EffiSkill: Agent Skill Based Automated Code Efficiency Optimization
Code efficiency is a fundamental aspect of software quality, yet how to harness large language models (LLMs) to optimize programs remains challenging. Prior approaches have sought for one-shot rewriting, retrieved exemplars, or prompt-based search, b…
Authors: Zimu Wang, Yuling Shi, Mengfan Li
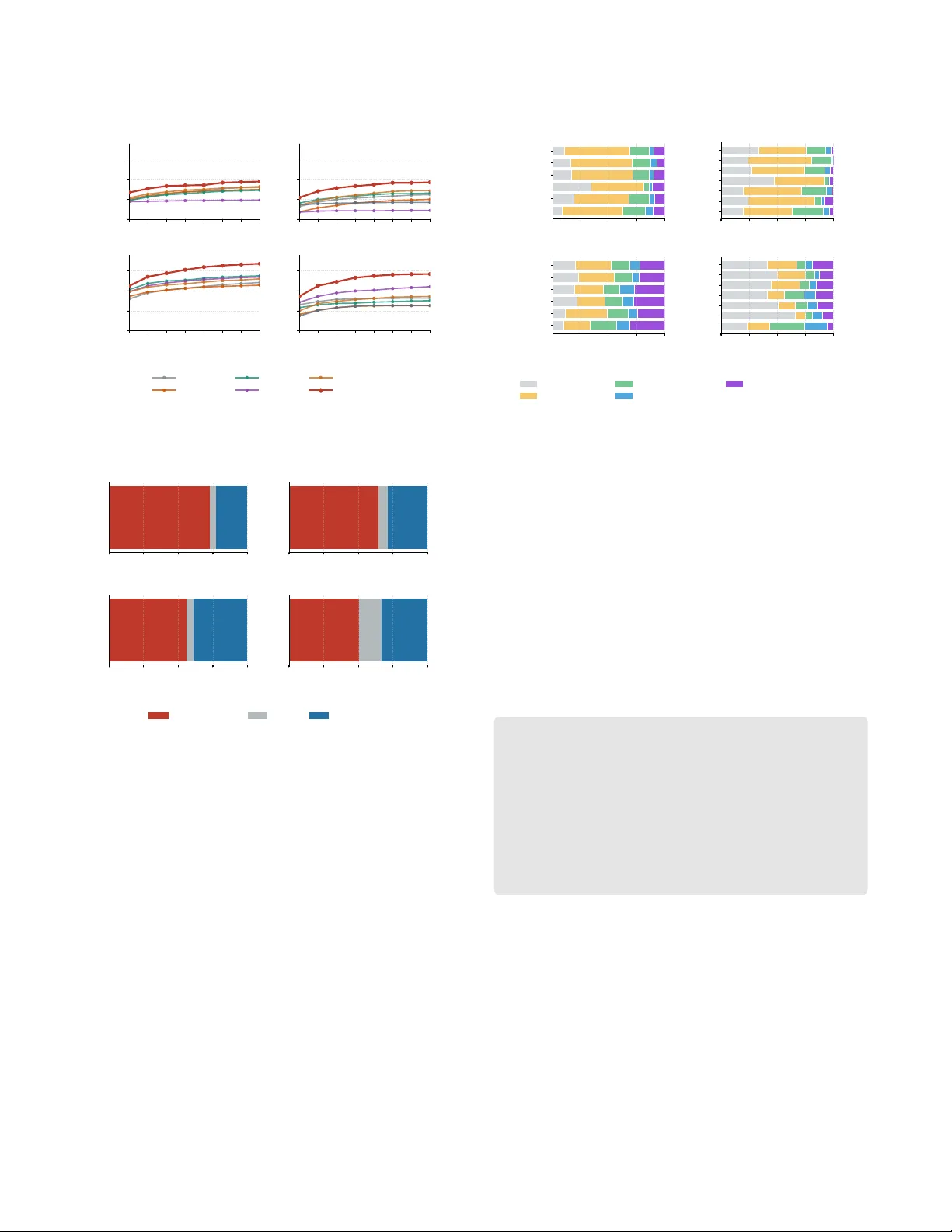
EiSkill: Agent Skill Based A utomated Code Eiciency Optimization Zimu W ang ∗ zm.wang@berkeley .edu Shanghai Jiao T ong University University of California, Berkeley USA Y uling Shi ∗ yuling.shi@sjtu.edu.cn Shanghai Jiao T ong University China Mengfan Li lmf2951510526@sjtu.edu.cn Shanghai Jiao T ong University China Zijun Liu zl3031@columbia.edu Columbia University USA Jie M. Zhang jie.zhang@kcl.ac.uk King’s College London United Kingdom Chengcheng W an ccwan@sei.ecnu.edu.cn East China Normal University Shanghai Innovation Institute China Xiaodong Gu † xiaodong.gu@sjtu.edu.cn Shanghai Jiao T ong University China Abstract Code eciency is a fundamental aspect of softwar e quality , yet how to harness large language models (LLMs) to optimize programs remains challenging. Prior approaches have sought for one-shot rewriting, r etrieved exemplars, or pr ompt-based search, but they do not explicitly distill reusable optimization knowledge, which limits generalization beyond individual instances. In this paper , we present ESkill, a framework for code-eciency optimization that builds a portable optimization toolbox for LLM- based agents. The key idea is to model recurring slow-to-fast trans- formations as reusable agent skills that captur e both concrete trans- formation mechanisms and higher-level optimization strategies. ESkill adopts a two-stage design: Stage I mines Operator and Meta Skills from large-scale slow/fast program pairs to build a skill library; Stage II applies this librar y to unseen programs through execution-free diagnosis, skill retrieval, plan composition, and can- didate generation, without runtime feedback. Results on EBench-X show that ESkill achieves higher opti- mization success rates, improving over the strongest baseline by 3 . 69 to 12 . 52 percentage points across model and language settings. These ndings suggest that mechanism-level skill reuse provides a useful foundation for execution-free code optimization, and that the resulting skill library can serve as a reusable resource for broader agent workows. 1 Introduction The computational eciency of software is a fundamental aspect of software quality [ 11 , 18 ]. Inecient implementations can in- crease latency , waste computational resources, and degrade user experience, and such ineciencies have long been studied as perfor- mance bugs in software systems [ 22 , 30 ]. A utomatically improving the eciency of existing code, which we refer to in this paper as ∗ Both authors contributed equally to this research. † Corresponding author . Retrieve Agent Skills LLM Agent Generate Debug Optimize e.g. compress dynamic programming state Plan Stage Action Stage Figure 1: O verview of agent skills as reusable knowledge. code optimization, has therefore become an important problem in automated software engineering. Early work on code optimization mainly relied on manually de- signed rules that target spe cic ineciency patterns, such as loop- related ineciencies or performance miscongurations [ 24 , 30 ]. Although eective in narrow settings, these approaches require sub- stantial expert eort and often provide limited coverage [ 11 ]. More recently , large language models (LLMs) have enabled data-driven approaches that generate optimized code directly from inecient programs using pr ompting, retrie val augmentation, or search-based renement [ 10 , 19 , 44 ]. While these methods show encouraging progress, their current formulations still leave an important gap be- tween instance-lev el optimization and r eusable optimization knowl- edge. A central limitation of existing LLM-based approaches is that they primarily operate at the level of individual examples. Pr ompting- based methods typically attempt to rewrite a program in one shot, which makes it dicult to handle optimizations that require struc- tured, multi-step reasoning. Search-based methods such as SBLLM [ 10 ] partially address this issue by iteratively exploring candidate r ewrites, but they still r ely on retrieved examples and generic sear ch prompts Conference’17, July 2017, W ashington, DC, USA Zimu W ang, Y uling Shi, Mengfan Li, Zijun Liu, Jie M. Zhang, Chengcheng W an, and Xiaodong Gu to guide optimization. As a result, the optimization knowledge re- mains tied to specic instances rather than being distilled into reusable principles. This instance-centric design is restrictive because performance- improving edits often exhibit recurring transformation patterns across tasks. For example, dierent programs may b enet from the same underlying optimization mechanism, such as replacing brute-force enumeration with a more ecient aggregation strategy , reformulating a computation algebraically , compressing dynamic- programming state, or reducing constant-factor ov erhead through more suitable data structures. Tr eating every optimization task inde- pendently misses this recurring structure and prevents the system from building a transferable repertoire of optimization knowledge. In this paper , we propose ESkill, a framework that addresses this gap by explicitly modeling code optimization through reusable agent skills . Figure 1 presents the general notion of agent skills as reusable knowledge, which motivates our approach. In our set- ting, an agent skill is a structured unit of optimization knowl- edge distilled from recurring slow-to-fast program transforma- tions. Rather than representing optimization knowledge only as raw example pairs or implicit model behavior , ESkill captures it as reusable transformation mechanisms that can be retriev ed and applied to new tasks. This skill-based view shifts the optimization process from surface-lev el instance matching toward mechanism- level reuse . ESkill follows a two-stage design. Stage I (Skill Mining) op- erates oine on paired slow and fast programs to extract recur- ring optimization patterns and distill them into a reusable skill library . The resulting library contains two complementary forms of knowledge: Operator Skills , which encode concrete optimization mechanisms, and Meta Skills , which provide higher-level proce- dural guidance for selecting and composing those me chanisms. Stage II (Skill-Guided Optimization) applies this library to un- seen programs through structured diagnosis, skill retrieval, plan composition, and candidate generation, enabling the e xploration of multiple optimization routes beyond one-shot re writing. A practical property of our setting is that inference is execution- free : when optimizing a new program, the system does not rely on repeated candidate execution or runtime feedback inside the optimization loop. This simplies deployment, as many realistic software-engineering settings do not provide convenient access to execution environments, repr esentative workloads, or the budget required to evaluate multiple candidate rewrites online . Although we evaluate ESkill in the setting of competitive- programming optimization, this should be understood as an ex- perimental scenario for validating the framework rather than a limitation of the contribution itself. Competitive-pr ogramming cor- pora provide abundant paired slow/fast solutions with measurable eciency dierences, making them a practical and well-controlled testbed for studying how optimization skills can be mined and reused. This choice is also shaped by the current availability of benchmarks that expose ne-grained eciency dierences with reliable execution signals. The broader contribution is a skill-based optimization framew ork that can, in principle, be extended to other software-engineering domains when suitable optimization corp ora become available. Operator Skill Card Metadata: skill_id , type , language name , description family , tags , triggers Body: • When to use • Transformation steps • Expected comple xity ef- fect • Common pitfalls • When not to use • Minimal example Meta Skill Card Metadata: skill_id , type , language name , description Body: • Overview • Core loop • Routing heuristics • Budgeting / control logic • Decision checklist Figure 2: Structure of the two skill-card artifacts in ESkill. W e evaluate ESkill on EBench-X [ 36 ], a benchmark for code- eciency optimization, and compare it against strong baselines including prompting-based, retrieval-based, and search-based meth- ods such as SBLLM [ 10 ]. Experimental results show that ESkill consistently achieves higher optimization performance across all settings. Measured by optimization success rate, it impr oves ov er the strongest baseline by 12 . 03 percentage points on C++ and 4 . 98 points on Python with GPT -5-mini, and by 12 . 36 and 8 . 67 percent- age points on C++ and Python, respectively , with Q wen3-Coder- 30B- A3B-Instruct. Beyond eectiveness, the learned skill library also provides a structured view of the optimization knowledge used by the system. While we do not claim full interpretability in a strict sense, this e xplicit intermediate abstraction makes the optimization process more analyzable than purely black-box rewrite prompting. More broadly , ESkill is designe d not only as a standalone method, but also as a p ortable optimization toolbox for LLM-based agents. The skill librar y produced by ESkill is organized as a plug-and-play resource that can, in principle, be integrated into broader agent workows, allowing optimization knowledge mined oine to be reused across dierent downstream coding settings. This perspective is particularly relevant as coding agents become increasingly modular and tool-oriented [5, 26]. W e summarize our contributions as follows: (1) W e introduce performance-improving agent skills as a reusable abstraction for code-eciency optimization and show how recurring optimization patterns can be distilled from large- scale slow/fast program pairs. (2) W e propose ESkill, a two-stage framework that integrates oine skill mining with skill-guided optimization for LLM- based code eciency improvement. (3) W e conduct an extensive evaluation on EBench-X, demon- strating that ESkill outperforms or remains competitive with strong baselines while enabling structur ed analysis of learned optimization skills. (4) W e organize the mined skills as a p ortable optimization library that can be r eused as a plug-and-play toolb ox in broader agent workows. EiSkill: Agent Skill Based Automated Code Eiciency Optimization Conference’17, July 2017, W ashington, DC, USA Optimized Code S T A G E I : O f f l i n e S k i l l M i n i n g S T A G E I I : O p t i m i z a t i o n I n f e r e n c e INPUT: F ast / Slow Code Pairs I N P U T : Unoptimized statement + code O U T P U T : Skill library Analyze Traces Traces Clustering Induce Skills Diagnose &Retrieve skills Compose plans Generate Candidat es ProblemBrief · SlowAudit DeltaSummary Hybrid Clustering Operator Skill Meta Skill Example Operator Skills: BFS -> formula full DP -> rolling state factorial loop -> small-k nCk O U T P U T : Diagnose -> OptimizationBrief Multi skill set Plan-guided rewrite Figure 3: O verview of ESkill: Skill mining and execution-free optimization. 2 Background 2.1 Problem Denition Following prior work [ 10 , 44 ], we study code-eciency optimiza- tion for a functionally correct but inecient program. Let 𝑆 denote the input program to be optimized, and let 𝐶 denote the task-level context available to the optimizer , such as a problem statement, specication, or other natural-language description of the intended behavior . The obje ctive is to generate a new program 𝑂 that pre- serves the intended functionality of 𝑆 while improving eciency under the target evaluation protocol. Let T denote the evaluation test suite, and let 𝐶𝑜 𝑠 𝑡 ( ·) denote the benchmark-specic eciency metric. The desired output should satisfy two conditions: (1) se- mantic correctness, namely that 𝑂 preserves the behavior of 𝑆 on T ; and (2) eciency impr ovement, namely 𝐶 𝑜𝑠 𝑡 ( 𝑂 ) < 𝐶 𝑜 𝑠 𝑡 ( 𝑆 ) . A key constraint in our setting is that the optimizer receives no execution signal during inference. That is, when optimizing a new program, the system does not execute candidate rewrites, observe runtime traces, or iteratively rene the output using execution feedback. Instead, it must infer likely bottlenecks and optimization opportunities using only the input program, the available task context, and the mined skill library . This setting diers from search- based or reinforcement-style optimization frameworks that rely on repeated candidate execution during the optimization loop. This formulation is further motivated by practical software en- gineering scenarios. In many realistic deployment settings, an opti- mization assistant may have access to sour ce code and high-level intent, but not to a production-like execution environment, rep- resentative workloads, full external dependencies, or the budget required to run many candidate rewrites online. This setting arises, for example, in code-re view assistants, repository-scale optimiza- tion to ols, and enterprise development environments with strict latency , security , or sandbox constraints. Although competitive- programming benchmarks do not capture all aspects of industrial software optimization, they pro vide a controlled setting for study- ing a practically relevant problem: impro ving code eciency when inference-time execution feedback is unavailable. 2.2 Agent Skills Recent agent frameworks conceptualize skills as modular units that encapsulate task-specic instructions, tool-usage patterns, and auxiliary resources for recurring workows [ 1 , 33 ]. This notion aligns with a broader trend in LLM-based systems toward mod- ularity and compositionality , in which reusable abstractions can improve generalization and scalability [ 27 , 38 , 50 ]. In particular , tool-augmented language models learn to invoke external func- tions and reuse structured behaviors across tasks [ 38 ], while agent frameworks interleave reasoning and action to construct multi-step solutions [50]. In ESkill, we adopt a denition tailored specically to code- eciency optimization. W e dene an agent skill as a reusable , struc- tured unit of optimization knowledge that captures either a concrete transformation mechanism or higher-level control knowledge gov- erning its application. This denition distinguishes skills from raw prompts, retriev ed exemplars, and fully optimized programs. Our key observation is that, although individual slow/fast pr o- gram pairs are instance-specic, the underlying optimization mech- anisms often recur across supercially dierent tasks. ESkill there- fore abstracts optimization knowledge at the mechanism level : each skill species applicability conditions, transformation procedures, and potential constraints or failure modes. For e xample, a dynamic- programming state-reduction skill may eliminate r edundant dimen- sions, prune unreachable states, or replace scan-heavy transitions with mor e ecient formulations. Although the resulting implemen- tations may dier substantially in syntax or domain, the underlying optimization principle remains transferable. W e categorize skills into two types. Figure 2 illustrates the struc- ture of the corresponding skill cards used in ESkill. Operator Skills enco de concrete transformation mechanisms distilled from recurring slow-to-fast edits, including applicability signals, trans- formation procedures, expected complexity eects, and common pitfalls. Meta Skills , in contrast, capture higher-level control logic for orchestrating operator skills, including diagnosis, retrieval, compo- sition, and execution-free candidate assessment, drawing on recent Conference’17, July 2017, W ashington, DC, USA Zimu W ang, Y uling Shi, Mengfan Li, Zijun Liu, Jie M. Zhang, Chengcheng W an, and Xiaodong Gu advances in agentic reasoning, planning, and to ol-use orchestra- tion [ 3 , 50 ]. This distinction is central to ESkill: Operator Skills externalize reusable transformation knowledge, wher eas Meta Skills govern how such knowledge is selected and composed under task- specic constraints. In our implementation, both skill types are instantiated as skill cards rather than free-form prompts, making optimization knowledge explicit, inspectable, and reusable. The resulting skill library therefore serves as an interme diate represen- tation between raw optimization examples and downstream code generation. Section 3 describ es how these skills are constructe d and operationalized in our two-stage pipeline. 3 Proposed Approach: ESkill 3.1 Overview The key idea of ESkill is to treat code optimization not as one-shot rewriting, but as a pr ocess of composing reusable transformation mechanisms learned from prior examples. ESkill follows a two-stage paradigm that decouples the learn- ing of optimization knowledge from its application to new programs. Stage I: Skill Mining op erates oine on paired slow/fast solutions to extract recurring optimization patterns and distill them into a reusable skill library . Stage II: Skill-Guided Optimization applies this library to unse en programs through structured diagnosis, skill retrieval, and plan-driv en generation, enabling the exploration of multiple optimization routes rather than committing to a single rewrite. The learne d skill library consists of two complementary com- ponents. Operator Skills enco de reusable transformation mecha- nisms (e.g., algorithm replacement, state compression, and constant- factor reduction), together with their applicability conditions and expected eects. Meta Skills act as proce dural controllers that govern how Operator Skills are selected, combined, and execute d during optimization. From a workow perspective, Figur e 3 illustrates the following process. Stage I transforms slow/fast solution pairs into a compact set of transferable optimization operators. Stage II then applies these operators to new tasks by rst diagnosing bottlenecks, re- trieving relevant skills, composing multiple optimization plans, and generating candidate implementations accordingly . This design allows ESkill to explore diverse optimization strategies while remaining fully execution-free during inference. 3.2 Stage I: Skill Mining Stage I constructs the skill library from paired slow/fast solutions through a fully automated mining pipeline. At a high level, this stage comprises four steps: (1) extract structured optimization traces from paired solutions; (2) abstract each trace into a compact sig- nature; (3) cluster similar signatures and distill each cluster into an Operator Skill; and (4) construct Meta Skills from the mine d operator library . The goal is not to pr eserve individual code edits as isolated examples, but to recover the transformation mechanisms that repeatedly underlie performance improvements. Trace extraction. Given a paired slow/fast solution for the same task, we use gpt-5.1 [ 32 ] to generate a structured optimization trace. Each trace contains four elds: ProblemBrief , which summarizes the task context and inferred constraints; Slo w A udit , which identi- es dominant operations and likely bottlenecks in the slow solution; FastA udit , which captures the core optimization idea in the fast solution; and DeltaSummary , which describ es the transformation bridge between the two solutions. T ogether , these traces provide a normalized view of how performance improvements arise across tasks. Signature abstraction. W e then abstract each trace into a com- pact signature that summarizes the transformation me chanism expressed by the pair , including signals such as the optimization type, complexity shift, trigger conditions, bottleneck categor y , and problem characteristics. This step shifts the representation from instance-specic code e dits to reusable optimization knowledge that can be grouped across tasks and implementations. Clustering and operator-skill distillation. Next, we cluster the re- sulting signatures in a hybrid lexical-semantic space so that traces expressing the same underlying transformation mechanism are grouped together even when their surface wording diers. Con- cretely , each signature is represented by the concatenation of two normalized views: (1) a TF-IDF r epresentation with unigram and bigram features, and (2) a dense sentence embedding produced by the Sentence- Transformers model all-MiniLM-L6-v2 [ 39 ]. T o keep cluster granularity data-driven, we estimate the cluster count 𝑘 automatically by maximizing the cosine-silhouette score over can- didate e ven values in a bounded range around √ 𝑛 traces, wher e 𝑛 is the number of traces. After ward, we t KMeans on the full hybrid representation to produce the nal clustering. Operator-Skill construction. Each cluster is summarized as a reusable prole of its shared transformation behavior , and this prole is dis- tilled into an Operator Skill. The resulting skill card records the transformation intent, applicability signals, expected eect, and common risks or pitfalls of the corresponding optimization mech- anism. T o ke ep the nal skill librar y compact, we merge highly similar summaries using TF-IDF cosine similarity with a merge threshold of 0.8, followed by a conservative LLM prompt to merge them into a single skill card. Meta-skill construction. After constructing the operator library , we build a small set of Meta Skills from the mined skill library . These procedural controllers specify how to diagnose a new optimization problem, retriev e relevant Operator Skills, and compose them into executable optimization plans. T ogether , the Operator Skills and Meta Skills form the skill registry used in Stage II. 3.3 Stage II: Skill-Guided Optimization Stage II applies the mined skill library to unseen optimization tasks. Rather than attempting to identify a single correct rewrite upfront, ESkill explores multiple plausible optimization routes thr ough a structured pipeline consisting of diagnosis, retrieval, planning, and candidate generation. Diagnosis. Given a problem statement and a baseline solution, ESkill rst produces a structured optimization brief that summa- rizes likely bottlenecks, dominant operations, inferred constraints, EiSkill: Agent Skill Based Automated Code Eiciency Optimization Conference’17, July 2017, W ashington, DC, USA Algorithm 1 ESkill T wo-Stage W orkow Input: Paired corpus D 𝑝 𝑎𝑖 𝑟 , test tasks Q Output: Skill registry R and generated candidates O 1 // Stage I: Skill Mining 2 T ← ExtractTraces ( D 𝑝 𝑎𝑖 𝑟 ) 3 Σ ← BuildSignatures ( T ) 4 C ← HybridCluster ( Σ ) 5 S 𝑜 𝑝 ← DistillOperatorSkills ( C ) 6 S 𝑚𝑒 𝑡 𝑎 ← InduceMetaSkills ( S 𝑜 𝑝 ) 7 R ← BuildRegistr y ( S 𝑜 𝑝 , S 𝑚𝑒 𝑡 𝑎 ) 8 return R 9 // Stage II: Skill-Guided Optimization 10 O ← ∅ 11 foreach 𝑞 ∈ Q do 12 𝑏 ← Diagnose ( 𝑞, R ) 13 K ← RetrieveSkills ( 𝑏, R ) 14 Π ← ComposePlans ( 𝑏, K ) 15 Y ← GenerateCandidates ( 𝑞, Π ) 16 O ← O ∪ Y 17 end 18 return O and the anticipated optimization scope. This step converts the in- put task into a form that can be matched against the learned skill library . Skill retrieval. Conditioned on the diagnosis, ESkill retriev es 3 candidate sets of Operator Skills, where each set represents a plausible optimization route. This retrie val process is deliberately designed to return multiple alternatives, as inecient programs often admit several valid optimization directions, and committing to a single skill choice too early can unduly narrow the search space. Plan Composition. For each retrieved skill bundle, the Meta Skills act as procedural controllers that compose the selected Operator Skills into 2 to 3 optimization plans. Each plan species a coherent transformation strategy , the anticipated eciency improvement, and the main risks that must be manage d during rewriting. This design intr oduces diversity both in the skills considered and in how those skills are applied. Candidate generation. Finally , ESkill generates optimized code candidates by following the composed plans while preserving the original program interface and intended behavior . Because candi- date generation does not depend on iterative execution feedback inside the generation loop, the method can apply the mined skill library through a retrieve-and-compose workow while still ex- ploring multiple plausible optimization routes. 4 Experimental Setup 4.1 Research Questions W e study the following research questions: RQ1: Overall eectiveness. Does ESkill improve program eciency on EBench-X r elative to strong baselines, including prompting-based, retrieval-based, supervised, and optimization-oriented methods? RQ2: Ablation analysis. How do the key components of E- iSkill (diagnosis, skill r etrieval, and multi-plan composi- tion) contribute to its performance? RQ3: Consistency across languages. Does ESkill remain eective when transferred from Python to C++ under the same evaluation protocol? RQ4: Analysis of learned skills. What kinds of optimization skills are learned, and what insights do these patterns provide into how ESkill impr oves code eciency? 4.2 Benchmark and Evaluation Protocol Skill-Mining Corpus. The Stage I skill library is mine d fr om paired slow/fast solutions constructed from external competitive- programming corpora. For C++, we use the PIE dataset [ 44 ] with gem5-simulated runtime, following the original PIE measurement setting. For Python, we aggregate solutions from PIE, Mercury [ 9 ], DeepMind Code Contests, and CodeParrot APPS, and measure ef- ciency using CP U instruction counts following COFFE [ 35 ]. For each problem with multiple valid solutions, we construct a slo w/- fast pair by selecting one slower and one faster implementation, and dene the sp eedup ratio as 𝑟 = 𝑇 slow / 𝑇 fast , where 𝑇 denotes the language-specic eciency measure. W e exclude pairs with 𝑟 < 2 to avoid treating marginal dierences as meaningful opti- mizations. The nal mining corpus contains 900 Python pairs and 900 C++ pairs. W e further verify that there is no overlap between the constructed mining corpus and the tasks in EBench-X [ 36 ], maintaining a strict separation between mining and evaluation data. Benchmark. W e evaluate ESkill on EBench-X [36], a bench- mark for code-eciency optimization that provides functional test suites and execution-based runtime measurement. EBench-X con- tains 623 optimization tasks with expert-written canonical solu- tions across six programming languages. W e focus on the Python and C++ subsets. Python serves as the primary evaluation setting, whereas C++ is used to assess cross-language transfer . Input programs. For every task, the input to be optimized is the canonical solution provided by EBench-X. Using the same expert-written starting point for all methods supports a fair com- parison among optimization strategies. Public/private split and ranking protocol. For each task, we parti- tion the provided test cases into public and private subsets using a xed random see d (42), with 20% assigned to public tests and the remaining 80% to private tests. Public tests are used only for candi- date selection. Among the generated candidates, we retain those that pass all public tests and rank them by runtime on the public tests. Private tests are reserved exclusively for nal evaluation. All reported correctness and eciency results are compute d on the private tests. Models. W e instantiate all compared methods using two LLM backbones: GPT -5-mini [ 31 ] and Qwen3-Coder-30B- A3B-Instruct [ 37 ]. Conference’17, July 2017, W ashington, DC, USA Zimu W ang, Y uling Shi, Mengfan Li, Zijun Liu, Jie M. Zhang, Chengcheng W an, and Xiaodong Gu Using the same backbones across methods allows us to b etter isolate the eect of the optimization strategy from that of the underlying model. Candidate budget. Each method is allocated the same generation budget of 𝑘 = 8 candidates per task. This places the evaluation in a small multi-candidate regime consistent with T op- 𝑘 coding evaluation [ 4 ] and recent software-engineering benchmarks that report 𝑘 = 8 by sampling eight candidates [ 51 ]. Unless otherwise stated, all reported T op- 𝑘 results use this xed budget. Execution environment. All candidates ar e evaluated oine us- ing the ocial EBench-X execution harness. Experiments are conducted on a machine equipped with an AMD EPYC 7302 CPU (16 cores, 32 threads, 3.0 GHz) and 112 GB RAM, running Ubuntu 20.04. Programs are executed using Python 3.11.11 (bookworm) and gcc:14.2.0-bookworm. T o reduce runtime variability and measure- ment noise, we execute each candidate thr ee times and report the mean runtime as the nal result. 4.3 Baselines W e compare EffiSkill with baselines from four categories. Prompting. Instruction directly prompts the LLM to optimize code without interme diate reasoning or retrieval. Co T [ 47 ] adds zero-shot chain-of-thought guidance to rst identify bottlenecks before generating optimized code. Retrieval-augmented. RA G [ 25 ] retrieves top- 𝑘 similar (slow , fast) pairs from PIE via CodeBERT embeddings as few-shot opti- mization examples. FasterPy [ 48 ] augments generation with opti- mization summaries retrieved via UniX coder from historical code transformations. Evolutionary search. SBLLM [ 10 ] initializes candidates via Co T prompting and renes them with transformation patterns; we adopt a single-iteration variant without execution-based selection for fair comparison. Fine-tuning. ECoder [ 17 ] ne-tunes on execution-validated slow/fast pairs to directly generate optimized code; as it applies only to open-weight backb ones, we report results for Qwen3-Coder- 30B- A3B-Instruct in T able 1. 4.4 Metrics W e follow prior work on code-eciency optimization [10], where the objective is to improv e runtime over the input program while preserving functional correctness. For each task, let 𝑜 denote the input canonical program, and let { 𝑐 𝑗 } 𝑘 𝑗 = 1 denote the ranked candidate list produced by a method. W e report OPT@ 𝒌 , dened as the percentage of tasks for which at least one of the top- 𝑘 candidates passes all test cases and attains a runtime reduction of at least 10% relative to the input program on the private tests, following prior work [10]. T op- 𝑘 protocol. For each task, every method produces 𝑘 = 8 candidates. Candidates are ranke d using the public-test protocol described ab ov e, whereas all reported T op-1 and T op-8 results are computed on the private tests. T able 1: Optimization p erformance on EBench-X. " ∗ " and " † " denote one-sided paired b ootstrap tests against the b est non- ESkill baseline in the same setting ( 𝑝 < 0 . 05 and 𝑝 < 0 . 10 , respectively). Model Method Python C++ OPT@1 (%) OPT@8 (%) OPT@1 (%) OPT@8 (%) GPT -5-mini Instruction 18.62 31.62 31.62 48.15 RAG 19.90 29.37 34.19 45.43 Co T 18.62 28.73 40.93 54.74 SBLLM 17.34 18.94 38.84 53.45 FasterPy 21.19 32.42 38.84 51.69 ESkill 26.48 ∗ 37.40 ∗ 44.62 † 66.77 ∗ Qwen3-Coder Instruction 12.52 24.40 26.00 32.58 RAG 7.22 19.74 16.37 25.04 Co T 16.05 26.00 23.11 30.02 SBLLM 6.90 8.67 28.41 43.98 FasterPy 13.96 28.25 19.90 34.19 ECoder 14.29 16.69 14.77 25.20 ESkill 21.35 ∗ 36.60 ∗ 34.19 ∗ 56.50 ∗ 5 Experimental Results In this section, we report the experimental results that answer the research questions introduced in Section 4.1. Unless other wise specied, all experiments follow the evaluation protocol describe d in Section 4. 5.1 RQ1: O verall Eectiveness W e evaluate whether ESkill improves code eciency over strong baselines on EBench-X. T able 1 reports results for two LLM back- bones and two programming languages using OPT @ 𝑘 with a xed candidate budget of 𝑘 = 8 , where signicance markers indicate a one-sided paired bootstrap test against the best non-ESkill base- line in the same model–language setting. For each comparison, we compute paired task-level performance dier ences, resample the paired tasks with replacement, and estimate the probability that the mean improvement is no greater than zero. Here, ∗ denotes 𝑝 < 0 . 05 and † denotes 𝑝 < 0 . 10 . Overall, ESkill achieves the strongest optimization success rates. Across all four model–language settings, it attains the best OPT @1 and OPT @8 , indicating that its main advantage is a higher likelihood of producing at least one candidate that is both function- ally correct and measurably faster than the input program within a small e xecution-free budget. This result is particularly important in our setting, where the central challenge is not merely to generate candidate rewrites, but to convert a limited candidate budget into successful eciency improvements while pr eserving correctness. This advantage is consistent across b oth backbones. Under GPT - 5-mini, ESkill achieves the str ongest results on Python and also attains the best optimization success rates on C++. Under Qwen3- Coder-30B- A3B-Instruct, the same pattern holds: ESkill again achieves the b est OPT @1 and OPT @8 on both Python and C++. T aken together , these results suggest that ESkill primarily im- proves the coverage of successful optimizations, thereby increasing the likelihood that a xed candidate set contains at least one useful optimization. T o further characterize this advantage, we analyze candidate- budget scaling, task-level comparisons, and ne-grained outcome EiSkill: Agent Skill Based Automated Code Eiciency Optimization Conference’17, July 2017, W ashington, DC, USA 0 20 40 60 OPT@k (%) (a) Python / GPT -5-mini (b) Python / Qwen3-Coder-30B 1 2 3 4 5 6 7 8 0 20 40 60 OPT@k (%) (c) C++ / GPT -5-mini 1 2 3 4 5 6 7 8 (d) C++ / Qwen3-Coder-30B Candidate Budget k Instruction RAG CoT SBLLM FasterPy EffiSkill Figure 4: Optimization success growth from 𝑘 = 1 to 𝑘 = 8 . 0 25 50 75 100 455 26 142 (a) Python / GPT -5-mini vs SBLLM 0 25 50 75 100 401 41 181 (b) Python / Qwen3-Coder -30B vs EffiCoder 0 25 50 75 100 348 34 241 (c) C++ / GPT -5-mini vs CoT 0 25 50 75 100 313 103 207 (d) C++ / Qwen3-Coder -30B vs Instruction T asks (%) EffiSkill W ins Ties Losses Figure 5: T ask-level win/loss comparison against the strongest non-ESkill baselines. distributions. Figure 4 shows that ESkill benets more consis- tently from additional candidates as 𝑘 increases, with especially pronounced gains on C++. This nding suggests that the diagnosis– retrieval–planning pipeline improves not only the top-ranked can- didate, but also the overall quality of the candidate set produce d under a xed generation budget. Figure 5 provides a complemen- tary task-level comparison with the strongest non-ESkill baseline in each setting. In all four settings, ESkill wins on more tasks than it loses, indicating that its advantage is broadly distributed rather than driven by a small number of favorable cases. Figur e 6 further shows that ESkill consistently reduces the proportion of tasks with no improvement and shifts more tasks into meaningful improvement ranges, particularly in the C++ settings. Collectively , these analyses reinforce the interpretation of Table 1: ESkill’s main strength is reliable optimization discovery . Relative to direct prompting baselines such as Instruction and Co T , ESkill more Instruction RAG CoT SBLLM FasterPy EffiSkill (a) Python / GPT -5-mini Instruction RAG CoT SBLLM FasterPy EffiCoder EffiSkill (b) Python / Qwen3-Coder-30B 0 25 50 75 100 Instruction RAG CoT SBLLM FasterPy EffiSkill (c) C++ / GPT -5-mini 0 25 50 75 100 Instruction RAG CoT SBLLM FasterPy EffiCoder EffiSkill (d) C++ / Qwen3-Coder-30B T asks (%) No improvement Mild (1.00-1.10) Moderate (1.10-1.25) Strong (1.25-1.50) V ery strong (>1.50) Figure 6: Fine-graine d distribution of top-8 optimization. eectively converts the candidate budget into successful optimiza- tions, highlighting the value of explicit diagnosis, skill retrieval, and multi-plan composition over one-shot rewriting. Relative to retrieval-based and optimization-oriente d baselines, its consistently stronger OPT @ 𝑘 results suggest that mechanism-level skill reuse is a promising inductive bias for execution-free optimization. T able 1 reports OPT @ 𝑘 results with 𝑘 = 8 candidates per task, with Python and C++ shown side by side. Best results are high- lighted in light gray . Where signicance markers are present, the improvements of ESkill are statistically signicant under this test. The overall evidence from T able 1 and Figures 4–6 supports the same conclusion: among the compared metho ds, ESkill is the most reliable for identifying useful optimizations across a broad set of tasks under a xed execution-free candidate budget. Answer to RQ1: ESkill is the most consistent method for improving optimization success on EBench-X. It achieves the best OPT @1 and OPT @8 in all four model–language settings and uses the candidate budget more eectively than competing methods. Additional analyses further show that ESkill wins on a majority of tasks against the strongest baseline in each setting and shifts more tasks fr om no improvement into moderate and strong improv ement ranges. Its main advantage therefore lies in reliably nding optimized candidates under a small execution- free budget. 5.2 RQ2: Ablation Study T o assess the contribution of each inference-stage component, we evaluate three ablations. w/o Retrieval removes skill retrieval and generates candidates directly from the diagnosis brief. w/ Random Skills replaces retrieved skills with uniformly sampled ones from the library . w/o Multi P lans retains diagnosis and retrieval but restricts generation to a single plan per retrieved bundle. All settings use the same backb one, candidate budget ( 𝑘 = 8 ), and ranking protocol. Conference’17, July 2017, W ashington, DC, USA Zimu W ang, Y uling Shi, Mengfan Li, Zijun Liu, Jie M. Zhang, Chengcheng W an, and Xiaodong Gu T able 2: Ablation results on EBench-X. Model Method OPT@1 (%) OPT@8 (%) GPT -5-mini ESkill 26.48 37.40 w/o Retrieval 12.20 27.45 w/ Random Skills 13.80 27.82 w/o Multi Plans 18.78 25.84 Qwen3-Coder ESkill 21.35 36.60 w/o Retrieval 7.22 9.15 w/ Random Skills 12.36 13.80 w/o Multi Plans 11.88 14.29 T able 2 shows that each component contributes materially , with dierent degradation patterns across backbones. Skill relevance is critical. Replacing retrieved skills with ran- dom ones consistently reduces performance on both models, indi- cating that the benet does not arise from adding arbitrary skills alone; it depends on whether the selected skills align with the di- agnosed bottleneck. For example, OPT@8 declines from 37 . 40% to 27 . 82% on GPT -5-mini and fr om 36 . 60% to 13 . 80% on Qwen3-Coder- 30B- A3B-Instruct. Multi-plan composition drives candidate quality . Restrict- ing generation to a single plan substantially reduces OPT@8 , es- pecially on Qwen3-Coder-30B-A3B-Instruct, where OPT@8 drops from 36 . 60% to 14 . 29% . This indicates that diversied plan explo- ration plays an important role in discovering high-quality optimiza- tion candidates. Retrieval improves robustness. Removing retrieval leads to substantial degradation in b oth OPT@1 and OPT@8 on Q wen3- Coder-30B- A3B-Instruct, suggesting that diagnosis alone is insuf- cient. On GPT -5-mini, the degradation is more pronounced in OPT@1 than in OPT@8 , suggesting that direct generation can oc- casionally produce strong candidates, but retrieval helps surface them more reliably among the top-ranked outputs. Answer to RQ2: Each comp onent of ESkill contributes to its performance. Relevant skill retrieval improves alignment with optimization bottlenecks, while multi-plan composition appears to b e a major factor in impro ving OPT@8 . Retrieval also improves robustness by helping promote high-quality candidates to top- ranked outputs. T ogether , these components account for the gains achieved by ESkill. 5.3 RQ3: Consistency Across Languages W e next assess whether ESkill maintains its eectiveness across programming languages under the same evaluation protocol. As shown in T able 1, the framework consistently impro ves optimiza- tion success on both Python and C++. On Python, ESkill achieves the best OPT @1 and OPT @8 for both backbones, reaching 26 . 48% / 37 . 40% with GPT -5-mini and 21 . 35% / 36 . 60% with Qwen3-Coder- 30B- A3B-Instruct. On C++, the improv ements are larger: ESkill reaches 44 . 62% and 66 . 77% with GPT -5-mini, and 34 . 19% and 56 . 50% with Qwen3-Coder-30B- A3B-Instruct. Relative to the strongest non- ESkill baseline in each setting, this corresponds to gains of + 12 . 03 points on C++ and + 4 . 98 points on Python for GPT -5-mini, and T able 3: Skill-family summary across both backb ones. Family Representative transformations Usage (%) Implementation & constant-factor constant-factor cleanup; lighter data structures; cheaper arithmetic 54.2 Algebraic / closed-form reformulation loop elimination; parity / bitwise simplication; range counting 19.7 DP / state compression state reformulation; rolling-state compression 13.1 Combinatorics & number theory modular combinatorics; coprimality reasoning; binomial simplication 9.5 Graph / data structure / set operations graph restructuring; set-intersection reformulation; incremental search 3.5 + 12 . 52 points on C++ and + 8 . 35 points on Python for Qwen3- Coder-30B- A3B-Instruct. T ogether , these r esults suggest that the diagnosis–retrieval–composition pipeline is eective in both lan- guage settings rather than being tie d to a single programming language. Overall, the results suggest that ESkill remains eectiv e across languages with dierent syntax, idioms, and performance charac- teristics. The improv ements are particularly pronounced on C++, where the margin on OPT @8 is substantially larger , suggesting that the framework is especially eective in the more optimization- sensitive C++ setting. Answer to RQ3: ESkill generalizes across Python and C++ at the framework level. It achieves the best OPT @1 and OPT @8 in both languages, with particularly strong gains on C++ of up to + 12 . 36 points over the strongest non-ESkill baseline. Its primary advantage across languages is more reliable optimization discovery under an execution-free candidate budget. 5.4 RQ4: Analysis of Learned Skills Finally , we analyze the learned skill librar y to b etter understand how ESkill improv es program eciency . A key advantage of ESkill over black-box prompting methods is that its optimization behavior is mediated by e xplicit, reusable skills. Each skill describes a recognizable optimization idea, such as constant-factor cleanup, replacing arithmetic loops with closed forms, or simplifying small-parameter combinatorial computation. This makes it possible to inspect both what kinds of optimization knowledge are learned and how that knowledge is combined during inference. For clarity , we use two analysis units. A candidate-skill pair denotes one skill attached to one generated candidate. A problem- bundle observation denotes one distinct combination of problem and retrieved skill set after merging candidates that share the same bundle on the same problem. Across the two backbones studied here, this yields 7,260 valid candidate-runtime measurements, 16,412 candidate-skill pairs, and 3,134 problem-bundle observations. EiSkill: Agent Skill Based Automated Code Eiciency Optimization Conference’17, July 2017, W ashington, DC, USA T o make the distribution easier to interpret, we group the 29 operator skills into ve semantic families accor ding to their opti- mization intent. T able 3 summarizes the resulting library structure. The dominant family is implementation and constant-factor opti- mization, which accounts for 54.2% of all candidate-skill pairs and appears in 623 problems. Algebraic reformulation and dynamic- programming compression also appear frequently , indicating that the learned library is not limite d to local cleanups. At the same time, combinatorics and number-theoretic skills account for only 9.5% of usage but are associated with larger average gains, suggesting a stable backbone of broadly useful skills together with a smaller set of high-impact specialized op erators. The usage distribution is concentrated but not collapsed. Al- though the library contains 29 skills, the entropy of the empirical usage distribution corresponds to only about 10–13 eectively ac- tive skills. Moreov er , the top-5 skills account for 68.3% of all skill usages under GPT -5-mini and 70.0% under Qwen3-Coder-30B-A3B- Instruct. W e therefore interpret the library as a compact core plus a specialized tail, rather than as a uniformly distributed or obviously redundant inventory . The bundle-level results further suggest that these skills are composed coherently at inference time. For example, the recur- ring bundle that combines constant-factor cleanup, right-sized data structures, and cheaper arithmetic appears in 133 problem–bundle observations across the two backb ones (101 under GPT -5-mini and 32 under Qwen3-Coder-30B-A3B-Instruct) and achieves a mean improvement of 0.341. Similar recurring bundles also arise for dynamic-programming compression and combinatorial simpli- cation, suggesting that ESkill do es not rely on isolated heuristics, but on reusable optimization recipes. Overall, these observations suggest that the learned skill library is both inspectable and practically useful. It captures reusable op- timization mechanisms at a human-readable lev el, while still sup- porting exible composition across pr oblems and model backbones. Answer to RQ4: The learne d skill library is compact, diverse, and operationally meaningful. It contains 29 operator skills, with the top-5 accounting for 68.0–70.0% of usage, and organizes them into coherent optimization families and recurring skill bundles. These results indicate that ESkill impr oves eciency through explicit, reusable optimization mechanisms rather than opaque black-box rewriting. 6 Discussion 6.1 Why Do es Skill-Base d Optimization W ork? ESkill improves inference-time optimization by shifting the level at which reuse occurs. Conventional pr ompting and exemplar re- trieval primarily reuse surface-level patterns in programs, whereas ESkill externalizes recurring slow-to-fast transformations as e x- plicit Operator Skills . As a result, the reusable unit is a transforma- tion mechanism rather than an instance. This supports generaliza- tion across programs that exhibit similar performance bottlenecks but dier syntactically , allowing the model to reason about how to restructure computation rather than what to imitate. Empirically , this is reected in the compact skill library (29 Operator Skills), where the top-5 skills account for only 68.0–69.7% of usage, sug- gesting a stable and compositional set of reusable transformations. A second key factor is compositionality . Many performance issues require coordinated changes across multiple aspects of a program, such as state representation, transition structure, and constant-factor optimization. ESkill explicitly supp orts this through its diagnosis–retrieval–planning pipeline, which identies bottle- neck classes, retrieves multiple relevant skills, and composes them into candidate optimization plans. This structured exploration con- strains the search space while preserving diversity . For example , the best-performing candidate in Section 6.2 combines sev eral transfor- mations, including state reformulation, rolling-state compr ession, and compact data representations, replacing a tuple-based dynamic program with a bitset formulation and improving eciency . Third, the skill library acts as a structured prior over candidate generation. By conditioning generation on a small set of retrieved transformation mechanisms, the model is guide d toward mor e tar- geted and empirically grounded rewrites. This is particularly im- portant in our setting, where optimization is p erformed without execution-time fe edback. This mechanism-level prior eectively regularizes generation, which may help explain why ESkill con- sistently outperforms direct prompting under the same backbone model. 6.2 Case Study W e present a representativ e success case on chmax-rush! . The task applies 𝑄 prex/sux assignments to an initially zero array and asks for the number of valid choices of left or right op erations. An operation is invalid if it overwrites a larger existing value. This case is informative because the bottleneck in the input program is ex- plicit and the dier ence in optimization behavior is straightforward to inspect. Input program. The original solution determines validity by scan- ning subsequent op erations and enforcing pairwise constraints, which yields an O ( 𝑄 2 ) b ottleneck. ops = [ tuple ( map ( int , input ().split())) for _ in range (Q)] req = [0] * Q for i, (p1, v1) in enumerate (ops): for j in range (i + 1, Q): p2, v2 = ops[j] if v1 <= v2: continue if p1 == p2: print (0); exit() if p1 < p2: if req[i] == 2 or req[j] == 1: print (0); exit() req[i], req[j] = 1, 2 else : if req[i] == 1 or req[j] == 2: print (0); exit() req[i], req[j] = 2, 1 print ( pow (2, req.count(0), 998244353)) Prompting-based candidate. A standard prompting baseline mainly renes the implementation, but preserves the same pairwise rea- soning pattern. P, V = [...], [...] req = [0] * Q for i in range (Q): for j in range (i + 1, Q): if V[i] <= V[j]: continue if P[i] == P[j]: print (0); return if P[i] < P[j]: if req[i] == 2 or req[j] == 1: print (0); return req[i], req[j] = 1, 2 else : if req[i] == 1 or req[j] == 2: print (0); return Conference’17, July 2017, W ashington, DC, USA Zimu W ang, Y uling Shi, Mengfan Li, Zijun Liu, Jie M. Zhang, Chengcheng W an, and Xiaodong Gu req[i], req[j] = 2, 1 print ( pow (2, req.count(0), 998244353)) ESkill candidate. In contrast, ESkill changes the underlying computational formulation. It replaces repeated pairwise checks with aggregated masks over value ranks and positions, and then resolves constraints through mask intersections. # build aggregated masks ranks = compress(V) mask_rank_lt = build_rank_masks(ranks) mask_pos_lt, mask_pos_gt, mask_pos_eq = build_pos_masks(P, N) # resolve constraints full = (1 << Q) - 1 left_req = right_req = 0 for i in range (Q): later = full ^ ((1 << (i + 1)) - 1) cand = later & mask_rank_lt[ranks[i]] if not cand: continue if cand & mask_pos_eq[P[i]]: print (0); return greater = cand & mask_pos_gt[P[i]] less = cand & mask_pos_lt[P[i]] if greater and less: print (0); return left_req |= greater | (1 << i if less else 0) right_req |= less | (1 << i if greater else 0) # ... (omitted due to space limit) The comparison indicates that the pr ompting-based candidate preserves the original pair wise-check structure and therefore re- mains O ( 𝑄 2 ) , whereas ESkill replaces repeated pairwise com- parisons with aggregated mask operations, reducing the overall complexity to O ( 𝑄 + 𝑁 ) , where 𝑁 is the array length. The improv e- ment therefore comes from algorithmic r eformulation rather than local implementation cleanup. Runtime comparison. For the exact examples shown above , the prompting-based candidate runs in 3838.11 ms , whereas the E- iSkill candidate runs in 1434.23 ms , yielding a 2.68 × improvement on eciency . Although this e xample is not intended to demonstrate the largest absolute gain, it highlights a qualitative dierence in optimization behavior: ESkill produces a non-trivial algorithmic rewrite that is not obtained by the pr ompting-based baseline in this example. 6.3 Threats to V alidity W e identify the following threats to the validity of our study: External V alidity . Our evaluation is conducted on competitive- programming benchmarks. These benchmarks provide clean slow/- fast program pairs and controlled eciency measurements, but they do not fully capture the complexity of real-world software systems. In practical settings, optimization can depend on factors such as external libraries, compiler behavior , hardware environments, and cross-le context. Therefor e, our ndings should be interpreted as evidence for the eectiveness of skill-based optimization in a con- trolled code-eciency setting, rather than as a direct claim that the same performance will transfer unchanged to all software domains. Internal V alidity . The reported results may be inuenced by design choices in both skill construction and evaluation. The qual- ity of the mined skill library depends on LLM-generated traces, clustering decisions, and ltering thresholds, all of which can aect downstream optimization performance. Rep orted performance may also vary with the candidate budget, ranking setup, and execution environment. T o mitigate this threat, we apply the same genera- tion budget, evaluation protocol, and execution harness across all compared methods. Construct V alidity . W e evaluate eectiveness using the opti- mization success rate under a xed execution-free budget. This metric aligns with the goal of generating correct and more ecient code, but it does not capture other practical dimensions such as read- ability , maintainability , or broader resource trade-os. Moreov er , because both the skill-mining corpus and the evaluation b enchmark come from the competitive-pr ogramming domain, some distribu- tional similarity may remain, ev en though we explicitly che cked for direct task overlap and found none. Our conclusions are also base d on tw o backbones and two programming languages, so broader val- idation across additional models, languages, and software domains is still needed. 7 Related W ork Large language models have demonstrated strong capabilities across diverse software engineering tasks such as code generation [ 4 , 12 , 41 , 42 ], program repair [ 20 , 46 ], testing [ 2 , 7 ], and many other tasks [ 13 , 14 , 34 , 40 , 45 ]. Among these, code eciency optimization— transforming functionally correct but slow co de into faster e quivalents— has emerged as a distinct challenge, as recent benchmarks consis- tently rev eal a substantial gap between LLM-generated code and human-expert solutions [9, 28, 36, 43]. In contrast to classical rule-based or search-based techniques [ 21 , 29 ], recent work leverages LLMs for source-level eciency im- provement. These methods dier in how they represent and de- liver optimization knowledge —reusable patterns, transformations, or high-level strategies that impro ve runtime eciency while pre- serving program semantics. Prompting-based approaches ask models to rewrite code without supplying additional knowledge. PIE’s zero-shot GPT -4 baseline achiev es roughly 1 . 3 × speedup, far below the 6 . 86 × of PIE-SFT under identical conditions [ 44 ]. ECO [ 23 ] further nds that chain-of-thought instructions yield no signicant gain—suggesting the bottleneck may lie in the lack of explicit optimization knowledge rather than reasoning capac- ity alone. Retrieval-augmented methods supply knowledge at inference time: PIE-RA G [ 44 ] retrieves similar slo w–fast pairs as few-shot examples, and SBLLM [ 10 ] combines evolutionary search with adaptive retrieval. How ever , such knowledge is typically tied to concrete co de instances rather than explicitly abstracted into transferable principles, so eectiveness is bounded by corpus cov- erage and instance similarity . Fine-tuning internalizes knowledge into model weights. PIE-SFT [ 44 ], Supersonic [ 6 ], and ECo der [ 17 ] consistently outperform retrieval-only methods, yet the y encode knowledge in language-specic parameters, which may limit cross- language transferability . Perf Coder [ 49 ] comes closest to explicit knowledge representation by training a dedicated Planner to gen- erate natural-language strategies; however , strategies are produced online without explicit oine curation, the approach relies on a ded- icated Planner model, and it is primarily evaluated on C++. RL and self-evolution methods such as Afterburner [ 8 ], ELearner [ 16 ], and CSE [ 15 ] leverage execution feedback to iterativ ely rene code, but every step r equires a live execution environment, making them unsuitable for latency-sensitive or compute-restricted settings. EiSkill: Agent Skill Based Automated Code Eiciency Optimization Conference’17, July 2017, W ashington, DC, USA Across these paradigms, optimization knowledge remains either strictly implicit—buried in weights or narrow retrieval instances—or fundamentally runtime-dependent. Our approach instead addresses this limitation by explicitly distilling optimization strategies into a reusable skill library designed to be language-agnostic: each skill encodes a high-level algorithmic principle validated oine via execution feedback, enabling single-pass inference that requires neither live execution environments nor deployment-time model training. 8 Conclusion In this paper , we presented ESkill, a two-stage framework for code-eciency optimization that explicitly models reusable opti- mization knowledge as agent skills. By separating oine skill min- ing from execution-free skill-guided optimization, ESkill enables LLM-based agents to reuse mechanism-level optimization knowl- edge instead of relying on one-shot rewriting or instance-level exemplar matching. Experimental results on EBench-X show that ESkill consistently improves optimization success across GPT - 5-mini and Q wen3-Coder-30B- A3B-Instruct, and in b oth Python and C++, achieving the best OPT @1 and OPT @8 in all settings. These results indicate that ESkill is more likely to produce at least one correct and eciency-improving candidate within a xed execution-free budget. Our analyses further show that these gains arise from the in- teraction of structured diagnosis, relevant skill retrie val, and plan diversity , rather than from any single component. The learned skill library captures a compact yet diverse set of reusable optimization operators, including both broadly applicable constant-factor im- provements and higher-impact spe cialized transformations, and remains eective b eyond the primary Python setting, extending to C++, where the margins in optimization success are often even larger . Taken together , these ndings suggest that explicit skill reuse is a practical basis for execution-free code optimization. A natural direction for future work is to extend ESkill to additional lan- guages and broader software-engineering optimization scenarios, while improving the quality , scope, and novelty of the skill library . More broadly , our results indicate that the mined skills can serve as a reusable optimization toolbox for coding agents, which may support the integration of optimization knowledge into real-world development worko ws. Data A vailability Statement All data and artifacts are publicly available at https://doi.org/10. 5281/zenodo.19249527. References [1] Anthropic. 2026. The Complete Guide to Building Skills for Claude. https://resources.anthropic.com/hubfs/The- Complete- Guide- to- Building- Skill- for- Claude.pdf . Accessed: 2026-03-18. [2] Pengyu Chang, Yixiong Fang, Silin Chen, Yuling Shi, Beijun Shen, and Xiaodong Gu. 2026. T est vs Mutant: Adversarial LLM Agents for Robust Unit T est Genera- tion. arXiv preprint arXiv:2602.08146 (2026). [3] Guoxin Chen, Zhong Zhang, Xin Cong, Fangda Guo, Y esai Wu, Y ankai Lin, W enzheng Feng, and Y asheng W ang. 2025. Learning Evolving T ools for Large Language Models. In The Thirteenth International Conference on Learning Repre- sentations . https://openreview .net/forum?id=wtrDLMF U9v [4] Mark Chen, Jerry T worek, Heewoo Jun, et al. 2021. Evaluating Large Language Models Trained on Code. arXiv preprint arXiv:2107.03374 (2021). [5] Silin Chen, Shaoxin Lin, Yuling Shi, Heng Lian, Xiaodong Gu, Longfei Y un, Dong Chen, Lin Cao, Jiyang Liu, Nu Xia, et al . 2025. Swe-exp: Experience-driven software issue resolution. arXiv preprint arXiv:2507.23361 (2025). [6] Zimin Chen, Sen Fang, and Martin Monperrus. 2023. Supersonic: Learning to Generate Source Code Optimizations in C/C++. CoRR abs/2309.14846 (2023). [7] Zhi Chen, Zhensu Sun, Yuling Shi, Chao Peng, Xiaodong Gu, David Lo, and Lingxiao Jiang. 2026. Rethinking the V alue of Agent-Generated T ests for LLM- Based Software Engineering Agents. arXiv preprint arXiv:2602.07900 (2026). [8] Mingzhe Du, Anh Tuan Luu, Yue Liu, Y uhao QING, Dong HU ANG, Xinyi He, Qian Liu, Zejun MA, and See-Kiong Ng. 2025. Afterburner: Reinforcement Learning Facilitates Self-Improving Code Eciency Optimization. In ICML 2025 W orkshop on Programmatic Representations for Agent Learning . https://openreview .net/ forum?id=RTI8LsGjSi [9] Mingzhe Du, Luu A Tuan, Bin Ji, Qian Liu, and See-Kiong Ng. 2024. Mercury: A code eciency benchmark for code large language models. Advances in Neural Information Processing Systems 37 (2024), 16601–16622. [10] Shuzheng Gao, Cuiyun Gao, W enchao Gu, and Michael Lyu. 2024. Search-based llms for code optimization. arXiv preprint arXiv:2408.12159 (2024). [11] Spandan Garg, Roshanak Zilouchian Moghaddam, Colin B. Clement, Neel Sun- daresan, and Chen W u. 2022. De epDev-PERF: a deep learning-based approach for improving software performance. In ESEC/FSE . A CM, 948–958. [12] Chao Hu, W enhao Zeng, Yuling Shi, Beijun Shen, and Xiaodong Gu. 2026. In Line with Context: Repository-Level Code Generation via Context Inlining. In The ACM International Conference on the Foundations of Software Engineering (FSE) . [13] Minghao Hu, Junzhe W ang, W eisen Zhao, Qiang Zeng, and Lannan Luo. 2025. FlowMalTrans: Unsupervised Binary Code Translation for Malware Detection Using Flow-A dapter Architecture. (2025). [14] Minghao Hu, Qiang Zeng, and Lannan Luo. 2026. Zero-Shot Vulnerability Detection in Low-Resource Smart Contracts Through Solidity-Only Training. arXiv:2603.21058 [cs.CR] [15] T u Hu, Ronghao Chen, Shuo Zhang, Jianghao Yin, Mou Xiao Feng, Jingping Liu, Shaolei Zhang, W enqi Jiang, Yuqi Fang, Sen Hu, et al . 2026. Controlled self-evolution for algorithmic code optimization. arXiv preprint (2026). [16] Dong Huang, Jianb o Dai, Han W eng, Puzhen Wu, Yuhao Qing, Heming Cui, Zhijiang Guo, and Jie Zhang. 2024. Elearner: Enhancing eciency of generated code via self-optimization. Advances in Neural Information Processing Systems 37 (2024), 84482–84522. [17] Dong Huang, Guangtao Zeng, Jianbo Dai, Meng Luo, Han W eng, Yuhao Qing, Heming Cui, Zhijiang Guo, and Jie M Zhang. 2024. Ecoder: Enhancing code generation in large language models through eciency-aware ne-tuning. arXiv preprint arXiv:2410.10209 (2024). [18] ISO/IEC 25010. 2011. Systems and software engineering – Systems and software Quality Requirements and Evaluation (SQuaRE). [19] Gautier Izacard, Patrick S. H. Lewis, et al . 2023. Atlas: Few-shot Learning with Retrieval Augmented Language Models. J. Mach. Learn. Res. 24 (2023), 251:1– 251:43. [20] Carlos E Jimenez, John Y ang, Alexander W ettig, Shunyu Y ao, K exin Pei, Or Press, and Karthik R Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world Github Issues? . In ICLR . [21] Guoliang Jin, Linhai Song, Xiaoming Shi, Joel Scherpelz, and Shan Lu. 2012. Understanding and dete cting real-world performance bugs. ACM SIGPLAN Notices 47, 6 (2012), 77–88. [22] Milan Jovic, Andrea A damoli, and Matthias Hauswirth. 2011. Catch Me If Y ou Can: Performance Bug Detection in the Wild. In OOPSLA . ACM, 155–170. [23] Su-Hyeon Kim, Joonghyuk Hahn, Sooyoung Cha, and Y o-Sub Han. 2025. ECO: Enhanced Code Optimization via Performance- A ware Prompting for Code-LLMs. arXiv preprint arXiv:2510.10517 (2025). [24] Rahul Krishna, Muhammad Shaque Iqbal, Mohammad Amin Javidian, Baishakhi Ray , and Pooyan Jamshidi. 2020. CADET: Debugging and Fixing Miscongura- tions using Counterfactual Reasoning. arXiv preprint arXiv:2010.06061 (2020). [25] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler , Mike Lewis, W en-tau Yih, Tim Rocktäschel, et al . 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems 33 (2020), 9459–9474. [26] Han Li, Yuling Shi, Shaoxin Lin, Xiaodong Gu, Heng Lian, Xin W ang, Yantao Jia, T ao Huang, and Qianxiang W ang. 2025. Swe-debate: Competitive multi-agent debate for software issue resolution. arXiv preprint arXiv:2507.23348 (2025). [27] Xiangyi Li, W enbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Y ubo Li, Bingran Y ou, Haotian Shen, Jiankai Sun, Shuyi W ang, Qunhong Zeng, Di W ang, Xuandong Zhao, Yuanli W ang, Roey Ben Chaim, Zonglin Di, Yip eng Gao, Junwei He, Yizhuo He, Liqiang Jing, Luyang Kong, Xin Lan, Jiachen Li, Songlin Li, Yijiang Li, Y ueqian Lin, Xinyi Liu, Xuanqing Liu, Haoran Lyu, Ze Ma, Bowei W ang, Runhui W ang, Tianyu W ang, W engao Y e, Yue Zhang, Hanwen Xing, Yiqi Xue, Steven Dillmann, and Han chung Lee. 2026. SkillsBench: Benchmarking How W ell Agent Skills W ork Across Diverse Tasks. arXiv:2602.12670 [cs.AI] https://arxiv .org/abs/2602.12670 Conference’17, July 2017, W ashington, DC, USA Zimu W ang, Y uling Shi, Mengfan Li, Zijun Liu, Jie M. Zhang, Chengcheng W an, and Xiaodong Gu [28] Jiawei Liu, Songrun Xie, Junhao W ang, Y uxiang W ei, Yifeng Ding, and Lingming Zhang. 2024. Evaluating Language Models for Ecient Code Generation. arXiv preprint arXiv:2408.06450 (2024). [29] Adrian Nistor , Po-Chun Chang, Cosmin Radoi, and Shan Lu. 2015. Caramel: Detecting and xing performance problems that have non-intrusive xes. In 2015 IEEE/ACM 37th IEEE International Conference on Software Engineering , V ol. 1. IEEE, 902–912. [30] Adrian Nistor , Tian Jiang, and Lin Tan. 2013. Discovering, Reporting, and Fixing Performance Bugs. In MSR . IEEE Computer Society , 237–246. [31] OpenAI. 2025. GPT -5 mini. https://developers.openai.com/api/docs/mo dels/gpt- 5- mini. [32] OpenAI. 2025. GPT -5.1: A smarter , more conversational ChatGPT. https://op enai. com/index/gpt- 5- 1/. Accessed: 2026-03-17. [33] OpenAI. 2026. From Model to Agent: Equipping the Resp onses API with a Com- puter Environment. https://openai.com/index/equip- responses- api- computer- environment/. Accessed: 2026-03-18. [34] W eihan Peng, Yuling Shi, Yuhang W ang, Xinyun Zhang, Beijun Shen, and Xi- aodong Gu. 2025. Swe-qa: Can language models answer repository-level code questions? arXiv preprint arXiv:2509.14635 (2025). [35] Y un Peng, Jun W an, Yichen Li, and Xiaoxue Ren. 2025. COFFE: A Code Eciency Benchmark for Code Generation. Proceedings of the ACM on Software Engineering 2, FSE (2025), 242–265. [36] Y uhao Qing, Boyu Zhu, Mingzhe Du, Zhijiang Guo, Terry Yue Zhuo, Qianru Zhang, Jie M Zhang, Heming Cui, Siu-Ming Yiu, Dong Huang, et al . 2025. EBench-X: A Multi-Language Benchmark for Measuring Eciency of LLM- Generated Code. arXiv preprint arXiv:2505.13004 (2025). [37] Qwen. 2025. Qwen/Qwen3-Coder-30B-A3B-Instruct. https://huggingface.co/ Qwen/Qwen3- Coder- 30B- A3B- Instruct. [38] Timo Schick, Jane Dwivedi- Y u, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer , Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language Models Can T each Themselves to Use T ools. arXiv:2302.04761 [cs.CL] https://arxiv .org/abs/2302.04761 [39] Sentence- Transformers. 2020. all-MiniLM-L6-v2: Sentence Embeddings using MiniLM. https://huggingface.co/sentence- transformers/all- MiniLM- L6- v2. Hug- ging Face model, accessed: 2026-03-17. [40] Y uling Shi, Yichun Qian, Hongyu Zhang, Beijun Shen, and Xiaodong Gu. 2025. LongCodeZip: Compress Long Context for Code Language Models. In 2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE) . IEEE, 141–153. [41] Y uling Shi, Songsong W ang, Chengcheng Wan, Min W ang, and Xiaodong Gu. 2024. From co de to correctness: Closing the last mile of co de generation with hierarchical debugging. arXiv preprint arXiv:2410.01215 (2024). [42] Y uling Shi, Chaoxiang Xie, Zhensu Sun, Y eheng Chen, Chenxu Zhang, Longfei Y un, Chengcheng W an, Hongyu Zhang, David Lo, and Xiao dong Gu. 2026. CodeOCR: On the Eectiveness of Vision Language Models in Code Under- standing. arXiv:2602.01785 [cs.CL] https://ar xiv .org/abs/2602.01785 [43] Y uling Shi, Hongyu Zhang, Chengcheng W an, and Xiaodong Gu. 2025. Between lines of code: Unraveling the distinct patterns of machine and human program- mers. In 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE) . IEEE, 1628–1639. [44] Alexander Shypula, Aman Madaan, Yimeng Zeng, Uri Alon, Jacob Gar dner , Milad Hashemi, Graham Neubig, Parthasarathy Ranganathan, Osbert Bastani, and Amir Y azdanbakhsh. 2023. Learning Performance-Improving Co de Edits. arXiv preprint arXiv:2302.07867 (2023). [45] Chaofan Wang, Tingrui Y u, Chen Xie, Jie W ang, Dong Chen, W enrui Zhang, Y uling Shi, Xiao dong Gu, and Beijun Shen. 2026. EV OC2RUST: A Skeleton- guided Framework for Project-Lev el C-to-Rust Translation. In 2026 IEEE/ACM 48th International Conference on Software Engineering, SEIP Track (ICSE-SEIP) . [46] Y uhang W ang, Y uling Shi, Mo Y ang, Rongrui Zhang, Shilin He , Heng Lian, Y uting Chen, Siyu Ye , Kai Cai, and Xiaodong Gu. 2026. SWE-Pruner: Self-Adaptiv e Context Pruning for Coding Agents. arXiv preprint arXiv:2601.16746 (2026). [47] Jason W ei, Xuezhi W ang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al . 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems 35 (2022), 24824–24837. [48] Y ue Wu, Minghao Han, Ruiyin Li, Peng Liang, Amjed Tahir , Zengyang Li, Qiong Feng, and Mojtaba Shahin. 2025. FasterPy: An LLM-based Code Execution Eciency Optimization Framework. arXiv preprint arXiv:2512.22827 (2025). [49] Jiuding Y ang, Shengyao Lu, Hongxuan Liu, Shayan Shirahmad Gale Bagi, Zahra Fazel, T omasz Czajkowski, and Di Niu. 2025. Perf Coder: Large Language Models for Interpretable Co de Performance Optimization. arXiv preprint (2025). [50] Shunyu Y ao, Jerey Zhao , Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. ReA ct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629 [cs.CL] https://ar xiv .org/abs/2210.03629 [51] Yilin Zhang, Xinran Zhao, Zora Zhiruo W ang, Chenyang Y ang, Jiayi W ei, and T ongshuang Wu. 2025. cast: Enhancing co de retrieval-augmented generation with structural chunking via abstract syntax tree. arXiv preprint (2025).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment