lea ve no trace: Learning to reset for safe and autonomous reinforcement learning. arXiv pr eprint arXiv:1711.06782 , 2017. Benjamin Eysen bach, Abhishek Gupta, Julian Ibarz, and Sergey Levine. Diversit y is all you need: Learning skills without a reward function. arXiv pr eprint arXiv:1802.06070 , 2018. Carlos Florensa, Da vid Held, Markus W ulfmeier, Michael Zhang, and Pieter Abb eel. Rev erse curriculum generation for reinforcem en t learning. In Confer enc e on r ob ot le arning , pages 482–495. PMLR, 2017. Dylan J F oster, Zak aria Mhammedi, and Dhruv Rohatgi. Is a go o d foundation necessary for efficient reinforcemen t learning? the computational role of the base mo del in exploration. In The Thirty Eighth A nnual Confer enc e on L e arning The ory , pages 2026–2142. PMLR, 2025. Justin F u, A viral Kumar, Ofir Nach um, George T uck er, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcemen t learning. arXiv pr eprint arXiv:2004.07219 , 2020. Quen tin Gallouédec and Emmanuel Dellandréa. Cell-free latent go-explore. In International Confer enc e on Machine L e arning , pages 10571–10586. PMLR, 2023. Noah Golowic h, F an Chen, Dhruv Rohatgi, Raghav Singhal, Carles Domingo-Enrich, Dylan J F oster, and Aksha y Krishnam urthy . Reject, resample, rep eat: Understanding parallel reasoning in language mo del inference. arXiv pr eprint arXiv:2603.07887 , 2026. Zhaohan Guo, Shantan u Thakoor, Miruna Pîslar, Bernardo A vila Pires, Floren t Altché, Coren tin T allec, Alaa Saade, Daniele Calandriello, Jean-Bastien Grill, Y unhao T ang, et al. Byol-explore: Exploration by b ootstrapp ed prediction. A dvanc es in neur al information pr o c essing systems , 35:31855–31870, 2022. Abhishek Gupta, Justin Y u, T ony Z Zhao, Vik ash Kumar, Aaron Rovinsky , Kelvin Xu, Thomas Devlin, and Sergey Levine. Reset-free reinforcement learning via multi-task learning: Learning dexterous manipulation b eha viors without human interv ention. In 2021 IEEE international c onfer enc e on r ob otics and automation (ICRA) , pages 6664–6671. IEEE, 2021. Danijar Hafner, Kuang-Huei Lee, Ian Fischer, and Pieter Abb eel. Deep hierarc hical planning from pixels. A dvanc es in Neur al Information Pr o c essing Systems , 35:26091–26104, 2022. 21 T o dd Hester, Matej V ecerik, Olivier Pietquin, Marc Lanctot, T om Schaul, Bilal Piot, Dan Horgan, John Quan, Andrew Sendonaris, Ian Osband, et al. Deep q-learning from demonstrations. In Pr o c e e dings of the AAAI c onfer enc e on artificial intel ligenc e , volume 32, 2018. Rein Houtho oft, Xi Chen, Y an Duan, John Sch ulman, Filip De T urck, and Pieter Abb eel. Vime: V ariational information maximizing exploration. In A dvanc es in Neur al Information Pr o c essing Systems , volume 29, 2016. Suning Huang, Zheyu Aqa Zhang, Tianhai Liang, Yihan Xu, Zhehao K ou, Chenhao Lu, Guow ei Xu, Zhengrong Xue, and Huazhe Xu. Men tor: Mixture-of-experts net work with task-oriented p erturbation for visual reinforcemen t learning. In International Confer enc e on Machine L e arning , pages 26143–26161. PMLR, 2025. Daniel Jarrett, Corentin T allec, Florent Altché, Thomas Mesnard, Remi Munos, and Mic hal V alko. Curiosit y in hindsight: In trinsic exploration in sto chastic en vironments. In International Confer enc e on Machine L e arning , pages 14780–14816. PMLR, 2023. Chi Jin, Akshay Krishnamurth y , Max Simc howitz, and Tiancheng Y u. Reward-free exploration for reinforce- men t learning. In International Confer enc e on Machine L e arning , pages 4870–4879. PMLR, 2020. Stev en Kapturowski, Víctor Camp os, Ray Jiang, Nemanja Rakićević, Hado v an Hasselt, Charles Blundell, and A dria Puigdomenech Badia. Human-level atari 200x faster. arXiv pr eprint arXiv:2209.07550 , 2022. Mic hael Kearns and Satinder Singh. Near-optimal reinforcement learning in p olynomial time. Machine le arning , 49(2):209–232, 2002. Alex Kendall and Y arin Gal. What uncertain ties do we need in bay esian deep learning for computer vision? A dvanc es in neur al information pr o c essing systems , 30, 2017. Junsu Kim, Y ounggy o Seo, and Jinw o o Shin. Landmark-guided subgoal generation in hierarchical reinforcement learning. A dvanc es in neur al information pr o c essing systems , 34:28336–28349, 2021. Lev ente K o csis and Csaba Szepesvári. Bandit based mon te-carlo planning. In Eur op e an c onfer enc e on machine le arning , pages 282–293. Springer, 2006. Bala ji Lakshminaray anan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertain ty estimation using deep ensembles. A dvanc es in neur al information pr o c essing systems , 30, 2017. Mic hael Laskin, Denis Y arats, Hao Liu, Kimin Lee, Alb ert Zhan, Kevin Lu, Catherine Cang, Lerrel Pin to, and Pieter Abb eel. Urlb: Unsup ervised reinforcement learning b enc hmark. arXiv pr eprint arXiv:2110.15191 , 2021. Jo el Lehman and Kenneth O Stanley . Abandoning ob jectiv es: Evolution through the search for nov elt y alone. Evolutionary c omputation , 19(2):189–223, 2011. Gen Li, Y uxin Chen, Y uejie Chi, Y uantao Gu, and Y uting W ei. Sample-efficien t reinforcement learning is feasible for linearly realizable mdps with limited revisiting. A dvanc es in Neur al Information Pr o c essing Systems , 34:16671–16685, 2021. Grace Liu, Mic hael T ang, and Benjamin Eysenbac h. A single goal is all y ou need: Skills and exploration emerge from contrastiv e rl without rewards, demonstrations, or subgoals. arXiv pr eprint arXiv:2408.05804 , 2024. Hao Liu and Pieter Abb eel. Behavior from the void: Unsup ervised active pre-training. A dvanc es in Neur al Information Pr o c essing Systems , 34:18459–18473, 2021. Marlos C Machado, Marc G Bellemare, Erik T alvitie, Jo el V eness, Matthew Hausknech t, and Michael Bo wling. Revisiting the arcade learning environmen t: Ev aluation proto cols and op en problems for general agents. Journal of Artificial Intel ligenc e R ese ar ch , 61:523–562, 2018. 22 Augustine Ma vor-P arker, Kimberly Y oung, Caswell Barry , and Lewis Griffin. How to stay curious while a voiding noisy tvs using aleatoric uncertaint y estimation. In International c onfer enc e on machine le arning , pages 15220–15240. PMLR, 2022. Zak Mhammedi, Adam Blo ck, Dylan J F oster, and Alexander Rakhlin. Efficien t mo del-free exploration in lo w-rank mdps. A dvanc es in Neur al Information Pr o c essing Systems , 36:66782–66817, 2023a. Zak aria Mhammedi, Dylan J F oster, and Alexander Rakhlin. Represen tation learning with m ulti-step inv erse kinematics: An efficient and optimal approach to rich-observ ation rl. In International Confer enc e on Machine L e arning , pages 24659–24700. PMLR, 2023b. Zak aria Mhammedi, Dylan J F oster, and Alexander Rakhlin. The p ow er of resets in online reinforcement learning. A dvanc es in Neur al Information Pr o c essing Systems , 37:12334–12407, 2024. Dip endra Misra, Mik ael Henaff, Akshay Krishnamurth y , and John Langford. Kinematic state abstraction and pro v ably efficient rich-observ ation reinforcement learning. In International c onfer enc e on machine le arning , pages 6961–6971. PMLR, 2020. V olo dymyr Mnih, Kora y Kavuk cuoglu, David Silver, Andrei A Rusu, Jo el V eness, Marc G Bellemare, Alex Gra ves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcemen t learning. natur e , 518(7540):529–533, 2015. F aisal Mohamed, Catherine Ji, Benjamin Eysenbac h, and Glen Berseth. T emp oral representations for explo- ration: Learning complex exploratory b eha vior without extrinsic rew ards. arXiv pr eprint arXiv:2603.02008 , 2026. Shakir Mohamed and Danilo Jimenez Rezende. V ariational information maximisation for intrinsically motiv ated reinforcement learning. A dvanc es in neur al information pr o c essing systems , 28, 2015. Jean-Baptiste Mouret and Jeff Clune. Illuminating searc h spaces by mapping elites. arXiv pr eprint arXiv:1504.04909 , 2015. Viv ek Myers, Chongyi Zheng, Anca Dragan, Sergey Levine, and Benjamin Eysenbac h. Learning temp oral distances: Contrastiv e successor features can pro vide a metric structure for decision-making. In International Confer enc e on Machine L e arning , pages 37076–37096. PMLR, 2024. Y aniv Oren, Villiam V ado cz, Matthijs TJ Spaan, and W endelin Böhmer. Epistemic monte carlo tree search. arXiv pr eprint arXiv:2210.13455 , 2022. Ian Osband, Charles Blundell, Alexander Pritzel, and Benjamin V an Roy . Deep exploration via b o otstrapped dqn. In A dvanc es in Neur al Information Pr o c essing Systems , volume 29, 2016. Ian Osband, John Aslanides, and Albin Cassirer. Randomized prior functions for deep reinforcemen t learning. A dvanc es in neur al information pr o c essing systems , 31, 2018. Pierre-Y ves Oudeyer, F rdric Kaplan, and V erena V Hafner. In trinsic motiv ation systems for autonomous men tal developmen t. IEEE tr ansactions on evolutionary c omputation , 11(2):265–286, 2007. Long Ouyang, Jeffrey W u, Xu Jiang, Diogo Almeida, Carroll W ainwrigh t, Pamela Mishkin, Chong Zhang, Sandhini Agarw al, Katarina Slama, Alex Ray , et al. T raining language mo dels to follow instructions with h uman feedback. A dvanc es in neur al information pr o c essing systems , 35:27730–27744, 2022. Jac k Park er-Holder, Aldo Pacc hiano, Krzysztof M Choromanski, and Stephen J Rob erts. Effective diversit y in p opulation based reinforcemen t learning. A dvanc es in Neur al Information Pro c essing Systems , 33: 18050–18062, 2020. Deepak Pathak, Pulkit Agra wal, Alexei A Efros, and T rev or Darrell. Curiosity-driv en exploration by self-sup ervised prediction. In International c onfer enc e on machine le arning , pages 2778–2787. PMLR, 2017. 23 Deepak Pathak, Dhira j Gandhi, and Abhina v Gupta. Self-sup ervised exploration via disagreement. In International c onfer enc e on machine le arning , pages 5062–5071. PMLR, 2019. Justin K Pugh, Lisa B Soros, and Kenneth O Stanley . Qualit y div ersity: A new fron tier for ev olutionary computation. F r ontiers in R ob otics and AI , 3:40, 2016. Mohammed Abu Qassem, Iyad Abuhadrous, and Hatem Elaydi. Mo deling and simulation of 5 dof educational rob ot arm. In 2010 2nd International Confer enc e on A dvanc e d Computer Contr ol , volume 5, pages 569–574. IEEE, 2010. Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Y our language mo del is secretly a rew ard mo del. A dvanc es in neur al information pr o c essing systems , 36:53728–53741, 2023. Ara vind Ra jeswaran, Vik ash Kumar, Abhishek Gupta, Giulia V ezzani, John Sch ulman, Emanuel T o doro v, and Sergey Levine. Learning complex dexterous manipulation with deep reinforcemen t learning and demonstrations. arXiv pr eprint arXiv:1709.10087 , 2017. Tim Salimans and Richard Chen. Learning montezuma’s rev enge from a single demonstration. arXiv pr eprint arXiv:1812.03381 , 2018. Jürgen Schmidh ub er. Curious mo del-building control systems. In Pr o c. international joint c onfer enc e on neur al networks , pages 1458–1463, 1991. John Sch ulman, Filip W olski, Prafulla Dhariwal, Alec Radford, and Oleg Klimo v. Pro ximal policy optimization algorithms, 2017. arXiv preprint Ramanan Sek ar, Oleh Rybkin, K ostas Daniilidis, Pieter Abb eel, Danijar Hafner, and Deepak P athak. Planning to explore via self-supervised world mo dels. In International c onfer enc e on machine le arning , pages 8583–8592. PMLR, 2020. Prana v Shy am, W o jciech Jaśko wski, and F austino Gomez. Mo del-based active exploration. In International c onfer enc e on machine le arning , pages 5779–5788. PMLR, 2019. Da vid Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George V an Den Driessche, Julian Sc hrittwieser, Ioannis Antonoglou, V eda Panneershelv am, Marc Lanctot, et al. Mastering the game of go with deep neural netw orks and tree search. natur e , 529(7587):484–489, 2016. Da vid Silver, Thomas Hub ert, Julian Schritt wieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graep el, et al. A general reinforcement learning algorithm that mas ters chess, shogi, and go through self-play . Scienc e , 362(6419):1140–1144, 2018. Bradly C Stadie, Sergey Levine, and Pieter Abbeel. Incentivizing exploration in reinforcement learning with deep predictiv e mo dels. arXiv pr eprint arXiv:1507.00814 , 2015. Op en Ended Learning T eam, Adam Sto oke, Anuj Maha jan, Catarina Barros, Charlie Deck, Jakob Bauer, Jakub Sygnowski, Ma ja T rebacz, Max Jaderb erg, Michael Mathieu, et al. Op en-ended learning leads to generally capable agen ts. arXiv pr eprint arXiv:2107.12808 , 2021. Josh T obin, Rachel F ong, Alex Ray , Jonas Sc hneider, W o jciech Zaremba, and Pieter Abb eel. Domain randomization for transferring deep neural netw orks from simulation to the real world. In 2017 IEEE/RSJ international c onfer enc e on intel ligent r ob ots and systems (IROS) , pages 23–30. IEEE, 2017. Jianren W ang, Yifan Su, Abhinav Gupta, and Deepak Pathak. Evolutionary p olicy optimization. arXiv pr eprint arXiv:2503.19037 , 2025. Yib o W ang and Jiang Zhao. Learning off-policy with mo del-based intrinsic motiv ation for active online exploration. arXiv pr eprint arXiv:2404.00651 , 2024. 24 Guo wei Xu, Ruijie Zheng, Y ongyuan Liang, Xiyao W ang, Zhecheng Y uan, Tianying Ji, Y u Luo, Xiaoyu Liu, Jiaxin Y uan, Pu Hua, et al. Drm: Mastering visual reinforcemen t learning through dorman t ratio minimization. arXiv pr eprint arXiv:2310.19668 , 2023. Dong Yin, Sridhar Thiagara jan, Nevena Lazic, Nived Ra jaraman, Botao Hao, and Csaba Szepesv ari. Sample efficien t deep reinforcement learning via lo cal planning. arXiv pr eprint arXiv:2301.12579 , 2023. W enshuai Zhao, Jorge Peña Queralta, and T omi W esterlund. Sim-to-real transfer in deep reinforcement learning for robotics: a surv ey . In 2020 IEEE symp osium series on c omputational intel ligenc e (SSCI) , pages 737–744. IEEE, 2020. 25 A Wh y GWTW is Exp onen tially F aster: A Concrete Example Consider the problem of finding the deep est no de in an unknown tree. DFS and BFS ma y , in the w orst case, need to visit every no de b efore reaching it. GWTW takes a different approach: it adv ances a p opulation of particles in parallel, kills those that reach leav es, and clones surviv ors to maintain the population size. This pruning-and-cloning mechanism redirects all computational effort tow ard branches that remain alive. W e illustrate this with a concrete tree where DFS and BFS b oth require Θ ( 2 𝐷 ) no de ev aluations to find the unique deep est no de, while GWTW succeeds with only O ( 𝐷 log ( 𝐷 / 𝛿 ) ) . T ree construction. Let 𝐷 b e a depth parameter. W e construct a tree 𝑇 with a unique deepest node at depth 𝐷 + 1 : • Spine (golden path): No des 𝑣 0 (ro ot), 𝑣 1 , . . . , 𝑣 𝐷 + 1 . Each spine no de 𝑣 𝑖 ( 0 ≤ 𝑖 ≤ 𝐷 − 1 ) has exactly tw o c hildren: 𝑣 𝑖 + 1 and a trap ro ot 𝑡 𝑖 . No de 𝑣 𝐷 has a single c hild 𝑣 𝐷 + 1 , whic h is a leaf and the unique deep est no de. • T rap subtrees: Each 𝑡 𝑖 ro ots a subtree where every internal no de has 6 children: 2 internal no des and 4 lea ves (immediate dead ends). T rap subtrees extend down to depth 𝐷 − 1 , at which p oint all 6 children are lea ves (at depth 𝐷 ). Because eac h trap no de spawns 2 internal c hildren, the traps grow like binary trees. The total num b er of no des in 𝑇 is Θ ( 2 𝐷 ) . Inefficiency of DFS and BFS. Both algorithms must pro cess the full tree volume: • BFS explores lay er by lay er. T o reach depth 𝐷 + 1 , it m ust visit all Θ ( 2 𝐷 ) no des at preceding levels. Cost: Θ ( 2 𝐷 ) . • DFS (randomized) has a 1 / 2 probability of entering a trap at eac h spine no de. Since the earliest traps con tain Θ ( 2 𝐷 ) no des that must b e exhaustively explored b efore backtrac king, even a single wrong turn is catastrophic. Cost: Θ ( 2 𝐷 ) . Note that indep endent random walks also fail: reaching 𝑣 𝐷 + 1 requires taking the correct branch 𝐷 times in a ro w, which happ ens with probability 2 − 𝐷 . Analysis of GWTW . GWTW maintains 𝐵 particles, all starting at 𝑣 0 . A t each step: (1) every particle mo ves to a uniformly random c hild; (2) particles landing on leav es die; (3) survivors are resampled with replacemen t to restore the p opulation to 𝐵 . Let 𝑥 𝑖 denote the exp ected fraction of particles at spine no de 𝑣 𝑖 . When particles at 𝑣 𝑖 step forward, b oth c hildren ( 𝑣 𝑖 + 1 and 𝑡 𝑖 ) are non-leav es, so all golden-path particles survive: 𝑥 𝑖 / 2 land on 𝑣 𝑖 + 1 and 𝑥 𝑖 / 2 enter the trap. Mean while, trap particles each choose among 6 c hildren ( 2 internal, 4 leav es), surviving with probability 1 / 3 . The total survivor fraction is: 𝑆 𝑖 = 𝑥 𝑖 | {z } golden surviv ors + 1 − 𝑥 𝑖 3 | {z } trap surviv ors = 1 + 2 𝑥 𝑖 3 . (1) After resampling, the fraction on the golden path b ecomes: 𝑥 𝑖 + 1 = 𝑥 𝑖 / 2 𝑆 𝑖 = 3 𝑥 𝑖 2 ( 1 + 2 𝑥 𝑖 ) . (2) Starting from 𝑥 0 = 1 , this recurrence pro duces: 1 → 1 / 2 → 3 / 8 → 9 / 28 → · · · , con verging monotonically from ab ov e to the fixed p oint 𝑥 ∗ = 1 / 4 . Since the map 𝑓 ( 𝑥 ) = 3 𝑥 2 + 4 𝑥 is strictly increasing with 𝑓 ( 1 / 4 ) = 1 / 4 , the sequence remains ab o ve 1 / 4 for all 𝑖 . This is the k ey insight: because traps kill particles at rate 2 / 3 p er step while the golden path kills none, GWTW automatically maintains at least 25% of its population on the correct path, regardless of the exp onential volume of the traps. Cost of GWTW . A t each depth, the exp ected num b er of golden-path particles is at least 𝐵 / 4 . By a Chernoff b ound, the probability that this count drops to zero at any single depth is at most exp ( − 𝑐 𝐵 ) for a 26 constan t 𝑐 > 0 . Applying a union b ound ov er 𝐷 lev els, the probability that GWTW ev er loses the golden path is at most 𝐷 · exp ( − 𝑐 𝐵 ) ≤ 𝛿 whenev er 𝐵 ≥ 1 𝑐 ln 𝐷 𝛿 . The total num b er of no de ev aluations is therefore: Cost gwtw = O ( 𝐵 · 𝐷 ) = O 𝐷 log 𝐷 𝛿 , (3) whic h is exp onentially smaller than the Θ ( 2 𝐷 ) cost of DFS and BFS. Note that for any fixed search strategy , adv ersarial trees can b e constructed that force Ω ( 2 𝐷 ) w ork. The fundamental reason GWTW succeeds is that parallel exploration with redistribution amplifies the probability of adv ancing at eac h depth level: in the example ab o ve, at each level GWTW only requires at le ast one of 𝐵 particles to follo w the spine rather than en ter a trap, after whic h cloning restores the p opulation to 𝐵 for the next level. A single walk er, by contrast, m ust c ho ose the spine o ver a trap at all 𝐷 lev els in sequence, succeeding with probability 2 − 𝐷 . GWTW con verts this multiplicativ e success probability into an additive failure probability of 𝐷 · 𝑒 − 𝑐 𝐵 for a constant 𝑐 > 0 . B Pitfall Timer Reset Pitfal l! features a 20-minute timer, after which the game ends. T o allow for non-episodic exploration, we reset the timer at eac h step by directly writing to the Atari emulator’s RAM via ale.setRAM() . The timer is enco ded across tw o RAM bytes: byte 88 stores the min utes and byte 89 stores the seconds. Because the game uses a non-standard internal enco ding, we maintain hardco ded lo okup tables that map standard min ute and second v alues to the corresp onding RAM integers exp ected by the emulator. W e av oid setting the timer to exactly 20:00 or 0:00, as b oth b oundary v alues trigger unintended side effects in the game state; in practice, we reset it to 19:59. This timer reset is applied only during Phase I exploration and is disabled during Phase I I and ev aluation. C Observ ation Pro cessing Details This app endix provides full details of the observ ation pro cessing pip elines summarized in the main text. C.1 A tari The pip eline uses standard DeepMind Acme wrapp ers. The environmen t is initialized using the NoFrameskip v ariant (or v0 with sticky actions) to obtain raw 60 Hz frames with the full 18-action space exp osed. T emp oral p o oling and grayscaling. After each action rep eat of 4 frames, temp oral max-p o oling is applied elemen t-wise ov er the last 2 of the 4 frames to prev ent sprite flick ering artifacts. The resulting R GB image is con verted to grayscale via the standard luminosity formula 𝑌 = 0 . 299 𝑅 + 0 . 587 𝐺 + 0 . 114 𝐵 . Do wnsampling. The grayscale image is resized to the target resolution of 84 × 84 pixels. T wo v ariants are used: • Standar d (Montezuma, Pitfal l): The gra yscale frame ( 210 × 160 ) is directly resized to 84 × 84 using bilinear in terp olation. • With sp atial max-p o oling (V entur e): A 2 × 2 spatial max-p o oling step is applied first to preserve small, brigh t sprites (e.g., the play er dot) that would otherwise b e smo othed out b y bilinear interpolation. This reduces the resolution to 105 × 80 , which is then resized to 84 × 84 via bilinear interpolation. Normalization and frame stacking. Pixel v alues are cast to floating-p oin t and scaled to [ 0 , 1 ] . The 4 most recen t pro cessed frames are stac ked along the channel axis, producing a final observ ation tensor of shap e 84 × 84 × 4 . F or Phase I I (bac kward learning) on Montezuma’s R evenge , a fifth frame is appended corresp onding to the most recen t rew ard observ ation—i.e., the frame at whic h the agent last received a rew ard (see App endix G for details). 27 C.2 A droit Pixel rendering. Rather than using the standard gym rendering interface, we attac h a mujoco.MovableCamera to the physics state and render directly at 120 × 120 pixels in RGB. F or each task, the camera p ose is lo ck ed to a fixed, task-sp ecific viewp oint: • hammer-v0 : Look at = [ 0 , − 0 . 15 , 0 . 15 ] , Distance = 0 . 7 , Azimuth = − 45 ◦ , Elev ation = − 45 ◦ . • door-v0 : Look at = [ 0 , − 0 . 1 , 0 . 25 ] , Distance = 0 . 8 , Azimuth = 60 ◦ , Elev ation = − 35 ◦ . • relocate-v0 : Look at = [ 0 , − 0 . 1 , 0 . 15 ] , Distance = 0 . 9 , Azimuth = − 180 ◦ , Elev ation = − 45 ◦ . Gra yscaling, normalization, and frame stacking. The rendered RGB image is conv erted to grayscale via the luminosity formula. F our consecutive frames are stack ed along the channel axis, pro ducing a tensor of shap e 120 × 120 × 4 . Pixel v alues are normalized to [ 0 , 1 ] . C.3 An tMaze Scene mo dification. T o make the task visually solv able, the environmen t scene is dynamically mo dified: a semi-transparen t red sphere is injected at the goal coordinates via a scene callbac k, and the flo or color is set to dark gray ( [ 0 . 2 , 0 . 2 , 0 . 2 ] ) for improv ed contrast when textures are disabled. Dual camera rendering. T wo views are rendered at 120 × 120 pixels using a mujoco.MovableCamera : • Glob al top-down view: Lo ck ed high ab ov e the maze center (Lo ok at = [ 18 , 12 , 0 ] , Distance = 55 , Azimuth = 90 ◦ , Elev ation = − 90 ◦ ). T extures are disabled to provide a clean structural map of the maze lay out and goal mark er. • Thir d-p erson e go c entric view: Dynamically trac ks the agent’s p osition (Distance = 8 , Azimuth = 135 ◦ , Elev ation = − 45 ◦ ) with textures enabled for rich visual feedback of the ant’s limbs and surroundings. Both views are conv erted to grayscale and resized to 120 × 120 using Lanczos resampling. F rame stacking v arian ts. During Phase I (exploration), only the global top-down view is used, yielding an observ ation of shap e 120 × 120 × 1 . During Phase I I (p olicy distillation), the global frame is stac ked with 4 historical ego centric frames, pro ducing an observ ation of shap e 120 × 120 × 5 (channel 0: global map; channels 1–4: temp oral ego centric history). Pixel v alues are normalized to [ 0 , 1 ] . D MuJoCo Rew ard and Dead-State Extraction This app endix details the sparse reward and dead-state detection logic used during Phase I exploration for the MuJoCo en vironments. D.1 An tMaze: Flip Detection If the an t flips ov er, it cannot recov er, rendering the remainder of the episo de useless. W e detect flips using t wo quantities extracted from the MuJoCo physics state at every step: 1. Z-c o or dinate ( 𝑧 ): the absolute heigh t of the ant torso, retrieved via physics.data.qpos[2] . 2. Upwar d ve ctor ( 𝑧 up ): the ( 2 , 2 ) elemen t of the torso’s 3 × 3 orientation rotation matrix physics.data.xmat[torso_id] , represen ting the Z-comp onent of the torso’s lo cal “up” vector in the world frame. The ant is flagged as flipp ed if either 𝑧 < 0 . 2 (torso near the ground) or 𝑧 up < 0 (torso upside-down). Upon detection, the particle is assigned a dead state. If the agent triggers goal_achieved on the same step as a flip, the particle is still marked as dead . 28 D.2 A droit: Sparse Contact Rew ards F or all Adroit tasks, the standard contin uous rewards are replaced by a sparse reward wrapp er that parses the MuJoCo contact information at every step. Contact is ev aluated by extracting geometry (geom) IDs from the mo del and iterating through active collisions in physics.data.contact , using explicit geom whitelists to preven t false p ositiv es (e.g., the hand contacting the table rather than the target ob ject). If the underlying en vironment flags goal_achieved = True , th e agent receives a + 1 te rminal reward. The task-sp ecific logic is: • hammer-v0 : Contact is chec ked b etw een the 19 geoms comprising the rob ot hand (wrist, palm, and finger join ts) and the hammer ob ject. A reward of + 1 is assigned when the hand first contacts the hammer ( hammer_lifted = True ). If contact is subsequently lost, the particle is marked as dead . • door-v0 : Contact is chec ked b et ween the hand geoms and the do or latch/handle geoms. A reward of + 1 is assigned up on first contact ( handle_touched = True ). Loss of contact triggers a dead state. • relocate-v0 : Con tact is chec k ed b etw een the ball and all geoms exc ept a whitelist of forbidden surfaces (flo or and table geoms). A reward of + 1 is assigned when the ball is pick ed up ( ball_held = True ). If the ball touc hes a forbidden surface (e.g., it is dropp ed), the particle is marked as dead . E P article P olicy T raining Ob jectiv es This app endix provides the full training ob jectives for the particle p olicies describ ed in Section 5.3 . In b oth settings, the environmen t reward is discarded entirely; all training targets are identically zero. Bo otstrap masks induce div ersity across particles within a group. E.1 A tari (Discrete Actions) Eac h particle m ain tains a netw ork 𝑓 𝜓 , parameterized by 𝜓 (A tari conv olutional torso + 512-unit linear la yer with ReLU), that maps state-action pairs ( 𝑠 , 𝑎 ) to scalar predictions. T o induce div ersity across particles, eac h stored state-action pair ( 𝑠 𝑗 , 𝑎 𝑗 ) in the replay buffer ( Section 5.1 ) is tagged with a binary b o otstrap mask 𝑚 𝑗 ∈ { 0 , 1 } , drawn indep endently at collection time. Giv en a mini-batch of 𝑛 samples B = { ( 𝑠 𝑗 , 𝑎 𝑗 , 𝑚 𝑗 ) } 𝑛 𝑗 = 1 , the loss is: L ( 𝜓 ; B ) = 1 𝑛 𝑛 𝑗 = 1 𝑚 𝑗 · 𝑓 𝜓 ( 𝑠 𝑗 , 𝑎 𝑗 ) 2 . The constan t zero target means that these netw orks carry no reward information and p erform no temp oral credit assignmen t; the b o otstrap mask 𝑚 𝑗 is what causes eac h particle’s netw ork to train on a different random subset of the group’s exp erience, pro ducing diverse prediction landscap es and thus diverse action-selection b eha vior. Although the netw orks conv erge tow ard zero, exact numerical ties across actions are rare in practice b ecause the different masked training subsets induce small but p ersistent differences in the predicted v alues, so the arg max still pro duces a deterministic, temp orally consistent action for each state (see the remark in Section 5.3 ). E.2 MuJoCo (Con tin uous Actions) Eac h particle maintains a Soft Actor-Critic (SA C) mo dule. Both the actor and the twin critic use indep endent CNN observ ation enco ders (standard Atari con volutional torso with orthogonal initialization). The actor net work maps the flattened visual embedding through a tw o-lay er MLP ( 128 × 128 , ReLU) to the mean and v ariance of a T anh-squashed Normal distribution ov er actions in [ − 1 , 1 ] . The twin critic consists of tw o indep enden tly parameterized netw orks 𝑄 𝜙 1 and 𝑄 𝜙 2 ; each concatenates the visual embedding with the action v ector and passes the result through a tw o-lay er MLP ( 128 × 128 , ReLU) to pro duce a scalar 𝑄 -v alue. The training pro cedure mirrors the discrete case. Each sample stored in the replay buffer is tagged with a binary b ootstrap mask 𝑚 𝑗 ∈ { 0 , 1 } to induce div ersity across particles. Given a mini-batc h of 𝑛 samples B = { ( 𝑠 𝑗 , 𝑎 𝑗 , 𝑚 𝑗 ) } 𝑛 𝑗 = 1 , the three losses are as follo ws. The critic loss , minimized ov er ( 𝜙 1 , 𝜙 2 ) , trains b oth 29 net works to output zero: L critic ( 𝜙 1 , 𝜙 2 ; B ) = 1 𝑛 𝑛 𝑗 = 1 𝑚 𝑗 · h 1 2 𝑄 𝜙 1 ( 𝑠 𝑗 , 𝑎 𝑗 ) 2 + 1 2 𝑄 𝜙 2 ( 𝑠 𝑗 , 𝑎 𝑗 ) 2 i . The actor loss , minimized ov er 𝜃 , is entrop y-regularized. F or each state 𝑠 𝑗 in the batch, an action 𝑎 ′ 𝑗 ∼ 𝜋 𝜃 ( · | 𝑠 𝑗 ) is sampled from the current p olicy , and L actor ( 𝜃 ; B ) = 1 𝑛 𝑛 𝑗 = 1 𝑚 𝑗 · 𝛼 log 𝜋 𝜃 ( 𝑎 ′ 𝑗 | 𝑠 𝑗 ) − 𝑄 min ( 𝑠 𝑗 , 𝑎 ′ 𝑗 ) , where 𝑄 min ( 𝑠 , 𝑎 ) = min 𝑄 𝜙 1 ( 𝑠 , 𝑎 ) , 𝑄 𝜙 2 ( 𝑠 , 𝑎 ) . The temp er atur e loss , minimized ov er scalar 𝛼 > 0 , adjusts the en tropy weigh t automatically: L temp ( 𝛼 ; B ) = 1 𝑛 𝑛 𝑗 = 1 − 𝛼 · log 𝜋 𝜃 ( 𝑎 ′ 𝑗 | 𝑠 𝑗 ) + 𝐻 target , where 𝐻 target = − dim ( A ) , i.e., the negative dimensionality of the action space. F Distributed Implemen tation Details This app endix provides a detailed description of the distributed architecture used to scale GowU to high- dimensional en vironments. The system decouples en vironment sim ulation, p opulation management, and parameter optimization, enabling high-throughput exploration. It consists of three main logical components comm unicating asynchronously: a c entr al c o or dinator , a p o ol of distribute d r ol lout workers , and asynchr onous le arning no des . F.1 Cen tral Co ordinator The central co ordinator acts as the orchestrator of the search. It manages the global state of the p opulation and co ordinates the branches of exploration. Its resp onsibilities are as follows: P opulation state managemen t. The co ordinator tracks the status of all 𝑀 × 𝑁 particles, including eac h particle’s current environmen t c heckpoint, cumulativ e reward, and surviv al status ( alive or dead , as defined in Section 3 ). State-lineage tree main tenance. The co ordinator hosts the global state-lineage tree ( Section 4.1 ) and is resp onsible for expanding it with new no des as work ers rep ort completed rollouts. The Go-With-The-Winner loop. The co ordinator drives the top-level iterations of the GWTW lo op ( Algorithm 2 ). Eac h iteration pro ceeds in three phases: 1. Dispatc h: The co ordinator issues remote pro cedure calls (RPCs) to trigger rollouts on the work er p o ol, pro viding each work er with the starting chec kp oint, the group index, and the ensemble member index. The work ers independently fetch the latest p olicy weigh ts from the learning nodes before b eginning their rollouts. 2. Aggregate: It w aits for all parallel rollouts to complete and collects the resulting endp oin ts, tra jectories, and rew ards. 3. Sync and prune: The co ordinator applies the winner-selection and pruning logic ( Section 4.2 ) and instructs the w orkers to ov erwrite failing particles with clones of the winners. F.2 Distributed Rollout W ork ers The work ers are parallel execution no des that drive environmen t interactions. They act as stateless clients that execute directiv es issued by the co ordinator. 30 State restoration. Each work er receives a compact en vironment snapshot (c heckpoint) from the global lineage tree and restores the lo cal simulator to that exact state b efore starting a rollout. Ensem ble weigh t fetc hing. T o initialize a rollout, the w orker fetches the latest p olicy parameters from the learning no de using tw o indices provided by the co ordinator: • Gr oup index 𝑔 ∈ { 1 , . . . , 𝑀 } : identifies the parameter batch b elonging to the w orker’s group. • Ensemble memb er index idx ∈ { 0 , . . . , 𝑁 − 1 } : indexes into the group’s ensemble to select a single set of net work weigh ts, where 𝑁 is the num b er of particles (and ensemble members) p er group. The co ordinator computes the ensem ble member index determinis tically from the particle’s global index 𝑖 ∈ { 0 , . . . , 𝑁 𝑀 − 1 } via idx = 𝑖 mo d 𝑁 and passes it directly to the work er during dispatc h. Rollout execution. The work er steps through the en vironment for the prescrib ed num b er of steps, sampling actions from the p olicy parameterized by the fetched weigh ts. Bac k-rep orting. Up on completing the rollout, the work er transmits the endp oint environmen t chec kp oint and cum ulative reward back to the coordinator. The co ordinator uses these to create a new no de in the state-lineage tree ( Section 4.1 ), which stores only the endp oint chec kp oin t, cumulativ e reward, and a parent p oin ter. F.3 Async hronous Learning No des T o keep exploration dynamic, the uncertaint y estimator and particle p olicy weigh ts must up date contin uously as new states are discov ered. Distributed experience repla y . W orkers stream their state-action data into per-group replay buffers ( Section 5.1 ). Async hronous up dates. Learning no des consume data from these buffers contin uously , running gradient- descen t steps to up date the uncertaint y estimator ( Section 5.2 ) and the particle p olicies ( Section 5.3 ). The uncertain ty estimator is trained on data aggregated from all 𝑀 groups, while each group’s p olicy ensemble is trained on group-sp ecific data only . P arameter broadcasting. Up dated weigh ts are p erio dically pushed to a parameter server from which the co ordinator and work ers fetch the latest parameters to guide subsequent rollouts. F.4 Computational Resources T able 6 rep orts wall-clock run time, exploration score, and the n umber of RND SGD steps for Phase I of GowU on Montezuma’s R evenge , a veraged ov er 100 seeds. Eac h run uses the distributed architecture describ ed in Section 5.1 with 1 TPU for the RND uncertain ty estimator, 1 TPU for the ensemble of particle p olicies, 128 CPUs (one p er rollout work er), and 1 CPU for the co ordinator. T able 6: Computational cost of GowU Phase I on Montezuma’s R evenge , av eraged ov er 100 seeds. Metric 100M frames 200M frames 300M frames 400M frames Clo c k runtime (hours) 13 . 72 ± 2 . 50 27 . 43 ± 6 . 73 39 . 28 ± 13 . 58 46 . 89 ± 21 . 05 A verage score 49 , 382 ± 20 , 924 77 , 006 ± 25 , 844 91 , 518 ± 26 , 843 98 , 758 ± 25 , 782 RND SGD steps 2 . 89 M ± 0 . 45 M 5 . 88 M ± 1 . 28 M 8 . 61 M ± 3 . 22 M 11 . 20 M ± 11 . 55 M G Implemen tation Details for the Bac kw ard Algorithm Here, we describ e our implementation of the backw ard algorithm. W e first explain how demonstrations are decomp osed in to segments and then detail the curriculum learning strategy applied to eac h segment. Finally , w e provide the sp ecific configuration parameters and hyperparameters used in our exp erimen ts. 31 G.1 Ov erview and segmentation Our approach builds on the backw ard learning algorithm of Salimans and Chen ( 2018 ), as also used in the robustification p hase of Go-Explore ( Ecoffet et al. , 2021 ), and extends it with several mo difications. The agen t learns to solv e the task by starting from states near the end of a demonstration and gradually mo ving the starting p oin t backw ards. T o break a single long backw ard tra jectory into smaller, more manageable ch unks— making training faster and more stable—we decomp ose each demonstration tra jectory 𝜏 = { 𝑠 0 , 𝑎 0 , 𝑟 0 , . . . , 𝑠 𝑇 } in to at most 𝐾 max segmen ts delineated b y reward even ts. Concretely , w e first identify all timesteps at which the agent receives a non-zero reward. If there are more su c h timesteps than 𝐾 max , we evenly downsample them to obtain exactly 𝐾 max b oundary p oints. Let 𝑇 𝑘 denote the 𝑘 -th selected b oundary; segment 𝑘 then co vers the p ortion of the tra jectory culminating at 𝑇 𝑘 . F or Atari, we set 𝐾 max = 10 ; for the MuJoCo tasks (A droit and AntMaze), we set 𝐾 max = 1 , treating the entire demonstration as a single segmen t where the starting state is progressively mov ed bac k tow ard the initial state. Our implementation supp orts training on m ultiple demonstrations simultaneously: each demonstration is segmented indep enden tly . Imp ortan tly , the resulting segmen ts are not simply aggregated into a flat p o ol; the system tracks the ordering of segments and whic h demonstration each segment originates from, since each segment’s curriculum window is allow ed to extend bac kward b eyond the segment’s own start b oundary . Distributed architecture. The system uses a distributed actor-learner architecture. A centralized curriculum server main tains the global curriculum state—tracking the current start index, and success rates for every segment—and serves starting states to the actors. Multiple distributed actors concurrently fetch start states from the curriculum server, execute episo des, and stream tra jectories to a centralized le arner , whic h contin uously up dates the PPO p olicy weigh ts. Bac kground evaluators run asynchronously , p erio dically fetc hing the latest weigh ts to assess p erformance (se e Section G.6 ). This architecture allo ws the algorithm to learn differen t stages of the task in parallel, scaling efficiently with the num b er of actors. G.2 Curriculum strategy F or a c hosen s egmen t ending at 𝑇 end , the curriculum main tains a curr ent start index 𝑡 curr (initially set to 𝑇 end ) and a fixed window size Δ . This index represents the latest p oint in the tra jectory from whic h the agen t is currently learning to reac h the segment’s goal. The curriculum dynamically adjusts the start p osition based on the agent’s p erformance. State sampling. At the beginning of an episo de, a start index 𝑡 start is sampled uniformly from the interv al [ 𝑡 curr − Δ , 𝑡 curr ] . The en vironment is reset to the state 𝑠 𝑡 start from the demonstration. Success criteria. An episo de is considered successful if the agent achiev es a return 𝑅 agent comparable to the return of the demonstration segment from 𝑡 start to 𝑇 end , denoted as 𝑅 demo ( 𝑡 start ) . Success is strictly defined as: 𝑅 agent ≥ 𝑅 demo ( 𝑡 start ) − 𝜀 tol where 𝜀 tol is a tolerance parameter (see T able 8 for environmen t-sp ecific v alues). An episo de is terminated early if the num b er of steps exceeds 𝜇 · 𝐿 + 𝑏 , where 𝐿 is an exp onential moving av erage (with smo othing factor 𝛼 = 0 . 9 ) of successful rollout lengths, 𝜇 = 2 . 0 is a multiplier, and 𝑏 is a fixed buffer ( 𝑏 = 500 by default; 𝑏 = 100 for A droit). F or Atari, training episo des are additionally terminated early up on loss of life; for An tMaze, episo des are terminated if the ant flips ov er (see App endix D ). Curriculum progression. The curriculum tracks the success rate 𝑆 o ver a buffer of the most recent 𝑁 update rollouts. T wo distinct success thresholds gov ern progression: • Regression (moving bac kwards): If 𝑆 ≥ 𝑆 req (default 0 . 2 ), the window mo ves backw ard to include earlier states. The current start index is up dated as 𝑡 curr ← max ( 0 , 𝑡 curr − 𝛿 back ) , where the step size 𝛿 back is sampled uniformly from [ 𝛼 dec · Δ , 𝛽 dec · Δ ] . Here, 𝛼 dec and 𝛽 dec are decrease multipliers that con trol the step size range (see T able 8 ). This sto c hastic step size prev ents the curriculum from getting stuc k in lo cal cycles. Note that the low er b ound is the absolute b eginning of the demonstration (the initial state), not the b eginning of the segment; this means the curriculum window for a given segment can extend well b eyond the segment’s own start b oundary , and each segment’s curriculum even tually 32 requires the agent to achiev e the segment’s reward target starting from the very b eginning of the demonstration. • Simplification (mo ving forw ards): If 𝑆 < 𝑆 req , the task is deemed too difficult, and the windo w mo ves forward. The up date is 𝑡 curr ← min ( 𝑇 end , 𝑡 curr + 𝛿 fwd ) , where the step size 𝛿 fwd is sampled uniformly from [ 𝛼 inc · Δ , 𝛽 inc · Δ ] , with 𝛼 inc and 𝛽 inc b eing the increase multipliers. • Completion criterion: When 𝑡 curr reac hes step 0 (the b eginning of the demonstration), a stricter threshold 𝑆 req,begin = 0 . 95 must b e met b efore the segment is considered solved. This ensures the agent can reliably execute the full tra jectory from the very start of the demonstration to the segmen t’s reward b oundary . G.3 En vironmen t-sp ecific configurations The bac kward curriculum is configured differently across environmen t families: A tari (Montezuma’s Revenge, Pitfall!, V enture). Demonstrations are decomp osed into up to 𝐾 max = 10 segmen ts. The windo w size is Δ = 25 , and the decrease/increase m ultipliers are ( 𝛼 dec , 𝛽 dec ) = ( 0 . 25 , 0 . 75 ) and ( 𝛼 inc , 𝛽 inc ) = ( 0 . 5 , 1 . 0 ) , resp ectively . F or Montezuma’s R evenge and V entur e , reward clipping is applied (b ounding cum ulative targets to [ − 1 , 1 ] ) with a strict tolerance 𝜀 tol = 0 . F or Pitfal l! , rewards are scaled b y 0 . 001 (without clipping) and the tolerance is relaxed to 𝜀 tol = 1500 to accommo date the game’s scoring structure, where the agent can lose p oin ts. F or Montezuma’s R evenge , the agent’s observ ations include the frame at which the last reward was received, providing context when the same ro om app ears multiple times in a demonstration. A dditionally , after successfully achieving the segment’s reward target, the agent is allo wed to contin ue playing for a random num b er of extra frames (up to ∼ 𝑒 7 ≈ 1096 ); this provides additional exploration b ey ond the target state. A droit (do or, hammer, relo cate). The entire demonstration is treated as a single segmen t ( 𝐾 max = 1 ). The windo w size is reduced to Δ = 3 , and all multipliers are set deterministically to 1 / 3 , remo ving the sto chastic step-size v ariation. In termediate contact rew ards from Phase I are discarded; only task-completion even ts are used as reward signals. During the backw ard curriculum, the goal configuration (i.e., the randomized target lo cation and ob ject placement) is held fixed to the one used during exploration. Whenever an actor samples a start index of 0 from the curriculum window, the episo de uses a clean environmen t reset (i.e., a true env.reset() , which randomizes the goal configuration). This allows the p olicy to b egin generalizing across target lo cations and ob ject placements. An tMaze. As with Adroit, the demonstration is treated as a single segment ( 𝐾 max = 1 ). The window size is Δ = 25 . An action rep eat of 4 is applied. Clean environmen t resets are used whenever an actor samples a start index of 0 , as describ ed ab ov e for Adroit. The PPO batch size is reduced from 128 to 64 (this is mainly to a void out-of-memory errors). G.4 Agen t arc hitecture W e use Pro ximal Policy Optimization (PPO) as the underlying reinforcement learning algorithm. The p olicy and v alue functions use separate encoders based on the IMP ALA ResNet architecture ( Esp eholt et al. , 2018 ), eac h follow ed by fully connected la yers. F or Atari, each enco der feeds into a dense la yer of size 1024 , follow ed b y p olicy and v alue heads of size 512 . F or Adroit and AntMaze, the architecture is scaled down (to av oid out-of-memory errors): the dense lay er is 512 , and the p olicy and v alue heads are 256 each. The encoder input v aries by en vironment; see App endix C for details on the observ ation processing pip eline for each en vironment family . G.5 Hyp erparameters and configuration F or each demonstration, we run on 5 random seeds. Consisten t with Go-Explore , w e use reward clipping on Montezuma’s R evenge and V entur e , and reward scaling on Pitfal l! . 33 T able 7: PPO Hyp erparameters (defaults; see Section G.3 for environmen t-sp ecific ov errides). P arameter V alue Optimizer A dam Learning Rate 1 × 10 − 4 Discoun t F actor ( 𝛾 ) 0.999 GAE Lam b da ( 𝜆 ) 0.95 Unroll Length 128 Batc h Size 128 (64 for AntMaze) Num Ep ochs 1 Num Minibatc hes 8 En tropy Cost 1 × 10 − 3 V alue Cost 0.5 PPO Clipping ( 𝜀 ) 0.1 Max Gradien t Norm 0.5 Shared Dense La yer 1024 (512 for Adroit/An tMaze) P olicy/V alue Head 512 (256 for Adroit/An tMaze) T able 8: Backw ard Algorithm Configuration (defaults; see Section G.3 for environmen t-sp ecific ov errides). P arameter V alue Required Success Rate ( 𝑆 req ) 0.2 Completion Threshold ( 𝑆 req,begin ) 0.95 Start delta windo w ( Δ ) 25 (3 for Adroit) Min Rollouts for Up date ( 𝑁 update ) 32 Decrease Multipliers ( 𝛼 dec , 𝛽 dec ) 0.25, 0.75 ( 1 3 , 1 3 for A droit) Increase Multipliers ( 𝛼 inc , 𝛽 inc ) 0.5, 1.0 ( 1 3 , 1 3 for A droit) F ailure Reward T olerance ( 𝜀 tol ) 0 (1500 for Pitfall) EMA Smo othing F actor ( 𝛼 ) 0.9 Early T ermination Multiplier ( 𝜇 ) 2.0 Rollout Length Buffer ( 𝑏 ) 500 (100 for Adroit) G.6 Ev aluation A bac kground ev aluator runs concurren tly with training: it p erio dically fetches the latest p olicy weigh ts from the learner and executes ev aluation rollouts using the deterministic (mo de) v ersion of the p olicy . During training, we run 10 rollouts per ev aluation for A tari and 30 for MuJoCo, and track the best-p erforming c heckpoint based on these p erio dic ev aluations. T raining budget. F or Atari, we train for 15 – 20 B environmen t frames. F or MuJoCo, training con tinues un til all segments hav e b een solved with the 95% completion threshold ( 𝑆 req,begin ). Final ev aluation. After training is complete, we p erform a dedicated ev aluation of the b est c heckpoint iden tified during training. This chec kp oin t is ev aluated on 500 rollouts to pro duce the final p olicy score. Ev aluation heuristics. A w ell-known exploit in Montezuma’s R evenge allo ws the agent to remain in a treasure ro om and collect 1 , 000 -p oin t rewards indefinitely by rep eating a sp ecific action sequence, without progressing to the next level. T o prev ent this from inflating ev aluation scores, the ev aluator monitors for consecutiv e rewards of exactly 1 , 000 p oin ts. If 30 or more such consecutive rewards are detected, the rollout is immediately discarded. 34 H Montezuma’s R evenge Middle Ro om Bug During exploration, w e discov ered a previously undo cumen ted bug in Montezuma’s R evenge that o ccurs in the midd le r o om of each level (the ro om containing a torch and a rolling skull). Figure 7 illustrates the bug sequence frame b y frame: the agent, p ositioned on the rop e on the right-hand side of the ro om (F rame − 4 ), jumps to the left and progressiv ely approaches the platform where the rolling skull patrols (F rames − 3 through − 1 ), even tually making contact with the platform (F rame 0 ). If the agent is carrying a key at the time of contact, the k ey is consumed and a reward is collected. Since the key in the first room respawns p eriodically after a sufficien t delay ( Salimans and Chen , 2018 ), the agent can return, re-acquire it, and rep eat the pro cess indefinitely , creating an infinite reward lo op that traps the agent in the same level and preven ts further exploration. F rame − 4 F rame − 3 F rame − 2 F rame − 1 F rame 0 Figure 7: F rame-b y-frame illustration of the middle ro om bug in Montezuma’s R evenge . The agent starts on the rop e (F rame − 4 ), jumps left, and hits the skull platform (F rame 0 ), losing a key and collecting an unin tended reward. T o preven t the algorithm from exploiting this glitch, we emplo y a tw o-step visual detection heuristic that activ ates whenever a p ositive reward is registered. Step 1: Lo cation v erification. W e first determine whether the agent is currently in the middle ro om. A fixed 20 × 20 spatial crop of the current frame is extracted from a region that uniquely iden tifies this ro om. The crop is compared against a pre-recorded set of reference crops from the middle room across different game lev els using the L2 norm (Euclidean distance). If the pixel-wise distance is b elow a small threshold, the agen t is confirmed to b e in the middle ro om. Step 2: Action v erification. If the lo cation chec k passes, we verify whether the agent has just p erformed the bugged action (jumping off the rope). W e insp ect the agen t’s last four frames (as sho wn in Figure 7 ) and isolate a b ounding b ox cov ering the area where the rop e sequence takes place. The maximum pixel-wise difference betw een consecutive frames in this region is computed; if it exceed s a threshold, it indicates a sudden burst of mov ement consistent with the visual signature of the agent jumping off the rop e. In terven tion. If a p ositive reward is received while b oth visual conditions are simultaneously satisfied, the rew ard is flagged as an exploit and the particle is immediately marked as dead . This ensures the buggy particle will never b e selected as a winner; instead, at the next GowU redistribution step, it will b e replaced b y a clone of the current winner—a non-buggy particle—and exploration resumes from a v alid state. 35
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment