LLM-Powered Workflow Optimization for Multidisciplinary Software Development: An Automotive Industry Case Study
Multidisciplinary Software Development (MSD) requires domain experts and developers to collaborate across incompatible formalisms and separate artifact sets. Today, even with AI coding assistants like GitHub Copilot, this process remains inefficient;…
Authors: Shuai Wang, Yinan Yu, Earl Barr
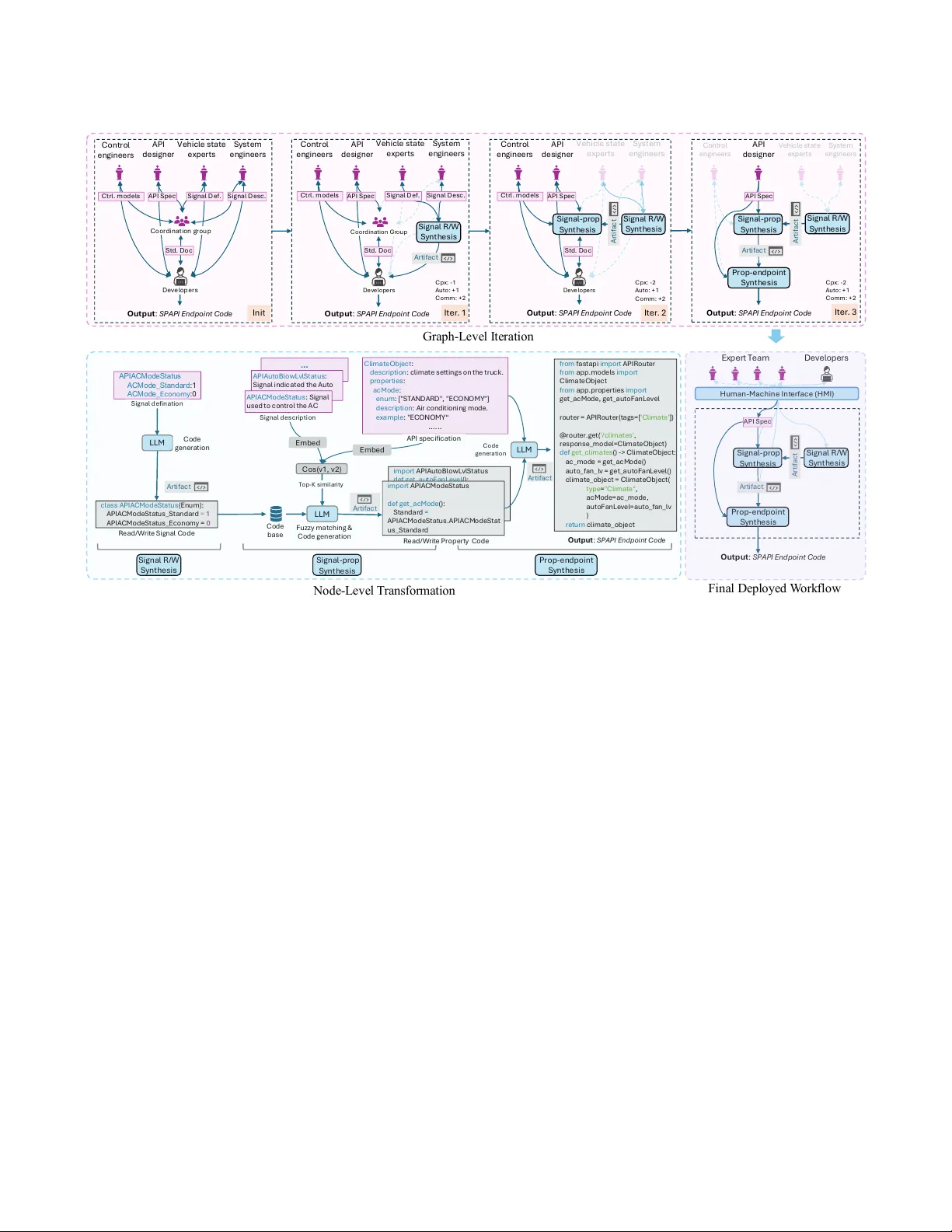
LLM-Pow ered W orkf low Optimization for Multidisciplinary Soware De velopment: An A utomotive Industry Case Study Shuai W ang Chalmers University of T echnology Gothenburg, Sweden shuaiwa@chalmers.se Yinan Y u Chalmers University of T echnology Gothenburg, Sweden yinan@chalmers.se Earl Barr University College London London, United Kingdom e.barr@ucl.ac.uk Dhasarathy Parthasarathy V olvo Group Gothenburg, Sweden dhasarathy .parthasarathy@volvo.com Abstract Multidisciplinary Software De velopment (MSD ) r equires domain ex- perts and developers to collaborate across incompatible formalisms and separate artifact sets. T oday , e ven with AI co ding assistants like GitHub Copilot, this process remains inecient; individual coding tasks are semi-automate d, but the workow conne cting domain knowledge to implementation is not. Dev elopers and experts still lack a shared view , resulting in repeate d coordination, clarication rounds, and error-pr one handos. W e address this gap through a graph-based worko w optimization approach that progressively re- places manual coordination with LLM-powered services, enabling incremental adoption without disrupting established practices. W e evaluate our approach on spapi , a production in-vehicle API sys- tem at V olvo Group involving 192 endpoints, 420 properties, and 776 CAN signals across six functional domains. The automated workow achiev es 93.7% F1 score while reducing per-API de velop- ment time from approximately 5 hours to under 7 minutes, saving an estimated 979 engineering hours. In production, the system re- ceived high satisfaction from both domain experts and developers, with all participants reporting full satisfaction with communication eciency . Ke ywords Multidisciplinary Software Development, A utomation, W orkow Optimization, Large Language Model A CM Reference Format: Shuai W ang, Yinan Y u, Earl Barr, and Dhasarathy Parthasarathy. 2026. LLM- Powered W orkow Optimization for Multidisciplinary Software De velop- ment: An A utomotive Industry Case Study . In 34th ACM Joint European Soft- ware Engineering Conference and Symposium on the Foundations of Software Engineering (FSE Companion ’26), July 05–09, 2026, Montreal, QC, Canada. A CM, Montreal, Canada, 11 pages. https://doi.org/10.1145/3803437.3805251 This work is licensed under a Cr eative Commons Attribution 4.0 International License . FSE Companion ’26, Montreal, QC, Canada © 2026 Copyright held by the owner/author(s). ACM ISBN /2026/07 https://doi.org/10.1145/3803437.3805251 D ep l o y m e n t - R e ad y C o d e C o n t r o l e n g i n e e r s A P I d e s i g n e r V e h i c l e s t a t e e x pe r t s Sy s t e m e n g i n e e r s S t d . D o c D e v e l o p e r s Co o r d i n a t i o n g r o u p E x p er t T ea m D e p l o y m e n t - R ead y C o d e Ct r l . d o c A P I S p e c S i g n a l D e f . S y s . d o c S e rv e r 2 S e rv e r 3 S e rv e r 1 E x p e r t s D o m a i n k n o w l e d g e c o n t r o l S p e c S i g n a l s I n t e g r a t i o n O u t p u t C o m m u n i c a t i o n D e v e l o p e r s r e v i e w ( a ) C om m on M S D W or kf l ow ( b ) O pt i m i z e d W or kf l ow Figure 1: Comparison of workows in the Multidisciplinary Software Development (MSD) process: (a) a typical MSD work- ow and (b) optimize d workow through automated transla- tion via our graph-based approach. 1 Introduction In many industrial software projects, domain experts and software developers must collaborate across disciplinar y boundaries, coordi- nating through heterogeneous artifacts that each party produces, maintains, and evolves independently . Exp erts contribute specica- tions, signal denitions, and design documents grounded in their respective domains, while de velopers must r econcile these artifacts and translate them into a unied, executable codebase. This coordi- nation pattern is straightfor ward when artifacts are few and stable, but becomes a persistent b ottleneck as systems grow in scope and the number of contributing disciplines increases. The automotive industry , with its deep regulatory requirements, safety-critical con- straints, and multidisciplinary teams, oers an instructive example of how document-to-code translation can dominate engineering eort [31]. This pattern is characteristic of Multidisciplinary Software De- velopment (MSD), which arises whene ver software systems must encode specialized kno wledge from non-software domains. In MSD settings, domain experts (engineers, scientists, regulators, or busi- ness analysts) produce specications using discipline-specic for- malisms that software developers must interpret, align, and im- plement as coherent system behavior [ 24 ]. The collaboration is FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada Shuai W ang, Yinan Y u, Earl Barr, and Dhasarathy Parthasarathy inherently two-way: developers translate domain requirements into code, while domain experts must understand implementation constraints to rene their specications [ 15 , 41 ]. This continuous dialogue creates value by embedding deep expertise into software, but it also introduces persistent operational challenges that scale poorly with system complexity . This paper presents a practical case study in automotive soft- ware development at V olvo Group. W e use spapi as a running example: an in-vehicle web server that exposes vehicle state and control-related properties through RESTful APIs to driver-facing mobile applications as well as backend ser vices. Developing spapi requires a multidisciplinary team, including product owners, busi- ness translators, UI and app designers, Android engineers, software developers, control engineers working in MA TLAB/Simulink, sys- tem engineers, and system architects. These roles r ely on distinct technical vocabularies, toolchains, and artifact formats, and changes in one domain often propagate to others in ways that ar e dicult to anticipate or track. Using this case study , we highlight recurring operational problems in translating domain artifacts into co de and show how LLM-based automation can substantially reduce manual overhead while maintaining delivery quality . Figure 1 illustrates a common pattern we obser ve in MSD: re- quirements are authored across heterogeneous documents by dier- ent stakeholders, then manually translated by developers into im- plemented endpoints, followed by repeated feedback cycles where feasibility and constraints are communicate d back to domain ex- perts for renement. In spapi , this translation spans a patchwork of documents and a correspondingly tedious patchwork of imple- mentation tasks, which slows delivery and increases the risk of de- fects. Our goal, shown in Figure 1(b), is to automate the translation from domain artifacts to spapi endpoints. Achieving this requires transforming the MSD workow itself: we reorganize the hand- os and dependencies so that LLM-power ed services can replace repeated manual coordination. W e design this worko w transfor- mation using a graph-based r epresentation of the artifacts and their dependencies. W e make four contributions relevant to practitioners facing similar MSD challenges: • W e showcase the operational reality of artifact-driv en mul- tidisciplinary development at scale by characterizing the translation bottleneck in spapi , an in-vehicle API system at V olvo Group. The failure modes we identify generalize across industries where software must enco de spe cialized domain knowledge, oering practitioners a v ocabulary for diagnosing similar ineciencies in their own workows. • W e show that automating translation requires transform- ing the MSD workow itself, not just accelerating individ- ual co ding tasks. W e mo del the workow as a graph of artifacts, dependencies, and handos, and use this repre- sentation to systematically restructure the process so that LLM-powered services can incrementally replace manual coordination while keeping domain experts in the lo op and minimizing disruption to established practices. • W e provide quantitative evidence fr om a deployed system that generates 192 real-world API endpoints across six in- dustrial domains. Compared to semi-automated implemen- tations (human developers assisted by GitHub Copilot), the automated workow achieves a 93.7% F1 scor e and reduces per- API development time from approximately 5 hours to under 7 minutes, saving an estimated 979 engineering hours across the endpoint portfolio. • W e report deployment experience and stakeholder feedback from production use at a major automotive manufacturer . Do- main experts and developers using the system daily reported high satisfaction (averaging 4.80 and 4.67, respectively , on a 5-point scale), indicating that the approach delivers practical value beyond oine metrics. The r est of this paper is organized as follows. Section 2 describes the spapi system and its workow challenges. Section 3 pr esents our optimization approach. Section 4 reports results and stakeholder feedback. Se ction 5 discusses practical considerations, Section 6 reviews r elated work, and Section 7 concludes. 2 The spapi System spapi is an in-vehicle web ser ver deployed at V olvo Group that provides an authenticated API lay er mapping vehicle signals and control state to well-typed RESTful endpoints. Driver-facing mobile applications and backend eet services consume these endpoints to display vehicle status, adjust comfort settings, and monitor oper- ational parameters across the vehicle ’s functional domains. Developing and maintaining spapi has required 15 to 20 full- time engineers (FTEs) to deliver more than 100 APIs across six functional domains: driver productivity , connected systems, energy management, vehicle systems, visibility , and dynamics. Three types of artifacts drive this workow . OpenAPI specications dene end- point behavior , data types, and interface contracts; they capture the essential complexity of the system and serve as the authoritative source for mobile and cloud integration [ 20 ]. Signal denitions describe low-level CAN bus messages that encode vehicle state, au- thored by control engineers and system architects with knowledge of the physical systems. Mapping documents bind high-level API properties to their underlying signals, spe cifying how abstractions like “climate mode ” translate to specic CAN message elds. The typical workow proceeds through a sequence. Domain experts produce requirements and signal descriptions based on ve- hicle capabilities and business ne eds. Developers manually convert those documents into endpoints, adapters, data models, and tests, consulting the various artifact types to understand how each API property should behave. A dedicated coordination group , supple- mented by direct contact with domain experts, resolves ambiguities that arise when specications are incomplete or inconsistent. Under this workow , dening a single API could take as long as 10 weeks from initial specication to deployment-ready code. Observed Pr oblems. Four problems characterize the worko w’s failure modes, each contributing to ineciency that comp ounds as the system scales. Fragmented artifacts. Multiple overlapping documents, in- cluding API specications, signal denitions, detaile d descriptions, and coordination notes, describe related information in dierent formats and at dierent levels of abstraction. Developers must cross- reference and align these sources to produce correct implementa- tions. When artifacts fall out of sync, as they frequently do during LLM-Powered W orkf low Optimization for Multidisciplinary Soware Development FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada requirements evolution, the reconciliation burden compounds and error opportunities multiply . Manual-translation overload. Developers spend substantial eort transcribing information from specications and signal de- nitions into code, drawing time away from higher-value work such as design, testing, and verication. Even with co ding agents like GitHub Copilot, they must still locate relevant artifacts, interpret domain-specic formalisms, reconcile inconsistencies, and consult domain experts to resolve ambiguities. This burden scales with API and signal count. With over 400 unique properties and 776 associated CAN signals in the spapi system, translation remains a persistent bottleneck that co ding assistants alone cannot remove; the workow itself must be automated. Ambiguity-driven churn. Underspecied domain documents trigger repeated clarication between developers and experts, con- suming time and sometimes invalidating earlier implementation decisions. Signal denitions in spapi were often so concise as to be ambiguous, requiring consultation with vehicle state experts, system engineers, and sometimes control engineers, whose disci- pline has deep technical foundations spanning decades [ 5 ]. A single ambiguous signal could delay implementation by days. Coordination bottlene cks. The co ordination group created to streamline information ow in spapi development pro ved insu- cient for managing hundreds of API properties and vehicle signals. Developers began bypassing it to contact domain experts directly , creating ad hoc communication patterns that were hard to track and prone to inconsistency . Once such workarounds start delivering value, organizational inertia makes them dicult to replace , even when their ineciency is widely recognized. Industry Implications. These problems are not unique to auto- motive systems. Similar bottlenecks arise wherever software must encode specialized domain knowledge and development requires ongoing coordination across disciplinary boundaries. The consequences comp ound at scale. Manual transcription shifts engineering time away from architecture, testing, and verica- tion, increasing both development costs and defect risk. Fragmented artifacts and frequent clarication cycles produce inconsistent im- plementations, with conicts discover ed late in integration when rework costs are highest. As product scope or regulatory require- ments grow , stang and co ordination overhead increase dispro- portionately , y et adding engineers provides only temporary relief without addressing underlying ineciencies. Perhaps most criti- cally , domain understanding becomes concentrate d in role-specic artifacts and individual expertise; when personnel change or speci- cations evolve , the implicit knowledge embedded in translation decisions can be lost, forcing costly rediscovery . These failure modes motivate automation strategies that reduce manual handos through tighter artifact-code integration and tar- geted tooling. The following sections describ e our approach and its application to spapi . Our A pproach. W e address these challenges through an iterative workow optimization approach that models the MSD process as a graph and progressively automates manual translation nodes. The workow graph repr esents participants (domain experts, dev elop- ers, and automated services) as nodes, with artifact exchanges as edges. This r epresentation makes explicit the communication struc- ture that drives development eort and highlights where manual translation creates bottlenecks. W e apply a series of graph transformations that replace manual nodes with LLM-powered services, reducing complexity and com- munication overhead while preserving the information ows that domain experts rely upon. Each transformation targets a sp ecic translation task: generating signal access code from denitions, aligning API properties with corresponding signals, and assem- bling complete endpoints from validated components. Rather than replacing the entire workow at once , we incrementally automate individual tasks, validating each step with domain experts before proceeding to the next. This graph-based perspe ctive enables systematic identication of automation opportunities and provides a framework for mea- suring improvement across iterations. The result is a production pipeline comprising three coordinated services that reduce per- API development time from appro ximately 5 hours to under 7 minutes while achieving quality comparable to manual implementation. 3 Methods and Implementation This section describes our approach to automating artifact-driven multidisciplinary workows. W e model the development pr ocess as a graph and apply iterative transformations that replace manual translation tasks with LLM-powered services. 3.1 W orkow Graph Representation T o formalize the complex interactions in software development, we represent the workow as a directed dependency graph G = ( V , R ) . W e dene nodes V as concrete artifacts (e.g., specication documents, signal denitions, or constraint descriptions) and edges R as information dep endencies. Formally , let V = { 𝑑 1 , 𝑑 2 , . . . , 𝑑 𝑛 } denote the set of documents generated during the workow . A relation ( 𝑑 𝑖 , 𝑟 𝑖 𝑗 , 𝑑 𝑗 ) ∈ R exists if the production or validation of do cument 𝑑 𝑗 depends on the information contained in 𝑑 𝑖 . The workow G is thus represented as a set of relational triples: G = { ( 𝑑 𝑖 , 𝑟 𝑖 𝑗 , 𝑑 𝑗 ) | 𝑑 𝑖 , 𝑑 𝑗 ∈ V , 𝑟 𝑖 𝑗 ∈ R } (1) This formulation shifts the problem of workow automation fr om managing human coordination to a structured transformation of a document dependency graph into executable code. Figure 2 (Init) shows the initial workow graph for spapi . Four expert roles participate: API designers responsible for OpenAPI specications, vehicle state experts who dene CAN signal seman- tics, system engine ers who integrate signals across subsystems, and control engineers who establish vehicle behavior constraints. These experts produce artifacts that developers must translate into code, with a coordination group mediating communication. The graph is densely connected: all four expert roles interact with each other and with developers, resulting in signicant coordination overhead. Without an explicit graph representation, such workow transfor- mations tend to remain ad-hoc, making coordination bottlene cks dicult to reason about systematically or evaluate across iterations. This workow graph G serves as the starting point for opti- mization. Our goal is to systematically replace manual translation FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada Shuai W ang, Yinan Y u, Earl Barr, and Dhasarathy Parthasarathy C o d e g e n e ra t i o n … A P I A u t o B l o w Lv l S t a t u s : S i g n a l i n d i c a t e d t h e A u t o B l o w e r l e v e l m o d e O u t p u t : S P A P I E n d p o i n t C o d e C o n t r o l e n g i n e e r s A P I d e s i g n e r V e h i c l e s t a t e e x pe r t s S y s t e m e n g i n e e r s Ct r l . m o d e l s A P I S p e c S i g n a l D e f . S i g n a l D e s c . S t d . D o c D e v e l o p e r s Co o r d i n a t i o n g r o u p C o n t r o l e n g i n e e r s A P I de s i g n e r V e h i c l e s t a t e e x pe r t s S y s t e m e n g i n e e r s Ct r l . m o d e l s S t d . D o c D e v e l o p e rs C o o rd i n a t i o n G r o u p S i g n a l R / W S y n t h e s i s S i g n a l D e s c . S i g n a l D e f . A P I S p e c C o n t r o l e n g i n e e r s A P I de s i g n e r V e h i c l e s t a t e e x pe r t s S y s t e m e n g i n e e r s Ct r l . m o d e l s S t d . D o c D e v e l o p e rs A P I S p e c Si g n a l R / W S y n t h e s i s S i g n a l - pr o p S y n t h e s i s P r o p - e n dpo i n t S y n t h e s i s C o n t r o l e n g i n e e r s A P I de s i g n e r A P I S p e c S i g n a l R / W S y n t h e s i s S i g n a l - pr o p S y n t h e s i s O u t p u t : S P A P I E n d p o i n t C o d e O u t p u t : S P A P I E n d p o i n t C o d e O u t p u t : S P A P I E n d p o i n t C o d e I n i t V e h i c l e s t a t e e x p e r t s S y s t e m e n g i n e e r s P r o p - e n dp o i n t S y n t h e s i s A P I S p e c Si g n a l R / W S y n t h e s i s S i g n a l - p r o p S y n t h e s i s A P I A C M o d e S t a t u s A C M o d e _S t a n d a r d :1 A C M o d e _ E c o n o m y :0 c l a s s A P I A C M o d e S t a t u s ( E n u m ) : A P I A C M o d e S t a t u s _ S t a n d a r d = 1 A P I A C M o d e S t a t u s _ E c o n o m y = 0 LLM C o d e b a s e S i g n a l d e f i n a t i o n R e a d / W r i t e S i g n a l C o d e C l i m a t e O b j e c t : d e s c r i p t i o n : c l i ma t e s e t t i n g s o n t h e t r u c k . p r o p e r t i e s : a c Mo d e : e n u m : [ " S T A N D A R D " , " E C O N O M Y " ] d e s c r i p t i o n : A i r c o n d i t i o n i n g m o d e . e x a mp l e : " E C O N O M Y “ … . . . A P I A C M o d e S t a t u s : S i g n a l u s e d t o c o n t r o l t h e A C C o s ( v 1, v 2) LLM C o d e g e n e r a t i o n F u z z y m a t c h i n g & C o d e g e n e r a t i o n f r o m f a s t a p i i m p o r t A P I R o u t e r f r o m a p p .m o d e l s i mp o r t C l i m a t e O b j e c t f r o m a p p .p r o p e r t i e s i mp o r t g e t _ a c M o d e , g e t _ a u t o F a n Le v e l r o u t e r = A P I R o u t e r ( t a g s = [ ' C l i m a t e ' ]) @ r o u t e r .g e t ( ' / c l i ma t e s ' , r e s p o n s e _ m o d e l = C l i m a t e O b j e c t ) d e f g e t _ c l i m a t e s () - > C l i ma t e O b j e c t : a c _ m o d e = g e t _ a c M o d e ( ) a u t o _ f a n _ l v = g e t _ a u t o F a n Le v e l ( ) c l i m a t e _ o b j e c t = C l i m a t e O b j e c t ( t y p e = " C l i ma t e " , a c M o d e = a c _ m o d e , a u t o F a n Le v e l = a u t o _ f a n _ l v ) r e t u r n c l i m a t e _ o b j e c t i m p o r t A P I A u t o B l o w Lv l S t a t u s d e f g e t _ a u t o F a n Le v e l (): i m p o r t A P I A C M o d e S t a t u s d e f g e t _ a c M o d e (): S t a n d a r d = A P I A C Mo d e S t a t u s .A P I A C M o d e S t a t u s _ S t a n d a r d E m b e d S i g n a l d e s c r i p t i o n A P I s p e c i f i c a t i o n E m b e d T o p - K s i m i l a ri t y R e a d / W r i t e P r o p e r t y C o d e O u t p u t : S P A P I E n d p o i n t C o d e LLM Si g n a l R / W S y n t h e s i s S i g n a l - pr o p S y n t h e s i s P r o p - e n dp o i n t S y n t h e s i s G ra ph - L e ve l I t e ra t i on I t er . 1 I t er . 2 I t er . 3 N ode - L e ve l T ra ns for m a t i on O u t p u t : S P A P I E n d p o i n t C o d e F i na l D e pl oye d W ork fl ow A r t i f a c t A r t i f a c t A r t i f a c t A r t i f a c t A r t i f a c t A r t i f a c t A r t i f a c t A r t i f a c t A r t i f a c t E x p er t T eam D e v e l o p e r s C p x : - 1 A u t o : + 1 C o m m : + 2 C p x : - 2 A u t o : + 1 C o m m : + 2 C p x : - 2 A u t o : + 1 C o m m : + 2 H u m an - M ac h i n e I n t e rf ac e ( H M I ) Figure 2: Iterative workow optimization framework for vehicle API generation. The upper part illustrates graph-level optimization, depicting how the initial manual workow undergoes three iterative renements to achieve a highly automated workow . The low er-right part illustrates the nal deployed workow , which comprises three server nodes. The lower-left part illustrates the detailed structure of each node. nodes with automated services, reducing graph complexity and communication overhead while preserving the information ows that domain experts require. 3.2 W orkow Optimization Framework Our framework aims to optimize the w orkow by operating at two distinct levels: node-level transformation , which automates individ- ual manual tasks, and graph-level restructuring , which streamlines the workow by eliminating redundant coordination dependencies. Node-level Transformation. At the node level, we formalize the conversion of manual translation tasks into LLM-driv en automated services. For each document node 𝑑 𝑖 ∈ V , we denote its associate d input materials as M 𝑖 (e.g., domain specications and signal def- initions) and human-provided renement instructions as I 𝑖 . The transformation process is modeled as a function: 𝑓 LLM : ( M 𝑖 , I 𝑖 ) → 𝑐 𝑖 (2) where 𝑐 𝑖 represents a modular , executable code artifact. T o ensure reliability , each 𝑐 𝑖 must pass an automated validation check Φ test : Φ test ( 𝑐 𝑖 , M 𝑖 ) → { pass, fail } (3) where Φ test relies on test cases synthesized fr om M 𝑖 . Only artifacts that satisfy Φ test = pass are accepted. Upon successful validation, the manual node 𝑑 𝑖 is substituted by an automated ser vice node 𝑠 𝑖 , which encapsulates 𝑐 𝑖 and exposes a programmatic interface. This substitution is denoted as 𝑑 𝑖 ⇒ 𝑠 𝑖 . Graph-level Restructuring. Following node-level transformations, the initial graph G evolves into an intermediate state G ′ . W e then rene the topology by identifying and removing redundant coor- dination edges. An e dge ( 𝑣 𝑖 , 𝑟 𝑖 𝑗 , 𝑣 𝑗 ) ∈ G ′ is dened as redundant if the information dependency 𝑟 𝑖 𝑗 can be resolved through dir ect programmatic invocation between their corresponding automated services. Formally , we dene an edge as isRedundant if: ∃ 𝑠 𝑖 , 𝑠 𝑗 such that 𝑑 𝑖 ⇒ 𝑠 𝑖 , 𝑑 𝑗 ⇒ 𝑠 𝑗 , and 𝑠 𝑗 can directly consume outputs of 𝑠 𝑖 . The optimized workow graph G ∗ is reached through an iterative reduction process: G ( 𝑘 + 1 ) = { 𝑟 ∈ G ( 𝑘 ) | ¬ isRedundant ( 𝑟 ) } (4) The process converges at a xed point where G ( 𝑘 + 1 ) = G ( 𝑘 ) . Throughout this reduction, domain experts conduct reviews to ensure that no essential information ow is lost. LLM-Powered W orkf low Optimization for Multidisciplinary Soware Development FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada T able 1: Scoring scheme for transformation impact across three dimensions Dimension Score Description Complexity -1 T ask or exchange removed or com- bined 0 No change +1 T ask or exchange added A utomation -1 T ask becomes more manual 0 No change +1 T ask becomes more automatic Communication -2 Less explainable AND less exe- cutable -1 Less explainable OR less executable 0 No change +1 More explainable OR more exe- cutable +2 More explainable AND more exe- cutable 3.3 Measuring Transformation Impact T o formalize the assessment, we model a transformation 𝜏 as a mapping from an original workow 𝑊 to a transformed workow 𝑊 ′ = 𝜏 ( 𝑊 ) . The overall impact of 𝜏 is evaluated along the three dimensions dened in T able 1. Let the scoring function for each dimension 𝑑 ∈ { complexity , automation , communication } be 𝑠 𝑑 ( 𝜏 ) ∈ Z , where the range and semantics of 𝑠 𝑑 are given directly by the discr ete levels in T able 1. Each score reects expert judgment on how the transformation changes the corresponding property when comparing 𝑊 and 𝑊 ′ . The transformation impact vector is then dened as s ( 𝜏 ) = 𝑠 complexity ( 𝜏 ) , 𝑠 automation ( 𝜏 ) , 𝑠 communication ( 𝜏 ) . The rst dimension measures graph complexity: whether a trans- formation adds or removes tasks and communication edges. The second measures automation level: whether work shifts from man- ual to automatic execution. The third measures communication quality through the lens of duality , i.e., the degree to which arti- facts are both explainable to humans and executable by machines. Source code with meaningful identiers and comments exemplies high duality [ 10 ]. Transformations that produce executable code with clear documentation score positively on this dimension. 3.4 Node-Level A utomation W e implemented three automated services to replace manual trans- lation tasks in the spapi workow . Each service corresponds to a distinct translation step, and together they form the pipeline sho wn in the lower portion of Figure 2. 3.4.1 Signal R/W Synthesis. The rst service generates Python code for reading and writing CAN signals. It takes signal denitions as input (signal names, data types, value ranges, and enumeration mappings) and produces functions that interface with the vehicle ’s CAN bus. c l a s s C A N S i g n a l F u n c t i o n W r i t e r ( d s p y . S i g n a t u r e ): " " " G e n e r a t e a P y t h o n f u n c t i o n t o r e a d o r w r i t e a C A N S i g n a l . - R e a d / w r i t e t h e C A N v a l u e o r i t s e n u m e q u i v a l e n t . - E n u m c l a s s n a m e = C A N S i g n a l n a m e ( n o c h a n g e s ) . - F u n c t i o n n a m e s : s t a r t w i t h ' r e a d _ ' o r ' w r i t e _ ' . - C h e c k m i n / m a x i f a v a i l a b l e . - I n c l u d e d o c s t r i n g s . " " " C A N _ S i g n a l : d i c t = d s p y . I n p u t F i e l d ( d e s c = " C A N s i g n a l m e t a d a t a " ) c o d e : str = d s p y . O u t p u t F i e l d ( d e s c = " G e n e r a t e d P y t h o n m o d u l e " ) 1 2 3 4 5 6 7 8 9 10 11 Figure 3: A simplied DSPy signature for Signal R/W Syn- thesis. The LLM generates Python functions to read or write CAN signals based on signal metadata. T a s k : A l i g n an A P I p r o p e r t y w i t h C A N s i g n a l ( s ) . L e t ’ s t h i n k s t e p by s t e p : 1) I d e n t i f y t h e A P I p r o p e r t y i n t e n t ( n a m e / v a l u e s / u n i t ) . 2) S e l e c t s e m a n t i c a l l y e q u i v a l e n t C A N s i g n a l ( s ) . 3) C h e c k v a l u e d o m a i n s ; if m i s m a t c h e d , w r i t e an e x p l i c i t m a p p i n g (e . g . , O N / O F F 0 / 1 ) . 4) C h e c k u n i t s ; if d i f f e r e n t , a n n o t a t e t h e r e q u i r e d c o n v e r s i o n (e . g . , m / s k m / h ) . 5) If t h e p r o p e r t y c o m p o s e s m u l t i p l e s i g n a l s , s p e c i f y t h e o n e - to - m a n y c o m p o s i t i o n . R e t u r n J S O N as d e f i n e d by : < D E F I N E D _ J S O N _ S C H E M A > Figure 4: Representative prompt used in the Signal-Property matching task ( simplied for clarity ). W e use the DSPy framework [ 21 ] for structured prompting, as illustrated in Figure 3. LLMs can be adapted to diverse tasks through prompting [ 7 , 8 ] and excel at processing semi-structured inputs [ 19 , 27 ]. DSPy’s TypedPredictor ensures that generated code conforms to expected typ es; if output violates constraints, the system automatically re-prompts the model. Recent work on constrained generation [ 6 , 28 , 35 ] enables LLM outputs to satisfy syntactic requirements, facilitating integration with traditional software tooling. For validation, we generate test cases using a separate LLM call and prompt the code-generating LLM to self-debug based on test failures. Once veried, signal R/W code is stored in a vector database indexed by structured signal descriptions, enabling retrieval for downstream synthesis steps. Our test-based validation approach aligns with recent work on LLM-driven test automation in automotive settings [37]. 3.4.2 Signal-Property Synthesis. The second service aligns API properties with their corresponding CAN signal handlers. A key challenge in synthesizing deployable API endp oints is correctly aligning application-level API properties with underlying CAN sig- nals. Given an API property , the system must identify the relevant CAN signals and determine how their values should be interpreted and composed to produce semantically correct behavior . This is dicult be cause API and CAN specications often diverge. V alue domains may dier (e.g., ON/OFF vs. 0/1 ), units may not match (e.g., m/s on CAN vs. km/h in the API), and some properties aggregate multiple CAN signals (e.g., a time property derived from separate minute and second signals). So, naive matching by names or types is unreliable and may introduce silent semantic errors. FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada Shuai W ang, Yinan Y u, Earl Barr, and Dhasarathy Parthasarathy from fastapi import APIRouter , Depends, HTTPExcept ion from pydantic import BaseModel from typing import Any router = APIRouter () # ======== Models (Generated from OpenAPI ) ======== class SpeedRespo nse ( BaseModel ) : speed : float unit : str # ======== Shared Dependenci es ======== def get_auth_c ontext () - > Any : # Authentica tion / authorizat ion logic return { "role" : "user" } # ======== Endpoint Template ======== @ router . get ("/vehicle /speed" , response_m odel =Response) async def get_vehicl e_speed ( request : " SpeedReque st " , auth_ctx : Any = Depends( get_auth_c ontext )) : try : speed = read_vehic le_speed () response = Response(s peed=speed, unit= "km/h" ,) return response except Exception : raise HTTPExcept ion ( status_cod e = 500 , detail= " … " ) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 Figure 5: Example of a FastAPI endpoint b oilerplate template. T a s k : I n s t a n t i a t e ( n o t f r e e l y g e n e r a t e ) a F a s t A P I e n d p o i n t f r o m an A P I s p e c i f i c a t i o n . I n p u t s : - < F a s t A P I _ E n d p o i n t _ B o i l e r p l a t e _ T e m p l a t e > - < A P I _ S P E C I F I C A T I O N > C o n s t r a i n t s : 1) T r e a t t h e O p e n A P I s p e c i f i c a t i o n as t h e s i n g l e s o u r c e of t r u t h . 2) Do n o t m o d i f y r o u t e s , m e t h o d s or s c h e m a s . 3) U s e t h e F a s t A P I t e m p l a t e w i t h o u t m o d i f i c a t i o n . 4) F i l l o n l y e n d p o i n t - s p e c i f i c l o g i c ( p r o p e r t y a c c e s s a n d r e s p o n s e c o m p o s i t i o n ) . 5) R e l y on F a s t A P I ‘ s s c h e m a - d r i v e n v a l i d a t i o n . Figure 6: A representativ e prompt used in the API Endpoint synthesis task ( simplied for clarity ). T o make these assumptions explicit and veriable, we use a JSON alignment template as an intermediate representation. The LLM must enumerate all contributing CAN signals and specify explicit value mappings, enum correspondences, and unit conversions when needed. As shown in Figure 4, generation is further guided by a chain-of-thought prompt encouraging stepwise r easoning over (i) property intent, (ii) value and unit consistency , and (iii) whether the mapping is direct, transforme d, or composed from multiple signals. T ogether , the template constraint and structured reasoning reduce hallucinated assumptions and improve robustness across heterogeneous signal specications. 3.4.3 Property-Endpoint Synthesis. The third service assembles property handlers into deployable API endpoints based on the Ope- nAPI specication. Given the API contract and generate d property accessors, it produces complete FastAPI endpoint implementations, including routing, request validation, response serialization, and error handling. Synthesizing endpoints directly from specications is error- prone. Naively generated endpoints may violate the OpenAPI con- tract by using inconsistent parameter names, omitting or introduc- ing response elds, or mismatching route paths and H T TP methods. V alidation logic such as range checks or enum constraints may also be partially implemented or omitte d, leading to subtle contract violations that are hard to detect at runtime. T o mitigate these risks, this ser vice adopts a contract-rst, template- based generation strategy . A FastAPI endpoint boilerplate template (Figure 5) xes endpoint structure, routing, schemas, and cross- cutting concerns such as authentication, logging, and error han- dling. The LLM is restricted to instantiating endpoint-spe cic logic within predened slots, guided by the prompt sho wn in Figure 6. V alidation is delegate d to FastAPI’s schema-driven mechanisms, ensuring consistent enforcement of constraints spe cied in the OpenAPI document. 3.5 Graph-Level Optimization Following node-level synthesis, the initial worko w is modeled as a coordination graph G ( 0 ) , where nodes represent development activities or automated services, and e dges denote information dependencies and human-mediate d coordination. Graph-level opti- mization is an iterative process that restructures G ( 𝑘 ) by introduc- ing executable services to absorb coordination overhead. Formally , each optimization step applies a transformation 𝜏 𝑘 : G ( 𝑘 ) → G ( 𝑘 + 1 ) that replaces manual hand-os with automated services, thereby eliminating edges resolved programmatically . As illustrated in Figure 2, the transformation of the spapi work- ow proceeds through three successive iterations: Iteration 1: Signal R/W Synthesis. By generating executable signal access code directly from denitions, this ser vice eliminates the re- quirement for developers to consult vehicle state experts, removing the associated coordination edge from G ( 0 ) . Iteration 2: Signal-Property Synthesis. This stage automates the alignment between API properties and CAN signals. By generating mapping code, the service absorbs the complex interactions previ- ously required between API designers, vehicle state experts, and system engineers, eliminating two additional edges. Iteration 3: Pr operty-Endpoint Synthesis. This transformation en- codes vehicle-specic constraints (e.g., access permissions and value ranges) directly into OpenAPI annotations. The LLM utilizes these constraints during generation to ensure architectural compliance, removing the need for manual review by contr ol engineers. The cumulative impact of these transformations is quantied in T able 2. Each step 𝜏 𝑘 consistently increments the automation level while enhancing communication quality by producing out- puts that are both explainable and executable. Collectively , these optimizations reduce d the workow complexity by 5 edges, im- proved communication quality by 6 units, and increased the overall automation index by 3 relative to the manual baseline . 3.6 Deployed System After iterative optimization, the nal system replaces all manual translation steps with automated services and reaches a stable conguration validated by domain experts. The resulting workow , shown in the lower-right of Figure 2, consists of three server nodes LLM-Powered W orkf low Optimization for Multidisciplinary Soware Development FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada T able 2: Cumulative transformation impact across three iter- ations. Iteration Comp. A uto. Comm. 1: Signal R/W -1 +1 +2 2: Signal-Property -2 +1 +2 3: Property-Endpoint -2 +1 +2 Net change -5 +3 +6 in a linear pipeline. Compared with the initial manual workow , it achieves a net complexity reduction of 5, a communication quality improvement of 6, and an automation incr ease of 3. System overview . The system takes as input an initial workow graph G ( 0 ) with dense manual coordination and a set of domain artifacts, including OpenAPI specications, signal denitions, and constraint documents. It outputs an optimized workow graph G ∗ in which manual translation nodes are r eplaced by service nodes and redundant coordination edges are removed, yielding a compact executable pipeline. A r chitecture and interaction. Each node in G ∗ is deployed as an independent server with a well-dened API and composed se quen- tially to mirror the optimized workow graph. The architecture decouples workow logic from the underlying language model, enabling substitution of open-source or proprietar y LLMs under dierent cost, latency , and privacy constraints. A unied human– machine interface allows domain experts to inspect API-to-signal mappings, review generated co de, and request r egeneration with added constraints, preserving human oversight without manual translation. Execution and adaptability . The system supports both fully auto- mated and human-in-the-loop execution. For well-specie d tasks, the pipeline runs end-to-end without intervention; ambiguous map- pings or specication inconsistencies are agged for expert review . By replacing input artifacts or domain-spe cic instructions, the framework can be adapted to new APIs, vehicle platforms, or other translation-heavy workows. 4 Evaluation RQ1: [ Overall performance ] Does the automated workow achieve code quality comparable to AI-assisted human development (with Copilot) across dier ent automotive domains? RQ2: [ Reliability ] Do the spe cic te chniques employed (b oiler- plate templates, co de composition, and automated debug- ging) each contribute measurably to system reliability? RQ3: [ Eciency ] Does the automated workow reduce develop- ment time compared to AI-assisted processes while main- taining acceptable quality? RQ4: [ Human factors ] Do domain experts and developers report satisfaction with the deployed system sucient to supp ort continued production use? 4.1 Experimental Setup W e conducted experiments on 192 real-world automotive API end- points collected fr om six distinct industrial domains at V olvo Group, as summarized in T able 3. These APIs collectively span 420 unique properties and 776 associate d CAN signals, representing the full scope of the spapi system. W e use the original production implementations dev eloped by engineers (assisted by GitHub Copilot) as ground truth, referred to as the baseline . Precision (P) measures the correctness of gen- erated property-level code, computed as 𝑃 = | Correct | | Generated | . Recall (R) measures coverage of the original API spe cication, computed as 𝑅 = | Correct | | Baseline | . F1 is the harmonic mean of precision and recall, computed as 𝐹 1 = 2 𝑃 𝑅 𝑃 + 𝑅 . The baseline implementations wer e review ed and deployed in production and thus reect accepted system behavior . In this do- main, semantic errors typically appear as enum mismatches, value range violations, or missing signal bindings, all targeted by our validation and automated debugging mechanisms. W e therefore adopt a conservative matching strategy , agging ambiguous cases for human re view rather than generating potentially incorrect code. T o address RQ4, we invited all practitioners with direct e xperi- ence of both workows to provide structured fee dback: four domain experts and two developers. This complete set of qualied evalua- tors rated the system on role-specic criteria using a 5-point scale. Experts assessed communication eort, functional cov erage, and implementation accuracy; developers assessed communication e- ciency , debugging eort, and co de maintainability . Baseline workow . Because no existing automated solutions tar- get API development in industrial automotive settings, we com- pare our system with APIs developed by human engineers assiste d by proprietary AI coding agents. In this baseline , engineers were allowed to use GitHub Copilot. W e assess both API quality and development time. LLM usage and time cost. The system separates oine processing from deployment-time execution to manage LLM usage eciently . All compute-intensive LLM operations occur oine and do not aect runtime performance. In our experiments, we use GPT -4o (2024-05-13). During oine processing, the LLM scans and lters the CAN database and derives read/write equations for relevant signals. In a full run involving 192 APIs and 776 CAN signals, the system made about 15,000 LLM calls over 20.6 hours, averaging 396 seconds and 80 calls per API. During deployment, the generated read/write equations are reused. The LLM is invoked only for lightweight tasks such as matching API properties to signals and synthesizing the nal end- point. On average, each API requires ab out 5 LLM calls, taking roughly 10 se conds. This overhead is low enough for practical engineering workows. T able 3 summarizes code quality results acr oss all six automotive domains. The automated workow performs strongly throughout: four domains (Driver productivity , Energy , Visibility , and Dynamics) achieve perfect precision of 100%, meaning all generate d property- level code was correct. The other two domains (Connected systems and V ehicle system) still achieve precision above 94%. Recall is slightly lower , ranging from 86.5% to 95.7% across do- mains. This reects our conser vative property-to-signal alignment strategy , which applies strict ltering to retain only high-condence FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada Shuai W ang, Yinan Y u, Earl Barr, and Dhasarathy Parthasarathy T able 3: Performance and satisfaction scores across six automotive domains. Domain Domain Experts Num Performance Satisfaction P R F1 Expert Developer Driver productivity HMI/UX, business translators, regulators 34 1.000 0.957 0.978 4.93 4.86 Connected systems Business translators, dealers, sales sta 53 0.948 0.907 0.927 4.76 4.69 Energy Control/mechanical/electrical engineers, emissions 18 1.000 0.913 0.955 4.86 4.71 V ehicle system System architects, embedded software engineers 34 0.974 0.886 0.928 4.77 4.62 Visibility Mechanical engineers, designers, HMI/UX 14 1.000 0.925 0.961 4.88 4.75 Dynamics Control engineers 39 0.983 0.865 0.920 4.75 4.55 T otal - 192 0.976 0.902 0.937 4.80 4.67 T able 4: Ablation study: impact of individual te chniques on code quality and satisfaction. Conguration Performance Satisfaction P R F1 Expert Developer Full automated workow 0.976 0.902 0.937 4.80 4.67 without boilerplate templates 0.968 0.895 0.930 4.74 4.45 without code composition 0.956 0.883 0.918 4.69 4.43 without automated debugging 0.911 0.841 0.875 4.33 4.15 T able 5: Signal code accuracy before and after automate d debugging, by signal type. Stage Signal T ype Enum Bool Numerical Object T otal Count 634 90 33 19 776 Initial LLM output 96.50% 96.70% 90.90% 89.50% 93.40% After automated debugging 100% 100% 100% 100% 100% matches. Properties with ambiguous signal mappings are agged for human revie w rather than used to genera te potentially incor- rect code. Even so, average recall exceeds 90%, indicating broad coverage of the original specications. The overall F1 score of 93.7% shows that the automated work- ow produces code quality comparable to baseline development across diverse automotive domains. Performance also r emains sta- ble across dierent expert roles: the system handles APIs requiring input from control engineers (Dynamics, Energy) as eectively as those involving HMI/UX designers or business translators. Stakeholder satisfaction scores (Section 4.4) provide further val- idation: both experts and dev elopers report high satisfaction and note that the system supports transparent monitoring through well-dened interfaces. Answer to RQ1: Y es. The optimized worko w achieves 93.7% F1 with consistent performance across six div erse domains, meeting production quality standards. 4.2 RQ2: Reliability of Code Generation T echniques W e conducte d an ablation study to quantify the contribution of each technique to overall system reliability . T able 4 shows performance when individual components are removed. Removing boilerplate templates reduces F1 from 93.7% to 93.0% and decreases developer satisfaction from 4.67 to 4.45. Without T able 6: Property-to-signal matching performance by embed- ding strategy . Embedding Input P R F1 Raw signal code 0.763 0.277 0.406 Original descriptions 0.861 0.451 0.592 Rewritten descriptions 0.980 0.925 0.952 templates, generated code exhibits inconsistent structure and style, requiring additional manual cleanup. Removing code composition (assembling endpoints from reusable, validated fragments) reduces F1 to 91.8% and satisfaction scores to 4.69 and 4.43 for experts and developers respectively . The most signicant impact comes from removing automated debugging. Without test-based validation and self-correction, F1 drops to 87.5%, and satisfaction scor es fall to 4.33 and 4.15. This rep- resents a substantial degradation that would likely be unacceptable for production use. T able 5 pr ovides detailed analysis of the debugging component. W e categorized the 776 CAN signals into ve functional types and measured accuracy before and after the debugging phase. Initial LLM outputs achieve high accuracy for most categories (96.5% for Enum, 96.7% for Bool) but lower accuracy for more complex types (90.9% for Numerical, 89.5% for Object). Common errors include sub- tle syntax mismatches, such as using LowSupplyPress ( Enum_Value ) instead of the correct LowSupplyPress [ Enum_Value ] . After auto- mated debugging, all signal types reach 100% accuracy , validating our two-stage strategy of generating an initial draft followed by test-based renement. Eect of Embedding Strategies on Property-Signal Matching. W e also evaluated the impact of embedding strategy on property-to- signal matching, a critical step in the pipeline. T able 6 compares three approaches: embedding raw signal code, emb edding original textual descriptions from documentation, and embedding rewritten descriptions enriched with claried semantics. All congurations maintain high precision due to strict simi- larity thresholds, but recall varies substantially . Raw signal co de performs poorly (F1 = 0.406) be cause code lacks semantic context. Original textual descriptions improve performance (F1 = 0.592), but brevity and ambiguity limit accuracy . Re written descriptions, LLM-Powered W orkf low Optimization for Multidisciplinary Soware Development FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada T able 7: Detection performance for common sp ecication errors. Error T ype P R F1 Out-of-range value 0.979 1.000 0.989 Invalid enum value 0.989 1.000 0.994 T able 8: Quality and time comparison: automated vs. baseline development. Conguration Performance Time P R F1 Per API System T otal Full automated workow 0.976 0.902 0.937 396s 20.6h without Signal R/W Synthesis 0.965 0.913 0.939 +1.5h +288.0h without Signal-Property Synthesis 0.992 0.953 0.972 +2.5h +480.0h without Property-Endpoint Synthesis 0.980 0.907 0.942 +1.1h +211.2h Baseline workow (Copilot) 0.959 0.906 0.932 +5.1h +979.2h where LLMs expand and clarify signal semantics, achieve F1 of 0.952, demonstrating that investment in description quality yields substantial returns. 4.2.1 Robustness to Specification Errors. T o assess robustness in real-world conditions, we e valuated the system’s ability to detect errors in user-pro vided specications. W e manually injected two common error types into Y AML specication les: numerical val- ues exceeding dened ranges and enum values not present in the allowed set. As shown in T able 7, the system detects these errors with high precision, achieving F1 scor es of 0.989 and 0.994 r espectively . Be- yond ensuring correctness under ideal inputs, the pip eline ser ves as a validation layer that pr ovides early feedback to help users identify and correct specication errors before they propagate to generated code. Answer to RQ2: Y es, each technique contributes measurably to system reliability . Automated debugging has the largest impact, improving F1 by 6.2 percentage points and enabling 100% accuracy on signal co de after renement. Boilerplate templates and co de composition each contribute smaller but meaningful improvements. The embedding strategy for property-signal matching also signi- cantly aects performance, with enriched descriptions improving F1 from 0.592 to 0.952. 4.3 RQ3: Development Time Comparison W e compared our automated workow against baseline dev elop- ment by systematically replacing each automated service with human engineers and measuring both quality and time. T able 8 presents the results. The fully automated workow completes API generation in 396 seconds per endpoint (appr oximately 6.6 minutes), while the base- line workow requires approximately 5.1 additional hours per end- point, a reduction of over 97% in development time . Across the full portfolio of 192 APIs, automation saved approximately 979 hours of engineering eort compared to the baseline workow . Baseline development achieves higher recall in some congu- rations, revealing a quality-eciency tradeo. When humans p er- form Signal-Property Synthesis with the help from Github Copilot, T able 9: Detaile d satisfaction ratings from domain experts and developers. Role Evaluation Criterion Score A verage Expert (n=4) Communication eciency 5.00 4.80 Accuracy of implementation 4.89 Coverage of functional requirements 4.51 Developer (n=2) Communication eciency 5.00 4.67 Debugging eort 4.37 Code style and maintainability 4.64 F1 increases from 93.7% to 97.2% because engineers can resolve ambiguous mappings that the automated system conservatively ags for review . Howev er , this 3.5 percentage point improvement requires 2.5 additional hours p er API (480 hours total across the portfolio), a tradeo that is dicult to justify at scale. Each automated service contributes meaningful time savings. Signal R/W Synthesis saves 1.5 hours p er API by automating the translation of signal denitions into access code. Signal-Property Synthesis saves 2.5 hours per API – the largest contribution – by automating the cognitively demanding task of mapping API prop- erties to signals. Property-Endpoint Synthesis saves 1.1 hours per API by automating endpoint assembly from validated comp onents. Answer to RQ3: Y es. Per- API dev elopment time decreases from 5.1 hours to under 7 minutes (97% reduction), saving approximately 979 engineering hours across 192 APIs. 4.4 RQ4: Stakeholder Satisfaction W e invited four domain experts and two developers who work with the spapi system to evaluate the deployed workow . Each participant rated the system on three criteria using a 5-p oint scale. T able 9 pr esents the detailed results. Both groups report high overall satisfaction, with experts av- eraging 4.80 and developers averaging 4.67. Most notably , all six participants gave perfect scores of 5.0 for communication eciency , indicating unanimous recognition that the automated workow eectively reduces coordination overhead–the primary pain point identied in the baseline process. Experts rated accuracy of implementation at 4.89, reecting con- dence in the correctness of generate d code. The slightly lower score for coverage of functional requirements (4.51) aligns with our quantitative nding that recall is somewhat lo wer than precision; some edge cases require manual handling. Developers rated code style and maintainability at 4.64, indicating that generated code meets their quality standards, though debugging eort received a slightly lower scor e of 4.37, suggesting room for improvement in error diagnostics. The system is deployed in pr oduction at V olvo Group and con- tinues to serve as the primary mechanism for API development. Practitioners reported improved transparency and reproducibility compared to the baseline workow , particularly due to the ability to trace API-to-signal mappings and consistently regenerate code as specications evolve. Answer to RQ4: Y es. Despite the small sample size, which rep- resents the complete population of practitioners directly involv ed in both workows, all participants reported satisfaction levels sup- porting continued production use. The unanimous impr ovement in FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada Shuai W ang, Yinan Y u, Earl Barr, and Dhasarathy Parthasarathy communication eciency and sustaine d production deployment provide converging evidence that the approach eectively addresses the coordination bottleneck motivating this work. 4.5 Threats to V alidity Internal validity . The ground truth may itself contain errors. W e mitigate this by using production code that has undergone review and testing. External validity . Our evaluation focuses on a single API system at one automotive manufacturer . While the 192 endpoints span six functional domains involving div erse expert roles ( control en- gineers, HMI designers, system architects, business translators), generalization to other organizations or industries requires further validation. Construct validity . Property-level F1 may not capture all aspects of code quality . W e supplement quantitative metrics with stake- holder satisfaction ratings to address this limitation. 5 Discussion On choosing workflows to automate . Although Section 3 pro- vides technical criteria for workow automation, selecting suitable workows ultimately still requires informed judgment. Beyond technical feasibility , successful adoption also depends on organiza- tional readiness, stakeholder alignment, and openness to change , all of which are often dicult to e valuate in advance. In the case of spapi , the workow was not only well-scoped but also supported by a team willing to experiment and iteratively rene the process, which proved critical to achieving tangible and sustained b enets. On the use of LLMs in workflow automation . Our results show that LLMs can support multiple stages of workow automa- tion, including parsing, translation, generation, and evaluation. Howev er , ee ctive use of LLMs still requires experience and en- gineering judgment, particularly when deciding whether a task should be handled by an LLM alone or by a hybrid solution combin- ing scripts and LLMs. The iterative nature of our approach allows LLM usage to evolve alongside the workow itself, as teams gradu- ally rene these design choices and impr ove the balance between automation, control, and reliability ov er time. On multidisciplinary collaboration . Multidisciplinar y soft- ware development often suers from unclear ownership between developers and domain experts. By representing workows explic- itly and enabling LLM-driven translations into domain-accessible forms, our graph-base d approach improves transparency and partic- ipation. This makes workows mor e iterable and shareable, helping move teams closer to practical joint ownership . From a software engineering perspective, our ndings suggest that translation-heavy MSD workows constitute a distinct class of coordination-intensive processes. In such workows, dev elopment eort is dominated not by algorithmic complexity , but by repeated artifact translation, handos, and clarication cycles across roles. Our results indicate that eective automation in these settings lies primarily in restructuring artifact ows and co ordination structures, rather than optimizing individual co ding tasks. W e b elieve this perspective can inform the design of future LLM-assisted tools that operate at the workow level rather than the function or le lev el. 6 Related work Improving MSD:. Although software is increasingly being adopte d across diverse elds, research on improving MSD remains relatively limited [ 36 , 38 ]. Previous research includes a survey of non-software engineers [ 24 ] to understand their persp ectives on eective col- laboration with software engineers, as well as a study [ 14 ] that uses activity theory to interpret sources of friction in MSD . Other studies have investigated specic types of multidisciplinary collab- oration, such as those involving data scientists [ 9 , 23 ] and machine learning engineers [ 25 , 26 , 32 ], emphasizing the nature of these collaborations and the sociotechnical challenges that arise. Addi- tionally , some research has addressed sector-sp ecic challenges in MSD , such as in healthcare [ 39 ] and automotive domains [ 18 , 29 ], identifying collaboration issues and their associated costs. AI in MSD:. As AI becomes more prevalent in software engi- neering, recent research has explored how AI can help address collaboration challenges in MSD . One inter view study [ 30 ] used the concept of shared mental models to analyze communication gaps between AI developers and domain experts. Other studies [ 33 , 40 ] explored the use of prompting as a means for rapid prototyping among participants with varie d workows. Research in Human- Computer Interaction (HCI) has also examined multi-participant interactions with AI systems [ 16 ], including the development of guidelines [ 3 ] and taxonomies [ 12 ] for human- AI collaboration. Additional works have focused on designing improved interactions [1, 17] to enhance the agency of domain experts. LLMs for REST APIs: In connection with the case study , an ex- panding body of research leverages LLMs for various asp ects of REST API engineering. This includes generating API logic from specications [ 11 ], creating API documentation from source code [ 13 ], producing tests for APIs [ 22 , 37 ], and enabling APIs as tools for LLM applications [2, 4, 34]. In contrast to prior work that improves isolated tasks, we tar- get the workow that connects heterogeneous domain artifacts to implemented APIs. W e model this MSD workow as a graph and transform it so LLM-power ed services can incrementally replace manual translation and coordination while preser ving domain- expert involvement, demonstrated in production on spapi . 7 Conclusion In this paper , we show that LLM-p owered workow automation works in production MSD settings. By modeling workows as graphs and selectively automating translation steps, we reduce co- ordination o verhead while preserving human oversight. The spapi deployment at V olvo Group validates this approach at scale . The pattern we address is not automotiv e-specic; it applies wherever software encodes domain knowledge. Acknowledgment This work was partially funded by the Autonomous Systems and Software Program (W ASP), supporte d by the Knut and Alice W allen- berg Foundation, and the Chalmers Articial Intelligence Research Centre (CHAIR). The authors thank Erdem Halil and Shaphan Ma- nipaul Sam Kirubahar for their valuable te chnical contributions to the research foundations. LLM-Powered W orkf low Optimization for Multidisciplinary Soware Development FSE Companion ’26, July 05–09, 2026, Montreal, QC, Canada References [1] Mateen Ahme d Abbasi, Petri Ihantola, T ommi Mikkonen, and Niko Mäkitalo. 2025. T owards Human-AI Synergy in Requirements Engineering: A Framework and Preliminary Study. 2025 Sixth International Conference on Intelligent Data Science Technologies and Applications (IDST A) (2025). doi:10.1109/IDSTA66210. 2025.11202850 [2] Adam Alami and Neil A. Ernst. 2025. Human and Machine: How Software Engineers Perceive and Engage with AI-A ssisted Code Reviews Compared to Their Peers. arXiv preprint (2025). https://arxiv .org/abs/2501.02092 [3] Saleema Amershi, Dan W eld, Mihaela V or voreanu, Adam Fourney , Besmira Nushi, Penny Collisson, Jina Suh, Shamsi Iqbal, Paul N Bennett, Kori Inkpen, et al . 2019. Guidelines for human-AI interaction. In Proceedings of the 2019 chi conference on human factors in computing systems . 1–13. [4] Jayachandu Bandlamudi, Ritwik Chaudhuri, Ne elamadhav Gantayat, Kushal Mukherjee, Prerna Agarwal, Renuka Sindhgatta, and Sameep Mehta. 2025. A framework for testing and adapting rest apis as llm tools. arXiv preprint arXiv:2504.15546 (2025). [5] Stuart Bennett. 1993. A Histor y of Control Engineering 1930-1955 (1st ed.). Peter Peregrinus, GBR. [6] Luca Beurer-Kellner , Marc Fischer, and Martin T . V echev . 2024. Guiding LLMs The Right W ay: Fast, Non-Invasive Constrained Generation. In Forty-rst International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 . OpenReview .net. https://op enreview .net/forum?id=pXaEYzrFae [7] T om B. Brown, Benjamin Mann, Nick Ryder , Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastr y , Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger , Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler , Jere y Wu, Clemens Winter , Christopher Hesse , Mark Chen, Eric Sigler , Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner , Sam McCandlish, Alec Radford, Ilya Sutskever , and Dario Amo dei. 2020. Language Models are Few-Shot Learners. arXiv:2005.14165 [cs.CL] [8] Sébastien Bube ck, V arun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar , Peter Lee, Yin T at Lee, Yuanzhi Li, Scott Lundberg, Harsha Nori, Hamid Palangi, Mar co T ulio Ribeiro, and Yi Zhang. 2023. Sparks of Articial General Intelligence: Early experiments with GPT -4. [9] Gabriel Busquim, Allysson Allex Araújo, Maria Julia Lima, and Marcos Kali- nowski. 2024. T owards Ee ctive Collaboration b etween Software Engine ers and Data Scientists developing Machine Learning-Enabled Systems. In Brazilian Symposium on Software Engineering (SBES) . Curitiba, Brazil. [10] Casey Casalnuovo, Earl T . Barr , Santanu Kumar Dash, Prem Devanbu, and Emily Morgan. 2020. A theory of dual channel constraints (ICSE-NIER ’20) . Association for Computing Machinery , New Y ork, N Y , USA, 25–28. [11] Saurabh Chauhan, Zeeshan Rasheed, Abdul Malik Sami, Zheying Zhang, Jussi Rasku, Kai-Kristian K emell, and Pekka Abrahamsson. 2025. Llm-generated mi- croservice implementations from restful api denitions. arXiv:2502.09766 (2025). [12] Dominik Dellermann, Adrian Calma, Nikolaus Lipusch, Thorsten W eber, Sascha W eigel, and Philipp Eb el. 2021. The future of human-AI collaboration: a tax- onomy of design knowledge for hybrid intelligence systems. arXiv preprint arXiv:2105.03354 (2021). [13] Sida Deng, Rubing Huang, Man Zhang, Chenhui Cui, Dave To wey , and Rongcun W ang. 2025. LRASGen: LLM-based RESTful API Specication Generation. arXiv preprint arXiv:2504.16833 (2025). [14] Zixuan Feng, Thomas Zimmermann, Lorenzo Pisani, Christopher Gooley , Jeremiah W ander , and Anita Sarma. 2025. When Domains Collide: An Ac- tivity Theory Exploration of Cross-Disciplinar y Collaboration. arXiv preprint arXiv:2506.20063 (2025). [15] Benjamin Guerineau, Chen Zheng, Matthieu Bricogne, Alexandre Durupt, Louis Rivest, Har vey Rowson, and Benoît Eynard. 2017. Management of Heterogeneous Information for Integrated Design of Multidisciplinary Systems. Procedia CIRP 60 (2017), 320–325. doi:10.1016/j.procir .2017.02.020 Complex Systems Engineering and Development Proceedings of the 27th CIRP Design Conference Craneld University , UK 10th – 12th May 2017. [16] Muhammad Hamza, Dominik Siemon, Muhammad Azeem Akbar , and T ahsinur Rahman. 2024. Human-AI Collaboration in Software Engineering: Lessons Learned from a Hands-On W orkshop. In Proceedings of the A CM/IEEE International W orkshop on Software-intensive Business (I WSiB ’24) . doi:10.1145/3643690.3648236 [17] Jerey Heer . 2019. Agency plus automation: Designing articial intelligence into interactive systems. Proceedings of the National Academy of Sciences 116, 6 (2019), 1844–1850. [18] Hans-Martin Heyn, Khan Mohammad Habibullah, Eric Knauss, Jennifer Horko, Markus Borg, Alessia Knauss, and Polly Jing Li. 2023. Automotive perception software development: An empirical investigation into data, annotation, and ecosystem challenges. arXiv preprint arXiv:2303.05947 (2023). [19] Gonzalo Jaimovitch-López, Cèsar Ferri, José Hernández-Orallo, Fernando Martínez-Plumed, and María José Ramírez-Quintana. 2023. Can language models automate data wrangling? Machine Learning 112, 6 (2023), 2053–2082. [20] Frederick P . Br ooks Jr . 1987. No Silver Bullet - Essence and Accidents of Software Engineering. Computer 20, 4 (1987), 10–19. doi:10.1109/MC.1987.1663532 [21] Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, K eshav Santhanam, Sri V ardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T Joshi, Hanna Moazam, et al . 2023. Dspy: Compiling declarative language model calls into self-improving pipelines. arXiv preprint arXiv:2310.03714 (2023). [22] Myeongsoo Kim, Tyler Stennett, Dhruv Shah, Saurabh Sinha, and Alessandro Orso. 2024. Leveraging large language models to improve rest api testing. In Proceedings of the 2024 A CM/IEEE 44th International Conference on Software Engi- neering: New Ideas and Emerging Results . 37–41. [23] Miryung Kim, Thomas Zimmermann, Robert DeLine, and Andrew Begel. 2016. Characterizing the Roles of Data Scientists in a Large Software Company . In ICSE’16: Proce edings of the 38th International Conference on Software Engineering . Austin, TX, USA. [24] Paul Luo Li, Amy J Ko, and Andrew Begel. 2017. Cross-disciplinary perspectives on collaborations with software engineers. In 2017 IEEE/ACM 10th International W orkshop on Cooperative and Human Aspects of Software Engineering (CHASE) . IEEE, 2–8. [25] Hanjun Luo, Chiming Ni, Jiaheng W en, Zhimu Huang, Yiran W ang, Bingduo Liao, Sylvia Chung, Yingbin Jin, Xinfeng Li, W enyuan Xu, XiaoFeng W ang, and Hanan Salam. 2025. HAI-Eval: Measuring Human- AI Synergy in Collaborative Coding. arXiv preprint (2025). https://arxiv .org/abs/2512.04111 [26] Lucy Ellen Lwakatare, Aiswarya Raj, Jan Bosch, Helena Holmström Olsson, and Ivica Crnkovic. 2019. A T axonomy of Software Engineering Challenges for Machine Learning Systems: An Empirical Investigation. In Agile Processes in Software Engine ering and Extreme Programming , Philippe Kruchten, Steven Fraser , and François Coallier (Eds.). 227–243. [27] A vanika Narayan, Ines Chami, Laurel Orr , Simran Arora, and Christopher Ré. 2022. Can foundation models wrangle your data? arXiv:2205.09911 (2022). [28] Kanghee Park, Jiayu W ang, Taylor Berg-Kirkpatrick, Nadia Polikarp ova, and Loris D’ Antoni. 2024. Grammar- Aligned Decoding. arXiv:2405.21047 [cs.AI] [29] Joakim Pernstål, R. Feldt, T. Gorschek, and D . Florén. 2019. Communication Problems in Software Development — A Model and Its Industrial Application. International Journal of Software Engineering and Knowledge Engine ering 29, 10 (2019), 1497–1538. [30] David Piorkowski, Soya Park, April Yi W ang, Dakuo W ang, Michael Muller, and Felix Portnoy . 2021. How ai developers o vercome communication challenges in a multidisciplinary team: A case study . Proce edings of the ACM on human-computer interaction 5, CSCW1 (2021), 1–25. [31] Shaphan Manipaul Sam Kirubahar and Erdem Halil. 2025. Generating APIs through Library Learning using Large Language Models. (2025). [32] David Sculley , Gary Holt, Daniel Golovin, Eugene Davydov , T odd P hillips, Diet- mar Ebner , Vinay Chaudhary, Michael Y oung, Jean-Francois Crespo, and Dan Dennison. 2015. Hidden technical debt in machine learning systems. Advances in neural information processing systems 28 (2015). [33] Hari Subramonyam, Divy Thakkar , Andre w Ku, Juergen Dieber , and Anoop K Sinha. 2025. Prototyping with prompts: Emerging approaches and challenges in generative ai design for collaborative software teams. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems . 1–22. [34] Chunliang Tao , Xiaojing Fan, and Y ahe Y ang. 2024. Harnessing llms for api interactions: A frame work for classication and synthetic data generation. In 2024 5th International Conference on Computers and Articial Intelligence T echnology (CAIT) . IEEE, 628–634. [35] Shubham Ugare, T arun Suresh, Hangoo Kang, Sasa Misailovic, and Gagan- deep Singh. 2024. SynCode: LLM Generation with Grammar Augmentation. arXiv:2403.01632 [cs.LG] https://ar xiv .org/abs/2403.01632 [36] Shuai W ang and Yinan Y u. 2025. iQUEST: An Iterative Question-Guided Frame- work for Kno wledge Base Question Answ ering. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers) . 15616–15628. doi:10.18653/v1/2025.acl- long.760 [37] Shuai W ang, Yinan Y u, Robert Feldt, and Dhasarathy Parthasarathy . 2025. Au- tomating a Complete Software T est Process Using LLMs: An A utomotive Case Study . arXiv:2502.04008 [cs.SE] https://arxiv .org/abs/2502.04008 [38] Xixi W ang, Miguel Costa, Jordanka Kovaceva, Shuai W ang, and Francisco C Pereira. 2025. Plugging Schema Graph into Multi- T able QA: A Human-Guided Framework for Reducing LLM Reliance. arXiv preprint arXiv:2506.04427 (2025). [39] Jens H. W eber-Jahnke, Morgan Price, and James Williams. 2013. Software engineering in health care: Is it really dierent? And how to gain impact . In 2013 5th International W orkshop on Software Engineering in Health Care (SEHC) . IEEE Computer Society , Los Alamitos, CA, USA, 1–4. doi:10.1109/SEHC.2013.6602469 [40] Zhixiong Zeng, Shuai W ang, Nan Xu, and W enji Mao. 2021. Pan: Pr ototype-based adaptive network for robust cross-modal retrieval. In Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval . 1125–1134. [41] Chen Zheng, Matthieu Bricogne, Julien Le Duigou, Peter Hehenberger , and Benoit Eynard. 2018. Knowledge-based engineering for multidisciplinar y systems: Integrated design based on interface model. Concurrent Engineering (2018).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment