Surrogate-based categorical neighborhoods for mixed-variable blackbox optimization
In simulation-based engineering, design choices are often obtained following the optimization of complex blackbox models. These models frequently involve mixed-variable domains with quantitative and categorical variables. Unlike quantitative variable…
Authors: Charles Audet, Youssef Diouane, Edward Hallé-Hannan
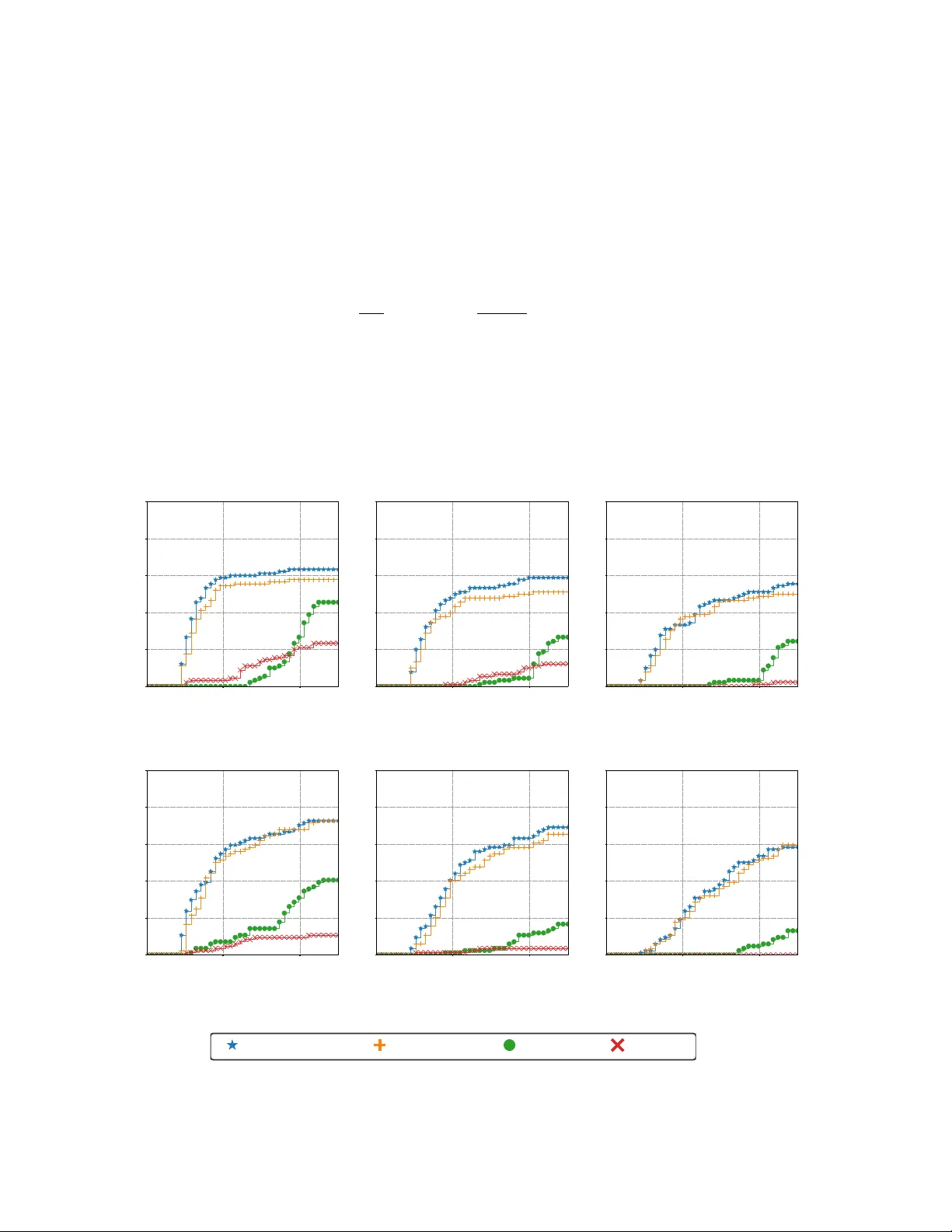
Surrogate-based categorical neigh b orho o ds for mixed-v ariable blac kb o x optimization Charles Audet ∗ Y oussef Diouane ∗ Edw ard Hallé-Hannan † , ∗ Sébastien Le Digab el ∗ Christophe T rib es ∗ Marc h 31, 2026 Abstract In sim ulation-based engineering, design c hoices are often obtained follo w- ing the optimization of complex blac kb o x mo dels. These mo dels frequen tly in volv e mixed-v ariable domains with quan titative and categorical v ariables. Unlik e quantitativ e v ariables, categorical v ariables lack an inheren t structure, whic h mak es them difficult to handle, especially in the presence of con- strain ts. This work proposes a systematic approach to structure and mo del categorical v ariables in constrained mixed-v ariable blac kb o x optimization. Surrogate mo dels of the ob jectiv e and constraint functions are used to induce problem-sp ecific categorical distances. F rom these distances, surrogate-based neigh b orho ods are constructed using notions of dominance from bi-ob jectiv e optimization, jointly accounting for information from b oth the ob jectiv e and the constrain t functions. This study addresses the lac k of automatic and constrain t-aw are categorical neighborho od construction in mixed-v ariable blac kb o x optimization. As a pro of of concept, these neigh b orhoo ds are em- plo yed within CatMADS , an extension of the MADS algorithm for categorical v ariables. The surrogate mo dels are Gaussian processes, and the resulting metho d is called CatMADS GP . The metho d is b enc hmarked on the Cat-Suite collection of 60 mixed-v ariable optimization problems and compared against state-of-the-art solvers. Data profiles indicate that CatMADS GP ac hieve sup e- rior p erformance for b oth unconstrained and constrained problems. Keyw ords. Blac kb o x optimization, deriv ativ e-free optimization, mixed- v ariable problems, constrained optimization, categorical v ariables. ∗ GERAD and Departmen t of Mathematics and Industrial Engineering, Polytec hnique Mon- tréal. 6079, Succ. Cen tre-ville Montréal, Québ ec H3C 3A7, Canada ( Charles.Audet@gerad.ca , y oussef.diouane@p olym tl.ca , edw ard.halle-hannan@p olym tl.ca , sebastien.le-digab el@p olym tl.ca , c hristophe.trib es@p olym tl.ca ) † First and corresp onding author. 1 F unding: This research is funded b y a Natural Sciences and Engineering Research Council of Canada (NSER C) PhD Excellence Scholarship (PGS D), a F onds de Recherc he du Québ ec (FR QNT) PhD Excellence Sc holarship and an Institut de l’Énergie T rottier (IET) PhD Excellence Sc holarship, as well as by the NSER C discov ery grants RGPIN-2020-04448 (Audet), R GPIN- 2024-05093 (Diouane) and R GPIN-2024-05086 (Le Digab el). 1 In tro duction In most cases, design choices in engineering and machine learning imply the constrained optimization of complex computer sim ulations that are exp ensive-to-evaluate blac kb oxes with no analytical expressions. In addition, these blackboxes ma y inv olve differen t t yp es of v ariables, suc h as con tin uous, integer and categorical v ariables. The latter are qualitative and lac k structure. F or example, in aerospace engineering, optimal aircraft design in volv es sim ulations with c hoices of materials or propulsion systems [ 12 , 32 ]. Deep learning mod els are characterized by h yp erparameters, such as the activ ation function or the choice of optimizer, whose v alues affect the training and v alidation pip eline [ 7 , 16 , 22 ]. Standard optimization metho ds using gradien ts and relaxations in the presence blac kb o xes and categorical v ariables are not suited for this con text. The motiv ation of this work is to impro ve the optimization of categorical v ariables in a constrained blackbox settings where information is limited and constrain ts may b e difficult to handle. This is done b y prop osing a systematic approac h to structure categorical v ariables with neighborho o ds constructed using surrogate mo dels of the ob jective and constrain t functions. These neigh b orho o ds can b e directly incorp orated in to mixed-v ariable metho ds using categorical neigh b orho o ds. As a pro of-of-concept, they are are emplo yed with CatMADS [ 6 ], a mixed-v ariable extension of the Mesh Adaptiv e Direct Searc h ( MADS ) algorithm [ 4 ] for constrained blackbox optimization. Notation The notation used follo ws [ 6 ]. V ectors are in b old, and scalars are in normal fon t. Sup erscripts are reserved for types of v ariables. Subscripts without parentheses index v ariables, e.g. , x cat 1 is the first categorical v ariable. Subscripts with paren theses are reserv ed for indexing an iteration k , e.g. x ( k ) , or for listing p oints, e.g. x (1) , x (2) , . . . , x ( s ) . Sets are denoted using capital letters with either normal or calligraphic fon t, e.g. A or A , except for the set of known p oin ts noted X . 1.1 Constrained mixed-v ariable blac kb o x optimization This study tackles inequality constrained mixed-v ariable blackbox optimization problems form ulated as min x ∈ Ω f ( x ) , (1) where f : X → R is the ob jectiv e function with R = R ∪ { + ∞} , X is the domain of the ob jective and constraint functions, x ∈ X is a p oint, Ω : = { x ∈ X : g j ( x ) ≤ 0 , j ∈ J } is the feasible set defined by the constrain ts, g j : X → R is the j -th constrain t function of the problem with j ∈ J and | J | ∈ N is the num b er of constrain ts. 2 The constrain ts defining the feasible set Ω are supposed to be r elaxable and quantifiable , meaning that when they are ev aluated, they can return a prop er v alue without b eing satisfied [ 23 ]. An unr elaxable constrain t, whic h must b e satisfied to hav e a prop er blac kb ox execution, is considered out of the domain, such that if x ∈ X , then it is assigned f ( x ) = + ∞ . Similarly , if a p oin t x ∈ X hits a hidden c onstr aint that crashes or in v alidates the output v alues, then it is simply assigned f ( x ) = + ∞ . The functions in volv ed in the main optimization problem are supp osed to be blackb oxes , whic h are defined as follows in [ 8 ]: “ any pr o c ess that when pr ovide d an input, r eturns an output, but the inner working of the pr o c ess is not analytic al ly available ”. F or example, the strain exp erienced by a b eam can b e estimated using a finite element sim ulation that outputs strain v alues for a giv en geometry , material and loading conditions. The lack of an analytical expression implies that deriv atives are una v ailable with resp ect to the con tinuous v ariables. The function ev aluations are determined by executing a pro cess that is p ossibly time-consuming. The problems considered are said to b e mixed-v ariable. Each v ariable is either c ontinuous ( con t ), inte ger ( int ) or c ate goric al ( cat ). The v ariables of the same type are con tained in a corresp onding column v ector called a c omp onent . F or t ∈ { cat , in t , cont } , the comp onent of type t is expressed as x t : = x t 1 , x t 2 , . . . , x t n t ∈ X t : = X t 1 × X t 2 × . . . × X t n t , (2) where x t i ∈ X t i represen ts the i -th v ariable of t yp e t , and X t i denotes its b ounds. The v ariable index i ranges ov er the set I t : = { 1 , 2 , . . . , n t } . The num b er of v ariables of type t is noted n t ∈ N . The set of t yp e t is noted X t and it is such that x t ∈ X t . F ollo wing the comp onen ts, a p oint x ∈ X is defined by a partition by t yp es, and the domain is expressed as Cartesian pro ducts of the sets by types, such that x : = x cat , x int , x cont ∈ X : = X cat × X int × X cont . (3) The categorical v ariables take c ate gories represen ting qualitative v alues. F or i ∈ I cat , the i -th categorical v ariable x cat i tak es v alues in the set X cat i : = { c 1 , c 2 , . . . , c ℓ i } , where c j is a category with j ∈ { 1 , 2 , . . . , ℓ i } and ℓ i is the num b er of categories of the v ariable. F or example, the color for an ob ject could b e taking a category in the set { red, blue, green } . These v ariables are inheren tly difficult to treat b ecause their sets are not ordered and usual distance functions are not suitable [ 7 , 19 ]. The categorical set X cat is assumed to b e finite. The total n umber of categorical comp onents is |X cat | = Q n cat i =1 ℓ i . The integer and contin uous v ariables take quan titativ e v alues and they b elong to ordered sets in which standard distance functions are w ell-defined. These v ariables are t ypically muc h easier to optimize than the categorical ones. F or con venience, the in teger and contin uous v ariables ma y b e regroup ed in a quantitativ e comp onen t suc h that x qnt : = x int , x cont ∈ X qnt : = X int × X cont . Note that this study do es not consider meta variables , which influence the inclusion or b ounds of other v ariables [ 7 , 16 ]. The problems hav e fixed dimensions and b ounds. 3 1.2 Researc h gap, ob jectiv es and con tributions Ba yesian optimization (BO) framew orks ha ve b een successfully applied to mixed-v ariable blac kb ox problems [ 27 , 29 , 33 , 37 ]. How ever, BO do es not provide lo cal optimization mec hanisms, con vergence guaran tees, or principled stopping criteria. Several metaheuris- tics rely on op erations based on Gow er-t yp e distances that reduce categorical differences to mismatches b etw een categories. Suc h generic measures are not problem-informed and can lead to a large n umber of unnecessary ev aluations. There are other mixed-v ariable methods, suc h as CatMADS and MV-MADS , that handle categorical v ariables with neighborho o ds [ 6 , 1 , 24 ]. In these metho ds, neigh- b orho o ds are used to generate candidate solutions b y mo difying the v ariables of an incum b ent. The main adv antage of these neigh b orho o ds is that they introduce a lo cal mec hanism th at leads to theoretical guarantees for discrete v ariables. The p erformance of neigh b orho o d-based approaches dep ends highly on the quality of the neighborho o ds. In MV-MADS , neigh b orho o ds are constructed with user-defined rules, which can b e difficult to establish in a blackbox con text. In practice, these neighborho o ds are primarily in tended to handle discrete v ariables, but they may also mo dify the contin uous v ariables of an incum b ent. The theoretical results of MV-MADS assume that the points in the user-defined neigh b orho o ds b elong to the feasible set Ω . This constitutes an imp ortan t metho dological restriction for handling constrain ts and do es not capitalize on informa- tion from relaxable constraints. CatMADS fo cuses instead on neigh b orho o ds strictly for categorical v ariables and constructs them using categorical distances defined solely from the ob jectiv e function: The constrain t functions are th us not considered. This can b e problematic for problems in whic h the b eha vior of the constraint functions changes drastically with resp ect to the categorical v ariables. Figure 1 illustrates a simple example with one categorical v ariable x cat ∈ { purple , red , green } and tw o contin uous v ariables. Eac h plane corresp onds to a category , and the colored regions denote feasibilit y . Each plane also shows some level curves of the ob jective function. In Figure 1 , the curren t solution x ( k ) lies in the contin uous subspace asso ciated with the categorical comp onen t x cat = red . It corresp onds to a lo cal minimum with resp ect to the contin uous v ariables. How ever, the global minimum x ⋆ resides in the con tinuous subspace asso ciated with x cat = green . In the setting, reaching this global minim um from x ( k ) can b e difficult when using a neighborho o d-based approac h. F rom x ( k ) in the subspace of red , ob jective-based or user-defined neigh b orho o ds would likely prioritize the category purple . The restriction of the ob jectiv e function in the red and purple subspaces app ears more similar. Consequently , an ob jectiv e-based neighborho o d ma y focus on the purple category , although: 1) its asso ciated con tin uous subspace is highly infeasible and yields p o orer feasible v alues, and 2) the feasible regions in the con tinuous subspaces of red and green are m uch more similar. This can degrade the p erformance of neighborho o d-based metho ds and the qualit y of the lo cal minima with resp ect to the categorical v ariables. T o mitigate this issue, one could rely on global mec hanisms such as BO or design b etter-informed neigh b orho o ds. In the presence of noise or nonsmo othness, BO may fail to prop erly tackle the contin uous v ariables and by consequence the mixed-v ariable problem itself. More lo cal and robust mec hanisms ma y therefore b e needed to ensure incremental progress. 4 0 3 6 6 4 8 4 2 6 x ( k ) x ⋆ (a) Categorical neighborho o d relying only on ob jectiv e information. 0 3 6 6 4 8 4 2 6 x ( k ) x ⋆ (b) Categorical neighborho o d in tegrating ob jec- tiv e and constraints information. Figure 1: A motiv ating example where the incumbent x ( k ) has ob jectiv e v alue f ( x ( k ) ) = 3 , while the global minimum x ⋆ has f ( x ⋆ ) = 1 . The neigh b orho o d on the left selects purple based strictl y on pr oximity with the objective. The neighborhood on the right selects green based on pro ximity of both the constraints and the objective. This motiv ates the dev elopment of lo cal neigh b orho o ds that are b etter-informed and robust. The research gap addressed is the automatic construction of problem-sp ecific categorical neighborho o ds that incorp orate information from b oth the ob jectiv e and the constrain t functions in a blackbox setting. Note that, hereafter, categorical neighbor- ho o ds are referred to simply as neighborho o ds. The w ork do es not aim to in tro duce a new optimization metho d, but rather to provide additional structural information that facilitates handling categorical v ariables. These better-informed neigh b orho o ds pro vide a systematic structure for categorical v ariables, impro ve in terpretability , and are particularly well suited for blackbox constrained optimization. They enhance the qualit y of lo cal minima with resp ect to categorical v ariables and improv e the efficiency neigh b orho o d-based methods. The num b er of ev aluations for optimizing categorical v ariables may decrease, since each categorical neighbor is selected in a more informed manner. The present work is structured through four ob jectives, represen ting the main con tri- butions of the work. The first ob jectiv e is to construct a problem-sp ecific categorical distance using kernel-based surrogate mo dels, suc h as Gaussian Pro cesses (GPs), so that categorical comp onents with similar predicted ob jectiv e v alues are considered closer. The second ob jective is to define a categorical distance that captures similarit y with resp ect to the constraint functions by aggregating surrogate mo dels of the constraints. Building on these tw o distances, the third ob jective is to construct categorical neighborho o ds balancing similarit y b et ween the ob jectiv e and the constrain ts. The first three ob jectives are developed indep endently of any sp ecific optimization framew ork and for purely cate- gorical domains. The fourth ob jectiv e is to generalize the prop osed neighborho o ds to mixed-v ariable domains. As a pro of of concept for the fourth ob jectiv e, the neigh b orho o ds are used in CatMADS . 5 1.3 Related work In [ 6 ], categorical distance is constructed using a basic in terp olation of the ob jectiv e function. Neighborho o ds are c haracterized with this single distance function and they are constructed without accoun ting the constrain t functions, whic h ma y lead to neighborho o ds con taining elements that are highly dissimilar in terms of feasibilit y . In [ 1 , 24 ], categorical neigh b orho o ds are sp ecified manually by the user, whic h requires prior knowledge ab out the problem structure, which may b e ambiguous in a blac kb o x context. The primary fo cus of CatMADS and MV-MADS lies in the optimization pro cess, while neighborho o d design remains secondary . In con trast, the presen t work emphasizes the systematic construction of categorical neigh b orho o ds, indep endently of an y particular optimization framew ork. Sev eral metaheuristic metho ds ha ve b een prop osed to address categorical v ariables in mixed-v ariable optimization. These metho ds construct candidate p oints with op erations transforming categorical v ariables of existing solutions. Suc h op erations hav e similar roles to categorical neighborho o ds. CatCMA extends the co v ariance matrix adaptation ev olution strategy (CMA-ES) to problems in v olving b oth categorical and con tinuous v ariables [ 18 ]. In this approach, categorical v ariables are mo deled by probability vectors o ver their resp ective categories, while contin uous v ariables are mo deled by a m ultiv ariate normal distribution. A joint probabilistic distribution ov er categorical and contin uous v ariables is introduced to guide the optimization in mixed-v ariable domains. The Non- dominated Sorting Genetic Algorithm-I I (NSGA-2) [ 13 ], although originally dev elop ed for multi-ob jective optimization, has also b een extended to mixed-v ariable problems in volving categorical v ariables. [ 10 ] pro vides implemen tations with crossov er and mutation op erators tailored to eac h v ariable type, from which candidate p oin ts are generated ov er a p opulation of solutions. Candidate p oin ts are constructed with these op erators applied to a p opulation of solutions. F or more details, the surv ey [ 36 ] provides an exhaustiv e surv ey for mixed-v ariable metaheuristics. In Bay esian optimization, categorical v ariables are structured with similarity mea- sures, called kernels . In optimization, kernels are problem-sp ecific similarity measures c haracterizing surrogate mo dels that guide the optimization. In the literature, v arious tec hniques exist for constructing categorical k ernels, most notably one-hot enc o ding and matrix-based approaches. One-hot enco ding assigns a unique binary v ariable to eac h category , and they are assigned their corresp onding h yp erparameter weigh ting the imp ortance of each category in the k ernel [ 14 ]. Matrix-based approac hes hav e sho wn great results in BO [ 27 , 29 , 31 , 33 ]. The elements of these matrices are h yp erparameters that mo del correlations and anti-correlations b et ween differen t categories [ 29 ]. The similarities b et ween categories are directly enco ded in matrices. Other techniques for enco ding categorical v ariables include contin uous latent spaces. In [ 37 ], each categorical v ariable is assigned a 2D con tinuous space, in whic h its categories are mapp ed in a w ay that correlated categories are close, and uncorrelated ones are far. The co ordinates of the categories can b e view ed as hyperparameters represen ting correlations. The rest of this do cumen t is organized as follo ws. An illustrativ e optimization problem is introduced in Section 2 to guide the presentation. The essential concepts of k ernels and GPs are presen ted in Section 3 . In Section 4 , the categorical distances and neigh b orho o ds are developed. The nov el neigh b orho o ds are adapted and used within the CatMADS 6 framew ork in Section 5 to pro vide pro of of concept. Lastly , some n umerical exp erimen ts b enc hmarking CatMADS using the new neighborho o ds with other solvers are presented in Section 6 . 2 An illustrativ e mec hanical-part design problem T o outline the prop osed con tributions, a mec hanical-part design problem is used as an illustrativ e example in the following sections. The goal is to minimize the physical strain of a structural piece sub ject to a budget constrain t and an ecological score constrain t. A p oin t represen ts a design, and it is comp osed of three categorical v ariables and tw o con tinuous v ariables. The categorical v ariables correspond to the c hoice of supplier u ∈ { a , b } , the material a ∈ { alum , steel , comp 1 , w ood } , and the shap e s ∈ { square , cir cle , ellipse } . The contin uous v ariables are a length l ∈ [5 , 10] and a ratio of recycle material r ∈ [0 , 1] . The domain and a p oin t are defined as x = ( u, a, s, l , r ) ∈ X = X cat × X cont (4) where X cat = { a , b } × { alum , steel , comp , w ood } × { square , cir cle , ellipse } , and X cont = [5 , 10] × [0 , 1] . The categorical set X cat con tains 2 × 4 × 3 = 24 categorical comp onen ts, and the feasible region Ω is unkno wn. The problem is inten tionally constructed as a blackbox in accordance with the scop e of this w ork. The functions are ev aluated through numerical iterativ e routines to a prescrib ed accuracy . By design, the problem features strong interactions b etw een the categorical v ariables and constraint feasibilit y . Each categorical comp onent x cat = ( u, a, s ) ∈ X cat induces a differen t feasible region ov er the con tinuous subspace X cont = [5 , 10] × [0 , 1] . Some categories ma y app ear in tuitively similar, e.g. , the circle and ellipse categories for the cross-section shap e. Ho wev er, the ob jectiv e function, and, in particular, the constrain t functions, b eha ve very differently across categories. As a result, constructing categorical neighborho o ds without incorp orating information from b oth the ob jective and the constraints can lead to misleading similarity measures and p o or optimization p erformance. The difficulty of the problem is outlined in Figure 2 that describ es three Latin Hyp ercub e Sampling (LHS) exp erimen ts and a graph. In the histogram of Figure 2a , LHS is p erformed indep enden tly within eac h categorical comp onen t. Each bar represents the p ercentage of feasible p oints obtained for a given n umber of samples. Only the categorical comp onent for which at least one feasible p oin t w as sampled is presented. As the num b er of p oin ts p er categorical comp onent in- creases, more comp onents with feasible p oints are discov ered. The categorical comp onent ( a , alum , cir cle ) do es not ha ve any feasible p oint with 250 samples (there is no blue bin), but it do es with 5 000 and 100 000 samples. The histogram suggests that only six categorical comp onents may b e capable of ac hieving feasibility . The graph in Figure 2b sho ws the b est feasible ob jectiv e v alue obtained by performing an LHS with 100 000 p oin ts for eac h categorical component. Overall, b est ob jectiv e v alues are asso ciated with smaller p ercentages of feasibility . 1 comp for “comp osite” 7 ( b , w ood , circle ) ( a , w ood , ellipse ) ( a , comp , square ) ( a , alum , cir cle ) ( b , steel , square ) ( b , alum , square ) 0 2 . 5 5 7 . 5 10 % feasible 250 5000 100000 (a) F easibility rate p er categorical comp o- nen t. 10 − 2 10 − 1 10 0 10 1 0 6 12 18 24 30 ( b , w ood , circle ) ( a , w ood , ellipse ) ( b , steel , square ) ( a , alum , cir cle ) ( a , comp , square ) ( b , alum , square ) % feasible Best ob jective v alue (b) Best ob jective function v alue vs. % feasible with 100 000 p oints per categorical comp onen t. Figure 2: Statistical analysis of feasibility p er categorical comp onent in the piece machining problem. 3 Mixed-v ariable k ernels This study uses similarity measures derived from a v ailable data to induce categorical distances including k ernel-based measures. A similarity measure quantifies how close or related t wo data points are in the decision space. A k ernel is a particular type of similarit y measure. The data p oints of Problem ( 1 ) lie in the domain X , and the k ernel is defined on this domain. F rom such a kernel, a categorical k ernel is extracted and used to construct categorical neigh b orho o ds. In practice, kernels can compare mixed- v ariable p oints, enabling the construction of interpolation mo dels that rely exclusiv ely on similarit y measures, suc h as mixed-v ariable Gaussian pro cesses. F ormally , a k ernel κ : X × X → R is a symmetric similarity measure, such that 1. κ ( x , y ) = κ ( y , x ) for any x , y ∈ X , and 2. for an y finite set of p oin ts { x (1) , x (2) , . . . , x ( p ) } with p ∈ N , the symmetric p × p matrix [ K ] i,j = κ x ( i ) , x ( j ) for i, j ∈ { 1 , 2 , . . . , p } is p ositiv e semi-definite. Suc h k ernel κ is said to b e p ositive semi-definite. The k ernel is constructed following the approac h of the classic textb o ok [ 30 ]. F or t ∈ { cat , qn t } and i ∈ I t , eac h v ariable x t i ∈ X t i is assigned a one-dimensional kernel κ t i : X t i × X t i → R of the appropriate v ariable type. The one-dimensional kernels are combined with m ultiplications that conserv e symmetry and semi-p ositive definiteness. Common k ernels for quantitativ e v ariables include p olynomial, Matern or Gaussian k ernels, e.g. , see [ 30 ]. Typically , the quantitativ e k ernel can b e built directly as pro duct 8 of one-dimensional Gaussian kernels, i.e. , κ qnt x qnt , y qnt : = n qnt Y i =1 exp Ä − θ qnt i x qnt i − y qnt i 2 ä , (5) where θ qnt := θ qnt 1 , θ qnt 2 , . . . , θ qnt n qnt ∈ R n qnt + is the v ector of hyperparameters of the quan titative kernel. The quantitativ e kernel and the follo wing ones are all parameterized b y hyperparameters. F or readabilit y , hyperparameters are not explicitly noted in the argumen ts of k ernels. 3.1 Categorical kernels As mentioned in Section 1.3 , there are currently t wo main state-of-the-art approaches for constructing categorical kernels: one-hot enco ding and matrix-based methods. Again, the matrix-based approach enco des similarit y measures b et ween categories directly into matrices. More precisely , eac h categorical v ariable x cat i ∈ X cat i is assigned a positive semi-definite matrix T i ∈ R ℓ cat i × ℓ cat i where ℓ cat i is the num b er of categories of x cat i . A matrix T cat i : = L i L ⊤ i is built as a symmetric and p ositive semi-definite matrix where L i is a low er-triangular matrix parameterized b y a hypersphere decomp osition (lengths and angles) [ 11 , 20 ]. An elemen t of a matrix L i con tains h yp erparameters of the categorical k ernel, whereas an elemen t of a matrix T cat i is a correlation measure b e- t ween tw o categories of the corresponding categorical v ariable. F or example, in the mac hining piece problem, the similarit y matrix asso ciated with the material choice a ∈ { alum (A) , steel (S) , comp (C) , wood (W) } can b e expressed as T cat a = ϑ A , A ϑ S , A ϑ S , S ϑ C , A ϑ C , S ϑ C , C ϑ W , A ϑ W , S ϑ W , C ϑ W , W (6) where ϑ i,j ∈ [ − 1 , 1] denotes a similarity measure b etw een categories i and j , with i, j ∈ { A , S , C , W } , and T cat a is symmetric b y construction. The v alues of ϑ i,j are implicitly determined through the hyperparameters of the low er-triangular matrix L a in the h yp ersphere decomp osition, suc h that T cat a = L a L ⊤ a . F or similarities b et ween iden tical categories (auto-correlations), the homoscedastic parametrization fixes a constant v alue across categories, t ypically ϑ i,i = 1 , whereas the heteroscedastic parametrization allo ws ϑ i,i ∈ [ − 1 , 1] to b e learned as adjustable h yp erparameters. F or the matrix-based approac h, the categorical kernel is derived from the categorical matrices T cat 1 , T cat 2 , . . . , T cat n cat . Essentially , tw o p oin ts x and y are compared v ariable-wise, with each matrix T cat i pro viding the correlation parameter comparing categories x cat i and y cat i . These correlation parameters are then multiplied. The num b er of h yp erparameters asso ciated to the categorical v ariable x cat i dep ends on the n umber of categories ℓ i and the c h osen parametrization of L cat i . While more hyperparameters increase mo deling flexibilit y , they also imply greater computational costs: see [ 33 ] for a detailed presentation of parametrizations and the hypersphere decomp osition. The matrix-based approac h typically in volv es man y h yp erparameters. in BO. Al- ternativ e approac hes with few er hyperparameters are a v ailable. The common one-hot 9 enc o ding tec hnique assigns a unique binary v ariable to each category . The categorical comp onen t x cat ∈ X cat is represented b y a total of P n cat i =1 ℓ i binary v ariables, where ℓ i ∈ N is the num b er of categories of the i -th categorical v ariable x cat i . F or each categorical v ariable, exactly one of its binary v ariables is assigned the v alue 1 , and the others are set to 0 . In the machining problem, recall that the categorical v ariables are u ∈ { a , b } , a ∈ { alum , steel , comp , wood } and s ∈ { square , circle , ellipse } . The categori- cal comp onent ( b , w ood , circle ) w ould b e represen ted b y ((0 , 1) , (0 , 0 , 0 , 1) , (0 , 1 , 0)) , whereas ( a , steel , ellipse ) w ould b e represented by ((1 , 0) , (0 , 1 , 0 , 0) , (0 , 0 , 1)) . With this approac h, each binary v ariable can b e assigned a h yp erparameter. Then, a categorical k ernel can b e defined via Gaussian kernels as follows κ cat x cat , y cat : = n cat Y i =1 exp − E i x cat i − E i y cat i 2 θ cat i (7) where E i ( x cat i ) ∈ z ∈ { 0 , 1 } ℓ i : 1 ⊤ z = 1 is the one-hot representation of the i -th categorical v ariable x cat i , and θ cat i ∈ R ℓ i is the v ector of hyperparameters of x cat i , and ∥ u − v ∥ 2 w := ( u − v ) ⊤ diag ( w ) ( u − v ) is the weigh ted Euclidean norm. In ( 7 ) , the norm represen ts distances b etw een binary v ectors, where the weigh ts are the h yp erparameters of the binary v ariables. 3.2 A djusting the k ernels with mixed-v ariable GPs Once appropriate quan titativ e and categorical k ernels are defined, the k ernel κ : X × X → R can b e constructed with the pro duct κ ( x , y ) : = κ cat x cat , y cat κ qnt x qnt , y qnt , (8) whic h is parameterized b y a vector of hyp erparameters θ : = ( θ cat , θ qnt ) . T o adjust the hyperparameters of the k ernel, a regression mo del linking input data p oin ts to their corresp onding images is required. In BO, GPs are commonly used as surrogate mo dels for ob jective and constrain t functions, as they can represent a wide v ariety of functions, including mixed-v ariable ones. F or readability , the construction of GP surrogates is presented for the ob jectiv e function. This surrogate is noted ˜ f and it is constructed with a set of p oin ts X : = { x (1) , x (2) , . . . , x ( p ) } and a vector of corresponding images f = ( f ( x (1) ) , f ( x (2) ) , . . . , f ( x ( p ) )) . This pro cedure yields a prediction function ˆ f : X → R and a v ariance function ˆ σ 2 : X → R + that, in the noiseless setting, can b e expressed as in [ 30 ]: ˆ f ( x ) : = κ ( x ) ⊤ K − 1 f , ˆ σ 2 ( x ) : = κ ( x , x ) − κ ( x ) ⊤ K − 1 κ ( x ) ≥ 0 , (9) where κ : X × X → R is the kernel, κ ( x ) : = κ ( x , x (1) ) , κ ( x , x (2) ) , . . . , κ ( x , x ( p ) ) ∈ R p is the kernel vector comparing an input p oin t x ∈ X and the p oints in X , and K ∈ R p × p is the k ernel matrix that compares all p oints in X suc h that [ K ] i,j : = κ x ( i ) , x ( j ) for i, j ∈ { 1 , 2 , . . . , p } . The k ernel characterizes the GP by quantifying ho w correlated or similar input p oin ts are, i.e. , ho w close their output should b e. Concretely , it con trols the general b ehavior 10 of the fit, e.g. , the smo othness in a contin uous setting. In the mixed-v ariable setting, defining an appropriate mixed-v ariable kernel is key to constructing a GP surrogate that can mo del the functions of interest. In fact, the GP that b est fits the av ailable data is found by adjusting the hyperparameters of the kernel. They are typically obtained by maximizing the marginal likelihoo d of the GP [ 30 ]: θ ⋆ ∈ argmax θ log P [ f | X , θ ] where log P [ f | X , θ ] = − 1 2 f ⊤ K − 1 f − 1 2 log det ( K ) − p 2 log (2 π ) . (10) The marginal likelihoo d is con tinuously differentiable. Hence, it can b e optimized with standard con tinuous solv ers. After this step, the GP is prop erly constructed and the categorical k ernel is finely adjusted to the data problem. The categorical kernel is used in the next section. The GP surrogates of the constrain t functions are constructed using the same pro ce- dure as for the ob jective function. Sp ecifically , for j ∈ J , eac h constrain t function g j is pro vided a probabilistic surrogate ˜ g j with a predictive mean function ˆ g j : X → R and v ariance function ˆ σ 2 j : X → R + , as well as its own kernel and hyperparameters. 4 Surrogate-based categorical neigh b orho o ds Kernels and surrogate mo dels are used to construct neigh b orho o ds that structure categor- ical v ariables. The prop osed neigh b orho o ds are defined using t wo categorical distances, one asso ciated with the ob jective function and another one asso ciated with the constraint functions. Pro ximity b et ween categorical v ariables simultaneously considers similarities in the ob jective and cons train t functions. This section fo cuses exclusiv ely on categorical v ariables. Quantitativ e v ariables are temp orarily omitted to simplify the presen tation. The surrogate mo dels ˜ f and ˜ g , as w ell as the kernel, are defined on the categorical set X cat . A neighborho o d constructed at an incum b ent u ∈ X cat is denoted N ( u ; m ) where m ∈ { 1 , 2 , . . . , |X cat |} is the num b er of neigh b ors. This notation is formalized at the end of the section. Section 4.1 presen ts categorical distances that establish pro ximity with resp ect to the ob jectiv e function. Afterw ards, Section 4.2 prop oses a categorical distance for the constrain t functions. Based on these categorical distances, surrogate-based neighborho o ds are dev elop ed in Section 4.3 . 4.1 Categorical distance f or the ob jectiv e function Kernels are equiv alent to scalar pro ducts in Hilb ert spaces [ 25 ]. This prop erty allows categorical k ernels to b e transformed into categorical distances. Let ϕ : X cat → H b e a mapping that maps the categorical comp onen ts of the categorical set X cat in to a Hilb ert space H equipp ed with a scalar pro duct. Then, the categorical kernel is uniquely defined according to the Mo ore-Aronsza jn Theorem [ 3 ] and satisfies κ cat ( u , v ) = ϕ ( u ) ⊤ ϕ ( v ) . Note that the categorical k ernel κ cat is still computed as describ ed in Section 3 , i.e. , with Gaussian kernels or matrices. The categorical distance d f : X cat × X cat → R + is defined with the categorical kernel [ 15 ], and it is ensured to b e a metric via the implicit mapping 11 ϕ : d f ( u , v ) : = κ cat ( u , u ) + κ cat ( v , v ) − 2 κ cat ( u , v ) = ϕ ( u ) ⊤ ϕ ( u ) + ϕ ( v ) ⊤ ϕ ( v ) − 2 ϕ ( u ) ⊤ ϕ ( v ) = ∥ ϕ ( u ) − ϕ ( v ) ∥ 2 . (11) Although the mapping ϕ and the Hilb ert space H are not explicitly kno wn, ( 11 ) sho ws that the categorical distance can b e equiv alently interpreted in a Hilbert space with d f ( u , v ) = ∥ ϕ ( u ) − ϕ ( v ) ∥ 2 . Without constrain t functions, categorical neigh b orho o ds are characterized only by the categorical distance. Hence, unconstrained neigh b orho o ds can b e viewed as b eing implicitly constructed in a Hilb ert space, where tw o categorical comp onen ts u , v ∈ X cat that are more similar corresp ond to a smaller distance ∥ ϕ ( u ) − ϕ ( v ) ∥ 2 . Figure 3 illustrates this Hilb ert space as a t wo-dimensional con tinuous space, where categorical comp onents are mapp ed in to con tinuous vectors. Note that this is only an equiv alent represen tation. In practice, the distance is computed as d f ( u , v ) = κ cat ( u , u ) + κ cat ( v , v ) − 2 κ cat ( u , v ) . X cat = { u , v , w } ϕ H ϕ ( u ) ϕ ( v ) ϕ ( w ) N ( u ; 2) = N ( v ; 2) = { u , v } N ( w ; 2) = { w , u } Figure 3: Visualization of a unconstrained neighborho o d equiv alently constructed in a Hilb ert space. In Figure 3 , the categorical comp onents are mapp ed in a Hilb ert space via an implicit mapping ϕ . Sc hematically , neigh b orho o ds con taining tw o elements can be viewed as follo ws: the neigh b orho o ds constructed at u and v coincide and con tain the comp onents { u , v } , while the neighborho o d constructed at w con tains { w , u } . On the one hand, the construction of the categorical distance d f requires non-negligible computational effort, notably b ecause of the maximization of the marginal lik eliho o d of the GP in ( 10 ) . On the other hand, it is induced by a finely-tuned kernel. The categorical distance in ( 11 ) is constructed from the problem data through the k ernel, so that correlated categorical comp onents are em b edded closer to each other in a Hilb ert space, while uncorrelated comp onents are placed farther apart. This b ehavior is particularly useful for constructing categorical neigh b orho o ds. This distance is finer than binary categorical distances, such as the Hamming distance, whic h treats all mismatches equally and do es not use information from the problem. As an example, let X cat = { r , b , g } and d HM denote the Hamming distance. Then d HM ( r , g ) = d HM ( r , b ) = 1 , implying that it is not p ossible to determine whether green or blu e is closer to red. If a surrogate mo del is av ailable, but no k ernel is defined, the categorical pseudo- distance can b e approximated by a pseudo-distance using prediction v alues, such that d f ( u , v ) ≈ ˆ f ( u ) − ˆ f ( v ) . This pseudo-distance trivially satisfies symmetry and tri- angular inequalit y prop erties, but not the iden tity of indiscernibles property since d f ( u , v ) = 0 ⇔ u = v when ˆ f is not injective. Hence, categorical comp onen ts with 12 similar prediction v alues are considered close. Conceptually , this mimics the b ehavior of a k ernel inducing an interpolation mo del, suc h as GPs. Although simple, this pseudo- distance captures pro ximity with resp ect to the ob jectiv e function f . That said, when a kernel with adjusted hyperparameters is av ailable, the categorical distance of ( 11 ) is generally preferable, as it corresp onds to measuring similarity in an inner-pro duct Hilb ert space. 4.2 Categorical pseudo-distance for constrain t functions As discussed previously , the main goal is to construct neighborho o ds that incorp orate information from b oth the ob jectiv e and constraint functions. This section dev elops a pseudo-distance that establishes proximit y with resp ect to the constrain t functions. When a neighborho o d is constructed at a feasible comp onent, it should first maintain feasibilit y and then promote improv emen t in the ob jectiv e function, i.e. , similarity with resp ect to the ob jective. In this setting, differences in the degree of feasibility b etw een categorical comp onents that are b oth predicted to b e feasible are of limited imp ortance. F rom an optimization p ersp ective, once feasibilit y is predicted, the fo cus should instead b e on improving the ob jectiv e function. In particular, large distances b et ween a “highly feasible” comp onent and a “marginally feasible” comp onent should b e a voided, as b oth satisfy the constraints and should b e compared primarily regarding the ob jective. F or this reason, the prop osed pseudo- distance is constructed so that it ev aluates to zero when b oth compared comp onen ts are predicted to b e feasible. The next functions are used to construct the pseudo-distance. F or eac h j ∈ J , a function ˆ g + j : X cat → R is defined from the predictiv e model ˆ g j : X cat → R and its asso ciated uncertaint y mo del ˆ σ j : X cat → R + , b oth deriv ed from the surrogate mo del ˜ g j of the j -th constraint. Let λ ≥ 0 b e a relaxation parameter used to relax a predicted constrain t v alue ˆ g j ( u ) using its asso ciated uncertaint y ˆ σ j ( u ) ≥ 0 . The function ˆ g + j sets to zero any predicted constrain t v alue ˆ g j ( u ) that is feasible after relaxation b y λ ˆ σ j ( u ) and normalizes the remaining v alues, such that ˆ g + j ( u ) : = ® 0 if ˆ g j ( u ) − λ ˆ σ j ( u ) ≤ 0 , ψ ( ˆ g j ( u )) otherwise , (12) where ψ is a normalization function ensuring that ˆ g + j ( u ) ∈ [0 , 1] holds for an y u ∈ X cat . F or example, ψ ma y apply a min-max normalization on the b ounds of ˆ g j ( u ) when ˆ g j ( u ) − λ ˆ σ j ( u ) > 0 is considered. Note that if the surrogate mo del do es not provide an uncertain ty measure, then λ can b e set to zero, meaning that no uncertaint y is tak en in to account. F or readability , ( 12 ) ma y b e expressed in a v ector form ˆ g + : X cat → R | J | + , considering all indices j ∈ J compactly . The pseudo-distance function asso ciated with the constrain t functions is constructed from the vector function ˆ g + , as follows : d g ( u , v ) : = ∥ ˆ g + ( u ) − ˆ g + ( v ) ∥ p , (13) where p ≥ 1 and d g ( u , v ) = 0 are ensured when both argumen ts are predicted to b e feasible after relaxation, i.e. , when ˆ g ( u ) − λ ˆ σ ( u ) ≤ 0 and ˆ g ( v ) − λ ˆ σ ( v ) ≤ 0 . The 13 normalization function ψ ensures that the pseudo-distance d g is not biased by the relativ e scales of the constraint function v alues. The symmetry and triangular inequalit y prop erties are trivially satisfied by virtue of the p -norm. Ho wev er, the iden tity of indiscernibles is not resp ected, i.e. , d g ( u , v ) = 0 ⇔ u = v since the vector function ˆ g + is not injectiv e by design. This last unsatisfied prop erty makes ˆ g + a pseudo-distance function instead of a distance function. 4.3 Surrogate-based neighborho o ds The no v el categorical neigh b orho o ds are developed in this section. A neigh b orho o d is constructed at a comp onent u ∈ X cat . The other comp onents in the neigh b orho o d are selected based on trade-offs b et w een distances concerning the ob jective and the constrain t functions. This selection is formalized using notions of dominance inspired by bi-ob jective optimization. In the follo wing, tw o ranking functions are derived from the distance functions in tro duced in previous sections: a primary and a secondary ranking function, b oth parameterized b y a comp onent u ∈ X cat at which the neighborho o d is constructed. Conceptually , the first selected components corresp ond to P areto-optimal solutions concerning the tw o ranking functions, while subsequent comp onents prioritize the primary ranking function ov er the secondary one. The primary and secondary ranking functions are defined in tw o cases dep ending on the comp onen t u ∈ X cat . If u is feasible, then the primary ranking function is deriv ed from d g (constrain ts), since the priorit y is to construct neighborho o ds with comp onen ts that maintain feasibility . Otherwise, u is infeasible, and the primary ranking function is based on d f (ob jective), allowing greater flexibility with resp ect to feasibilit y . This ma y allo w finding promising solutions that are difficult to reach when imp osing feasibility at all times. The primary and secondary ranking functions, noted p u : X cat → R + and s u : X cat → R resp ectively , are parameterized b y u ∈ X cat and defined as follows p u ( v ) : = d g ( u , v ) and s u ( v ) : = d f ( u , v ) if u ∈ Ω , p u ( v ) : = d f ( u , v ) and s u ( v ) : = d g ( u , v ) if u ∈ Ω . (14) An illustrativ e example is presented b efore introducing the formal ordering rules that determine the comp onen ts selected in a neighb orho o d. These rules are induced by the ranking functions. In this example, there are tw elve categorical comp onents. Hence, elev en comp onen ts m ust b e ordered, since the neighborho o d stems from u ∈ X cat , which is naturally ordered first. Visually , the ordering of the comp onents is p erformed in the space of images ( s u , p u ) across three steps, each corresp onding to a sub-figure from left to righ t in Figure 4 . The first four comp onen ts are the Pareto solutions, i.e. , the nondominated solutions, in the space of images. The Pareto comp onen ts are ordered among themselves solely with the primary ranking function p u . The components 5 and 6 are not P areto, but they ha v e a primary ranking function v alue of zero with the comp onen t u at which the neighborho o d is constructed. This situation ma y most notably occur when the primary ranking function is based on the pseudo-distance d g : recall that when b oth comp onents are predicted to b e feasible, this pseudo-distance returns zero. Among themselves, comp onents 5 and 6 14 p u s u 1 2 3 4 (a) P areto comp onen ts. p u s u 5 6 1 2 3 4 (b) Non-P areto comp onen ts with p u ( v ) = 0 . p u s u 5 6 1 2 3 4 7 8 9 10 11 (c) Remaining comp onen ts ordered with the primary ranking function. p u s u 1 2 3 4 5 (d) Unconstrained problem. Figure 4: Ordering components with ranking functions. ( a )-( c ) three steps for constrained problems. ( d ) single step for unconstrained problems. The comp onen t u is lo cated at the origin and is not display ed. are ordered using the secondary ranking function. Finally , the remaining comp onen ts 7 to 11 are directly ordered with the primary ranking function. Note that when the problem is unconstrained, the comp onent u ∈ Ω and, consequen tly , the primary ranking function is based on d g . Ho wev er, in this case, the pseudo-distance function d g is alwa ys set to zero b y conv ention, since its comp onen ts are alwa ys feasible. Therefore, only the distance function of the ob jective d f is considered. An unconstrained example is illustrated with six components (including u that is not displa yed) in Figure 4d , where the ordering is done directly based on their heigh t. The relation establishing a partial order on the categorical set X cat , giv en a component u ∈ X cat and ranking functions, is now formally introduced. Definition 1 (Ordering relation) Given a c omp onent u ∈ X cat , and r anking func- tions p u : X cat → R + and s u : X cat → R + , the or dering r elation ⪯ define d on the c ate goric al set X cat is such that for any p air v , w ∈ X cat , v is or der e d b efor e or tie d to w , note d v ⪯ w , when any of the fol lowing c onditions hold: 1. p u ( v ) = p u ( w ) = 0 and s u ( v ) ≤ s u ( w ) , 2. p u ( v ) > 0 , p u ( w ) > 0 and p u ( v ) ≤ p u ( w ) , 3. v is not dominate d by any c omp onent of X cat \ { u } in the sp ac e of images ( p u , s u ) , but w is dominate d by at le ast one such c omp onent, 4. p u ( v ) ≤ p u ( w ) . The ordering relation in Definition 1 does not establish a total order, b ecause there can b e ties, notably when v and w are suc h that p u ( v ) = p u ( w ) and s u ( v ) = s u ( w ) . Nev ertheless, it pro vides a systematic wa y to iden tify promising categorical comp onents with information from b oth the ob jectiv e and constraint functions. If the problem is unconstrained, then only the first condition is used since all comp onents are feasible, as illustrated in Figure 4d . 15 No w that the ordering relation is formally defined, the neighborho o ds based on surrogate mo dels are finally in tro duced. Definition 2 (Surrogate-based neighborho o d) F or a given c omp onent u ∈ X cat and inte ger m ∈ { 1 , 2 , . . . , |X cat |} , the surrogate-based neighborho o d N ( u ; m ) ⊆ X cat is the set c ontaining m c ate goric al c omp onents of lowest or dering with r esp e ct to an or dering r elation ⪯ define d on X cat . The r elation v ⪯ w is satisfie d whenever v ∈ N ( u ; m ) and w / ∈ N ( u ; m ) . Definition 2 generalizes distance-induced neighborho o ds in [ 6 ] b y using relations instead of a single distance for selecting components. In fact, when a problem is unconstrained, a surrogate-based neigh b orho o d is equiv alen t to a distance-induced neigh b orho o d using d f . That said, the implemen tation in [ 6 ] uses a basic mixed-v ariable in terp olation to construct the categorical distance. The k ernel-induced categorical distance d f in tro duced in Section 4.1 provides a more structured similarity measure, as it is induced b y an inner pro duct in a Hilb ert space through w ell-defined categorical kernels. The impro vemen ts do es not only concerns constrained problems. 4.4 Illustrativ e case study of the mec hanical-part problem The mechanical-part design problem from Section 2 is used here to dev elop a case study with categorical neigh b orho o ds. A single Latin Hyp ercub e Sampling (LHS) of 96 p oin ts is p erformed on the mixed-v ariable domain describ ed in Section 2 , in whic h three p oints are generated for eac h of the 32 categorical comp onen ts. Only one p oint sample is feasible, that is, x ⋆ = ( b , w ood , circle , 5 . 5 , 1) with ob jective function v alue f ( x ⋆ ) = 28 . 55 is kno wn. In study , the goal is to find another triplet of categorical v ariables maintaining feasibilit y and improving the ob jectiv e v alue without mo difying the con tinuous v ariables. The contin uous v ariables are fixed, and the curren t categorical comp onent is noted u = ( b , w ood , circle ) ∈ X cat . The neighborho o d resulting of the Go w er distance has exactly six categorical comp onents, at distance one from u . T able 1 compares three neigh b orho o d-generation strategies pro ducing exactly six p oints. Eac h p oint has same con tinuous v ariables of x ⋆ and is differen t than u . The first and simplest strategy uses the Go wer distance. The second strategy uses an ob jectiv e-based categorical distance [ 6 ], induced b y a mixed-v ariable Inv erse Distance W eigh ting (IDW) regression mo del. The third strategy employs the surrogate-based neigh b orho o ds from Definition 2 , using GPs as surrogate mo dels. The results highligh t clear differences b etw een the three strategies. The Gow er distance and the ob jective-based neighborho o d fail to iden tify any feasible p oin t, whereas the surrogate-based neighborho o d prop osed identifies four feasible p oints. Recall that Figure 2b shows the results of a Latin Hyp ercub e Sampling with 100 000 samples p er categorical comp onen t, suggesting that only six categorical components are lik ely to admit feasible con tinuous regions. The prop osed metho d identifies four of these six comp onents within the six ev aluations, while the incumbent component accoun ts for another one. The only remaining feasible comp onen t is ( b , alum , square ) , which app ears to b e extremely unlik ely to yield feasible p oints, with only 0 . 01% feasibility observed in a LHS of 100 000 p oin ts in Figure 2b . 16 Strategy Neighbor Supplier Material Shape f g 1 g 2 F easible Gow er distance 1 b alum circle 18.4928 -0.1300 0.0150 No 2 b steel circle 14.5128 -0.0225 0.0625 No 3 b comp circle 9.5329 -0.0800 0.0575 No 4 b w ood square 24.0428 0.0050 0.0650 No 5 b w ood ellipse 24.5628 -0.1075 0.0125 No 6 a w ood cir cle 28.3468 0.3450 0.5600 No Ob jective-based [ 6 ] 1 a w ood cir cle 28.3468 0.3450 0.5600 No 2 b w ood square 24.0428 0.0050 0.0650 No 3 b alum circle 18.4928 -0.1300 0.0150 No 4 b w ood ellipse 24.5628 -0.1075 0.0125 No 5 b steel circle 14.5128 -0.0225 0.0625 No 6 b comp circle 9.5329 -0.0800 0.0575 No Surrogate-based 1 a alum cir cle 18 . 2868 − 0 . 0225 − 0 . 0451 Y es 2 b alum circle 18.4928 -0.1300 0.0150 No 3 a w ood cir cle 28.3468 0.3450 0.5600 No 4 a w ood ellipse 24 . 3568 − 0 . 6900 − 0 . 4715 Y es 5 b steel square 10 . 0028 − 0 . 0225 − 0 . 0451 Y es 6 a comp square 8 . 8169 − 0 . 0225 − 0 . 0451 Y es T able 1: Neigh b ors of u = ( b , wood , cir cle ) prop osed b y three strategies. Only the surrogate-based strategy impro ves the ob jectiv e v alue while maintain- ing feasibilit y . The best impro vemen t is obtained with the categorical component ( a , comp , square ) , yielding an ob jective v alue of 8 . 8169 . This comp onen t also corre- sp onds to that of the b est solution identified in Section 2 using an LHS with 100 , 000 p oin ts p er comp onent. The ordering and selection of categorical comp onen ts in the surrogate-based neigh- b orho o d are presen ted in Figure 5 . The figure plots the primary and secondary ranking functions p u and s u in tro duced in Section 4.3 , with logarithmic scales for readability . The selected comp onents are sho wn in blue, together with their categorical comp onen t and a n umber indicating their ranking. On the horizontal axis p u , an axis break is in tro duced to displa y comp onen ts with distance zero on a logarithmic scale. In the figure, the feasible neigh b ors all ha ve a distance of zero with respect to p u : they lie on the v ertical axis. The ob jectiv e-based approach identifies ( b , steel , square ) , which corresp onds to the comp onen t rank ed fifth b y the surrogate-based approac h. 5 A dapting surrogate-based neigh b orho o ds for mixed- v ariable direct searc h The categorical neighborho o ds developed in Section 4 are no w used for optimization in this section, which also rein tro duces the integer and con tinuous v ariables discarded previously . 5.1 A dapting the surrogate-neigh b orho o ds for mixed-v ariables domains The pseudo-distance and distance functions from Section 4 require minor adaptations no w that the surrogate mo dels are defined on the domain X rather than on the categorical set X cat . They are no w computed b et ween p oin ts in the domain, while the quantitativ e v ariables are held fixed so that comparisons only concern the categorical v ariables. More 17 10 − 4 10 − 3 10 − 2 10 − 1 10 0 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 0 ( b , steel , square ) ( a , alum , cir cle ) ( a , w ood , ellipse ) ( a , comp , square ) ( b , w ood , ellipse ) ( b , alum , cir cle ) 2 3 1 4 5 6 p u s u Figure 5: Ordering of categorical comp onents with the surrogate-based neigh b orho o d in the mec hanical-part design problem. The incumbent u = ( b , wood , cir cle ) is at the origin and it is not displa yed. precisely , for a given a nd fixed quantitativ e component x qnt ∈ X , the distances introduced in Section 4 are computed on the set ( X × X ) x qnt : = ( x , y ) ∈ X × X : x qnt = y qnt . (15) The distance and pseudo-distance functions are said to b e parameterized b y the quan titative comp onent x qnt , since it influences their b eha vior without app earing as an explicit argumen t. Consequen tly , the primary and secondary ranking functions p x : X → R + and s x : X → R are now defined on the domain X and parameterized at a p oint x ∈ X , whic h can b e either feasible or infeasible. In this context, an argument of the ranking functions shares the same quan titative comp onen t as the incumbent solution, that is x qnt . The ordering relation ⪯ th us compares p oints of the domain sharing the same quan titative comp onent, making the comparisons effectiv ely on categorical comp onents. Finally , surrogate-based neigh b orho o ds m ust b e generalized to the mixed-v ariable setting. They are redefined b y considering the ordering relation on the full domain and b y choosing that the neigh b orho o ds themselves contain categorical comp onents only . This choice ensures consistency with b oth the CatMADS framework and the notion of lo cal minima discussed in the next section. The follo wing definition adapts Definition 2 in the more general mixed-v ariable case. Definition 3 (Mixed-v ariab le surrogate-based neighborho o d) F or a given p oint x ∈ X and inte ger m ∈ { 1 , 2 , . . . , |X cat |} , the surrogate-based neighborho o d N ( x ; m ) ⊆ 18 X cat is the set c ontaining m c ate goric al c omp onents of the lowest or dering with r esp e ct to an or dering r elation ⪯ define d on X . The r elation y ⪯ z is satisfie d whenever y = ( y cat , x qnt ) ∈ X wher e y cat ∈ X cat ∩ N ( x ; m ) and z = ( z cat , x qnt ) ∈ X wher e z cat ∈ X cat \ N ( x ; m ) . Note that Definition 3 reduces to Definition 2 when restricted to categorical comp onents. Moreo ver, a consequence of this definition is that for an y x ∈ X and m ∈ { 1 , 2 , . . . , |X cat |} , N ( x ; m ) = ¶ y cat (1) , y cat (2) , . . . , y cat ( m ) © ⊆ X cat in which y cat (1) = x cat and where Ä y cat (1) , x qnt ä ⪯ Ä y cat (2) , x qnt ä ⪯ . . . ⪯ Ä y cat ( m ) , x qnt ä . In the next sections, the surrogate-based neigh b orho o ds from Definition 3 are used to handle the categorical v ariables. 5.2 Bac kground on CatMADS CatMADS is a direct searc h framework that iterativ ely seeks p oin ts yielding a strict decrease of the ob jective function and/or the constraints [ 6 ]. It generalizes MADS by tac kling categorical v ariables with neighborho o ds induced by data from the problem. The quantitativ e v ariables are essentially treated as they are in MADS . F or simplicity , CatMADS is presented in Algorithm 1 without considering constrain ts. Algorithm 1: The CatMADS framew ork for unconstrained problems (adapted from [ 6 ]). 0. Initialization . Set k = 0 , p erform an Design of Exp eriment (DoE) and define an initial mesh 1. Opp ortunistic searc h (optional). 2. Opp ortunistic p oll . P erform p olling around the incum b en t solution 3. Opp ortunistic extended p oll (optional). If Steps 1 & 2 are unsuccessful, p erform quan titative p olls around p oin ts in P cat ( k ) with ob jective function v alues sufficien tly close to f ( x ( k ) ) 4. Up date . Set k ← k + 1 , up date mesh and c heck stopping criterion If the iteration is successful, increase mesh size and GO TO Step 1. Else, decrease mesh size, and if the mesh is at its minimum size, then STOP Before any optimization is done, a DoE samples p oints in the domain using a p ortion of the budget of ev aluations. The DoE is used to gather information on the problem and construct categorical neighborho o ds, as well as for determining an initial solution. The main steps of the CatMADS algorithm are Steps 1, 2, and 3. If a solution with strictly low er ob jective function v alue is found during these steps, it b ecomes the incum b ent solution and the iteration is deemed suc c essful . Otherwise, the iteration is unsuc c essful . The se ar ch is an optional step allo wing flexible ev aluation of p oints at the in tersection of the mesh and the domain. The p oll is the core mechanism of CatMADS . A t iteration k , trial p oints are generated around the incumbent x ( k ) through t wo p olls, 19 a quan titative one and a categorical one. The quantitativ e p oll fixes the categorical comp onen t and p erforms a standard MADS poll on the quantitativ e v ariables. The categorical p oll fixes the quantitativ e comp onent and explores neigh b oring categorical comp onen ts selected through a surrogate-based ordering relation. T w o consecutive quan titative p olls on R 2 are illustrated in Figure 6 . Figure 6c illustrates b oth p oll t yp es. x qn t ( k ) y qn t (1) y qn t (2) y qnt (3) (a) Quan titative poll P qnt ( k ) . x ∗ y qn t (4) y qn t (5) y qn t (6) y qn t (7) (b) Quan titative poll P qnt ( k +1) . N ( x ( k ) ; 3) x ( k ) (c) CatMADS (unconstrained) P cat ( k ) . Figure 6: ( a )–( b ) MADS (quan titative) p olls at iteration k and k + 1 where x ( k ) = x ( k +1) , and ( c ) a CatMADS p oll. Arro ws emerging from an incum b ent solution represent a p ositiv e basis. Quantitativ e comp onen ts pro duced are on the mesh in gray and within the blac k square, called the fr ame . The frame delimits the region in whic h a quan titative p oll can pro duce quan titative comp onents. In the example in Figure 6c , x cat ( k ) = red and the num b er of comp onents in the neigh b orho o d is three. The neigh b orho o d contains the red (incum b ent), yello w , and purple categories. Eac h colored plane represents the quantitativ e domain asso ciated with one categorical comp onent. V ertical arro ws corresp ond to the categorical p oll, while the quan titative p oll is p erformed within the red plane. If b oth the searc h and poll steps fail to impro v e the ob jectiv e, the optional step, called the extende d p ol l , may b e launched at Step 3. This step revisits p oin ts in the categorical p oll P cat ( k ) that almost impro ved the incumbent v alue f ( x ( k ) ) b y calibrating their quan titative v ariables with additional ev aluations. On an unsuccessful iteration, the mesh and frame are further discretized. CatMADS terminates when the mesh and frame ha v e reac hed their minim um allo w able discretization. In CatMADS , the constrain ts are handled with the progressive barrier strategy (PB) [ 5 ]. The PB w orks with tw o incumbent solutions, each with their o wn indep endent p oll, as describ ed ab ov e. The fe asible p ol l is p erformed around the fe asible incumb ent solution x fea , and this solution is considered feasible when it strictly impro ves the ob jectiv e function. The infe asible p ol l is p erformed at the infe asible incumb ent solution x inf , and this solution is forced to b ecome more feasible through the iterations. F or more details on the up date with the PB, see [ 8 , Chapter 12]. 20 5.3 Impro v emen ts of CatMADS with surrogate-based neigh b or- ho o ds In [ 6 ], categorical neighborho o ds are constructed using information from the ob jectiv e function only . Moreo ver, the implementation in [ 6 ] relies on a simple mixed-v ariable in terp olation. The surrogate-based neigh b orho o ds introduced here do not affect the theoretical con vergence results, as the prop osed metho d remains an instance of the CatMADS framework. How ever, the resulting categorical neigh b orho o ds incorporate information from b oth the ob jective and the constrain t functions and rely on an ob jective distance induced by kernel-based similarities. As a result, the categorical p olls should b e guided more effectiv ely to ward feasible regions than in the original implementation. Again, this has no impact on the theoretical results, but it is exp ected to improv e empirical p erformance and accelerate conv ergence. The improv ed categorical p oll with the surrogate-based neighborho o ds is illustrated in Figure 7 . x FEA x INF (a) Basic categorical p oll in [ 6 ]. x FEA x INF (b) P oll with surrogate-based neighborho o ds. Figure 7: The CatMADS framework in the presence of constraints. In Figure 7a , the infeasible regions are in gray and the feasible regions are colored. The feasible categorical p oll starts from the red category and selects the y ellow category , whic h is the most similar with respect to the ob jective function. The generated trial p oin t is infeasible. In con trast, in Figure 7b , the generated trial p oin t lies in the blue category . A similar b ehavior is observed for the infeasible categorical p oll. In the basic imple- men tation, the generated trial p oint comes from the category that is closest with resp ect to the ob jective function, whic h again leads to an infeasible trial p oint in Figure 7a . In comparison, the surrogate-based implementation selects a category that is less similar in terms of the ob jectiv e but considers the similarities of b oth the ob jectiv e and the constrain t functions. This results in a feasible trial p oin t in the red category in Figure 7b . 6 Computational exp erimen ts This section describ es the b enc hmarking of an instance of CatMADS using the no vel neigh b orho o ds, as describ ed in Section 5 . This is a pro of of concept demonstrating the 21 utilit y of surrogate-based neighborho o ds in mixed-v ariable blackbox optimization. Since the surrogate mo dels are GPs with one-hot enco ding of the categorical v ariables, the new resulting metho d is referred to as CatMADS GP . The implementation of CatMADS GP is identical to that of CatMADS , except for the construction of the neigh b orho o ds and a BO search step strategically reusing the surrogates. Moreo v er, in CatMADS , ID W interpolation is constructed follo wing the DoE, whereas CatMADS GP also up dates the GPs as long as a BO searc h step is p erformed. T o mitigate computational costs, the BO search step and up date of GPs are stopp ed whenev er the n um b er of ev aluations exceeds 500 or 33% of the budget of ev aluations. The GPs are implemented with the SMT Python lib rary [ 34 ]. F or a given problem, the n umber of neighbors is given by m = max (3 , |X cat | 1 / 2 ) [ 6 ]. This v alue scales with the total num b er of categories |X cat | , and ensures there are at least tw o differen t categorical comp onen ts other than the incumbent one. F or the detailed implemen tation, see [ 6 , Section 4.1]. The b enchmarking includes state of the art solvers used in different mixed-v ariable blac kb ox optimization applications [ 21 , 28 , 35 ]: • Pymo o , a Python library containing a collection of optimization algorithms. Sp ecif- ically , the mixed-v ariable implementation of a genetic algorithm is us ed [ 10 ]; • Optuna , a mixed-v ariable solv er extending the metaheuristic cov ariance matrix adaptation evolution strategy (CMA-ES) to categorical v ariables [ 2 ]. The solver is also a v ailable as a Python implementation; • CatMADS , a prototype implementation built on the NOMAD soft ware. It serves as the reference implemen tation of the original CatMADS framework, from which CatMADS GP is deriv ed. 6.1 Optimization results for the mechanical-part problem The mec hanical-part design problem from Section 2 is now treated as a mixed-v ariable blac kb ox optimization problem. T o emulate a realistic blackbox setting in which function ev aluations are exp ensiv e, a small budget of only 200 ev aluations is allow ed. All solv ers are initialized with the same DoE comprising 40 ev aluations, corresp onding to 20% of the budget, without any feasible p oint. As sho wn in Figure 2 , an imp ortan t difficult y of this problem is the identification of a feasible solution using a limited num b er of ev aluations. Con vergence graphs are presented in Figure 8 . The plot on the left shows the progress of the constraint aggregation function, and the one on the righ t shows the progress of the b est feasible ob jective function. F easibilit y is declared when h ( x fea ) ≤ 10 − 8 , as represen ted b y the horizon tal dashed line. On the left plot, the curves are in terrupted as so on as a feasible solution is generated. The plots on the righ t start at this v alue. Pymo o is the first metho d to reach feasibilit y , as shown on the left of Figure 8 . Ho wev er, the corresp onding ob jectiv e function v alue is high and remains unc hanged throughout the budget. This indicates that Pymo o is stuc k in a sub optimal categorical comp onen t. In con trast, CatMADS GP and CatMADS reach feasibilit y later, but with lo wer ob jective v alues. Both metho ds identify significantly b etter solutions, suggesting th at 22 25 50 75 100 125 150 175 200 Number of ev aluations 10 − 9 10 − 7 10 − 5 10 − 3 10 − 1 Best aggregated constrain t violation 25 50 75 100 125 150 175 200 Number of ev aluations 5 10 15 20 25 30 Best feasible ob jective value CatMADS GP CatMADS Pymo o Optuna Figure 8: Con v ergence graphs for the mechanical-part design problem with a budget of 200 . they reach more fa vorable categorical comp onents. Finally , Optuna fails to pro duce a feasible p oint. The mechanical-part problem w as run with m ultiple seeds. The seed affects both the DoE and the sto c hastic comp onen ts of the solv ers, such as sampling pro cedures or the generation of directions. The results lead to similar conclusions as those observ ed in Figure 8 . Pymo o reaches feasibility in most runs, and when it do es, it is usually the first one. How ev er, in approximately 75% of the runs, the resulting ob jective function v alue remains high, as observed in Figure 8 . CatMADS GP and CatMADS consistently achiev e the b est ob jectiv e v alues, and CatMADS GP reac hes feasibilit y faster than CatMADS . Optuna rarely finds a feasible p oin t. 6.2 Data profiles with existing solvers In this section, CatMADS GP is tested on the 30 unconstrained and 30 constrained mixed- v ariable problems of the Cat-Suite collection [ 17 ]. As in CatMADS [ 6 ], the ev aluation budget p er problem is set to 250 n , where n is the n um b er of v ariables, and the initial DoE consists of 20% of this budget. Eac h problem is instan tiated with three different seeds, resulting in a total of 180 instances. An instance, denoted p ∈ P , corresp onds to a problem with a sp ecific seed. The set of all instances is denoted P . The conv ergence test for an instance p ∈ P dep ends on an initial ob jectiv e v alue f 0 ∈ R . This v alue is defined as • the least ob jectiv e function v alue in the common DoE, for unconstrained prob- lems [ 9 ]; • the smallest ob jectiv e function v alue among the first feasible solutions found b y the solv ers, for constrained problems [ 9 ]. This definition enables the comparison of solv ers even when the DoE fails to pro duce a feasible solution. The set of solv ers in the comparison is S = { CatMADS GP , CatMADS , Pymo o , Optuna } . A solver s ∈ S τ -solv es an instance p ∈ P if it pro duces a feasible incum b ent solution 23 x fea ∈ Ω such that the reduction f 0 − f ( x fea ) is within τ of the smallest reduction f 0 − f ⋆ obtained b y any solver on this instance [ 26 ]. More precisely , the τ -con vergence test is defined as f 0 − f ( x fea ) ≥ (1 − τ )( f 0 − f ⋆ ) , (16) where τ ∈ [0 , 1] is a given tolerance. A data profile [ 26 ] represen ts the fraction of instances τ -solv ed b y a solv er s ∈ S as a function of the computational budget. It is defined as data s ( κ ) : = 1 |P | ß p ∈ P : k p,s n p + 1 ≤ κ ™ ∈ [0 , 1] , (17) where k p,s ≥ 0 is the n umber of ev aluations required by solv er s to τ -solv e instance p , and n p is the n umber of v ariables in p . In the follo wing plots, κ represen ts budgets measured in m ultiples of ( n p + 1) ev aluations. The data profiles comparing CatMADS GP with the solv ers from the literature on the unconstrained and constrained instances are presented in Figures 9a and 9b . 100 200 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 P ortion of τ -solv ed instances τ = 10 − 2 100 200 Groups of n p + 1 ev aluations τ = 10 − 3 100 200 τ = 10 − 5 (a) Unconstrained test problems. 100 200 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 P ortion of τ -solv ed instances τ = 10 − 2 100 200 Groups of n p + 1 ev aluations τ = 10 − 3 100 200 τ = 10 − 5 (b) Constrained test problems. CatMADS GP CatMADS Pymo o Optuna Figure 9: Comparison results on the test problems. 24 The data profiles for unconstrained problems in Figures 9a and 9b sho w that CatMADS GP p erforms b est across all tolerances, follo wed by CatMADS . The p erfor- mances of the three other metho ds significantly deteriorate as the tolerance τ gets smaller. F or instance, at τ = 10 − 2 and 250( n p + 1) ev aluations, CatMADS GP τ -solv es appro ximately 65% of the problems, compared to 60% for CatMADS , 45% for Pymo o and 25% for Optuna . F or the constrained case, the profiles in Figure 9b show that b oth CatMADS v ariants clearly outp erform Pymo o and Optuna o ver all tolerances. T o b etter analyze the relative p erformance of the t wo v arian ts, Figure 10a shows the p erformance profiles constructed using only the tw o CatMADS v ariants. CatMADS GP dominates CatMADS for the three tolerances on the constrained problems. The most significant impro vemen t is at τ = 10 − 3 . 100 200 0 . 0 0 . 2 0 . 4 0 . 6 0 . 8 1 . 0 P ortion of τ -solv ed instances τ = 10 − 2 100 200 Groups of n p + 1 ev aluations τ = 10 − 3 100 200 τ = 10 − 5 (a) Constrained test problems. CatMADS GP CatMADS Figure 10: Comparison results on the constrained test problems b etw een the tw o CatMADS v ariants. 25 7 Discussion This w ork in tro duces a no vel approac h to structure categorical v ariables through neigh b or- ho o ds constructed from surrogate mo dels. These neighborho o ds incorp orate information from b oth the ob jectiv e and the constrain t functions, making them suitable for con- strained mixed-v ariable optimization. T o balance similarit y with resp ect to the ob jective and constrain t functions, the construction relies on dominance relations. As a proof of concept, the surrogate-based neigh b orho o ds are first illustrated on the mechanical-part design problem. A distinctive feature of this problem is the diffi- cult y of identifying feasible p oin ts among the categorical comp onen ts. The proposed neigh b orho o ds navigate this c hallenge more effectiv ely than alternativ e neigh b orho o d strategies. The surrogate-based neigh b orho o ds are then integrated into the CatMADS algorithm, resulting in the new metho d CatMADS GP , that is tested against sev eral state-of-the-art solv ers. Data profiles indicate that CatMADS GP consisten tly ac hieves b etter p erformance on the Cat-Suite collection. These results suggest that surrogate-based neigh b orho o ds pro vide a promising mec hanism for constrained mixed-v ariable blackbox optimization. F urther impro vemen ts could extend this study . The curren t implemen tation of CatMADS GP uses a fixed num b er of neigh b ors throughout the iterations, and more sophisticated strategies could dynamically adjust the num b er of neighbors. F uture extensions w ould define and analyze neigh b orho o ds in volving meta v ariables [ 7 ], i.e. , v ariables whose v alues dictate the num b er of v ariables and/or or constraints present in the optimization problem. Data a v ailabilit y statemen t Scripts and data are publicly av ailable at https://github.com/bbopt/surrogate_ based_neighborhoods . Conflict of in terest statemen t The authors state that there are no conflicts of in terest. A c kno wledgmen ts W e gratefully ac knowledge Dr. Paul Sav es for his help with the implemen tation of SMT and the kernel. References [1] M.A. Abramson, C. Audet, J.W. Chrissis, and J.G. W alston. Mesh A daptive Direct Searc h Algorithms for Mixed V ariable Optimization. Optimization L etters , 3(1):35–47, 2009. 26 [2] T. Akiba, S. Sano, T. Y anase, T. Oh ta, and M. Ko y ama. Optuna: A Next-generation Hyp erparameter Optimization F ramework. In Pr o c e e dings of the 25th ACM SIGKDD International Confer enc e on Know le dge Disc overy and Data Mining . Asso ciation for Computing Mac hinery , 2019. [3] N. Aronsza jn. Theory of Repro ducing Kernels. T r ansactions of the Americ an mathematic al so ciety , 68(3):337–404, 1950. [4] C. Audet and J.E. Dennis, Jr. Mesh A daptive Direct Search Algorithms for Con- strained Optimization. SIAM Journal on Optimization , 17(1):188–217, 2006. [5] C. Audet and J.E. Dennis, Jr. A Progressiv e Barrier for Deriv ative-F ree Nonlinear Programming. SIAM Journal on Optimization , 20(1):445–472, 2009. [6] C. Audet, Y. Diouane, E. Hallé-Hannan, S. Le Digabel, and C. T rib es. CatMADS: Mesh A daptiv e Direct Search for constrained blac kb o x optimization with categorical v ariables. T echnical Rep ort G-2025-42, Les cahiers du GERAD, 2025. [7] C. Audet, E. Hallé-Hannan, and S. Le Digab el. A General Mathematical F ramework for Constrained Mixed-v ariable Blac kb o x Optimization Problems with Meta and Categorical V ariables. Op er ations R ese ar ch F orum , 4(12), 2023. [8] C. Audet and W. Hare. Derivative-F r e e and Blackb ox Optimization . Springer Series in Op erations Research and Financial Engineering. Springer, Cham, Switzerland, 2017. [9] C. Audet, W. Hare, and C. T rib es. Benc hmarking constrained, multi-ob jective and surrogate-assisted deriv ative-free optimization metho ds. T ec hnical Rep ort G-2025-36, Les cahiers du GERAD, 2025. [10] J. Blank and K. Deb. Pymo o: Multi-Ob jective Optimization in Python. IEEE A c c ess , 8:89497–89509, 2020. [11] D. Brigo, F. Mercurio, and F. Rapisarda. Parameterizing correlations: a geometric in terpretation. IMA Journal of Management Mathematics , 18(1):55–73, 2007. [12] J.H. Bussemak er, P .D. Ciampa, T. De Smedt, B. Nagel, and G. La Ro cca. System Arc hitecture Optimization: An Op en Source Multidisciplinary Aircraft Jet Engine Arc hitecting Problem. In AIAA A VIA TION 2021 F orum . American Institute of A eronautics and Astronautics, 2021. [13] K. Deb, A. Pratap, S. Agarwal, and T. Meyariv an. A fast and elitist multiob jective genetic algorithm: NSGA-I I. IEEE T r ansactions on Evolutionary Computation , 6(2):182–197, 2002. [14] E.C. Garrido-Merchán and D. Hernández-Lobato. Dealing with categorical and in teger-v alued v ariables in Bay esian Optimization with Gaussian pro cesses. Neur o- c omputing , 380:20–35, 2020. 27 [15] A. Gretton, K.M. Borgwardt, M.J. Rasc h, B. Schölk opf, and A. Smola. A Kernel T w o-Sample T est. The Journal of Machine L e arning R ese ar ch , 13(25):723–773, 2012. [16] E. Hallé-Hannan, C. Audet, Y. Diouane, S. Le Digab el, and P . Sav es. A distance for mixed-v ariable and hierarchical domains with meta v ariables. Neur o c omputing , 653:131208, 2025. [17] E. Hallé-Hannan, C. Audet, Y. Diouane, S. Le Digab el, and C. T rib es. Cat-Suite: A collection of optimization problems with categorical and quantitativ e v ariables for b enc hmarking. T ec hnical Rep ort G-2025-39, Les cahiers du GERAD, 2025. [18] R. Hamano, S. Saito, M. Nom ura, K. Uc hida, and S. Shirak a w a. CatCMA: Sto c hastic Optimization for Mixed-Category Problems. T echnical Rep ort 2405.09962, Arxiv, 2024. [19] T. Hastie, R. Tibshirani, and J. F riedman. The Elements of Statistic al L e arning . Springer Series in Statistics. Springer New Y ork Inc., New Y ork, NY, USA, 2001. [20] P . Jäc kel and R. Reb onato. The Most General Metho dology to Create a V alid Correlation Matrix for Risk Managemen t and Option Pricing Purp oses. Journal of R isk , 2(2):17–27, 1999. [21] Y. Jina and P .V. Kumar. Bay esian optimisation for efficient material discov ery: a mini review. Nanosc ale , 15(26):10975–10984, 2023. [22] D. Lakhmiri. Hyp erNOMAD . https://github.com/bbopt/HyperNOMAD , 2019. [23] S. Le Digab el and S.M. Wild. A taxonom y of constraints in black-box simulation- based optimization. Optimization and Engine ering , 25(2):1125–1143, 2024. [24] S. Lucidi, V. Piccialli, and M. Sciandrone. An Algorithm Mo del for Mixed V ariable Programming. SIAM Journal on Optimization , 15(4):1057–1084, 2005. [25] J. Mercer. F unctions of p ositive and negativ e t yp e, and their connection the theory of integral equations. Philosophic al tr ansactions of the r oyal so ciety of L ondon A , 209(441-458):415–446, 1909. [26] J.J. Moré and S.M. Wild. Benchmarking Deriv ativ e-F ree Optimization Algorithms. SIAM Journal on Optimization , 20(1):172–191, 2009. [27] J. P elamatti, L. Brev ault, M. Balesdent, E.-G. T albi, and Y. Guerin. Efficien t global optimization of constrained mixed v ariable problems. Journal of Glob al Optimization , 73(3):583–613, 2019. [28] R.P . Prager and H. T rautmann. Exploratory Landscap e Analysis for Mixed-V ariable Problems. IEEE T r ansactions on Evolutionary Computation , 2024. [29] P .Z.G. Qiand, H. W u, and C.F.J. W u. Gaussian pro cess mo dels for computer exp erimen ts with qualitative and quan titative factors. T e chnometrics , 50(3):383–396, 2008. 28 [30] C.E. Rasmussen and C.K.I. Williams. Gaussian Pr o c esses for Machine L e arning . The MIT Press, 2006. [31] O. Roustan t, E. P adonou, Y. Deville, A. Clément, G. P errin, J. Giorla, and H. W ynn. Group kernels for Gaussian pro cess metamo dels with categorical inputs. Unc ertainty Quantific ation , 8(2):775–806, 2020. [32] P . Sav es, N. Bartoli, Y. Diouane, T. Lefebvre, J. Morlier, C. Da vid, E. Nguy en V an, and S. Defo ort. Constrained Ba yesian Optimization Over Mixed Categorical V ariables, with Application to Aircraft Design. In A er oBest , 2021. [33] P . Sav es, Y. Diouane, N. Bartoli, T. Lefebvre, and J. Morlier. A mixed-categorical correlation k ernel for Gaussian pro cess. Neur o c omputing , 550:126472, 2023. [34] P . Sa ves, R. Lafage, N. Bartoli, Y. Diouane, J.H. Bussemak er, T. Lefebvre, J.T. Hw ang, J. Morlier, and J.R.R.A Martins. SMT 2.0: A Surrogate Mo deling T o olb ox with a fo cus on Hierarc hical and Mixed V ariables Gaussian Pro cesses. A dvanc es in Engine ering Softwar e , 188:103571, 2024. [35] P . Sridevi, Z. Arefin, and S.I. Ahamed. An integrated mac hine learning and hy- p erparameter optimization framework for noninv asive creatinine estimation using photopleth ysmography signals. He althc ar e Analytics , 7:100395, 2025. [36] E.-G. T albi. Metaheuristics for v ariable-size mixed optimization problems: A unified taxonom y and surv ey. Swarm and Evolutionary Computation , 89:101642, 2024. [37] Y. Zhang, S. T ao, W. Chen, and D.W. Apley . A Latent V ariable Approach to Gaus- sian Pro cess Mo deling with Qualitativ e and Quantitativ e F actors. T e chnometrics , 62(3):291–302, 2020. 29
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment