jaxsgp4: GPU-accelerated mega-constellation propagation with batch parallelism
As the population of anthropogenic space objects transitions from sparse clusters to mega-constellations exceeding 100,000 satellites, traditional orbital propagation techniques face a critical bottleneck. Standard CPU-bound implementations of the Si…
Authors: Charlotte Priestley, Will H, ley
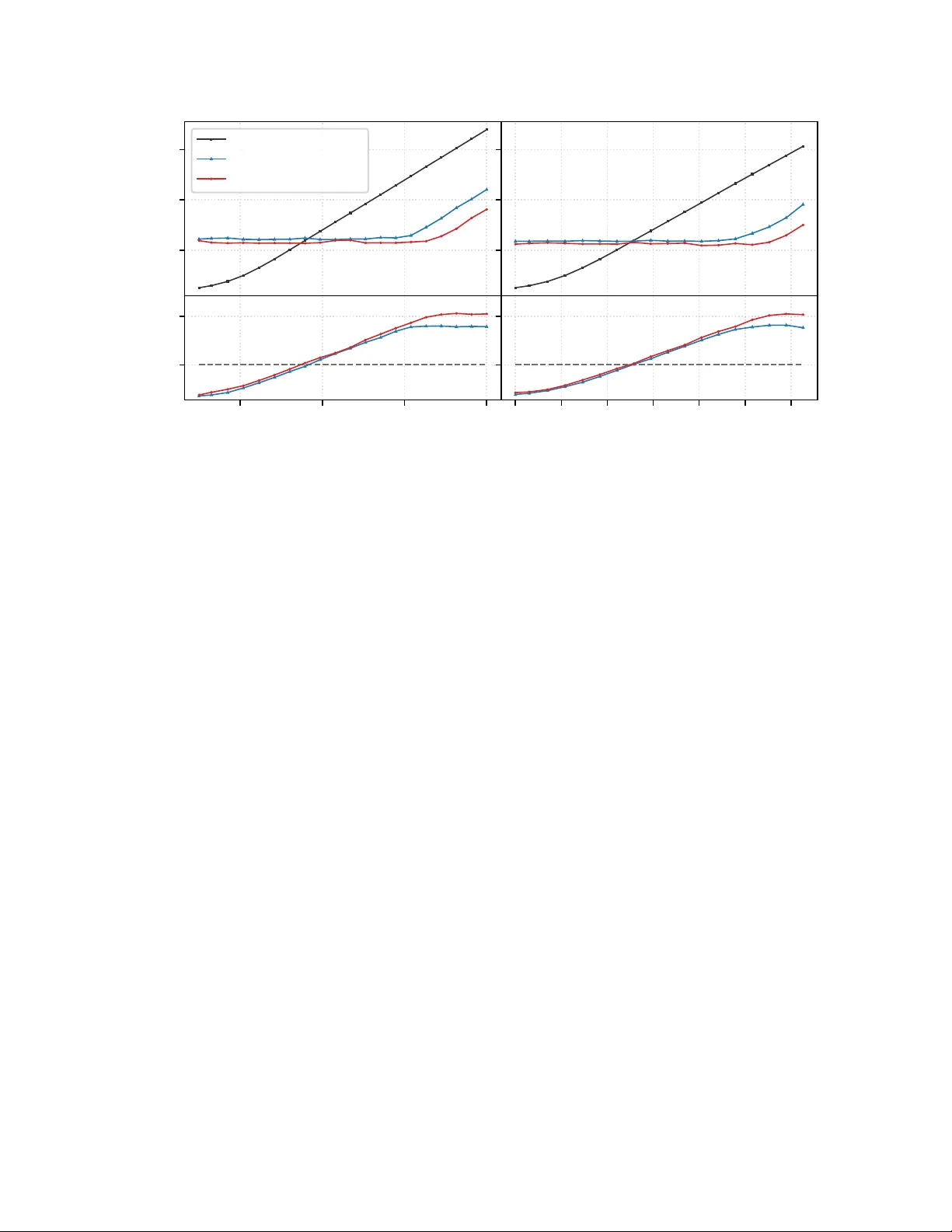
JA X S G P 4 : G P U - AC C E L E R A T E D M E G A - C O N S T E L L A T I O N P R O P A G A T I O N W I T H B A T C H PA R A L L E L I S M Charlotte Priestley 1,2,3 and Will Handley 1,2,3 1 Kavli Institute for Cosmology , University of Cambridge, Cambridg e, UK 2 Institute of Astr onomy , University of Cambridge , Cambridge, UK 3 P olyChor d Ltd., London, UK A B S T R A C T As the population of anthropogenic space objects transitions from sparse clusters to mega- constellations exceeding 100,000 satellites, traditional orbital propagation techniques face a critical bottleneck. Standard CPU-bound implementations of the Simplified General Perturbations 4 (SGP4) algorithm are less well suited to handle the requisite scale of collision a v oidance and Space Situational A wareness (SSA) tasks. This paper introduces jaxsgp4 , an open-source high-performance reimple- mentation of SGP4 utilising the JAX library . JAX has gained traction in the landscape of computational research, offering an easy mechanism for Just-In-T ime (JIT) compilation, automatic vectorisation and automatic optimisation of code for CPU, GPU and TPU hardware modalities. By refactoring the algorithm into a pure functional paradigm, we le verage these transformations to e xecute massi vely parallel propagations on modern GPUs. W e demonstrate that jaxsgp4 can propagate the entire Starlink constellation (9,341 satellites) each to 1,000 future time steps in under 4 ms on a single A100 GPU, representing a speedup of 1500 × ov er traditional C++ baselines. Furthermore, we argue that the use of 32-bit precision for SGP4 propagation tasks of fers a principled trade-off, sacrificing negligible precision loss for a substantial gain in throughput on hardw are accelerators. 1 Introduction The orbital en vironment is undergoing unprecedented e xpansion. As of March 2026, despite only 12,200 activ e satellites currently in orbit 1 , the Federal Communications Commission (FCC) and International T elecommunication Union (ITU) hav e recei ved licence applications for 1,896,629 planned constellation satellites to be launched in the coming decades 2 . This trajectory is only accelerating [ 1 ]; for instance, SpaceX’ s proposal for ‘orbital data centres’ in lo w Earth orbit (LEO) added an additional one million satellites to the global forecast in January 2026. While not all proposed assets will reach orbit, the immediate need to future-proof our current infrastructure has already been recognised. The U.S. Space Force ‘Space Fence’ system, operational since 2020, is e xpected to track an order of magnitude more than the 26,000 objects managed by its predecessor . Similarly , the industry-standard T wo-Line Element (TLE) set format is being phased out due to its inability to support catalogue numbers abov e 99,999. In this era of me ga-constellations, the ability to perform massi vely parallel calculations will be vital for Space Situational A wareness (SSA), which underpins the safety and continuity of satellite operations. Such capacity is equally critical for mitigating the contamination of our telescopes amid mounting concerns over the impacts of meg a-constellations on the future of astronomical observation [2]. Orbital propagation (the task of predicting the future position and velocity of a satellite from a known state), is the computational kernel of these applications. The Simplified General Perturbations 4 (SGP4) model from the simplified perturbations family (SGP , SGP4, SDP4, SGP8, SDP8) [ 3 ] remains the most ubiquitous propag ator . This popularity reflects the fact that the TLE data format (the de-facto uni versal standard for distrib uting publicly a v ailable satellite data) is specific to this family of models, such that an yone working with TLE data must employ a simplified perturbations 1 https://www.space- track.org/ , data retrieved 25th March 2026 2 https://planet4589.org/space/con/conlist.html , data retriev ed 25th March 2026 model to get accurate predictions. For ease of adaptability , SGP4 also has the benefit of being open source and the underlying equations easily accessible. The history and dev elopment of the theory as well as the current equations can be found in [4]. The source code introduced in [ 5 ], available in full at the CelesT rak website 3 , is widely-recognised as the most comprehensi ve and up-to-date v ersion of SGP4 av ailable to the public. While this ‘of ficial’ release is av ailable in several languages, including C++, FOR TRAN, MA TLAB, and Pascal, these implementations are designed for serial execution or limited multi-threading. They are less well-suited to vectorise across the millions of satellite-time combinations required by modern conjunction assessment screenings. Modern probabilistic programming languages such as JAX 4 and PyTorch [ 6 ] offer an attractive solution to this computational bottleneck. JAX provides a frontend for XLA (Accelerated Linear Algebra), allo wing Python code to be compiled and optimised for hardware accelerators (GPUs and TPUs) via a NumPy-lik e interface. It has seen wide adoption in scientific and numerical computing o wing to its simple mechanisms for Just-In-T ime (JIT) compilation, automatic vectorisation, and automatic dif ferentiation. W e emphasise that these probabilistic programming framew orks provide two distinct capabilities: automatic differentiation and GPU-accelerated batch parallelism. While the two are often conflated, they serve fundamentally dif ferent purposes; automatic differentiation is essential for gradient-based optimisation, whereas parallelism le verages the huge processing power of GPUs to enable 1000s of tasks to be processed simultaneously . In practice, batch parallelism is often significantly underappreciated. This is likely because most practitioners’ intuitions about GPUs are shaped by training deep learning models, where one selects the largest network that will fit on a single GPU, or e ven distrib utes it across many , leaving no room to run multiple instances in parallel. In scientific computing, howe ver , models are orders of magnitude smaller than trillion-parameter neural networks, meaning that running a single ev aluation on a GPU leaves the v ast majority of the device idle. This represents a largely untapped axis of computational po wer: by batching many independent e valuations, one can e xploit a factor of thousands more parallelism than a single ev aluation alone. SGP4 has already been implemented in one such framework: ∂ SGP4 5 , built on PyTorch . Howe ver , this effort focused on the benefits of a differentiable implementation for gradient-based analysis, treating the potential for massi ve parallelism as a secondary con venience [ 7 ]. As a result, ∂ SGP4’ s memory scaling is not optimised for massi vely-parallel workloads (see Section 3). Y et, it is this parallelism that may prove the more impactful capability: recent w ork has sho wn across scientific applications that exploiting batch parallelism on GPUs can actually be a much more powerful axis than gradients, including for example, in applications to cosmology [ 8 ][ 9 ][ 10 ] and gravitational wa ve inference [ 11 ]. Orbital propagation is a natural fit for this paradigm as each satellite’ s trajectory can be computed independently . Moreover , unlike ‘special perturbation’ techniques, which numerically integrate the equations of motion such that each timestep depends sequentially on the last, SGP4 is a ‘general perturbation’ technique, providing an analytical solution to the equations of motion such that the state at any time can be ev aluated directly from the initial conditions. SGP4 therefore yields two independent potential ax es for parallelism, o ver satellites and ov er times, making it especially well-placed to reap the benefits of GPU acceleration. It is this untapped potential that moti v ates us to explore the prospects of GPU-accelerated batch parallelism as a solution to the increased computational demands of an exponentially growing satellite population. In this work, we present jaxsgp4 , a JAX -nativ e implementation of SGP4 for massi v ely-parallel propagations that can be implemented on modern hardware (CPU/TPU/GPU), and make it a v ailable through an open-source repository 6 . W e demonstrate ho w refactoring SGP4 for data-parallel e xecution on hardware accelerators addresses the computational bottleneck of the mega-constellation era. In Section 2, we giv e an overvie w of how the SGP4 propagation model was translated into JAX . In Section 3 we benchmark the performance of jaxsgp4 on GPU, and demonstrate its utility for large-scale propagation tasks with the Starlink constellation. W e consider the viability of 32-bit propagations in Section 4, and in Section 5 we outline jaxsgp4 ’ s automatic differentiation capabilities. W e discuss these methods in Section 6 and conclude in Section 7. 2 jaxsgp4: Implementation The core contrib ution of this w ork is the translation of the procedural, state-hea vy SGP4 algorithm into a functional architecture compatible with JAX ’ s transformation system. 3 https://celestrak.org/publications/AIAA/2006- 6753/ 4 https://jax.readthedocs.io 5 https://github.com/esa/dSGP4 6 https://github.com/cmpriestley/jaxsgp4 2 2.1 Architectur e and Refactoring Standard SGP4 implementations take a state-heavy object-oriented approach, relying on a mutable ‘Satellite’ state to store changing satellite data over time. Additionally , standard SGP4 depends on complex branching logic (e.g., modifying drag modelling depending on an object’ s perigee altitude). JAX , ho wever , requires ‘pure’ functions— functions that depend only on inputs and ha ve no side ef fects—to apply its transformations ef fectively . In this paradigm, a function will always return the same results gi ven the same inputs; functions ha ve no hidden states and can not mutate objects or global variables. W e rewrote the SGP4 logic into Python directly from the current equations laid out in [ 4 ] originally taken from [ 3 ], with reference to the sgp4 Python library 7 for implementation specifics. Our implementation uses the standard WGS72 geopotential constants. The initialisation logic (the computation of numerous constant terms that takes place before the main time-dependent propagation algorithm can proceed), often separated in standard libraries, was integrated directly into the jaxsgp4 computational graph. This allows the accelerator to handle the full pipeline from TLE parsing to Cartesian state vector output ( r , v ). T o validate this refactoring, we benchmarked the accuracy of jaxsgp4 against the standard C++ SGP4 implementation using the activ e Starlink catalogue. Our tests confirmed that jaxsgp4 matches the C++ baseline to within expected machine precision tolerances, including edge cases like near -circular orbits and low-perigee trajectories. Finally , because the codebase relies entirely on JAX array primitives, it is hardware-agnostic (running on CPUs, GPUs, or TPUs without modification) and nati vely supports both 32-bit and 64-bit floating-point precision. The benefits of this precision flexibility are discussed further in Section 4. 2.2 J AX K ey Concepts Refactoring the algorithm into a purely functional form makes it compatible with the full suite of JAX transformations, including jax.grad for automatic dif ferentiation (see Section 5). W e le verage three k ey JAX concepts to achie ve the performance gains presented in the main body of this work (Section 3): Just-In-T ime (JIT) compilation, functional control flow , and automatic vectorisation. JIT Compilation T o maximise throughput, the entire propagation routine can be Just-In-Time (JIT) compiled using jax.jit . JIT compilation traces the sequence of operations and fuses them into optimized XLA k ernels targeted for the specific hardware. For an algorithm like SGP4, which in volves hundreds of sequential arithmetic operations, this fusion improv es memory ef ficiency by keeping intermediate v ariables in fast, on-chip re gisters. Once compiled, the routine bypasses the Python interpreter entirely , allowing ex ecution speeds comparable or faster than nativ ely compiled C++ code. Control Flo w XLA compilation requires static computational graphs, meaning the path through a function cannot depend on the values of its inputs. Ho we ver , SGP4 contains significant branching logic, altering calculations based on the v alues of certain orbital parameters such as epoch perigee height. T o make the function compatible with JAX , standard Python if/else statements were replaced with JAX control flow primiti v es like jax.lax.cond . These allow the compiler to trace both branches and ex ecute them ef ficiently on parallel hardware. Along the same lines, traditional implementations include runtime v alidity checks that further complicate SGP4’ s branching logic, such as exiting the propagation routine if eccentricity e xceeds 1.0 or mean motion becomes negati ve. As is standard when porting to GPU, we removed these runtime checks from the core propagation routine to conserve functional purity . Instead, anomalous physical states are allo wed to compute mathematically and are flagged via error codes, effecti vely deferring validity filtering to a computationally ine xpensi v e post-processing step. V ectorisation A ke y advantage of this implementation is that we may apply JAX ’ s jax.vmap (vectorising map). Standard SGP4 implementations propagate multiple satellites to multiple time steps using nested, sequential loops. Using jax.vmap , we are able to automatically transform our base propagation function, f ( s, t ) → ( r , v ) , to operate ov er arrays. By composing a vmap ov er the time inputs with a second vmap ov er the satellite parameters, we can ev aluate large batches simultaneously . This approach av oids manual thread management and maps the independent calculations directly to the thousands of cores a vailable on modern GPUs, enabling the simultaneous propagation of entire constellations. 7 https://github.com/brandon- rhodes/python- sgp4 3 3 Perf ormance Benchmarking T o assess to what extent exploiting modern hardware accelerators (GPUs) can improve the scalability of satellite propagation, we ev aluated jaxsgp4 on both NVIDIA T4 and A100 GPUs against the official C++ code found in [ 5 ] on a standard CPU. 3.1 Experimental Setup Performance benchmarks were conducted in a cloud-based environment (Google Colab). The proposed JAX implemen- tation was ex ecuted on both an NVIDIA T esla T4 GPU with 16 GB of GDDR6 VRAM, and an NVIDIA A100-SXM4 GPU with 40GB of HBM2 memory . The T4 is one of NVIDIA ’ s more cost-effecti ve entry-le v el models, and while newer -generation GPUs exist, the A100 is still widely used as an industry-standard high-performance card. Traditional SGP4 implementations are inherently single-threaded and CPU-bound; they cannot nati vely exploit modern hardware accelerators (GPUs). The baseline C++ implementation was consequently ex ecuted on an Intel Xeon CPU @ 2.20 GHz. The baseline C++ implementation refers to the official code from [ 5 ], regarded as the most accurate and up-to-date public version of the SGP4 theory since the United States Department of Defence (DoD) first released the equations and source code in [ 3 ]. This was compiled with the sgp4 Python package version 2.25 8 utilising 64-bit precision. The JAX implementation utilised 32-bit precision to better optimise GPU ef ficiency , this choice is discussed in more detail in Section 4. All TLE data used in the analyses of this section was tak en from Celes-T rak 9 , and comprises of TLEs for the Starlink constellation with an epoch date of the 13 th January 2026. Timing Specifics For statistical stability , for each timing measurement in our benchmark an adaptiv e number of iterations were recorded such that the total e xecution time for each measurement exceeded 0.2 seconds. Fiv e of such trials were conducted, from which we report the corresponding minimum time taken for a single run of the code. As is standard practice in computer science, the minimum value is reported (rather than the mean or median) on the premise that artefacts caused by system noise, such as transient operating system interrupts, will only slo w the process do wn, and therefore the minimum value is most lik ely to reflect the true ability of the hardware [12]. T o ensure a fair comparison of computational throughput, for the JAX implementation the latency associated with transferring data from the CPU host to the GPU de vice was excluded from timing measurements (by pre-con verting inputs to jax arrays), isolating the propagation kernel performance. In practice, this reflects how the code would be deployed: TLE data is loaded onto the GPU once and reused across man y propagation calls, meaning the one-off transfer cost is amortised over the lifetime of the application. The measured JAX time also excludes the initial compilation cost (warm-up), representing the steady-state performance expected in a production en vironment. Finally , we note that in the C++ case the recorded time only includes the time taken for the main propagation routine; it does not include the time taken for the initialisation phase of the algorithm. This initialisation phase inv olves the computation of constant terms from the raw TLE data. These constant terms are then used in the propagation routine in combination with the input time to make predictions of satellite motion. Unlike the standard C++ library , jaxsgp4 integrates both initialisation and propagation into a single call. As a result, the JAX timings reflect the time taken for the full pipeline from TLE parsing to state vector output ( r , v ) , and as such give a conserv ati v e estimate of JAX ’ s capability . The propagation phase is the most computationally demanding so we do not expect this to ha ve a major impact on the results. 3.2 Scaling Analysis The main adv antage of a ref actored SGP4 e xplored in this paper is that it allo ws us to e xploit the ability of GPUs to perform massiv ely-parallel computations. Ha ving rewritten the algorithm into a pure, functional paradigm compatible with JAX ’ s transformations, we make it possible to run huge numbers of computations in parallel by applying the jax.vmap (vectorising map) transformation to automatically batch over function inputs. This capacity for parallel computations means the time taken to propagate with jaxsgp4 does not increase with increased workload until hardw are saturation. Howe ver , the advantage of a flat scaling re gime only becomes apparent at suf ficiently lar ge batch sizes; each call to the GPU carries a fixed, one-of f cost, which for smaller batches, dominates the total ex ecution time. Below this threshold, codes run directly on CPU with lo wer overhead will often be faster . Once the batch size is large enough, this fixed dispatch cost is amortised and the GPU processes additional work in parallel at 8 https://pypi.org/project/sgp4/ 9 https://celestrak.com 4 10 − 4 10 − 2 10 0 W all-clock Time [s] Baseline C++ (CPU) jaxsgp4 (T4 GPU) jaxsgp4 (A100 GPU) 10 1 10 3 10 5 10 7 Number of T ime Points 10 0 10 3 Speedup [ JAX / C++] 1565 × 258 × 10 0 10 1 10 2 10 3 10 4 10 5 10 6 Number of Satellites 1457 × 292 × Figure 1: Scaling performance comparison between JAX /GPU and C++/CPU implementations of the SGP4 algorithm, for a single satellite propagated to multiple times (left) and multiple satellites propagated to a single time (right). jaxsgp4 exploits the potential of modern GPUs to perform massi vely-parallel computations, exhibiting a flat scaling regime where increased w orkload does not increase w all-clock time until hardware saturation (top). The ‘break-ev en’ point for each GPU (Speedup=1, denoted by dashed line in bottom panels), at which the benefit of parallel computation for large batch sizes o vercomes the initial dispatch o verhead, occurs at batch sizes of ∼ 300-500. In the bottom panels, we also specify the maximum speedup achiev ed by jaxsgp4 ov er the C++ baseline. This occurs in the linear hardware saturation regime, at which point the GPUs are operating at maximum computational ef ficienc y . no extra time cost, making it significantly f aster than a CPU which must handle each computation sequentially . This break-e ven point, much like the point of hardw are saturation, must be assessed empirically as it depends on the complex interplay between a number of factors such as the specific task considered. In light of this, we set out to assess how the time taken for jaxsgp4 to complete a propagation task on GPU scales as we batch ov er each input of the SGP4 propag ation routine (increasing the number of time points being propagated tow ards or the number of satellites to be propagated). The results of this analysis are giv en in Figure 1 in relation to the standard C++ baseline performance, where we ha ve utilised 32-bit and 64-bit precision for jaxsgp4 and C++ respectiv ely in vie w of the conclusions reached by the cost-benefit analysis in section 4. Computation times are giv en for propagating up to 10 million time points and ∼ 1.8 million satellites, a workload suf ficiently lar ge to e xplore the hardware saturation regime in each case. Since this required more satellites than currently e xist, an artificial catalogue of one million satellites w as created by tiling the existing Starlink TLE data (9341 satellites). This ensured the propagation task remained representativ e of real-world scenarios, while still stressing the GPU to complete each computation in full, no different to the scenario in which all the satellites are distinct. The number of satellites is capped at 1,832,980 as at this point the T4 GPU runs out of memory . It is noteworthy that even lo w-grade hardware is capable of handling a number of satellites comparable to the total number proposed for future launch across all current me ga-constellation filings. The time taken by the traditional CPU-bound C++ implementation scales linearly with the scale of the task as it can only ex ecute each propagation in sequence. In contrast, jaxsgp4 exhibits a flat scaling curv e for batch sizes belo w 10 5 ; propagating a single satellite with jaxsgp4 on an A100 GPU takes the same w all-clock time as propagating 100,000 satellites thanks to the device’ s ability to handle the workload in parallel. The advantages of jaxsgp4 become apparent at moderate batch sizes, to the order of hundreds of satellites or times, at which point the benefits of parallel computation start to rapidly outweigh the cost of increased computational overhead. The maximum speedup achiev ed by jaxsgp4 ov er the C++ baseline occurs once the GPU reaches peak utilisation. This is evidenced on the curv e by the transition from flat to a linear regime, at which point the GPU reaches its full capacity for parallelism and remains operating at its peak computational efficienc y . Using an entry-level T4 NVIDIA GPU, we find jaxsgp4 deliv ers a maximum speedup of around 250 × ov er the standard C++ routine, when batch sizes exceed of order 100,000 times or satellites. W ith the more costly , high-performance A100 GPU, jaxsgp4 continues to deliv er improv ements ov er C++ past this scale, until it is as much as 1500 × faster than the standard routine for propagation tasks in volving batches of order 10 6 . 5 1 2 7 21 58 160 443 1224 3382 9341 Number of Satellites 1 2 4 10 21 46 100 215 464 1000 Number of T ime Points 0.018 0.023 0.041 0.091 0.21 0.57 1.8 4.9 13.9 32.0 0.02 0.027 0.061 0.16 0.4 1.2 3.6 10.1 29.1 63.3 0.031 0.04 0.1 0.29 0.89 2.4 6.7 15.2 59.9 161.9 0.052 0.082 0.22 0.69 1.9 6.1 17.0 54.0 119.6 398.5 0.094 0.16 0.47 1.8 5.0 10.8 34.6 107.1 302.2 722.1 0.18 0.32 1.2 3.4 10.5 23.5 80.7 232.3 643.7 1332.2 0.39 0.76 2.4 8.1 21.3 61.6 176.5 489.7 1097.6 1585.5 0.82 1.6 4.6 16.1 49.2 132.9 362.5 867.3 1395.0 1556.4 1.6 3.3 9.7 36.7 106.3 290.9 811.0 1380.7 1741.6 1531.5 3.9 7.4 26.2 77.4 215.5 625.1 1101.7 1688.7 1537.3 1592.2 10 − 3 10 − 2 10 − 1 10 0 10 1 10 2 10 3 JAX / C++ Speedup Factor Figure 2: GPU-accelerated JAX vs C++ SGP4 performance comparison. Blue indicates JAX is faster , Red indicates C++ is faster . The standard C++ implementation is inherently single-threaded and was run on a standard CPU while the JAX benchmark was run on an NVIDIA A100 GPU. Log-spaced ax es sho w the relati ve performance of each implementation across different scales. 3.3 Full-Catalogue Propagation Follo wing a discussion of scaling specifics, we no w consider a more realistic propagation scenario to demonstrate the advantages of GPU-accelerated jaxsgp4 for large-scale SSA tasks. Figure 2 sho ws the speedup achiev ed by jaxsgp4 ov er traditional CPU-bound C++ routines for a range of scenarios in volving propagating a number satellites each to a number of future times. The jaxsgp4 implementation was run on an NVIDIA A100 GPU utilising 32-bit precision. W e observe two distinct performance re gimes. For tasks in volving belo w order 10 2 individual propagations, such as taking 21 satellites each to 10 future times, the traditional serial-bound C++ implementation actually outperforms jaxsgp4 at light computational loads. The true advantage of GPU-accelerated jaxsgp4 comes in its ability to outperform traditional propagation routines by orders of magnitude at the large scale, for example, workloads in volving simultaneous propagations of an entire constellation of satellites. W e find for the full Starlink catalogue propagated to 1,000 time steps, jaxsgp4 completes the task on an NVIDIA A100 GPU in 3.8 ms. This represents a speedup of ov er 1592 × compared to the serial C++ implementation. For a more detailed discussion on scaling specifics, refer to section 3.2. 4 Precision: 32-bit vs. 64-bit While SGP4 is traditionally run in 64-bit precision to minimise numerical round-of f error accumulation, doing so limits computational throughput on hardware accelerators. Modern GPU architectures are heavily optimised for 6 0 . 0 2 . 5 5 . 0 7 . 5 10 . 0 12 . 5 T ime since epoch [days] 0 1 2 3 4 Position error [km] 1 km/day 0 . 0 2 . 5 5 . 0 7 . 5 10 . 0 12 . 5 T ime since epoch [days] 0 . 000 0 . 001 0 . 002 0 . 003 0 . 004 V elocity error [km/s] Figure 3: Relativ e error accumulation ov er two weeks running jaxsgp4 with 32 bit precision versus the standard SGP4 implementation which uses 64 bit precision. The median and 5 th - 95 th percentile regions are highlighted in blue. The dashed line depicts a conserv ati v e lo wer bound on physical error gro wth due to limitations of the SGP4 model itself. jaxsgp4 errors are order 1e-9, 1e-12 for position and v elocity respecti vely (floating point) when the same analysis is performed using 64 bit precision. 32-bit operations (FP32), of fering considerably higher Floating Point Operations Per Second (FLOPS) and memory bandwidth utilisation with FP32 o v er FP64. In this section, we analyse the accurac y trade-off of utilising FP32 for SGP4 propagation tasks. W e argue that the resulting floating-point quantisation errors are acceptable when conte xtualised within the kilometre-scale intrinsic physical inaccuracies associated with the TLE format and SGP4’ s modelling limitations. Predictions made with SGP4+TLEs fundamentally in volve errors of se veral kilometres due to the inaccuracies of the input TLE format, which comprises mean rather than osculating elements, as well as the physical assumptions made by the SGP4 model, for e xample, in its highly simplified treatment of atmospheric drag. While the TLE format is being superseded by the Orbit Mean-Elements Message (OMM), this is a change in data encoding rather than in the underlying element representation, and the same physical limitations apply . An often-quoted heuristic for SGP4+TLE prediction accuracy is an error of approximately 1km at epoch which de grades by an additional 1-3km a day [13, 5, 14, 15]. T o isolate the error introduced purely by reduced numerical precision, we ev aluated the output of jaxsgp4 running in FP32 against the standard FP64 C++ implementation. The TLE data and implementation specifics used in this analysis are as described in Section 3.1. T o ensure the v alidity of our baseline, we first v erified that an FP64 configuration of jaxsgp4 successfully reproduces the results of the standard C++ implementation to within expected FP64 machine epsilon tolerances, specifically yielding deviations on the order of 10 − 9 km (micrometres) for position and 10 − 12 km/s for velocity . Figure 3 illustrates the gro wth of the absolute deviation in predicted position and velocity when propagating 100 Starlink TLEs for a two-week duration using 32-bit jaxsgp4 , compared against the standard 64-bit C++ predictions. T ypical LEO radius is approximately 6 . 6 × 10 3 metres, and FP32 provides approximately 7 decimal digits of precision. Consequently , the minimum positional quantisation error is roughly 0.7 metres. Over a two-week propagation, we observe that the median positional error associated with precision loss begins at approximately 1 m at epoch and remains under 1 km o ver the course of the propagation. Even in the 95 th percentile of worst-case scenarios, the deviation grows at roughly 2 km per week. When compared to the inherent physical error of the SGP4 model—depicted as a conservati ve lower -bound growth of 1 km per day (dashed line in Figure 3)—the numerical error introduced by FP32 is dwarfed by the limitations of the propagation routine itself. V elocity deviations e xhibit a similarly negligible fractional error , at most on the order of a few metres per second after two weeks. W e therefore conclude that 32-bit precision offers a virtuous trade-off, sacrificing negligible operational accuracy for substantial performance gains on modern hardware accelerators. 7 5 Differentiable Orbital Mechanics Beyond ra w computational speed, refactoring SGP4 into a pure functional paradigm in JAX introduces the capability of automatic diff erentiation (autodiff) to the model. Autodiff allows for fast and exact computation of gradients of the final state vector with respect to the initial orbital elements (e.g., inclination, eccentricity , or the drag term B ∗ ). This differentiability allo ws users to perform gradient-based optimisation of the model and facilitates the integration of SGP4 with modern machine-learning techniques. The benefits of a differentiable SGP4 implementation ha ve been explored by recent w ork: Acciarini et al. [ 7 ] introduced the PyT orch-based ∂ SGP4, and proposed its utility for a number of applications including gradient-based orbit determination, exact state transition matrix computation and cov ariance propagation. They further demonstrate ho w differentiability enables neural networks to be composed directly with the propagator, improving accuracy beyond baseline SGP4. More recently , Naylor et al. [ 16 ] have proposed the use of a differentiable propagator to optimise inspection trajectories in order to improv e the quality of captured images. jaxsgp4 inherits these capabilities directly; the propagator is composed entirely of differentiable JAX primitiv es so transformations such as jax.grad and jax.jacobian can be easily applied. Moreov er , the composability of JAX transformations means that batched gradients over large catalogues of satellites are obtained simply by combining jax.grad with jax.vmap , requiring no additional implementation effort while benefiting from the same hardware acceleration described in Section 5. W e note that ∂ SGP4, the most established dif ferentiable SGP4 implementation, also supports GPU-accelerated batch propagation. Howe ver , our local benchmarks find that jaxsgp4 offers a > 10 × improv ement in speed ov er ∂ SGP4. Additionally its O ( N + M ) memory scaling compared to ∂ SGP4’ s O ( N M ) enables jaxsgp4 to handle large workloads that exceed ∂ SGP4’ s GPU memory capacity . 6 Discussion The results presented in this work demonstrate that the transition from serial, CPU-bound propagation routines to parallel, accelerator-nati ve architectures represents more than a mere software optimization; it is a qualitati v e shift in the scale of computationally feasible astrodynamics. Modern SSA tasks in v olve enormous computational loads, for example, the continuous e v aluation of hundreds of millions of satellite-debris pairs in all-vs-all conjunction screening. In this large-scale regime, we e vidence the potential for orders of magnitude improv ement o ver current baselines, where tasks which previously took hours can no w be completed in seconds. W e expect these findings to become increasingly important in the coming decades, as the rise of mega-constellations and improvements to our tracking capabilities stand to dramatically increase the number of catalogued objects in orbit. Acknowledging this progress, we no w consider certain limitations of jaxsgp4 . The current jaxsgp4 implementation focuses on near-Earth orbits (orbital periods under 225 minutes), as in the original SGP4 formulation first dev eloped by Ken Cranford in 1970 [ 17 ]. The Deep Space e xtensions (SDP4) [ 18 ], later integrated into SGP4, are currently under dev elopment and require additional, state-dependent branching logic which may complicate XLA compilation. Lastly , a small cav eat when operating in FP32 with the current jaxsgp4 is the representation of the TLE epoch inside the jaxsgp4 Satellite object, where it is encoded as a day-of-year plus fractional day (e.g., 316.22557474). Stored as a single FP32 value, the integer day component consumes most of the significant digits. This results in a systematic ’zero error’ of approximately 1 second at worst, which at LEO v elocities, translates to kilometre-scale position errors. This can be easily resolved in future by updating the Satellite object to store the epoch as separate integer day and fractional day fields. For no w , the preferred interface when operating in FP32 is to supply time since epoch in minutes (rather than Julian date) to jaxsgp4 ’ s propagation routine, as this bypasses epoch reconstruction entirely: typical propagation windows of up to 14 days ( ≈ 20,160 minutes) are well within FP32’ s representable range, and a value of zero at epoch is exact. Beyond the implementation-specific limitations of jaxsgp4 , it is important to acknowledge the broader cost trade-offs of the GPU-accelerated paradigm. While GPUs provide substantial performance improv ements, these gains incur significantly higher hardware and operational costs. For example, at on-demand Google Cloud Compute Engine rates 10 , the A100 GPU instance (a2-highgpu-1g) at $3.67 per hour is approximately 10 × more expensi ve per hour than a comparable CPU-only instance (n1-standard-8) at $0.38. Howev er , despite the A100 being more expensi v e on a per-hour basis, the ∼ 1500 × speedup achieved by the GPU implementation means the total cost to complete a 10 https://cloud.google.com/compute/all- pricing , accessed March 2026 8 large-scale propagation task is approximately 150 × cheaper on the GPU. Even the more affordable T4 GPU, at roughly 2 × the hourly cost of a comparable CPU instance, achieves a ∼ 250 × speedup, making it substantially cheaper overall for large w orkloads. It is important to recognise, howe ver , that these peak performance gains are realised only at large computational scales due to the characteristic scaling behaviour of GPUs. For smaller -scale propagation tasks, the GPU ov erhead reduces the effecti ve speedup, and the cost advantage diminishes accordingly . The break-ev en point for cost efficienc y ov er the CPU occurs for tasks inv olving of order 10 3 individual computations; for instance, propagating 3000 satellites to a single time costs roughly the same dollar amount on both the CPU and the A100 (though the GPU completes the task approximately 10 × faster). Beyond this threshold, the GPU becomes both faster and cheaper per propagation. T aken together , these results demonstrate that for lar ge-scale propagation tasks, the speedup achie ved by jaxsgp4 far outweighs the increased per-hour cost of GPU hardware, making such tasks not only faster but also more cost-ef fecti ve. Nonetheless, practitioners should consider the scale of their workload when e v aluating whether the GPU-accelerated approach offers a meaningful cost benefit o v er traditional CPU-bound methods. A final aspect worth discussing is the expected performance scaling of jaxsgp4 for dif ferent GPU models. As observ ed in Section 3, the performance characteristics of jaxsgp4 are highly dependent on the underlying hardware; orbital propagation is generally a memory-bound operation, therefore performance is generally correlated with GPU memory bandwidth. The NVIDIA A100 utilised in our benchmarks features approximately fiv e times the memory bandwidth of the NVIDIA T4, which aligns with the proportionally higher peak achie ved speedup observed in Figure 1. Memory bandwidth has roughly doubled with each generation of NVIDIA GPUs, lea ving a substantial gap between the A100 and successiv e Hopper (2022) and Blackwell (2025) generations. Relative to the A100, the current frontier (NVIDIA B200) has approximately fiv e times the memory bandwidth, which, assuming the computation remains memory bound, would of fer a ∼ 7500 × speedup over current C++ SGP4 baselines at its peak ef ficienc y . 7 Conclusions As the orbital population scales exponentially , our computational tools must evolv e from serial, CPU-bound paradigms to parallel, accelerator-nati ve architectures. In this paper , we introduce jaxsgp4 , a high-performance, purely functional reimplementation of the SGP4 algorithm utilising the JAX framew ork. W e demonstrate the ability of jaxsgp4 to dramatically improve the scalability of satellite propagation by exploiting the parallelisation capabilities of modern GPU hardware. Our analysis confirms that refactoring our current propagation algorithms to run on modern GPU hardware does not just represent an optimisation of current code, b ut a shift in the scale of what is possible, speeding up constellation-wide propagation times by three orders of magnitude ov er C++ baselines. In addition, we argue that the use of 32-bit precision for SGP4 propagations is well-justified, offering a substantial gain in throughput on GPUs whilst introducing only negligible positional errors in the conte xt of the kilometre-scale physical inaccuracies of the SGP4 model itself. Finally , we note that jaxsgp4 has the additional benefit of being fully differentiable, f acilitating gradient-based optimisation and composability with modern machine-learning techniques. Future work will focus on inte grating SDP4 Deep Space perturbations into the computational graph. Additionally , while SGP4 remains ubiquitous due to its speed and compatibility with the TLE catalogue, its low physical accuracy limits its utility for precision manoeuvrers. Applying the JAX transformation paradigm to high-fidelity semi-analytical models (such as SGP4-XP or Gauss’ s V ariational Equations) or high-precision numerical propagators, could yield tools capable of matching SGP4’ s traditional runtime speeds while delivering the accurac y required for the next generation of space traffic management. Follo w-up work may also e xplore a range of science applications, in particular , those with large-scale propagation as a central computational requirement. Monte Carlo simulations of the K essler syndrome, in which cascading collisions are modelled across thousands of stochastic realisations of the full orbital population, are a natural candidate for GPU- accelerated propagation. Similarly , forecasting the contamination of astronomical observations by me ga-constellations requires propag ating entire catalogues across dense grids of future times and telescope pointings. Beyond batch parallelism alone, gradient-based constellation optimisation (for example minimising collision risk or maximising cov erage subject to orbital constraints) stands to benefit from both axes of jaxsgp4 : differentiability for gradient-based optimisation and batch parallelism for ev aluating candidate configurations at scale. 9 Acknowledgements This work was supported by the UKRI GLITTER grant [EP/Y037332/1] and the UKRI Frontier Research Guarantee [EP/X035344/1]. The authors were supported by the research en vironment and infrastructure of the Handley Lab at the Univ ersity of Cambridge. Data A vailability The source code for jaxsgp4 is publicly av ailable at https://github.com/cmpriestley/jax_sgp4 . All bench- mark scripts, data, and plotting code required to reproduce the figures in this paper are archived on Zenodo at https://doi.org/10.5281/zenodo.19322209 . Software and T ools The authors acknowledge the use of AI tools in preparing this manuscript and the accompanying software. Specifically , generativ e language models Gemini 3.1 Pro Previe w (Google DeepMind) and Claude Opus 4.6 (Anthropic) were used to assist with drafting the text. The AI coding agent Claude Code (Anthropic) was used as a tool during software de velopment. All AI-generated outputs were revie wed, edited, and validated by the authors to ensure their accuracy . All ideas, data, analysis and conclusions presented in this work are solely those of the authors. References [1] Andrew Falle, Ewan Wright, Aaron Boley , and Michael Byers. One million (paper) satellites. Science , 382(6667):150–152, 2023. [2] Alejandro S. Borlaff, Pamela M. Marcum, and Ste v e B. Howell. Satellite megaconstellations will threaten space-based astronomy . Natur e , 648:51–57, 2025. [3] Felix R. Hoots and Ronald L. Roehrich. Models for propagation of NORAD element sets. T echnical Report Spacetrack Report No. 3, Aerospace Defense Command, United States Air Force, December 1980. [4] Felix R. Hoots, P aul W . Schumacher Jr ., and Robert A. Glover . History of analytical orbit modeling in the U.S. space surveillance system. J ournal of Guidance , Control, and Dynamics , 27(2):174–185, 2004. [5] David A. V allado, Paul Crawford, Richard Hujsak, and T . S. Kelso. Re visiting spacetrack report #3. In AIAA/AAS Astr odynamics Specialist Conference and Exhibit , number AIAA 2006-6753, K eystone, Colorado, August 2006. [6] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradb ury , Gregory Chanan, Tre vor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Y ang, Zachary DeV ito, Martin Raison, Alykhan T ejani, Sasank Chilamkurthy , Benoit Steiner , Lu Fang, Junjie Bai, and Soumith Chintala. PyT orch: An imperati ve style, high-performance deep learning library . In Advances in Neur al Information Pr ocessing Systems 32 , pages 8024–8035, 2019. [7] Giacomo Acciarini, Atılım Güne ¸ s Baydin, and Dario Izzo. Closing the gap between SGP4 and high-precision propagation via dif ferentiable programming. Acta Astronautica , 226:694–701, 2025. [8] T oby Lovick, David Y allup, Davide Piras, Alessio Spurio Mancini, and Will Handle y . High-dimensional bayesian model comparison in cosmology with gpu-accelerated nested sampling and neural emulators, 2025. [9] Samuel Alan K ossof f Leene y . Jax-bandflux: differentiable superno v ae salt modelling for cosmological analysis on gpus, 2025. [10] A N Ormondroyd, W J Handle y , M P Hobson, and A N Lasenby . Non-parametric reconstructions of dynamical dark energy via fle xknots. Monthly Notices of the Royal Astr onomical Society , 541(4):3388–3400, July 2025. [11] Metha Prathaban, David Y allup, James Alve y , Ming Y ang, W ill T empleton, and W ill Handley . Gravitational-wa ve inference at gpu speed: A bilby-like nested sampling kernel within blackjax-ns, 2025. [12] Jiahao Chen and Jarrett Revels. Rob ust benchmarking in noisy environments, 2016. [13] Creon Le vit and W illiam Marshall. Improved orbit predictions using two-line elements. Advances in Space Resear c h , 47(7):1107–1115, 2011. [14] T . S. Kelso. V alidation of SGP4 and IS-GPS-200D against GPS precision ephemerides. In Proceedings of the 17th AAS/AIAA Space Flight Mechanics Confer ence , number AAS 07-127, Sedona, Arizona, January 2007. 10 [15] W . Dong and Z. Chang-yin. An accurac y analysis of the SGP4/SDP4 model. Chinese Astr onomy and Astr ophysics , 34(1):69–76, 2010. [16] Jack Naylor , Ragha v Mishra, Nicholas H. Barbara, and Donald G. Dansereau. dlite: Differentiable lighting- informed trajectory ev aluation for on-orbit inspection, 2025. [17] M. H. Lane and F . R. Hoots. General perturbations theories derived from the 1965 lane drag theory . T echnical Report Project Space T rack Report No. 2, Aerospace Defense Command, United States Air Force, December 1979. [18] R. S. Hujsak. A restricted four body solution for resonating satellites with an oblate earth. In AIAA 17th Aer ospace Sciences Meeting , number AIAA 79-136, New Orleans, Louisiana, January 1979. 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment